1. Introduction
With the rapid development of the electronics industry, analog circuits have been widely used in critical fields such as industrial automation, healthcare, aerospace, transportation, and network communications. Statistics show that although analog circuits account for only about 20% of electronic systems, they contribute to over 80% of system failures [
1]. Faults in analog circuits can lead to system malfunctions and even abnormal shutdowns of equipment, significantly impacting system stability and reliability. However, due to the complexity and diversity of analog circuit faults, their detection and diagnosis are often challenging, especially when fault characteristics are subtle or fault phenomena are difficult to reproduce. These faults may cause false alarms and even lead to the abnormal shutdown of equipment [
2,
3]. Therefore, developing an effective method for accurately diagnosing faults in analog circuits is of great significance for improving the maintainability, safety, and reliability of electronic systems [
4,
5].
Faults in analog circuits are predominantly attributed to the instability of circuit interconnections. Substandard manufacturing processes, progressive fault degradation mechanisms, and harsh operational conditions such as complex electromagnetic interference environments, sustained mechanical vibration, extreme thermal conditions, and humidity variations can exacerbate the degradation and physical loosening of electronic components and circuit interconnections, rendering analog circuits susceptible to malfunction [
6,
7,
8]. If the faulty circuit is located in a critical area, such as a flight control system, signal anomalies caused by faults may result in catastrophic accidents [
9]. Therefore, by accurately identifying faults, triggering internal protection mechanisms for fault isolation and signal reconstruction, the safety of the system can be significantly improved. Currently, existing methods for diagnosing faults in analog circuits can be roughly divided into two categories: model-based methods and data-driven methods [
10,
11]. Model-based methods analyze the operational principles of circuits to establish corresponding fault models for identifying different faults [
12]. Han speculated that vibration and temperature would cause faults, and they built a physical model of the avionics system to prove this [
13]. By controlling the intensity of vibration and temperature, false alarms were reduced. However, in many cases, the structure of analog circuits is extremely complex, making it difficult to establish precise models of faults [
14,
15,
16]. Compared to model-based methods, data-driven approaches rely less on specialized backgrounds and can extract valuable information from large amounts of test data, thereby establishing relationships between fault features and fault categories [
17,
18]. Guan proposed a threshold-based false alarm recognition method, which introduced support vector machines with a “one-against-one” strategy to identify different faults [
19]. Shen proposed a fault identification method based on empirical mode decomposition (EMD) and a Hidden Markov model (HMM) to suppress built-in test (BIT) false alarms caused by faults [
20]. Zhu and Zhang used the Bayesian optimization algorithm to integrate manifold regularized extreme learning machines to further improve the accuracy and efficiency of fault diagnosis [
21]. Cui et al. proposed a fault diagnosis method based on Self-Organizing Maps (SOMs) [
22]. They used unsupervised learning to obtain the SOM topology and established a multi-class support vector machine (SVM), which improved the accuracy of the fault diagnosis method. However, the effectiveness of traditional data-driven methods largely depends on the quality of features extracted by signal processing techniques, which increases the complexity of algorithm design and compromises transferability.
In recent years, intelligent diagnostic methods based on deep learning technologies have attracted wide attention from scholars due to their outstanding performance. In contrast, deep learning (DL) models do not require complex signal processing techniques. DL models have deep-layered network structures, which can automatically extract inherent fault patterns from a large amount of operational data. Deep learning methods can adaptively extract representative feature information from collected circuit data without requiring extensive expert knowledge, and they have significant pattern classification capabilities [
23]. In recent years, deep learning-based fault diagnosis methods have continued to develop and have been applied to analog circuit systems with rich electronic technology [
24,
25]. Common deep neural networks include convolutional neural networks (CNNs), recurrent neural networks (RNNs), Stacked Autoencoders (SAEs), Deep Belief Networks (DBNs), and some of their improved variants [
26,
27,
28]. However, these DL-based diagnostic methods have inherent weaknesses in certain aspects, such as long-term dependency modeling, generalization ability, global context modeling, scalability, and parallel computing capability. Long short-term memory (LSTM) can model context dependencies, which can improve the model’s generalization ability. Shi proposed a severity assessment method based on LSTM networks, which addresses the issue of the high frequency and difficult evaluation of intermittent open-circuit faults [
29]. Zheng proposed an event classification method for power grid faults based on LSTM, aiming to achieve the end-to-end discrimination of power grid fault event types to meet the needs of intelligent power grids [
30]. Zhang considered the problem of sensor fault detection in stochastic linear time-varying systems, introduced a soft sensor model, designed a state estimator, and realized a real-time online application diagnosis program [
31]. Shi put forward a novel Generative Adversarial Network (GAN) model grounded in LSTM. This innovative model has the remarkable capability of autonomously generating fault data even when the sample size is scarce. As a result, it effectively addresses the long-standing issues of the limited availability of intermittent fault data and the high cost associated with experimental triggering [
32]. Fang proposed an improved GAN to overcome limited fault data [
33]. The attention mechanism can identify the important parts in all features and allocate more attention to them, while weakening non-critical features. This can improve the model’s robustness and alleviate the problem of long-term dependencies [
34]. Wang proposed a multi-task convolutional neural network that utilizes feature-level attention guidance to achieve accurate and real-time fault diagnosis and working condition identification in mechanical systems [
35]. Ye optimized the DCGAN using rare fault samples, enhancing its ability to extract features from minority classes [
36]. However, most existing fault detection methods do not consider spatial–temporal correlations.
To derive spatial–temporal fused features, a hybrid network is proposed [
37]. Hybrid networks have been proposed for fusion in CNNs and recurrent neural networks, spatial–temporal fusion networks [
38], as well as fusion in CNNs and LSTMs [
39]. Recently, CNN-LSTM networks have been developed for various applications, including fault detection, causality identification [
40,
41], time series prediction [
42], and image classification [
43,
44]. The advantage of CNN-LSTM networks is that the CNN component focuses on the most salient features, while the LSTM component extends its properties in a sequential manner, allowing the network to extract both spatial and temporal features.
Inspired by pioneering work, this study aims to design a spatial–temporal feature attention network (STFAN). The proposed model can extract deep spatial–temporal fusion features, enabling the detection of different fault modes. The proposed model has the following features: (i) In the proposed model, an efficient convolutional attention network (ECA) is introduced to adaptively capture the dynamic correlation of spatial variables. (ii) The extraction of spatial features among variables in the original data relies on the CNN and ECA models. The global feature extraction of each variable relies on the LSTM model. (iii) The two types of features are integrated through the weighting of the softmax layer or the voting mechanism. The spatial features of the CNN can be input as the initial state of LSTM, providing a spatial prior for sequence modeling. The main innovative contributions of this work can be summarized as follows:
- (1)
To address the spatial and temporal correlation of fault feature data, a network model capable of simultaneously extracting spatial–temporal features has been proposed. Multiple convolutional layers can expand the range of feature extraction, enabling better extraction of spatial dimension features. The addition of BiLSTM allows the model to consider both past and future contexts, enhancing its ability to understand and capture complex temporal dependencies. This model can better represent features, improving the model performance and generalization ability.
- (2)
Through the adaptive feature selection mechanism of the ECA module, the model can more effectively capture key features while suppressing noise interference, and simultaneously enhance its ability to understand the global contextual information of sequential data. This approach has achieved significant performance improvements across multiple tasks and demonstrated high-precision stability in repeated experiments, reducing the model’s sensitivity to random initialization.
- (3)
The proposed model method was applied in the field of fault diagnosis of airborne electronic systems. Experimental comparisons were made between the STFAN and BP, SVM, RNN, LSTM, and the proposed method showed significantly better performance in accuracy and stability than the others.
This study consists of the following main sections.
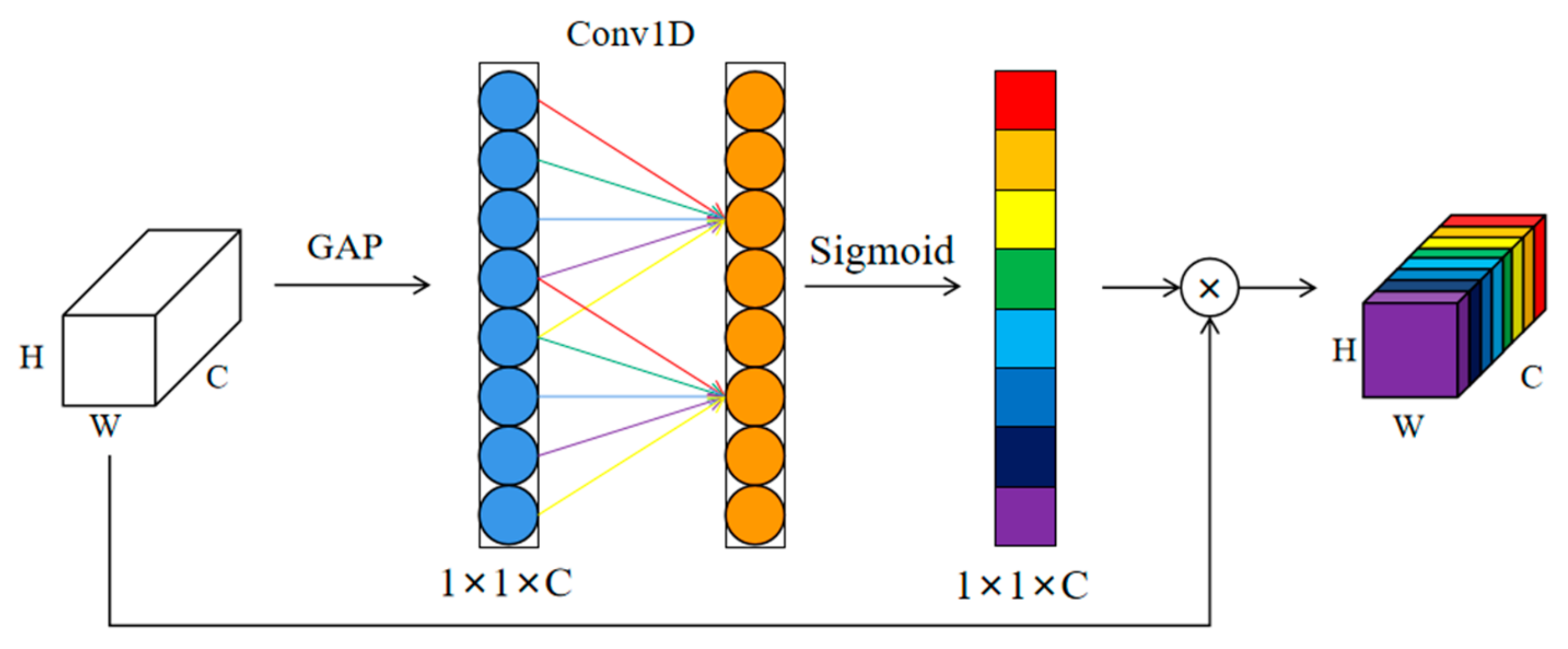
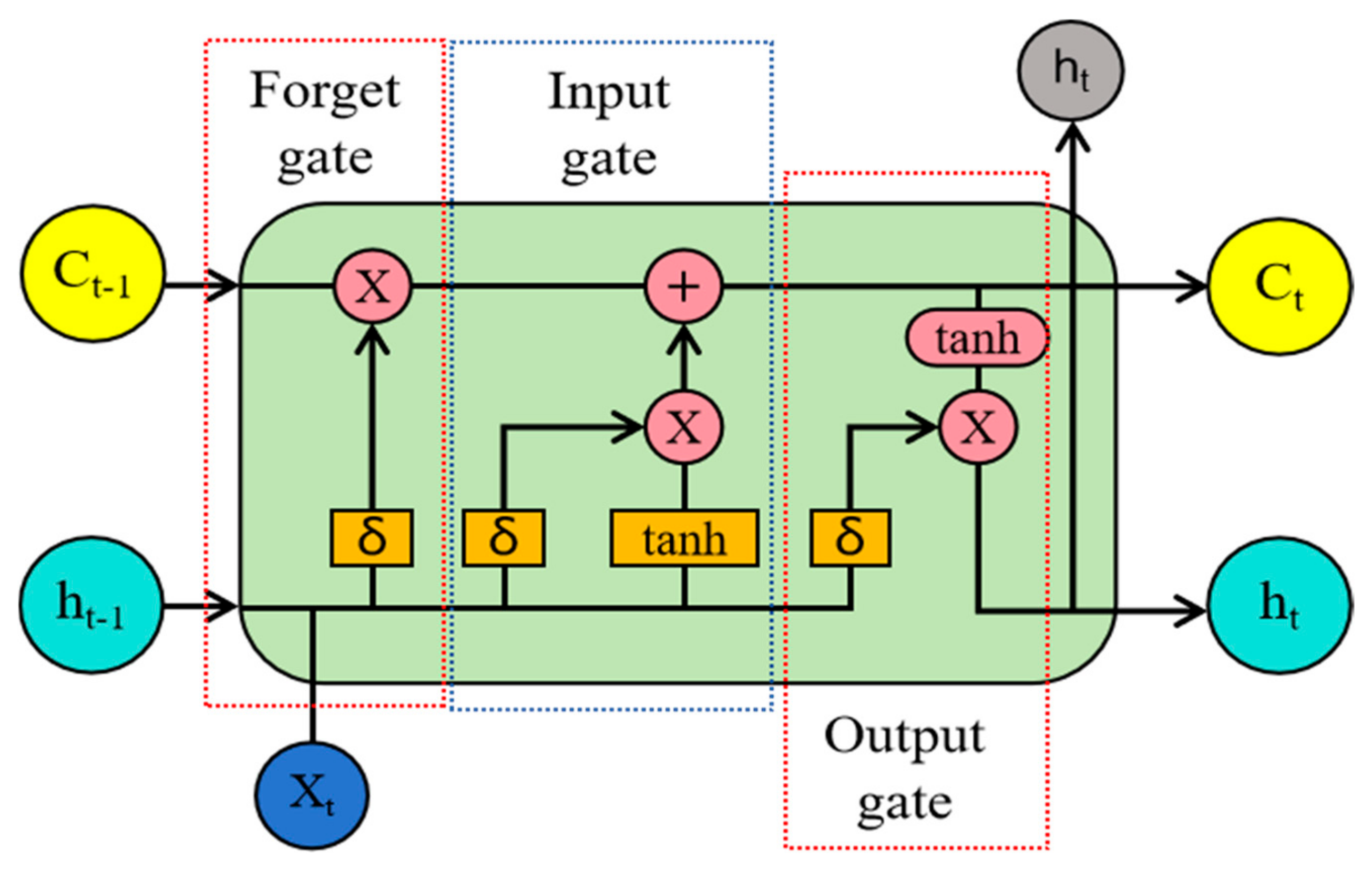
Section 2 introduces the related work, including the ECA-ResNet and LSTM;
Section 3 introduces the spatial feature extraction model and the temporal feature extraction model, and establishes the STFAN model;
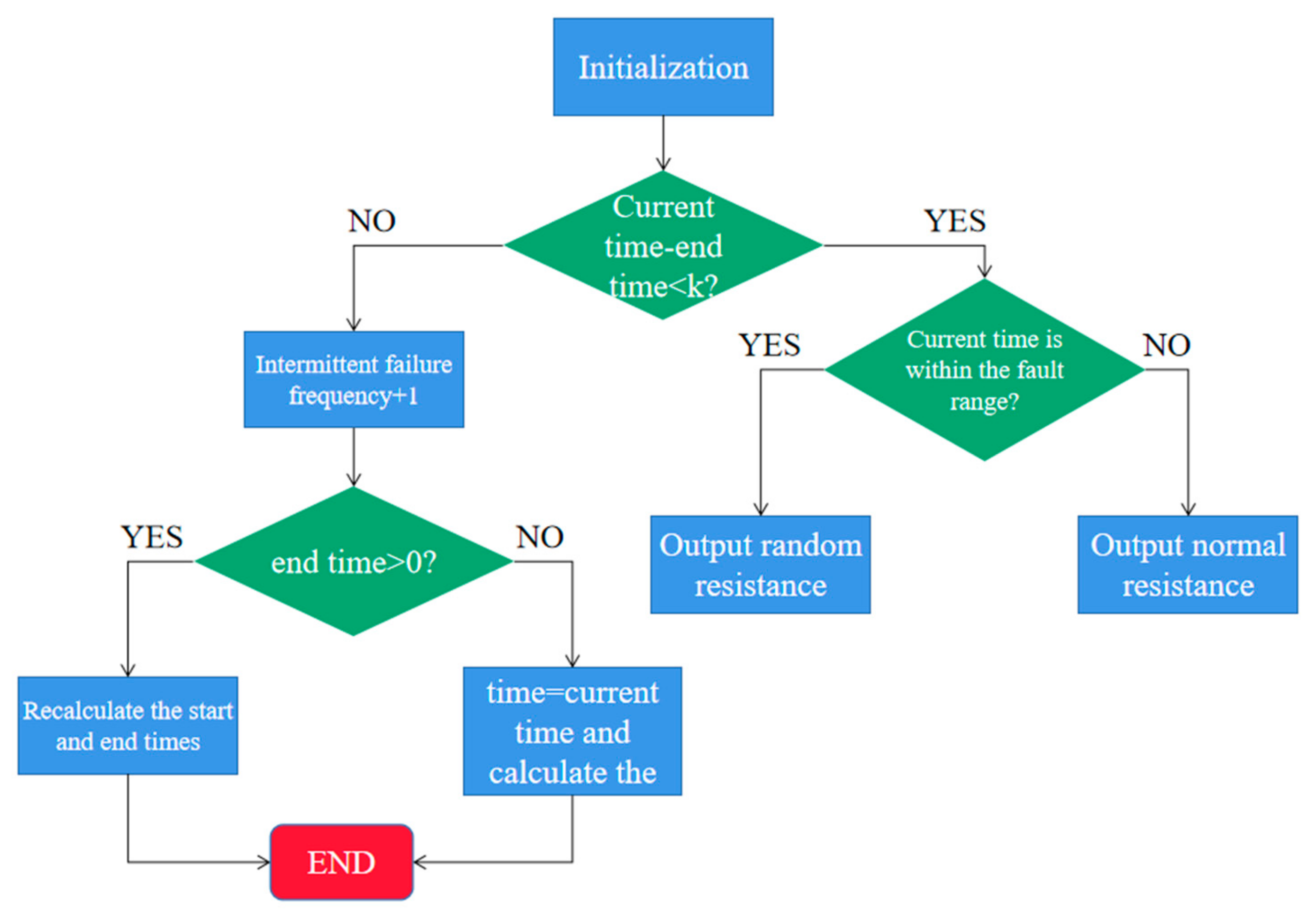
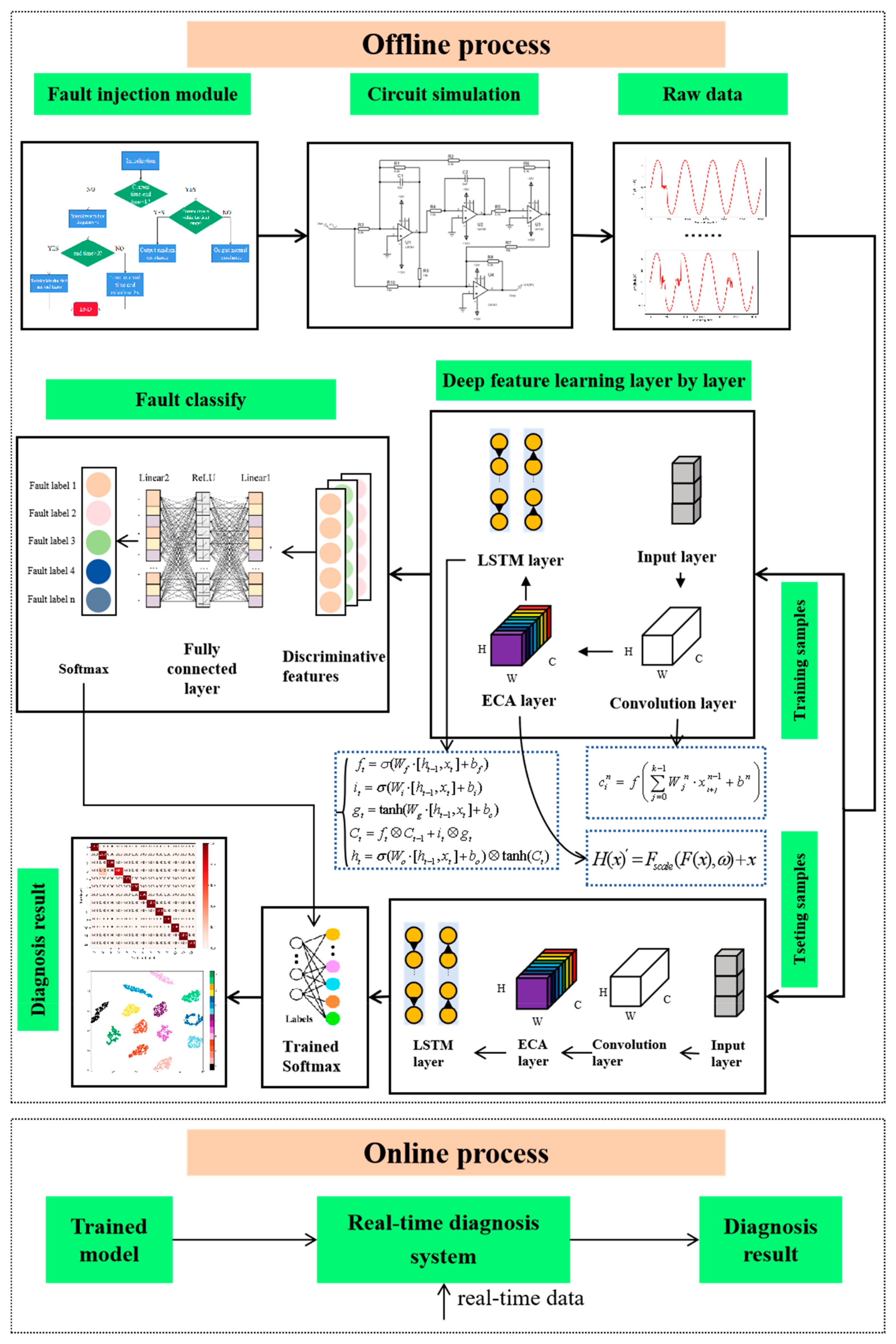
Section 4 proposes a fault injection module and provides an overall diagnostic framework;
Section 5 experimentally validates the superiority of the proposed method; and this work is summarized in
Section 6.
3. Methodology
In this section, the spatial feature extraction model and the temporal feature extraction model are introduced, respectively. Among them, the spatial feature extraction adopts the ECA-ResNet network model embedded with multiple convolutional layers, and the temporal feature extraction adopts BiLSTM. Finally, the complete STFAN network structure is established.
3.1. Spatial Feature Extraction
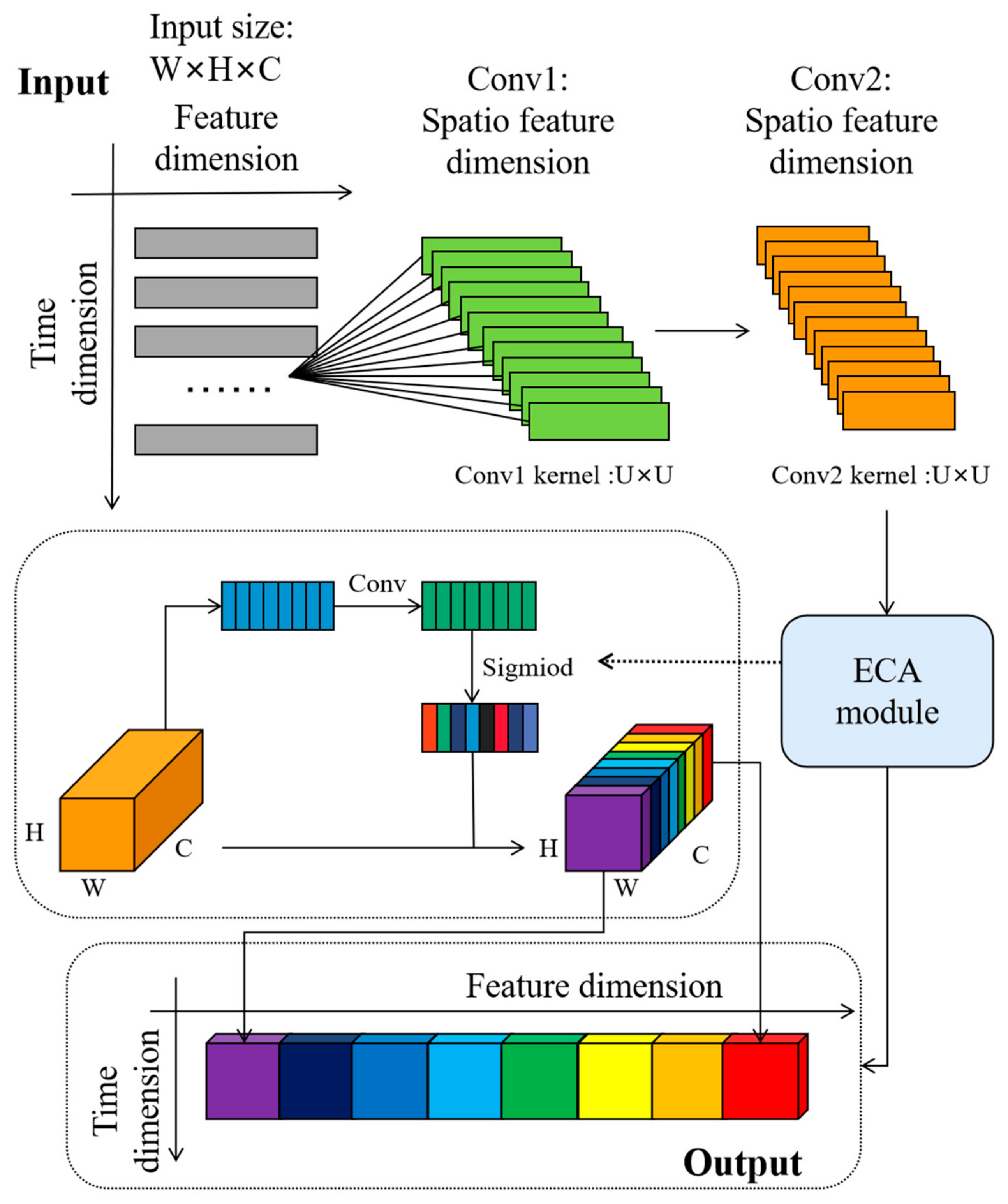
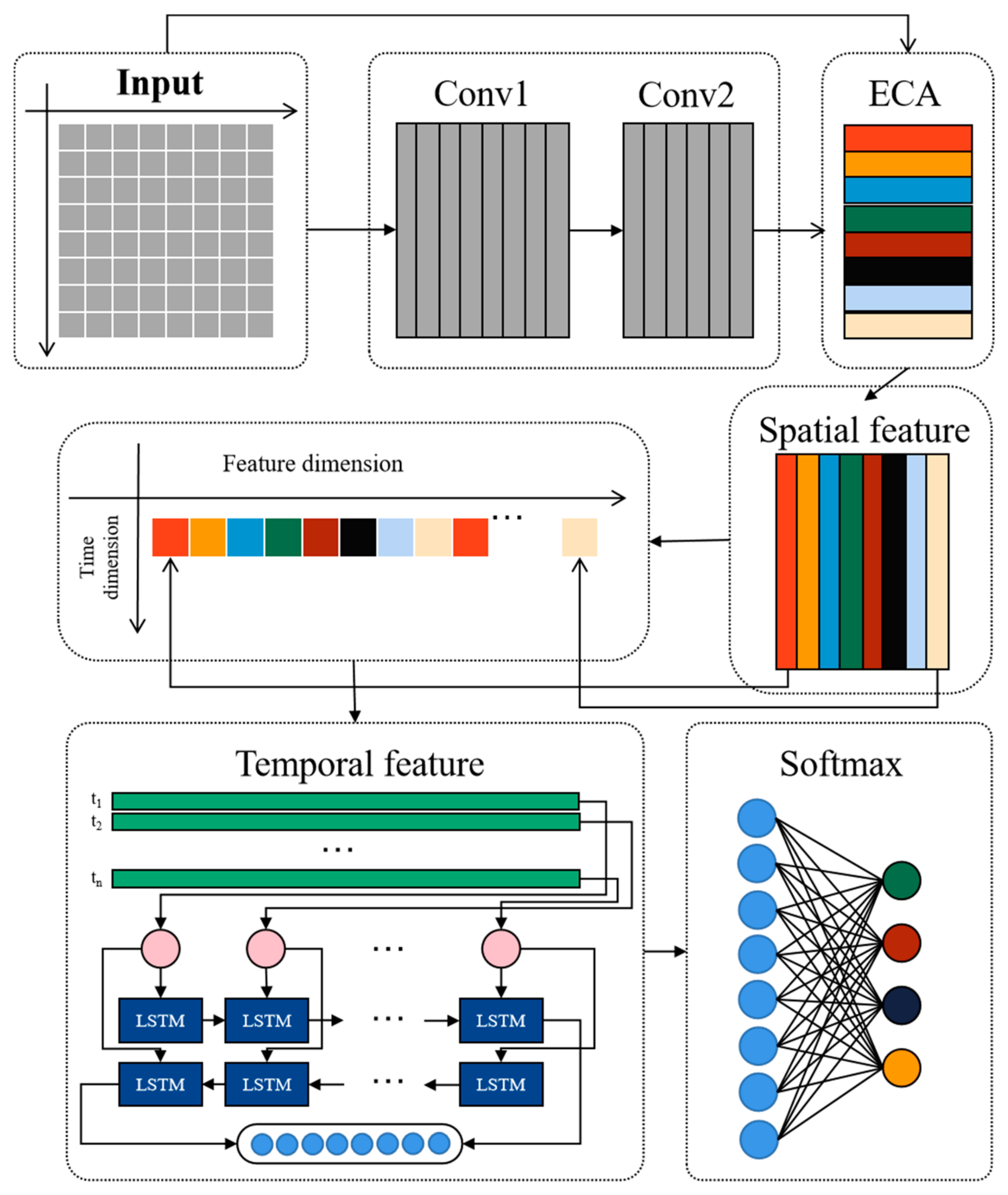
To obtain a comprehension of fault information, multiple convolutions for feature extraction are introduced. Convolution possesses outstanding capabilities in extracting local features. It can gradually obtain higher-level feature representations through multiple convolution layers. These advanced feature representations can help LSTM better understand abstract features within input sequences, which consequently enhances the performance. Additionally, it effectively reduces the model’s parameter count through parameter sharing and exploits local receptive fields to model the local structures of the data efficiently. This approach mitigates the risk of overfitting and enhances the model’s generalization ability.
The purpose of multiple convolutions is to automatically learn and extract spatial features from the data. By using a sliding window approach, local feature extraction is performed on the input data. This process involves element-wise multiplication and summation operations between the convolution kernels and input data, effectively capturing local structures and patterns within the input data. The multiple convolutions can be illustrated as Equation (12).
The structure of the proposed spatial feature dimension model is shown in
Figure 3.
3.2. Temporal Feature Extraction
BiLSTM consists of two LSTM units operating in opposite directions. LSTM introduces the concepts of gate units and cell state. The input gate controls the input information from the previous layer, while the forget gate manages the memory information from the previous time step. The training process of the BiLSTM network includes two steps: forward propagation and backward propagation. Forward propagation processes the input from the beginning to the end of the sequence, while backward propagation processes the input in reverse. This bidirectional approach allows the model to consider both past and future states, enhancing its understanding and ability to capture complex temporal dependencies. During the training process, the network parameters are iteratively adjusted through optimization algorithms to improve its performance in handling sequential data.
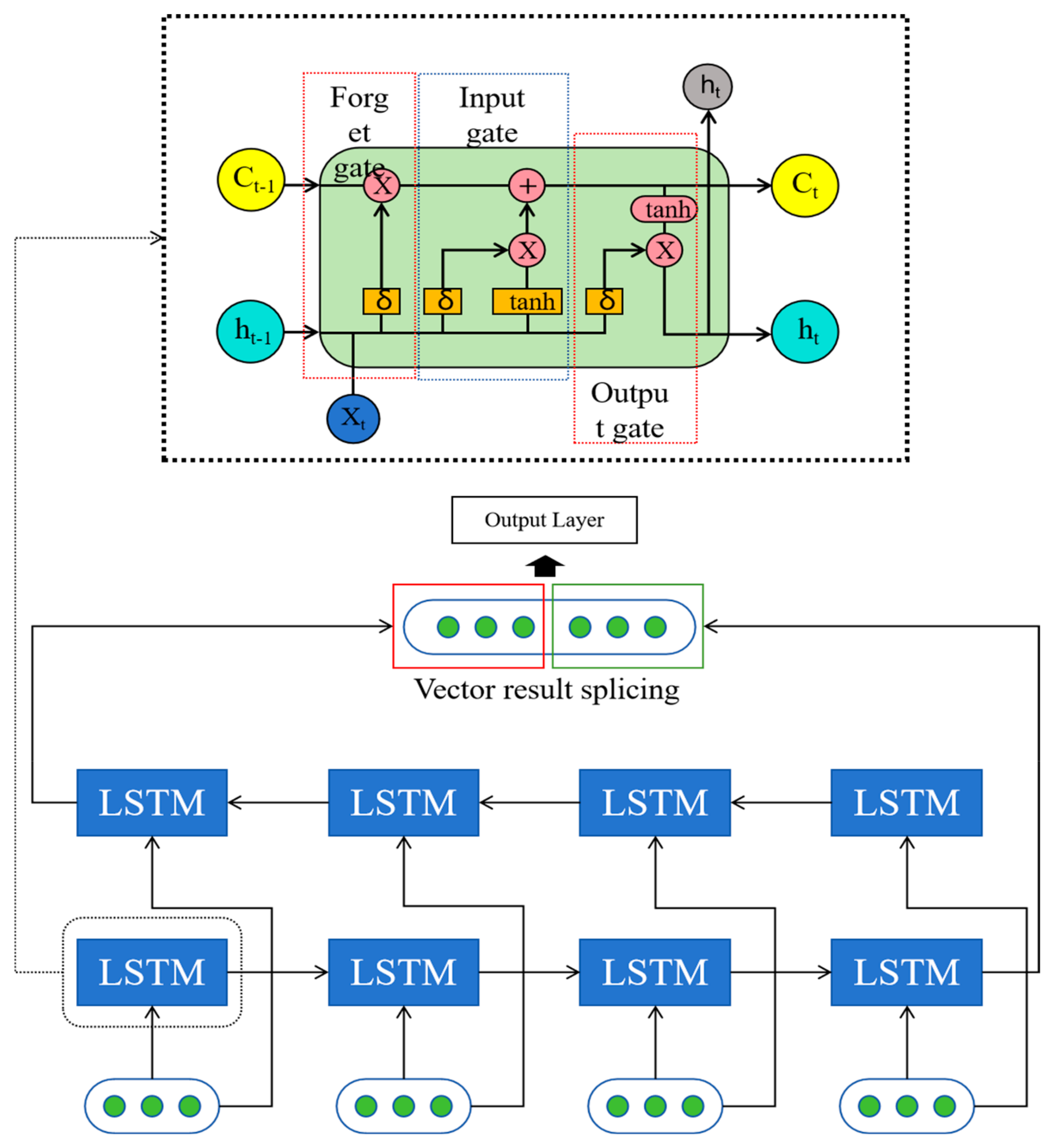
As shown in
Figure 4, a single-layer BiLSTM consists of two LSTM units, one processing the input sequence in the forward direction, and the other processing the sequence in the reverse direction. After processing is complete, the outputs of the two LSTMs are concatenated. The final BiLSTM output is obtained only after computing all time steps. The forward LSTM produces a result vector after four time steps, while the backward LSTM also produces another result after four time steps. These two result vectors are concatenated to yield the final output of BiLSTM.
The proposed BiLSTM model is able to learn temporal sequences and extract global features. The BiLSTM model preserves patterns of temporal changes through its cell state, making it capable of learning long-term information. By inputting the subsequence image feature data outputted by ECA and the original image data into BiLSTM for global learning, deep spatial–temporal fusion features can be extracted.
3.3. STFAN Method
In this paper, a novel method called spatial–temporal feature attention network (STFAN) is proposed. This method includes three parts: multiple convolutions, the ECA module, and BiLSTM module. Spatial features (CNN/ECA) represent the local structural correlations of signals, while temporal features (BiLSTM) capture the dynamic evolution patterns of sequences. These two types of features have an inherent complementarity in the information dimension, which conforms to the principle of maximum entropy. Moreover, the hierarchical feature extraction of the CNN and the temporal dependence modeling of LSTM form a multi-scale synergy. The specific fusion principle is as follows: Firstly, the feature space is expanded through tensor concatenation. Then, gating units are introduced to dynamically adjust the contribution degrees of spatial and temporal features. Finally, the two types of features are integrated through the weighting of the softmax layer or the voting mechanism. The spatial features of the CNN can be input as the initial state of LSTM, providing a spatial prior for sequence modeling. On the other hand, the temporal context of BiLSTM can modulate the feature extraction process of the CNN. The spatial features are expanded in the temporal dimension of LSTM to form a spatio-temporal joint feature tensor. The temporal features are compressed into a spatial feature enhancement vector through operations such as global average pooling, achieving the maximization of the mutual information between spatial and temporal features.
This model is a deep learning model for fault diagnosis, designed to handle data with both temporal and spatial features. Firstly, the model uses convolution to process the original one-dimensional data, achieving dimensionality expansion and local feature extraction. Then, the model utilizes an ECA module based on residual networks to focus on important features, enhancing the model’s perception of specific characteristics. Next, the model uses BiLSTM to focus on temporal features, capturing the temporal correlations in the data. Finally, the model uses softmax for classification, categorizing the data into different classes for fault diagnosis. The model combines the processing of temporal and spatial features to comprehensively analyze and diagnose faults. The structure of the proposed STFAN method is shown in
Figure 5.
This approach has better automatic feature extraction capability compared to traditional feature engineering methods. Traditional methods often require the manual selection and extraction of features, which may be limited when dealing with complex data. Using deep learning models, especially models that combine a CNN and BiLSTM, can automatically learn and extract important features from the data, thereby improving the accuracy and efficiency of fault diagnosis.
Compared to a single model, the method that combines multiple models can comprehensively capture features in the data. A CNN is suitable for extracting local features, ECA enhances the correlation between features, and BiLSTM can capture long-term dependencies in time series data. Therefore, this multi-model approach can more effectively utilize the diversity of data and improve the accuracy of fault diagnosis.
Compared to other deep learning models, ECA has a better channel attention mechanism, which can better explore the features in the data. Traditional attention mechanisms may only focus on partial channels’ information, while ECA can simultaneously consider all channels, thus having a more comprehensive understanding of the features and improving the model’s accuracy.
The classifier consists of two feed-forward multi-layer perception layers and a softmax function. The data with temporal–spatial correlated features, extracted and fused through LSTM, will be fed into the classifier for final pattern recognition. The softmax can be represented as Equation (13).
6. Conclusions
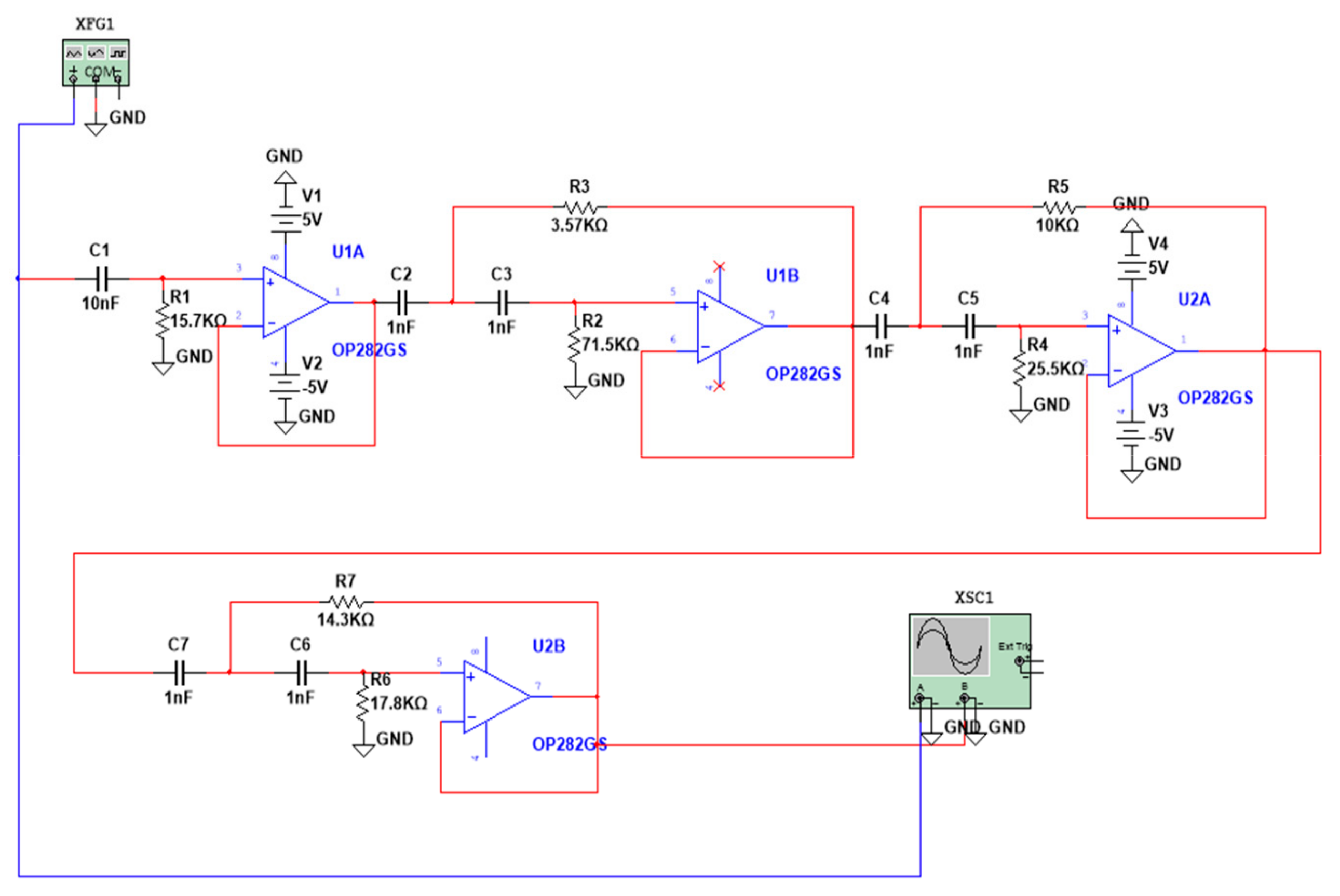
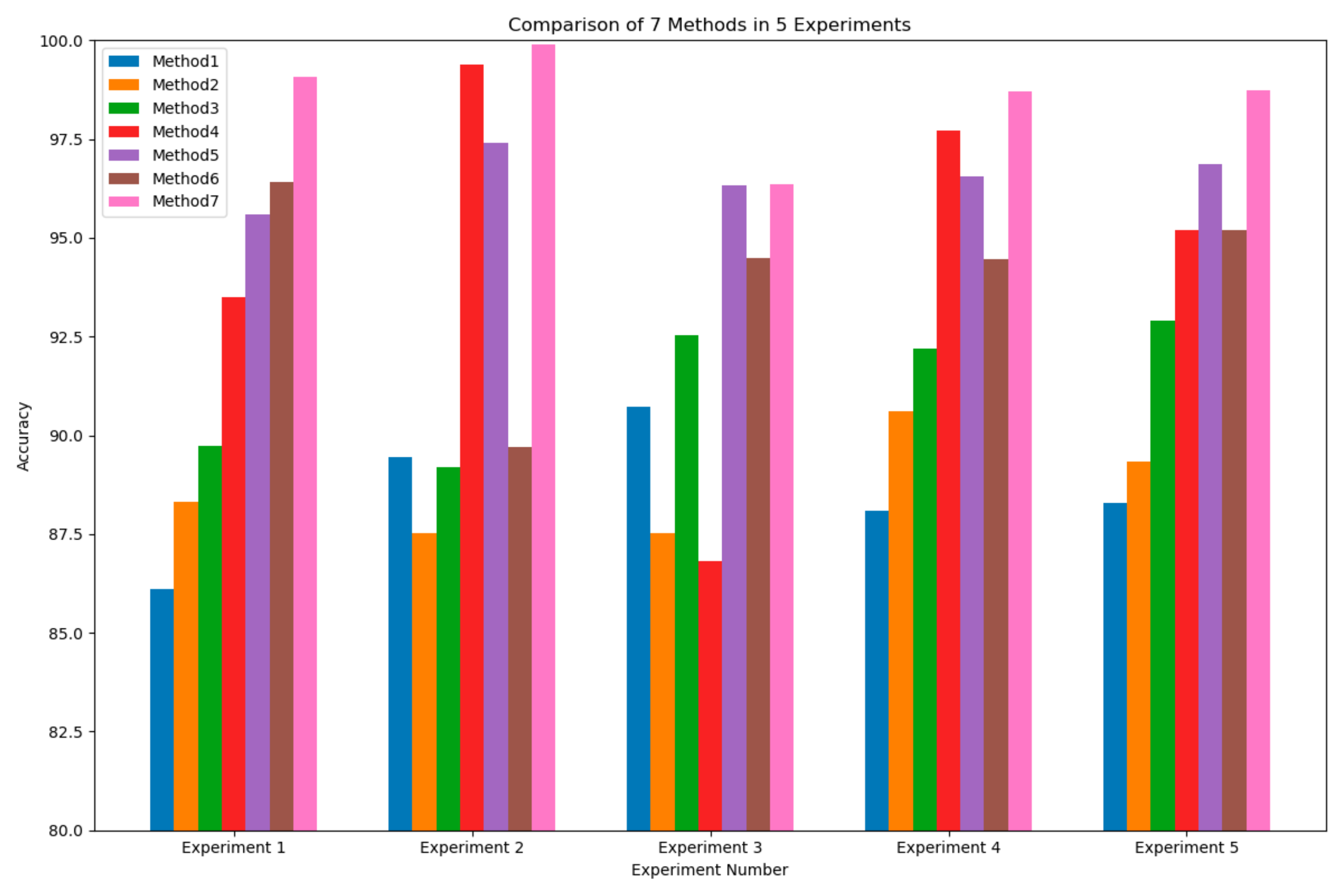
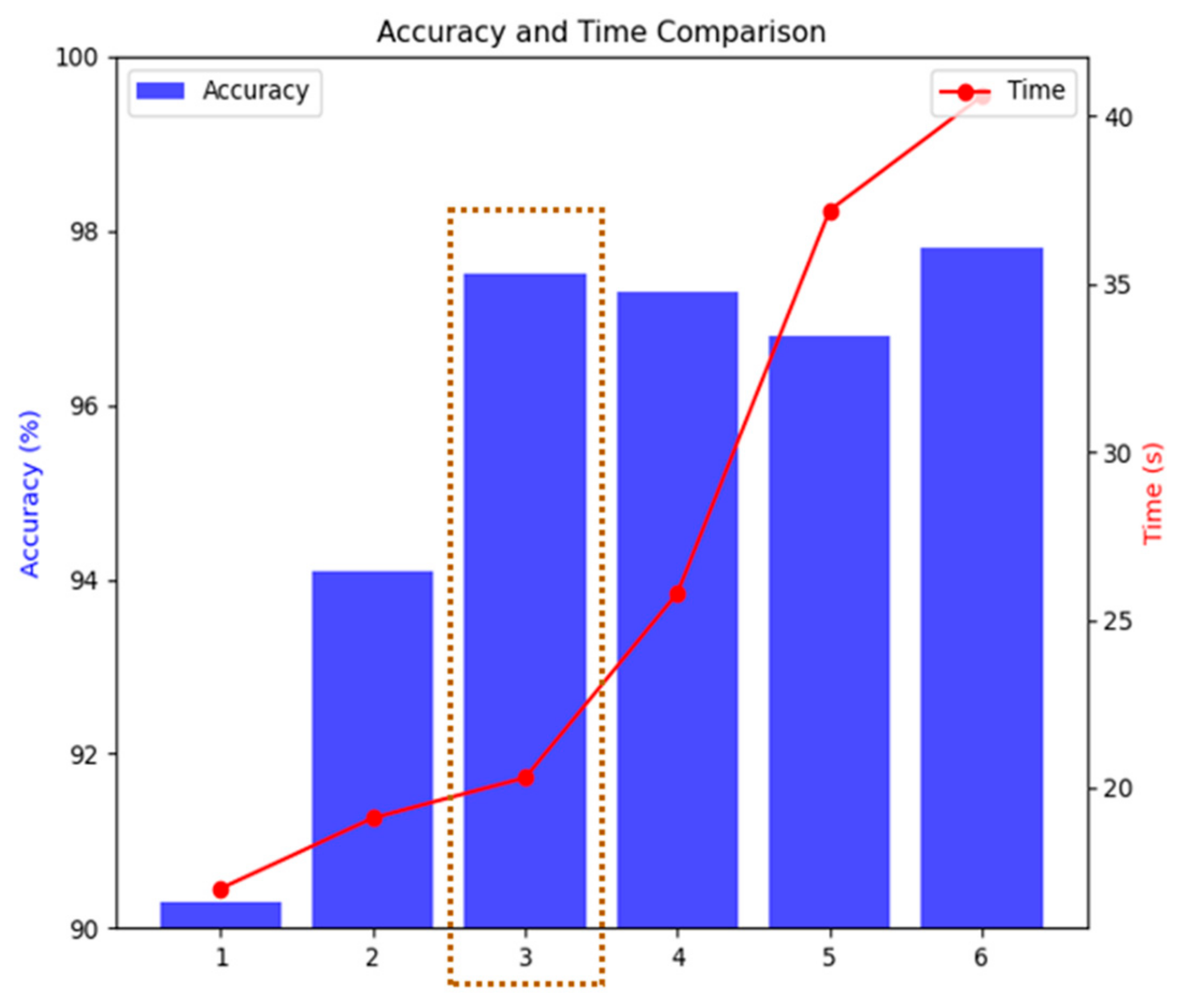
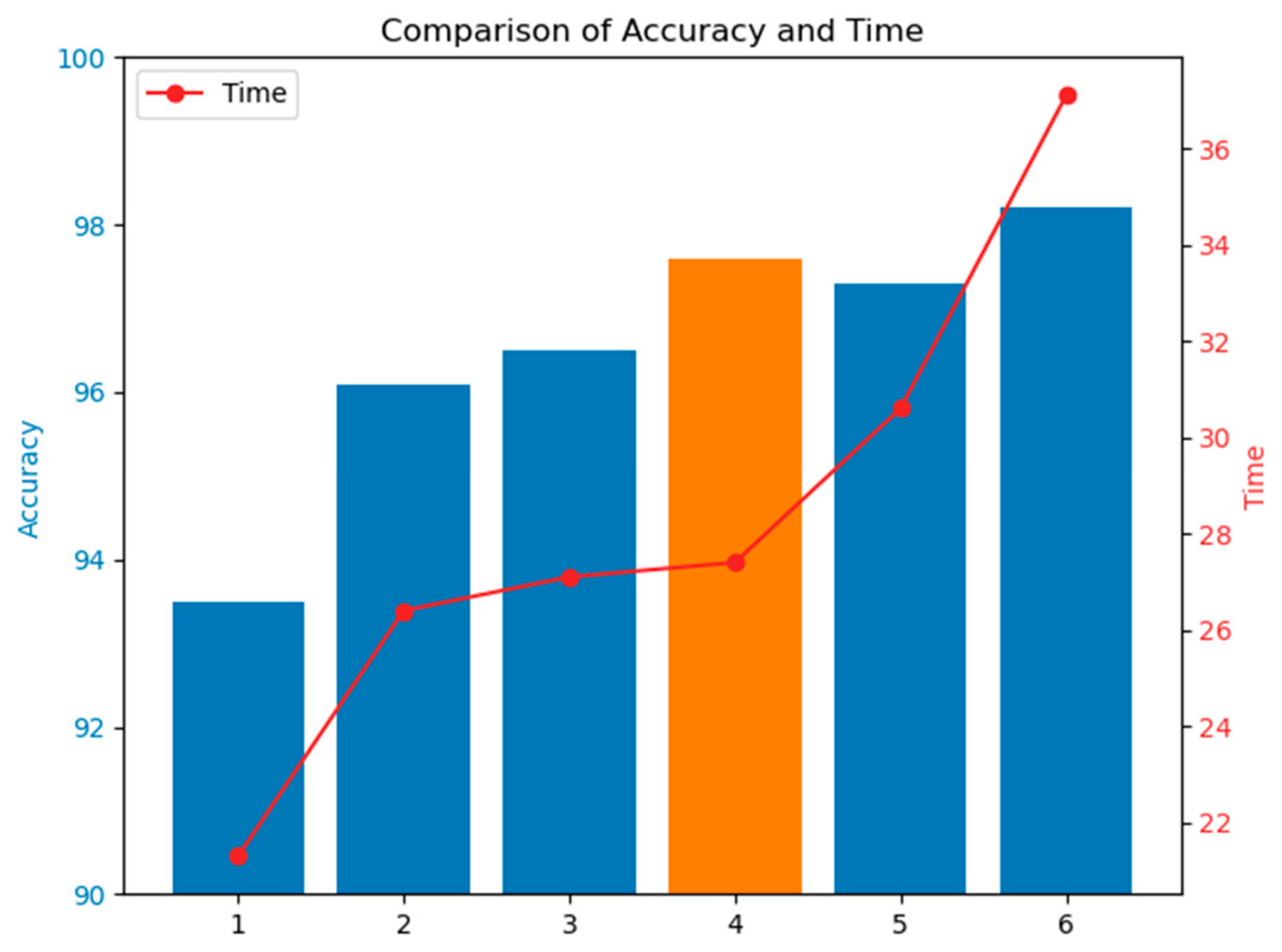
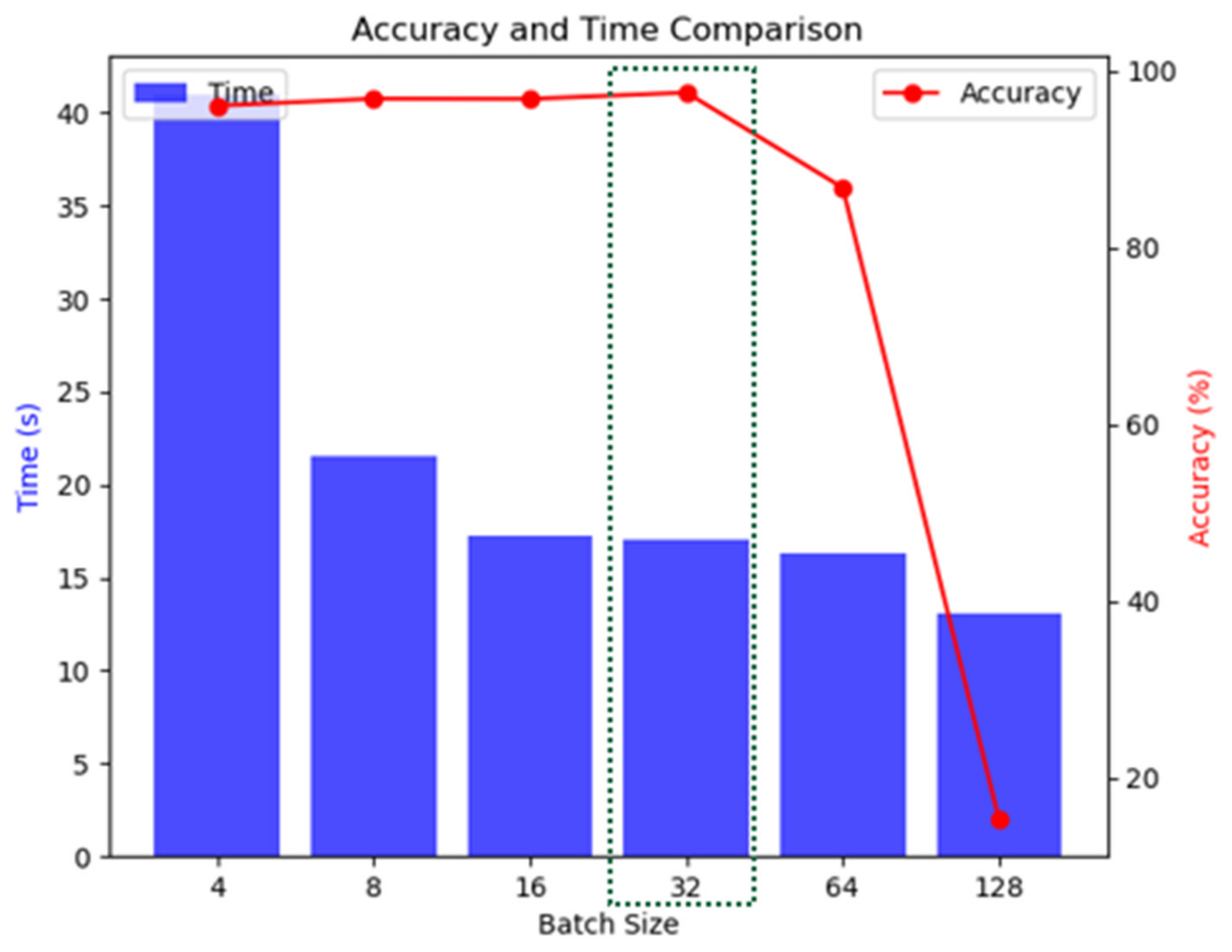
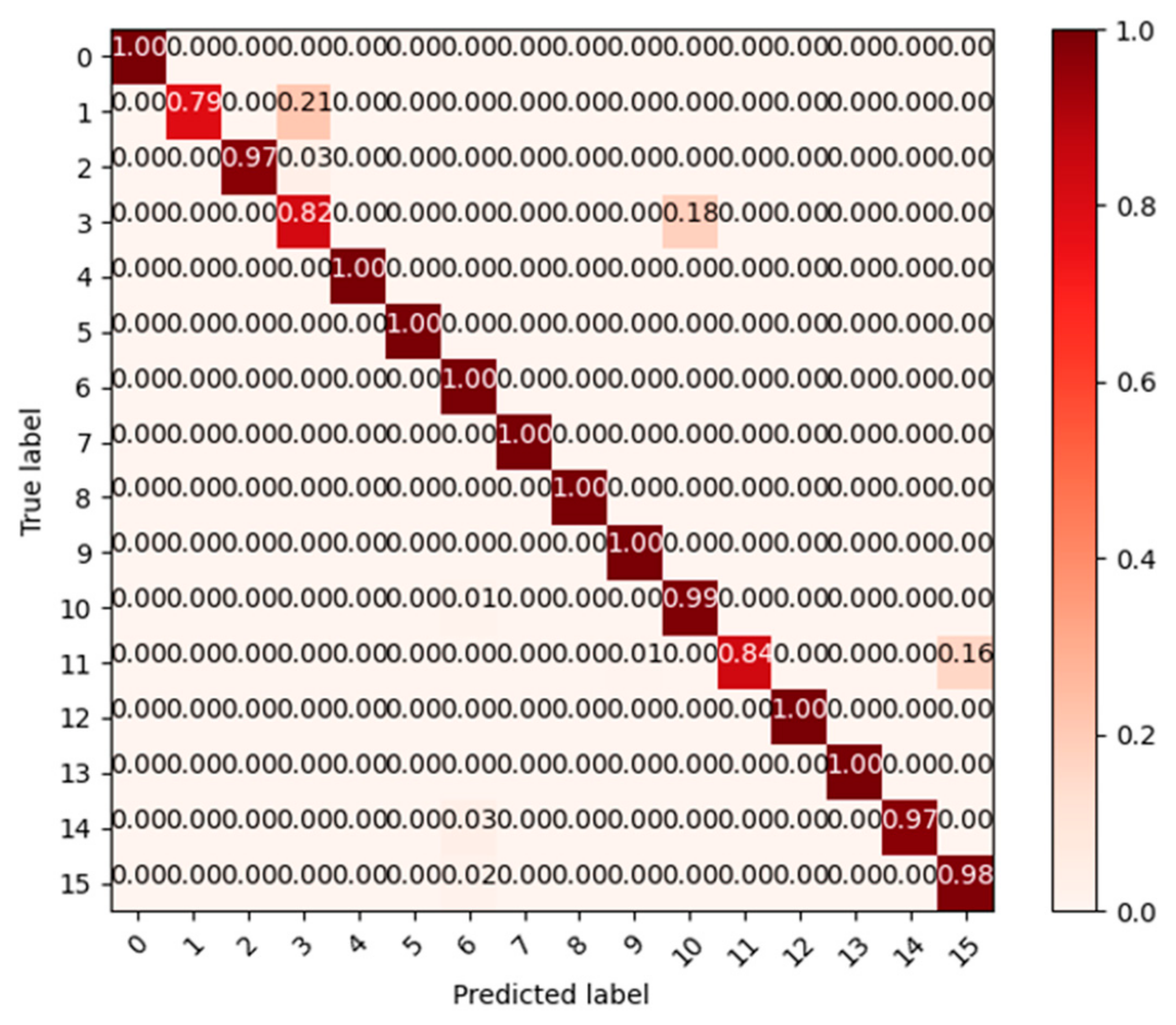
In this paper, a fault diagnosis method based on the STFAN is proposed. Multiple convolution layers are employed due to their capability to extract the most important features from the dataset. At the same time, they can be combined with the ability of LSTM to detect and store long-term dependencies between the extracted data. By extracting features from time and space dimensions, the problems of wide spatial distribution and random occurrence and disappearance time of complex faults can be effectively solved. Moreover, we add the ECA module to the network. The introduction of the attention mechanism enables the network to selectively focus on more important features, which enhances the model’s attention to features, and improves the model’s understanding of the entire time series data. The attention network captures longer-term dependencies and features, and ensures the stability of the accuracy rate of repeated experiments. In addition, we proposed a fault injection strategy to simulate the different operating states of circuit elements, which solves the problem of insufficient fault data. According to the characteristics of faults, a simulation model for the high-order Butterworth circuit was developed. The proposed network is trained and tested on a circuit dataset. Comparative analyses with the results of other deep learning models demonstrate an average accuracy improvement of 7.9% over the BPNN, 7.5% over the SVM, and 5.0% over the RNN in five experiments. Additionally, the stability of the proposed method has significantly improved compared to the ISTFAN. Based on experimental verification, our main conclusions are as follows:
- (1)
By using multiple convolutional networks and BiLSTM, the effective extraction of both spatial and temporal features has been achieved.
- (2)
By embedding the ECA module, key features are emphasized, enhancing the stability of the model’s accuracy across multiple experiments.
- (3)
Experimental results show that the proposed STFAN model effectively extracts the spatial–temporal features of different faults, significantly improving the accuracy of fault diagnosis in analog circuits.
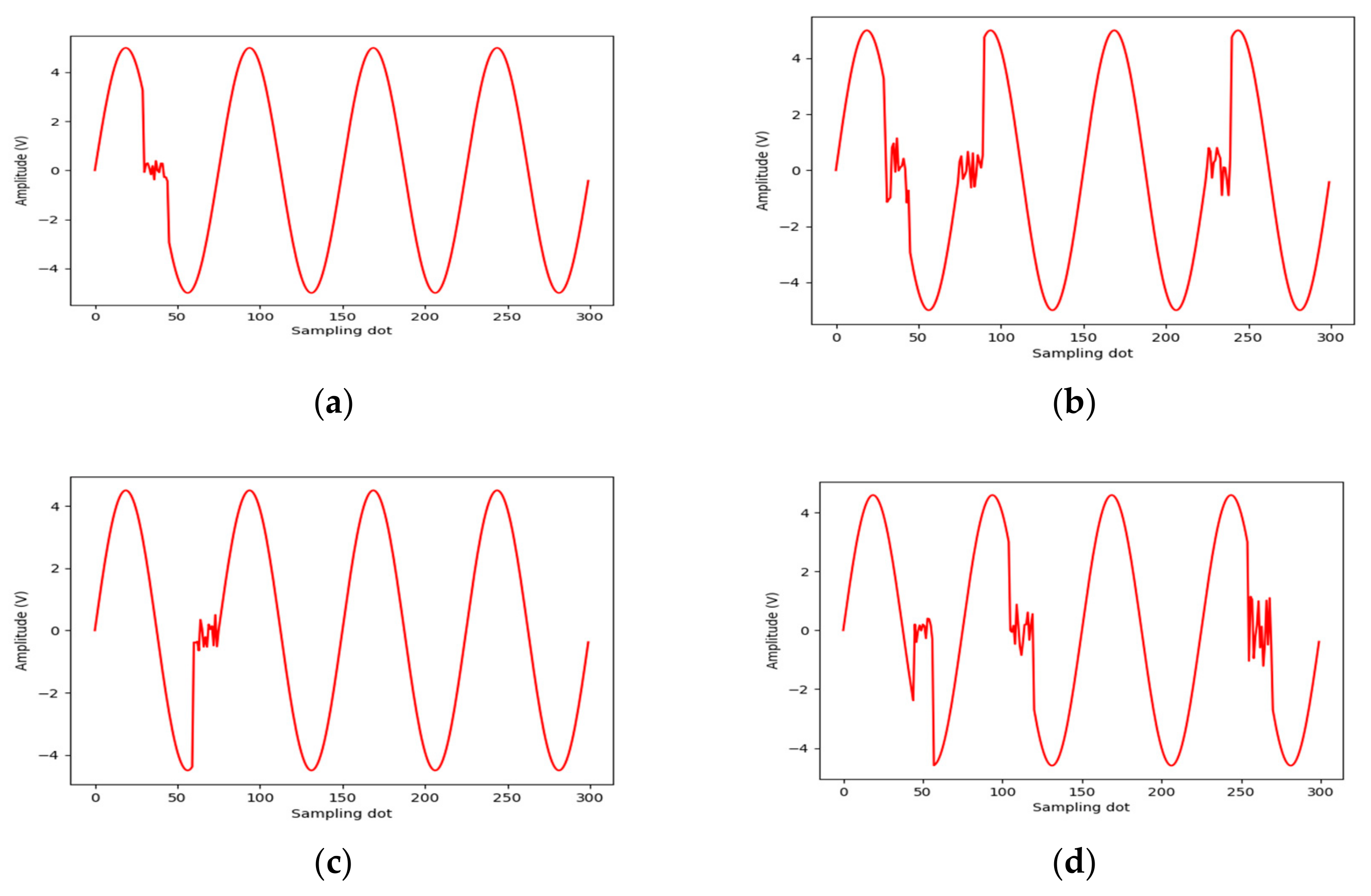
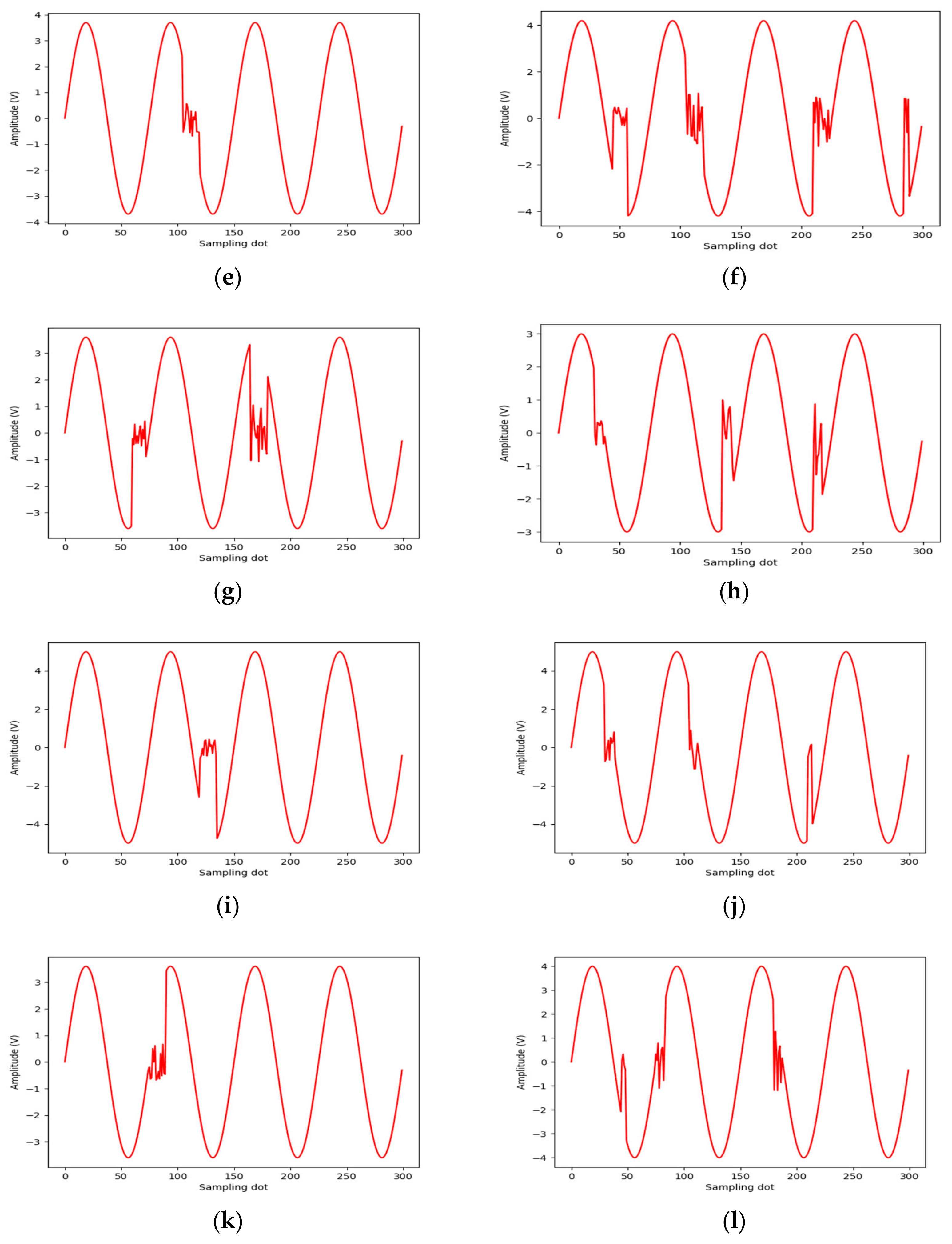
In future work, we plan to apply the proposed method to hardware circuits. Additionally, we have only conducted diagnostic studies on faults; achieving fault prediction in real-world conditions would offer greater practical value. A hardware-in-the-loop (HIL) testbed is currently under development, and we plan to systematically address deployment challenges in physical systems in subsequent work. The simulation results in this study provide a methodological foundation for future real-environment testing.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}