
Exploration of Cross-Modal AIGC Integration in Unity3D for Game Art Creation


Abstract
1. Introduction
- (1)
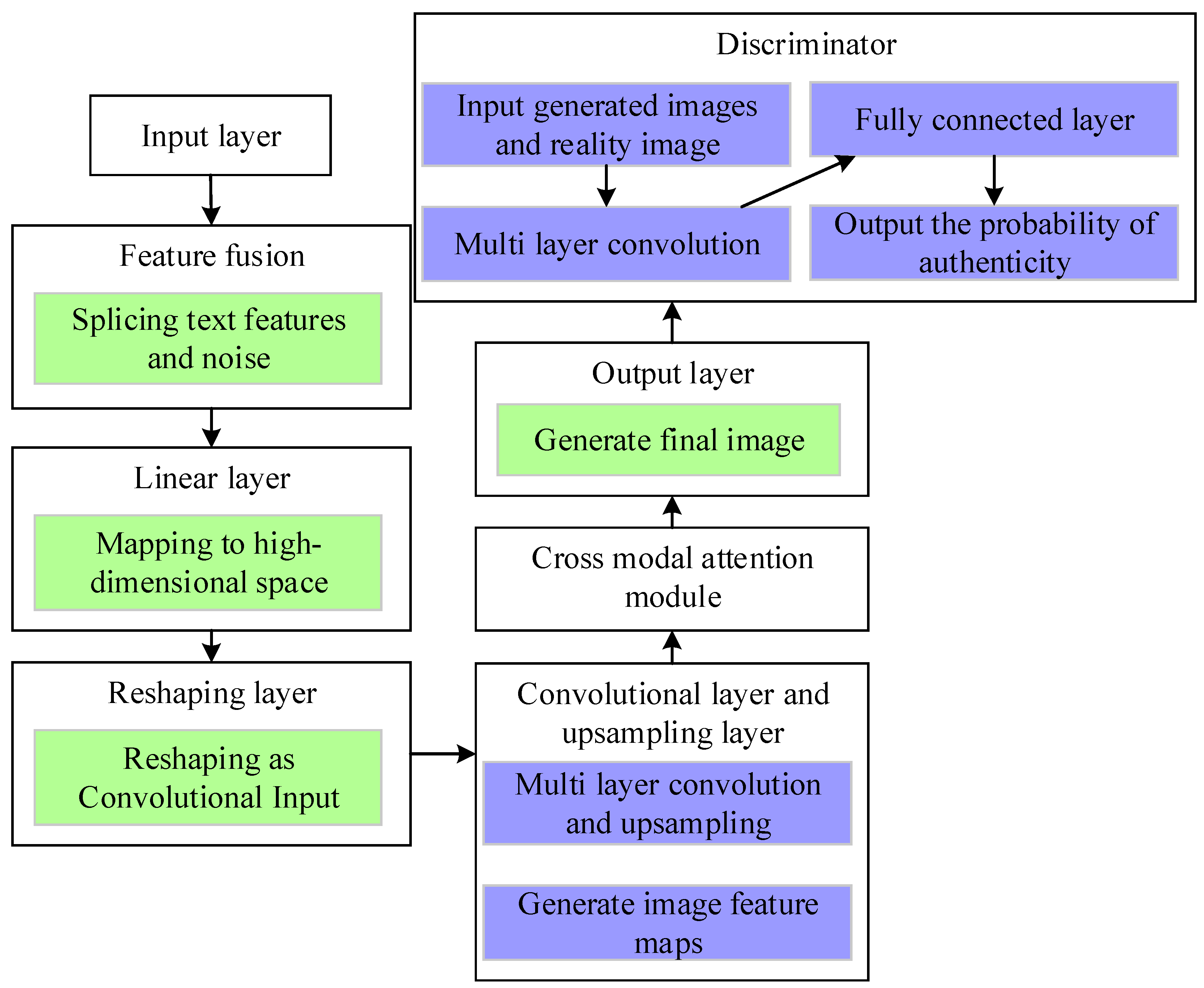
- A cross-modal AIGC framework is developed, leveraging a Transformer–GAN architecture that integrates GANs with Transformer models. This architecture enhances both the diversity and global coherence of generated images, addressing limitations in conventional unimodal generative methods.
- (2)
- A cross-modal attention mechanism is introduced, enabling dynamic computation of attention weights between textual descriptions and generated images. This mechanism facilitates precise semantic alignment between input prompts and generated content, significantly improving fidelity and variation in generated outputs.
- (3)
- Deep learning model integration within the Unity3D game engine is achieved through the Barracuda inference framework, ensuring the real-time execution of AI-driven content generation. This approach enables on-device inference with low-latency processing, optimizing efficiency for interactive game environments.
- (4)
- An asynchronous computation pipeline is implemented to optimize the cross-modal attention mechanism, preventing interference with the main rendering thread during gameplay. This optimization enhances system responsiveness, ensuring seamless real-time content adaptation without compromising interactivity or rendering performance.
2. Research Theory
2.1. Literature Review
2.2. Theoretical Framework
- (1)
- Satisfaction with Visual Content: An overall evaluation of visual elements, including image quality, stylistic coherence, and consistency with the game’s atmosphere, was provided by the participants.
- (2)
- Game Immersion: The influence of AI-generated visuals on player immersion and overall gaming experience was measured.
- (3)
- Image Quality and Style Preferences: Preferences regarding image details, color schemes, and artistic style were explored, alongside comparisons between AI-generated and traditional visuals.
- (4)
- Content Generation Efficiency: Player perceptions of the efficiency and time requirements of the AI-generated content were assessed, with particular attention paid to their acceptance of AI-driven alterations in visual production.
2.3. Key Technologies
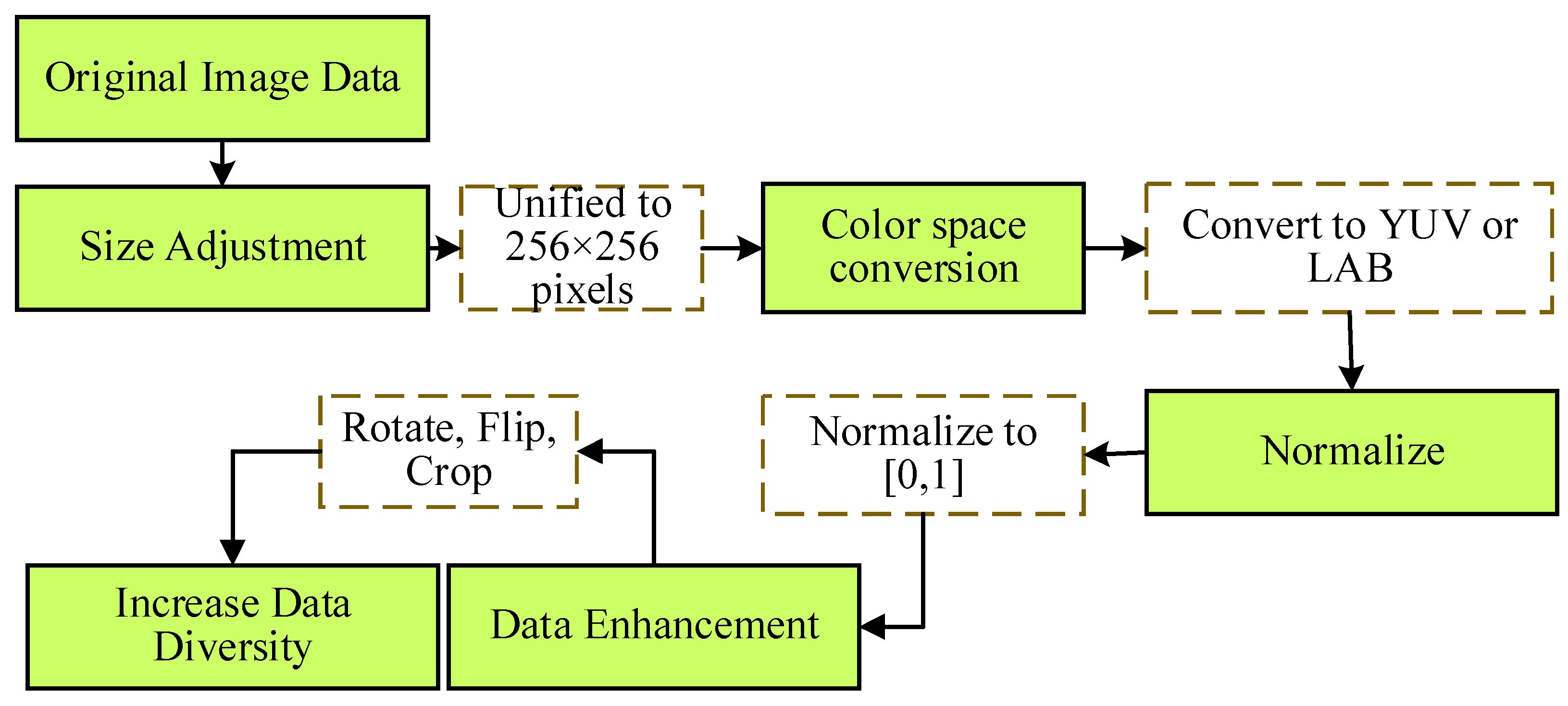
3. Experiments and Analysis
3.1. Experimental Design
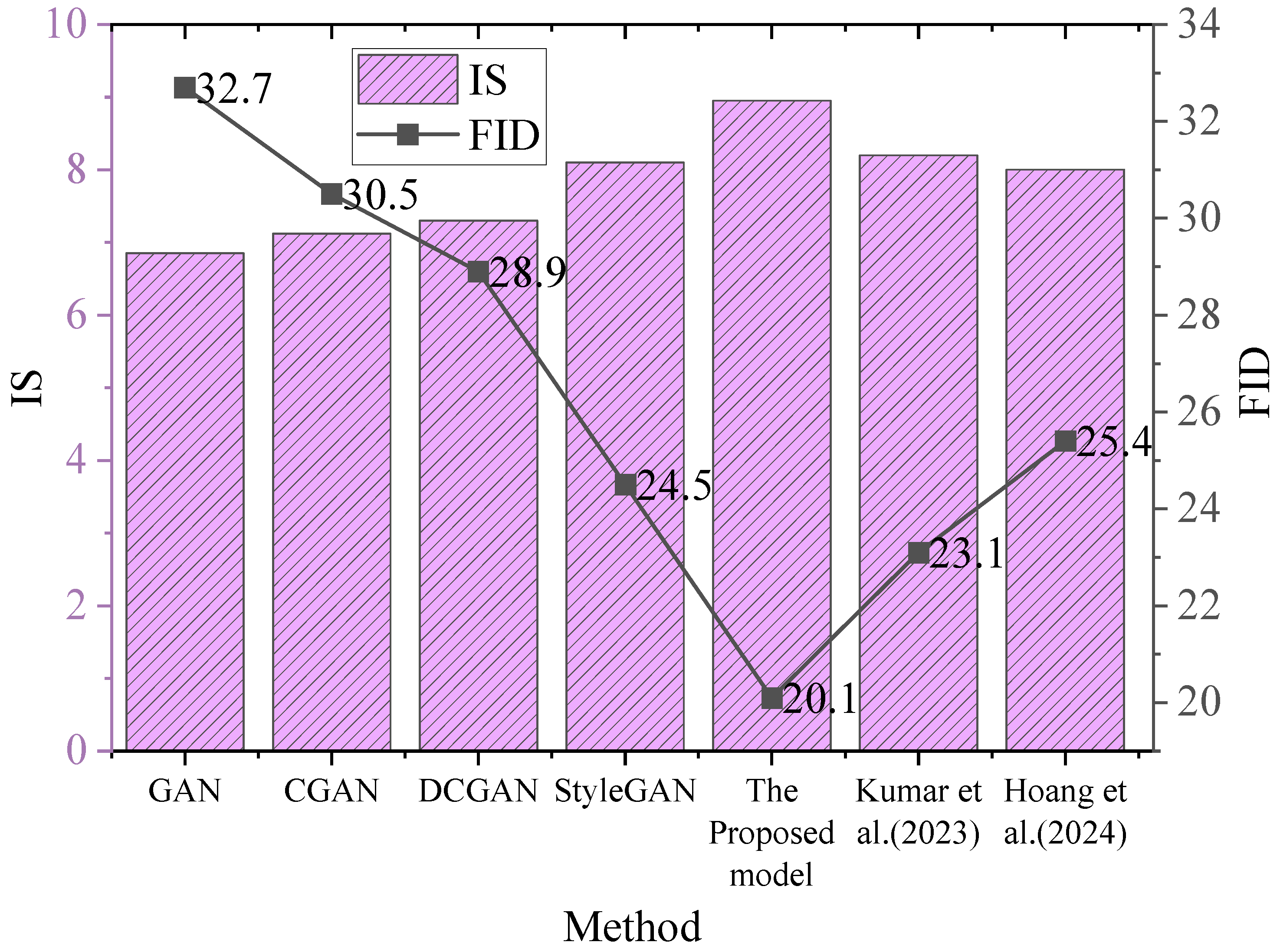
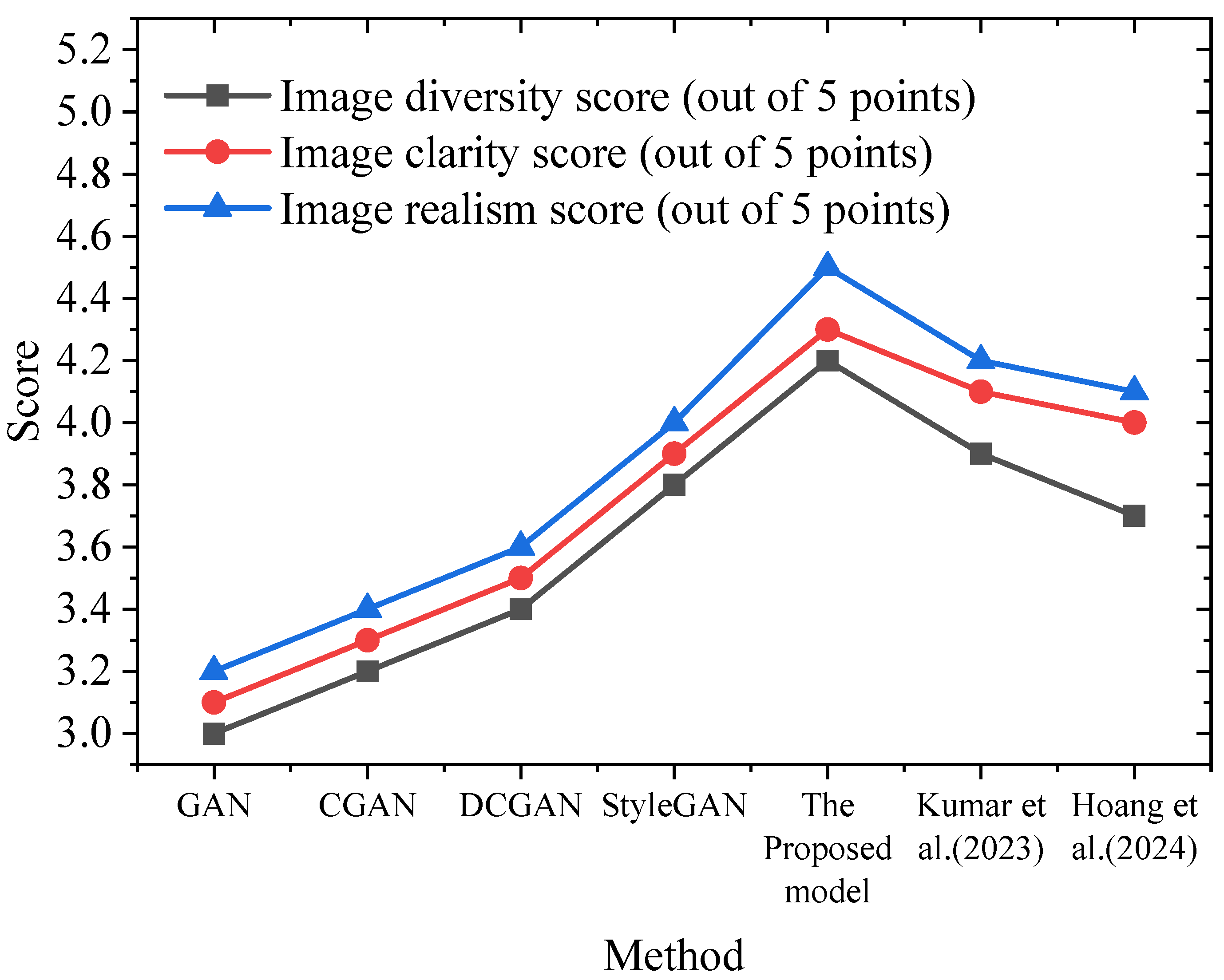
3.2. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- AlZoubi, O.; AlMakhadmeh, B.; Yassein, M.B.; Mardini, W. Detecting naturalistic expression of emotions using physiological signals while playing video games. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 1133–1146. [Google Scholar] [CrossRef]
- Sekhavat, Y.A.; Azadehfar, M.R.; Zarei, H.; Roohi, S. Sonification and interaction design in computer games for visually impaired individuals. Multimed. Tools Appl. 2022, 81, 7847–7871. [Google Scholar] [CrossRef]
- von Gillern, S.; Stufft, C. Multimodality, learning and decision-making: Children’s metacognitive reflections on their engagement with video games as interactive texts. Literacy 2023, 57, 3–16. [Google Scholar] [CrossRef]
- Itzhak, N.B.; Franki, I.; Jansen, B.; Kostkova, K.; Wagemans, J.; Ortibus, E. An individualized and adaptive game-based therapy for cerebral visual impairment: Design, development, and evaluation. Int. J. Child-Comput. Interact. 2022, 31, 100437. [Google Scholar] [CrossRef]
- Delmas, M.; Caroux, L.; Lemercier, C. Searching in clutter: Visual behavior and performance of expert action video game players. Appl. Ergon. 2021, 99, 103628. [Google Scholar] [CrossRef]
- Anantrasirichai, N.; Bull, D. Artificial intelligence in the creative industries: A review. Artif. Intell. Rev. 2021, 55, 589–656. [Google Scholar] [CrossRef]
- Zhang, W.; Shankar, A.; Antonidoss, A. Modern art education and teaching based on artificial intelligence. J. Interconnect. Netw. 2021, 22, 2141005. [Google Scholar] [CrossRef]
- Lv, Z. Generative artificial intelligence in the metaverse era. Cogn. Robot. 2023, 3, 208–217. [Google Scholar] [CrossRef]
- Lai, G.; Leymarie, F.F.; Latham, W. On mixed-initiative content creation for video games. IEEE Trans. Games 2022, 14, 543–557. [Google Scholar] [CrossRef]
- Mikalonytė, E.S.; Kneer, M. Can Artificial Intelligence make art?: Folk intuitions as to whether AI-driven robots can be viewed as artists and produce art. ACM Trans. Hum.-Robot Interact. 2022, 11, 43. [Google Scholar] [CrossRef]
- Vinchon, F.; Lubart, T.; Bartolotta, S.; Gironnay, V.; Botella, M.; Bourgeois-Bougrine, S.; Burkhardt, J.-M.; Bonnardel, N.; Corazza, G.E.; Glăveanu, V.; et al. Artificial Intelligence & Creativity: A manifesto for collaboration. J. Creat. Behav. 2023, 57, 472–484. [Google Scholar]
- Caramiaux, B.; Alaoui, S.F. Explorers of Unknown Planets’ Practices and Politics of Artificial Intelligence in Visual Arts. Proc. ACM Hum.-Comput. Interact. 2022, 6, 477. [Google Scholar] [CrossRef]
- Abbott, R.; Rothman, E. Disrupting creativity: Copyright law in the age of generative artificial intelligence. Fla. L. Rev. 2023, 75, 1141. [Google Scholar]
- Leichtmann, B.; Hinterreiter, A.; Humer, C.; Streit, M.; Mara, M. Explainable artificial intelligence improves human decision-making: Results from a mushroom picking experiment at a public art festival. Int. J. Hum.–Comput. Interact. 2023, 40, 4787–4804. [Google Scholar] [CrossRef]
- Zhang, B.; Romainoor, N.H. Research on artificial intelligence in new year prints: The application of the generated pop art style images on cultural and creative products. Appl. Sci. 2023, 13, 1082. [Google Scholar] [CrossRef]
- Sunarya, P.A. Machine learning and artificial intelligence as educational games. Int. Trans. Artif. Intell. 2022, 1, 129–138. [Google Scholar]
- Wagan, A.A.; Khan, A.A.; Chen, Y.L.; Yee, P.L.; Yang, J.; Laghari, A.A. Artificial intelligence-enabled game-based learning and quality of experience: A novel and secure framework (B-AIQoE). Sustainability 2023, 15, 5362. [Google Scholar] [CrossRef]
- Lu, Y.; Liu, J.; Lv, L.; Gao, X.; Chen, W.; Zhang, Y. Re-EnGAN: Unsupervised image-to-image translation based on reused feature encoder in CycleGAN. IET Image Process. 2022, 16, 2219–2227. [Google Scholar] [CrossRef]
- de Souza, V.L.T.; Marques, B.A.D.; Batagelo, H.C.; Gois, J.P. A review on generative adversarial networks for image generation. Comput. Graph. 2023, 114, 13–25. [Google Scholar] [CrossRef]
- Özçift, A.; Akarsu, K.; Yumuk, F.; Söylemez, C. Advancing natural language processing (NLP) applications of morphologically rich languages with bidirectional encoder representations from transformers (BERT): An empirical case study for Turkish. Automatika 2021, 62, 226–238. [Google Scholar] [CrossRef]
- Gu, J.; Meng, X.; Lu, G.; Hou, L.; Minzhe, N.; Liang, X.; Yao, L.; Huang, R.; Zhang, W.; Jiang, X.; et al. Wukong: A 100 million large-scale chinese cross-modal pre-training benchmark. Adv. Neural Inf. Process. Syst. 2022, 35, 26418–26431. [Google Scholar]
- Erdem, E.; Kuyu, M.; Yagcioglu, S.; Frank, A.; Parcalabescu, L.; Plank, B.; Babii, A.; Turuta, O.; Erdem, A.; Calixto, L.; et al. Neural natural language generation: A survey on multilinguality, multimodality, controllability and learning. J. Artif. Intell. Res. 2022, 73, 1131–1207. [Google Scholar] [CrossRef]
- Goel, S.; Bansal, H.; Bhatia, S.; Rossi, R.; Vinay, V.; Grover, A. Cyclip: Cyclic contrastive language-image pretraining. Adv. Neural Inf. Process. Syst. 2022, 35, 6704–6719. [Google Scholar]
- Zhang, W.; Cui, Y.; Zhang, K.; Wang, Y.; Zhu, Q.; Li, L.; Liu, T. A static and dynamic attention framework for multi turn dialogue generation. ACM Trans. Inf. Syst. 2023, 41, 15. [Google Scholar] [CrossRef]
- Kaźmierczak, R.; Skowroński, R.; Kowalczyk, C.; Grunwald, G. Creating Interactive Scenes in 3D Educational Games: Using Narrative and Technology to Explore History and Culture. Appl. Sci. 2024, 14, 4795. [Google Scholar] [CrossRef]
- Huang, Y.-L.; Yuan, X.-F. StyleTerrain: A novel disentangled generative model for controllable high-quality procedural terrain generation. Comput. Graph. 2023, 116, 373–382. [Google Scholar] [CrossRef]
- Värtinen, S.; Hämäläinen, P.; Guckelsberger, C. Generating role-playing game quests with GPT language models. IEEE Trans. Games 2022, 16, 127–139. [Google Scholar] [CrossRef]
- Li, C.; Wang, Y.; Zhou, Z.; Wang, Z.; Mardani, A. Digital finance and enterprise financing constraints: Structural characteristics and mechanism identification. J. Bus. Res. 2023, 165, 114074. [Google Scholar] [CrossRef]
- Zhang, R.; Cao, Z.; Huang, Y.; Yang, S.; Xu, L.; Xu, M. Visible-Infrared Person Re-identification with Real-world Label Noise. IEEE Trans. Circuits Syst. Video Technol. 2025, 1-1. [Google Scholar] [CrossRef]
- Zhang, R.; Yang, B.; Xu, L.; Huang, Y.; Xu, X.; Zhang, Q.; Jiang, Z.; Liu, Y. A Benchmark and Frequency Compression Method for Infrared Few-Shot Object Detection. IEEE Trans. Geosci. Remote. Sens. 2025, 63, 5001711. [Google Scholar] [CrossRef]
- Gao, R. AIGC Technology: Reshaping the Future of the Animation Industry. Highlights Sci. Eng. Technol. 2023, 56, 148–152. [Google Scholar] [CrossRef]
- Ren, Q.; Tang, Y.; Lin, Y. Digital Art Creation under AIGC Technology Innovation: Multidimensional Challenges and Reflections on Design Practice, Creation Environment and Artistic Ecology. Comput. Artif. Intell. 2024, 1, 1–12. [Google Scholar] [CrossRef]
- Deng, J. Governance Prospects for the Development of Generative AI Film Industry from the Perspective of Community Aesthetics. Stud. Art Arch. 2024, 3, 153–162. [Google Scholar] [CrossRef]
- Kumar, L.; Singh, D.K. Pose image generation for video content creation using controlled human pose image generation GAN. Multimed. Tools Appl. 2023, 83, 59335–59354. [Google Scholar] [CrossRef]
- Hoang, N.L.; Taniguchi, T.; Hagiwara, Y.; Taniguchi, A. Emergent communication of multimodal deep generative models based on Metropolis-Hastings naming game. Front. Robot. AI 2024, 10, 1290604. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Subcategory | Number of Participants | |
|---|---|---|---|
| Age | 18–24 years | 31 | 62.0% |
| 25–34 years | 13 | 26.0% | |
| 35 years and above | 6 | 12.0% | |
| Gender | Male | 36 | 72.0% |
| Female | 14 | 28.0% | |
| Gaming Experience | High | 22 | 44.0% |
| Middle | 16 | 32.0% | |
| Low | 12 | 24.0% | |
| Model Comparison | t-Value | Degrees of Freedom (df) | p-Value | 95% Confidence Interval | Cohen’s d (Effect Size) |
|---|---|---|---|---|---|
| Traditional GAN vs. Proposed Model | −6.14 | 58 | <0.001 | [−1.7, −0.9] | −1.8 |
| CGAN vs. Proposed Model | −5.81 | 58 | <0.001 | [−1.6, −0.8] | −1.7 |
| DCGAN vs. Proposed Model | −5.34 | 58 | <0.001 | [−1.5, −0.7] | −1.6 |
| StyleGAN vs. Proposed Model | −4.90 | 58 | <0.001 | [−1.3, −0.6] | −1.5 |
| Study [34] vs. Proposed Model | −4.25 | 58 | <0.001 | [−1.2, −0.3] | −1.4 |
| Study [35] vs. Proposed Model | −4.02 | 58 | <0.001 | [−1.1, −0.2] | −1.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Li, J.; Hu, W. Exploration of Cross-Modal AIGC Integration in Unity3D for Game Art Creation. Electronics 2025, 14, 1101. https://doi.org/10.3390/electronics14061101
Liu Q, Li J, Hu W. Exploration of Cross-Modal AIGC Integration in Unity3D for Game Art Creation. Electronics. 2025; 14(6):1101. https://doi.org/10.3390/electronics14061101
Chicago/Turabian StyleLiu, Qinchuan, Jiaqi Li, and Wenjie Hu. 2025. "Exploration of Cross-Modal AIGC Integration in Unity3D for Game Art Creation" Electronics 14, no. 6: 1101. https://doi.org/10.3390/electronics14061101
APA StyleLiu, Q., Li, J., & Hu, W. (2025). Exploration of Cross-Modal AIGC Integration in Unity3D for Game Art Creation. Electronics, 14(6), 1101. https://doi.org/10.3390/electronics14061101