1. Introduction
Internet of Things (IoT) devices have come to be used in industry, agriculture, remote healthcare, intelligent transportation, and various other scenarios [
1]. Despite the fact that these devices offer numerous smart and innovative services, they are fraught with significant security vulnerabilities. The majority of IoT devices are characterized by their compact size; low-power CPUs; and limited memory, storage, and power capabilities, rendering them inadequate for supporting the security software or intrusion-prevention systems typically deployed in PC settings [
2]. These limited system resources hinder the deployment of complex security protocols and intrusion-prevention mechanisms, exposing IoT devices to brute-force cyberattacks. Consequently, routine vulnerability scans and threat evaluations are expected to become standard practice in the near future. The Internet-wide port scan (IWPS) technique, which has recently emerged as a widely recognized vulnerability-scanning method for IoT devices, is capable of identifying open ports on communication devices and conducting a thorough scan of the entire network.
As a network analysis tool, the IWPS technique is designed to identify vulnerabilities and security threats associated with the various services operating on each port of the interconnected devices. This broad scanning capability can be routinely executed by network administrators or service providers. Network administrators or service providers can regularly scan their own network devices. If vulnerabilities or security threats are found, they can update the device or fix the vulnerability in time, to avoid being exploited by hackers. In this way, network administrators or service providers can improve the security of their own devices and systems. However, every technology has two sides. The IWPS technique also has some risks and drawbacks. The active scanning behavior of an IWPS may trigger the defense mechanisms of the target system (such as the IPS intrusion detection system), causing legitimate requests to be misjudged as attacks. For example, Cisco’s AI firewall relies on fingerprint-recognition algorithms in encrypted traffic detection, and high-frequency scanning may be identified as a DDoS attack feature. In addition, deep vulnerability scanning may involve the acquisition of sensitive data (such as server configuration and user information). These risks do not negate the value of the IWPS technique, however, and they provide some additional research directions. In an IWPS, the scanners can comprehensively examine ports through the transmission control protocol (TCP) handshake method [
3]. In this approach, the scanners dispatch synchronization (SYN) packets to every port of a device, and each port will return information or remain unresponsive based on its status (open or closed).
Several IWPS modes exist, including open and half-open scanning. Open scanners like Nmap [
4] are well suited for vertical scans of specific network segments. An open scanner is tailored for synchronous scans, where it anticipates responses from targets until a timeout threshold is reached. Although open scanners can detect dropped scan packets, they operate at a relatively slow pace. Given the system constraints, an open scanner requires several weeks to scan the entire Internet, making it an inefficient approach for an IWPS. On the other hand, half-open scanners, such as Zmap [
5] and Masscan [
6], employ a stealthy half-TCP handshake method that minimizes network impact. For instance, Zmap is engineered for swift scanning by generating millions of packets that do not depend on tracking port responses. However, Zmap’s accuracy is significantly lower than Nmap’s when operating at high scanning rates, due to failures at the endpoints of wireless local area networks (WLANs), which result in numerous non-responses from ports. The half-open scanners are incapable of identifying dropped packets or discerning the causes of such losses. In light of the above, it is strongly advised to pursue high-rate, high-accuracy Internet-wide scanning solutions.
In this paper, we focused on open scans, and we analyzed, through experiments, the factors that affect the speed of open scans. We found that allocating tasks according to the location of the scanner and the target can greatly improve scanning efficiency. Based on this, we propose an area-aware efficient IWPS approach. The key contribution of this paper includes three aspects. Firstly, we found that the location of the scanner can affect its detection efficiency. Secondly, a new IWPS method was designed to improve detection efficiency and accuracy. Thirdly, the effectiveness of the proposed algorithm was verified by experiments. The details are as follows:
Through experiments, we found that the location of the scanner and its targets seriously affect its scanning speed. For example, scanners in China can quickly scan devices in China, but they are much slower at scanning devices in the US. The reason is that cross-border data transfers are much slower than local data transfers for most countries, and the scanning rate is closely related to network transmission speed.
A novel IWPS approach that considers the regional attributes of scanners and targets was provided for improving open scan rates. An IWPS is a huge task. Excluding IPv6 addresses, IPv4 addresses alone are about 4.3 billion, which is much larger than the task space in edge computing. Therefore, some complex algorithms that need more computing resources and delay are not suitable for an IWPS. Firstly, we cluster all scanners according to their locations, and we construct a list of scan horizons for each cluster. When a scan task arrives, we slice the task based on the IP address and allocate each sub-task with the consideration of the scanners’ workload balancing. These are all original contributions of our paper.
Experimental analysis is conducted on a real IWPS testbed. In the experiments, the scan rate of our approach is 3×–4× that of Nmap, and the detection accuracy increased by 8%, which demonstrates the effectiveness of our proposed approach.
The paper is organized as follows. The related works are reviewed in
Section 2. The system scenario is introduced in
Section 3. The algorithm is proposed in
Section 4.
Section 5 discusses the simulation results, and
Section 6 presents the conclusions.
2. Related Works
In this section, we offer an overview of the currently available scanning tools. Nmap, one of the most prevalent and extensively utilized port scanning tools, is well suited for vertical scans on small network segments. Nonetheless, due to its system constraints, Nmap necessitates several weeks to scan the entire Internet comprehensively. Consequently, its application for Internet-wide scanning is impractical. Zmap and masscan can probe the whole IPv4 address space within a day. Unlike Nmap, which maintains a TCP connection state to manage retransmissions, timeouts, and track scanned hosts, Zmap and masscan do not establish connections for each probe. By bypassing the TCP/IP stack, the rate of dispatching scanning packets is bounded only by the rate supported by the server’s network interface card (NIC). However, Zmap and masscan are incapable of identifying dropped packets or determining the causes of such losses, resulting in low accuracy.
The authors in [
7] created a novel port scanning tool that can identify a significant number of open ports among all 65,000 available ports in a network. This tool constructs a correlation graph of the open ports and employs a reinforcement learning approach to continuously update the graph, resulting in improved coverage and decreased intrusiveness. PMap, a high-efficiency port detection system proposed in [
8], optimizes the discovery process of accessible ports through a comprehensive analysis of all available 65 K network endpoints. Empirical evaluations demonstrate its superiority over conventional techniques in three critical dimensions as follows: target identification accuracy, network coverage breadth, and operational stealth characteristics. In the context of the medium access control protocol outlined in IEEE 802.11ah, the authors in [
9] proposed novel models for the security analyses of IoT based on the network performance of IWPS over IEEE 802.11ah. The results verified that the network-oblivious IWPS can degrade IoT security and increase risk. The authors further introduced an IWPS algorithm aimed at determining an optimal scan rate in [
10]. To accommodate the heterogeneous traffic generated by IoT devices and the arrival of scan packets, the authors developed a queue model. Following this, a mathematical framework was introduced to assess the throughput for both IoT communications and scanning activities. Based on these models, the authors presented an algorithm to optimize the balance between minimizing risks for each device and maintaining an optimal scan rate, thereby enhancing security while preserving the quality of service. The authors in [
11] proposed a novel stateless scanning method, which can establish TCP connections and obtain further responses in a completely stateless manner. Based on this method, they implemented a stateless scanner named ZBanner. Focusing on the scanning traffic congestion, the authors in [
12] noted that a high scan rate is essential to expedite the scanning process. However, this can paradoxically lead to congestion within a WLAN, reducing the overall efficiency of the scans. To address the problem, the authors developed a model that quantifies the effects of scanning traffic on IoT data communication and suggested a method for optimizing the scan rate. In [
13], the authors introduced an innovative WLAN environment classification technique, which categorizes environments into six distinct states. By recognizing the dynamic characteristics, they created a sophisticated IWPS analysis system. To investigate the entities behind Internet scanning and their motivations, the authors in [
14] examined traffic over eight months across six honeypots situated in different continents. They crafted a traffic classification approach that can identify data produced by scanning tools like Masscan, ZMap, and the Mirai botnet.
For the vast address space of IPv6, the authors in [
15] formulated an asynchronous IPv6 scanning tool to enhance both the hit and scan rates. This scanner capitalizes on regional identifier coding to swiftly and flexibly modify search trajectories without substantial computational overhead. In contrast to conventional alternatives, this method unveils an additional 6% of active addresses within an equivalent scanning timeframe. Similarly, the authors in [
16] introduced a target generation algorithm grounded in subpattern analysis, tailored for comprehensive IPv6 scanning. This approach undergoes pattern refinement processes to further condense the scope of the scanning operation. Compared with other algorithms, empirical evaluations across real-world network environments corroborate that the address patterns unearthed by the scanner offer a more advantageous scanning spectrum. The authors in [
17] proposed 6Hit, an adaptive IPv6 address exploration framework leveraging reinforcement learning (RL) for intelligent target generation. Their method starts by partitioning the IPv6 address space into distinct topological clusters through the structural analysis of seed address distributions. Subsequently, it implements dynamic resource allocation based on real-time reward signals derived from regional scanning performance metrics. Through continuous feedback loops that analyze the historical detection patterns, the system progressively refines its search focus toward regions exhibiting a higher active address concentration. In [
18], the authors introduce 6GAI to achieve more efficient target address generation. 6GAI was built with a Generative Adversarial Net (GAN) integrated with a Convolutional Bottleneck Attention Module (CBAM). The authors in [
19] presented HMap6, an advanced IPv6 reconnaissance framework that optimizes seed utilization efficiency through marginal utility metrics in cross-prefix active address discovery. This system implements adaptive heuristic algorithms for rapid seed acquisition and BGP-aware topological pattern recognition, enabling probabilistic scanning resource allocation across heterogeneous network environments. Addressing the challenge of improper space partitioning in large-scale IPv6 scanning, the authors in [
20] have designed an ensemble learning-driven methodology for IPv6 address generation. Initially, they employed a maximum-covering splitting indicator to subdivide the IPv6 address space, and they subsequently utilized an advanced isolation forest algorithm to filter out outlier addresses. Lastly, they conducted preliminary scans on samples drawn from partitioned address regions and generated targeted IPv6 addresses.
The above studies explored the IWPS approach from different aspects and achieved excellent results. However, most of them are based on half-open scanners, which cannot identify packet loss and find it difficult to solve the problem of low accuracy. The open scanners have a higher accuracy, but also result in a low scan rate. Therefore, methods for improving the efficiency of open scanners represent an important but rarely researched field. In the following, we propose an area-aware IWPS approach to improve the scan rate of open scans.
3. Considered Scenario and Motivation
In this section, we will introduce our considered scenario. We will also use experimental data to illustrate our motivation.
3.1. Considered Scenario
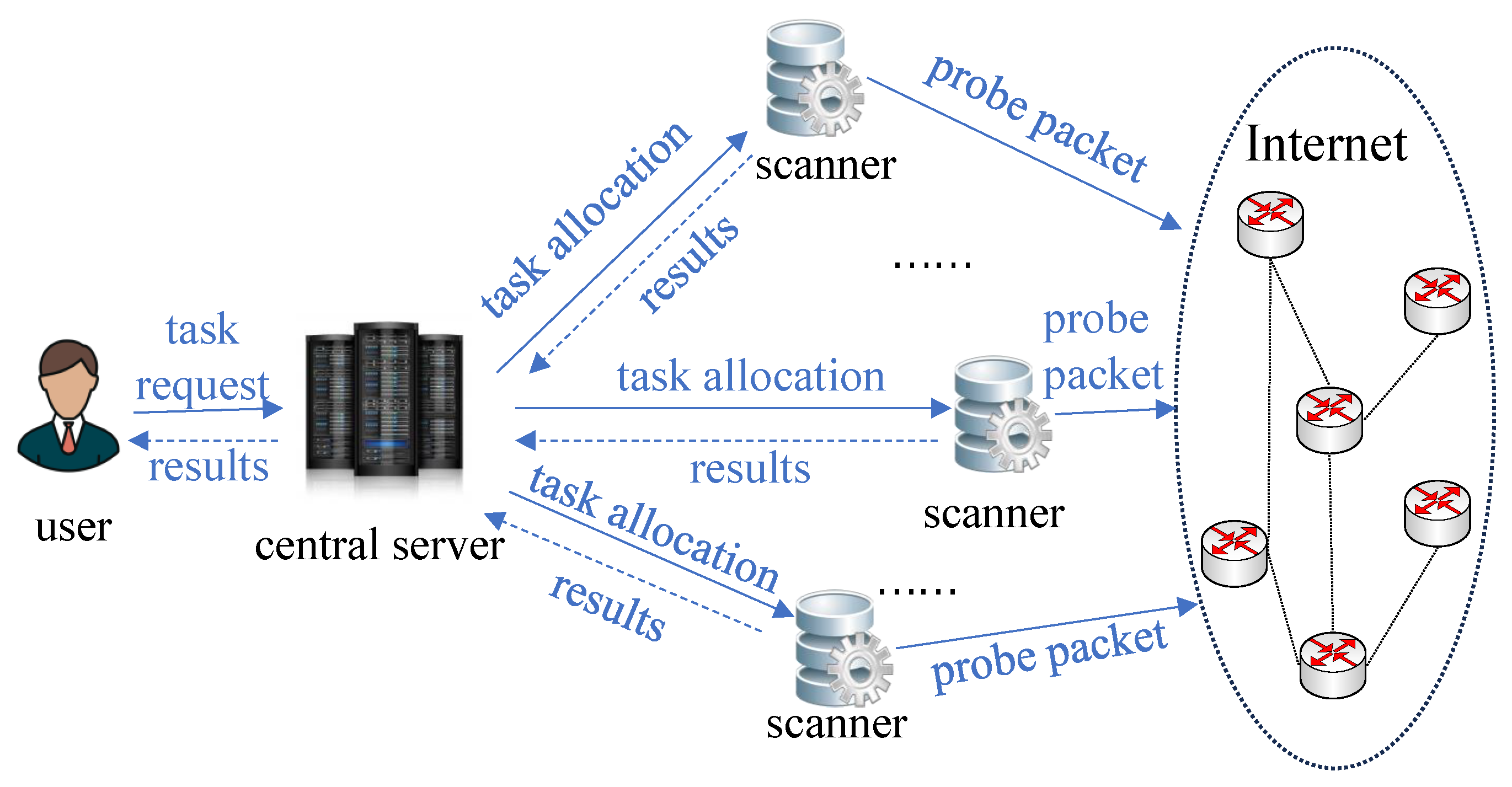
As shown in
Figure 1, we consider Internet-wide IoT WLAN networks where devices connect to the Internet using IEEE 802.11 protocols for data transmission to serve providers and users. To bolster device security, network operators and security administrators employ port scanners like Nmap to conduct comprehensive scans of the connected devices for vulnerability identification, and they design effective intrusion protection measures [
21]. Various IWPS techniques are available, encompassing open and half-open scans. This study specifically examines the open scan method, which utilizes a full TCP handshake approach.
In an open scan, a scanner generates SYN packets directed at multiple ports on a device or across various devices. The target devices respond based on the status of their ports. Open ports acknowledge with SYN-Acknowledgement (SYN-ACK) packets, while closed ports reply with reset (RST) packets. Upon detecting an open port on a device, the scanner attempts to send a specific packet to that port to retrieve version information about the services and applications operating on it. This process aids in comprehensively assessing the security posture and potential vulnerabilities of the devices, thereby facilitating the implementation of robust security measures.
In the process of scanning, the state of the network is important, as it may affect the efficiency of the scan packets, causing an increase in scan delays that result in missing responses due to unsuccessful transmissions. Additionally, if the scan delay exceeds the predefined scan timeout period, the port scanner might interpret port access as being restricted by a firewall. Therefore, longer scan delays can also contribute to the absence of replies, reducing the accuracy of the scan.
3.2. Motivation
At present, the task allocation strategy of most IWPS tools (i.e., Nmap) is random; that is, the central server randomly assigns port scan tasks to all scanners. In general, there tend to be several hundred scanners which spread across countries around the world. Due to the random scheduling of the central node, the IP addresses of assigned port scan tasks and scanners are often not in the same country or region. Intuitively, the port connection latency within the same country or region is higher than that between countries and regions. In other words, scanners can process domestic ports more efficiently than international ports. To test this hypothesis, we conducted an experiment. In detail, we deployed scanners with the same configuration in each of the six regions and assigned the same port scan tasks. We recorded the average delay of scanners in different regions to detect targets in different regions. The results are as shown in
Figure 2.
The
X-axis of
Figure 2 is the target IP address of port scan tasks, the
X-axis is the average delay, and the different colored cylinders represent the country where the scanner (probe node) is located. Taking AU as an example, the six cylinders, respectively, represent the average delay from AU to AU, GB to AU (the scanner is in GB, and the scan target is in AU), NL to AU, JP to AU, SG to AU, and US to AU. It can be seen from
Figure 2 that scanners in different countries have different port scan efficiencies for the same task. In general, the scanner can complete port scan tasks with scan targets whose IP is in their own country more efficiently than with targets in other countries. In addition to the local country, the efficiency of the scanners in different countries is also different. For example, the efficiency from GB to NL is much higher than the efficiency from JP to NL.
Based on the above experimental results, the traditional randomized task allocation mode (such as Nmap) leads to low efficiency and high task delay. However, a simple location-based allocation algorithm also easily leads to workload imbalance among scanners. An effective method for achieving global workload balancing while ensuring local efficiency remains a major challenge. Therefore, we will explore the task allocation mode associated with geographical location to improve task completion efficiency in the next section.
4. Algorithm Design
In this section, we present our area-aware efficient IWPS method. First, we provide an overview of the approach, and then, we explain its algorithm.
4.1. Overview of Proposed Approach
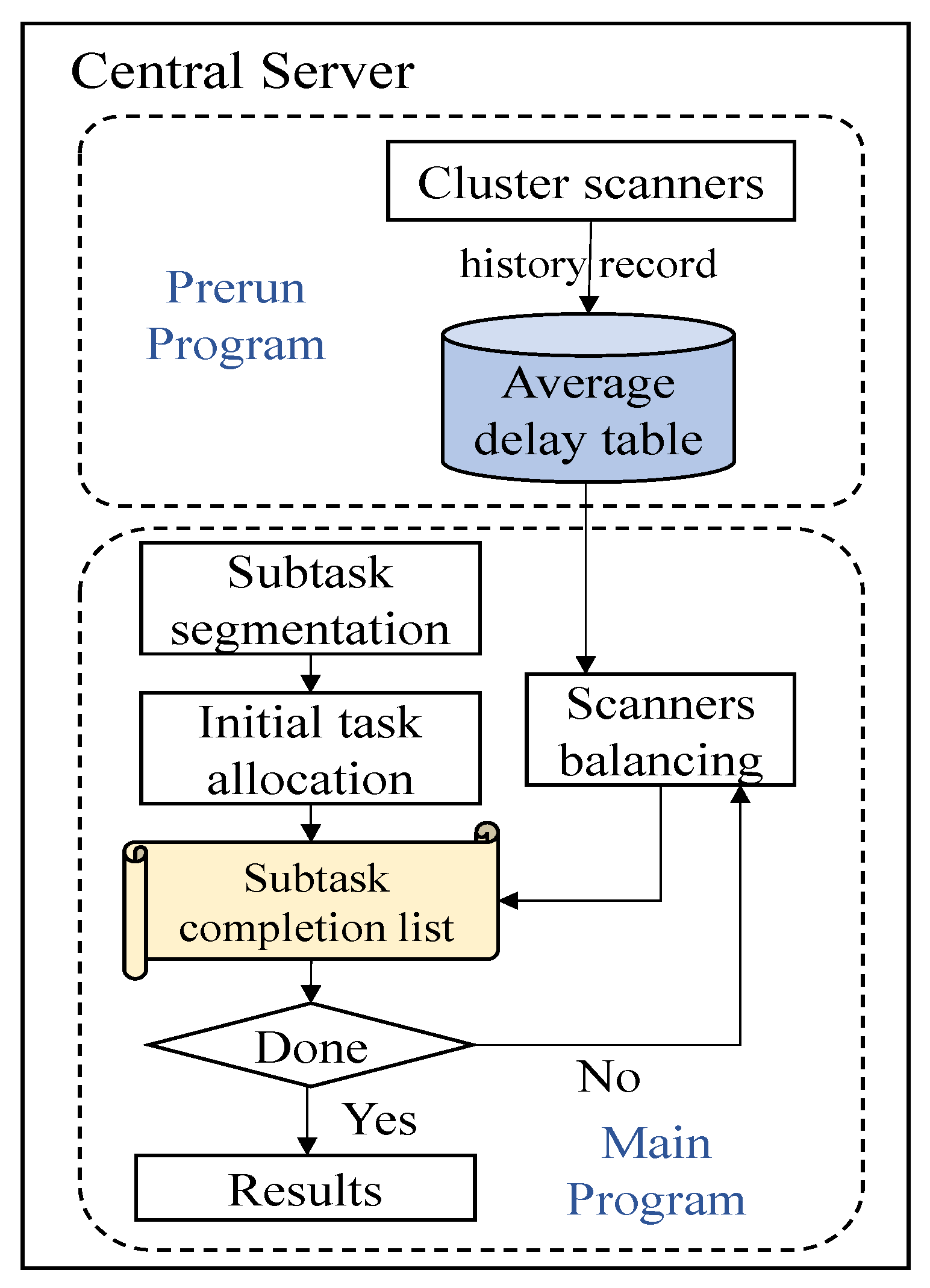
The objective of our approach is to reduce the average detection delay and improve task completion efficiency. To achieve this goal, we allocate IWPS tasks according to the area characteristics of scanners and propose an area-aware efficient IWPS method, as shown in
Figure 3. The policy is divided into two phases. The first phase involves the prerun program which is responsible for the analysis of scanner information and historical request records. In this phase, we cluster the scanners according to their geographical location and construct the average delay table for each cluster. Note that the average delay table does not need to be updated in real time, we only need to update it once a few days or weeks, thus reducing the computational workload of the central server.
The second phase involves the main program, which is executed when users or network administrators submit an IWPS task. First, the central server divides the task into multiple sub-tasks according to the regional information. Then, it executes the initial task allocation and maintains the subtask completion list to judge whether all tasks have been completed. If not, the central server will execute the scanner workload balancing program to redistribute the subtasks. This process is repeated until all subtasks are completed. If all subtasks have been completed, the central server will return the results to the users. The details of each step are presented next.
4.2. Proposed Algorithm
The algorithm has two objectives, one is to enable the scanners to complete the tasks that they are good at, that is, to detect tasks according to regional characteristics; and the other is to ensure the workload balance among scanners, so as to improve the overall efficiency. The proposed area-aware efficient IWPS algorithm is detailed in Algorithm 1.
As mentioned before, the algorithm is divided into the following two parts: the prerun program and main program. The prerun program (as shown in lines 1–4) mainly clusters the scanners by region and constructs the average delay table. The average delay can be calculated from the historical records. To reduce computation overhead, we do not need to update the average delay table in real time, only once every few weeks.
When a task request arrives, the central server executes the main program (as shown in lines 5–19). In order to enable scanner clusters to scan IP in the appropriate region, we first split the task into multiple subtasks according to the IP address. Then, we construct the subtask completion list to record the completion status of all subtasks to determine whether the entire task is completed. However, assigning tasks only according to regional information can easily lead to workload imbalance in the system. To solve the problem, we employ a two-layer workload balancing mechanism (as lines 9–19). The first layer is the inter-cluster workload balancing. The central server dynamically assigns subtasks to scanner clusters multiple times. Initially, the central server assigns subtasks to all the idle scanners clusters. More specifically, for each idle cluster, the central server reads the average delay table of the cluster from the beginning, and it determines whether the subtask in the area of the first item is completed by checking the completion list. If the subtask has been completed, it will read the next item in the average delay table; if not, it will continue to judge whether the subtask is being processed by another scanner cluster; if not, the task will be assigned to the scanner cluster, and if so, the two clusters will be combined to complete the subtask. After the first assignment, although each scanner’s cluster is assigned the subtask it is best at, the workload of each cluster is different. When a scanner cluster completes its subtask first, it will report to the central server that the subtask has been completed and is idle. When the central server receives the information, it updates the subtask completion list and repeats the first assignment process to reassign a new subtask to the cluster. This process is repeated until all subtasks are complete. Through multiple dynamic allocations, it not only ensures that the scanners cluster performs its best subtask each time, but it also avoids some clusters being idle due to the imbalanced workload among clusters, thus effectively improving task completion efficiency. The second layer is the workload balancing of scanners in the same cluster (as shown in line 17). Each scanner cluster maintains a FIFO task queue. Each scanner in the cluster obtains a group of targets to be detected each time from the task queue. After completing the detection, it will continue to obtain targets from the task queue until the task queue is empty. We realize the workload balancing of scanners in the cluster by sharing the task queue.
| Algorithm 1 Area-aware efficient IWPS algorithm |
| Require: scan tasks, IP address of scanners |
| Ensure: subtasks allocation policy |
| 1: | /* Prerun program */ |
| 2: | Cluster all scanners, the scanners in the same region are classified into the same cluster; |
| 3: | Construct the average scan delay table for each cluster, which records the average scan delay from the cluster to different regions; |
| 4: | Arrange the table in descending order of delay; |
| 5: | /* Main program */ |
| 6: | Receive the task request from users; |
| 7: | Split the task into subtasks according to the regional characteristics; |
| 8: | Construct the subtask completion list to records the completion status of all subtask; |
| 9: | while not all subtasks are completed do |
| 10: | Find the clusters that are idle; |
| 11: | Retrieve the average delay table of the idle cluster from the beginning, and combine the subtask completion list to find the uncompleted subtask with lowest delay; |
| 12: | if there are other clusters performing the subtask then |
| 13: | Merge the two scanner clusters to complete the subtask together; |
| 14: | else |
| 15: | Allocate the subtask to the cluster individually; |
| 16: | end if |
| 17: | Scanners in the cluster complete the subtask together by sharing the task queue; |
| 18: | Listen the subtask completion signals from the scanner cluster and update the subtask completion list ; |
| 19: | end while |
It is worth noting that we did not design the task allocation strategy through complex algorithms, such as reinforcement learning and dynamic programming, nor did we strictly pursue the optimal solution in theory; we only designed a greedy algorithm. The reason is that the reinforcement learning-based scanning methods are based on neural networks, often require a lot of computation, and are suitable for task detection in small networks. IWPS is a huge task. Excluding IPv6 addresses, IPv4 addresses alone are about 4.3 billion. If we use complex algorithms (such as reinforcement learning and dynamic programming) for accurate allocation, it will incur a huge computing workload and delay, which, in turn, reduces the efficiency of the system. Similarly, if we persist with using the theoretical optimal solution, this can easily lead to complex mechanisms and low algorithm robustness, which is not conducive to actual deployment. Therefore, a greedy algorithm with low complexity and easy deployment is a good choice. Moreover, our algorithm is not based on a robust mathematical model. This is because many factors affect the efficiency of IWPS, and there are even some factors that we are not clear about. For example, the network bandwidth and computing power of the scanner will affect the detection rate. In addition, some unknown factors will affect the efficiency, such as the regional characteristics found in this paper. Therefore, it is very difficult to build an accurate theoretical model for IWPS. We can ignore many factors to simplify the model, but the simplified model often results in a big gap in the actual situation, making it difficult to carry out scientific research. So, the paper depends on real experiments rather than a robust mathematical model. In the future, we will probe more influencing factors and build accurate mathematical models to provide a theoretical basis for our research.
5. Simulation Results
This section presents the experimental analysis of the proposed policy to demonstrate its effectiveness in a real network system environment. In our lab, we have a network scan platform with more than 200 scanners, which runs the scan strategy of Nmap. These scanners are leased from more than 50 countries around the world. In order to verify the effectiveness of the proposed algorithm, we back up the original Nmap scan strategy and deploy the proposed scan strategy to some scanners in the platform to compare its scan efficiency changes.
Figure 4,
Figure 5 and
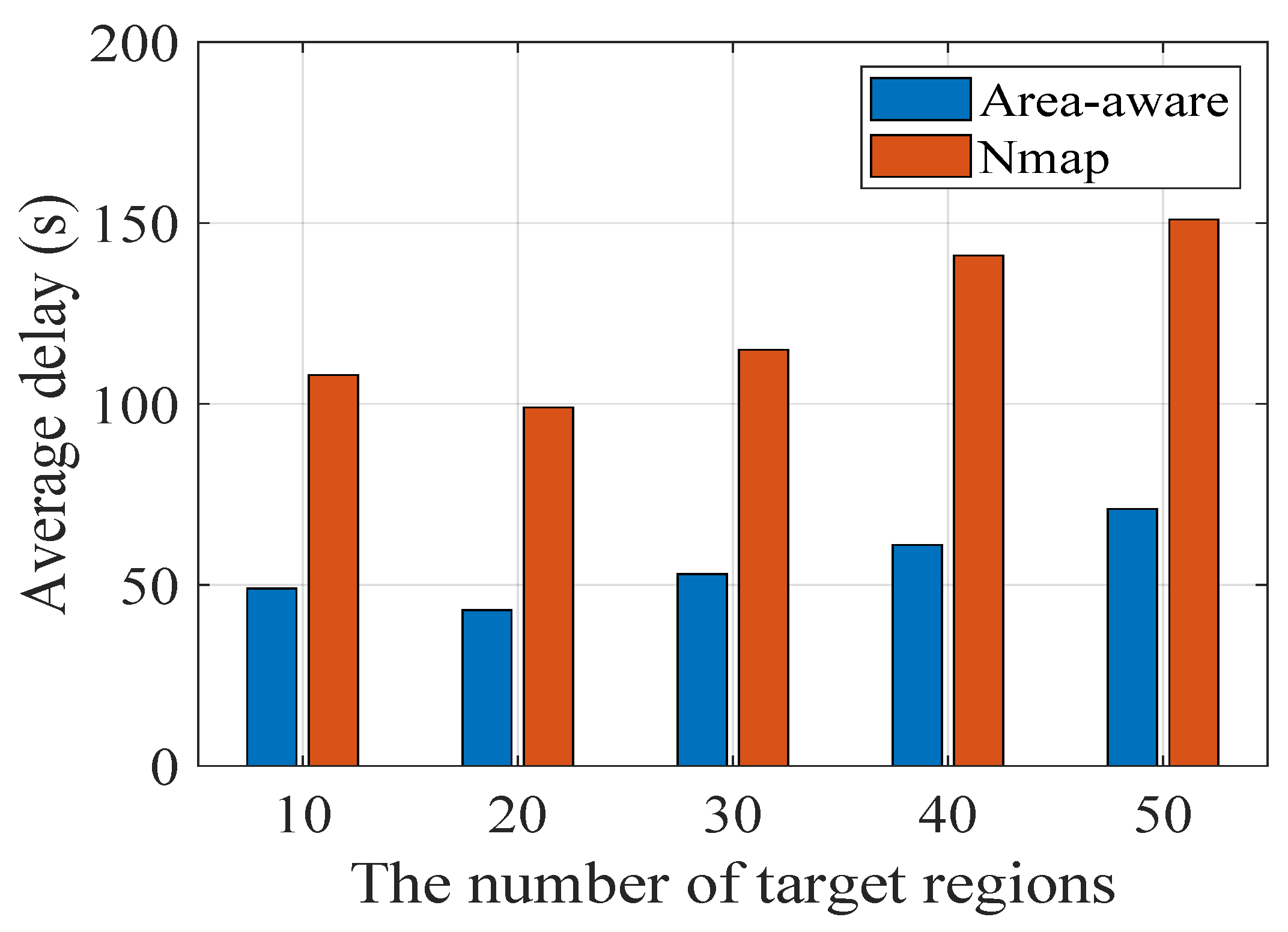
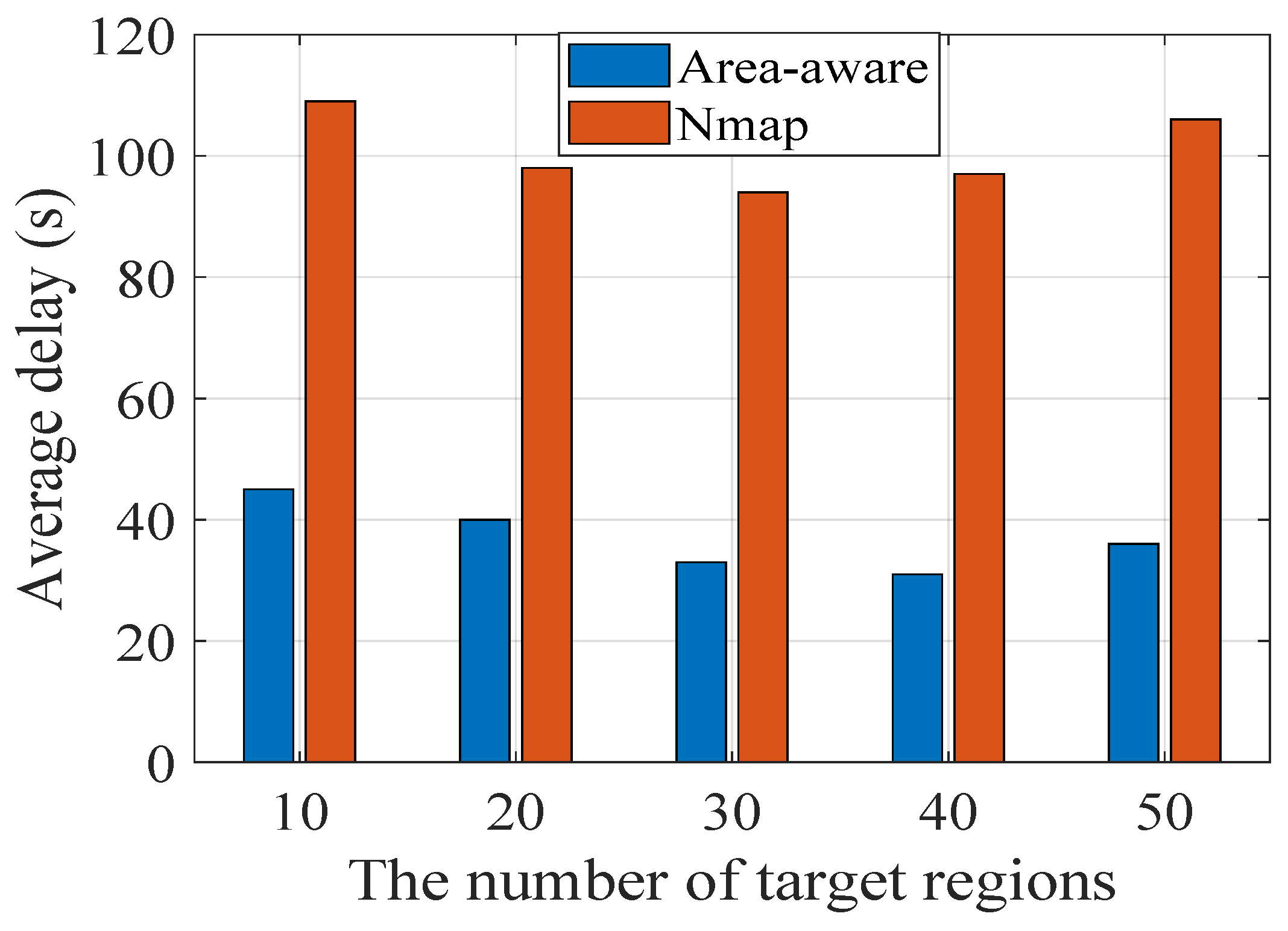
Figure 6 show the effect of the number of scanner clusters and target regions. The
X-axis represents the number of target regions, which is the number of regions included in the scanning task. For each region, we take 100,000 IP addresses to scan. The
Y-axis represents the average delay for each scanner across 100,000 IP addresses. The comparison algorithm is now the most popular Nmap. We analyze the performance of our proposed algorithm and Nmap for five scanner clusters in
Figure 4. In the experiment, the scanners are divided into five clusters according to their region, and each cluster has a different scanner. The average scan delay of Nmap in five scan clusters, ten scan clusters, and twenty scan clusters is 132 s, 124 s, and 102 s, respectively. The average scan delay of our area-aware algorithm in five scan clusters, ten scan clusters, and twenty scan clusters is 51 s, 39 s, and 32 s, respectively. On the whole, the average scan delay of Nmap is 3–4 times that of our algorithm, which shows the efficiency of our algorithm. Specifically, as the number of target regions increases, the average scan delay shows a trend of first decreasing and then increasing. The reason is that with the increase in target regions, there are more target regions that the scanner clusters are good at scanning, and thus, the average delay decreases. However, the number of regions that the scanner clusters are good at is limited. As the number of target regions increases, the number of regions that the scanner clusters are not good at scanning increases rapidly, increasing the average scanner delay. In addition, the target regions that the scanner cluster is good at scanning mean the scanner cluster performs the scan tasks in these regions with low delay. In other words, these regions rank high in the average delay table of this cluster.
Comparing
Figure 4,
Figure 5 and
Figure 6, we can observe that as the number of scanner clusters increases, the average delay decreases slightly. The reason is that each cluster has its shortcomings. For example, the scanner cluster in China has a very long delay and even fails to scan the IP address of the US. The greater the number of scanner clusters is, the less shortcomings exist. For most of the scan tasks, the system can be completed with low delay. The increase in the number of clusters is beneficial in improving the scan’s efficiency. Therefore, in practical systems, we often rent scanners in different areas to jointly complete scan tasks.
The system workload balancing status is shown in
Figure 7,
Figure 8 and
Figure 9.
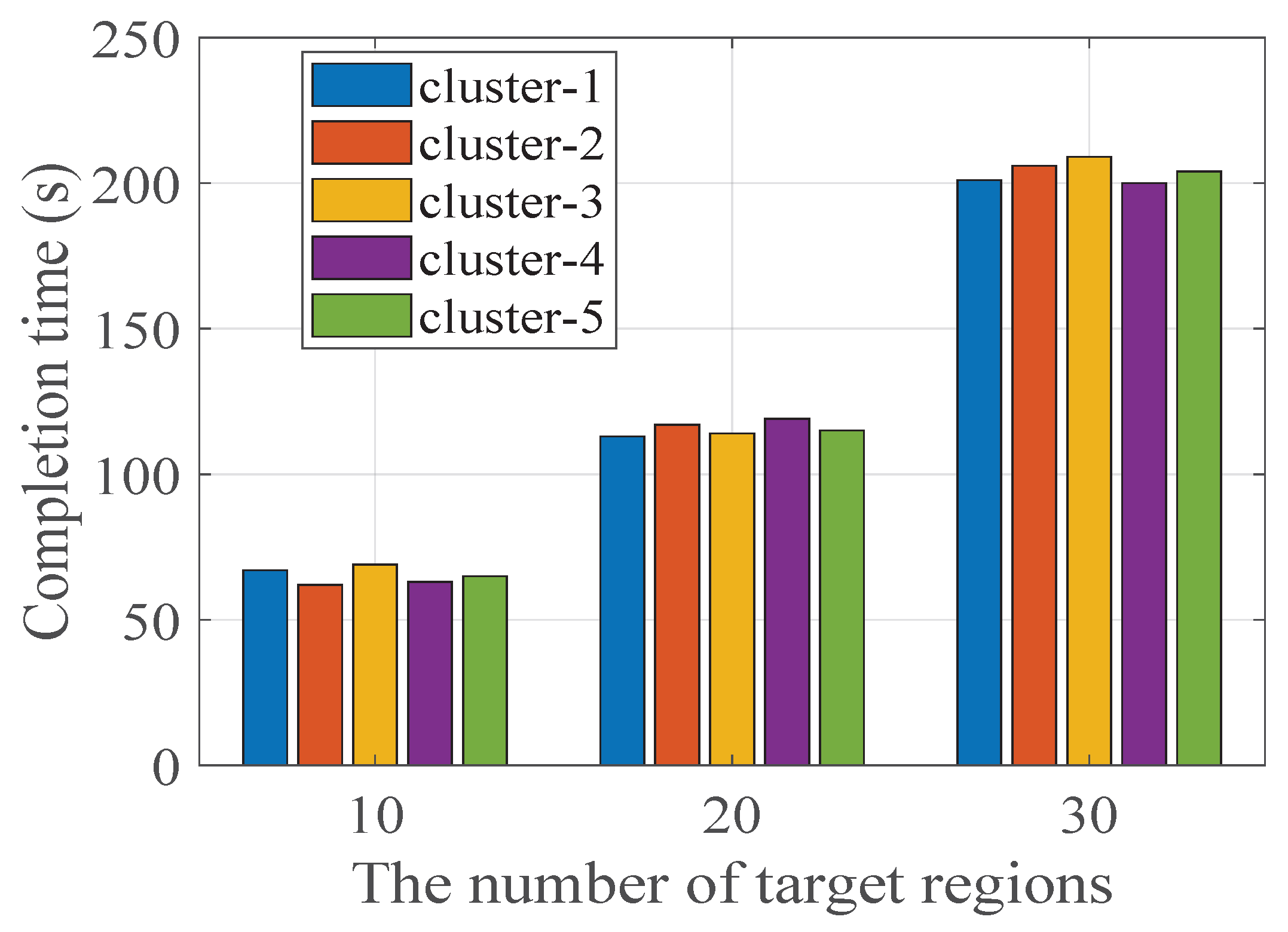
Figure 7 shows the inter-cluster workload balancing status. The
Y-axis is the task completion time of the cluster. If there is a cluster whose completion time is significantly higher than that of other clusters, it means that the cluster has a heavy workload and needs to spend more time to complete the task. Similarly, if there is a cluster whose task completion time is significantly lower than that of other clusters, it means that the cluster’s workload is light and it has entered the idle state very early. Whether the completion time is too high or too low, it shows that the workload among clusters is not balanced, which results in a waste of resources and is not conducive to improving the efficiency of network scans. From
Figure 7, when the number of target addresses is 10, the completion time of the five clusters is 64 s, 61 s, 67 s, 61 s, and 63 s, respectively. When the number of target addresses is 20, the completion time of the five clusters is 126 s, 130 s, 126 s, 131 s, and 127 s, respectively. When the number of target addresses is 30, the completion time of the five clusters is 201 s, 208 s, 212 s, 200 s, and 205 s, respectively. The completion time of each cluster is similar across different numbers of target regions. In other words, for different scan tasks, the workload of each cluster is relatively balanced, which also verifies the effectiveness of our inter-cluster workload balancing policy.
Figure 8 presents the completion time of scanners in cluster-3, and
Figure 9 shows the completion time of scanners in cluster-5. The number of scanners within clusters is different, cluster-3 has four scanners and cluster-5 has three scanners. The completion time of the four scanners in cluster-3 is 68 s, 71 s, 67 s, and 70 s, respectively, when the number of target addresses is 10. The completion time is 114 s, 110 s, 110 s, and 112 s, respectively, when the number of target addresses is 20. The completion time is 200 s, 213 s, 204 s, and 208 s, respectively, when the number of target addresses is 30. The completion time of the three scanners in cluster-5 is similar. It can be seen that although the number of scanners in cluster-3 and cluster-5 is different, the completion times of scanners in the same cluster are relatively consistent, which also verifies the effectiveness of the intra-cluster balance mechanism.
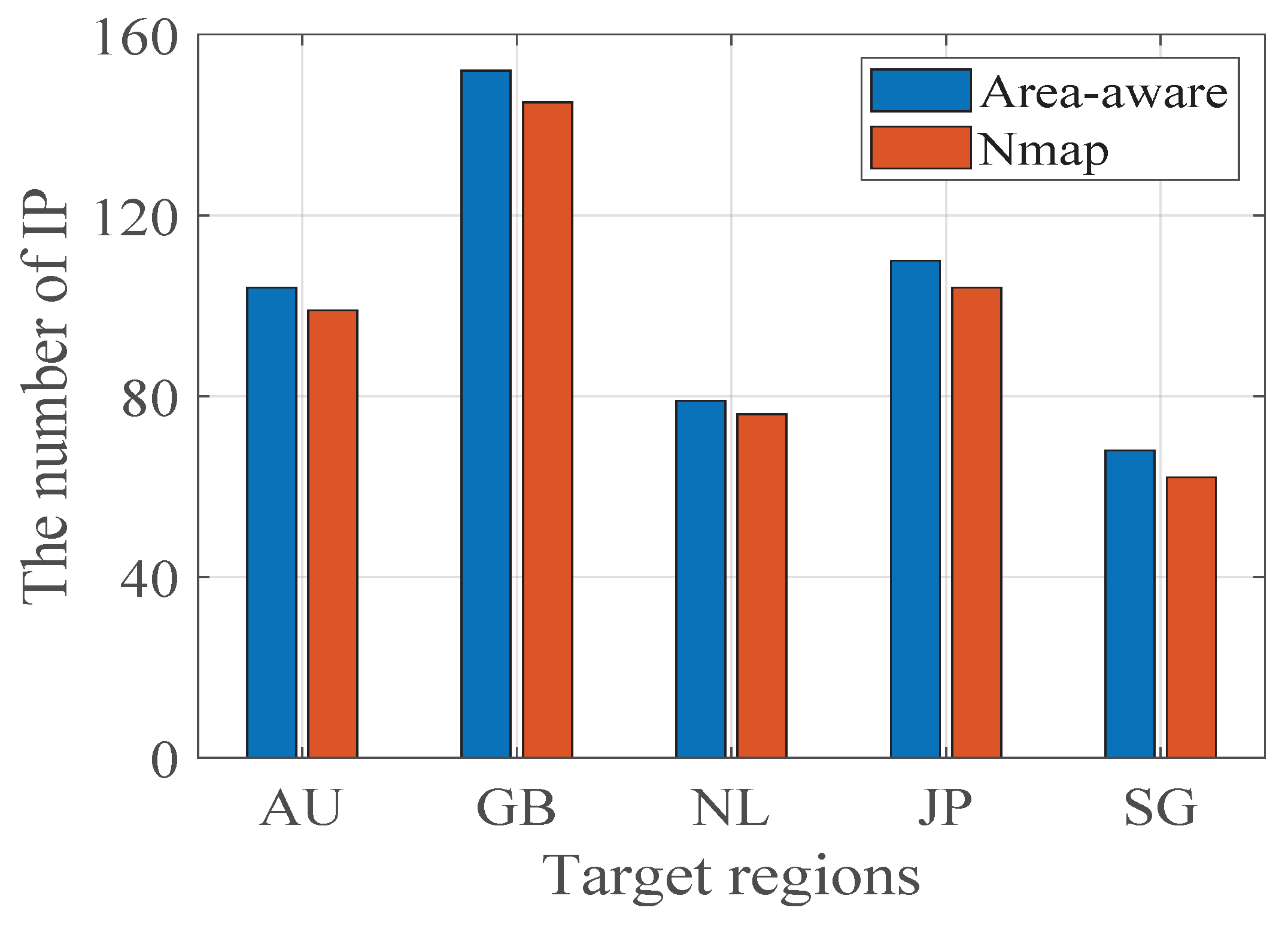
Figure 10 shows a comparison of the accuracy. We scanned 10,000 IP addresses in different countries and recorded the number of live IP addresses. The horizontal coordinate is the target country, and the vertical coordinate is the number of surviving IP addresses. From the figure, the number of live IP addresses using our area-aware algorithm is 104, 152, 79, 110, and 68, respectively. The number of live IP addresses by Nmap is 99, 145, 76, 104, and 62. We can find that our area-aware algorithm can detect more live IP addresses than Nmap. The reason is that for some IP addresses, only scanners in the same country can access them. For example, some government websites in China can only be accessed by network equipment in China. Our algorithm assigns tasks based on geographical location, which can improve the accuracy of detection.
From
Figure 7,
Figure 8 and
Figure 9, we can also observe that the completion time of the cluster increases significantly with the increase in the number of target regions. There are two reasons for this. The main reason is that the increase in the number of scanning addresses leads to an increase in the completion time. In the experiment, for each region, we take 100,000 IP addresses to scan. As the number of regions increases, the number of IP addresses to be scanned also increases. Since the number of scanners does not change, the completion time increases. The second point is that as the number of target regions keeps increasing, the number of regions that the scanner clusters are not good at increases rapidly, increasing completion time.
6. Discussion
We proposed an area-aware efficient IWPS approach. From previous works on IWPS, we find that most of them are based on half-open scanners, which cannot identify packet loss and find it difficult to solve the problem of low accuracy. The open scanners have higher accuracy but also result in a low scan rate. Therefore, a method for improving the efficiency of open scanners represents an important but rarely researched work. Through numerous experiments, we find that scanners in different countries have different port scan efficiencies for the same task. In general, the scanner can complete port scan tasks with scan targets whose IP is in their own country more efficiently than those in other countries. Based on this, we proposed an area-aware efficient IWPS approach to improve scan efficiency. First, we clustered the scanners according to region and built an average delay table for each cluster. The average delay table records the average time delay for scanners in the cluster to detect IP addresses in different regions. Second, to avoid wasting resources, we also designed a two-layer balancing mechanism to ensure the workload balance of the system. Compared with the most popular open scan tool, Nmap, the scan rate of our proposed policy shows a 3–4-fold improvement, and the detection accuracy increased by 8%.
However, our study also leaves some problems unresolved. First, the paper is not based on a robust mathematical model nor can it be described mathematically. The reason is that many factors affect the efficiency of IWPS, and there are even some factors that we are not clear about. It is very difficult to build an accurate theoretical model for IWPS or describe our methods mathematically. Therefore, we need to build accurate mathematical models and describe our method mathematically to provide a theoretical basis for our research in the future. Second, there is no discussion on how the approach would perform in different real-world scenarios, such as with varying network congestion or dynamic IP allocations. The reason is that, at present, our experimental platform cannot collect the network congestion status in various regions. Finally, we plan to continue following the latest research on IWPS and will resume conducting in-depth research.
7. Conclusions
In this study, we proposed a novel area-aware IWPS approach to improve the scan rate. Specifically, through experiments, we found that scanners in different regions have different scan rates for the same scan task, with differences in scan rates exceeding 10×. Therefore, we clustered the scanners according to region and built an average delay table by history record to guide the assignment of tasks. When the task requests arrive, we split the tasks according to IP address and assign them to the appropriate clusters. In order to avoid resource waste caused by idle scanners, we designed a two-layer workload balancing mechanism which includes inter-cluster workload balancing and intra-cluster workload balancing. Finally, we verified the effectiveness of our algorithm by real experiments. Compared with the most popular open scan tool, Nmap, the scan rate of our proposed policy improved by 3–4 times, and the detection accuracy increased by 8%.
In the future, we will explore more factors affecting scan speed and will design more efficient IWPS approaches. In addition, we will further verify the applicability of our proposed algorithm in different scenarios and explore the network detection method under dynamic IP address assignment.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}