1. Introduction
CPSs provide critical infrastructure for many important use cases, such as resilient smart cities, smart health care, or hybrid military operations. CPSs are often distributed, with components spread across different locations and owned by different entities. Increasingly, cyber–physical systems rely also on the concept of federation. The purpose of forming a federation is to allow the CPS components provided by various parties to cooperate and exchange information securely and efficiently without relying on a central authority, thus improving the resilience of the overall system.
For example, in smart grids, different energy providers can federate their systems to optimize energy distribution and balance loads between regions. Similarly, smart factories can share production data with suppliers and customers to optimize supply chains and improve product quality. A federation also allows a CPS to scale more easily by adding new components and systems operated by independent entities without requiring significant changes to the existing infrastructure. This also enables greater flexibility in adapting to changing mission needs and requirements.
From a cyber security perspective, the federation can improve the cyber resilience of CPS by distributing trust and reducing the impact of a single point of failure. It also enables the implementation of controlled data sharing and advanced privacy-preserving techniques, such as federated machine learning, where sensitive information can be kept local and confidential while still contributing to training global models and data analytics. In a federated environment, each participant retains control over their cyber–physical capabilities and operations while accepting and fulfilling the requirements outlined in earlier agreed-upon arrangements, particularly in the joint security policy. Establishing an effective IAM framework across the federation of separate administrative domains is necessary to ensure trust and secure communication between CPS belonging to federated partners.
In a federated CPS environment, a DL can be used to implement resilient authentication and authorization and an immutable record of CPS identities and transactions performed between the federation members. You can find many ways to authenticate using a distributed ledger [
1,
2]. In [
3], we presented a novel LAAFFI that enables authentication, authorization, and secure communication of IoT devices in federated environments. LAAFFI was designed to support a wide range of IoT devices, from computationally powerful and grid-connected equipment to small battery-operated wireless devices with limited computing resources and limited or non-existent secure storage space. To provide such a flexible authentication and authorization mechanism, LAAFFI takes advantage of the unique fingerprint of IoT devices based on their configuration and additional hardware modules, such as PUF, in combination with DL.
When developing an authentication and authorization framework for CPS, in addition to evaluating its security, it is necessary to assess its scalability, throughput, and latency, as well as identify potential bottlenecks in the system. To address this challenge, we built a detailed model of Hyperledger Fabric v2.1 [
4] using CPN [
5]. Based on our CPN model, we were able to assess throughput, latency, utilization rate, and queue length in each peer and critical processing steps within each element.
The developed Petri net model is also usable for other solutions using Hyperledger Fabric. It can be used successfully to model and test the performance of the authentication process of CPS devices (using Hyperledger Fabric), which was presented in [
1,
6].
The main contributions of our work are as follows:
We have developed a novel and effective approach to modeling distributed ledgers with Colored Timed Petri nets.
We have implemented a Petri net model of the Hyperledger Fabric (a widely used instantiation of a permissioned distributed ledger) using CPN Tools (a well-known software package for CPN models that supports editing and syntax checks, interactive and automatic simulation, state space analysis, manipulate token using programming language similar to Standard Modeling Language (SML) and performance analysis).
We implemented a prototype of a DL-based application providing authentication and authorization for cyber–physical systems and experimentally evaluated its performance with respect to latency, throughput (number of operations or transactions per second), and transmission overhead.
We have compared the results obtained from our experimental evaluation with the simulation results performed with our CPN model.
Section 2 presents how to model distributed ledgers, presented in other articles.
Section 3 introduces distributed ledger technologies and explains the rationale behind choosing Hyperledger Fabric as a target of our evaluation. It also introduces the LAAFFI protocol for the authentication and authorization of IoT devices based on DL and demonstrates how the framework meets the requirements introduced by federated CPS.
Section 4 describes how CPN can be used to model Hyperledger Fabric applications, such as LAAFFI.
Section 5 introduces a hierarchical CPN model of transactions in the Hyperledger Fabric environment.
Section 6 discusses issues related to the parameterization and calibration of our CPN model. The results of our model validation and overall HLF performance analysis in the context of LAAFFI are presented in
Section 7, while
Section 8 discusses the differences between our approach and those presented in other articles. Finally,
Section 9 summarizes our main results and identifies possible directions for future work.
2. Related Work
The results of performance studies of distributed ledgers, including HLF, based on both experimental and analytical–theoretical analysis were presented in [
7,
8,
9,
10,
11,
12,
13]. Experimental modeling is based on direct observation and measurement of actual blockchain systems [
7,
8,
9]. Benchmarking is a method of comparing the performance of different blockchain platforms using standardized tests. This allows for an assessment of how different solutions perform against each other. However, the results may depend on the specific tests used and the environmental conditions. The performance measurements have to be carried out in an environment isolated from other factors, such as other virtual machines and running services [
11]. In an environment where resources are also used for other tasks, the results may vary. Furthermore, some networking environments, such as the WAN, have higher latency and lower bandwidth, which can significantly affect the system performance.
Several benchmarking frameworks exist, such as Blockbench, DAGbench, and Hyperledger Caliper [
8,
11]. We relied on Hyperledger Caliper [
14], which enables the collection of blockchain network performance data, such as the number of transactions, the frequency of their arrival, block size, latency, and throughput. Experimental performance analysis of execution time, average latency, throughput, and scalability of HLF v0.6 and v1.4 has been presented in [
9], while a comprehensive performance experiment over HLF v1.0, assigning different values to configurable system parameters, including transaction arrival rate, block size, approval policy, channel numbers, and resource allocation, has been described in [
15].
Unlike experimental, analytical modeling uses mathematical tools to describe and analyze the blockchain system’s performance. Analytical modeling mainly covers three types of stochastic models: Markov chains [
16], queueing [
17], and different extensions of the SPN [
18], such as the GSPN [
19] or the SRN [
11]. The choice of modeling tool depends on the specific aspects of Hyperledger Fabric one wants to study. The SRN and GSPN are popular stochastic models, while hierarchical models facilitate the analysis of complex systems.
Markov chains are a stochastic process with a discrete state space. They allow us to model a blockchain system as a sequence of states where transitions between states occur with a certain probability. Markov chains have been applied to model the Raft in HLF and the Tangle algorithm in IOTA [
20]. The SPN determines the activation time of Petri net transitions according to an exponential distribution, thus creating a link to Markov chain theory. The SPN generates, usually extensive, Markov chains based on a concise description of the system using the SPN modeling language. This concise description helps to address one of the main challenges associated with Markov models—the size of their state space. Traditional Markov models suffer from the state space explosion problem, where the number of states grows exponentially with system complexity, making analysis computationally infeasible for large systems. The SPN formalism captures the system’s structure and behavior in a way that reduces redundancy in the state space. While SPNs can be mapped to Continuous-Time Markov Chains (CTMCs) for analysis, the Petri net representation often allows for a more compact and manageable state space than directly defining the Markov model. It is also worth adding that SPNs can be analyzed using state aggregation, symmetry reduction, or symbolic methods. These methods exploit the structure and symmetries of the Petri net to reduce the state space further and make analysis more efficient.
Therefore, choosing the appropriate Petri net formalism for modeling is crucial for optimizing the model’s complexity and the state space’s size.
The GSPN extends a Petri net with the ability to model random event durations. The GSPN was used to analyze the impact of HLF block ordering service configuration on the overall system’s performance.
The SRN provides extension of the formalism derived from GSPNs [
21]. The SRN greatly enhances the modeling capabilities of GSPNs by adding supervisor functions, marking-dependent arc multiples, overall transition priorities, and network-level reward rates and can be more accurate than the GSPN, especially when modeling complex system behavior. A comprehensive SRN model of HLF release v1.0+ presented in [
11] analyzes the key stages of transaction processing in this version of HLF. The SRN allows detailed analysis of the performance of individual phases (endorsement, ordering, validation) and calculation of required performance metrics.
To summarize, the SPN, GSPN, and SRN help reduce model complexity compared to traditional Markov models by providing a structured and compact representation. However, as the network size increases, the computational complexity of analyzing these models grows [
11], particularly for SRNs, due to the added complexity of reward computations. Thus, while SRNs are powerful tools for performance evaluation, they are still limited by computational complexity (exponential in the worst case) when applied to very large or complex systems [
22]. An important limitation of an SRN model is its computational complexity.
Another limitation from the point of view of accurately modeling, the performance of the developed LAAFFI protocol is the difficulty of taking into account the different types of transactions and their various detailed characteristics, such as operation execution times, concrete data sizes, block sizes generated, and so on.
Other mathematical models used in blockchain performance modeling are
fork-join queues. An example of work using this model is presented in [
17]. In this work, the
fork-join queue is proposed to analyze delays in the block synchronization process in the permissioned blockchain. The
fork-join queue model is specifically used to analyze the consensus mechanism’s delays. A queue theory-based model focused on the flow of a transaction within the scope of HLF v2.0 has been proposed in [
23].
The hierarchical models facilitate the analysis of complex systems by breaking them down into smaller subsystems that are easier to model. Hierarchical models focusing on the time constraints of the HLF transaction approval and block creation and the probability of transaction rejection were presented in [
12,
22]. The analytical models used in studies are often simplified versions of real systems. For example, a model using the SRN [
11] focuses on the key stages of transaction processing but does not take into account all aspects of HLF. This simplification can lead to an under- or overestimation of some performance metrics. For example, an oversimplified model might not capture the impact of a customized way of validating transactions using a custom VSCC, which can affect system performance. The purpose of validation is to confirm the model’s accuracy and ensure that it can be used to analyze and optimize the performance of HLF [
22]. For example, data collected from the HLF network running in the lab can be used to parameterize and validate SRN models [
11]. The use of a realistic IOTA simulator to investigate the impact of different design parameters on IOTA’s performance was discussed in [
24]. Many existing works studied the system performance of HLF from the perspective of an overall system (for instance, [
25]). In this work, a comprehensive evaluation was performed by observing various configurable network components affecting blockchain performance.
3. Background
A distributed ledger is a type of decentralized, immutable database. Each organization participating in a distributed ledger maintains a copy of the ledger on its nodes. A node is a computer or a virtual machine with the appropriate software to create, manage, and provide distributed ledger services. Distributed ledger nodes do not have to have an identical hardware and software configuration, increasing the system’s resilience to security flaws and vulnerabilities found in specific hardware, drivers, or software. Exploiting a security vulnerability on a single node would not make all nodes vulnerable. The entire distributed ledger is immune to the failure of individual nodes since each organization can have several nodes operating in a peer-to-peer network—a distributed ledger stores data as transactions submitted by users belonging to the organization [
26]. The process of adding transactions to the ledger can vary depending on the implementation of the distributed ledger. Once a node has constructed a block containing transactions, it sends this block to other nodes to verify all transactions included in the block. After verifying the block, the nodes need to reach a consensus on adding the block to the distributed ledger, e.g., based on voting. No single organization can modify the distributed ledger independently. Transaction blocks cannot be deleted or overwritten, so all changes made since the ledger was created can be traced.
There are many implementations of distributed ledgers. In
Table 1, we have compared solutions that we believe are most relevant to the CPS. Compared to other solutions, Hyperledger Fabric is the perfect solution to use whenever a distributed ledger is required. Hyperledger Fabric, IOTA, and Quorum offer the ability to authenticate clients and authorize them to protect access to data. These three solutions also offer the ability to store private data that are especially protected. Hyperledger Fabric offers modularity, i.e., it is possible to change the consensus algorithm, the type of database or the use of the HSM. An additional advantage of Hyperledger Fabric is the ability to create many distributed ledgers within a single service, which the listed competitors cannot do. Each of the cited solutions can support smart contracts. The performance of Hyperledger Fabric, IOTA, and Quorum is rated high. In addition, Hyperledger Fabric and IOTA are general-purpose ledgers, while Quorum and Ethereum are mainly used for financial services. Based on this comparison, we have selected Hyperledger Fabric as the target of the Petri net model. The detailed reasons for choosing Hyperledger Fabric are described in [
3].
Each Hyperledger Fabric node provides at least one of two services: peer and ordering. The Peer service is responsible for executing and storing chaincodes, as well as storing and updating the ledger. Each Peer service can perform several roles [
27]. The first is the role of a peer leader, which, in a situation where an organization has multiple nodes in the channel, is the node responsible for receiving the block from the ordering service and forwarding it inside the organization to nodes with the committing role. The nodes with the committing role receive the blocks for approval, verify them, and add them to the stored distributed ledger. A Hyperledger Fabric peer node can also have an endorsing role. A node with this role has chaincode installed, receives requests from applications, and can generate transaction proposals. The last role is the anchor role. This role is assigned to nodes used to communicate with Hyperledger Fabric nodes belonging to other organizations. Each organization must have at least one node with this role. A node with the ordering service can have one of two roles. The role of the ordering service leader can be assigned to one single node in the entire network. A node with this role creates a block from the received transactions. The ordering service in the Hyperledger Fabric implementation that we have modeled uses the Raft [
28] consensus algorithm. The leader among all nodes is selected automatically and without favoring any node. The remaining nodes have a follower role. If the leader is not reachable, a new leader is chosen from the remaining nodes. Nodes with this role receive messages from the leader in order to have the same state of knowledge as the leader and to be able to replace the leader if the leader is unavailable.
In addition to the distributed ledger, Hyperledger Fabric also has an additional database. This database stores the last values for each identifier of the data. Its purpose is to reduce the response time by querying the database for the value of an identifier rather than looking through the entire distributed ledger. The default database is the NoSQL LevelDB database [
29]. Alternatively, CouchDB can be used [
30], which stores data in JSON format and is less efficient than LevelDB, but supports simple queries.
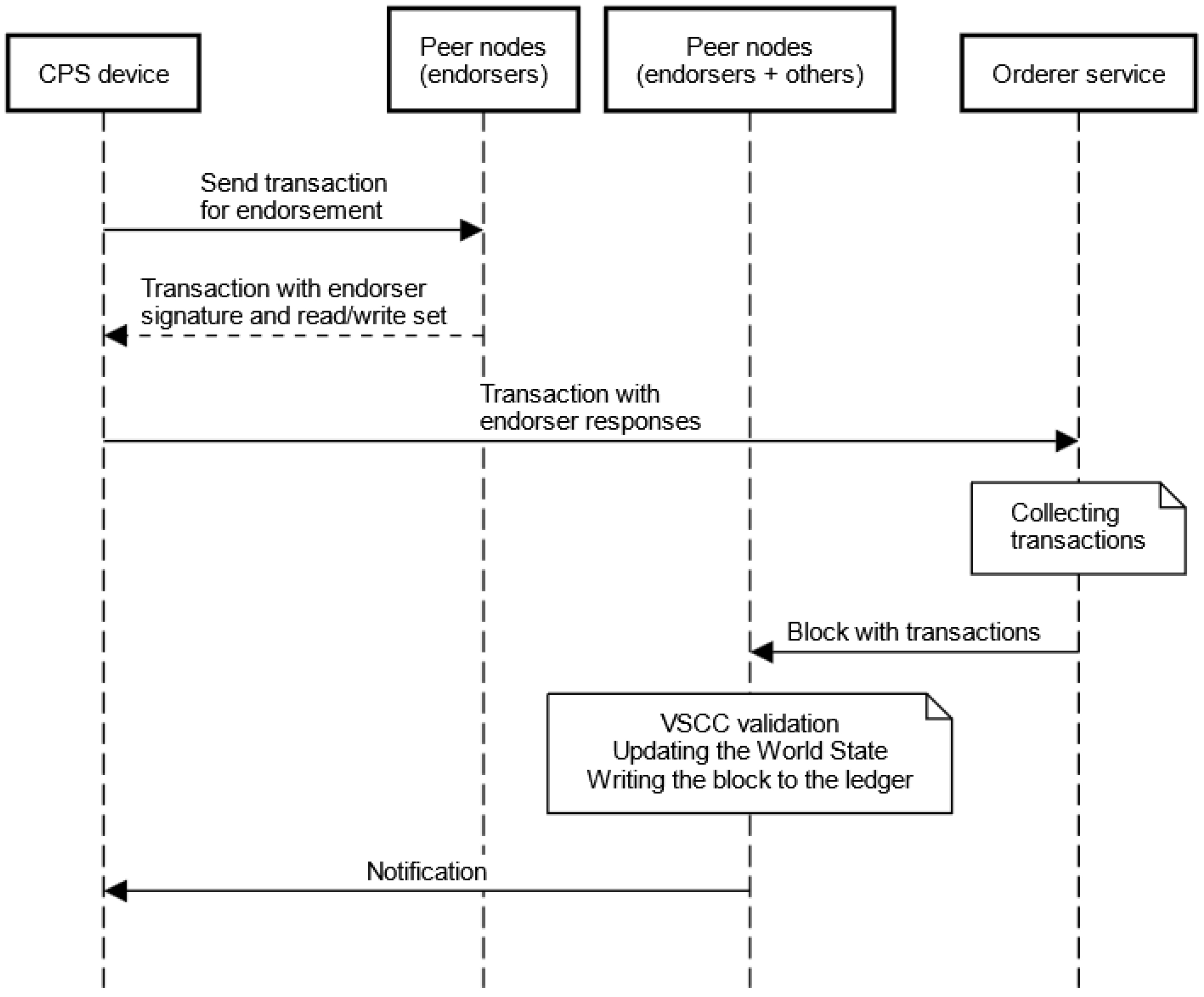
To write data to the distributed ledger, the client (application) generates a transaction proposal and sends it to one or more peer nodes with the endorser role. This proposal contains, among other things, the input to the chaincode selected by the client. Nodes with the endorser role execute the transaction proposal in simulation mode. During this simulation, the nodes check how the transaction would affect the distributed ledger. The result of this simulation is a Read-Write set, which describes the data that are read and will be changed by this transaction. The nodes sign the response containing the Read-Write set and then send it to the client (application). The application collects responses, and if the responses meet the endorsement policy, the proposal and signed responses are sent to the ordering service. The transaction is queued and, if the conditions for creating a block are met, added to the block. The block is sent to all the peer nodes in the channel. Each node then verifies the transactions stored in the block. The verification process consists of two operations: the VSCC and MVCC. The VSCC is responsible for verifying that the transaction meets the conditions written in the endorsement policy. MVCC checks for “double spending” attacks. In the case of the developed protocol, the use of MVCC will not allow, among other things, the registration of a device with the same ID.
Once the verification process is completed, the World State is updated, the block is written to the distributed ledger, and the notification is sent to the client.
Figure 1 shows a simplified sequence diagram of adding transactions.
In the work [
3], we proposed the LAAFFI based on HLF. The novelty of the proposed solution consists of registering in HLF, a unique fingerprint of CPS (IoT) devices according to their available resources and designing a protocol to establish trust and secure communication between CPS devices with HLF and between CPS devices, even belonging to different organizations that form a federation. Our solution supports devices with various capabilities, including devices with additional hardware resources, such as PUF or the TPM, and simple CPS devices with minimal computing resources, such as Arduino. Our framework is also fully decentralized, and the data stored in the DL are replicated between nodes, increasing the reliability of the entire solution. All the LAAFFI interactions with DL nodes are recorded in HLF, providing accountability in a federated environment. The private data feature of HLF allows for keeping the data confidential. However, in this case, only the organization that owns the CPS devices can issue a communication key because only that organization can access the parameter table stored as private data.
The authentication process is required to confirm the identity of the CPS device and protect data against unauthorized access. The following describes how a device that writes to a distributed ledger is authenticated based on the LAAFFI protocol [
3]. The LAAFFI uses a distributed ledger to store unique device-specific data to create cryptographic keys. The device and the ledger nodes can create the same key, so the key does not have to be transmitted. To enable LAAFFI authentication, the device must complete a registration process, during which the device’s unique data are stored in a distributed ledger. The details of this process are presented in [
3].
Hyperledger Fabric is highly scalable. Detailed measurements of the LAAFFI’s performance using HLF were presented by us in the article [
3]. According to our measurements, eight HLF peers can handle over 5000 authentication operations per second. This value can be increased by having more peers or increasing individual nodes’ performance. Since the authentication operation does not require consensus, the choice of consensus algorithm in HLF does not affect the process.
The use of distributed ledgers as a secure, trusted data store for CPS devices was proposed in [
31,
32]. Distributed ledgers have also been proposed as a solution to trust management in smart cities [
33], e.g., for trading energy [
34]. A distributed ledger solution for sensor authentication in a medical environment was presented in [
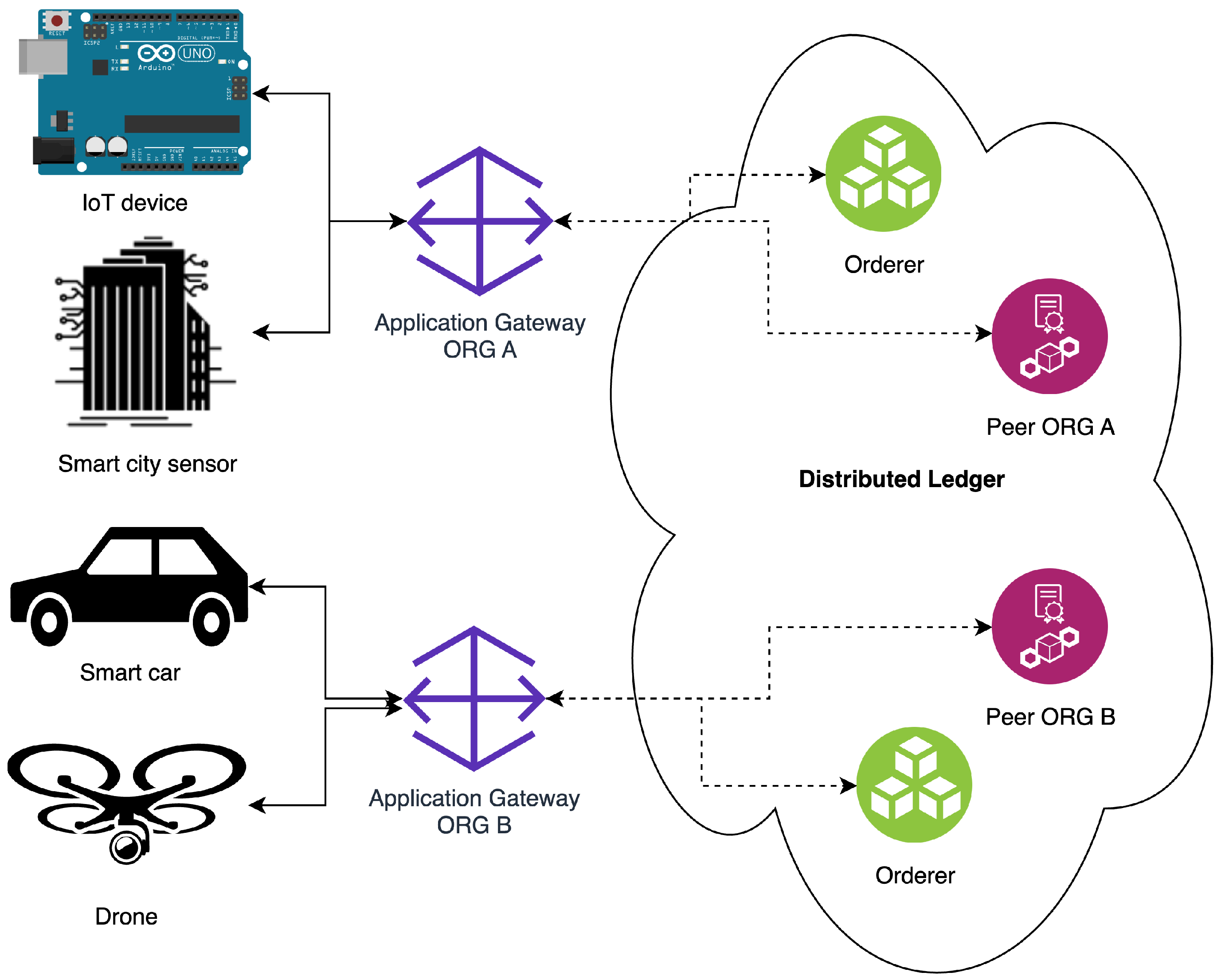
35]. Consider an exemplary use case of connecting CPS devices (e.g., IoT device, smart city sensor, smart car, or drone) of two organizations to the distributed ledger presented in
Figure 2.
As an example scenario, the LAAFFI and Hyperledger Fabric can be used to build a decentralized, interoperable environment for parcel locker service across different operators. Hyperledger Fabric, in such a situation, will serve as a shared distributed ledger between operators for parcel tracking, automated billing, authentication, and authorization of couriers and customers. Meanwhile, the LAAFFI protocol will be used to authenticate and authorize customers and couriers using Hyperledger Fabric. In such an example, there are many scenarios. One of them that is worth presenting is the receipt of a package. A customer who wants to pick up a package from a parcel locker walks up to it with their smartphone. The phone, using Bluetooth, is authenticated with the LAAFFI. After successfully authenticating the smartphone, the parcel locker checks with Hyperledger Fabric to see which box to open. After the customer receives the package and confirms that the package has arrived intact, payment can be automatically collected and credited to the distributed ledger.
Suppose any CPS device wants to securely transmit valid data acquired from its sensor and write them to the HLF. The sequence diagram of this transaction is shown in
Figure 3. The CPS device must be authenticated to ensure the authenticity of the recorded data written to the HLF. For this purpose, a CPS device creates a symmetric key based on its unique data. This key is used to encrypt the transmitted data. The message is sent using an application gateway to a distributed ledger node with a Peer service (peer node). The peer node can decrypt the data because it can reconstruct the key based on the data stored during the device registration process in the distributed ledger. Since only the device and a peer node can create a symmetric key, this cryptographic key can also be used for authentication. After decryption, the peer node sends the data to the application gateway. The application gateway interprets the received data and decides on the required action. The received data will be stored in the distributed ledger in the example described here. The application gateway sends a transaction proposal to nodes with the endorser role to perform this. These nodes simulate the execution of the transaction and sign the result of this simulation. The signed results return to the application gateway, and if the conditions written in the endorsement policy are met, the gateway creates a transaction containing all the signed results. The transaction is sent to a node with an ordering service. This node collects the incoming transactions and sorts them, and if one of the conditions for creating a block is met, it creates the block with these transactions. The block is then sent to all peer nodes. These nodes verify the transactions, update the World State, and add the block to the distributed ledger. Once the block is added, one of the peer nodes informs the application gateway that the specified transaction, sent by the gateway, has been added to the distributed ledger.
Security of the LAAFFI protocol, including an analysis of possible attacks and a formal security analysis, is discussed in detail in our other work [
3].
4. Performance Modeling of Federated Hyperledger Fabric Using Colored Petri Nets
The primary goal of our work was to build an adequate model of the Hyperledger Fabric environment, allowing us to evaluate the performance of the proposed LAAFFI protocol [
3], taking into account the specifics of the transactions performed to ensure the security of the operation of CPS devices in the federation, i.e., CPS device registration, confirmation of the identity of the CPS device, and transfer of data from the device to the distributed ledger. It can be obtained by constructing an HLF transaction writing model that allows testing its performance depending on, among other things, the number of distributed ledger nodes, the number and type of transactions sent to be added, and the block parameter to be written to the ledger. To obtain an accurate model of the HLF environment for the LAAFFI protocol, it is also necessary to tune and calibrate the model based on measurements obtained from an experimental analysis of individual peer operations. The basic operations within the LAAFFI protocol that have the most significant impact on performance include writing data to HLF, which requires consensus among organizations, and checking the block creation conditions according to the rules established for the protocol. These rules specify which and/or how many organizations must sign a transaction to be added to the distributed ledger. The rules also write the minimum properties of a block with transactions for the block to be created and added to the distributed ledger. The development of the HLF transaction writing model will allow for studying the performance parameters of the distributed ledger for different configurations depending on the transactions’ arrival rates and their sizes.
A transaction corresponds to the operations that require creating a block and modifying the state of the database. In our case, operations such as registering a CPS device in the DL or adding its permissions are of concern. The other operations only require reading from the DL or database, which is not critical for scalability evaluation. Therefore, they are omitted from the model construction. Each transaction in HLF undergoes three phases: endorsement, ordering, and validation. We analyze operations corresponding to each transaction phase in detail and collect data from an HLF setup running a realistic workload to parameterize and validate our model.
The most critical metrics in the context of distributed ledger performance are transaction throughput, transaction latency, and queue length [
8,
10,
11,
36].
Transaction throughput is the rate at which the DL commits valid transactions in the defined time, presented as the number of TPS. Transaction throughput is a key indicator of platform scalability [
8,
10]. The main factors affecting throughput are block size, approval policy, number of approval nodes, and consensus mechanism.
Transaction latency quantifies the time that elapses from when a transaction is submitted to when the transaction is confirmed to the client. The end-to-end latency consists of three elements: endorsement latency, ordering latency, and commit latency. Low latency is essential to ensuring the application’s smooth operation. Factors affecting latency are block size, the type and policy of approval of executed transactions, and federation architecture, i.e., the number of approval nodes and network load.
Queue length at individual nodes refers to the number of blocks waiting to be processed by the peer nodes. Long queues can indicate the existence of bottlenecks in the system. Factors affecting queue length are the transaction arrival rate (high transaction arrival rates can lead to long queues), the transaction processing time, and the number of processing nodes.
Scalability is the ability of a system to handle an increasing number of transactions and CPS devices without a significant performance loss. In particular, the decrease in the throughput and increase in latency is expected to occur at a rate that is not more than linear in the number of participants and frequency of the transactions. Factors affecting scalability are the federation structure (number of organizations, number of nodes of a given type in each organization), consensus mechanism, and network performance. Although important performance metrics also include utilization of resources such as CPU, RAM, and network bandwidth, we do not focus on evaluating these metrics, as they are specific to the target computing platform. We mainly evaluate metrics relevant to the LAAFFI protocol design.
Having a precise model of core LAAFFI operations, we can ask various what-if questions, such as the following:
How do performance metrics (throughput, transaction latency, and mean queue length) change along with the federation structure, e.g., the number of organizations in the federation and the number of endorsing peers per organization? How much performance will be influenced by changes in the structure of the distributed ledger?
How do the performance metrics vary at each peer with an increasing transaction request arrival rate?
How does internal HLF configuration, e.g., consensus mechanism and batch timeout, influence performance metrics?
Several well-established computing techniques and tools are available to evaluate the performance of distributed systems. The choice of a specific modeling and validation tool depends on the purpose of the analysis and the available data. Experimental modeling and measurement are closer to reality but require significant resources and the collection of large amounts of data. In this context, Hyperledger Caliper [
8,
37,
38] is a popular benchmarking tool for Hyperledger Fabric applications. Analytical modeling, such as using mathematical formulas or analytical tools such as SPNs, SRNs, and GSPNs, on the other hand, is more flexible and easier to analyze but requires simplifications.
To build a precise model of basic LAAFFI operations, the modeling tool should meet several requirements, the most important of which are the following:
Hierarchical representation of model components corresponding to complex operations performed in the HLF environment.
Coverage of the full Hyperledger Fabric transaction process (e.g., submission, validation, ordering) enabling the evaluation of required performance metrics, e.g., throughput, response time, and resource utilization. It should also provide for examining the impact of the structure of the federated environment: different numbers of organizations/nodes, different types of transactions, etc.
Provide for the modular implementation of specific phases of transactions and functions as consensus algorithms, e.g., Raft or PBFT;
The model must be sufficiently detailed to account for certain low-level details, such as network latency and chaincode operations time.
The model must enable assessment of throughput (scalability), identification of bottlenecks, and developing a better understanding of the environment’s operation.
CPNs and the supporting CPN Tools meet the above-mentioned requirements. First, the CPN Tools enable advanced features such as simulation data generation, latency analysis, and performance monitoring of large distributed systems [
39]. Second, CPN Tools is a robust framework for modeling and analyzing the performance of distributed ledgers, enabling a detailed study of synchronization, throughput, and response time in blockchain systems. They provide accurate and flexible analysis models.
CPNs [
40] provide the basis for graphical notation and a semantic basis for modeling concurrency, synchronization, and communication in distributed systems. Including time, that is, the extension of Petri nets as CTPNs with a timed aspect (further referred to as CPNs), makes it possible to model the elapsed time between executing individual transitions of a Petri net [
41]. Transitions in CPN nets can have specific activation times, which allows us to model the time required to perform a given operation (or for the system to remain in certain states). In addition to transition durations, timed Petri nets can also consider the introduction of delay. This is important in modeling the passage of time in parallel or distributed systems. The timed analysis of Petri nets allows simulation of the behavior of the system over time, which allows for predicting its performance and evaluating performance indicators, in particular, the duration of operations, the waiting time for transition activation, or the number of tokens waiting for transition activation (queue length). The Colored Petri net allows you to define token types corresponding to the data types found in popular programming languages [
42]. This makes it possible to perform various operations on tokens. Each location is assigned a specific color (data type), and only tokens with this type can be stored. Color manipulation is performed through expressions applied to the transitions. In a Colored network, for a transition to be active, its input places must contain the correct number of tokens with the proper values. Using Colored Petri nets makes it possible to consider various objects’ properties, which can be changed as the token passes through transitions and can affect the behavior of the entire Petri net.
There are many examples of CPNs used in various areas [
5], such as modeling communication protocols, modeling mobile telecommunication systems, or developing software for distributed systems. The practical application of CPNs has also covered many stages of system construction, from requirements to design, validation, and implementation.
We used CPN Tools v4.01 to model and simulate ledger transaction writing in distributed ledger nodes. This analytical tool is well suited for modeling and analyzing large and complex distributed systems, such as the modeled federated environment, for several reasons [
39]:
It allows the construction of hierarchical models;
Complex information can be represented in token values and model captions;
Timing information can be included in models;
There are mature and well-tested tools for creating, simulating, and analyzing CPN models.
The CPN ML language was also used for modeling. The CPN ML was developed for CPN Tools by extending SML with support for Petri nets. The SML is a functional programming language that provides primitives for concisely modeling sequential aspects of systems (such as data manipulation) and for creating compact and parameterizable models. The SML is based on the Lambda calculus, which has a formal syntax and semantics. This implies that CPN Tools have an expressive and sound formal foundation. Moreover, due to incorporating the SML [
5], CPN Tools are flexible enough to build a detailed model of the transaction validation processes of the federated Hyperledger Fabric environment and analyze the impact of various configuration parameters on throughput and latency. Using a high-level language allowed greater manipulation of tokens, collection of statistics for the various elements modeled, and model parameterization.
CPN Tools allow models to be organized into multiple modules (pages). Modules can be organized hierarchically, enabling a top-down approach when constructing CPN models. The Petri net hierarchy allows multiple non-hierarchical nets (i.e., modules or pages) to be connected using substituted transitions or fusion [
42], where pages are linked. The pages can be ordered hierarchically, enabling a “top-down” approach when constructing Petri net models. The presented transition allows you to merge subpages with overpages through nests (places in overpages) and port places (places in subpages). On the other hand, a merge is a set of indistinguishable places, i.e., they represent one place but are drawn individually on different pages. A token added (removed) to a place belonging to a merger is automatically added to (removed from) other places belonging to the same merger. Places belonging to a merge can be on the same page or on different pages. Once the model has been built using CPN Tools, it should be parameterized and tuned based on the measured performance characteristics of the executed transactions. Finally, the adequacy of the model should be verified and evaluated by comparing the measured results for the real environment with the simulation results obtained.
5. Hierarchical CPN Model of Transactions in Hyperledger Fabric Environment
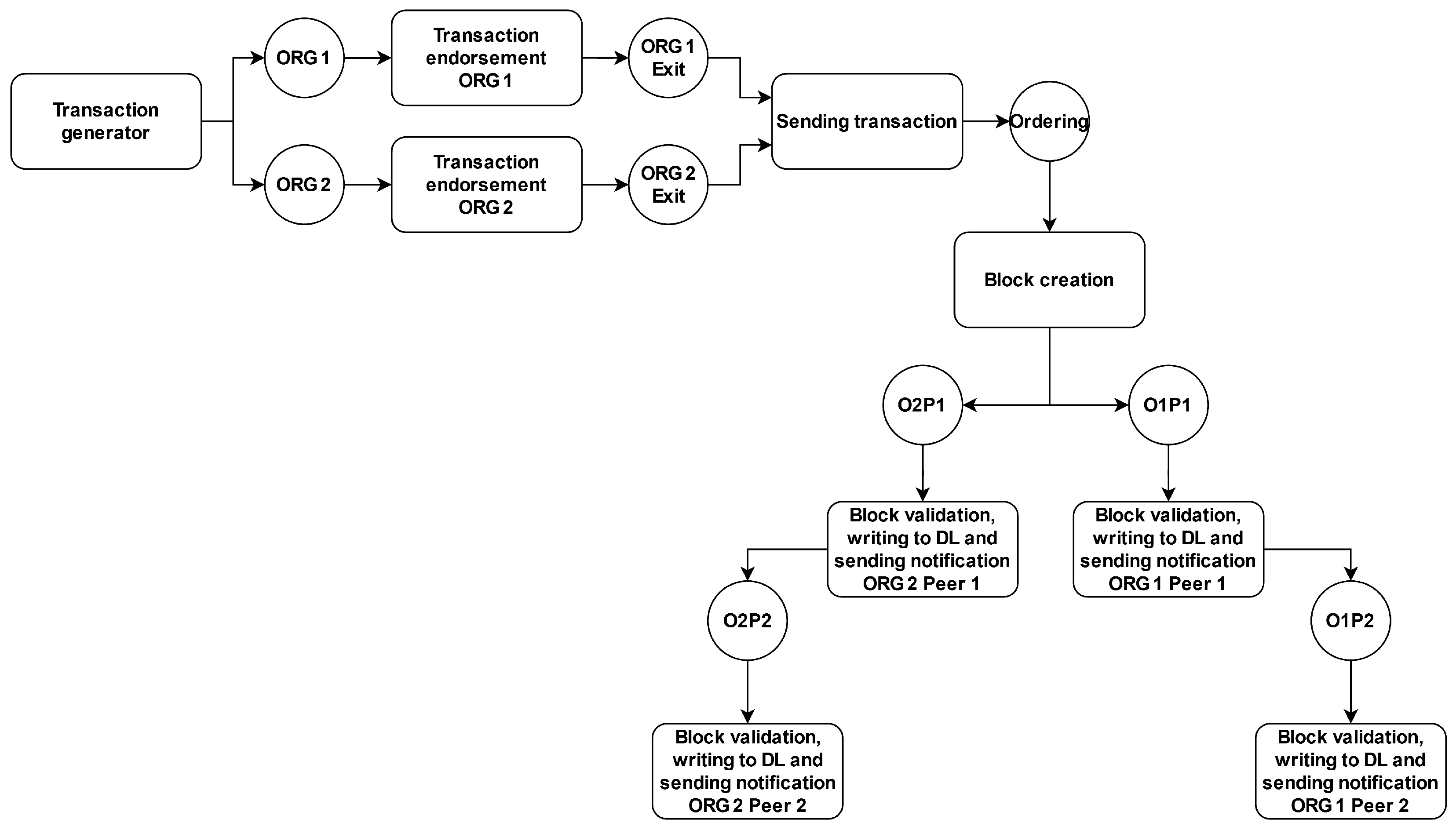
The process of adding transactions to a distributed ledger is divided into five stages, where each stage is presented as a separate module—a Petri net page. The first stage includes generating and sending the transaction to the organization. The second stage consists of the transaction’s approval by the organization’s node. The number of pages in the second stage depends on the number of organizations. In the third stage, the transaction is sent to the block-building service. The fourth stage is the block-building process. The last stage is the process of verifying, validating, and adding the block to the distributed ledger. The hierarchy of the parties is shown in
Figure 4. Dividing the model into pages allows for the modeling of modifications to the Hyperledger Fabric implementation by replacing a particular stage with a new one without affecting other pages. Some page types shown in
Figure 4 can occur multiple times, but always in the same place in the hierarchy. For example, there can be two pages of transaction generation, where each side can have different parameters (frequency, size) of the transactions generated.
Figure 5 shows a page model for two organizations, each consisting of two nodes. The modeled process for adding transactions is specific to the process performed by Hyperledger Fabric and cannot be directly generalized to other distributed ledger implementations.
When building the model, it was assumed that other parameters of the environment, e.g., network bandwidth, are invariant over time. It was also assumed that all hardware parameters are identical for all nodes. For the transaction approval policy, it was assumed that it is sufficient for one of the organization’s nodes to confirm a transaction and that each organization will confirm each transaction. The model uses global variables that allow you to configure the model before starting the simulation:
DiffTime: Setting for the transaction generator. Specifies the time between the generated transactions;
max_block_size: The variable specifies the maximum block size in bytes;
max_block_time: Max waiting time before generating the next block (batch timeout);
TPS: The number of transactions generated per second by the generator;
size_min: Minimum transaction size;
size_max: Maximum transaction size;
max_transaction: Variable introduced to limit the number of transactions generated to simulate the model.
The first page is
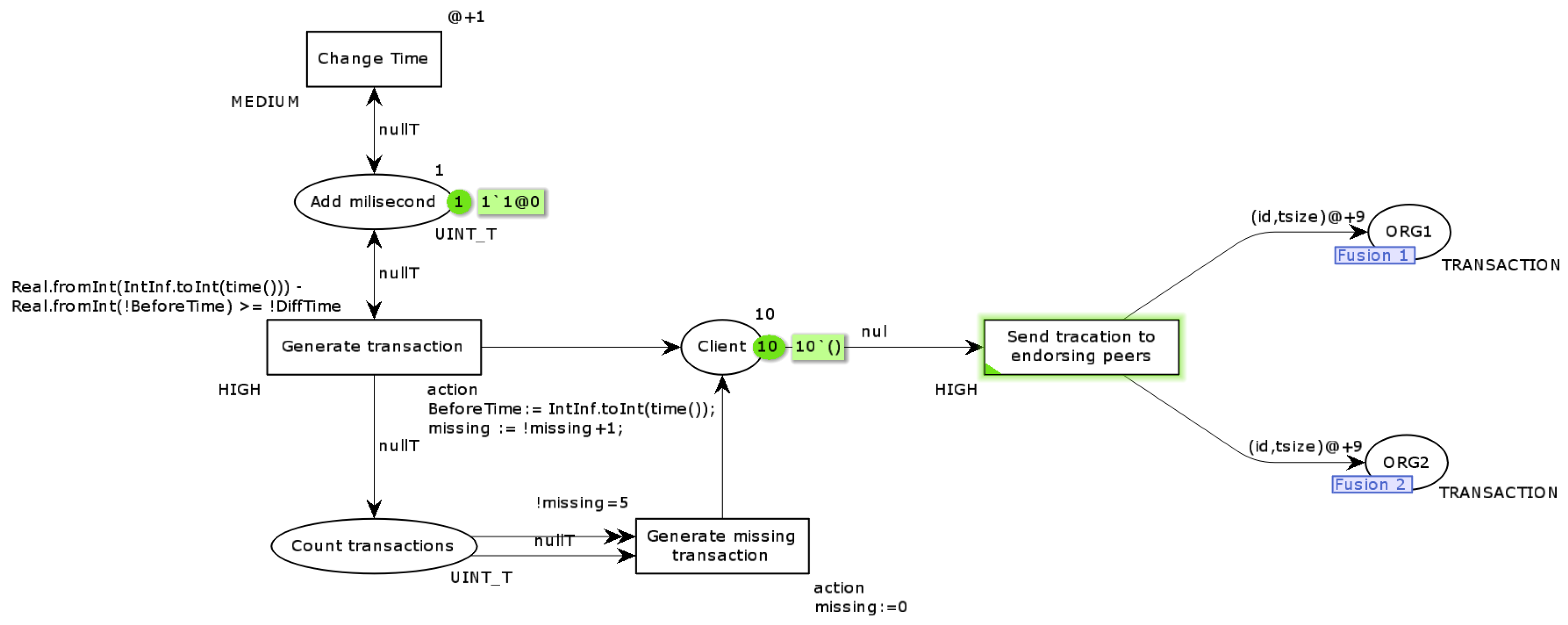
Transaction generator. The model page responsible for the token generation process is shown in
Figure 6.
On this page, the client’s stage of creating a transaction has been modeled. Among the essential properties that this stage must meet are generating tokens at the appropriate frequency and giving each token the proper color to indicate the transaction number and size of that transaction. Since it was assumed that one unit of simulation time corresponds to 1 ms, this resulted in the need to generate an additional token in specific units of time for values of the frequency of token generation that are not divisors of the value 1000. On this page, the tokens represent a single transaction. The model of the Transaction generator page is prepared to generate one type of transaction. This means that when modeling a real-world environment where there will be different transactions (e.g., device registration, device data writing), you need to duplicate the page in the Petri net model with varying transaction generation frequency and transaction size values.
Since the code assigned to some of the transitions is illegible in the figures, we have included it in the text of the article. The code in transition Send transaction to endorsing peers is presented in Listing 1.
| Listing 1. Code at transition Send transaction to endorsing peers. |
| output(id,tsize); |
| action |
| number := !number+ 1; |
| let |
| val sizeT = discrete (!size_min,!size_max) |
| val idT = !number |
| val fd = TextIO.openAppend "Endorser.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^";"^ "TimeTX" ^ ";" ^Int.toString (idT) ^ ";" ^ Int.toString (sizeT) ^ ";" ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in |
| (idT,sizeT) |
| end; |
Transition Generate missing transactions and place Count transactions with adjacent arcs is added to the page only when generating additional tokens for token generation frequency values that are not divisors of 1000. Otherwise, there is no need to generate additional tokens. Change time transition is performed when no other operation can be performed. This transition in each simulation unit allows for creating a new token in place of Add millisecond. The appearance of a token in this place forces a check of the caret condition in the Generate transaction transition. With this transition, it is possible to generate a new token, since CPN Tools only checks active transitions when a token is created at the preceding location. If the gatekeeping condition in the Generate transaction transition is not met, then when a token appears in the Add millisecond location it would cause the Generate transaction transition to never be active, and thus new tags would not be generated. The initial tagging occurs at locations: Add milisecond is 1 token to generate new tags, and Client is 10 tokens. The passage Send transaction to endorsing peers changes the color of the token. From then on, the token has its own unique identifier and a value that determines the size. The size value is randomized between the values of 6570 and 6577 bytes. This value is based on the size of the transactions obtained when performing distributed ledger performance tests. Furthermore, during the execution of this transition, an entry is generated in the event log for later analysis of simulation results. The transitions ORG1 and ORG2 are the transitions that are marked with a merge with the places on other pages of the developed model. The value of the token on the arc between Send the transaction to endorsing peers and places ORG1, ORG2 is derived from the average value of the time to send a transaction between a client and a node with the Peer service and the endorsing role during the execution of the performance test.
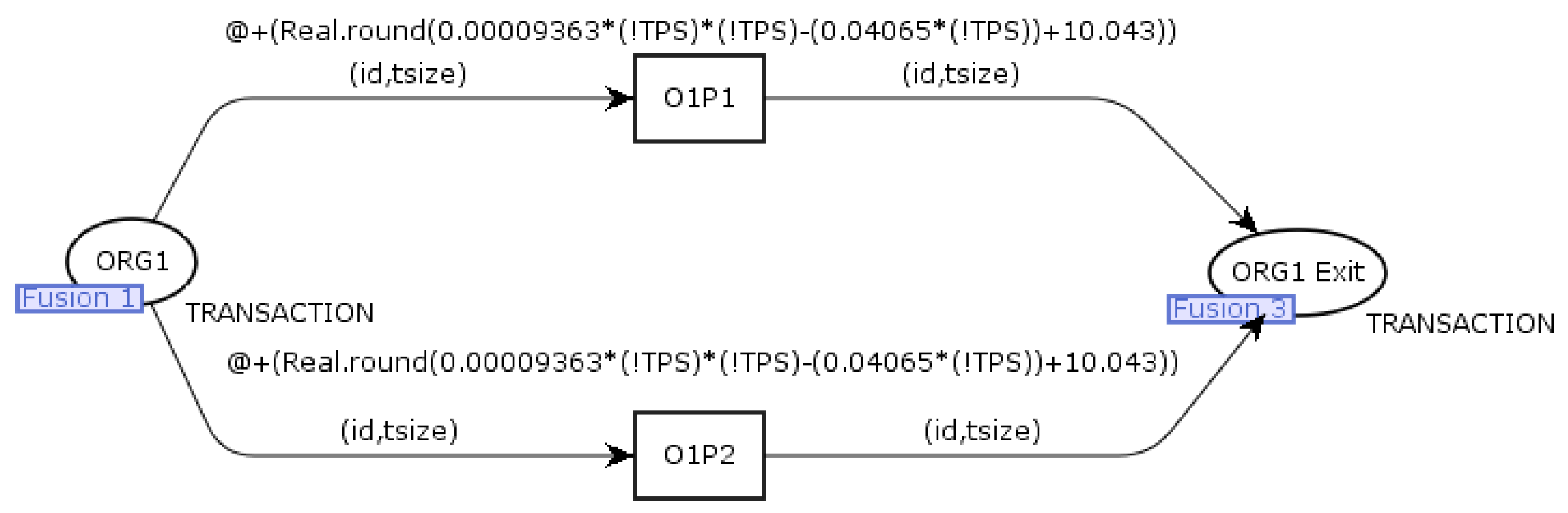
Figure 7 shows an example of a
Transaction endorsement page. The model on this page is responsible for simulating the transaction approval process. The
ORG1 place is connected by merging with the place of the same name on the
Transaction generator page. The function at the transitions
O1P1,
O1P2 to calculate the duration of this step was determined based on the results of the Hyperledger Fabric performance testing. The
ORG1Exit place is connected by a merge to the place on the next page.
Figure 7 shows only one occurrence of this page; the prepared model uses two such pages, one for each organization. Only two nodes were modeled on the presented page (
O1P1,
O1P2, respectively), but the page model can be extended to include more.
The next page models the process of sending an approved transaction to the Ordering service. The entire model of this page is shown in
Figure 8. The places
ORG1Exit and
ORG2Exit are merged with the corresponding places on the
Ordering page. The duration value of the
Collecting signed transactions transition was calculated in distributed ledger performance tests. When the
Collecting signed transactions transition is executed, an entry is generated in the event log for later performance analysis. This process is presented in Listing 2. The
Ordering place is merged with the place on the next page.
| Listing 2. Code at transition Sending transaction to ordering service. |
| input(id,tsize) |
| action |
| let |
| val fd = TextIO.openAppend "Endorser.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^";"^ "EndorsingTX" ^";" ^ Int.toString(id) ^ ";" ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in |
| () |
| end; |
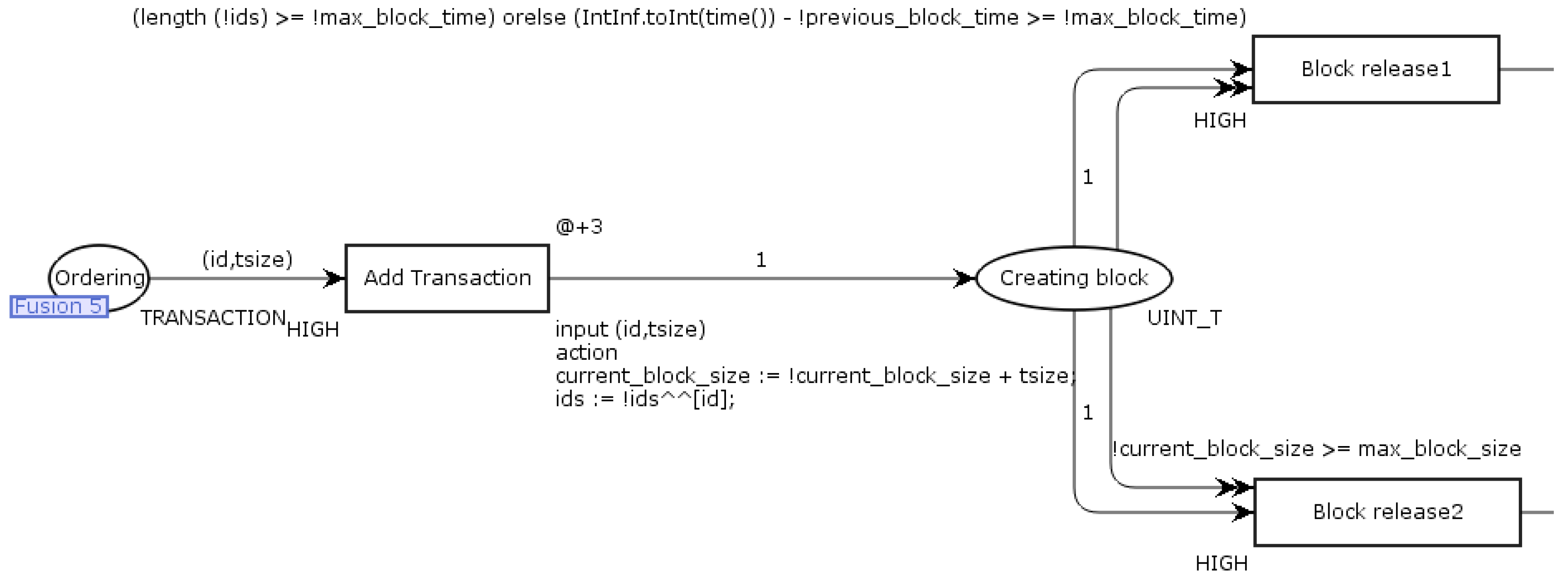
Figure 9 shows the penultimate page (
Block creation), where the Ordering service model is located. The Ordering page merges with the page of the same name located on the
Transaction submission page. The
Add transactions transition contains code responsible for creating block parameters based on the properties of incoming tokens (transactions). The creation of a block and sending it on is carried out when the properties meet one of two conditions: the number of transactions reaches the value specified before the simulation, or when the specified size is reached. The token from the place
Creating block will only go through one of the transitions
Block release 1 or
Block release 2, depending on which condition is met. In
Figure 9, the codes at the transitions
Block release 1 or
Block release 2 are shown in Listings 3 and 4. These code snippets are responsible for changing the color of the token (which is now a representation of the block) and generating an entry containing the length of the queues for the event log for later analysis of the simulation results.
| Listing 3. Code at transition Block release. |
| action |
| temp_cbs := !current_block_size; |
| temp_ids := !ids; |
| previous_block_time := IntInf.toInt(time()); |
| current_block_size := 0; |
| ids := nil; |
| Q4_Size:= !Q4_Size+1; |
| Q3_Size:= !Q3_Size+1; |
| Q2_Size:= !Q2_Size+1; |
| Q1_Size:= !Q1_Size+1; |
| let val fd = TextIO.openAppend "block.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^ ";" |
| ^Int.toString(length(!temp_ids)) ^ ";1\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in ()end; |
| let val fd = TextIO.openAppend "Queue.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^ ";" |
| ^Int.toString(!Q1_Size)^ ";" ^Int.toString(!Q2_Size)^ ";" ^Int.toString(!Q3_Size)^ ";" |
| ^Int.toString(!Q4_Size) ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in ()end; |
| Listing 4. Code at transition Block release2. |
| action |
| temp_cbs := !current_block_size; |
| temp_ids := !ids; |
| current_block_size := 0; |
| ids := nil; |
| Q4_Size:= !Q4_Size+1; |
| Q3_Size:= !Q3_Size+1; |
| Q2_Size:= !Q2_Size+1; |
| Q1_Size:= !Q1_Size+1; |
| let val fd = TextIO.openAppend "block.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^ ";" ^Int.toString(length(!temp_ids)) ^ ";2\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in ()end; |
| let val fd = TextIO.openAppend "Queue.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^ ";" ^Int.toString(!Q1_Size)^ ";" ^Int.toString(!Q2_Size)^";" ^Int.toString(!Q3_Size)^ ";" ^Int.toString(!Q4_Size)^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in ()end; |
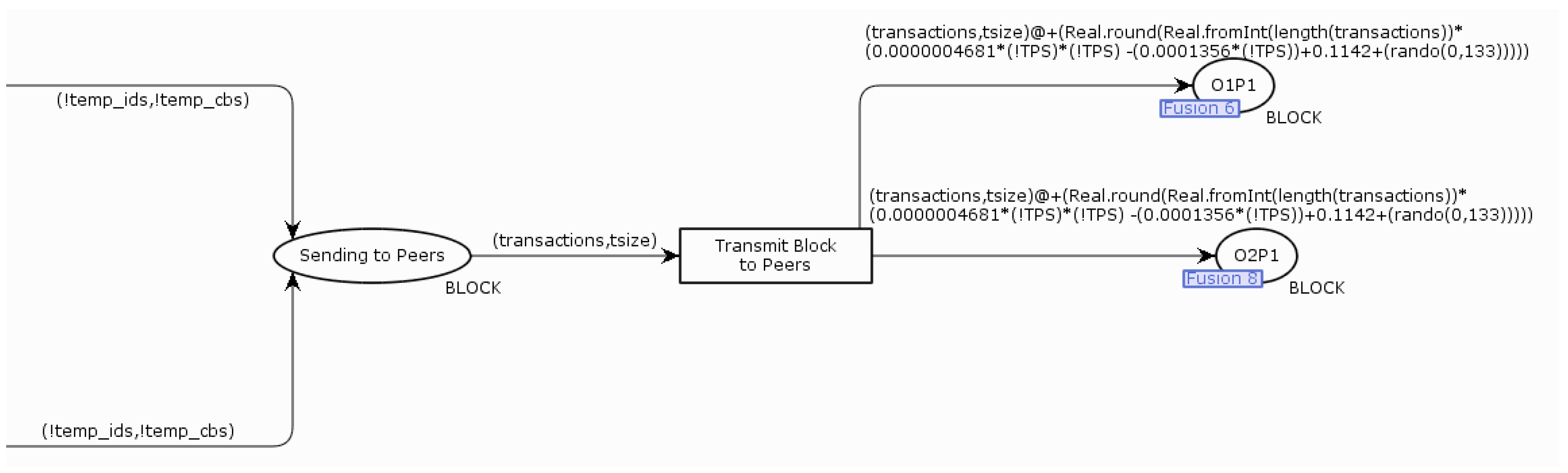
Figure 10 shows the further flow of the model on this page. The token that now represents the block is transmitted to the nodes of the organization with the Peer service having a leader role. The value of the token on the arc between
Transmit Block to Peers and the places
O1P1,
O2P1 is derived from the average value of the transaction transmission duration between the Ordering service and the nodes with the Peer service having the leader role during the performance test execution. The entire function did not fit in
Figure 10. The code in the
Transmit Block to Peers transition is responsible for adding an entry specifying the beginning of the processing time of the entire block (Listing 5) to the event log. The
O1P1 and
O2P1 places are merged with the places on the next page.
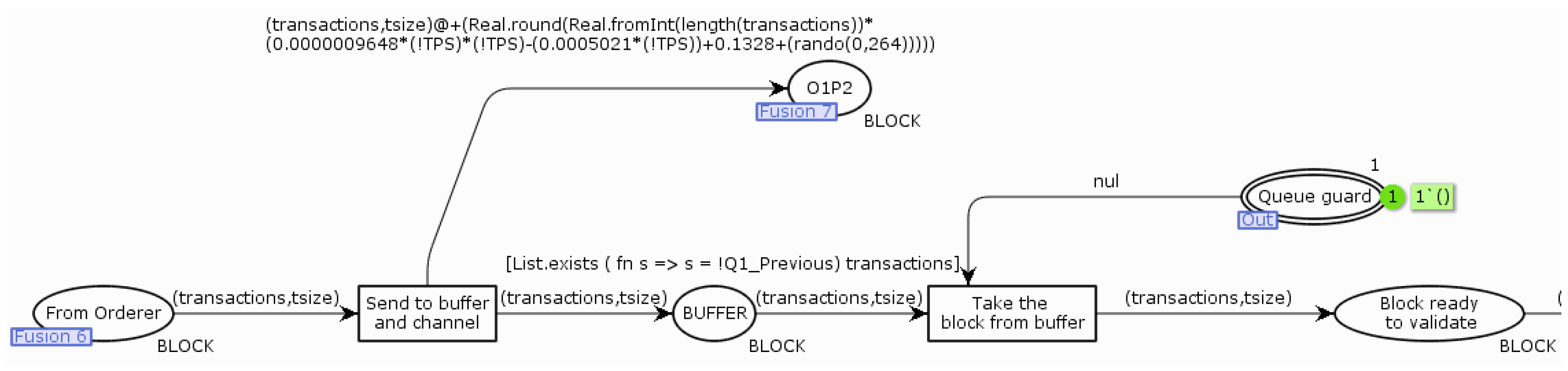
The last page contains a model that shows the process of verifying the block and the process of distributing the notification to customers. In
Figure 11,
Figure 12 and
Figure 13, the model for only one organization has been rearranged—this page will look very similar for the other organizations. The
From orderer place is connected by a merge to the
O1P1 place on the previous page. The arc from the
Send to buffer and channel transition to the
O1P2 place and the
O1P2 place occurs only on the page that models the operation of a node that has a leader role within one organization. For the other nodes (which do not have a leader role), the initial place is merged with the
O1P2 place. The other nodes receive blocks from the leader of the Peer service, not from the Ordering service. Tags can pass through the
Take the block from buffer transition only if the tokens in the
Buffer place representing the block contains a transaction with a number greater than the last transaction number from the previous token and there is a token in the
Queue guard place. The
Take the block from buffer transition also contains code (Listing 6) responsible for generating an event in the event log for further analysis of the simulation results. The
Queue guard place limits the number of simultaneously verified tokens to 1. The value of the timestamp at the
Validate the transactions transition is derived from the average value of the duration of the transaction validation during the execution of the performance test. When a token passes through the transition
Commit the block, an additional token is generated for the place
Queue guard, and thus it is possible to start validating the next token. The code in the
Commit the block transition is responsible for generating an event in the event log, specifying the end time of block processing (Listing 7). The token value at transition
Send confirmation to client is derived from the average transmission duration of the notification of adding a transaction to the distributed ledger. The
Log notification transition records the time the client received the notification in the event log. Listing 8 at this transition is also responsible for writing the event to the model execution log.
| Listing 5. Code at transition Transmit block to peers. |
| input(transactions,tsize) |
| action |
| let |
| val fd = TextIO.openAppend "Ordering.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^";"^ "Block_START" ^";" ^ Int.toString(hd(transactions)) ^ ";" ^ Int.toString(List.last(transactions)) ^ ";" ^ Int.toString(tsize) ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in |
| () |
| end; |
| Listing 6. Code at transition Take the block from buffer. |
| input(transactions,tsize) |
| action |
| Q1_Size:= !Q1_Size-1; |
| Q1_Previous:=List.last(transactions)+2; |
| let |
| val fd = TextIO.openAppend "P1O1.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^";"^ |
| "Take" ^";" ^ Int.toString(hd(transactions)) ^ ";" ^ Int.toString(List.last(transactions)) ^ ";" ^ Int.toString(tsize) ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in |
| () |
| end |
| Listing 7. Code at transition Commit the block. |
| input(transactions,tsize) |
| action |
| let |
| val fd = TextIO.openAppend "P1O1.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^";"^ "RELEASE" ^";" ^ Int.toString(hd(transactions)) ^ ";" ^ Int.toString(List.last(transactions)) ^ ";" ^ Int.toString(tsize) ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in |
| () |
| end |
| Listing 8. Code at transition Log notification. |
| input(transactions,tsize); |
| action |
| let val fd = TextIO.openAppend "peer1org1.txt" |
| val _ = TextIO.output (fd, Int.toString(IntInf.toInt(time())) ^ ";" ^ Int.toString(hd(transactions)) ^ ";" ^ Int.toString(List.last(transactions)) ^ ";" ^Int.toString(length(transactions)) ^ "\n") handle e => (TextIO.closeOut fd; raise e); |
| val _ = TextIO.closeOut fd |
| in ()end |
| end; |
6. Model Parametrization and Calibration
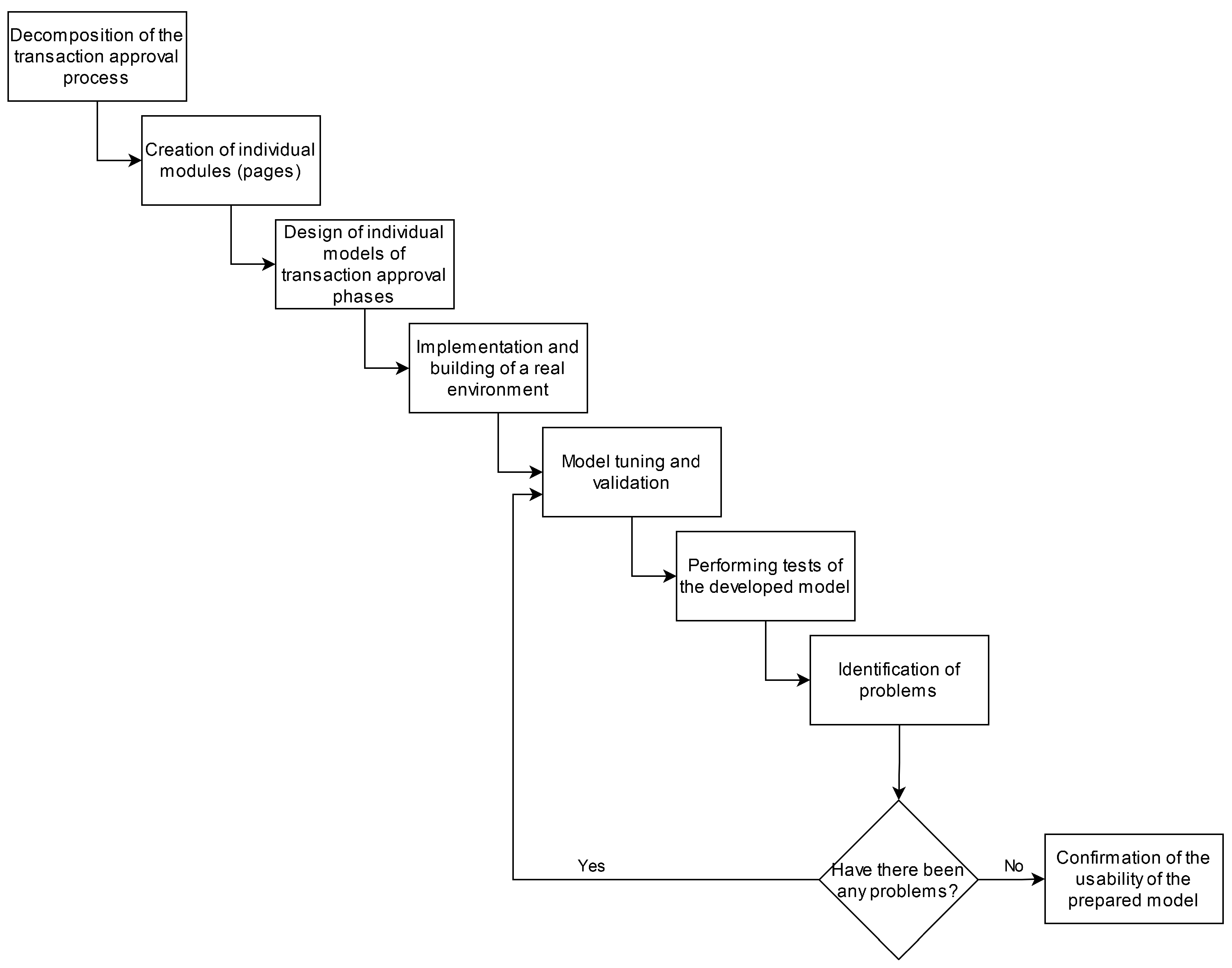
Figure 14 shows the phases of model design and testing. The first step was the decomposition of the transaction approval process in Hyperledger Fabric. Based on this process, separate pages were created for each step of the transaction approval process. A model of the transaction approval process was built from the pages. Next, the real Hyperledger Fabric environment was built, and the tests required to determine the duration of each transaction approval step were run on it. The next step was to configure the duration of each stage of the model and run tests on the prepared Petri net model. If problems were identified, the time parameters of each step were corrected, and tests were performed again. When the tests of the prepared Petri net model agreed with the results obtained from the real environment tests, the model was considered correct.
To correctly configure the Petri net model, that is, to obtain an adequate model of the performance of operations under the LAAFFI protocol, we needed to determine the duration of each stage of the HLF transaction approval. We achieved this by performing tests on the distributed ledger, during which we collected all the necessary characteristics, i.e., the duration of each stage, data transfer time, and the transaction size. Four tests were performed for different numbers of nodes in the organization, the duration of the block build (BatchTimeout), and the number of transactions in a block (MaxMessageCount). The values shown in
Table 2 were collected during the performance tests of the LAAFFI protocol [
3].
Each examination consisted of several tests during which Hyperledger Caliper was used to generate transactions at the specified frequency, that is, 100, 200, 300, 400, 500, and 550 TPS. Each transaction consisted of writing 100 bytes of data to the ledger.
Table 3 shows the values of all the HLF configuration properties used while conducting this research. The complete results of our experiments are publicly available in [
43].
The test results, consisting of the execution times of each stage, the size of each transaction, the number of transactions in a block, and the number of blocks, were post-processed as follows:
For each test block, the execution time of each stage was calculated.
The execution times of all tests were grouped according to the stages and the frequency of the arrival of the transactions.
For each group, the mean and standard deviation of handling a single transaction in a block were calculated. These yielded the mean duration and standard deviation of transaction handling for different frequencies of transaction arrival.
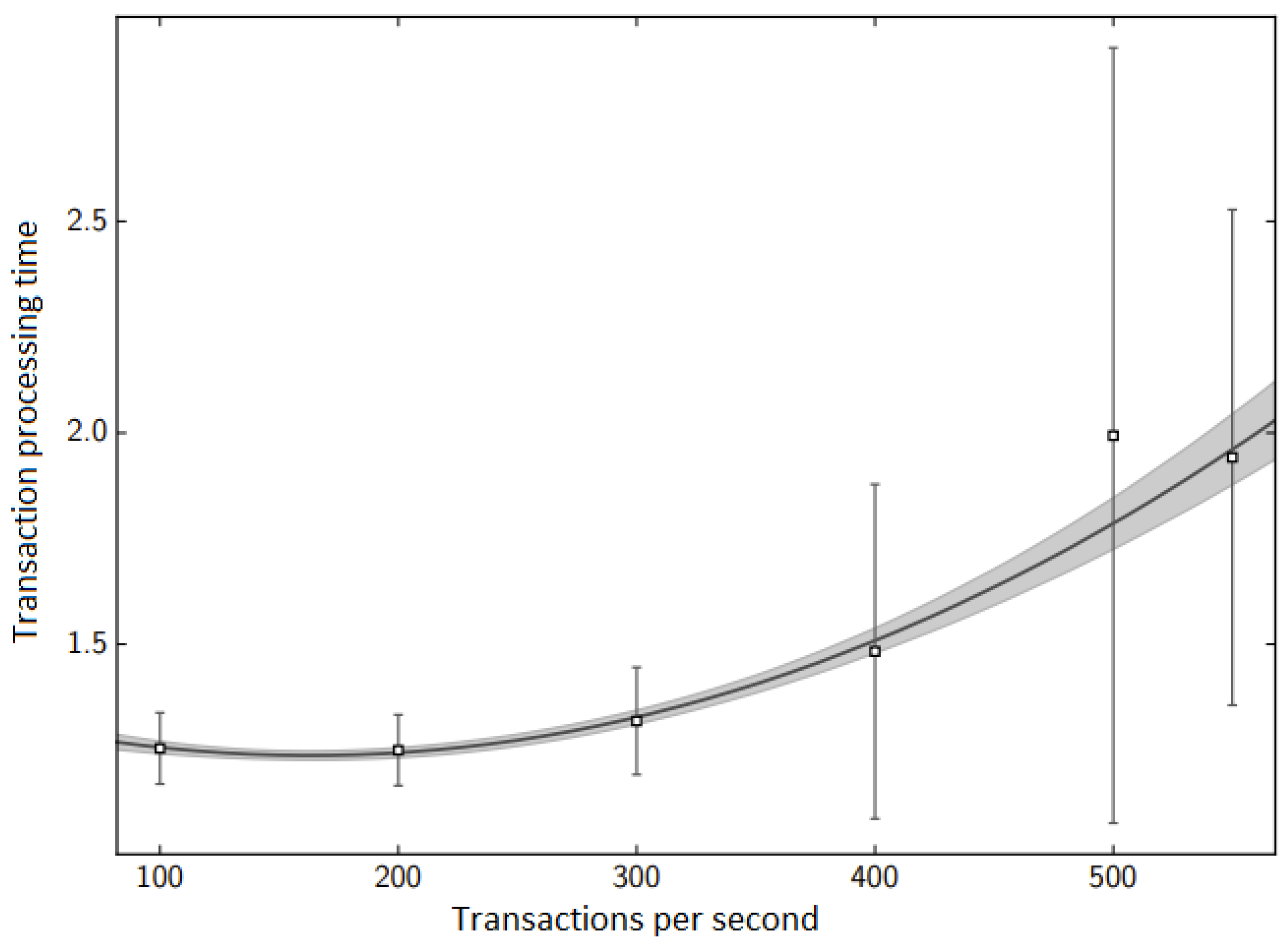
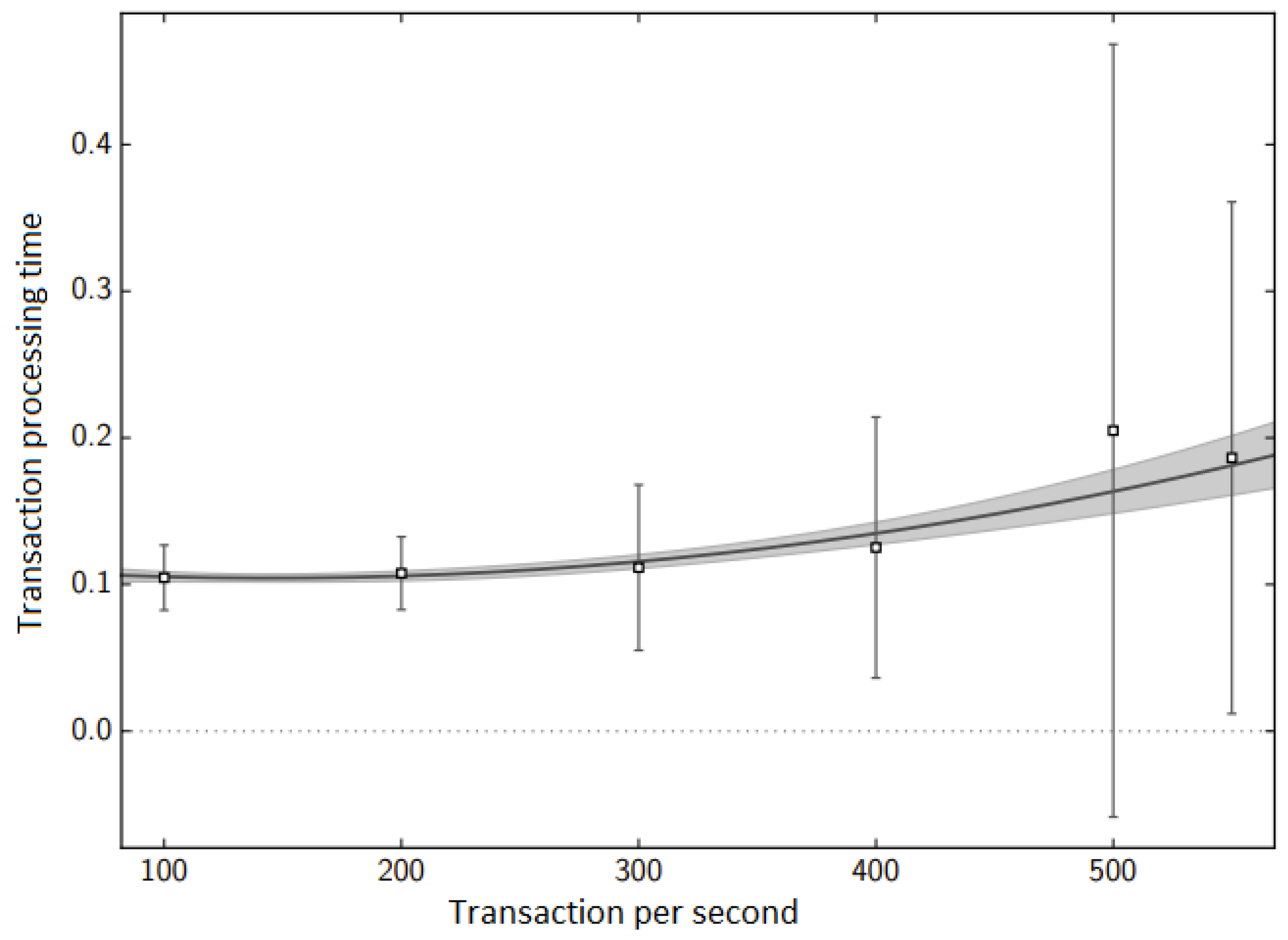
The functions were determined to calculate each step’s duration in the Petri net model. We used a service
http://curve.fit/, accessed on 14 February 2025, to create an approximate continuous function for the results obtained (
Figure 15 and
Figure 16).
If the value of a stage’s average duration did not depend on the frequency with which transactions arrive at the distributed ledger, then the model used a constant-time value.
7. Model Validation and Overall System Performance Analysis
When the model is simulated, files containing a log of the operations performed are created. From this log, all relevant distributed ledger parameters can be obtained. To check whether the Petri net model behaves identically to the test results, we used the following parameter values obtained from the log files:
The duration of writing 50,000 transactions in the distributed ledger;
The required number of blocks to store 50,000 transactions;
The average duration of processing transactions (latency);
Of the average queue length during the simulation.
During the tests, a transaction size between 6570 and 6577 bytes was obtained. However, the size would differ if a different amount of data was written to the distributed ledger or a different endorsement policy was used. Furthermore, the calculated parameters would be different for other chain codes.
The simulation results obtained from our Petri net model agree satisfactorily with the results from our experimental environment, as shown in
Figure 15 and
Figure 16. The only significant difference in simulated and measured transaction processing time can be observed in the case of 500 transactions per second. It is caused by an inaccurate fit of the determined function for this value. The difference is due to the chosen parameters of the block being created. For 500 TPS, there was a situation where two conditions for creating a block were met in a very short interval. As a result, two blocks were created, one containing several hundred transactions, while the other contained a few transactions.
Table 8 shows the values of the coefficient of variation for the tests conducted for the two stages depending on the frequency of arrival of new transactions. For a frequency of 500 transactions per second, the value of the coefficient of variation is the highest. These results indicate that the network is on the verge of stable operation. In this situation, some blocks are queued, which means that nodes’ processors cannot keep up with performing operations required for processing incoming blocks, i.e., the length of the task queue in the processor is greater than 1.0.
8. Discussion
To our knowledge, we are first to use Colored Petri nets to model HLF operations. In our work, we also demonstrated the possibility of constructing a very precise and well-tuned model to the temporal characteristics of a given environment, mainly through measurements of the execution times of various operations constituting real HLF peers and the appropriate construction of approximation functions. This approach has only been presented on a more general level in work [
11]. As we indicated in
Section 2, several prior contributions focused on the modeling of specific performance aspects of Hyperledger Fabric, such as the effect of the impact of queue lengths on selected HLF parameters such as transaction latency, transaction throughput or nodes utilization [
11], or the impact of Sybil attacks on HLF performance [
18]. The models presented in other articles [
44,
45] are more basic. One of the assumptions of such models is the homogeneous nature of the HLF environment, which is not always a correct assumption. This is because organizations can be built from peers with different hardware characteristics, the duration of data transfer between peers can differ due to variation in the available network bandwidth, and the peers themselves can be switched off. The models presented [
11,
19,
46] are also built for a specific number of peers/organizations and the authors do not adequately differentiate between the concepts of peer and organization in HLF. This means that these models cannot be used in practice without reconstruction.
Our approach is more comprehensive, allowing simulation studies to specify the size and number of transactions, block parameters (maximum size, maximum number of transactions in a block, time between consecutive blocks), the number of peers, and organizations. Our modular approach makes it possible to simulate different HLF networks and endorsement policies. It is possible to define the characteristics of each transaction approval step for each HLF peer individually before executing the simulation, so as to simulate the real environment. Each peer can reflect different hardware configurations and have various data transfer latencies. Taking the above into account, it is difficult for us to directly relate the obtained results regarding efficiency to the results of other studies regarding the modeling and evaluation of HLF performance metrics. We can compare the general relationships obtained from our model with the results of essential relationships, such as the relationship between the transaction latency and the number of transactions generated by the CPS devices, or the number of transactions in a block, and the latency. As can be seen in
Figure 15 and
Figure 16, the transaction processing time increases depending on the number of transactions generated by CPS devices.
9. Conclusions
We presented a novel and effective approach to modeling DL with timed CPNs. We used CPNs because they provide a robust framework for modeling and analyzing distributed ledger performance. This allows for a detailed study of synchronization, throughput, and response time in blockchain systems. In particular, CPNs supports the modular implementation of specific phases of HLF transactions and functions, such as Raft or PBFT consensus algorithms. The CPN model can account for low-level details, such as network latency and chaincode operation times. The model also enables an assessment of throughput, scalability, and identification of bottlenecks. Using the CPN simulation model requires implementing the protocol under study and conducting performance tests of this implementation before carrying out tests based on the Petri net model. This is needed to parameterize the CPN model adequately. However, once it is developed and parameterized adequately, with the ability to easily adjust the parameters depending on the configuration of the distributed ledger, the cost of testing using the model is less than the cost of performing the tests in a real system. Another advantage is that studying the performance parameters for different configurations of distributed ledgers is easier. Once the model is adequately partitioned into pages, it can scale successfully to analyze distributed ledgers consisting of multiple organizations and nodes within each organization.
We have demonstrated that CPNs can be used to effectively model the performance of the LAAFFI, a distributed ledger-based application that provides authentication and authorization for the CPS. Details of the LAAFFI, as well as results of its experimental performance and security analyses, are presented in [
3]. We implemented a prototype of the LAAFFI and experimentally evaluated its performance regarding latency, throughput, and transmission overhead. To implement a CPN simulation model of the LAAFFI, we chose CPN Tools software package as the modeling environment because it offers advanced features such as simulation data generation, latency analysis, and performance monitoring of large distributed systems. To assess the model, we compared the results obtained from our experimental evaluation with the simulation results performed with our CPN model. Our results show that the developed model agrees adequately with the experimental environment and thus can be used to evaluate the performance of distributed ledger applications effectively.
In future work, we plan to extend our CPN model of HLF in several ways. First, we plan to include other consensus algorithms. Second, we want to evaluate the performance of the LAAFFI in a more realistic setting. For example, we plan to deploy teh LAAFFI on a real-world cyber–physical system and measure its performance under different load conditions. Based on such realistic measurements we can better parametrize our CPN model. Third, we also plan to use our model to optimize the performance of the LAAFFI. For example, we can use our model to identify application bottlenecks and develop strategies to mitigate those bottlenecks. Finally, we also plan to try to create a universal CPN model for different DLs, and thus model other consensus mechanisms suitable for private DLs with node verification. We believe that our work significantly contributes to the field of distributed ledger modeling. Our CPN model is a powerful tool that can be used to evaluate and optimize the performance of diverse distributed ledger applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}