1. Introduction
Machine learning (ML), as defined by El Naqa et al. [
1], is an evolving branch of computational algorithms designed to emulate human intelligence by learning from the surrounding environment. These algorithms use input data to automatically adapt their architecture through several iterations in order to emulate human intelligence and produce an outcome. Although there are several types of ML, the overall objective of ML is to learn from a task, generalize from new unseen data and produce an outcome.
In recent years, the number of physical devices capable of interconnecting and generating information about particular entities has enormously increased, opening a whole new research area named the Internet of Things (IoT). Despite IoT being a deeply studied research area, many definitions are still evolving. Li et al. [
2] defines IoT as a “dynamic global network infrastructure with self-configuring capabilities based on standards and interoperable communication protocols”. Dorsemaine et al. [
3] describes it as a “Group of infrastructures interconnecting connected objects and allowing their management, data mining, and access to the data they generate”. The rapid increase in the number of smart devices, such as cellphones and wearables, has introduced a new era in which ML algorithms are integrated into IoT systems to perform training using the large volumes of data produced. There are many practical examples in various areas where ML algorithms are applied in smart devices to solve day-to-day common tasks. For instance, Filipe et al. [
4] design and develop an end-to-end implementation of a voice-activated smart home controller that, through the usage of ML, automatically adapts to the user’s patterns. Kavitha et al. [
5] study the application of clustering techniques for early-stage anomaly detection in wearable devices’ data to provide smart healthcare. Makroum et al. [
6] conduct a systematic review of articles with the main objective of using smart devices for monitoring and better management of diabetes.
In a traditional ML setting, all the networked devices send their data to a central server, where an ML model is trained and then shared over the network. Although such centralized settings are very common, they come with many challenges, such as data privacy, data-intensive communications, and limited connectivity. To overcome these challenges, a new paradigm has emerged: federated learning (FL). This approach was proposed in 2016 by McMahan et al. [
7], and it is based on the idea of having a decentralized setting in which the networked devices can train a local ML model and share their knowledge among other devices to collaboratively learn, while keeping sensitive data safe. This paradigm has been rapidly adopted in many areas, with particular interest in robotics, as collaboration among robots to solve specific tasks is a deeply studied research area. For instance, Borboni et al. [
8] provide a systematic literature review of publications on the expanding role of artificial intelligence in collaborative robots and their industrial applications. Soori et al. [
9] present an overview of current research on the development of AI techniques in advanced robotic systems, such as autonomous driving, robotic surgery, and service robotics, among others. Gallala et al. [
10] present a method that enables human–robot interactions through technologies, like mixed reality, IoT, collaborative robots, and AI techniques, achieving efficient human–robot interactions.
Despite FL being an emerging research area extensively studied in numerous works, many open challenges remain to be addressed. Motivated by the potential of FL applied to a distributed network of robotic agents, this work extends a study of Gutierrez-Quintana et al. [
11]. In this extension, we explore the implementation of a federated setting within a well-known robotics framework to facilitate collaboration in robotic environments, enabling networked agents to share their knowledge and learn collaboratively. The experimental results demonstrated that the proposed framework improved the generalization ability of the training agents, allowing them to incorporate shared knowledge into their respective local models to efficiently solve a common problem. Furthermore, as the number of agents increased, the framework contributed to stabilizing the obtained rewards.
The rest of this paper is structured as follows.
Section 2 reviews the related work and background on federated learning and its application in robotics.
Section 3 details the system architecture, including the integration of the proposed techniques.
Section 4 describes the methodology, outlining the experimental design, algorithm configuration, and reward function.
Section 5 presents the experimental results and performance analysis. Finally,
Section 6 concludes this paper providing a discussion of the findings, highlighting the implications and potential limitations of the proposed approach and outlining future research directions.
2. Related Work
This section is a review of the literature of an FL framework, providing novel examples of FL applications for robotics to illustrate the state of the art and their challenges.
The concept of federated learning was first introduced by McMahan et al. [
7] and Konečný et al. [
12]. In their work, the authors presented an alternative to traditional machine learning (ML) methods in which the learning process is distributed and performed on-device. According to the authors, in an FL framework, the devices on the network perform collaborative learning by sharing their local gradients with a central server that aggregates them and returns an average to a selected set of devices. The authors were able to experimentally demonstrate that an FL framework improves upon traditional ML in terms of communication cost and data security. Since data remain local on each device, this reduces the number of communication rounds while keeping data secure. Although FL represents an improvement over traditional techniques, it still faces key challenges such as communication reliability in distributed systems, data privacy, system heterogeneity and data heterogeneity. Fu et al. [
13] systematically present recent advances in the field of FL client selection. Since FL is relatively new, many studies have aimed to identify suitable mechanisms for client selection. The authors review recent works based on criteria for prioritizing FL clients. Although many algorithms have been studied, the authors note that most rely on experimental results, and an in-depth theoretical analysis and metrics for a suitable unified client selection algorithm are still needed. Chen et al. [
14] present a software architecture that addresses the problem of operating multiple tasks for human–robot collaboration, being able to recognize gesture and speech interactions in real time. Through a multi-threaded architecture and relying on an integration strategy, the authors successfully presented an alternative to FL, demonstrating on their validation experiments an accuracy of >98% for 16 designed dynamic gestures and >95% for 16 designed dynamic gestures.
One of the advantages of an FL framework is that networked devices can collaboratively train ML models using shared knowledge while preserving data privacy. In robotics, collaboration is a rapidly growing research area, with challenges such as the design of localization algorithms for multi-robot networks [
15], multi-agent human–robot interactions [
16], etc. Despite emerging as a solution for current problems, there are still open issues such as performance optimization and privacy concerns, as discussed in Anjos et al. [
17]. Yu et al. [
18] studied the intersection of FL and robotics for vision-based obstacle avoidance. In their research, the authors analyzed the performance of an FL approach compared to a traditional centralized process for addressing vision-based obstacle avoidance in mobile robots. Through a series of simulated and real-world experiments, they demonstrated that a federated framework could improve the performance of a centralized process while offering benefits in communication optimization and privacy preservation. Sim-to-real is another research area focused on transferring knowledge from software simulations to the real world. This area is extensively studied in the context of autonomous driving, as training a robot in every possible scenario is not feasible. Liang et al. [
19] proposed a federated transfer reinforcement learning (FTRL) framework for autonomous driving. In their work, the authors introduced an online method in which participating agents could share their knowledge in real time, even while interacting in different environments. Their research demonstrated that the proposed framework improved the performance of traditional methods, achieving a 42% reduction in collisions and a 27% increase in the average distance covered. In another study, Liu et al. [
20] addressed the challenge of enabling robots to learn efficiently in new environments while leveraging prior knowledge. They proposed a scalable architecture called lifelong federated reinforcement learning (LFRL) for cloud robotic systems, which evolves a shared model using a knowledge fusion algorithm. The results showed that LFRL enabled robots to utilize prior knowledge while quickly adapting their navigation learning to new environments. Additionally, the proposed algorithm successfully fused prior knowledge to evolve a shared model.
After reviewing the literature on the intersection of robotics and FL, it is evident that this remains a relatively new and challenging research area with much still to explore. To the best of our knowledge, one topic that has not yet been thoroughly investigated is the use of existing robotic tools to facilitate knowledge sharing among networked robots. In this paper, we introduce an FL architecture that leverages a well-established robotics framework to collaboratively train a set of agents. Unlike previous works, our primary motivation is to assess the reliability and robustness of this robotics framework in a federated setting, with the aim of obtaining experimental results that can inform future studies on more complex tasks.
3. System Description
This section covers a brief description of the fundamentals of an FL framework. We also introduce our proposal, the different elements that compose the system, and the technologies used for the implementation. It is worth mentioning that our proposed framework is not tied to a particular ML technique and that this work is an extension of Gutierrez-Quintana et al. [
11] in which we study the application of ML techniques for robotic simulations.
3.1. Software Platform
The main objective for the set of federated agents is to train a local model with private data. Thus, a set of machine learning tools is required. At the moment, there are two well-known alternatives, Tensorflow [
21] and Pytorch [
22], which are sets of open source ML libraries developed by Google and Meta AI, respectively. In Novac et al. [
23], an analysis is made to determine if the selection of either any of these libraries could potentially impact the system’s overall performance, concluding that Pytorch v2.3.1 is better suited for tasks in which speed is a key component, whereas Tensorflow offers the best accuracy. In comparison with our previous work, we have decided to move forward with the PyTorch framework this time due to its user-friendly interface and overall easier integration.
The next element of the infrastructure is the technology that will be the middleware of the system. Since, in this work, we study the implementation of an FL framework for robotic applications, the development from scratch of a network module is far from our objective. Therefore, we focus on the utilization of a set of tools that could facilitate the back-end transmission and reception of messages in real-time robotic systems. In Tsardoulias et al. [
24], different robotic frameworks are analyzed, with the Robot Operating System 2 (ROS 2) framework being the one that kept our interest. ROS 2 (ROS 2 web page
https://www.ros.org (accessed on 23 March 2025)) is an open source set of libraries based on DDS, a networking middleware that follows a publish–subscribe pattern to transfer serialized messages within a set of nodes [
25]. On top of being a friendly framework for the integration of heterogeneous hardware and software components, ROS 2 also facilitates the implementation of modular architectures without the need of starting from scratch [
26,
27]. Also, in terms of robustness to network failures, ROS 2 has a set of mechanisms called quality of service (QoS) that guarantee reliable communication. One of the QoS mechanisms is related to reliability. Depending on the selected configuration, you can either expect that messages are delivered until successfully received or that you can send a message without guaranteeing delivery. Overall, the selection of ROS 2 is strongly driven by its communication interfaces (ROS 2 interfaces
https://docs.ros.org/en/humble/Concepts/Basic/About-Interfaces.html (accessed on 23 March 2025)), which facilitate the transmission of diverse information in robotic systems, such as computer vision images and sensor data.
The platform is completed by a simulation component developed in Unity (Unity web page
https://docs.unity3d.com/Manual/ (accessed on 23 March 2025)), a powerful video game motor used to create 2D and 3D virtual scenes. In the Unity environment, an artificial agent will be deployed to interact with its surroundings. This component will connect through a ROS 2 TCP endpoint (ROS-TCP-endpoint repository
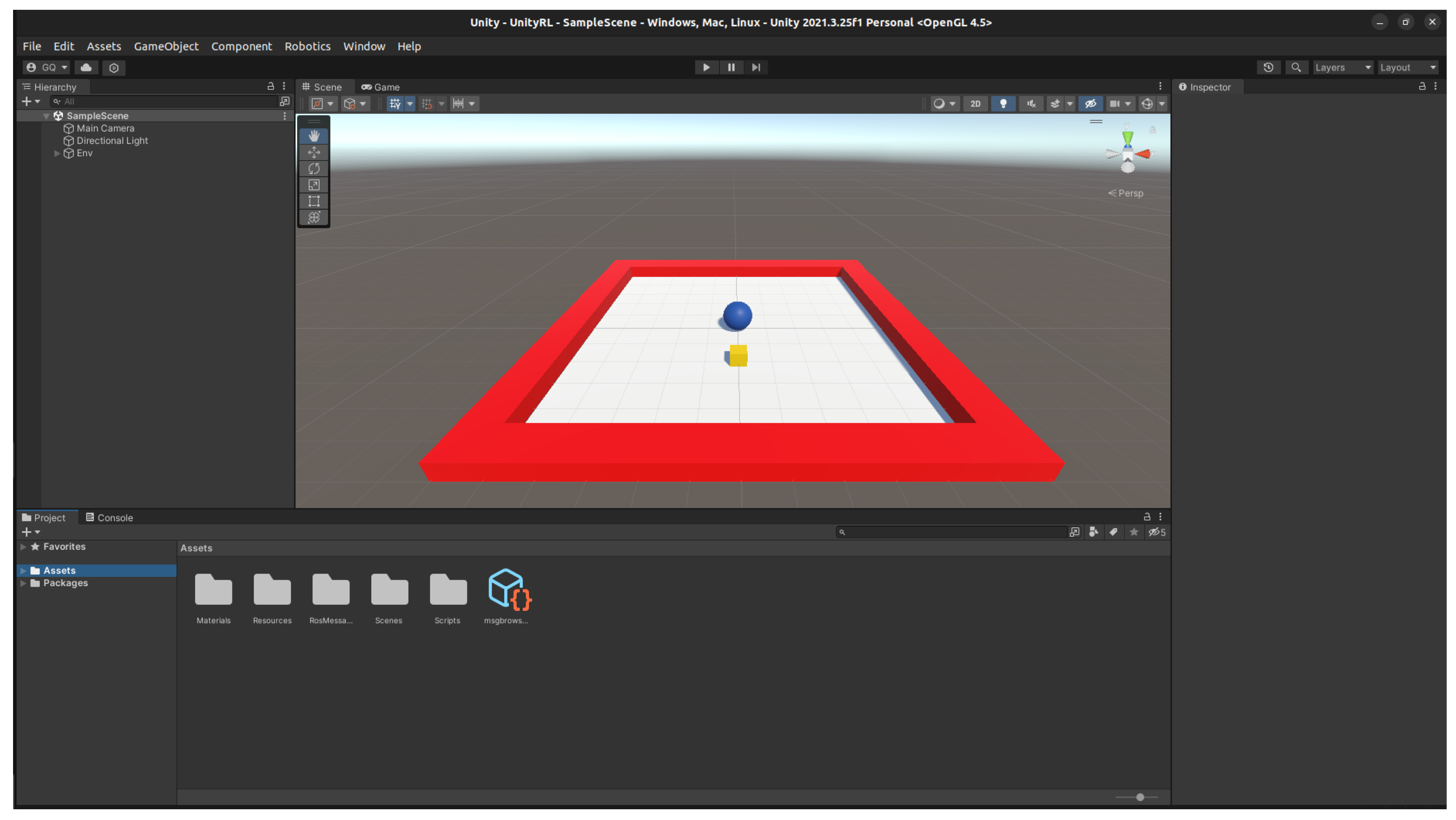
https://github.com/Unity-Technologies/ROS-TCP-Endpoint (accessed on 23 March 2025)) to the Python 3 module, which includes a set of ROS 2 services responsible for the learning process. An example of the environment can be seen in
Figure 1.
3.2. Deep Reinforcement Learning
We are considering the standard definition of an artificial agent given in [
28], which describes an RL agent interacting with an environment in sequences of discrete time steps. At each time step
t, the agent selects an action
and receives a representation of the environment
as an observation. A numerical reward,
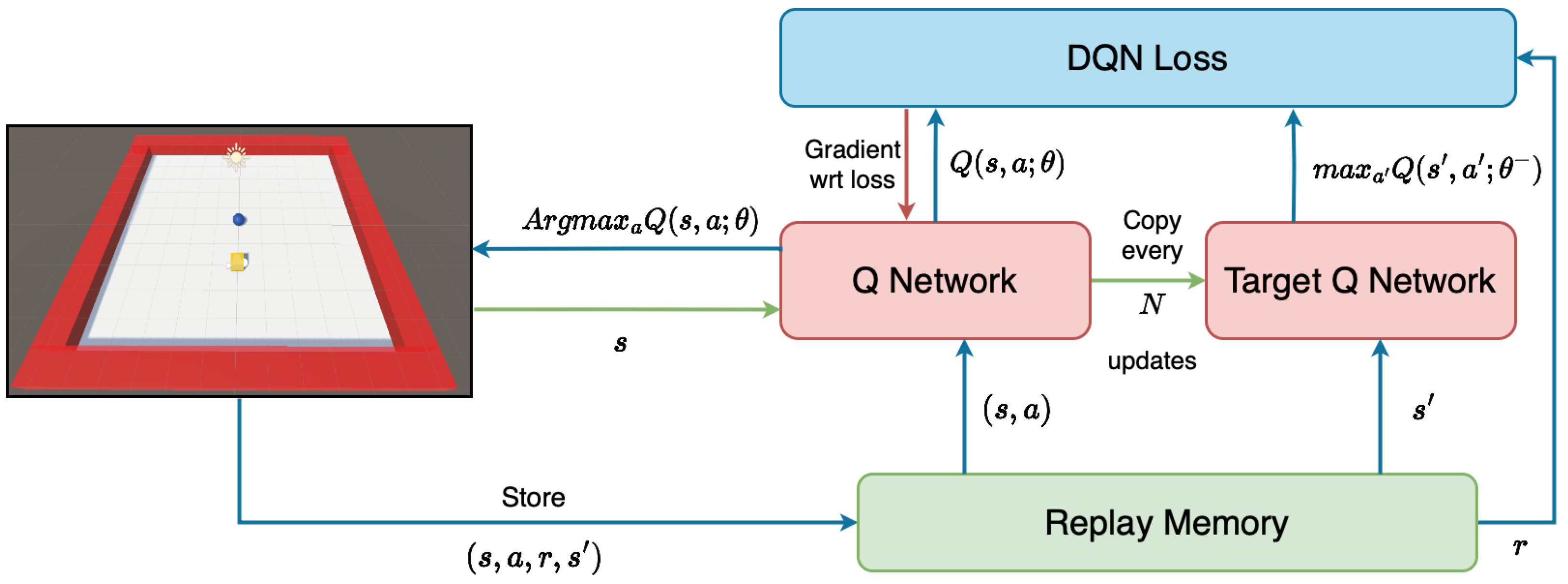
, is returned to the agent as a consequence of the selected action. For the training algorithm, we have selected Double Deep Q Networks (DDQNs) [
29] for this work. A DDQN is a novel adaptation of the DQN algorithm, a technique in which an agent learns to estimate the optimal action/value function
to maximize future rewards. The motivation for the DDQN arises from an issue in the DQN algorithm, which is likely to overestimate values, and it introduces two separate neural networks that decouple the action selection and value estimation processes, improving stability. A diagram of the DDQN architecture can be seen in
Figure 2. A detailed description of this architecture can be found in [
29].
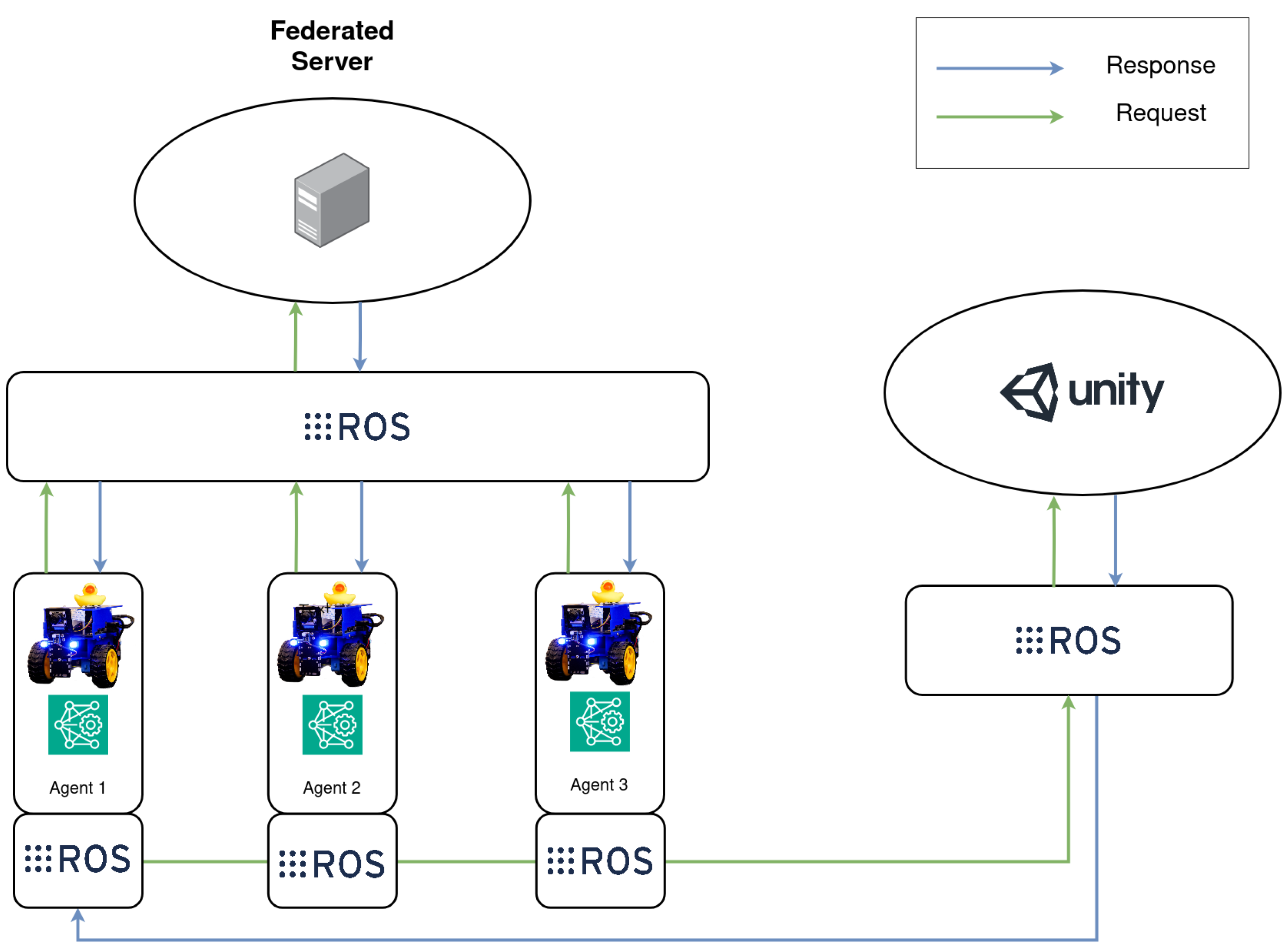
3.3. Federated Framework Architecture
In essence, the proposed framework is a federated platform that eases the learning process for a set of agents by enforcing a collaborative strategy in which each networked agent can expand its knowledge by sharing its progress. At the same time, privacy is guaranteed since it is not necessary to transmit data.
The framework is a horizontal system developed on top of ROS 2, in which each agent is represented as a node—an individual unit of computation that will be responsible for a singular and modular purpose. The set of agents
that participate in the collaborative process is uniquely identified as
, where
i is its corresponding index in the set. Each agent,
, will interact with its environment and train a local model for a set of
N training rounds. On the other hand, the federated server is a singular node that receives learning updates from each agent
and aggregates these into a global model that will be returned to the entire set of agents. The proposed FL framework can be seen in
Figure 3.
Moving on to the framework’s collaborative training, this is an iterative process in which the set of agents, K, establishes synchronous communication with the federated server to share local knowledge and subsequently receive a global update. During each round, i, each agent, , will train a local model, and after finishing, it will send a request to the federated server to update the global model. One training round is completed after the federated server has received and aggregated the contributions from the entire set of agents, K, and the updated model has been returned to them.
In FL, the aggregation model is defined by Qi et al. [
30] as a summarizing process in which the model parameters of all the parties are combined after each round to form an updated global model. As research progresses, various novel architectures have been designed to tackle current challenges in FL, such as communication overhead, data privacy concerns, and global model enhancement, each with its own advantages and disadvantages [
31,
32]. For this work, we have decided to use a vanilla version of the FedAvg algorithm [
7], which aggregates local updates into the global model by computing an average, as follows:
where
is the global update,
K is the set of participant clients, and
is the local update of client
. In the context of the RL framework,
, which is the local gradient of each agent
after performing a step in the local model with local data. The pseudo-code for the entire process is shown in Algorithm 1.
| Algorithm 1 Vanilla implementation of the FedAvg [7] algorithm. is the set of indexed agents, E is the number of local epochs, and g is the gradient of each agent after performing a step in the local model with local data. |
Server Executes: initialize global model for each round do for each agent in parallel do end for end for function AgentUpdate(w): for each local epoch do end for return g to the server end function
|
4. Methodology
The objective of the designed experiments is to evaluate the reliability of the proposed framework as a platform for multi-agent robotic applications. The experiments were designed to compare the performance of a classic methodology against a federated option in terms of rewards and computation time. Although the scenario in which the agents will work is essentially the same, the exploration process of each agent during the training time is different. This variability can provide us with valuable insights into the framework’s ability to help the agents converge to an optimal policy.
4.1. Algorithm Design
The main objective of robotic navigation is to reach the goal safely and efficiently. Based on the Euclidean distance formula, the robotic agent will try to minimize its distance to the target. To reach the goal, we have defined a set of three discrete actions: move forward, rotate left, and rotate right (For simplicity, the robotic agent will move and rotate at constant values. These two parameters are set by the developer at the Unity platform). After initializing a new episode, the robotic agent and target will spawn at different random coordinates to prevent bias. An episode will finalize if the robotic agent has reached the target, or if a collision has been detected, only excluding collisions between the robotic agent and the target.
For the agent’s task of minimizing its distance to the target, we considered two options:
Based on different experimental results, we observed that the first option was a better alternative for the distance minimization task. The learning process of the robotic agent was more stable, as it was less susceptible to getting stuck on local optimal solutions due to the constant update on the distance parameter.
A robotic agent must complete a set of conditions to effectively reach its goal:
If the orientation angle of the robotic agent is within a defined range, then the robotic agent has successfully minimized its direction and oriented itself. Following the same methodology as in the distance minimization task, the agent must also learn to orient itself by minimizing its angle to the target.
We have defined an observation space, , with a length of , and it consists of the following variables:
: X coordinate of the agent.
: Z coordinate of the agent.
: X coordinate of the target.
: Z coordinate of the target.
: Current angle from agent to target.
: Current distance from agent to target.
: Boolean flag that indicates if the goal has been reached.
By providing the neural network with this information, the robotic agent will be able to effectively minimize its distance to the target, while being able to orient itself and avoid any collisions.
4.2. Reward Function
The proposed reward function encourages the robotic agent to reach the target in a facing orientation while also avoiding collisions during navigation. Additionally, the robotic agent is encouraged to navigate towards the target as quickly as possible, thereby minimizing the exploration time. According to the defined reward function, if the agent reaches the target, it will receive a positive reward of 1. On the other hand, if the robotic agent collides, a reward of −1 will be given.
To encourage the robotic agent’s ability to effectively minimize its initial distance and orientation angle to the target, a small positive reward of 0.1 will be given during each time step if , where d is the Euclidean distance from the robotic agent to the target and is the orientation angle at time t. If these conditions are not met, and the robotic agent is not in a terminal state, then a small reward of −0.01 will be given. We believe that this small negative reward will incentivize the robotic agent to explore different actions to avoid suboptimal states, resulting in a minimized episode duration.
The final reward function is defined as follows:
5. Experiments
This section covers the experiments carried out to evaluate the proposed framework. First, we describe the model architecture, hyperparameters, and training strategy. Then, we analyze the performance based on reward consistency and variance across different agent configurations. Finally, we evaluate the navigation efficiency by comparing the number of steps and rewards obtained during testing.
5.1. Training Setup
Regarding the architecture of the model, the robotic agents will locally train an ML model with the architecture described in
Figure 2. Both the Q network and the target network are fully connected feedforward neural networks with an input layer of
n neurons, where
n is the number of variables in the observation space
. These are followed by six hidden layers with shapes of 128, 128, 64, 64, 32 and 32 neurons, each followed by a ReLU activation function, and finally an output layer with a dimension equal to the number of actions. We have used the ADAM optimizer, a batch size of 32, and mean square error (MSE) as the loss function.
In a federated alternative, the number of training rounds is the parameter that will dictate the frequency at which the participant agents will share their knowledge, and it is a parameter that needs to be carefully tuned. Having too many sharing rounds can lead to a global model that is not robust enough because of the lack of development of local models. On the other hand, having a small number of rounds will diminish the effect of federation. After several iterations and optimizations of the system, we observed that balancing the number of training episodes E and training rounds N was the most effective approach for ensuring experimental consistency. For all of the different experiments, we have defined the number of episodes as 800, with a training round occurring every 200 episodes.
The last parameter to consider is the number of working agents in the network. By varying the number of networked agents, we can test how the proposed framework manages to scale the workload and its ability to generate a global model. To evaluate the performance of the proposed framework, we will set a base case which consists of a single robotic agent trained in a classical methodology, and we will continue by incrementing the number of networked agents by one until reaching a total of three.
Finally, the experiments were conducted on two different systems. The first one was a system running Ubuntu 22.04, powered by an AMD Ryzen™ 5 5600G processor. The system also includes 16 GB of RAM for efficient multitasking and data processing, along with an NVIDIA GeForce RTX 3060 Ti GPU, which offers AI-enhanced performance. The second one was a system running Ubuntu 22.04, powered by an AMD Ryzen™ 5 pro 3500u, and 16 GB of RAM. ROS 2 in its Humble release version provided a flexible and robust framework for developing and executing the experiments.
5.2. Results
Once the experiments were conducted, we proceeded to analyze the results. During the evaluation phase, at each time step, we save the agent’s reward, the current step, and the number of steps per episode into a .log file, having a separate file for each agent. These data are then curated and processed using data analysis tools, like Pandas v2.2.2 and NumPy v1.26.4, and the graph images are generated using Matplotlib v3.9.2, all of which are Python packages. The evaluation phase was conducted using 200 episodes, with a limit of 200 steps per episode. First, we analyze the average reward obtained on the experiments to experimentally evaluate the reliability of the framework when the workload is increased. We believe that by increasing the number of participant agents in the network, the training process of every agent will benefit itself by having more diverse interactions, improved generalization, and a richer set of experiences, leading to better adaptation and convergence of the learning process. In this sense, the average reward obtained on the evaluation phase can be seen in
Figure 4. All the rewards were normalized, and a moving window of 20 data points was selected for the moving average.
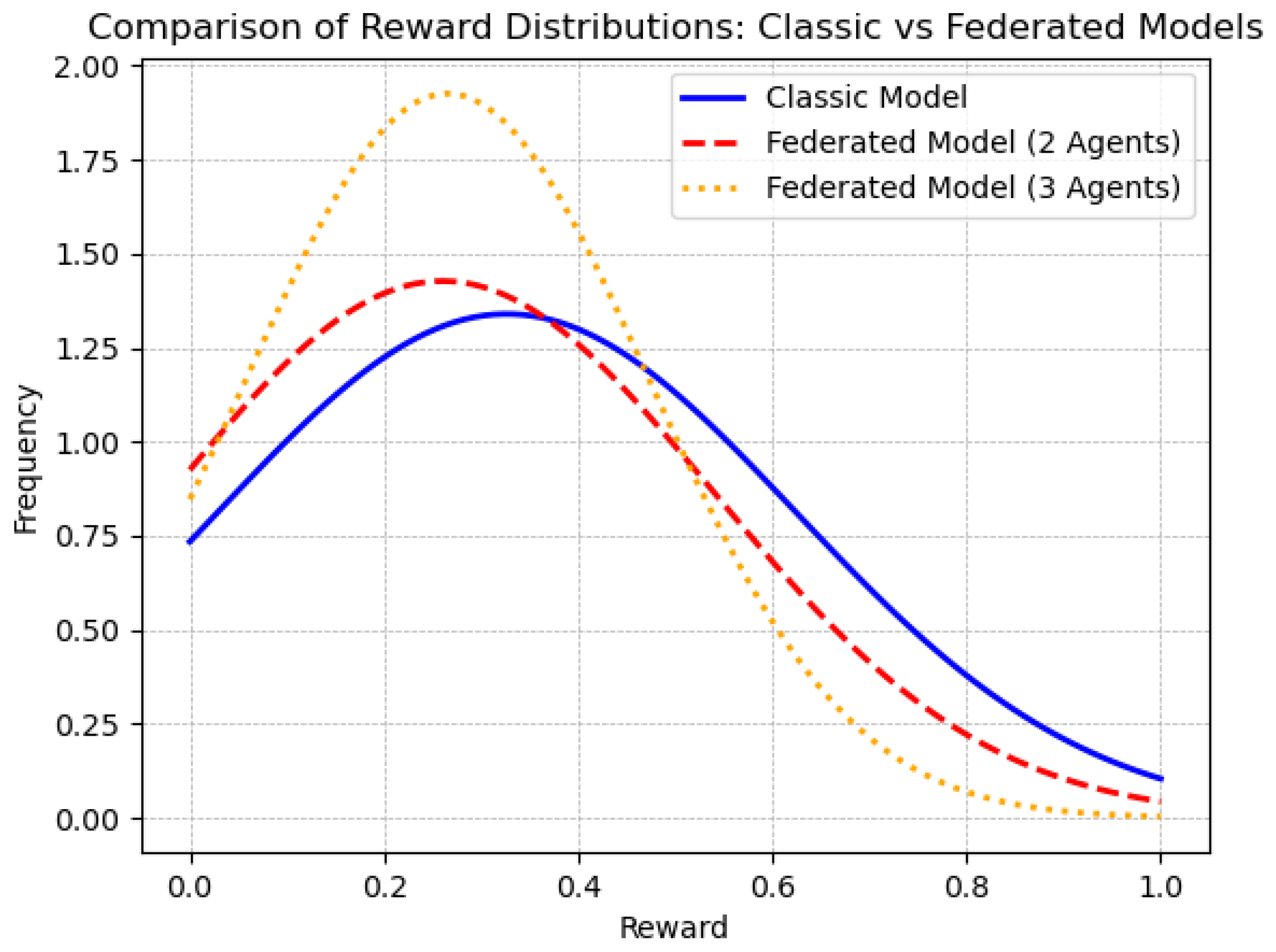
In general, we observed that our proposed framework helps the robotic agents achieve more stable performance. As can be seen in
Table 1, as the number of robotic agents increases, the variance in the reward tends to be more consistent across the network. The stabilizing effect of the framework is illustrated in
Figure 5, where the normal distribution of the evaluation rewards is compared.
On the other hand, we also believe that as a result of having a more diverse training process, the robotic agents will be able to optimize their exploration process, requiring a smaller number of steps per episode to complete a task. Taking this into account, in
Figure 6, a comparison of the mean number of steps and the mean reward obtained during the evaluation can be observed. It is observed that while the mean reward fluctuated from the base case to the experiments with two and three agents running simultaneously, the mean number of steps per episode decreased.
From the different experimental results, it can be observed that the agents were able to stabilize their training process, reducing the variation in the obtained rewards. Although the mean reward obtained in the base case was slightly higher than in the experiments with two and three agents, the variance was reduced as the number of training robotic agents increased. This finding suggests that the learning process of the robotic agents is more consistent when the different local results are combined into a global model. The results indicate that the robotic agents benefit from integrating the generated knowledge of their peers, allowing them to better generalize the problem.
On the other hand, having more steps and more rewards in the base experiment does not necessarily indicate that the agent was performing better. One crucial aspect of our experiments is that navigation during the evaluation phase is truncated to a fixed number of steps. If the agent neither collides nor reaches the target within this limit, the episode ends. Thus, the reduction in the number of steps in subsequent experiments suggests that the agents are becoming more efficient by reaching the target or making decisive movements more quickly. Meanwhile, the slight fluctuations in the average reward could be a result of the agents focusing on reducing steps while still maintaining a stable performance overall.
6. Conclusions and Future Directions
As previously mentioned, this paper introduces a federated learning framework tailored for robotic systems, leveraging the Robot Operating System 2 and deep reinforcement learning to enable decentralized multi-agent learning. The proposed approach addresses key challenges in traditional centralized learning, such as privacy concerns, communication overhead, and scalability, by allowing agents to train local models and share knowledge in a collaborative yet privacy-preserving manner. Our results demonstrate that our proposal improves model generalization, stabilizes training dynamics, and enhances the efficiency of robotic agents in a simulated navigation task. The code of the proposed framework is available on GitHub (GitHub link:
https://github.com/MauGutierrez/ros2-federated/tree/development (accessed on 23 March 2025)). One of the main contributions of this work is the successful integration of FL with ROS 2 and Unity-based simulations, creating a flexible and scalable platform for robotic learning. Additionally, our experimental results highlight that increasing the number of participating agents enhances the learning efficiency while reducing variance in the obtained rewards. These findings reinforce the potential of FL as a viable alternative to centralized learning approaches for real-world robotic applications, where distributed collaboration is essential.
This study has several limitations. First, while the framework demonstrates improvements in the results with an increasing number of participant agents, each networked agent must be carefully optimized to avoid disrupting the global process. During the RL exploration phase, the framework encounters non-equally distributed data, particularly before convergence. In the best-case scenario, all agents converge to a similar state; in the worst-case scenario, each agent converges to a different state. This issue is especially prevalent when the robotic agents operate in heterogeneous environments, which is often the case. Additionally, since knowledge-sharing rounds are synchronous, the overall execution time is constrained by the slowest agent. Furthermore, transitioning from a simulation to the real world presents significant challenges due to the substantial hardware and software resources required for each robotic agent. Finally, while the FedAvg algorithm provides a solid foundation for aggregation, a more robust method is needed to effectively manage outliers during training. By doing so, we think the overall performance could be significantly improved, minimizing the communication overhead and the needed time for convergence, which would ultimately help us to handle heterogeneous data.
Building upon these contributions, our future work will focus on several key aspects. First, we will aim to extend the number of participating agents to evaluate the scalability and robustness of the FL framework in more complex environments. Increasing the number of agents will allow us to analyze how knowledge sharing impacts learning dynamics and whether additional strategies are required to manage communication and computational overhead. Second, we plan to integrate the framework with heterogeneous robotic systems, including different types of robots with varying sensor configurations and capabilities. This will help us assess the adaptability of the proposed approach to real-world multi-agent scenarios, where agents may have diverse functionalities and operate under different constraints. Lastly, we will focus on the implementation of social techniques to maximize the collaborative process across the network. Moreover, efforts will be directed towards enhancing the generalization ability of robotic agents to integrate dynamic environments that may significantly differ from one another.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}