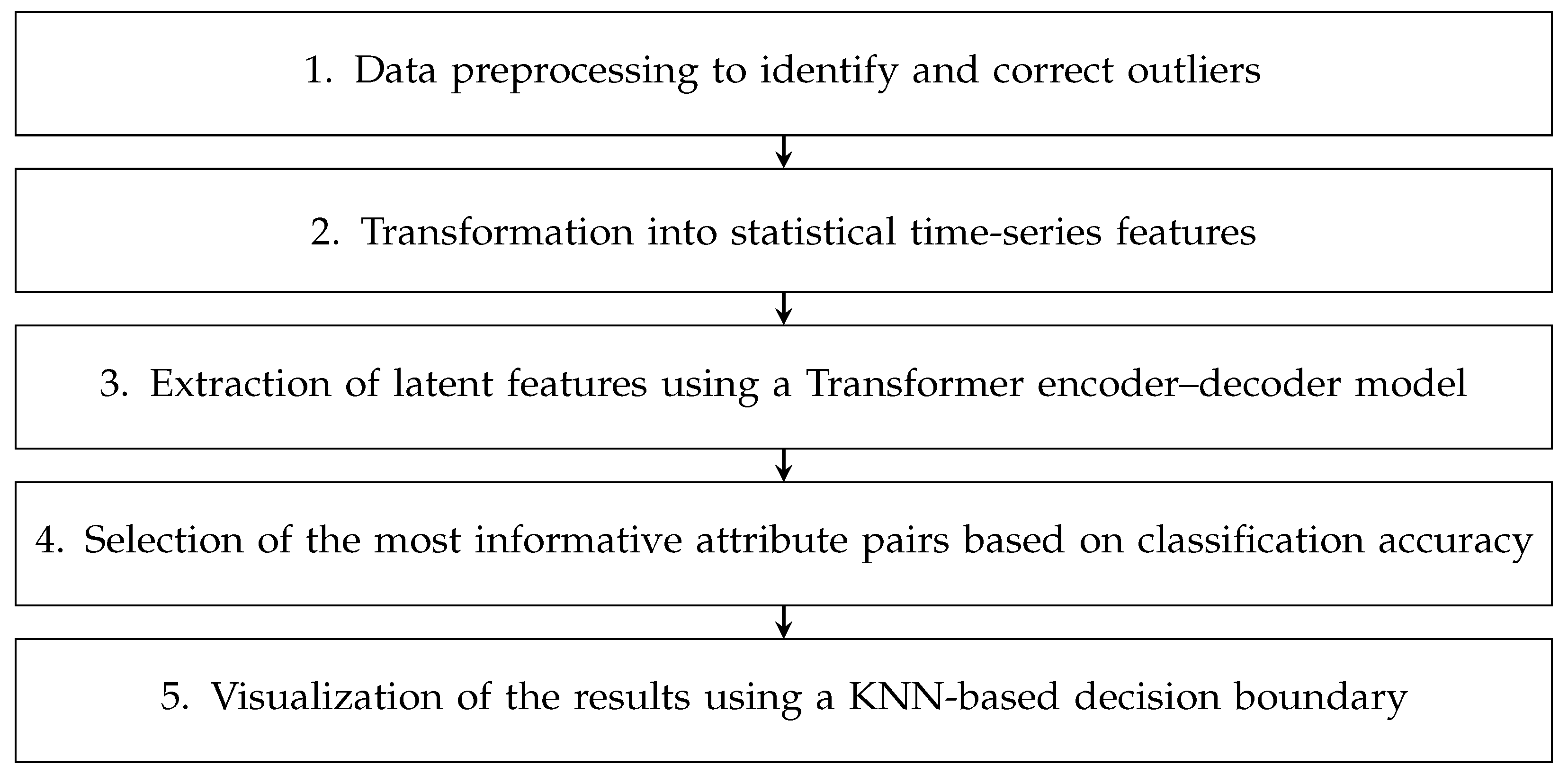
This study consists of three sections, which aim to evaluate the performance of the steam trap predictive maintenance system:
Data collection was carried out by building a sensor network in two actual factories and receiving process data from the factories, and the experiment was conducted by building a machine learning operations (MLOps) environment. Finally, the performance evaluation was performed in three ways. First, the fault diagnosis performance of various machine learning models was measured and compared. Second, the clustering performance of the two-dimensional diagnostic projection generated by various characteristic factors was compared. Finally, the experiment was conducted to compare the thermal energy efficiency of a steam system scheduled for maintenance based on fault diagnosis with that of a steam system in its existing state and to input the effect of the scheduled maintenance system.
4.1. Data Acquisitions
Data for the experiment were obtained by installing sensors in large-scale aluminum processing plants and food manufacturing plants and performing precise diagnostics to secure learning data. Temperature sensors were strategically placed with the assistance of steam trap maintenance engineers at each plant and external steam trap experts. The training dataset was created by collecting work schedule data, including factory operating hours and planned maintenance (PM) dates, as well as temperature and humidity levels inside the factories, external weather conditions, the steam system configuration, and the purpose of steam-utilizing facilities. Additionally, temperature sensors were installed in the steam traps with the help of professional engineers.
We removed and corrected outliers from the sensor data to ensure data quality. Outliers were primarily identified using the 1.5 × IQR (Interquartile Range) rule, and additional criteria were applied, such as detecting values that remained unchanged up to the second decimal place for extended periods. Detected outliers were removed and corrected using the nearest neighbor interpolation method to maintain data continuity.
Furthermore, during the data validation process, we discovered that due to wireless sensor malfunctions, the inlet and outlet temperature values were swapped in some cases. To address this issue, we carefully analyzed the recorded data, identified incorrect assignments, and restored the proper order of temperature values. This correction allowed us to recover and ensure the integrity of the collected data. To improve fault diagnosis accuracy, we conducted a multi-step validation process. First, a primary fault diagnosis was performed based on the collected data. For cases where the diagnosis was unclear, a secondary on-site diagnosis was conducted using a portable thermal imaging camera in collaboration with factory engineers and external experts. Finally, for certain steam traps, a detailed inspection was performed by physically disassembling them, verifying the results of the secondary diagnosis, and completing the labeling of the acquired data.
The training data used for fault diagnosis and reliability assessment are presented in
Table 2; various environmental and operational parameters are included.
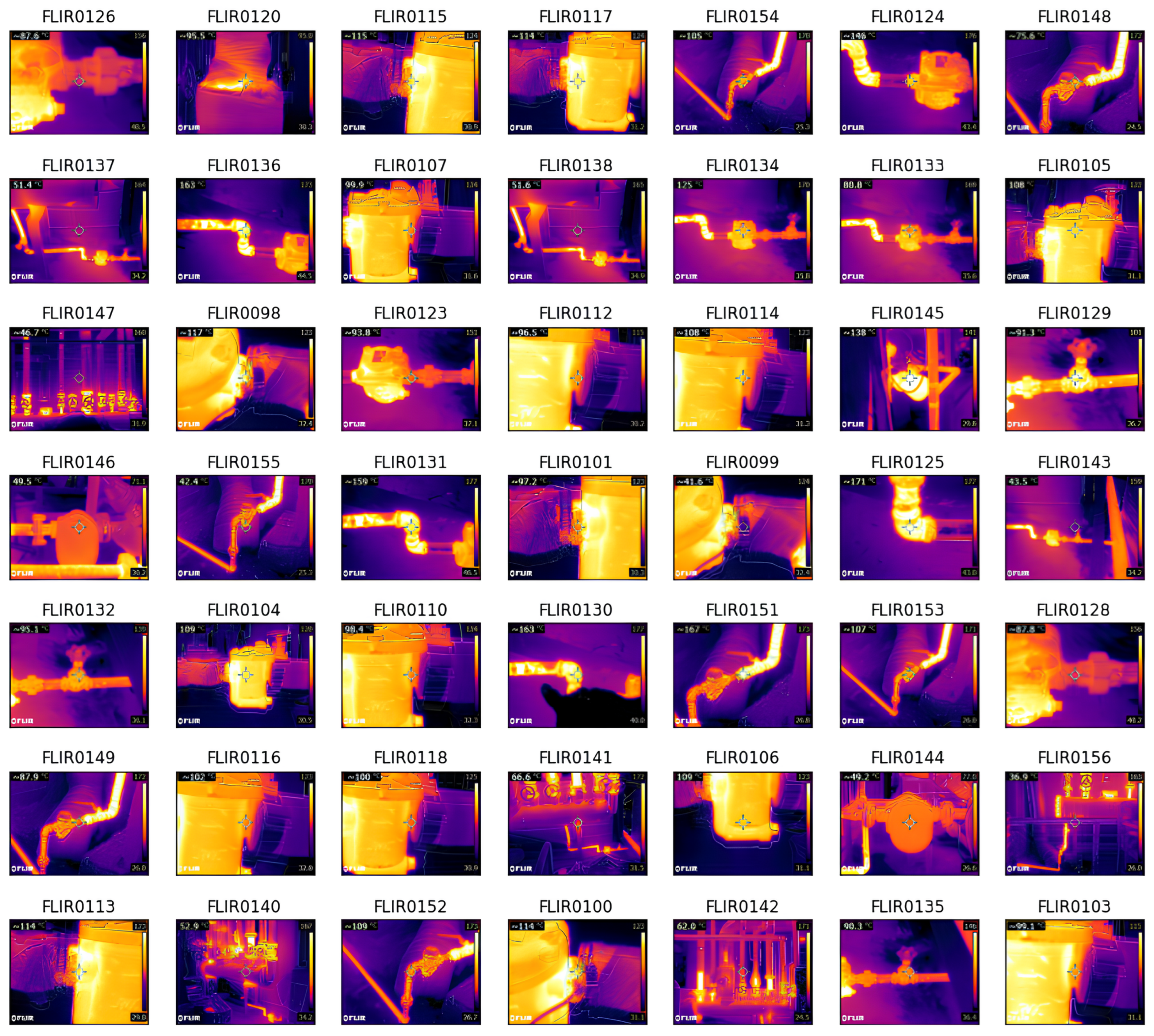
Figure 2 illustrates the thermal imaging of steam traps, which provides a visual representation of the temperature distribution across the main equipment in the steam system.
4.2. Experiment Settings
We acquired data from two factories to build experimental data and conducted a performance experiment on two-dimensional diagnostic projection, which can verify the reliability of the fault detector and fault diagnostic.
All data were collected online using the Industrial IoT platform. Some data were extracted from documents and worksheets and stored on the platform. Sensor data collection was performed at five-minute intervals and the other data were sampled at the same interval to build a training dataset. Afterwards, factory engineers and external experts worked on labeling the fault diagnosis and status.
Performance evaluation was performed by measuring the following evaluation indicators using 5-fold stratified cross-validation, where the data were split into folds while preserving the class distribution.
In this paper, the Transformer model and the machine learning and deep learning models below were compared with regard to their performance with the training data under the same conditions.
A performance evaluation of the two-dimensional diagnostic projection was conducted by comparing the distance between clusters and the dispersion of clusters, using the following cluster performance measurement indicators:
Within-Cluster Sum of Squares (WCSS): Measures the compactness of clusters by calculating the sum of squared distances between each data point and the centroid of its assigned cluster. Lower values indicate tighter, well-defined clusters.
Bayesian Information Criterion (BIC): Evaluates the trade-off between model complexity and goodness of fit. Lower values indicate better clustering performance with minimal overfitting.
Davies–Bouldin Index (DBI): Assesses cluster separation and compactness by comparing intra-cluster dispersion with inter-cluster distances. Lower values indicate better-defined clusters.
Adjusted Rand Index (ARI): Measures clustering accuracy by comparing the agreement between predicted clusters and ground truth labels. Higher values indicate stronger alignment with actual fault patterns.
Calinski–Harabasz Index (CHI): Computes the ratio of between-cluster dispersion to within-cluster variance. Higher values indicate well-separated clusters with minimal overlap.
Table 3 presents the hyperparameter settings for the models utilized in our experiments. The optimal hyperparameters for each model were determined using RGHL (Rapid Genetic Exploration with Random-Direction Hill-Climbing for Linear Exploitation), a hyperparameter optimization technique that combines genetic algorithms with local search strategies to efficiently explore and exploit the hyperparameter space. This approach enables rapid convergence to near-optimal solutions while maintaining a balance between exploration and exploitation. The optimized values for each model are summarized in
Table 3 [
25].
4.3. Performance Evaluation
The performance evaluation of the fault diagnosis was conducted using a merged dataset, which integrates data from both the aluminum processing plant and the food manufacturing plant. To ensure unbiased evaluation, attributes that could identify the factory, such as the factory name, were removed before conducting the experiment.
Table 4 compares fault diagnosis performance across models using AUC, CA, F1-score, Precision, and Recall. The Transformer model outperforms all others, achieving the highest AUC (0.927), CA (0.932), and F1-score (0.938), demonstrating its superior diagnostic capability. While AdaBoost and Gradient Boosting perform well, they fall short of the Transformer, confirming the effectiveness of deep learning-based fault detection.
Figure 3 illustrates the Receiver Operating Characteristic (ROC) curves for the Transformer-based fault diagnosis model, evaluating its ability to classify steam trap conditions into four categories: Unused (Class 0), Leaked (Class 1), Normal (Class 2), and Blocked (or closed valve) (Class 3).
Each solid line represents the ROC curve of an individual class, with the area under the curve (AUC) values indicated in the legend. The model achieves high AUC scores for all classes, with Class 0 and Class 1 reaching 0.93, while Class 2 and Class 3 achieve 0.91, indicating strong classification performance.
Additionally, the micro-average ROC curve (AUC = 0.92) and the macro-average ROC curve (AUC = 0.93) provide aggregated performance metrics, showcasing the model’s overall classification effectiveness across multiple fault types. The diagonal dashed line (y = x) represents the random classifier baseline, against which the model’s superior predictive capability is evident.
This result demonstrates the robustness of the Transformer model in identifying different fault conditions in steam traps, aiding in effective predictive maintenance and operational optimization.
While the current model demonstrates stable performance across different cross-validation folds, we anticipate that as more data become available, the stability of cross-validation results will further improve. This expectation is based on well-established statistical principles in machine learning, where larger datasets tend to reduce variance in model performance across different subsets of data.
Future research will aim to verify this hypothesis by incorporating additional sensor data from multiple industrial sites, analyzing the relationship between training data size and cross-validation robustness.
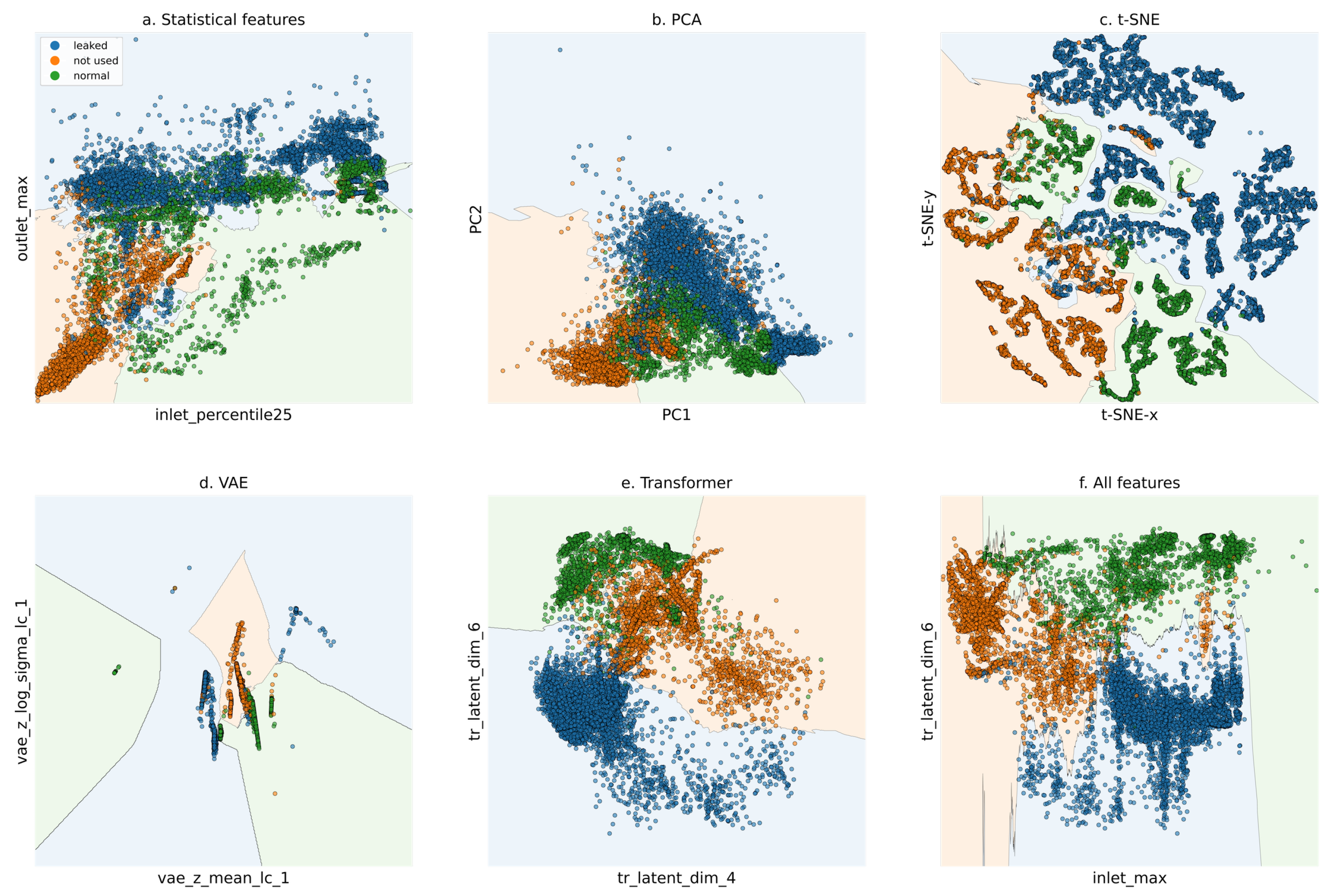
Figure 4 shows a visualization of the performance evaluation of the two-dimensional diagnostic projection, illustrating different methods from (a) to (f). (a) represents the visualization using simple statistics, providing a basic statistical perspective on the data distribution; (b) applies Principal Component Analysis (PCA) to reduce dimensionality while maintaining the overall variance of the dataset; (c) utilizes t-Distributed Stochastic Neighbor Embedding (t-SNE) to highlight local relationships within the data; (d) employs a Variational Autoencoder (VAE) to extract latent representations and project them into two dimensions; (e) presents the Transformer-based diagnostic projection, which shows a more stable distribution and clear decision boundaries between clusters compared to other visualizations, minimizing overlap between clusters. Finally, (f) combines all the properties from (a) to (e) to create a comprehensive visualization.
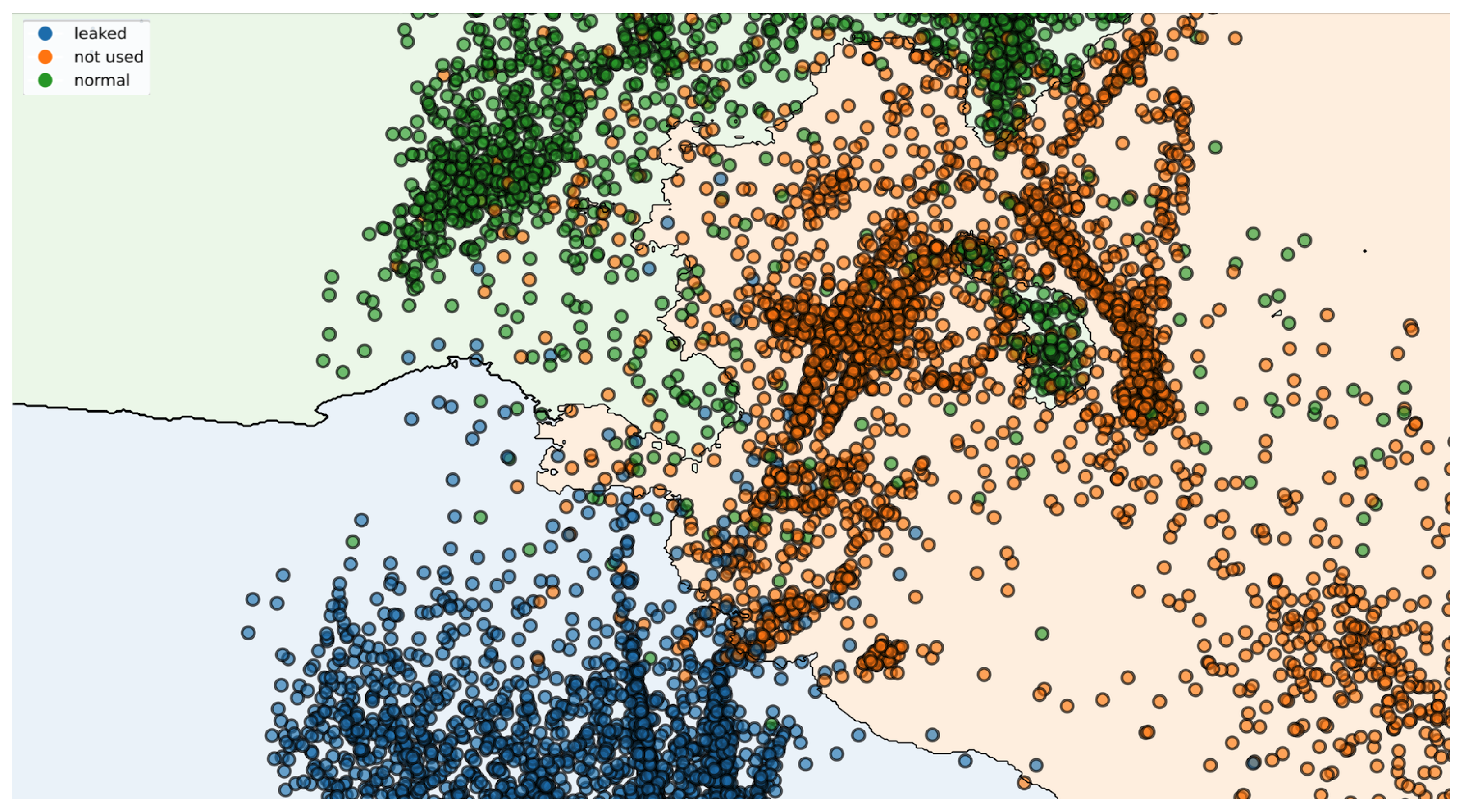
Figure 5 provides a detailed view of the overlapping regions in panel e of
Figure 4, showing that the normal (green) and leaked (blue) clusters are relatively well separated. While some overlap between the normal and leaked clusters with the unused clusters is observed, it is considered negligible, as it does not significantly impact the diagnostic results.
Table 5 demonstrates that the Transformer model delivers the best overall clustering quality, achieving the lowest DBI, a high ARI, and the highest CHI, ensuring that clusters are well separated and cohesive. The All Features model has the highest ARI but struggles with cluster separation, and the VAE model performs well in terms of compactness (WCSS) but lacks separation (low CHI). These results highlight the effectiveness of our proposed model for fault diagnosis in steam trap predictive maintenance.
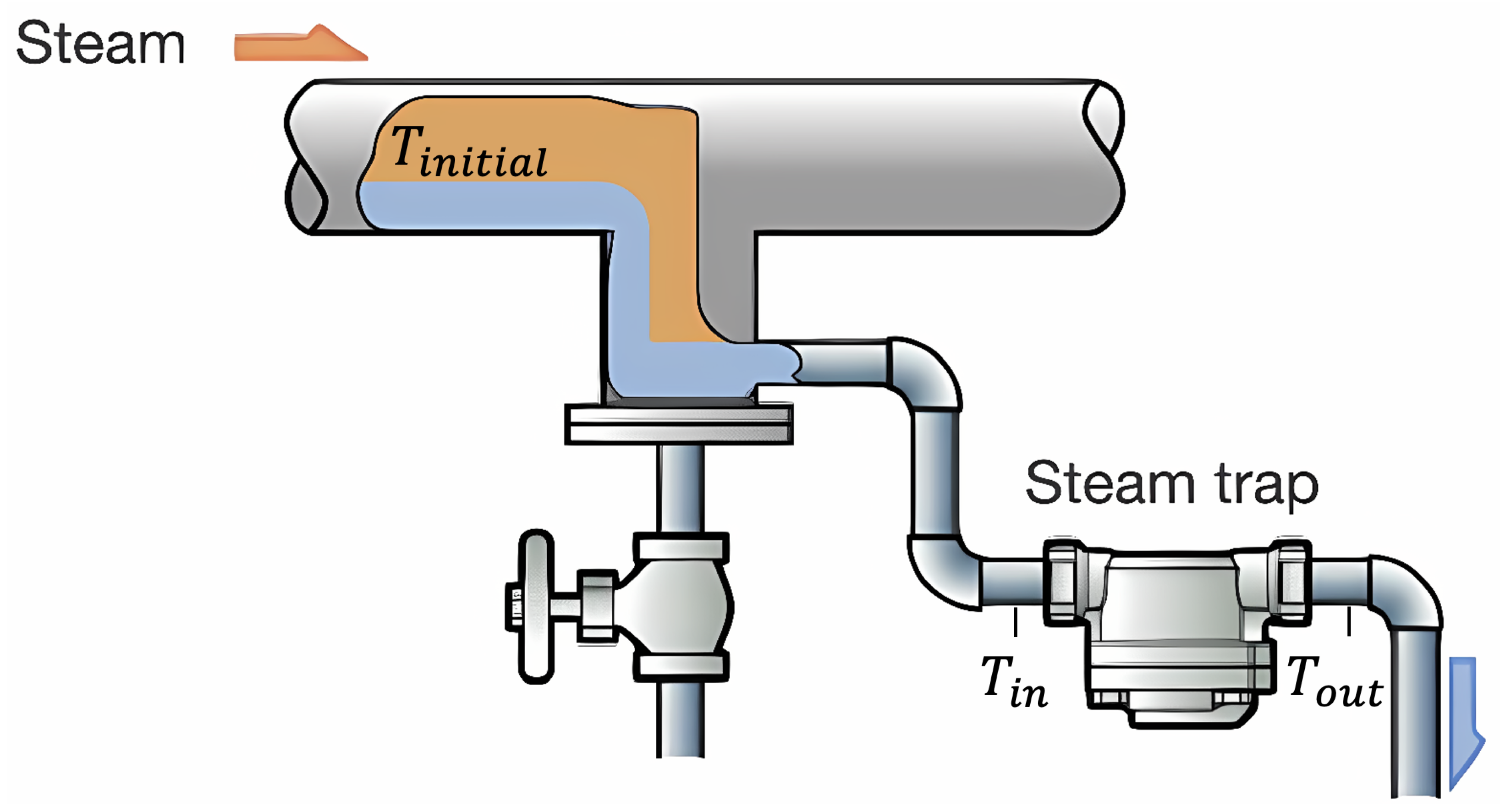
Figure 6 is referenced from the Miyawaki Inc. Steam Trap description article [
26] and shows the structure of the steam trap and the temperature measurement location. It shows the temperature
) inside the steam pipe, the temperature (
) at the input of the steam trap, and the temperature (
) at the output of the steam trap in the steam system.
The thermal energy efficiency (
) is calculated as the ratio of the useful energy output to the total energy input, as shown in Equation (
1):
In the case of a steam system, the thermal energy efficiency can be expressed as follows:
To evaluate the impact of the predictive maintenance system, we define the thermal energy efficiencies before (
) and after (
) the system’s implementation. These are calculated as follows:
Here, the variables are defined as follows:
: Initial steam temperature at 1 atmosphere of pressure.
: Discharge temperature at the steam trap for the i-th measurement.
t: The time point when the predictive maintenance system is introduced.
: The installation period for the predictive maintenance system.
n: The total number of data points.
The thermal energy efficiency before (
) is calculated using the average efficiency over the data collected prior to the system’s implementation. Similarly, the thermal energy efficiency after (
) is computed using the data collected after the installation and stabilization period (
). By comparing
and
, the effectiveness of the predictive maintenance system can be quantitatively evaluated.
We measured the thermal energy savings with the data obtained before and after the introduction of the predictive maintenance system at the two plants. The aluminum processing plant achieved an energy-saving rate of 7.2%, and the food manufacturing plant achieved 5.772%, for an average energy saving rate of 6.92%.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}