1. Introduction
Surface soil moisture (SSM) is a key terrestrial environmental variable that connects agriculture, ecology, and hydrology, and is also a critical parameter in hydrological, meteorological, and agricultural applications [
1,
2]. The detection of SSM can be used for planning irrigation, monitoring water quality, managing water resources, and estimating crop yields. Understanding the temporal and spatial distribution of and dynamic changes in SSM can allow us to better address natural disasters such as droughts and floods, and more effectively guide agricultural production. Therefore, obtaining surface soil moisture data in a timely and accurate manner is of significant importance for studying climate issues, establishing hydrological models, and monitoring droughts [
3,
4].
Traditional SSM monitoring typically employs methods such as gravimetric, resistance, and probe techniques [
5]. Although these methods offer quite good accuracy and are simple to operate, they require a significant workforce and lots of material resources. Additionally, they are susceptible to environmental and human factors. Moreover, due to the limited number of sampling points, they can only reflect the local conditions of the area being measured, making it difficult to obtain a large amount of SSM information in a short time, and making it hard to meet the needs of soil moisture monitoring over a wide area.
The development of remote sensing technology has made it possible to monitor soil moisture dynamics over large areas and over long periods. Currently, there are two main types of soil moisture monitoring based on remote sensing technology: the first is microwave remote sensing-based soil moisture monitoring, which mainly utilizes the nonlinear relationship between radar backscatter coefficients and other parameters with soil moisture, employing active and passive microwave remote sensing and their synergistic effects to invert soil moisture. However, this method is significantly affected by surface roughness and vegetation cover, and its accuracy needs improvement; the second type is soil moisture monitoring based on optical remote sensing images, which involves extracting water surface areas to establish related inversion models. This method is greatly affected by weather conditions, and its inversion accuracy is closely related to its imaging quality [
6]. A comparison of soil moisture monitoring is shown in
Table 1. Therefore, the direct inversion of soil moisture based on remote sensing technology is significantly affected by environmental factors such as weather conditions and surface roughness, which limits the improvement of its inversion accuracy.
Remote sensing technology, as an important means of obtaining surface information, provides a rich data source for the extraction of water area. However, traditional remote sensing image processing methods are mostly based on manual operations and simple image analysis algorithms, which have problems such as low efficiency and a low degree of automation. With the continuous development of machine learning and artificial intelligence technologies, new solutions and methods have been provided for the extraction of water areas [
7]. Machine learning is an algorithm driven by data that can automatically learn from large amounts of data and extract useful features and information. In the extraction of water area, machine learning algorithms can utilize various features, such as spectral, texture, and shape features, from remote sensing images to achieve the automatic identification and extraction of water area [
8]. However, this task has several problems: (1) Large-scale water bodies are mainly of medium to low resolution, and the spatial details of the water bodies are not obvious, making it difficult to effectively extract small water bodies, resulting in low overall accuracy. (2) The spectral characteristics of water bodies are mainly related to the interaction of factors such as the bands reflected by the surface, sediment concentration, and transmission depth. Changes in these factors lead to different reflection and absorption characteristics of water bodies at different bands, increasing the difficulty of water area extraction. (3) The texture and shape of water areas in remote sensing images are influenced by various factors, such as terrain and landforms, wind waves, and vegetation cover, requiring algorithms to have high robustness and adaptability. (4) The shadows of buildings, mountains, and other objects in remote sensing images may be similar to the spectral characteristics of water bodies, leading to misjudgments during water body extraction.
Convolutional neural network-based algorithms have made significant contributions to the intelligent interpretation of water area extraction in remote sensing, achieving inputs of images of arbitrary size and obtaining pixel-level attribute information. To address the issues in the automatic identification and extraction of water areas mentioned above, it is common to increase the size of the convolutional kernel. This is because a larger convolutional kernel means a larger receptive field, which can capture more contextual information. The network can extract richer feature information, thereby improving the accuracy of water area extraction. However, large kernel convolutions have more parameters, leading to a more complex model, increasing the risk of overfitting, and significantly increasing the computational overhead and memory consumption of the model [
9].
In this study, we designed a CNN-based fundamental model with a larger receptive field, which preserves long-range dependencies within images and extracts richer feature information. This model can obtain a large amount of surface soil moisture information in a short time, meeting soil moisture monitoring needs within a wide area, and providing more accurate data for soil moisture inversion. Overall, the contributions of this study include the following:
- (1)
Monitoring soil moisture based on remote sensing images by establishing a related inversion model through the extraction of water area.
- (2)
Proposing a new water area extraction model, DCU-Net, which improves the accuracy of water area extraction, thereby enabling more accurate monitoring of soil moisture.
2. Related Work
With the rapid development of large-scale data and computing resources, convolutional neural networks have also seen richer extensions. Based on AlexNet [
10], many deeper and more efficient convolutional neural network architectures have been proposed, such as VGG [
11], GoogleNet [
12], ResNet [
13,
14], EfficientNet [
15,
16], and others. In addition to architectural design, more complex convolutional operations have been developed [
17], such as deep convolution and deformable convolution [
18,
19], which have a larger receptive field, retain more global information, and can improve the problem of losing target features in deep network layers.
With the remarkable achievements of Transformers in large-scale language models [
20,
21,
22], Vision Transformers (ViTs) [
23,
24,
25] have also rapidly emerged in the field of computer vision and become the preferred architecture for research on and the practice of large-scale vision models. Some research has demonstrated that ViTs can outperform CNNs and significantly enhance performance in various computer vision tasks. Through in-depth analysis, it can be seen that CNNs and ViTs can be compared in the following two dimensions:
- (1)
At the Core Operator Level: The multi-head self-attention mechanism (MHSA) of ViTs has the ability to model long-range dependencies and the characteristic of adaptive spatial aggregation, enabling it to learn more powerful robustness from massive data than CNNs.
- (2)
From an Architectural Perspective: ViTs integrate a series of advanced components that are not available in conventional CNNs, such as Layer Normalization and Feed-Forward Networks (FFNs). However, the MHSA in ViTs has high computational costs and memory complexities, which, to some extent, restricts its wide application in downstream tasks.
The algorithm for water extraction based on convolutional neural Networks (CNNs) applied to soil moisture monitoring has gained the favor of many researchers due to its speed and efficiency. Ronneberger et al. proposed the U-Net network [
26] on the basis of the FCN network [
27], constructing a shallow convolutional neural network based on the Encoder–Decoder concept and combining high-level semantic information with low-level semantic information through skip connections, enabling the precise pixel-level extraction of targets under conditions of small sample sizes. Given that the water body contours and color information in high-resolution remote sensing images are significantly different from the background, Liu Jiadian et al. proposed an improved U-Net model for water body extraction from remote sensing images [
28]. By reducing the number of layers in the U-Net network, they achieved rapid and accurate extraction of water areas. However, the lightweight model failed to balance the relationship between computational speed and extraction accuracy, and the extraction accuracy in complex images needs improvement compared to deep convolutional neural networks. On the other hand, the extraction speed of deep convolutional neural networks cannot easily meet the needs of large-scale water body extraction tasks. To balance computational speed and accuracy, Wang et al. proposed the InternImage feature extraction network [
29], which uses Deformable convolution to replace conventional convolution kernels, thus introducing dynamic weights with long-range dependencies, obtaining a larger receptive field while controlling the amount of computation, and extracting more global information.
3. Materials and Methods
3.1. Overview of the Study Area
The Ningxia Hui Autonomous Region (35.44′ N–39.47′ N, 105.45′ E–111.30′ E), located in the northwest of China, borders the Yellow River to the north and is part of the Yellow River basin. The terrain of Ningxia can be mainly divided into three parts: the western mountainous area; the Loess Plateau; and the Hetao Plain. The climate of Ningxia is typically a temperate continental climate with sparse precipitation, with annual rainfall ranging roughly from 100 mm to 400 mm, mostly concentrated in the summer. Water resources in Ningxia are relatively scarce, relying heavily on the Yellow River, which flows through the central part of Ningxia, providing significant support for agricultural irrigation in the region. Therefore, soil moisture monitoring based on water body changes in Ningxia is of great importance for the growth of crops and the evolution of the ecological pattern in the area.
3.2. Research Data
The study period was from 2017 to 2022, and we used remote sensing images of the Yellow River basin in different periods within Ningxia Hui Autonomous Region as the data source, all of which were remote sensing data with cloud cover of less than 10%.
3.3. Water Extraction Model (Deformable Conv Unit-Net)
Typically, images of large-scale water bodies are dominated by medium to low resolutions, making it difficult to effectively extract small water bodies and affecting overall accuracy; water bodies are significantly influenced by various factors, such as terrain, which places high adaptability requirements on water extraction algorithms; the spectral characteristics of various objects are similar to those of water bodies, and the extraction algorithm needs to retain as much detail information from the image as possible. To better address these issues, the water body extraction algorithm is required to have a larger receptive field while ensuring adequate extraction speed.
To increase the effective receptive field of the model and its ability to mine detailed features, large kernel convolutions and increased network depth are commonly used. However, this significantly increases computational costs and affects extraction speed. Additionally, standard convolutions have a high degree of inductive bias and lack adaptive spatial aggregation capabilities, which limits their ability to learn more general patterns from large-scale data.
Therefore, this paper proposes the DCU-Net model, whose network structure is shown in
Figure 1. The DCU module based on deformable convolution is used in the network layers where feature information is rich. The following are true in this module: (1) The flexible receptive field adapts to low-resolution images, where water area details are sparse, making it difficult for traditional convolutions with fixed receptive fields to effectively capture key features. The DCU introduces learnable offsets, allowing the sampling points of the convolutional kernel to dynamically adjust based on the input content. (2) Local feature enhancement: The DCU module can focus on key regions of the target in low-resolution images, enhancing its ability to extract local features. (3) Diversity and generalization capability in large-scale water body data: In large-scale datasets, water bodies exhibit high diversity in scale, shape, and posture. The DCU, by dynamically adjusting sampling positions, can better adapt to this data diversity. (4) Information recovery capability in low-resolution images: in low-resolution images, information loss is severe, and traditional convolutions may overlook key features. DCU, through offset learning, can recover crucial water body features from sparse information. The DCU module has a lightweight design while acquiring richer gradient information flow, accelerating convergence speed, and enhancing training efficiency. This helps the network better learn the features of the input data, thereby improving the model’s accuracy in extracting water information.
3.4. Deformable Convolution Unit
Under normal circumstances, water remote sensing images are characterized by their large scale, low resolution, and complex surrounding environments. Conventional semantic segmentation models extract limited image detail information, resulting in their inability to accurately extract all water information, which affects their accuracy in soil moisture monitoring.
To address these issues, in the task of water body extraction from remote sensing images, we propose the Deformable Convolution Unit, as shown in
Figure 2. In this module, we use two layers of regular convolution operations to retain more semantic information. In the lower layers, where semantic information is richer, we apply Deformable convolution, whose sampling positions better match the shape and size of water boundaries. It is capable of learning the detailed features of objects, better excluding the interference of complex background environments, and obtaining a more complete water image.
In deformable convolution, the following process is carried out: (1) We detach the original convolution weights
into depth-wise and point-wise parts, where the depth-wise part is responsible for the original location-aware modulation scalar
, and the point-wise part represents the shared projection weights
among sampling points. (2) Introducing the multi-group mechanism, we split the spatial aggregation process into G groups, each of which has individual sampling offsets
and modulation scales
, and thus, different groups on a single convolution layer can have different spatial aggregation patterns, resulting in stronger features for downstream tasks. (3) To alleviate the instability issues, the sum of the modulation scalars is constrained to 1, which makes the training process of models at different scales more stable [
29].
The calculation process is shown in Equation (1).
where
denotes the total number of aggregation groups. For the
g-th group,
denotes the location-irrelevant projection weights of the group, where
represents the group dimension.
denotes the modulation scalar of the
k-th sampling point in the
g-th group, normalized by the sofmax function along the dimension
.
represents the sliced input-feature map.
is the offset corresponding to the grid sampling location
pk in the
g-th group.
4. Experiments
4.1. Implementation Details
The DCUNet water extraction algorithm was built using the Pytorch 10.2 deep learning framework and Python language. The model’s training, optimization, and testing were performed on an Ubuntu 18.04 operating system, with a memory capacity of 128 GB, utilizing two high-performance NVIDIA RTX 3090 graphics cards (24 GB each). During the experiment, the initial learning rate was set to 0.01, and the batch_size was set to 16. It took approximately 5 min to train the entire network in each round. During the whole training process, the training model with the best performance was saved.
4.2. Dataset
The data used in this study contained remote sensing images of the Yellow River basin in Ningxia Province from different periods between 2017 and 2022, with an original size of 10,980 pixels × 10,980 pixels. To improve the speed of model training, this study cropped the images around the water area and resized the cropped images to 512 pixels × 512 pixels, as shown in
Table 2. The data annotation software labelme was used for manual annotation of the water area’s edge lines to create the dataset. A total of 12,600 samples were created, including 9600 positive samples and 3000 negative samples without water labels. The dataset was divided into training, validation, and test sets in an 8:1:1 ratio.
To verify the effect of the model before and after the improvement in the water body extraction tasks,
,
,
, and
were chosen as evaluation metrics, with their calculation methods shown in Equations (2)–(5).
where
represents the number of pixels correctly extracted as water bodies,
represents the number of pixels incorrectly extracted as water bodies, and
represents the number of water body pixels incorrectly classified as background.
4.3. Ablation Study
To improve the integrity of water body extraction, this study constructed a water body extraction algorithm named DCU-Net, which mainly includes the DCU module that introduces deformable convolution. To verify the effectiveness of the DCU module in water body extraction tasks, ablation experiments were conducted using the U-Net model as the baseline network. The DCU module was added under the same conditions to compare the performance of different models. The experimental results are shown in
Table 3.
In
Table 3, we can see that in the water extraction task, the baseline network achieved an IOU of 89.31%, while the DCU-Net network with the DCU module achieved an IOU of 92.29%, an improvement of 2.98% over the baseline network. This indicates that the water areas extracted by our proposed algorithm are closer to the true value labels. The baseline network achieved a Precision of 94.76%, while the DCU-Net achieved a Precision of 96.13%, an improvement of 1.37%. This shows that DCU-Net can more accurately identify water areas, reducing the impact of complex environments on water extraction effectiveness. The baseline network’s Recall reached 91.78%, and DCU-Net’s Recall reached 92.14%, an increase of 0.36%. This indicates that DCU-Net is more sensitive to water feature information in images, filtering out invalid information that does not belong to water features. The
score of DCU-Net reached 94.32%, an improvement of 1.49% over the baseline network. This demonstrates that DCU-Net has superior performance in the water extraction task and can better cope with complex environments.
4.4. Comparison Study
To demonstrate the effectiveness of DCU-Net in water body extraction tasks, we conducted a series of comparative experiments. Several mainstream image segmentation algorithms were implemented, including U-Net, DenseUNet, UNet++, and Deeplabv3. The same experimental parameters were used in the experiments, and the results are shown in
Table 4.
From the comparative experiments above, it can be seen that compared with mainstream image segmentation algorithms, DCU-Net achieves the highest scores in all four metrics (IOU, Precision, Recall, and ). Compared to the second-best network, Deeplabv3, DCU-Net leads to improvements of 0.95%, 0.26%, 0.71%, and 0.47%, respectively, in IOU, Precision, Recall, and . DCU-Net exhibits the lowest latency performance, with the processing speed of a single image reaching 33.6 ms. It possesses a more rapid inference speed and thus has a significant advantage in real-time performance. These results indicate that DCU-Net can more effectively extract the spatial detail information of water bodies in medium- and low-resolution images, cope with the challenges brought by complex environmental changes, and improve the accuracy of water body extraction.
To verify the extraction effect of DCU-Net, some images were selected from the dataset we created as detection samples and compared with the baseline network. The detection results are shown in
Table 5. In the images in
Table 5, the white boxes represent areas where DCU-Net extracted water bodies more accurately compared to the baseline network, while the yellow boxes indicate areas that the baseline network failed to extract. From these results, we can see that DCU-Net has higher accuracy in areas where the water environment is complex and the water feature information is not obvious. The water boundaries are more accurate, meaning this model can provide more precise data support for soil moisture monitoring and has good applicability.
5. Discussion
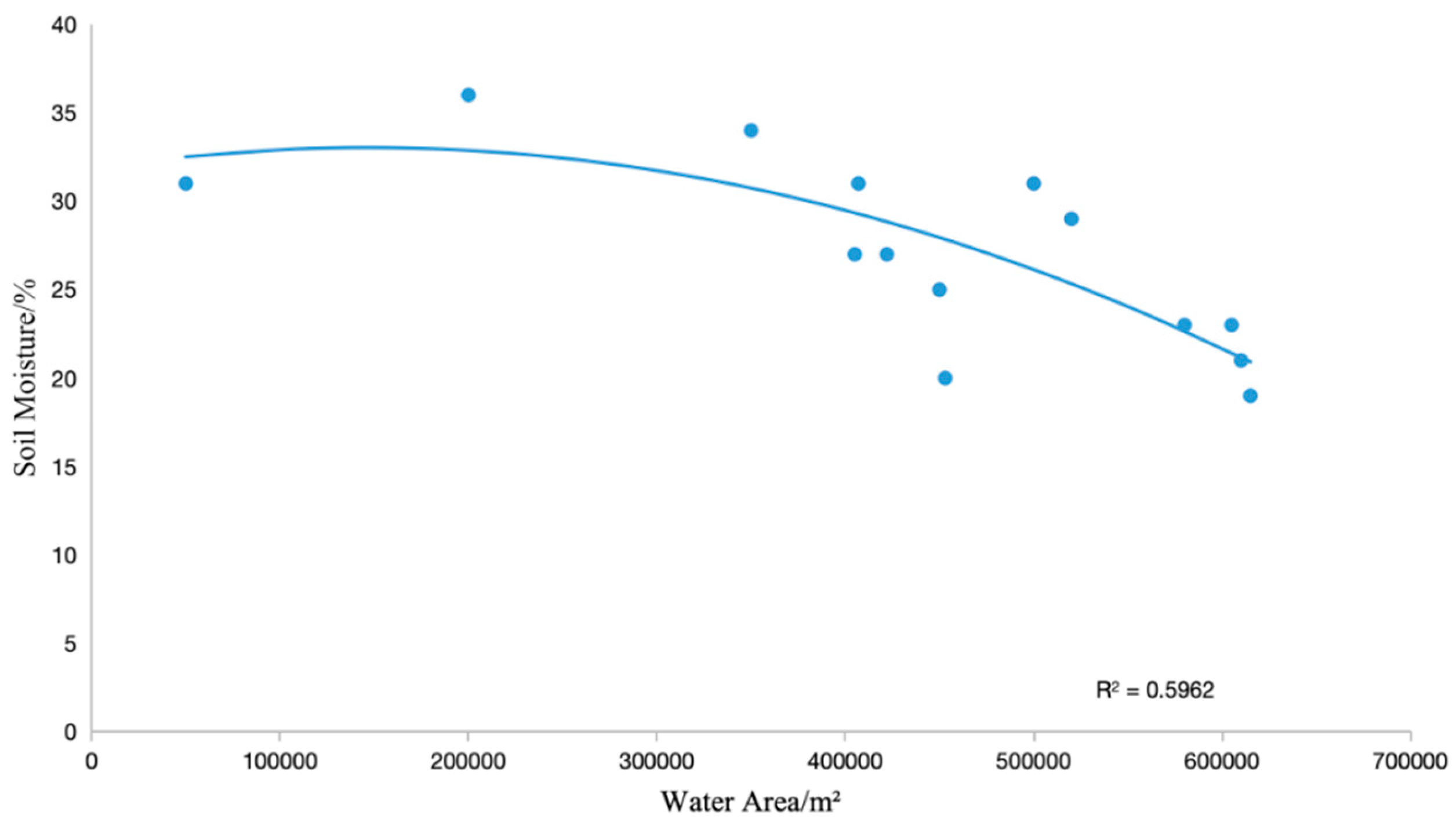
The variation in soil moisture within a region is a result of the combined effects of regional climate, surface water infiltration capacity, and human activities. During the transformation process from atmospheric precipitation to surface water and then to soil water, the replenishment sources for soil water and surface water are the same, and soil water mainly comes from the infiltration of surface water. Therefore, this study determines the relationship between the two based on the surface water area data in Ningxia Province and the measured soil moisture data at different depths during the same period, achieving soil moisture inversion within a wide area based on the surface water area.
The goodness of fit (
) is commonly used to measure the correlation between two variables. In this study, the effectiveness of surface water area on soil moisture inversion is estimated by calculating the correlation coefficient. When the correlation coefficient between surface water area and soil moisture is positive, it indicates a positive correlation between the two, and vice versa for a negative correlation. Furthermore, the larger the
value, the stronger the correlation between the two. Regression analysis was performed using the surface water area data in Ningxia Province extracted by DCU-Net and the measured soil moisture data at a depth of 20 cm below the surface during the same period, with the results shown in
Figure 3. The goodness of fit between the surface water area and soil moisture in the Ningxia region is 0.5962, indicating a strong correlation.
6. Conclusions
This study created a large-scale, multi-scenario, pixel-level water body extraction benchmark dataset based on multi-year remote sensing images from Ningxia Province. The dataset was constructed considering various factors, such as different light intensities, types of water bodies, and levels of complexity of the background. Utilizing this dataset, the DCU-Net network was applied for the pixel-level extraction of water body areas.
To address issues encountered during water body extraction in the region, while controlling the computational load to ensure extraction speed, the DCU module was proposed. This module was applied in the lower layers of the network, which are rich in semantic information, to build the DCU-Net network. Our extensive experiments verify that DCU-Net has excellent performance. Compared to the baseline network, our proposed algorithm shows improvements in four metrics: IoU, Precision, Recall, and score. This indicates that the algorithm performs better in water body extraction tasks, is better equipped to handle complex environments, and provides more accurate data support for soil moisture monitoring.
Based on the water body area data from different periods in Ningxia Province and the measured soil moisture data from the same time, this study determined the relationship between soil moisture and water body area using a cubic fitting polynomial method, achieving high-precision inversion of soil moisture. Our results indicate a strong correlation between soil moisture and water body area. Therefore, the accuracy of water body extraction by DCU-Net can provide robust data support for soil moisture monitoring in Ningxia Province.





{kind=link}
{kind=link}
{kind=link}