
LLM-WFIN: A Fine-Grained Large Language Model (LLM)-Oriented Website Fingerprinting Attack via Fusing Interrupt Trace and Network Traffic

Abstract
1. Introduction
- We analyze interrupt-based WF attacks and network-traffic-based WF attacks on LLMs separately. Our findings reveal that interrupt-based WF attacks can be weakened by the inherent defense of interactive LLM visits, while network-traffic-based WF attacks exhibit similar effects on LLMs as they do on general websites.
- We design a novel fine-grained LLM-oriented website fingerprinting attack that fuses interrupt traces and network traffic to enhance website fingerprinting attacks. We propose two fusion policies: a prior-fusion-based, one-stage classifier and a post-fusion-based, two-stage classifier.
- We conduct comprehensive analyses and ablation studies on 25 LLMs to verify the effectiveness of the proposed attack, LLM-WFIN. The results demonstrate that LLM-WFIN using post fusion outperforms that using prior fusion and achieves up to 81.6% attack classification accuracy even under effective defenses.
2. Related Work
2.1. LLMs-Oriented Attacks
2.2. Website Fingerprinting Attacks and Defenses
2.2.1. Network-Traffic-Based Website Fingerprinting Attack and Defense
2.2.2. Interrupt-Based Website Fingerprinting Attack and Defense
2.3. Website Fingerprinting Attacks and Defenses
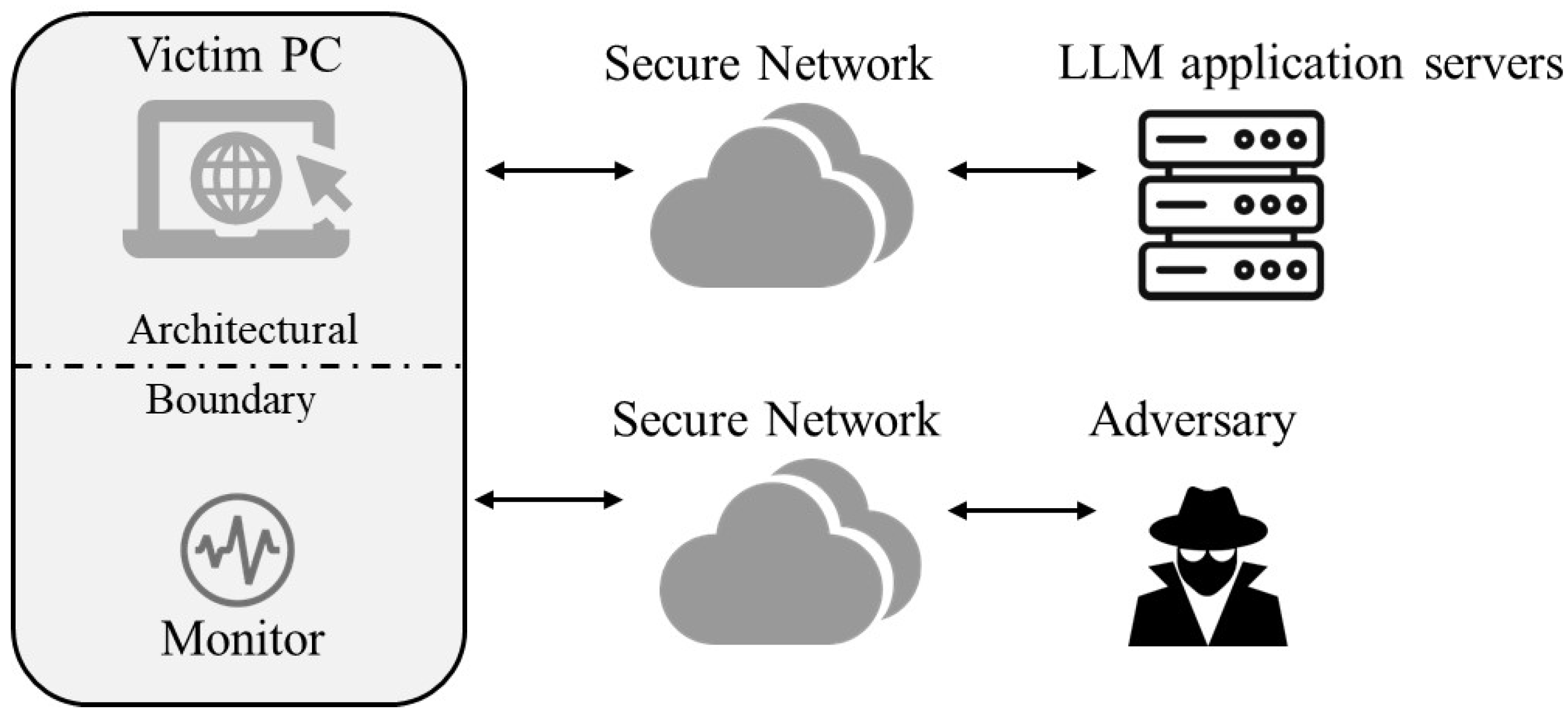
3. Background
3.1. LLM Applications
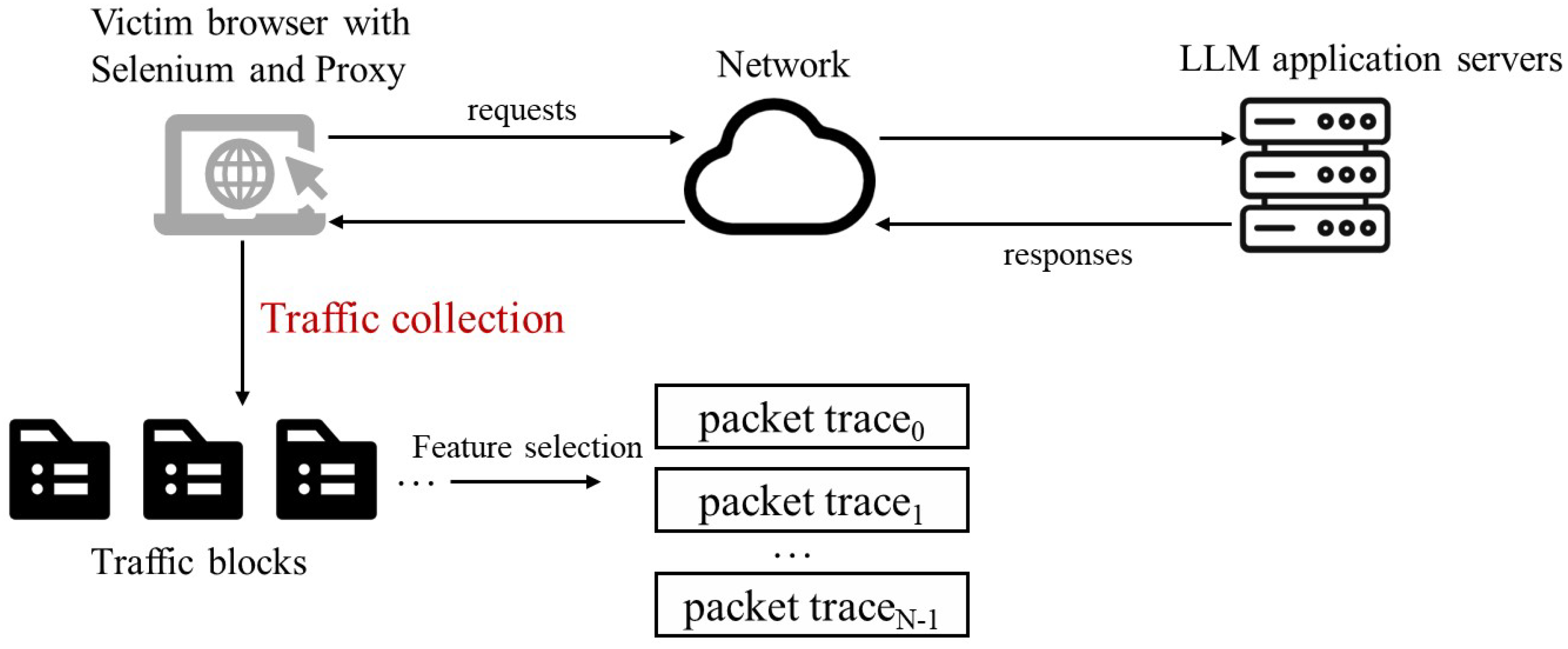
3.2. Network-Traffic-Based WF Attack on LLM Applications
3.3. Interrupt-Based WF Attack on LLM Applications
- begin
- int Trace[T*1000]
- loop {
- counter = 0;
- begin = time();
- do {
- comment: count iterations
- counter++;
- } while (time() - begin < P)
- Trace[begin] = counter;
- }
- end
4. Observation of WF Attacks on LLM Applications
4.1. Hypothesis
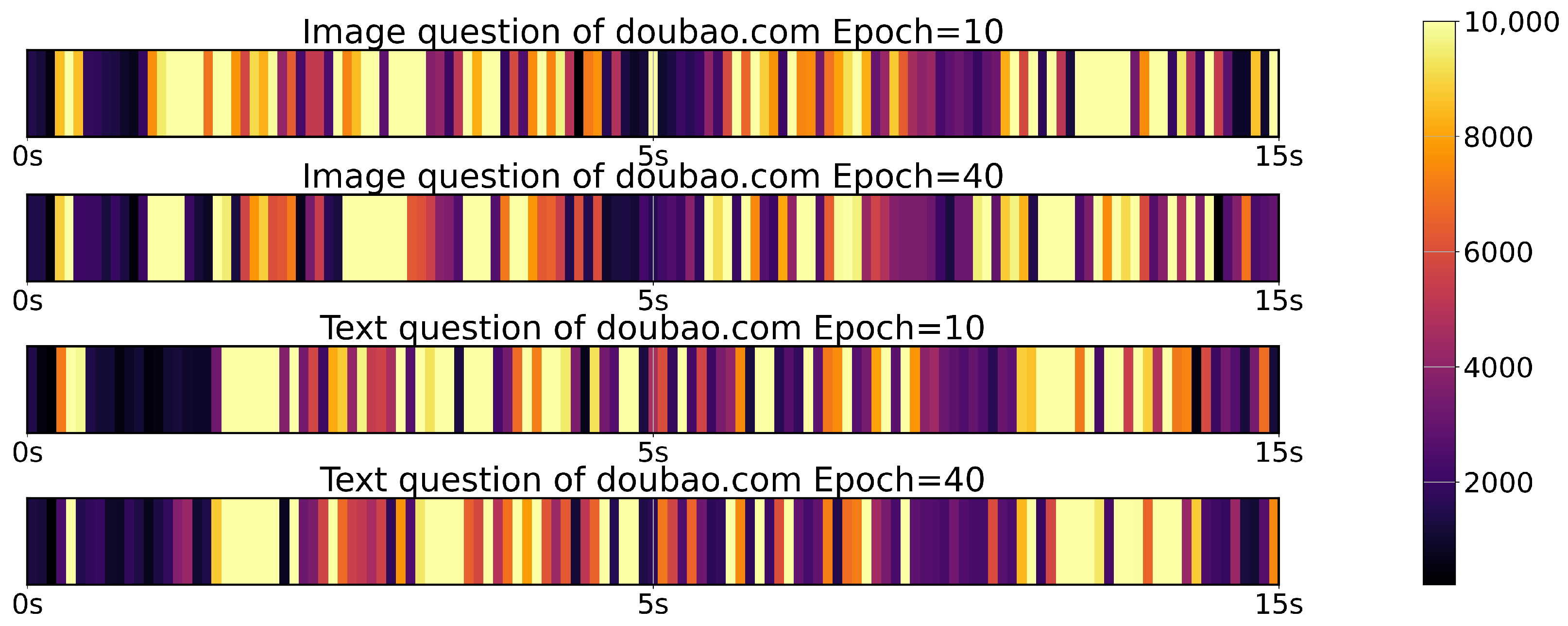
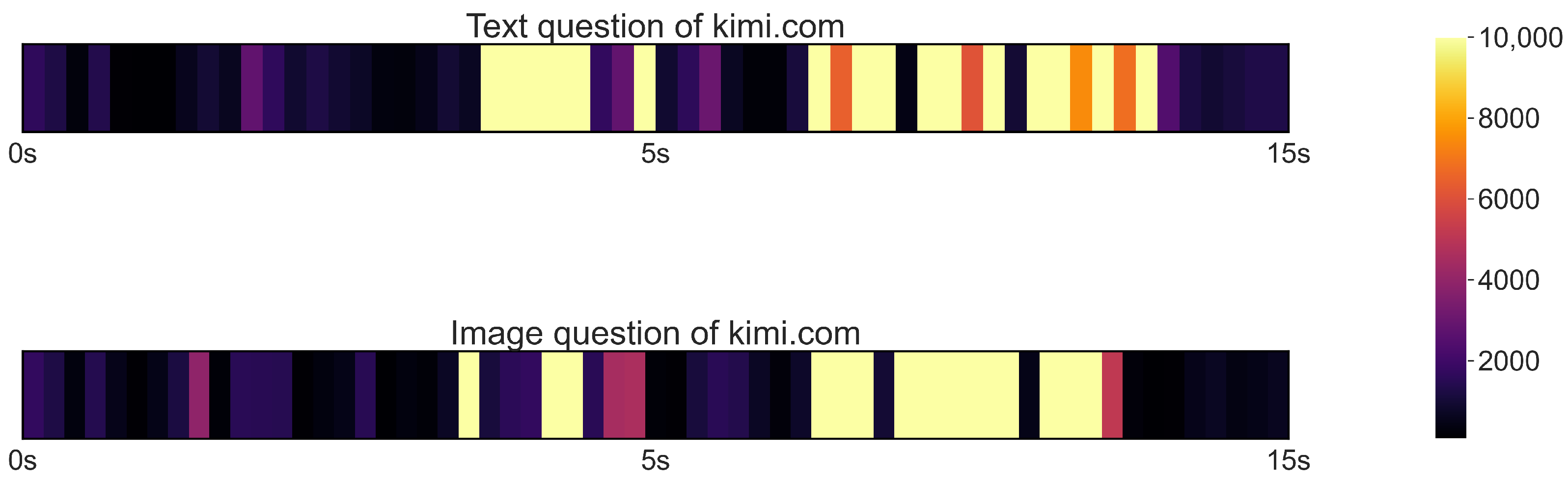
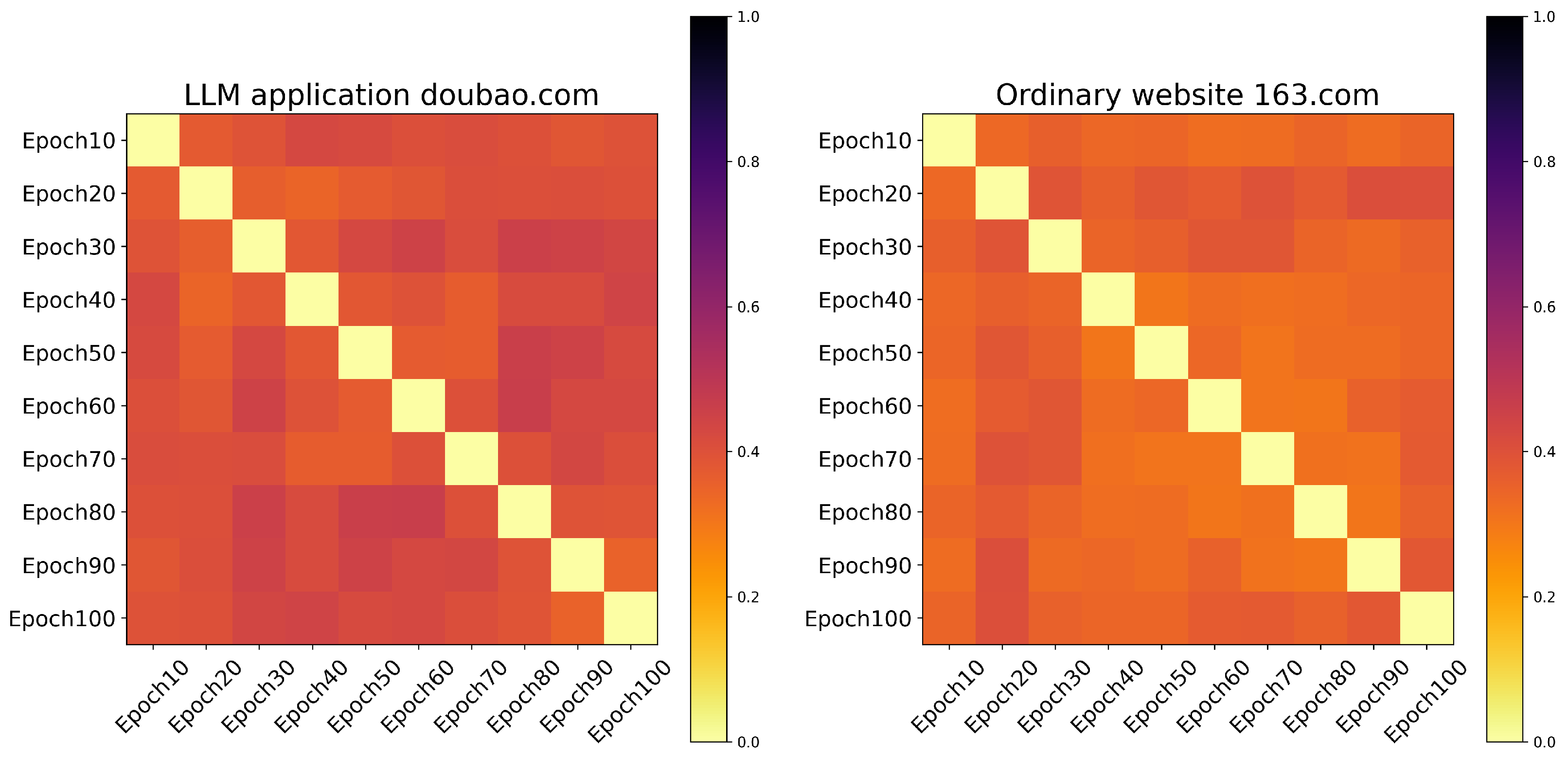
4.2. Network-Traffic-Based Attack on LLM Applications
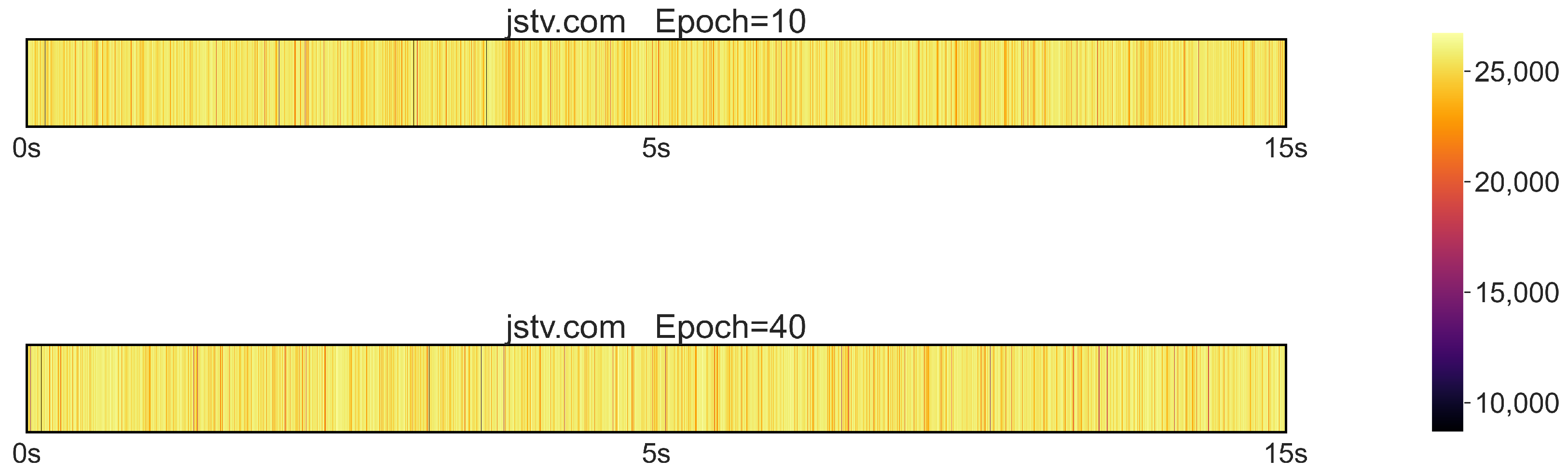
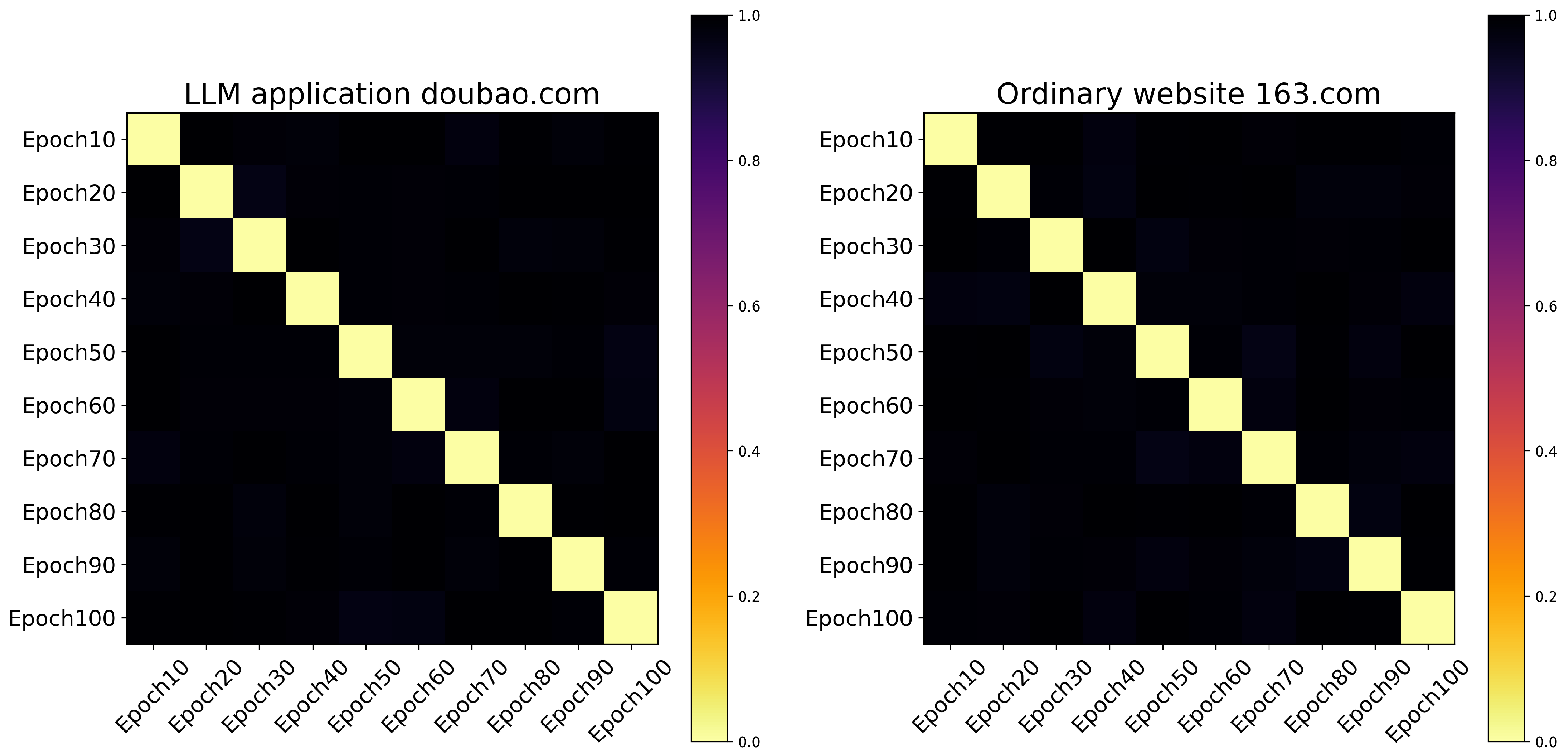
4.3. Interrupt-Based Attacks on LLM Applications
4.4. Motivation for a Novel LLM-Oriented Attack
5. Proposed Novel LLM-WFIN Attack
5.1. Why Two Kinds of Traces in LLM-WFIN?
5.2. How to Fuse Two Traces in an LLM-WFIN Attack
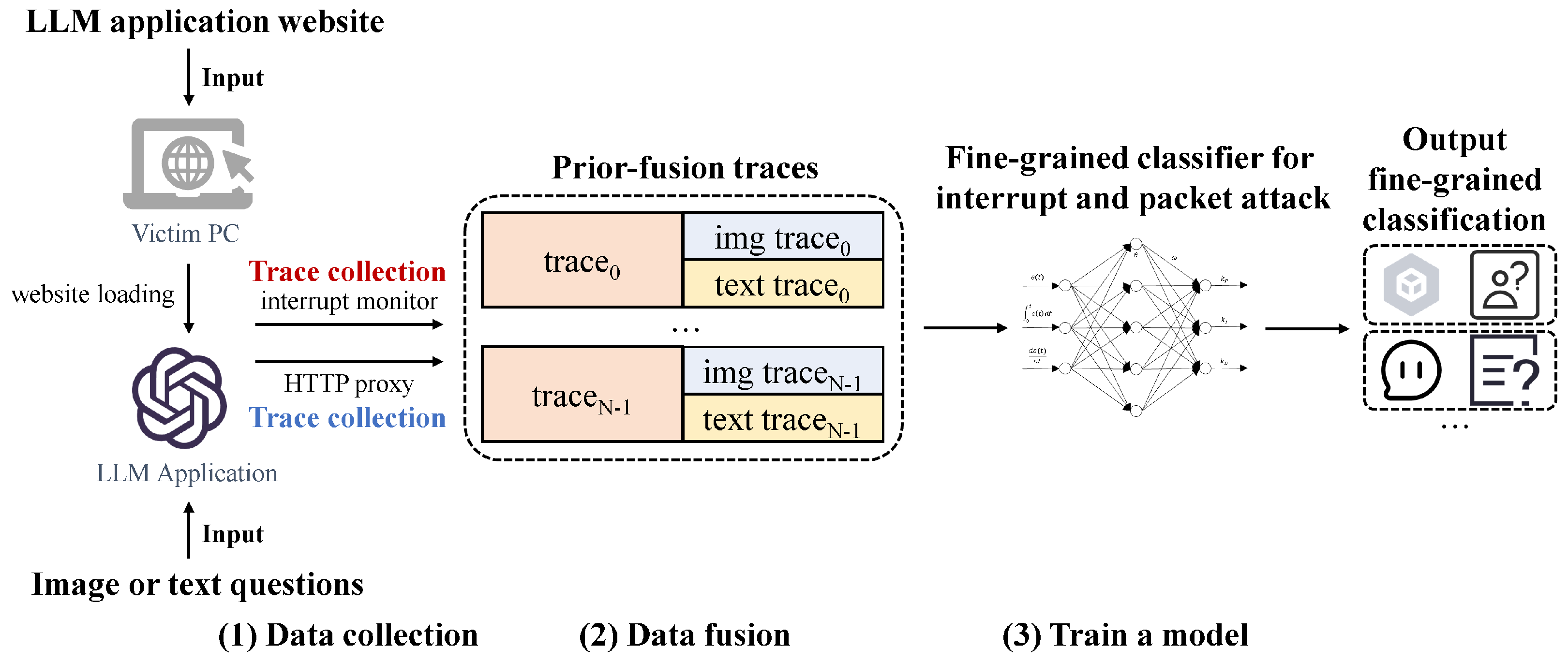
5.3. One-Stage LLM-WFIN-Prior Attack Model Using the Prior-Fusion Policy
- Data collection. When the application inputs are prepared for accessing LLM websites, the two types of traces are collected. During the loading phase of LLM websites, interrupt traces are collected by the interrupt monitor. Subsequently, packet traces are captured by the HTTP proxy during the LLM querying phase.
- Data fusion. The two traces are fused into a unified trace by simple concatenation. More effective multimodality fusion modules, such as those described in [36,37,38,39], can be utilized for higher accuracy, albeit with increased computational complexity. Additionally, to address data alignment issues, each short interrupt trace (1–3 s) is downscaled by two orders of magnitude to match the corresponding packet trace.
- Training a model. A classifier assisted by machine learning methods is trained for LLM-WFIN-Prior to directly identify websites along with their querying content types. The choice of machine learning methods significantly impacts classification results; further comparisons and analyses are detailed in Section 4.2.
5.4. Two-Stage LLM-WFIN-Post Attack Model Using the Post-Fusion Policy
- Data collection. Similar to the procedure of LLM-WFIN-Prior, interrupt traces and packet traces are collected during the LLM website loading phase and querying phase, respectively.
- Train two models. Two classifiers are trained separately using interrupt traces and packet traces. In other words, the LLM-WFIN-Post attack combines the existing interrupt-based attack and network-traffic-based attack. The primary differences lie in two points: (a) non-LLM applications are replaced by LLM-oriented websites; (b) the network-traffic-based packet traces focus solely on the querying content type, while interrupt traces address LLM website identification.
- Fusion of classification results. To obtain the fine-grained classification results for LLM websites with content types, the prediction labels from the interrupt-based attack model and the network-packet-based attack model are merged. Higher classification accuracy results in a stronger LLM-WFIN-Post attack, exposing more of the user’s browsing privacy.
6. Result and Analysis
6.1. Experiments Configuration
6.2. Comparative Results Under Varying Learning Methods
6.3. Comparative Results Under Varying Defenses
6.4. Comparative Results Between LLMs and Other Non-LLM Websites
6.5. Ablation Study
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. LLM Application Websites
| so.com | wenku.baidu.com | kimi.moonshot.cn | yiyan.baidu.com |
| doubao.com | tongyi.aliyun.com | metasearch.cn | aippt.cn |
| baidu.com | tiangong.cn | czd.com | deepseek.com |
| chatglm.cn | design.meitu.com | zhihu.com | sudamobile.com |
| gaoding.com/ai | 10jqka.com.cn | xfyun.cn | huoshan.com |
| minimax.chat | liblib.art | processon.com | modao.cc |
| immersive-translate.owenyoung.com |
References
- AI Industry Analysis: 50 Most Visited AI Tools and Their 24B+ Traffic Behavior—WriterBuddy. Available online: https://writerbuddy.ai/blog/ai-industry-analysis (accessed on 10 March 2024).
- Yan, M.; Fletcher, C.W.; Torrellas, J. Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures. In Proceedings of the 29th USENIX Security Symposium, Online, 12–14 August 2020. [Google Scholar]
- Nazari, N.; Xiang, F.; Fang, C.; Makrani, H.M.; Puri, A.; Patwari, K.; Sayadi, H.; Rafatirad, S.; Chuah, C.-N.; Homayoun, H. LLM-FIN: Large Language Models Fingerprinting Attack on Edge Devices. In Proceedings of the 2024 25th International Symposium on Quality Electronic Design (ISQED) 2024, San Francisco, CA, USA, 3–5 April 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Dong, G.; Wang, P.; Chen, P.; Gu, R.; Hu, H. Floating-Point Multiplication Timing Attack on Deep Neural Network. In Proceedings of the 2019 IEEE International Conference on Smart Internet of Things (SmartIoT), Tianjin, China, 9–11 August 2019; pp. 155–161. [Google Scholar] [CrossRef]
- Patwari, K.; Hafiz, S.M.; Wang, H.; Homayoun, H.; Shafiq, Z.; Chuah, C.-N. DNN Model Architecture Fingerprinting Attack on CPU-GPU Edge Devices. In Proceedings of the 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P) 2022, Genoa, Italy, 6–10 June 2022; pp. 337–355. [Google Scholar] [CrossRef]
- Willison, S. Prompt Injection Attacks Against GPT-3. Simon Willison’s Weblog. Available online: https://simonwillison.net/2022/Sep/12/prompt-injection/ (accessed on 10 March 2024).
- Greshake, K.; Abdelnabi, S.; Mishra, S.; Endres, C.; Holz, T.; Fritz, M. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, Copenhagen Denmark, 30 November 2023; pp. 79–90. [Google Scholar] [CrossRef]
- Xie, S.; Dai, W.; Ghosh, E.; Roy, S.; Schwartz, D.; Laine, K. Does Prompt-Tuning Language Model Ensure Privacy? arXiv 2023, arXiv:2304.03472. [Google Scholar]
- Shumailov, I.; Zhao, Y.; Bates, D.; Papernot, N.; Mullins, R.; Anderson, R. Sponge Examples: Energy-Latency Attacks on Neural Networks. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy (EuroS&P), Vienna, Austria, 6–10 September 2021. [Google Scholar] [CrossRef]
- Cook, J.; Drean, J.; Behrens, J.; Yan, M. There’s always a bigger fish: A clarifying analysis of a machine-learning-assisted side-channel attack. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; pp. 204–217. [Google Scholar]
- Bhat, S.; Lu, D.; Kwon, A.H.; Devadas, S. VAR-CNN: A Data-Efficient Website Fingerprinting attack based on Deep learning. Proc. Priv. Enhancing Technol. 2019, 2019, 292–310. [Google Scholar] [CrossRef]
- Esmradi, A.; Yip, D.W.; Chan, C.F. A comprehensive survey of attack techniques, implementation, and mitigation strategies in Large Language Models. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2024; pp. 76–95. [Google Scholar] [CrossRef]
- Carlini, N.; Ippolito, D.; Jagielski, M.; Lee, K.; Tramer, F.; Zhang, C. Quantifying memorization across neural language models. arXiv 2022, arXiv:2202.07646. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N. Jailbreaking Leading Safety-Aligned Llms with Simple Adaptive Attacks. 2024. Available online: https://arxiv.org/abs/2404.02151 (accessed on 10 March 2024).
- Dong, Z.; Zhou, Z.; Yang, C.; Shao, J.; Qiao, Y. Attacks, Defenses and Evaluations for LLM Conversation Safety: A Survey. arXiv 2024, arXiv:2402.09283. [Google Scholar] [CrossRef]
- Tian, Z.; Cui, L.; Liang, J.; Yu, S. A Comprehensive Survey on Poisoning Attacks and Countermeasures in Machine Learning. ACM Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Roy, S.S.; Naragam, K.V.; Nilizadeh, S. Generating Phishing Attacks Using ChatGPT. arXiv 2023, arXiv:2305.05133. [Google Scholar]
- Panchenko, A.; Niessen, L.; Zinnen, A.; Engel, T. Website Fingerprinting in Onion Routing Based Anonymization Networks. In Proceedings of the 10th Annual ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 17 October 2011. [Google Scholar] [CrossRef]
- De La Cadena, W.; Mitseva, A.; Hiller, J.; Pennekamp, J.; Reuter, S.; Filter, J.; Engel, T.; Wehrle, K.; Panchenko, A. TrafficSliver: Fighting Website Fingerprinting Attacks with Traffic Splitting. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022. [Google Scholar] [CrossRef]
- Wang, T.; Cai, X.; Nithyanand, R.; Johnson, R.; Goldberg, I. Effective Attacks and Provable Defenses for Website Fingerprinting. In Proceedings of the USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 143–157. [Google Scholar]
- Panchenko, A.; Lanze, F.; Zinnen, A.; Henze, M.; Pennekamp, J.; Wehrle, K.; Engel, T. Website Fingerprinting at Internet Scale. In Proceedings of the NDSS 2016, San Diego, CA, USA, 21–24 February 2016. [Google Scholar] [CrossRef]
- Rimmer, V.; Preuveneers, D.; Juárez, M.; Van Goethem, T.; Joosen, W. Automated Feature Extraction for Website Fingerprinting through Deep Learning. arXiv 2017, arXiv:1710.01590. [Google Scholar]
- Sirinam, P.; Imani, M.; Juarez, M.; Wright, M. Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1928–1943. [Google Scholar]
- Oh, S.E.; Mathews, N.; Rahman, M.S.; Wright, M.; Hopper, N. GANDALF: GAN for Data-Limited Fingerprinting. Proc. Priv. Enhancing Technol. 2021, 2021, 305–322. [Google Scholar] [CrossRef]
- Dyer, K.P.; Coull, S.E.; Ristenpart, T.; Shrimpton, T. Peek-a-Boo, I Still See You: Why Efficient Traffic Analysis Countermeasures Fail. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 332–346. [Google Scholar] [CrossRef]
- Juarez, M.; Afroz, S.; Acar, G.; Diaz, C.; Greenstadt, R. A Critical Evaluation of Website Fingerprinting Attacks. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 263–274. [Google Scholar]
- Wang, T.; Goldberg, I. Walkie-Talkie: An Efficient Defense Against Passive Website Fingerprinting Attacks. In Proceedings of the 26th USENIX Security Symposium, Vancouver, BC, Canada, 16–18 August 2017; pp. 1375–1390. [Google Scholar]
- Cai, X.; Nithyanand, R.; Johnson, R. CS-BuFLO: A Congestion Sensitive Website Fingerprinting Defense. In Proceedings of the 13th Workshop on Privacy in the Electronic Society, Scottsdale, AZ, USA, 3 November 2014; pp. 121–130. [Google Scholar]
- Cai, X.; Nithyanand, R.; Wang, T.; Johnson, R.; Goldberg, I. A Systematic Approach to Developing and Evaluating Website Fingerprinting Defenses. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 227–238. [Google Scholar] [CrossRef]
- JavaScript|MDN. MDNWeb Docs. Available online: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript (accessed on 1 March 2024).
- Genkin, D.; Pachmanov, L.; Tromer, E.; Yarom, Y. Drive-By Key-Extraction Cache Attacks from Portable Code. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 83–102. [Google Scholar] [CrossRef]
- Weiss, J.O.B.; Alves, T.; Kundu, S. EZClone: Improving DNN Model Extraction Attack via Shape Distillation from GPU Execution Profiles. arXiv 2023, arXiv:2304.03388. [Google Scholar]
- Pasquini, D.; Kornaropoulos, E.M.; Ateniese, G. LLMMap: Fingerprinting for Large Language Models. arXiv 2024, arXiv:2407.15847. [Google Scholar]
- Lightbody. GitHub—Lightbody/Browsermob-Proxy: A Free Utility to HelpWeb DevelopersWatch and Manipulate Network Traffic From Their AJAX Applications. GitHub. Available online: https://github.com/lightbody/browsermob-proxy (accessed on 13 February 2024).
- Selenium. Selenium. Available online: https://www.selenium.dev/zh-cn (accessed on 13 February 2024).
- Li, W.; Zhou, H.; Yu, J.; Song, Z.; Yang, W. Coupled mamba: Enhanced multi-modal fusion with coupled state space model. arXiv 2024, arXiv:2405.18014. [Google Scholar]
- Hemker, K.; Simidjievski, N.; Jamnik, M. HEALNet: Multimodal Fusion for Heterogeneous Biomedical Data. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024. [Google Scholar]
- Shankar, S.; Thompson, L.; Fiterau, M. Progressive fusion for multimodal integration. arXiv 2022, arXiv:2209.00302. [Google Scholar]
- Zhou, M.; Huang, J.; Yan, K.; Hong, D.; Jia, X.; Chanussot, J.; Li, C. A General Spatial-Frequency Learning Framework for Multimodal Image Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 1–18. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties. Int. Stat. Rev. 1989, 57, 238. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks; National Key Lab for Novel Software Technology, Nanjing University: Nanjing, China, 2015. [Google Scholar]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LLM Fingerprinting Attack | Attack Type | Target Leakage | Side Channel | Attack Accuracy |
|---|---|---|---|---|
| DNN architecture attack [5] | Attacks on LLM model | DNN architecture | Memory, CPU, and GPU usage | 99% |
| EZClone [32] | Attacks on LLM model | DNN architecture | GPU profiles | 100% |
| LLM-FIN [3] | Attacks on LLM model | LLM family | Memory usage | 95% |
| LLMmap [34] | Attacks on LLM model | LLM version | Query | 95% |
| Our LLM-WFIN | Attacks on LLM applications | LLM website and interaction content type | Interrupt and Network traffic | 97.2% |
| Attack | Trace Collection Phase | Classification Target | Accuracy |
|---|---|---|---|
| Packet-based WF attack [11] on general non-LLM applications | Querying | Websites | 98.1% |
| Our test, packet-based LLM application attack | Querying | Websites with content type | 92.1% |
| Our test, packet-based LLM application attack | Querying | Content type | 98.6% |
| Interrupt-based WF attack [10] on general non-LLM applications | Loading | Websites | 96.6% |
| Our test, interrupt-based LLM application attack | Loading | Websites | 96.6% |
| Our test, interrupt-based LLM application attack | Querying | Websites with content type | 6.5% |
| Interrupt and Packet-based LLM application attack | Loading and querying | Websites with content type | [95.4%, 99.9%] |
| Item | Configuration |
|---|---|
| Operating System | Linux, Windows |
| Browser | Chrome 92 |
| Number of LLM Applications | 25 |
| Size of LLM Application Website Interrupt Trace | 2500 |
| Size of LLM Application Interrupt Trace | 2500 |
| Size of LLM Application Network Packet Trace | 2500 |
| Classification Model | LSTM, CNN, KNN, RF, SVM, LSTM+CNN |
| Total dataset size | 7500 |
| Model | LLM-WFIN-Post | LLM-WFIN-Prior |
|---|---|---|
| Random Forest | 90.5 ± 1.2% | 90.6 ± 1.3% |
| KNN | 90.4 ± 1.4% | 87.4 ± 1.1% |
| SVM | 92.9 ± 1.3% | 88.9 ± 1.5% |
| CNN | 93.6 ± 0.9% | 90.6 ± 0.7% |
| LSTM | 94.3 ± 0.8% | 91.3 ± 1.0% |
| CNN+LSTM | 97.2 ± 0.6% | 93.4 ± 0.9% |
| Attack | Accuracy |
|---|---|
| Interrupt-based WF attack [10] | 96.6% |
| Packet-based WF attack [11] | 98.1% |
| Packet-based LLM application attack with randomized packets | 81.6 ± 1.5% |
| Packet-based LLM application query type attack | 98.6 ± 0.5% |
| Interrupt-based LLM application attack | 6.5 ± 3.2% |
| Interrupt and packet-based LLM application attack (post-fusion) | 97.2 ± 0.7% |
| Interrupt and packet-based LLM application attack (prior to fusion) | 93.2 ± 1.0% |
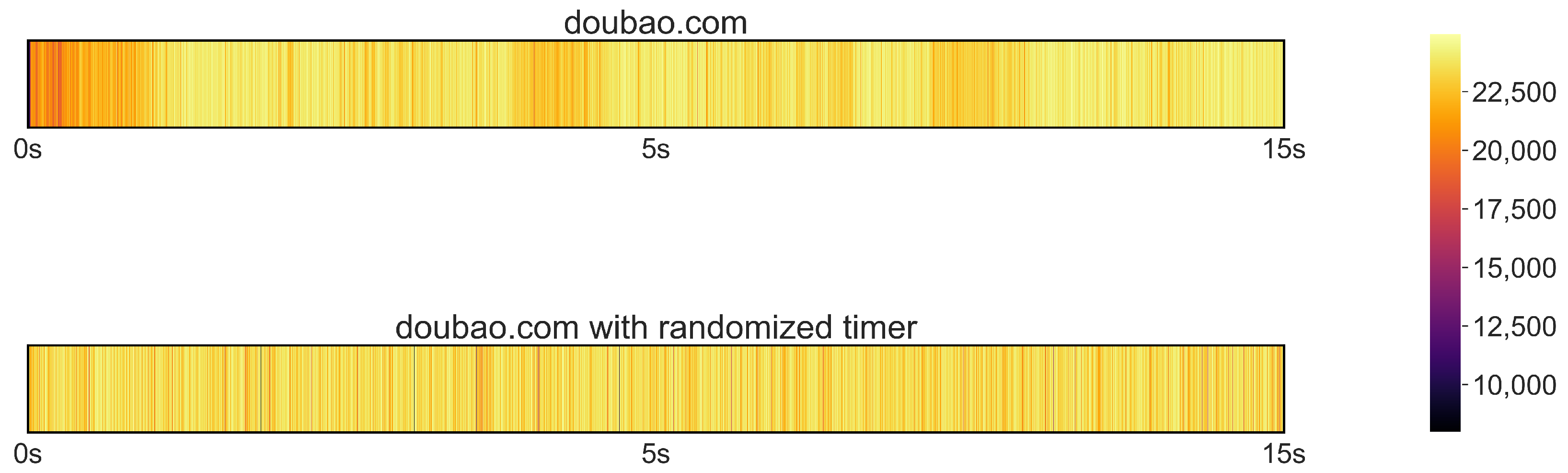
| Interrupt and packet-based LLM application attack (post-fusion) with randomized timer | 15.6% (92.1 ± 1.2%) |
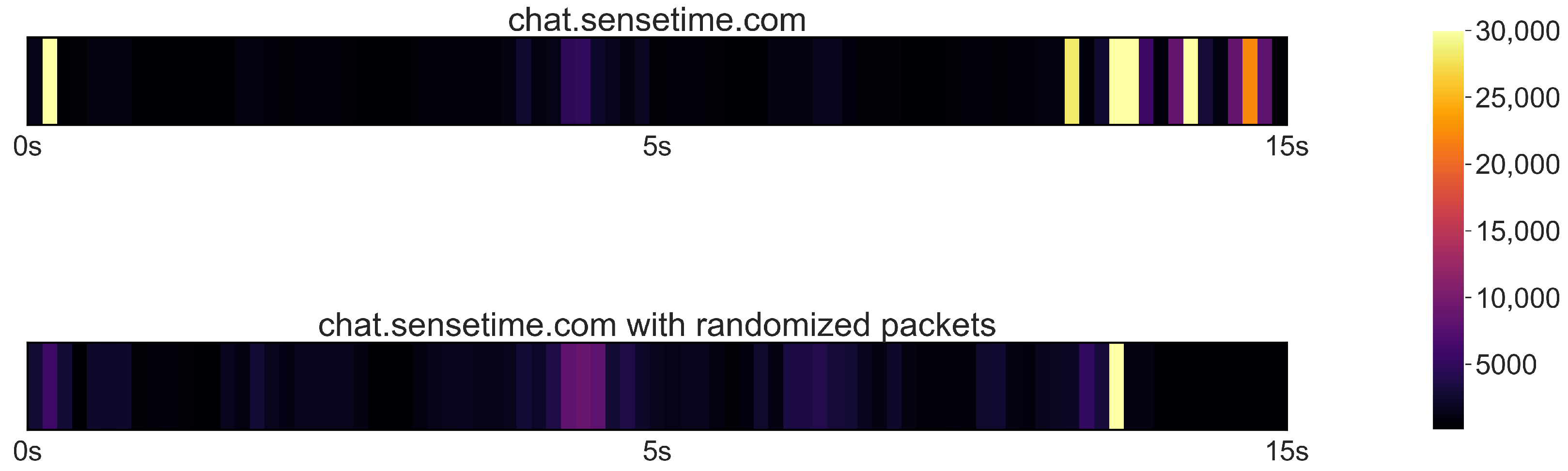
| Interrupt and packet-based LLM application attack (post-fusion) with randomized packets | 78.3 ± 1.8% |
| Interrupt and packet-based LLM application attack (post-fusion) with randomized timer and packets | 10.2% (81.6 ± 1.5%) |
| Interrupt and packet-based LLM application attack (prior to fusion) with randomized timer | 6.3 ± 3.1% |
| Interrupt and packet-based LLM application attack (prior to fusion) with randomized packets | 80.3 ± 1.6% |
| Interrupt and packet-based LLM application attack (prior to fusion) with randomized timer and packets | 3.2 ± 1.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, J.; Yang, H.; Wen, R. LLM-WFIN: A Fine-Grained Large Language Model (LLM)-Oriented Website Fingerprinting Attack via Fusing Interrupt Trace and Network Traffic. Electronics 2025, 14, 1263. https://doi.org/10.3390/electronics14071263
Jiao J, Yang H, Wen R. LLM-WFIN: A Fine-Grained Large Language Model (LLM)-Oriented Website Fingerprinting Attack via Fusing Interrupt Trace and Network Traffic. Electronics. 2025; 14(7):1263. https://doi.org/10.3390/electronics14071263
Chicago/Turabian StyleJiao, Jiajia, Hong Yang, and Ran Wen. 2025. "LLM-WFIN: A Fine-Grained Large Language Model (LLM)-Oriented Website Fingerprinting Attack via Fusing Interrupt Trace and Network Traffic" Electronics 14, no. 7: 1263. https://doi.org/10.3390/electronics14071263
APA StyleJiao, J., Yang, H., & Wen, R. (2025). LLM-WFIN: A Fine-Grained Large Language Model (LLM)-Oriented Website Fingerprinting Attack via Fusing Interrupt Trace and Network Traffic. Electronics, 14(7), 1263. https://doi.org/10.3390/electronics14071263