
Improving the Speech Enhancement Model with Discrete Wavelet Transform Sub-Band Features in Adaptive FullSubNet †


Abstract
1. Introduction
1.1. Traditional Statistical Methods
1.2. Deep Learning-Based Methods
- Multi-layer perceptron (MLP);
- Convolutional neural networks (CNNs);
- Recurrent neural networks (RNNs);
- Generative adversarial networks (GANs);
- Attention-based models like Transformers.
1.3. Training Targets for SE Methods
1.4. FullSubNet-Based Frameworks
1.5. Alternative Transformations for Speech Enhancement
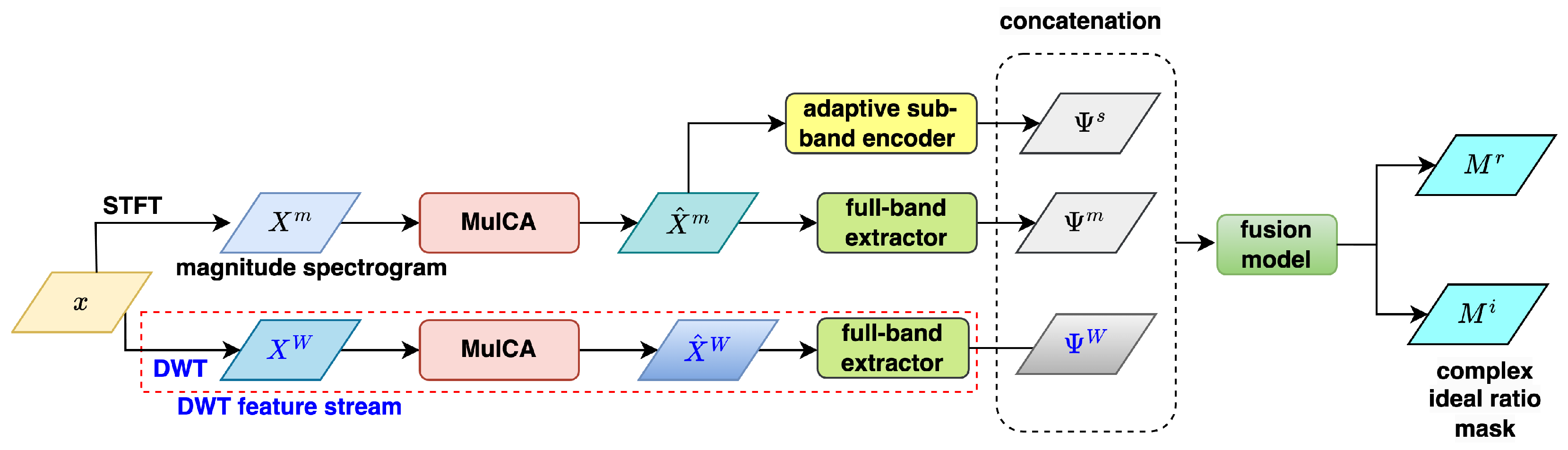
2. Adaptive FullSubNet
- Input stage: the input noisy speech signal x is transformed into the time-frequency domain using STFT, producing: magnitude spectrogram , real-part spectrogram , and imaginary-part spectrogram .
- Full-band feature extraction: Following the FullSubNet+ architecture, A-FSN processes the input spectrograms , , and to extract global spectral information and long-distance cross-band dependencies. It includes a multi-scale time-sensitive channel attention (MulCA) module to assign weights to frequency bins. Furthermore, it utilizes temporal convolutional network (TCN) blocks to replace LSTMs for efficient modeling in the full-band extractor. In the following, we provide additional details about the MulCA module and the TCA blocks:
- The MulCA module processes an input feature matrix (spectrogram here) through three parallel 1D depthwise convolutions with different kernel sizes along the time axis, extracting multi-scale features for each channel (frequency bin). These outputs undergo average pooling and ReLU activation, producing three time-scale features. A fully connected layer then combines these features into a single fusion feature, which is further processed by two additional fully connected layers to generate a weight vector representing the importance of each channel. Finally, this weight vector is applied to the input feature matrix via element-wise multiplication, resulting in a weighted feature matrix.
- Each of the TCN blocks consists of a sequence of operations including input convolution, depthwise dilated convolution to capture long-range dependencies, and output convolution. The use of dilated convolutions allows TCNs to process sequences with varying dilation rates, effectively capturing both short-term and long-term temporal patterns.
- Adaptive sub-band processing: A-FSN incorporates an adaptive sub-band encoder module to process the unfolded magnitude spectrogram, drawing inspiration from the downsampling approach commonly used in time-domain speech enhancement techniques. The adaptive sub-band encoder is largely based on the encoding component of MANNER [47], a highly effective SE framework. The MANNER encoder is composed of a down-convolution layer, a residual Conformer (ResCon) block, and a multi-view attention (MA) block. By performing downsampling and feature encoding, and by stacking multiple encoder layers to form the sub-band encoder, compact and efficient sub-band features are extracted for further processing.
- Feature fusion: A fusion model combines the output of the full-band extractors (, , and ) with the adaptive sub-band encoder (). The fusion model is built by stacking Conformer layers, similar to a TCN Block, with increasing dilation parameters. This design makes it easier to gather both long-term and short-term traits of speech. Notably, FullSubNet+ uses LSTM for the sub-band fusion model, but A-FSN replaces LSTM with Conformers to speed up implementation.
- cIRM prediction: The fused features are used to predict the complex ideal ratio mask (cIRM), , and , which suppress noise while preserving speech components in the time-frequency domain.
- Speech reconstruction: The enhanced complex spectrogram is converted back to the time domain using inverse STFT (iSTFT), producing the final clean speech waveform.
3. Presented Framework: DWT Features-Equipped A-FSN (WA-FSN)
- The real and imaginary spectrogram inputs are replaced with frame-wise DWT feature sequences by simply adding a DWT operation module at the front end of A-FSN. Other modules, such as MulCA, the full-band extractor, the magnitude-based adaptive sub-band encoder, and the fusion model, remain unchanged. This localized revision allows us to focus specifically on the impact of DWT features on A-FSN.
- We employ one-level and two-level (extended) DWT to generate features, requiring, at most, six convolution operations. As a result, the additional computational load introduced by this approach is lightweight.
- DWT is a distortionless transformation that preserves all information from the input signal, similar to STFT’s real and imaginary spectrograms. Therefore, DWT features retain phase information, which is considered crucial for building an effective SE framework.
- DWT features can be viewed as time-domain features since they are generated by convolving input time-domain signals with predefined analysis filters. The resulting WA-FSN thus combines both time-domain and STFT-domain features to learn the cIRM, whereas the original A-FSN uses only STFT-domain features. Unlike typical learnable time-domain features in DNN-based SE models that require trainable convolution filters, DWT employs predefined filters for low-pass and high-pass operations. This makes DWT features easier to extract and more interpretable. Additionally, the importance of specific DWT sub-band features can be evaluated in WA-FSN by simply zeroing them out.
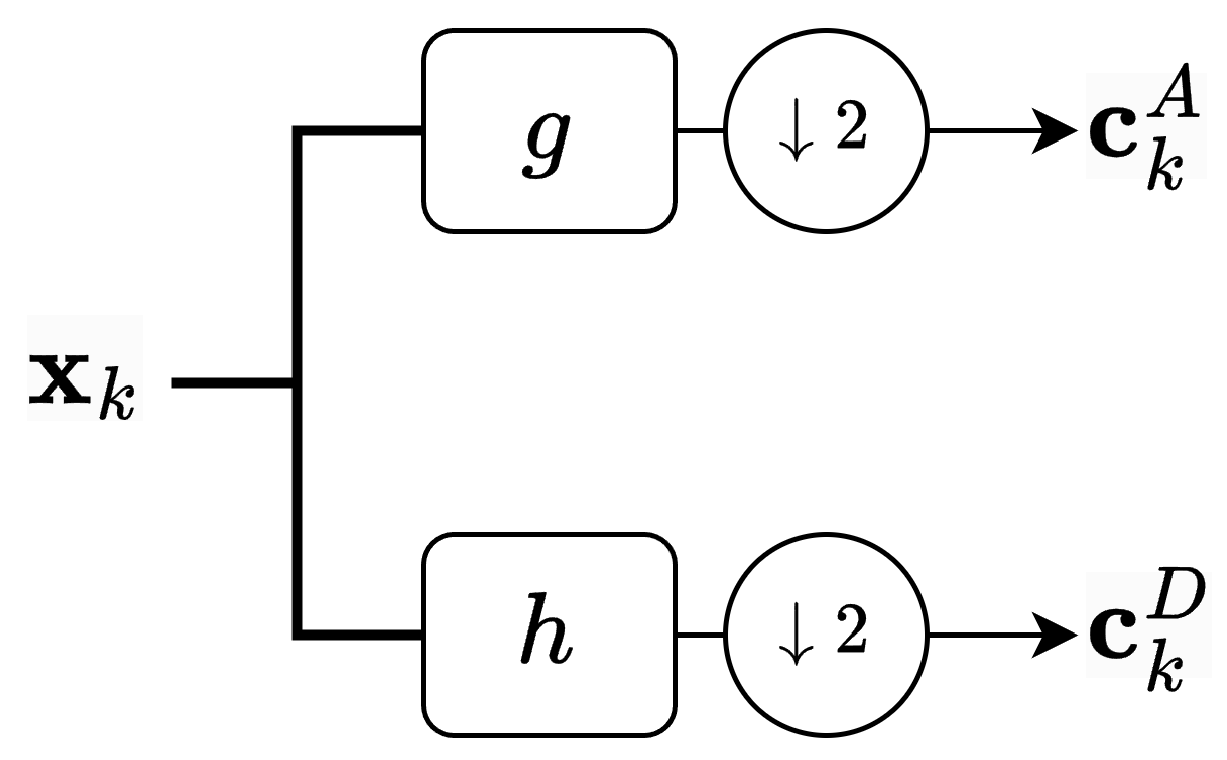
3.1. One-Level DWT Features
- Two individual branchesIn this arrangement, the two matrices and are vertically zero-padded to extend their size to , matching the dimensions of the original data matrix X. This is expressed as follows:where is a zero matrix of size . The matrices and are then processed separately by the MulCA module and the full-band extractor to produce the final DWT feature matrices, and . This setup mirrors the original A-FSN’s treatment of complex-valued spectrograms, where the real and imaginary components are handled as two independent feature branches.
- Single branch with concatenationHere, the matrices and are concatenated vertically to form a single DWT feature matrix:which is then passed through the MulCA module and full-band extractor to generate the final DWT feature matrix, . This approach reduces the number of processing branches compared to the first arrangement, leading to a smaller model size and lower computational cost. Additionally, since and are combined into a single input, MulCA can simultaneously assign weights across both sub-bands, covering the entire frequency range and capturing mutual information between and more effectively.
- Single branch with droppingIn this arrangement, one of the two branches from the first setup is discarded. Either or , as defined in Equation (2), is used as the sole DWT feature input to undergo processing by the MulCA module and full-band extractor, resulting in a final DWT feature matrix of either or . By adopting a single branch, this approach also reduces computational complexity and model size compared to the first arrangement. Additionally, it allows us to investigate which sub-band feature—approximation () or detail ()—is more critical for enhancing WA-FSN’s performance in speech enhancement tasks.
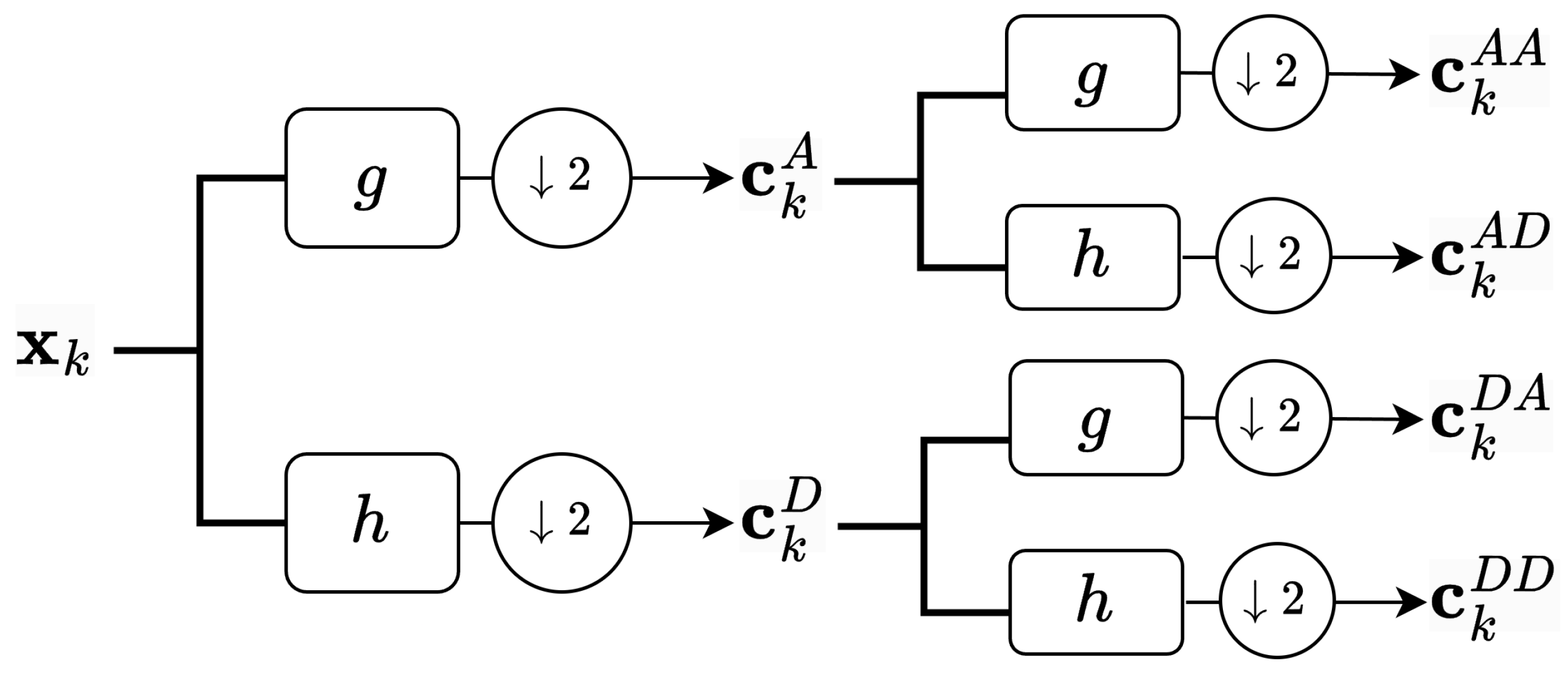
3.2. Two-Level DWT Features
- Concatenation of all sub-bandsAll four sub-band feature matrices are concatenated vertically to form a single DWT feature matrix:
- Concatenation of adjacent sub-bandsTo evaluate the relative importance of specific sub-bands, we selectively concatenate two or three adjacent sub-band matrices vertically to form a single DWT feature matrix. The possible configurations are as follows:
- (a)
- The lowest three sub-bands:
- (b)
- The highest three sub-bands:
- (c)
- The lowest two sub-bands:
- (d)
- The highest two sub-bands:
- The DWT maintains a computational efficiency advantage over DFT/FFT for large N while providing more detailed frequency analysis. This makes it particularly useful for applications requiring multi-resolution analysis.
- The two-level DWT still requires floating-point operations because:
- –
- First level processes N samples:
- –
- Second level processes N/2 samples:
- –
- Total:
- Runtime complexity for both one-level and two-level DWT remains , as the algorithm still processes the signal linearly.
- Two-level DWT provides finer frequency resolution in lower frequency bands without significantly increasing computational complexity compared to one-level DWT.
- Two-level DWT requires slightly more memory to store intermediate results, but the order of magnitude remains the same as one-level DWT.
4. Experimental Setup
- Perceptual estimation of speech quality (PESQ) [51]: This metric assesses the perceived speech quality, ranging from −0.5 to 4.5, with higher scores indicating better quality. PESQ objectively quantifies speech quality by comparing processed speech to the original clean speech. The computation involves time alignment, level alignment, time-frequency mapping, frequency warping, and compressive loudness scaling.
- Short-time objective intelligibility (STOI) [52]: This metric evaluates the objective intelligibility of short-time, time-frequency areas in an utterance using the discrete-time Fourier transform. STOI scores range from 0 to 1, with higher values indicating better intelligibility. The calculation involves applying STFT to processed and clean signals, conducting one-third octave band analysis, normalizing and clipping energy, and computing linear correlation coefficients between estimated and original signals.
- Scale-invariant signal-to-noise ratio (SI-SNR) [53]: This metric measures artifact distortion between processed and clean speech. It is calculated as follows:wherewith being the inner product of and .
5. Experimental Results and Discussions
5.1. Selection of Sub-Band Fusion Model Structure
- As with the original A-FSN (using complex spectrograms), selecting a Conformer other than LSTM as the fusion model can improve PESQ and STOI scores moderately while degrading SI-SNR. This indicates that using Conformer in A-FSN is primarily intended to reduce the model’s complexity, as opposed to enhancing its SE behavior.
- When Conformer is used as the fusion model, the presented WA-FSN (with DWT features) provides worse PESQ, comparable STOI, and higher SI-SNR than the original A-FSN. However, replacing Conformer with LSTM for the fusion model in the WA-FSN significantly promotes all of the three metrics. Furthermore, WA-FSN with LSTM outperforms A-FSN with Conformer in STOI and SI-SNR scores apparently.
- Conformer excels at handling complex spectrograms, while LSTM is proficient in dealing with certain parts of wavelet features. Our interpretation is that Conformer, in order to reduce computational complexity, tends to extract fixed and partial information. However, for wavelet features, it is more suitable to retain the entire feature information. Therefore, the computationally more complex LSTM is better suited for handling wavelet features.
5.2. Results for WA-FSN with One-Level DWT Features
- All versions of WA-FSN with one-level DWT outperform A-FSN in the two SE metrics, PESQ and STOI, confirming that the DWT features can benefit A-FSN by providing superior or comparable SE outputs. However, A-FSN gives better SI-SNR scores than most WA-FSN variants (except for the concatenation case).
- The two-branch WA-FSN, which processes the approximation and detail parts separately ( and ) and has the same model structure as A-FSN, outperforms A-FSN moderately in PESQ but substantially in STOI. This result suggests that when it comes to two-branch processing, it is more prudent to select the DWT-wise approximation and detail portions than the real and imaginary spectrograms.
- Regarding the three cases that deal with DWT features using a single branch, the STOI results are very similar, implying that STOI has less relevance to the selection of DWT-sub-bands. However, using either or alone results in significantly higher PESQ scores than using both in concatenation. One possible explanation is that the one-branch model is less effective at dealing with the full-band information (in the concatenation of and ) to calibrate the speech signal more precisely. Contrarily, the concatenation case outperforms the individual half-band cases ( and ) in SI-SNR, likely due to the fact that the concatenation case can provide superior noise reduction to the entire bands. However, this explanation requires further validation.
5.3. Experiments on WA-FSN with Two-Level DWT Features
- When two-level DWT is utilized, each of the resulting WA-FSN variants outperforms the original A-FSN in terms of PESQ, STOI, and SI-SNR, apparently indicating a superior performance in the SE task.
- Using either of the lowest three sub-bands or the lowest two sub-bands can further improve PESQ (from to and ), respectively, compared to the full-band case. However, the cases with the highest three sub-bands and the highest two sub-bands attain lower PESQ scores ( and , respectively), indicating that the lower sub-bands contribute more to PESQ than the higher sub-bands.
- In terms of STOI, the choice of sub-bands does not result in a significant difference, but selecting three sub-bands seems preferable to selecting two ( and vs. and ). In contrast, cases with two sub-bands have a higher SI-SNR than those with three sub-bands. Notably, the selection of the two highest sub-bands achieves an SI-SNR value ( dB) that is significantly better than all other selections.
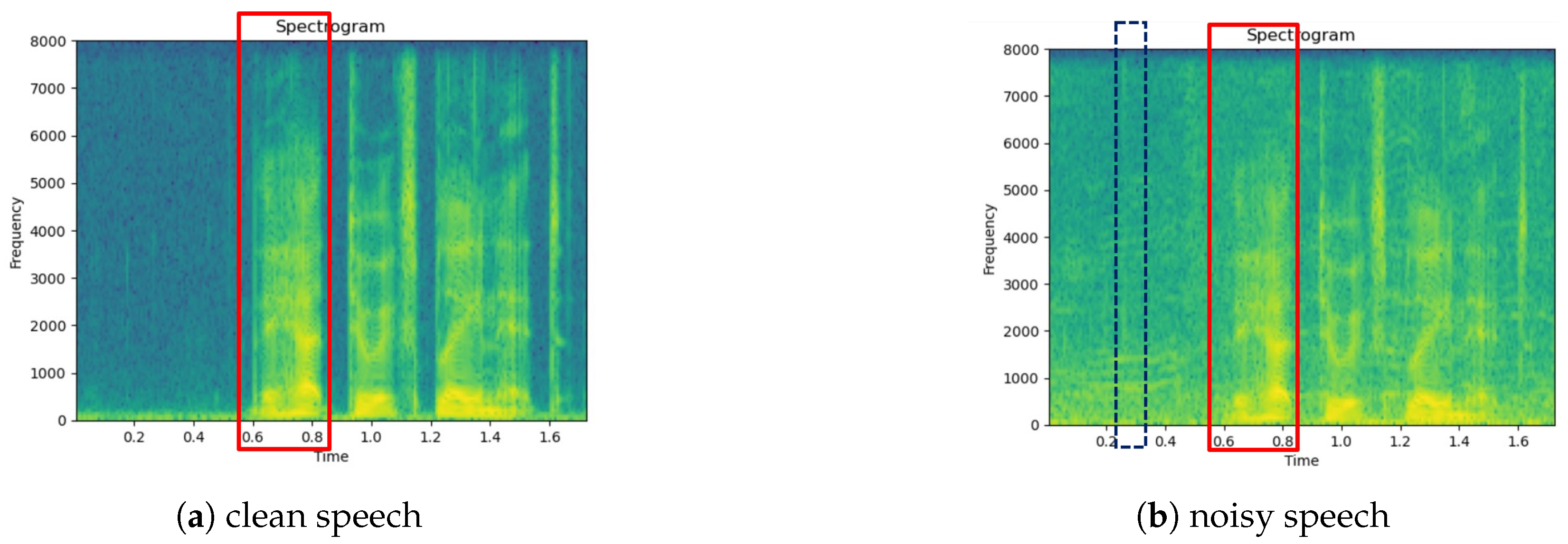
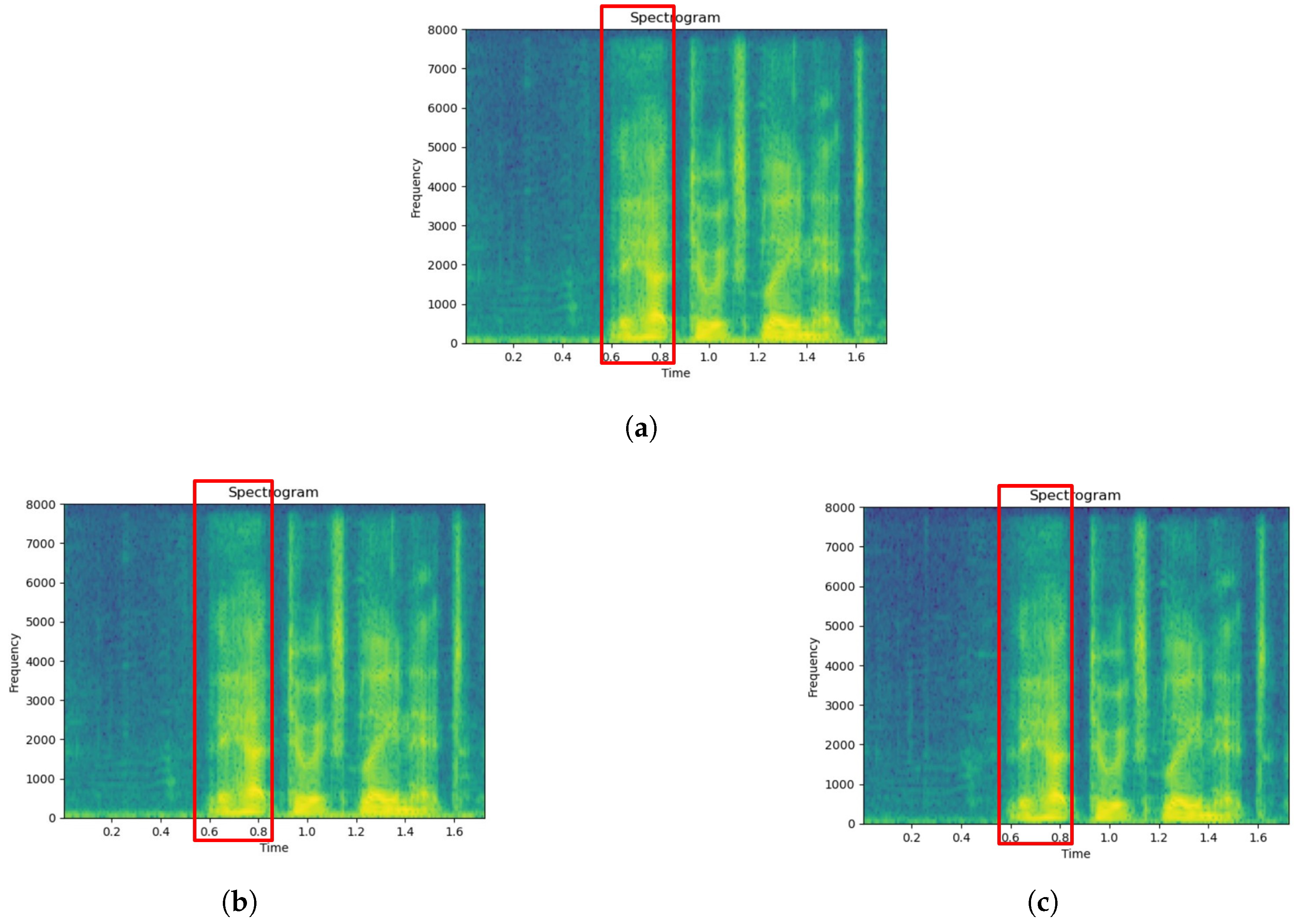
5.4. Spectrogram Demonstration for SE Methods
- Comparing Figure 5a and b, which correspond to a clean utterance and its unprocessed noisy counterpart, respectively, we can observe that noise significantly distorts the entire time range of the utterance, causing the formant and harmonic structure of the speech component to almost completely disappear.
- Compared to the original noisy utterance, the enhanced versions produced by the WA-FSN variants effectively reduce noise distortion and emphasize the distinction between speech and non-speech segments. For example, the area between 0.6 and 0.8 s, highlighted by a red box in Figure 6 (using at least three sub-bands) and Figure 7 (using two sub-bands), shows a greater variation in energy compared to the unprocessed noisy case in Figure 5b.
- Figure 7a,b, which utilize two sub-bands in WA-FSN, exhibit slightly more residual noise (notably around 2.5 s, marked by a blue box) compared to Figure 6a–c, which employ at least three sub-bands. This suggests that using more sub-bands can enhance noise reduction. However, the difference is not entirely evident, likely because the full-band magnitude spectrogram provides comprehensive information. Additionally, the distinction between Figure 7a (using the lowest two sub-bands) and Figure 7b (using the highest two sub-bands) is not clear, possibly due to the similar speech enhancement metrics shown in Table 4.
6. Conclusions
- Investigate the impact of different wavelet functions: Examining wavelet functions such as db4 and db8 could help identify those that better capture specific noise patterns or speech characteristics, potentially improving WA-FSN performance.
- Develop advanced fusion strategies: Creating more sophisticated methods for combining features from DWT and STFT could enhance effectiveness. This might include using learning-based techniques to dynamically adjust the importance of each feature type depending on the characteristics of the input signal.
- Optimize WA-FSN for real-time deployment: To enable real-time application, it will be important to reduce computational complexity while maintaining performance. This could involve techniques such as model pruning or knowledge distillation.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boll, S.F. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Scalart, P.; Filho, J.V. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Atlanta, GA, USA, 7–10 May 1996. [Google Scholar]
- Gauvain, J.L.; Lee, C.H. Maximum a posteriori estimation for multivariate Gaussian mixture observations of Markov chains. IEEE Trans. Speech Audio Process. 1994, 2, 291–298. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 443–445. [Google Scholar]
- Wu, J.; Huo, Q. An environment-compensated minimum classification error training approach based on stochastic vector mapping. IEEE Trans. Audio Speech Lang Process. 2006, 14, 2147–2155. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.; Lee, C. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech, Lang. Process. 2015, 23, 7–19. [Google Scholar]
- Zhao, Y.; Wang, D.; Merks, I.; Zhang, T. DNN-based enhancement of noisy and reverberant speech. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar]
- Wang, D. Deep learning reinvents the hearing aid. Inst. Electr. Electron. Eng. (IEEE) Spectr. 2017, 54, 32–37. [Google Scholar]
- Chen, J.; Wang, Y.; Yoho, S.E.; Wang, D.; Healy, E.W. Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises. J. Acoust. Soc. Am. 2016, 139, 2604–2612. [Google Scholar]
- Karjol, P.; Kumar, M.A.; Ghosh, P.K. Speech enhancement using multiple deep neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar]
- Kounovsky, T.; Malek, J. Single channel speech enhancement using convolutional neural network. In Proceedings of the ECMSM, Donostia-San Sebastian, Spain, 24–26 May 2017. [Google Scholar]
- Chakrabarty, S.; Wang, D.; Habets, E.A.P. Time-frequency masking based online speech enhancement with multi-channel data Using convolutional neural Networks. In Proceedings of the IWAENC, Tokyo, Japan, 17–20 September 2018. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef]
- Fu, S.; Tsao, Y.; Lu, X.; Kawai, H. Raw waveform-based speech enhancement by fully convolutional networks. In Proceedings of the APSIPA ASC, Kuala Lumpur, Malaysia, 12–15 December 2017. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. 1-D convolutional neural networks for signal processing applications. In Proceedings of the ICASSP, Brighton, UK, 12–17 May 2019. [Google Scholar]
- Wang, D.; Rong, X.; Sun, S.; Hu, Y.; Zhu, C.; Lu, J. Adaptive Convolution for CNN-based Speech Enhancement Models. arXiv 2025, arXiv:2502.14224. [Google Scholar]
- Sach, M.; Franzen, J.; Defraene, B.; Fluyt, K.; Strake, M.; Tirry, W.; Fingscheidt, T. EffCRN: An Efficient Convolutional Recurrent Network for High-Performance Speech Enhancement. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023; pp. 656–660. [Google Scholar]
- Yin, H.; Bai, J.; Wang, M.; Huang, S.; Jia, Y.; Chen, J. Convolutional Recurrent Neural Network with Attention for 3D Speech Enhancement. arXiv 2023, arXiv:2306.04987. [Google Scholar]
- Jannu, C.; Vanambathina, S.D. Convolutional Transformer based Local and Global Feature Learning for Speech Enhancement. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 731–743. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Sun, L.; Du, J.; Dai, L.; Lee, C. Multiple-target deep learning for LSTM-RNN based speech enhancement. In Proceedings of the Hands-Free Speech Communication and Microphone Arrays (HSCMA), San Francisco, CA, USA, 1–3 March 2017. [Google Scholar]
- Cheng, L.; Pandey, A.; Xu, B.; Delbruck, T.; Liu, S.C. Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement. arXiv 2024, arXiv:2408.12425. [Google Scholar]
- Botinhao, C.V.; Wang, X.; Takaki, S.; Yamagishi, J. Speech Enhancement for a Noise-Robust Text-to-Speech Synthesis System Using Deep Recurrent Neural Networks. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Andreev, P. Generative Models for Speech Enhancement. Ph.D. Thesis, HSE University, Moscow, Russia, 2024. Available online: https://www.hse.ru/data/2024/10/04/1888260947/%D0%90%D0%BD%D0%B4%D1%80%D0%B5%D0%B5%D0%B2_summary.pdf (accessed on 27 March 2025).
- Shetu, S.S.; Habets, E.A.; Brendel, A. GAN-Based Speech Enhancement for Low SNR Using Latent Feature Conditioning. arXiv 2023, arXiv:2410.13599. [Google Scholar]
- Strauss, M. SEFGAN: Harvesting the Power of Normalizing Flows and GANs for Efficient High-Quality Speech Enhancement. arXiv 2023, arXiv:2312.01744. [Google Scholar]
- Chen, J.; Mao, Q.; Liu, D. Dual-Path Transformer Network: Direct Context-Aware Modeling for End-to-End Monaural Speech Separation. arXiv 2020, arXiv:2007.13975. [Google Scholar]
- Zhang, S.; Chadwick, M.; Ramos, A.G.; Parcollet, T.; van Dalen, R.; Bhattacharya, S. Real-Time Personalised Speech Enhancement Transformers with Cross-Attention. In Proceedings of the Interspeech 2023, Dublin, Ireland, 20–24 August 2023. [Google Scholar]
- Chao, F.A.; Hung, J.W.; Chen, B. Multi-view Attention-based Speech Enhancement Model for Noise-robust Automatic Speech Recognition. In Proceedings of the 32nd Conference on Computational Linguistics and Speech Processing (ROCLING 2020), Taipei, Taiwan, 24–26 September 2020. [Google Scholar]
- Bai, J.; Li, H.; Zhang, X.; Chen, F. Attention-Based Beamformer For Multi-Channel Speech Enhancement. arXiv 2024, arXiv:2409.06456. [Google Scholar]
- Wang, Y.; Narayanan, A.; Wang, D. On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar]
- Roman, N.; Woodruff, J. Ideal binary masking in reverberation. In Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 629–633. [Google Scholar]
- Narayanan, A.; Wang, D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar] [CrossRef]
- Williamson, D.S.; Wang, Y.; Wang, D. Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 483–492. [Google Scholar] [CrossRef] [PubMed]
- Erdogan, H.; Hershey, J.R.; Watanabe, S.; Roux, J.L. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- Hao, X.; Su, X.; Horaud, R.; Li, X. Fullsubnet: A full-band and sub-band fusion model for real-time single-channel speech enhancement. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Chen, J.; Wang, Z.; Tuo, D.; Wu, Z.; Kang, S.; Meng, H. Fullsubnet+: Channel attention fullsubnet with complex spectrograms for speech enhancement. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022. [Google Scholar]
- Tsao, Y.S.; Ho, K.H.; Hung, J.W.; Chen, B. Adaptive-FSN: Integrating Full-Band Extraction and Adaptive Sub-Band Encoding for Monaural Speech Enhancement. In Proceedings of the 2023 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing, 2nd ed.; Academic: San Diego, CA, USA, 1999. [Google Scholar]
- Mitra, S.K. Digital Signal Processing, a Computer-Based Approach, 4th ed.; Wcb/McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Vani, H.Y.; Anusuya, M.A. Hilbert Huang transform based speech recognition. In Proceedings of the 2016 Second International Conference on Cognitive Computing and Information Processing (CCIP), Mysuru, India, 2–13 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Ravanelli, M.; Bengio, Y. Speech and speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar]
- Wu, P.-C.; Li, P.-F.; Wu, Z.-T.; Hung, J.-W. The Study of Improving the Adaptive FullSubNet+ Speech Enhancement Framework with Selective Wavelet Packet Decomposition Sub-Band Features. In Proceedings of the 2023 9th International Conference on Applied System Innovation (ICASI), Chiba, Japan, 21–25 April 2023. [Google Scholar]
- Park, H.J.; Kang, B.H.; Shin, W.; Kim, J.S.; Han, S.W. MANNER: Multi-View Attention Network For Noise Erasure. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 7842–7846. [Google Scholar] [CrossRef]
- Veaux, C.; Yamagishi, J.; King, S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database. In Proceedings of the Conference on Asian Spoken Language Research and Evaluation (OCOCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013. [Google Scholar]
- Thiemann, J.; Ito, N.; Vincent, E. Demand: A collection of multi-channel recordings of acoustic noise in diverse environments. In Proceedings of the Meetings Acoust, Montreal, QC, Canada, 2–7 June 2013. [Google Scholar]
- Daubechies, I. Orthonormal bases of compactly supported wavelets. Commun. Pure Appl. Math. 1988, 41, 909–996. [Google Scholar]
- Union, I.T. Perceptual Evaluation of Speech Quality (pesq): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs. ITU-T Recommendation, P. 862. 2001. Available online: https://cir.nii.ac.jp/crid/1574231874837257984 (accessed on 27 March 2025).
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010. [Google Scholar]
- Isik, Y.; Roux, J.L.; Chen, Z.; Watanabe, S.; Hershey, J.R. Single-channel multi-speaker separation using deep clustering. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Defossez, A.; Synnaeve, G.; Adi, Y. Real time speech enhancement in the waveform domain. arXiv 2020, arXiv:2006.12847. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transform | FLOPs | Runtime Complexity |
|---|---|---|
| DFT (direct computation) | ||
| DFT (FFT algorithm) | ||
| One-level DWT (filter length M) | ||
| Two-level DWT (filter length M) |
| Feature | A-FSN | WA-FSN | ||
|---|---|---|---|---|
| Fusion Model | Conformer | LSTM | Conformer | LSTM |
| PESQ | 2.8051 | 2.7885 | 2.7586 | 2.7926 |
| STOI | 0.9406 | 0.9394 | 0.9405 | 0.9422 |
| SI-SNR | 17.65 | 18.02 | 18.02 | 18.55 |
| Methods | PESQ | STOI | SI-SNR | ||
|---|---|---|---|---|---|
| unprocessed | 1.9700 | 0.9210 | 8.45 | ||
| A-FSN (LSTM) | 2.7885 | 0.9394 | 18.02 | ||
| WA-FSN | two branches | 2.8184 | 0.9432 | 17.86 | |
| one branch | concatenation | 2.7926 | 0.9422 | 18.55 | |
| 2.8875 | 0.9425 | 17.97 | |||
| 2.8886 | 0.9424 | 17.99 | |||
| Methods | PESQ | STOI | SI-SNR | |
|---|---|---|---|---|
| unprocessed | 1.9700 | 0.9210 | 8.45 | |
| A-FSN (LSTM) | 2.7885 | 0.9394 | 18.02 | |
| WA-FSN with one-level DWT features | concatenation | 2.7926 | 0.9422 | 18.55 |
| WA-FSN with two-level DWT features | all four sub-bands | 2.8676 | 0.9432 | 18.25 |
| the lowest three sub-bands | 2.8937 | 0.9430 | 18.24 | |
| the highest three sub-bands | 2.8277 | 0.9437 | 18.27 | |
| the lowest two sub-bands | 2.8782 | 0.9423 | 18.34 | |
| the highest two sub-bands | 2.7912 | 0.9424 | 18.83 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.-T.; Hung, J.-W. Improving the Speech Enhancement Model with Discrete Wavelet Transform Sub-Band Features in Adaptive FullSubNet. Electronics 2025, 14, 1354. https://doi.org/10.3390/electronics14071354
Wu Z-T, Hung J-W. Improving the Speech Enhancement Model with Discrete Wavelet Transform Sub-Band Features in Adaptive FullSubNet. Electronics. 2025; 14(7):1354. https://doi.org/10.3390/electronics14071354
Chicago/Turabian StyleWu, Zong-Tai, and Jeih-Weih Hung. 2025. "Improving the Speech Enhancement Model with Discrete Wavelet Transform Sub-Band Features in Adaptive FullSubNet" Electronics 14, no. 7: 1354. https://doi.org/10.3390/electronics14071354
APA StyleWu, Z.-T., & Hung, J.-W. (2025). Improving the Speech Enhancement Model with Discrete Wavelet Transform Sub-Band Features in Adaptive FullSubNet. Electronics, 14(7), 1354. https://doi.org/10.3390/electronics14071354