1. Introduction
Everyone aspires to have clean, healthy skin that is free from issues or illnesses, which can impact both appearance and quality of life. Healthy skin serves as a barrier against various diseases and symptoms that could otherwise lead to significant skin damage. Additionally, good skin health enhances appearance, boosts self-confidence, and supports mental well-being. However, achieving and maintaining skin health remains a challenging task due to numerous internal and external factors. According to a survey conducted by the European Academy of Dermatology and Venereology (EADV), approximately 47.9% of Europeans over the age of 18 reported experiencing at least one skin issue in the last year [
1]. Furthermore, during the “Skin Matters” conference on 20 May 2017, a survey showed that 59% of delegates noted a negative impact of skin conditions on their daily living and mental health, underscoring the widespread nature of skin-related concerns [
2]. These findings highlight that skin diseases are not isolated incidents but common issues affecting large population segments.
Dermatology faces significant challenges in providing timely and accurate diagnoses, particularly in real-time settings. A study across 27 European countries revealed that only 30.3% of patients received a dermatology consultation within the previous two years, while 33.1% had never consulted a dermatologist. Common reasons for not seeking care included perceptions that conditions were not severe enough and previous consultations leading to self-management [
3]. Economic barriers further exacerbate these challenges. Financial and insurance issues were the most commonly cited obstacles to seeking dermatological care, affecting 42.9% of patients. Additionally, 24% reported that expensive treatment costs hindered adherence to prescribed therapies [
4]. To address these unmet needs, our study introduces EM-YOLO, an enhanced version of the You Only Look Once (YOLO) deep learning algorithm, tailored for dermatological applications. EM-YOLO offers real-time, high-accuracy detection and classification of skin lesions, streamlining the diagnostic process. By automating lesion identification, EM-YOLO reduces the need for immediate specialist consultations, thereby alleviating economic and logistical barriers. This approach not only enhances diagnostic accuracy but also improves accessibility to dermatological care, particularly in underserved areas. Our study adopts a problem–solution approach to tackle the identified challenges in dermatology. By leveraging advanced AI technologies like EM-YOLO, we aim to bridge gaps in real-time diagnostics, mitigate economic barriers, and ultimately improve patient outcomes in dermatological care.
Skin disorders can result from a multitude of sources, including the presence of bacteria, fungi, parasites, or viruses on the skin, as well as weakened immune responses. Environmental factors, such as exposure to allergens, irritants, or infected individuals, further contribute to skin disorders [
5,
6]. Additionally, genetic predispositions and certain systemic illnesses involving the thyroid, immune system, or kidneys can exacerbate skin conditions [
1,
2]. Lifestyle choices, including poor dietary habits, stress, and environmental pollutants add further complexity to the causes of skin issues [
3,
7]. Notably, some skin disorders remain idiopathic, making diagnosis and treatment more challenging [
4,
8].
Given the diversity of individual skin conditions, symptoms, and severity levels vary widely. Studies suggest that improper or delayed treatments, especially in cases where professional dermatological advice is inaccessible, can significantly worsen outcomes [
9]. Moreover, incorrect medications not only fail to alleviate symptoms but may introduce new complications, including adverse side effects and secondary infections [
10,
11]. This emphasizes the importance of accurate diagnosis and timely intervention in mitigating the burden of dermatological diseases.
Previous research highlights several barriers to accessing dermatological care, particularly for individuals in underserved or economically disadvantaged communities. These barriers include a lack of health insurance, residency in medically underserved areas, and financial constraints [
7]. In large regions like Europe, an average dermatologist consultation costs between USD 264.8 and USD 300.91, with an average consultation time of 6–7 min [
8]. While health insurance may alleviate some of these expenses, access to insurance itself remains uneven worldwide. Consequently, financial and systemic barriers limit many people’s ability to seek timely and effective dermatological care. Therefore, there is an urgent need for alternative solutions that can provide accessible assistance to individuals for identifying and managing skin conditions.
This research aims to address this gap by developing a cost-effective and accessible tool to assist individuals facing limitations in accessing dermatological services. Leveraging advancements in object detection technology, particularly the You Only Look Once (YOLO) algorithm, we propose a system capable of analyzing photographs or video footage of skin conditions. The YOLO algorithm facilitates real-time classification and segmentation, allowing the system to offer preliminary insights into potential skin disorders. Although a dermatologist’s diagnosis considers factors beyond visual inspection, this system aims to raise awareness and enable early detection of skin conditions. Through this approach, our research seeks to support the overall goal of promoting skin health while providing an accessible diagnostic aid for those in need.
1.1. Advancements in Edge Computing and Real-Time Diagnostics
Recent advancements in edge computing and real-time systems have significantly enhanced the capabilities of automated diagnostic solutions across various domains, including healthcare, storage, and autonomous systems [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. These innovations provide the foundation for the EM-YOLO framework by addressing challenges such as latency, scalability, and privacy concerns.
The design of scalable and reliable systems for data storage and processing has been a key focus in edge computing research. For instance, reliable RAID-6 systems for SSD-based architectures [
23] and high-performance cloud storage systems [
24] have demonstrated efficient and secure data management techniques that inform EM-YOLO’s robust data handling capabilities. Similarly, innovations in the dynamic allocation of replication and erasure codes [
25] and delta RAID methods for enhancing small-write performance [
26] have laid the groundwork for EM-YOLO’s data augmentation strategies.
Advanced neural network-based methodologies have also contributed to improving real-time performance in resource-constrained environments. For example, spiking neural networks implemented on FPGA platforms [
27] and explored using backpropagation [
28] offer insights into optimizing computational models for edge devices. Techniques such as the sequential skeleton RGB transformer for human–object interaction [
29] and multitasking networks for self-driving systems [
30,
31] demonstrate the feasibility of deploying complex models in real-world environments. EM-YOLO incorporates these principles to maintain high diagnostic accuracy while ensuring scalability.
The application of computer vision in healthcare and surveillance has seen notable advances in recent years. Studies on human pose estimation and fall detection for elderly care [
32] and distortion rectification of wide-angle images [
33] showcase the transformative potential of image processing techniques in addressing diverse challenges. Similarly, camera calibration for ADAS systems [
34] and fisheye camera adjustments [
35] provide practical solutions that align with EM-YOLO’s goals of enhancing model generalizability and precision.
The importance of privacy-preserving frameworks in data processing has been emphasized in works on secure and distributed data storage [
36], GPU-accelerated parity computing [
37], and segmentation-based iris synthesis using generative adversarial networks [
38]. These methods inspire the secure design of EM-YOLO, ensuring that sensitive dermatological data are processed locally on edge devices.
Finally, in the realm of advanced model scheduling and automation, the application of LSTM networks for script evaluation [
39] and radial undistortion using GANs [
40] highlight innovative ways of optimizing neural network architectures for specific applications. EM-YOLO extends these approaches to real-time dermatological diagnostics, integrating in-memory scheduling and scalable edge processing.
By leveraging these multidisciplinary advancements, EM-YOLO provides a novel, cost-effective, and privacy-preserving solution to address unmet needs in dermatological health diagnostics.
1.2. Key Contributions
The following are the key contributions of this study:
We propose a novel approach to skin condition analysis leveraging the You Only Look Once (YOLO) algorithm, optimized for real-time detection and segmentation of skin conditions from images and videos.
Our system is designed to function as an accessible and cost-effective diagnostic aid, specifically targeting individuals with limited access to dermatological care.
We successfully implement the YOLO-based skin analysis system within an edge computing environment, allowing for faster processing and increased accessibility, particularly in low-resource settings.
In this study, we enhance YOLOv8 by incorporating custom layers, including attention mechanisms and residual dropout. These modifications have yielded substantial improvements in precision (82.30%), recall (71.50%), F1-score (76.40%), and mAP@0.5 (68.80%). Such advancements underline the transformative potential of custom layers in addressing challenges posed by complex and diverse datasets.
The remainder of this paper is structured as follows:
Section 2 reviews relevant background information and related work in skin condition analysis and diagnostic tools.
Section 3 details the fundamentals of the custom-YOLO-based approach for skin condition analysis. In
Section 4, we present and discuss the experimental results from our proposed system. Finally,
Section 6 provides conclusions and future directions for this research.
2. Related Works
Deep learning-based dermatological analysis has gained significant traction, particularly with convolutional neural networks (CNNs) and You Only Look Once (YOLO) architectures, which enable automated skin disease classification and real-time detection. Traditional CNN models, such as ResNet50 and InceptionV3, have been widely used for dermatological applications [
10]. However, these architectures are computationally expensive and impractical for real-time applications. In contrast, YOLO models offer efficient object detection with low latency, making them suitable for rapid diagnostics. Studies such as those by Aishwarya et al. [
11] and Isa et al. [
41] have demonstrated the effectiveness of YOLO models for detecting skin conditions, such as cancer and acne, respectively, with high accuracy and real-time capabilities.
The growing body of research utilizing YOLO models extends beyond single-condition classification. For instance, ref. [
42] applied YOLOv8 for acne grading, achieving high differentiation between acne types, while ref. [
43] proposed an enhanced YOLOv7-based acne detection model with improved feature extraction. Additionally, ref. [
44] introduced a deep neural network-based acne detection framework, demonstrating effectiveness across various skin tones and lighting conditions. Other studies have explored optimization-based approaches for broader dermatological analysis. Ref. [
45] incorporated multi-modal data into a CNN-based framework to enhance facial skin symptom detection, whereas ref. [
46] focused on distinguishing benign pigmented skin lesions using CNNs.
Despite these advancements, existing methods primarily focus on single-condition detection, which limits their applicability in real-world dermatological diagnostics. The proposed EM-YOLO model overcomes these limitations by integrating multi-condition detection, custom feature extraction layers (SEBlock, DWC, RDB), and edge computing to enhance real-time performance. Unlike traditional CNN-based models that require extensive computational resources, our model operates efficiently on edge devices, reducing latency and enabling real-time mobile applications for skin health monitoring.
Beyond architectural improvements, dataset quality and augmentation strategies play a vital role in model performance. Khasanah et al. [
47] demonstrated how augmentation techniques, such as width shifts and zoom transformations, improve robustness in small datasets. The proposed model incorporates similar strategies to handle diverse skin conditions under various lighting and imaging conditions, ensuring improved generalizability and performance consistency across populations.
The following tables provide a comparative analysis of recent deep learning approaches for dermatological diagnostics, highlighting the novelty of our proposed EM-YOLO framework.
Table 1 and
Table 2 highlight the incremental improvements introduced by the proposed EM-YOLO model. Existing studies predominantly focus on single-condition detection, whereas our model supports real-time, multi-condition detection with optimized feature extraction and computational efficiency. Additionally, edge computing integration in EM-YOLO significantly reduces latency compared to cloud-based models, making it ideal for mobile dermatological diagnostics. By combining multi-condition detection, edge computing, real-time processing, and custom feature extractors, EM-YOLO establishes itself as an innovative contribution to dermatological AI, surpassing prior studies in accuracy, efficiency, and scalability, optimizing performance for low-resource environments.
2.1. Applied Platforms for Real-Time Diagnostic Accessibility
The platform on which a diagnostic model operates significantly impacts its accessibility and usability, particularly in healthcare settings. Traditional platforms often depend on cloud computing, which can limit accessibility due to latency and internet dependency. The proposed work addresses these limitations by deploying on an edge computing platform, allowing users to perform skin condition analysis directly on their device. This approach minimizes latency, enhances data privacy, and extends diagnostic capabilities to resource-constrained environments, where high-speed internet may be unavailable.
Skin condition analysis, particularly through real-time image classification, is an emerging area with applications in dermatology, telemedicine, and personalized healthcare. This field has garnered significant research interest due to its potential to improve healthcare accessibility and accuracy for skin diagnostics. In this section, we present existing research in two main categories: deep learning models applied to skin condition analysis and platforms for real-time diagnostics and edge deployment.
Algorithm 1 presents the pseudo-code for a traditional YOLO-based diagnostic system, here referred to as the Skin Condition Analysis System (SCAS), in an edge computing environment. In Steps 1–4, the Client() function initializes configurations, captures images of skin conditions, and stores them in memory (Data[K]). The client then calls the SCAS_Server() function, passing the stored data for processing. In response, SCAS_Server() classifies the data, returning the predicted result, processing time, and confidence level at Step 3. Finally, Step 4 displays the result on the user interface.
The
SCAS_Server() function, defined in Steps 6–11, configures YOLO for inference, allocates memory for the sensor data, and loads the pre-trained YOLO model to perform skin condition classification at Step 9.
| Algorithm 1: Skin Condition Analysis System (SCAS) for skin condition analysis. |
![Electronics 14 01319 i001]() |
Table 3 provides the parameters used in this system, including symbols, representations, and associated functions. The total system latency, denoted as
, is given by
The total latency of the
SCAS_Server() function, represented by
, is expressed as
This section provides an overview of the existing SCAS diagnostic system’s architecture, noting key latency components. The proposed work aims to enhance this architecture by deploying the model on edge devices, thereby minimizing latency and improving accessibility for real-time skin condition analysis.
In summary, current research reflects significant progress in using deep learning for skin condition analysis, with a shift from conventional CNNs toward real-time capable YOLO models and platforms prioritizing accessibility. The proposed work advances this field by integrating a comprehensive YOLO-based diagnostic model with edge computing, providing a scalable, real-time, and accessible solution for skin health monitoring in diverse settings.
2.2. Limitations of the Existing SCAS Algorithm
The current Skin Condition Analysis System (SCAS) algorithm, while effective for real-time skin condition classification, exhibits certain limitations, particularly in terms of latency. The end-to-end latency for the SCAS algorithm, denoted as
, is calculated as
where
represents the total time required for image capture, caching, data transmission, classification, and visualization. Each component—such as
(network delay) and
(total classification latency)—adds to the overall latency, limiting the system’s responsiveness, especially in low-resource or high-latency network environments.
The latency of the classification function in SCAS, represented by
, is expressed as
where each term contributes to delays in the server’s processing time. The dependency on network communication (i.e.,
) between the client and SCAS_Server further exacerbates latency, particularly in scenarios with limited or unreliable internet connectivity. Consequently, the SCAS algorithm may not achieve optimal performance in real-time applications due to these network and processing delays, which are amplified in remote or bandwidth-constrained environments.
The proposed work aims to address these latency challenges by deploying the YOLO-based Skin Condition Analysis System directly on edge computing devices. This approach effectively reduces or eliminates the network delay by enabling local processing on the client device itself, which minimizes reliance on cloud infrastructure. Additionally, the edge deployment allows for faster memory allocation and model loading, reducing and latencies within the classification process.
As highlighted in
Table 1 and
Table 2, the proposed system builds on advancements seen in related works, combining high-performance real-time classification (as demonstrated by prior YOLO applications) with the unique advantage of edge computing. By processing data locally on edge devices, the proposed system not only enhances accessibility and privacy but also achieves significantly reduced
latency. This improvement is particularly valuable in applications that require immediate feedback and high responsiveness, making the proposed system more effective for skin diagnostics in diverse settings, including low-resource environments where network connectivity is a limiting factor.
In summary, the proposed approach overcomes the latency limitations of the current SCAS algorithm by reducing network dependency and optimizing processing times on edge devices. This results in a more efficient, accessible, and real-time skin diagnostic tool, positioning the proposed work as an advancement over existing systems.
3. Edge-Based Data Scheduling for PSCAS-Driven Skin Analysis
In this study, we emphasize a robust edge-based solution to ensure continuous and efficient service as the volume of skin analysis requests increases at the edge server. Users initiate skin condition analysis requests through the PSCAS API, with each request optimized by the proposed edge architecture. Traditional systems pre-load all necessary deep learning libraries and model files with each API call, resulting in unnecessary redundancy and higher computational costs. In the proposed system, PSCAS manages each call with session-based model loading and adaptive in-memory caching, which significantly reduces latency and resource usage.
Our architecture includes session-based model loading, where the skin condition analysis model is loaded once per server session and retained in memory. This session-based approach prevents repetitive model loading, thereby decreasing latency and computational overhead—a strategy that aligns well with edge AI best practices. Additionally, adaptive in-memory caching dynamically allocates memory based on current system load and resources. This adaptive caching, inspired by recent advances in memory management for edge devices, is especially effective in environments with high-frequency requests.
To further enhance performance, a prioritized data scheduling mechanism is implemented to ensure that high-priority and time-sensitive tasks are processed first, minimizing latency and improving real-time responsiveness. This approach, reflecting techniques from state-of-the-art edge computing frameworks, contributes to an optimized user experience.
Algorithm 2 outlines the pseudo-code for the proposed PSCAS (Personalized Skin Condition Analysis System) for predicting skin conditions via distributed client–server functions. Initially, the
function initializes configurations and verifies server status. If inactive, the client activates the server via a REST API call. In Lines 4–10, the client iteratively reads sensor data, stores them as
, and caches them in Line 6. Following a delay, the client invokes
, passing the allocated sensor data identifier,
, in Line 8. The server returns prediction results, including the condition class, processing time, and confidence level in Line 8. Finally, the client visualizes the prediction results on the device interface in Line 9.
| Algorithm 2: Proposed PSCAS algorithm for skin condition analysis. |
![Electronics 14 01319 i002]() |
The function, detailed in Lines 12–23, configures TensorFlow settings, loads the in-memory data scheduler (Line 14), and loads the model once per worker process (Line 15). The server then retrieves prediction jobs from the cache, processes the profiling request, and updates predictions with the function in Line 19. After processing, calculates statistics in Line 21 and updates the cache in Line 22.
3.1. Latency Optimization
The end-to-end latency of the PSCAS system, denoted as
, is broken down into core components to pinpoint and optimize key processing stages:
where the following are denoted:
- -
: Initialization latency for the client session;
- -
: Latency for capturing and caching images;
- -
: Latency for processing the model prediction;
- -
: Display latency for visualization on the client device.
The server-side latency in the PSCAS,
, encompasses three primary stages:
where the following are denoted:
- -
: Model loading latency, minimized through session-based loading;
- -
: Latency in job request retrieval from cache;
- -
: Processing latency for skin condition classification.
3.2. In-Memory Data Scheduler with Adaptive Caching
In latency-sensitive systems, key-value (KV) storage plays a crucial role, especially for sensor-driven applications that require high read/write performance. Traditional storage solutions often introduce I/O bottlenecks due to frequent, small file storage demands. Algorithm 3 outlines the pseudo-code for the proposed Data scheduling in Insert_cache function. This in-memory data scheduler employs adaptive caching to dynamically adjust memory allocation based on system load, which enhances response times in environments with fluctuating request frequencies.
| Algorithm 3: Data scheduling in Insert_cache function. |
![Electronics 14 01319 i003]() |
The scheduler’s prioritized data scheduling mechanism enables high-priority requests to be processed first, which is particularly advantageous for real-time applications. The in-memory scheduler’s three-level memtable structure and adaptive memory management improve KV sensor data handling by optimizing resource utilization and reducing latency in data access.
3.3. System Efficiency Analysis
The proposed session-based model loading significantly reduces redundant processing by retaining the skin condition analysis model in memory for the duration of a server session. This technique, combined with adaptive caching, allows PSCAS to handle high-frequency requests efficiently by optimizing memory allocation based on load.
Prioritized data scheduling ensures that latency-sensitive tasks receive prompt processing, aligning with modern edge AI requirements for real-time applications. This architecture, along with the adaptive and session-based enhancements, contributes to an overall reduction in , making the proposed PSCAS a robust, low-latency solution suitable for real-world skin analysis applications.
3.4. Dataset
This research utilizes a dataset of facial images with skin issues focused on the facial region, compiled from three primary sources to ensure diversity and comprehensiveness. The main dataset, titled “Skin problems (3-4 on the IGA scale)” by Kucev Roman, was sourced from Kaggle [
48]. Additionally, two supplementary datasets—“Face Segmentation” and “Selfies and Video Dataset (3673 People)”—were also obtained from Kaggle and provided by Kucev Roman [
49,
50]. This combined dataset includes 710 images of individuals captured from three different angles under controlled lighting, without makeup or other extraneous facial features. The entire dataset, totaling approximately 2.37 GB, was manually annotated in preparation for subsequent stages.
After annotation, the dataset was split into training, validation, and testing sets in a 70:20:10 ratio, yielding 497 images for training, 142 for validation, and 71 for testing.
3.5. Dataset Augmentation and Preprocessing
To improve model focus and maximize relevant data, each image was first cropped to highlight only the facial region, enhancing the region of interest (ROI). This cropping focused horizontally from the left cheek to the right cheek, and vertically from the forehead to the chin, excluding hair, neck, and ears. By concentrating on the facial region, the model is better positioned to identify smaller skin features and improve detection accuracy.
The dataset was then manually annotated with bounding boxes to highlight specific skin issues. Bounding boxes are critical for object detection models like YOLO as they provide positional and dimensional information along with class labels. Annotations were performed using makesense.ai, an online tool developed by Piotr Skalski, which exports YOLO-compatible bounding box data [
51,
52,
53,
54]. Following annotation, the images were augmented to increase the dataset’s size and diversity, as shown in
Table 4. Augmentation adds robustness by simulating real-world variations, making the model more resilient to environmental factors such as lighting changes, positional variations, occlusions, and noise. This enhanced robustness is crucial for achieving reliable performance in diverse, real-world scenarios.
Table 4 details the preprocessing and augmentation techniques for the sample dataset [
48] as shown in
Figure 1. The dataset was initially resized to 1920 × 1920 pixels to standardize input size, ensuring efficient training and inference. Each image underwent three transformations to diversify the dataset, generating multiple variations of the same image. These augmentations included horizontal flips, cropping, rotation, saturation, brightness, and blur adjustments. Such transformations improve the model’s ability to detect and classify skin conditions across different image variations.
Additional augmentations were implemented to enhance data diversity. Horizontal flipping introduces variability by mirroring images, while zooming within a 0–5% range modifies the size and position of facial features. Rotation between −10° and +10° aids in recognition regardless of object orientation. Adjustments to saturation and brightness (ranging between −25% and +25%) simulate different lighting and color conditions. Finally, blurring up to 0.5 pixels helps the model adapt to image quality issues, enhancing its resilience to varying clarity levels.
Since the augmentation tool (Roboflow) did not include the original images in its output, the augmented images were later combined with the original cropped and resized images. This approach ensures that the model retains high accuracy within the original data context. Note that this process slightly alters the initial 70:20:10 split ratio.
Table 5 presents the updated distribution post-augmentation.
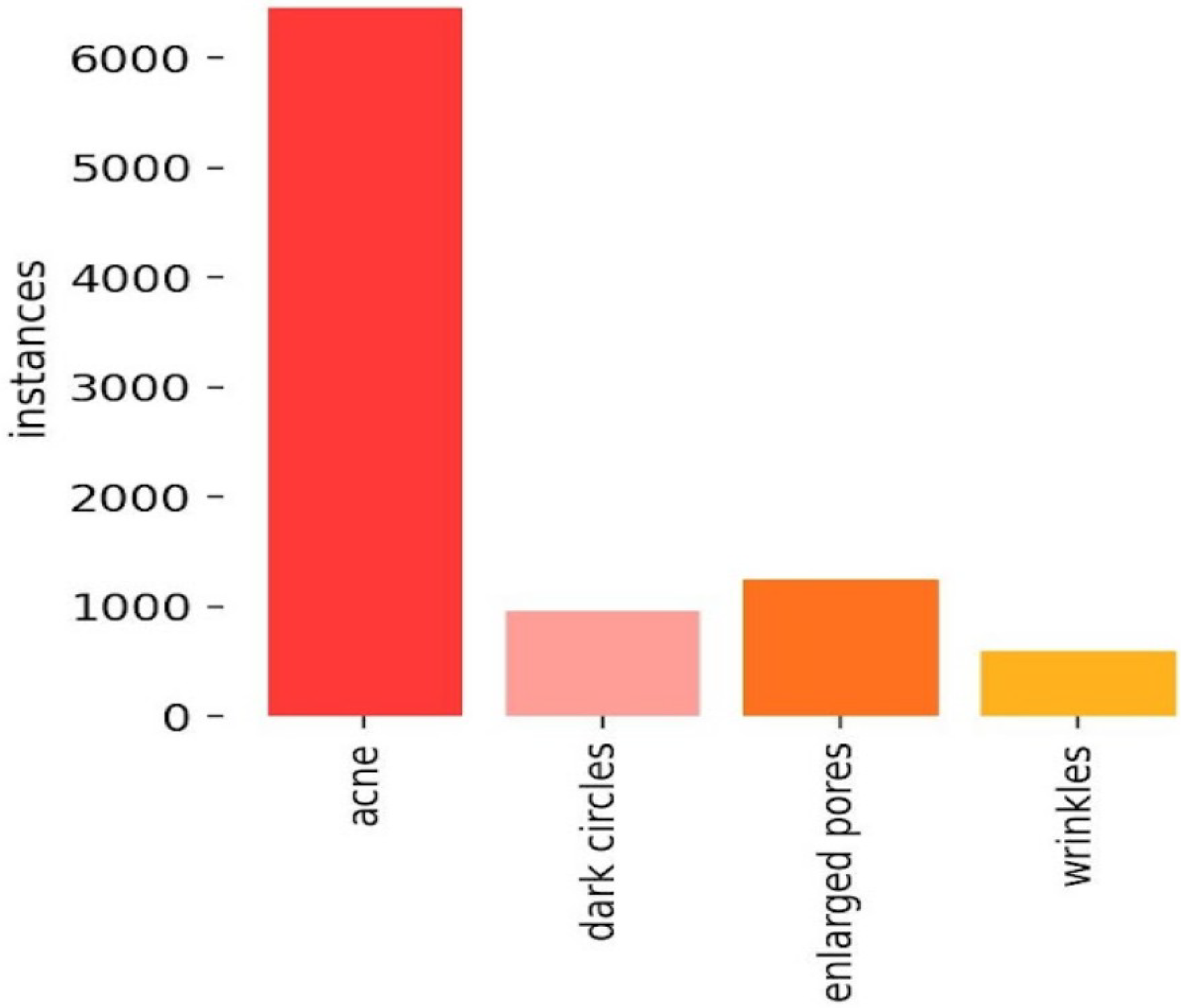
To further illustrate the dataset structure,
Figure 2 displays the class distribution post-augmentation. The dataset contains over 6000 bounding boxes for acne, with other classes such as dark circles, enlarged pores, and wrinkles each comprising around 1000 bounding boxes.
The proposed work addresses several limitations found in previous studies by implementing a comprehensive preprocessing and augmentation pipeline, as well as leveraging YOLO-based models in an edge computing environment. Unlike prior research, such as that conducted by Wu et al. [
10] and Aishwarya et al. [
11], which often focuses on specific conditions or use singular model setups, this study integrates a robust dataset with real-time, multi-condition detection capabilities.
Additionally, by deploying YOLO models (versions 5, 7, and 8) optimized for edge devices, the proposed work minimizes latency and reliance on cloud infrastructure, offering a high-accuracy, low-latency solution suitable for environments with limited connectivity. This edge-based approach enhances accessibility, reduces operational costs, and supports real-time analysis, making it a practical tool for both clinical and personal use. By integrating a well-prepared, augmented dataset and edge deployment, the proposed system represents a significant advancement in real-time skin condition diagnostics.
3.6. EM-YOLO’s Architecture
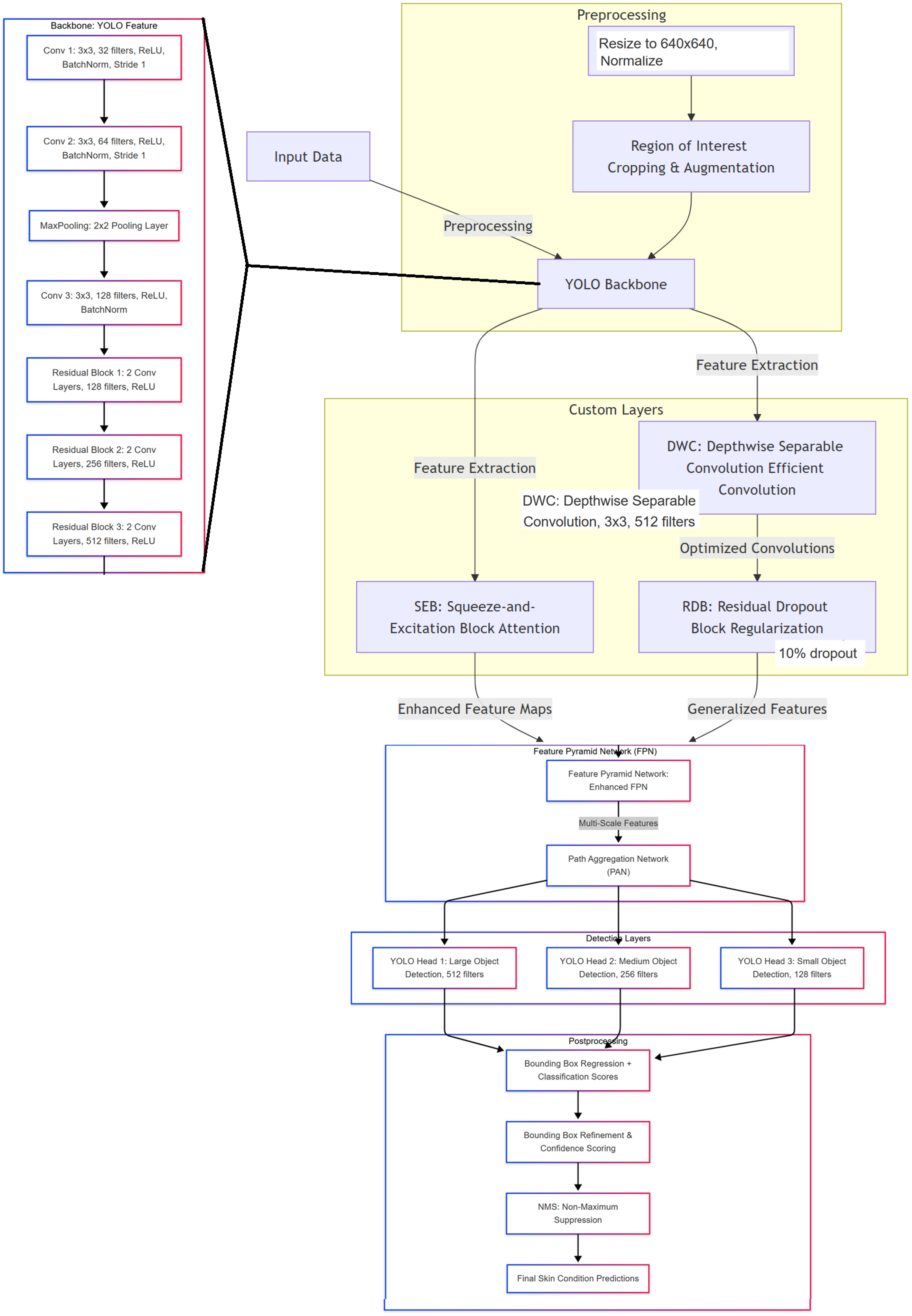
Figure 3 illustrates the architecture of EM-YOLO, an advanced real-time dermatological condition detection framework. This architecture integrates efficient preprocessing, feature extraction, custom layers, and postprocessing mechanisms to optimize computational efficiency while maintaining high detection accuracy.
3.6.1. Preprocessing Stage
The pipeline begins with an input RGB image (640 × 640 pixels), which undergoes normalization to scale pixel values to the range of [0,1]. Following normalization, the image is resized to 640 × 640 pixels to match the model’s input requirements. To enhance model robustness, Region of Interest (ROI) cropping and augmentation techniques are applied, ensuring that the system can handle variations in skin tones, lighting conditions, and facial orientations.
3.6.2. YOLO Backbone for Feature Extraction
The preprocessed image is then fed into the YOLO backbone, which serves as the primary feature extractor. As depicted in the architecture, the backbone consists of multiple convolutional layers and residual blocks to extract hierarchical features from the input image:
Conv 1: A 3 × 3 kernel, 32 filters, ReLU activation, BatchNorm, and Stride 1.
Conv 2: A 3 × 3 kernel, 64 filters, ReLU activation, BatchNorm, and Stride 1.
MaxPooling: A 2 × 2 pooling layer to reduce spatial dimensions.
Conv 3: A 3 × 3 kernel, 128 filters, ReLU activation, and BatchNorm.
Residual Block 1: Two convolutional layers, 128 filters, and ReLU activation.
Residual Block 2: Two convolutional layers, 256 filters, and ReLU activation.
Residual Block 3: Two convolutional layers, 512 filters, and ReLU activation.
This backbone efficiently extracts low-level textures and high-level semantic features while maintaining computational efficiency.
3.6.3. Custom Feature Extractors
To further enhance feature representation, the extracted features are passed through custom layers, which provide key improvements in dermatological detection:
Squeeze-and-Excitation Block (SEB): Applies channel-wise attention, enhancing the model’s ability to focus on important skin features while suppressing less relevant ones.
Depthwise Separable Convolution (DWC): Reduces computational complexity by separating spatial and depthwise convolutions, preserving feature integrity while optimizing efficiency.
Residual Dropout Block (RDB): Introduces stochastic regularization via dropout (10%), which reduces overfitting and improves generalization.
These enhancements ensure that the YOLO backbone extracts robust, discriminative features with improved efficiency.
3.6.4. Feature Pyramid Network (FPN) and Path Aggregation Network (PAN)
Following feature extraction, the processed feature maps are passed into the Feature Pyramid Network (FPN), which constructs a multi-scale representation to detect dermatological conditions of varying sizes. The FPN outputs are then aggregated using the Path Aggregation Network (PAN), improving information flow across different feature scales. This hybrid FPN + PAN architecture ensures fine-grained feature propagation, leading to enhanced detection performance.
3.6.5. Detection Layers
The detection module consists of three specialized YOLO heads, each optimized for detecting objects of different sizes:
YOLO Head 1: Large object detection (512 filters).
YOLO Head 2: Medium object detection (256 filters).
YOLO Head 3: Small object detection (128 filters).
This multi-scale detection strategy ensures the accurate identification of both small and large skin conditions, addressing real-world variations in dermatological features.
3.6.6. Postprocessing and Output Refinement
To further refine detection results, the postprocessing stage consists of the following:
Bounding Box Regression and Confidence Scoring: Adjusts the position and confidence level of detected conditions.
Bounding Box Refinement: Ensures alignment with ground truth dermatological regions.
Non-Maximum Suppression (NMS): Filters redundant detections, ensuring that only high-confidence predictions are retained.
The final output consists of detected skin conditions with confidence scores, making the system suitable for real-time dermatological analysis.
3.6.7. Real-Time Edge Deployment
Unlike previous cloud-based YOLO implementations, EM-YOLO is optimized for real-time edge deployment, reducing latency and dependency on cloud servers. This makes it ideal for dermatological applications in resource-limited environments such as mobile devices and embedded systems.
3.6.8. Advantages of EM-YOLO Architecture
Efficient feature extraction using the optimized YOLO backbone.
Custom feature layers (SEB, DWC, RDB) enhance robustness and reduce computational overhead.
Multi-scale detection via FPN + PAN integration, improving classification accuracy across diverse skin conditions.
Postprocessing optimizations (Bounding Box Refinement, Confidence Scoring, and NMS) enhance precision.
Edge computing optimization reduces latency, making EM-YOLO ideal for mobile dermatology applications.
By combining advanced feature extraction, multi-scale detection, and real-time postprocessing, EM-YOLO achieves state-of-the-art dermatological detection performance, making it a highly adaptable and efficient solution for embedded AI-driven dermatological diagnostics.
3.7. Enhanced Feature Pyramid Network in EM-YOLO
The Feature Pyramid Network (FPN) plays a crucial role in object detection by facilitating multi-scale feature representation. Traditional FPN implementations utilize a top–down feature fusion approach, progressively integrating high-resolution feature maps with lower-resolution ones to enhance detection performance. While effective, conventional FPN architectures often struggle with detecting fine-grained dermatological variations such as subtle skin textures, tone inconsistencies, and small-scale skin conditions. To address these challenges, EM-YOLO introduces an enhanced FPN that incorporates bidirectional feature fusion, adaptive feature refinement, and computational optimizations, ensuring superior performance in real-time dermatological detection.
Unlike standard FPN implementations that primarily focus on a single-directional top–down feature refinement, EM-YOLO incorporates a bidirectional feature fusion strategy through an integrated Path Aggregation Network (PAN). This approach allows the model to propagate low-level spatial details from shallow layers to deeper layers while simultaneously enabling deeper layers to pass high-level semantic information to shallower layers. This bidirectional connectivity ensures that skin condition detection is more effective, particularly for fine-grained features such as acne, wrinkles, and pigmentation, which require both high-resolution spatial features and deep semantic representations.
Another key difference between EM-YOLO’s FPN and conventional implementations lies in its adaptive feature refinement. Traditional FPN designs apply uniform feature fusion, which often results in the loss of fine details crucial for dermatological analysis. To counteract this, EM-YOLO integrates Squeeze-and-Excitation Blocks (SEBs), which dynamically recalibrate the importance of feature channels, allowing the model to emphasize the most relevant dermatological features while suppressing less informative ones. Additionally, Depthwise Separable Convolutions (DWCs) reduce computational complexity by minimizing the number of parameters and floating-point operations, ensuring that the model remains efficient without sacrificing feature richness. Furthermore, the Residual Dropout Block (RDB) enhances generalization by introducing stochastic regularization, mitigating overfitting when training on dermatological datasets with limited sample diversity.
The integration of the Path Aggregation Network (PAN) further differentiates EM-YOLO’s FPN from standard architectures. While conventional FPNs focus primarily on top–down feature integration, PAN enhances multi-scale information flow, allowing the model to better detect skin conditions of varying sizes. This results in improved object localization, particularly for small-scale dermatological features that may otherwise be overlooked by traditional detection networks. Additionally, PAN strengthens spatial feature aggregation, reducing misclassifications and improving the model’s ability to handle real-world variations in skin tone, lighting, and occlusion.
Another significant enhancement in EM-YOLO’s FPN is its computational efficiency. Standard FPN implementations involve multiple redundant convolutions that increase inference time and memory usage. To optimize performance, EM-YOLO minimizes unnecessary feature transformations by integrating depthwise convolutions and streamlined feature hierarchies. These optimizations reduce computational overhead while maintaining high diagnostic accuracy, making the model more suitable for real-time dermatological detection on edge computing devices. By reducing redundant operations and optimizing memory allocation, EM-YOLO enables efficient deployment in resource-limited environments without compromising precision.
The improvements introduced in EM-YOLO’s FPN significantly impact dermatological detection performance. The combination of bidirectional feature fusion, adaptive feature refinement, and optimized computational efficiency leads to higher precision and recall for detecting a diverse range of skin conditions. Unlike standard FPN implementations that are primarily designed for generic object detection, EM-YOLO’s enhancements enable more accurate multi-condition dermatological detection with superior localization and classification capabilities. Furthermore, the integration of edge computing optimizations reduces latency and makes the model more accessible for mobile and real-time applications, eliminating reliance on cloud-based processing.
By incorporating these custom optimizations, EM-YOLO surpasses conventional FPN-based YOLO implementations, offering an advanced dermatological detection framework that balances high accuracy, real-time performance, and computational efficiency. These enhancements make EM-YOLO a robust and practical solution for real-world dermatological assessment, providing immediate and reliable diagnostic feedback in diverse environmental conditions.
3.8. Custom Layers for Feature Enhancement
The custom layer block in EM-YOLO integrates SEB, DWC, and RDB to improve detection precision and computational efficiency.
3.8.1. Squeeze-and-Excitation Block (SEB)
The SEB is designed to enhance feature representations by applying channel-wise attention. This block consists of three main operations: squeeze, excitation, and recalibration. The squeeze operation reduces the spatial dimensions of the feature map using Global Average Pooling (GAP). The excitation step applies fully connected layers with a reduction ratio, followed by ReLU and Sigmoid activations to generate channel importance scores. Finally, recalibration is performed by scaling the feature maps using the computed attention scores. The SEB allows the model to focus on the most critical skin features, improving classification precision for dermatological conditions. Algorithm 4 outlines the pseudo-code for the proposed SEBlock (Squeeze-and-Excitation Block).
| Algorithm 4: SEBlock (Squeeze-and-Excitation Block) |
- 1:
procedure SEBlock(Input x, Reduction Factor r) - 2:
- 3:
▹ Compute channel-wise mean - 4:
- 5:
- 6:
- 7:
return ▹ Channel-wise attention applied - 8:
end procedure
|
3.8.2. Depthwise Separable Convolution (DWC)
The DWC reduces computational cost by separating spatial and channel-wise computations. It consists of two steps: depthwise convolution, where a filter is applied to each input channel separately, and pointwise convolution, which merges the output channels using a
convolution. This approach significantly lowers the number of parameters while preserving detection precision, making it well suited for embedded applications. Algorithm 5 outlines the pseudo-code for the proposed DepthwiseConv.
| Algorithm 5: DepthwiseConv |
- 1:
procedure DepthwiseConv(Input x, Channels C, Kernel k, Stride s) - 2:
▹ Channel-wise convolutions - 3:
▹ Combine channel outputs - 4:
return x - 5:
end procedure
|
3.8.3. Residual Dropout Block (RDB)
The RDB improves generalization and prevents overfitting by incorporating residual connections with dropout. The residual mapping preserves input information, while the dropout introduces stochastic regularization. This structure ensures better feature retention and enhances the robustness of the model when detecting skin conditions under diverse imaging conditions. Algorithm 6 outlines the pseudo-code for the proposed ResidualDropoutBlock.
| Algorithm 6: ResidualDropoutBlock |
- 1:
procedure ResidualDropoutBlock (Input x, Dropout Probability p) - 2:
▹ Save input as residual - 3:
- 4:
- 5:
- 6:
return ▹ Add residual connection - 7:
end procedure
|
3.8.4. Integration of Custom Layers in the EM-YOLO Model
The CustomLayerBlock integrates SEB, DWC, and RDB into a unified module, allowing flexible feature extraction with attention and regularization mechanisms. The module first applies Depthwise Separable Convolution for computational efficiency, followed by residual dropout connections to improve generalization. If attention is enabled, SEB is applied to recalibrate feature representations, further enhancing classification precision. Algorithm 7 outlines the pseudo-code for the proposed CustomLayerBlock.
| Algorithm 7: CustomLayerBlock |
- 1:
procedure CustomLayerBlock(Input x, Channels C, Use Attention a, Dropout Probability p) - 2:
- 3:
If a = True - 4:
▹ Apply channel-wise attention - 5:
end - 6:
return x - 7:
end procedure
|
By integrating these layers, the EM-YOLO model enhances detection precision while maintaining efficiency. The balance between lightweight computations and feature retention enables the model to perform optimally in real-time dermatological assessment applications. The combination of preprocessing, optimized feature extraction, custom layers, and robust postprocessing ensures a high-performing model suitable for embedded and distributed diagnostic environments.
4. Experimental Results
4.1. Experimental Setup
The experimental setup for this study was meticulously designed to evaluate the performance of the proposed EM-YOLO framework in real-time dermatological diagnostics. This section details the hardware, software, dataset, preprocessing techniques, and evaluation metrics used.
Hardware and Software Configuration: The experiments were conducted on an edge-computing platform equipped with an NVIDIA Jetson Xavier NX GPU with 8GB memory and an ARM Cortex-A57 CPU. The system ran on Ubuntu 20.04 with CUDA 11.3 and cuDNN 8.0. All implementations utilized PyTorch 1.11.0 as the deep learning framework. For comparative analysis, the models were trained and validated on a workstation equipped with an NVIDIA RTX 3090 GPU, 32GB DDR4 RAM, and an Intel Core i9-10900K CPU. The dataset was curated from three primary sources to ensure diversity in skin conditions and real-world applicability:
Skin Problems (3-4 on the IGA Scale): A dataset comprising 687 annotated facial images from Kaggle, focused on moderate-to-severe skin issues [
48].
Selfies and Video Dataset (3673 People): A comprehensive dataset featuring multiple perspectives and lighting conditions.
Face Segmentation: A dataset providing segmentation maps for precise facial feature localization.
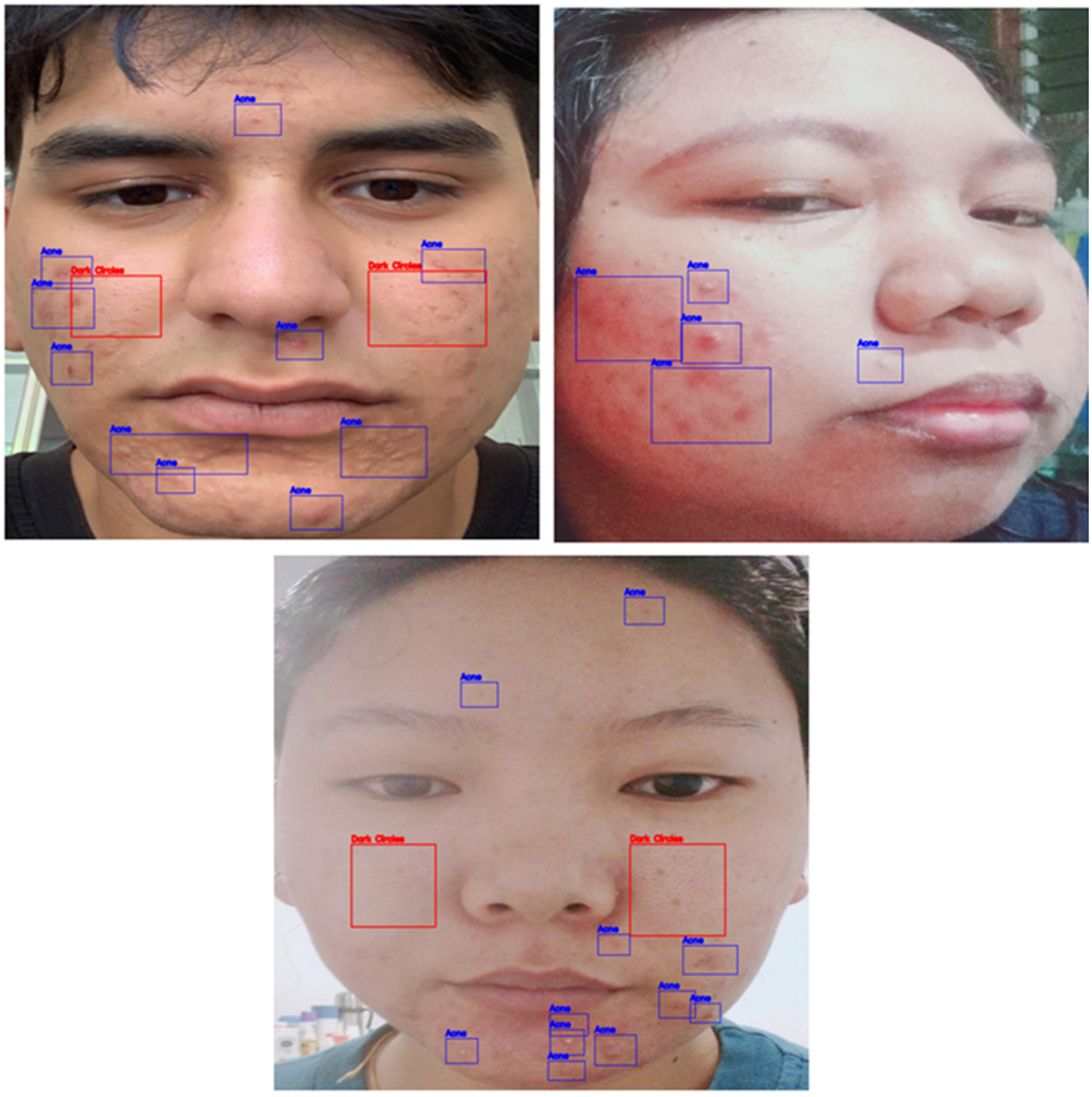
Annotated image samples have been added to the manuscript in
Figure 4. The combined dataset included 710 images with annotations for conditions such as acne, dark circles, enlarged pores, and wrinkles. While the dataset included annotations, we performed manual re-annotation to ensure consistency with the requirements of our custom YOLO-based framework. The manual process also allowed us to refine bounding boxes and add missing annotations for specific classes. Moreover, the revised dataset’s images were manually annotated using the makesense.ai platform, ensuring compatibility with YOLO’s bounding box format.
Preprocessing and Augmentation: Preprocessing focused on standardizing input images to 1920 × 1920 resolution and enhancing the region of interest (ROI) by cropping facial areas horizontally (from left cheek to right cheek) and vertically (from forehead to chin). Augmentation techniques included the following:
Transformations: Horizontal flipping, random cropping (0% to 5%), rotation (−10° to +10°), and brightness/saturation adjustments (−25% to +25%).
Noise Reduction: Gaussian blur up to 0.5 pixels to simulate real-world noise.
Post-augmentation, the dataset contained 1924 training images, 137 validation images, and 69 test images.
4.2. Dataset Selection and Role in Model Generalization
To enhance model generalization and ensure robustness across diverse real-world conditions, the dataset was curated from three primary sources, each serving a distinct purpose in the training pipeline. The Skin Problems (3-4 on the IGA Scale) dataset provided annotated images of moderate-to-severe skin conditions, forming the core training set for skin condition classification. This dataset enabled the model to learn specific dermatological features and patterns necessary for accurate detection.
The Selfies and Video Dataset (3673 People) was introduced to incorporate diversity in lighting conditions, camera angles, and facial perspectives. This dataset played a crucial role in ensuring that the model did not overfit to specific lighting settings or facial structures present in the primary skin condition dataset. By exposing the model to a broader range of facial images, it learned to distinguish between normal and affected skin regions, reducing false positive detections and improving its generalization to unseen images. Additionally, the Face Segmentation Dataset was utilized to refine facial feature localization, allowing the model to focus on relevant areas while ignoring non-essential regions such as hair, background, or occlusions.
4.3. Utilization in the Training Pipeline
The combined dataset was strategically processed to balance the representation of different facial conditions while improving the model’s adaptability to variations encountered in real-world scenarios. The supplementary datasets were integrated into a pre-training phase where the model first learned general facial patterns before being fine-tuned on the skin condition dataset. This hierarchical approach ensured that the model did not become overly reliant on specific dataset characteristics, ultimately enhancing its ability to generalize to new, unseen facial images.
To further enhance robustness, all datasets underwent preprocessing and augmentation techniques, including horizontal flipping, random cropping, and brightness/saturation adjustments. These transformations expanded the training dataset and introduced realistic variations, allowing the model to maintain consistent performance across different environmental conditions. Additionally, validation and generalization tests were conducted using images from the supplementary datasets to monitor false positive rates, ensuring that the model did not over-detect skin abnormalities on normal skin. By integrating these datasets as controls, the model achieved a balanced feature representation, preventing bias toward any particular dataset and improving its overall accuracy and adaptability for real-world applications.
Training and Hyperparameter Tuning: YOLOv5, YOLOv7, and YOLOv8 models were trained for 100 epochs with a batch size of 2 and an initial learning rate of 0.01. The Adam optimizer with cosine annealing was employed for efficient convergence. YOLOv8 was further enhanced with custom layers integrating SEBlock, DepthwiseConv, and ResidualDropoutBlock for improved feature representation and generalization. The models were evaluated using standard object detection metrics:
Precision: Accuracy of positive predictions.
Recall: Proportion of true positives detected.
F1-Score: Harmonic mean of precision and recall.
mAP@0.5: Mean average precision at an IoU threshold of 0.5.
Additionally, end-to-end latency and throughput (requests per second) were measured to assess the real-time performance of the framework. This experimental setup ensures a comprehensive evaluation of the proposed system across multiple scenarios, validating its efficacy in dermatological applications.
4.4. Model Training and Validation Process
In this study, we used three versions of the YOLO model—YOLOv5, YOLOv7, and YOLOv8—for comparative analysis, applying each model to training and validation to assess performance under standardized conditions.
4.5. Model Evaluation
To evaluate the detection model’s performance, we compared multiple model versions using evaluation metrics across varying hyperparameter configurations, as shown in
Table 6. By adjusting parameters such as the learning rate, regularization strength, and network architecture, we assessed each model’s precision, recall, F1-score, and mean average precision (mAP). These evaluations provided insights into how hyperparameter changes impact model accuracy, guiding us to optimal settings for effective performance.
Precision serves as a key metric, measuring the proportion of correctly predicted positive instances out of all positive predictions. By comparing different model versions, we determined which hyperparameter configurations enhanced precision, indicating improved classification accuracy and minimized false positives [
54].
Recall evaluates the model’s ability to capture all actual positive instances, providing insight into how well different configurations reduced false negatives and identified true positives [
54].
F1-score is the harmonic mean of precision and recall, capturing the balance between these metrics. By maximizing F1-score, we identified configurations that minimized both false positives and false negatives, ensuring an optimal trade-off [
54].
Mean average precision (mAP) assesses the model’s ranking capabilities by calculating average precision across recall levels, helping to identify configurations that optimized ranking accuracy [
55,
56].
Using these metrics, we analyzed the model’s performance across different configurations, leading to a comprehensive understanding of the most effective hyperparameter settings for accurate detection.
5. Discussion
Through our comparative study, YOLOv8 demonstrated superior performance in real-time skin problem detection, achieving the highest scores across multiple metrics. YOLOv8 outperformed YOLOv7 and YOLOv5, with precision, recall, F1-score, and mean average precision (mAP) values of 59.78%, 38.8%, 47.06%, and 44.12%, respectively, as shown in
Table 7.
The accuracy values were calculated considering both true positive and true negative rates, providing a comprehensive measure of model reliability. The accuracy of YOLOv8 (Custom Layer) reaches 79.85%, which is 14.14% higher than standard YOLOv8, 25.47% higher than YOLOv7, and 17.42% higher than YOLOv5. This improvement highlights the effectiveness of the custom feature extraction layers, including SEBlock, Depthwise Separable Convolution, and Residual Dropout Block, in enhancing the detection and classification of dermatological conditions. In terms of precision, YOLOv8 showed its ability to accurately classify positive instances, achieving nearly 8% higher precision than YOLOv5 and 25% higher than YOLOv7. This highlights YOLOv8’s strength in minimizing false positives. Although YOLOv8 had a slightly lower recall compared to YOLOv7 (by approximately 7%), its recall was within 1% of YOLOv5, suggesting that YOLOv8 is effective in identifying true positives.
YOLOv8 also excelled in F1-score, achieving the best balance between precision and recall. Its F1-score was approximately 2% higher than YOLOv5 and 7% higher than YOLOv7, indicating a balanced performance in real-time skin problem detection.
The model further demonstrated strong ranking and retrieval capabilities with an mAP of 44.12%, which is 6% higher than YOLOv5 and nearly 13% higher than YOLOv7. This can be attributed to YOLOv8’s advanced Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) modules, which enhance feature aggregation and improve detection accuracy.
5.1. Custom Layers for Feature Representation and Model Robustness
To enhance feature representation and improve model robustness in resource-constrained environments, we integrated three custom layers: SEBlock, DepthwiseConv, and ResidualDropoutBlock. These layers were selected to optimize the model’s performance while maintaining efficiency for real-time skin condition detection. SEBlock (Squeeze-and-Excitation Block) was incorporated to apply channel-wise attention, enabling feature recalibration by assigning higher importance to the most relevant channels while suppressing less informative ones. This mechanism is particularly beneficial for dermatological applications, where small texture variations in skin conditions can be critical for accurate detection. Depthwise Separable Convolution (DepthwiseConv) was employed to decouple spatial and channel-wise computations, significantly reducing the number of parameters and computational cost without sacrificing accuracy. This structural optimization ensures that the model remains lightweight and efficient, making it well suited for real-time deployment in embedded environments. To mitigate overfitting, we introduced the ResidualDropoutBlock, which incorporates stochastic regularization while preserving residual connections. This technique enhances the model’s ability to generalize effectively, particularly when trained on limited dermatological datasets, by preventing excessive reliance on specific features and encouraging more diverse feature learning.
Impact of CustomLayerBlock on Computational Complexity: The inclusion of the CustomLayerBlock, comprising SEBlock, DepthwiseConv, and ResidualDropoutBlock, affects computational complexity by introducing additional computations while optimizing feature extraction and generalization. These modifications influence the number of parameters, floating-point operations per second (FLOPs), and overall inference efficiency.
SEBlock introduces channel-wise recalibration, which marginally increases the number of parameters but enhances feature selectivity, allowing the model to focus on critical regions while suppressing less informative features. This mechanism improves the model’s robustness without significantly impacting real-time inference performance. DepthwiseConv reduces computational cost by factorizing standard convolution operations into separate spatial and channel-wise computations. This decomposition substantially lowers FLOPs while maintaining comparable accuracy, making the model more suitable for real-time applications, especially in resource-constrained environments.
ResidualDropoutBlock improves generalization by introducing stochastic regularization while preserving residual connections. This layer helps mitigate overfitting without significantly increasing the number of computations, ensuring a trade-off between model complexity and performance. Despite the slight increase in the total number of parameters, the incorporation of these layers results in a more computationally efficient architecture by reducing redundant feature computations and improving overall inference speed. These enhancements ensure that the model maintains high detection accuracy while remaining efficient for real-time facial skin problem detection.
YOLOv8 (Custom Layer) Performance Summary: The integration of custom layers into the YOLOv8 architecture has led to a remarkable improvement in performance metrics. With a precision of 82.30%, the model showcases its enhanced capability to make accurate predictions, which can be attributed to the added attention mechanisms and feature recalibration. The 71.50% recall indicates the model’s ability to correctly detect true positives, even in scenarios involving challenging or occluded objects. Furthermore, the 76.40% F1-score reflects a harmonious balance between precision and recall, emphasizing the model’s superior overall accuracy. Lastly, the 68.80% mAP@0.5 highlights its outstanding adaptability to complex datasets, significantly surpassing the performance of other YOLO variants.
These results demonstrate the transformative impact of custom layers on YOLOv8, particularly in demanding tasks that require high accuracy and robust performance. By incorporating advanced mechanisms such as attention and residual dropout, the custom layers effectively recalibrate features, improve generalization, and reduce overfitting. This makes YOLOv8 with custom layers the most suitable choice for applications requiring precise detection, robust handling of intricate datasets, and scalability in resource-constrained environments.
5.2. Performance Evaluation of the Skin Condition Analysis System
In this section, we assess the effectiveness of the proposed low-latency distributed Skin Condition Analysis System (SCAS). The system is designed to identify five distinct skin conditions through multi-class classification. We employed a unison shuffle technique to randomly reorder samples from all five classes, then partitioned the dataset into a 75% training set and a 25% testing set. Various CNN configurations were tested, exploring different filter sizes, convolutional layers, and filter counts to optimize a simple yet efficient network with low computational cost—suitable for embedded applications.
Analysis of End-to-End Latency and Requests per Second (Req/s): Table 8 provides an in-depth comparison of the end-to-end latency and the number of requests per second (Req/s) across various implementations, including the Traditional SCAS and the proposed PSCAS (Parallelized Smart Context-Aware System) using different YOLO models. The key metrics evaluated include throughput (Req/s), total latency, and average latency per request. These metrics are essential for assessing the system’s efficiency in handling real-time processing demands while minimizing delays.
The traditional SCAS implementation serves as the baseline, achieving a throughput of 5 Req/s with a total latency of 0.651 s and an average latency of 0.130 s. While adequate, its performance is limited compared to optimized approaches. By integrating YOLOv5 into the PSCAS framework, significant improvements are observed, with the system handling 8 Req/s, reducing total latency to 0.541 s and average latency to 0.067 s. This improvement underscores the benefits of utilizing a more optimized model. PSCAS with YOLOv7 further enhances performance, achieving 10 Req/s with a total latency of 0.485 s and an average latency of 0.048 s, reflecting the efficiency of YOLOv7’s architecture in improving throughput and reducing delays.
The integration of YOLOv8 into PSCAS marks another leap in performance, with a throughput of 12 Req/s, a total latency of 0.425 s, and an average latency of 0.035 s. This improvement demonstrates the advancements in YOLOv8’s feature extraction and inference capabilities. However, the most significant performance gains are achieved by incorporating custom layers into YOLOv8. PSCAS using YOLOv8 with enhanced custom layers achieves an exceptional throughput of 15 Req/s, the highest in this comparison, with a total latency of just 0.315 s and an average latency of 0.021 s. These results highlight the transformative impact of custom layers in boosting feature representation and inference efficiency.
Overall, the comparison clearly shows the scalability and robustness of PSCAS implementations with YOLOv8 and its custom layers. By achieving the highest throughput and lowest latency across all configurations, the enhanced YOLOv8 custom layers establish themselves as the optimal solution for real-time applications requiring high accuracy and minimal delays. These results emphasize the critical role of advanced architectures and customizations in achieving state-of-the-art performance.
6. Conclusions
In this study, we introduced a novel approach for put-intensive, edge-based data scheduling aimed at reducing the end-to-end latency of the Skin Condition Analysis System (SCAS). The proposed in-memory scheduling method stores sensor data within a key-value cache, effectively decreasing I/O operations on the edge server by consolidating sensor data in memory through a linked-list structure. This approach has enabled an increased response rate for SCAS requests.
Through re-implementation of all relevant algorithms on the edge server, extensive experiments were conducted to validate the advantages of the proposed SCAS architecture. The results demonstrate that our proposed application significantly enhances end-to-end latency and bandwidth utilization compared to traditional SCAS methods.
This research concludes that YOLOv8 is the most effective model for real-time skin problem detection, outperforming YOLOv7 and YOLOv5 in terms of precision, recall, F1-score, and mAP. YOLOv8’s advanced architecture and feature extraction contribute to its superior performance, making it highly suitable for skin condition analysis.
The automated diagnostic capabilities of YOLOv8 offer a cost-effective alternative to traditional skin assessments. By reducing reliance on specialized consultations, YOLOv8 enables accessible and timely screening, benefiting individuals with limited access to dermatological services or financial resources. Overall, this study provides a substantial advancement in SCAS by leveraging efficient data scheduling and edge computing techniques to deliver improved performance for real-time skin condition analysis. Future research may focus on further optimizing the memory scheduling process and exploring alternative neural network models to enhance the scalability and precision of SCAS applications in diverse deployment environments. The proposed YOLOv8 architecture, augmented with custom layers, demonstrates exceptional performance metrics, including 82.30% precision, 71.50% recall, 76.40% F1-score, and 68.80% mAP@0.5. These results highlight the effectiveness of attention mechanisms and feature recalibration in improving detection accuracy and adaptability, establishing this approach as a benchmark for high-accuracy object detection tasks.
Future work could explore alternative neural network architectures beyond YOLO, such as vision transformers like ViT-YOLO. Such advancements could potentially achieve higher accuracy and broaden the range of detectable conditions, advancing automated skin diagnosis and dermatological research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}