
Real-Time Multi-Scale Barcode Image Deblurring Based on Edge Feature Guidance

Abstract
1. Introduction
- We proposed an efficient edge feature-guided multi-scale deblurring network (EGMSNet) that leverages edge features and multi-scale information to enhance structural details, ensuring better preservation of barcode edges and overall image clarity.
- We introduced a feature filtering mechanism (FFM) that amplifies responses in important regions, recovers clean features, and reduces noise artifacts.
- We constructed three independent datasets of blurred and clear image pairs for Barcode, QRCode, and Data Matrix codes, aiming to guide the deblurring of barcode images better.
2. Related Work
3. Methodology
3.1. Overall Architecture
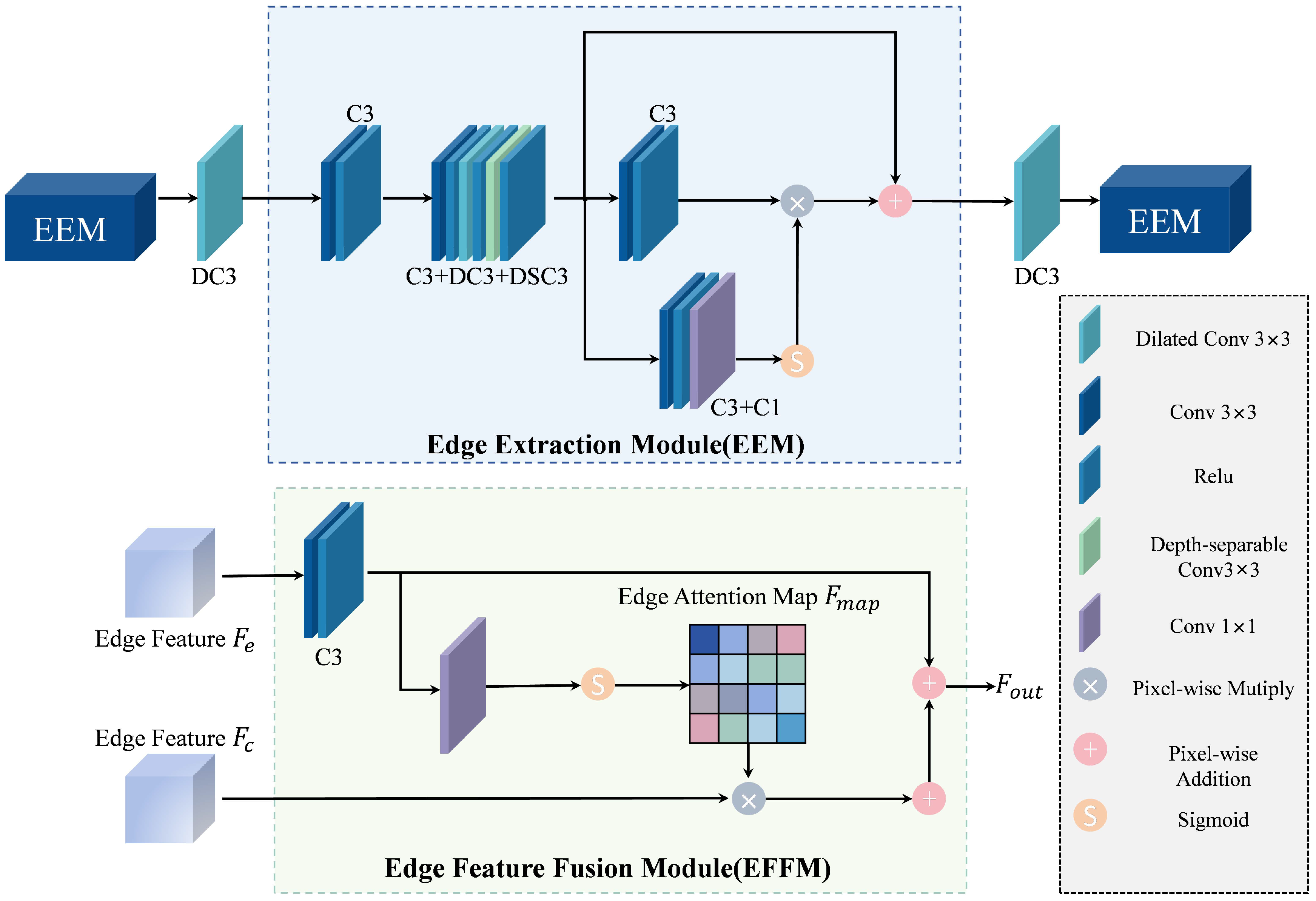
3.2. Edge Branch
3.3. Feature Filtering Mechanism (FFM)
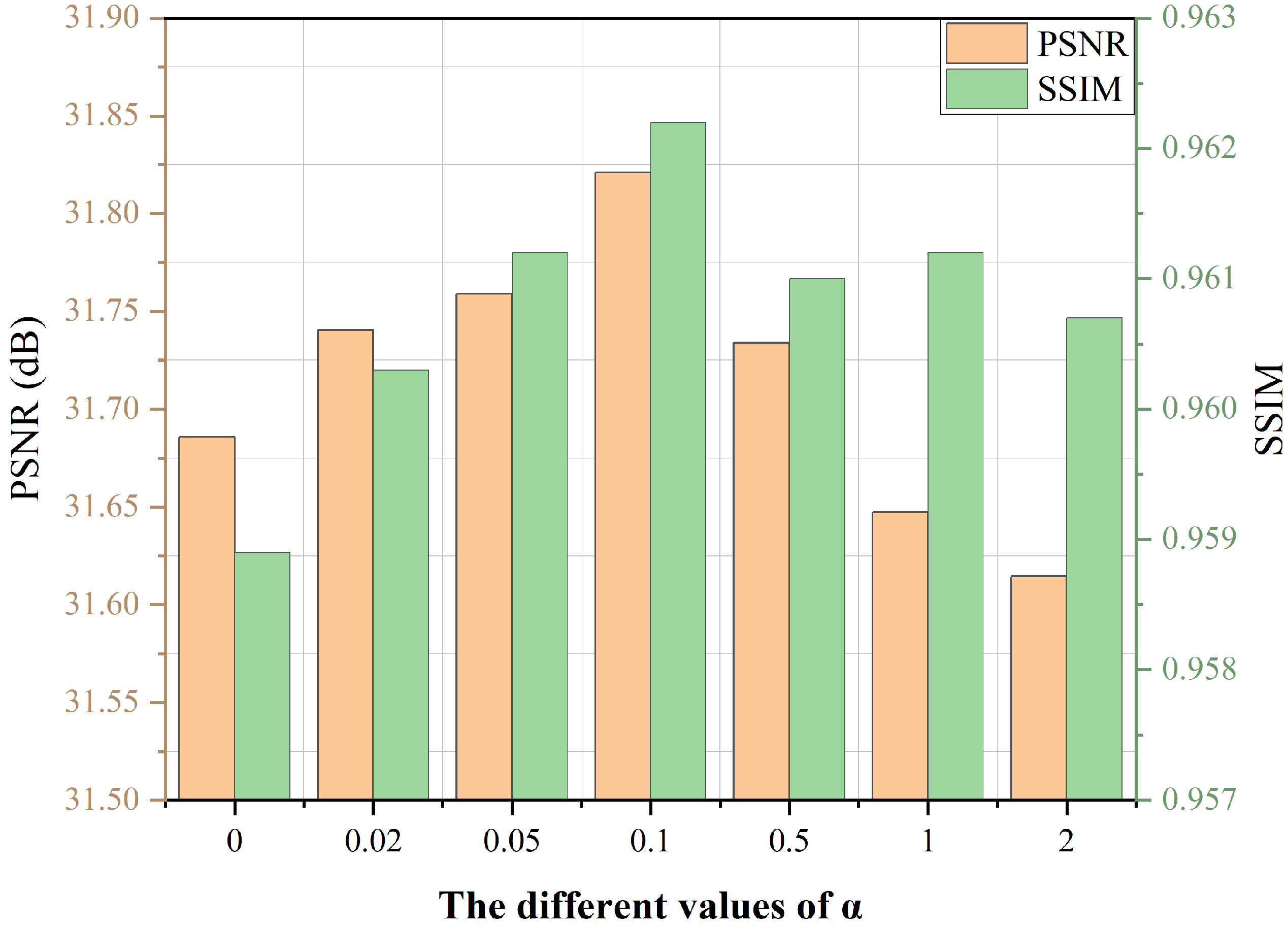
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. Implementation Details
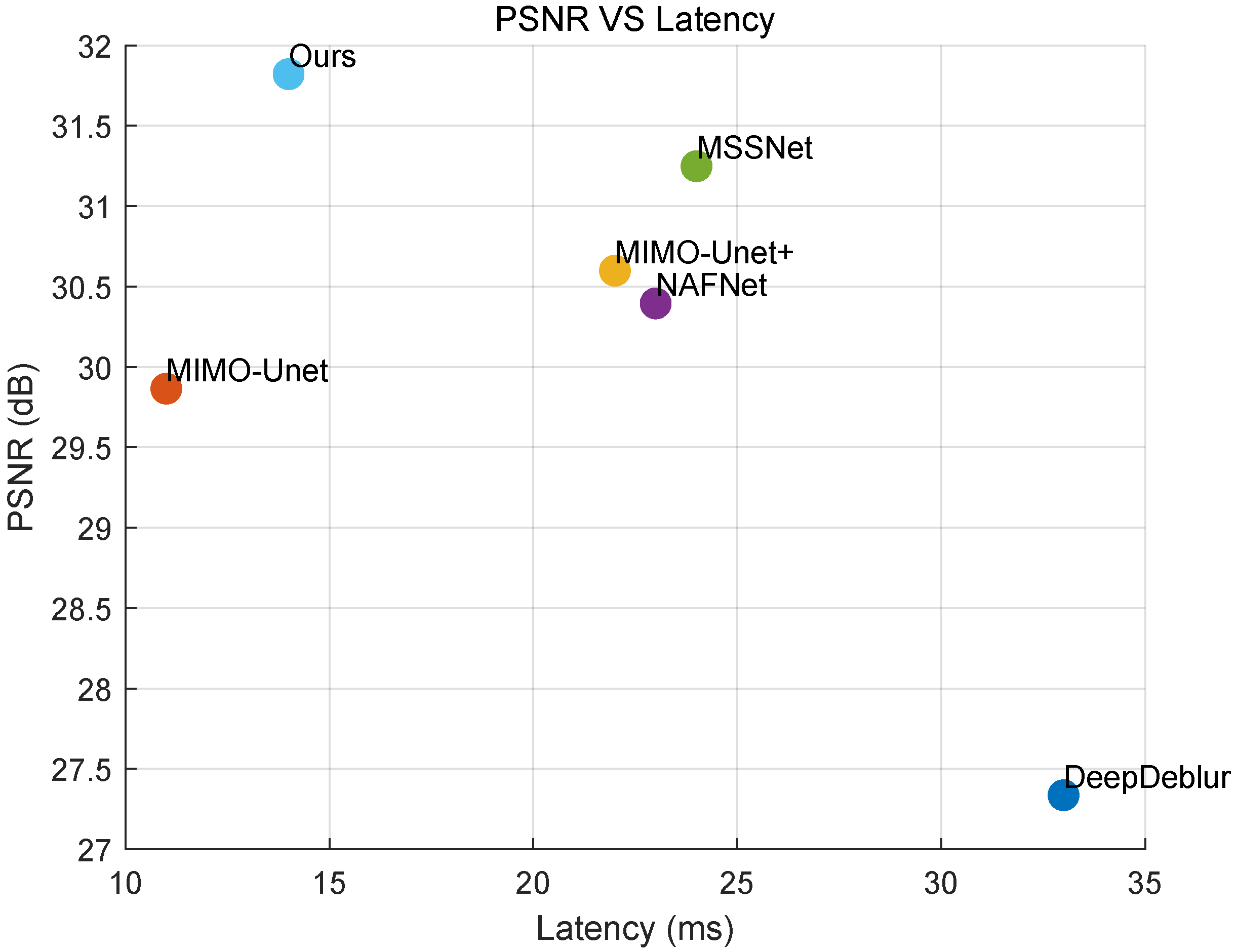
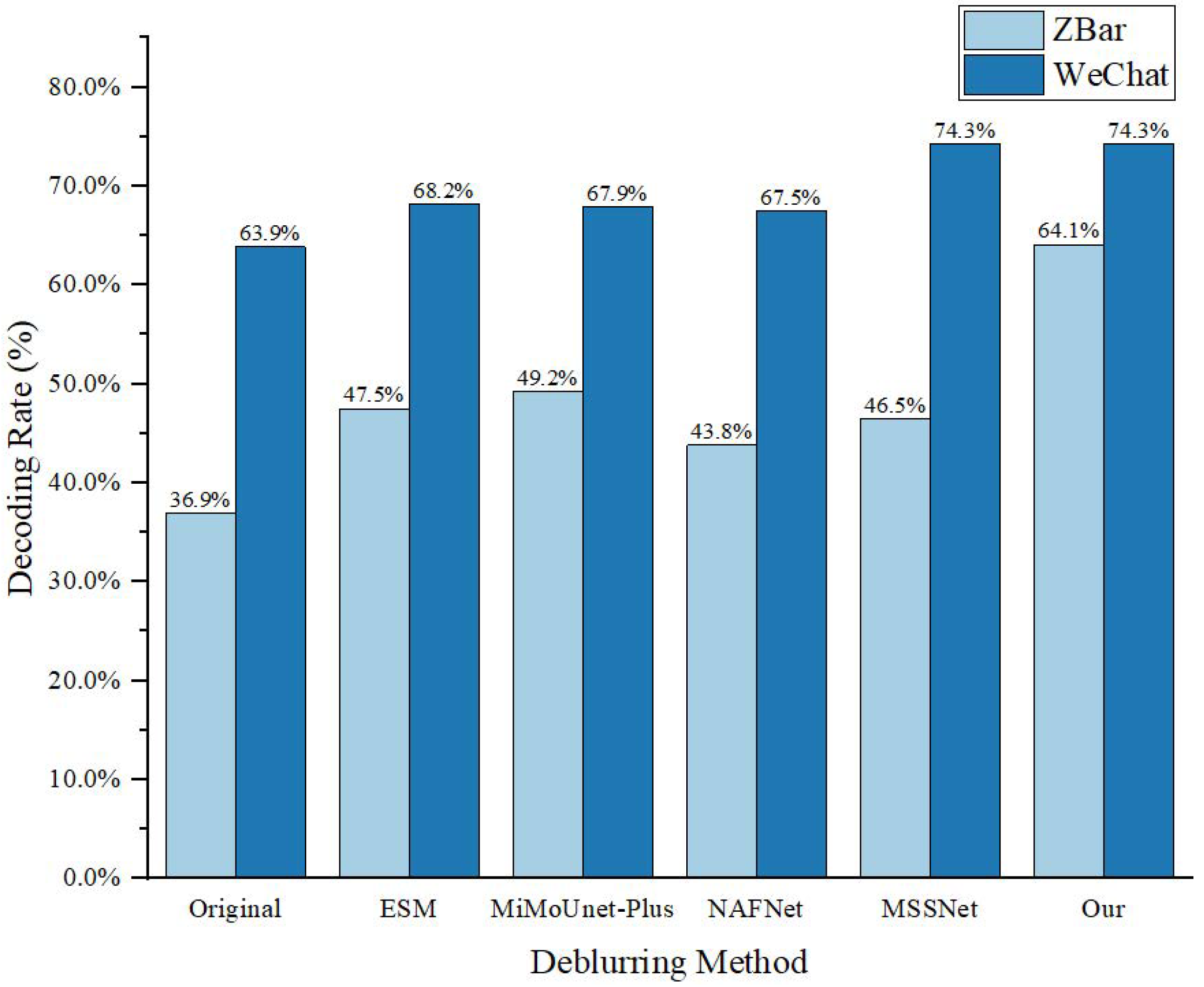
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, Y.G.; Woo, E. Consumer acceptance of a quick response (QR) code for the food traceability system: Application of an extended technology acceptance model (TAM). Food Res. Int. 2016, 85, 266–272. [Google Scholar] [CrossRef] [PubMed]
- M’hand, M.A.; Boulmakoul, A.; Badir, H.; Lbath, A. A scalable real-time tracking and monitoring architecture for logistics and transport in RoRo terminals. Procedia Comput. Sci. 2019, 151, 218–225. [Google Scholar] [CrossRef]
- Ji, Y.; Sun, D.; Zhao, Y.; Tang, J.; Tang, J.; Song, J.; Zhang, J.; Wang, X.; Shao, W.; Chen, D.; et al. A high-throughput mass cytometry barcoding platform recapitulating the immune features for HCC detection. Nano Today 2023, 52, 101940. [Google Scholar] [CrossRef]
- Lin, P.Y. Distributed Secret Sharing Approach With Cheater Prevention Based on QR Code. IEEE Trans. Ind. Inform. 2016, 12, 384–392. [Google Scholar] [CrossRef]
- Hu, K.; Chen, Z.; Kang, H.; Tang, Y. 3D vision technologies for a self-developed structural external crack damage recognition robot. Autom. Constr. 2024, 159, 105262. [Google Scholar] [CrossRef]
- Bai, Y.; Cheung, G.; Liu, X.; Gao, W. Graph-Based Blind Image Deblurring From a Single Photograph. IEEE Trans. Image Process. 2019, 28, 1404–1418. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Fang, F.; Lei, S.; Li, F.; Zhang, G. Enhanced sparse model for blind deblurring. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 631–646. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Blind image deblurring using dark channel prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1628–1636. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1107–1114. [Google Scholar]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Cho, S.J.; Ji, S.W.; Hong, J.P.; Jung, S.W.; Ko, S.J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4641–4650. [Google Scholar]
- Chen, L.; Chu, X.; Zhang, X.; Sun, J. Simple baselines for image restoration. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 17–33. [Google Scholar]
- Kim, K.; Lee, S.; Cho, S. Mssnet: Multi-scale-stage network for single image deblurring. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 524–539. [Google Scholar]
- Michaeli, T.; Irani, M. Blind deblurring using internal patch recurrence. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part III 13. Springer: Cham, Switzerland, 2014; pp. 783–798. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Purohit, K.; Rajagopalan, A.N. Region-Adaptive Dense Network for Efficient Motion Deblurring. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11882–11889. [Google Scholar] [CrossRef]
- Li, D.; Zhang, Y.; Cheung, K.C.; Wang, X.; Qin, H.; Li, H. Learning degradation representations for image deblurring. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 736–753. [Google Scholar]
- Fang, Z.; Wu, F.; Dong, W.; Li, X.; Wu, J.; Shi, G. Self-supervised non-uniform kernel estimation with flow-based motion prior for blind image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18105–18114. [Google Scholar]
- Mao, X.; Liu, Y.; Liu, F.; Li, Q.; Shen, W.; Wang, Y. Intriguing findings of frequency selection for image deblurring. Proc. AAAI Conf. Artif. Intell. 2023, 37, 1905–1913. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17683–17693. [Google Scholar]
- Tsai, F.J.; Peng, Y.T.; Lin, Y.Y.; Tsai, C.C.; Lin, C.W. Stripformer: Strip transformer for fast image deblurring. In Proceedings of the European Conference on Computer vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 146–162. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Kong, L.; Dong, J.; Ge, J.; Li, M.; Pan, J. Efficient frequency domain-based transformers for high-quality image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5886–5895. [Google Scholar]
- Liu, N.; Sun, H.; Yang, J. Recognition of the stacked two-dimensional bar code based on iterative deconvolution. Imaging Sci. J. 2010, 58, 81–88. [Google Scholar]
- Xu, W.; McCloskey, S. 2D Barcode localization and motion deblurring using a flutter shutter camera. In Proceedings of the 2011 IEEE Workshop on Applications of Computer Vision (WACV), Kona, HI, USA, 5–7 January 2011; pp. 159–165. [Google Scholar] [CrossRef]
- Sörös, G.; Semmler, S.; Humair, L.; Hilliges, O. Fast blur removal for wearable QR code scanners. In Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; ISWC ’15. pp. 117–124. [Google Scholar] [CrossRef]
- van Gennip, Y.; Athavale, P.; Gilles, J.; Choksi, R. A Regularization Approach to Blind Deblurring and Denoising of QR Barcodes. IEEE Trans. Image Process. 2015, 24, 2864–2873. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed]
- Park, D.; Kang, D.U.; Kim, J.; Chun, S.Y. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 327–343. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Fang, F.; Wang, T.; Li, J.; Sheng, Y.; Zhang, G. Multi-Scale Grid Network for Image Deblurring With High-Frequency Guidance. IEEE Trans. Multimed. 2022, 24, 2890–2901. [Google Scholar] [CrossRef]
- Zhang, J.; Cui, G.; Zhao, J.; Chen, Y. High-Frequency Attention Residual GAN Network for Blind Motion Deblurring. IEEE Access 2022, 10, 81390–81405. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | QRCode Dataset | |||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | MAE | Params (M) | FLOPs (G) | Runtime (s) | |
| DCP [8] | 21.2259 | 0.8721 | 0.0371 | N/A | N/A | 136.659 |
| RGTV [6] | 19.8732 | 0.7911 | 0.0463 | N/A | N/A | 24.339 |
| ESM [7] | 21.9150 | 0.8789 | 0.0347 | N/A | N/A | 13.156 |
| DeepDeblur [10] | 27.3358 | 0.9151 | 0.0327 | 11.694 | 335 | 0.033 |
| MIMO-Unet [11] | 29.8646 | 0.9433 | 0.0248 | 6.802 | 63.639 | 0.011 |
| MIMO-Unet+ [11] | 30.5985 | 0.9519 | 0.0223 | 16.102 | 151.34 | 0.022 |
| NAFNet [12] | 30.3950 | 0.9485 | 0.0230 | 64.887 | 63.236 | 0.023 |
| MSSNet [13] | 31.2483 | 0.9565 | 0.0327 | 15.591 | 145.23 | 0.024 |
| Ours | 31.8211 | 0.9622 | 0.0192 | 6.831 | 39.794 | 0.014 |
| Method | Data Matrix Dataset | EAN13 Dataset | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | MAE | PSNR | SSIM | MAE | |
| DCP [8] | 24.3528 | 0.7271 | 0.0479 | 18.6741 | 0.7095 | 0.0755 |
| RGTV [6] | 20.4702 | 0.7201 | 0.0490 | 16.8041 | 0.6855 | 0.0833 |
| ESM [7] | 24.7180 | 0.7376 | 0.0462 | 21.3252 | 0.7435 | 0.0644 |
| DeepDeblur [10] | 24.1110 | 0.7201 | 0.0490 | 25.5796 | 0.8126 | 0.0416 |
| MIMO-UNet [11] | 26.0586 | 0.7762 | 0.0400 | 27.0412 | 0.8306 | 0.0384 |
| MIMO-UNet+ [11] | 26.5528 | 0.7856 | 0.0392 | 28.2813 | 0.8328 | 0.0353 |
| NAFNet [12] | 26.9079 | 0.7940 | 0.0388 | 26.4733 | 0.8096 | 0.0429 |
| MSSNet [13] | 27.1040 | 0.7963 | 0.0382 | 25.3145 | 0.8022 | 0.0447 |
| Ours | 27.5142 | 0.8157 | 0.0346 | 28.6011 | 0.8369 | 0.0340 |
| Base | Edge | SSM | FSM | PSNR | SSIM | Params (M) | |
|---|---|---|---|---|---|---|---|
| a | ✓ | 31.45 | 0.9597 | 6.448 | |||
| b | ✓ | ✓ | 31.55 | 0.9602 | 6.821 | ||
| c | ✓ | ✓ | 31.5804 | 0.9610 | 6.454 | ||
| d | ✓ | ✓ | 31.5307 | 0.9604 | 6.452 | ||
| e | ✓ | ✓ | ✓ | 31.6307 | 0.9612 | 6.458 | |
| f | ✓ | ✓ | ✓ | ✓ | 31.8211 | 0.9622 | 6.831 |
| Models | PSNR | SSIM | Params (M) | |
|---|---|---|---|---|
| a | Addition | 31.6981 | 0.9546 | 6.728 |
| b | Concat+conv | 31.7425 | 0.9582 | 6.739 |
| c | EFFM | 31.8211 | 0.9622 | 6.831 |
| d | FFM* | 31.5901 | 0.9605 | 6.841 |
| e | FFM | 31.8211 | 0.9622 | 6.831 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Jiang, X.; Zhang, X.; Zhu, C.; Hu, X.; Zhang, G.; Li, Y.; Zhang, C. Real-Time Multi-Scale Barcode Image Deblurring Based on Edge Feature Guidance. Electronics 2025, 14, 1298. https://doi.org/10.3390/electronics14071298
Shi C, Jiang X, Zhang X, Zhu C, Hu X, Zhang G, Li Y, Zhang C. Real-Time Multi-Scale Barcode Image Deblurring Based on Edge Feature Guidance. Electronics. 2025; 14(7):1298. https://doi.org/10.3390/electronics14071298
Chicago/Turabian StyleShi, Chenbo, Xin Jiang, Xiangyu Zhang, Changsheng Zhu, Xiaowei Hu, Guodong Zhang, Yuejia Li, and Chun Zhang. 2025. "Real-Time Multi-Scale Barcode Image Deblurring Based on Edge Feature Guidance" Electronics 14, no. 7: 1298. https://doi.org/10.3390/electronics14071298
APA StyleShi, C., Jiang, X., Zhang, X., Zhu, C., Hu, X., Zhang, G., Li, Y., & Zhang, C. (2025). Real-Time Multi-Scale Barcode Image Deblurring Based on Edge Feature Guidance. Electronics, 14(7), 1298. https://doi.org/10.3390/electronics14071298