

Self-MCKD: Enhancing the Effectiveness and Efficiency of Knowledge Transfer in Malware Classification


Abstract

1. Introduction
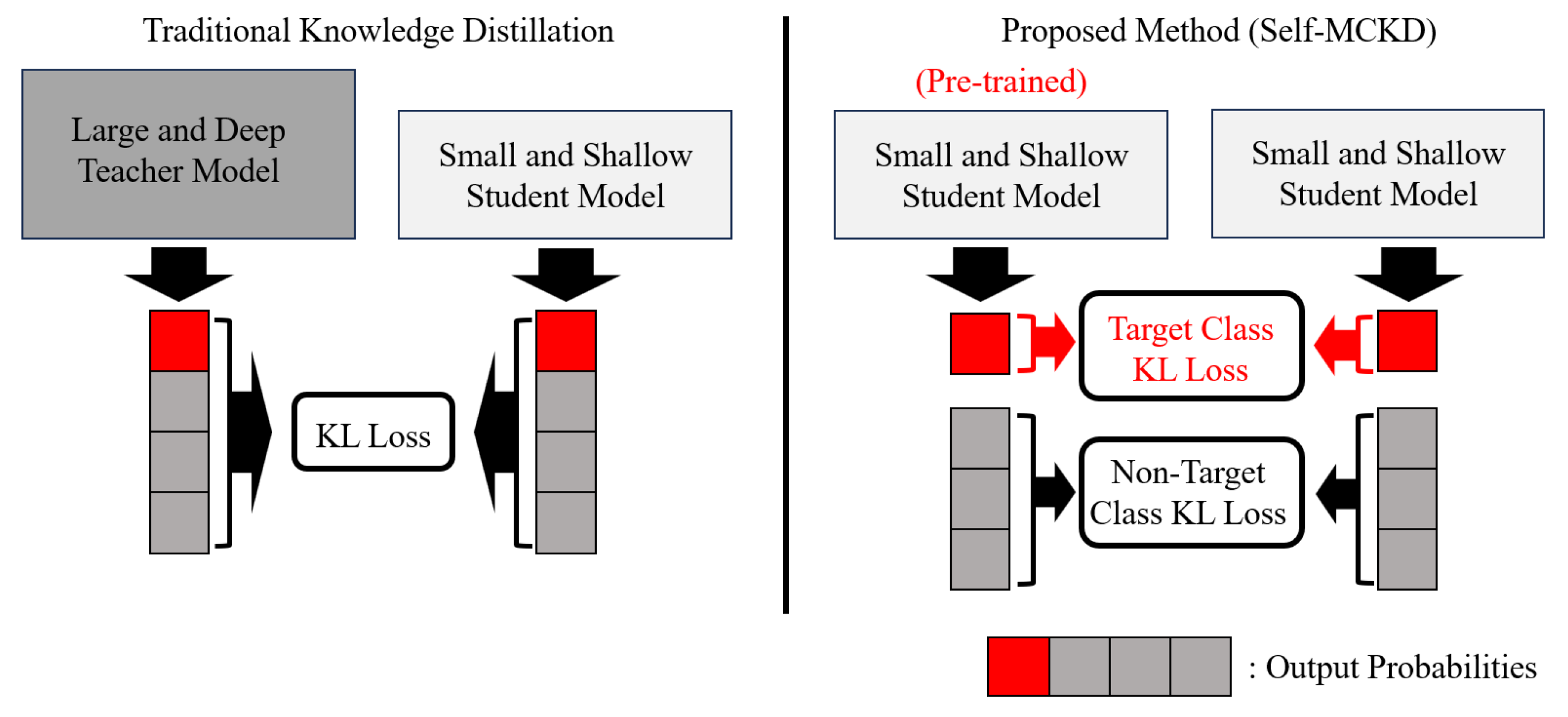
- We propose Self-MCKD, a novel knowledge distillation technique for AI-based malware classification methods. Self-MCKD separates the output logits into the target class and non-target classes, assigning a weighted importance factor that maximizes the effectiveness of knowledge transfer.
- To enhance the knowledge transfer efficiency, we introduce small and shallow AI-based malware classification methods as both the teacher and student models in Self-MCKD.
- From the experimental results using representative benchmark datasets, we show that Self-MCKD significantly improves the performance of a small and shallow baseline model, even surpassing that of a large and deep baseline model. Also, we show that Self-MCKD outperforms previous knowledge distillation techniques in both its effectiveness and efficiency. Specifically, with the same FLOPs, MACs, and parameters, Self-MCKD achieves improvements in accuracy, recall, precision, and F1-score of 0.2% to 1.4% while reducing the training time by 20 s.
2. Related Works
2.1. AI-Based Malware Classification Methods
2.2. Lightweight Techniques for DL-Based Malware Classification Methods
3. Preliminary
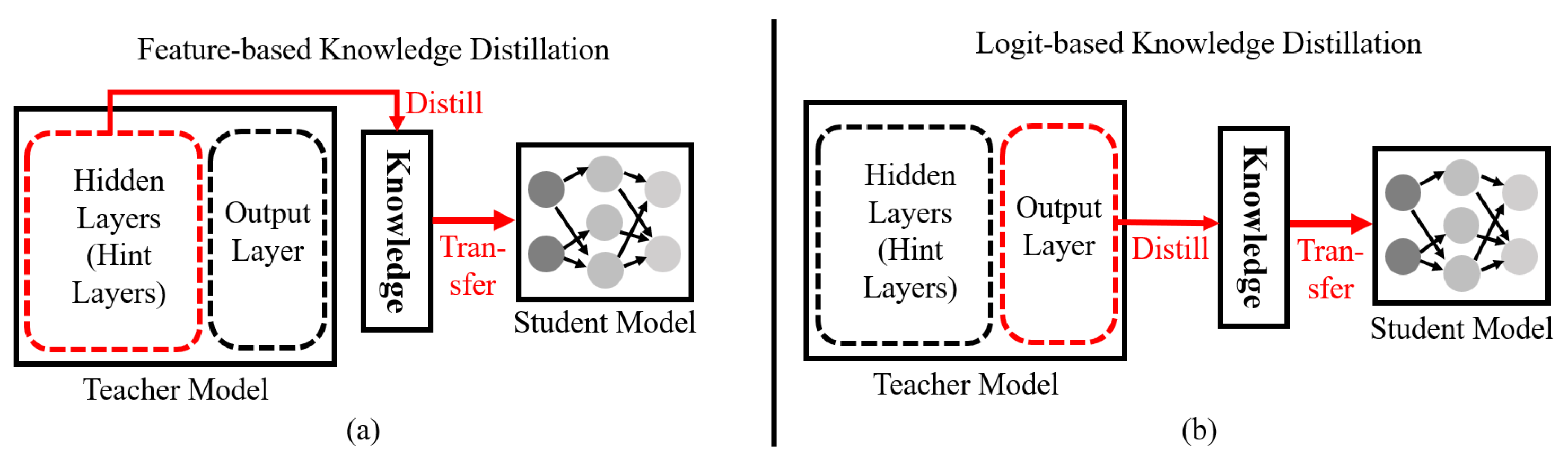
Knowledge Distillation
4. The Proposed Method
4.1. Revisiting Traditional Knowledge Distillation
4.2. Notations for Self-MCKD
4.3. Reformulating Knowledge Distillation for Self-MCKD
| Algorithm 1 Self-MCKD loss function pseudo-code |
| Input: Student logits , pre-trained student logits , target malware , factors , , temperature |
| Output: Self-MCKD Loss 1. Compute the target malware and non-target malware masks: |
| 2. Normalize logits with temperature: |
| 3. Concatenate the probabilities: |
| 4. Compute the TMKD loss: |
| 5. Compute the NMKD loss: |
| 6. Return the total loss: |
5. Evaluation Results
- How do the factors of TMKD and of NMKD influence the performance of Self-MCKD?
- Does Self-MCKD show a good performance on small and shallow malware classification models using various malware datasets?
- Does Self-MCKD show a better performance than that of the other knowledge distillation methods?
5.1. Experimental Environments
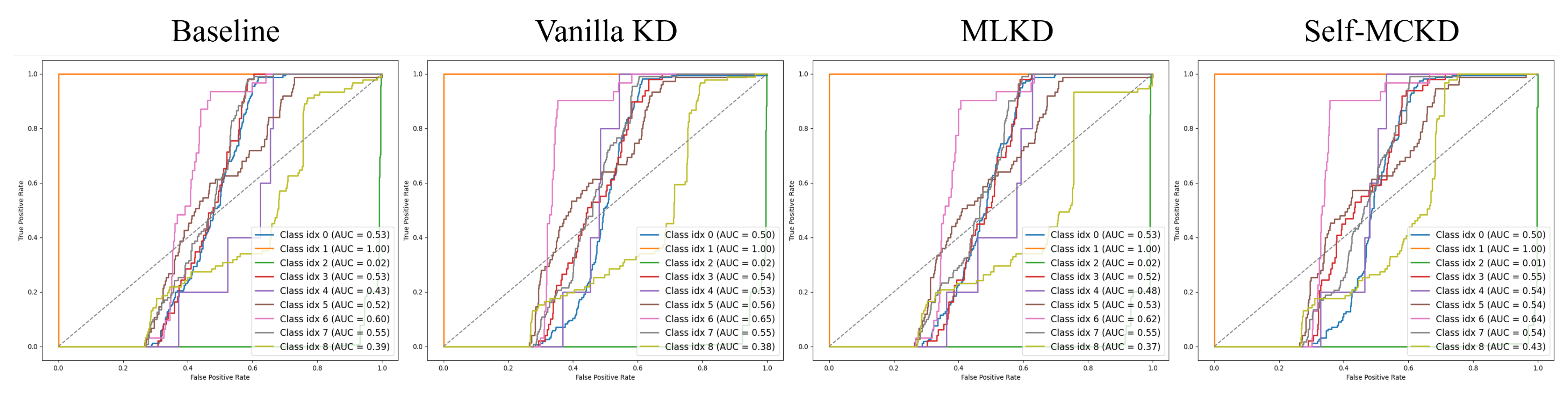
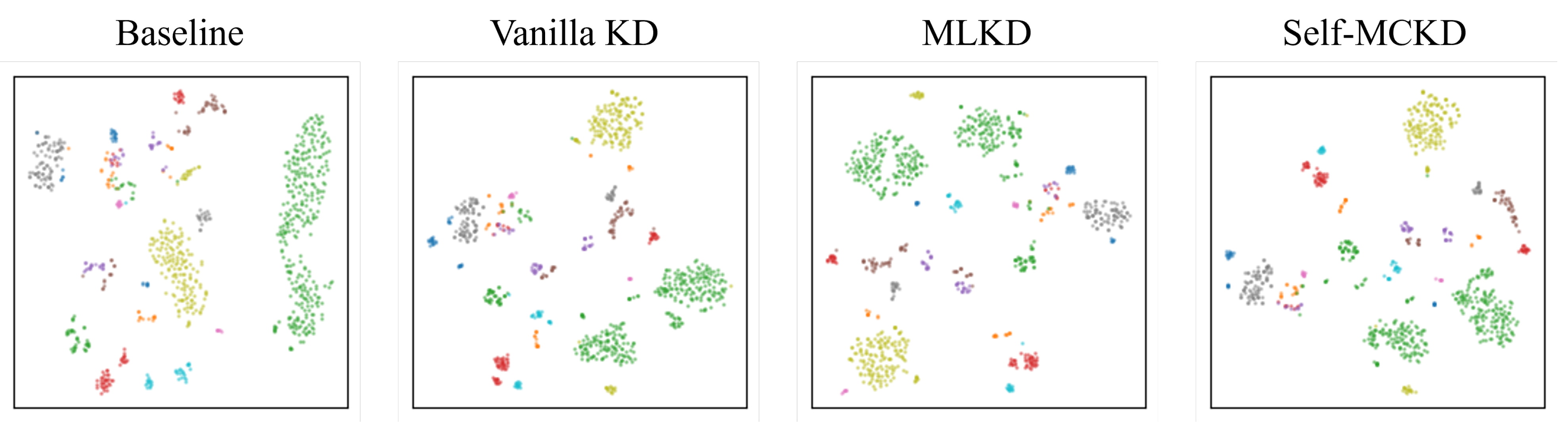
5.2. Experimental Analysis
5.2.1. How Do the Factors of TMKD and of NMKD Influence the Performance of Self-MCKD?
5.2.2. Does Self-MCKD Show a Good Performance on Small and Shallow Malware Classification Models Using Various Malware Datasets?
5.2.3. Does Self-MCKD Show a Better Performance than That of the Other Knowledge Distillation Methods?
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kan, Z.; Wang, H.; Xu, G.; Guo, Y.; Chen, X. Towards light-weight deep learning based malware detection. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 600–609. [Google Scholar]
- Moon, J.; Kim, S.; Song, J.; Kim, K. Study on machine learning techniques for malware classification and detection. KSII Trans. Internet Inf. Syst. 2021, 15, 12. [Google Scholar]
- Wang, Z.; Li, Z.; He, D.; Chan, S. A lightweight approach for network intrusion detection in industrial cyber-physical systems based on knowledge distillation and deep metric learning. Expert Syst. Appl. 2022, 206, 117671. [Google Scholar] [CrossRef]
- Idika, N.; Mathur, A.P. A survey of malware detection techniques. Purdue Univ. 2007, 48, 32–46. [Google Scholar]
- You, I.; Yim, K. Malware obfuscation techniques: A brief survey. In Proceedings of the 2010 International Conference on Broadband, Wireless Computing, Communication and Applications, Fukuoka, Japan, 4–6 November 2010; pp. 297–300. [Google Scholar]
- Cui, Z.; Xue, F.; Cai, X.; Cao, Y.; Wang, G.; Chen, J. Detection of malicious code variants based on deep learning. IEEE Trans. Ind. Inform. 2018, 14, 3187–3196. [Google Scholar] [CrossRef]
- Nataraj, L.; Yegneswaran, V.; Porras, P.; Zhang, J. A comparative assessment of malware classification using binary texture analysis and dynamic analysis. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; ACM: New York, NY, USA, 2011; pp. 21–30. [Google Scholar]
- Hardy, W.; Chen, L.; Hou, S.; Ye, Y.; Li, X. DL4 MD: A deep learning framework for intelligent malware detection. In Proceedings of the International Conference on Data Science (ICDATA); The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp): Las Vegas, NV, USA, 2016. [Google Scholar]
- Drew, J.; Moore, T.; Hahsler, M. Polymorphic malware detection using sequence classification methods. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 81–87. [Google Scholar]
- Ahmadi, M.; Ulyanov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel feature extraction, selection and fusion for effective malware family classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; ACM: New York, NY, USA, 2016; pp. 183–194. [Google Scholar]
- Gibert, D. Convolutional Neural Networks for Malware Classification. Master’s Thesis, University Rovira i Virgili, Tarragona, Spain, 2016. [Google Scholar]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.B.; Wang, Y.; Iqbal, F. Malware classification with deep convolutional neural networks. In Proceedings of the 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Prajapati, P.; Stamp, M. An empirical analysis of image-based learning techniques for malware classification. In Malware Analysis Using Artificial Intelligence and Deep Learning; Springer: Cham, Switzerland, 2021; pp. 411–435. [Google Scholar]
- Fathurrahman, A.; Bejo, A.; Ardiyanto, I. Lightweight convolution neural network for image-based malware classification on embedded systems. In Proceedings of the 2021 International Seminar on Machine Learning, Optimization, and Data Science (ISMODE), Jakarta, Indonesia, 29–30 January 2022; pp. 12–16. [Google Scholar]
- Su, J.; Vasconcellos, D.V.; Prasad, S.; Sgandurra, D.; Feng, Y.; Sakurai, K. Lightweight classification of IoT malware based on image recognition. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 2, pp. 664–669. [Google Scholar]
- Jiang, K.; Bai, W.; Zhang, L.; Chen, J.; Pan, Z.; Guo, S. Malicious code detection based on multi-channel image deep learning. J. Comput. Appl. 2021, 41, 1142. [Google Scholar]
- Runzheng, W.; Jian, G.; Xin, T.; Mengqi, Y. Research on malicious code family classification combining attention mechanism. J. Front. Comput. Sci. Technol. 2021, 15, 881. [Google Scholar]
- Zhu, D.; Xi, T.; Jing, P.; Wu, D.; Xia, Q.; Zhang, Y. A transparent and multimodal malware detection method for android apps. In Proceedings of the 22nd International ACM Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Miami Beach, FL, USA, 25–29 November 2019; ACM: New York, NY, USA, 2019; pp. 51–60. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision; Chapman and Hall/CRC: Boca Raton, FL, USA, 2022; pp. 291–326. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhi, Y.; Xi, N.; Liu, Y.; Hui, H. A lightweight android malware detection framework based on knowledge distillation. In Network and System Security: 15th International Conference, NSS 2021, Tianjin, China, 23 October 2021; Springer: Cham, Switzerland, 2021; pp. 116–130. [Google Scholar]
- Xia, M.; Xu, Z.; Zhu, H. A Novel Knowledge Distillation Framework with Intermediate Loss for Android Malware Detection. In Proceedings of the IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, QLD, Australia, 8–20 December 2022; pp. 1–6. [Google Scholar]
- Wang, L.H.; Dai, Q.; Du, T.; Chen, L. Lightweight intrusion detection model based on CNN and knowledge distillation. Appl. Soft Comput. 2024, 165, 112118. [Google Scholar] [CrossRef]
- Shen, J.; Yang, W.; Chu, Z.; Fan, J.; Niyato, D.; Lam, K.Y. Effective intrusion detection in heterogeneous internet-of-things networks via ensemble knowledge distillation-based federated learning. arXiv 2024, arXiv:2401.11968. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006; pp. 535–541. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4133–4141. [Google Scholar]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. Distilling knowledge via knowledge review. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 20–25 June 2021; pp. 5008–5017. [Google Scholar]
- Zhao, B.; Cui, Q.; Song, R.; Qiu, Y.; Liang, J. Decoupled knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11953–11962. [Google Scholar]
- Yuan, L.; Tay, F.E.H.; Li, G.; Wang, T.; Feng, J. Revisiting knowledge distillation via label smoothing regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3903–3911. [Google Scholar]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware images: Visualization and automatic classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011; pp. 1–7. [Google Scholar]
- Ronen, R.; Radu, M.; Feuerstein, C.; Yom-Tov, E.; Ahmadi, M. Microsoft malware classification challenge. arXiv 2018, arXiv:1802.10135. [Google Scholar]
- Huang, D.; Li, T.O.; Xie, X.; Cui, H. Themis: Automatic and Efficient Deep Learning System Testing with Strong Fault Detection Capability. In Proceedings of the 2024 IEEE 35th International Symposium on Software Reliability Engineering (ISSRE), Tsukuba, Japan, 28–31 October 2024; pp. 451–462. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Jin, Y.; Wang, J.; Lin, D. Multi-level logit distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 17–24 June 2023; pp. 24276–24285. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MMCC | (, ) | (0.1, 0.9) | (0.2, 0.8) | (0.3, 0.7) | (0.4, 0.6) | (0.5, 0.5) |
| Accuracy | 98.25% | 98.07% | 98.44% | 98.34% | 98.52% | |
| (, ) | (0.6, 0.4) | (0.7, 0.3) | (0.8, 0.2) | (0.9, 0.1) | ||
| Accuracy | 98.25% | 98.62% | 98.44% | 98.25% | 98.44% | |
| Malimg | (, ) | (0.1, 0.9) | (0.2, 0.8) | (0.3, 0.7) | (0.4, 0.6) | (0.5, 0.5) |
| Accuracy | 99.25% | 99.25% | 99.36% | 99.25% | 99.46% | |
| (, ) | (0.6, 0.4) | (0.7, 0.3) | (0.8, 0.2) | (0.9, 0.1) | ||
| Accuracy | 99.57% | 99.57% | 99.57% | 99.57% | 99.36% |
| Dataset | Model | FLOPs | MACs | Params | Accuracy | Training Time | |
|---|---|---|---|---|---|---|---|
| MMCC | Baseline | VGG16 | 627.04 M | 313.52 M | 14.77 M | 98.25% | 91 m 8 s |
| VGG8 | 136.01 M | 68.00 M | 3.96 M | 97.70% | 42 m 23 s | ||
| ResNet110 | 508.42 M | 254.21 M | 1.74 M | 97.79% | 94 m 17 s | ||
| ResNet32 | 138.89 M | 69.45 M | 0.47 M | 96.87% | 48 m 39 s | ||
| Self-MCKD + VGG8 | 272.02 M | 136.01 M | 3.96 M | 98.62% | 28 m 19 s | ||
| Self-MCKD + ResNet32 | 277.78 M | 138.90 M | 0.47 M | 98.53% | 35 m 21 s | ||
| Malimg | Baseline | VGG16 | 627.04 M | 313.52 M | 14.77 M | 99.25% | 72 m 52 s |
| VGG8 | 136.01 M | 68.00 M | 3.96 M | 99.04% | 33 m 18 s | ||
| ResNet110 | 508.42 M | 254.21 M | 1.74 M | 99.36% | 82 m 5 s | ||
| ResNet32 | 138.89 M | 69.45 M | 0.47 M | 99.04% | 41 m 51 s | ||
| Self-MCKD + VGG8 | 272.02 M | 136.01 M | 3.96 M | 99.57% | 27 m 11 s | ||
| Self-MCKD + ResNet32 | 277.78 M | 138.90 M | 0.47 M | 99.25% | 30 m 52 s | ||
| Dataset | Baseline | Technique | Accuracy | Recall | Precision | F1-Score | Training Time |
|---|---|---|---|---|---|---|---|
| MMCC | VGG8 | None | 97.70% | 97.70% | 97.67% | 97.68% | 42 m 23 s |
| Vanilla KD | 98.44% | 98.34% | 98.36% | 98.29% | 28 m 43 s | ||
| MLKD | 98.43% | 98.44% | 98.44% | 98.37% | 33 m 34 s | ||
| Self-MCKD | 98.62% | 98.71% | 98.73% | 98.69% | 28 m 19 s | ||
| ResNet32 | None | 96.87% | 97.42% | 97.39% | 97.39% | 48 m 39 s | |
| Vanilla KD | 97.79% | 97.06% | 96.83% | 96.82% | 35 m 26 s | ||
| MLKD | 97.70% | 97.70% | 97.74% | 97.57% | 38 m 20 s | ||
| Self-MCKD | 98.53% | 98.44% | 98.47% | 98.41% | 35 m 21 s | ||
| Malimg | VGG8 | None | 99.04% | 98.72% | 98.81% | 98.73% | 33 m 18 s |
| Vanilla KD | 99.36% | 99.04% | 99.08% | 99.03% | 27 m 13 s | ||
| MLKD | 99.25% | 99.25% | 99.32% | 99.25% | 29 m 1 s | ||
| Self-MCKD | 99.57% | 99.25% | 99.29% | 99.25% | 27 m 11 s | ||
| ResNet32 | None | 99.04% | 99.25% | 99.28% | 99.26% | 41 m 51 s | |
| Vanilla KD | 99.14% | 98.82% | 98.96% | 98.80% | 30 m 54 s | ||
| MLKD | 98.92% | 98.82% | 98.85% | 98.82% | 31 m 39 s | ||
| Self-MCKD | 99.25% | 99.25% | 99.36% | 99.26% | 30 m 52 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, H.-J.; Lee, H.-J.; Kim, G.-N.; Choi, S.-H. Self-MCKD: Enhancing the Effectiveness and Efficiency of Knowledge Transfer in Malware Classification. Electronics 2025, 14, 1077. https://doi.org/10.3390/electronics14061077
Jeong H-J, Lee H-J, Kim G-N, Choi S-H. Self-MCKD: Enhancing the Effectiveness and Efficiency of Knowledge Transfer in Malware Classification. Electronics. 2025; 14(6):1077. https://doi.org/10.3390/electronics14061077
Chicago/Turabian StyleJeong, Hyeon-Jin, Han-Jin Lee, Gwang-Nam Kim, and Seok-Hwan Choi. 2025. "Self-MCKD: Enhancing the Effectiveness and Efficiency of Knowledge Transfer in Malware Classification" Electronics 14, no. 6: 1077. https://doi.org/10.3390/electronics14061077
APA StyleJeong, H.-J., Lee, H.-J., Kim, G.-N., & Choi, S.-H. (2025). Self-MCKD: Enhancing the Effectiveness and Efficiency of Knowledge Transfer in Malware Classification. Electronics, 14(6), 1077. https://doi.org/10.3390/electronics14061077