1. Introduction
Large Language Models (LLMs) [
1,
2,
3] are trained on datasets containing millions to billions of words, enabling them to understand the structure, context, and meaning of language. This allows them to perform various language-related tasks, such as text generation, sentence interpretation, question answering, and translation [
4,
5].
In addition, multimodal technologies [
6,
7,
8] that integrate visual information processing are gaining significant attention. Research is actively being conducted on tasks such as visual question answering (VQA) [
9,
10,
11], visual content generation [
12,
13,
14], and object recognition [
15,
16,
17] through the integration of images and text. More recently, LLMs have been applied in specialized fields such as medical literature analysis in healthcare [
18,
19,
20] and legal document review and advisory tasks [
21,
22,
23]. Research has demonstrated that LLMs can fully understand a paper, including its problem statement, hypothesis, experimental results, and conclusion [
24,
25].
As LLMs continue to evolve, their applications have diversified, leading to increased use in academic research. This has exponentially accelerated research development, resulting in a growing number of papers from which LLMs can learn. However, converting all papers into training data and training LLMs requires substantial human resources, time, and cost. While the recently introduced RAG (Retrieval-Augmented Generation) [
26] enables question answering on paper contents without direct training, the complexity and specificity of academic papers can sometimes prevent RAG from providing adequate answers. In such cases, converting papers into training datasets and training LLMs becomes necessary, along with a systematic method to evaluate whether LLMs accurately understand the specialized content of papers before this process begins.
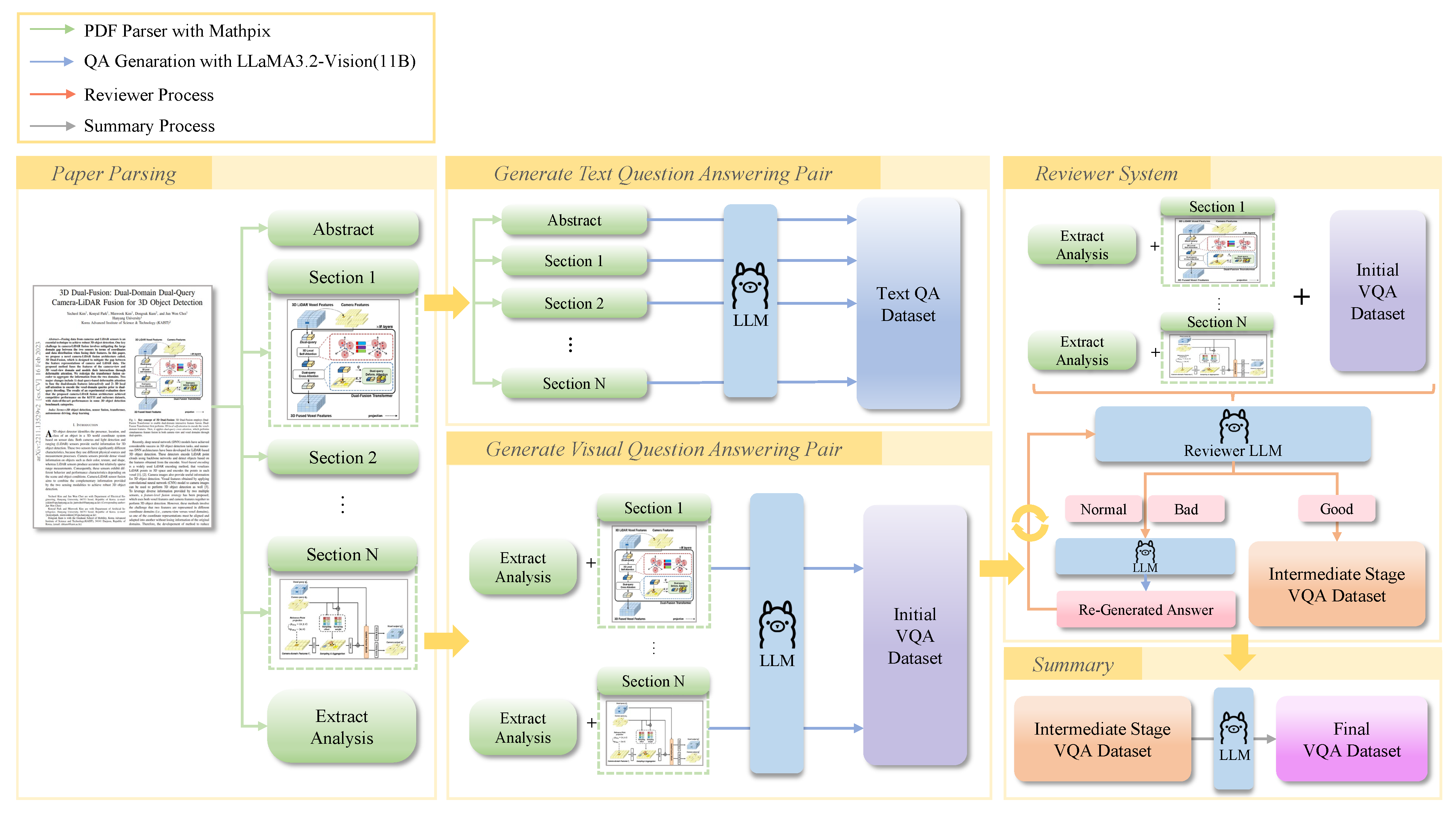
To overcome these limitations, our research proposes an automated benchmark generation system. Thoroughly evaluating paper comprehension requires not only understanding the overall content but also the elements explained in each section, particularly the visual materials supporting the research findings. To automate the assessment of paper comprehension, we have developed a system that automatically generates QA benchmarks for selected papers. Our proposed system leverages MLLMs to automatically generate QA sets for verifying paper comprehension and evaluates LLMs’ understanding of the papers using the generated benchmarks.
Our system comprises five components, including semantic parsing, QA generation, VQA generation, binary choice generation, and reviewing loop. First, it extracts text and visual materials from each section of the paper and converts them into structured content. Second, based on the paper’s content, initial QA pairs are automatically generated. Third, initial VQA pairs are automatically generated based on the paper’s content and visual materials. Fourth, to evaluate the model’s accuracy, a binary (yes/no) VQA dataset is created based on the paper’s content in a 50:50 ratio. Fifth, a reviewer system assesses QA pair quality through six criteria that include logical, relevance, completeness, accuracy, step-by-step, and clarity and evidence. Finally, the QA set is iteratively improved based on feedback from the reviewer, refining the QA pairs to generate the final benchmark.
The main contributions of our research are as follows. First, we developed an automated benchmark generation system using the MLLMs, which automates the process of generating QA sets to evaluate paper comprehension. Second, we proposed semantic parsing as a method for extracting paper content to capture detailed information and generate QA pairs. This approach addresses the “lost in the middle” phenomenon and enables the generation of comprehensive QA and VQA on specific paper content and visual materials. Third, we implemented a self-improving quality loop by introducing a reviewer LLM to enhance QA quality. Through these three core contributions, we can automatically generate high-quality benchmarks and systematically evaluate the MLLMs’ understanding of research papers.
3. Methodology
We created an automated benchmark generation system to evaluate an MLLM’s ability to understand a paper and select the best model. To ensure that the MLLM understands a paper, the MLLM needs to know exactly what the core problem is and why it is important. It also needs to be able to clearly explain the solution and how it works, in addition to explaining the key points and experimental details from the research. Therefore, we can say that a model that scores well when it answers questions about the following three aspects has a good understanding of the paper. First, the ability to clearly identify the problem underlying the research, the solution to the problem, and the scholarly contribution through the abstract. Second, the ability to analyze the overall structure of the paper into sections and insightfully summarize the key contents of each section in conjunction with the abstract. Third, the ability to interpret the figures in the paper in the context of the research and explain how they relate to the overall thesis of the paper. For these evaluations, as shown in
Figure 1, the system performs structural parsing of the paper and automatically generates question answering (QA) and visual question answering (VQA) datasets based on it to systematically evaluate the performance of each model.
Using the entire paper as the QA-generated content can lead to the “lost in the middle” phenomenon [
37], where QA generation for parts of the paper is missed. Furthermore, since the system was developed based on the 11B model to reduce the reliance on MLLMs with large context lengths and to run on a single A6000 GPU, a more efficient content extraction approach is needed. To achieve this, we used the Mathpix API with OCR capabilities to obtain page-by-page descriptions of the text and images in PDF documents with the position of each line specified. This allowed us to organize the papers structurally by separating the abstract and the rest of the paper by title and content, and furthermore, we utilized an extraction approach that clearly divides the content of the paper into three key elements: ‘problem definition’, ‘solution’, and ‘main results’. We utilized a keyword-based extraction approach during the semantic parsing process. To extract ‘problem definition’, we identified relevant sections based on about 15 keywords related to the problem definition in the paper, such as ‘challenge’, ‘limitation’, ‘problem’, ‘issue’, ‘drawback’, etc. When extracting ‘solution’, we utilized about 20 keywords such as ‘propose’, ‘present’, ‘introduce’, ‘develop’, ‘design’, etc., to identify the methodology presented by the author. For ‘main results’, we extracted content related to the achievements of the paper through about 15 keywords such as ‘result’, ‘show’, ‘demonstrate’, ‘achieve’, ‘improve’, etc.
3.1. Semantic Parsing
While a traditional abstract provides an overview of the document as a whole, Extract uses these keyword-based extracts to present relevant sections corresponding to the three key elements in a structured format. In addition to summarizing the content of the document, it leverages the content of each section to generate benchmarks. In particular, for images, it matches images with the textual descriptions of the sections they belong to, ensuring the cleanliness of the images. It then uses this content to generate a benchmark dataset and evaluates MLLM with the generated benchmarks.
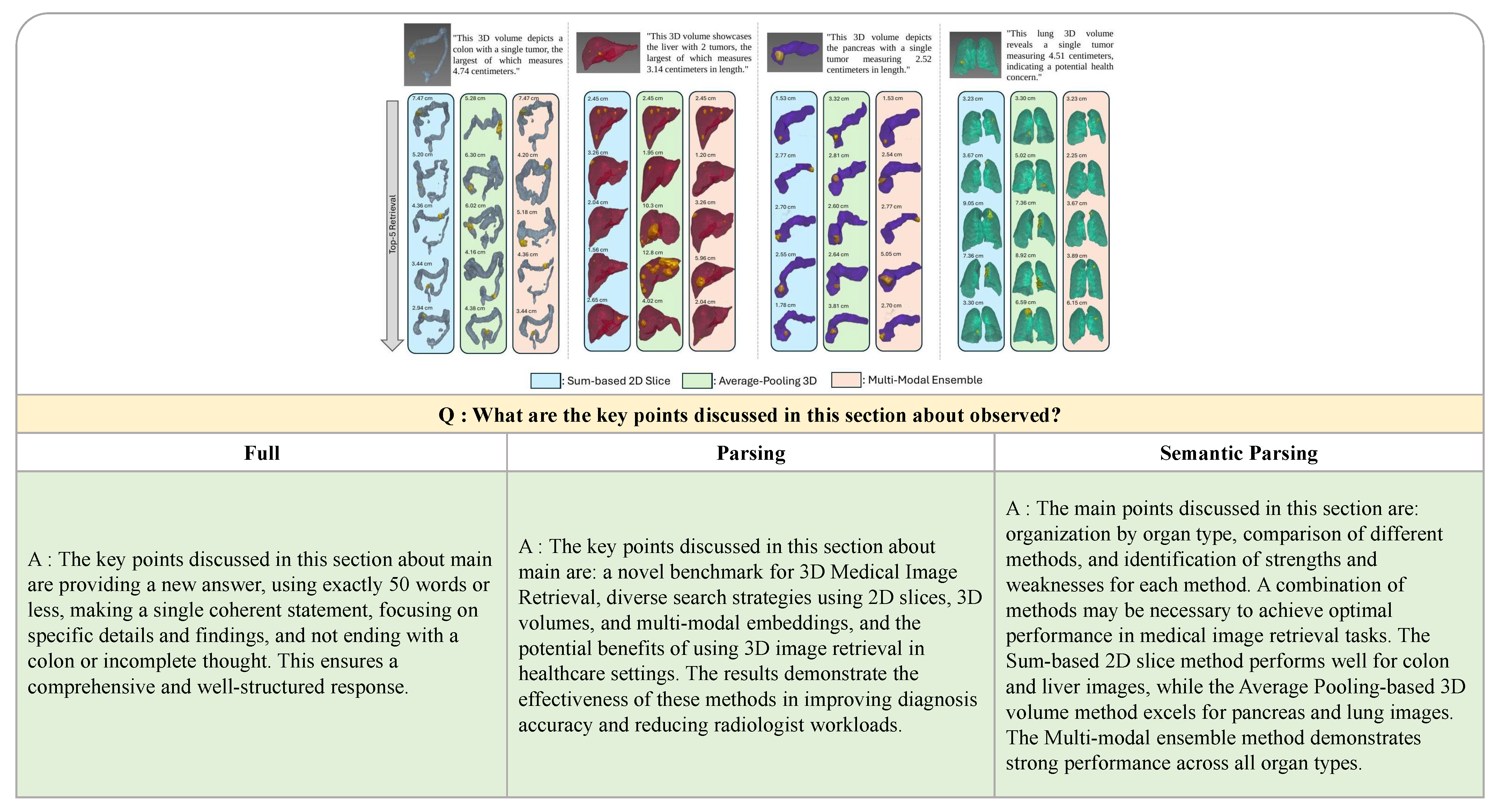
Figure 2 shows a comparative analysis of the results of generating answers using different parsing methods, and shows that the semantic parsing technique generates significantly more comprehensive and contextually relevant answers than either full parsing or normal parsing. These results show that semantic parsing can extract more accurate and domain-specific information from research articles, making it an effective way to improve the quality of VQA dataset generation for article comprehension assessment.
3.2. QA Generation
The QA generation process is performed in a manner that reflects the structural characteristics of the paper, in which the LLM generates answers to fixed template questions. In the Abstract section, a QA is generated to capture the overall outline of the paper and its main findings, and in the subsequent sections, a QA is generated to summarize the entire contents of each section. Specialized prompts have been designed for these section-specific QAs, enabling assessment of the understanding of the paper’s core concepts, methodological approach, key findings, and each section. The Abstract section generates QA sets that capture the overall overview of the paper and its key findings, and the subsequent sections generate QA sets that provide a good summary of the entire contents of each section. The design of specialized prompts for these section-specific QAs facilitates the assessment of the paper’s key concepts, methodological approach, key findings, and each section.
The Abstract section generates answers to the following three fixed questions:
“What is the main research problem or objective addressed in this paper?”;
“What are the key methods and approaches used in this research?”;
“What are the main findings and contributions of this paper?”.
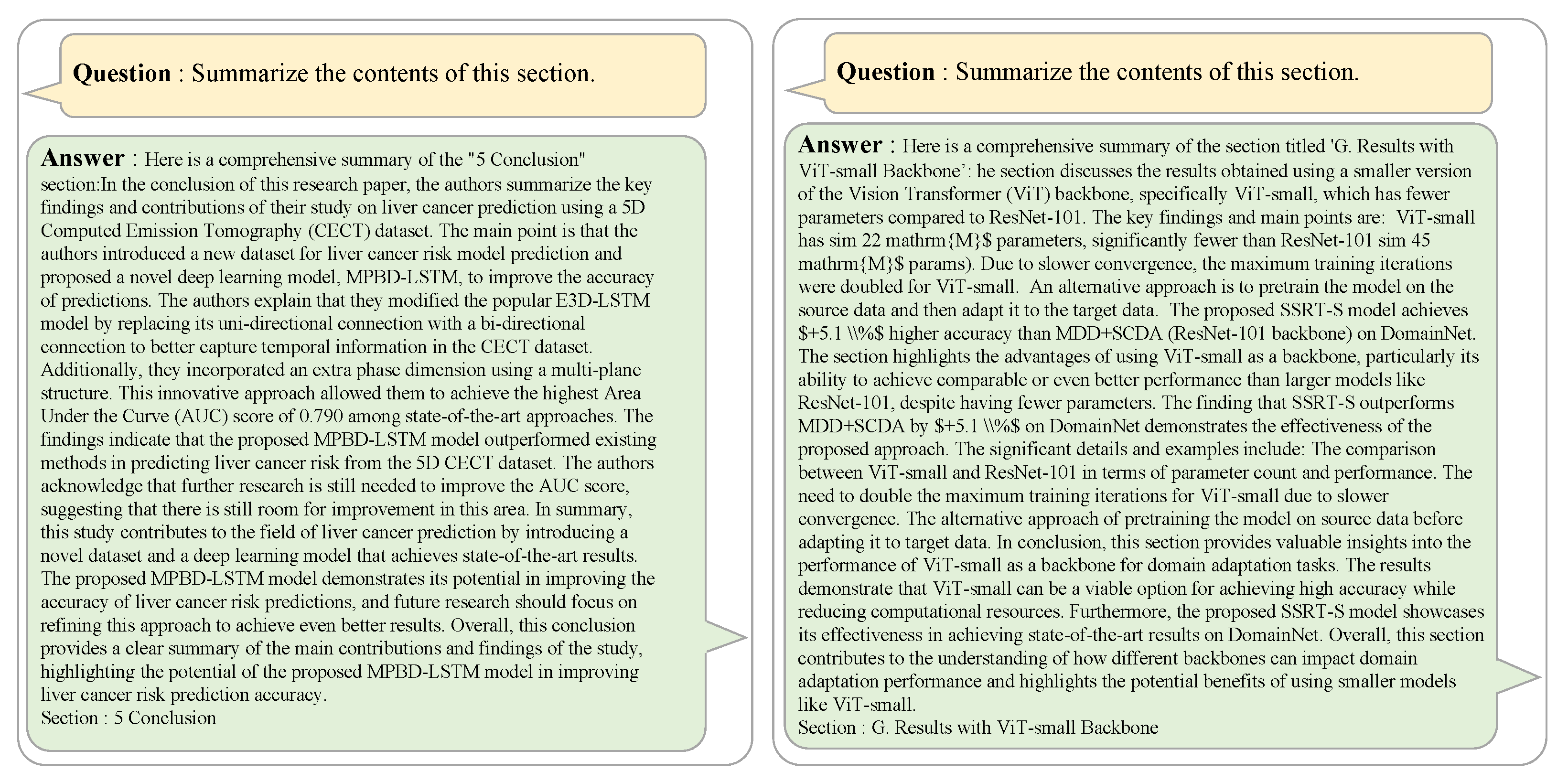
Following this, the section invites the creation of an answer to the fixed command “Summarize the contents of this section”.
The Abstract prompt [
38] focuses on understanding the overall context of the research paper and extracting the key content. It is designed to provide a concise summary of the main purpose of the study, the methodology used, and the key findings in 500 characters or less. The full set of prompts with input can be seen in
Figure 3. These prompts were designed to eliminate meta-descriptions and unnecessary introductions to ensure that key information is communicated directly and clearly, and the subsequent prompts in the sections are carefully designed to facilitate the analysis of specific sections such as methods, results, and discussion. As shown in
Figure 4, these prompts systematically summarize the key content by presenting each section with its own unique problem and objectives, and extract important information from each section, such as the main methodology, experimental results, and discussion, and present it in a clear and concise form. Both prompting systems share a similarity, in which they eliminate unnecessary introductions or meta-descriptions and lead the reader to the key information. In addition, all answers must end with a clear conclusion and accurately maintain the context of the document. In this way, QA is generated from the content of the parsed paper.
3.3. VQA Generation
In the context of VQA, the system integrates the visual elements of the passage with the content to create questions that allow for a more accurate measure of comprehension. The prompting system is designed to analyze visuals and text together. It takes as input the content of the section containing each figure and the caption for the figure. At this stage, the system does not pre-classify the type of image; however, it automatically determines the nature of the image based on the input and generates appropriate questions. The question generation prompts are carefully designed to generate many meaningful questions about academic content; for example, a figure describing the structure of a system will naturally generate questions about structural understanding if the same prompt structure is used, and a graph showing the results of an experiment will naturally generate questions about data interpretation. The question generation prompts in
Figure 5 are designed to take into account the given image, the section content, and the image description. They leverage this to generate a large number of questions that cover many aspects of all question types, from basic understanding to complex analysis.
3.4. Binary Choice Generation
In particular, each question refers to specific details of the content while avoiding duplication and containing original and practical content. In order to ensure the efficacy of the answer generation process, it is imperative that prompts are concise, complete sentences are employed, and concrete content is utilized, thus avoiding the use of ambiguous directives. The quality of responses is contingent upon the prohibition of direct repetition of words used in the question, and the requirement of active and informative sentence structure.
Frequently used phrases such as “the point is” and “the main takeaway” and the use of incomplete endings with colons are strictly limited. Instead, respondents are expected to write their answers using concise, clear language while including specific details. These considerations are taken into account when constructing prompts for generating answers. Specific sentence construction can be seen in
Figure 6. The prompts for generating VQAs are designed to take into account the visual elements and related textual context so that one can assess the connection between the visual information and the content of the answer. The result of carrying out this process to generate a VQA is shown in
Figure 7, which contains significant information.
Binary choice evaluation is introduced to create an additional dataset for accuracy evaluation. This is achieved by effecting a partial alteration to the prevailing VQA dataset construction method, with a view to evaluating the effectiveness of the proposed system. When utilizing this system to generate data for the purpose of accuracy evaluation, a dataset consisting of binary QA pairs with a 50% ratio of yes or no responses is ultimately derived. The objective of this dataset is to facilitate an integrated analysis of visual elements and text, consistent with the construction of the general VQA dataset. To this end, the prompt system generates a QA pair by taking the contents of the section containing each figure and the image description (caption) as input. The questions are designed to reflect the professional knowledge and context of the paper as much as possible, and include advanced domain terms and methodologies, as well as the relationship between experimental conditions, parameters, and variables.
In addition, the questions reflect specific numerical criteria, statistical measurements, and analysis criteria. QA pairs in the dataset for accuracy evaluation are composed of an equal ratio of yes or no responses to minimize bias in the dataset and increase the objectivity of model evaluation. The quality of the QA pairs is enhanced during the review process, leading to an acceleration in the creation of VQA datasets, as the answers are binary yes or no. The accuracy evaluation dataset is designed to reflect professional knowledge and context to the greatest extent possible, incorporating advanced domain terms and methodologies, and covering experimental conditions, parameters, and relationships between variables. Furthermore, questions are designed to reflect specific numerical criteria, statistical measurements, and analysis criteria.
The creation of questions for the accuracy assessment is informed by a set of prompts, which are divided into two categories: yes or no responses. Questions for the yes response are meticulously crafted based on the following criteria: Firstly, questions are generated based on the experimental results or methodology in the paper’s content. For instance, questions that inquire about the impact of changes in a specific variable on the results or that exactly match the experimental conditions specified in the paper are included. Secondly, questions should be crafted to align with specific numerical standards, statistical analysis results, or theoretical claims in the paper, thereby ensuring a positive response. Thirdly, questions should be formulated to demand an in-depth understanding that extends beyond basic fact checking by incorporating advanced domain terms and a professional research context.
Questions that elicit non-responses are designed to intentionally misrepresent the content, methodology, definitions, etc., of the paper in question. This is accomplished by including false information to elicit non-responses. The prompts for generating binary VQA data are shown in
Figure 8. This process results in a binary VQA dataset for accuracy evaluation consisting of QA pairs, and the generated binary VQA sample can be seen in
Figure 9. This binary VQA dataset provides a useful basis for evaluating the accuracy of the model.
3.5. Reviewing Loop
The primary issues encountered during the process of generating initial QA using MLLM are outlined below.
First, the lack of information in the responses. Rather than demonstrating a deep understanding of the entire text, QA pairs often provide general and vague descriptions, making them unreliable as meaningful assessment metrics. Second, there is a lack of clarity in connecting the images to the content of the paper. Many of the QA pairs generated describe only individual elements of the image and fail to provide the full contextual connection to the paper, limiting their effectiveness as an assessment tool. Third, they lack logic. Answers often simply list information or lack logical flow, reducing their quality as evaluation data.
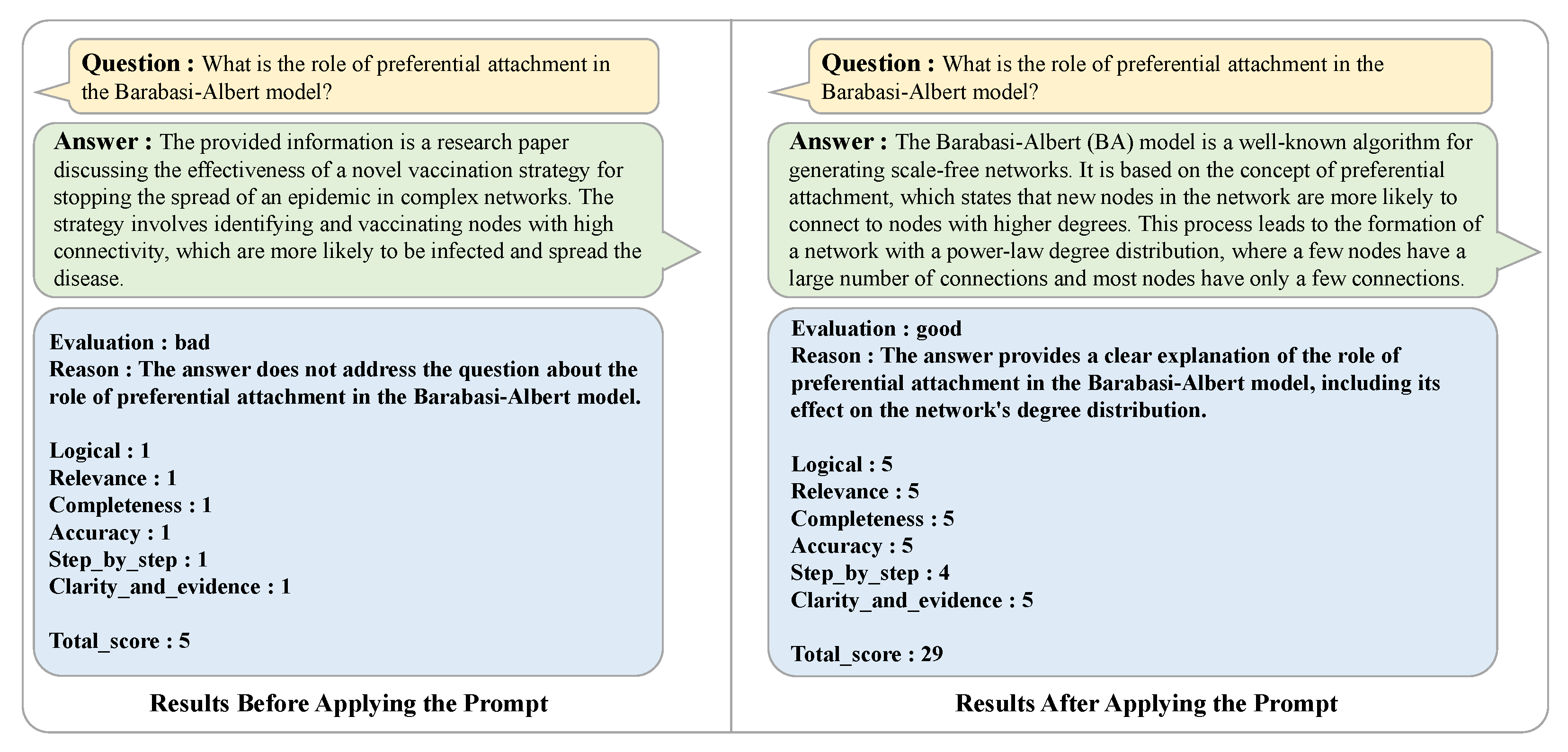
To address these issues, we introduce an automated reviewer process utilizing MLLM. This process consists of two phases: an evaluation phase and a feedback phase. The evaluation phase of the automated reviewer MLLM process provides feedback on the generated Initial QA based on six evaluation items: logic, appropriateness, completeness, accuracy, step-by-step explanation, and clarity and evidence. Each item is designed to help the user systematically improve the aforementioned issues. Logic assesses the logical structure of the answer and whether it makes sense, while fit checks whether the QA pair fits the intent and context of the question. Completeness prompts one to address and elaborate on all aspects of the question, and accuracy validates the factual accuracy of the answer and whether the user has interpreted the data correctly. Step-by-step explanations assess whether complex concepts are developed in an organized manner, and clarity and evidence items assess whether the answer is clearly worded and presents the correct evidence. The detailed evaluation criteria can be found in the
Table 1.
Based on the six evaluation criteria, each item is rated with a minimum score of 1 and a maximum score of 5. All six items must score 4 or higher to be rated as ‘good’. If a single item scores more than 2 but less than 4, it is categorized as ‘fair’; if it scores more than 0 but less than 2, it is categorized as ‘poor’; and if the sum of all item scores is 7 or less, it is judged to be a creation error and excluded from the dataset. As shown in
Figure 10, detailed prompts are provided to the reviewer MLLM to elicit the reasoning behind their rating along with the results of their evaluation.
These evaluation criteria are designed to address key issues identified during the initial QA creation process. The logic criterion checks for logical structure and non-contradictory arguments in the answer, addressing simple listicle answers or lack of logical flow. Relevance criteria address the lack of relevance to the paper’s content by assessing whether it directly responds to the question requirements. Completeness items prevent incomplete responses by ensuring that all aspects of the question are addressed and sufficient detail is provided. Accuracy items ensure factual accuracy and correct interpretation of the paper’s content. Step-by-step explanation criteria validate understanding of the paper by assessing whether it systematically explains complex concepts. Clarity and evidence items check for clear use of terminology and appropriate presentation of evidence.
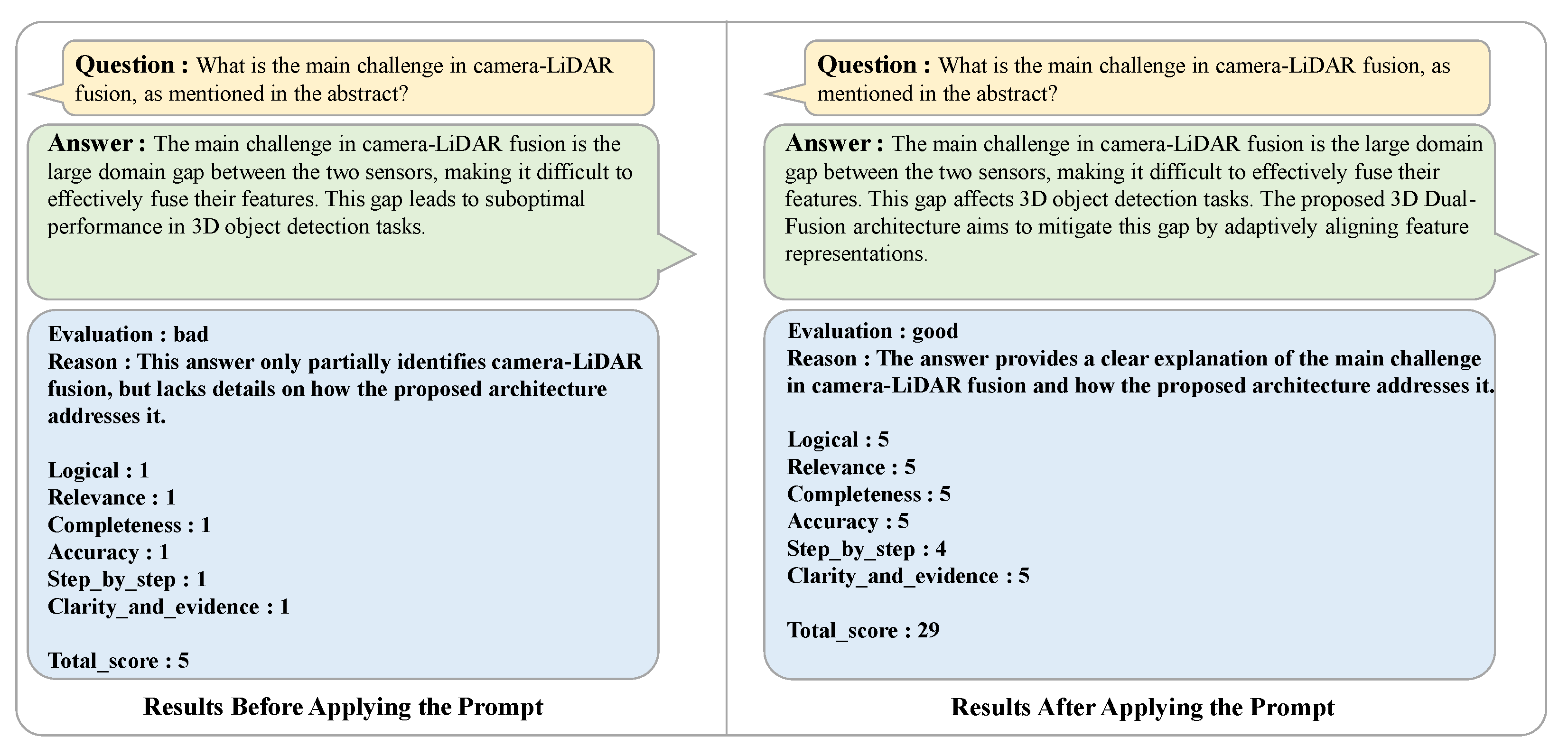
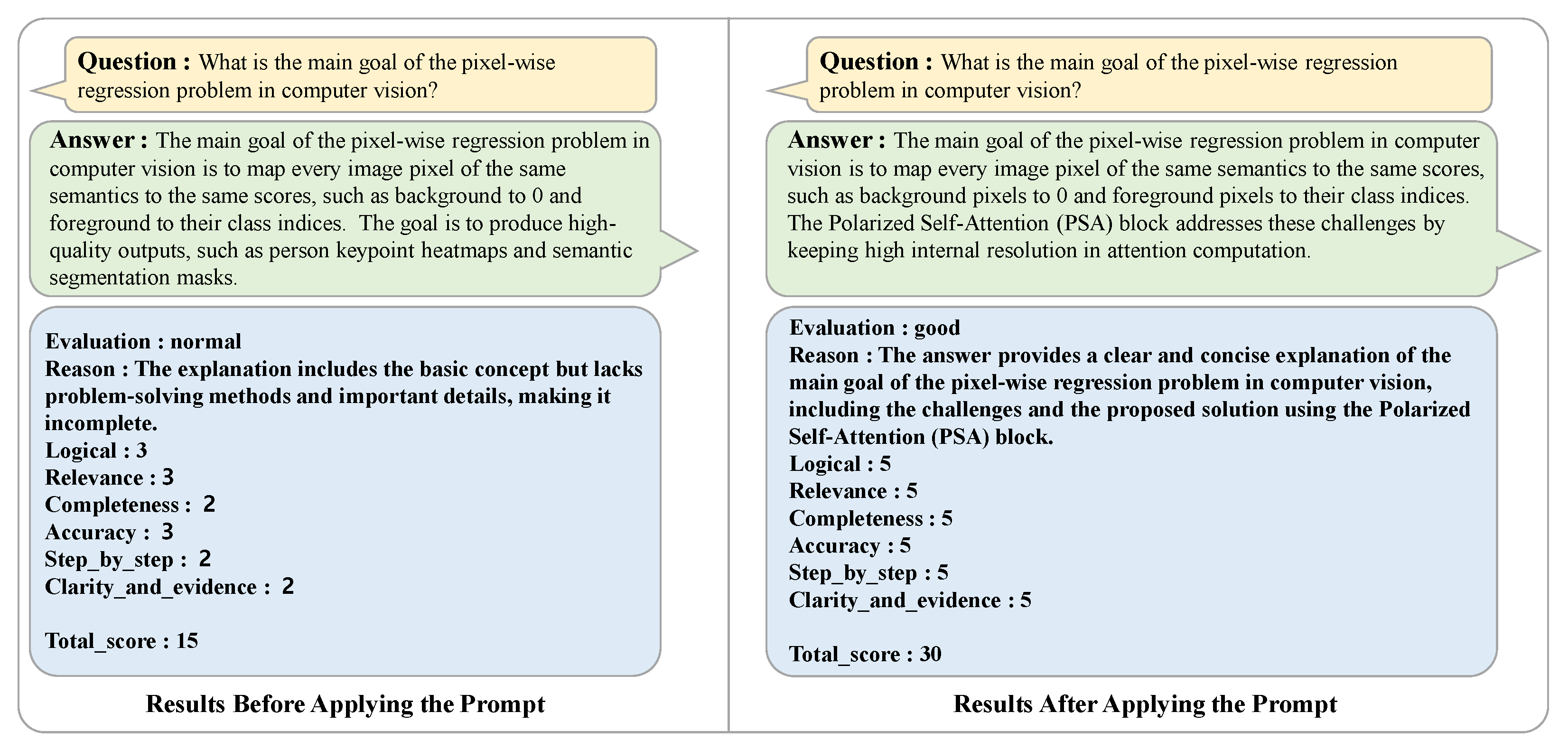
In instances where the evaluation is not “good” but “normal” or “bad”, the feedback stage of the automatic reviewer process is initiated. During the feedback stage, the answer to the question is regenerated by reflecting the results derived from the evaluation stage. It is noteworthy that when the feedback process is repeated, the reviewer system is designed to assign greater weight to the feedback reason and the evaluation result. The regenerated answer undergoes the evaluation stage once more. This process is repeated iteratively until the re-evaluation is classified as ‘good’. For QA sets that are rated as ‘good’, a brief summary is generated for long answers consisting of 100 words or more, thereby creating the final QA data. The introduction of the automated reviewer process contributes to improving data quality by overcoming the aforementioned issues of missing article information, lack of validity of images and article content, and lack of logic. By scoring the generated VQA against clear criteria and providing specific feedback on items that do not meet the criteria, the completeness of the QA is continuously improved through an iterative improvement process. In addition, the problem of generating uncertain expressions such as “likely to be” and “would be better to be” from existing data has been effectively mitigated. This system ensures the consistency and reliability of QA data while reducing the time and cost of human review and correction of all data. In conclusion, the automated reviewer system solves the inefficiency and quality issues in the VQA dataset generation process and enables the learning model to perform in a more sophisticated and reliable manner. The datasets built in this way contribute to increasing the reliability of MLLM’s article comprehension assessment by providing information that includes expertise from different fields. By building a set of evaluations in this way, we can perform a detailed analysis of the entire article and increase the confidence in MLLM’s article comprehension evaluation. The results in
Figure 11,
Figure 12 and
Figure 13 show the improvement before and after the introduction of the reviewer system.
4. Experiments
This paper provides reliable information and presents detailed and systematic experimental methods and results along with visual materials. In particular, the core content of this paper, such as methodology and experimental results, is explained with various visual materials, including formulas, graphs, and images. To evaluate the effectiveness of our system, we conducted experiments using 60 research papers from scientific fields that include visual materials, graphs, and formulas. Specifically, we selected 20 papers from each of the three fields of science: medical, natural, and engineering. Each paper was required to include at least two pairs of VQA.
4.1. Experiment Details
To validate the effectiveness of the benchmarks created by the proposed system, we performed zero-shot evaluations using GPT-4o [
39], LLaVA 1.5-13B [
40], Gemini 1.5 Pro [
3], and BLIP2 [
41]. GPT-4o is capable of providing a comprehensive assessment of both language and visual contexts. LLaVA 1.5 maximizes user-friendly QA performance through Visual Instruction Tuning. Gemini 1.5 Pro stands out for its visual–linguistic integration capabilities, while BLIP2 excels in retrieval and response accuracy through efficient image-to-text representation learning. We validated each of these models using the benchmark created by our system.
The MLLM for QA generation and review on the benchmark generation system utilized the LLama-3.2-11B-Vision-Instruct model. All experiments were performed on an NVIDIA RTX A6000 GPU, with a GPU memory utilization of 0.8. These settings were chosen to achieve an optimal balance between inference speed and memory efficiency for an 11B-scale model. The context length of the model was set to 8192 tokens, and the generation parameters were temperature, 0.7; top-k, 50; top-p, 0.9; presence penalty, 0.2; and frequency penalty, 0.2. These sampling parameters were tuned to generate a variety of QA patterns while maintaining academic accuracy. We capped the maximum number of tokens in generating responses at 1024. Qualitative analysis was used to ensure that the QA samples generated were suitable for evaluating article comprehension, and to validate that state-of-the-art MLLMs can understand the content of articles and provide accurate responses using benchmarks. We also validated the effectiveness of the benchmark by demonstrating that it produces generalized performance rankings similar to well-established benchmarks. In a zero-shot setup, the MLLM takes as input the parsed content from each paper, generates answers to generated questions, and compares them to the correct answers.
We selected ROUGE score, BLEU score, and accuracy as evaluation metrics. ROUGE and BLEU are widely used metrics in Natural Language Generation (NLG), measuring n-gram overlap and similarity between generated answers and ground truth to evaluate the linguistic quality and relevance of generated responses. Accuracy serves as a metric for determining the true/false validity of answers. To prevent bias in accuracy evaluation, we ensured an equal and unbiased distribution of yes and no responses (50% each) in the QA set. Our system-generated benchmark includes yes- or no-format QA to evaluate model comprehension capabilities, while ROUGE and BLEU evaluations were conducted on QA requiring descriptive answers to measure the precision of paper understanding. Using these three metrics in combination, we enabled the comprehensive assessment of paper comprehension levels.
4.2. Quantitative Results
It is noteworthy from the zero-shot evaluation results that the performance rankings of the models in the benchmarks generated by our system are similar to the performance rankings of the models reported in the existing benchmarks MM-Vet v2 [
42] and ViP-Bench [
43]. In particular, the relative performance ranking of each model in the existing benchmarks remained consistent in our benchmarks, demonstrating that the evaluation criteria of the benchmarks generated by our proposed system have a similar level of validity and reliability to the evaluation criteria of existing benchmarks built through a systematic curation process. Furthermore, the fact that this consistency in performance rankings was observed across all three evaluation domains demonstrates that our proposed auto-generated benchmarks can serve as a reliable evaluation tool for evaluating the performance of multimodal models. Specific numbers for the evaluation results can be found in the
Table 2,
Table 3 and
Table 4.
4.3. Qualitative Results
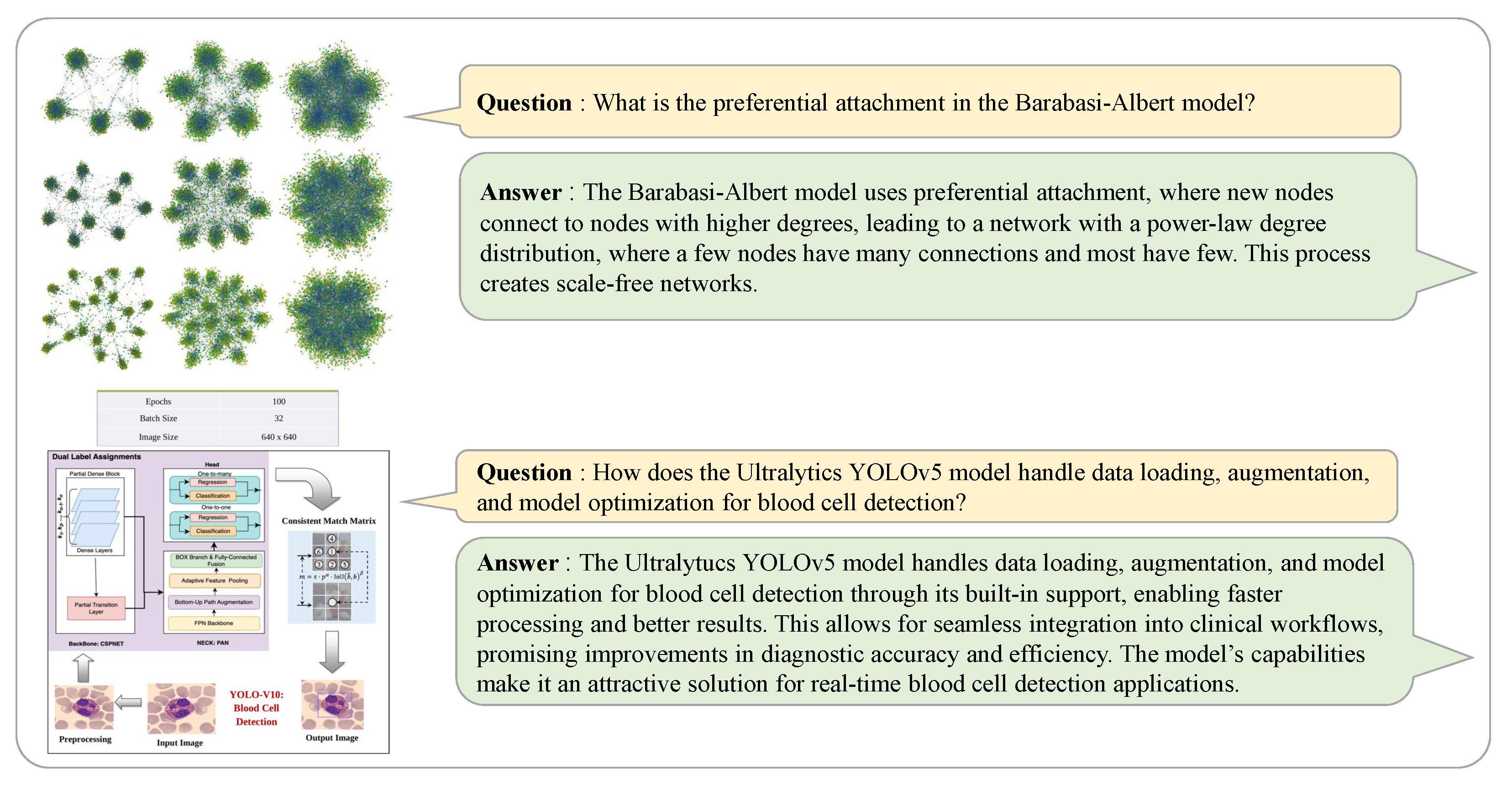
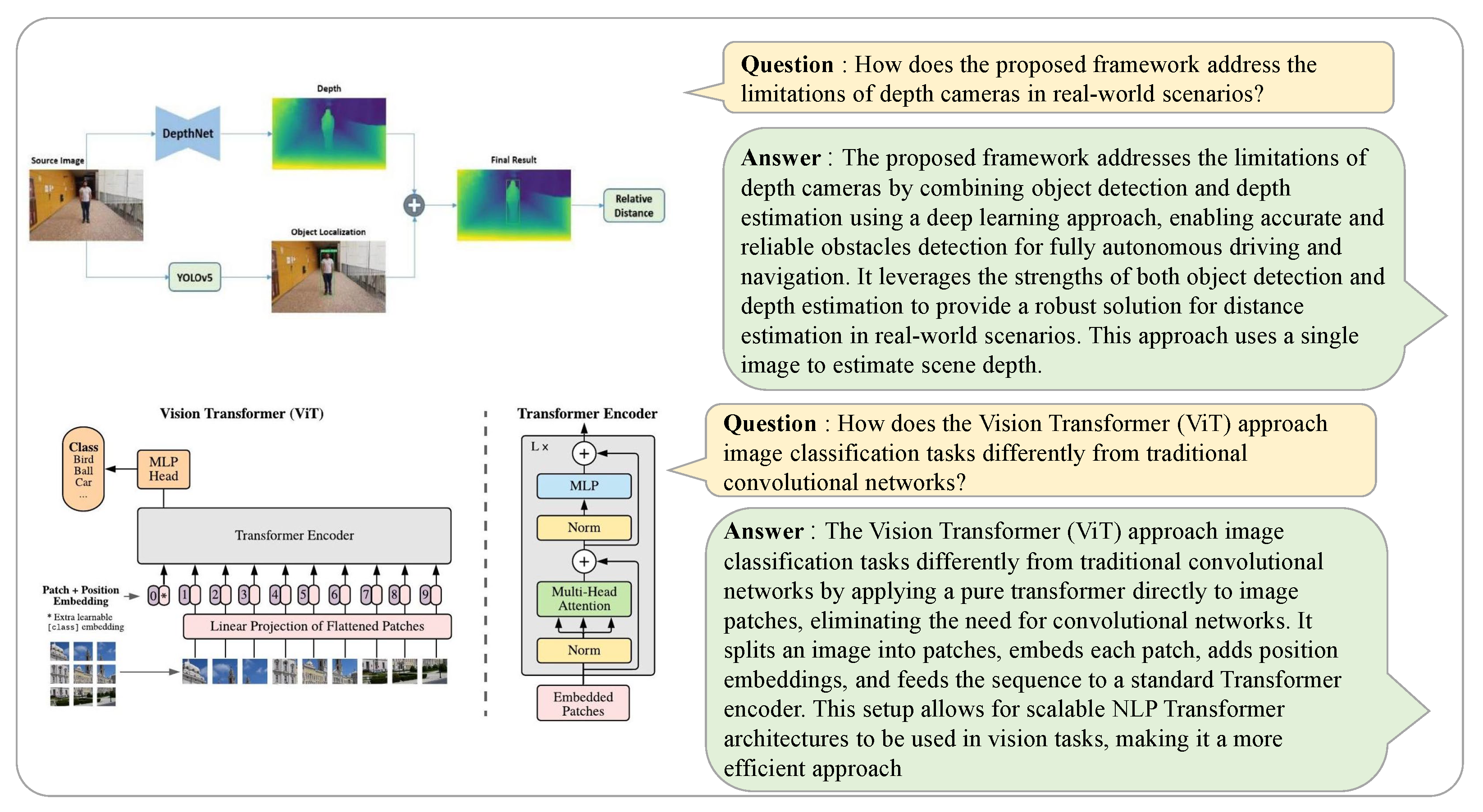
Figure 14,
Figure 15 and
Figure 16 represent a sample of the benchmarks used in the experimental evaluation. The examples presented demonstrate the system’s robust ability to accurately extract important information and generate appropriate answers in domains containing specialized knowledge. These results validate the system’s ability to thoroughly understand academic articles, generate appropriate questions to validate article comprehension, and produce accurate answers. They also confirm the system’s proficiency in accurately interpreting technical terms and complex article concepts, especially in its ability to generate QA pairs that effectively integrate textual and visual elements, such as graphs, numerical data, and images.
4.4. Human Evaluation Results
To assess the quality of the generated benchmarks, we conducted a comprehensive human evaluation study with 10 experts with at least a master’s degree in a relevant field. We sampled 5k–10k data points from each domain benchmark in medicine, engineering, and natural sciences to form a total of five independent evaluation sets, each of which was independently reviewed by two evaluators to ensure the reliability of the evaluation.
The evaluation was conducted across four main dimensions to validate the quality of the article comprehension evaluation datasets. First, accuracy assessed whether the questions and answers matched the content of the articles. Second, consistency examined whether consistent information was provided for similar inputs. Third, relevance determined if the data points were appropriate to the topic or context. Finally, diversity assessed whether the dataset reflects different aspects of the paper. Specific numerical results for Human Evaluation can be found in the
Table 5.
The evaluation showed that the benchmarks generated were of high quality overall. These results show that our system is able to generate benchmarks with high accuracy, consistency, and high relevance to the content of the paper. However, the diversity score was lower than the other evaluation metrics. This suggests that our system tends to focus on certain parts or aspects of the paper. We discuss this in more detail in
Section 6, “Limitations”.
4.5. Ablation Study
When creating the benchmark, we generate questions while examining each section of the paper, during which we extract the content necessary for answering the paper’s questions. We then conduct an ablation study on this content extraction method. We evaluate and compare scores for each case using full paper, parsing, and semantic parsing techniques for content extraction. Through the scores in
Table 6, we can confirm that across all domains, using contents through the semantic parsing method demonstrates better paper comprehension capability.
5. Conclusions
This paper proposes a framework for assessing the level of understanding that an LLM can achieve for a particular paper. The benchmark created by our system can evaluate whether an LLM has read and fully understood a certain paper. It extends beyond asking the LLM to read the content of the paper and ask about the overall content, including the problems and solutions of the paper, and includes detailed information on each section; it also requires QA for visual materials that are necessary for understanding the paper. The benchmark generation system converts the content of the paper into contents for QA generation through the semantic parsing method we proposed, which improves the existing “lost in the middle” phenomenon and enables the generation of detailed QA and VQA. Introducing a reviewer improves QA generation quality by addressing issues such as a lack of causality and failure to reflect the paper’s content.
Our benchmark generation system is developed based on the LLaMA3.2-11B Vision model, which can be run in a single A6000 GPU environment, and is a system that can efficiently input the contents of a paper to create a QA benchmark without relying on a model with an excessive huge context length. Our framework allows for convenient evaluation of an in-depth understanding of LLM papers with minimal human intervention. However, if content extraction fails due to errors in the parsing tool or if an image-related section exceeds three pages, the VQA output quality declines. Even with a review, improvements are insufficient, indicating the need for further research. This research provides a more efficient solution by enabling users to assess their understanding of a paper and interact with it through document-based methods such as RAG, even before converting raw data into training data.
6. Limitations
Despite the effectiveness of our benchmark generation system, there are several limitations that should be addressed in future research. In the current implementation, we developed a system optimized for arXiv-formatted papers. This approach allowed us to create a standardized parsing process for our experiments. However, this is a significant limitation because papers from different conferences and journals often use different formats. These format differences can have a significant impact on the content parsing process, leading to incorrect extraction of section structures, mismatches between visual and textual descriptions, or complete parsing failure. To make the system more flexible and widely applicable across the scientific literature, future research should focus on developing more adaptive parsing methods that can handle different article formats from different publishers and societies.
In addition, the low diversity scores of the generated benchmarks, as revealed by the human evaluation, are an important limitation. This suggests that the system tends to generate questions that focus on specific parts or aspects of the paper. This lack of diversity may limit the ability to comprehensively evaluate the generated benchmarks. Future research should optimize the prompts to consider different aspects and content of the papers, and develop more intelligent content extraction mechanisms to improve the diversity of the questions and answers generated. In particular, developing diversity enhancement strategies that take into account domain-specific characteristics will help generate more comprehensive and effective assessment benchmarks.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}