
DualAD: Exploring Coupled Dual-Branch Networks for Multi-Class Unsupervised Anomaly Detection



Abstract
1. Introduction
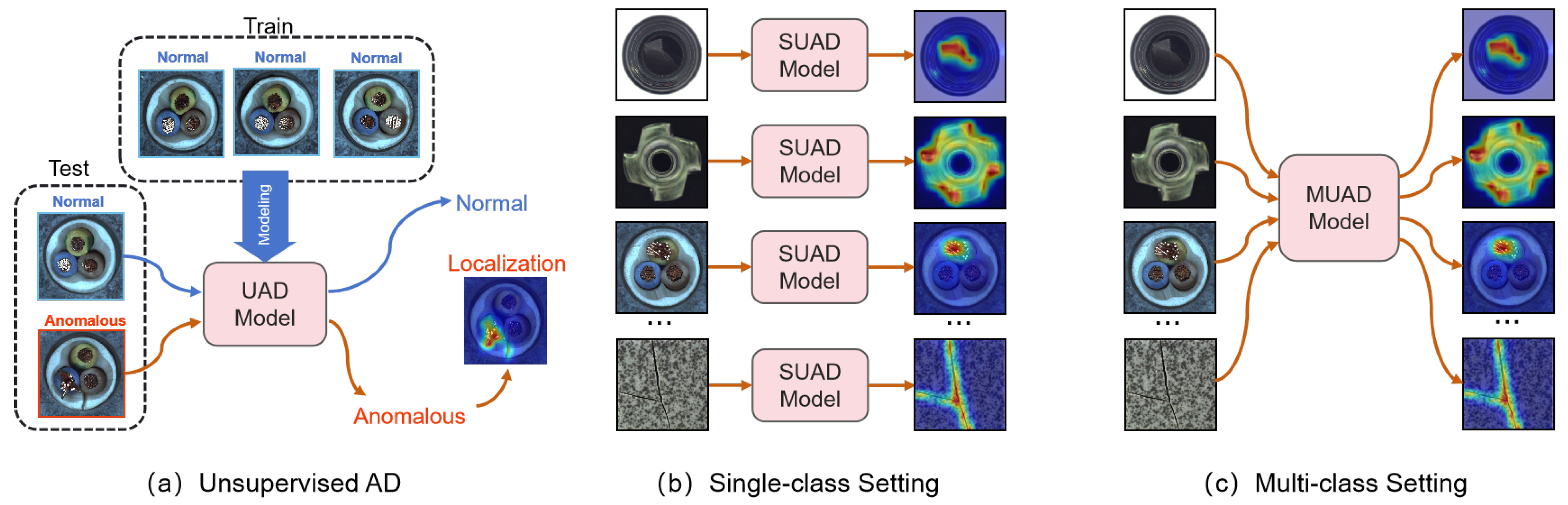
- We propose the DualAD, which tackles multi-class unsupervised anomaly detection tasks and explores a novel end-to-end feature reconstruction framework (see Section 3.3).
- We introduce the CDBN, which integrates a WSN and an NDN, leveraging their combined strengths to achieve superior overall performance (see Section 3.3.2).
- We present a homogeneous CDBN design entirely based on the transformer and explore a more lightweight heterogeneous design that combines a transformer with an MMLP (see Section 3.3.3).
- We conduct extensive experiments on the popular MVTec AD and VisA benchmark datasets, comparing our framework to recent state-of-the-art methods. The results demonstrate the superior performance of DualAD and its effectiveness across different pre-trained backbones (see Section 4).
2. Related Work
2.1. Unsupervised Anomaly Detection
- (1)
- Memory-based methods. These methods attempt to build prototype banks of pre-trained features for normal samples [1,17,18,19,20,21] and detect anomalies by matching against these normal templates. Roth et al. [1] directly compute the distance between the test sample and the most similar normal feature template to estimate the degree of anomaly. Liu et al. [19] and Gu et al. [20] enhance the input’s normality by matching with normal features. Zhang et al. [21] estimate the anomalous region by calculating the residual between the sample and the normal template, assisting the segmentation network’s decision. These methods are conceptually simple and effective. However, the cost of building prototype banks and the detection cost both increase with the number of categories, which limits their scalability in multi-class settings.
- (2)
- Normalizing flow-based methods. These methods seek to map the pre-trained features of normal samples to simpler probability distributions [2,22,23,24,25], such as multivariate Gaussian distributions. Rudolph et al. [22] first introduced normalizing flows for density estimation of multi-scale image features. However, this method primarily focuses on image-level anomaly detection. Gudovskiy et al. [23] enhanced anomaly localization by using conditional normalizing flows and introducing 2D hard positional encoding. Yu et al. [2] proposed a 2D normalizing flow and employed a vision transformer as the feature extractor for the first time. Lei et al. [25] introduced an anomaly localization paradigm based on normalizing flows and latent template comparison. These methods provide accurate density estimation for data, allowing for effective anomaly detection. However, they generally require significant computational resources for training, especially when dealing with high-dimensional data, leading to substantial training time and computational costs. Furthermore, these methods assume that the distribution of normal data is known and that the data must adhere to certain distributional properties. For more complex data distributions, the performance of the model may be affected.
- (3)
- Knowledge Distillation-based methods. These methods employ a pre-trained network as a teacher model, training a student model to learn its representation of normal samples [3,26,27,28], with anomalies being identified based on the output differences between the teacher and student models. Bergmann et al. [3] first utilized knowledge distillation for anomaly detection, which ensembles several student models trained on normal data at different scales. Wang et al. [27] introduced a pyramid feature matching mechanism between the teacher and student models, further improving anomaly localization efficiency and accuracy. Zhang et al. [28] proposed a denoising teacher-student network paradigm that enhanced the constraints on anomalous data. These methods are based on the assumption that a student network constrained only on the outputs of normal samples during training will generate different feature representations for anomalous samples compared to the teacher network. However, in practice, this assumption does not always hold true.
- (1)
- Image-level methods. These methods use the RGB pixels of the original image for reconstruction.The most basic approach involves autoencoders (AEs) [29,30,31], which map input images to latent space through an encoder and then reconstruct them via a decoder. The reconstruction is optimized by minimizing the difference between the original input and the output, typically using loss functions like Mean Squared Error (MSE). While these methods are conceptually simple, they face challenges in handling more complex scenarios. To improve reconstruction performance, generative models have been introduced. Variational autoencoders (VAEs) [32,33] learn the latent probabilistic distribution of the data, with the encoder outputting distribution parameters instead of a fixed latent vector. The loss function incorporates Kullback–Leibler (KL) divergence as a regularization term to constrain the latent space distribution. Generative Adversarial Networks (GANs) [34,35] employ adversarial training between a generator and a discriminator, where the generator learns the distribution of normal data, and the discriminator identifies outliers as potential anomalies. Diffusion-based methods [36,37,38] learn the data distribution through a series of noise addition and denoising steps to reconstruct inputs.
- (2)
- Feature-level methods. With the increasing popularity of embedding-based methods that leverage pre-trained networks for feature extraction, recent studies have introduced feature-level reconstruction techniques. These methods aggregate outputs from multiple stages of pre-trained networks and utilize different strategies for feature reconstruction. Methods by You et al. [5] and Lu et al. [39] employ end-to-end matching approaches, using an AE to reconstruct aggregated pre-trained features in a manner similar to image reconstruction. Meanwhile, Deng et al. [6], Zhang et al. [40], and He et al. [41] adopt multi-stage matching strategies, aggregating reconstruction differences between intermediate layers across multiple scales of the pre-trained network and decoder to assess anomaly severity.Reconstruction-based methods are relatively easy to train and highly practical, but they are prone to the “identical shortcut” problem [5], where the model may learn techniques that effectively reconstruct anomalies, leading to ambiguous decision boundaries. To mitigate this issue, various enhancement strategies have been employed. Some methods augment reconstruction networks with memory mechanisms. Gong et al. [8] introduced the memory mechanism by adding a learnable memory module between the encoder and decoder. This module can be viewed as a dictionary organized in a matrix form, with each vector corresponding to a “word” in the dictionary. During training, the matrix parameters are jointly optimized with the AE to learn the feature patterns of normal data. The memory module is designed to reorganize abnormal features into normal ones, thereby improving the normality of the decoder’s output. Many subsequent methods have extended this design. For instance, Liu et al. [42] extended the memory module to multi-level features, while Hou et al. [43] used block-wise queries to prevent poor reconstruction of anomalous features due to limited anomaly patterns.
- (3)
- Enhancement strategies. Reconstruction-based methods are easy to train and demonstrate strong practicality; however, they are prone to the “identical shortcut” problem [5], where the model may learn specific techniques that effectively restore anomalies, resulting in ambiguous decision boundaries. To mitigate this issue, various enhancement strategies are employed. Some methods augment reconstruction networks with memory mechanisms. Gong et al. [8] introduce the memory mechanism by adding a learnable memory module between the encoder and decoder. This module can be viewed as a dictionary organized in a matrix form, with each vector corresponding to a “word” in the dictionary. During training, the matrix parameters are jointly optimized with the AE to learn the feature patterns of normal data. The memory module is designed to reorganize anomalous features into normal ones, thereby improving the normality of the decoder’s output. Many subsequent methods have extended this design. For instance, Liu et al. [42] extend the memory module to multi-level features, while Hou et al. [43] use block-wise queries to prevent poor reconstruction of anomalous features due to limited anomaly patterns. Furthermore, pseudo-anomalies can be added to the normal data for self-supervised training, helping to better model the normal distribution. Li et al. [44] generate anomalous images by randomly selecting a block from a normal image and pasting it into another region. Wyatt et al. [36] and Tien et al. [45] generate block-level image anomalies using simplex noise. Zavrtanik et al. [7,46] synthesize more realistic, shape-random image anomalies by combining Perlin noise with the Describable Textures Dataset [47]. In addition to adding pseudo-anomalies to the original images, Liu et al. [48] and You et al. [5] introduce anomalies at the feature level by adding Gaussian noise.
2.2. Multi-Class Unsupervised Anomaly Detection
3. Materials and Methods
3.1. Task Definition and Setups
3.2. Revisiting Transformer-Based MUAD
3.3. Proposed Method
3.3.1. Feature Extractor
| Algorithm 1: Feature Extraction Process |
 |
3.3.2. Coupled Dual-Branch Network for Feature Reconstruction
3.3.3. Memory-Augmented Heterogeneous CDBN
3.3.4. Pseudo Anomalies
3.3.5. Training and Inference
3.4. Experimental Setup
3.4.1. Datasets and Evaluation Metrics
3.4.2. Baselines and Backbones
3.4.3. Implementation Details
4. Results
4.1. Quantitative Comparisons with SoTAs on MVTec AD and VisA
4.2. Ablation Studies
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AD | Anomaly detection |
| UAD | Unsupervised anomaly detection |
| SUAD | Single-class unsupervised anomaly detection |
| MUAD | Multi-class unsupervised anomaly detection |
| CDBN | Coupled Dual-Branch Network |
| WSN | Wide–Shallow Network |
| NDN | Narrow-Deep Network |
| MMLP | Memory-Augmented Multi-Layer Perceptron |
| MCA | Multi-head Cross Attention |
| FFN | Feed-Forward Network |
| MSE | Mean Squared Error |
| AUROC | Area Under the Receiver Operating Curve |
| AP | Average Precision |
| F1max | F1-score at optimal threshold |
References
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14318–14328. [Google Scholar]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4183–4192. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- You, Z.; Cui, L.; Shen, Y.; Yang, K.; Lu, X.; Zheng, Y.; Le, X. A unified model for multi-class anomaly detection. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA. USA, 28 November–9 December 2022; pp. 4571–4584. [Google Scholar]
- Deng, H.; Li, X. Anomaly detection via reverse distillation from one-class embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9737–9746. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 8330–8339. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.v.d. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference On Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Zou, Y.; Jeong, J.; Pemula, L.; Zhang, D.; Dabeer, O. Spot-the-difference self-supervised pre-training for anomaly detection and segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 392–408. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Yi, J.; Yoon, S. Patch svdd: Patch-level svdd for anomaly detection and segmentation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Cohen, N.; Hoshen, Y. Sub-image anomaly detection with deep pyramid correspondences. arXiv 2020, arXiv:2005.02357. [Google Scholar]
- Hyun, J.; Kim, S.; Jeon, G.; Kim, S.H.; Bae, K.; Kang, B.J. ReConPatch: Contrastive patch representation learning for industrial anomaly detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 2052–2061. [Google Scholar]
- Liu, W.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Diversity-measurable anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12147–12156. [Google Scholar]
- Gu, Z.; Liu, L.; Chen, X.; Yi, R.; Zhang, J.; Wang, Y.; Wang, C.; Shu, A.; Jiang, G.; Ma, L. Remembering normality: Memory-guided knowledge distillation for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16401–16409. [Google Scholar]
- Zhang, H.; Wu, Z.; Wang, Z.; Chen, Z.; Jiang, Y.G. Prototypical residual networks for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16281–16291. [Google Scholar]
- Rudolph, M.; Wandt, B.; Rosenhahn, B. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1907–1916. [Google Scholar]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 98–107. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1088–1097. [Google Scholar]
- Lei, J.; Hu, X.; Wang, Y.; Liu, D. PyramidFlow: High-Resolution Defect Contrastive Localization using Pyramid Normalizing Flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14143–14152. [Google Scholar]
- Salehi, M.; Sadjadi, N.; Baselizadeh, S.; Rohban, M.H.; Rabiee, H.R. Multiresolution knowledge distillation for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14902–14912. [Google Scholar]
- Wang, G.; Han, S.; Ding, E.; Huang, D. Student-teacher feature pyramid matching for anomaly detection. In Proceedings of the The British Machine Vision Conference (BMVC), Online, 22–25 November 2021. [Google Scholar]
- Zhang, X.; Li, S.; Li, X.; Huang, P.; Shan, J.; Chen, T. Destseg: Segmentation guided denoising student-teacher for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3914–3923. [Google Scholar]
- Collin, A.S.; De Vleeschouwer, C. Improved anomaly detection by training an autoencoder with skip connections on images corrupted with stain-shaped noise. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7915–7922. [Google Scholar]
- Mishra, P.; Piciarelli, C.; Foresti, G.L. Image anomaly detection by aggregating deep pyramidal representations. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; pp. 705–718. [Google Scholar]
- Ristea, N.C.; Madan, N.; Ionescu, R.T.; Nasrollahi, K.; Khan, F.S.; Moeslund, T.B.; Shah, M. Self-supervised predictive convolutional attentive block for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13576–13586. [Google Scholar]
- Dehaene, D.; Eline, P. Anomaly localization by modeling perceptual features. arXiv 2020, arXiv:2008.05369. [Google Scholar]
- Dehaene, D.; Frigo, O.; Combrexelle, S.; Eline, P. Iterative energy-based projection on a normal data manifold for anomaly localization. arXiv 2020, arXiv:2002.03734. [Google Scholar]
- Yan, X.; Zhang, H.; Xu, X.; Hu, X.; Heng, P.A. Learning semantic context from normal samples for unsupervised anomaly detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3110–3118. [Google Scholar] [CrossRef]
- Liang, Y.; Zhang, J.; Zhao, S.; Wu, R.; Liu, Y.; Pan, S. Omni-frequency channel-selection representations for unsupervised anomaly detection. IEEE Trans. Image Process. 2023, 32, 4327–4340. [Google Scholar] [CrossRef] [PubMed]
- Wyatt, J.; Leach, A.; Schmon, S.M.; Willcocks, C.G. AnoDDPM: Anomaly detection with denoising diffusion probabilistic models using simplex noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 650–656. [Google Scholar]
- Zhang, H.; Wang, Z.; Wu, Z.; Jiang, Y.G. DiffusionAD: Norm-guided one-step denoising diffusion for anomaly detection. arXiv 2023, arXiv:2303.08730. [Google Scholar]
- He, H.; Zhang, J.; Chen, H.; Chen, X.; Li, Z.; Chen, X.; Wang, Y.; Wang, C.; Xie, L. A diffusion-based framework for multi-class anomaly detection. Proc. AAAI Conf. Artif. Intell. 2024, 38, 8472–8480. [Google Scholar] [CrossRef]
- Lu, R.; Wu, Y.; Tian, L.; Wang, D.; Chen, B.; Liu, X.; Hu, R. Hierarchical vector quantized transformer for multi-class unsupervised anomaly detection. In Proceedings of the 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; pp. 8487–8500. [Google Scholar]
- Zhang, J.; Chen, X.; Wang, Y.; Wang, C.; Liu, Y.; Li, X.; Yang, M.H.; Tao, D. Exploring plain vit reconstruction for multi-class unsupervised anomaly detection. arXiv 2023, arXiv:2312.07495. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Liu, Z.; Nie, Y.; Long, C.; Zhang, Q.; Li, G. A hybrid video anomaly detection framework via memory-augmented flow reconstruction and flow-guided frame prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 13588–13597. [Google Scholar]
- Hou, J.; Zhang, Y.; Zhong, Q.; Xie, D.; Pu, S.; Zhou, H. Divide-and-assemble: Learning block-wise memory for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 8791–8800. [Google Scholar]
- Li, C.L.; Sohn, K.; Yoon, J.; Pfister, T. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9664–9674. [Google Scholar]
- Tien, T.D.; Nguyen, A.T.; Tran, N.H.; Huy, T.D.; Duong, S.; Nguyen, C.D.T.; Truong, S.Q. Revisiting reverse distillation for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 24511–24520. [Google Scholar]
- Zavrtanik, V.; Kristan, M.; Skočaj, D. DSR—A dual subspace re-projection network for surface anomaly detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 539–554. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Liu, Z.; Zhou, Y.; Xu, Y.; Wang, Z. Simplenet: A simple network for image anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 20402–20411. [Google Scholar]
- Van Den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural discrete representation learning. Adv. Neural Inf. Process. Syst. 2017, 30, 6309–6318. [Google Scholar]
- Jiang, X.; Chen, Y.; Nie, Q.; Liu, J.; Liu, Y.; Wang, C.; Zheng, F. Toward Multi-class Anomaly Detection: Exploring Class-aware Unified Model against Inter-class Interference. arXiv 2024, arXiv:2403.14213. [Google Scholar]
- Sitzmann, V.; Martel, J.; Bergman, A.; Lindell, D.; Wetzstein, G. Implicit neural representations with periodic activation functions. Adv. Neural Inf. Process. Syst. 2020, 33, 7462–7473. [Google Scholar]
- Zhao, Y. Omnial: A unified cnn framework for unsupervised anomaly localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3924–3933. [Google Scholar]
- He, H.; Bai, Y.; Zhang, J.; He, Q.; Chen, H.; Gan, Z.; Wang, C.; Li, X.; Tian, G.; Xie, L. Mambaad: Exploring state space models for multi-class unsupervised anomaly detection. arXiv 2024, arXiv:2404.06564. [Google Scholar]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 17–24 June 2021; pp. 9650–9660. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Stages | Depths | Channels | Strides |
|---|---|---|---|---|
| Eff-b4 | [1, 2, 3, 4, 5] | [1, 4, 5, 12, 10] | [24, 32, 56, 160, 448] | [2, 4, 8, 16, 32] |
| Res34 | [1, 2, 3, 4] | [3, 4, 6, 3] | [64, 128, 256, 512] | [4, 8, 16, 32] |
| Res50 | [1, 2, 3, 4] | [3, 4, 6, 3] | [256, 512, 1024, 2048] | [4, 8, 16, 32] |
| WRes50 | [1, 2, 3, 4] | [3, 4, 6, 3] | [256, 512, 1024, 2048] | [4, 8, 16, 32] |
| ViT-S | [1, 2, 3, 4] | [3, 3, 3, 3] | [384, 384, 384, 384] | [16, 16, 16, 16] |
| Category | RD4AD [6] | UniAD [5] | ViTAD [40] | DiAD [38] | MambaAD [53] | Ours | |
|---|---|---|---|---|---|---|---|
| WRes50 (IN1K) | Eff-b4 (IN1K) | ViT-S (DINO) | Res50 (IN1K) | Res34 (IN1K) | WRes50 (IN1K) | ||
| Texture | Carpet | 99.6/97.2 | 99.9/99.4 | 99.9/99.4 | 99.9/98.3 | 99.9/99.4 | 99.8/97.7 |
| Grid | 99.4/96.5 | 99.5/97.3 | 99.9/99.1 | 99.8/97.7 | 100./100. | 100./99.1 | |
| Leather | 100./100. | 100./100. | 100./100. | 99.7/97.6 | 100./100. | 100./100. | |
| Tile | 99.3/96.4 | 99.8/98.2 | 100./100. | 99.9/98.4 | 99.3/95.4 | 100./100. | |
| Wood | 99.8/98.3 | 99.6/96.6 | 99.6/96.7 | 100./100. | 99.6/96.6 | 99.9/98.3 | |
| Object | Bottle | 99.9/98.4 | 100./100. | 100./100. | 96.5/91.8 | 100/100 | 100./100. |
| Cable | 89.5/82.5 | 95.9/88.0 | 99.1/95.7 | 98.8/95.2 | 99.2/95.7 | 99.4/96.7 | |
| Capsule | 96.9/96.9 | 97.8/94.4 | 99.0/95.5 | 97.5/95.5 | 98.7/94.5 | 99.5/96.9 | |
| Hazelnut | 69.9/86.4 | 100./99.3 | 99.9/98.6 | 99.7/97.3 | 100./100. | 100./100. | |
| Metal Nut | 100./99.5 | 99.9/99.5 | 99.9/98.4 | 96.0/91.6 | 100./99.5 | 100/98.9 | |
| Pill | 99.6/96.8 | 98.7/95.7 | 99.3/96.4 | 98.5/94.5 | 99.5/96.2 | 99.8/97.9 | |
| Screw | 99.3/95.8 | 96.5/89.0 | 97.0/93.0 | 99.7/97.9 | 97.9/94.0 | 99.1/95.8 | |
| Toothbrush | 99.9/94.7 | 97.4/95.2 | 99.6/96.8 | 99.9/99.2 | 99.3/98.4 | 98.5/95.2 | |
| Transistor | 95.2/90.0 | 98.0/93.8 | 98.3/92.5 | 99.6/97.4 | 100./100. | 100./100. | |
| Zipper | 99.9/99.2 | 99.5/97.1 | 99.3/97.1 | 99.1/94.4 | 99.8/97.5 | 99.5/97.5 | |
| Mean | 96.5/95.2 | 98.8/96.2 | 99.4/97.3 | 99.0/96.5 | 99.6/97.8 | 99.7/98.3 | |
| Category | RD4AD [6] | UniAD [5] | ViTAD [40] | DiAD [38] | MambaAD [53] | Ours | |
|---|---|---|---|---|---|---|---|
| WRes50 (IN1K) | Eff-b4 (IN1K) | ViT-S (DINO) | Res50 (IN1K) | Res34 (IN1K) | WRes50 (IN1K) | ||
| Texture | Carpet | 98.5/99.0 | 99.8/98.5 | 99.5/99.0 | 99.4/98.6 | 99.8/99.2 | 99.4/99.0 |
| Grid | 98.0/96.5 | 98.2/63.1 | 99.7/98.6 | 98.5/96.6 | 100./99.2 | 99.9/98.3 | |
| Leather | 100./99.3 | 100./98.8 | 100./99.6 | 99.8/98.8 | 100./99.4 | 100./99.1 | |
| Tile | 98.3/95.3 | 99.3/91.8 | 100./96.6 | 96.8/92.4 | 98.2/93.8 | 100./96.1 | |
| Wood | 99.2/95.3 | 98.6/93.2 | 98.7/96.4 | 99.7/93.3 | 98.8/94.4 | 99.6/95.8 | |
| Object | Bottle | 99.6/97.8 | 99.7/98.1 | 100./98.8 | 99.7/98.4 | 100./98.8 | 100./98.4 |
| Cable | 84.1/85.1 | 95.2/97.3 | 98.5/96.2 | 94.8/96.8 | 98.8/95.8 | 99.0/98.5 | |
| Capsule | 94.1/98.8 | 86.9/98.5 | 95.4/98.3 | 89.0/97.1 | 94.4/98.4 | 97.8/98.8 | |
| Hazelnut | 60.8/97.9 | 99.8/98.1 | 99.8/99.0 | 99.5/98.3 | 100./99.0 | 100./98.5 | |
| Metal Nut | 100./94.8 | 99.2/62.7 | 99.7/96.4 | 99.1/97.3 | 99.9/96.7 | 99.8/97.6 | |
| Pill | 97.5/97.5 | 93.7/95.0 | 96.2/98.7 | 95.7/95.7 | 97.0/97.4 | 98.6/98.7 | |
| Screw | 97.7/99.4 | 87.5/98.3 | 91.3/99.0 | 90.7/97.9 | 94.7/99.5 | 97.1/99.4 | |
| Toothbrush | 97.2/99.0 | 94.2/98.4 | 98.9/99.1 | 99.7/99.0 | 98.3/99.0 | 96.1/98.6 | |
| Transistor | 94.2/85.9 | 99.8/97.9 | 98.8/93.9 | 99.8/95.1 | 100./96.5 | 100./97.0 | |
| Zipper | 99.5/98.5 | 95.8/96.8 | 97.6/95.9 | 95.1/96.2 | 99.3/98.4 | 98.4/98.6 | |
| Mean | 94.6/96.1 | 96.5/96.8 | 98.3/97.7 | 97.2/96.8 | 98.6/97.7 | 99.0/98.2 | |
| Category | RD4AD [6] | UniAD [5] | ViTAD [40] | DiAD [38] | MambaAD [53] | Ours | |
|---|---|---|---|---|---|---|---|
| WRes50 (IN1K) | Eff-b4 (IN1K) | ViT-S(DINO) | Res50 (IN1K) | Res34 (IN1K) | WRes50 (IN1K) | ||
| Complex structure | PCB1 | 95.5/91.9 | 92.7/87.8 | 94.7/91.8 | 88.7/80.7 | 93.0/91.6 | 99.2/96.6 |
| PCB2 | 97.8/94.2 | 87.7/83.1 | 89.9/85.3 | 91.4/84.7 | 93.7/89.3 | 98.3/93.9 | |
| PCB3 | 96.2/91.0 | 78.6/76.1 | 91.2/83.9 | 87.6/77.6 | 94.1/86.7 | 96.3/89.3 | |
| PCB4 | 99.9/99.0 | 98.9/94.3 | 98.9.96.6 | 99.5/97.0 | 99.9/98.5 | 99.8/98.0 | |
| Multiple instance | Macaroni1 | 61.5/76.8 | 79.8/69.9 | 83.9/76.7 | 85.2/78.8 | 89.8/81.6 | 94.5/88.8 |
| Macaroni2 | 84.5/83.8 | 71.6/69.9 | 74.7/74.9 | 57.4/69.5 | 78.0/73.8 | 80.9/75.8 | |
| Capsules | 90.4/81.3 | 55.6/76.9 | 87.6/79.8 | 69.0/78.5 | 95.0/88.8 | 90.5/82.4 | |
| Candle | 92.8/86.0 | 94.0/86.1 | 91.2/83.7 | 9.0/87.6 | 96.9/90.1 | 97.0/91.3 | |
| Single instance | Cashew | 95.8/90.7 | 92.8/91.4 | 94.2/86.1 | 95.7/89.7 | 97.3/91.1 | 99.0/94.8 |
| Chewing Gum | 97.5/92.1 | 96.2/95.2 | 97.7/91.4 | 99.5/95.9 | 98.9/94.2 | 99.5/97.5 | |
| Fryum | 97.9/91.5 | 83.0/85.0 | 97.4/90.9 | 95.0/87.2 | 97.7/90.5 | 96.3/88.6 | |
| Pipe Fryum | 98.9/96.5 | 94.7/93.9 | 99.0/94.7 | 98.1/93.7 | 99.3/97.0 | 99.6/97.5 | |
| Mean | 92.4/89.6 | 85.5/84.4 | 91.7/86.3 | 88.3/85.1 | 94.5/89.4 | 95.9/91.2 | |
| Category | RD4AD [6] | UniAD [5] | ViTAD [40] | DiAD [38] | MambaAD [53] | Ours | |
|---|---|---|---|---|---|---|---|
| WRes50 (IN1K) | Eff-b4 (IN1K) | ViT-S(DINO) | Res50 (IN1K) | Res34 (IN1K) | WRes50 (IN1K) | ||
| Complex structure | PCB1 | 96.2/99.4 | 92.8/93.3 | 95.8/99.5 | 88.1/98.7 | 95.4/99.8 | 99.3/99.7 |
| PCB2 | 97.8/98.0 | 87.8/93.9 | 90.6/97.9 | 91.4/95.2 | 94.2/98.9 | 98.1/98.8 | |
| PCB3 | 96.4/97.9 | 78.6/97.3 | 90.9/98.2 | 86.2/96.7 | 93.7/99.1 | 96.3/99.0 | |
| PCB4 | 99.9/97.8 | 98.8/94.9 | 99.1/99.1 | 99.6/97.0 | 99.9/98.6 | 99.7/98.2 | |
| Multiple instance | Macaroni1 | 75.9/99.4 | 79.9/97.4 | 85.8/98.5 | 85.7/94.1 | 91.6/99.5 | 94.7/99.4 |
| Macaroni2 | 88.3/99.7 | 71.6/95.2 | 79.1/98.1 | 62.5/93.6 | 81.6/99.5 | 81.0/98.4 | |
| Capsules | 82.2/99.4 | 55.6/88.7 | 79.2/98.2 | 58.2/97.3 | 91.8/99.1 | 83.0/99.3 | |
| Candle | 92.3/99.1 | 94.1/98.5 | 90.4/96.2 | 92.8/97.3 | 96.8/99.0 | 96.6/99.0 | |
| Single instance | Cashew | 92.0/91.7 | 92.8/98.6 | 87.8/98.5 | 91.5/90.9 | 94.5/94.3 | 97.9/99.2 |
| Chewing Gum | 94.9/98.7 | 96.3/98.8 | 94.9/97.8 | 99.1/94.7 | 97.7/98.1 | 98.9/98.9 | |
| Fryum | 95.3/97.0 | 83.0/95.9 | 94.3/97.5 | 89.8/97.6 | 95.2/96.9 | 92.0/97.7 | |
| Pipe Fryum | 97.9/99.1 | 94.7/98.9 | 97.8/99.5 | 96.2/99.4 | 98.7/99.1 | 99.2/99.4 | |
| Mean | 92.4/98.1 | 85.5/95.9 | 90.5/98.2 | 86.8/96.0 | 94.3/98.5 | 94.7/98.9 | |
| Method | Params (M) | FLOPs (G) | Metrics | ||||
|---|---|---|---|---|---|---|---|
| DualAD(Ho) | WRes50 | 137.3 | 24.1 | 98.8 | 99.6 | 97.9 | 98.1 |
| Res34 | 89.0 | 17.4 | 98.3 | 99.4 | 97.4 | 97.9 | |
| Res50 | 98.0 | 18.2 | 98.3 | 99.3 | 97.6 | 97.9 | |
| Eff-b4 | 86.7 | 15.3 | 98.8 | 99.6 | 98.0 | 98.0 | |
| ViT-S | 91.6 | 19.4 | 98.5 | 99.4 | 98.2 | 98.0 | |
| DualAD(He) | WRes50 | 97.5 | 15.5 | 99.0 | 99.7 | 98.3 | 98.2 |
| Res34 | 40.9 | 7.2 | 98.2 | 99.4 | 97.6 | 97.9 | |
| Res50 | 54.2 | 9.6 | 98.3 | 99.4 | 97.8 | 98.1 | |
| Eff-b4 | 37.5 | 4.8 | 98.7 | 99.6 | 98.2 | 98.1 | |
| ViT-S | 50.2 | 10.5 | 98.4 | 99.4 | 98.1 | 98.1 | |
| Method | Backbones | ||
|---|---|---|---|
| WRes50 | Eff-b4 | ViT-S | |
| 91.7/96.9/94.3/96.6 | 97.3/99.1/96.8/96.9 | 96.8/98.8/97.2/97.6 | |
| 97.7/99.2/97.1/97.6 | 98.6/99.5/97.8/97.1 | 97.9/99.3/97.8/97.8 | |
| 96.1/98.7/95.9/97.3 | 98.2/99.3/97.5/97.0 | 97.7/99.1/97.6/97.7 | |
| MMLP | 97.3/98.8/96.7/97.3 | 95.1/97.3/94.8/96.9 | 97.2/98.5/96.9/97.6 |
| DualAD(Ho) | 98.8/99.6/97.9/98.1 | 98.8/99.6/98.0/98.0 | 98.5/99.4/98.2/98.0 |
| DualAD(He) | 99.0/99.7/98.3/98.2 | 98.7/99.6/98.2/98.1 | 98.4/99.4/98.1/98.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, S.; Chen, Y.; Wang, L.; Huang, W.; Xu, R.; Qian, Y. DualAD: Exploring Coupled Dual-Branch Networks for Multi-Class Unsupervised Anomaly Detection. Electronics 2025, 14, 594. https://doi.org/10.3390/electronics14030594
He S, Chen Y, Wang L, Huang W, Xu R, Qian Y. DualAD: Exploring Coupled Dual-Branch Networks for Multi-Class Unsupervised Anomaly Detection. Electronics. 2025; 14(3):594. https://doi.org/10.3390/electronics14030594
Chicago/Turabian StyleHe, Shiwen, Yuehan Chen, Liangpeng Wang, Wei Huang, Rong Xu, and Yurong Qian. 2025. "DualAD: Exploring Coupled Dual-Branch Networks for Multi-Class Unsupervised Anomaly Detection" Electronics 14, no. 3: 594. https://doi.org/10.3390/electronics14030594
APA StyleHe, S., Chen, Y., Wang, L., Huang, W., Xu, R., & Qian, Y. (2025). DualAD: Exploring Coupled Dual-Branch Networks for Multi-Class Unsupervised Anomaly Detection. Electronics, 14(3), 594. https://doi.org/10.3390/electronics14030594