Abstract
The safe operation of freight train equipment is crucial to the stability of the transportation system. With the advancement of intelligent monitoring technology, vision-based anomaly detection methods have gradually become an essential approach to train equipment condition monitoring. However, due to the complexity of train equipment inspection scenarios, existing methods still face significant challenges in terms of accuracy and generalization capability. Freight trains defect detection models are deployed on edge computing devices, onboard terminals, and fixed monitoring stations. Therefore, to ensure the efficiency and lightweight nature of detection models in industrial applications, we have improved the YOLOv8 model structure and proposed a network architecture better suited for train equipment anomaly detection. We adopted the lightweight MobileNetV4 as the backbone to enhance computational efficiency and adaptability. By comparing it with other state-of-the-art lightweight networks, we verified the superiority of our approach in train equipment defect detection tasks. To enhance the model’s ability to detect objects of different sizes, we introduced the Content-Guided Attention Fusion (CGAFusion) module, which effectively strengthens the perception of both global context and local details by integrating multi-scale features. Furthermore, to improve model performance while meeting the lightweight requirements of industrial applications, we incorporated a staged knowledge distillation strategy on large-scale datasets. This approach significantly reduces model parameters and computational costs while maintaining high detection accuracy. Extensive experiments demonstrate the effectiveness and efficiency of our method, proving its competitiveness compared with other state-of-the-art approaches.
1. Introduction
Heavy-duty freight trains play a crucial role in the transportation industry. However, due to the frequent loading and unloading of goods and long-distance transportation, the components of freight trains are prone to damage. To ensure transportation safety, defect detection of train equipment becomes both essential and critical. Traditional methods often rely on manual inspection, but with the growing demand for inspections, real-time detection methods based on computer vision have gradually become key to train defect detection and an integral part of intelligent railway operations. Accurate and efficient detection technologies can significantly enhance the safety and maintenance efficiency of train equipment.
The existing anomaly detection methods pay more attention to defect detection in a single device, such as defect detection in fan systems based on CNNs [1] and defect detection in steel rails [2,3]. For catenary systems, there is also research on methods based on deep learning to realize the visual detection of the crack of the catenary clamp of high-speed railway [4]. In addition, some work focuses on accident detection at railway crossings [5]. Although these studies have achieved remarkable results in their respective application scenarios, most are aimed at specific equipment components or special scenarios and lack a general method for the unified treatment of multiple anomalies. For example, the segmentation detection method proposed in the article [6] for track valve anomalies only applies to a single component of a specific type of train and does not have portability and generalization abilities. The inspection of train equipment parts usually requires the inspection of tens of thousands of parts, and it is impossible to design a detection method for each part, so a learnable detection method that can detect a variety of categories is needed. The complexity of train equipment defect detection lies in the difference among various components and the impact of various environmental factors on the actual scene. On the one hand, defects on the surface of different equipment types may present complex and changeable forms, and their manifestations are significantly affected by factors such as lighting conditions, the working environment, and the degree of wear. On the other hand, the scale of the current publicly available train equipment datasets is limited, and the coverage cannot meet the needs of various components and their defect characteristics in practical applications. Moreover, in certain application scenarios, anomaly detection models need to be deployed on resource-constrained devices, such as IoT devices or handheld inspection equipment. These environments impose strict limitations on computational resources, necessitating the design and implementation of lightweight models. These problems make anomaly detection in train equipment still face significant challenges in research and practical application.
To solve these problems, we propose a lightweight detection method based on multi-scale feature fusion. First, we build a train equipment anomaly detection dataset with various anomaly types and real-scene distribution characteristics, providing a more practical basis for algorithm research. Secondly, in terms of model design, we improved the YOLOv8 detection structure and used lightweight MobileNetV4 [7] as the backbone network to reduce the computational overhead and improve the model’s adaptability. At the same time, we introduced Content-Guided Attention Fusion (CGAFusion) [8], which significantly enhanced the model’s perception of global information and local details by using multi-scale feature fusion technology. Efficient multi-scale feature extraction and detail perception can be achieved while ensuring that the model is lightweight. In addition, to further improve the detection performance of the model and meet the demand for lightweight models in industrial applications, we introduced knowledge distillation technology. In the process of knowledge distillation, we construct a phased training strategy, design an improved model based on YOLOv8m as a teacher model, and conduct pre-training on COCO2017 in the COCO [9] series dataset. The predictions of the teacher model are used as false labels to guide the optimization of the student model. At the same time, we design the distillation loss function of the feature level and the output level so that the student model can significantly reduce the model volume and computational complexity while maintaining accuracy.
Our main contributions are as follows:
- We replaced the original YOLOv8 backbone with the Mobilenetv4 network structure, improving the model’s feature extraction capability and providing multi-scale features for detection.
- We designed an attention-guided multi-scale fusion module suitable for object detection, effectively fusing high-level and low-level detail features and enhancing the model’s detection ability.
- We designed a knowledge distillation process where a larger model serves as the teacher model to guide the training of a student model with higher performance and lighter weight, making it more competitive in industrial applications.
2. Related Work
2.1. Defect Detection of Train Equipment
Freight train defect detection is crucial to intelligent train maintenance. For a long period, freight train equipment anomaly detection was conducted through manual visual inspection [10]. However, manual inspection is highly time-consuming, and its accuracy is significantly influenced by the worker’s experience, making it quite limited. With the advancement of machine vision, detection systems based on machine vision have proven to be a reliable replacement for manual inspection [11]. Many methods focus on research on rail surface [12,13] and wheel tread [14,15] defect detection. Initially, machine vision was applied in track and specific-component inspections. Min et al. [16] proposed a real-time detection method for rail surface defects, while Ramanpreet et al. [6] utilized the U-net segmentation network for rail-valve segmentation and developed a computer vision-based algorithm to determine rail-valve defects. Jiang et al. [17] developed a YOLOv5-based detection method for the wear of switch sliding baseplates. With the continuous development of deep neural networks, many outstanding deep models have been applied to railway anomaly detection. Chen et al. proposed a hierarchical object detection scheme and constructed a two-stage detection method for mobile train inspection using multiple neural networks. Fu et al. [18] introduced a two-stage attention-aware method for the bearing shed oil defect detection task. Some studies have focused on improving image acquisition systems. For example, Bodini et al. [19] deployed an observation and evaluation system using a high-speed camera array and developed a comprehensive image analysis program, and Guo et al. [20] developed a system consisting of 16 high-speed cameras for capturing wheeltread images and utilized a support vector machine (SVM) for defect localization. Sresakoolchai et al. [21] utilized deep neural networks and multiple regression techniques to perform defect detection on various railway components, including rails and fasteners, based on track data collected by inspection vehicles. Saini et al. [22] proposed a data collection method using drones and enhanced image data contours through data augmentation. They employed Mask R-CNN to perform a two-stage detection task. As the YOLO algorithm has demonstrated practicality in industrial applications, many studies have been conducted around YOLO-based models. However, the multi-scale feature fusion mechanism in YOLO may fail to fully utilize both high-level semantic information and low-level spatial details. To address this issue, Gold-YOLO [23] and GD-YOLOv8 [24] adopted the Gather-and-Distribute module. Furthermore, Marta Garcia Minguell et al. [25] applied YOLOv5 and Faster RCNN [26], and Mao et al. [27] and Zhang et al. [28] applied CenterNet and Yolov8, respectively. The effectiveness of many popular target detection algorithms in this direction is proved, such as is the case of EfficientDet [29] in railway defect detection, proving the effectiveness of various popular object detection algorithms in this field.
2.2. Knowledge Distillation
Model compression is a crucial approach to obtaining lightweight models in industrial applications, and knowledge distillation is one of the most important techniques in this area. Knowledge distillation was first introduced by Hinton et al. [30] as a technique for improving the performance of smaller student models by transferring knowledge from a larger teacher model. It enhances the student model’s performance by allowing it to learn the behavior of a high-performing teacher model on a large-scale dataset [31]. For object detection tasks, knowledge distillation must consider both the classification of objects and the localization of the detected targets. Label Assignment Distillation (LAD) [32] and Localization Distillation (LD) [33] focus on distilling classification labels and target positions, respectively, making them suitable for most object detectors. The authors of [34] proposed an adversarial training approach where the feature maps of the teacher and student models were treated as positive and negative samples, respectively. This task-specific distillation strategy has inspired many subsequent studies. To apply the GNN model to high-speed train bogie defect detection, Wan et al. [35] proposed a novel distillation method named GraKD, which adversarially extracts latent knowledge from the teacher model to a lightweight student model. Furthermore, many works have explored knowledge distillation based on the widely used YOLO object detection algorithm. Zhu et al. [36] proposed a knowledge distillation method based on YOLOv5s, which improves detection accuracy by fusing feature and output dimension results. DD-YOLO [37] combined knowledge distillation with neural architecture search (NAS) to improve accuracy while reducing the number of parameters. Yang et al. [38] used YOLOv5m as the teacher model and YOLOv5n and YOLOv5n-slim as student models, achieving significant improvements in accuracy.
3. Method
To address the lack of defect detection datasets in train equipment, we collected and annotated a dataset comprising images of various components covering common defect types in freight trains. Based on this dataset, we designed a lightweight detection model suitable for industrial applications. The model design is based on the YOLO architecture, where we modified the MobileNet [39] model as the backbone feature extractor. To effectively fuse the features from different network layers, we introduced the CGAfusion [8] module, which leverages attention mechanisms to guide multi-scale feature fusion, enhancing the model’s ability to detect targets of varying sizes. We designed feature-level and output-layer distillation loss functions, utilizing a pre-trained teacher network to guide the knowledge distillation process. The model architecture and knowledge distillation workflow are illustrated in Figure 1.
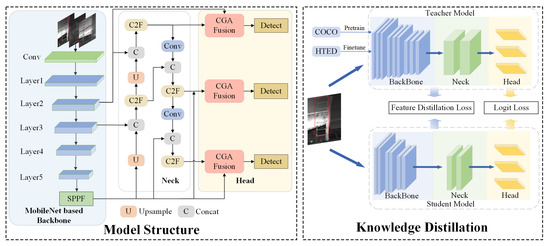
Figure 1.
On the left side, we illustrate the implementation process of our model. We use the MobileNet-based feature extraction network as the backbone and employ the CGAFusion module for feature fusion. On the right side, we depict the knowledge distillation process, where a pre-trained and fine-tuned teacher model guides the distillation. The process is supervised through loss functions at the feature level and the output layer.
3.1. Heavy-Duty Train Equipment Defect (HTED) Dataset
Some existing vehicle equipment datasets are designed for research targeting specific components [40]; therefore, they usually include only a single type of component area, making the datasets less comprehensive. Additionally, certain datasets suffer from indistinct features in some component areas due to limitations in lighting conditions or imaging equipment. We constructed a dataset containing four types of equipment defects named the Heavy-duty Train Equipment Defect (HTED) dataset to facilitate research on defect detection for key train equipment. HTED consists of 1866 images collected from three types of heavy-duty freight trains. The data are collected from real-world scenarios using the Trouble of Moving Freight Car Detection System (TFDS) [41], which is installed on both sides of the tracks at the entrance and exit of the loading and unloading station. The camera angles and position are fixed, with a lighting compensation device installed nearby to ensure sufficient and stable illumination. We identified and selected the four most common types of heavy-duty train body defects: support rod deformation, ladder deformation, ladder missing, and door latch defects. The data were manually annotated by using the Labelme tool, with example data shown in Figure 2.

Figure 2.
Illustration of the HTED dataset. From left to right are door latch defects, ladder missing, ladder deformation, and support rod deformation, showcasing the manually annotated results.
3.2. MobileNetV4-Based Backbone
To improve the model’s lightweight characteristics and computational efficiency, we utilized the MobileNet architecture as the backbone feature extractor. Specifically, we adopted the Universal Inverted Bottleneck (UIB) module proposed in MobileNetV4 [7], which has been widely applied in previous studies [42,43]. This module expands the input feature map channels by using a 1 × 1 convolutional layer, enhancing the network’s representational capacity. It then applies depthwise separable convolution, where each channel undergoes independent convolution operations to reduce computational complexity. Feature extraction begins with an initial convolutional layer that captures basic low-level features from the input image. These features are subsequently fed into five core layers, each progressively extracting higher-level features. The UIB and fused_ib modules within these core layers incrementally capture more abstract representations. The backbone structure ensures multi-level and efficient feature extraction, enhancing the model’s ability to capture complex image features effectively.
In the task of freight train defect detection, the targets often exhibit complex textures, varying shapes, and significant scale differences. The Universal Inverted Bottleneck (UIB) module in MobileNetV4 offers significant advantages for such tasks. UIB utilizes depthwise separable convolutions, which drastically reduce computational complexity compared with traditional large-scale CNNs while maintaining strong feature extraction capabilities. The HTED dataset includes a variety of abnormal targets at different scales. For example, categories such as escalator loss belong to large-size abnormal targets, while issues like broken bottom door latches represent smaller-size abnormal targets. By employing a deeper bottleneck structure, richer features can be extracted at different scale layers, which allows the model to adapt to scenarios with defects of varying sizes. Furthermore, UIB integrates Dynamic Batch Normalization, which enhances its generalization ability across different scenarios.
3.3. Content-Guided Feature Fusion Module
Traditional attention mechanisms typically assign weights to all spatial positions or channels during computation, resulting in high computational complexity and storage overhead. Furthermore, they often lack the capability to effectively fuse multi-scale features, making it challenging to flexibly handle objects of varying sizes. Chen et al. [8] proposed the Content-Guided Attention (CGA) mechanism, which combines channel attention and geometric attention, effectively integrating features from different scales.
We adopted the content attention mechanism and applied it to multi-scale feature fusion. Specifically, channel attention is computed by performing a pooling operation on each feature map channel, generating a weight for each channel. In the spatial dimension, geometric attention introduces additional geometric information (such as spatial position encoding or shape information) to generate weights for each spatial position. The feature fusion module combines the advantages of both attention mechanisms through a weighted summation strategy. By applying the fused attention weights to the original feature map, the model adjusts both the channel and spatial dimensions, enhancing focus on critical information while suppressing irrelevant or redundant information, resulting in more discriminative feature representations.
The implementation of CGAFusion is shown in Figure 3. After concatenating the high-level and low-level features, channel attention and geometric attention are computed separately. The attention weights (channel attention) and (spatial attention) are calculated as follows:
where represents a convolutional layer with a kernel size of k, while denotes the channel-wise concatenation operation. and , and represent the global average pooling across the spatial dimension, global average pooling across the channel dimension, and global max pooling across the channel dimension, respectively. We combine spatial attention and channel attention by summing them to compute the fused attention weight W. The fused attention weight W is multiplied by the original feature map. Finally, a convolutional layer is applied to adjust the channel dimensions, resulting in the final refined feature map.
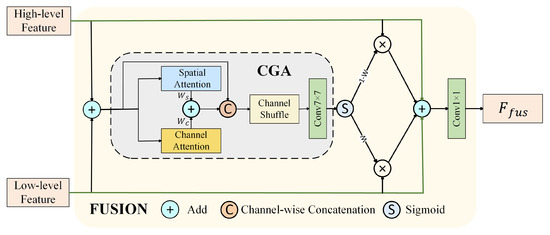
Figure 3.
The flowchart of the Content-Guided Attention Fusion module. Channel attention and geometric attention are fused by using a weighted summation approach to generate the final feature weight matrix, which is then used to perform a weighted fusion of high-level and low-level features.
We applied the CGA Fusion module before the detection head in the object detection network. By combining multi-scale outputs from different layers of the network, a fused feature representation is formed. This fused feature retains information from various scales while integrating global context and local details, providing a richer representation. With this design, the CGA Fusion module effectively improves the network’s performance in multi-scale object detection by enhancing its ability to perceive global information while better capturing fine-grained local features. Ultimately, these fused features are fed into the subsequent detection modules, further boosting detection accuracy and adaptability to complex scenarios.
3.4. Knowledge Distillation
Industrial application scenarios often demand lightweight and efficient detection models. Therefore, we adopted knowledge distillation to obtain a model better suited for industrial requirements. Since our dataset size is relatively smaller than large-scale datasets, direct training on our dataset provides limited performance improvement. To maximize the benefits of knowledge distillation and further enhance model performance, we opted for a staged distillation approach.
We employed a high-performance model constructed with MobileNetv4_Medium and YOLOv8m as the teacher network, while the previously introduced model served as the student network. The teacher model was pre-trained on the COCO dataset to learn more general feature representations. Subsequently, the teacher network’s detection results on the target dataset were used as pseudo-labels to guide the learning of the student network. Through this strategy, the student network inherits the knowledge acquired by the teacher network from the large-scale dataset, effectively leveraging the diversity of the COCO dataset to improve generalization capability. At the same time, it is further optimized for the target dataset to better adapt to our specific task.
During the knowledge distillation process, we leveraged the structural similarity between the teacher and student models by selecting Channel-wise Distillation Loss (CWD Loss) as the feature-level distillation loss function. CWD Loss effectively aligns feature representations along the channel dimension, facilitating the transfer of the teacher network’s feature representation capabilities and significantly improving the student network’s performance in object detection tasks. This structure-aligned distillation strategy not only enhances the detection accuracy of the student network but also ensures its lightweight characteristics, meeting the requirements of industrial application scenarios. The implementation of CWD Loss is as follows:
where , denote the feature vector of the c-th channel with dimensions and represents the squared Euclidean distance ( norm). Since the teacher and student models have different numbers of channels in their corresponding feature outputs, the loss cannot be directly calculated. To address this, a 1 × 1 convolution is applied to adjust the number of channels in the student model to match that of the teacher model.
We also designed a logit-level loss function to further utilize the output information from the teacher model to supervise the training of the student model. The teacher model’s output is treated as pseudo-labels to guide the student model in learning a decision distribution closer to the teacher’s. The loss function is defined as follows:
where L is the total number of layers, represents the total number of elements in the feature map of the i-th layer, and and denote the feature values at the j-th position in the i-th layer for the student and teacher models, respectively.
We combined the two loss functions with weighted integration to form the total loss function used in our knowledge distillation process:
4. Experiments
4.1. Dataset and Metrics
4.1.1. Dataset
We compiled the Heavy-duty Train Equipment Defect dataset (HTED). The dataset was collected from three different models of heavy-duty trains, considering both environmental complexity and defect representativeness, making it a valuable data resource for heavy-duty train defect detection and maintenance technologies. To enhance data diversity, we applied data augmentation techniques such as geometric transformations and color transformations, which have been proven effective in numerous studies.
To verify the effectiveness of our method on a large-scale dataset, we conducted tests on the COCO dataset. The COCO dataset (Common Objects in Context) is one of the most widely used open-source datasets in computer vision, containing over 200,000 images covering 80 common object categories, such as people, animals, furniture, and vehicles. These images are collected from real-world scenarios, featuring complex backgrounds and contextual relationships. The COCO dataset provides object annotations in the form of bounding boxes, class labels, and precise pixel-level segmentation masks for each instance. Its emphasis on object relationships and visual complexity in real-world scenes makes COCO a crucial benchmark for evaluating the robustness of object detection and segmentation algorithms.
4.1.2. Metrics
mAP (mean Average Precision) represents the mean of Average Precision (AP) across all classes, reflecting the overall detection performance of a model. For each class, AP is calculated as the area under the Precision-Recall (P-R) curve. mAP is obtained by averaging the AP values for all classes, providing a comprehensive evaluation of the model’s detection capability.
mAP@50 refers to the mAP calculated at an Intersection over Union (IoU) threshold of 0.5, while mAP@50-95 is the average mAP calculated across multiple IoU thresholds ranging from 0.5 to 0.95, with a step size of 0.05 (a total of 10 thresholds). Compared with mAP@50, mAP@50-95 offers a more comprehensive assessment of the model’s performance under varying overlap requirements, better reflecting its robustness.
The number of parameters and floating point operations per second (FLOPs) are metrics for measuring the size of a model, directly reflecting its complexity and computational cost. The number of parameters represents the total number of learnable weights in the model, while FLOPs indicate the amount of computation required for a single forward pass, measuring the model’s computational complexity.
4.2. Performance Evaluation
Our experiments were conducted in a computing environment with a 12-core Intel(R) Xeon(R) Gold 6248R CPU and an NVIDIA GeForce RTX 3090 GPU. YOLOv8 is a state-of-the-art object detection algorithm that offers five model variants, n, s, m, l, and x, arranged in increasing order of parameter size. Since our dataset is relatively small, the performance differences among YOLOv8m, YOLOv8l, and YOLOv8x are minimal. Therefore, we selected the n, s, and m versions of YOLOv8 to compare with our model on the HTED dataset. Additionally, we included GD-YOLOv8 [24], which is also based on YOLOv8, and the Gold-YOLO [23] model, an improved version of YOLOv6, for comparative experiments. The results are shown in Table 1.

Table 1.
Comparison results on the HTED dataset are presented, where we compared our method with the YOLOv8 series, Gold-YOLO, and GD-YOLOv8 in terms of mAP50/mAP50-95 metrics for each category in the dataset. The best mAP50-95 results are highlighted in bold. SR-Deformation represents support rod deformation, L-Deformation represents ladder deformation, L-Missing represents ladder missing, DL-Broken represents door latch broken.
Our model outperformed the other models on the HTED dataset overall. Some comparison models, such as GD-YOLOv8, performed poorly on our dataset, likely due to the visual similarity among certain categories in the dataset, which led to misclassification. The comparative methods generally performed poorly in the “door latch broken” category. This is because the defective data in this category closely resemble the normal data in appearance, and the target size in this category is relatively smaller than others. Our method employs multi-scale feature fusion to enhance the model’s ability to detect targets with significant size variations more accurately. This improvement is further substantiated in the subsequent ablation experiments. Our model demonstrated superior performance in most categories, validating its effectiveness on the Train Equipment Defect dataset. Our method achieved inference time comparable to small models while maintaining accuracy close to larger models, demonstrating its lightweight design and high performance. To demonstrate the reliability of our method’s performance, we conducted 5-fold cross-validation and calculated the confidence interval of mAP. The confidence interval for the YOLOv8n model is (0.84192, 0.84407), while the confidence interval for our method is (0.85915, 0.86285).The detection results of our model on the HTED dataset are shown in Figure 4.

Figure 4.
Detection results of the model on the HTED dataset. From left to right are support rod deformation, ladder missing, ladder deformation, and door latch defects.
Our method still has some failure cases, mainly involving misclassification. While the model demonstrates high accuracy in anomaly localization, it may encounter missed or false detection due to the small size of certain defects. We believe that this issue arises because the model tends to confuse small defects with normal samples when making judgments. In future research, we plan to strengthen the distinction between positive and negative samples to improve this, while also incorporating a confidence scoring mechanism to reduce the probability of false positives.
To verify the effectiveness of our method on large-scale datasets, we trained the model on the COCO dataset. We compared its performance with YOLOv5n, YOLOv5m, YOLOv5n6, YOLOv6n, YOLOv8n, and YOLOv8m on the COCO dataset. In industrial applications, the number of parameters and inference speed are crucial indicators. To demonstrate the excellent performance of our model in terms of model size, we calculated the number of parameters and FLOPs, with the comparison results presented in Table 2.
Table 2.
The results tested on the COCO dataset compare our method with YOLOv5n, YOLOv5m, YOLOv5n6, YOLOv6n, YOLOv8n, and YOLOv8m in terms of performance on the dataset and model size.
Our model outperforms similarly scaled models in detection accuracy while achieving competitive results comparable to the larger YOLOv8m model with only about one-fifth of its parameter count. This significant reduction in model size makes our approach particularly suitable for resource-constrained environments, such as real-time train equipment monitoring systems, where both accuracy and efficiency are critical. The combination of the lightweight MobileNetV4 backbone, the CGAFusion module for enhanced feature representation, and the staged knowledge distillation strategy ensures that our model maintains high detection performance without compromising speed or computational efficiency. Experimental results on the HTED dataset further validate the effectiveness of our method, demonstrating its ability to balance precision, model size, and inference speed, making it a promising solution for industrial anomaly detection tasks.
4.3. Ablation Studies
To evaluate the performance improvements contributed by each module, we conducted ablation experiments on our method. These experiments primarily analyzed the contributions of network structure modifications and the knowledge distillation approach. The ablation experiment results for the backbone network and attention-based feature fusion module are shown in Table 3. We use the YOLOv8n network as the baseline and compare the performance of using Shufflenet and Fasternet as backbone networks, as well as incorporating the Swin-Transformer structure for feature fusion. Replacing the backbone with the Mobilenet-based network resulted in an improvement in mAP50-95. Furthermore, integrating the CGAFusion module into the YOLOv8n network further enhanced the mAP50-95 score. Compared with other feature fusion methods, such as BiFPN, our approach achieves higher performance improvement with only a slight increase in the number of parameters.
Table 3.
Ablation study on different backbone networks and feature fusion modules. × indicates that the corresponding module is not included.
In our method, the teacher model was pre-trained on the COCO dataset, followed by distillation applied to both the output layer and feature layers after fine-tuning on the HTED dataset. To verify the effectiveness of the knowledge distillation strategy, we designed an ablation experiment on the distillation strategy. We compared the effect of pre-training on the COCO dataset for the feature and output layers only and the effect of pre-training and distillation directly on the HTED dataset. The experimental results are shown in Table 4.
Table 4.
Ablation study on different distillation methods compares the impact of different distillation losses and varying datasets for teacher network pre-training on experimental performance. √ indicates that the corresponding loss function is applied, while × indicates that it is not applied.
Based on the experimental results, we analyzed the potential application of the model on edge AI hardware. We believe that NVIDIA Jetson is the most suitable platform for deploying our model. According to the study [44,45], the YOLOv8 architecture has complementary characteristics with NVIDIA Jetson, with its energy consumption not exceeding 70 × FLOPs/W. Compared with other hardware, Jetson supports CUDA acceleration, which will provide higher inference performance for our model and allow for timely optimization and updates when more data become available in the future.
5. Conclusions
This paper proposes a new YOLO-based network structure that leverages the lightweight nature of the MobileNetV4 architecture. MobileNetV4 is employed as the feature extractor, replacing the backbone of the YOLOv8 structure, which improves the model’s feature extraction capability. The Content-Guided Attention Fusion (CGAFusion) module is integrated into the network, enhancing the fusion of multi-layer features in the Neck and feature extraction network, thereby improving the detection capability for objects of varying scales. To achieve a high-performance yet lightweight model, a knowledge distillation strategy is designed, where both the feature and output layers of a pre-trained teacher model are distilled to guide the training of the student model. The proposed method is validated on the self-constructed HTED dataset, demonstrating superior performance compared to various YOLO series models and other advanced YOLO-based methods. Furthermore, the model also exhibits competitive performance on large-scale datasets such as COCO. In future research, our focus will be on developing few-shot learning techniques to rapidly adapt to defect detection tasks when samples of unknown defect categories are limited. Additionally, we will explore deploying the model on embedded devices and handheld mobile devices, which will be a crucial step in the practical application of deep learning models.
Author Contributions
Conceptualization, Z.M.; methodology, Z.M.; software, Z.M. and S.Z.; validation, Z.M. and S.Z.; formal analysis, Z.M., S.Z. and C.L.; writing—original draft preparation, Z.M.; writing—review and editing, S.Z. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by Fundamental Research Funds for the Central Universities (2023JBZY032).
Data Availability Statement
Restrictions apply to the availability of these data. Data were obtained from China Energy Railway Equipment Co., Ltd.
Conflicts of Interest
Author Ziqin Ma was employed by China Energy Railway Equipment Co., LTD. The other authors conducted the research without any conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the existing affiliation information. This change does not affect the scientific content of the article.
References
- Aung, K.H.H.; Kok, C.L.; Koh, Y.Y.; Teo, T.H. An Embedded Machine Learning Fault Detection System for Electric Fan Drive. Electronics 2024, 13, 493. [Google Scholar] [CrossRef]
- Gan, J.; Li, Q.; Wang, J.; Yu, H. A hierarchical extractor-based visual rail surface inspection system. IEEE Sens. J. 2017, 17, 7935–7944. [Google Scholar] [CrossRef]
- Hoshi, T.; Baba, Y.; Gavai, G. Railway Anomaly detection model using synthetic defect images generated by CycleGAN. arXiv 2021, arXiv:2102.12595. [Google Scholar]
- Han, Y.; Liu, Z.; Lyu, Y.; Liu, K.; Li, C.; Zhang, W. Deep learning-based visual ensemble method for high-speed railway catenary clevis fracture detection. Neurocomputing 2020, 396, 556–568. [Google Scholar] [CrossRef]
- Das, S.; Kong, X.; Lavrenz, S.M.; Wu, L.; Jalayer, M. Fatal crashes at highway rail grade crossings: A US based study. Int. J. Transp. Sci. Technol. 2022, 11, 107–117. [Google Scholar] [CrossRef]
- Pahwa, R.S.; Chao, J.; Paul, J.; Li, Y.; Nwe, M.T.L.; Xie, S.; James, A.; Ambikapathi, A.; Zeng, Z.; Chandrasekhar, V.R. Faultnet: Faulty rail-valves detection using deep learning and computer vision. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 559–566. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4: Universal Models for the Mobile Ecosystem. In Computer Vision—ECCV 2024, Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2025; pp. 78–96. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Mital, A.; Govindaraju, M.; Subramani, B. A comparison between manual and hybrid methods in parts inspection. Integr. Manuf. Syst. 1998, 9, 344–349. [Google Scholar] [CrossRef]
- Park, J.K.; Kwon, B.K.; Park, J.H.; Kang, D.J. Machine learning-based imaging system for surface defect inspection. Int. J. Precis. Eng. Manuf.-Green Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- Du, J.; Zhang, R.; Gao, R.; Nan, L.; Bao, Y. RSDNet: A New Multiscale Rail Surface Defect Detection Model. Sensors 2024, 24, 3579. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Qin, Y.; Qian, Y.; Guo, F.; Wang, Z.; Jia, L. Hybrid deep learning architecture for rail surface segmentation and surface defect detection. Comput.-Aided Civ. Infrastruct. Eng. 2022, 37, 227–244. [Google Scholar] [CrossRef]
- Wen, Y.; Gao, X.; Luo, L.; Li, J. Improved YOLOv8-Based Target Precision Detection Algorithm for Train Wheel Tread Defects. Sensors 2024, 24, 3477. [Google Scholar] [CrossRef] [PubMed]
- Xing, Z.; Zhang, Z.; Yao, X.; Qin, Y.; Jia, L. Rail wheel tread defect detection using improved YOLOv3. Measurement 2022, 203, 111959. [Google Scholar] [CrossRef]
- Min, Y.; Xiao, B.; Dang, J.; Yue, B.; Cheng, T. Real time detection system for rail surface defects based on machine vision. Eurasip J. Image Video Process. 2018, 2018, 3. [Google Scholar] [CrossRef]
- Jiang, Q.; Gao, R.; Zhao, Y.; Yu, W.; Dang, Z.; Deng, S. Research on a Wear Defect Detection Method for a Switch Sliding Baseplate Based on Improved Yolov5. Lubricants 2024, 12, 422. [Google Scholar] [CrossRef]
- Fu, X.; Li, K.; Liu, J.; Li, K.; Zeng, Z.; Chen, C. A two-stage attention aware method for train bearing shed oil inspection based on convolutional neural networks. Neurocomputing 2020, 380, 212–224. [Google Scholar] [CrossRef]
- Bodini, I.; Petrogalli, C.; Faccoli, M.; Mazzù, A. Vision-based damage analysis in shoe-braking tests on railway wheel steels. Wear 2022, 510, 204514. [Google Scholar] [CrossRef]
- Guo, G.; Peng, J.; Yang, K.; Xie, L.; Song, W. Wheel tread defects inspection based on SVM. In Proceedings of the 2017 Far East NDT New Technology & Application Forum (FENDT), Xi’an, China, 22–24 June 2017; pp. 251–253. [Google Scholar]
- Sresakoolchai, J.; Kaewunruen, S. Railway defect detection based on track geometry using supervised and unsupervised machine learning. Struct. Health Monit. 2022, 21, 1757–1767. [Google Scholar] [CrossRef]
- Saini, A.; Singh, D.; Alvarez, M. FishTwoMask R-CNN: Two-stage Mask R-CNN approach for detection of fishplates in high-altitude railroad track drone images. Multimed. Tools Appl. 2024, 83, 10367–10392. [Google Scholar] [CrossRef]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2024, 36, 51094–51112. [Google Scholar]
- CanYang, X.; Yingying, L.; Yongqiang, L.; Runliang, T.; Tao, G. Lightweight rail surface defect detection algorithm based on an improved YOLOv8. Measurement 2025, 242, 115922. [Google Scholar] [CrossRef]
- Minguell, M.G.; Pandit, R. TrackSafe: A comparative study of data-driven techniques for automated railway track fault detection using image datasets. Eng. Appl. Artif. Intell. 2023, 125, 106622. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Mao, Y.; Zheng, S.; Li, L.; Shi, R.; An, X. Research on Rail Surface Defect Detection Based on Improved CenterNet. Electronics 2024, 13, 3580. [Google Scholar] [CrossRef]
- Zhang, X.; Shen, B.; Li, J.; Ruan, J. Lightweight Algorithm for Rail Fastener Status Detection Based on YOLOv8n. Electronics 2024, 13, 3399. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Nguyen, C.H.; Nguyen, T.C.; Tang, T.N.; Phan, N.L. Improving object detection by label assignment distillation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1005–1014. [Google Scholar]
- Zheng, Z.; Ye, R.; Hou, Q.; Ren, D.; Wang, P.; Zuo, W.; Cheng, M.M. Localization distillation for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10070–10083. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Hong, W.; Wang, F.; Yu, J. Gan-knowledge distillation for one-stage object detection. IEEE Access 2020, 8, 60719–60727. [Google Scholar] [CrossRef]
- Wan, W.; Chen, J.; Xie, J. Graph-Based Model Compression for HSR Bogies Fault Diagnosis at IoT Edge via Adversarial Knowledge Distillation. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1787–1796. [Google Scholar] [CrossRef]
- Zhu, A.; Xie, J.; Wang, B.; Guo, H.; Guo, Z.; Wang, J.; Xu, L.; Zhu, S.; Yang, Z. Lightweight defect detection algorithm of tunnel lining based on knowledge distillation. Sci. Rep. 2024, 14, 27178. [Google Scholar] [CrossRef] [PubMed]
- Xing, Z.; Chen, X.; Pang, F. DD-YOLO: An object detection method combining knowledge distillation and Differentiable Architecture Search. IET Comput. Vis. 2022, 16, 418–430. [Google Scholar] [CrossRef]
- Yang, Q.; Li, F.; Tian, H.; Li, H.; Xu, S.; Fei, J.; Wu, Z.; Feng, Q.; Lu, C. A new knowledge-distillation-based method for detecting conveyor belt defects. Appl. Sci. 2022, 12, 10051. [Google Scholar] [CrossRef]
- Sinha, D.; El-Sharkawy, M. Thin mobilenet: An enhanced mobilenet architecture. In Proceedings of the 2019 IEEE 10th annual ubiquitous computing, electronics & mobile communication conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 280–285. [Google Scholar]
- Zhang, Y.; Liu, M.; Chen, Y.; Zhang, H.; Guo, Y. Real-time vision-based system of fault detection for freight trains. IEEE Trans. Instrum. Meas. 2019, 69, 5274–5284. [Google Scholar] [CrossRef]
- Liu, R.; Wang, Y. Principle and Application of TFDS. Chin. Railw. 2005, 2, 26–27. [Google Scholar] [CrossRef]
- Kounadis-Bastian, D.; Schrüfer, O.; Derington, A.; Wierstorf, H.; Eyben, F.; Burkhardt, F.; Schuller, B. Wav2Small: Distilling Wav2Vec2 to 72K parameters for Low-Resource Speech emotion recognition. arXiv 2024, arXiv:2408.13920. [Google Scholar]
- Cui, Y.; Li, M.; Huang, X.; Yang, Y. Lightweight UAV Image Drowning Detection Method Based on Improved YOLOv7. In Proceedings of the 2024 WRC Symposium on Advanced Robotics and Automation (WRC SARA), Beijing, China, 23 August 2024; pp. 350–356. [Google Scholar]
- Neamah, O.N.; Almohamad, T.A.; Bayir, R. Enhancing road safety: Real-time distracted driver detection using Nvidia Jetson Nano and YOLOv8. In Proceedings of the 2024 Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 22–23 May 2024; pp. 194–198. [Google Scholar]
- Pravallika, A.; Kumar, C.A.; Praneeth, E.S.; Abhilash, D.; Priya, G.S. Efficient Vehicle Detection System Using YOLOv8 on Jetson Nano Board. In Proceedings of the 2024 IEEE International Conference on Information Technology, Electronics and Intelligent Communication Systems (ICITEICS), Bangalore, India, 28–29 June 2024; pp. 1–6. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).