
Transliteration-Aided Transfer Learning for Low-Resource ASR: A Case Study on Khalkha Mongolian


Abstract
1. Introduction
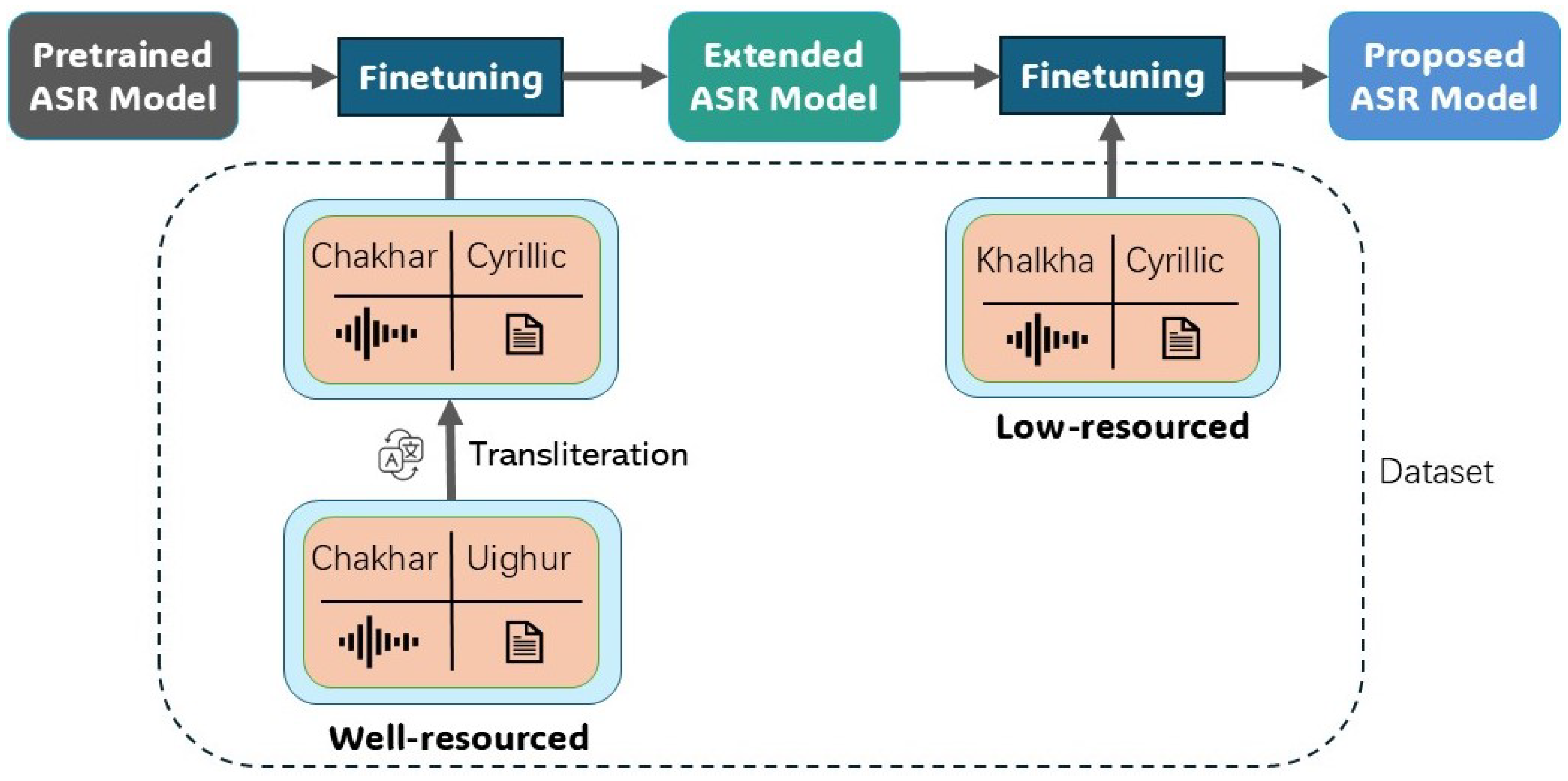
2. Methodology
2.1. Transliteration
 and a soft sign
and a soft sign  [26]. Vowels are marked in red. Based on these differences, the following key difficulties are faced in the specific process of transliteration.
[26]. Vowels are marked in red. Based on these differences, the following key difficulties are faced in the specific process of transliteration. ” (4 letters) in traditional Mongolian, whereas in Cyrillic Mongolian, it appears as “
” (4 letters) in traditional Mongolian, whereas in Cyrillic Mongolian, it appears as “ ” (3 letters). Figure 4 shows the one-to-many phenomenon when considering G2P when translating traditional Mongolian into Cyrillic Mongolian, and the letters that do not correspond are marked in red.
” (3 letters). Figure 4 shows the one-to-many phenomenon when considering G2P when translating traditional Mongolian into Cyrillic Mongolian, and the letters that do not correspond are marked in red. (pil). Although its direct semantic translation into Cyrillic Mongolian would be
(pil). Although its direct semantic translation into Cyrillic Mongolian would be  (tavag), we have chosen to render it as
(tavag), we have chosen to render it as  (pil) in Cyrillic in order to preserve the alignment between acoustic and textual features in the dataset and thus facilitate subsequent fine-tuning. It should be noted, however, that is not recognized as a standard term in Cyrillic Mongolian usage.
(pil) in Cyrillic in order to preserve the alignment between acoustic and textual features in the dataset and thus facilitate subsequent fine-tuning. It should be noted, however, that is not recognized as a standard term in Cyrillic Mongolian usage.2.2. Fine-Tuning of End-to-End Transfer Learning
3. Experiment
3.1. Datasets
3.2. Experimental Setup
4. Methods
4.1. Zero-Shot Evaluation
4.2. DFT (Direct Fine-Tuning)
4.3. MDFT (Merged Dataset Fine-Tuning)
4.4. EFT (Extended Fine-Tuning)
4.5. TFT (Targeted Fine-Tuning)
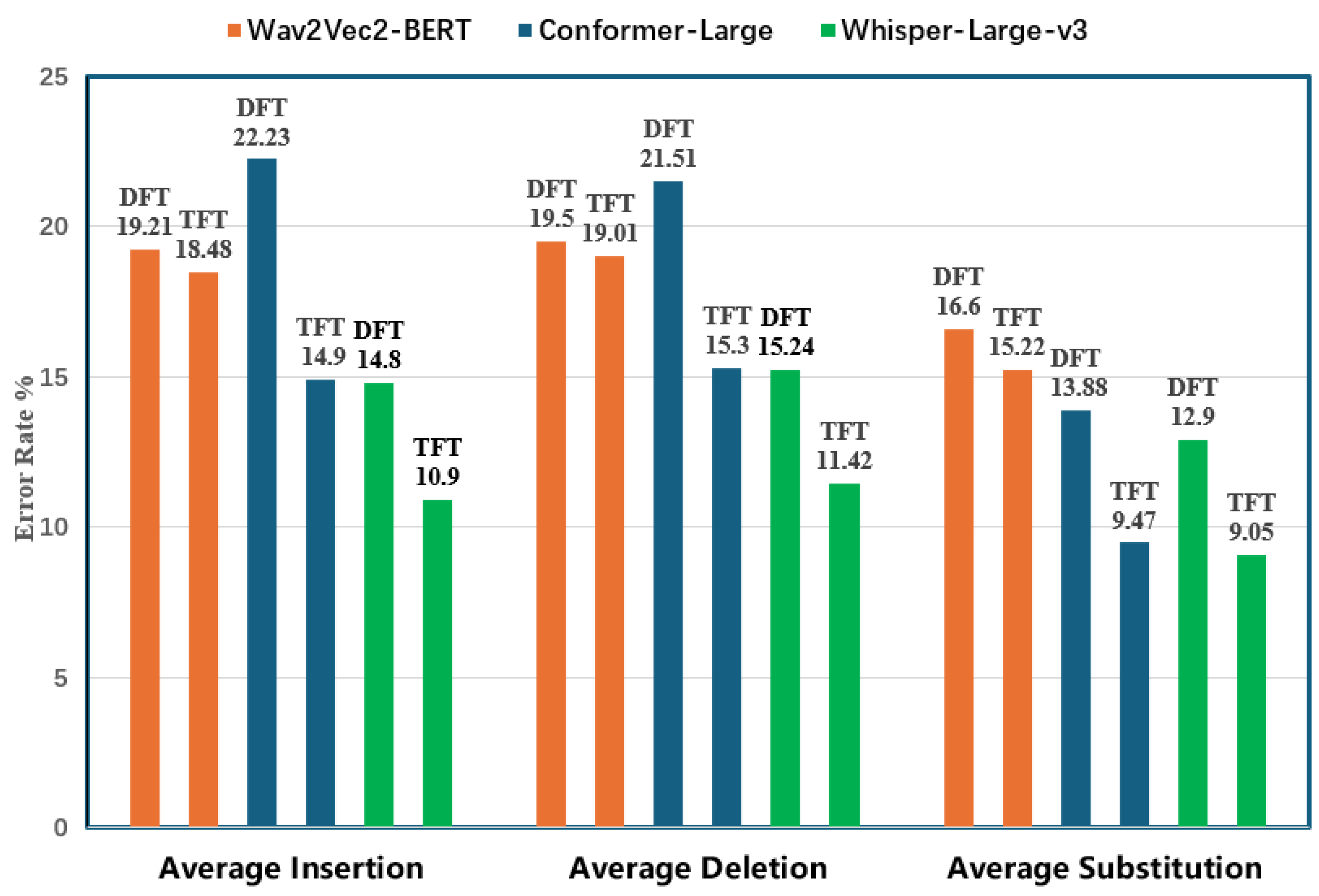
5. Result Analysis
5.1. Method Analysis
5.2. Analysis from Model Perspective
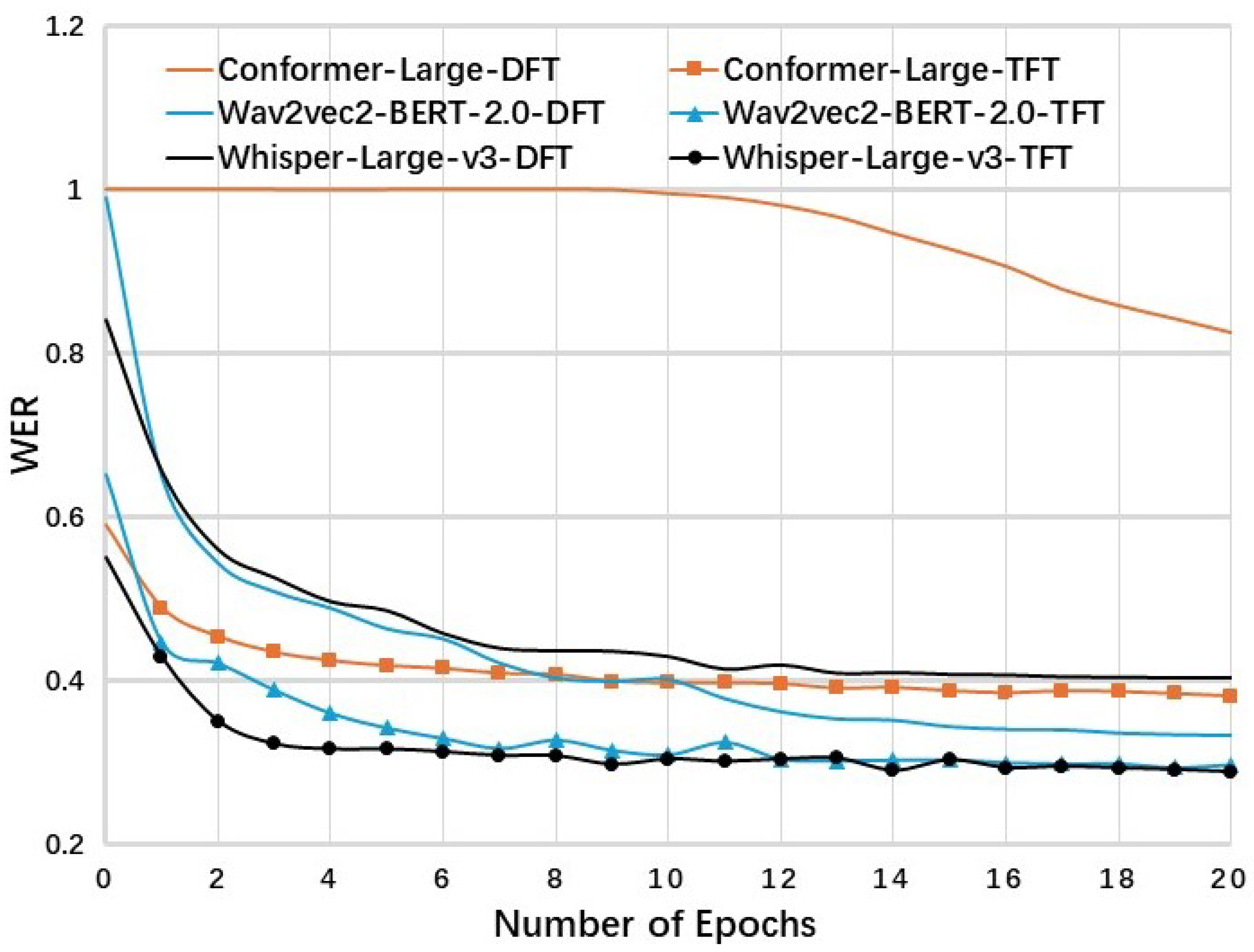
5.3. Analysis of Training Process
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Janhunen, J.A. Mongolian; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Burjgin, J.; Bilik, N. Contemporary Mongolian population distribution, migration, cultural change, and identity. In China’s Minorities on the Move; Routledge: London, UK, 2015; pp. 53–68. [Google Scholar]
- Shi, L.; Bao, F.; Wang, Y.; Gao, G. Research on Khalkha Dialect Mongolian Speech Recognition Acoustic Model Based on Weight Transfer. In Proceedings of the Natural Language Processing and Chinese Computing: 8th CCF International Conference, NLPCC 2019, Dunhuang, China, 9–14 October 2019; pp. 519–528. [Google Scholar]
- Zhi, T.; Shi, Y.; Du, W.; Li, G.; Wang, D. M2ASR-MONGO: A free mongolian speech database and accompanied baselines. In Proceedings of the 2021 24th Conference of the Oriental COCOSDA International Committee for the Co-Ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), Singapore, 18–20 November 2021; pp. 140–145. [Google Scholar]
- Wu, Y.; Wang, Y.; Zhang, H.; Bao, F.; Gao, G. MNASR: A Free Speech Corpus For Mongolian Speech Recognition And Accompanied Baselines. In Proceedings of the 2022 25th Conference of the Oriental COCOSDA International Committee for the Co-Ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), Hanoi, Vietnam, 24–26 November 2022; pp. 1–6. [Google Scholar]
- Liu, Z.; Ma, Z.; Zhang, X.; Bao, C.; Xie, X.; Zhu, F. Mongolian Speech Corpus IMUT-MC; Science Data Bank: Beijing, China, 2022. [Google Scholar]
- Reitmaier, T.; Wallington, E.; Kalarikalayil Raju, D.; Klejch, O.; Pearson, J.; Jones, M.; Bell, P.; Robinson, S. Opportunities and challenges of automatic speech recognition systems for low-resource language speakers. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 6 Mau–30 April 2022; pp. 1–17. [Google Scholar]
- Fendji, J.L.K.E.; Tala, D.C.; Yenke, B.O.; Atemkeng, M. Automatic speech recognition using limited vocabulary: A survey. Appl. Artif. Intell. 2022, 36, 2095039. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Qin, C.X.; Qu, D.; Zhang, L.H. Towards end-to-end speech recognition with transfer learning. EURASIP J. Audio Speech Music. Process. 2018, 2018, 18. [Google Scholar] [CrossRef]
- Shivakumar, P.G.; Georgiou, P. Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations. Comput. Speech Lang. 2020, 63, 101077. [Google Scholar] [CrossRef] [PubMed]
- Joshi, V.; Zhao, R.; Mehta, R.R.; Kumar, K.; Li, J. Transfer learning approaches for streaming end-to-end speech recognition system. arXiv 2020, arXiv:2008.05086. [Google Scholar]
- Sullivan, P.; Shibano, T.; Abdul-Mageed, M. Improving automatic speech recognition for non-native English with transfer learning and language model decoding. In Analysis and Application of Natural Language and Speech Processing; Springer: Berlin/Heidelberg, Germany, 2022; pp. 21–44. [Google Scholar]
- Qin, S.; Wang, L.; Li, S.; Dang, J.; Pan, L. Improving low-resource Tibetan end-to-end ASR by multilingual and multilevel unit modeling. EURASIP J. Audio Speech Music. Process. 2022, 2022, 2. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, W.Q. Improving automatic speech recognition performance for low-resource languages with self-supervised models. IEEE J. Sel. Top. Signal Process. 2022, 16, 1227–1241. [Google Scholar] [CrossRef]
- Jimerson, R.; Liu, Z.; Prud’Hommeaux, E. An (unhelpful) guide to selecting the best ASR architecture for your under-resourced language. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 2, pp. 1008–1016. [Google Scholar]
- Li, Z.; Rind-Pawlowski, M.; Niehues, J. Speech Recognition Corpus of the Khinalug Language for Documenting Endangered Languages. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; pp. 15171–15180. [Google Scholar]
- Mengke, D.; Meng, Y.; Mihajlik, P. Tandem Long-Short Duration-based Modeling for Automatic Speech Recognition. In Proceedings of the 3rd Annual Meeting of the Special Interest Group on Under-resourced Languages@ LREC-COLING 2024, Torino, Italia, 20–21 May 2024; pp. 331–336. [Google Scholar]
- Sukhadia, V.N.; Umesh, S. Domain adaptation of low-resource target-domain models using well-trained asr conformer models. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 295–301. [Google Scholar]
- Mihajlik, P.; Kádár, M.S.; Dobsinszki, G.; Meng, Y.; Kedalai, M.; Linke, J.; Fegyó, T.; Mády, K. What kind of multi-or cross-lingual pre-training is the most effective for a spontaneous, less-resourced ASR task? In Proceedings of the 2nd Annual Meeting of the Special Interest Group on Under-resourced Languages: SIGUL 2023, Dublin, Ireland, 18–20 August 2023. [Google Scholar]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep automatic speech recognition with 1d time-channel separable convolutions. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6124–6128. [Google Scholar]
- Khare, S.; Mittal, A.R.; Diwan, A.; Sarawagi, S.; Jyothi, P.; Bharadwaj, S. Low Resource ASR: The Surprising Effectiveness of High Resource Transliteration. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021; pp. 1529–1533. [Google Scholar]
- Li, H.; Sarina, B. The study of comparison and conversion about traditional Mongolian and Cyrillic Mongolian. In Proceedings of the 2011 4th International Conference on Intelligent Networks and Intelligent Systems, Kuming, China, 1–3 November 2011; pp. 199–202. [Google Scholar]
- Bao, F.; Gao, G.; Yan, X.; Wang, H. Language model for cyrillic mongolian to traditional mongolian conversion. In Proceedings of the Natural Language Processing and Chinese Computing: Second CCF Conference, NLPCC 2013, Chongqing, China, 15–19 November 2013; pp. 13–18. [Google Scholar]
- Na, M.; Bao, F.; Wang, W.; Gao, G.; Dulamragchaa, U. Traditional Mongolian-to-Cyrillic Mongolian Conversion Method Based on the Combination of Rules and Transformer. In Proceedings of the 2023 IEEE 9th International Conference on Cloud Computing and Intelligent Systems (CCIS), Dali, China, 12–13 August 2023; pp. 440–445. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Zheng, G.; Xiao, Y.; Gong, K.; Zhou, P.; Liang, X.; Lin, L. Wav-BERT: Cooperative acoustic and linguistic representation learning for low-resource speech recognition. arXiv 2021, arXiv:2109.09161. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 28–29 July 2023; pp. 28492–28518. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Zero-Shot | DFT | MDFT | EFT | TFT |
|---|---|---|---|---|---|
| Wav2Vec2-BERT | - | 15.56/55.35 | 17.42/57.77 | 20.97/63.29 | 15.33/52.82 |
| Conformer-Large | - | 21.16/59.25 | 16.12/43.01 | 24.55/59.37 | 14.50/39.99 |
| Whisper-Large-v3 | 45.73/92.60 | 13.96/43.02 | 16.27/49.95 | 21.96/61.35 | 10.75/31.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mengke, D.; Meng, Y.; Mihajlik, P. Transliteration-Aided Transfer Learning for Low-Resource ASR: A Case Study on Khalkha Mongolian. Electronics 2025, 14, 1137. https://doi.org/10.3390/electronics14061137
Mengke D, Meng Y, Mihajlik P. Transliteration-Aided Transfer Learning for Low-Resource ASR: A Case Study on Khalkha Mongolian. Electronics. 2025; 14(6):1137. https://doi.org/10.3390/electronics14061137
Chicago/Turabian StyleMengke, Dalai, Yan Meng, and Péter Mihajlik. 2025. "Transliteration-Aided Transfer Learning for Low-Resource ASR: A Case Study on Khalkha Mongolian" Electronics 14, no. 6: 1137. https://doi.org/10.3390/electronics14061137
APA StyleMengke, D., Meng, Y., & Mihajlik, P. (2025). Transliteration-Aided Transfer Learning for Low-Resource ASR: A Case Study on Khalkha Mongolian. Electronics, 14(6), 1137. https://doi.org/10.3390/electronics14061137