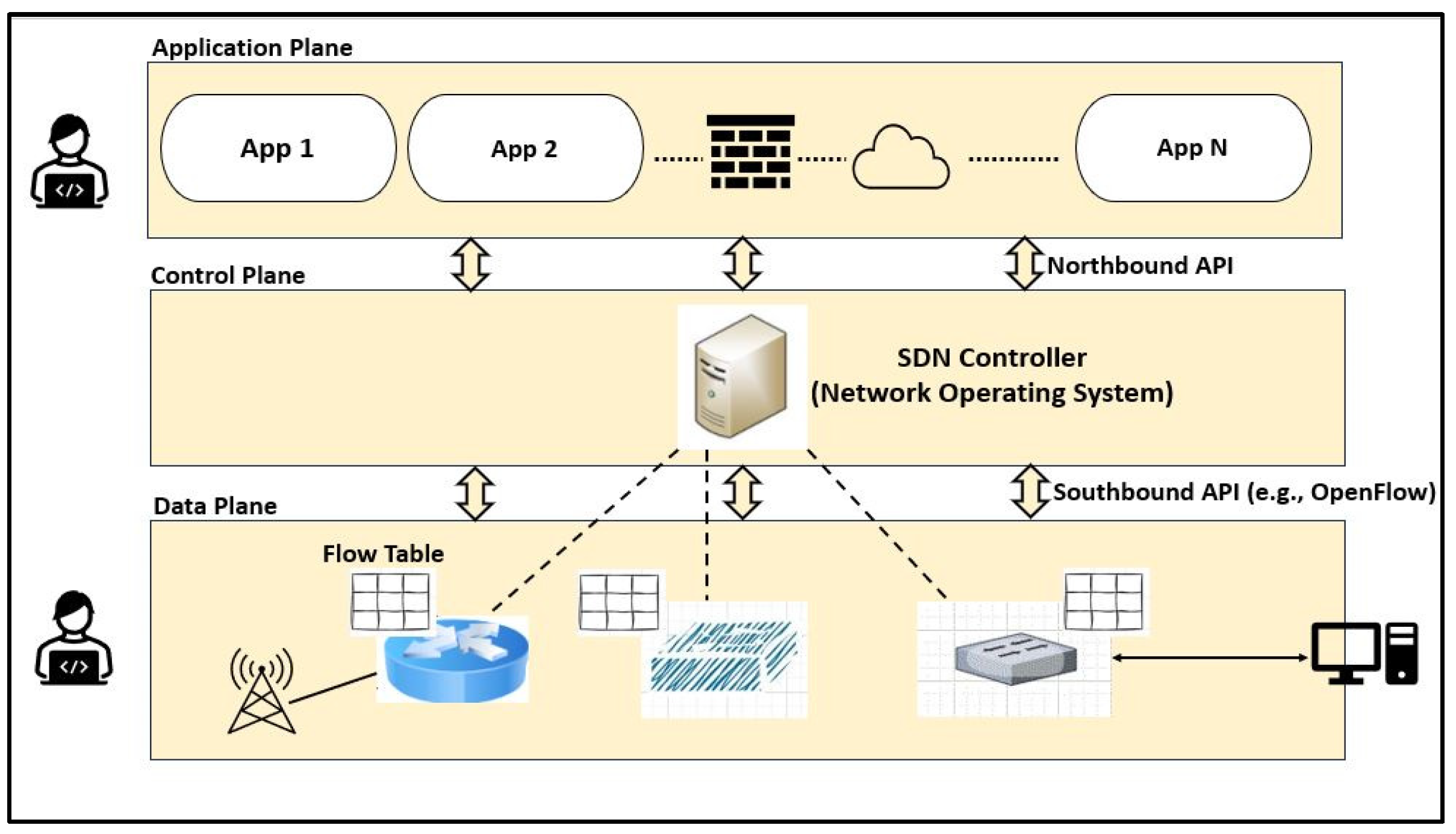
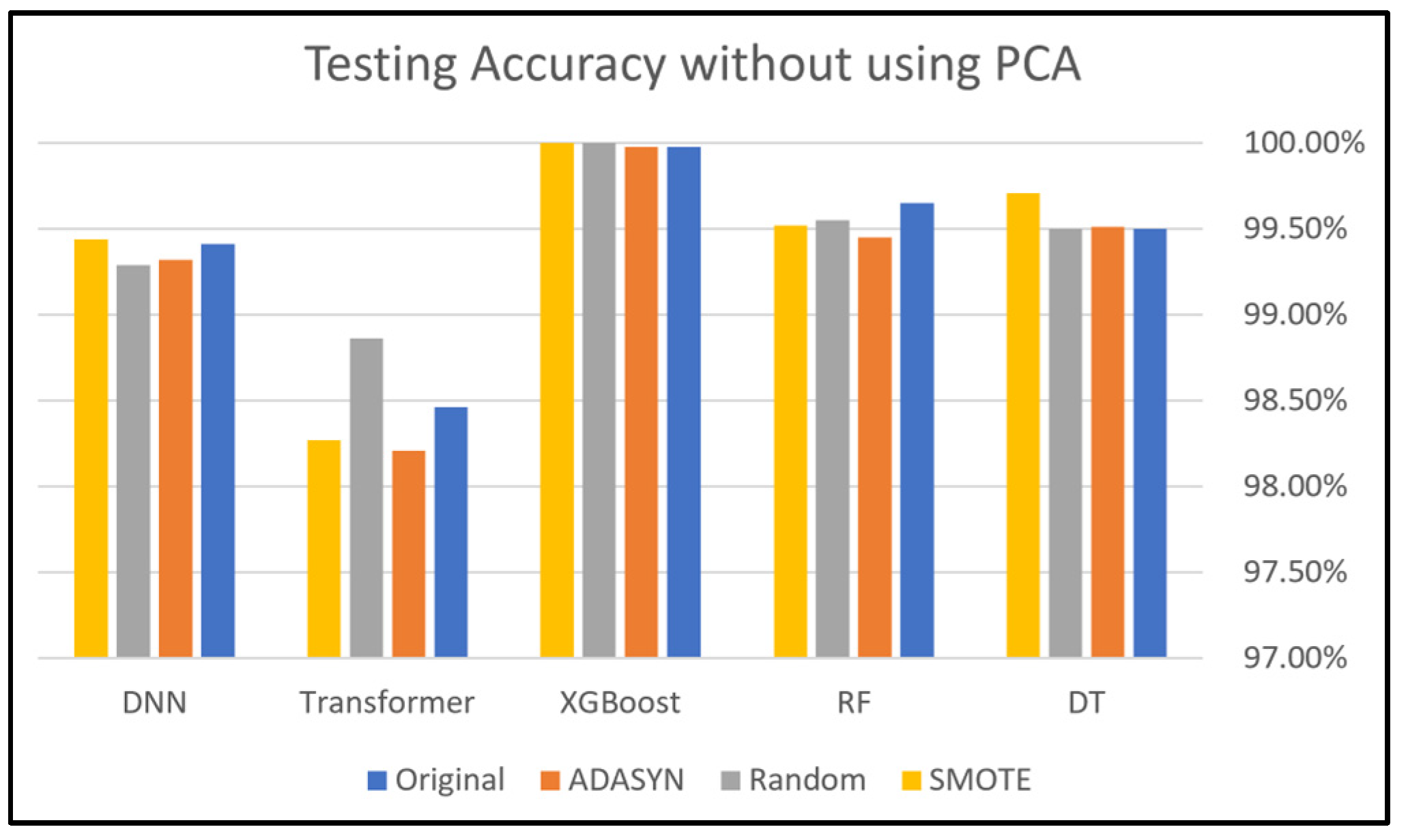
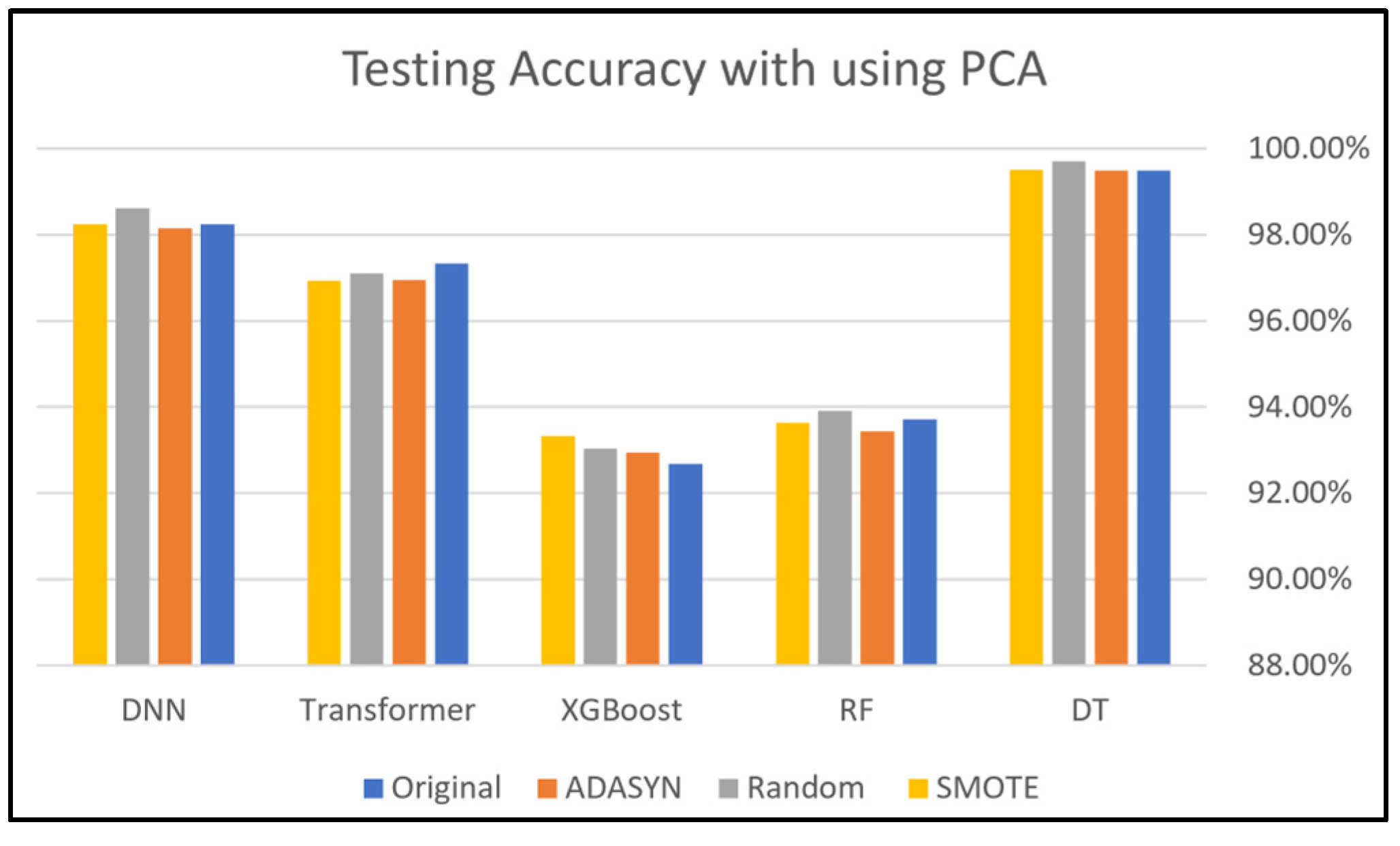
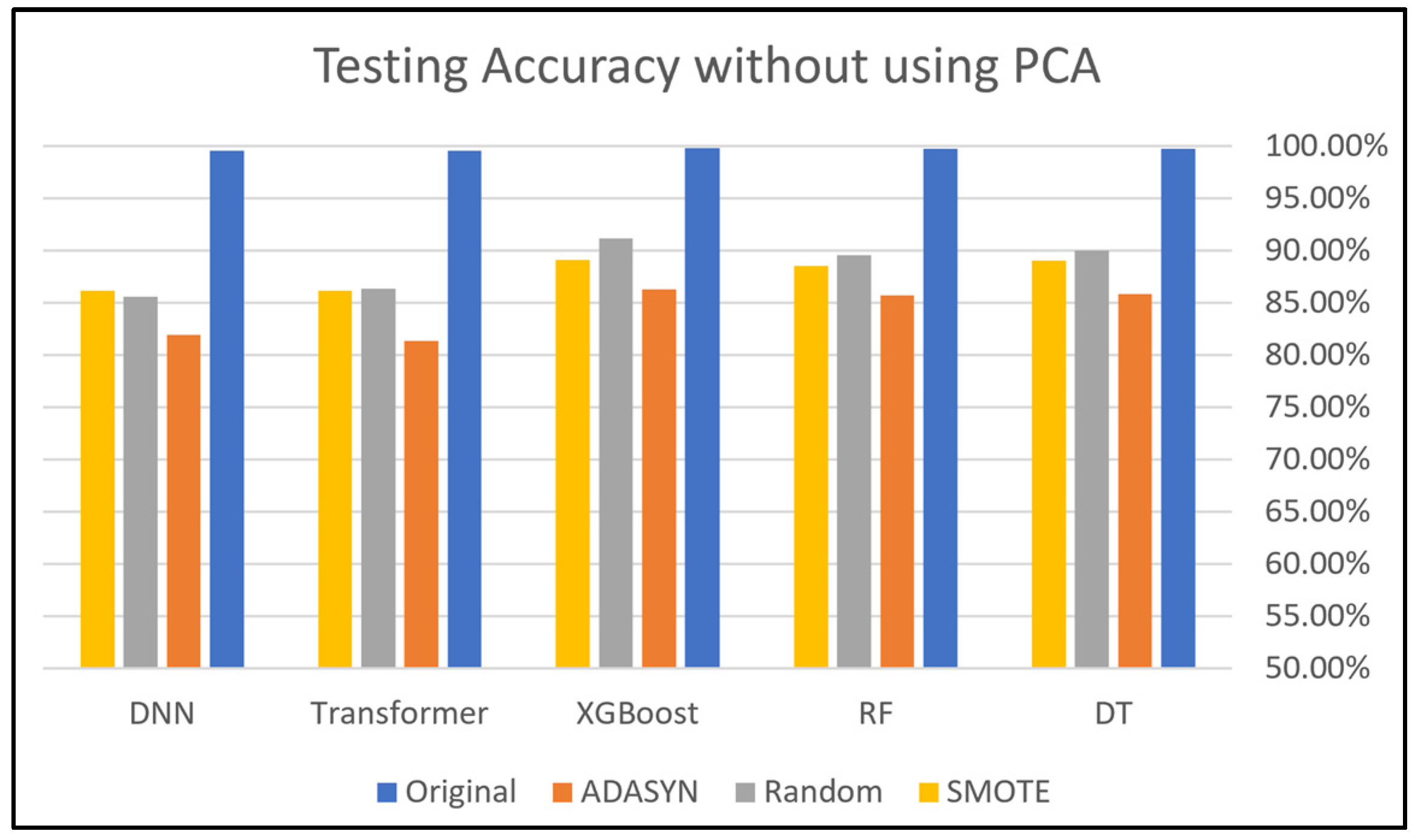
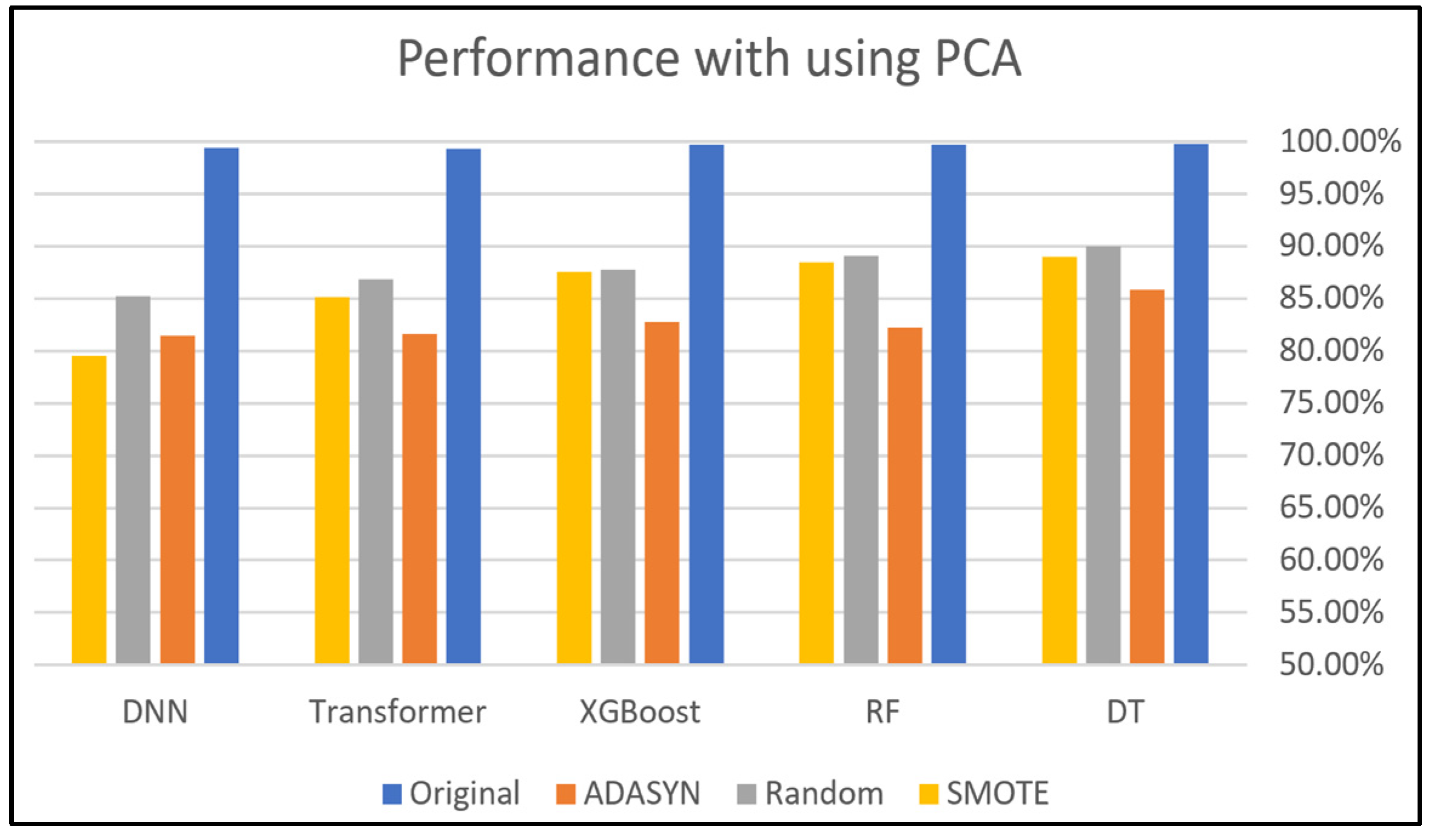
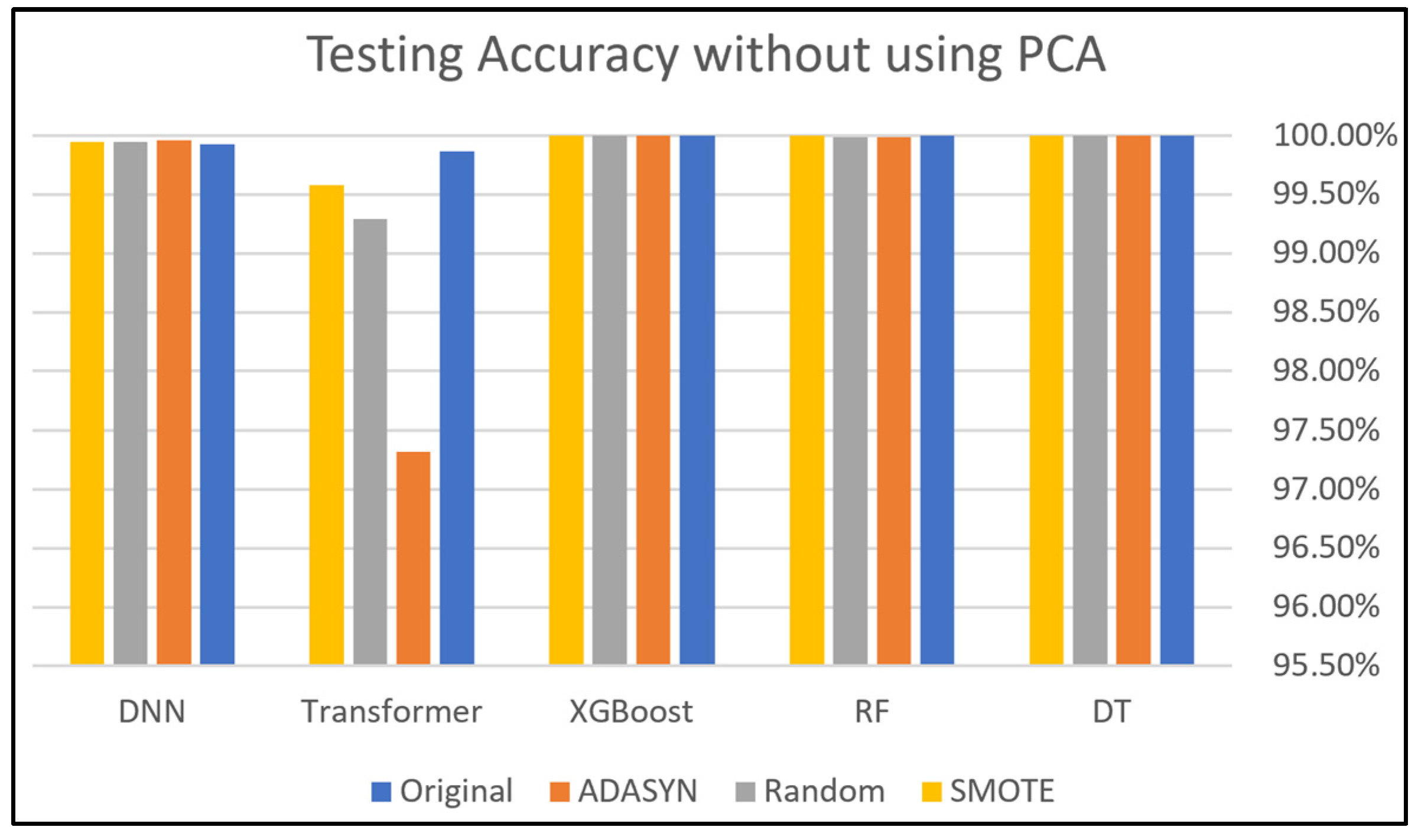
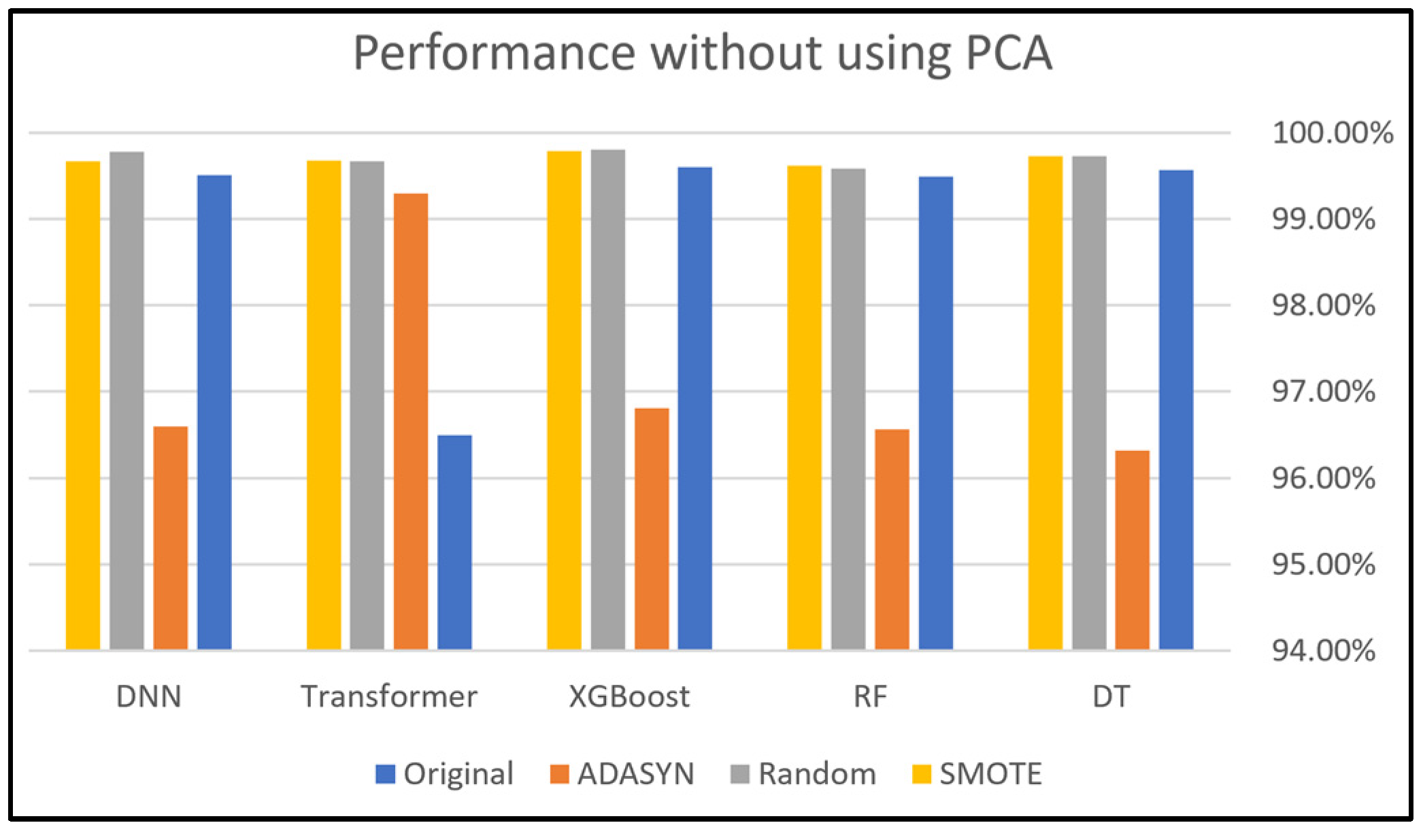
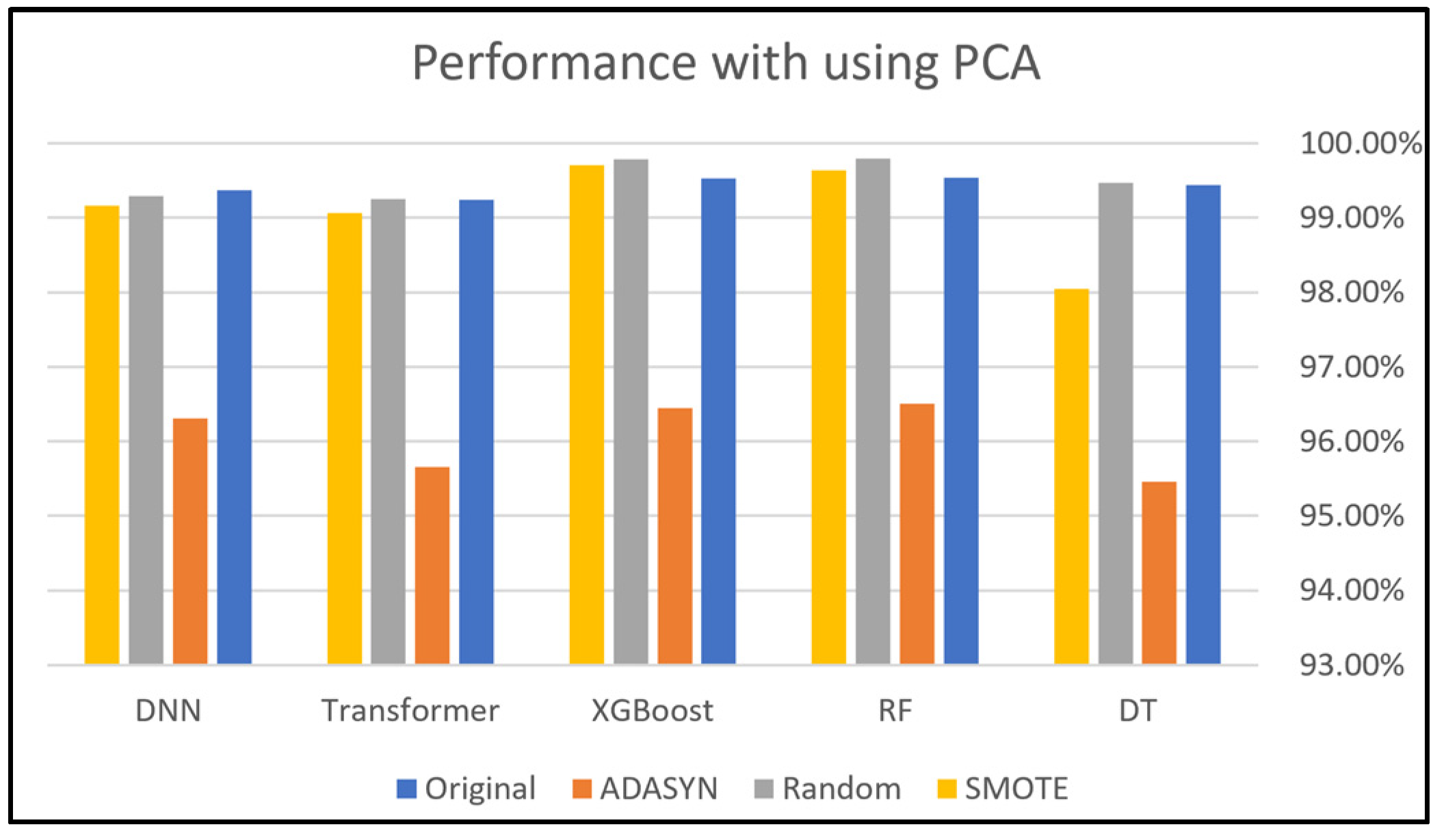
This section presents and discusses the findings of this work. A comparison study was conducted to demonstrate the impact of using oversampling techniques: Random Oversampling, SMOTE, and ADASYN on the performance of DNN, Transformer, XGBoost, RF, and DT classifiers on four SDN datasets. The original dataset, which refers to a dataset without applying oversampling techniques, was also included in this study to compare it with the oversampling techniques. In addition, this study analyzes the performance of using PCA along with these oversampling techniques to evaluate its effectiveness on classification performance. Moreover, computational cost analysis using oversampling and PCA techniques was provided in this study.
The experiments in this research were conducted on a personal computer equipped with an NVIDIA® GeForce RTX™ 4090 GPU with 24 GB of memory. All of this hardware was designed by NVIDIA, a manufacturer located in Santa Clara, CA, USA.
5.10. Evaluation of Predicting Attack Types
This subsection is dedicated to a detailed analysis of evaluating the detection performance of attack types of Dataset 2, given the evidence from previous experiments that the performance of this dataset was affected and had different behaviors.
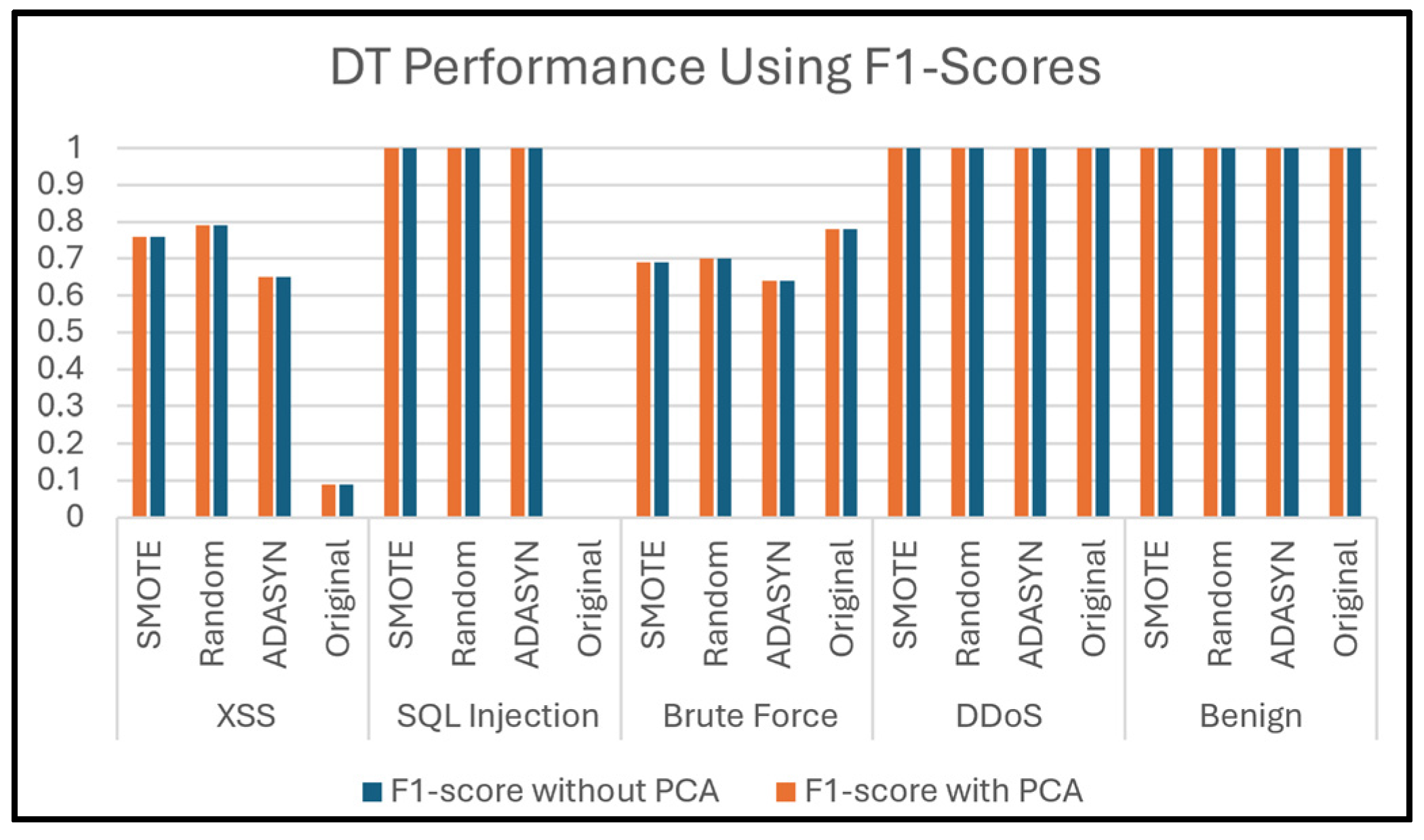
Figure 17 presents the F1-score values of the DT classifier when classifying five attack types of Dataset 2. It is clear, in the beginning, the effectiveness of PCA in maintaining performance.
For benign and DDoS attacks, the classifier achieves perfect classification with an F1-score of 1, demonstrating its excellent capability in detecting these attacks across all oversampling techniques, both with and without PCA. This indicates that the classes of these attacks are well-represented and easily distinguishable in this dataset. On the other hand, oversampling techniques maintain an F1-score of 100% in all cases, with and without PCA, suggesting that class imbalance does not impact the classifier’s ability to detect these types of attacks, irrespective of class balancing or dimensionality reduction techniques.
Conversely, for Web Attack Brute Force, the original dataset yields an F1-score of 78%, showing moderate detection performance. However, using ADASYN produces the lowest F1-score of 64% among oversampling techniques, possibly attributable to providing synthetic samples that do not accurately reflect the true distribution of Brute Force features. Random Oversampling yields 70%, while SMOTE achieves a similar score of 69%, but neither matches the performance of the original dataset.
The DT classifier struggles significantly in classification SQL Injection attacks within the original dataset, with a low F1-score of 0%. This implies that the classifier was unable to correctly classify any instances of this type in the original dataset. A likely explanation for this failure is the class imbalance, where SQL Injection attacks are underrepresented in the dataset, or the lack of sufficient training samples. All oversampling techniques (ADASYN, Random, and SMOTE) significantly improved performance, achieving an F1-score of 1 in both cases (with and without PCA), indicating the effectiveness of oversampling in handling the imbalance for this attack type. In summary, the inability of the DNN classifier to predict SQL Injection attacks in the original dataset highlights the critical role of oversampling techniques in addressing class imbalance. By balancing the dataset, oversampling allows the classifier to learn more discriminative patterns, leading to perfect classification in this situation. In addition, the absence of enhancement using PCA indicates that dimensionality reduction alone cannot resolve data representation issues.
Furthermore, the classifier achieved a low F1-score value when predicting XSS attacks in the original dataset of only 9%, indicating severe challenges in distinguishing this class, likely due to class imbalance or feature similarity. ADASYN enhances the F1-score to 65%, Random Oversampling to 79%, and SMOTE to 76%. These findings underscore that oversampling significantly helps in XSS detection, although it does not entirely resolve the challenge.
Figure 17.
Prediction of attack types using DT.
Figure 17.
Prediction of attack types using DT.
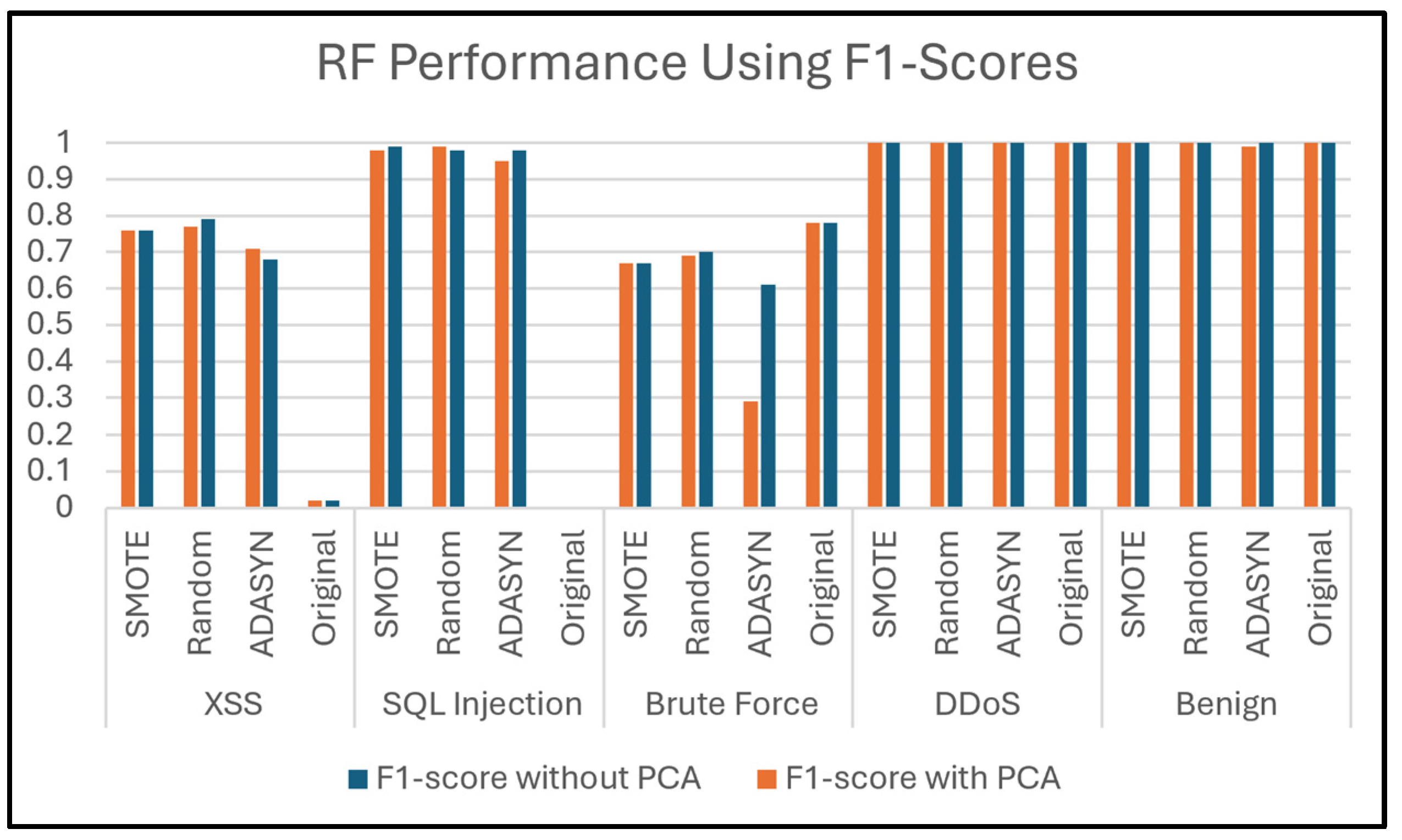
Figure 18 illustrates the F1-score values of the RF classifier when predicting attack types of Dataset 2. It is clear, only in most cases here, the effectiveness of PCA in maintaining performance.
A perfect classification is achieved by the classifier for benign and DDoS attacks and it achieves excellent prediction of these attacks across all oversampling techniques, both with and without PCA. This indicates that the classes of these attacks are well-represented and easily distinguishable in this dataset. On the other hand, oversampling techniques maintain a very high level of F1-score in all cases, with and without PCA, suggesting that class imbalance does not impact the classifier’s ability to detect these types of attacks, irrespective of class balancing or dimensionality reduction techniques.
Conversely, the original dataset of the Web Attack Brute Force class results in an F1-score of 78%, showing moderate detection performance. However, using ADASYN produces the lowest F1-score of 61% among oversampling techniques, possibly attributable to providing synthetic samples that do not accurately reflect the true distribution of Brute Force features. Random Oversampling yields 70%, while SMOTE achieves a similar score of 69%, but neither matches the performance of the original dataset. All oversampling results are almost identical (or very close) to their results without using it, except the F1-score when ADASYN was applied decreased to 29%. This consistency, in most cases, demonstrates that PCA generally does not substantially alter the F1-score across most attack types and oversampling techniques when using the RF classifier and indicates that PCA effectively retains the critical features needed for accurate classification in most cases. However, a notable exception is observed for Brute Force attacks when applying ADASYN, which may be attributed to its nature of oversampling that focuses on difficult-to-classify samples near decision boundaries and its interaction with dimensionality reduction. When PCA is applied after oversampling, it may discard some of the newly generated variations or synthetic features critical for distinguishing between Brute Force attacks and other classes.
This classifier struggles significantly in classification SQL Injection attacks within the original dataset, with a low F1-score of 0%. This implies that the classifier was unable to correctly classify any instances of this type in the original dataset. A likely explanation for this failure is the class imbalance, where SQL Injection attacks are underrepresented in the dataset, or the lack of sufficient training samples. All oversampling techniques (ADASYN, Random, and SMOTE) significantly improved performance, achieving a high F1-score (95 to 99%) in both cases, with and without PCA, indicating the effectiveness of oversampling in handling the imbalance for this attack type. In summary, the inability of the RF classifier to predict SQL Injection attacks in the original dataset highlights the critical role of oversampling techniques in addressing class imbalance. By balancing the dataset, oversampling allows the classifier to learn more discriminative patterns, leading to perfect classification in this case. In addition, the absence of enhancement using PCA indicates that dimensionality reduction alone cannot resolve data representation issues.
Furthermore, the classifier achieves extremely low in the original dataset of XSS attacks, with an F1-score of only 2%, indicating a severe challenge in distinguishing this class, likely due to class imbalance or feature similarity. Using oversampling significantly improves performance. ADASYN enhances the F1-score to 68%, Random Oversampling to 79%, and SMOTE to 76%. These findings underscore that oversampling significantly helps in XSS detection, although it does not entirely resolve the challenge. The use of PCA with this type of attack is not much different from the case of not using it.
Figure 18.
Prediction of attack types using RF.
Figure 18.
Prediction of attack types using RF.
Figure 19 depicts the F1-score values of the XGBoost classifier when predicting attack types of Dataset 2.
For benign and DDoS attacks, the classifier achieves perfect classification with a high F1-score, demonstrating excellent performance in detecting these attacks across all oversampling techniques, both with and without PCA. This indicates the robustness of the XGBoost classifier in detecting these types of attacks, irrespective of class balancing or dimensionality reduction techniques.
In contrast, for Web Attack Brute Force, the original dataset produces a high F1-score; nevertheless, the efficiency of oversampling strategies varies. Using ADASYN, the F1-score drops significantly to 63%, possibly attributable to providing synthetic samples that do not accurately reflect the true distribution of Brute Force features. Random Oversampling improves the F1-score to 75%, while SMOTE achieves a similar score of 69%, but neither matches the performance of the original dataset. PCA marginally decreases the F1-score, indicating that dimensionality reduction could eliminate essential information necessary for accurate classification.
The XGBoost classifier has difficulties in classification SQL Injection attacks within the original dataset, with a low F1-score of 56%, likely due to class imbalance or overlapping features with other attack types. Oversampling significantly improves performance. Both ADASYN and Random Oversampling lead to a perfect F1-score of 1, while SMOTE also achieves an F1-score of 1. These results highlight the effectiveness of oversampling in tickling the imbalanced nature of SQL Injection data.
Furthermore, the classifier performs poorly on XSS attacks in the original dataset, with an F1-score of only 22%, indicating severe difficulties in detecting this type, likely due to limited representation or significant overlap with other classes. Overlapping greatly improves performance. ADASYN enhances the F1-score to 68%, while Random Oversampling achieves the best score of 80%, and SMOTE yields 76%. However, PCA slightly reduces the results for all oversampling techniques, which may indicate that dimensionality reduction removes important low-variance features critical for distinguishing XSS attacks.
These findings underscore the need for careful selection of oversampling techniques and dimensionality reduction. The negligible difference between F1-scores with and without PCA suggests that dimensionality reduction does not significantly affect the performance of XGBoost for this task.
Figure 19.
Prediction of attack types using XGBoost.
Figure 19.
Prediction of attack types using XGBoost.
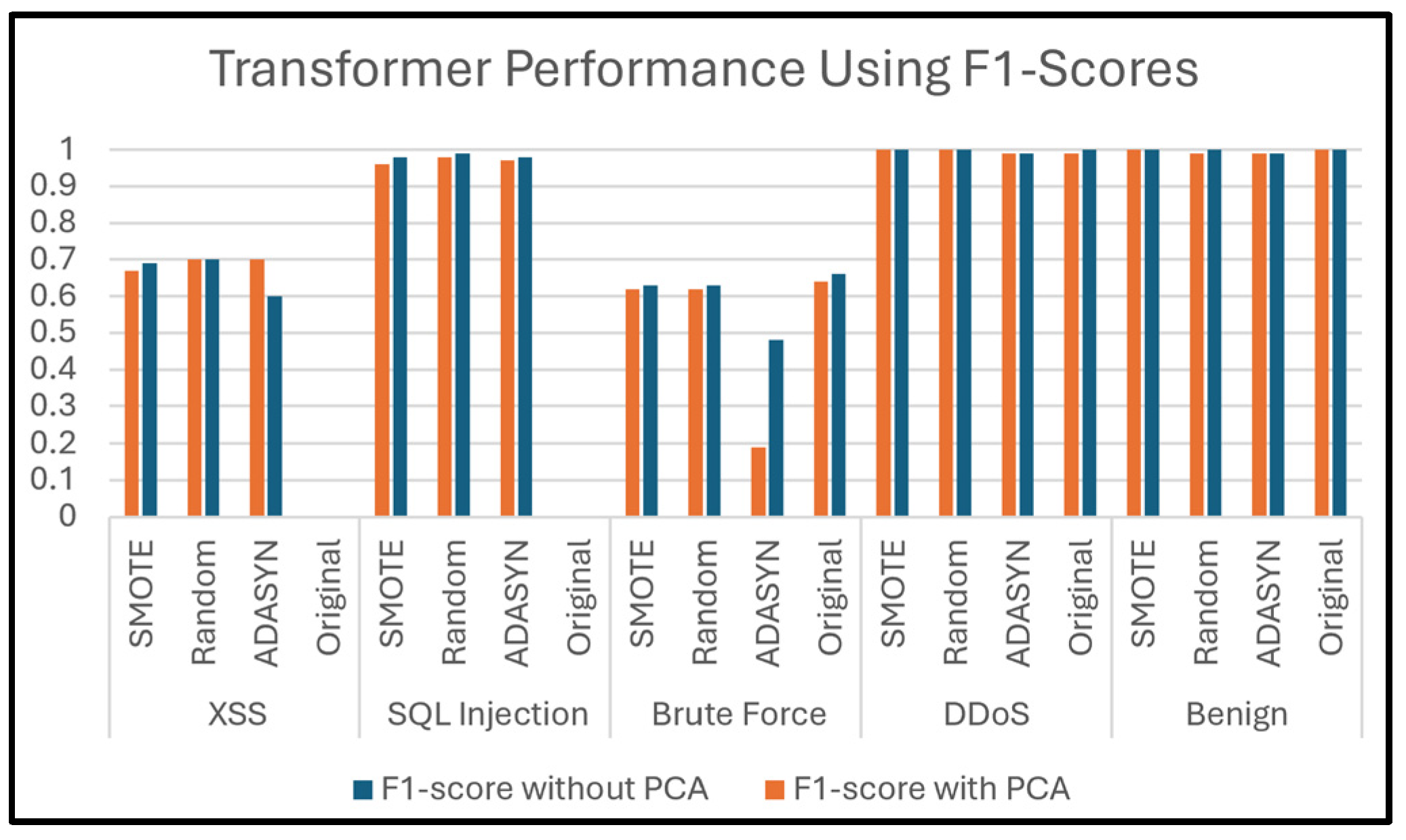
Figure 20 compares the findings of the F1-score achieved by a Transformer classifier, which reached 99% or more, achieving consistently high performance across all scenarios for benign and DDoS samples, regardless of the oversampling technique or PCA. This demonstrates that the classifier performs exceptionally well in the detection of these two types of attacks, exhibiting robustness and consistency. The use of techniques like ADASYN, Random, and SMOTE, as well as the original dataset, maintained this perfect score, showing that the classifier was highly capable of identifying these classes without misclassification. PCA also had no impact on the F1 score for these categories, indicating that the reduction in dimensionality did not affect the separability of benign and DDoS data points. This could be attributed to the inherent distinction between these classes and the others, where features were already highly discriminative.
In contrast, the results for Brute Force attacks exhibit a significant drop compared to the previous two classes. Without PCA, the scores range from 63% to 66%, depending on the oversampling technique, while applying PCA results in a slight decline to values between 62% and 64%. Applying ADASYN significantly drops the F1-score values to 48% without PCA and 19% when using PCA. This suggests that Brute Force attacks pose a greater difficulty for the classifier, and the application of PCA appears to exacerbate this challenge, especially with ADASYN. To clarify, their data may have specific features that are either lost during dimensionality reduction or are not well represented by synthetic samples generated by this oversample algorithm. SMOTE and Random Oversampling yield comparable results to the original dataset, implying that they neither significantly enhance nor degrade detection capability.
The classifier performs relatively well for SQL Injection and XSS attacks, with F1 scores between 96% and 99% for the first type and between 60% and 70% for XSS among all oversampling techniques in the absence of PCA. Also, the performance of XSS was significantly lower compared to SQL Injection. With PCA, the scores remain stable for SQL Injection but slightly vary for XSS. Notably, oversampling improves performance for XSS detection by ADASYN and Random Oversampling. The actual problem lies in the original data, where the F1-score was 0% for SQL Injection and XSS. This demonstrates that the Transformer classifier suffers significant challenges in the classification of these two classes before using oversampling techniques. Overall, the findings highlight that the classifier’s performance is heavily influenced by the attack type and the chosen data preprocessing technique.
Figure 20.
Prediction of attack types using Transformer.
Figure 20.
Prediction of attack types using Transformer.
Figure 21 shows the evaluation of the DNN classifier performance using the F1-score when predicting attack types of Dataset 2. A perfect classification is achieved by the classifier for benign and DDoS attacks and it achieves perfect identification of these attacks across all oversampling techniques, both with and without PCA. This indicates the robustness of the DNN classifier in detecting these types of attacks, irrespective of class balancing or dimensionality reduction techniques.
On the other hand, for Web Attack Brute Force, the original dataset yields a high F1-score, but oversampling techniques show varying effectiveness. Using ADASYN, the F1-score drops significantly to 19%, possibly attributable to providing synthetic samples that do not accurately reflect the true distribution of Brute Force features. Random Oversampling improves the F1-score to 55%, while SMOTE achieves a similar score of 59%, but neither matches the performance of the original dataset. PCA marginally decreases the F1-score, indicating that dimensionality reduction could eliminate essential information necessary for accurate classification.
The DNN classifier has difficulties in classifying SQL Injection attacks within the original dataset, evidenced by an extremely low F1-score of 0%, likely due to class imbalance or overlapping features with other attack types. Oversampling significantly improves performance. All oversampling techniques lead to a high level of F1-score (98% without using PCA), highlighting the effectiveness of oversampling for addressing the imbalanced nature of SQL Injection data. However, PCA slightly reduces F1-scores for the SMOTE technique, which may indicate that dimensionality reduction removes important low-variance features critical for differentiating SQL Injection attacks.
Moreover, the classifier exhibits inadequate performance on XSS assaults in the original dataset, achieving an F1-score of only 2%, which suggests substantial challenges in identifying this type might be attributable to insufficient representation or significant overlap with other classes. There is considerable performance improvement when overlap occurs. ADASYN enhances the F1-score to 70%, while Random Oversampling and SMOTE achieve a score of 71%. These findings underscore the need for careful selection of oversampling techniques and dimensionality reduction. The negligible difference between F1-scores with and without PCA suggests that dimensionality reduction does not significantly affect the performance of DNN for this task. Lastly, it is clear, in most cases, the effectiveness of PCA in maintaining performance.
Figure 21.
Prediction of attack types using DNN.
Figure 21.
Prediction of attack types using DNN.
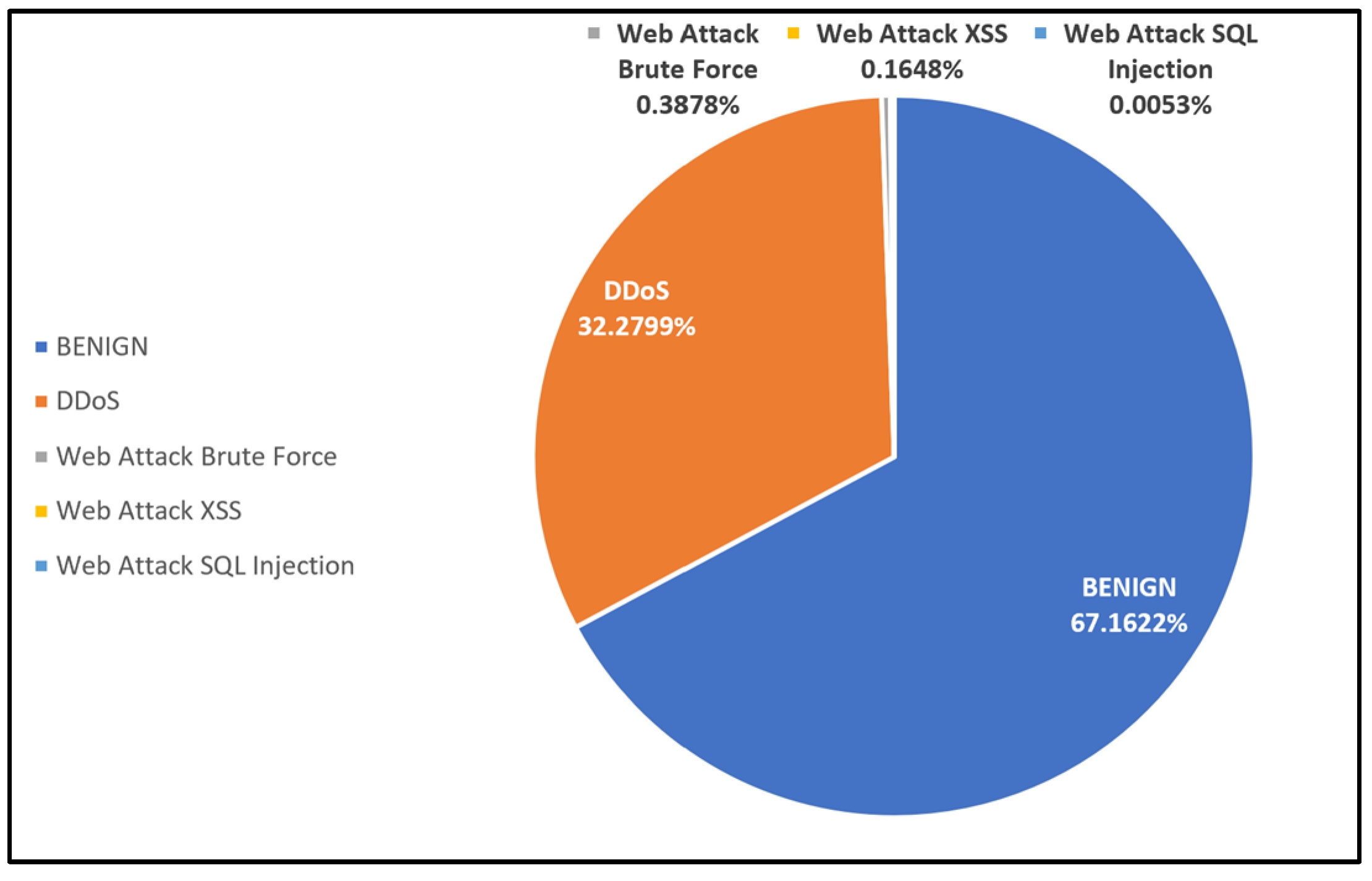
Overall, Dataset 2 suffers from imbalanced class issues that lead classifiers to become biased toward detecting benign and DDoS classes more effectively than others. This can be observed in the results of
Figure 17,
Figure 18,
Figure 19,
Figure 20 and
Figure 21. Brute Force, XSS, and SQL Injection attacks occur at significantly lower frequencies, which can further affect classifier performance if temporal variations are not handled properly.
5.12. Computational Cost
The computation cost of Oversampling and PCA techniques was also recorded in this study and measured in seconds.
Table 13 indicates that ADASYN consumed the highest computational time compared to SMOTE and Random Oversampling. This can be observed clearly with the result of Dataset 2, in which ADASYN needed 144.67 s to complete its task. However, Random Oversampling exhibited the lowest computational cost among all oversampling techniques used in this research. This is evident with Dataset 1, where Random Oversampling needed only 0.04 s to finish its task. This highlights the trade-off between selecting the oversampling technique that provides the best synthetic data generation and the simplest technique that exhibits the lowest computation cost.
Table 13.
Computational cost of oversampling techniques.
Table 13.
Computational cost of oversampling techniques.
| Dataset | ADASYN (Seconds) | SMOTE (Seconds) | Random (Seconds) |
|---|
| 1 | 1.06 | 0.39 | 0.04 |
| 2 | 144.67 | 40.91 | 4.83 |
| 3 | 1.29 | 0.56 | 0.14 |
| 4 | 16.03 | 4.09 | 0.66 |
As observed, ADASYN has the highest computational cost because it adaptively generates synthetic samples based on the density of minority class instances. This requires additional calculations to determine the level of imbalance and assign varying numbers of synthetic points per instance. Unlike SMOTE, which distributes synthetic samples uniformly, ADASYN consumes more process time when generating synthetic data in the area where the classification is difficult due to weight adjustment for kNN. In essence, while Random Oversampling is straightforward but prone to overfitting (which can be tackled when training the ML/DL classifier), SMOTE offers a more diversified approach, and ADASYN further refines this by focusing on difficult instances to enhance classifier performance. SMOTE requires more processing than Random Oversampling because it provides a more varied method and generates synthetic samples by calculating distances between minority class instances and their nearest neighbors. This step adds complexity compared to Random Oversampling, which duplicates existing minority samples without any calculations. Therefore, Random Oversampling is the fastest.
Table 14 presents the computational cost results of PCA on both the original and oversampled datasets. Across all four datasets, the computational cost of PCA is high once oversampling is applied. This can be observed clearly in Dataset 2, in which PCA needed 0.46 s to accomplish its task. Meanwhile, PCA takes less time when processing original datasets. These results show the influence of oversampling techniques on PCA’s computation cost. Therefore, it is important to balance the benefits of using oversampling algorithms by considering the computation cost.
The computational cost differs between the original and oversampled datasets owing to the increased number of samples in the oversampled type. Since PCA depends on calculating the covariance matrix and performing eigen decomposition, an increase in dataset size results in higher computational complexity. The variation in computational cost is probably impacted by the nature of the oversampling process and the structure of added data.
Table 14.
Computational cost of PCA.
Table 14.
Computational cost of PCA.
| Dataset | Original Dataset (Seconds) | Oversampled Dataset (Seconds) |
|---|
| 1 | 0.01 | 0.01 |
| 2 | 0.14 | 0.46 |
| 3 | 0.01 | 0.01 |
| 4 | 0.04 | 0.10 |
Indeed, there are many advantages to employing PCA for attack detection with SDN datasets. PCA helps eliminate redundant and highly correlated features, which can improve model efficiency and prevent overfitting. Additionally, PCA enhances computational performance by lowering the number of input features, leading to faster training times and reducing memory usage. This is beneficial in high-dimensional datasets like Datasets 2 and 4, where processing large amounts of data can be computationally expensive. Our findings demonstrate that lower dimensional representations reduce the processing time of classifiers while maintaining their classification performance.
Generally, using all available features that do not include redundancy or noise enhances the classification performance of classifiers but increases computational cost. However, applying PCA reduces the dimensionality of data by selecting more relevant features, which speed up the computation process.
Despite its advantages, PCA has certain limitations when selecting the number of PCA components. The low number of components may lead to the possibility of losing significant information, thus negatively impacting the classification performance of a classifier. Increasing the number of components causes more irrelevant information to be added to the data. As a result, PCA will keep a high number of components, which will also impact the performance of the classifier. However, this can be tackled by using a different number of PCA components during the experiments to explore the impact of changing the number of components, as was performed in this research.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}