
ZNSage: Towards Hardware-Agnostic Swap Metadata Management on ZNS SSDs

Abstract
1. Introduction
- We fully resolve the limitations of traditional SSD-based swapping by leveraging ZNS SSDs, significantly improving swap performance.
- Unlike prior work, such as ZNSwap, which imposes hardware restrictions, ZNSage provides a generalized swap solution applicable to all ZNS SSDs, regardless of vendor or model.
- We minimize page faults that may occur during swap zone garbage collection, further improving system efficiency.
2. Background
2.1. Multi-Stream and ZNS SSDs as SSD Garbage Collection Optimization Techniques
- Indirect Page Invalidity Updates (via Side Channels): This method does not control page placement but instead relies on side channels to update page invalidity information, ensuring that invalid pages are excluded from GC copying. Only the application layer can determine whether a page is still valid; however, because the application and storage layers are completely separated, once data are written, their validity does not automatically update. The SSD TRIM command serves precisely this purpose, but due to its significant interface overhead, it is typically applied at coarse granularities (e.g., 1MB LBA regions for Linux swap), limiting its practical effectiveness [7].
- Lifetime-Based Page Placement: This method groups pages with similar lifetimes into the same flash block, so when their lifespan ends, the entire block can be erased at once, eliminating the need for page copying. A well-known example is multi-stream, introduced in 2014 [8,9,10]. However, this technique had severe resource constraints (supporting fewer than 10 streams in most implementations) and lacked demonstrated benefits at the application level, leading to diminished interest in the technology.
- Minimal Interface Constraints Due to Firmware or Hardware Limitations: Prior research on multi-stream has shown that using only one or two streams does not yield significant performance improvements [8,9]. If stream merging or stream recycling is required due to resource limitations [8], or if file size constraints prevent unrestricted stream creation [9], the substantial interface overhead (“stream I/O tax”) makes adoption impractical.
- Integration into the SSD’s Primary I/O Path: Modern SSDs prioritize maximizing their primary I/O performance through mechanisms such as channel and way parallelism, fully hardware-accelerated data paths, and firmware-based implementations only for secondary I/O operations (e.g., Set/GetFeature, TRIM). Since operations integrated into the primary I/O path exhibit superior performance, using streams as an auxiliary mechanism imposes inherent limitations on overall SSD performance. For stream I/O to provide clear application-level performance gains, it must be integrated into the primary I/O path.
- Minimize GC overhead by including only valid pages in GC operations;
- Ensure sequential physical writes whenever a zone write command is issued.
2.2. LBA Format and PI [22] in SSDs
3. Design
3.1. Employing ZNS SSD as a Swap Device
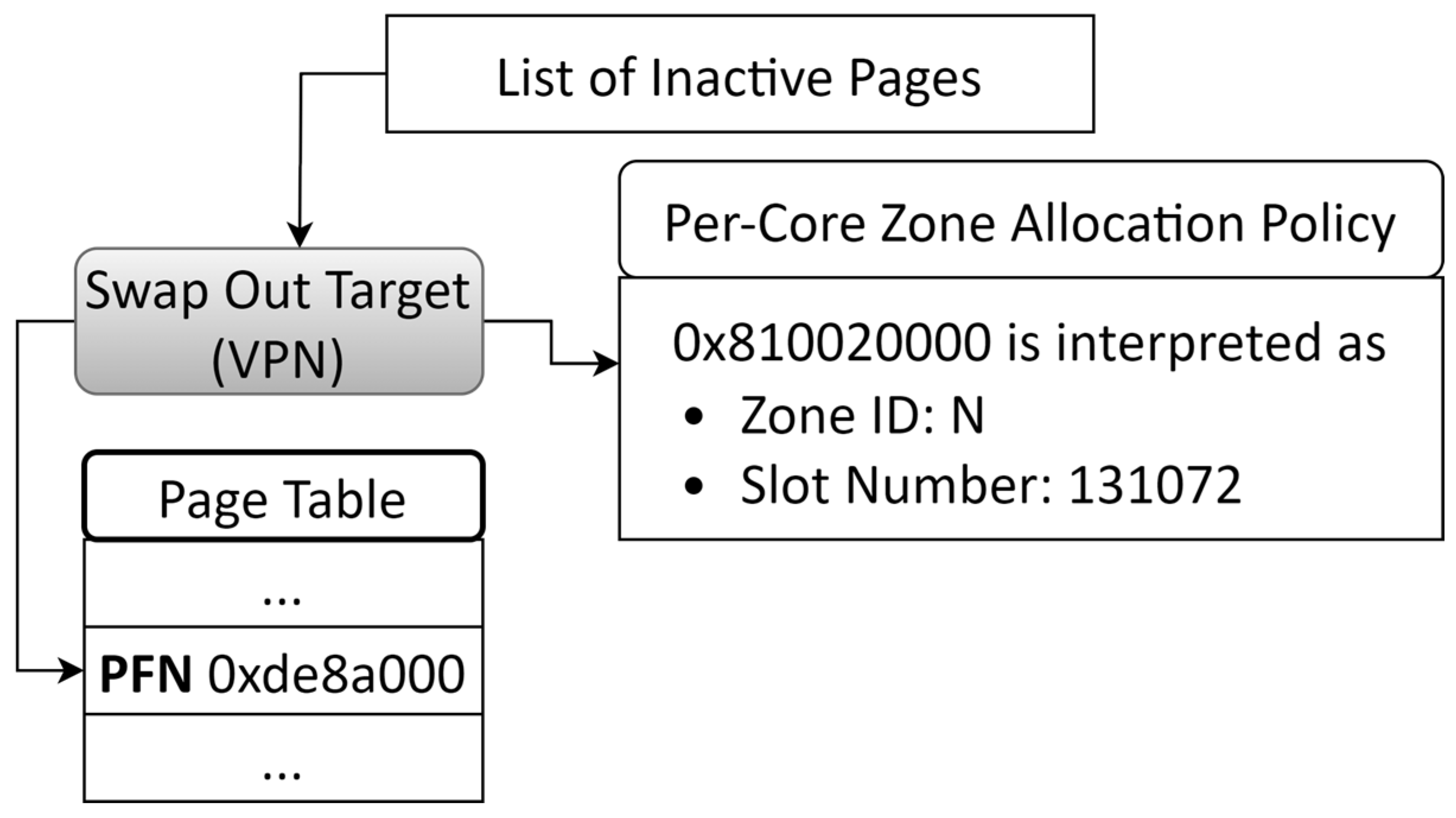
3.2. ZNS SSD-Agnostic Swap Subsystem in Linux
- Hardware Constraints: As explained earlier, not all ZNS SSDs support the required LBA format, and the use of metadata space varies across firmware, interfaces (NVMe, SAS, SATA), and vendor specifications. This creates significant hardware dependencies and portability issues.
- Minimal Memory Overhead: The assumption that significant system memory is required for mapping storage is questionable. For a system with 64 GB+ of RAM, the recommended swap size is 4 GB [24]. Assuming a 4 KB page size, this corresponds to a maximum of 1 M swap pages, each requiring 24 bytes of reverse mapping metadata, amounting to only 24 MB—a trivial amount of memory.
- No Persistence Requirement: Unlike file system metadata, swap page mappings do not require persistence. Since swap pages exist solely to extend system memory, they are only valid while the system is powered on. Thus, storing swap metadata in persistent SSD storage is unnecessary.
- Existing Metadata Usage: The metadata space utilized by ZNSwap is already allocated for critical functions in enterprise environments, such as data integrity protection (PI) [22] and user data expansion. Using this space for swap metadata requires careful consideration, as data integrity and storage capacity extensions take precedence over swap-related functions.
4. Implementation
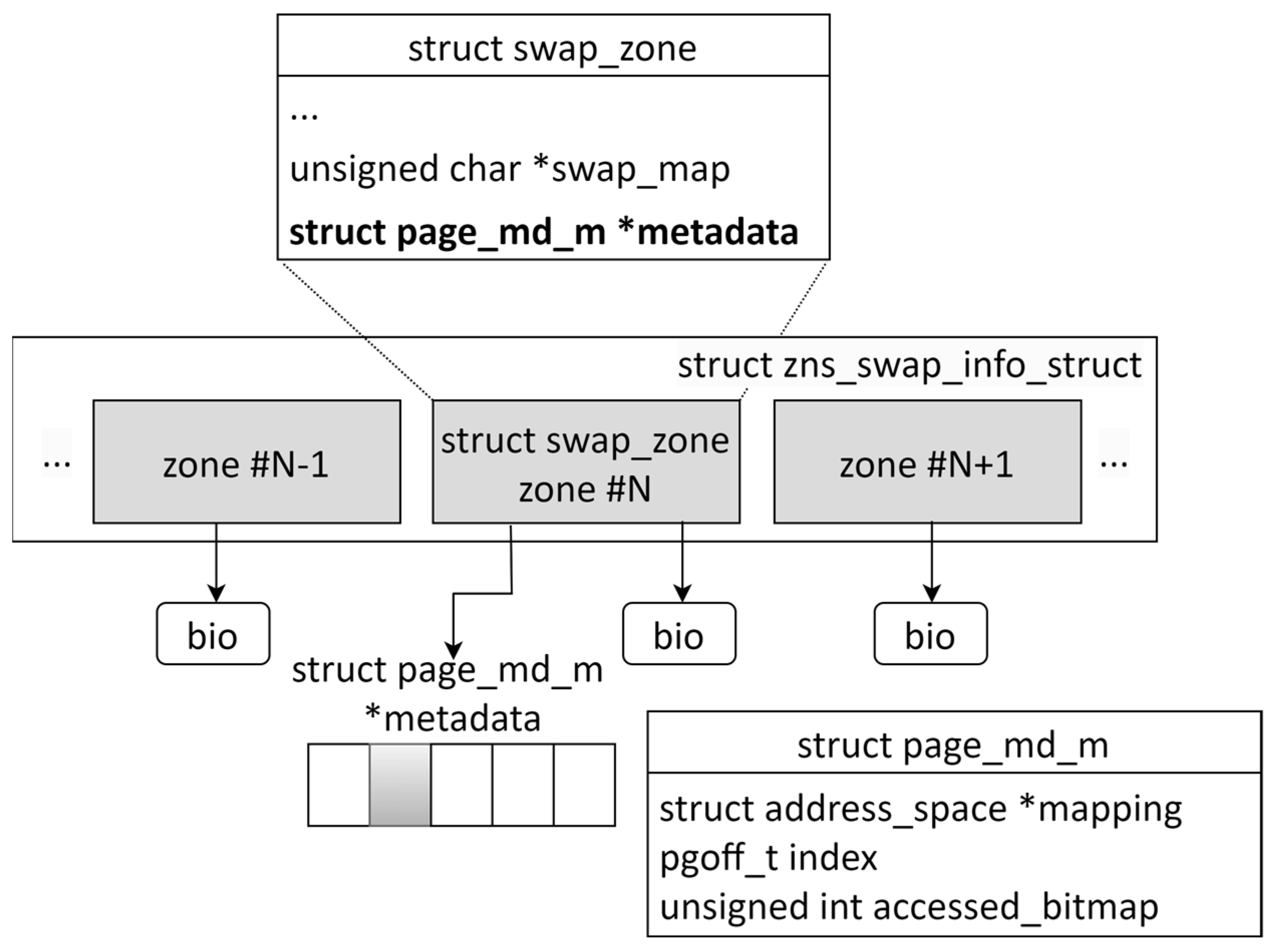
4.1. Reverse Mapping Data Structure for Swap Pages
4.2. Managing Reverse Mapping Data in System Memory
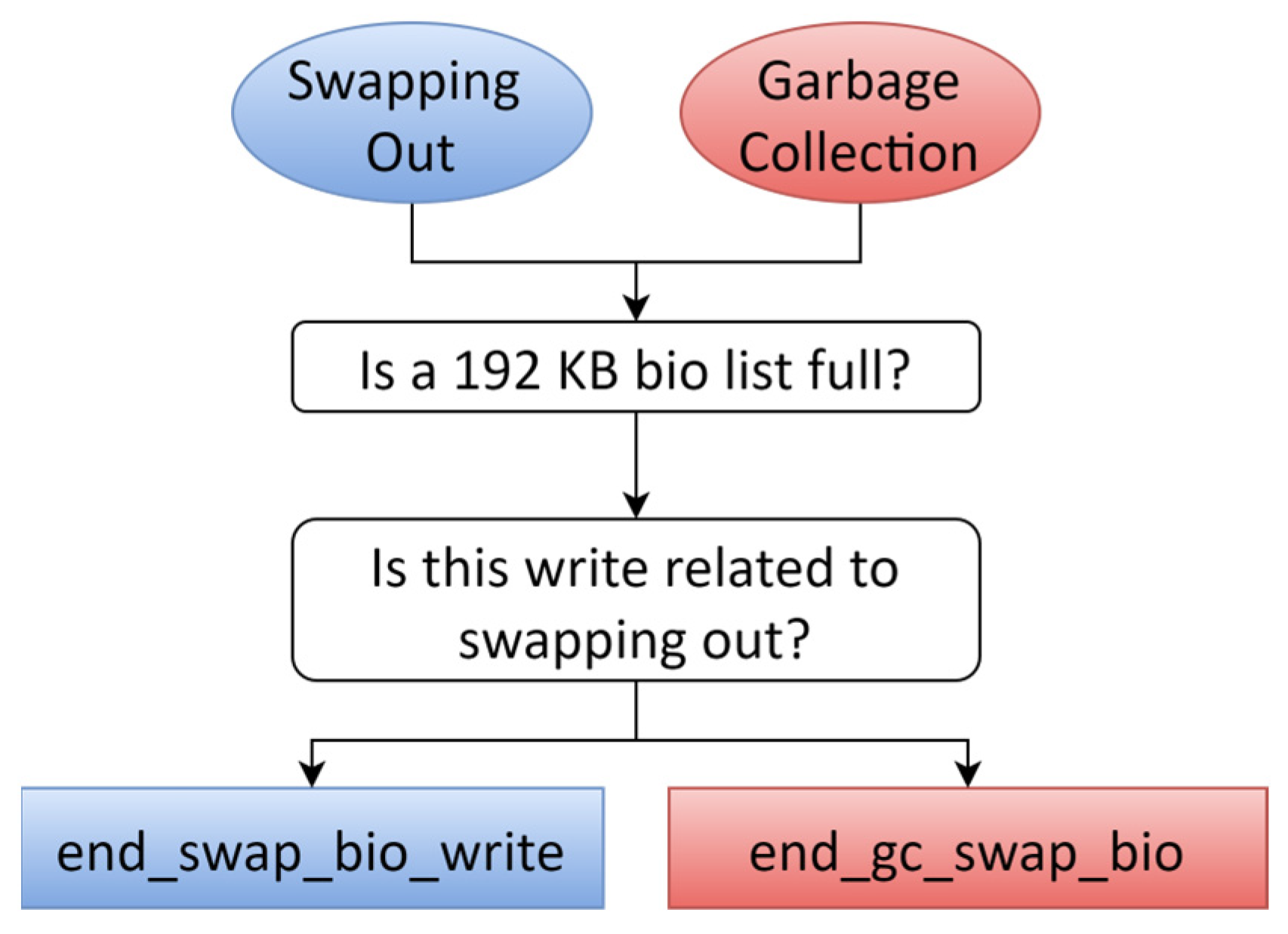
4.3. Overall Swap-Out Process
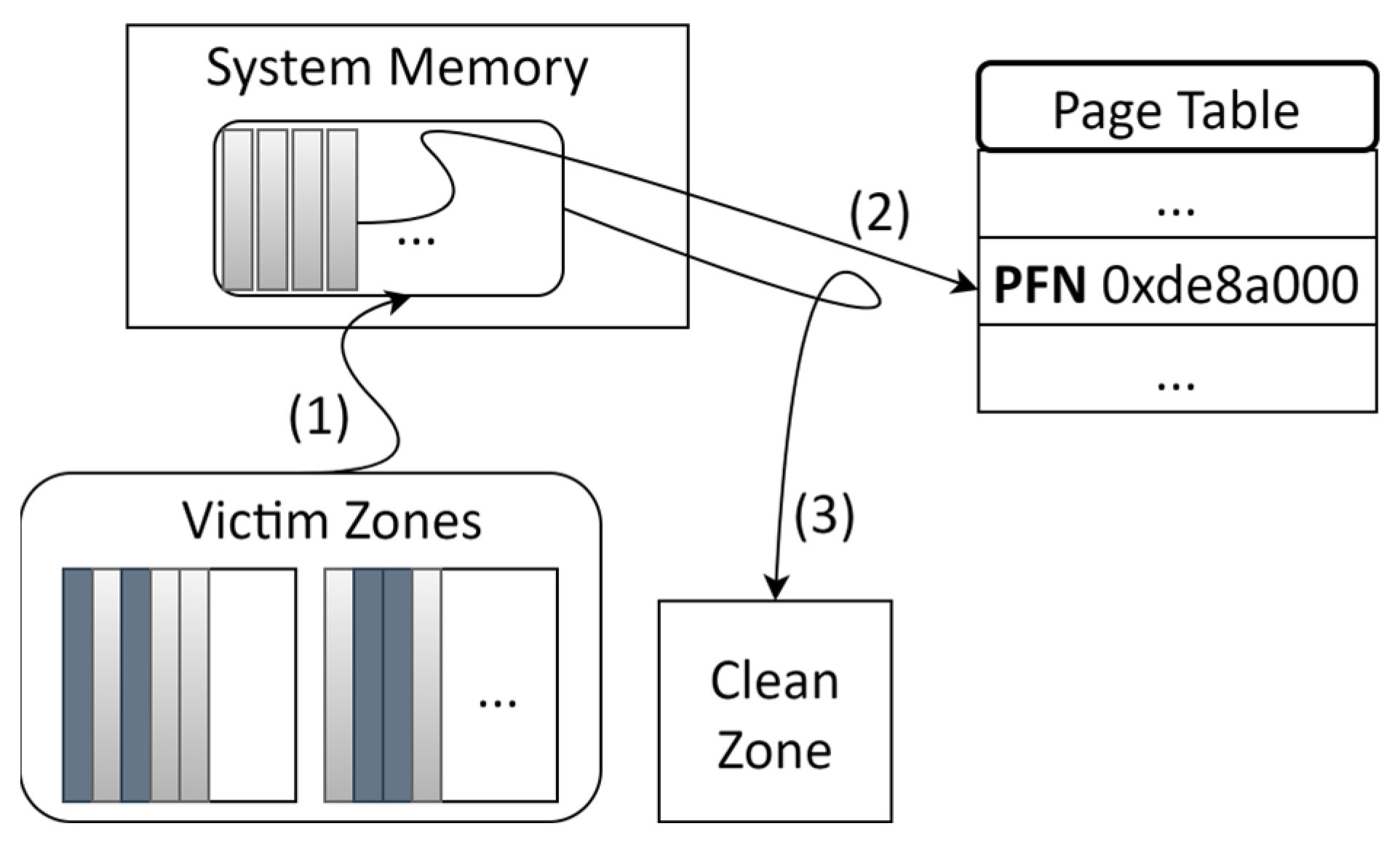
4.4. Garbage Collection Optimization via Page Fault Minimization
5. Evaluation
5.1. Experimental Setup
5.2. Micro-Benchmarks
5.2.1. Benchmark Setup for vm-Scalability
5.2.2. vm-Scalability Performance Results
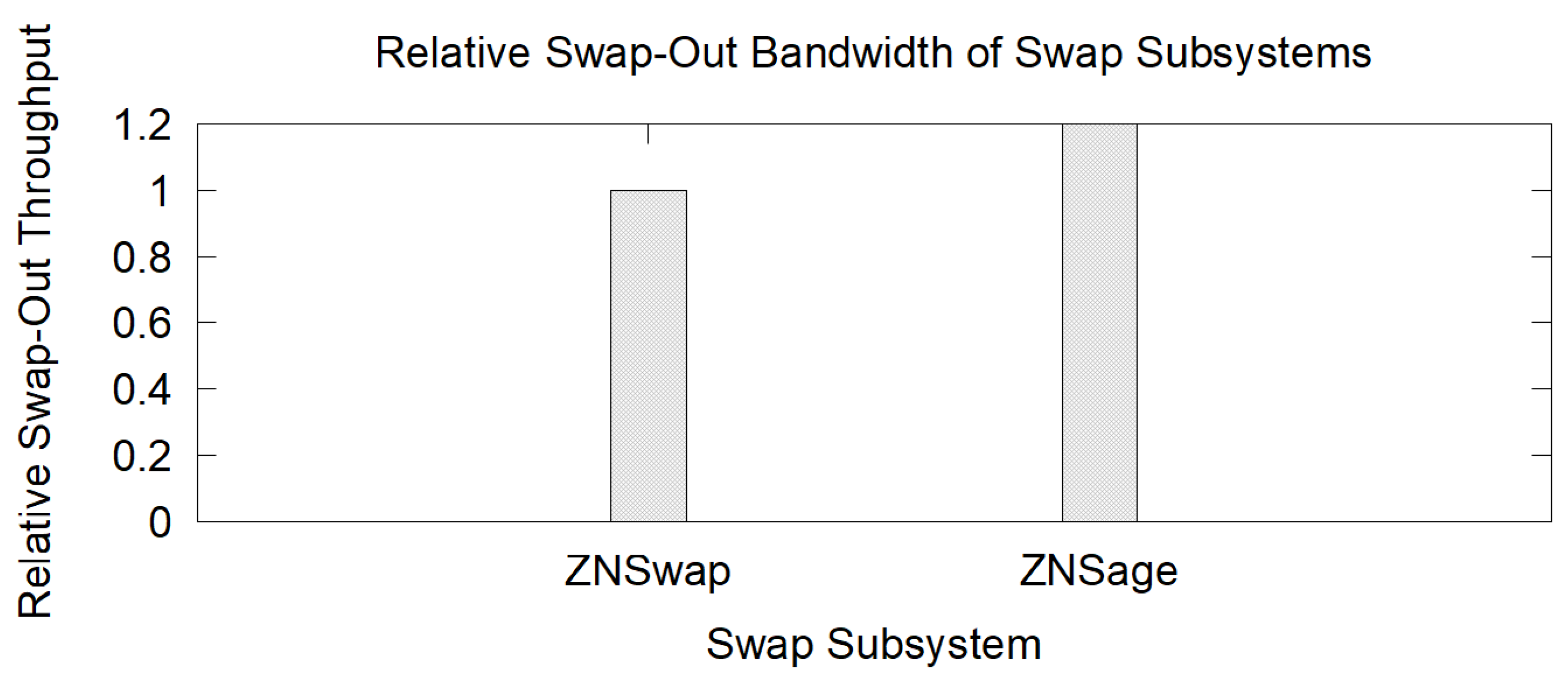
5.2.3. Performance Comparison with ZNSwap
5.3. Macro-Benchmarks
5.3.1. Benchmark Setup for Memcached and YCSB
5.3.2. Memcached–YCSB Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Herreria, A.A. Balancing Act: HDDs and SSDs in Modern Data Centers. Western Digital Blog, 25 July 2024. Available online: https://blog.westerndigital.com/a-balancing-act-hdds-and-ssds-in-modern-data-centers/ (accessed on 10 February 2025).
- Rana, A. Sequential vs. Random Read/Write Performance in Storage. StoredBits, 2 September 2024. Available online: https://storedbits.com/sequential-vs-random-data/ (accessed on 10 February 2025).
- Jacob, B. The Memory System; Morgan & Claypool Publishers: Kentfield, CA, USA, 2009. [Google Scholar]
- Green, S. DRAM or Not? The Difference Between DRAM and DRAM-Less SSDs (and Why It Matters). Phison Blog, 1 July 2024. Available online: https://phisonblog.com/dram-or-not-the-difference-between-dram-and-dram-less-ssds-and-why-it-matters/ (accessed on 10 February 2025).
- NVM Express. Zoned Namespace Command Set Specification, Revision 1.2. NVM Express, 5 August 2024. Available online: https://nvmexpress.org/wp-content/uploads/NVM-Express-Zoned-Namespace-Command-Set-Specification-Revision-1.2-2024.08.05-Ratified.pdf (accessed on 10 February 2025).
- Bjørling, M.; Aghayev, A.; Holmberg, H.; Ramesh, A.; Le Moal, D.; Ganger, G.R.; Amvrosiadis, G. ZNS: Avoiding the Block Interface Tax for Flash-Based SSDs. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 21), Berkeley, CA, USA, 14–16 July 2021; pp. 689–703. [Google Scholar]
- Bergman, S.; Cassel, N.; Bjørling, M.; Silberstein, M. ZNSwap: Unblock Your Swap. In Proceedings of the 2022 USENIX Annual Technical Conference (USENIX ATC 2022), Carlsbad, CA, USA, 1–18 October 2022. [Google Scholar]
- Kang, J.-U.; Hyun, J.; Maeng, H.; Cho, S. The Multi-Streamed Solid-State Drive. In Proceedings of the 6th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 14), Philadelphia, PA, USA, 17–18 June 2014. [Google Scholar]
- Yang, J.; Pandurangan, R.; Choi, C.; Balakrishnan, V. AutoStream: Automatic Stream Management for Multi-Streamed SSDs. In Proceedings of the 10th ACM International Systems and Storage Conference, Haifa, Israel, 22–24 May 2017; pp. 1–11. [Google Scholar]
- Kim, T.; Hong, D.; Hahn, S.S.; Chun, M.; Lee, S.; Hwang, J.; Lee, J.; Kim, J. Fully Automatic Stream Management for Multi-Streamed SSDs Using Program Contexts. In Proceedings of the 17th USENIX Conference on File and Storage Technologies (FAST 19), Boston, MA, USA, 25–28 February 2019; pp. 295–308. [Google Scholar]
- Samsung Semiconductor Newsroom. Samsung Introduces Its First ZNS SSD with Maximized User Capacity and Enhanced Lifespan. Samsung Newsroom, 2 June 2021. Available online: https://news.samsungsemiconductor.com/global/samsung-introduces-its-first-zns-ssd-with-maximized-user-capacity-and-enhanced-lifespan/ (accessed on 10 February 2025).
- Western Digital. Ultrastar DC ZN540 Data Sheet. Western Digital Documentation. September 2021. Available online: https://documents.westerndigital.com/content/dam/doc-library/en_us/assets/public/western-digital/collateral/data-sheet/data-sheet-ultrastar-dc-zn540.pdf (accessed on 10 February 2025).
- Chung, W. Benefits of ZNS in Datacenter Storage Systems. In Proceedings of the Flash Memory Summit, Santa Clara, CA, USA, 6–8 August 2019; Available online: https://files.futurememorystorage.com/proceedings/2019/08-06-Tuesday/20190806_ARCH-102-1_Chung.pdf (accessed on 10 February 2025).
- Choi, G.; Lee, K.; Oh, M.; Choi, J.; Jhin, J.; Oh, Y. A New LSM-Style Garbage Collection Scheme for ZNS SSDs. In Proceedings of the 12th USENIX Workshop on Hot Topics in Storage and File Systems, Online, 13–14 July 2020. [Google Scholar]
- Holmberg, H. ZenFS, Zones, and RocksDB. SDC 2020. September 2020. Available online: https://www.snia.org/educational-library/zenfs-zones-and-rocksdb-who-likes-take-out-garbage-anyway-2020 (accessed on 23 March 2025).
- Oh, G.; Yang, J.; Ahn, S. Efficient Key-Value Data Placement for ZNS SSD. Appl. Sci. 2021, 11, 11842. [Google Scholar] [CrossRef]
- Stavrinos, T.; Kourtis, K.; Ioannidis, S. Don’t Be a Blockhead: Zoned Namespaces Make Work on Conventional SSDs Obsolete. In Proceedings of the Workshop on Hot Topics in Operating Systems, Ann Arbor, MI, USA, 31 May–2 June 2021; pp. 144–151. [Google Scholar]
- Han, K.; Gwak, H.; Shin, D.; Hwang, J.-Y. ZNS+: Advanced Zoned Namespace Interface for Supporting In-Storage Zone Compaction. In Proceedings of the 15th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 21), Online, 14–16 July 2021; pp. 147–162. [Google Scholar]
- Lee, H.-R.; Lee, C.-G.; Lee, S.; Kim, Y. Compaction-Aware Zone Allocation for LSM-Based Key-Value Store on ZNS SSDs. In Proceedings of the 14th ACM Workshop on Hot Topics in Storage and File Systems, New York, NY, USA, 27–28 June 2022; pp. 93–99. [Google Scholar]
- Jung, J.; Shin, D. Lifetime-Leveling LSM-Tree Compaction for ZNS SSD. In Proceedings of the 14th ACM Workshop on Hot Topics in Storage and File Systems, New York, NY, USA, 27–28 June 2022; pp. 100–105. [Google Scholar]
- Jung, S.; Lee, S.; Han, J.; Kim, Y. Preemptive Zone Reset Design within Zoned Namespace SSD Firmware. Electronics 2023, 12, 798. [Google Scholar] [CrossRef]
- Snow, N. What Is T10 Protection Information? Kioxia Blog, 26 September 2023. Available online: https://blog-us.kioxia.com/post/2023/09/26/what-is-t10-protect-information (accessed on 10 February 2025).
- Park, J.; Choi, S.; Oh, G.; Im, S.; Oh, M.-W.; Lee, S.-W. FlashAlloc: Dedicating Flash Blocks by Objects. Proc. VLDB Endow. 2023, 16, 3266–3278. [Google Scholar]
- Both, D. What’s the Right Amount of Swap Space for a Modern Linux System? Opensource.com, 11 February 2019. Available online: https://opensource.com/article/19/2/swap-space-poll (accessed on 10 February 2025).
- VM-Scalability. Available online: https://git.kernel.org/pub/scm/linux/kernel/git/wfg/vm-scalability.git/about/ (accessed on 10 February 2025).
- Fitzpatrick, B. Distributed Caching with Memcached. Linux J. 2004, 124, 5. [Google Scholar]
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking Cloud Serving Systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- Khaleqi Qaleh Jooq, M.; Behbahani, F.; Al-Shidaifat, A.; Khan, S.R.; Song, H. A High-Performance and Ultra-Efficient Fully Programmable Fuzzy Membership Function Generator Using FinFET Technology for Image Enhancement. AEU—Int. J. Electron. Commun. 2023, 163, 154598. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LBA Format (lbaf) | Metadata Size (ms) | LBA Data Size (lbads) | Relative Performance (rp) |
|---|---|---|---|
| 0 | 0 | 9 | 0 |
| 1 | 8 | 9 | 0 |
| 2 | 0 | 12 | 0 |
| 3 | 8 | 12 | 0 |
| 4 | 64 | 12 | 0 |
| CPU | Intel Core i7-12700K (3.6 GHz, 8 cores), hyper-threading (HT) disabled, performance mode enabled, turbo mode disabled |
| System memory | 16 GB DRAM |
| ZNS SSD | SK Hynix ZNS SSD (32 TB)—zone capacity: 96 MB, zone size: 96 MB Western Digital ZN540 ZNS SSD (8 TB)—zone capacity: 1077 MB, zone size: 2 GB |
| Operating system | Ubuntu 22.04, Cgroup memory limit: 2 GB, swap space: 512 GB |
| CPU | Intel Core i5-12500K (3.0 GHz, 6 cores), hyper-threading (HT) disabled, performance mode enabled, turbo mode disabled |
| System memory | 16 GB DRAM |
| Network | 2.5 Gbps Ethernet |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, I.; Koo, M.J. ZNSage: Towards Hardware-Agnostic Swap Metadata Management on ZNS SSDs. Electronics 2025, 14, 1301. https://doi.org/10.3390/electronics14071301
Jo I, Koo MJ. ZNSage: Towards Hardware-Agnostic Swap Metadata Management on ZNS SSDs. Electronics. 2025; 14(7):1301. https://doi.org/10.3390/electronics14071301
Chicago/Turabian StyleJo, Insoon, and Min Jee Koo. 2025. "ZNSage: Towards Hardware-Agnostic Swap Metadata Management on ZNS SSDs" Electronics 14, no. 7: 1301. https://doi.org/10.3390/electronics14071301
APA StyleJo, I., & Koo, M. J. (2025). ZNSage: Towards Hardware-Agnostic Swap Metadata Management on ZNS SSDs. Electronics, 14(7), 1301. https://doi.org/10.3390/electronics14071301