1. Introduction
Because of its powerful data organization and management ability, as well as mature transaction processing and data consistency guarantee, the relational database is widely used in many industries, such as finance, retail, medical, and so on. However, there is a high threshold for the use of the structured query language SQL, so researchers have proposed Text-to-SQL tasks that aim to translate natural language problems into structured query statements. By constructing the natural language interface of the database, this task has become a research hotspot in the natural language processing and database community, so that users can extract key information efficiently without a professional background.
The challenge of Text-to-SQL lies in bridging the semantic gap between natural language and SQL queries, encoding complex natural language inputs, and decoding them into richly structured SQL query statements. Previous studies have been dedicated to addressing these challenges, treating Text-to-SQL as a sequence-to-sequence task, focusing on encoder–decoder architectures, and training machine learning models using Text-to-SQL corpora [
1,
2,
3,
4].
The process of implementing Text-to-SQL based on the encoder–decoder architecture begins with data pre-processing, where training data are collected and cleaned. Afterward, the encoder transforms a natural language query into encoded information, capturing both syntax and semantic details. The decoder then utilizes this encoded information to progressively generate the corresponding SQL query, including components such as SELECT, FROM, and WHERE.
This study aims to address three critical technical challenges in the Chinese Text-to-SQL domain: (1) insufficient modeling of cross-lingual schema linking that fails to capture deep semantic correlations between Chinese linguistic features and database schemas; (2) underexplored potential of open-source large language models (LLMs) for semantic parsing tasks; (3) error propagation effects inherent in conventional multi-stage processing pipelines that significantly degrade system performance. To overcome these limitations, we propose an integrated framework combining cross-lingual alignment enhancement, lightweight model fine-tuning, and establishing a robust mapping mechanism between Chinese natural language queries and structured SQL representations. The technical specifics of each challenge and our corresponding innovative solutions will be systematically elaborated below.
Cross-language schema linking for Chinese Text-to-SQL needs to be strengthened. Existing solutions exhibit significant limitations. On one hand, current approaches tend to suit simple queries, but their performance drops as the number of database schema complexities and multi-table joins increase. On the other hand, while database schemas are usually in English, user idioms (take Chinese for example) and the data they record may be in other languages. In such cases, SQL parsers trained on English Text-to-SQL corpora greatly diminish in performance, or may even fail to comprehend the natural language queries correctly.
Thus, the associated benchmarks have become increasingly intricate, from single-domain datasets to multi-domain datasets, accumulating more and more complex query–SQL pairs. Single-domain datasets collect query–SQL pairs for a single database in real-world tasks, such as ATIS [
5], SEDE [
6], etc. Cross-domain datasets contain multiple databases, to test the performance of models on complex, unseen SQL queries and their ability to generalize to new domains, such as WikiSQL [
7] and Spider [
8].
Many existing studies are conducted on Spider for its challenging nature, which involves various complex operators. Research on Chinese Text-to-SQL tasks, in comparison, is less frequent. Due to the increasing complexity of the existing test benchmarks, and the obvious difference between the description of Chinese natural language questions and the language used by the database schema items, it is necessary to strengthen cross-language schema linking for the complex Chinese Text-to-SQL test benchmarks.
The potential of open-source LLMs has not been fully tapped. Recently, open-source large language models (LLMs) have flourished, offering rich linguistic knowledge learned from vast corpora through pre-training, better capturing the diversity and variability of natural language, and understanding contextual relationships within, excelling in tasks such as programming, logical reasoning, and text generation.
Cutting-edge research combining pre-trained large-scale language models with prompt engineering has achieved remarkable results [
9,
10,
11,
12,
13].
However, most studies based on LLMs utilize closed-source ones with vast parameter scales, such as OpenAI LLMs, overlooking the potential of open-source LLMs. Addressing Text-to-SQL tasks with closed-source LLMs offers little room for optimization and often requires considerable inference costs. Although open-source LLMs are somewhat limited in context understanding and text generation quality compared to closed-source ones, this issue can be rectified through supervised fine-tuning.
Multi-stage pipeline method leads to error propagation. For Text-to-SQL tasks, end-to-end methods often increase the learning difficulty. Most existing methods adopt a multi-stage model, assisting the SQL decoder with auxiliary tasks such as schema item classification and encoding token types, collaboratively resolving the Text-to-SQL task [
3,
14,
15].
Multi-stage methods decompose complex tasks into stages, each fulfilled by specialized components or modules, thereby enhancing the overall system performance. However, multi-stage pipeline methods also present the challenge of error propagation [
16,
17,
18]. Error propagation refers to mistakes in one stage of the pipeline potentially cascading to subsequent stages, causing errors in system output.
Addressing error propagation is a significant challenge in designing multi-stage pipeline systems.
To explore the performance of open-source large language models on Chinese Text-to-SQL tasks, and research potential methods to strengthen cross-linguistic schema linking and reduce the learning difficulty of Text-to-SQL conversion, we conducted preliminary experiments on the Chinese Text-to-SQL CSpider dataset. Initially, we supervised fine-tuned a relatively small-scale open-source LLM such as LlaMa2-7b-chat using only basic question representations to organize training data, resulting in nearly a 40% improvement in exact match on the development set. This pre-experiment convinced us that using LLMs to tackle Chinese Text-to-SQL tasks is an effective future method.
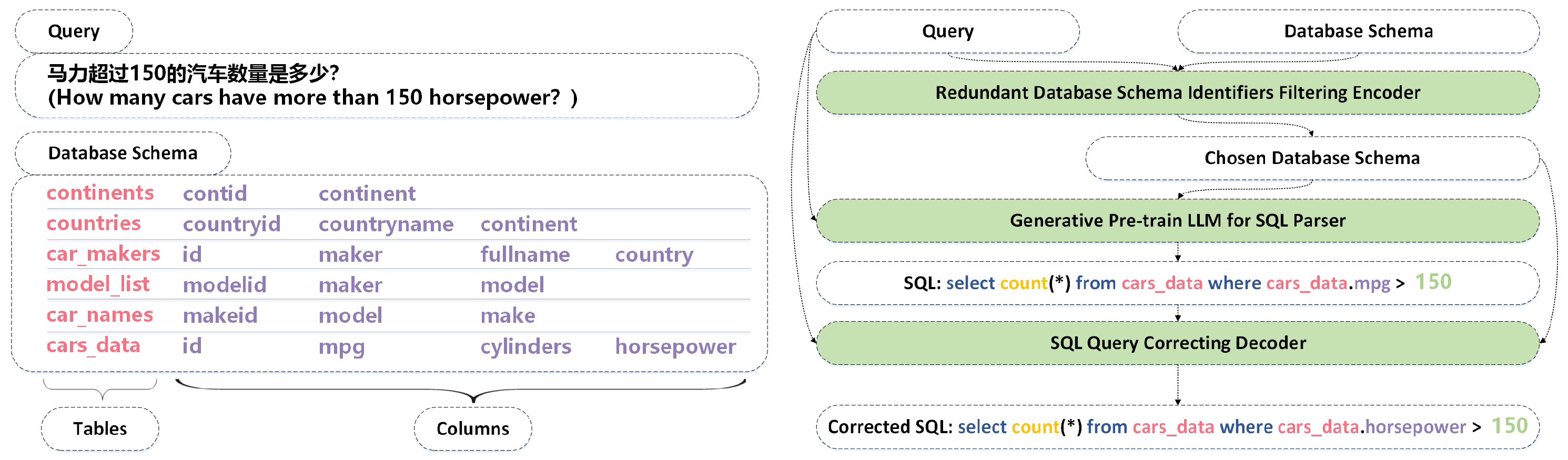
We propose a three-stage pipeline method: Redundant Database Schema Items Filtering Encoder (RDsiF-Encoder for short), generative pre-trained LLM for SQL parser, and SQL query correcting decoder, to validate the feasibility of our ideas:
Stage 1: Train a filtering encoder to discard database information irrelevant to the query, improving cross-lingual schema linking accuracy and reducing the SQL parser’s learning difficulty.
Stage 2: Utilize a supervised fine-tuned LLM to parse the query and generate the corresponding SQL statement.
Stage 3: Train a correcting decoder to refine the SQL statements from Stage 2, further enhancing the overall model performance.
Contributions We propose a three-stage pipeline method (
Figure 1) to address Chinese Text-to-SQL challenges, emphasizing three key improvements over existing approaches:
Schema Filtering with Cross-Language Optimization: Unlike conventional schema linking methods [
3,
19] that focus on structural encoding, we design a filter encoder enhanced with a Chinese information injected layer and data type-aware attention. This specifically addresses ambiguity in cross-language schema linking and eliminates interference from data type-mismatched columns, overcoming limitations in existing graph-based encoders [
4,
20] that neglect cross-lingual alignment.
IECQN question representation for LLM fine-tuning: We propose IECQN question representation (Instruction, Example, Chosen schema, Question, NatSQL) for LLM fine-tuning, which systematically structures prompts beyond the decomposition strategies in [
12] and achieves better alignment with database contexts than the holistic representations in [
13].
Error Correction for Multi-Stage Pipelines: Unlike existing solutions that use prompt engineering methods for error correction [
12], we introduce a dedicated correction model trained on a newly collected dataset to rectify error propagation across stages.
We conducted a series of evaluations and analyses, and the results show that our methods have achieved state-of-the-art (SOTA) performance in execution accuracy on the CSpider dataset.
Outline The remainder of this paper is structured as follows.
Section 2 introduces the latest Text-to-SQL solutions and related studies.
Section 3 presents our contributions to the task.
Section 4,
Section 5 and
Section 6 includes the experimental setup, results, and conclusions of this work.
3. Methodology
Pre-processing and post-processing play pivotal roles in Text-to-SQL task optimization [
28]. The pre-processing stage enhances generation efficiency and accuracy through schema pruning, while post-processing ensures SQL executability via error correction and validation. These complementary components form a critical optimization pathway for large language models (LLMs) in Text-to-SQL applications. To address the adaptability challenges of conventional methods in complex Chinese database scenarios, we propose a novel modular three-stage optimization framework that systematically integrates (1) data-driven pre-processing for redundant schema filtering, (2) core LLM-based SQL generation, and (3) post-processing with dedicated error correction models. This architecture represents the first comprehensive implementation of integrated pre-processing–post-processing optimization specifically designed for Chinese Text-to-SQL applications.
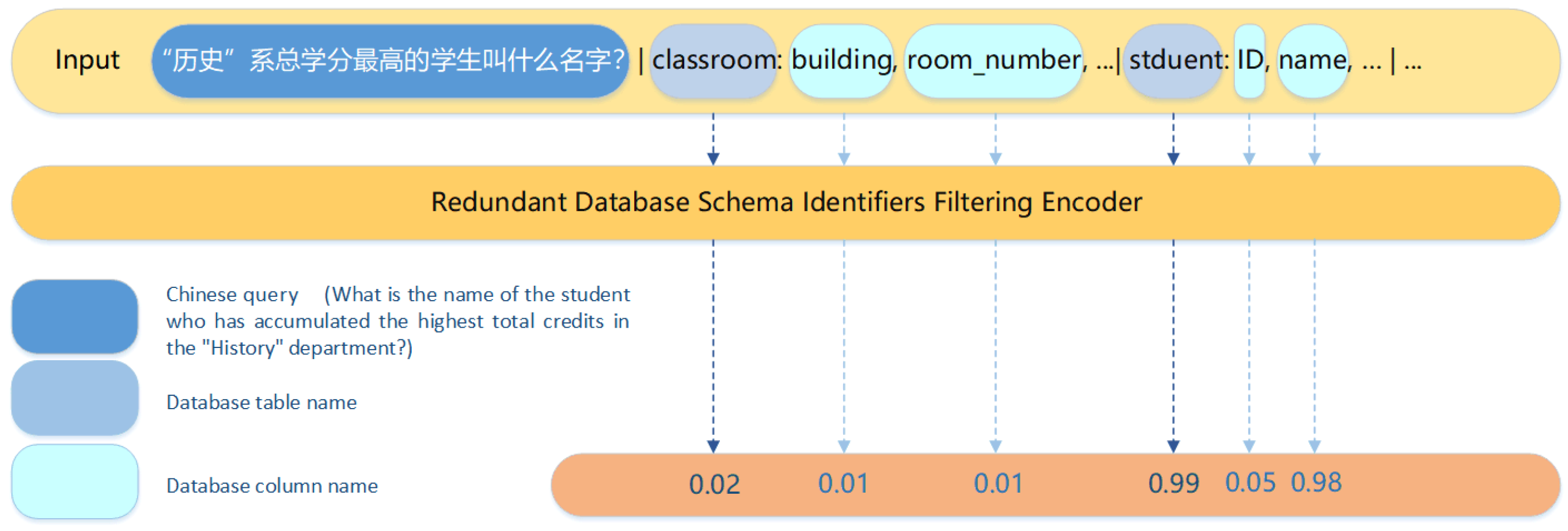
3.1. Redundant Database Schema Items Filtering Encoder
In a given database
D, with tables list
and columns lists
, where
, natural language queries typically do not involve all database schema items. Superfluous schema items are likely to negatively affect Text-to-SQL parser performance. Moreover, aligning entities mentioned in natural language queries with database schema items is one of the challenges in Text-to-SQL tasks. Thus, we did not use all database schema items as prompts for the LLM but trained a RDsiF-Encoder instead. We define the filtering task as a classification process, where, for each query
Q, the probability of each schema item in the database being necessary to
Q is predicted, and superfluous tables and columns are filtered out. The diagram is shown in
Figure 2.
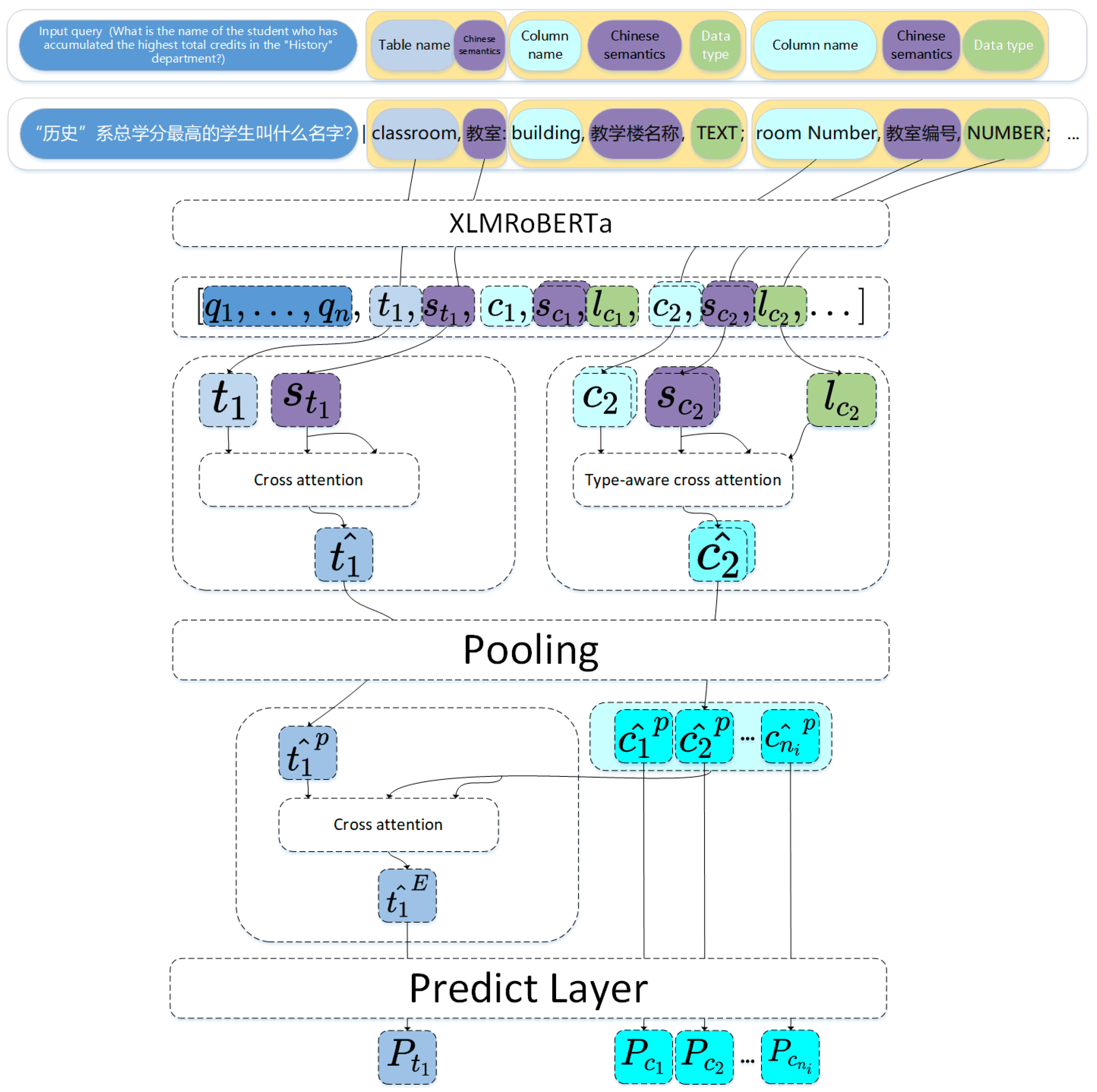
3.1.1. Organization Method of Input Data
In order to make the classifier fully capture the correspondence between question Q and the schema item, the Chinese semantics of the schema item and the data type of the column are taken as part of the input. Specifically, we organize the input to the model in the following form: , where represents the number of columns contained in table , s represents the Chinese semantic information corresponding to the schema item, and l represents the data type corresponding to the column, such as NUMBER and TEXT.
We input the combination of query and database schema items into XLM-RoBERTa, a cross-lingual pre-trained language model. The RDsiF-Encoder structure is detailed in
Figure 3.
3.1.2. Chinese Information Injected Layer for Schema Items
For the Chinese Text-to-SQL task, there is a noteworthy aspect: schema items are predominantly named in English, often with the inclusion of abbreviations, while the queries are presented in Chinese. The cross-linguistic nature and the abstract expression of schema items undoubtedly increase the difficulty of classification.
The omission of schema items in the Text-to-SQL mapping inevitably hinders generative models from capturing potential correct schema items. Thus, it is necessary to enhance cross-language schema linking to address this limitation.
Therefore, we designed Chinese information injected layer (CII layer for short) to inject the Chinese semantic information of schema items into their corresponding original embedding. Even if the original names of the database schema items are abstract, the Chinese information injection layer can help the filtering encoder to capture the schema items involved in the natural language query
Here, the multi-head scaled dot-product attention mechanism [
29] combines the schema item embedding
with its Chinese semantic information
to capture the associations between the database schema and the Chinese natural language description. This mechanism computes weighted similarities between
and
, using these similarities as attention scores to guide the blending of information, and finally obtains the Chinese semantic injected schema embedding
.
The multi-head mechanism (with H heads, and ) enables the model to learn information in parallel across different subspaces, with each head capturing different dimensions of semantic relevance. This enriches the semantic features captured by the model.
Subsequently, Chinese semantic injected schema embedding is combined with the original embedding through residual connection, followed by layer normalization, to ensure training stability and to retain the original information. The resulting is an enhanced embedding representation infused with Chinese semantic information, which improves the model’s ability to recognize and understand abstract database schema items.
3.1.3. Type-Aware Cross Attention for Columns
Queries often involve the values of a certain column. According to the data type of the value, columns with mismatched data types will be filtered out. In order to enhance the ability of the classifier to perceive the data type of the column, type-aware cross attention is designed based on the CII layer. Specifically, the implementation process is as follows.
The realization process of type-aware cross attention is similar to that of CII layer. The difference is that the Chinese semantic information and data type information are added, and the representation capability of the output column embedding is enhanced through the integration, so that the classifier can perceive the data type of the input column.
3.1.4. Column Injected Layer for Tables
The information involved in
Q may not involve table names, which prevents the classifier from correctly classifying potential tables. For example, column
c, which is necessary for
Q, belongs to table
t, but table
t is not explicitly mentioned in
Q. Drawing on the work of [
3], we designed a column injected layer to enhance the relevance of tables to their columns.
is the enhanced table embedding that injects information about the columns it contains.
3.1.5. Tables and Columns Classifier
To complete the binary classification task, two fully connected layers are set up at the end of the encoder.
where x refers to the enhanced table embedding
or the pooled type-aware column embedding
.
3.2. Generative Pre-Trained LLM for SQL Parser
Language models that have undergone pre-training have learned a wealth of linguistic knowledge from large corpora, better capturing the diversity and fluctuation of natural language and understanding the contextual relationships within. This ability to comprehend context allows the generative SQL parser to adapt more flexibly to various language expressions and query structures, better handling complex natural language queries.
Using open-source LLMs to tackle Text-to-SQL tasks provides more room for optimization, achieving an advantage in parameter scale while ensuring performance.
Before conducting supervised fine-tuning for the large language model (LLM), it is essential to prepare training data. In the context of Text-to-SQL, particular attention should be given to the method of representing questions. In question representation, a primary challenge is the effective combination of natural language questions with database schema information. The goal of question representation is to control the probability of the LLM generating SQL statements, maximizing the likelihood of generating correct SQL queries.
where
denotes the probability of generating the correct SQL query
given the query
Q and the associated database schema information
D. The function
f encapsulates the question representation process, and the optimization aims to maximize this conditional probability, ensuring the generation of accurate SQL queries by the LLM.
To organize the training and test data required for LLM supervised fine-tuning, we proposed a question representation method: IECQN.
In IECQN, first, the instruction (I) articulates the task to be solved by the SQL parser and the output standard; then, an example (E) output helps the SQL parser clarify the output standard further; the chosen database schema information (C) is expressed through listing the N most relevant tables and M columns within those tables associated with the question; next, the natural language query (Q) is presented. Finally, we use an intermediate representation to bridge the gap between natural language questions and SQL queries. NatSQL simplifies queries while preserving core SQL functionalities, significantly reducing the generation complexity for LLMs. Its natural language-like expressions align better with Chinese semantic logic, alleviating the model’s pressure to handle complex SQL syntax (such as deep nesting and HAVING clauses). Additionally, NatSQL and standard SQL support bidirectional lossless conversion, retaining complete semantic information for seamless plug-and-play usage. Therefore, we use the NatSQL corresponding to the original gold SQL query as the target response.
Most existing methods for LLMs focusing on prompt engineering and in-context learning do not explore the potential of supervised fine-tuning; the goal of supervised fine-tuning is to minimize the following empirical loss:
Here, the goal is to find the best-performing parameters which minimize the accumulated loss over the training set . The function f takes query and its corresponding database information , encapsulates the question representation process. denotes the SQL query generated by . The loss function evaluates the deviation of this prediction from the gold annotation . Through this optimization, the fine-tuned model is better positioned to capture the nuances of the targeted tasks and perform with greater accuracy.
As pre-trained language models grow larger, the difficulty of traditional fine-tuning increases. Considering computational resources and training costs, we opted for parameter-efficient fine-tuning. The trainable parameters in some parameter-efficient fine-tuning (PEFT) methods are significantly fewer compared to the parameter scale of a LLM [
30,
31,
32].
The fine-tuned is used for inference, creating NatSQL queries by processing the input natural language question and the specified database. The question representation method used during inference is consistent with the method employed to organize the training data.
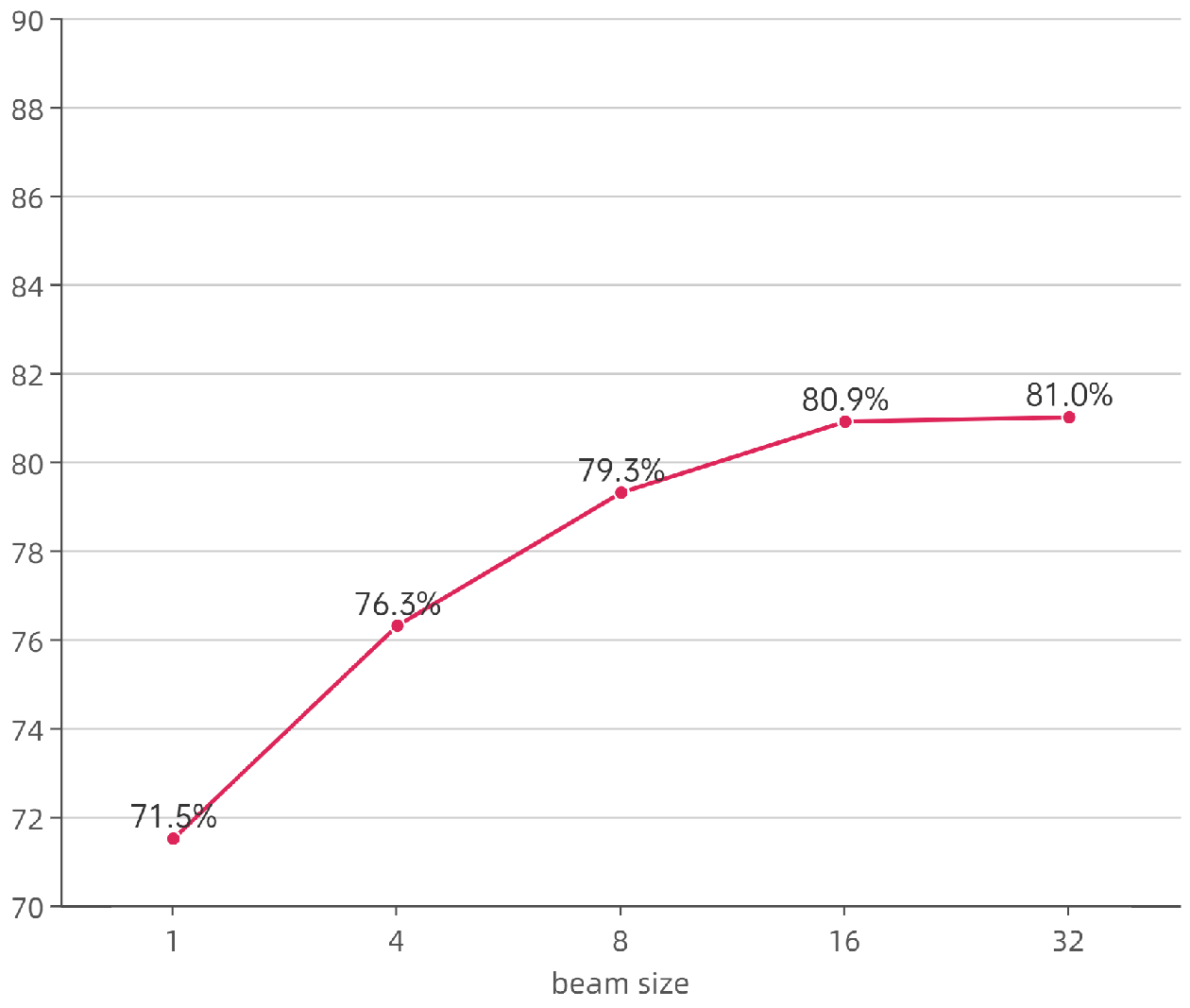
SQL parser first generates intermediate representation NatSQL, which can be translated to SQL queries via a non-trainable transpiler [
23]. During inference, a beam search of size B is performed, with the first executable SQL query output to ensure execution accuracy.
We conducted a series of experiments to validate the effectiveness of our proposed question representation method IECQN, while also discussing the vast potential of supervised fine-tuning on LLMs for Text-to-SQL tasks.
3.3. SQL Query Correcting Decoder
A widely recognized downside of multi-stage pipeline methods is error propagation, where incorrect categorization of redundant items inevitably affects the generative capabilities of large language models for SQL query generation. Hence, we collected correct and incorrect inference results from
(i denotes a specific parameter-efficient fine-tuning) to train an SQL query correcting decoder, mitigating the effects of error propagation. Given a natural language query
Q, database schema information
D, and the erroneous SQL query
, the goal of the correcting decoder is to predict the edit operations
m required for correction and the corrected SQL
. Following existing works [
33], we defined the correction task as a sequence-to-sequence generation:
The equation represents the probability of correctly predicting each edit operation and the updated SQL snippet at time step t, conditioned on the input query Q, schema D, the erroneous SQL , and the sequence of all previously predicted edits and SQL snippets up to time . This sequence-to-sequence generation framework serves to iteratively refine the erroneous query towards the correct form, ultimately producing the corrected SQL .
To ensure that the training data for the correcting decoder reflects the true distribution of errors, we performed k-fold cross-validation on the Chinese Text-to-SQL dataset using a specific pre-trained LLM, synthesizing a correction dataset.
Specifically, for the training set, the Chinese Text-to-SQL training set was divided into k parts, using k-1 subsets to supervised fine-tune the LLM while evaluating on the remaining subset. If the parsing result is not an exact set match or execution match to the gold annotation, it is marked as erroneous; otherwise, it is deemed correct and included in the correction training set. For the test set, LLM is supervised fine-tuned on the training set of the complete Chinese Text-to-SQL dataset to obtain
, and then
is evaluated on the development set of the Chinese Text-to-SQL dataset. Then, the evaluation results are included in the test set of the error correction data set. The training data of organization and fine-tuning methods used for the supervised fine-tuning of LLM are consistent with those mentioned in
Section 3.2. The specific pre-trained LLM refers to the pre-trained LLM used by the generative pre-trained LLM SQL parser.
We used three editing operations: replace, insert, and delete, to correct the erroneous SQL queries in the correction dataset relative to the target output, completing the construction of the correction dataset (
Figure 4).
It is worth noting that CSpider is translated from the Spider dataset, which was annotated by eleven different annotators to extract gold SQL queries, with inconsistent annotation styles.
Also, the IECQN representation method we proposed in
Section 3.2 uses NatSQL as an intermediate representation. When the intermediate representation is converted to SQL queries, its style (NatSQL style for short) has certain differences from the gold SQL queries. For differences in style see the diagram below.
Gold SQL style tends to use uppercase letters to represent keywords, table names, and column names, and employs the AS keyword to alias tables. In contrast, NatSQL style leans towards the use of lowercase letters, directly utilizing table names without the AS keyword.
The construction rules for these two styles of SQL queries are inconsistent (
Figure 5), and the ultimate output of the generative NatSQL parser is the former. Considering all the above factors, to reduce the learning difficulty of the correction model and avoid conflicts in the construction rules between the erroneous SQL queries and the target outputs, when correcting the erroneous SQL queries, the NatSQL style SQL query corresponding to the original gold SQL in the CSpider dataset is taken as the target output. In this way, we can reduce the risk of erroneous corrections due to style differences, enhancing the robustness and accuracy of the correction decoder when dealing with actual SQL queries.
5. Results
5.1. Results on CSpider
We compared our proposed method with the following methods: RAT-SQL [
4], LGESQL [
39], FastRAT [
40], ChatGPT [
9], Heterogeneous Graph + Relative Position Attention [
21], RESDSQL [
3], and Auto-SQL-Correction [
33].
On the development set of the CSpider dataset, the performance of FGCSQL and other methods on the EM and EX evaluation metrics is shown in
Table 1.
Our best model variant, FGCSQL, performs closely to the SOTA on the EM metric (−0.4% difference), and it outperforms all baseline variants on the EX metric. This indicates that our three-stage pipeline method can significantly reduce the learning difficulty of Text-to-SQL conversion. Our FGCSQL achieved a competitive performance, improving EX from 79.1% to 81.1%, showcasing the effectiveness of our method. Notably, all model variants that combine with NatSQL show significant improvement on the EX metric compared to previous studies, as using NatSQL as an interim representation bridges the gap between natural language and SQL queries, further reducing the learning difficulty.
5.2. Generalization Validation
To evaluate the model’s generalization capability, we conducted experiments on the BIRD development set. BIRD’s database design simulates real-world scenarios, featuring cluttered data rows and complex schemas. Its difficulty stratification (Simple/Moderate/Challenging) effectively validates the model’s ability to handle schema redundancy in Chinese Text-to-SQL tasks.
Sampling Methodology: Through stratified sampling from 1534 development set samples, we constructed a 200-sample subset (proportionally distributed across difficulty levels) by translating English questions to Chinese, ensuring linguistic and task complexity representation.
Challenge Characteristics: Notably, BIRD contains numerous challenging cases involving numerical reasoning and nested queries, which impose heightened demands on Text-to-SQL solutions.
Experimental Results: Our three-stage pipeline achieved an execution accuracy (EX) of
66.27% without fine-tuning on the BIRD training data. While this performance gap (compared to the current SOTA [
41] EX of 73.01% on BIRD) reveals improvement potential, it preliminarily demonstrates our method’s cross-dataset generalization capability, particularly in handling complex schema relationships unseen during training.
5.3. Ablation Studies
To analyze the effectiveness of each design component, we conducted a series of ablation experiments on the CSpider development set.
5.3.1. Effect of Chinese Information Injection Layer
The design of the Chinese Information Injection Layer aims to address the difficulties of cross-language schema linking and reduce the parsing difficulty for the subsequent generative SQL parser. The AUC is calculated separately for table and column classification with and without the use of the Chinese information injected layer and type-aware attention, with the experimental results shown in
Table 2.
The CII layer improves the filtering encoder’s table classification AUC and column classification AUC by 0.89% and 0.92%, respectively. Type-aware attention improves the filter encoder’s column classification AUC by 0.82%. The enhanced performance of the AUC indicates that the CII layer is helpful to capture the mapping features between the Chinese information and the corresponding English schema items, and type-aware attention improves the classifier’s type perception ability for column information.
5.3.2. Effect of Redundant Database Schema Items Filtering Encoder
The design of the Redundant Database Schema Items Filtering Encoder aims to resolve the issues with end-to-end methods increasing the learning difficulty of Text-to-SQL. By filtering the database schema items corresponding to the natural language queries in CSpider through the Redundant Item Filtering Encoder, the most relevant database schema items are provided for the IECQN query representation.
Table 3 shows the performance comparison between using filtered database schema items and using all schema items as database information in the question representation, for LlaMa2-7b-chat and ChatGLM2-6b following LoRA fine-tuning.
For the fine-tuned LlaMa2-7b-chat as the SQL parser, using the filtered database schema item information led to a 4.0% increase in EM and a 7.9% increase in EX.
For the fine-tuned ChatGLM2-6b as the SQL parser, using the filtered database schema item information led to a 4.9% increase in EM and an 8.3% increase in EX.
By filtering out irrelevant information that would negatively impact the SQL parser using the Redundant Item Filtering Encoder, the fine-tuned LLM experienced a significant performance boost.
In order to qualitatively analyze the effect of RDsiF-Encoder filtering related schema items, we tested three queries to calculate the output probability of RDsiF-Encoder and draw the schema correlation probability heatmap (
Figure 7). The probabilistic heat map uses a color gradient from blue to red to represent varying probability levels. Blue shades indicate low probabilities. Red shades indicate high probabilities (intensity increases as the color transitions toward red).
Through visualization heatmap analysis, it is found that the redundancy pattern filtering mechanism in this study can effectively identify core table columns across queries of varying complexity. In simple query cases, the model focuses on the correct target car_names.model with a probability >0.98, accurately filtering out other table columns. When processing complex queries involving multi-table joins, the system demonstrates semantic understanding capabilities: despite two distinct query expressions, it consistently identifies the core table car_makers (probabilities 0.991 and 0.990) and its key columns fullname (0.993 and 0.739) and id (0.984 and 0.987), while moderately associating with the maker column in the model_list table (0.650 and 0.620 probabilities) to establish table joins.
Notably, the model can differentiate the semantic differences between columns with the same name across tables: when queries emphasize “car version”, the model column in the car_names table achieves a relevance of 0.981, while the identically named model column in the model_list table only scores 0.082, indicating the system captures contextual table structure differences through column information injection. Additionally, when users employ alternative expressions like “names”, the fullname column’s probability decreases from 0.993 to 0.739, yet the system maintains high-confidence selection of core table columns, proving that the Chinese semantic injection strategy effectively enhances robustness against natural language expression variations. These cases confirm that the filtering module significantly optimizes schema linking accuracy, establishing a reliable foundation for subsequent SQL generation.
5.3.3. Effect of IECQN Question Representation
By using IECQN question representation, an effective expression of natural language questions and database schema information increases the likelihood of generating the correct SQL queries. To validate the effectiveness of IECQN query representation, we compared the parser trained with basic question representation (BS) to one trained with IECQN representation, and the experimental results are shown in
Table 4.
Compared to basic question representation training, using IECQN representation led to a 12.0% increase in EM and 12.9% increase in EX for the fine-tuned LlaMa2-7b-chat as the SQL parser. For the fine-tuned ChatGLM2-6b as the SQL parser, a 27.6% increase in EM and 28.6% increase in EX were observed.
This is because the database information in IECQN representation is customized for the natural language question, eliminating interference from redundant information. On the other hand, using NatSQL as the target output narrows the gap between natural language queries and SQL statements, further lowering the learning difficulty of Text-to-SQL.
5.3.4. Effect of Parameter-Efficiently Fine-Tuned LLM
The purpose of using a parameter-efficiently fine-tuned LLM as the SQL parser is to explore the potential of an open-source LLM in Chinese Text-to-SQL tasks, achieving comparable or even superior performance to larger scale language models with lower training costs.
We compared the performance of LoRA fine-tuned LlaMa2-7b-chat and ChatGLM2-6b with basic question representation with the original un-fined-tuned models. Evaluations used the same input context organization method: BS. Given ChatGPT’s excellent performance on various natural language tasks, we also added comparison results with ChatGPT.
Table 5 shows the experimental results.
Parameter-efficiently fine-tuned LlaMa2-7b-chat improved by 38.8% in EM and 44.6% in EX. Parameter-efficiently fine-tuned ChatGLM2-6b improved by 38.8% in EM and 44.6% in EX as well. Compared to the closed-source ChatGPT, parameter-efficiently fine-tuned LlaMa2-7b-chat was 20.5% ahead in EM and 2.9% ahead in EX. The significant gap in EM compared to EX is because EM is insensitive to the execution results of generated SQL; sometimes the correct SQL for the same query varies substantially in expression order and logic, with EM occasionally misclassifying correct SQL as wrong, leading to false negatives. This means some SQL queries generated by ChatGPT are more diverse and flexibly expressed, yet the execution results are accurate.
The parameter-efficiently fine-tuned open-source LLM achieved comparable performance in Chinese Text-to-SQL tasks, particularly the parameter-efficiently fine-tuned LlaMa2-7b-chat, which surpassed the 20b-parameter ChatGPT in both metrics.
5.3.5. Effect of SQL Query Correcting Decoder
The SQL query correcting decoder aims to resolve the error propagation problem inherent in multi-stage pipeline methods. In our experiments, the LLM used in the generative SQL parser was LlaMa2-7b-chat. We compared the output SQL queries from the first two stages of FGCSQL with the complete FGCSQL, with the results presented in
Table 6.
The use of the correction decoder led to a 0.7% improvement in EM, and a not significant 0.2% improvement in EX, nonetheless achieving the best performance on the CSpider dataset. This is because the correction decoder somewhat shields against the negative impact that misclassification of redundant items could have on generative LLM SQL query generation, reducing error propagation, and, on the other hand, reduces the risks of incorrect corrections due to style differences, enhancing the robustness and accuracy of the correction decoder when handling practical SQL queries.
5.4. Prompt Format Sensitivity Analysis
To evaluate the potential constraints of the IECQN instruction template on model outputs, we designed two categories of prompt variants: (1) Elements Reordering (ICEQ): adjusting the sequence of instruction, example, and chosen schema items to ICEQ, thereby disrupting the original template’s linear logic chain; (2) Weak-format Expressions: weakening the imperative nature of instructions through semantic softening and format simplification.
See
Figure 8 for examples of the modified prompts. By comparing the model performance under these variants, we conducted analysis from two perspectives: output stability (EX fluctuation) and semantic robustness (format sensitivity).
"Based on" → "Using the available": Softens the dependency on chosen database schema items by implying flexibility in interpreting “available” information.
"Convert" → "Try to generate": Replaces a direct command with a suggestion, reducing pressure on absolute correctness and allowing for potential fallibility.
Remove "only return the complete SQL statement": Eliminates the mandatory constraint, allowing unconstrained model outputs.
"###Input:\nquery \n\n###Response:\n" → "query": Directly presents the query without formatting markers.
5.4.1. Output Stability
Table 7 shows that, under the reordered prompts (ICEQ), the model achieves 80.7% EX on the test set, only 0.2% lower than the original IECQN’s 80.9%. However, the weak-format version yields 79.2% EX with a larger fluctuation of 1.7%. Further analysis reveals that 54.2% of the errors in the weak-format outputs stem from generating non-SQL content (e.g., explanatory text, code block markers), indicating significant model dependency on explicit instruction structures.
5.4.2. Format Robustness Metric
We define format robustness as , where and denote the output of the i-th sample under the original and variant prompts, respectively. The experimental results reveal the following:
This confirms that, while maintaining command intensity (non-weak formats), the IECQN structure effectively decouples domain semantics from format dependency, preserving core semantics while enabling generalization across prompt expression variants.
5.5. Error Analysis and Correction Effectiveness Evaluation
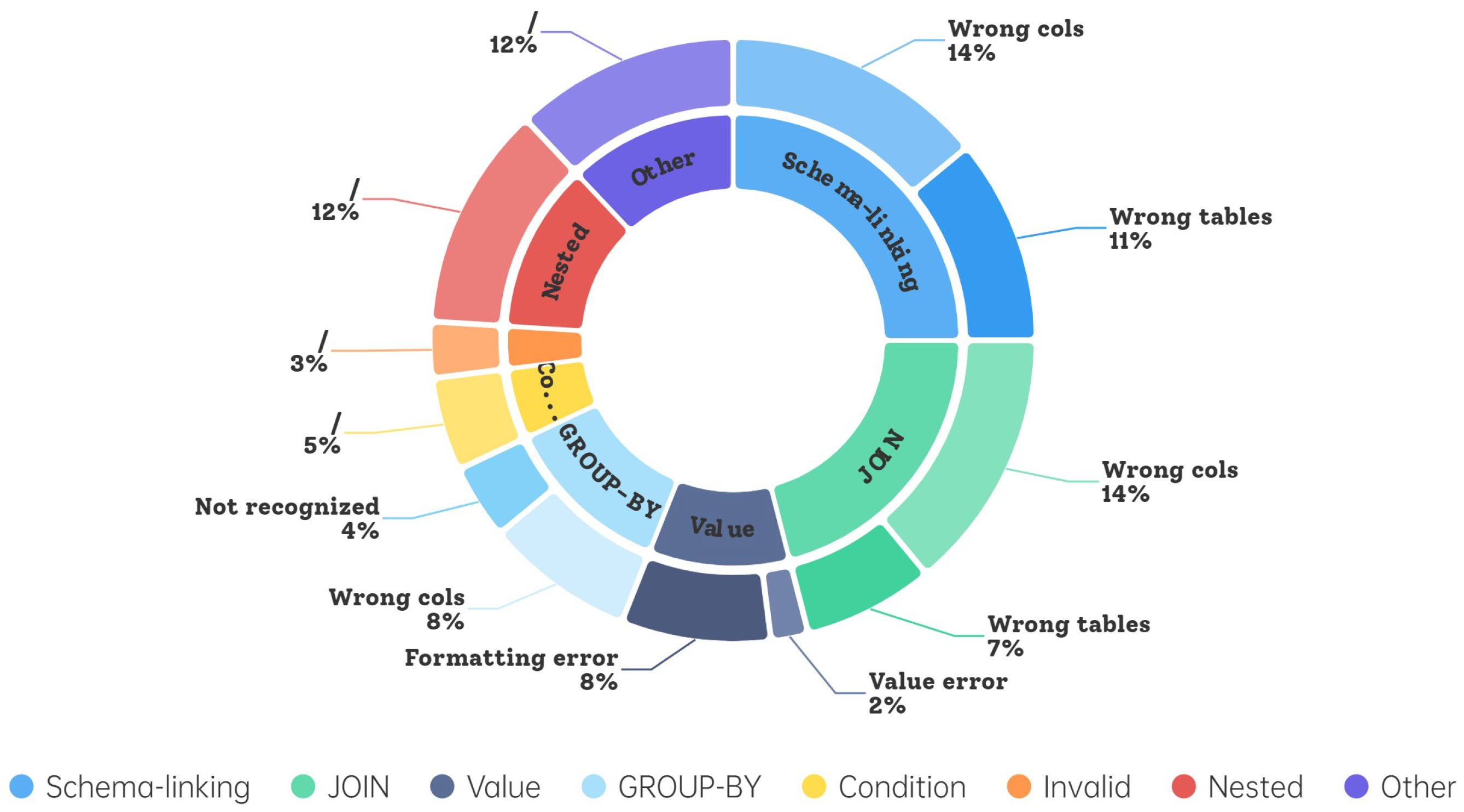
To systematically identify potential errors in the SQL parsing process, we conducted a manual analysis of 100 randomly selected error cases from the correction dataset where the execution results differed from the gold SQL. The categorical error distribution is visualized in
Figure 9.
Schema-linking Errors Occur when the model fails to accurately map entities to corresponding table/column names in the database schema, typically manifested as confusion between homonymous fields or misuse of redundant schema information. These errors stem from incomplete filtering of irrelevant schema elements during the schema filtering phase, leading to entity mapping deviations in LLM-generated SQL.
Value Errors Characterized by incorrect value associations between user queries and database entries, including numerical discrepancies or format inconsistencies (e.g., date formatting mismatches).
JOIN Errors Involve improper join types or missing join conditions, particularly failures in detecting implicit relationships implied in user questions.
GROUP-BY Errors Manifest as incorrect grouping column selection or omission of essential grouping operations (e.g., parsing “calculate average salary per department” as a non-grouped aggregation).
Condition Errors Include comparison operator misuse (e.g., “>” vs. “>=”) and flawed logical condition nesting.
Nested Operation Errors Involve incorrect implementation or undetected nested queries/set operations.
Invalid SQL Structurally malformed SQL statements that fail execution.
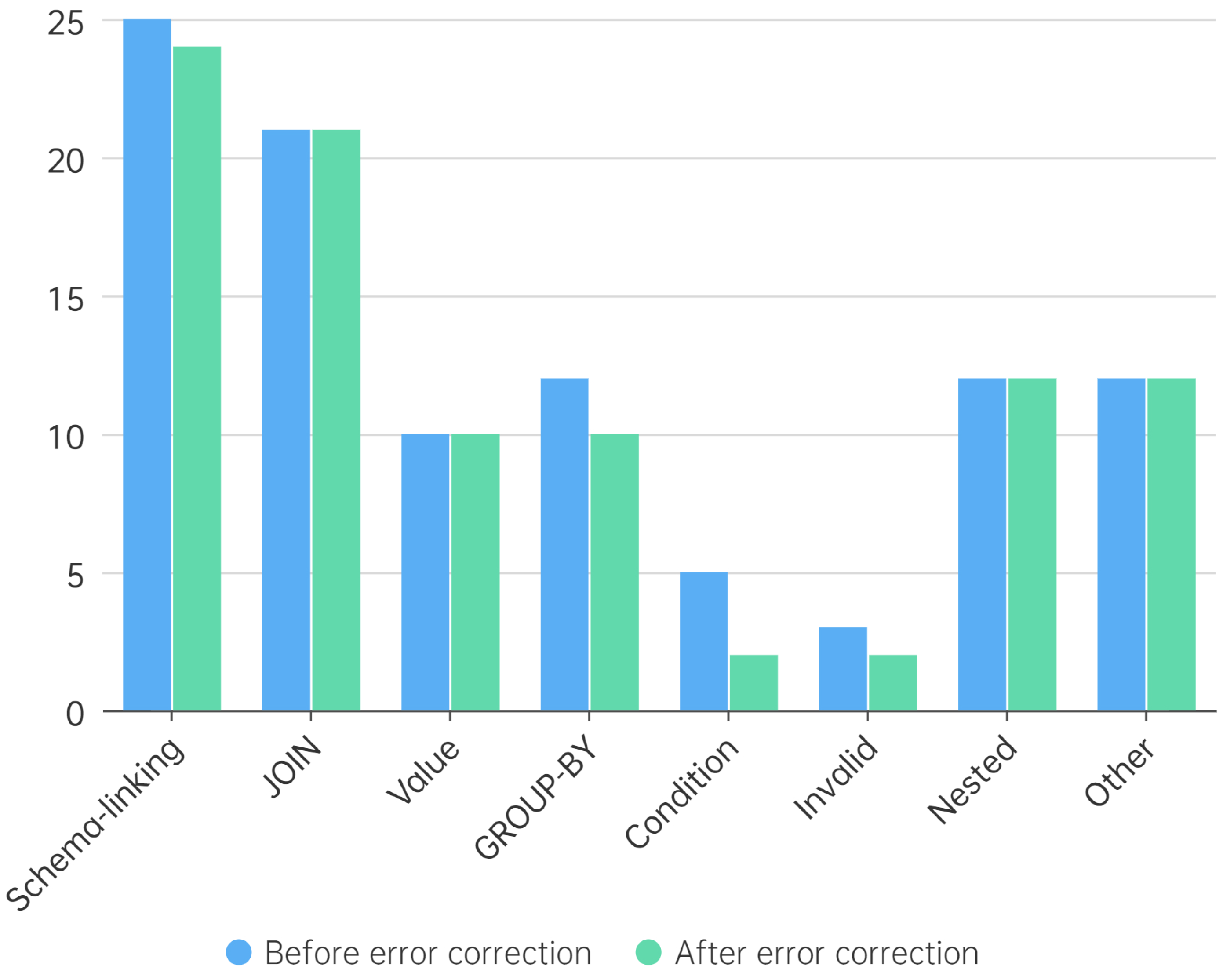
Figure 10 is the error correction statistics of the SQL query correcting decoder for these 100 error samples.
The correction model successfully rectified only one schema-linking error, indicating strong coupling between schema linking errors and upstream processing stages.
No value errors were corrected, primarily due to the absence of database value samples in the correction process.
JOIN and nested operation errors showed zero correction rates, highlighting limitations in addressing semantic-level errors requiring sophisticated cross-table dependency analysis.
The SQL query correcting decoder has a more obvious correction effect on syntax-level errors (such as Condition and GROUP-BY), demonstrating effective mitigation of error propagation in grammatical constructs.
This error distribution suggests that, while our correction decoder effectively handles syntactic-level anomalies, it faces inherent challenges with semantic-level errors that demand deeper contextual understanding. Future improvements should focus on enhancing cross-table dependency analysis and implementing value-linking mechanisms.
6. Conclusions
6.1. Theoretical and Practical Implications
The proposed FGCSQL framework advances the field of cross-lingual Text-to-SQL parsing through three key contributions with both theoretical and practical significance. First, the three-stage pipeline architecture (filtering–generation–correction) establishes a theoretically grounded framework for decoupling schema linking, SQL parsing, and error correction—components that are traditionally entangled in end-to-end approaches. This decomposition provides new insights into managing error propagation in multi-stage semantic parsing systems.
Practically, the integration of parameter-efficient fine-tuning with open-source LLMs (e.g., LlaMa2-7b-chat) demonstrates a viable path for developing domain-specific Text-to-SQL systems without requiring massive computational resources. The operational success of Chinese-specific components (e.g., the Chinese information injected layer) offers a blueprint for adapting Text-to-SQL systems to non-English contexts, addressing a critical gap in multilingual NLP applications.
6.2. Summary of Ideas and Experimental Performance
This study introduces FGCSQL, a three-stage pipeline method for open-source large language model (LLM)-driven Chinese Text-to-SQL transformation. The proposed pipeline includes a redundant database schema items filtering encoder, a generative pre-trained LLM for SQL parsing, and an SQL query correcting decoder. These components are designed to address the challenges associated with Text-to-SQL tasks, particularly those involving cross-lingual schema linking, the complexity of queries, and error propagation within multi-stage processing.
The FGCSQL model demonstrates competitive performance on the CSpider dataset, a large-scale Chinese benchmark for cross-domain semantic parsing and Text-to-SQL tasks. The model achieves near SOTA performance on exact match (EM) and surpasses all baseline variants on exact execution (EX), showing that the three-stage pipeline method significantly reduces the learning difficulty of Text-to-SQL translation.
Extensive ablation studies and comparison with various baseline approaches, including methods like LlaMa2-7b-chat with basic question representation, RAT-SQL, LGESQL, and others, highlight the effectiveness of each component within FGCSQL. Notable findings include the impact of the Chinese information injected layer and type-aware attention on improving schema item classification, and the effectiveness of the IECQN query representation, which customizes database schema information to natural language queries and uses NatSQL as an intermediate representation, further minimizing the learning difficulty.
FGCSQL boasts superior execution precision compared to similar methods like ChatGPT, and displays the advantage of leveraging open-source LLMs, particularly those with parameter-efficient fine-tuning, which significantly outperform larger closed-source models like ChatGPT in both EM and EX.
Lastly, the SQL query correcting decoder, designed to mitigate error propagation, showcases incrementally improved EM and benchmarks as the best performance on the CSpider dataset. The correction decoder demonstrates increased robustness and accuracy in dealing with practical SQL queries.
6.3. Limitations and Future Work
Two primary limitations warrant discussion. First, defining schema filtering as a binary classification task may lead to some potentially relevant tables/columns being mistakenly judged as redundant and lost, thereby affecting the contextual integrity and semantic accuracy of subsequent SQL generation. Second, our error correction mechanism, which focuses on syntactic validity and semantic alignment with user intent, does not guarantee that SQL statements are fully executable, which is a critical flaw for more complex queries.
Future research can advance the technical boundaries from the following directions: (1) integrate structural meta-information such as primary and foreign key relationships in the schema filtering stage to reduce the probability of mistakenly deleting key schema items; (2) design a value linking module based on real value retrieval, which identifies and completes implicit values through real data distribution analysis and context awareness, alleviating SQL parsing errors caused by values; (3) introduce execution feedback in the error correction stage to ensure the executability of the parsing results.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}