
Frequency-Domain Masking and Spatial Interaction for Generalizable Deepfake Detection


Abstract
1. Introduction
- (1)
- Introducing masked image modeling into the frequency domain and integrating it with Vision Transformers.
- (2)
- Proposing a high-frequency convolutional module to capture critical frequency components across spatial and channel dimensions.
- (3)
- Designing a spatial-frequency attention module to holistically interpret image details by fusing spatial and frequency-domain information.
- (4)
- Experimental results demonstrate superior detection accuracy and robust generalization capability of the proposed model.
2. Related Work
2.1. Deepfake Methods
2.2. Frequency-Domain Deepfake Detection
2.3. Masked Image Modeling
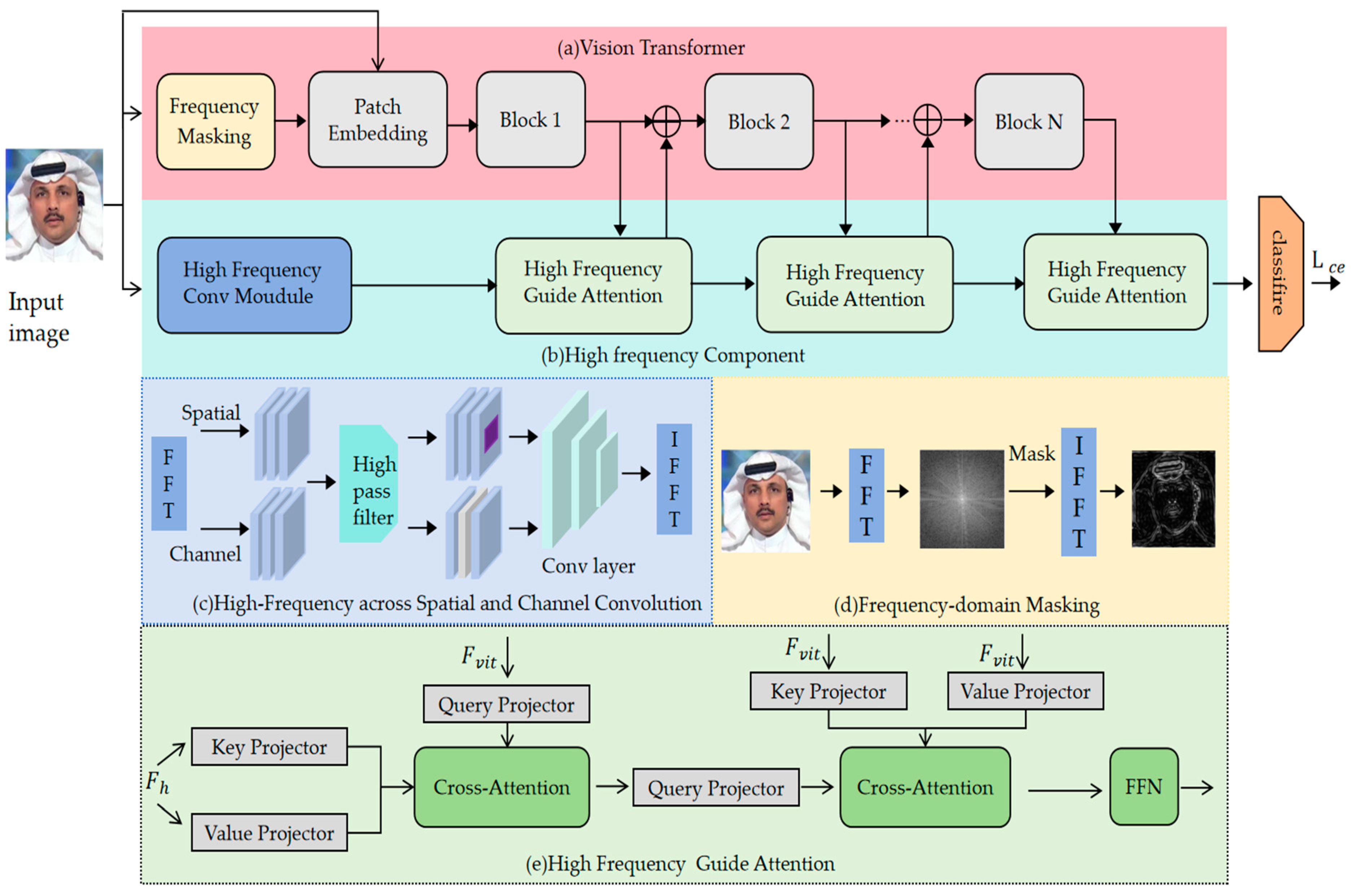
3. Method
3.1. Frequency Masking
3.2. High-Frequency Feature Convolution
3.3. Spatial-Frequency Attention
3.4. Loss Function
4. Experiments
4.1. Experiments Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Evaluations
4.2.1. Intra-Dataset Evaluation
4.2.2. Cross-Manipulation Evaluation
4.2.3. Cross-Dataset Evaluation
4.3. Ablation Study
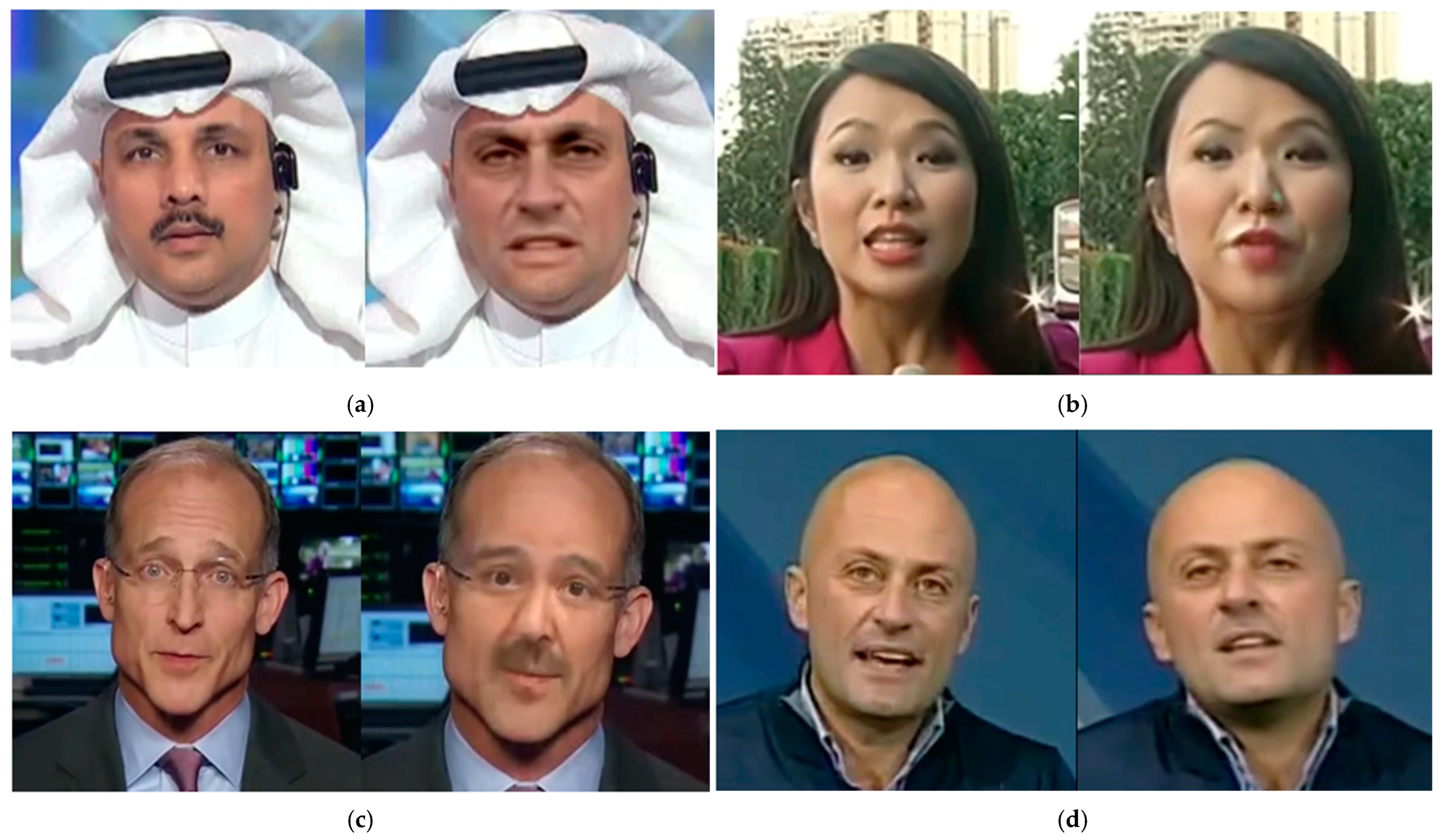
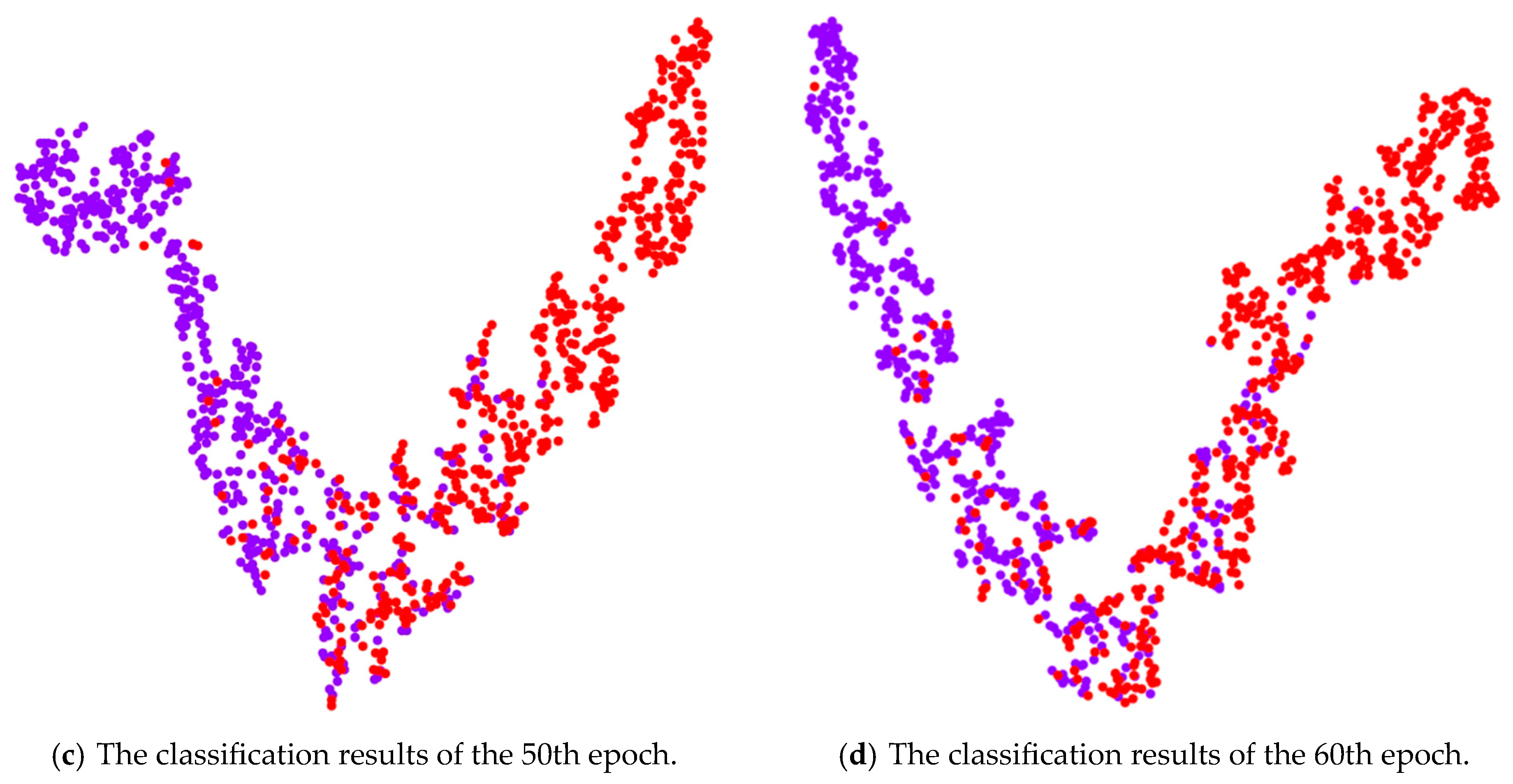
4.4. Visualize
4.4.1. Analysis of Classification Decision
4.4.2. Feature Distribution Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Du, Y.; Luo, D.; Yan, R.; Wang, X.; Liu, H.; Zhu, H.; Song, Y.; Zhang, J. Enhancing job recommendation through llm-based generative adversarial networks. Proc. AAAI Conf. Artif. Intell. 2024, 38, 8363–8371. [Google Scholar] [CrossRef]
- Miao, J.; Tao, H.; Xie, H.; Sun, J.; Cao, J. Reconstruction-based anomaly detection for multivariate time series using contrastive generative adversarial networks. Inf. Process. Manag. 2024, 61, 103569. [Google Scholar] [CrossRef]
- Wang, P.; Liu, Z.; Wang, Z.; Zhao, Z.; Yang, D.; Yan, W. Graph generative adversarial networks with evolutionary algorithm. Appl. Soft Comput. 2024, 164, 111981. [Google Scholar] [CrossRef]
- Yan, N.; Gu, J.; Rush, A.M. Diffusion models without attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8239–8249. [Google Scholar]
- Chen, H.; Zhang, Y.; Cun, X.; Xia, M.; Wang, X.; Weng, C.; Shan, Y. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 7310–7320. [Google Scholar]
- Qu, Z.; Meng, Y.; Muhammad, G.; Tiwari, P. QMFND: A quantum multimodal fusion-based fake news detection model for social media. Inf. Fusion 2024, 104, 102172. [Google Scholar] [CrossRef]
- Peng, L.; Jian, S.; Kan, Z.; Qiao, L.; Li, D. Not all fake news is semantically similar: Contextual semantic representation learning for multimodal fake news detection. Inf. Process. Manag. 2024, 61, 103564. [Google Scholar] [CrossRef]
- Liu, C.; Chen, H.; Zhu, T.; Zhang, J.; Zhou, W. Making DeepFakes more spurious: Evading deep face forgery detection via trace removal attack. IEEE Trans. Dependable Secur. Comput. 2023, 20, 5182–5196. [Google Scholar] [CrossRef]
- Ba, Z.; Liu, Q.; Liu, Z.; Wu, S.; Lin, F.; Lu, L.; Ren, K. Exposing the deception: Uncovering more forgery clues for deepfake detection. Proc. AAAI Conf. Artif. Intell. 2024, 38, 719–728. [Google Scholar] [CrossRef]
- Husseini, S.; Dugelay, L. A comprehensive framework for evaluating deepfake generators: Dataset, metrics performance, and comparative analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 372–381. [Google Scholar]
- Yu, P.; Xia, Z.; Fei, J.; Lu, Y. A survey on deepfake video detection. Iet Biom. 2021, 10, 607–624. [Google Scholar] [CrossRef]
- Shiohara, K.; Yamasaki, T. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18720–18729. [Google Scholar]
- Perov, I.; Gao, D.; Chervoniy, N.; Zhou, W.; Zhang, W. Deepakala: Integrated, flexible and extensible face-swapping framework. arXiv 2020, arXiv:2005.05535. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Niessner, M. Faceforensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-df: A large-scale challenging dataset for deepfake forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 14–19 June 2020; pp. 3207–3216. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y. Wilddeepfake: A challenging real-world dataset for deepfake detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2382–2390. [Google Scholar]
- Chen, H.; Li, Y.; Lin, D.; Li, B.; Wu, J. Watching the big artifacts: Exposing deepfake videos via bi-granularity artifacts. Pattern Recognit. 2023, 135, 109179. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. AW-MSA: Adaptively weighted multi-scale attentional features for DeepFake detection. Eng. Appl. Artif. Intell. 2024, 127, 107443. [Google Scholar] [CrossRef]
- Gao, J.; Concas, S.; Orrù, G.; Feng, X.; Marcialis, G.L.; Roli, F. Generalized deepfake detection algorithm based on inconsistency between inner and outer faces. In International Conference on Image Analysis and Processing; Springer Nature: Cham, Switzerland, 2023; pp. 343–355. [Google Scholar]
- Liu, B.; Liu, B.; Ding, M.; Zhu, T.; Yu, X. TI2Net: Temporal identity inconsistency network for deepfake detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 4691–4700. [Google Scholar]
- Xu, F.; Wang, R.; Huang, Y.; Guo, Q.; Ma, L.; Liu, Y. Countering malicious deepfakes: Survey, battleground, and horizon. Int. J. Comput. Vis. 2022, 130, 1678–1734. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning rich features for image manipulation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1053–1061. [Google Scholar]
- Liu, H.; Li, X.; Zhou, W.; Chen, Y.; He, Y.; Xue, H.; Zhang, W.; Yu, N. Spatial-phase shallow learning: Rethinking face forgery detection in frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 772–781. [Google Scholar]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing face forgery detection with high-frequency features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16317–16326. [Google Scholar]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAImageed, W. Two-branch recurrent network for isolating deepfakes in videos. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII 16. Springer International Publishing: New York, NY, USA, 2020; pp. 667–684. [Google Scholar]
- Durall, R.; Keuper, M.; Pfreundt, F.; Keuper, J. Unmasking deepfakes with simple features. arXiv 2019, arXiv:1911.00686. [Google Scholar]
- Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Li, J.; Ji, R. Local relation learning for face forgery detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 1081–1088. [Google Scholar]
- Concas, S.; Perelli, G.; Marcialis, G.L.; Puglisi, G. Tensor-based deepfake detection in scaled and compressed images. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3121–3125. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in frequency: Face forgery detection by mining frequency-aware clues. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 86–103. [Google Scholar]
- Miao, C.; Tan, Z.; Chu, Q.; Liu, H.; Hu, H.; Yu, N. F2 trans: High-frequency fine-grained transformer for face forgery detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1039–1051. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Niessner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- FaceSwap. 2018. Available online: https://github.com/MarekKowalski/FaceSwap/ (accessed on 29 October 2018).
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar]
- Stuchi, A.; Angeloni, M.A.; Pereira, R.F.; Boccato, L.; Folego, G.; Prado, P.V.S. Improving image classification with frequency domain layers for feature extraction. In Proceedings of the 2017 IEEE 27th International Workshop on Machine Learning for Signal Processing (MLSP), Tokyo, Japan, 25–28 September 2017; pp. 1–6. [Google Scholar]
- Sarlashkar, A.N.; Bodruzzaman, M.; Malkani, M. Feature extraction using wavelet transform for neural network based image classification. In Proceedings of the Thirtieth Southeastern Symposium on System Theory, Tuskegee, AL, USA, 8–10 March 1998; pp. 412–416. [Google Scholar]
- Franzen, F. Image classification in the frequency domain with neural networks and absolute value DCT. In Proceedings of the Image and Signal Processing: 8th International Conference, ICISP 2018, Cherbourg, France, 2–4 July 2018; Proceedings 8. Springer International Publishing: New York, NY, USA, 2018; pp. 301–309. [Google Scholar]
- Chen, M.; Sedighi, V.; Boroumand, M.; Fridrich, J. JPEG-phase-aware convolutional neural network for steganalysis of JPEG images. In Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, Philadelphia, PA, USA, 20–22 June 2017; pp. 75–84. [Google Scholar]
- Denemark, T.D.; Boroumand, M.; Fridrich, J. Steganalysis features for content-adaptive JPEG steganography. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1736–1746. [Google Scholar] [CrossRef]
- Fujieda, S.; Takayama, K.; Hachisuka, T. Wavelet convolutional neural networks for texture classification. arXiv 2017, arXiv:1707.07394. [Google Scholar]
- Li, J.; You, S.; Robles-Kelly, A. A frequency domain neural network for fast image super-resolution. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet-srnet: A wavelet-based cnn for multi-scale face super resolution. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1689–1697. [Google Scholar]
- Wang, H.; Wu, X.; Huang, Z.; Xing, E.P. High-frequency component helps explain the generalization of convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8684–8694. [Google Scholar]
- Xu, K.; Qin, M.; Sun, F.; Wang, Y.; Chen, Y.K.; Ren, F. Learning in the frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1740–1749. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 3247–3258. [Google Scholar]
- Wang, S.Y.; Wang, O.; Zhang, R.; Owens, A.; Efros, A.A. CNN-generated images are surprisingly easy to spot... for now. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8695–8704. [Google Scholar]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9653–9663. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Azari, F.; Robertson, A.M.; Tobe, Y.; Tobe, Y.; Watton, P.N.; Birder, L.A.; Yoshimura, N.; Matsuoka, K.; Hardin, C.; Watkins, S. Elucidating the high compliance mechanism by which the urinary bladder fills under low pressures. arXiv 2025, arXiv:2501.10312. [Google Scholar]
- Huang, L.; You, S.; Zheng, M.; Wang, F.; Qian, C.; Yamasaki, T. Green hierarchical vision transformer for masked image modeling. Adv. Neural Inf. Process. Syst. 2022, 35, 19997–20010. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Adv. Neural Inf. Process. Syst. 2022, 35, 10078–10093. [Google Scholar]
- Gao, P.; Ma, T.; Li, H.; Lin, Z.; Dai, J.; Qiao, Y. Convmae: Masked convolution meets masked autoencoders. arXiv 2022, arXiv:2205.03892. [Google Scholar]
- Fei, Z.; Fan, M.; Zhu, L.; Huang, J.; Wei, X.M.; Wei, X. Masked auto-encoders meet generative adversarial networks and beyond. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 24449–24459. [Google Scholar]
- Kordi, F.; Yousefi, H. Crop classification based on phenology information by using time series of optical and synthetic-aperture radar images. Remote Sens. Appl. Soc. Environ. 2022, 27, 100812. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FF++ (HQ) | FF++ (LQ) |
|---|---|---|
| Xception | 97.80 | 87.21 |
| Multi-task | 88.72 | 76.74 |
| EfficientNetB4 | 98.94 | 88.14 |
| Face X-ray | 87.40 | 61.60 |
| Two-Branch | 98.70 | 86.59 |
| RFM | 98.79 | 89.83 |
| GFFD | 98.95 | 88.27 |
| SPSL | 95.32 | 82.82 |
| FST+Efficient-b4 | 98.81 | 91.27 |
| ALFE(Xception) | 99.10 | 92.60 |
| PESAF | 99.32 | 92.86 |
| Ours | 98.18 | 96.17 |
| Methods | Train | Test | |||
|---|---|---|---|---|---|
| DF | F2F | FS | NT | ||
| Freq-SCL | DF | 98.91 | 58.90 | 66.87 | 63.61 |
| RECCE | 99.65 | 70.66 | 74.29 | 67.34 | |
| DisGRL | 99.67 | 71.76 | 75.21 | 68.74 | |
| Ours | 99.78 | 62.34 | 84.68 | 56.67 | |
| Freq-SCL | F2F | 67.55 | 93.06 | 55.35 | 66.66 |
| RECCE | 75.99 | 98.06 | 64.53 | 72.32 | |
| DisGRL | 75.73 | 98.69 | 65.71 | 74.15 | |
| Ours | 73.08 | 99.52 | 72.84 | 74.46 | |
| Freq-SCL | FS | 75.90 | 54.64 | 98.82 | 56.70 |
| RECCE | 82.39 | 64.44 | 98.82 | 56.70 | |
| DisGRL | 82.73 | 64.85 | 99.01 | 56.96 | |
| Ours | 92.44 | 78.87 | 99.68 | 71.86 | |
| Freq-SCL | NT | 79.09 | 74.21 | 53.99 | 88.54 |
| RECCE | 78.83 | 80.89 | 63.70 | 93.63 | |
| DisGRL | 80.29 | 83.30 | 65.23 | 94.10 | |
| Ours | 68.15 | 87.12 | 79.11 | 96.21 | |
| Methods | WDF | CDF | ||
|---|---|---|---|---|
| AUC ↑ | EER ↓ | AUC ↑ | EER ↓ | |
| Xception | 62.72 | 40.65 | 61.80 | 41.73 |
| Add-Net | 62.35 | 41.42 | 65.29 | 38.90 |
| F3Net | 57.10 | 45.12 | 61.51 | 42.03 |
| RFM | 57.75 | 45.45 | 65.63 | 38.54 |
| MultiAtt | 59.74 | 43.73 | 67.02 | 37.90 |
| MAT | 59.74 | 43.73 | 67.02 | 37.90 |
| RECCE | 64.31 | 40.53 | 68.71 | 35.73 |
| DisGRL | 66.73 | 39.24 | 70.03 | 34.23 |
| PESAF | - | - | 73.61 | 32.70 |
| Ours | 75.82 | 31.49 | 74.86 | 31.56 |
| Method | Baseline | SFA | HFC | FM | DF | FS | NT |
|---|---|---|---|---|---|---|---|
| F2F | √ | 67.47 | 64.25 | 69.36 | |||
| √ | √ | 70.31 | 68.04 | 70.67 | |||
| √ | √ | 69.51 | 67.66 | 70.24 | |||
| √ | √ | √ | 72.40 | 70.01 | 71.22 | ||
| √ | √ | √ | √ | 73.08 | 72.84 | 74.46 |
| Mask Ratio | AUC |
|---|---|
| 15% | 68.89 |
| 30% | 73.08 |
| 45% | 70.26 |
| 60% | 70.41 |
| 75% | 69.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Wang, Y. Frequency-Domain Masking and Spatial Interaction for Generalizable Deepfake Detection. Electronics 2025, 14, 1302. https://doi.org/10.3390/electronics14071302
Luo X, Wang Y. Frequency-Domain Masking and Spatial Interaction for Generalizable Deepfake Detection. Electronics. 2025; 14(7):1302. https://doi.org/10.3390/electronics14071302
Chicago/Turabian StyleLuo, Xinyu, and Yu Wang. 2025. "Frequency-Domain Masking and Spatial Interaction for Generalizable Deepfake Detection" Electronics 14, no. 7: 1302. https://doi.org/10.3390/electronics14071302
APA StyleLuo, X., & Wang, Y. (2025). Frequency-Domain Masking and Spatial Interaction for Generalizable Deepfake Detection. Electronics, 14(7), 1302. https://doi.org/10.3390/electronics14071302