1. Introduction
Multi-exposure image Fusion (MEF) offers a cost-effective high dynamic imaging (HDR) solution by accepting a sequence of images taken under varying exposure conditions as inputs and producing high-quality images with enhanced dynamic range [
1] as an output. Utilizing two-dimensional image information for character recognition and defect detection on metallic workpieces is a common industrial application within machine vision. However, due to the typically smooth and reflective surfaces of metals, severe localized reflections often occur when identifying and inspecting metallic surfaces, as illustrated in
Figure 1. Different lighting equipment choices and polarizing filters are used in the industrial field to address these reflections. However, these methods are costly, inefficient, and unable to meet real-time requirements. Therefore, this paper adopts a deep learning-based multi-exposure image fusion approach to address the issues of low dynamic range and uneven local lighting in images of metal materials. Recently, many end-to-end deep learning-based MEF algorithms [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13] have been introduced and have become mainstream in the MEF field. However, there are still four primary issues that persist in industrial scenarios: (1) Under extreme exposure levels, such as combining a highly overexposed and an underexposed image, the resulting fused image often performs poorly. Moreover, most existing algorithms typically limit the number of images that can be fused. When the number of source images is restricted, and there is a significant difference in exposure between them, the efficacy of these algorithms in producing a satisfactory fused result decreases; (2) There are a lack of training data. One of the biggest challenges in applying deep learning to image fusion is the need for authentic fused images for supervised learning. Some approaches attempt to address this issue by manually constructing ground truths, which often need to be inaccurate and set a ceiling on network learning potential. Moreover, for industrial scenarios, acquiring well-exposed images of smooth workpieces in practical applications is particularly challenging. (3) Balancing efficiency and quality is challenging, making practical deployment difficult. Most existing MEF methods struggle to balance efficiency and quality. MEFNet [
14] can process images in real-time, benefiting from operations at a low resolution. However, it relies solely on MEF-SSIM [
15] (MEF Structural Similarity Index) as its loss function, which may result in the loss of information from the source images. Qu [
16] proposed a new method named TransMEF, which uses Transformer technology to enhance the quality of fused images. However, this method does not consider processing speed, making applying it in natural industrial environments challenging; and (4) existing Image Quality Assessment (IQA) methods rarely address the objective evaluation of uneven illumination. The goal expectation is to minimize the effects of uneven lighting while preserving the detail of the industrial image. This requirement differs from the treatment of natural images, where the lighting element is often considered a significant factor affecting image quality and is included in most IQA algorithms’ metrics. Consequently, most current evaluation metrics do not adequately measure whether the lighting in industrial images is uniform.
To address problems (1) and (2), this paper proposes an unsupervised, fully convolutional network named MEF-AT, capable of handling an arbitrary number of exposure images. Multiple industrial images with different exposures can be taken for image fusion according to their complexity for complex industrial scenes. This paper also adopts an unsupervised approach for network training to overcome the lack of authentic fused images. The paper combines multi-dimensional attention mechanisms and a DGF module [
17] with the fully convolutional network supported by training storage units during training to resolve issue (3). The attention mechanism enhances image detail retention by operating across channel and spatial dimensions. The DGF module applies complex industrial scenarios through its learnable parameters for the generated low-resolution weight maps. It uses a guide image to produce high-resolution weight maps fused to generate high-quality industrial images. During training, the training storage units store intermediate fused images produced, serving as supervisory auxiliary signals to further enhance the dynamic range of the fused images. This paper proposes a new evaluation metric named Illumination Component Gradient (ICG) to tackle issue (4). ICG uses multi-scale Gaussian functions to extract the illumination component of images and calculates the average gradient of this component to objectively and accurately assess the level of uneven illumination. The contributions of this paper are summarized as follows:
An unsupervised, fully convolutional network with a multidimensional attention mechanism is proposed. It can receive images of any spatial resolution and exposure number, generate high-quality fused images in real-time, and adapt to complex industrial scenarios.
A training storage unit is introduced to transform the training scheme in the unsupervised image fusion framework. Intermediate results during network training are used as auxiliary supervisory signals, effectively eliminating uneven illumination in industrial images and enhancing image dynamic range.
An image evaluation metric named ICG is proposed to measure the level of uneven illumination in industrial images, refining the evaluation metrics system for industrial images.
The remainder of the paper is organized as follows:
Section 2 describes current methods and applications of multi-exposure image fusion.
Section 3 introduces the proposed method. In
Section 4, experiments validate the effectiveness of this method. Finally, a discussion and overall conclusion surrounding the algorithm is given in
Section 5 and
Section 6.
2. Related Work
MEF tasks typically focus on finding appropriate methods to determine the weights of exposure sequence images. Mertens [
1] derived fusion weights based on exposure sequences’ exposure, contrast, and saturation. Since then, many pixel-level multi-exposure image fusion techniques [
18] have been developed, primarily aiming to enhance visual effects, but consequently increasing computational complexity. Li [
19] employed a guided filter to decompose source images into base and detail layers and utilized a weighted average technique to merge different layers, effectively leveraging spatial consistency information. The GGIF [
20] technique introduced gradient-domain edge-preserving smoothing instead of Gaussian smoothing to suppress noise interference and halo effects. Compared to per-pixel MEF algorithms, patch-based methods produce smoother weight maps, require less post-processing, and carry a heavier computational load [
21,
22]. Some approaches [
2,
23,
24] prefer to frame the MEF task as an optimization problem. However, these methods, which almost always involve manually designed features, have limited applicability to complex industrial scenarios due to their general inflexibility and relatively high time consumption, challenging practical application in the industrial field.
Deep learning-based MEF methods have significantly improved performance and visual effects in recent years. DeepFuse [
2] was the first to integrate deep learning with MEF tasks, constructing a novel CNN (Convolutional Neural Network) architecture and employing MEF-SSIM as the training loss function for unsupervised learning. MEF-GAN [
3] introduced Generative Adversarial Networks to MEF for the first time, incorporating a self-attention mechanism to correct artifacts in the fused images. AGAL [
4] utilized dual GANs to impose global and local constraints, with the global discriminator allowing the fused image to learn the overall exposure distribution of the ground truth and the local discriminator focusing on detail preservation. PMGI [
5] and SDNet [
6] maintained the similarity between the fusion results and source images using gradients and intensities. MEF-CL [
25] and HoLoCo [
7] introduced contrastive learning to the MEF task, modeling the contrastive relationships between source and reference images, thus achieving better fusion performance without adding any model parameters. HALDeR [
8] introduced a multi-scale attention mechanism, extending attention coverage from different angles to achieve good exposure correction and prevent color distortion. CF [
9] combined MEF with super-resolution tasks through a multi-scale coupled feedback module, allowing the two tasks to collaborate and interact. The specially designed coupled feedback network performed well on both tasks. Han [
10] proposed a depth-perception enhanced network for MEF, known as DPE-MEF, which utilizes two modules to collect content details and handle the final result’s color mapping and correction. FCMEF [
26] introduced a Fourier Transform-based Pixel Intensity Transfer strategy to synthesize many images with varying exposure levels for training the image fusion network, enabling the trained network to maintain robustness and effectiveness when fusing images with extreme and diverse exposure levels.
In addition to the deep learning methods tailored for Multi-Exposure Fusion, various general image fusion frameworks that include MEF tasks have also been proposed. IFCNN [
11] implemented a universal image fusion model capable of handling various fusion tasks by adopting different fusion rules. U2Fusion [
12] utilizes DenseNet to extract features from source images, with information measures derived from these feature maps determining the extent of information retention in the images; it also employs Elastic Weight Consolidation to address the forgetting problem associated with continual learning. SwinFusion [
13] uses a Transformer-based deep feature reconstruction unit and a CNN-based image reconstruction unit to capture global and local information for reconstructing the fused image. SDDNet [
27] integrates dilated convolution with atrous spatial pyramid pooling by employing an improved spatial pyramid pooling (ASPP) module that reduces the computational complexity while effectively expanding the sensory field. STRNet [
28] consists of a squeeze-excited attention-based encoder, a multi-head attention-based decoder, and a concise design of the network by maintaining its fast processing speed.
However, due to the constraints of the network structures in the methods above, most are designed to accept a predefined number of exposure sequence images, which can be limiting when dealing with complex and variable industrial scenes. These limitations highlight the need for more adaptable solutions in MEF tasks to better accommodate the diverse requirements and unpredictable conditions typical of industrial environments.
3. Proposed Method
In order to ensure the real-time performance of the algorithm in industrial scenarios, this paper adopts the downsampling-upsampling image processing method. The network is presented with a low-resolution version of the input sequence to learn the generation of weight maps instead of directly generating fused images as in prior works [
5,
6,
7,
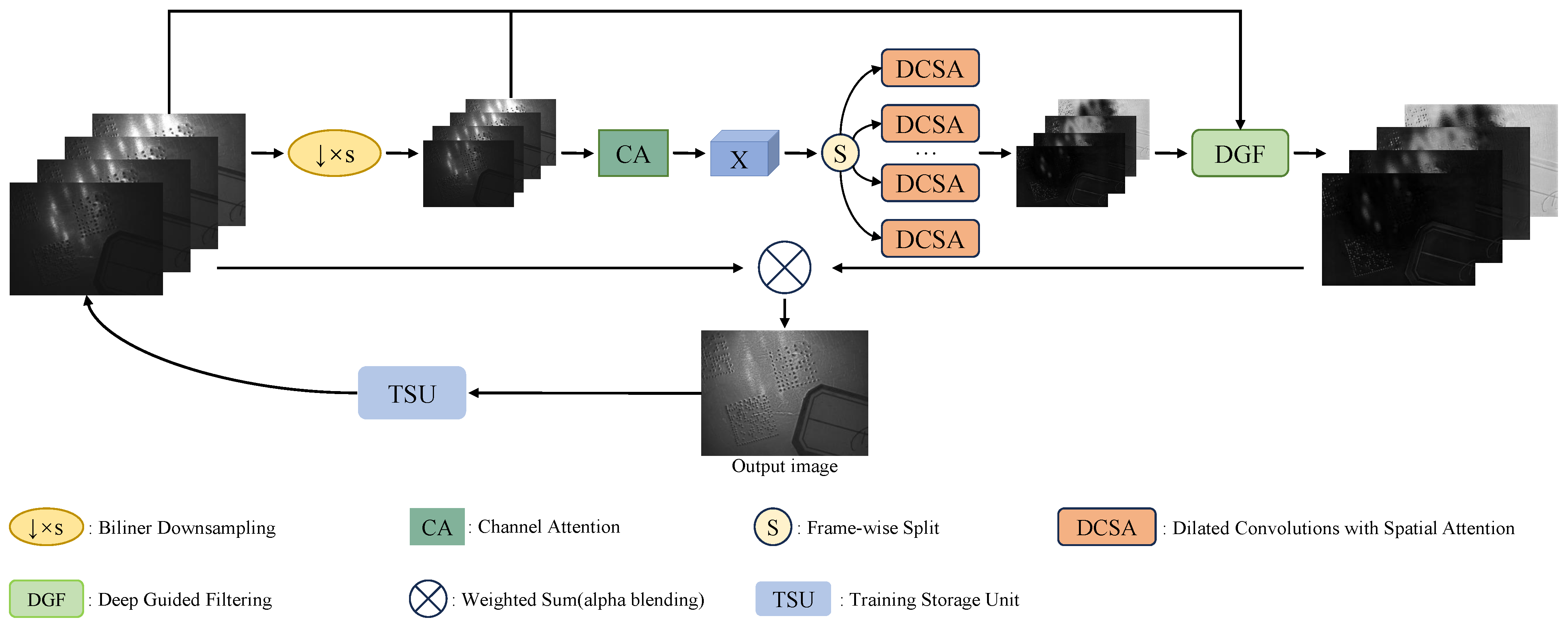
25]. This study employs a fully convolutional network to achieve flexibility, which accepts inputs of any size and produces outputs of the corresponding size (referred to as dense prediction). The network is shared among different exposure images, enabling it to handle an arbitrary number of exposures. The paper combines multi-dimensional attention mechanisms, training storage unit modules, and DGF-guided filtering modules with the fully convolutional network. This combination helps the network model extract and utilize critical information to generate high-quality fused images efficiently.
This article addresses network model design to meet real-time performance requirements, high quality, and flexibility when applying algorithms in industrial settings. The proposed MEF-AT network model consists of a bilinear downsampler, a multi-dimensional attention mechanism, a CAN network [
29], a training storage unit module, and a DGF guided filtering module.
Figure 2 illustrates the architecture of the model.
This paper initially downsamples the input sequence
to obtain a low-resolution version
, which is then fed into a fully convolutional network equipped with a multi-dimensional attention mechanism to produce a low-resolution weight map
. Specifically, the low-resolution input sequence image
is first passed through a Channel Attention (CA) module [
30], resulting in a feature map
. This feature map is then split along the batch size dimension and entered into a dilated convolution module with Spatial Attention (SA) to obtain the low-resolution weight map
.
,
, and
are inputs for the DGF upsampler to obtain a high-resolution weight map
. Finally, the fused image is obtained by computing the weighted sum of
and
. During training, a training storage unit utilizes the intermediate fusion results to enhance the fusion quality, forming a more effective training scheme.
3.1. Multi-Dimensional Attention Mechanism
The network is based on the fully convolutional network CAN. It is enhanced by adding channel and spatial attention mechanisms to improve the network’s ability to focus on and express critical information in complex industrial images. Small but critical pieces of information inevitably exist during the manufacturing process of workpieces. These pieces of information can often be lost due to the reflective properties of metal objects during photography. Therefore, focusing on these tiny critical details in industrial images has become one of the primary research focuses of this network design. This paper employs a multi-dimensional attention mechanism that adjusts the network’s focus on different image regions from global and local perspectives. The multidimensional attention mechanism enables the network model to automatically focus on the more important information regions in the industrial image by assigning weights to each position, while it can reduce the interference of the background on the image by lowering the weight of the background region, thus improving the robustness of the network model in complex environments. The mechanism improves the display of local details in the image, achieving a harmonious and unified overall appearance.
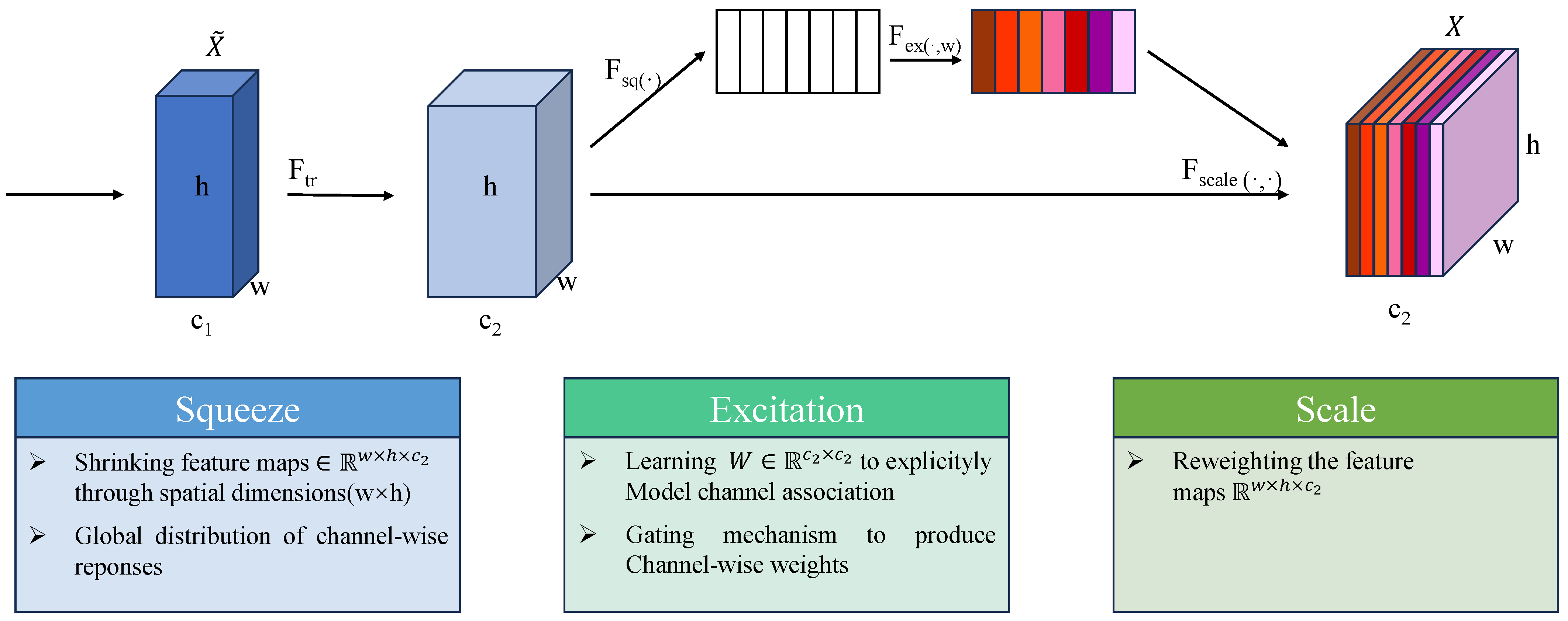
3.1.1. Channel Attention Mechanism
We first perform bilinear downsampling on the input sequence
at a rate s to obtain a lower-resolution version
. The downscaled sequences are fed into a CA module to generate a feature map
X. Specifically, each input sequence
undergoes a conv2d, and the results are concatenated to form a 4D tensor. Subsequently, an attention mechanism is applied along the channel dimension
.
In the channel attention mechanism,
consists of scalars
. The linear weights in the CA mechanism are denoted as
and
. They are the weight matrices of two fully connected layers. The functions
and
represent the ReLU and Sigmoid activation functions, respectively. The operator ⊙ denotes element-wise multiplication with automatic broadcasting. The structure of the channel attention mechanism is shown in
Figure 3.
The resultant feature map accumulates the rich contextual information necessary for predicting the subsequent weight maps
through the channel attention module that fuses features along the channel dimension. As illustrated in
Figure 4, by comparing subfigures (b,c) or (d,e), it is observed that upon enabling the CA module, the weight map of the QR code region (marked by red boxes) in the original image1 is highlighted as displayed, indicating focused attention on fine details in the image. Conversely, in the original image3, the weight map of the QR code region exhibits lower weights, demonstrating better suppression of uneven illumination in the image.
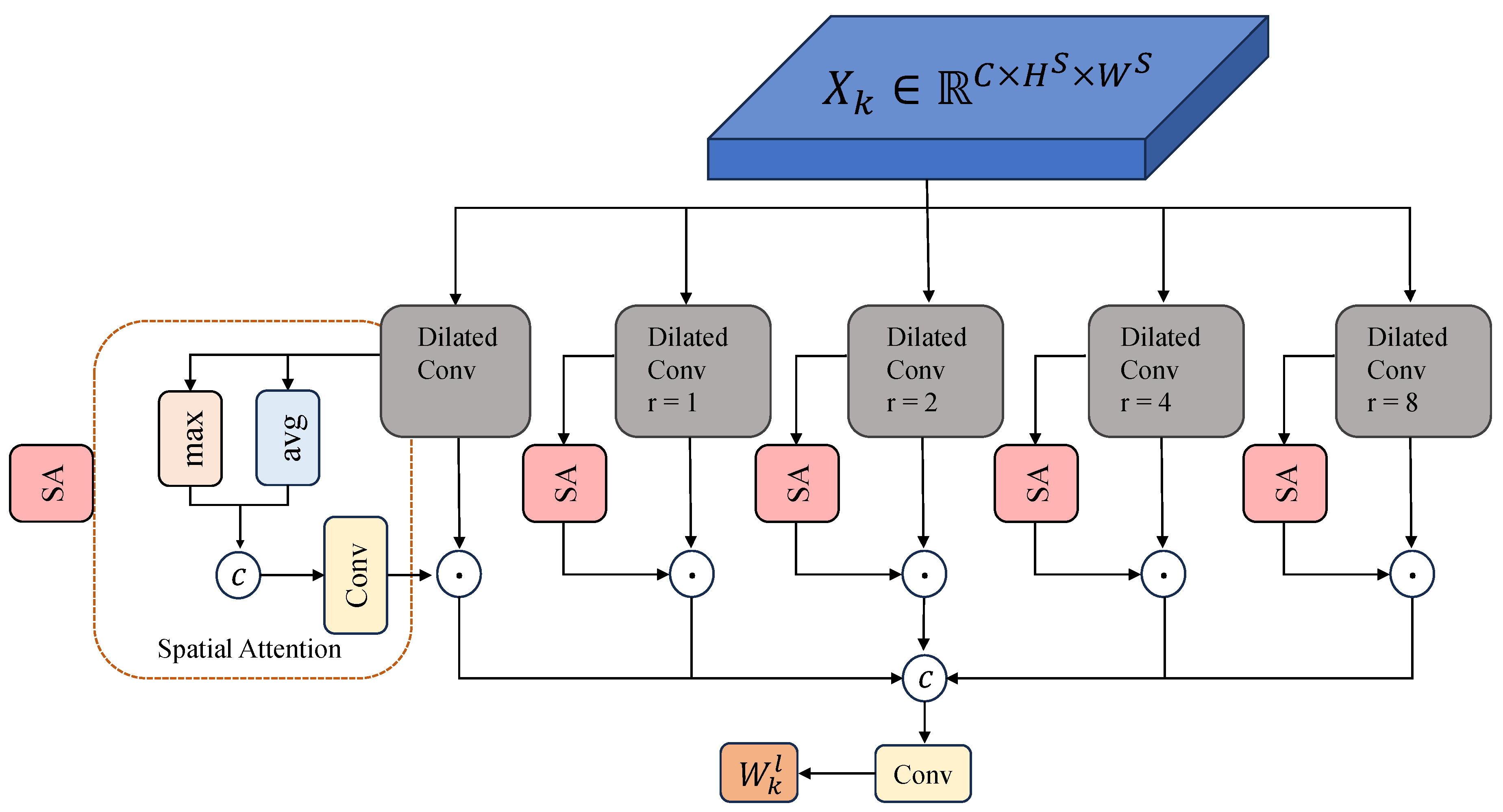
3.1.2. Dilated Convolutions Module with Spatial Attention
In this paper, we effectively promote the effective fusion of local and global information of industrial images by a Dilated Convolutions Module with Spatial Attention. The exposure sequence
X is further divided into
, (where each
). Each
is then input into a dilated convolution module with spatial attention. This module consists of five dilated convolution branches, with dilation rates set to 2, 4, 6, 8, and 10, respectively. Each branch generates a feature map that incorporates a spatial attention mechanism [
31]. In this context,
represents a dilated convolution with a dilation rate
r, where dilation helps to expand the receptive field of the convolutional layers without reducing the resolution of the feature map or increasing the number of parameters significantly. The operator ⊗ denotes the conv2d operation.
After obtaining the outputs
, from each of the five branches in the dilated convolution module, these branches are concatenated and passed through another convolutional layer to produce the final weight map
. Spatial Attention helps optimize the spatial weighting of intra-frame pixels, effectively preserving details and suppressing artifacts. Dilated convolutions systematically aggregate multi-scale contextual information. They exponentially expand the receptive field without losing resolution or coverage. The structure of this process is depicted in
Figure 5.
After completing the steps described, we gain multi-scale spatial attention from different dilation rates, allowing the generated feature maps to obtain more refined spatial structural information for predicting the subsequent weight maps
. In
Figure 4, by comparing panels (b,d) or (c,e), we observe that the image weights become smoother. Furthermore, this paper conducts an ablation study to validate the effectiveness of the two attention modules, channel attention and spatial attention, as shown in
Table 1. The study shows that activating either module leads to improved performance metrics. This result demonstrates that each attention mechanism contributes significantly to the network’s ability to finely tune the focus on crucial image details and enhance the overall quality of the image processing, leading to smoother and more accurate weight distributions in the output images.
3.2. Unsupervised Learning in Industrial Settings
Due to variations in industrial shooting conditions and the reflectivity of metal plates, controlling the exposure levels of the captured image sequences becomes challenging. When one or several source images exhibit significant exposure differences, the fusion performance of the images rapidly deteriorates. At the same time, because of the smooth and reflective properties of the metal workpieces, obtaining well-exposed images of metal plates can also be very challenging and time-consuming. Therefore, this paper adopts a fully convolutional network as the backbone, capable of accepting image sequences of any number and resolution while learning high-quality detail maps unsupervised.
After obtaining the low-resolution weight maps
, this paper uses a DGF module upsampling module to resize the weight maps back to their original resolution. The module uses guidance information provided by
,
, and
to generate higher-resolution weight maps with more detail. Traditional guided filters [
32] are non-parametric modules that compute similarly across all different tasks. However, due to the significant differences between tasks, a single non-parametric guided filtering layer cannot perform well across various scenarios.
In contrast, the DGF upsampling module introduces dilated convolutions and pointwise convolution blocks to replace average filters and local linear models. By replacing non-parametric operations with convolutional layers and introducing learnable parameters into the guided filtering layer, the DGF module can better adapt to complex industrial tasks. This adaptation allows for more flexible and effective processing of images with varying exposure and reflective characteristics, ultimately enhancing the fusion quality under diverse industrial imaging conditions.
Given the high cost and time consumption of obtaining detailed authentic images in industrial settings, this paper employs the MEF-SSIM loss to train the network unsupervised.
represents the parameters within the network described in this paper.
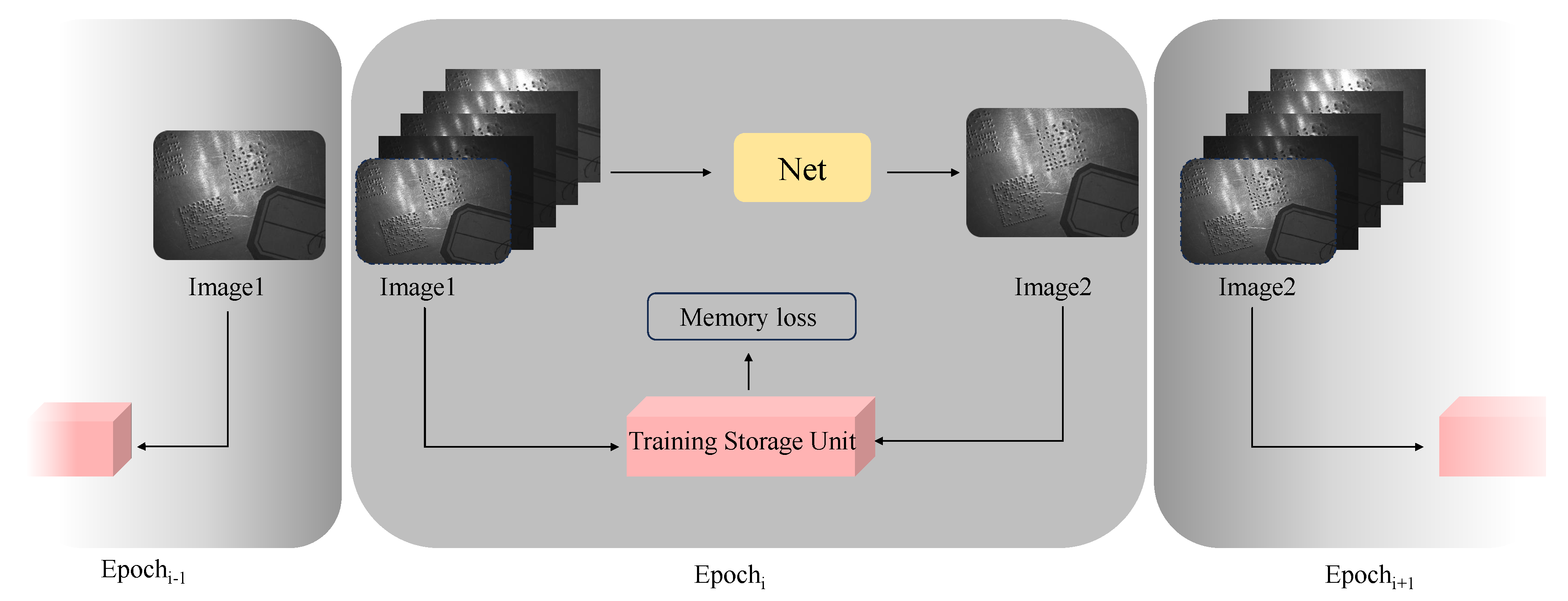
3.3. Training Storage Unit
In traditional unsupervised image fusion methods, intermediate results obtained during training are simply discarded. However, these intermediate results contain crucial information pertinent to the fusion task, such as pixel intensity distribution, structural similarity, and gradients. They can provide abundant supervised signals to guide the training process effectively. To further enhance the performance of unsupervised methods, this paper introduces a novel training storage unit that advocates self-evolving training. By designing a storage unit that collects outputs from a previous period and implementing a memory loss function that maximally utilizes the valid information from prior outputs, our approach fully leverages intermediate fusion results to improve fusion quality, thereby establishing an evolutionary training scheme.
As depicted in
Figure 6, the training storage unit architecture proposed in this paper is divided into two parts: the stage image storage module and the memory loss unit module. Stage image storage can store fused images derived from the image input sequence of the previous training epoch and integrate them into the image sequence, which will participate in training in the subsequent epoch. Using the output from the previous epoch as the selection source for the current epoch’s fusion images ensures that the current epoch’s output is superior to, or at least equivalent to, the previous epoch output.
The memory loss unit also utilizes the training results of intermediate fusion to further supervise the cooperative fusion of images. It is anticipated that clues about image fusion contained in previous outputs will be fully exploited during the training process of the current period.
The
[
33] (Structural Similarity Index) represents the structural similarity between two images, with
O and
denoting the output images of the current and previous epochs during the training process, respectively. It is assumed that for the first epoch,
.
stands for the Frobenius norm and ∇ represents the gradient operator. Therefore, this loss term can be expressed as:
3.4. ICG Evaluation Metric
For industrial images, uneven illumination distribution affects subsequent tasks such as recognition and detection. Compared to natural images, industrial images require that illumination effects be removed as thoroughly as possible. However, existing evaluation metrics often consider illumination information as one factor in assessing image quality, thus failing to fully describe whether the image illumination is uniform. Therefore, this paper proposes a no-reference uneven illumination evaluation metric for industrial images. The illumination component of an image with uneven illumination is extracted using a multi-scale Gaussian function approach. Then, the average gradient of the illumination component is solved to evaluate the degree of uneven illumination. The form of the Gaussian function is as follows:
In this equation,
c represents the scale factor and
is the normalization constant that ensures the Gaussian function
satisfies the normalization condition. The estimated value of the illumination component can be obtained by convolving the Gaussian function with the original image. The result is as follows:
Here, denotes the input image, and represents the estimated illumination component. Based on the Retinex theory, the choice of scale factor c in the Gaussian function determines the range of effect for the convolution kernel. A larger value of c expands the range of the Gaussian function’s convolution kernel, enhancing its ability to preserve the color tone and better extract the global characteristics of illumination. Conversely, a smaller value of c reduces the range of the Gaussian function’s convolution kernel, enabling better compression of the dynamic range and making the local characteristics of illumination more prominent.
This paper adopts a multi-scale Gaussian function approach to balance the extraction of global and local illumination characteristics. By utilizing Gaussian functions of different scales to extract the illumination components of the scene individually, followed by weighted processing, an estimation of the illumination components is obtained. The overall expression is as follows:
In Equation (
14),
represents the illumination component value at point
, which is obtained by extracting and weighting the illumination components using multiple Gaussian functions of different scales.
denotes the weight coefficient of the illumination component extracted by the
i scale Gaussian function, with
i ranging from 1 to N, representing the number of scales used.
The average grayscale value difference between adjacent blocks is minimal for images without illumination distortion. The more severe the uneven illumination, the more significant the difference. Therefore, the mean gradient of the illumination component is used to assess the degree of illumination unevenness. First, the image
is divided into
small rectangular blocks. For each
,the gradient
is defined as the sum of the absolute differences with its neighboring patches.
The average gradient is defined as:
A higher ICG value indicates more uneven illumination in the image. As illustrated in
Figure 7, this paper presents the illumination component images of different types of metal plates using various methods.
4. Experiment Results and Analysis
Given the current lack of an MEF dataset for smooth workpieces, this paper addresses the issue by creating an MEF dataset consisting of three different types of metals. To ensure a diverse and representative industrial scene dataset, we used the Hangzhou Hikrobot MV-CS016-10GM camera (resolution of 1408 × 1024) to collect data from steel, iron, and aluminum plates in static scenes (resolution of 720 × 540). For each sequence, the exposure value of the images was varied by adjusting the exposure time. The dataset comprised 80 scenes, each containing approximately 6 to 8 exposure images (K), totaling 600 images. Among these, 480 images were used for training and 120 for testing. We denote the number of images in the exposure sequence as K.
To evaluate the superiority of our method on natural image datasets as well, we conducted experiments using 360 exposure sequences from SICE part I. Following the training-testing split set by SICE [
34], 302 samples were used for training, and the remaining 58 samples were used for evaluation. We employed ICG, SD, and running time for the industrial dataset as evaluation metrics. For the SICE dataset, MEF-SSIM, PSNR, SSIM, and MI were used as the primary evaluation metrics to compare with our method.
The model training was conducted on an Ubuntu 20.04 operating system within the following development environment: Python 3.7.16, PyTorch 1.7.7, and CUDA 11.7.99. The hardware configuration included an Intel Core i7-12700K CPU and an NVIDIA GeForce RTX 3090 (24GB) GPU.
This paper conducts both qualitative and quantitative experiments on natural and industrial datasets and compares our method with eight previous MEF approaches. These approaches include traditional methods such as Mertens [
1] and Li20 [
23], as well as deep learning methods like DeepFuse [
2], MEFNet [
14], IFCNN [
11], DPEMEF [
10], TransMEF [
16] and HoLoCo [
7].
4.1. Industrial Dataset Experiment
The present study conducted qualitative and quantitative evaluations on an industrial image dataset, with the participation of six exposure images. In industrial imagery, we mainly focus on the quality of uneven illumination removal within the fused images. Therefore, this paper selected ICG and standard deviation (SD) as evaluation metrics for industrial images. The SD reflects the degree of pixel value dispersion within an image. A larger standard deviation indicates a wider range of variation in the pixel values of an image. A lower standard deviation is preferable for tasks involving dynamic enhancement and uneven illumination removal in industrial images. Additionally, in industrial settings, the real-time execution of algorithms is also a crucial factor in assessing algorithm performance. Hence, we conducted runtime testing of the algorithm on a GPU.
As demonstrated in
Table 2, the method proposed in this paper outperforms other algorithms in terms of enhancing image dynamic range and removing uneven illumination. Despite a slight lag behind the MEFNet method in runtime testing, the approach presented in this paper still meets the real-time requirements of industrial applications and exhibits commendable performance.
This paper conducted qualitative testing on industrial images, as depicted in
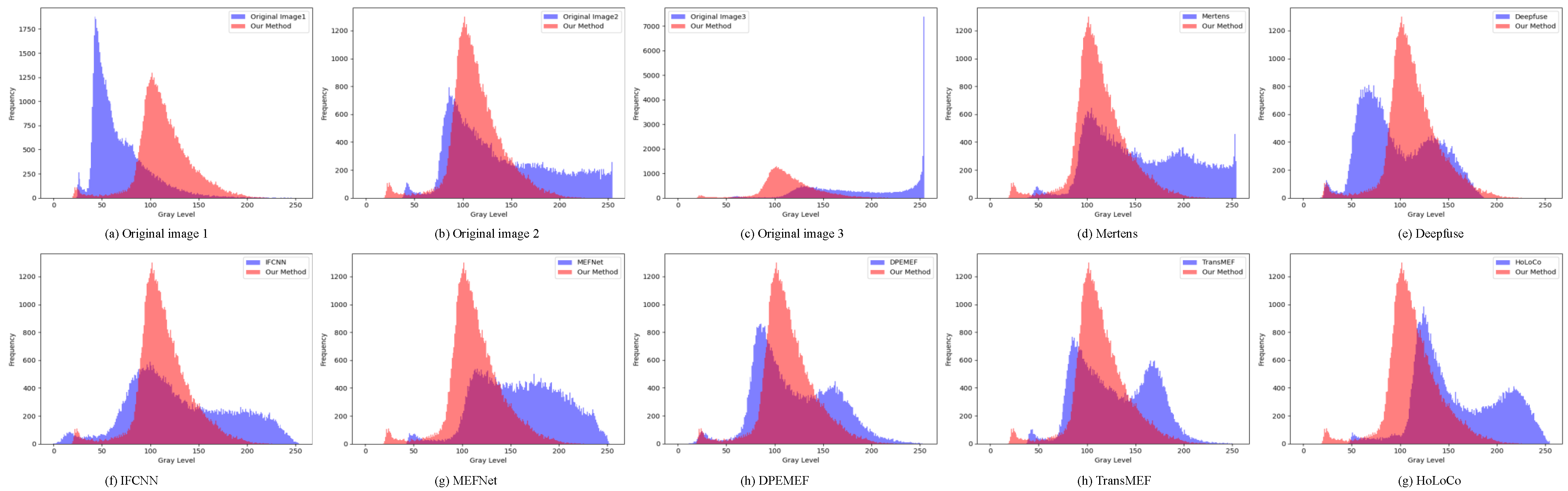
Figure 8. Compared to other algorithms, the proposed algorithm in this paper demonstrated excellent performance in terms of overall brightness uniformity of the images and successfully eliminated the uneven illumination in the images. To facilitate the observation of local image details, we have zoomed in on the red-boxed areas in the figure. We performed pixel distribution statistics separately for both local and global aspects of the fused images to more intuitively showcase the superiority of our approach. In
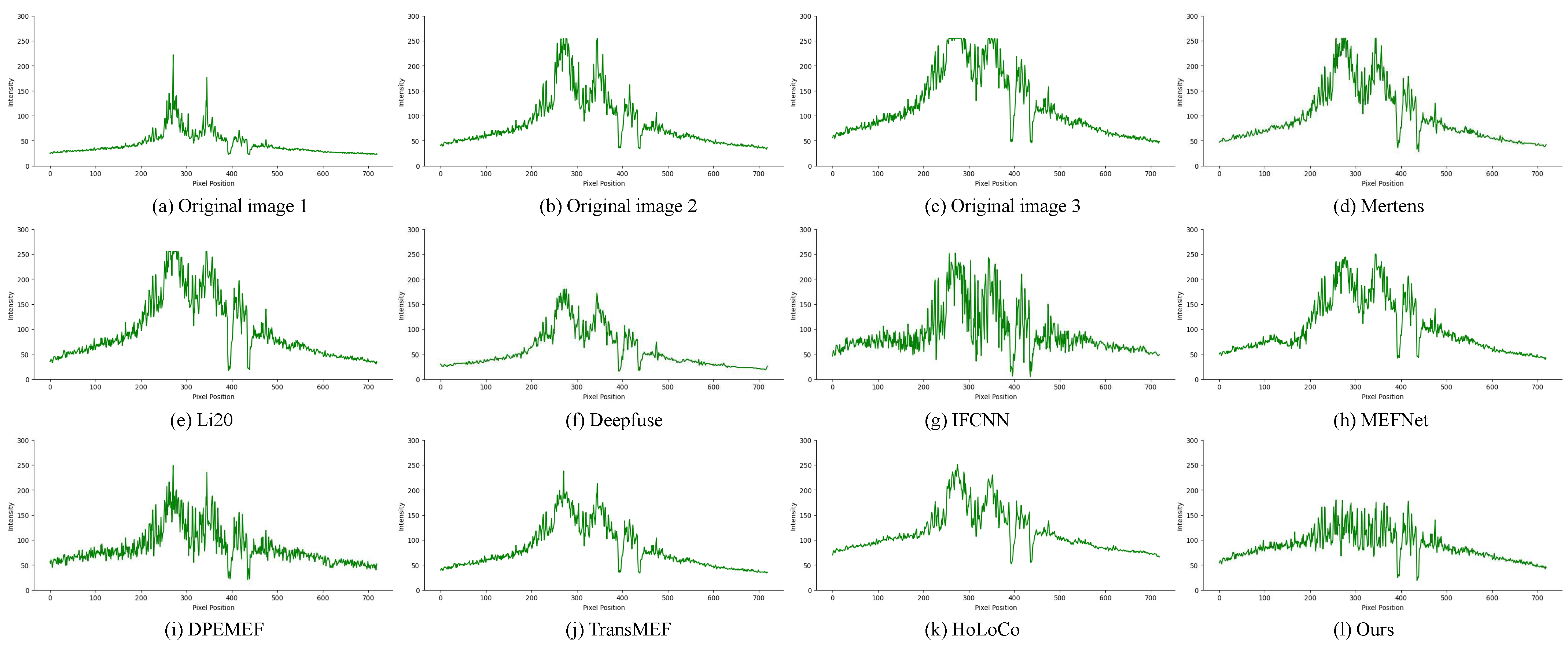
Figure 9, we provide a comparative statistical analysis of pixel distribution for the locally zoomed in image. This enables a more precise representation of the concentration intervals of image grayscale values and the count of pixels for each grayscale level. Additionally, from a global perspective, we conducted pixel statistics on the blue line region in
Figure 8, as illustrated in
Figure 10. The pixel statistics approach aids in assessing the overall level of grayscale value variation in the image.
Based on
Figure 9, it can be observed that the fusion results of the Mertens, MEFNet, and HoLoCo methods primarily distributed gray values in the overly bright range of 150–200. DeepFuse performed well in local zoom, but exhibited an overall lower grayscale value. The IFCNN method showed distribution across various grayscale value ranges, but maintained a certain proportion of pixels in underexposed and overexposed regions. The pixel peak distribution of the DPEMEF and TransMEF methods was between 50–100 and 100–150, and the overall brightness uniformity of the images were poor. Compared to the methods above, the proposed method in this paper exhibited concentrated grayscale values within the suitable brightness range of 100–150 in the data of metal plates, with appropriate overall brightness effects.The regions with grayscale values below 50 in the industrial image represent the foreground area, the dot-like region of the image’s QR code. Through comparative observation, our method demonstrated relatively lower grayscale values in the foreground area, which helped to accentuate the image’s foreground region.
For the global pixel distribution, we aimed for a uniform variation in the grayscale values of the image background, without any abrupt changes in brightness. Based on the grayscale value distribution in the image’s linear region shown in
Figure 10, it is evident that in the DeepFuse method, the majority of pixels’ grayscale values were concentrated below 50, making it challenging to discern details in darker areas. The Mertens, Li20, and MEFNet methods showed a noticeable rise in grayscale values in high-light regions, whereas the IFCNN, DPEMEF, and TransMEF methods displayed drastic fluctuations. In contrast, there wass no significant upward trend in the grayscale curve of our method. It showed minimal grayscale value fluctuations, indicating a uniform distribution of grayscale values in the processed image and effective removal of uneven illumination. At the boundary between the foreground and background of the image (pixel position = 395, 438), there was a sharp decline in the grayscale values. Through comparison, it has been observed that our method effectively preserves the contrast between the foreground and background while simultaneously removing uneven illumination. In summary, the proposed method exhibits a smooth variation in the grayscale value curve of the images. It achieves a high contrast between the foreground and background, improves image dynamic range, and effectively eliminates the problem of uneven illumination.
We conducted qualitative analysis on several common metal sheet images to further evaluate our method, as illustrated in
Figure 11. Our method exhibited optimal performance across images of different types of metal sheets. Furthermore, in
Figure 7, we extracted the illumination components of selected images (first three rows) from
Figure 11 using a multi-scale Gaussian function for further analysis. It is clear from the analysis that our method demonstrated overall low gradient values in the images, with uniform illumination distributed throughout the entire image. This further substantiates our method’s capability to remove uneven illumination and enhance image dynamic range.
4.2. Experiments with Natural Datasets
This study chose a subset of exposure sequences from the SICE dataset as the test set, with the number of exposed images (k) set to 2. We compared the fusion results of our approach with several other fusion methods, utilizing various types of image evaluation metrics to assess the quality of the fused images comprehensively. Among these metrics, MEF-SSIM and SSIM are derived from image structural information and PSNR relies on pixel statistics, while mutual information (MI) is grounded in information theory.
As shown in
Table 3, the average values of these metrics in our method were 0.9630, 0.9355, 20.99, and 4.5725, respectively. The results indicate that our method outperforms others in preserving image information and providing higher image quality. Additionally, we conducted qualitative comparisons of different methods on three typical image sequences from the SICE dataset, as depicted in
Figure 12.
As depicted in the local detail images in
Figure 12, the fusion results of Mertens, TransMEF, and HoLoCo exhibited a natural visual effect but lacked detail and texture, with poor enhancement in darker areas. DeepFuse’s fused images suffered from low detail retention and exhibit deficiencies in effectively merging a wide range of exposures. MEFNet, IFCNN, and HoLoCo fusion results exhibited color distortions and relatively sparse detail information. In contrast, the method proposed demonstrated the best performance in enhancing brightness in darker areas and suppressing brightness in overexposed regions, exhibiting rich details, natural colors, and complete information retention.
4.3. Algorithmic Ablation Experiments
To further validate the effectiveness of each algorithm module, this paper conducted comparative studies on ablation experiments for the attention module, training storage unit, and DGF modules within an industrial image dataset.
Table 1 shows that when both the attention module and training storage unit module are employed simultaneously, all metrics and visual effects achieve optimal performance. This result is primarily attributed to the fact that both of them enhance the information exchange among different exposure images. Additionally, with the addition of the DGF upsampling module, further enhancements in the MEF-SSIM metric were achieved by introducing learnable parameters to guide the filter, thereby demonstrating the effectiveness of the DGF algorithm module.
4.4. Running Time for Different Number of Exposure Sequences
Our method can flexibly handle different numbers of exposure sequence images to accommodate the complex and diverse nature of industrial scenes. We conducted experiments on several common K values. We assessed the runtime on different platforms, including a CPU and GPU, and compared it with six deep learning-based MEF methods, as shown in
Table 4. The resolution of the evaluated images was 2K, and “-” indicates exclusion from the test due to DeepFuse’s strict input settings.
As shown in
Table 4, our approach achieved similar runtime performance to MEFNet in CPU environments with different values of K. In GPU environments, our method’s runtime was slightly higher than MEF-Net’s, yet it still met the real-time requirements of industrial applications. In contrast, other methods exhibit substantial performance overhead. Through experimentation, it is observed that our method’s runtime across various common K values can meet the real-time demands of industrial scenarios.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}