
Enhancing Domain-Specific Knowledge Graph Reasoning via Metapath-Based Large Model Prompt Learning

Abstract
1. Introduction
- Limited Structural Understanding: LLMs are trained primarily on unstructured text and lack the ability to fully comprehend the structured nature of knowledge graphs. This limitation hampers their ability to effectively navigate and reason over the complex relationships and entities within knowledge graphs.
- Inefficient Inference Paths: LLMs often struggle to identify and induce optimal reasoning paths, especially in multi-hop reasoning tasks. Their lack of structured reasoning capabilities can lead to inefficient or inaccurate inference, as they may not always select the most relevant paths for answering a query.
- Lack of Fact Verification: LLMs are known for their occasional factual errors and hallucinations, which can be particularly problematic when reasoning over knowledge graphs. Without a mechanism to verify the factual accuracy of their reasoning steps against the knowledge graph, these errors can propagate and affect the overall reliability of the reasoning process.
- Semantic Sparsity Discrepancy: Natural language, such as query task texts, typically exhibits low-density sparsity, which creates a significant difference in semantic space compared to the high-density structure of knowledge graphs. While LLMs have shown the ability to compensate for common sense deficiencies in natural language texts, they may still struggle when independently constructing a reasoning process based solely on the query target. This is primarily due to the limited information available for querying structured knowledge, which can lead to factual insufficiency and potential hallucinations. The challenge lies not in understanding the query intent, which LLMs are increasingly capable of, but in effectively constructing queries that align with the dense structure of knowledge graphs. This gap highlights the need for additional mechanisms to guide LLMs in accurately querying and utilizing structured knowledge.
2. Literature Review
2.1. Rule-Based Knowledge Reasoning
2.2. Representation Learning in Knowledge Reasoning
- The construction form of reasoning chain prompts: Relying solely on text reasoning chains is insufficient to fully stimulate large language models to generate reliable and authentic knowledge graph reasoning processes. Inspired by the triplet structure in knowledge graphs and the updating of graph nodes, structured features are used to construct metapaths to enhance prompts. A verification mechanism is repeatedly applied to update the generation results of metapaths, ensuring that they can more accurately guide the model in logical reasoning.
- Post-verification: Large language models typically cannot check the correctness of their reasoning processes on their own. After the reasoning process is completed, an external mechanism is needed for verification to ensure the accuracy of the reasoning results and to eliminate hallucinations.
2.3. Integration of Knowledge Graphs and Large Language Models
2.4. LLMs for Knowledge Reasoning
2.5. Prompt-Based Knowledge Reasoning Methods
3. Methodology
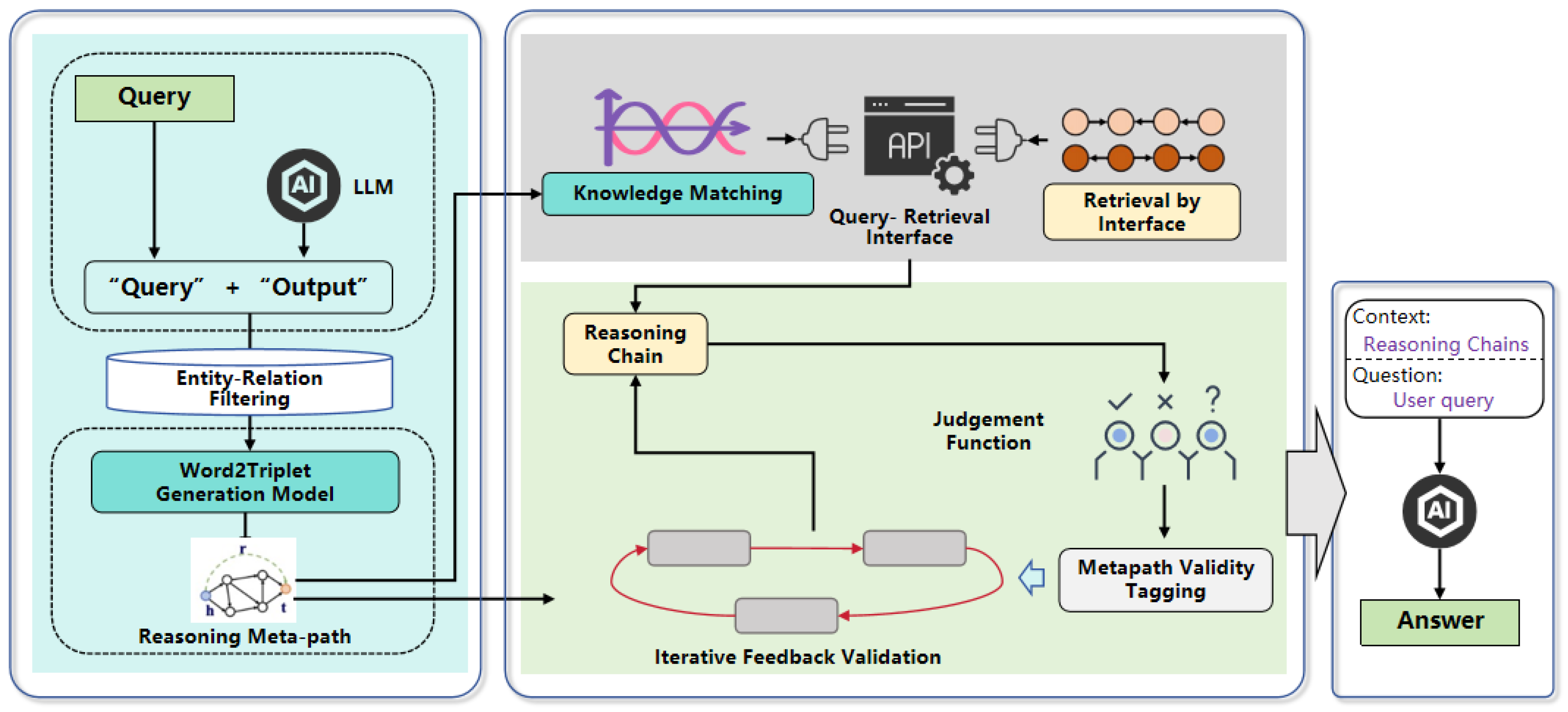
3.1. Proposed Framework
- In leveraging large language models to parse task prompts, several triplet examples are constructed as reasoning metapaths. These metapaths are verified and updated with the knowledge graph to obtain truly existing reasoning paths.
- The metapaths are used for iterative interaction between the large language model and the knowledge graph, promoting the step-by-step construction of reasoning by the large language model, and including the interpretation of prompts and evidence triplets extracted from the knowledge graph, namely a series of reasoning chains entirely drawn from within the knowledge graph.
- Algorithms for fact verification and loyalty verification are employed to ensure the reliability of the reasoning chains and to re-evaluate unreliable ones.
3.2. Construction and Verification of Reasoning Metapaths
3.2.1. Constructing Reasoning Metapaths Based on Zero-Shot Prompts
3.2.2. Feedback Validation of Reasoning Metapaths
- Initialization: Select a triplet to be validated, where h is the head entity, r is the relation, and t is the tail entity. Initialize a vector representing the triple and obtain the set S of all known triplets from the knowledge graph.
- Iterative Approximation: In each iteration, use the current triplet representation to predict the relation and check whether the triplet exists in the knowledge graph. Define an iterative process:
- Feedback Validation: After each iteration, use a scoring function to evaluate the existence of the current triplet. Define a scoring function :If the value of is close to zero, the triplet is considered to exist.
- Set Loss Function: Construct a loss function to assess the existence of the current triplet:Here, is a set threshold representing the allowable error range. This threshold determines the minimum score required for a triplet to be considered valid. Specifically, if the scoring function is less than , the triplet is considered to exist.
- Model Training: In each iteration, update the vector representation of the triplet using optimization algorithms such as stochastic gradient descent (SGD) to minimize the loss function:Here, is the learning rate of the optimization algorithm, which controls the step size of each update during the training process.
- Final Validation: Input the triplet to be validated into the trained model and determine the existence of the triplet based on the output value of the scoring function. If is less than the set threshold , then the triplet is considered to exist.
- Iteration Termination Condition: Set a threshold, and when the change in the output value of the scoring function is less than this threshold for several consecutive iterations, it can be considered that the existence of the triplet has reached a stable state, and the iteration can be stopped.
- Result Output: Finally, output the validation result to confirm whether the triplet exists in the knowledge graph.
3.3. Iterative Reasoning Steps on MetaPaths
- Utilize the interfaces of structured data to achieve precise and efficient data access and queries.
- Further leverage the reasoning capabilities of large language models to determine the next step of the question or the final result (solving the task).
3.3.1. Query Interface Design for Iterative Reasoning
- Extract Neighboring Relations: For a given entity e, extract all adjacent relations.
- Extract Triplets: For a given head entity e and a set of relations , extract all triplets that have a relation with e.
- Extract Neighboring Relations: Define a function , where e represents the input entity, and the output of the function is the set of all adjacent relations of that entity. It can be represented aswhere is the set of relations for entity e. Define a function get_neighborhood(entity), which takes an entity as input and returns all neighboring relations of that entity.
- Extract Triplets: Define another function , where e is the head entity and r is the set of relations. The output of the function is the set of all triplets connected to entity e through relation r. Mathematically, it can be represented aswhere is the set of triplets corresponding to entity e and relation r.
- After obtaining the neighboring relations and triplets, the large language model can use these steps to assist the reasoning process:
- Obtain neighboring relations: get_neighborhood(topic_entity).
- Based on the specific relations needed, call the function to obtain triplets:get_triples(topic_entity, relation).
- Use triplet data for reasoning to locate the answer entity: answer_entity = perform_reasoning(relevant_triples).
3.3.2. Design of the Judgment Function
3.3.3. Iterative Verification from Metapath to Knowledge Graph
- Determine the Current Entity and Metapath’s Current Position
- Define a function capable of receiving the current entity and the metapath P as inputs to ascertain the current position in the metapath. This position will guide how to search for adjacent entities that match the metapath pattern from the current entity.
- The common encoder TransE [40] is employed to accomplish this step, encoding entities and relations into vectors and predicting relationships between entities through vector operations. TransE is a translation-based embedding model that maps entities and relations in a knowledge graph into a low-dimensional vector space. Specifically, for a triplet , where h is the head entity, r is the relation, and t is the tail entity, TransE models the relationship as a translation from h to t via r. Here, h, r, and t are the vector representations of the head entity, relation, and tail entity, respectively.
- Utilize the principle of the encoder to determine the current entity and the current position of the metapath. Encode the current entity and the entity type e in the metapath into vectors. Then, also encode the relation type r in the metapath into a vector. In this way, adjacent entities that match the metapath can be predicted and searched through vector operations.
- Let be the vector representation of the current entity , be the vector representation of the entity type e in the metapath, and be the vector representation of the relation type r. The current position in the metapath can be determined with the following formula:
- Extract Adjacent Entities
- After determining the current entity and the current position of the metapath, the next step is to extract all adjacent entities of the current entity. This step is the core of the iterative framework, as it involves retrieving from the knowledge graph other entities directly connected to the current entity.
- Let be the vector representation of the current entity, and be the vector representation of the relation type. The adjacent entities can be predicted with the following formula:
- Judge Whether Adjacent Entities Conform to the Metapath
- After extracting the adjacent entities, it is necessary to determine whether these entities conform to the metapath pattern. This step involves verifying each adjacent entity to ascertain whether they are connected to the current entity through the relationship defined in the metapath.
- In this step, the adjacent entities can be compared with the next entity type in the metapath to determine if they match.
- Let be the vector representation of the adjacent entity, and be the vector representation of the next entity type in the metapath. The conformity of the adjacent entity to the metapath can be verified with the following formula:
- Update the Metapath and Current Entity
- After verifying whether the adjacent entities conform to the metapath, the metapath and current entity need to be updated for the next iteration. The adjacent entity that conforms to the metapath is set as the new current entity, and the metapath is updated to the next segment.
- Let be the vector representation of the new current entity, and be the updated metapath. The metapath and current entity can be updated with the following formula:
- Repeat Iteration Until Metapath Ends
- After updating the metapath and current entity, the aforementioned process must be repeated until all parts of the metapath have been traversed, or until no adjacent entities conforming to the metapath can be found. The principle of the encoder is utilized to determine when to stop the iteration. For example, a maximum number of iterations can be set, or the iteration can be halted when no adjacent entities conforming to the metapath are identified.
- Let be the vector representation of the final current entity, and be the final metapath. The condition to stop the iteration can be determined with the following formula:
- Serialization
- Finally, construct an output function to serialize the output. That is, extract all entities from the knowledge graph obtained at each step.
- As mentioned earlier, the extracted output must be transformed into a textual sentence comprehensible to large language models. For information from the knowledge graph, directly concatenate them into a long sentence marked by specific separation and boundary delimiters. The commonly adopted pattern is the following: “Here is… This is most relevant to answering the question.” The purpose of this prompt is to guide the LLM to select useful evidence (denoted as [X]) from the linearized extracted information (denoted as [Y]) based on the question (denoted as [Q]). Specifically, [X] represents the evidence selected by the model, [Y] represents the linearized extracted information from the knowledge graph, and [Q] represents the user’s question. For the final answer, the pattern followed is “Based on the question, please generate [Z].” Here, [Z] denotes the target result or answer. The purpose of this prompt is to predict the target result ([Z]) given the question ([Q]) and the linearized extracted information ([Y]) to obtain an exact answer.
3.3.4. Iterative Pattern Framework
- Call the metapath ‘Extract_Meta_Path()’ based on the topic entity to extract candidate one-hop metapath relationships.
- Based on the similarity with query annotations , linearize them to form input prompts. Then, utilize the large language model to select a useful set of relations based on the question.
- Based on the set of relations , call the ‘Extract_Triples(, )’ interface to collect triplets related to the head entity and the set of relations, which are added to the topic entity set .
| Algorithm 1 Iterative Framework for MetaPath |
|
3.4. Post-Reasoning Verification
3.4.1. Fact Verification
3.4.2. Fidelity Verification
4. Experimental Results
4.1. Data Preparation
4.1.1. Data Preparation for Question Answering with Reasoning
4.1.2. Data Preparation for Multi-Hop Reasoning
4.1.3. Data Preprocessing
- Converting the query into a predefined template: “Here is the query……Please generate the initial nodes relevant to the query purpose”.
- Utilizing a small automatic verification program to check whether the generated triplets exist in the knowledge graph. This verification process is iterative, ensuring the accuracy of the initial nodes.
- During each hop of the iterative reasoning, the query results are transformed into the form “Here is… This is most relevant to answering the question.” to guide the model in finding the next relevant node.
- At the final answer generation stage, all relevant information is summarized and transformed into the template “Based on the question, please generate [Z].” to consolidate the results of all metapaths and obtain the final answer.
- The purpose of this preprocessing step is to structure natural language queries into clear templates, thereby enhancing the accuracy and efficiency of LLMs in the reasoning process.
4.2. Results and Analysis
4.2.1. Results for Reasoning Question Answering Task
4.2.2. Results on Medical Domain Dataset
4.2.3. Results for Multi-Hop Reasoning Task
4.2.4. Ablation Studies
- Metapath Construction (MPC): The metapath construction component is responsible for initializing the reasoning paths based on zero-shot prompts. Removing this component resulted in a significant drop in performance on both WebQSP (F1: 69.3) and CWQ (F1: 62.5). This indicates that metapath construction is crucial for guiding the model to focus on relevant entities and relationships, thereby improving the overall reasoning accuracy.
- Iterative Verification (IV): The iterative verification component ensures that the reasoning paths are refined and validated at each step. When this component was removed, the performance decreased to 72.1 on WebQSP F1 and 66.7 on CWQ F1. This suggests that iterative verification plays a vital role in refining the reasoning paths and ensuring their validity, especially in complex multi-hop reasoning tasks.
- Post-Reasoning Checks (PRCs): The post-reasoning checks, including fact verification and fidelity verification, ensure the reliability of the final reasoning results. Removing this component led to a moderate decline in performance (WebQSP F1: 74.8; CWQ F1: 68.9). This highlights the importance of post-reasoning checks in eliminating errors and hallucinations, thereby enhancing the robustness of the reasoning process.
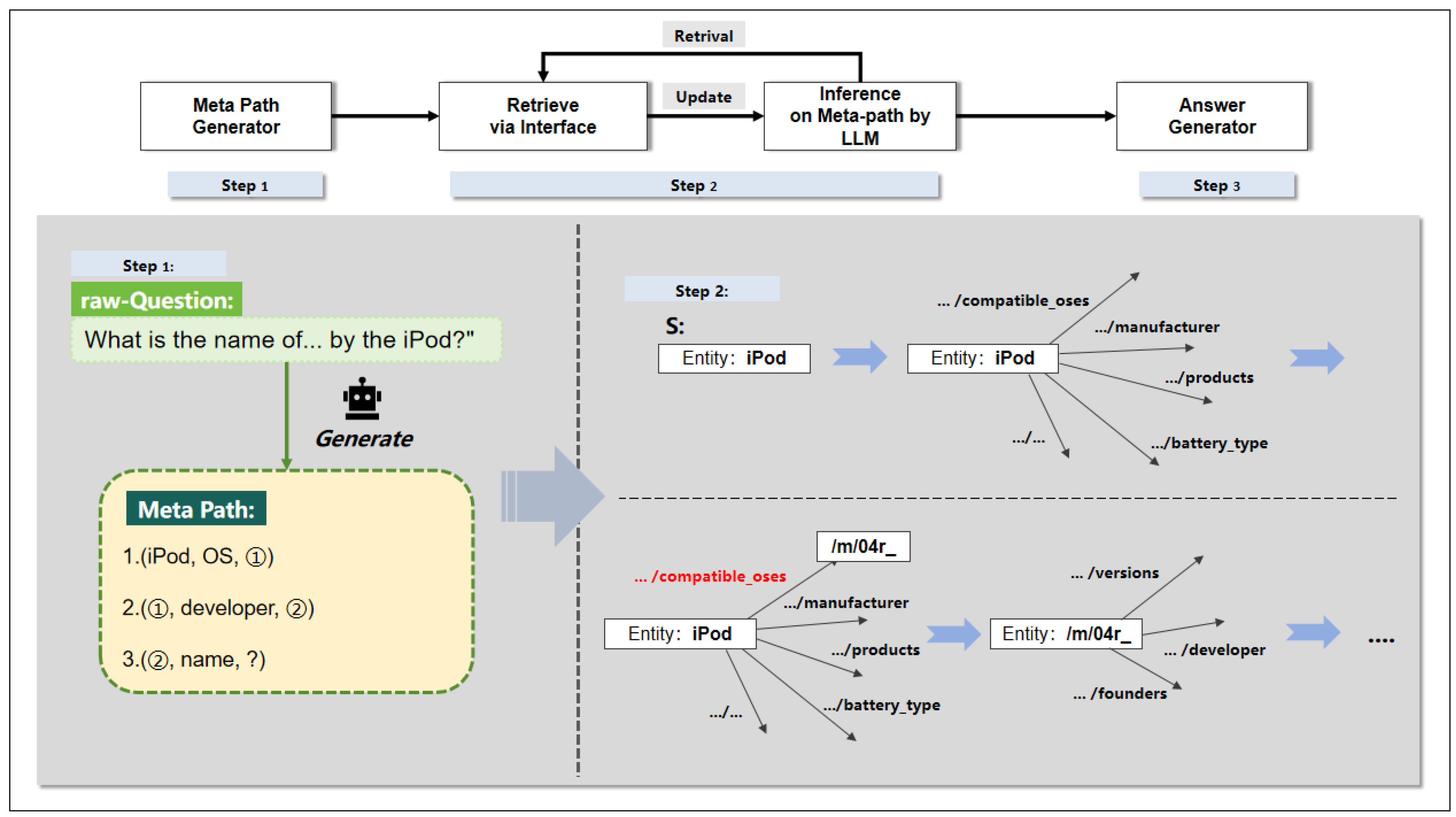
4.2.5. Case Study
- Prompt the model to judge all adjacent relationships based on the metapath, determining the most likely next-hop relationship that meets the metapath requirements, which is /computer/hardware_device/compatible_oses here. If there are multiple relationships that meet the conditions, multiple next-hop relationships will be obtained simultaneously.
- Move the starting point of the retriever to entity /m/02hrh0 according to the selected relationship, update the prompt template of the large model to reflect the current information obtained, and temporarily shield the effective metapath.
- Retrieve all adjacent relationships of entity /m/02hrh0 through the interface to obtain the next-hop relationship candidate list (the adjacent list of /m/02hrh0 is omitted here).
- Continue to update the prompt template of the large model and the metapath, and retrieve all adjacent relationships of entity /m/02hrh0 through the interface to obtain the next-hop relationship candidate list.
- Continuously perform iterative steps (1)–(4) until the judgment function determines that the current hop result can answer the question or all adjacent relationships cannot meet the conditions.
- Serialize all passed entities, connect them with the question, input them into the large language model, and output the final answer.
- From entity /m/02hrh0 (iPod) to /m/04r_ (Mac OS) based on the relationship /computer/hardware_device/compatible_oses;
- From /m/04r_ (Mac OS) to /m/0k8z (Apple Inc.) based on the relationship /software/operating_system/developer;
- Finally, from /m/0k8z (Apple Inc.) to its name “Apple Inc.” based on the relationship /organization/name.
4.2.6. Prompt Study
- Direct Prompting: Prompting a large language model to directly predict the answer.
- Chain-of-Thought Prompting (CoT Prompting): Prompting a large language model to generate step-by-step explanations before providing the answer.
- One-step Retrieval (OneR): Enhancing chain-of-thought prompting by retrieving K paragraphs using the original complex question as a query. The retrieval method provided the large model with a paragraph retriever based on BM, retrieving the K highest-ranked paragraphs as reasoning context, where K was selected from 3, 5, 7. A comparison of the results from different prompts is shown in Table 7.
5. Discussion and Conclusions
6. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge graphs: Opportunities and challenges. Artif. Intell. Rev. 2023, 56, 13071–13102. [Google Scholar] [CrossRef] [PubMed]
- Kejriwal, M. Domain-speCific Knowledge Graph Construction; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Steinigen, D.; Teucher, R.; Ruland, T.H.; Rudat, M.; Flores-Herr, N.; Fischer, P.; Milosevic, N.; Schymura, C.; Ziletti, A. Fact Finder–Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs. arXiv 2024, arXiv:2408.03010. [Google Scholar]
- Dash, T.; Srinivasan, A.; Vig, L. Incorporating symbolic domain knowledge into graph neural networks. Mach. Learn. 2021, 110, 1609–1636. [Google Scholar] [CrossRef]
- Pujara, J.; Miao, H.; Getoor, L.; Cohen, W. Knowledge graph identification. In Proceedings of the 12th International Semantic Web Conference, Sydney, NSW, Australia, 21–25 October 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 542–557. [Google Scholar]
- Kuželka, O.; Davis, J. Markov Logic Networks for Knowledge Base Completion: A Theoretical Analysis Under the MCAR Assumption. In Proceedings of the 35th Uncertainty in Artificial Intelligence Conference, PMLR, Tel Aviv, Israel, 22–25 July 2019; pp. 1138–1148. [Google Scholar]
- Galarraga, L.; Teflioudi, C.; Hose, K.; Suchanek, F. AMIE: Association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd International Conference on World Wide Web, ACM, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 413–422. [Google Scholar] [CrossRef]
- Galarraga, L.; Teflioudi, C.; Hose, K.; Suchanek, F. Fast rule mining in ontological knowledge bases with AMIE++. VLDB J. 2015, 24, 707–730. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J. RDF2Rules: Learning rules from RDF knowledge bases by mining frequent predicate cycles. arXiv 2015, arXiv:1512.07734. [Google Scholar]
- Wang, Q.; Liu, J.; Luo, Y.; Wang, B.; Lin, C.Y. Knowledge Base Completion via Coupled Path Ranking. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1308–1318. [Google Scholar] [CrossRef]
- Gardner, M.; Mitchell, T. Efficient and expressive knowledge base completion using subgraph feature extraction. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1488–1498. [Google Scholar] [CrossRef]
- Liu, Q.; Jiang, L.; Han, M.H.; Liu, Y.; Qin, Z. Hierarchical random walk inference in knowledge graphs. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, Pisa, Italy, 17–21 July 2016; pp. 445–454. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.; et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Deng, S.; Wang, C.; Li, Z.; Zhang, N.; Dai, Z.; Chen, H.; Xiong, F.; Yan, M.; Chen, Q.; Chen, M.; et al. Construction and applications of billion-scale pre-trained multimodal business knowledge graph. In Proceedings of the IEEE International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced language representation with informative entities. arXiv 2019, arXiv:1905.07129. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-BERT: Enabling Language Representation with Knowledge Graph. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), The Thirty-Second Innovative Applications of Artificial Intelligence Conference (IAAI 2020), The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI 2020), New York, NY, USA, 7–12 February 2020; AAAI Press: New York, NY, USA, 2020; pp. 2901–2908. [Google Scholar] [CrossRef]
- Liu, Y.; Wan, Y.; He, L.; Peng, H.; Yu, P.S. KGBART: Knowledge Graph-Augmented BART for Generative Commonsense Reasoning. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI 2021), Thirty-Third Conference on Innovative Applications of Artificial Intelligence (IAAI 2021), The Eleventh Symposium on Educational Advances in Artificial Intelligence (EAAI 2021), New Orleans, LA, USA, 2–9 February 2021; AAAI Press: New York, NY, USA, 2021; pp. 6418–6425. [Google Scholar]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. KagNet: Knowledge-aware graph networks for commonsense reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2829–2839. [Google Scholar] [CrossRef]
- Wang, X.; Gao, T.; Zhu, Z.; Zhang, Z.; Liu, Z.; Li, J.; Tang, J. Kepler: A unified model for knowledge embedding and pretrained language representation. Trans. Assoc. Comput. Linguist. 2021, 9, 176–194. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Melnyk, I.; Dognin, P.; Das, P. Grapher: Multi-stage knowledge graph construction using pretrained language models. In Proceedings of the NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, Virtual, 13 December 2021. [Google Scholar]
- Ke, P.; Ji, H.; Ran, Y.; Cui, X.; Wang, L.; Song, L.; Zhu, X.; Huang, M. JointGT: Graph-text joint representation learning for text generation from knowledge graphs. arXiv 2021, arXiv:2106.10502. [Google Scholar]
- Jiang, J.; Zhou, K.; Zhao, W.X.; Wen, J.R. UniKGQA: Unified Retrieval and Reasoning for Solving Multi-Hop Question Answering over Knowledge Graph. arXiv 2023, arXiv:2212.00959. [Google Scholar]
- Wang, X.; Kapanipathi, P.; Musa, R.; Yu, M.; Talamadupula, K.; Abdelaziz, I.; Chang, M.; Fokoue, A.; Makni, B.; Mattei, N.; et al. Improving natural language inference using external knowledge in the science questions domain. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: New Orleans, LO, USA, 2019; pp. 7208–7215. [Google Scholar]
- Feng, Y.; Chen, X.; Lin, B.Y.; Wang, P.; Yan, J.; Ren, X. Scalable multi-hop relational reasoning for knowledge-aware question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, 25–29 October 2014; pp. 1295–1309. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with language models and knowledge graphs for question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Stroudsburg, PA, USA, 6–11 June 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 535–546. [Google Scholar]
- Sun, Y.; Shi, Q.; Qi, L.; Zhang, Y. JointLK: Joint reasoning with language models and knowledge graphs for commonsense question answering. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Kerrville, TX, USA, 16–21 June 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 5049–5060. [Google Scholar]
- Zhang, X.; Bosselut, A.; Yasunaga, M.; Ren, H.; Liang, P.; Manning, C.D.; Leskovec, J. Greaselm: Graph reasoning enhanced language models. arXiv 2022, arXiv:2201.08860. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural. Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Wilmot, D.; Keller, F. Memory and knowledge augmented language models for inferring salience in long-form stories. arXiv 2021, arXiv:2109.03754. [Google Scholar]
- Wu, Y.; Zhao, Y.; Hu, B.; Minervini, P.; Stenetorp, P.; Riedel, S. An efficient memory-augmented transformer for knowledge-intensive NLP tasks. arXiv 2022, arXiv:2210.16773. [Google Scholar]
- Guu, K.; Lee, K.; Tung, V.; Pasupat, P.; Chang, M.W. Realm: Retrieval-augmented language model pre-training. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Logan, R.; Liu, N.F.; Peters, M.E.; Gardner, M.; Singh, S. Barack’s wife Hillary: Using knowledge graphs for fact-aware language modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5962–5971. [Google Scholar]
- Wang, Z.; Ye, L.; Wang, H.; Kwan, W.C.; Ho, D.; Wong, K.F. ReadPrompt: A Readable Prompting Method for Reliable Knowledge Probing. In Findings of the Association for Computational Linguistics: EMNLP 2023; Association for Computational Linguistics: Singapore, 2023; pp. 7468–7479. [Google Scholar]
- Wen, Y.; Wang, Z.; Sun, J. Mindmap: Knowledge graph prompting sparks graph of thoughts in large language models. arXiv 2023, arXiv:2308.09729. [Google Scholar]
- Luo, L.; Ju, J.; Xiong, B.; Li, Y.F.; Haffari, G.; Pan, S. Chatrule: Mining logical rules with large language models for knowledge graph reasoning. arXiv 2023, arXiv:2309.01538. [Google Scholar]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning structured embeddings of knowledge bases. In Proceedings of the 25th AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; AAAI Press: New Orleans, LO, USA, 2011; pp. 301–306. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.-H.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; Volume 1, pp. 163–173. [Google Scholar]
- Swaminathan, A.; Chaba, M.; Sharma, D.K.; Ghosh, U. GraphNET: Graph neural networks for routing optimization in software defined networks. Comput. Commun. 2021, 178, 169–182. [Google Scholar] [CrossRef]
- Dua, D.; Wang, Y.; Wang, X.; Singh, P.; Jha, A.; Wang, Z.; Wang, Z. Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Austin, TX, USA, 2020; pp. 4295–4306. [Google Scholar]
- Yih, W.T.; Richardson, M.; Meek, C.; Chang, M.W.; Suh, J. The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 201–206. [Google Scholar]
- Talmor, A.; Berant, J. The web as a knowledge-base for answering complex questions. arXiv 2018, arXiv:1803.06643. [Google Scholar]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A dataset for diverse, explainable multi-hop question answering. arXiv 2018, arXiv:1809.09600. [Google Scholar]
- Trivedi, H.; Balasubramanian, N.; Khot, T.; Sabharwal, A. MuSiQue: Multihop Questions via Single-hop Question Composition. Trans. Assoc. Comput. Linguist. 2022, 10, 539–554. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Question | Training | Testing |
|---|---|---|---|
| WebQSP | 4737 | 3780 | 957 |
| CWQ | 34,689 | 27,734 | 3475 |
| Methods | WebQSP | CWQ | ||
|---|---|---|---|---|
| F1 | Hits@1 | F1 | Hits@1 | |
| KV-Mem | 34.5 ± 1.2 | 46.7 ± 1.5 | 15.7 ± 0.8 | 21.1 ± 1.0 |
| Graft-Net | 62.8 ± 1.0 | 67.8 ± 1.2 | 32.7 ± 1.5 | 36.8 ± 1.3 |
| Topic Units | 67.9 ± 0.9 | 68.2 ± 1.1 | 36.5 ± 1.4 | 39.3 ± 1.2 |
| EmbedKGQA | - | 66.6 ± 1.1 | - | 44.7 ± 1.3 |
| NSM | 68.7 ± 1.0 | 74.3 ± 1.2 | 44.0 ± 1.5 | 48.8 ± 1.3 |
| UniKGQA | 72.2 ± 0.8 | 77.2 ± 1.0 | 49.4 ± 1.4 | 51.2 ± 1.2 |
| TextRay | 60.3 ± 1.2 | 72.2 ± 1.3 | 33.9 ± 1.4 | 40.8 ± 1.5 |
| DKGM-path | 77.6 ± 0.7 | 78.4 ± 0.9 | 70.9 ± 1.0 | 72.2 ± 1.1 |
| Methods | WebQSP | CWQ | ||
|---|---|---|---|---|
| F1 | Hits@1 | F1 | Hits@1 | |
| Llama2-7b | 61.8 ± 1.3 | 72.6 ± 1.4 | 64.0 ± 1.5 | 65.1 ± 1.6 |
| DKGM-path | 77.6 ± 0.7 | 78.4 ± 0.9 | 70.9 ± 1.0 | 72.2 ± 1.1 |
| Methods | Mediacalqa | |
|---|---|---|
| F1 | Hits@1 | |
| TextRay | 48.5 ± 1.2 | 52.3 ± 1.3 |
| NSM | 54.2 ± 1.4 | 57.4 ± 1.4 |
| Graft-Net | 52.1 ± 1.0 | 55.3 ± 0.7 |
| UniKGQA | 58.4 ± 1.2 | 61.2 ± 1.0 |
| DKGM-path | 62.3 ± 1.3 | 65.4 ± 0.9 |
| Methods | HotpotQA | MuSiQue | |||||
|---|---|---|---|---|---|---|---|
| Overall | Bridge | Comp. | Overall | 2-Hop | 3-Hop | 4-Hop | |
| Self-Ask | 49.4 ± 1.2 | 45.3 ± 1.3 | 68.6 ± 1.5 | 16.2 ± 0.8 | 24.4 ± 1.0 | 8.8 ± 0.9 | 7.5 ± 0.8 |
| IRCoT | 56.2 ± 1.1 | 53.4 ± 1.2 | 69.6 ± 1.4 | 24.9 ± 1.0 | 31.4 ± 1.1 | 19.2 ± 1.2 | 16.4 ± 1.3 |
| FLARE | 56.1 ± 1.0 | 54.2 ± 1.1 | 64.4 ± 1.3 | 31.9 ± 1.2 | 40.9 ± 1.3 | 27.1 ± 1.4 | 15.0 ± 1.2 |
| ProbTree | 60.4 ± 0.9 | 59.2 ± 1.0 | 65.9 ± 1.2 | 32.9 ± 1.1 | 41.2 ± 1.2 | 30.9 ± 1.3 | 14.4 ± 1.1 |
| DKGM-path | 61.9 ± 0.8 | 60.7 ± 0.9 | 69.3 ± 1.0 | 33.8 ± 1.1 | 41.4 ± 1.2 | 29.1 ± 1.3 | 18.3 ± 1.2 |
| Methods | WebQSP | CWQ | ||
|---|---|---|---|---|
| F1 | Hits@1 | F1 | Hits@1 | |
| Full Model | 77.6 | 78.4 | 70.9 | 72.2 |
| w/o MPC | 69.3 | 70.1 | 62.5 | 63.8 |
| w/o IV | 72.1 | 73.5 | 66.7 | 68.3 |
| w/o PRC | 74.8 | 75.6 | 68.9 | 70.1 |
| Methods | HotpotQA | MuSiQue | |||||
|---|---|---|---|---|---|---|---|
| Overall | Bridge | Comp. | Overall | 2-Hop | 3-Hop | 4-Hop | |
| Direct Promp. | 38.9 | 37.5 | 45.3 | 15.6 | 16.4 | 16.2 | 12.6 |
| CoT Promp. | 46.5 | 44.6 | 55.5 | 24.7 | 30.2 | 22.5 | 13.2 |
| OneR | 55.3 | 52.9 | 66.5 | 16.4 | 22.1 | 10.6 | 10.4 |
| DKGM-path | 61.9 | 60.7 | 69.3 | 33.8 | 41.4 | 29.1 | 18.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, R.; Zhou, B. Enhancing Domain-Specific Knowledge Graph Reasoning via Metapath-Based Large Model Prompt Learning. Electronics 2025, 14, 1012. https://doi.org/10.3390/electronics14051012
Ding R, Zhou B. Enhancing Domain-Specific Knowledge Graph Reasoning via Metapath-Based Large Model Prompt Learning. Electronics. 2025; 14(5):1012. https://doi.org/10.3390/electronics14051012
Chicago/Turabian StyleDing, Ruidong, and Bin Zhou. 2025. "Enhancing Domain-Specific Knowledge Graph Reasoning via Metapath-Based Large Model Prompt Learning" Electronics 14, no. 5: 1012. https://doi.org/10.3390/electronics14051012
APA StyleDing, R., & Zhou, B. (2025). Enhancing Domain-Specific Knowledge Graph Reasoning via Metapath-Based Large Model Prompt Learning. Electronics, 14(5), 1012. https://doi.org/10.3390/electronics14051012