1. Introduction
In the process of oil production, oil well production prediction is typically conducted to save time and resources in detecting well production, as well as to comprehensively evaluate and prepare for well development [
1]. However, current oil well production predictions face challenges, such as suboptimal performance and insufficient model generalization [
2], making efficient and accurate predictions difficult and impacting the scientific quality of production decisions and optimal resource allocation.
With the development of oil field technology and artificial intelligence, scholars, both domestically and internationally, have conducted extensive research on oil well production prediction [
3]. Traditional prediction methods, such as empirical formula methods [
4], curve fitting methods [
5], and numerical simulation methods [
6], suffer from excessive reliance on experience, complex computations, and poor adaptability. In the field of oil well production prediction, traditional methods primarily rely on physical-based models and empirical formulas [
7]. These methods typically involve analyzing key parameters such as reservoir fluid flow, reservoir pressure, and geological characteristics, combined with historical production data, to establish mathematical models for prediction [
8]. Common models include capacity equations, pressure recovery analysis, and material balance methods. For example, Van Everdingen A. F. explored the use of the Material Balance Equation (MBE) as a predictive tool for estimating future production [
9], while Xu J reviewed the development of reservoir simulation methods [
10], highlighting their importance in predicting oil well performance. The advantage of these methods lies in their solid physical foundation, making them particularly suitable for cases with limited early data.
In the field of reservoir engineering, oil well production prediction via artificial intelligence prediction methods has been widely applied in recent years, mainly including machine learning and deep learning techniques. These methods train on large amounts of historical production data, automatically mining potential nonlinear relationships, and are capable of effectively capturing dynamic changes under complex working conditions and multi-factor coupling. Common algorithms include Convolutional Neural Networks (CNN), Random Forest (RF) [
11], Long Short-Term Memory Networks (LSTM) [
12], and ensemble models [
13]. These methods do not rely on detailed physical model support and, when sufficient data is available, can significantly improve prediction accuracy, although they have higher requirements for data quality and quantity.
Deep learning methods have demonstrated especially strong performance in handling large-scale data and intricate nonlinear relationships. For example, research based on the GRU-KAN model improved prediction accuracy and efficiency by combining Gated Recurrent Units (GRU) and Kernel Attention Networks (KAN) [
14]; probabilistic machine learning methods were used to quantify the uncertainty in the prediction process, thereby improving the profitability of oil and gas wells [
15]; prediction models combining Principal Component Analysis (PCA) and GRU improved the accuracy of oil well production predictions [
16]; and data-driven regression models developed using sequential convolution and Long Short-Term Memory (LSTM) units have been applied to oil production forecasting, achieving high prediction accuracy [
17]. However, most of these studies lack optimization of the prediction models, leading to deficiencies in accuracy, efficiency, and adaptability, especially the tendency to fall into local optima, which impacts prediction accuracy.
Traditional methods (such as the empirical formula method and numerical simulation method) are difficult to adapt to the dynamic changes of the reservoir environment due to complex calculations and high data dependence. Artificial intelligence methods (especially deep learning) have gradually become an important means of oil well production prediction due to their powerful data processing capabilities. However, the current deep learning model still has shortcomings in prediction accuracy, generalization ability, and avoiding local optimality. Therefore, this paper proposes an oil well production prediction model based on IAM-BiLSTM and optimizes it through a Comprehensive Search Algorithm (CSA) to improve prediction accuracy and stability. First, by combining the Inter-Attention Mechanism with the BiLSTM structure, the IAM-BiLSTM model is designed to more effectively filter and retain key features, thereby improving prediction accuracy. Second, the paper introduces a CSA algorithm that combines the Monotone Basin Hopping Algorithm (MBH) and Sequential Quadratic Programming (SQP) algorithm, optimizing the model parameters through the global search ability of MBH and the local optimization ability of SQP. Finally, experimental results demonstrate that the IAM-BiLSTM model optimized by CSA significantly outperforms traditional methods in prediction performance.
2. Methodology
This chapter introduces the proposed IAM-BiLSTM model and the CSA optimization algorithm. First, it presents a BiLSTM-based prediction model incorporating an Inter-Attention Mechanism and explains its working principles. Then, it describes the CSA algorithm, which combines MBH and SQP, along with its improvement strategies.
2.1. IAM-BiLSTM Model
2.1.1. Inter-Attention Mechanism
The Inter-Attention Mechanism is a data processing method in machine learning [
18], widely applied in tasks such as natural language processing [
19], image recognition, and speech recognition [
20]. The degree of focus on different pieces of information in the attention mechanism is reflected through weights [
21]. The attention mechanism can be regarded as a multilayer perceptron (MLP) composed of a query matrix (Q), keys (K), and weighted averages (V).
The Inter-Attention Mechanism is a type of attention mechanism in deep learning used to capture the correlations and interactions between two different sequences or datasets [
22]. Its working principle is similar to that of the standard attention mechanism, with the difference being that one of the sequences is used as the Q, while the other sequence serves as the K and V. The corresponding attention weights and attention values are then calculated. The Inter-Attention Mechanism can effectively model the dependencies between two distinct sequences, thereby enhancing the model’s understanding of the input data.
2.1.2. BiLSTM Model
Standard Recurrent Neural Networks (RNNs) capture only limited contextual information in sequential tasks [
23]. To address this, Long Short-Term Memory (LSTM) introduces cell states and gating mechanisms—forget gate, input gate, and output gate—each controlled by the sigmoid function [
24]. However, conventional LSTMs may still ignore future context. Bidirectional LSTMs (BiLSTMs) [
25] solve this issue by running two LSTMs in opposite directions and combining their outputs, thus incorporating both past and future information.
Concretely, for a BiLSTM network, the output at time
,
is determined by the forward state
, the backward state
, and the input
. The update formulas are:
where
is the corresponding weight of each layer and
is the activation function of different layers.
2.1.3. IAM-BiLSTM Prediction Model
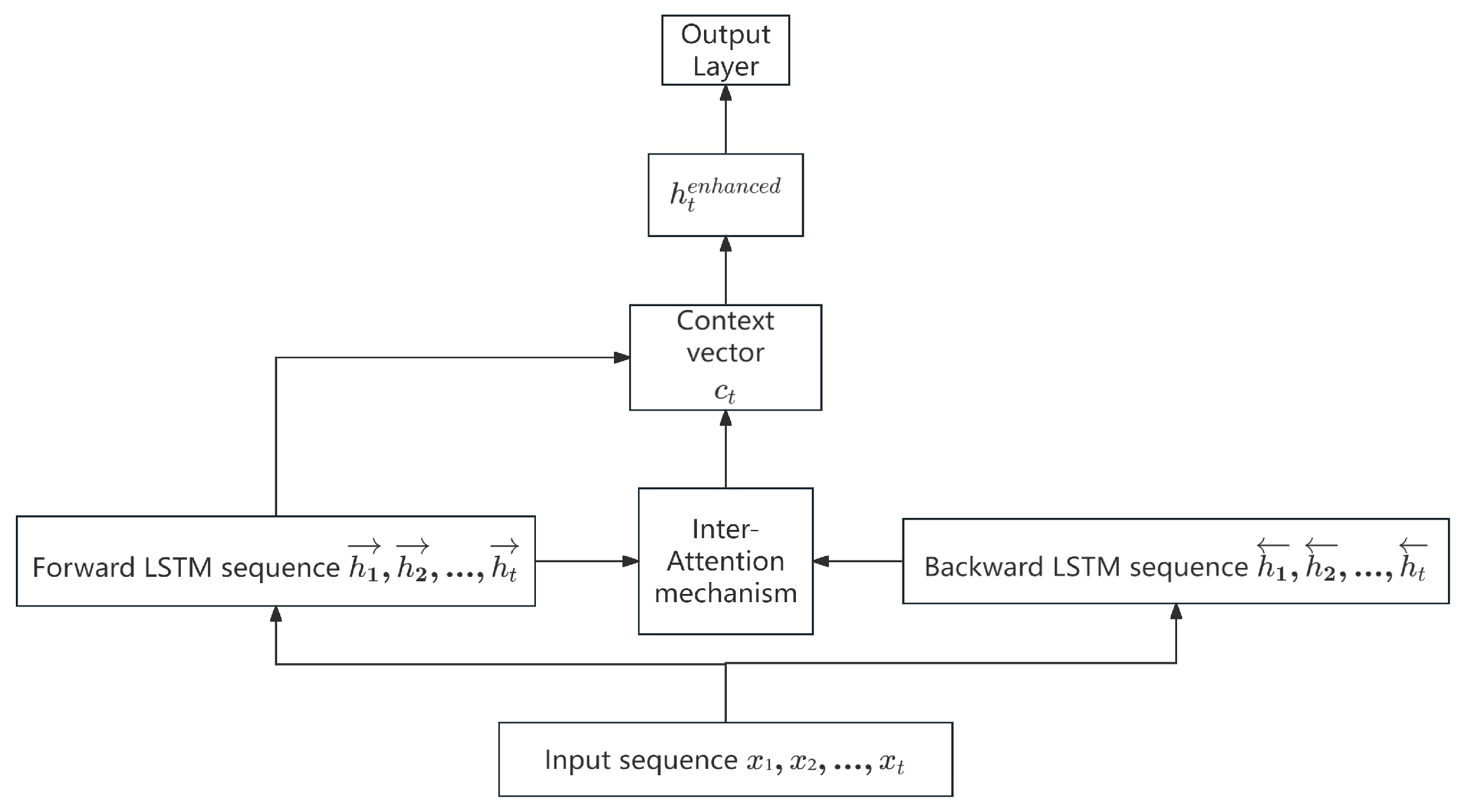
By introducing an Inter-Attention Mechanism between the forward and backward LSTMs, the forward and backward LSTMs are able to “attend” to each other’s hidden states at each time step, thereby better capturing the bidirectional dependencies within the sequence.
Table 1 outlines the implementation steps of the IAM-BiLSTM prediction model.
By incorporating the Inter-Attention Mechanism into BiLSTM, the forward and backward LSTMs can mutually attend to each other’s hidden states at each time step, enabling the capture of richer bidirectional information. A trainable feedforward network is used to compute the similarity scores, enhancing the model’s representational capacity. The context vector
, which summarizes the global information from the counterpart LSTM, aids in making more accurate predictions at the current time step.
Figure 1 illustrates the IAM-BiLSTM prediction model.
2.2. Comprehensive Search Algorithm
In oil well production prediction based on artificial intelligence methods, incorporating optimization algorithms can effectively enhance the accuracy of prediction models. This interdisciplinary approach improves prediction accuracy and efficiency across various fields. Azevedo B. F. conducted a comprehensive review of hybrid methods combining optimization and machine learning techniques [
26], including their applications in clustering and classification tasks. Krzywanski J. explored the applications of artificial intelligence and other advanced computational methods in energy systems [
27], including material production and optimization. These studies collectively demonstrate that the use of optimization algorithms can significantly improve the performance of prediction models.
2.2.1. Sequential Quadratic Programming (SQP)
The Sequential Quadratic Programming (SQP) algorithm is a nonlinear optimization method that iteratively refines the solution by solving Quadratic Programming (QP) subproblems. In this study, SQP is integrated with the Monotone Basin Hopping (MBH) algorithm to enhance global optimization capabilities, addressing the limitations of conventional deep learning parameter tuning. SQP applies a quasi-Newton method to the Kuhn–Tucker conditions, where the Lagrangian function is given by Formula (2):
where
denotes the decision variable vector,
is the objective function,
and
represent the equality and inequality constraints,
and
represent the equality and inequality constraints,
is the number of equality constraints, and
is the total number of constraints. In each iteration, the search direction
is determined by solving the following QP subproblem:
The new solution is then updated by
, where
is obtained via a line search. The Hessian approximation
is updated using the DFP formula:
where
is the difference in gradients of the Lagrangian and
is the difference in the solution estimates.
The steps of the SQP algorithm are shown in
Table 2.
2.2.2. Monotone Basin Hopping Algorithm (MBH)
The Monotone Basin Hopping Algorithm (MBH) is designed to find global optima in problems with many local minima [
28]. It extends the Basin Hopping Algorithm (BH) by introducing a monotonicity constraint: if a new point has a lower objective value but violates the monotonicity condition (i.e., one of its variables is larger than that in the current best solution), it is rejected. MBH was originally developed for molecular conformation problems in computational chemistry [
29], combining monotonic search and basin hopping to achieve global optimization.
MBH exhibits strong global search capabilities [
30]. Unlike traditional local search algorithms that easily get trapped in local optima, MBH uses a basin hopping strategy to explore the solution space globally, thus improving the probability of finding the global optimum. Additionally, randomness helps discover potentially better solutions. The MBH steps are summarized in
Table 3.
2.2.3. Comprehensive Search Algorithm (CSA)
Although the MBH algorithm can help find the global optimum or near-optimal solutions, there is still the risk of getting stuck in local optima. Therefore, it is combined with the SQP algorithm. SQP has weak global search capabilities but strong local search capabilities, allowing it to converge to local extrema in a short time. By combining them, their strengths can complement each other. The integration of Sequential Quadratic Programming (SQP) and Monotone Basin Hopping (MBH) algorithms provides a comprehensive optimization method that combines both global and local search capabilities, known as the Comprehensive Search Algorithm (CSA), as shown in
Figure 2. Its detailed steps are outlined in
Table 4.
2.3. CSA Optimization IAM-BiLSTM Prediction Model
This study uses the CSA to optimize the IAM-BiLSTM prediction model. First, historical data from a specific oil well in Sichuan is collected, and an IAM-BiLSTM prediction model is proposed. The historical data includes production data of each well, well pressure, wellhead temperature, separator pressure, separator temperature and manifold pressure. The CSA algorithm is then used to optimize the parameters of the prediction model. Finally, the optimized IAM-BiLSTM prediction model is applied to predict oil well production, and the prediction results are obtained. By comparing the results of the optimized IAM-BiLSTM model with other prediction algorithms, it is evident that the optimized IAM-BiLSTM prediction model demonstrates superior accuracy and feasibility in the field of oil well production prediction.
For the parameters of the proposed IAM-BiLSTM model that may influence prediction accuracy, this section employs the CSA to search for their optimal values to improve the model’s predictive performance. The optimization process for the IAM-BiLSTM model is illustrated in
Figure 3, and the steps are detailed in
Table 5.
3. Results and Discussion
In this section, we describe the experimental setup and compare the prediction results. In the experiments, the IAM-BiLSTM model is compared with the Back Propagation neural network (BP), Support Vector Machine (SVM), Extreme Gradient Boosting (XGBoost), BiLSTM, and AM-BiLSTM (Attention Mechanism-Bidirectional Long Short-Term Memory) for production prediction, and the comparative results are presented. Additionally, the results of optimizing the IAM-BiLSTM model using the Grey Wolf Optimizer (GWO) [
31], Particle Swarm Optimizer (PSO) [
32], and Whale Optimization Algorithm (WOA) [
33] are compared with those obtained using the CSA-optimized model. The models used in the experiments were primarily implemented in Python 3.10.
3.1. Data Types
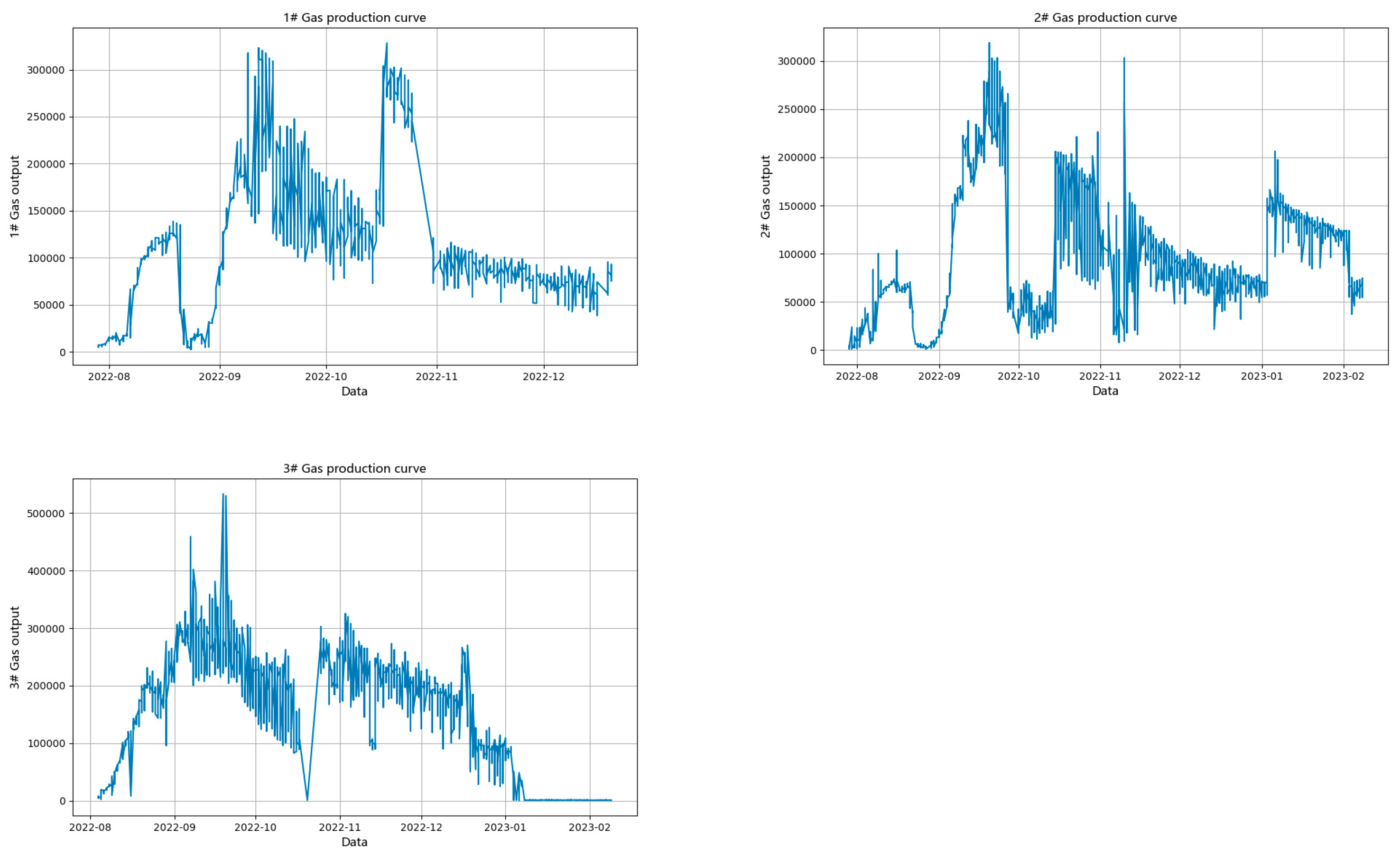
Based on the operating conditions of ground equipment and production equipment at a specific oil well site in Sichuan, the experimental data used consists of historical dynamic liquid level data collected on-site from three oil wells during 2021–2022. To enhance the generalization ability of the model, 1000 data points were randomly selected from each well to construct the dataset. Each dataset corresponds to dynamic liquid level data measured over a month for a specific well. The production variations for the three wells are shown in
Figure 4 [
34]. The standard deviation and variance reflect the fluctuation of a dataset, while the mean, minimum, and maximum values indicate the differences in production among the wells [
35]. The standard deviation, minimum, and maximum values of the oil well production data are listed in
Table 6. This dataset can be used to validate the proposed model’s performance in predicting wells with significant production disparities.
3.2. Evaluation Criteria
This study uses the Mean Squared Error (MSE) and Mean Absolute Error (MAE) as evaluation metrics to comprehensively assess the predictive performance of the model. The smaller the values of these metrics, the closer the predicted values are to the actual values, indicating better prediction performance.
where
is the actual oil production value,
is the predicted oil production value, and
is the total amount of oil production data in the test dataset.
3.3. Verifying the Effectiveness of the IAM-BiLSTM Prediction Model
3.3.1. Feature Engineering and Model Tuning
The proposed IAM-BiLSTM prediction model is designed for time series data. In addition to gas production, the dataset also includes well pressure, wellhead temperature, separator pressure, separator temperature, and manifold pressure. Data other than gas production are used as input features, and gas production is used as the target feature for prediction. The input features have been normalized to ensure consistency. We use the sliding window technique to convert the sequence data into feature-target pairs, making them suitable for training BP, SVM, and XGBoost models. The dataset is divided into 80% training and 20% testing to evaluate the model performance. In order to verify the improvement in prediction performance compared with machine learning methods, prediction models based on BP network, SVM, and XGBoost are established for comparison. The data collected from the three wellheads have the same characteristics, and all datasets are readings from field equipment sensors. The data characteristics are shown in
Table 7.
Additionally, to evaluate the impact of the attention mechanism on the prediction model, BiLSTM and AM-BiLSTM models were also constructed for comparison. The network parameters of the prediction models involved in this study are shown in
Table 8, where
and
represent the input and output for SVM, XGBoost, and the BP neural network, respectively,
is the hyperparameter for SVM, with other parameters set to default values,
is the optimization parameter for XGBoost, with other parameters also set to default values, and
denotes the number of neurons in the i-th hidden layer. For BiLSTM,
and
represent the input and output, respectively. To validate the model’s accuracy, the training batch size
, learning rate
, loss function, and optimizer are kept consistent across models.
3.3.2. Verification Results
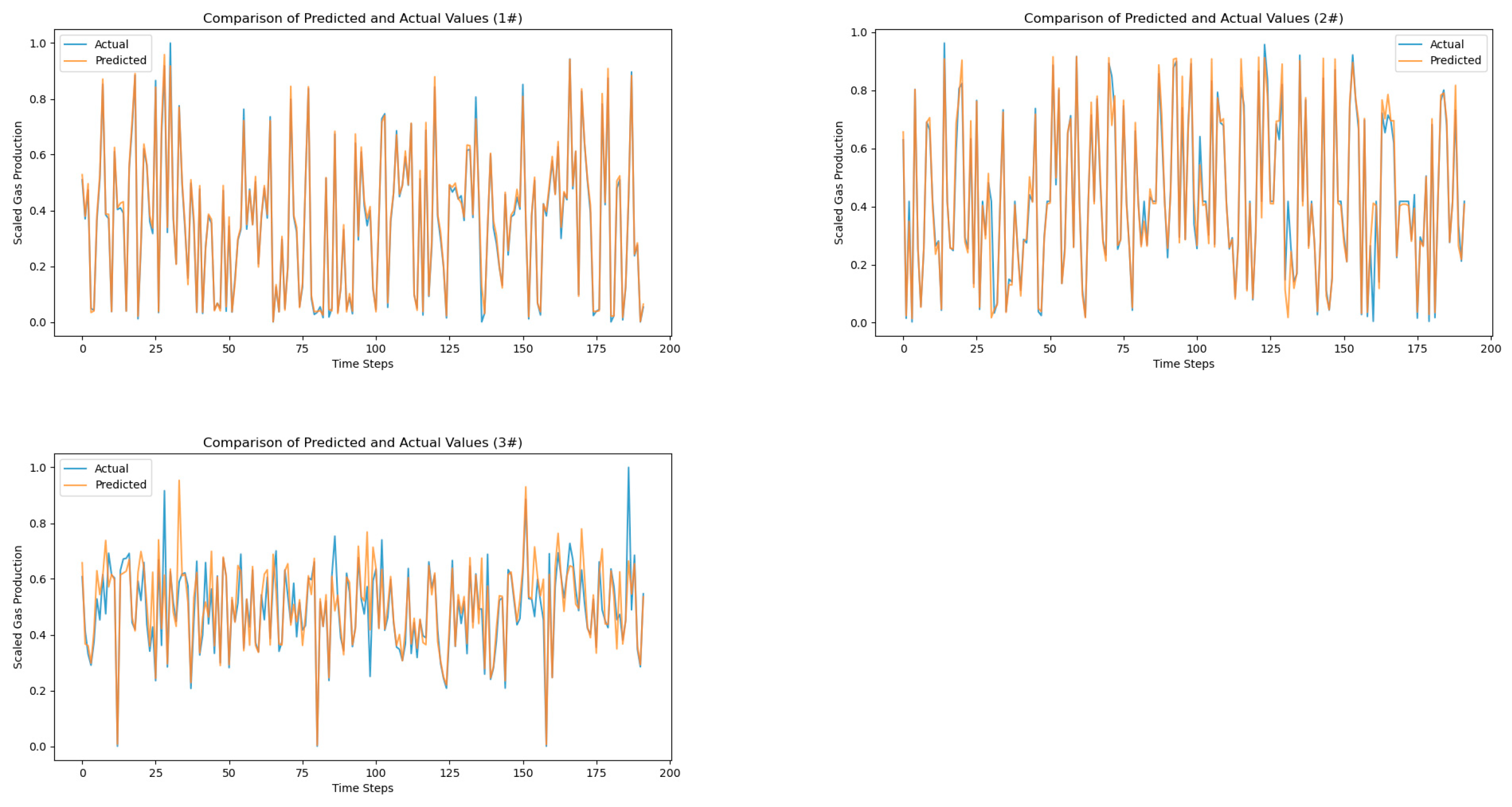
To verify the effectiveness of the proposed IAM-BiLSTM prediction model in the field of oil well production prediction, as well as the improvement in prediction accuracy brought by the Inter-Attention Mechanism to the BiLSTM model, production prediction models were established based on the aforementioned dataset and model parameters. The results of predicting oil well production using the IAM-BiLSTM prediction model are shown in
Figure 5.
After comparing the prediction results with several machine learning and deep learning methods,
Figure 6 was obtained, and the prediction accuracy calculation results are shown in
Table 9. The results can be summarized as follows:
The proposed IAM-BiLSTM prediction model significantly improves prediction accuracy. The MSE and MAE of the IAM-BiLSTM prediction model are 0.0152 and 0.0621, respectively, which represent reductions of 61.14% and 34.3% compared to the BP network, 73.2% and 42.3% compared to SVM, and 74.94% and 38.99% compared to XGBoost. This demonstrates that deep learning methods, compared to traditional machine learning methods, can significantly enhance the accuracy of prediction models.
The MSE and MAE of the IAM-BiLSTM prediction model, at 0.0152 and 0.0621, respectively, are reduced by 39.44% and 35.68% compared to BiLSTM, and by 46.08% and 31.06% compared to AM-BiLSTM. This indicates that the Inter-Attention Mechanism enhances the weight of valuable information when extracting feature information using BiLSTM, thereby further improving the model’s prediction accuracy.
In
Figure 6, the black curve (Actual Values) shows how the true data fluctuates frequently across 200 samples. The colored curves represent predictions by various models (BP, SVM, XGBoost, BiLSTM, IAM-BiLSTM, and AM_BiLSTM), all generally following the data’s oscillatory pattern. However, the IAM-BiLSTM model captures sharp peaks and troughs more accurately, demonstrating superior predictive performance compared to the other methods. Although AM_BiLSTM also tracks rapid changes relatively well, methods such as BP, SVM, and XGBoost display more noticeable deviations from the actual values.
3.4. CSA Optimization Performance Analysis
The above experimental results indicate that the IAM-BiLSTM prediction model demonstrates good prediction accuracy. However, determining reasonable learning rates and feature dimensions is essential for further improving the accuracy of the prediction model. Common methods for optimizing model parameters include GWO, PSO, and WOA.
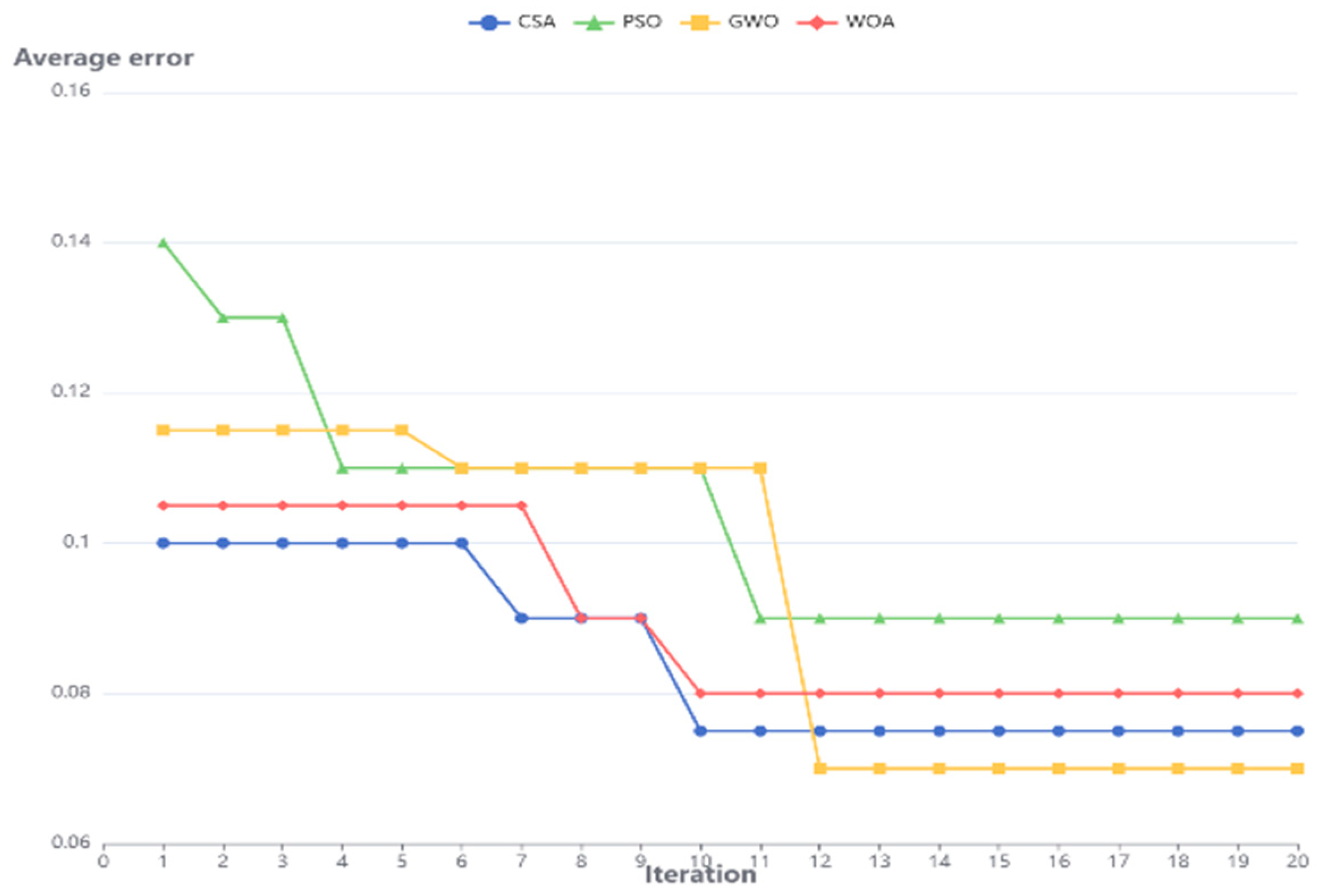
Existing optimization algorithms, such as PSO, WOA, and GWO, have certain limitations when dealing with complex high-dimensional optimization problems. For example, PSO converges quickly in the early stage, but is prone to fall into local optimality in the later stage; although WOA has strong global search capabilities, its optimization efficiency is low. In contrast, the Comprehensive Search Algorithm (CSA) combines the global search capability of MBH and the local optimization capability of SQP, which can effectively improve the convergence speed and accuracy of model parameter optimization. The experimental results show that the IAM-BiLSTM model optimized by CSA is superior to other optimization methods in terms of convergence speed (see
Figure 7). As can be seen from the figure, the fitness value of the IAM-BiLSTM model is optimized by the four algorithms, that is, the overall average error shows a downward trend. However, compared with GWO, PSO, and WOA, CSA achieves a shorter average convergence time and the smallest average error. In addition, the error convergence curve obtained by CSA is smoother, and it can be concluded that CSA exhibits better stability and convergence. Therefore, this paper selects CSA as the optimizer of the IAM-BiLSTM model to improve the reliability and generalization ability of the prediction model.
3.5. Performance Analysis and Evaluation of CSA Optimized IAM-BiLSTM Prediction Model
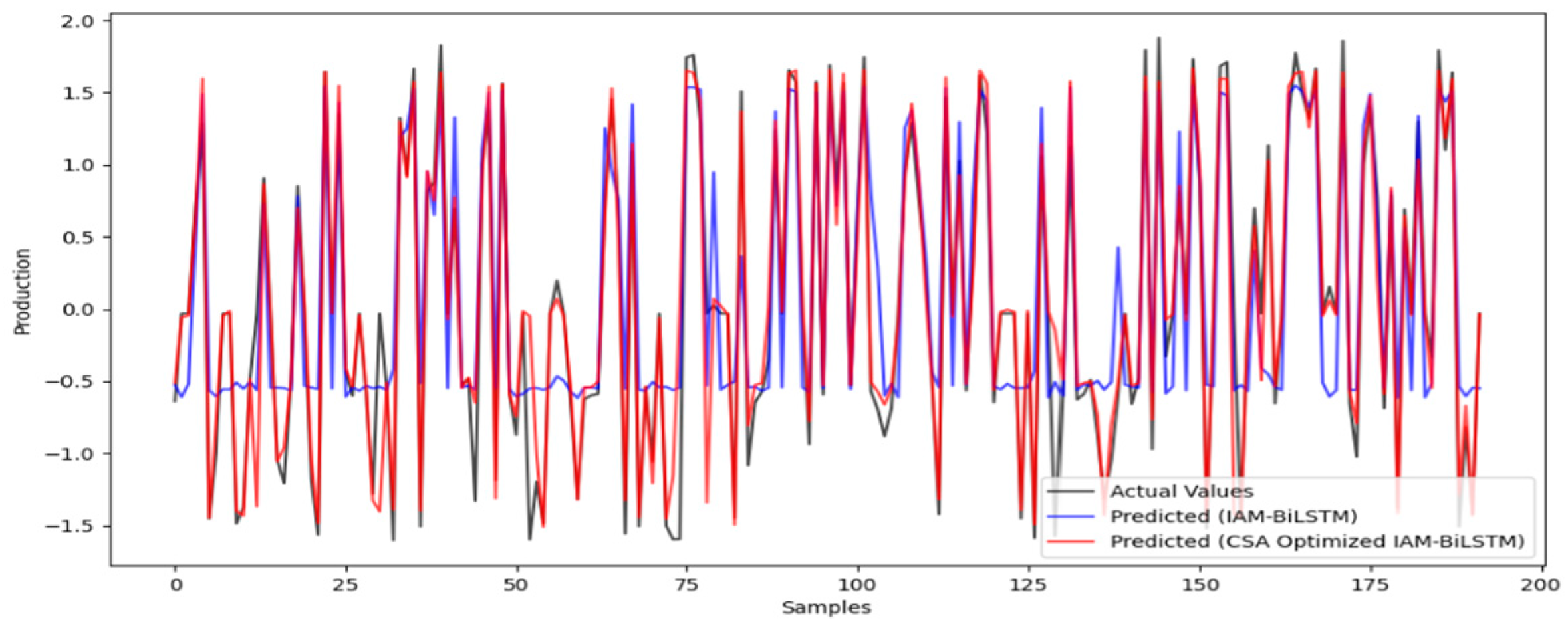
To further validate the optimization capability of CSA for the IAM-BiLSTM prediction model, the CSA-optimized IAM-BiLSTM prediction model was established using the aforementioned production historical data as the dataset. CSA was utilized to optimize the learning rate and feature dimensions of the IAM-BiLSTM prediction model, with specific parameters shown in
Table 10. The prediction results are illustrated in
Figure 8, and the prediction accuracy comparison results are presented in
Table 11. As shown in
Table 11, the MAE and MSE of the CSA-optimized IAM-BiLSTM prediction model are 0.0795 and 0.0123, respectively. Compared to IAM-BiLSTM, prediction accuracy has been improved. It can be concluded that optimizing the learning rate, batch size, and the number of neurons in the IAM-BiLSTM prediction model using CSA can effectively enhance the model’s prediction accuracy.
4. Results and Conclusions
The high-precision performance of the CSA-optimized IAM-BiLSTM model proposed in this study in oil well production prediction makes it of significant value in oilfield management and commercial applications. First, the model can help oilfield managers optimize production plans, reduce unnecessary equipment maintenance, and improve resource utilization, thereby reducing operating costs. Second, accurate prediction capabilities can help reduce production fluctuations and improve economic benefits. For example, reducing prediction errors can effectively reduce the production capacity loss of oil fields due to misjudgment. Finally, the high efficiency of the model can also reduce energy waste in oilfield production, optimize carbon emission management, and meet the requirements of sustainable development. Therefore, this study not only provides an innovative prediction method at the technical level, but also provides an important reference for intelligent production in the oil and gas industry.
This study validated the IAM-BiLSTM model using a dataset constructed from oilfield production data and compared the prediction performance with various baseline models. By applying multiple optimization algorithms to the parameter optimization of the IAM-BiLSTM model, the following conclusions were drawn:
A BiLSTM model based on the Inter-Attention Mechanism (IAM-BiLSTM) was proposed, which assigns different weights to hidden states, enhancing the influence of critical information. Experimental results show that the IAM-BiLSTM model outperforms traditional BiLSTM and AM-BiLSTM models in prediction accuracy.
Compared with optimization algorithms such as GWO, PSO, and WOA, the CSA-optimized IAM-BiLSTM model achieves faster and more stable convergence of its error iteration curve. Experimental results demonstrate that the CSA algorithm has excellent stability and convergence properties, improving the prediction accuracy of the IAM-BiLSTM model.
The proposed CSA-optimized IAM-BiLSTM model has been successfully applied to production prediction at a specific oil well site in Sichuan, verifying the method’s robustness and generalization ability.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}