Abstract
Commercial multi-document question-answering (QA) applications require a high multi-document retrieval performance, while simultaneously minimizing Application Programming Interface (API) usage costs of large language models (LLMs) and system complexity. To address this need, we designed the Dynamic-Selection-based, Retrieval-Augmented Generation (DS-RAG) framework, which consists of two key modules: an Entity-Preserving Question Decomposition (EPQD) module that effectively decomposes questions while preserving the entities of the original user’s question to reduce unnecessary retrieval and enhance performance, and a Dynamic Input Context Selection (DICS) module that optimizes the LLM input context based on the content of the user’s question, thereby minimizing API usage. We evaluated the proposed framework on a newly constructed dataset containing questions that require up to four multi-document retrievals. Experimental results demonstrated the new framework’s superior performance in terms of retrieval quality, input context optimization, and final answer generation compared to existing approaches. Consequently, the DS-RAG framework can be leveraged to develop domain-specific commercial QA applications in the future.
1. Introduction
Retrieval-augmented generation (RAG) is a technique that enhances the accuracy and relevance of answers to user queries by integrating external information into a large language model (LLM) [1,2,3,4]. Historically, RAG has been employed in general-purpose question-answering (QA) services to address the issue of hallucination in LLMs, using external data as an auxiliary resource to refine user queries and combine them with the LLM’s inherent knowledge, thereby yielding more accurate responses. Recently, commercially available RAG-based QA systems have been introduced in various domains, including finance, defense, healthcare, and law. Given the high costs, as well as security and privacy concerns, associated with training LLMs on proprietary documents, these systems typically maintain an internal database and employ a retriever to obtain the necessary context. The LLM then summarizes this context to generate natural-language answers or perform simple reasoning, such as comparisons, when necessary.
When developing a commercial QA application that leverages internal, domain-specific documents, the following considerations are critical:
- Consideration 1: Context Retrieval Performance. All essential context for generating accurate answers must be retrieved, as the LLM’s internal knowledge alone may be insufficient. Consequently, the retrieval process should capture as much relevant input context as possible to minimize the likelihood of generating incorrect answers.
- Consideration 2: Cost Efficiency with Commercial LLM APIs. Building and operating an on-premises LLM can be prohibitively expensive, prompting many organizations to rely on commercial LLM APIs. However, as the prompt size increases, so does the associated token cost. Therefore, strategies to minimize token usage—such as filtering out redundant or unnecessary document chunks—are essential for cost-effective operation.
- Consideration 3: Service Operation Overhead. Unlike general-purpose QA services, commercial QA applications often serve a smaller user base and thus operate on a reduced scale. Securing a large-scale infrastructure may be impractical in such cases, making it necessary to reduce system complexity and minimize the computing overhead.
In commercial QA applications, the retriever in a RAG framework commonly constructs an internal document store as a vector space to balance implementation complexity and processing speed [5]. It typically retrieves a fixed number of fixed-size document chunks based on similarity scores computed by a bi-encoder such as Dense Passage Retriever (DPR) [6]. This approach is effective when the context required to answer a user question is contained within a single document chunk. However, for multi-document questions that require multiple, distinct retrieved chunks, the necessary context may be missed if it is spread across various chunks, making it difficult to generate an accurate answer. Since internal documents often contain discrete and fragmented information, most user questions, even those not explicitly requesting a singular piece of data, tend to fall into the multi-document category. A straightforward attempt to resolve this issue by substantially increasing the size or number of retrieved chunks would drastically inflate the operational costs and overhead, as discussed in Considerations 1 and 2.
A common strategy to address this issue is question decomposition (QD), which breaks down the user’s original question into smaller sub-questions, retrieving document chunks for each. To apply QD effectively, it is crucial to ensure that all necessary chunks for the LLM’s input context are gathered with minimal omissions. Existing methods for generating sub-questions can be classified into three main categories: the first employs decomposition models [7,8,9], the second utilizes graph-based decomposition [10], and the third leverages LLMs [3,11,12]. The first and second approaches can be inefficient, as they often require complex models or functions for QD. In contrast, the third approach capitalizes on the LLM’s advanced natural language processing capabilities via an API, enabling sub-question creation in a simpler and more efficient manner. While this method does incur additional costs, it remains more efficient overall due to the relatively small size of user questions. Nevertheless, because decoder-based generative AI can occasionally omit or alter the original question during QD, careful prompt design is essential to mitigate these risks.
While QD increases the likelihood of retrieving all the document chunks required to generate an answer, it also raises the LLM API cost described in Consideration 2, as the quantity of retrieved chunks expands in proportion to the number of sub-questions. One approach to mitigate this issue is to initially retrieve chunks using bi-encoders, then re-rank them via cross-encoders [13,14,15,16], and finally, provide only a limited number of the most relevant chunks as input context to the LLM. In this setup, the best retrieval result for each sub-question can be passed to the LLM; however, if the user’s question includes a substantial amount of extraneous or overlapping information across sub-questions, this approach may still result in unnecessary LLM input, thereby further inflating the costs outlined in Consideration 2. A second approach is to aggregate the retrieved chunks for each sub-question, removing redundant or irrelevant information. This method can be subdivided into techniques that use the LLM itself and those that use re-composition models. Hasson et al. [17] proposed leveraging an LLM to merge the retrieved chunks and eliminate redundancy. Nevertheless, this strategy does not reduce the LLM API cost from Consideration 2, because all chunks must still be fed into the LLM. Conversely, Perez et al. [8] and Izacard et al. [18] introduced approaches that derive final answers from retrieved chunks via a seq2seq [19]-based re-composition model. While they can fuse multiple chunks, they remain limited in filtering out superfluous data and do not fully exploit modern LLMs’ advanced natural language processing capabilities.
Additionally, graph-based RAG methods structure documents as graphs and use them to optimize LLM prompting or employ a graph-based retriever [20,21,22]. These methods effectively organize internal documents and enhance retrieval performance, but more extensive resources are required to build and maintain them compared to vector embedding-based retrievals, which can be inefficient for commercial environments (see Consideration 3) where documents are continuously created or updated.
In this paper, we propose a novel Dynamic-Selection-Based RAG (DS-RAG) framework designed to address Considerations 1 through 3 for commercial multi-document QA applications. First, we designed an Entity-Preserving Question Decomposition (EPQD) module, which creates new prompts in the QD process. To prevent any transformation or omission in a complex original question, the EPQD module segments the question and then generates sub-questions for each segment using these newly created prompts. Next, we introduce a Dynamic Input Context Selector (DICS) module, which selects the retrieved chunks for input context rather than reordering or aggregating them. This module defines and applies selection criteria to identify and distinguish the necessary information, and then it selects the most suitable chunks per criterion to form the final input context. In doing so, it satisfies Considerations 1 and 2 by filtering out redundant or unnecessary content. In particular, existing RAG systems often fix the number of retrieved chunks in the input context to a top-K value, which can lead to waste or insufficiency if the information required for multi-document questions varies. The proposed module overcomes this limitation by dynamically adjusting the input context size based on the number of selection criteria. Additionally, DICS performs graph embedding for the selection criteria and text embedding for the retrieved chunks, followed by similarity analysis between the two. This design leverages the characteristics of graph embedding to enable customization based on the application’s purpose, the domain’s data characteristics, and the question format. Furthermore, it reduces the operational burden required for graphing all retrieved chunks, thereby aligning with Consideration 3. Finally, our framework is implemented by extending the LangChain [3].
The remainder of this paper is organized as follows. Section 2 presents the architecture of our proposed DS-RAG framework, including the designs of the EPQD and DICS modules. Section 3 details the dataset, experimental setup for performance evaluation, and corresponding results. Finally, Section 4 discusses the limitations of our framework and potential directions for future enhancement.
2. Architecture and Design of the DS-RAG Framework
This section introduces the architecture of our Dynamic-Selection-based, Retrieval-Augmented Generation (DS-RAG) framework and provides a detailed explanation of the methodology employed in the Entity-Preserving Question Decomposition (EPQD) and Dynamic Selection-Based RAG (DICS) modules.
2.1. DS-RAG Framework Architecture
The DS-RAG framework comprises a vector database, a retriever, the EPQD module, the DICS module, and an external commercial large language model (LLM) that interfaces with them via an Application Programming Interface (API). The vector database and retriever utilize those provided by the LangChain framework [3], while the LLM employs GPT4o [23]. The EPQD module decomposes the user’s original question into sub-questions, which are then forwarded to both the retriever and the DICS module. The DICS module establishes selection criteria based on the sub-questions, analyzes the retrieved chunks for similarity, constructs the final input context, and generates an answer using the LLM API. The functional architecture of the overall framework is illustrated in Figure 1.
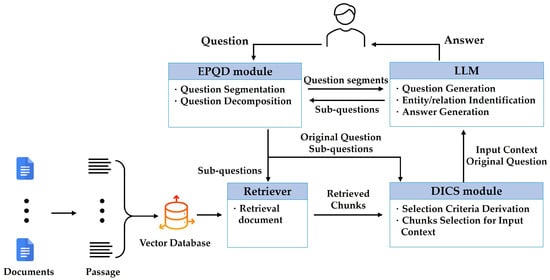
Figure 1.
Functional architecture of the DS-RAG framework.
2.2. Methodology of the EPQD Module
The purpose of question decomposition (QD) in a commercial multi-document question-answering (QA) application is to generate sub-questions as retrieval queries, thereby obtaining the retrieved chunks required to formulate answers within an LLM. Since no single document typically contains a direct answer to the user’s original question, and because the LLM’s inherent knowledge cannot always be fully utilized, all basic chunks necessary for generating an answer must be included in the input context. For example, if a user asks, “Which company had a larger operating profit in 2024, Apple or Amazon?”, there may not be a document that directly compares the two companies’ operating profits. Consequently, the RAG system must locate information regarding “Apple’s operating profit in 2024” and “Amazon’s operating profit in 2024”, provide these to the LLM, and allow the model’s inference capability to compare the two figures and produce an answer.
As mentioned in Section 1, LLMs enable straightforward and efficient sub-question generation, and yet this process can introduce variations or omissions relative to the original question. We identified such issues through a case study and propose the Entity Preserving Question Decomposition (EPQD) module to address them.
2.2.1. Case Study of the Existing Method
We conducted a case study using the most commonly adopted QD prompts from the LangChain framework [3] and bridge-type questions from the HotpotQA dataset [24]. Three key issues were identified:
- Issue 1: Excessive Sub-Question Generation. This refers to generating superfluous sub-questions that are unnecessary for producing an answer. In Table 1, sub-questions 1 and 2 (“Who is Charlie Chaplin?” and “Who is Bruce Bilson?”) are not needed in light of sub-questions 3 and 4. These extra sub-questions needlessly broaden the retrieval scope, increase the number of retrieved chunks, and reduce system efficiency.
 Table 1. Example of excessive sub-question generation in the QD Process.
Table 1. Example of excessive sub-question generation in the QD Process.
- 2.
- Issue 2: Missing Key Information. In some instances, a sub-question omits essential details required to retrieve the correct chunks for generating an answer. For example, the original question in Table 2 requests the number of derivative breeds for two dog breeds, indicating that the “number of derivative breeds from the original” is a crucial piece of information. How-ever, the generated sub-question neglects this component, potentially retrieving only a partial list of derivative breeds for “German Spitz” and “Norfolk”.
Table 2. Example of missing key information in the QD Process.
- 3.
- Issue 3: Question Variations. Here, the sub-question includes content unrelated to the original inquiry. Sub-question 3 in Table 3 introduces an entirely new topic that does not appear in the original prompt, and the associated retrieved chunk may confuse the LLM’s answer generation.
Table 3. Example of question variations in the QD process.
These issues become more frequent as questions grow in complexity or length, and they can occur randomly when performing QD with an LLM. Although the unnecessary sub-questions arising from Issues 1 and 3 can sometimes be filtered out during the selection process, doing so still imposes an additional overhead. In contrast, Issue 2 is critical because vital information might be lost entirely. Therefore, a more robust QD method is needed to mitigate these challenges.
2.2.2. Design of EPQD
The main objective of our EPQD design is to preserve, as much as possible, the entities in the original question within each sub-question, thereby preventing the omission issues outlined in Issue 2, while simultaneously avoiding the creation of duplicate or additional sub-questions (Issues 1 and 3). To achieve this, we first segment the original question into multiple phrases, and then provide both the segmented phrases and the original question as input to the LLM API to generate sub-questions for each phrase. The details of this design are as follows.
- Segmentation Rule:
There are numerous ways to segment a sentence, but our focus is semantic: we split the original question based on conjunctions or commas. This approach is particularly helpful for multi-document questions, as the targeted entities or items are often separated by conjunctions or commas. However, to avoid over-segmentation, we apply exceptions—e.g., quoted text enclosed by quotation marks (“ ”) is not split.
- Prompt Design:
When devising the prompt instructions for sub-question generation, we addressed the following three considerations (Table 4 provides the full prompt instruction):
Table 4.
Prompt instruction of EPQD.
- Consideration 1: Preserve the Original Question. Segmenting a question using conjunctions and commas effectively simplifies complex queries and facilitates the efficient generation of sub-questions by the LLM. However, excessive segmentation may result in overly brief phrases that risk losing the original question’s context and intent. To mitigate this, we generate sub-questions by incorporating each isolated phrase alongside the entire original question. This approach effectively addresses Section 2.2.1: Issues 2 and 3.
- Consideration 2: Ensure Completeness of Each Sub-Question. If sub-questions are overly fragmented, the retrieval may become excessively broad and risk omitting an essential document chunk. We thus ensure that each sub-question is grammatically intact and does not exceed the scope of the original question. This measure addresses Section 2.2.1: Issue 2.
- Consideration 3: Limit the Number of Sub-Questions. To reduce the possibility of redundant or extraneous sub-questions’ generation, we restrict the prompt to generate only one sub-question per segmented phrase. This addresses the inefficiency described in Section 2.2.1: Issue 1.
Moreover, we employ few-shot learning [25] to effectively generate sub-questions as retrieval queries and handle various exceptions. The examples we added to the prompt address two key objectives:
- Preserve Context. Questions in the HotpotQA dataset [24], for instance, may lose or alter the context and omit essential information when split by conjunctions or commas, resulting in overly simplistic sub-clauses, even if the original question itself is relatively straightforward. This phenomenon triggers Problems 2 and 3, so we added an extra example to the prompt to alleviate such issues.
- Remove Duplicate Entities. When generating sub-questions by referencing the preceding parts of the original question, it is possible for unnecessary retrieved chunks to be redundantly included across multiple sub-questions. This redundancy can reduce the efficiency of retrieval. To mitigate this issue, we incorporated additional examples into the prompt to minimize the inclusion of extraneous content in the generated sub-questions.
- Case Study of EPQD:
Table 5 presents the EPQD module’s generation of sub-questions for the sample questions associated with Section 2.2.1: Issues 1–3. For the first question, the EPQD results do not produce the superfluous sub-questions 1 and 2 observed in the LangChain [3]. For the second question, we note that the key phrase “How many derivative breeds…” is preserved, thus retaining the critical piece of information specified in the original question. Finally, in the third question, the EPQD module does not generate sub-question 3, which lies outside the scope of the original question. In Section 3.2, we present a quantitative comparison of the LangChain [3] and our EPQD module.
Table 5.
Comparative analysis of sub-question generation examples in LangChain and EPQD.
2.3. Methodology of the DICS Module
As discussed in Section 2.2, the EPQD approach serves two main purposes: (1) ensuring that retrieved chunks needed for generating the input context are included, and (2) minimizing irrelevant chunks. However, depending on the format and content of the original question, extraneous chunks may still be retrieved. To address this issue and to resolve the concern highlighted in Section 1: Consideration 2, we propose the DICS module. This module dynamically determines both the number of retrieved chunks and which specific chunks should be included in the input context, based on the composition of the original question. The DICS module comprises two primary functions: (1) deriving selection criteria from the original question, and (2) selecting the relevant chunks for the input context in accordance with these criteria. The following sections describe these two functions in detail.
2.3.1. Deriving Selection Criteria
Our key idea for deriving selection criteria is to isolate the common element in a multi-document question that effectively serves as a “bridge” for dividing the question content. This common element is then used to segment the question, and the resulting segments become the selection criteria. For example, consider the question: “Who has the earliest birth date for Taylor Swift or Neil Armstrong, who grew up in Wapakoneta?” The critical information for constructing the LLM input is twofold: “birth date of Taylor Swift” and “birth date of Neil Armstrong, who grew up in Wapakoneta”. These two pieces of information constitute the selection criteria, and their shared element is “birth date”. To identify this element in the original question and segment the content accordingly, we employ a graph-based approach. Figure 2 illustrates the process of constructing a question graph using sub-questions, identifying the common element (i.e., the core node), and deriving the selection criteria from the core node. The reason we do not directly convert the original question into a question graph is that shorter and simpler sentences reduce the likelihood of errors during graph generation. The detailed procedures for each step are described below.
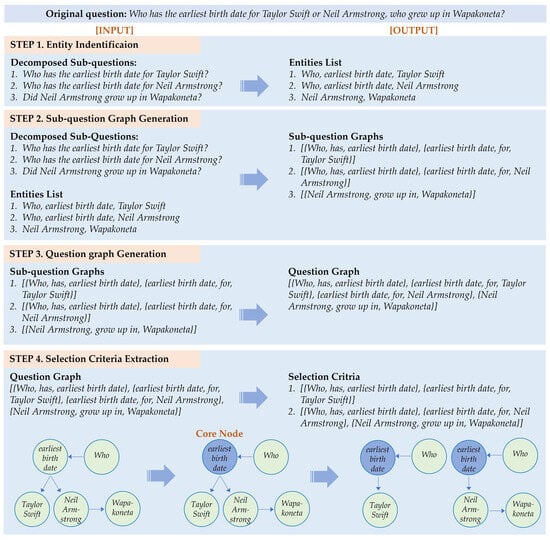
Figure 2.
Example of deriving selection criteria.
- Step 1. Entity Identification:
The first step in building a question graph is to generate graph nodes for each sub-question. To do this, we identify entities and treat them as nodes. Conventionally, entity extraction from sentences is performed using pre-trained language models, such as RoBERTa [26] and spaCy [27], which rely on pre-trained entity types. However, these models often struggle to recognize entities not covered by their training data, posing challenges for commercial applications focused on specific domains. Additional fine-tuning can help but increases implementation complexity. Recent advances in LLMs have enabled entity extraction through prompt engineering and few-shot learning [25]. In our research, we leverage these LLM-based techniques to identify entities in the question, subsequently categorizing them as nodes and edges in a question graph. Building on previous findings [28,29,30,31,32,33], we designed a succinct prompt for entity identification, provided in Appendix A.1.
- Step 2. Sub-Question Graph Generation:
In the second step, we create a graph for each sub-question. Following the node-generation process in Step 1, we add edges to complete the triple set. In this research, we define triples as (source node, edge, target node), which correspond to (subject, predicate, object) in conventional relation extraction tasks. We consider the relations in each sub-question as edges.
Existing approaches to relation extraction largely rely on encoder-based models (e.g., BERT [33]) or decoder-based LLMs [34,35,36]. Encoder-based methods inherit the same limitations mentioned in Step 1, while decoder-based methods may generate additional relation types not explicitly stated in the original text. In our approach, neither the derivation of selection criteria nor the selection of chunks to include in the input context utilizes the content of the graph edges (i.e., the relation types). Instead, we only need the edges’ direction. Therefore, the primary concern for relation extraction in the DICS module is to correctly identify pairs of entities for each relation Additionally, it is crucial to prevent the question graph from becoming unnecessarily complex by avoiding the generation of new relation types, unmentioned in the sub-question, by the LLM.
Case studies using the HotpotQA dataset [24] and the Multi-hop-RAG dataset [37] show that when the relation types explicitly present in the question are provided as input, the LLM is effective at identifying the correct entity pairs. Therefore, we generate the triple set using the following process. For consistency, the edge direction is determined based on the order in which the entities appear in the sub-question, ensuring that the edge is directed from the entity mentioned earlier to the one mentioned later. The instructions for the designed prompt are detailed in Appendix A.2.
- Extract the components, excluding the entities, from the sub-question to identify the relation type.
- Use the LLM to extract subject and target entity pairs for each relation type, storing the resulting pairs as a triple set. The entity appearing first in the sub-question is designated as the source node, and the next as the target node. We also record each node’s sub-question number and a unique node ID.
- If any entity remains unpaired after Step 2, we create a new triple by connecting the remaining entity to its immediately preceding entity via a null edge.
- Step 3. Question Graph Generation:
In the third step, the triple sets derived from each sub-question are integrated into a single question graph. During this process, redundant triples are removed to simplify the graph. If multiple edges exist between the same pair of nodes, all but the first identified edge, determined by the sub-question number and node ID of the source node, are discarded.
- Step 4. Selection Criteria Extraction:
Finally, we extract the selection criteria from the integrated question graph by focusing on the core node. This procedure comprises two sub-steps:
- Identifying the Core Node. Nodes with an in-degree of two or more are treated as candidate core nodes. Among these candidates, the node highest in the question hierarchy is chosen as the core node, allowing selection criteria to be identified at the most general level of the original question. Algorithm 1 provides the details of this process. The time and space complexities for identifying the core node are determined by the number of nodes N and edges E in the question graph. Since the question graph is constructed based on syntactic and semantic relationships, resulting in limited inter-node connectivity, it exhibits the characteristics of a sparse graph. Initialization and graph traversal are executed at most N + E times, and if there are multiple root nodes, a priority-based queue sorting is performed up to NlogN times. Therefore, the time complexity of Algorithm 1 is O(NlogN), and its space complexity is O(N + E).
| Algorithm 1 Identifying the Core Node |
| [Input] Gq: Represents the question graph, comprising the triple set as (sn, e, tn) Each node has the following attributes:
core_node: key node selected from the Gq according to the given exploration rules 1: Initialize question_word_node[ ] ← None, core_node ← None, outgoing_edges[ ] ← None 2: root_node_list[ ] ← Nodes in tripes with in-degree = 0 3: if Number of root_node_list = 1 then 4: current_node ← root_node_list.get_first ( ) 5: while current_node is not leaf node do 6: outgoing_edges.insert (get_outgoing_edges (current_node)) 7: if Number of outgoing_edges ≥ 2 then 8: core_node ← current_node 9: if current_node is question word then 10: root_node_list.insert (Nodes connected by outgoing_edges) 11: end if 12: break 13: end if 14: else current_node ← Node connected by outgoing_edges 16: end if 17: end while 18: end if 19: if number of root_node_list > 1 then 20: node_queue[ ] ← Sorted nodes of root_node_list[ ] by sub-question_number, node_ID in ascending order 21: for each node ∈ node_queue[ ] do 22: outgoing_edges.insert (get_outgoing_edges (node)) 23: if Number of outgoing_edges > 2 then 24: core_node ← node 25: if core_node is question word then 26: question_word_node.insert (core_node) 27: core_node ← None 28: else break 29: end if 30: else 31: next_nodes ← node connected by outgoing_edges 32: node_queue.append (next_nodes) 33: end if 34: end for 35: end if 36: if core_node is None then 37: core_node ← question_ word_node.get_first ( ) 38: end if 39: return core_node |
- 2.
- Extracting the Selection Criteria. After identifying the core node, we extract the selection criteria from the question graph. In the subsequent chunk selection for input context, the scope of reflection around the core node can be flexibly determined according to the range of questions intended for selection. Algorithm 2 outlines the selection criteria extraction process. The process of initializing and storing the triple set incoming to the core node is executed at most N + E times, while the repeated BFS traversals to store the triple set outgoing from the core node are performed fewer than N(N + E) times. Therefore, the time complexity of Algorithm 2 is O(N2 + NE) and the space complexity is O(N + E). Moreover, since most datasets contain at most several dozen nodes in the question graph, Algorithm 2 can be efficiently executed even in desktop-level computing environments.
| Algorithm 2 Selection Criteria Extraction |
| [Input] Gq, core_node [Output] criteria_list[ ]: The Selection Criteria List derived from the Question Graph (Gq). It is represented as a list of the triple set, (sn, e, tn) 1: Initialize criteria_list[ ] ← None, predecessors_list[ ] ← None 2: core_node_successors[ ] ← get_outgoing_nodes (core_node) 3: core_node_predecessors[ ] ← get_incoming_nodes (core_node) 4: for each incoming_node ∈ core_node_predecessors[ ] do 5: edge ← find_edge_between_nodes (Gq, core_node, incoming_node) 6: predecessors_list[ ] ← Add the triple (core_node, edge, incoming_node) 7: Explore all predecessors of incoming_node using Breadth-First Search (BFS) and add all triple to predecessors_list[ ] 8: end for 9: for each outgoing_node ∈ core_node_successors[ ] do 10: Create a new criteria 11: edge ← find_edge_between_nodes (Gq, core_node, outgoing_node) 12: criteria ← Add the triple (core_node, edge, outgoing_node) 13: Explore all successors of outgoing_node using Breadth-First Search (BFS) and add all triple to criteria 14: criteria ← Add all triple in predecessors_list[ ] 15: criteria_list.insert (criteria) 16: end for 17: return criteria_list[ ] |
2.3.2. Chunk Selection for Input Context
As previously mentioned, DS-RAG does not create input text by using a fixed number of retrieved chunks. Instead, it selects one retrieved chunk for each selection criterion derived in the preceding stage to construct the input context. This approach aims to minimize application operational costs, as discussed in Section 1, Consideration 2. To achieve this, we designed a graph-based selection (GS) model that graph-embeds the selection criteria, text-embeds the retrieved chunks, and selects chunks by analyzing the cosine similarity between these two embeddings.
The selection criteria are transmitted in graph format from the previous stage. By embedding the graph directly without converting it to text, we prevent potential information loss during the transformation process and allow for selective utilization of relevant parts of the user’s question as needed. This is particularly effective when the original question comprises core content alongside ancillary explanations. For example, consider the question discussed in Section 2.3.1: “Who has the earliest birth date for Taylor Swift or Neil Armstrong, who grew up in Wapakoneta?” In this instance, “who grew up in Wapakoneta?” is ancillary information describing “Neil Armstrong” and is unnecessary for generating the final answer via the LLM. However, if multiple individuals share the same name, such information may be required to identify the specific individual mentioned in the original question. The necessity of this information depends on the characteristics of the data in the domain where the application is utilized. Consequently, the ability to selectively incorporate this information increases the flexibility of developing a QA system. To derive the selection criteria, we identified a core node and ensured flexibility by allowing each application to selectively determine how many hops from the core node should be included for chunk selection. Figure 3 illustrates the structure of the proposed GS model, and the detailed design is presented as follows.
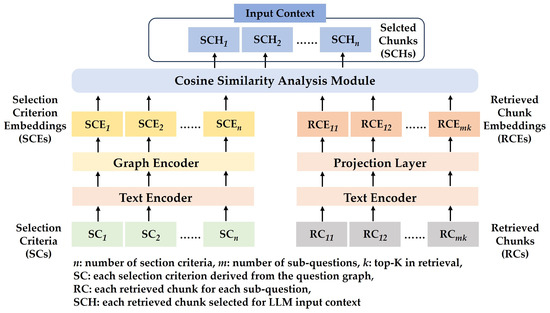
Figure 3.
Functional architecture of GS model.
- Selection Criteria Embedding:
The acquisition of embedding vectors for each selection criterion used in chunk selection involves first text-embedding the internal information of the graph using a text encoder, followed by graph embedding, which leverages the relationships between nodes through a graph encoder, and finally, extracting the representations of the desired node. In the proposed graph-based selection (GS) model, the text encoder employs the text-embedding-3-large model [38] because it is pre-trained on extensive datasets and supports higher dimensionality compared to other models, thereby enhancing efficiency in the subsequent graph-encoding stage. Let xn represent the information stored in node n, and the collection of text embeddings for all nodes, denoted as V*, is represented as follows, where has a value of 3072:
In order to enhance graph encoding performance and facilitate selection based on the entities in the original question, relation types are not embedded. Instead, edges are represented using connection information based on each node’s ID. The set of edges, , is defined accordingly, where and indicate the IDs of each node:
Next, the graph encoder updates the representation of the current node by incorporating information from its connected nodes. To reflect similarity during this update, a Graph Attention Network [39] is employed as the graph encoder. Finally, the selection criteria embedding is defined as follows:
Here, , is the dimension of the node representation for the selection criteria, and is set to 3072, matching the input dimension. The Graph Neural Network (GNN) parameter is trained such that the selection criteria embedding effectively aligns with the retrieved chunk embedding.
- Retrieved Chunk Embedding:
The text encoder for the retrieved chunks employs the same text-embedding-3-large model [38]. And during the cosine similarity analysis with the selection criteria embedding, a projection layer is introduced to preserve the semantic information of the text-embedded retrieved chunks while simultaneously aligning them more effectively with the node features. The retrieved chunk embedding generated through this projection layer is represented as follows, where is set to 3072 to enable direct comparison with the selection criteria embedding:
3. Experimental Results and Performance Evaluation
To evaluate the performance of the proposed Dynamic-Selection-based, Retrieval-Augmented Generation (DS-RAG) framework, we first analyzed the effectiveness of the Entity-Preserving Question Decomposition (EPQD) module in query decomposition and subsequently measured the performance of the DS-RAG framework for answer generation. The details are as follows.
3.1. Dataset
To effectively assess the performance of the EOPD and Dynamic Selection-Based RAG (DICS) modules, a multi-document question-answering (QA) dataset is required where multiple ground truth chunks must be input to the large language model (LLM) to generate accurate answers. Based on this criterion, we analyzed existing QA datasets and constructed a new multi-document QA dataset tailored to our experimental needs.
3.1.1. Analysis of Existing Datasets
We reviewed commonly used candidate datasets, specifically the HotpotQA dataset [24] and the recently introduced multi-hop RAG dataset [37]. The HotpotQA dataset [24], constructed from Wikipedia articles, includes bridge-type questions that follow a multi-document QA format. However, it presents several limitations:
- Short and Simple Questions: The questions are brief and structurally simple, making them insufficient for effectively comparing and analyzing the performance of our proposed query decomposition (QD) scheme.
- Limited Number of Ground Truth Chunks: Each question requires no more than two ground truth chunks, which restricts the ability to compare the performance of existing methods with the DICS module proposed in this paper.
- Incomplete Inclusion of Ground Truth Chunks: There are instances where not all ground truth chunks are included in the input context, and yet the LLM is still capable of generating correct answers.
In contrast, the Multi-hop RAG dataset [37], created using English news-related web pages, comprises questions that require between zero and four ground truth chunks. Despite this diversity, the dataset has its own set of challenges:
- Multiple Descriptions for a Single Answer: The questions are formulated with multiple descriptions pertaining to a single correct answer. Consequently, even if not all ground truth chunks are retrieved, modern LLMs can still generate accurate answers.
- Presence of Redundant Chunks: Many chunks within the documents allow the LLM to infer the correct answers without necessarily retrieving all ground truth chunks, leading to ambiguity and confusion in performance measurement.
Additionally, other datasets such as ComplexWebQuestion [7] are structured with documents built as knowledge bases, making them unsuitable for our targeted application environment. The IIRC dataset [40] presents the same constraints as the HotpotQA dataset [24], further limiting its applicability for our purposes. Moreover, the StrategyQA dataset [41] is less effective due to the insufficient content within its documents.
3.1.2. Construction of a Custom Multi-Document QA Dataset
Considering the aforementioned limitations of existing datasets, we constructed a new multi-document QA dataset that requires up to four distinct ground truth chunks for accurate answer generation and involves high question complexity, thereby enabling meaningful performance analysis of the proposed QD module. The methodology for creating this dataset was as follows:
- Question Generation: We first developed question frameworks and then selected 41 individuals from Wikipedia. Using data related to these individuals, we employed GPT4o [23] to generate complete questions. Additionally, the corresponding documents were created using Wikipedia web pages.
- Question Types: The question types included ranking types, which inquire about the rankings of individuals, and comparison types, which ask about the similarities or differences between individuals through comparisons. For ranking-type questions, the final answer is the name of a specific individual, whereas for comparison-type questions, the answer is “yes” or “no”. Both types are designed such that the correct answer does not explicitly exist within documents, requiring the LLM to infer the answer based on input context.
- Number of Ground Truth Chunks per Question: Each question includes between two and four individuals, with everyone having one associated ground truth chunk. Additionally, the ground truth chunks are inserted multiple times within the documents to create duplicate retrieved chunks.
- Question Complexity: To enhance the complexity of the questions and the difficulty of retrieval, questions were generated via the LLM to include two or more ancillary details about specific individuals, based on the content of the documents.
Table 6 presents the distribution of the generated dataset. The training dataset was created with questions pertaining to three individuals each to facilitate training convenience. We have publicly released the constructed dataset on GitHub, making it accessible for unrestricted use by anyone [42].
Table 6.
Distribution of custom multi-document QA dataset.
3.2. Experiment on the EPQD Module
To demonstrate the effectiveness of the EPQD module, we conducted experiments comparing LangChain’s [3] QD module with our proposed method, evaluating the extent to which the content of the original question is preserved. The objective of these experiments was to determine how effectively the proposed methodology minimizes the omission or addition of content by the LLM during the QD process. To achieve this, we established the following experimental setup and measured the corresponding results.
3.2.1. Experimental Setup
The detailed setup of the experiments was as follows:
- Experimental Method:
We assessed the preservation of the original question based on entities. This was achieved by comparing the set of entities in the original question with those in the sub-questions generated through QD, counting the number of entities that were either added or omitted. Entity identification for each question was performed using the method outlined in Section 2.3.1, and the LLM used was GPT4o [23]. The experiments were conducted on two datasets:
- Exp. 1: Conducted on 500 bridge-type questions from the HotpotQA dataset [24].
- Exp. 2: Conducted on 500 questions from a custom multi-document QA dataset [42], each involving three individuals.
- Performance Metrics:
The metrics used to measure the performance of QD were as follows:
- Entity Addition Rate (EAR): This metric calculates the proportion of entities included in the sub-questions that do not exist in the original question. A lower EAR indicates that fewer new entities are generated during the QD process, addressing Section 2.2.1: Issue 3.
- Entity Omission Rate (EOR): This metric calculates the proportion of entities present in the original question that are absent in the set of entities in the sub-questions. A lower EOR signifies that fewer entities from the original question are omitted during the QD process, addressing Section 2.2.1: Issue 2.
3.2.2. Results and Performance Evaluation
Table 7 presents the experimental results. In Exp. 1, where questions were simple and contain omitted content, LangChain [3] exhibited a relatively higher EAR compared to the EOR. This occurs because the LLM tends to arbitrarily generate additional entities due to the omitted content. In contrast, EPQD generated fewer new entities, thereby mitigating the issues discussed in Section 2.2.1, specifically Issue 3.
Table 7.
Experimental results comparing the QD performance of LangChain and EPQD.
In Exp. 2, because the complexity of questions was high, the performance differences between the two methods became more pronounced. LangChain [3] showed a relatively sharp increase in EOR, which is attributed to the higher number of entities included in the original questions and the complexity of the questions themselves. Notably, there was a tendency to omit most ancillary content, resulting in an EOR exceeding 70%. This suggests that the LLM arbitrarily determines additional content, potentially degrading retrieval performance under certain circumstances. In contrast, the EAR remained consistent, as most of the content was not omitted, a characteristic inherent to the dataset where the questions explicitly state the required information. Conversely, EPQD demonstrated a decrease in both EAR and EOR. This indicates that even for long and complex questions, EPQD performs effectively when the question content is explicitly expressed. These characteristics can be utilized as user guidelines in the development of commercial QA applications using our framework.
3.3. Experiment on the DICS Module
We assessed the performance of the proposed DS-RAG framework from two perspectives: (1) the generation of the input context, and (2) the final answer produced by the LLM. The details are as follows.
3.3.1. Experimental Setup
The experimental setup is described in detail below.
- Dataset:
As discussed in Section 3.1, we employed a custom multi-document QA dataset [42] to verify the performance on complex multi-document questions.
- Training the Graph-based Selection (GS) Model:
In the proposed GS model, the text encoder is used in its pre-trained form, while the graph encoder and projection layer are trained simultaneously using the training dataset. For efficient learning of the correlation between node features and the corresponding document chunks, we adopted the data preprocessing method proposed by G-retriever [22]. To effectively learn the mapping between each node feature and its ground truth chunk, we performed contrastive learning using InfoNCE Loss [43]. This approach enables the model to distinguish high-scoring positive pairs from low-scoring negative pairs, making it effective for learning the associations between different modalities [44]. In our study, the ground truth chunk corresponding to each selection criterion was designated as a positive pair, whereas all other chunks were treated as negative pairs.
- Benchmark Setup:
To evaluate the performance of the proposed DS-RAG framework, we implemented the following three benchmark systems. Each system was developed by extending the LangChain framework [3], and their configurations are as follows:
- NonQD-Reranking: This is a commonly used RAG system that does not perform QD. Instead, it retrieves documents using the original question and then conducts a reranking step between the original question and the retrieved chunks. This benchmark is designed to compare the potential improvement in retrieval performance gained through QD.
- EPQD-Reranking (SubQ): In this system, the EPQD module generates sub-questions. For each sub-question, retrieval is performed, and one chunk with the highest ranking is selected through a reranking process. These selected chunks are then aggregated to form the input context. This approach is intended to verify that applying for EPQD can address Section 1: Consideration 1.
- EPQD-Reranking (OriginalQ): Similar to the above, the EPQD module creates sub-questions, and retrieval is conducted for each sub-question. However, unlike the previous system, all retrieved chunks are subsequently reranked based on their similarity to the original question, and the top-K retrieved chunks are combined to form the input context. This system utilizes a reranker for selection and serves as a benchmark for comparing performance with the DICS module.
- Performance Metrics:
As discussed earlier, the performance of the DS-RAG framework is evaluated in two key areas: (1) the generation of the input context, and (2) the generation of the final answer. The specific metrics used to measure these are outlined in the following.
- F1-Score: Conventional metrics for assessing retrieval performance, such as HIT@k, Mean Average Precision (MAP), and Mean Reciprocal Rank (MRR), are primarily suited to measuring the effectiveness of a retriever or reranker. However, in the context of Section 1: Consideration 1 and 2, the input context generation performance hinges on how many ground truth chunks are included in the input context and how many unnecessary chunks are avoided. Therefore, we employ Precision, Recall, and their combined form, the F1-Score, as the first performance metric. The calculation formulas for Precision and Recall are as follows:
When the same ground truth chunk appears multiple times in the input context, it is counted only once.
- Average Number of Chunks (ANC): This metric represents the average number of chunks contained in the input context. From the perspective of Section 1: Consideration 2, it serves as a metric for relatively comparing the LLM API usage costs.
- Average Normalized Levenshtein Similarity (ANLS): ANLS [45] is commonly used to measure the performance of QA systems in terms of the similarity between the generated answer and the ground truth answer, based on the Levenshtein distance [46]. The formal definition of ANLS is given as follows:
Let N be the number of questions in the dataset and M be the number of ground truth answers per question. For and , denotes the ground truth answer corresponding to question i, while represents question i and denotes the answer generated by the system. In our dataset, M = 1 because there is only one ground truth answer per question. The term NL represents the normalized Levenshtein distance between the ground truth and the generated answer, and is set to 0.5.
- Parameter and Model Settings:
We conducted experiments on a custom multi-document QA dataset consisting of 500 ranking-type questions and 500 comparison-type questions. The key parameters and models employed in the experiments were as follows:
- Document Embedding Model: We utilized the text-embedding-ada-002 [38] model due to its favorable balance between cost and performance. Since the ground truth chunks in our dataset are relatively short, the chunk size was set to 250 and the overlap size to 50. To facilitate efficient retrieval, document embeddings were stored in a vector store provided by FAISS [5].
- Retrieval Configuration: When querying with the original question, we retrieved the top seven chunks; for sub-question queries, we retrieved the top three chunks. The LangChain framework [3] vectorstore retriever was used for both retrieval processes.
- Reranker: We employed the BGE-Reranker [15], which demonstrated a high performance in comparative retrieval evaluations on the Multi-hop RAG dataset [37] and achieved state-of-the-art results in QA similarity pair assessments.
- NonQD-Reranking and EPQD-Reranking (OriginalQ): After retrieval, the top four chunks were selected via reranking. Given that each question in our dataset has two to four ground truth chunks, we set k to 4.
- EPQD-Reranking (SubQ): For each sub-question, only the top chunk was selected after reranking.
- RS-RAG: In the DICS module, representations of outgoing nodes from the core node were utilized for selection criteria embeddings in cosine similarity analysis. This approach was adopted to focus the selection process on the core elements and their surrounding information, rather than on the additional information included in the question.
- Answer Generation: GPT4o [23] was used as the LLM to generate the final answers. To ensure the LLM did not rely on its pre-trained knowledge, we designed prompts that strictly restricted such usage. Detailed prompt instructions can be found in Appendix A.3 and Appendix A.4.
The modules of the DS-RAG framework implemented for the experiments, along with the dataset, have been made publicly available and can be downloaded at [42].
3.3.2. Results and Performance Evaluation
Table 8 presents the experimental results for the ranking-type and comparison-type question datasets. NonQD-Reranking showed the lowest performance across all metrics, indicating that QD is essential for multi-document QA. In contrast, EPQD-Reranking (SubQ) achieved the highest Recall values for both question types, demonstrating the effectiveness of the proposed EPQD module from the perspective of Section 1: Consideration 1. However, its ASC values of 8.584 and 7.456 imply that approximately five unnecessary chunks are included, given that the average number of ground truth chunks per question is three. Consequently, the Precision of EPQD-Reranking (SubQ) is less than half its Recall, resulting in an average F1-Score of approximately 0.5963.
Table 8.
Experimental results comparing the retrieval and answer generation performance of DS-RAG and benchmarks.
On the other hand, DS-RAG employing the DICS module achieved an average F1-Score of about 0.8771, primarily due to increased Precision arising from the dynamic selection of chunks via selection criteria. Meanwhile, EPQD-Reranking (OriginalQ) failed to consistently select the correct ground truth chunks, as evidenced by its lower Recall. This suggests that a reranking approach that selects fixed top-K chunks cannot avoid redundant or unnecessary chunks. Overall, the proposed DS-RAG framework fulfills Section 1: Consideration 1 through the EPQD module while mitigating the resulting side effect—namely, the issue in Section 1: Consideration 2—through the DICS module. One notable aspect is that, despite the low Precision value, EPQD-Reranking (SubQ) still achieves the highest ANLS score. This finding suggests that ANLS is predominantly influenced by Recall. The likely explanation is that, due to the LLM’s robust natural language processing capabilities, the inclusion of a substantial amount of extraneous content in the input context does not significantly impede correct answer generation.
Additionally, Table 9 compares the number of parameters of the BGE-Reranker with those of the proposed GS model, confirming that DS-RAG is more efficient from the standpoint of Section 1: Consideration 3.
Table 9.
Model size comparison: BGE-Reranker vs. GS model.
4. Discussion and Conclusions
In this research, we developed the Dynamic-Selection-based, Retrieval-Augmented Generation (DS-RAG) framework for commercial, multi-document question-answering (QA) applications. The Entity-Preserving Question Decomposition (EPQD) module supports the retriever in ensuring that all necessary chunks are identified, while the Dynamic Selection-Based RAG (DICS) module focuses on selecting only those chunks essential for answer generation, thereby optimizing the input context. We also constructed a new multi-document question-answering (QA) dataset, in which up to four distinct retrieved chunks are necessary for answer generation, and utilized this dataset to evaluate the performance of the EPQD and DICS modules. Our experiments demonstrated that the EPQD module effectively decomposes the original question, thereby enhancing both retrieval performance and answer generation quality. Furthermore, the DICS module was able to reduce the number of chunks included in the large language model (LLM) input context by more than half while maintaining a comparable performance. Consequently, our proposed DS-RAG framework satisfies the critical requirements of both context retrieval performance and cost efficiency when developing commercial multi-document QA applications. Additionally, the graph-based selection (GS) model used in the DICS module was designed to be approximately 30% smaller than the benchmark model, thereby addressing the need for a lower service operation overhead.
Despite these contributions, there remain several limitations and areas for improvement regarding commercial adoption. Below, we briefly outline future research directions related to these issues.
- Reducing LLM API Usage and Latency. Although the DS-RAG framework makes substantial efforts to minimize the cost of using an LLM API, it remains a significant burden from both cost and service latency perspectives. Meanwhile, various sizes of smaller large language models (SLLMs) are now available for on-premises deployment. If these SLLMs could be fine-tuned on the target domain data for a given application, it may become feasible to replace LLM usage entirely, enabling more practical service provision. Therefore, we plan to integrate currently available SLLMs with the DS-RAG framework to identify components that require further refinement and gradually enhance the system.
- Dataset Expansion and Diversity. We built a new dataset to analyze the performance of our framework in environments that necessitate a large number of multi-document chunks. However, real-world user questions are highly unpredictable and diverse, and our current dataset does not fully encompass this range. Moreover, although different domains have unique document characteristics, many existing datasets (including ours) rely on Wikipedia or other web data, limiting their ability to capture such domain-specific nuances. The evolving generation capabilities of LLMs offer potential solutions to this issue. Indeed, our study employed an LLM to construct a new dataset, demonstrating the feasibility of generating varied datasets through prompt engineering. In particular, if SLLMs can be fine-tuned with data from a specific domain, it may be possible to automatically generate domain-specialized QA datasets.
- Targeting the Domain. The defense domain stands out as one of the areas with the greatest need for multi-document QA applications, and yet related research is scarce. Despite the exponential growth in information collected by various intelligence, surveillance, and reconnaissance (ISR) assets and unmanned systems in field environments, many of these data go unused due to the practical impossibility of processing them all. Simple keyword-based retrieval can handle straightforward queries; however, because documents in the defense domain often contain fragmented or partial information, decision-makers require multi-document QA applications to synthesize critical insights. Future work will involve tailoring the DS-RAG framework to this domain, thereby enabling more effective information management and decision support in defense settings.
Author Contributions
Conceptualization, W.L. and J.J.; methodology of EPQD, S.H. and W.L.; methodology for deriving selection criteria, J.B. and W.L.; methodology of GS model, M.K. and W.L.; implementation, S.H., J.B. and M.K.; dataset construction, S.H. and M.K.; experiment, S.H. and M.K.; writing—original draft preparation, S.H., J.B. and M.K.; writing—review and editing, W.L. All authors have read and agreed to the published version of the manuscript.
Funding
The present research has been conducted by the Research Grant of Kwangwoon University in 2023.
Data Availability Statement
A custom multi-document QA dataset was developed to evaluate the performance of the proposed DS-RAG framework. This dataset is publicly available for download and use by anyone. It can be accessed at the following GitHub repository: https://github.com/Mulsanne2/DS-RAG (accessed on 16 January 2025).
Conflicts of Interest
The funders had no role in the design of the research; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results. The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RAG | Retrieval-Augmented Generation |
| LLM | Large Language Model |
| QA | Question-Answering |
| QD | Question Decomposition |
| EPQD | Entity-Preserving Question Decomposition |
| DICS | Dynamic Input Context Selector |
| DS-RAG | Dynamic-Selection-Based, Retrieval-Augmented Generation |
| API | Application Programming Interface |
| DPR | Dense Passage Retriever |
| GS | Graph-Based Selection |
| GNN | Graph Neural Network |
Appendix A
In this appendix, we provide the prompt instructions employed by the DICS module in our DS-RAG framework.
Appendix A.1
Table A1.
Prompt instruction for entity identification.
Table A1.
Prompt instruction for entity identification.
| Instruction |
|---|
| 1. Entities in all noun forms must be extracted. 2. Extracts all entities with explicitly stated meanings in sentences. 3. Extract entities as specifically as possible without duplicating. 4. All Entities should be individually meaningful, you shouldn’t extract meaningless Entities such as Be verbs 5. If a relationship is not explicitly stated, connect and extract related entities. if there is no relationship between entities, list them separately. 6. Interrogative word must should be treated as an Entity. |
Appendix A.2
Table A2.
Prompt instruction for relation extraction.
Table A2.
Prompt instruction for relation extraction.
| Instruction |
|---|
| 1. Relationships should be selected as an entity number corresponding to the target and subject. 2. Only the numbers are used in the triple-set. 3. All entered relationship numbers must exist at least once. |
Appendix A.3
Table A3.
Prompt instruction for ranking-type QA.
Table A3.
Prompt instruction for ranking-type QA.
| Instruction |
|---|
| 1. You are an assistant for question-answering tasks. 2. Use the following pieces of retrieved context to answer the question. 3. Answer using only the provided context. Do not use any background knowledge at all. 4. Provide the most accurate answer possible and respond using the full name of the subject mentioned in the question. 5. Provide only the full name, not a sentence. 6. If you don’t know the answer, say “I don’t know”. |
Appendix A.4
Table A4.
Prompt instruction for comparison-type QA.
Table A4.
Prompt instruction for comparison-type QA.
| Instruction |
|---|
| 1. You are an assistant for question-answering tasks. 2. Use the following pieces of retrieved context to answer the question. 3. Answer using only the provided context. Do not use any background knowledge at all. 4. Answer with only “yes” or “no” without adding a comma or period at the end. 5. If you don’t know the answer, say “I don’t know”. |
References
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, M.; Wang, H. Retrieval-augmented generation for large language models: A survey. arXiv 2024, arXiv:2312.10997. [Google Scholar]
- LangChain. Available online: https://github.com/hwchase17/langchain (accessed on 9 January 2025).
- LlamaIndex. Available online: https://www.llamaindex.ai/ (accessed on 9 January 2025).
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2021, 7, 535–547. [Google Scholar] [CrossRef]
- Karpukhin, V.; Oğuz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.-T. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Talmor, A.; Berant, J. The Web as a Knowledge-Base for Answering Complex Questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Perez, E.; Lewis, P.; Yih, W.-T.; Cho, K.; Kiela, D. Unsupervised Question Decomposition for Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Min, S.; Zhong, V.; Zettlemoyer, L.; Hajishirzi, H. Multi-hop Reading Comprehension through Question Decomposition and Rescoring. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 29–31 July 2019. [Google Scholar]
- Hasson, M.; Berant, J. Question Decomposition with Dependency Graphs. arXiv 2021, arXiv:2104.08647. [Google Scholar]
- Zhou, D.; Schärli, N.; Hou, L.; Wei, J.; Scales, N.; Wang, X.; Schuurmans, D.; Cui, C.; Bousquet, O.; Le, Q.; et al. Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. arXiv 2022, arXiv:2205.10625. [Google Scholar]
- Radhakrishnan, A.; Nguyen, K.; Chen, A.; Chen, C.; Denison, C.; Hernandez, D.; Durmus, E.; Hubinger, E.; Kernion, J.; Lukošiūtė, K.; et al. Question Decomposition Improves the Faithfulness of Model-Generated Reasoning. arXiv 2023, arXiv:2307.11768. [Google Scholar]
- Glass, M.; Rossiello, G.; Chowdhury, M.F.M.; Naik, A.; Cai, P.; Gliozzo, A. Re2G: Retrieve, Rerank, Generate. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022. [Google Scholar]
- Gao, T.; Yao, S.; Chen, X.; Nair, V.; Deng, Z.; Reddy, C.; Sun, F. Cohere-RARR: Relevance-Aware Retrieval and Reranking on the Open Web. arXiv 2023, arXiv:2311.01555. [Google Scholar]
- FlagEmbedding. Available online: https://github.com/FlagOpen/FlagEmbedding (accessed on 9 January 2025).
- FlashRank. Available online: https://github.com/PrithivirajDamodaran/FlashRank (accessed on 9 January 2025).
- Pereira, J.; Fidalgo, R.; Lotufo, R.; Nogueira, R. Visconde: Multi-Document QA with GPT-3 and Neural Reranking. In Proceedings of the 45th European Conference on Information Retrieval (ECIR 2023), Dublin, Ireland, 2–6 April 2023. [Google Scholar]
- Izacard, G.; Grave, E. Leveraging Passage Retrieval with Generative Models for Open-Domain Question Answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL), Online, 19–23 April 2021. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Gao, S.; Liu, Y.; Dou, Z.; Wen, J.-R. Knowledge Graph Prompting for Multi-Document Question Answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Dong, J.; Fatemi, B.; Perozzi, B.; Yang, L.F.; Tsitsulin, A. Don’t Forget to Connect! Improving RAG with Graph-based Reranking. arXiv 2024, arXiv:2405.18414. [Google Scholar]
- He, X.; Tian, Y.; Sun, Y.; Chawla, N.; Laurent, T.; LeCun, Y.; Bresson, X.; Hooi, B. G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering. In Proceedings of the 2024 Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- OpenAI. ChatGPT. Available online: https://chat.openai.com (accessed on 9 January 2025).
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- spaCy. Available online: https://spacy.io/ (accessed on 1 September 2024).
- Chen, Y.; Zheng, Y.; Yang, Z. Prompt-Based Metric Learning for Few-Shot NER. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- He, K.; Mao, R.; Huang, Y.; Gong, T.; Li, C.; Cambria, E. Template-Free Prompting for Few-Shot Named Entity Recognition via Semantic-Enhanced Contrastive Learning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 18357–18369. [Google Scholar] [CrossRef] [PubMed]
- Ashok, D.; Lipton, Z.C. PromptNER: Prompting for Named Entity Recognition. arXiv 2023, arXiv:2305.15444. [Google Scholar]
- Tang, Y.; Hasan, R.; Runkler, T. FsPONER: Few-Shot Prompt Optimization for Named Entity Recognition in Domain-Specific Scenarios. In Proceedings of the ECAI 2024, Santiago de Compostela, Spain, 19–24 October 2024. [Google Scholar]
- Liu, J.; Fei, H.; Li, F.; Li, J.; Li, B.; Zhao, L.; Teng, C.; Ji, D. TKDP: Threefold Knowledge-enriched Deep Prompt Tuning for Few-shot Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2024, 36, 6397–6409. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Xue, L.; Zhang, D.; Dong, Y.; Tang, J. AutoRE: Document-Level Relation Extraction with Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 11–16 August 2024. [Google Scholar]
- Li, X.; Chen, K.; Long, Y.; Zhang, M. LLM with Relation Classifier for Document-Level Relation Extraction. arXiv 2024, arXiv:2408.13889. [Google Scholar]
- Wadhwa, S.; Amir, S.; Wallace, B. Revisiting Relation Extraction in the era of Large Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023. [Google Scholar]
- Tang, Y.; Yang, Y. Multihop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries. In Proceedings of COLM, Philadelphia, PA, USA, 7 October 2024. [Google Scholar]
- OpenAI. Embeddings. Available online: https://platform.openai.com/docs/guides/embeddings (accessed on 9 January 2025).
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ferguson, J.; Gardner, M.; Hajishirzi, H.; Khot, T.; Dasigi, P. IIRC: A Dataset of Incomplete Information Reading Comprehension Questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Geva, M.; Khashabi, D.; Segal, E.; Khot, T.; Roth, D.; Berant, J. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Trans. Assoc. Comput. Linguist. 2020, 9, 346–361. [Google Scholar] [CrossRef]
- DS-RAG Framework. Available online: https://github.com/Mulsanne2/DS-RAG (accessed on 16 January 2025).
- van den Oord, A.; Li, Y.; Vinyals, O. Representation Learning with Contrastive Predictive Coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021. [Google Scholar]
- Biten, A.F.; Tito, R.; Mafla, A.; Gomez, L.; Rusiñol, M.; Jawahar, C.V. Scene Text Visual Question Answering. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Levenshtein, V.I. Binary Codes Capable of Correcting Deletions, Insertions, and Reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).