


Synergy of Internet of Things and Software Engineering Approach for Enhanced Copy–Move Image Forgery Detection Model


Abstract
1. Introduction
- Histogram equalization enhances the contrast of input images, improving their quality for enhanced feature extraction. This pre-processing step ensures that relevant details in the images are more prominent, assisting the detection of subtle manipulations. Improving image visibility assists in attaining more accurate results in subsequent forgery detection tasks.
- The SCNN technique learns complex features from pre-processed images, enabling the model to distinguish between authentic and forged regions. This methodology allows for the effectual comparison of image pairs, improving the detection of subtle forgeries. SCNN enhances the model’s accuracy in identifying image manipulations by focusing on feature similarity.
- The GJO model is utilized to fine-tune the SCNN’s hyperparameters, optimizing its performance and improving its learning efficiency. By adjusting the hyperparameters, the model attains improved accuracy in detecting image forgeries. This optimization ensures that the SCNN operates at its full potential, resulting in enhanced detection results.
- The RELM classifier is applied to the CMFD process, efficiently identifying forged areas in images. Its regularization improves the robustness and generalization of the model, resulting in more accurate forgery detection. The method can reliably distinguish between authentic and manipulated image regions by implementing the RELM classifier.
- The proposed FSCDL-CMFDA model uniquely incorporates the SCNN with GJO methods for hyperparameter tuning and BWO for further refinement. This integration provides a robust CMFD solution, improving efficiency and accuracy compared to conventional methods. The novelty is the hybrid use of advanced optimization techniques to fine-tune the model, significantly improving its performance in detecting complex forgeries.
2. Literature Survey
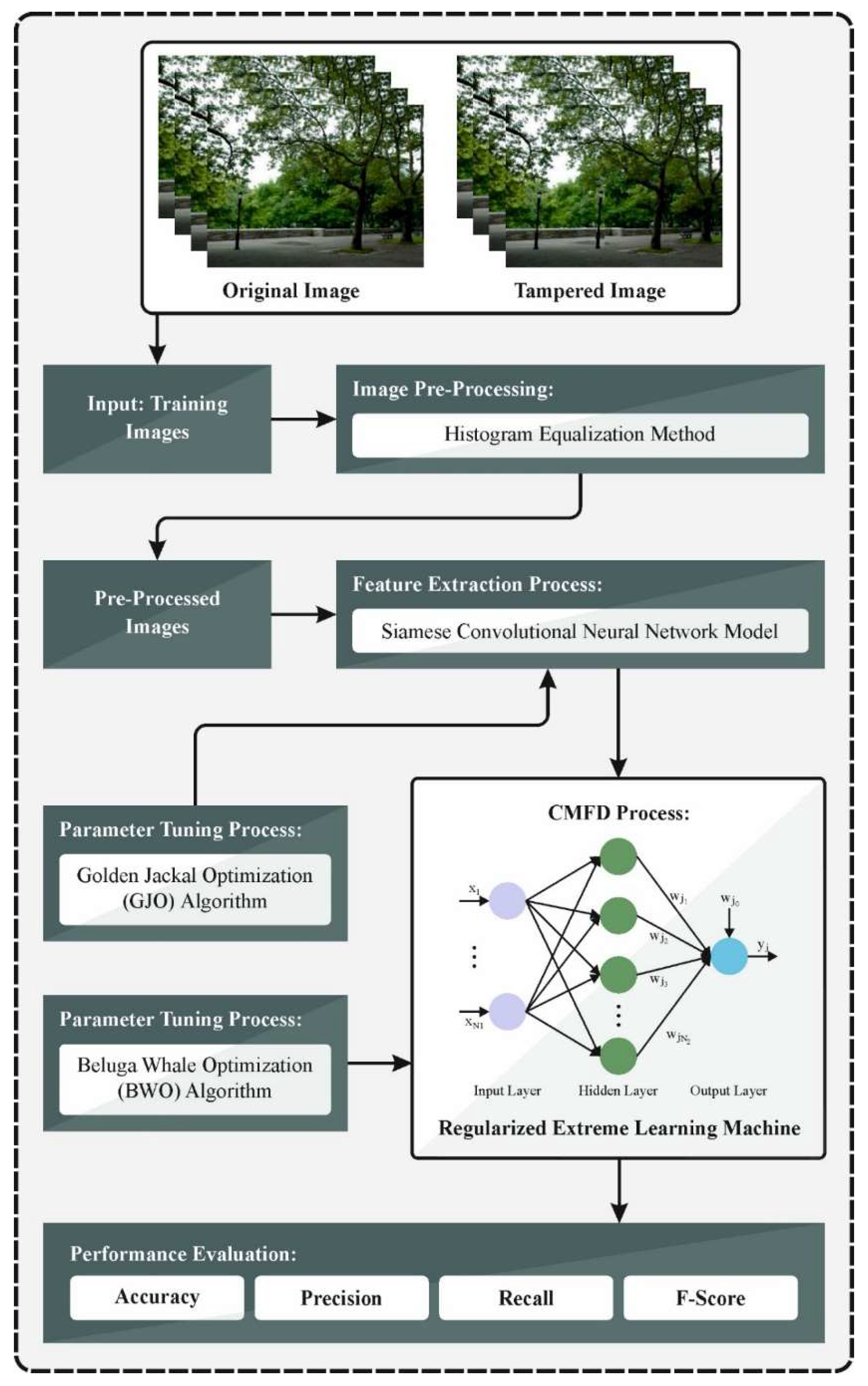
3. The Proposed Method
3.1. Image Pre-Processing
3.2. Feature Extraction
3.2.1. Steps of Exploration
3.2.2. Steps of Exploitation
3.2.3. Switching Between Exploration and Exploitation
3.3. RELM-Based Classification Model
3.4. Hyperparameter Tuning Using BWO Model
| Algorithm 1: BWO pseudocode |
| Start BWO Input: Choose the parameters of BWO . Output: The best location of the populations and the equivalent FF. While The utilizing , and values depend on Equations (26), (29), and (33). If Upgrade the places of the BWs according to Equation (24). Otherwise Upgrade the gorilla’s places the utilizing in Equation (25). end Calculate the FFs for the novel places and choose the optimum solution. If Upgrade the places of the BWs utilizing Equation (30). End Calculate the FFs for the novel locations and choose the optimum solution. End while End BWO |
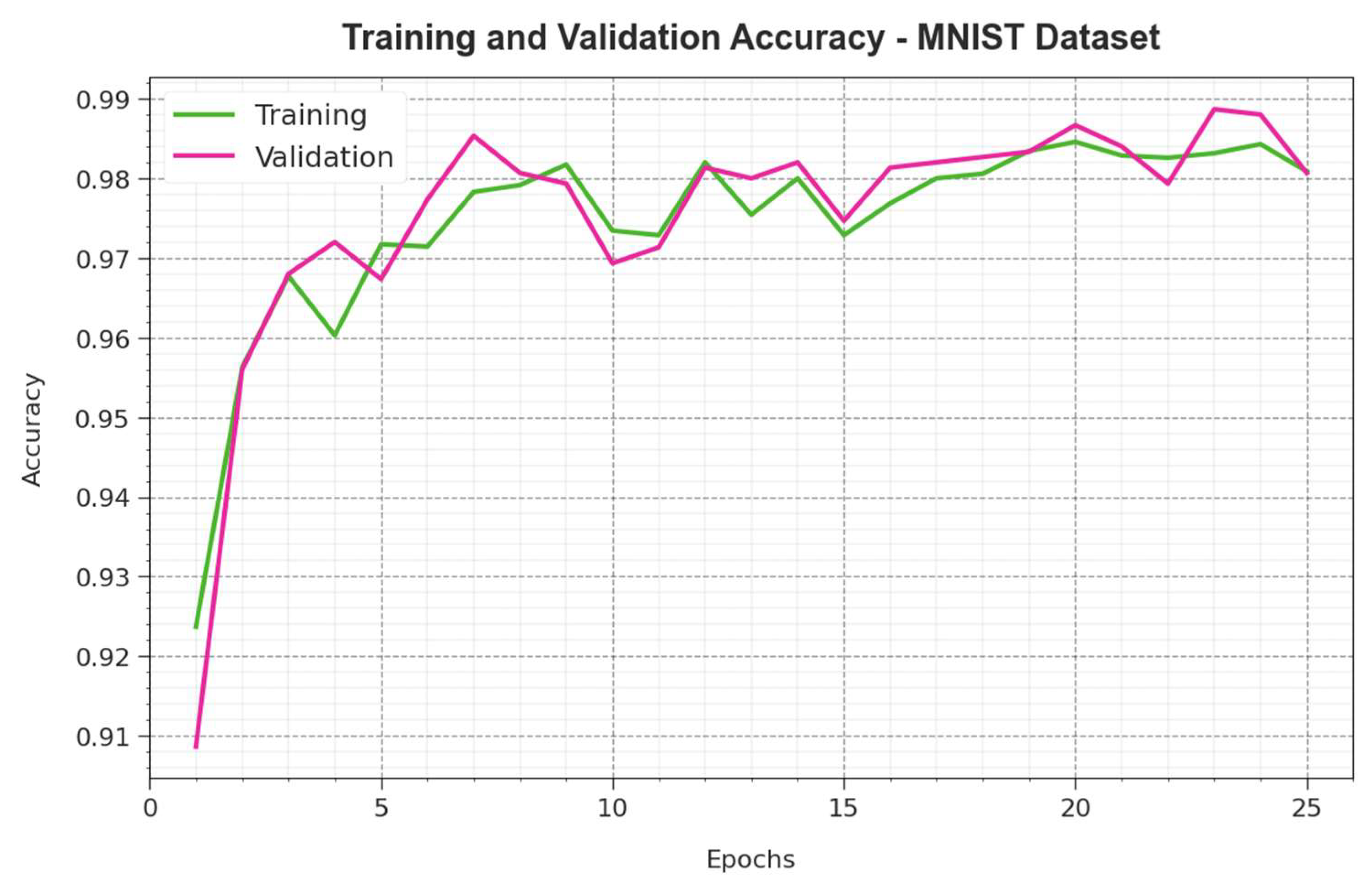
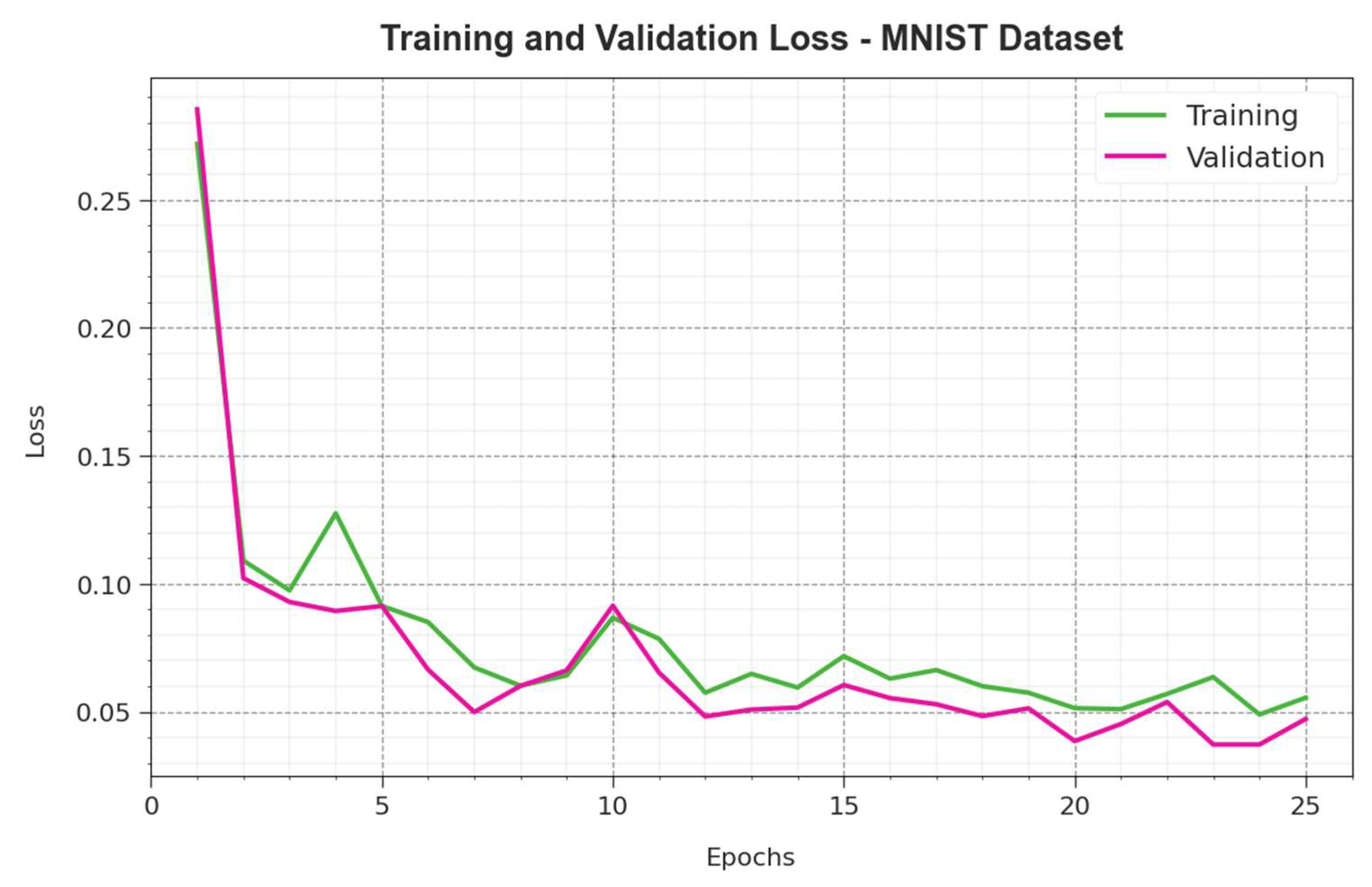
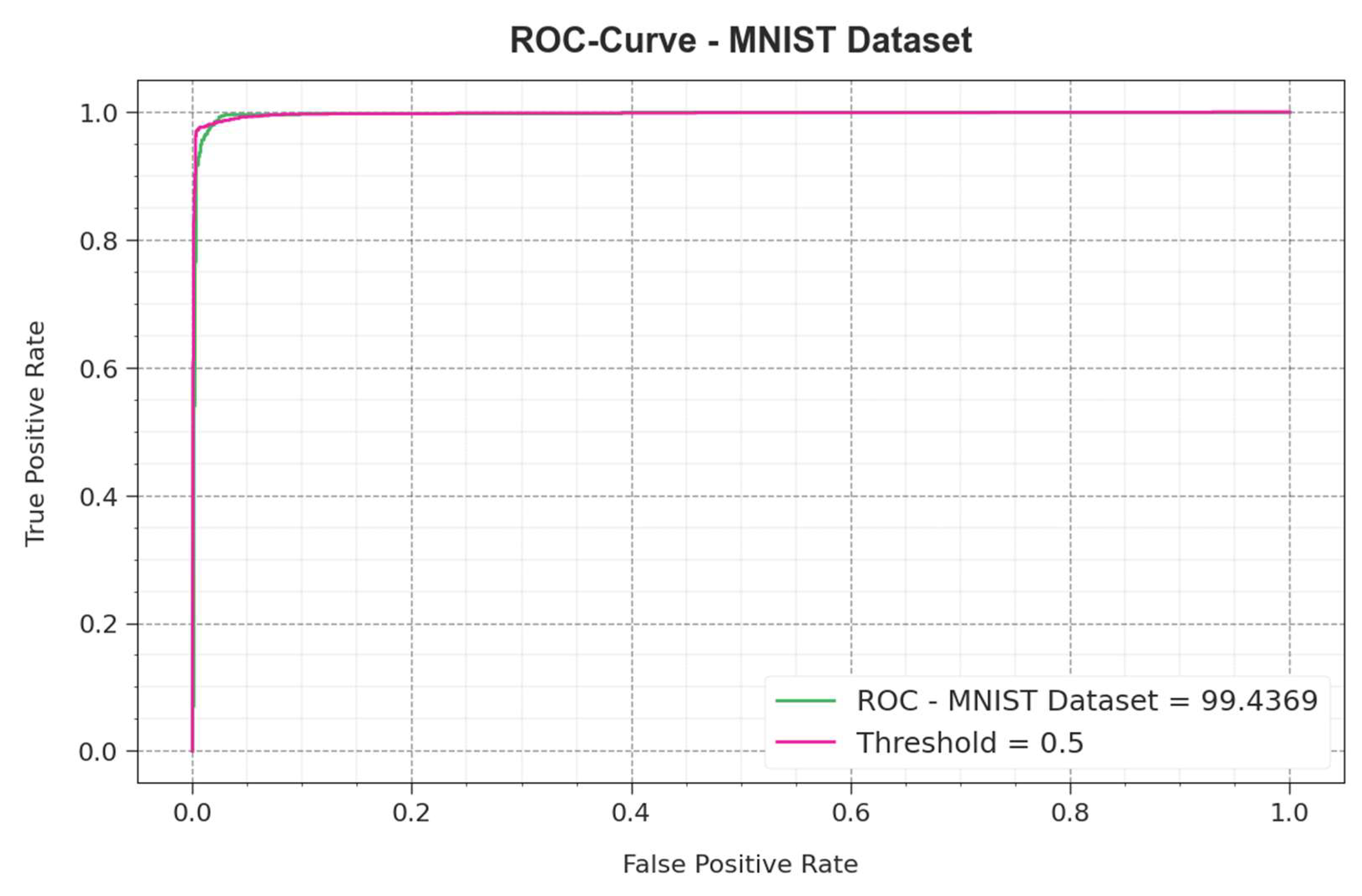
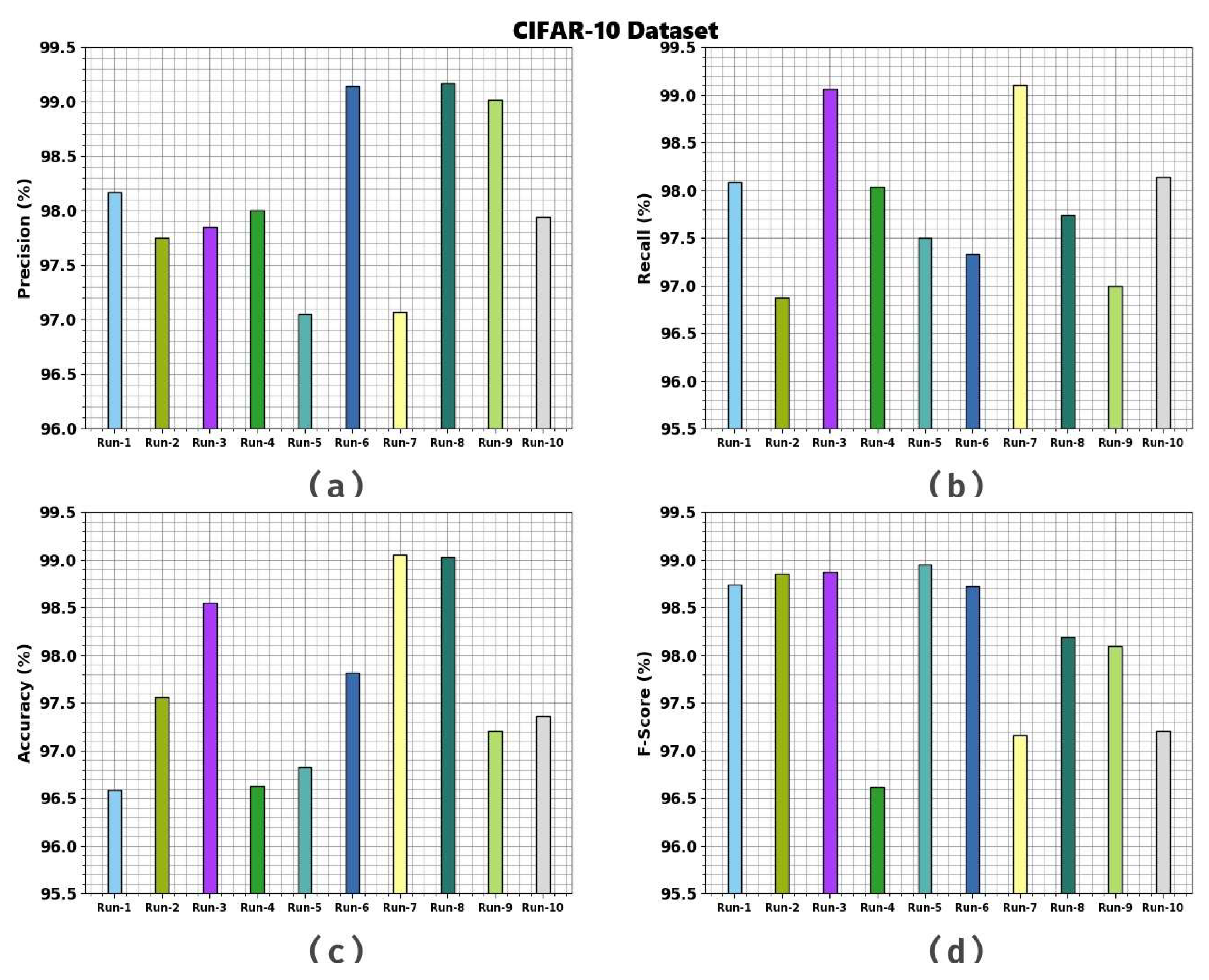
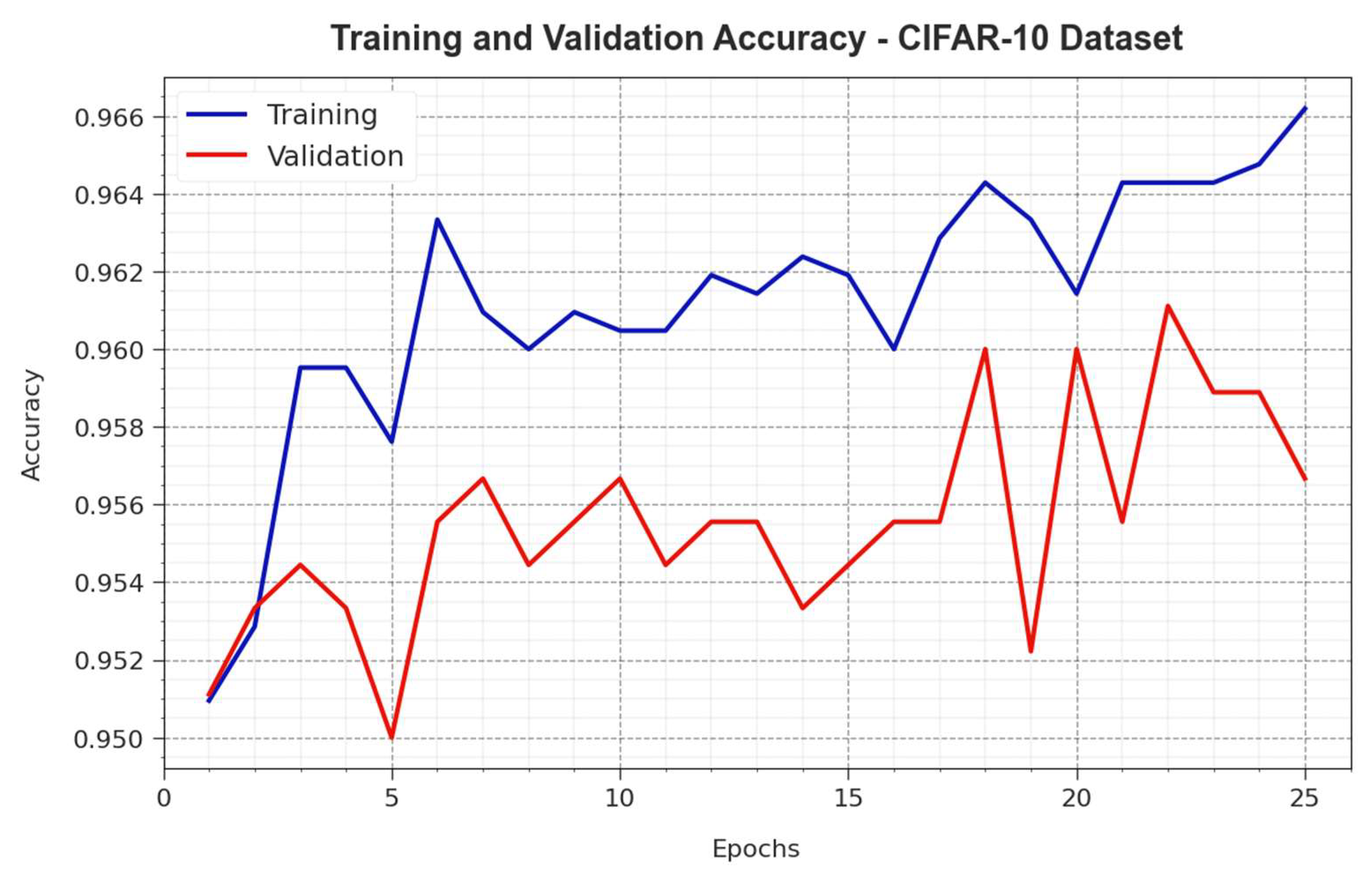
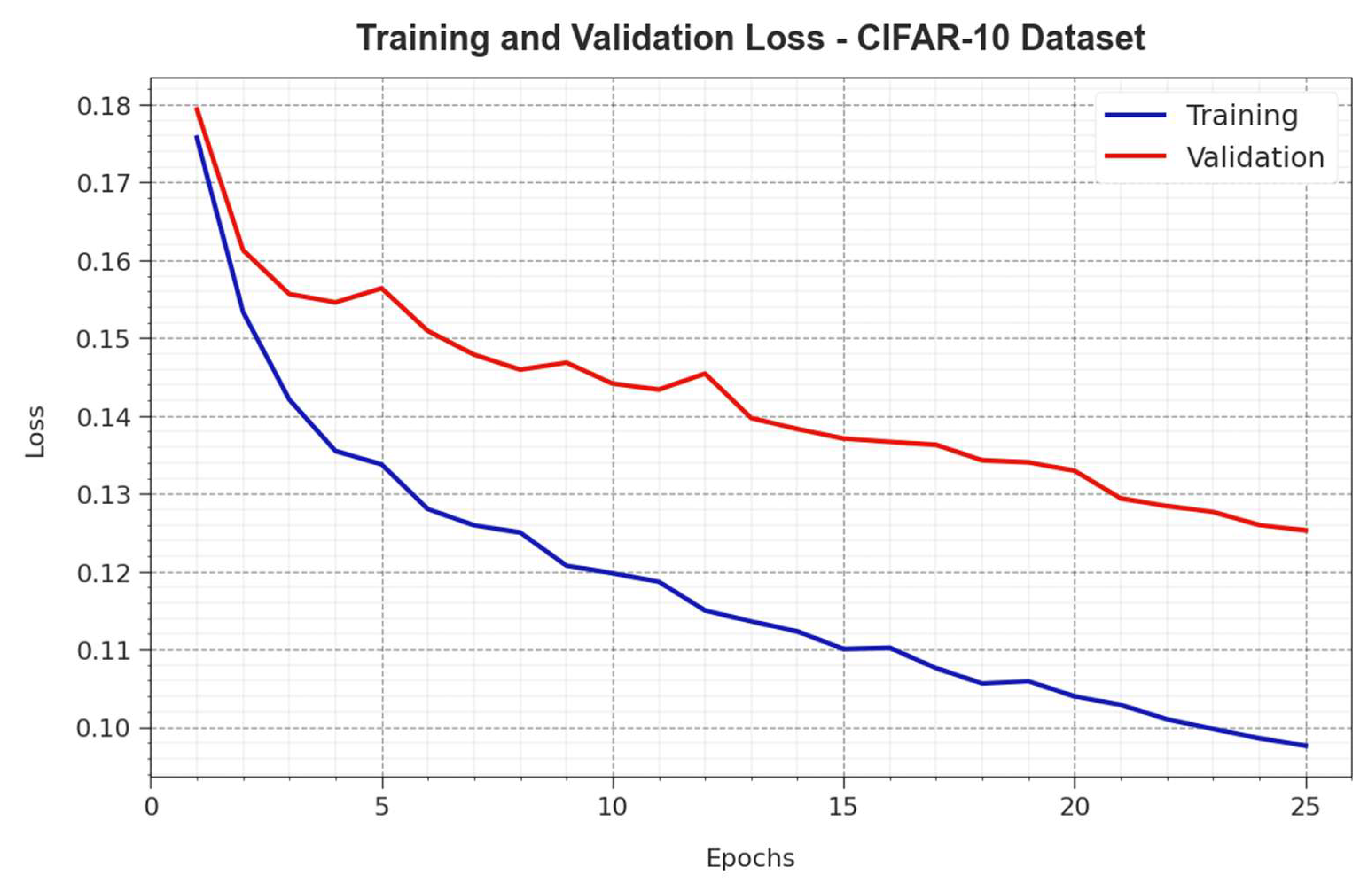
4. Result Analysis and Discussion
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Parveen, A.; Khan, Z.H.; Ahmad, S.N. Block-based copy–move image forgery detection using DCT. Iran J. Comput. Sci. 2019, 2, 89–99. [Google Scholar] [CrossRef]
- Kang, L.; Cheng, X.-P. Copy-move forgery detection in digital image. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing, Yantai, China, 16–18 October 2010; pp. 2419–2421. [Google Scholar]
- Alkawaz, M.H.; Sulong, G.; Saba, T.; Rehman, A. Detection of copy move image forgery based on discrete cosine transform. Neural Comput. Appl. 2018, 30, 183–192. [Google Scholar] [CrossRef]
- Touati, R.; Ferchichi, I.; Messaoudi, I.; Oueslati, A.E.; Lachiri, Z.; Kharrat, M. Pre-Cursor microRNAs from Different Species classification based on features extracted from the image. J. Cybersecur. Inform. Manag. 2021, 3, 5–13. [Google Scholar] [CrossRef]
- Abidin, A.B.Z.; Majid, H.B.A.; Samah, A.B.A.; Hashim, H.B. Copy-move image forgery detection using deep learning methods: A review. In Proceedings of the 2019 6th International Conference on Research and Innovation in Information Systems (ICRIIS), Johor Bahru, Malaysia, 2–3 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Kumar, N.; Meenpal, T. Salient keypoint-based copy–move image forgery detection. Austral. J. Forensic Sci. 2023, 55, 331–354. [Google Scholar] [CrossRef]
- Sabeena, M.; Abraham, L. Convolutional block attention based network for copy-move image forgery detection. Multimedia Tools Appl. 2023, 83, 2383–2405. [Google Scholar] [CrossRef]
- Sadeghi, S.; Dadkhah, S.; Jalab, H.A.; Mazzola, G.; Uliyan, D. State of the art in passive digital image forgery detection: Copy move image forgery. Pattern Anal. Appl. 2017, 21, 291–306. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, Y.; Ren, J.; Zhu, T.; Yan, Y.; Yang, H. Fusion of block and keypoints based approaches for effective copy-move image forgery detection. Multidimens. Syst. Signal Process. 2016, 27, 989–1005. [Google Scholar] [CrossRef]
- Abbas, M.N.; Ansari, M.S.; Asghar, M.N.; Kanwal, N.; O’Neill, T.; Lee, B. Lightweight deep learning model for detection of copy move image forgery with post-processed attacks. In Proceedings of the 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 21–23 January 2021; pp. 125–130. [Google Scholar]
- Kaur, N.; Jindal, N.; Singh, K. A deep learning framework for copy-move forgery detection in digital images. Multimed. Tools Appl. 2023, 82, 17741–17768. [Google Scholar] [CrossRef]
- Sharma, V.; Singh, N. Deep convolutional neural network with ResNet-50 learning algorithm for copy-move forgery detection. In Proceedings of the 2021 7th International Conference on Signal Processing and Communication (ICSC), Noida, India, 25–27 November 2021; pp. 146–150. [Google Scholar]
- Jaiswal, A.K.; Srivastava, R. Detection of copy-move forgery in digital image using multi-scale, multi-stage deep learning model. Neural Process. Lett. 2022, 54, 75–100. [Google Scholar] [CrossRef]
- Chaitra, B.; Reddy, P.B. An approach for copy-move image multiple forgery detection based on an optimized pre-trained deep learning model. Knowl.-Based Syst. 2023, 269, 110508. [Google Scholar]
- Ananthi, M.; Rajkumar, P.; Sabitha, R.; Karthik, S. A secure model on Advanced Fake Image-Feature Network (AFIFN) based on deep learning for image forgery detection. Pattern Recognit. Lett. 2021, 152, 260–266. [Google Scholar]
- Kumar, S.; Gupta, S.K.; Kaur, M.; Gupta, U. VI-NET: A hybrid deep convolutional neural network using VGG and inception V3 model for copy-move forgery classification. J. Vis. Commun. Image Represent. 2022, 89, 103644. [Google Scholar] [CrossRef]
- Gupta, R.; Singh, P.; Alam, T.; Agarwal, S. A deep neural network with hybrid spotted hyena optimizer and grasshopper optimization algorithm for copy move forgery detection. Multimed. Tools Appl. 2023, 82, 24547–24572. [Google Scholar] [CrossRef]
- Krishnaraj, N.; Sivakumar, B.; Kuppusamy, R.; Teekaraman, Y.; Thelkar, A.R. Research Article Design of Automated Deep Learning-Based Fusion Model for Copy-Move Image Forgery Detection. Comput. Intell. Neurosci. 2022, 2022, 8501738. [Google Scholar] [CrossRef] [PubMed]
- Eltoukhy, M.M.; Alsubaei, F.S.; Mortda, A.M.; Hosny, K.M. An efficient convolution neural network method for copy-move video forgery detection. Alex. Eng. J. 2025, 110, 429–437. [Google Scholar] [CrossRef]
- Timothy, D.P.; Santra, A.K. Detecting Digital Image Forgeries with Copy-Move and Splicing Image Analysis using Deep Learning Techniques. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 1299. [Google Scholar] [CrossRef]
- Prakash, C.S.; Jaiprakash, S.P.; Kumar, N. Toward Reliable Image Forensics: Deep Learning-Based Forgery Detection. In Emerging Threats and Countermeasures in Cybersecurity; Wiley: Hoboken, NJ, USA, 2025; pp. 23–37. [Google Scholar]
- Ghai, A.; Kumar, P.; Gupta, S. A deep-learning-based image forgery detection framework for controlling the spread of misinformation. Inf. Technol. People 2024, 37, 966–997. [Google Scholar] [CrossRef]
- Suresh, S.; Krishna, B.; Chaitanya, J. Enhancing Image Forgery Detection on Social Media via GrabCut Segmentation and RA Based MobileNet with MREA for Data Security. In Sustainable Development Using Private AI; CRC Press: Boca Raton, FL, USA, 2025; pp. 214–231. [Google Scholar]
- Singh, K.U.; Rao, A.; Kumar, A.; Varshney, N.; Chundawat, P.S.; Singh, T. Detecting and Locating Image Forgeries with Deep Learning. In Proceedings of the 2024 IEEE International Conference on Contemporary Computing and Communications (InC4), Bangalore, India, 15–16 March 2024; Volume 1, pp. 1–7. [Google Scholar]
- Kaur, H.; Singh, S.K.; Chhabra, A.; Bhardwaj, V.; Saini, R.; Kumar, S.; Arya, V. Chaotic Watermarking for Tamper Detection: Enhancing Robustness and Security in Digital Multimedia. In Digital Forensics and Cyber Crime Investigation; CRC Press: Boca Raton, FL, USA, 2025; pp. 101–112. [Google Scholar]
- Arivazhagan, S.; Russel, N.S.; Saranyaa, M. CNN-based approach for robust detection of copy-move forgery in images. Intel. Artif. 2024, 27, 80–91. [Google Scholar]
- Fatoni, F.; Kurniawan, T.B.; Dewi, D.A.; Zakaria, M.Z.; Muhayeddin, A.M.M. Fake vs Real Image Detection Using Deep Learning Algorithm. J. Appl. Data Sci. 2025, 6, 366–376. [Google Scholar] [CrossRef]
- Kuznetsov, O.; Frontoni, E.; Romeo, L.; Rosati, R. Enhancing copy-move forgery detection through a novel CNN architecture and comprehensive dataset analysis. Multimed. Tools Appl. 2024, 83, 59783–59817. [Google Scholar] [CrossRef]
- Alshehri, M. Breast Cancer Detection and Classification Using Hybrid Feature Selection and DenseXtNet Approach. Mathematics 2023, 11, 4725. [Google Scholar] [CrossRef]
- Santos, M.S.; Valadao, C.T.; Resende, C.Z.; Cavalieri, D.C. Predicting diabetic retinopathy stage using Siamese Convolutional Neural Network. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2024, 12, 2297017. [Google Scholar] [CrossRef]
- Attiya, I.; Al-qaness, M.A.; Abd Elaziz, M.; Aseeri, A.O. Boosting task scheduling in IoT environments using an improved golden jackal optimization and artificial hummingbird algorithm. AIMS Math. 2024, 9, 847–867. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X.; Yao, Y.; Qi, Y.; Peng, L. Regularized Extreme Learning Machine Based on Remora Optimization Algorithm for Printed Matter Illumination Correction. IEEE Access 2024, 12, 3718–3735. [Google Scholar] [CrossRef]
- Ali, H.H.; Ebeed, M.; Fathy, A.; Jurado, F.; Babu, T.S.; Mahmoud, A.A. A New Hybrid Multi-Population GTO-BWO Approach for Parameter Estimation of Photovoltaic Cells and Modules. Sustainability 2023, 15, 11089. [Google Scholar] [CrossRef]
- The MNIST Database of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist (accessed on 24 February 2023).
- CIFAR. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 24 February 2023).
- Maashi, M.; Alamro, H.; Mohsen, H.; Negm, N.; Mohammed, G.P.; Ahmed, N.A.; Ibrahim, S.S.; Alsaid, M.I. Modeling of Reptile Search Algorithm with Deep Learning Approach for Copy Move Image Forgery Detection. IEEE Access 2023, 11, 87297–87304. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MNIST Dataset | ||||
|---|---|---|---|---|
| No. of Runs | ||||
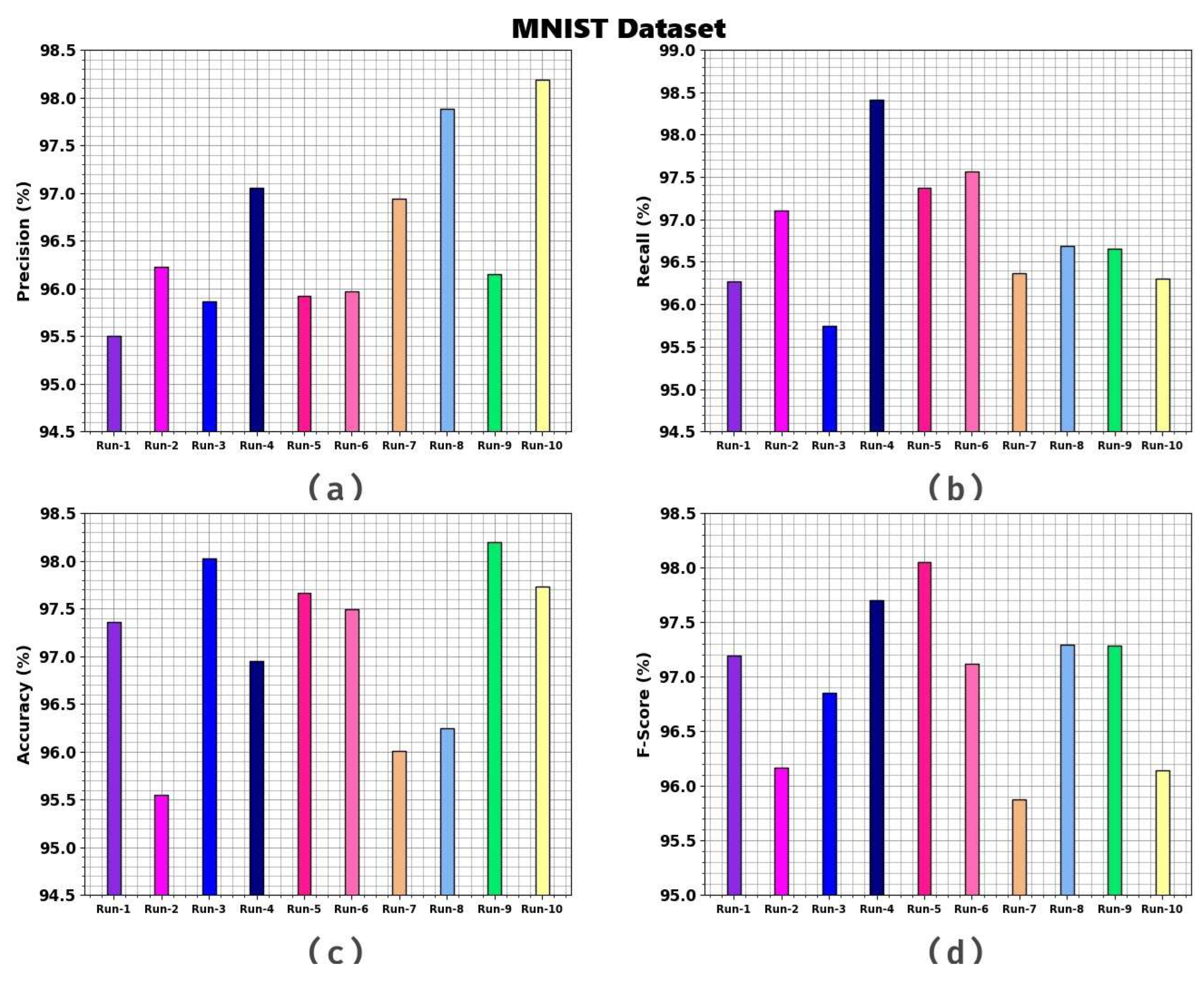
| Run-1 | 95.50 | 96.27 | 97.36 | 97.19 |
| Run-2 | 96.23 | 97.11 | 95.55 | 96.17 |
| Run-3 | 95.86 | 95.75 | 98.02 | 96.85 |
| Run-4 | 97.05 | 98.41 | 96.95 | 97.70 |
| Run-5 | 95.92 | 97.37 | 97.66 | 98.05 |
| Run-6 | 95.97 | 97.57 | 97.49 | 97.12 |
| Run-7 | 96.94 | 96.37 | 96.01 | 95.88 |
| Run-8 | 97.88 | 96.69 | 96.24 | 97.29 |
| Run-9 | 96.15 | 96.66 | 98.20 | 97.28 |
| Run-10 | 98.19 | 96.30 | 97.73 | 96.14 |
| Average | 96.57 | 96.85 | 97.12 | 96.97 |
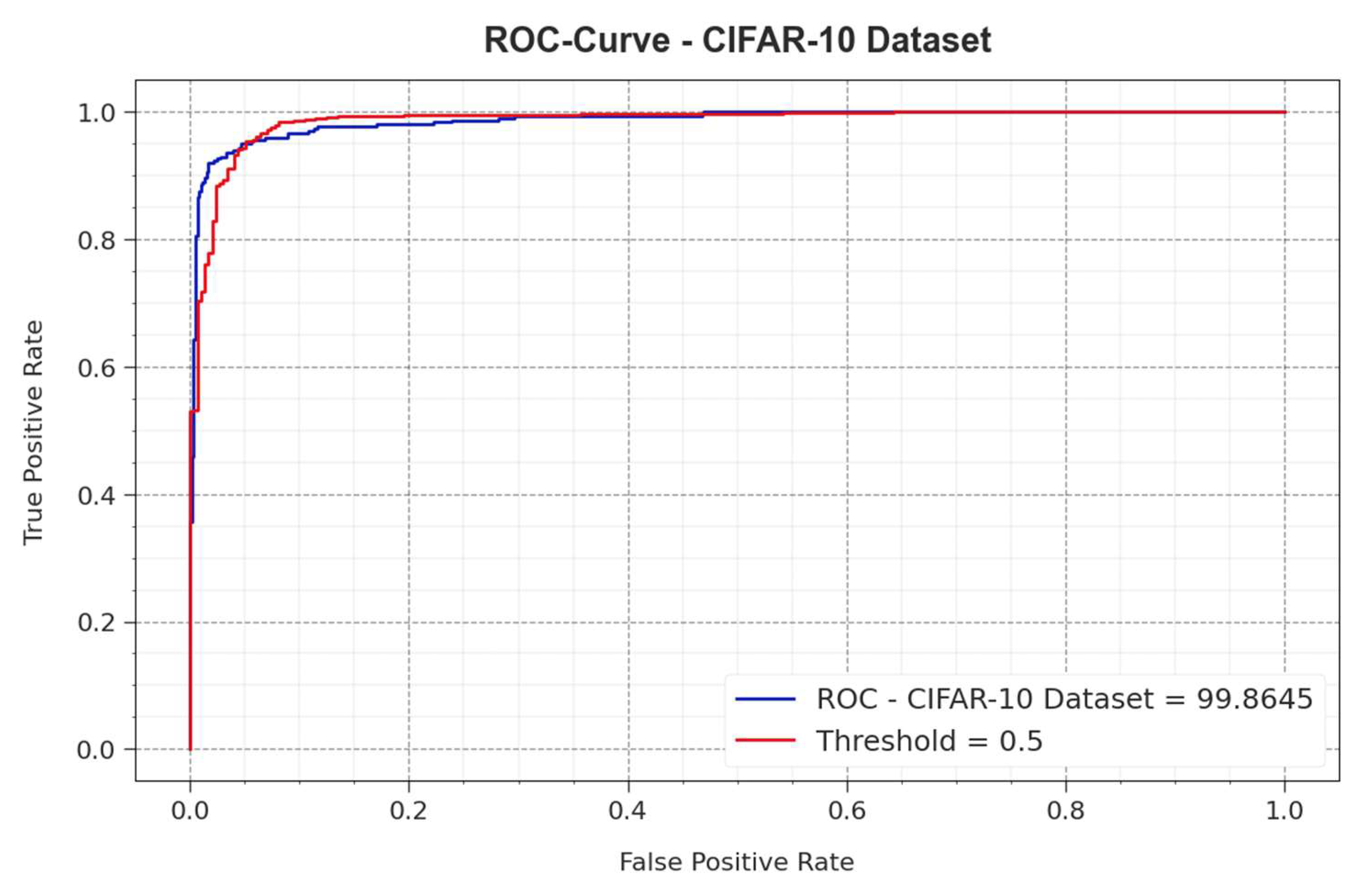
| CIFAR-10 Dataset | ||||
|---|---|---|---|---|
| No. of Runs | ||||
| Run-1 | 98.17 | 98.08 | 96.59 | 98.74 |
| Run-2 | 97.75 | 96.87 | 97.56 | 98.85 |
| Run-3 | 97.85 | 99.06 | 98.55 | 98.87 |
| Run-4 | 98.00 | 98.03 | 96.63 | 96.62 |
| Run-5 | 97.05 | 97.50 | 96.83 | 98.95 |
| Run-6 | 99.14 | 97.33 | 97.82 | 98.72 |
| Run-7 | 97.07 | 99.10 | 99.05 | 97.16 |
| Run-8 | 99.17 | 97.737 | 99.02 | 98.19 |
| Run-9 | 99.02 | 97.001 | 97.21 | 98.09 |
| Run-10 | 97.94 | 98.14 | 97.36 | 97.21 |
| Average | 98.12 | 97.88 | 97.66 | 98.14 |
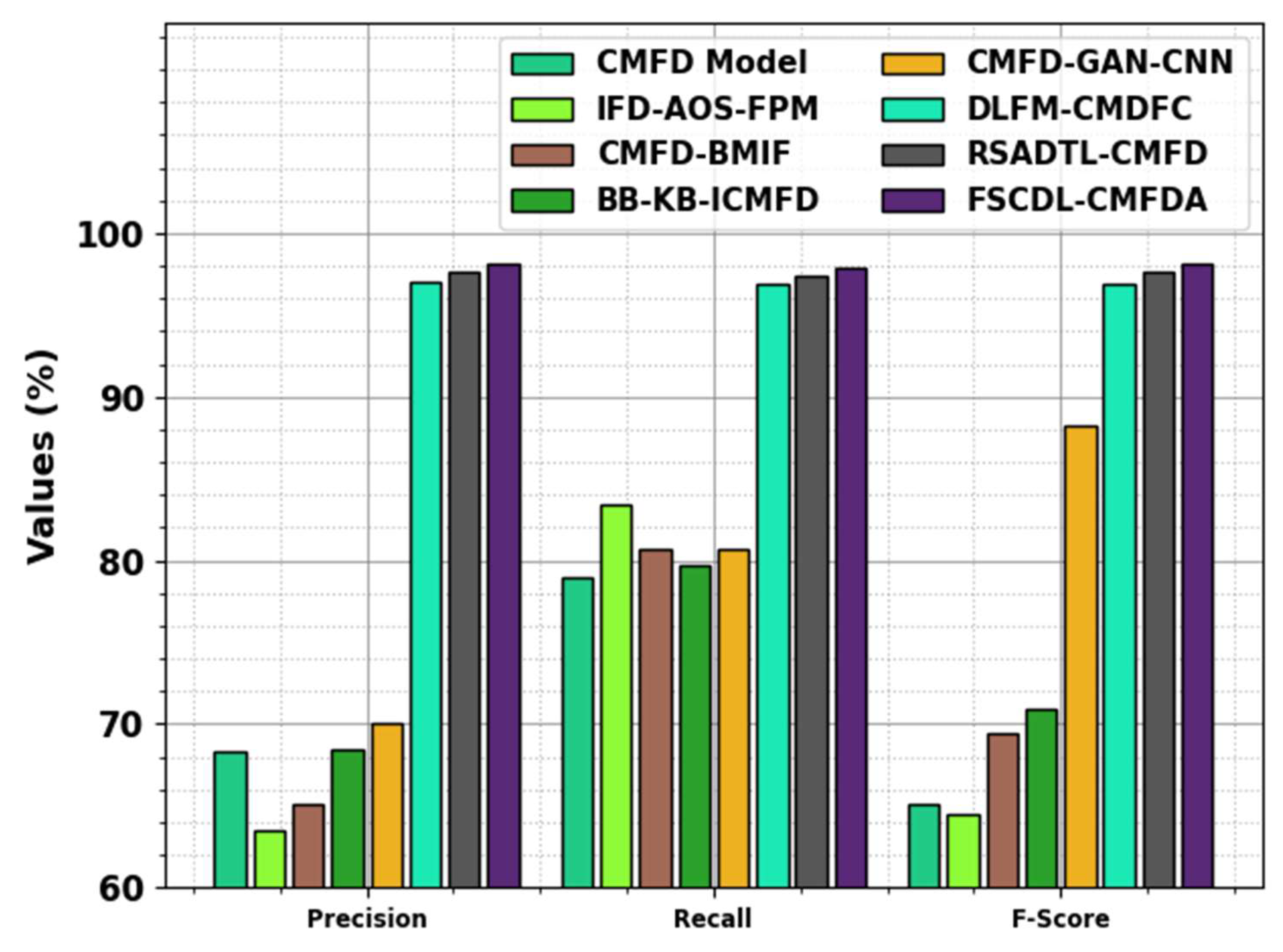
| Methods | |||
|---|---|---|---|
| CMFD | 68.29 | 78.98 | 65.06 |
| IFD-AOS-FPM | 63.53 | 83.36 | 64.46 |
| CMFD-BMIF | 65.09 | 80.69 | 69.43 |
| BB-KB-ICMFD | 68.41 | 79.69 | 70.95 |
| CMFD-GAN-CNN | 70.11 | 80.70 | 88.27 |
| DLFM-CMDFC | 96.97 | 96.91 | 96.88 |
| RSADTL-CMFD | 97.63 | 97.40 | 97.66 |
| FSCDL-CMFDA | 98.12 | 97.88 | 98.14 |
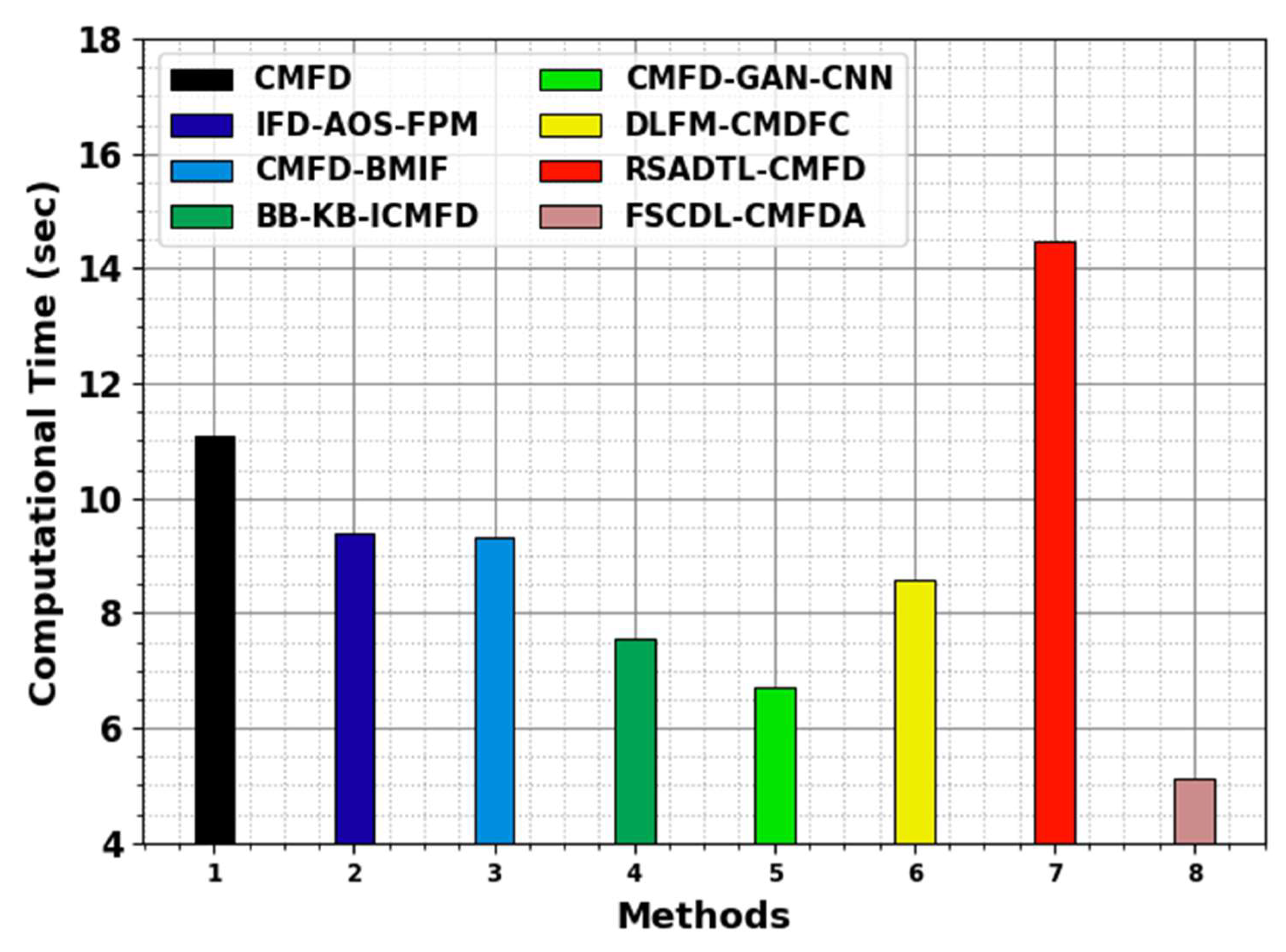
| Methods | CT (s) |
|---|---|
| CMFD | 11.10 |
| IFD-AOS-FPM | 9.39 |
| CMFD-BMIF | 9.31 |
| BB-KB-ICMFD | 7.56 |
| CMFD-GAN-CNN | 6.72 |
| DLFM-CMDFC | 8.59 |
| RSADTL-CMFD | 14.48 |
| FSCDL-CMFDA | 5.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Assiri, M. Synergy of Internet of Things and Software Engineering Approach for Enhanced Copy–Move Image Forgery Detection Model. Electronics 2025, 14, 692. https://doi.org/10.3390/electronics14040692
Assiri M. Synergy of Internet of Things and Software Engineering Approach for Enhanced Copy–Move Image Forgery Detection Model. Electronics. 2025; 14(4):692. https://doi.org/10.3390/electronics14040692
Chicago/Turabian StyleAssiri, Mohammed. 2025. "Synergy of Internet of Things and Software Engineering Approach for Enhanced Copy–Move Image Forgery Detection Model" Electronics 14, no. 4: 692. https://doi.org/10.3390/electronics14040692
APA StyleAssiri, M. (2025). Synergy of Internet of Things and Software Engineering Approach for Enhanced Copy–Move Image Forgery Detection Model. Electronics, 14(4), 692. https://doi.org/10.3390/electronics14040692