
Adaptive Microservice Architecture and Service Orchestration Considering Resource Balance to Support Multi-User Cloud VR



Abstract
1. Introduction
1.1. Motivations
1.2. Contributions
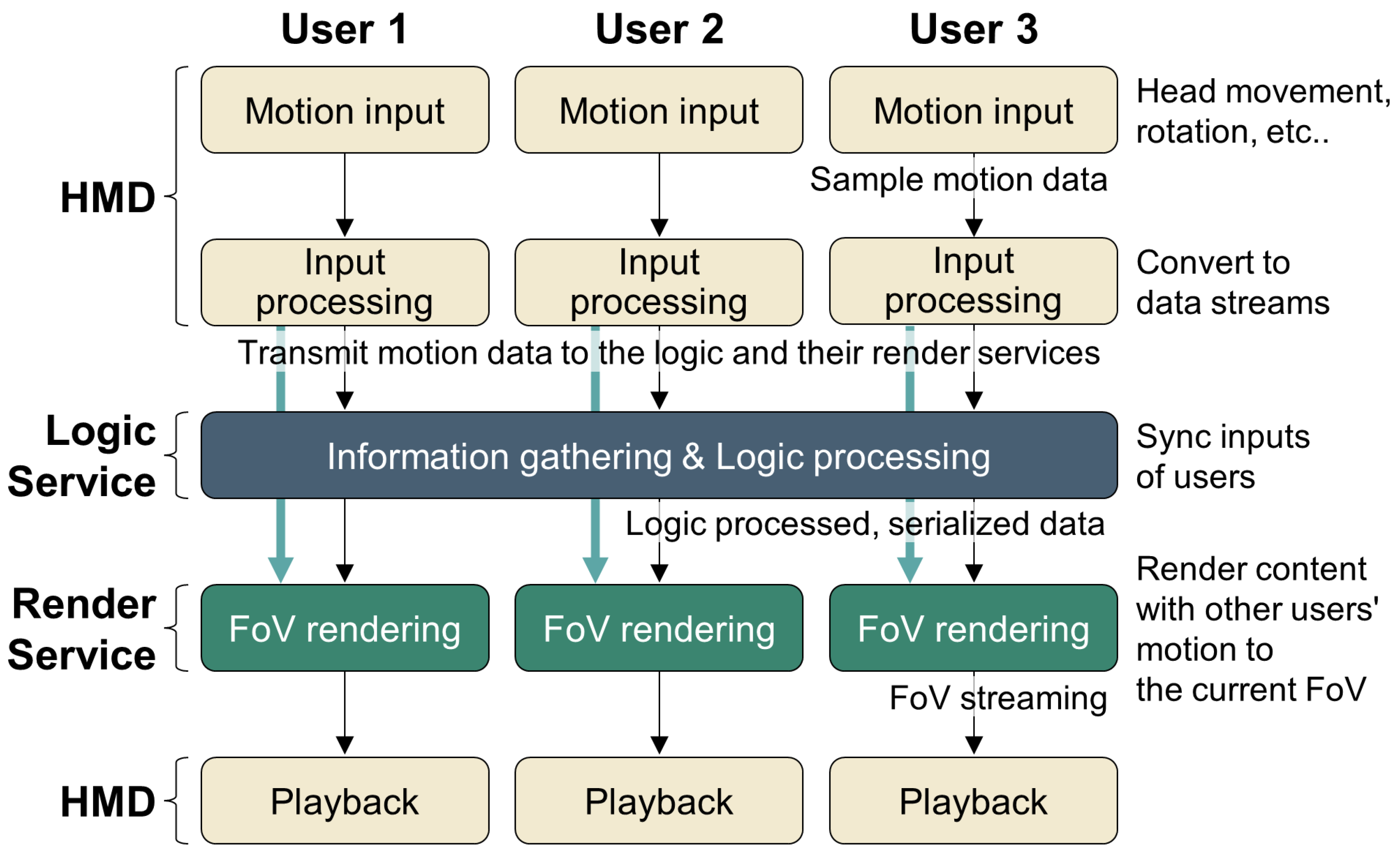
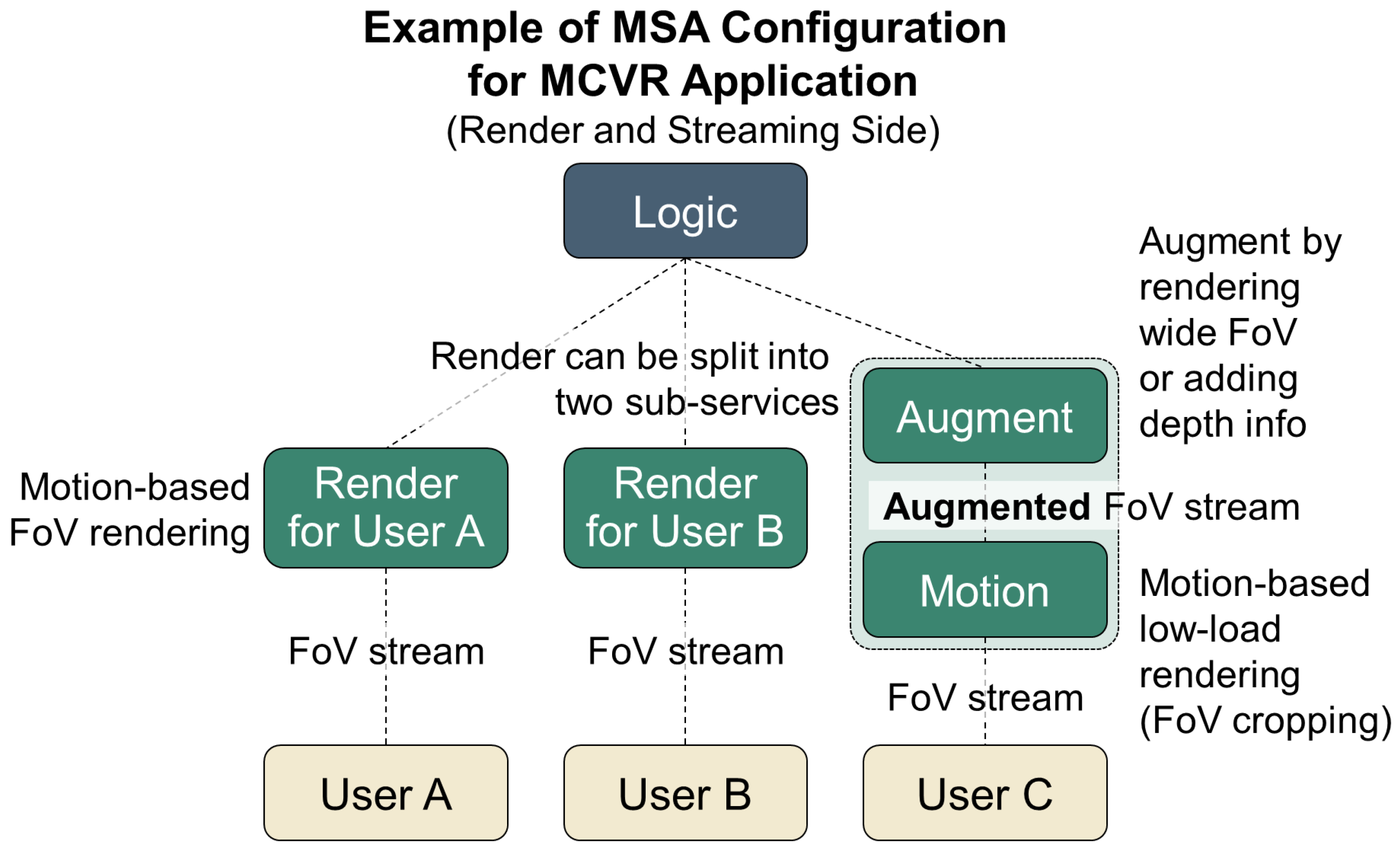
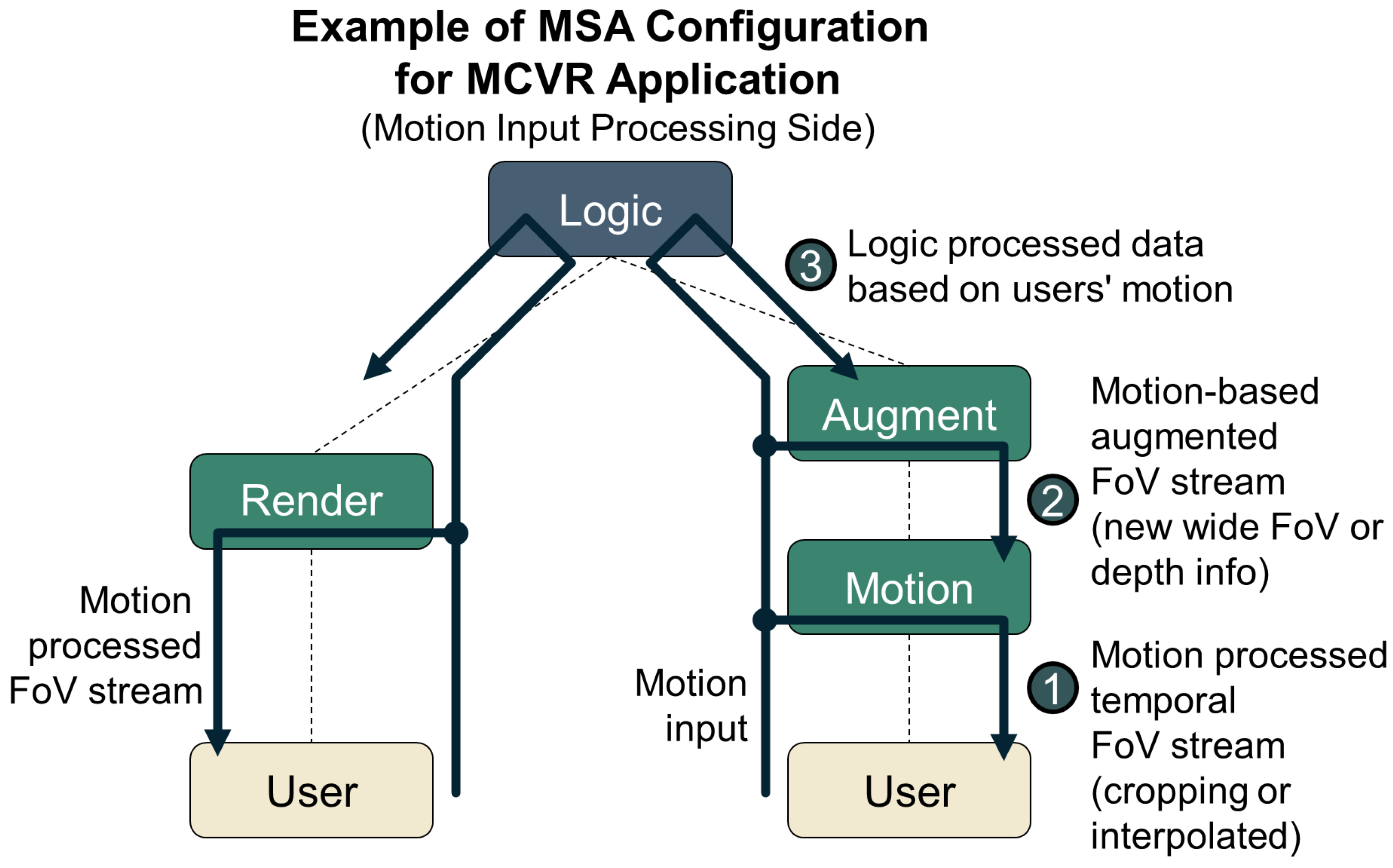
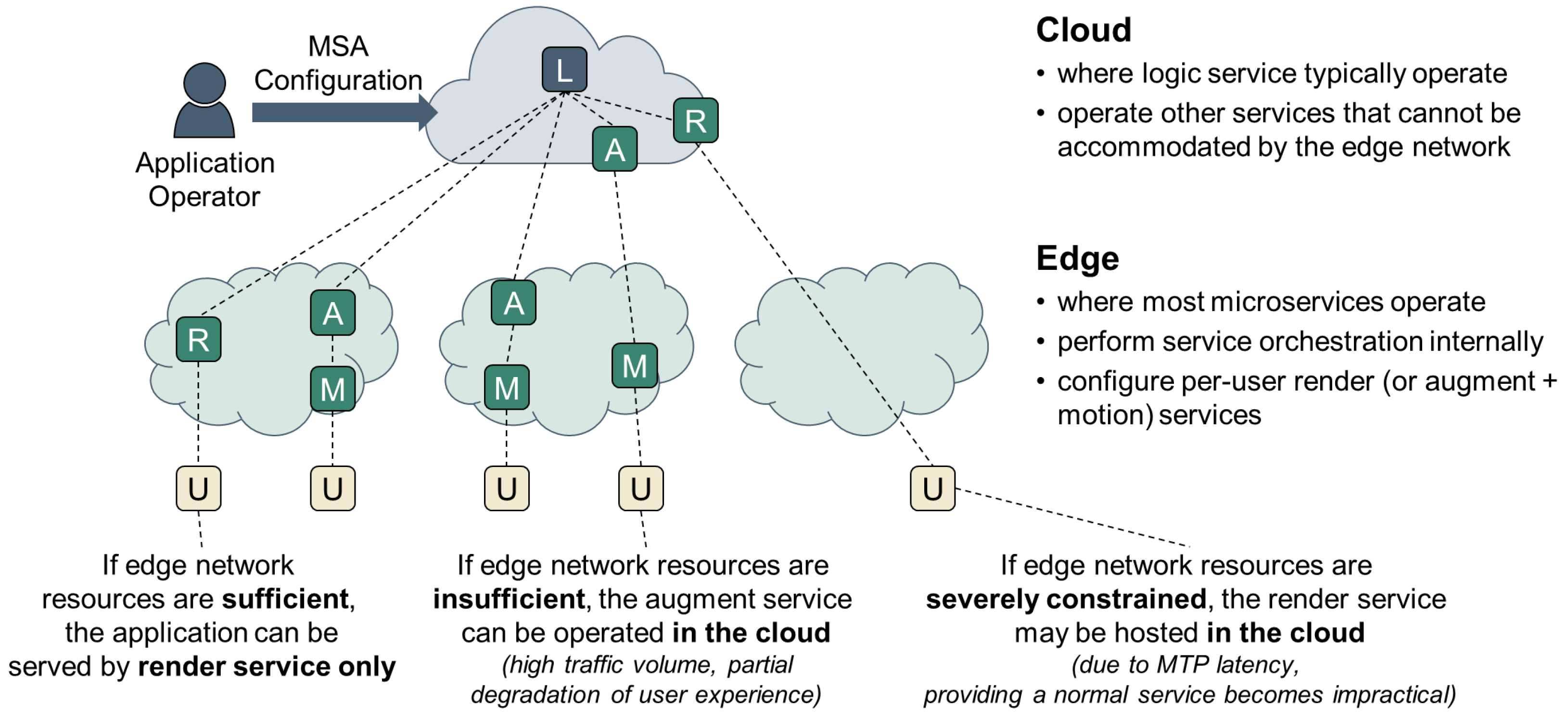
- To address scalability issues when providing MCVR through a single server, a design based on multiple microservices operating as individual units can be considered. The logic processing in MCVR includes handling core elements such as content logic, physics engine, and AI computations. This requires data collection and synchronization for all user inputs at a single point. The proposed method configures this as a single Logic service per application, primarily operating in the cloud. In addition, the function of rendering the Field of View (FoV) screen by processing user-specific motion data and streaming it is configured as a user-specific Render service operating in the edge network.
- Render services generate high volumes of traffic for users and have significant computing requirements. If such render services cannot be deployed within the edge network where the user is connected due to the resource constraints of edge devices, it will be impossible to meet the MTP latency threshold. In such situations, it is necessary to split the render service into two smaller services, Motion and Augment services. Motion services handle tasks such as video cropping or applying motion parallax based on depth information, which involves relatively low computational loads and can be placed closer to the user. Augment services transmit data to the motion service, which includes render data for a wide FoV screen or depth information for individual objects. This allows the motion service to operate independently.
- The MSA configuration of MCVR considered in this study consists of a single logic service and user-specific render or augment and motion services. Render services or augment and motion services can be deployed anywhere within the edge network as long as they meet the MTP latency threshold for the corresponding user without having a direct effect. We focus on the generated traffic between users and these services, and we perform service orchestration to minimize this traffic. Simultaneously, to maximize the number of services deployed within the edge network, resource balance is considered proportionally according to the situation.
2. Related Works
3. Adaptive MSA Configuration and Service Orchestration for Cloud–Edge Continuum-Based MCVR Offerings
3.1. Adaptive Configuration of Microservices for MCVR
3.2. Service Orchestration for MSA-Based MCVR to Satisfy MTP Latency Thresholds and Reduce Network Congestion
| Algorithm 1 PlanDeploymentStrategies |
| 1: the weight factor of the resource balance for calculating strategy selection metrics, initialized as 0 2: the priority queue for strategies 3: the list of planned strategies, which contains as many strategies as users 4: CreateStrategies() 5: 6: while do 7: clear the collections P and 8: for all do 9: 10: .enqueue() 11: end for 12: while do 13: 14: if has planned strategy then continue 15: 16: 17: 18: if then 19: 20: 21: end if 22: if then 23: P.add() 24: 25: if then 26: update associated with or 27: end if 28: end while 29: if all users have planned strategies then break 30: else 31: end while 32: 33: ProcessUsersWithoutStrategy() 34: DeployLogicServices() 35: 36: Output: 37: return P |
| Algorithm 2 CreateStrategies |
| 1: the list of strategies 2: for all do 3: the edge node to which the user u is directly connected, 4: the render service corresponding to the user u 5: for all do 6: the deployment strategy for the render service for the user u 7: 8: 9: if then continue 10: 11: the expected traffic from to by 12: 13: .add() 14: .add(CreateAltenativeStrategies()) 15: end for 16: end for 17: 18: Output: 19: return |
| Algorithm 3 CreateAlternativeStrategies |
| 1: Input: 2: the node directly connected to user u 3: the node that the render service is currently being considered for deployment 4: 5: the list of alternative strategies 6: 7: the augment service for the user u, paired with 8: the motion service for the user u, paired with 9: 10: 11: 12: 13: for all do 14: the network distance between and 15: the network distance between and 16: if then continue 17: 18: the deployment strategy for the augment service and the motion service for the user u 19: 20: 21: if then continue 22: 23: 24: the expected traffic from to by 25: the expected traffic from to by 26: 27: 28: .add() 29: end for 30: 31: Output: 30: return |
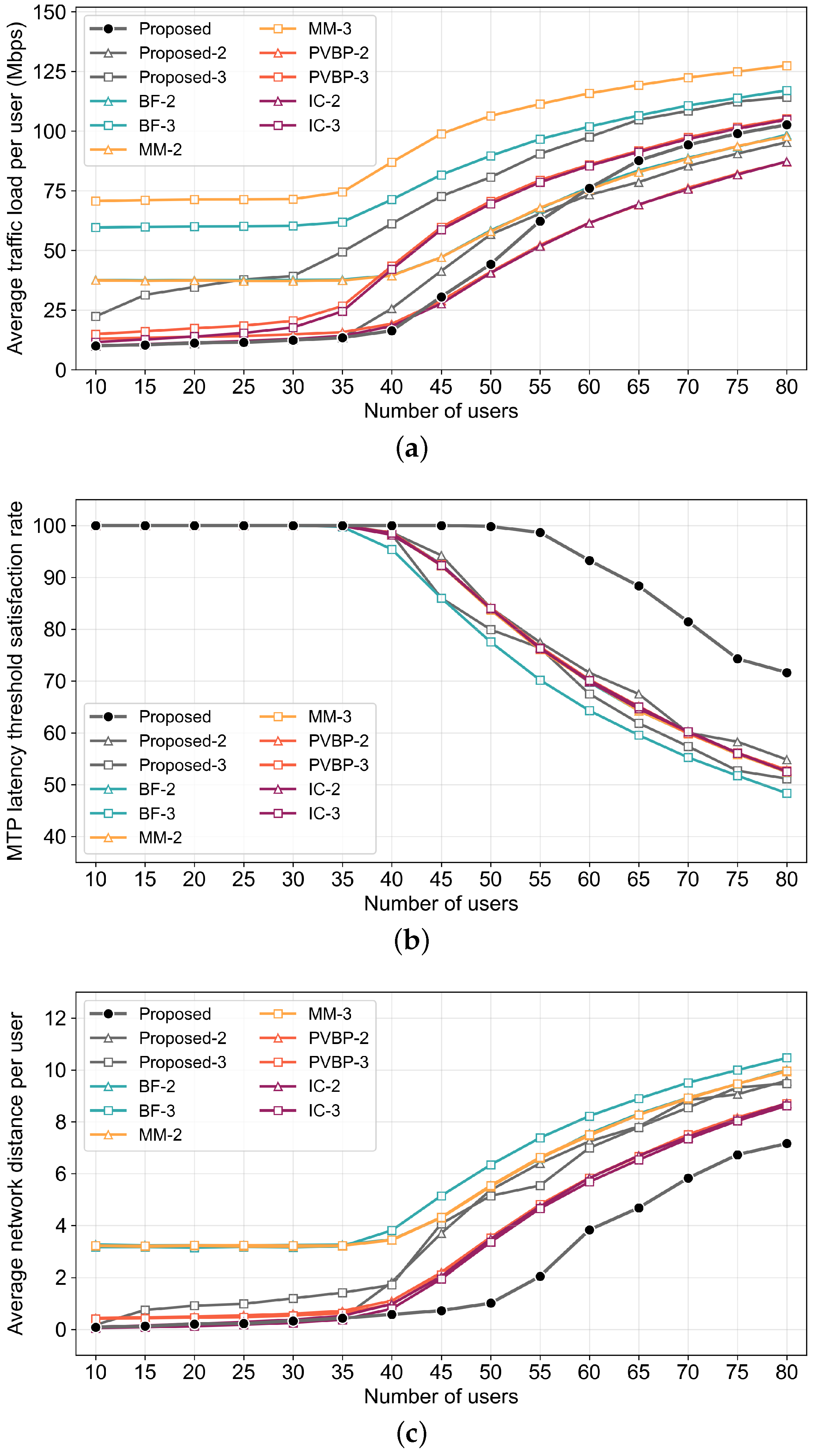
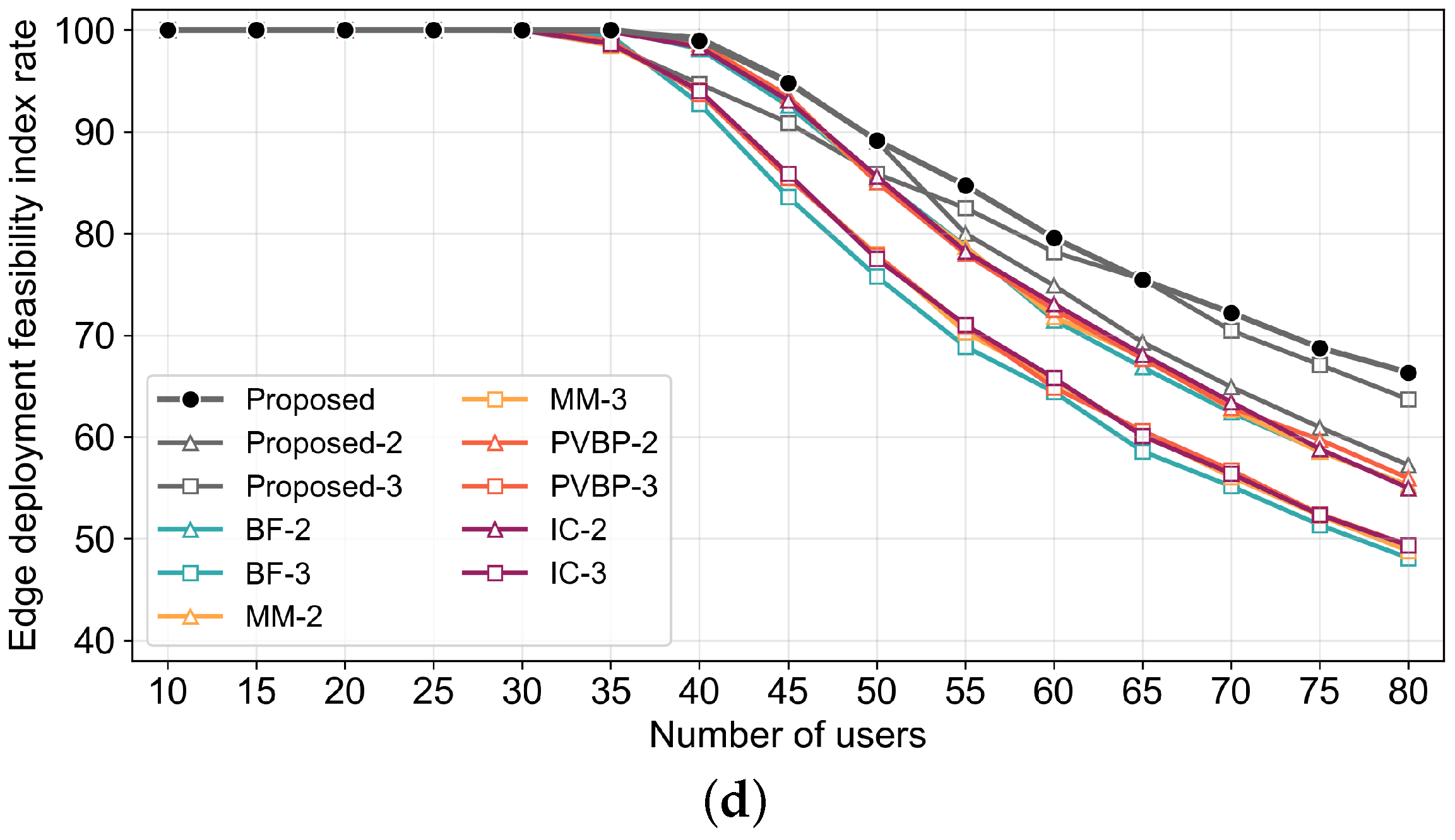
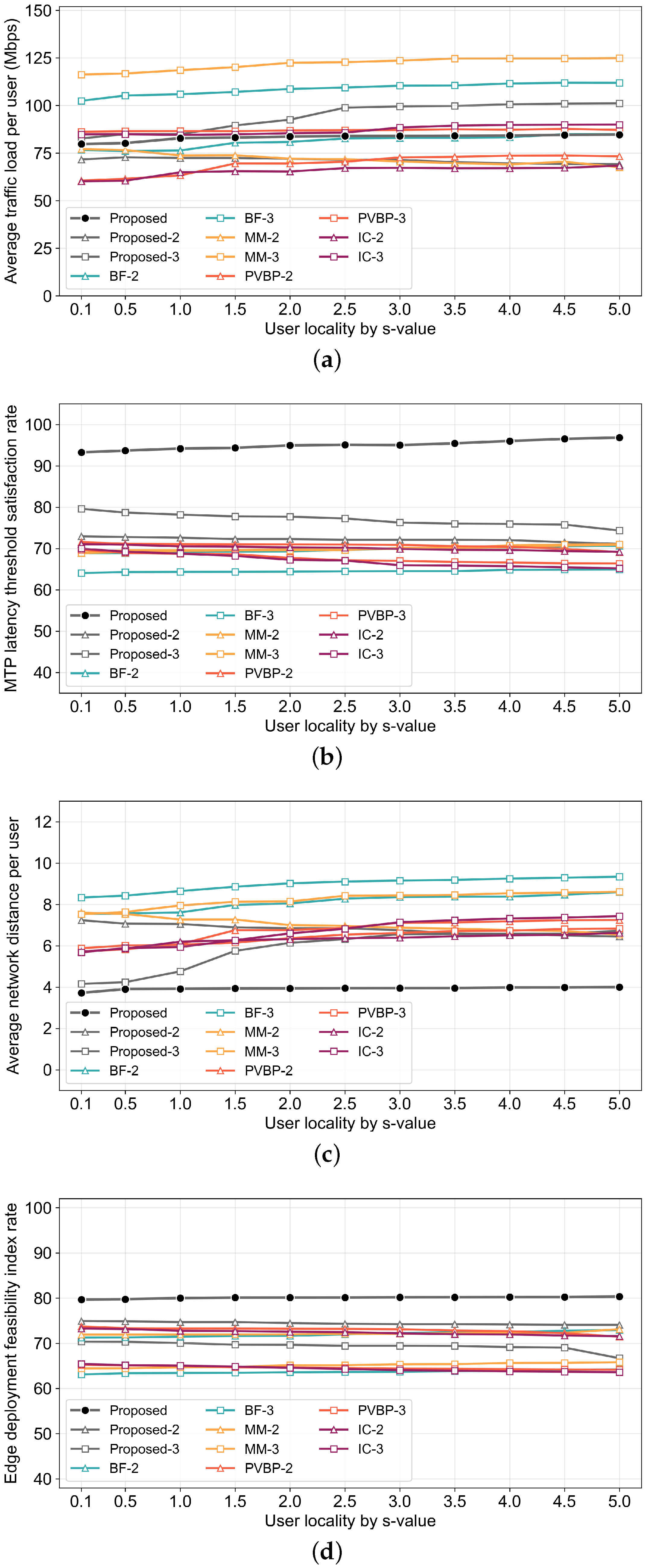
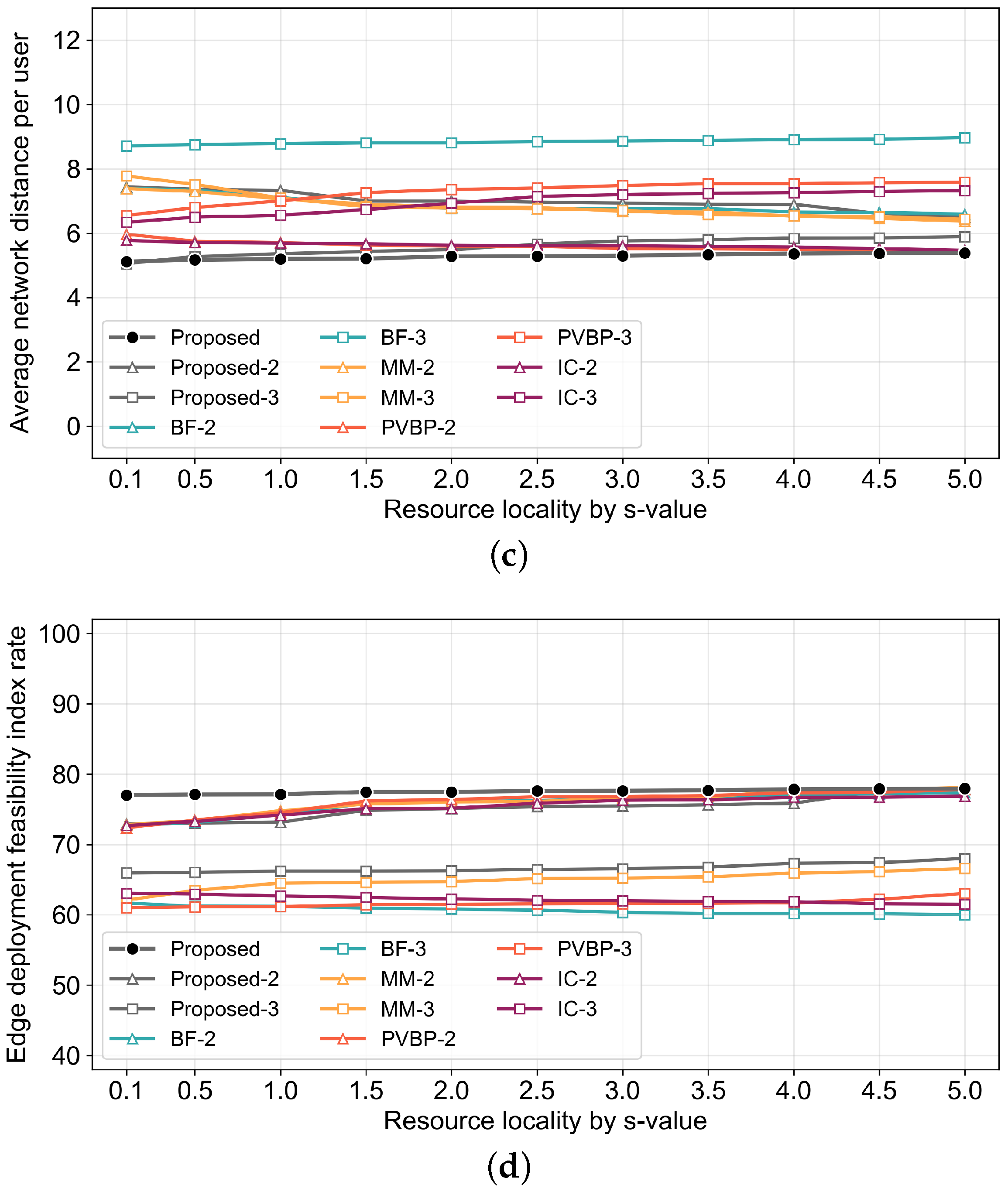
4. Simulation Results
4.1. Environmental Setup
- Traffic Load per User: The average network traffic generated during service provision for each user is calculated as the arithmetic mean of the sum of traffic on the paths between microservices and between each microservice and its corresponding user.
- MTP Latency Threshold Satisfaction Rate: The rate of users satisfying the MTP latency threshold is represented by the percentage of users for whom the render or motion service is deployed within the edge network.
- Network Distance per User: This metric represents the path length between the node where the render or motion service operates for the user and the user node, which indicates how close each management method can deploy services to the user. It indirectly reflects the satisfaction rate of the MTP latency threshold and the degree of network congestion management.
- Edge Deployment Feasibility Index: This metric represents the rate of microservices that can be deployed within a constrained edge network, which indicates the percentage of planned strategy services that are deployed within the edge network.
4.2. Simulation Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Freina, L.; Ott, M. A literature review on immersive virtual reality in education: State of the art and perspectives. In Proceedings of the International Scientific CONFERENCE Elearning and Software for Education, Bucharest, Romania, 25–26 April 2015; p. 10-1007. [Google Scholar]
- Moglia, A.; Ferrari, V.; Morelli, L.; Ferrari, M.; Mosca, F.; Cuschieri, A. A systematic review of virtual reality simulators for robot-assisted surgery. Eur. Urol. 2016, 69, 1065–1080. [Google Scholar] [CrossRef] [PubMed]
- Schmoll, R.S.; Pandi, S.; Braun, P.J.; Fitzek, F.H. Demonstration of VR/AR offloading to mobile edge cloud for low latency 5G gaming application. In Proceedings of the 2018 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–3. [Google Scholar]
- Wohlgenannt, I.; Simons, A.; Stieglitz, S. Virtual reality. Bus. Inf. Syst. Eng. 2020, 62, 455–461. [Google Scholar] [CrossRef]
- Zhao, S.; Abou-zeid, H.; Atawia, R.; Manjunath, Y.S.K.; Sediq, A.B.; Zhang, X.P. Virtual reality gaming on the cloud: A reality check. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Zou, W.; Feng, S.; Mao, X.; Yang, F.; Ma, Z. Enhancing quality of experience for cloud virtual reality gaming: An object-aware video encoding. In Proceedings of the 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, H.; Zhang, J.; Yin, X.; Zhou, K.; Pan, Z.; El Rhalibi, A. Cloud-to-end rendering and storage management for virtual reality in experimental education. Virtual Real. Intell. Hardw. 2020, 2, 368–380. [Google Scholar]
- Shea, R.; Liu, J.; Ngai, E.C.H.; Cui, Y. Cloud gaming: Architecture and performance. IEEE Netw. 2013, 27, 16–21. [Google Scholar]
- Kim, H.K.; Park, J.; Choi, Y.; Choe, M. Virtual reality sickness questionnaire (VRSQ): Motion sickness measurement index in a virtual reality environment. Appl. Ergon. 2018, 69, 66–73. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar]
- Lähderanta, T.; Leppänen, T.; Ruha, L.; Lovén, L.; Harjula, E.; Ylianttila, M.; Riekki, J.; Sillanpää, M.J. Edge computing server placement with capacitated location allocation. J. Parallel Distrib. Comput. 2021, 153, 130–149. [Google Scholar]
- Wang, L.; Jiao, L.; He, T.; Li, J.; Bal, H. Service placement for collaborative edge applications. IEEE/ACM Trans. Netw. 2020, 29, 34–47. [Google Scholar]
- Ning, Z.; Dong, P.; Wang, X.; Wang, S.; Hu, X.; Guo, S.; Qiu, T.; Hu, B.; Kwok, R.Y. Distributed and dynamic service placement in pervasive edge computing networks. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1277–1292. [Google Scholar]
- He, S.; Lyu, X.; Ni, W.; Tian, H.; Liu, R.P.; Hossain, E. Virtual service placement for edge computing under finite memory and bandwidth. IEEE Trans. Commun. 2020, 68, 7702–7718. [Google Scholar] [CrossRef]
- Farhadi, V.; Mehmeti, F.; He, T.; La Porta, T.F.; Khamfroush, H.; Wang, S.; Chan, K.S.; Poularakis, K. Service placement and request scheduling for data-intensive applications in edge clouds. IEEE/ACM Trans. Netw. 2021, 29, 779–792. [Google Scholar] [CrossRef]
- Li, Y.; Gao, W. MUVR: Supporting multi-user mobile virtual reality with resource constrained edge cloud. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 1–16. [Google Scholar]
- Alhilal, A.; Braud, T.; Han, B.; Hui, P. Nebula: Reliable low-latency video transmission for mobile cloud gaming. In Proceedings of the ACM Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 3407–3417. [Google Scholar]
- Gül, S.; Podborski, D.; Buchholz, T.; Schierl, T.; Hellge, C. Low-latency cloud-based volumetric video streaming using head motion prediction. In Proceedings of the 30th ACM Workshop on Network and Operating Systems Support for Digital Audio and Video, Istanbul, Turkey, 10–11 June 2020; pp. 27–33. [Google Scholar]
- Wang, L.; Jiao, L.; He, T.; Li, J.; Mühlhäuser, M. Service entity placement for social virtual reality applications in edge computing. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 468–476. [Google Scholar]
- Ahmed, E.; Rehmani, M.H. Mobile edge computing: Opportunities, solutions, and challenges. Future Gener. Comput. Syst. 2017, 70, 59–63. [Google Scholar] [CrossRef]
- Al-Shuwaili, A.; Simeone, O. Energy-efficient resource allocation for mobile edge computing-based augmented reality applications. IEEE Wirel. Commun. Lett. 2017, 6, 398–401. [Google Scholar] [CrossRef]
- Tian, S.; Yang, M.; Zhang, W. A practical low latency system for cloud-based vr applications. In PInternational Conference on Communications and Networking in China; Springer: Cham, Switzerland, 2019; pp. 73–81. [Google Scholar]
- Kim, W.S. Progressive Traffic-Oriented Resource Management for Reducing Network Congestion in Edge Computing. Entropy 2021, 23, 532. [Google Scholar] [CrossRef]
- Du, J.; Shi, Y.; Zou, Z.; Zhao, D. CoVR: Cloud-based multiuser virtual reality headset system for project communication of remote users. J. Constr. Eng. Manag. 2018, 144, 04017109. [Google Scholar] [CrossRef]
- Hou, X.; Lu, Y.; Dey, S. Wireless VR/AR with edge/cloud computing. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–8. [Google Scholar]
- Alencar, D.; Both, C.; Antunes, R.; Oliveira, H.; Cerqueira, E.; Rosário, D. Dynamic Microservice Allocation for Virtual Reality Distribution With QoE Support. IEEE Trans. Netw. Serv. Manag. 2022, 19, 729–740. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Y.; Xu, J.; Yuan, J.; Hsu, C.H. Edge server placement in mobile edge computing. J. Parallel Distrib. Comput. 2019, 127, 160–168. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S. An energy-aware edge server placement algorithm in mobile edge computing. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 66–73. [Google Scholar]
- Kumar, S.; Gupta, R.; Lakshmanan, K.; Maurya, V. A Game-Theoretic Approach for Increasing Resource Utilization in Edge Computing Enabled Internet of Things. IEEE Access 2022, 10, 57974–57989. [Google Scholar] [CrossRef]
- Yan, S.; Peng, M.; Abana, M.A.; Wang, W. An Evolutionary Game for User Access Mode Selection in Fog Radio Access Networks. IEEE Access 2017, 5, 2200–2210. [Google Scholar] [CrossRef]
- He, Q.; Cui, G.; Zhang, X.; Chen, F.; Deng, S.; Jin, H.; Li, Y.; Yang, Y. A game-theoretical approach for user allocation in edge computing environment. IEEE Trans. Parallel Distrib. Syst. 2019, 31, 515–529. [Google Scholar]
- Lai, P.; He, Q.; Grundy, J.; Chen, F.; Abdelrazek, M.; Hosking, J.; Yang, Y. Cost-effective app user allocation in an edge computing environment. IEEE Trans. Cloud Comput. 2020, 10, 1701–1713. [Google Scholar]
- Velasquez, K.; Abreu, D.P.; Curado, M.; Monteiro, E. Service placement for latency reduction in the internet of things. Ann. Telecommun. 2017, 72, 105–115. [Google Scholar]
- Taneja, M.; Davy, A. Resource aware placement of IoT application modules in Fog-Cloud Computing Paradigm. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 1222–1228. [Google Scholar]
- Csirik, J. On the multidimensional vector bin packing. Acta Cybern. 1990, 9, 361–369. [Google Scholar]
- Navrotsky, Y.; Patsei, N. Zip’s distribution caching application in named data networks. In Proceedings of the 2021 IEEE Open Conference of Electrical, Electronic and Information Sciences (Estream), Vilnius, Lithuania, 22–22 April 2021; pp. 1–4. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | CPU | Memory | GPU | Traffic |
|---|---|---|---|---|
| Logic | [20, 30] | [20, 30] | [20, 30] | [0.1, 1] |
| Render | [40, 60] | [40, 60] | [80, 100] | [8, 10] |
| Augment | [36, 54] | [36, 54] | [72, 90] | [10, 12] |
| Motion | [16, 24] | [16, 24] | [32, 40] | [8, 10] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.-J.; Kim, J.-H.; Lee, J.-H.; Han, J.-Y.; Kim, W.-S. Adaptive Microservice Architecture and Service Orchestration Considering Resource Balance to Support Multi-User Cloud VR. Electronics 2025, 14, 1249. https://doi.org/10.3390/electronics14071249
Choi H-J, Kim J-H, Lee J-H, Han J-Y, Kim W-S. Adaptive Microservice Architecture and Service Orchestration Considering Resource Balance to Support Multi-User Cloud VR. Electronics. 2025; 14(7):1249. https://doi.org/10.3390/electronics14071249
Chicago/Turabian StyleChoi, Ho-Jin, Jeong-Ho Kim, Ji-Hye Lee, Jae-Young Han, and Won-Suk Kim. 2025. "Adaptive Microservice Architecture and Service Orchestration Considering Resource Balance to Support Multi-User Cloud VR" Electronics 14, no. 7: 1249. https://doi.org/10.3390/electronics14071249
APA StyleChoi, H.-J., Kim, J.-H., Lee, J.-H., Han, J.-Y., & Kim, W.-S. (2025). Adaptive Microservice Architecture and Service Orchestration Considering Resource Balance to Support Multi-User Cloud VR. Electronics, 14(7), 1249. https://doi.org/10.3390/electronics14071249