
Elastic Balancing of Communication Efficiency and Performance in Federated Learning with Staged Clustering


Abstract
1. Introduction
- By employing theoretical modeling that encompasses various factors such as non-IID data, network conditions, and computing resources, we have designed a simulation theoretical framework grounded in FCL.
- Building on clustered federated learning, this paper introduces a flexible hierarchical clustering-based federated learning method that optimizes the average training time per round without significantly impacting model accuracy. The method dynamically adjusts cluster weights based on an elastic weighting factor, adaptively balancing model performance and training efficiency, thereby ensuring the flexibility required for real-world federated learning applications.
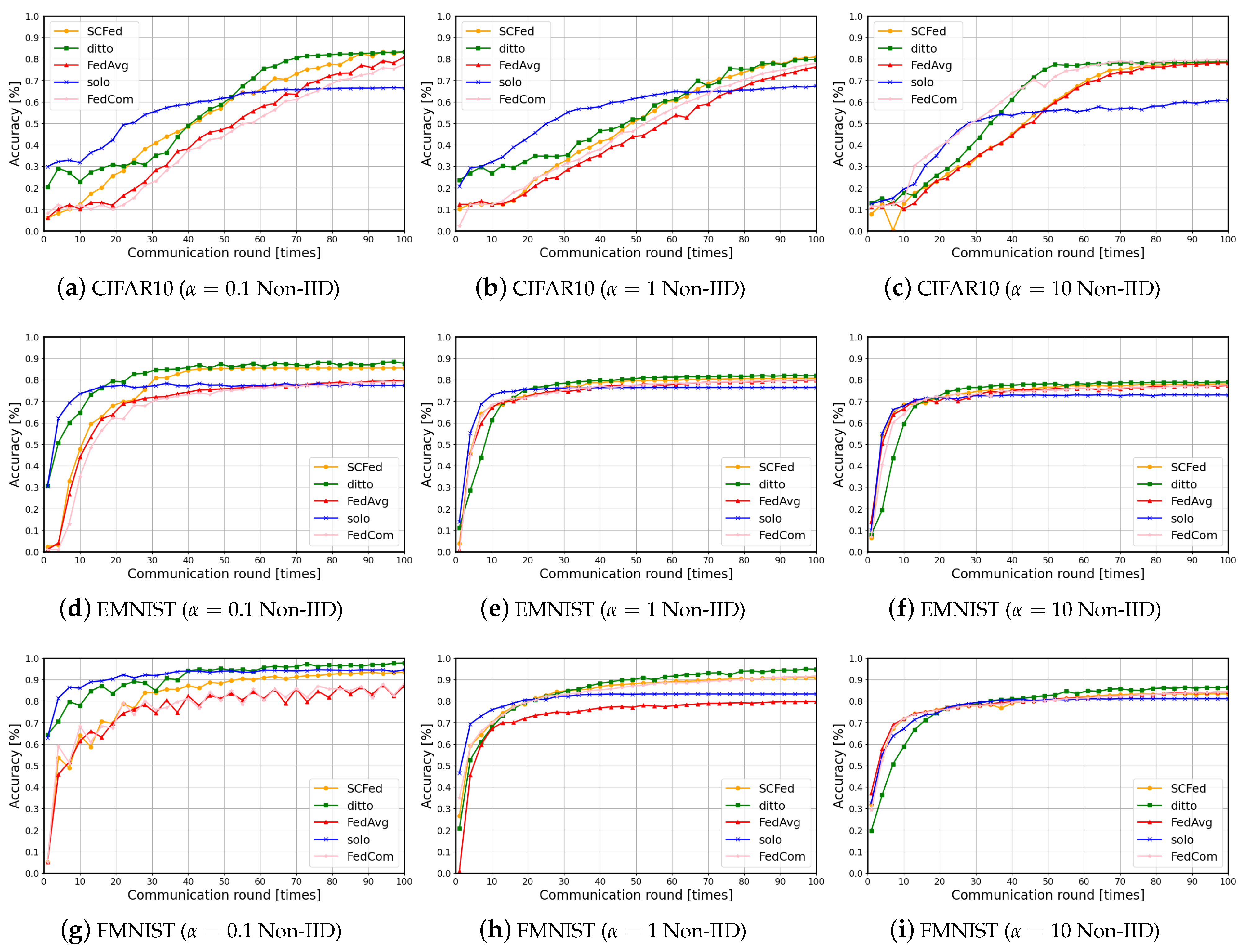
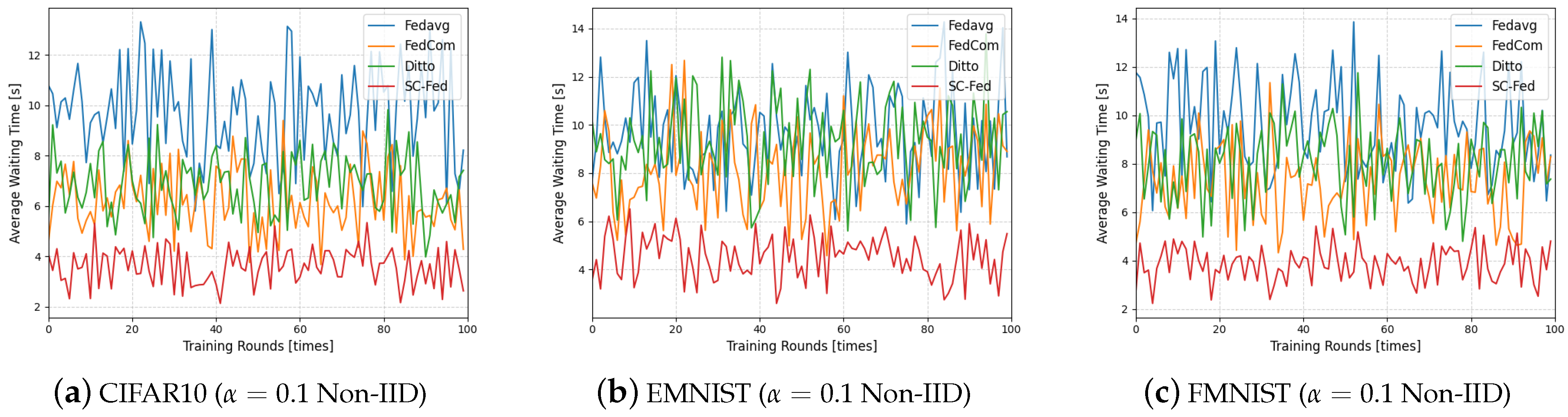
- Based on the theoretical framework and algorithm, this paper conducts comparative experiments with four baseline algorithms on three datasets. The experimental results demonstrate that our algorithm achieves higher model performance within the same time frame, while significantly reducing the average waiting time per training round.
2. Related Work
2.1. Personalized Federated Learning
2.2. Device Resources
3. Problem Statement
4. Overview and Implementation
4.1. Overview
4.2. Model Training Process
4.3. Implementation and Algorithm Description
| Algorithm 1 PCA-based clustering algorithm with resource optimization |
Require: Initial Model Parameters , Learning Rate , Communication Rounds T, Number of Principal Components r, Clustering Number k
|
4.4. Datasets and Settings
5. Experiment
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Non-IID | Non-independent and identically distributed |
| PCA | Principal component analysis |
| FCL | Federated clustered learning |
| FL | Federated learning |
| CFL | Clustered federated learning |
| PS | Parameter server |
| SGD | Stochastic gradient descent |
References
- Chuprov, S.; Bhatt, K.M.; Reznik, L. Federated Learning for Robust Computer Vision in Intelligent Transportation Systems. In Proceedings of the 2023 IEEE Conference on Artificial Intelligence (CAI), Santa Clara, CA, USA, 5–6 June 2023; pp. 26–27. [Google Scholar] [CrossRef]
- Ye, M.; Fang, X.; Du, B.; Yuen, P.C.; Tao, D. Heterogeneous federated learning: State-of-the-art and research challenges. ACM Comput. Surv. 2023, 56, 1–44. [Google Scholar] [CrossRef]
- Xiong, Z.; Zhu, H.; Liu, D.; Xian, J. Industrial Chain Data Evaluation in Automobile Parts Procurement via Group Multirole Assignment. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; pp. 1049–1054. [Google Scholar] [CrossRef]
- Lu, W.; Hu, W.; Kong, X.; Shen, Y.; Zhao, X. Multi-Objective Optimal Dispatch of Responsibility-Assignment Market via Federated Learning. In Proceedings of the 2022 25th International Conference on Electrical Machines and Systems (ICEMS), Chiang Mai, Thailand, 29 November–2 December 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Huang, W.; Ye, M.; Shi, Z.; Wan, G.; Li, H.; Du, B.; Yang, Q. Federated learning for generalization, robustness, fairness: A survey and benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9387–9406. [Google Scholar] [CrossRef]
- Feng, W.; Liu, H.; Peng, X. Federated Reinforcement Learning for Sharing Experiences Between Multiple Workers. In Proceedings of the 2023 International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 9–11 July 2023; pp. 440–445. [Google Scholar] [CrossRef]
- Zhao, Y. Comparison of Federated Learning Algorithms for Image Classification. In Proceedings of the 2023 2nd International Conference on Data Analytics, Computing and Artificial Intelligence (ICDACAI), Zakopane, Poland, 17–19 October 2023; pp. 613–615. [Google Scholar] [CrossRef]
- Wijethilaka, S.; Liyanage, M. A Federated Learning Approach for Improving Security in Network Slicing. In Proceedings of the GLOBECOM 2022—2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 915–920. [Google Scholar] [CrossRef]
- Novikova, E.S.; Chen, Y.; Meleshko, A.V. Evaluation of Data Heterogeneity in FL Environment. In Proceedings of the 2024 XXVII International Conference on Soft Computing and Measurements (SCM), Saint Petersburg, Russia, 22–24 May 2024; pp. 344–347. [Google Scholar] [CrossRef]
- Siriwardana, G.K.; Jayawardhana, H.D.; Bandara, W.U.; Atapattu, S.; Herath, V.R. Federated Learning for Improved Automatic Modulation Classification: Data Heterogeneity and Low SNR Accuracy. In Proceedings of the 2023 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 9–11 November 2023; pp. 462–467. [Google Scholar] [CrossRef]
- Chen, J.; Yan, H.; Liu, Z.; Zhang, M.; Xiong, H.; Yu, S. When federated learning meets privacy-preserving computation. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Wang, A.; Feng, Y.; Yang, M.; Wu, H.; Iwahori, Y.; Chen, H. Cross-Project Software Defect Prediction Using Differential Perception Combined with Inheritance Federated Learning. Electronics 2024, 13, 4893. [Google Scholar] [CrossRef]
- Gauthier, F.; Gogineni, V.C.; Werner, S.; Huang, Y.F.; Kuh, A. Clustered Graph Federated Personalized Learning. In Proceedings of the 2022 56th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–2 November 2022; pp. 744–748. [Google Scholar] [CrossRef]
- Cai, L.; Chen, N.; Wei, Y.; Chen, H.; Li, Y. Cluster-based Federated Learning Framework for Intrusion Detection. In Proceedings of the 2022 IEEE 13th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Beijing, China, 25–27 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, J.; Qiao, Z. SoFL: Clustered Federated Learning Based on Dual Clustering for Heterogeneous Data. Electronics 2024, 13, 3682. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, Y. A Personalized Federated Learning Method Based on Clustering and Knowledge Distillation. Electronics 2024, 13, 857. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, J.; Hong, W.; Quek, T.Q.S.; Ding, Z.; Peng, M. Ensemble Federated Learning With Non-IID Data in Wireless Networks. IEEE Trans. Wirel. Commun. 2024, 23, 3557–3571. [Google Scholar] [CrossRef]
- Chen, Y.A.; Chen, G.L. An Adaptive Clustering Scheme for Client Selections in Communication-Efficient Federated Learning. In Proceedings of the 2023 VTS Asia Pacific Wireless Communications Symposium (APWCS), Tainan City, Taiwan, 23–25 August 2023; pp. 1–3. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Chi, C.Y.; Quek, T.Q.S. Differentially Private Federated Clustering Over Non-IID Data. IEEE Internet Things J. 2024, 11, 6705–6721. [Google Scholar] [CrossRef]
- Zhou, X.; Ye, X.; Kevin, I.; Wang, K.; Liang, W.; Nair, N.K.C.; Shimizu, S.; Yan, Z.; Jin, Q. Hierarchical federated learning with social context clustering-based participant selection for internet of medical things applications. IEEE Trans. Comput. Soc. Syst. 2023, 10, 1742–1751. [Google Scholar] [CrossRef]
- Zuo, Y.; Liu, Y. User Selection Aware Joint Radio-and-Computing Resource Allocation for Federated Edge Learning. In Proceedings of the 2020 International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 21–23 October 2020; pp. 292–297. [Google Scholar] [CrossRef]
- Kim, J.; Song, C.; Paek, J.; Kwon, J.H.; Cho, S. A Review on Research Trends of Optimization for Client Selection in Federated Learning. In Proceedings of the 2024 International Conference on Information Networking (ICOIN), Ho Chi Minh City, Vietnam, 17–19 January 2024; pp. 287–289. [Google Scholar] [CrossRef]
- Huang, W.; Ye, M.; Shi, Z.; Li, H.; Du, B. Rethinking federated learning with domain shift: A prototype view. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 16312–16322. [Google Scholar]
- Zhao, X.; Xie, P.; Xing, L.; Zhang, G.; Ma, H. Clustered federated learning based on momentum gradient descent for heterogeneous data. Electronics 2023, 12, 1972. [Google Scholar] [CrossRef]
- Li, H.; Li, C.; Wang, J.; Yang, A.; Ma, Z.; Zhang, Z.; Hua, D. Review on security of federated learning and its application in healthcare. Future Gener. Comput. Syst. 2023, 144, 271–290. [Google Scholar] [CrossRef]
- Ye, R.; Wang, W.; Chai, J.; Li, D.; Li, Z.; Xu, Y.; Du, Y.; Wang, Y.; Chen, S. Openfedllm: Training large language models on decentralized private data via federated learning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 6137–6147. [Google Scholar]
- Beltrán, E.T.M.; Pérez, M.Q.; Sánchez, P.M.S.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun. Surv. Tutor. 2023, 25, 2983–3013. [Google Scholar] [CrossRef]
- Chen, H.; Chen, X.; Peng, L.; Ma, R. FLRAM: Robust Aggregation Technique for Defense against Byzantine Poisoning Attacks in Federated Learning. Electronics 2023, 12, 4463. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Kumar, K.N.; Mohan, C.K.; Cenkeramaddi, L.R. The Impact of Adversarial Attacks on Federated Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 2672–2691. [Google Scholar] [CrossRef] [PubMed]
- Guduri, M.; Chakraborty, C.; Maheswari, U.; Margala, M. Blockchain-Based Federated Learning Technique for Privacy Preservation and Security of Smart Electronic Health Records. IEEE Trans. Consum. Electron. 2024, 70, 2608–2617. [Google Scholar] [CrossRef]
- Yazdinejad, A.; Dehghantanha, A.; Srivastava, G. AP2FL: Auditable privacy-preserving federated learning framework for electronics in healthcare. IEEE Trans. Consum. Electron. 2023, 70, 2527–2535. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Kevin, I.; Wang, K.; Yan, Z.; Yang, L.T.; Wei, W.; Ma, J.; Jin, Q. Decentralized P2P federated learning for privacy-preserving and resilient mobile robotic systems. IEEE Wirel. Commun. 2023, 30, 82–89. [Google Scholar] [CrossRef]
- Fu, Y.; Li, C.; Yu, F.R.; Luan, T.H.; Zhao, P. An incentive mechanism of incorporating supervision game for federated learning in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2023, 24, 14800–14812. [Google Scholar] [CrossRef]
- Li, Z.; He, S.; Chaturvedi, P.; Hoang, T.H.; Ryu, M.; Huerta, E.A.; Kindratenko, V.; Fuhrman, J.; Giger, M.; Chard, R.; et al. APPFLx: Providing Privacy-Preserving Cross-Silo Federated Learning as a Service. In Proceedings of the 2023 IEEE 19th International Conference on e-Science (e-Science), Limassol, Cyprus, 9–13 October 2023; pp. 1–4. [Google Scholar] [CrossRef]
- El Houda, Z.A.; Nabousli, D.; Kaddoum, G. Cost-efficient Federated Reinforcement Learning- Based Network Routing for Wireless Networks. In Proceedings of the 2022 IEEE Future Networks World Forum (FNWF), Montreal, QC, Canada, 10–14 October 2022; pp. 243–248. [Google Scholar] [CrossRef]
- Abidin, N.Z.; Ritahani Ismail, A. Federated Deep Learning for Automated Detection of Diabetic Retinopathy. In Proceedings of the 2022 IEEE 8th International Conference on Computing, Engineering and Design (ICCED), Sukabumi, Indonesia, 28–29 July 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Ahmed, I.M.; Kashmoola, M.Y. Investigated Insider and Outsider Attacks on the Federated Learning Systems. In Proceedings of the 2022 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), Solo, Indonesia, 3–5 November 2022; pp. 438–443. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Sabah, F.; Chen, Y.; Yang, Z.; Azam, M.; Ahmad, N.; Sarwar, R. Model optimization techniques in personalized federated learning: A survey. Expert Syst. Appl. 2024, 243, 122874. [Google Scholar] [CrossRef]
- Long, G.; Xie, M.; Shen, T.; Zhou, T.; Wang, X.; Jiang, J. Multi-center federated learning: Clients clustering for better personalization. World Wide Web 2023, 26, 481–500. [Google Scholar] [CrossRef]
- Zhou, H.; Lan, T.; Venkataramani, G.P.; Ding, W. Every parameter matters: Ensuring the convergence of federated learning with dynamic heterogeneous models reduction. Adv. Neural Inf. Process. Syst. 2024, 36, 25991–26002. [Google Scholar]
- Haddadpour, F.; Mahdavi, M. On the convergence of local descent methods in federated learning. arXiv 2019, arXiv:1910.14425. [Google Scholar]
- Fang, X.; Ye, M.; Yang, X. Robust heterogeneous federated learning under data corruption. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 5020–5030. [Google Scholar]
- Sattler, F.; Müller, K.R.; Wiegand, T.; Samek, W. On the byzantine robustness of clustered federated learning. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8861–8865. [Google Scholar]
- Ghosh, A.; Chung, J.; Yin, D.; Ramchandran, K. An efficient framework for clustered federated learning. Adv. Neural Inf. Process. Syst. 2020, 33, 19586–19597. [Google Scholar] [CrossRef]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Konecnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Guo, J.; Liu, Z.; Tian, S.; Huang, F.; Li, J.; Li, X.; Igorevich, K.K.; Ma, J. TFL-DT: A trust evaluation scheme for federated learning in digital twin for mobile networks. IEEE J. Sel. Areas Commun. 2023, 41, 3548–3560. [Google Scholar] [CrossRef]
- Diao, E.; Ding, J.; Tarokh, V. Heterofl: Computation and communication efficient federated learning for heterogeneous clients. arXiv 2020, arXiv:2010.01264. [Google Scholar]
- Mei, Y.; Guo, P.; Zhou, M.; Patel, V. Resource-adaptive federated learning with all-in-one neural composition. Adv. Neural Inf. Process. Syst. 2022, 35, 4270–4284. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 1 February 2025).
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2921–2926. [Google Scholar]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and robust federated learning through personalization. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 6357–6368. [Google Scholar]
- Zhao, B.; Sun, P.; Fang, L.; Wang, T.; Jiang, K. FedCom: A byzantine-robust local model aggregation rule using data commitment for federated learning. arXiv 2021, arXiv:2104.08020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Datasets | CIFAR-10 | FMNIST | EMNIST | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Algorithm | ||||||||||
| Solo | 0.66 | 0.67 | 0.60 | 0.94 | 0.83 | 0.81 | 0.76 | 0.76 | 0.73 | |
| FedAvg [39] | 0.81 | 0.76 | 0.78 | 0.87 | 0.80 | 0.84 | 0.80 | 0.80 | 0.77 | |
| Ditto [57] | 0.83 | 0.80 | 0.78 | 0.98 | 0.95 | 0.86 | 0.88 | 0.82 | 0.79 | |
| FedCom [58] | 0.77 | 0.78 | 0.80 | 0.88 | 0.92 | 0.85 | 0.80 | 0.80 | 0.78 | |
| SC-Fed (Ours) | 0.83 | 0.81 | 0.79 | 0.93 | 0.91 | 0.83 | 0.81 | 0.81 | 0.78 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Cui, F.; Che, J.; Ni, M.; Zhang, Z.; Li, J. Elastic Balancing of Communication Efficiency and Performance in Federated Learning with Staged Clustering. Electronics 2025, 14, 745. https://doi.org/10.3390/electronics14040745
Zhou Y, Cui F, Che J, Ni M, Zhang Z, Li J. Elastic Balancing of Communication Efficiency and Performance in Federated Learning with Staged Clustering. Electronics. 2025; 14(4):745. https://doi.org/10.3390/electronics14040745
Chicago/Turabian StyleZhou, Ying, Fang Cui, Junlin Che, Mao Ni, Zhiyuan Zhang, and Jundi Li. 2025. "Elastic Balancing of Communication Efficiency and Performance in Federated Learning with Staged Clustering" Electronics 14, no. 4: 745. https://doi.org/10.3390/electronics14040745
APA StyleZhou, Y., Cui, F., Che, J., Ni, M., Zhang, Z., & Li, J. (2025). Elastic Balancing of Communication Efficiency and Performance in Federated Learning with Staged Clustering. Electronics, 14(4), 745. https://doi.org/10.3390/electronics14040745