
Detecting Cryptojacking Containers Using eBPF-Based Security Runtime and Machine Learning


Abstract
1. Introduction
2. Background and Literature Review
2.1. Container Anomaly Detection
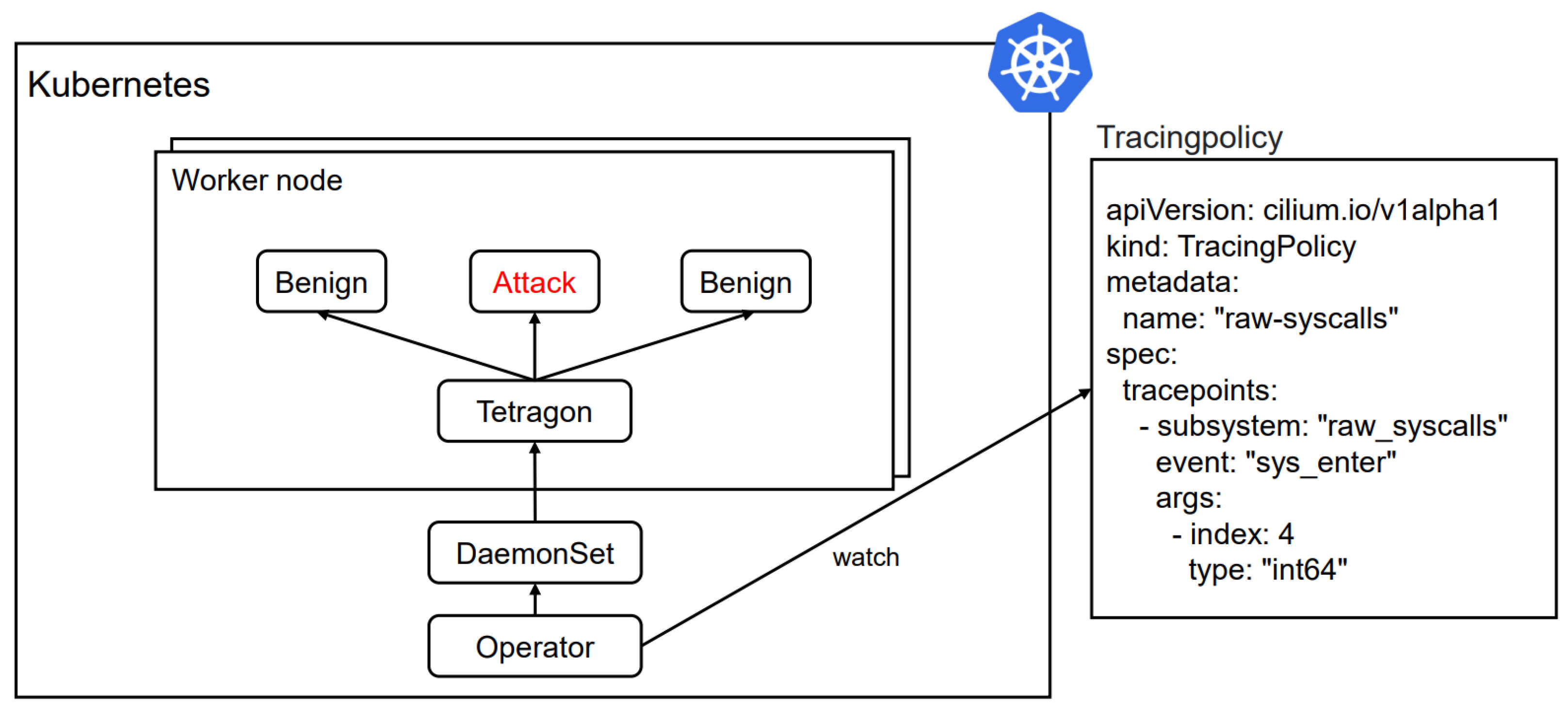
2.2. Tetragon
3. Cryptojacking Container Attack Detection Framework
| Algorithm 1 Cryptojacking detection workflow. |
Input: System Call Sequence Output: Best Performing Model
|
3.1. System Call Tracing Module
4. Evaluation
- Detection performance: Comparison of attack detection performance by ML models using overlapping and non-overlapping n-gram methods, with n ranging from 5 to 50.
- Systematic overhead: (1) The performance overhead introduced by eBPF-based syscall monitoring compared to the baseline performance under benign workloads and (2) comparison of monitoring overhead between eBPF and perf, analyzed by the number of containers.
4.1. Experimental Setup and Datasets
4.2. Performance Evaluation
4.3. Systematic Overhead Characterization
5. Discussion
5.1. System Calls Analysis for Cryptojacking Workloads
5.2. Flow-Based Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Google Cloud. Available online: https://bit.ly/41THxbT (accessed on 15 March 2025).
- Sysdig. Available online: https://sysdig.com/2022-cloud-native-security-and-usage-report/ (accessed on 15 March 2025).
- Tekiner, E.; Acar, A.; Uluagac, A.S.; Kirda, E.; Selcuk, A.A. SoK: Cryptojacking malware. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy (EuroS&P), Vienna, Austria, 6–10 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 120–139. [Google Scholar]
- Sultan, S.; Ahmad, I.; Dimitriou, T. Container security: Issues, challenges, and the road ahead. IEEE Access 2019, 7, 52976–52996. [Google Scholar] [CrossRef]
- hee Lee, J.; hyun Nam, J.; woo Kim, J. Analysis of the Impact of Host Resource Exhaustion Attacks in a Container Environment. J. Korea Inst. Inf. Secur. Cryptol. 2023, 33, 87–97. [Google Scholar]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Olivares-Mercado, J.; Portillo-Portilo, J.; Avalos, J.G.; Garcia Villalba, L.J. Detecting cryptojacking web threats: An approach with autoencoders and deep dense neural networks. Appl. Sci. 2022, 12, 3234. [Google Scholar] [CrossRef]
- Aponte-Novoa, F.A.; Povedano Álvarez, D.; Villanueva-Polanco, R.; Sandoval Orozco, A.L.; García Villalba, L.J. On detecting cryptojacking on websites: Revisiting the use of classifiers. Sensors 2022, 22, 9219. [Google Scholar] [CrossRef] [PubMed]
- Khan Abbasi, M.H.; Ullah, S.; Ahmad, T.; Buriro, A. A real-time hybrid approach to combat in-browser cryptojacking malware. Appl. Sci. 2023, 13, 2039. [Google Scholar] [CrossRef]
- Ning, R.; Wang, C.; Xin, C.; Li, J.; Zhu, L.; Wu, H. Capjack: Capture in-browser crypto-jacking by deep capsule network through behavioral analysis. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1873–1881. [Google Scholar]
- Gomes, F.; Correia, M. Cryptojacking detection with cpu usage metrics. In Proceedings of the 2020 IEEE 19th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 24–27 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–10. [Google Scholar]
- Iacovazzi, A.; Raza, S. Ensemble of random and isolation forests for graph-based intrusion detection in containers. In Proceedings of the 2022 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 27–29 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 30–37. [Google Scholar]
- Karn, R.R.; Kudva, P.; Huang, H.; Suneja, S.; Elfadel, I.M. Cryptomining detection in container clouds using system calls and explainable machine learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 674–691. [Google Scholar] [CrossRef]
- Tetragon. Available online: https://tetragon.io/ (accessed on 15 March 2025).
- eBPF. Available online: https://ebpf.io/ (accessed on 15 March 2025).
- Zhan, M.; Li, Y.; Yang, H.; Yu, G.; Li, B.; Wang, W. Coda: Runtime detection of application-layer cpu-exhaustion dos attacks in containers. IEEE Trans. Serv. Comput. 2022, 16, 1686–1697. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, X.; Wang, Q.; Yang, R.; Xin, B. Unsupervised anomaly detection for container cloud via bilstm-based variational auto-encoder. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3024–3028. [Google Scholar]
- Datadog. Available online: https://securitylabs.datadoghq.com/articles/threat-actors-leveraging-docker-swarm-kubernetes-mine-cryptocurrency/ (accessed on 15 March 2025).
- Kitahara, H.; Gajananan, K.; Watanabe, Y. Real-time container integrity monitoring for large-scale kubernetes cluster. J. Inf. Process. 2021, 29, 505–514. [Google Scholar] [CrossRef]
- Gantikow, H.; Reich, C.; Knahl, M.; Clarke, N. Rule-based security monitoring of containerized workloads. In Proceedings of the 9th International Conference on Cloud Computing and Services Science, Heraklion, Greece, 2–4 May 2019. [Google Scholar]
- Chang, H.; Kodialam, M.; Lakshman, T.; Mukherjee, S. Microservice fingerprinting and classification using machine learning. In Proceedings of the 2019 IEEE 27th International Conference on Network Protocols (ICNP), Chicago, IL, USA, 8–10 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–11. [Google Scholar]
- Ahmed, M.; Uddin, M.N. Cyber attack detection method based on nlp and ensemble learning approach. In Proceedings of the 2020 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Darabian, H.; Homayounoot, S.; Dehghantanha, A.; Hashemi, S.; Karimipour, H.; Parizi, R.M.; Choo, K.K.R. Detecting cryptomining malware: A deep learning approach for static and dynamic analysis. J. Grid Comput. 2020, 18, 293–303. [Google Scholar] [CrossRef]
- Zhang, X.; Niyaz, Q.; Jahan, F.; Sun, W. Early detection of host-based intrusions in Linux environment. In Proceedings of the 2020 IEEE International Conference on Electro Information Technology (EIT), Chicago, IL, USA, 31 July–1 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 475–479. [Google Scholar]
- Subba, B.; Biswas, S.; Karmakar, S. Host based intrusion detection system using frequency analysis of n-gram terms. In Proceedings of the TENCON 2017-2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2006–2011. [Google Scholar]
- Wang, X.; Lu, X. A host-based anomaly detection framework using XGBoost and LSTM for IoT devices. Wirel. Commun. Mob. Comput. 2020, 2020, 8838571. [Google Scholar] [CrossRef]
- Hoang, D.K.; Nguyen, D.T.; Vu, D.L. Iot malware classification based on system calls. In Proceedings of the 2020 RIVF International Conference on Computing and Communication Technologies (RIVF), Ho Chi Minh City, Vietnam, 14–15 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- XMRig. Available online: https://hub.docker.com/r/miningcontainers/xmrig (accessed on 15 March 2025).
- xmr-stak cpu. Available online: https://hub.docker.com/r/timonmat/xmr-stak-cpu/ (accessed on 15 March 2025).
- CloudSuite 4.0. Available online: https://github.com/parsa-epfl/cloudsuite (accessed on 15 March 2025).
- MariaDB. Available online: https://hub.docker.com/_/mariadb (accessed on 15 March 2025).
- i Muñoz, J.Z.; Suárez-Varela, J.; Barlet-Ros, P. Detecting cryptocurrency miners with NetFlow/IPFIX network measurements. In Proceedings of the 2019 IEEE International Symposium on Measurements & Networking (M&N), Catania, Italy, 8–10 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Pastor, A.; Mozo, A.; Vakaruk, S.; Canavese, D.; López, D.R.; Regano, L.; Gómez-Canaval, S.; Lioy, A. Detection of encrypted cryptomining malware connections with machine and deep learning. IEEE Access 2020, 8, 158036–158055. [Google Scholar] [CrossRef]
- Caprolu, M.; Raponi, S.; Oligeri, G.; Di Pietro, R. Cryptomining makes noise: Detecting cryptojacking via machine learning. Comput. Commun. 2021, 171, 126–139. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Workload | Number of Samples | Total |
|---|---|---|---|
| Cryptojacking | XMRig | 115,611 | 241,043 |
| xmr-stak-cpu | 125,432 | ||
| Benign | Web-Serving | 35,210 | 241,734 |
| Data-Caching | 50,596 | ||
| Media-Streaming | 112,003 | ||
| MariaDB | 43,925 |
| Workload | Description |
|---|---|
| Web-Serving | The workload creates a cluster featuring a web server, database server, memcached server and clients. The web server, which operates Elgg, establishes connections with both the memcached and database servers. Meanwhile, the clients are involved in activities such as logging in, messaging, blogging and interacting with posts through comments and likes. |
| Data-Caching | The client performs requests to access data on the memcached data caching server, simulating the behavior of a Twitter data caching server. |
| Media-Streaming | The workload runs an nginx web server to host videos of various lengths and qualities. The client performs load testing on the server by requesting different videos based on httperf. |
| MariaDB | MariaDB is an open-source relational database management system. Using the benchmarking tool sysbench, it performs read and write operations as well as transaction processing commands. |
| XMRig, xmr-stak-cpu | XMRig and xmr-stak-cpu are representative open source-based Monero mining programs that support -friendly RandomX, allowing users to mine Monero efficiently. |
| Model | Hyperparameters | Values |
|---|---|---|
| SVM | Kernel Type | RBF |
| Regularization (C) | 1.0 | |
| Gamma | Scale | |
| Kernel Coefficient | Scale (auto-adjust) | |
| KNN | k-Neighbors | 5 |
| Weighting | Uniform | |
| Distance Metric | Minkowski (p = 2) | |
| MLP | Hidden Layer Sizes | (100,) |
| Activation Function | ReLU | |
| Optimizer | Adam | |
| Learning Rate Init | 0.001 | |
| DT | Criterion | Gini |
| Splitter | Best | |
| RNN | LSTM Layer 1 Units | 35 |
| LSTM Layer 2 Units | 80 | |
| Dropout Rate | 0.2 | |
| Activation Function | ReLU | |
| Optimizer | Adam | |
| Loss Function | Categorical Crossentropy |
| n | ML Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| 50 | SVM | 94.75 | 95.01 | 94.75 | 94.72 |
| 5 | KNN | 99.15 | 99.15 | 99.15 | 99.15 |
| 10 | MLP | 97.53 | 97.56 | 97.53 | 97.53 |
| 35 | DT | 99.67 | 99.67 | 99.67 | 99.67 |
| 40 | RNN | 99.75 | 99.75 | 99.75 | 99.75 |
| n | ML Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| 35 | SVM | 90.65 | 90.82 | 90.82 | 90.26 |
| 5 | KNN | 98.05 | 98.05 | 98.05 | 98.04 |
| 5 | MLP | 95.00 | 94.97 | 95.00 | 94.87 |
| 5 | DT | 99.24 | 99.24 | 99.24 | 99.24 |
| 40 | RNN | 98.12 | 98.18 | 98.12 | 98.14 |
| Workload | Latency (ms) | Overhead | |
|---|---|---|---|
| Without Monitoring | With Monitoring | ||
| Web-Serving (BrowsetoElgg) | 406.636 | 434.058 | 1.07× |
| Web-Serving (AccessHomePage) | 344.916 | 370.972 | 1.08× |
| Web-Serving (SendMessage) | 153.971 | 181.111 | 1.18× |
| MariaDB | 19.263 | 29.24 | 1.52× |
| Data-Caching | 3.783 | 11.29 | 2.98× |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, R.; Ryu, J.; Kim, S.; Lee, S.; Kim, S. Detecting Cryptojacking Containers Using eBPF-Based Security Runtime and Machine Learning. Electronics 2025, 14, 1208. https://doi.org/10.3390/electronics14061208
Kim R, Ryu J, Kim S, Lee S, Kim S. Detecting Cryptojacking Containers Using eBPF-Based Security Runtime and Machine Learning. Electronics. 2025; 14(6):1208. https://doi.org/10.3390/electronics14061208
Chicago/Turabian StyleKim, Riyeong, Jeongeun Ryu, Sumin Kim, Soomin Lee, and Seongmin Kim. 2025. "Detecting Cryptojacking Containers Using eBPF-Based Security Runtime and Machine Learning" Electronics 14, no. 6: 1208. https://doi.org/10.3390/electronics14061208
APA StyleKim, R., Ryu, J., Kim, S., Lee, S., & Kim, S. (2025). Detecting Cryptojacking Containers Using eBPF-Based Security Runtime and Machine Learning. Electronics, 14(6), 1208. https://doi.org/10.3390/electronics14061208