
HistoMoCo: Momentum Contrastive Learning Pre-Training on Unlabeled Histopathological Images for Oral Squamous Cell Carcinoma Detection

Abstract
1. Introduction
- 1.
- To address the distributional divergence between histopathological images and natural images, we developed HistoMoCo, a custom pre-training framework tailored for histopathological images. HistoMoCo aims to generate enhanced image representations and initialize models for OSCC detection in histopathological images.
- 2.
- We provide comprehensive evaluations and analyses, highlighting the benefits of self-supervised learning for histopathological image analysis; demonstrating the proposed HistoMoCo provides high-quality representations and transferable initializations for histopathological images interpretation and OSCC detection.
- 3.
- We release our code and pre-trained parameters for further research in histopathology or OSCC detection tasks.
2. Related Work
2.1. Detection of Oral Squamous Cell Carcinoma
2.2. Application of MoCo in Medical Image Analysis
3. Preliminaries
3.1. Contrastive Learning
3.2. Momentum Contrastive (MoCo) Learning
3.2.1. Dictionary as a Queue
3.2.2. Momentum Update
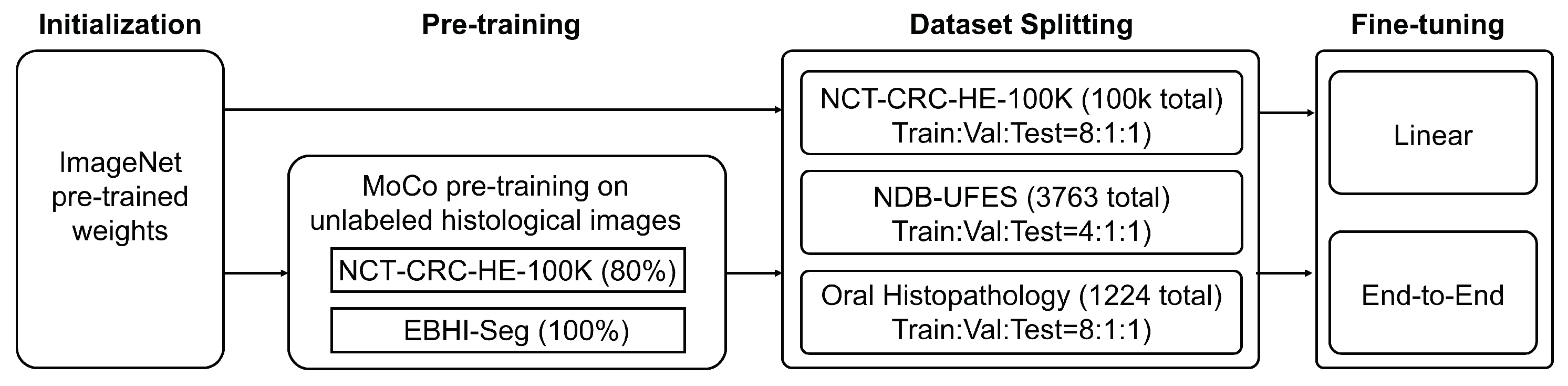
4. Methods
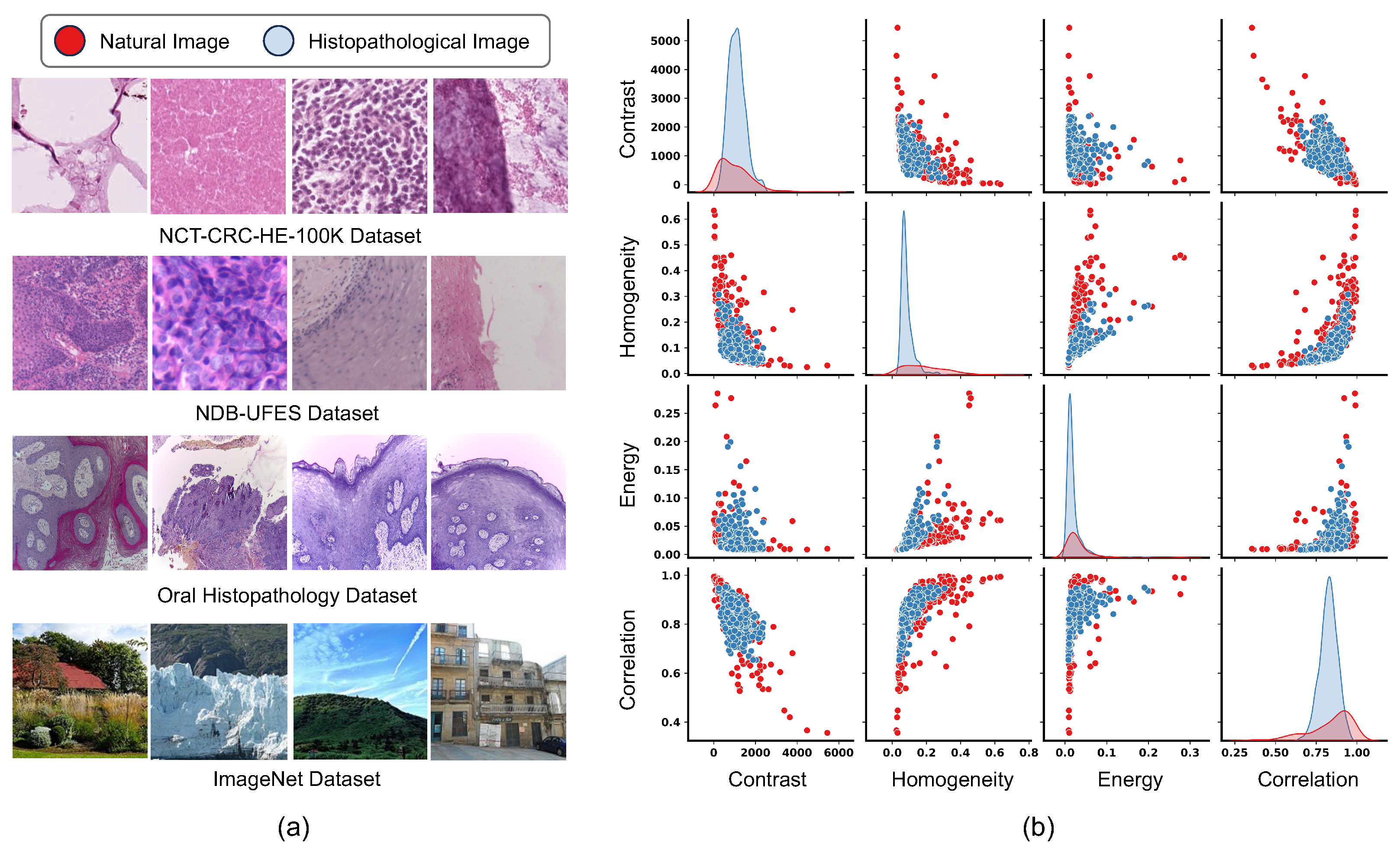
4.1. Histopathological Datasets and OSCC Detection Tasks
- 1.
- NCT-CRC-HE-100K [36] is a large pathology dataset comprising 100,000 H&E-stained histological images of human colorectal cancer and healthy tissues, extracted from 86 patients. It covers nine tissue types, with each image sized at 224 × 224 pixels.
- 2.
- EBHI-Seg [37] is a dataset for segmentation tasks, containing 2228 original H&E images and corresponding ground truth annotations, with each original H&E image also having a resolution of 224 × 224 pixels.
- 3.
- NDB-UFES [38] dataset (OSCC detection dataset) presents a total of 237 samples with histopathological images and sociodemographic and clinical data. Its subset comprises 3763 image patches for downstream classification tasks, with each patch classified as either OSCC or Normal, and sized at 512 × 512 pixels.
- 4.
- Oral Histopathology [39] (OSCC detection dataset) is composed of histopathological images of the normal epithelium of the oral cavity and images of OSCC. It includes two different magnifications, 100× and 400×, with a total of 290 samples classified as normal and 934 samples classified as OSCC, all with image sizes of 2048 × 1536.
4.2. HistoMoCo Pre-Training for Histopathological Interpretation
4.3. HistoMoCo Fine-Tuning
5. Experiments
5.1. Statistics of the Datasets
- NCT-CRC-HE-100K [36]: Nine tissue types: adipose, background, debris, lymphocytes, mucus, smooth muscle, normal colon mucosa, cancer-associated stroma, colorectal adenocarcinoma epithelium.
- EBHI-Seg [37]: Six tumor differentiation stages: normal, polyp, low-grade intraepithelial neoplasia, high-grade intraepithelial neoplasia, serrated adenoma, and adenocarcinoma.
- NDB-UFES [38]: Two types: oral squamous cell carcinoma, normal epithelium.
- Oral Histopathology [39]: Two types: oral squamous cell carcinoma, normal epithelium.
5.2. Experimental Setups
5.2.1. Baseline Models
- Scratch: models are initialized using Kaiming’s random initialization [44] and then fine-tuned on the target datasets.
- ImageNet: models are initialized with the officially released weights pre-trained on the ImageNet dataset and fine-tuned on the target datasets.
- MoCo: models are initialized with the officially released weights (https://github.com/facebookresearch/moco (accessed on 12 March 2025)) from [17] and fine-tuned on the target datasets.
5.2.2. Evaluation Metrics
5.3. Experimental Results
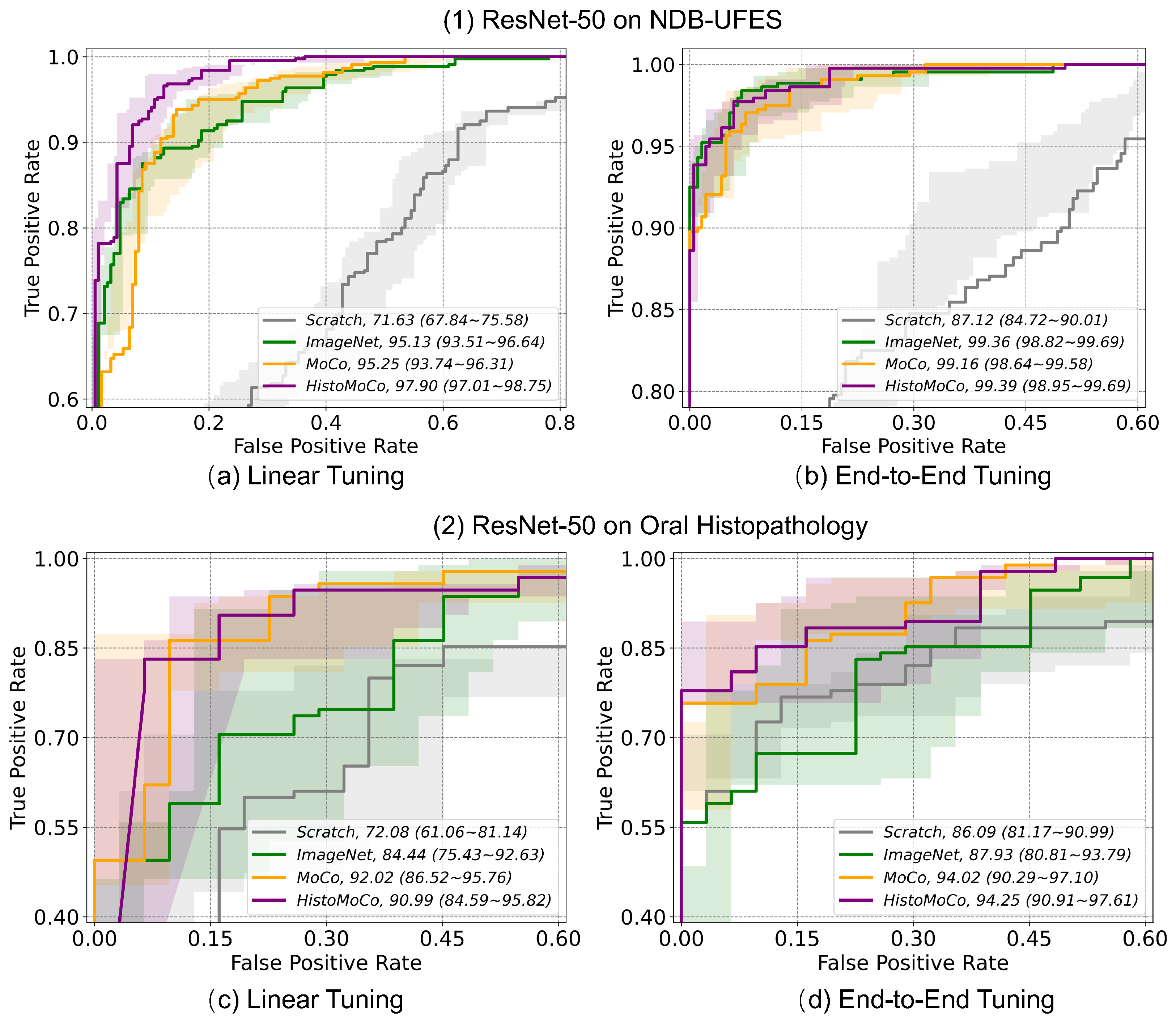
5.3.1. Transfer Performance of HistoMoCo Representations
5.3.2. Transfer Benefit of HistoMoCo on OSCC Detection Task
5.3.3. Performance Comparison with Similar Literature
5.3.4. Ablation Study
5.3.5. Sensitivity Analysis
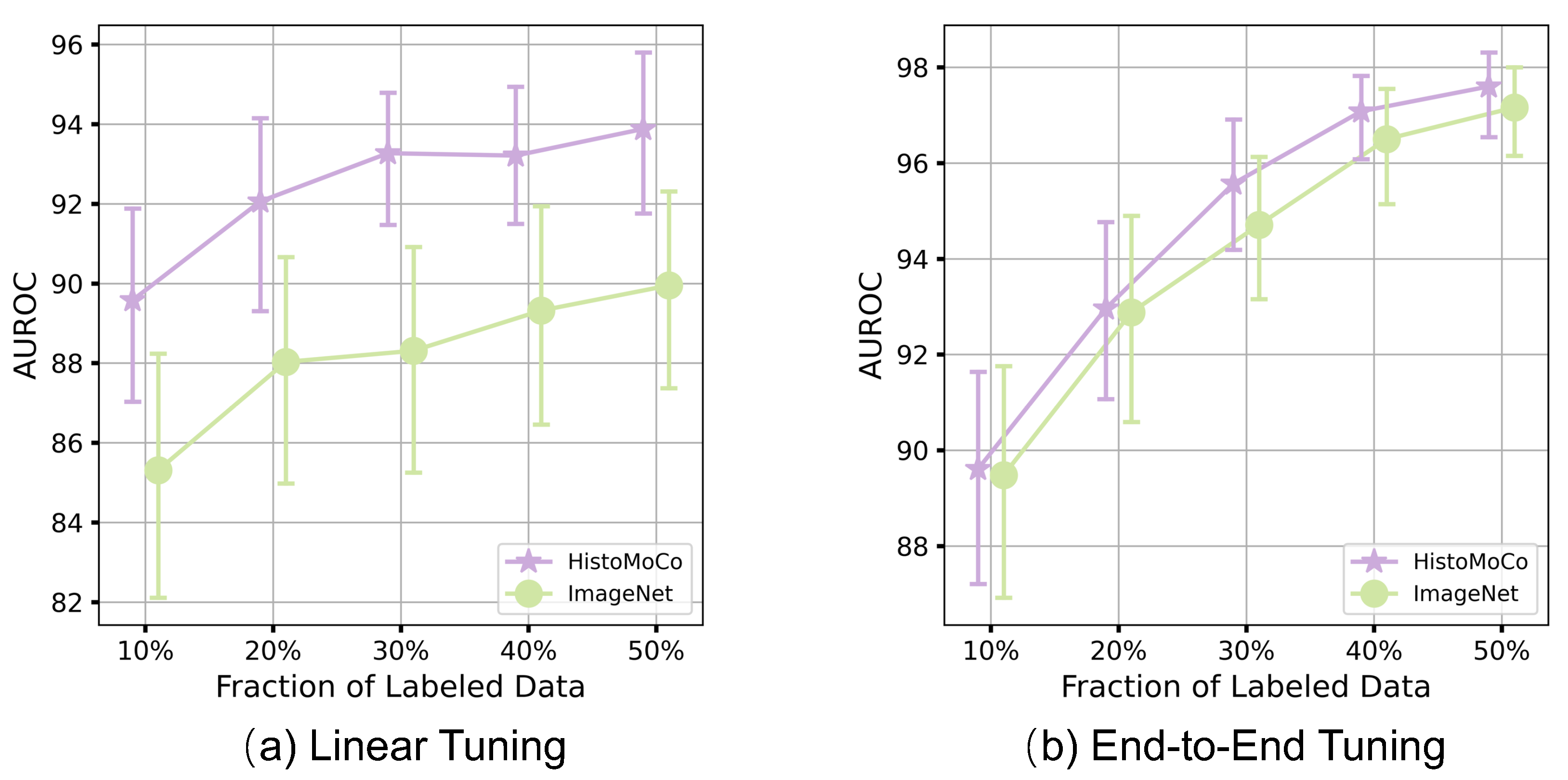
5.3.6. Robustness of HistoMoCo Against Data Insufficiency
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mohan, R.; Rama, A.; Raja, R.K.; Shaik, M.R.; Khan, M.; Shaik, B.; Rajinikanth, V. OralNet: Fused optimal deep features framework for oral squamous cell carcinoma detection. Biomolecules 2023, 13, 1090. [Google Scholar] [CrossRef] [PubMed]
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2020, 70, 313. [Google Scholar]
- Van der Laak, J.; Litjens, G.; Ciompi, F. Deep learning in histopathology: The path to the clinic. Nat. Med. 2021, 27, 775–784. [Google Scholar] [CrossRef] [PubMed]
- Coudray, N.; Ocampo, P.S.; Sakellaropoulos, T.; Narula, N.; Snuderl, M.; Fenyö, D.; Moreira, A.L.; Razavian, N.; Tsirigos, A. Classification and mutation prediction from non–small cell lung cancer histopathology images using deep learning. Nat. Med. 2018, 24, 1559–1567. [Google Scholar] [CrossRef]
- Fu, Q.; Chen, Y.; Li, Z.; Jing, Q.; Hu, C.; Liu, H.; Bao, J.; Hong, Y.; Shi, T.; Li, K.; et al. A deep learning algorithm for detection of oral cavity squamous cell carcinoma from photographic images: A retrospective study. EClinicalMedicine 2020, 27, 100558. [Google Scholar] [CrossRef]
- Albalawi, E.; Thakur, A.; Ramakrishna, M.T.; Bhatia Khan, S.; SankaraNarayanan, S.; Almarri, B.; Hadi, T.H. Oral squamous cell carcinoma detection using EfficientNet on histopathological images. Front. Med. 2024, 10, 1349336. [Google Scholar] [CrossRef]
- Gao, J.; Zhu, Y.; Wang, W.; Wang, Z.; Dong, G.; Tang, W.; Wang, H.; Wang, Y.; Harrison, E.M.; Ma, L. A comprehensive benchmark for COVID-19 predictive modeling using electronic health records in intensive care. Patterns 2024, 5, 100951. [Google Scholar] [CrossRef]
- Ma, L.; Zhang, C.; Gao, J.; Jiao, X.; Yu, Z.; Zhu, Y.; Wang, T.; Ma, X.; Wang, Y.; Tang, W.; et al. Mortality prediction with adaptive feature importance recalibration for peritoneal dialysis patients. Patterns 2023, 4, 100892. [Google Scholar] [CrossRef]
- Claudio Quiros, A.; Coudray, N.; Yeaton, A.; Yang, X.; Liu, B.; Le, H.; Chiriboga, L.; Karimkhan, A.; Narula, N.; Moore, D.A.; et al. Mapping the landscape of histomorphological cancer phenotypes using self-supervised learning on unannotated pathology slides. Nat. Commun. 2024, 15, 4596. [Google Scholar] [CrossRef]
- Ananthakrishnan, B.; Shaik, A.; Kumar, S.; Narendran, S.; Mattu, K.; Kavitha, M.S. Automated detection and classification of oral squamous cell carcinoma using deep neural networks. Diagnostics 2023, 13, 918. [Google Scholar] [CrossRef]
- Kavyashree, C.; Vimala, H.; Shreyas, J. Improving oral cancer detection using pretrained model. In Proceedings of the 2022 IEEE 6th Conference on Information and Communication Technology (CICT), Gwalior, India, 18–20 November 2022; pp. 1–5. [Google Scholar]
- Redie, D.K.; Bilgaiyan, S.; Sagnika, S. Oral cancer detection using transfer learning-based framework from histopathology images. J. Electron. Imaging 2023, 32, 053004. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Li, Z.; Tang, H.; Peng, Z.; Qi, G.J.; Tang, J. Knowledge-guided semantic transfer network for few-shot image recognition. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef]
- Liu, C.; Fu, Y.; Xu, C.; Yang, S.; Li, J.; Wang, C.; Zhang, L. Learning a few-shot embedding model with contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 8635–8643. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Misra, I.; Maaten, L.V.d. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6707–6717. [Google Scholar]
- Sowrirajan, H.; Yang, J.; Ng, A.Y.; Rajpurkar, P. Moco pretraining improves representation and transferability of chest X-ray models. In Proceedings of the Medical Imaging with Deep Learning, Lübeck, Germany, 7–9 July 2021; pp. 728–744. [Google Scholar]
- Liao, W.; Xiong, H.; Wang, Q.; Mo, Y.; Li, X.; Liu, Y.; Chen, Z.; Huang, S.; Dou, D. Muscle: Multi-task self-supervised continual learning to pre-train deep models for X-ray images of multiple body parts. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany; pp. 151–161. [Google Scholar]
- Liao, W.; Wang, Q.; Li, X.; Liu, Y.; Chen, Z.; Huang, S.; Dou, D.; Xu, Y.; Xiong, H. MTPret: Improving X-ray Image Analytics with Multi-Task Pre-training. IEEE Trans. Artif. Intell. 2024, 5, 4799–4812. [Google Scholar] [CrossRef]
- Chaitanya, K.; Erdil, E.; Karani, N.; Konukoglu, E. Contrastive learning of global and local features for medical image segmentation with limited annotations. Adv. Neural Inf. Process. Syst. 2020, 33, 12546–12558. [Google Scholar]
- Dufumier, B.; Gori, P.; Victor, J.; Grigis, A.; Wessa, M.; Brambilla, P.; Favre, P.; Polosan, M.; Mcdonald, C.; Piguet, C.M.; et al. Contrastive learning with continuous proxy meta-data for 3D MRI classification. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part II 24. Springer: Berlin/Heidelberg, Germany, 2021; pp. 58–68. [Google Scholar]
- Hollon, T.; Jiang, C.; Chowdury, A.; Nasir-Moin, M.; Kondepudi, A.; Aabedi, A.; Adapa, A.; Al-Holou, W.; Heth, J.; Sagher, O.; et al. Artificial-intelligence-based molecular classification of diffuse gliomas using rapid, label-free optical imaging. Nat. Med. 2023, 29, 828–832. [Google Scholar] [CrossRef]
- Nakhli, R.; Darbandsari, A.; Farahani, H.; Bashashati, A. Ccrl: Contrastive cell representation learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 397–407. [Google Scholar]
- Wu, H.; Wang, Z.; Song, Y.; Yang, L.; Qin, J. Cross-patch dense contrastive learning for semi-supervised segmentation of cellular nuclei in histopathologic images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 11666–11675. [Google Scholar]
- Yang, M.; Yang, Y.; Xie, C.; Ni, M.; Liu, J.; Yang, H.; Mu, F.; Wang, J. Contrastive learning enables rapid mapping to multimodal single-cell atlas of multimillion scale. Nat. Mach. Intell. 2022, 4, 696–709. [Google Scholar] [CrossRef]
- Li, J.; Zheng, Y.; Wu, K.; Shi, J.; Xie, F.; Jiang, Z. Lesion-aware contrastive representation learning for histopathology whole slide images analysis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 273–282. [Google Scholar]
- Wang, X.; Yang, S.; Zhang, J.; Wang, M.; Zhang, J.; Yang, W.; Huang, J.; Han, X. Transformer-based unsupervised contrastive learning for histopathological image classification. Med Image Anal. 2022, 81, 102559. [Google Scholar] [CrossRef]
- Chen, R.J.; Ding, T.; Lu, M.Y.; Williamson, D.F.; Jaume, G.; Song, A.H.; Chen, B.; Zhang, A.; Shao, D.; Shaban, M.; et al. Towards a general-purpose foundation model for computational pathology. Nat. Med. 2024, 30, 850–862. [Google Scholar] [CrossRef]
- Lu, M.Y.; Chen, B.; Williamson, D.F.; Chen, R.J.; Liang, I.; Ding, T.; Jaume, G.; Odintsov, I.; Le, L.P.; Gerber, G.; et al. A visual-language foundation model for computational pathology. Nat. Med. 2024, 30, 863–874. [Google Scholar] [CrossRef]
- Vorontsov, E.; Bozkurt, A.; Casson, A.; Shaikovski, G.; Zelechowski, M.; Liu, S.; Severson, K.; Zimmermann, E.; Hall, J.; Tenenholtz, N.; et al. Virchow: A million-slide digital pathology foundation model. arXiv 2023, arXiv:2309.07778. [Google Scholar]
- Xiang, J.; Wang, X.; Zhang, X.; Xi, Y.; Eweje, F.; Chen, Y.; Li, Y.; Bergstrom, C.; Gopaulchan, M.; Kim, T.; et al. A vision–language foundation model for precision oncology. Nature 2025, 638, 769–778. [Google Scholar] [CrossRef]
- Wu, L.; Fang, L.; He, X.; He, M.; Ma, J.; Zhong, Z. Querying labeled for unlabeled: Cross-image semantic consistency guided semi-supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8827–8844. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Xu, L.; Chen, D.Z.; Gao, H.; Wu, J. A robust shape-aware rib fracture detection and segmentation framework with contrastive learning. IEEE Trans. Multimed. 2023, 25, 1584–1591. [Google Scholar] [CrossRef]
- Kather, J.N.; Krisam, J.; Charoentong, P.; Luedde, T.; Herpel, E.; Weis, C.A.; Gaiser, T.; Marx, A.; Valous, N.A.; Ferber, D.; et al. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS Med. 2019, 16, e1002730. [Google Scholar] [CrossRef]
- Shi, L.; Li, X.; Hu, W.; Chen, H.; Chen, J.; Fan, Z.; Gao, M.; Jing, Y.; Lu, G.; Ma, D.; et al. EBHI-Seg: A Novel Enteroscope Biopsy Histopathological Haematoxylin and Eosin Image Dataset for Image Segmentation Tasks. arXiv 2022, arXiv:2212.00532. [Google Scholar] [CrossRef]
- Ribeiro-de Assis, M.C.F.; Soares, J.P.; de Lima, L.M.; de Barros, L.A.P.; Grão-Velloso, T.R.; Krohling, R.A.; Camisasca, D.R. NDB-UFES: An oral cancer and leukoplakia dataset composed of histopathological images and patient data. Data Brief 2023, 48, 109128. [Google Scholar] [CrossRef]
- Rahman, T.Y. A histopathological image repository of normal epithelium of oral cavity and oral squamous cell carcinoma. Mendeley Data 2019, 1. [Google Scholar] [CrossRef]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer learning for medical imaging. In Advances in Neural Information Processing Systems; Springer: Berlin/Heidelberg, Germany, 2019; Volume 32. [Google Scholar]
- Lu, S.; Chen, Y.; Chen, Y.; Li, P.; Sun, J.; Zheng, C.; Zou, Y.; Liang, B.; Li, M.; Jin, Q.; et al. General lightweight framework for vision foundation model supporting multi-task and multi-center medical image analysis. Nat. Commun. 2025, 16, 2097. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning representations by maximizing mutual information across views. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://dl.acm.org/doi/abs/10.5555/3454287.3455679 (accessed on 12 March 2025).
- Kornblith, S.; Shlens, J.; Le, Q.V. Do better imagenet models transfer better? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2661–2671. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | Task | Patients | Images | Targets |
|---|---|---|---|---|---|
| Used for pre-training of HistoMoCo | |||||
| NCT-CRC-HE-100K [36] | 224 × 224 | Classifaction | 86 | 100,000 | 9 |
| EBHI-Seg [37] | 224 × 224 | Segmentation | N/A | 2228 | 6 |
| Used for fine-tuning of HistoMoCo | |||||
| NDB-UFES [38] | 512 × 512 | Classifaction | 237 | 3763 | 2 |
| Oral Histopathology [39] | 2048 × 1536 | Classifaction | N/A | 1224 | 2 |
| Encoder | Fine-Tuning | Pre-Training | MaROC. | MiROC. | MaPRC. | MiPRC. | Acc. |
|---|---|---|---|---|---|---|---|
| ResNet-18 | Linear | Scratch | 0.888 | 0.887 | 0.508 | 0.453 | 0.562 |
| ImageNet | 0.986 | 0.982 | 0.920 | 0.895 | 0.919 | ||
| HistoMoCo | 0.982 | 0.984 | 0.890 | 0.898 | 0.985 | ||
| ResNet-18 | End-to-End | Scratch | 0.953 | 0.961 | 0.733 | 0.755 | 0.887 |
| ImageNet | 0.997 | 0.998 | 0.978 | 0.986 | 0.987 | ||
| HistoMoCo | 0.998 | 0.998 | 0.989 | 0.986 | 0.991 | ||
| ResNet-50 | Linear | Scratch | 0.794 | 0.572 | 0.379 | 0.142 | 0.105 |
| ImageNet | 0.992 | 0.987 | 0.951 | 0.926 | 0.912 | ||
| MoCo | 0.994 | 0.995 | 0.963 | 0.968 | 0.965 | ||
| HistoMoCo | 0.998 | 0.999 | 0.990 | 0.990 | 0.992 | ||
| ResNet-50 | End-to-End | Scratch | 0.970 | 0.967 | 0.824 | 0.817 | 0.879 |
| ImageNet | 0.999 | 0.999 | 0.993 | 0.995 | 0.991 | ||
| MoCo | 0.998 | 0.999 | 0.991 | 0.992 | 0.986 | ||
| HistoMoCo | 1.000 | 1.000 | 0.998 | 0.997 | 0.994 |
| Encoder | Fine-Tuning | Pre-Training | ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-18 | Linear | Scratch | 0.737 | 0.869 | 0.298 | 0.000 | 0.000 | 1.000 | 0.000 |
| ImageNet | 0.917 | 0.962 | 0.855 | 0.874 | 0.927 | 0.684 | 0.900 | ||
| HistoMoCo | 0.949 | 0.978 | 0.852 | 0.937 | 0.845 | 0.866 | 0.889 | ||
| ResNet-18 | End-to-End | Scratch | 0.864 | 0.936 | 0.812 | 0.843 | 0.900 | 0.604 | 0.870 |
| ImageNet | 0.983 | 0.993 | 0.928 | 0.938 | 0.961 | 0.850 | 0.949 | ||
| HistoMoCo | 0.991 | 0.996 | 0.947 | 0.953 | 0.973 | 0.888 | 0.963 | ||
| ResNet-50 | Linear | Scratch | 0.713 | 0.840 | 0.298 | 0.000 | 0.000 | 1.000 | 0.000 |
| ImageNet | 0.951 | 0.974 | 0.887 | 0.928 | 0.909 | 0.834 | 0.918 | ||
| MoCo | 0.952 | 0.979 | 0.893 | 0.919 | 0.930 | 0.807 | 0.924 | ||
| HistoMoCo | 0.979 | 0.990 | 0.935 | 0.935 | 0.948 | 0.904 | 0.953 | ||
| ResNet-50 | End-to-End | Scratch | 0.870 | 0.941 | 0.802 | 0.850 | 0.873 | 0.636 | 0.861 |
| ImageNet | 0.993 | 0.997 | 0.957 | 0.966 | 0.973 | 0.920 | 0.969 | ||
| MoCo | 0.991 | 0.996 | 0.951 | 0.957 | 0.973 | 0.898 | 0.965 | ||
| HistoMoCo | 0.994 | 0.997 | 0.957 | 0.964 | 0.975 | 0.914 | 0.969 |
| Encoder | Fine-Tuning | Pre-Training | ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-18 | Linear | Scratch | 0.728 | 0.888 | 0.738 | 0.869 | 0.768 | 0.645 | 0.816 |
| ImageNet | 0.834 | 0.939 | 0.770 | 0.811 | 0.905 | 0.355 | 0.856 | ||
| HistoMoCo | 0.855 | 0.954 | 0.794 | 0.805 | 0.958 | 0.290 | 0.875 | ||
| ResNet-18 | End-to-End | Scratch | 0.862 | 0.956 | 0.802 | 0.812 | 0.958 | 0.323 | 0.879 |
| ImageNet | 0.924 | 0.977 | 0.857 | 0.889 | 0.926 | 0.645 | 0.907 | ||
| HistoMoCo | 0.948 | 0.984 | 0.865 | 0.906 | 0.916 | 0.710 | 0.911 | ||
| ResNet-50 | Linear | Scratch | 0.721 | 0.876 | 0.246 | 0.000 | 0.000 | 1.000 | 0.000 |
| ImageNet | 0.848 | 0.945 | 0.770 | 0.875 | 0.811 | 0.645 | 0.842 | ||
| MoCo | 0.921 | 0.973 | 0.778 | 0.772 | 1.000 | 0.097 | 0.872 | ||
| HistoMoCo | 0.915 | 0.969 | 0.810 | 0.832 | 0.937 | 0.419 | 0.881 | ||
| ResNet-50 | End-to-End | Scratch | 0.859 | 0.956 | 0.786 | 0.827 | 0.905 | 0.419 | 0.864 |
| ImageNet | 0.882 | 0.958 | 0.825 | 0.876 | 0.895 | 0.613 | 0.885 | ||
| MoCo | 0.939 | 0.980 | 0.881 | 0.892 | 0.958 | 0.645 | 0.924 | ||
| HistoMoCo | 0.941 | 0.982 | 0.873 | 0.883 | 0.958 | 0.613 | 0.919 |
| Methods | Encoder | Param. | ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 |
|---|---|---|---|---|---|---|---|---|---|
| Linear Tuning | |||||||||
| UNI2-h [30] | ViT-h/14-reg8 | 630.76M | 0.982 | 0.992 | 0.936 | 0.926 | 0.972 | 0.902 | 0.948 |
| CONCH [31] | ViT-b/16 | 86.57M | 0.976 | 0.984 | 0.930 | 0.925 | 0.963 | 0.902 | 0.944 |
| DINO [47] | ResNet-50 | 25.56M | 0.970 | 0.985 | 0.917 | 0.960 | 0.920 | 0.909 | 0.940 |
| SwAV [16] | ResNet-50 | 25.56M | 0.958 | 0.981 | 0.896 | 0.896 | 0.964 | 0.738 | 0.929 |
| HistoMoCo | ResNet-50 | 25.56M | 0.979 | 0.990 | 0.935 | 0.935 | 0.948 | 0.904 | 0.953 |
| End-to-End Tuning | |||||||||
| DINO [47] | ResNet-50 | 25.56M | 0.975 | 0.988 | 0.925 | 0.970 | 0.930 | 0.920 | 0.940 |
| SwAV [16] | ResNet-50 | 25.56M | 0.962 | 0.986 | 0.905 | 0.940 | 0.925 | 0.850 | 0.930 |
| HistoMoCo | ResNet-50 | 25.56M | 0.994 | 0.997 | 0.957 | 0.964 | 0.975 | 0.914 | 0.969 |
| Methods | ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 |
|---|---|---|---|---|---|---|---|
| Linear Tuning | |||||||
| HistoMoCow/o NCT-CRC-HE-100K | 0.946 | 0.973 | 0.851 | 0.937 | 0.845 | 0.866 | 0.889 |
| HistoMoCo | 0.979 | 0.990 | 0.935 | 0.935 | 0.948 | 0.904 | 0.953 |
| End-to-End Tuning | |||||||
| HistoMoCow/o NCT-CRC-HE-100K | 0.983 | 0.990 | 0.945 | 0.953 | 0.973 | 0.888 | 0.963 |
| HistoMoCo | 0.994 | 0.997 | 0.957 | 0.964 | 0.975 | 0.914 | 0.969 |
| ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 | |
|---|---|---|---|---|---|---|---|
| Linear Tuning | |||||||
| moco-m = 0.999 | 0.979 | 0.990 | 0.935 | 0.935 | 0.948 | 0.904 | 0.953 |
| moco-m = 0.9 | 0.971 | 0.987 | 0.928 | 0.948 | 0.950 | 0.877 | 0.949 |
| moco-m = 0.5 | 0.599 | 0.734 | 0.703 | 0.703 | 1.000 | 0.005 | 0.826 |
| moco-m = 0.1 | 0.646 | 0.785 | 0.705 | 0.716 | 0.961 | 0.102 | 0.821 |
| End-to-End Tuning | |||||||
| moco-m = 0.999 | 0.994 | 0.997 | 0.957 | 0.964 | 0.975 | 0.914 | 0.969 |
| moco-m = 0.9 | 0.996 | 0.998 | 0.968 | 0.973 | 0.982 | 0.936 | 0.977 |
| moco-m = 0.5 | 0.745 | 0.875 | 0.742 | 0.777 | 0.886 | 0.401 | 0.828 |
| moco-m = 0.1 | 0.764 | 0.889 | 0.751 | 0.778 | 0.902 | 0.396 | 0.836 |
| ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 | |
|---|---|---|---|---|---|---|---|
| Linear Tuning | |||||||
| moco-k = 216 | 0.979 | 0.990 | 0.935 | 0.935 | 0.948 | 0.904 | 0.953 |
| moco-k = 214 | 0.983 | 0.993 | 0.951 | 0.979 | 0.950 | 0.952 | 0.964 |
| moco-k = 212 | 0.977 | 0.989 | 0.930 | 0.956 | 0.943 | 0.898 | 0.950 |
| moco-k = 210 | 0.982 | 0.992 | 0.933 | 0.959 | 0.945 | 0.904 | 0.952 |
| End-to-End Tuning | |||||||
| moco-k = 216 | 0.994 | 0.997 | 0.957 | 0.964 | 0.975 | 0.914 | 0.969 |
| moco-k = 214 | 0.994 | 0.998 | 0.962 | 0.964 | 0.982 | 0.914 | 0.973 |
| moco-k = 212 | 0.994 | 0.998 | 0.96 | 0.973 | 0.97 | 0.936 | 0.972 |
| moco-k = 210 | 0.994 | 0.998 | 0.965 | 0.973 | 0.977 | 0.936 | 0.975 |
| ROC. | PRC. | Acc. | Pre. | Sen. | Spe. | F1 | |
|---|---|---|---|---|---|---|---|
| Linear Tuning | |||||||
| moco-dim = 64 | 0.981 | 0.992 | 0.936 | 0.957 | 0.952 | 0.898 | 0.954 |
| moco-dim = 128 | 0.979 | 0.990 | 0.935 | 0.935 | 0.948 | 0.904 | 0.953 |
| moco-dim = 256 | 0.981 | 0.992 | 0.936 | 0.959 | 0.950 | 0.904 | 0.954 |
| End-to-End Tuning | |||||||
| moco-dim = 64 | 0.995 | 0.998 | 0.963 | 0.964 | 0.984 | 0.914 | 0.974 |
| moco-dim = 128 | 0.994 | 0.997 | 0.957 | 0.964 | 0.975 | 0.914 | 0.969 |
| moco-dim = 256 | 0.994 | 0.998 | 0.963 | 0.979 | 0.968 | 0.952 | 0.974 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, W.; He, Y.; Jiang, B.; Zhao, J.; Gao, M.; Zhang, X. HistoMoCo: Momentum Contrastive Learning Pre-Training on Unlabeled Histopathological Images for Oral Squamous Cell Carcinoma Detection. Electronics 2025, 14, 1252. https://doi.org/10.3390/electronics14071252
Liao W, He Y, Jiang B, Zhao J, Gao M, Zhang X. HistoMoCo: Momentum Contrastive Learning Pre-Training on Unlabeled Histopathological Images for Oral Squamous Cell Carcinoma Detection. Electronics. 2025; 14(7):1252. https://doi.org/10.3390/electronics14071252
Chicago/Turabian StyleLiao, Weibin, Yifan He, Bowen Jiang, Junfeng Zhao, Min Gao, and Xiaoyun Zhang. 2025. "HistoMoCo: Momentum Contrastive Learning Pre-Training on Unlabeled Histopathological Images for Oral Squamous Cell Carcinoma Detection" Electronics 14, no. 7: 1252. https://doi.org/10.3390/electronics14071252
APA StyleLiao, W., He, Y., Jiang, B., Zhao, J., Gao, M., & Zhang, X. (2025). HistoMoCo: Momentum Contrastive Learning Pre-Training on Unlabeled Histopathological Images for Oral Squamous Cell Carcinoma Detection. Electronics, 14(7), 1252. https://doi.org/10.3390/electronics14071252