
A Multi-Level Location-Aware Approach for Session-Based News Recommendation

Abstract
1. Introduction
2. Related Work
2.1. News Recommendation
2.2. Graph Neural Network
2.3. Attention Mechanism
3. Proposed Model
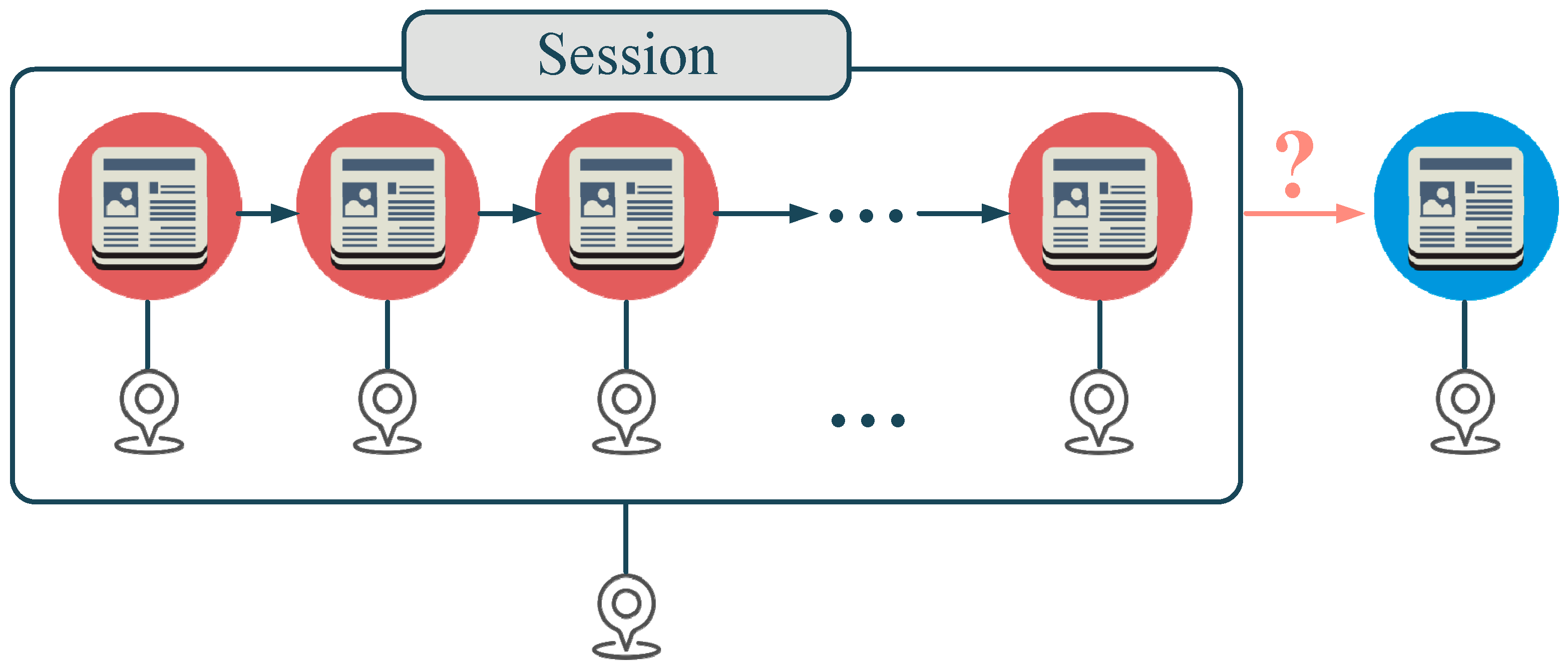
3.1. Problem Formulation
3.2. Model Overview
3.3. Text and Location Feature Extraction Layer
3.3.1. Text Feature Extraction
3.3.2. Location Feature Extraction
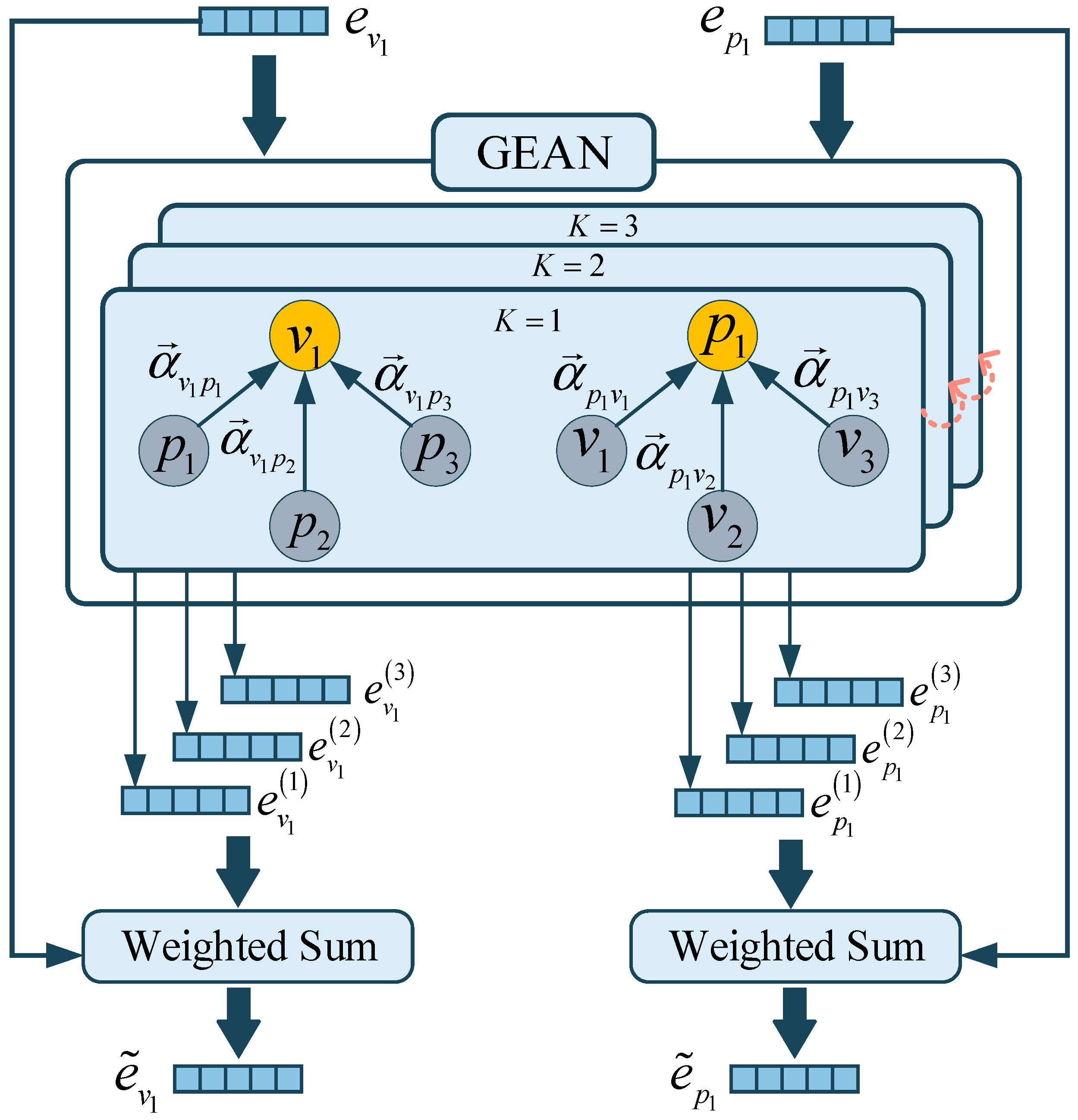
3.4. News-Level Location-Aware Layer
3.5. Session Feature Extraction Layer
3.5.1. Input Layer
3.5.2. Feature Extraction Layer
3.5.3. Output Layer
3.6. Session-Level Location-Aware Layer
3.7. Click-Through Rate Prediction Layer
3.8. Model Training
4. Experiment
4.1. Experiment Setting
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Comparison Methods and Parameter Settings
- Item KNN [33] is a neighbor-based approach that returns the most similar items based on the cosine similarity between the last news in a session and the rest of the news. In the experiment, the news text feature was used to calculate the cosine similarity. The core parameter recommended list length was set to 100.
- V-skNN [33] is also a neighbor-based method, similar to Item KNN, but different in that it recommends the most suitable news by considering all the news in the entire session. In the experiment, the number of similar sessions was set to 100, 200, 100, and 50 for the four data subsets, respectively, and the number of samples was set to 500, 1000, 500, and 300.
- GRU4REC [6] is an RNN-based method that uses RNN to model user sessions and predict the probability of future events in the current session (such as item click-through rate). In the experiment, the hidden state dimensions are set to 128, 256, 128, and 64, respectively, on the four data subsets, the GRU layers are all set to 3, the dropout ratios are 0.5, 0.7, 0.4, and 0.1, respectively, and the loss function is BPR.
- Chameleon [8] is a deep learning-based method that consists of two modules, one for learning news article representations and the other for providing session-based recommendations using an RNN. In the experiments, the regularization coefficient was set to 0.0001, 0.001, 0.0001, and 0.00001 for the four data subsets, respectively. The article embedding dimension was set to 1024 for all subsets, and the RNN layers were set to 2.
- CAGE [9] is a context-aware graph embedding method that constructs an auxiliary knowledge graph to mine the semantic information of news articles and uses a graph convolutional neural network to enrich the article embeddings. In the experiment, the knowledge graph embedding dimensions were set to 100, 100, 100, and 50 for the four data subsets, and the output dimensions of the first layer GCN were set to 150, 250, 125, and 125, while the output dimensions of the second layer GCN were set to 128, 128, 128, and 64.
- MLA4SNR is proposed method in this paper, in the experiments, the news embedding dimension is set to 768, the position embedding dimension is set to 768, the number of graph convolution layers in the news-level position-aware layer is set to 4, 3, 5, and 4, respectively, the number of graph convolution layers in the session-level position-aware layer is set to 2, 2, 3, and 2, respectively, the Transformer layers are set to 4, 5, 4, and 3, respectively, the attention head numbers are set to 4, 4, 4, and 2, respectively, and the regularization coefficients are set to 0.0001, 0.0001, 0.0001, and 0.00001 for the four data subsets.
4.2. Performance Comparison
4.3. Model Analysis
4.3.1. Ablation Analysis
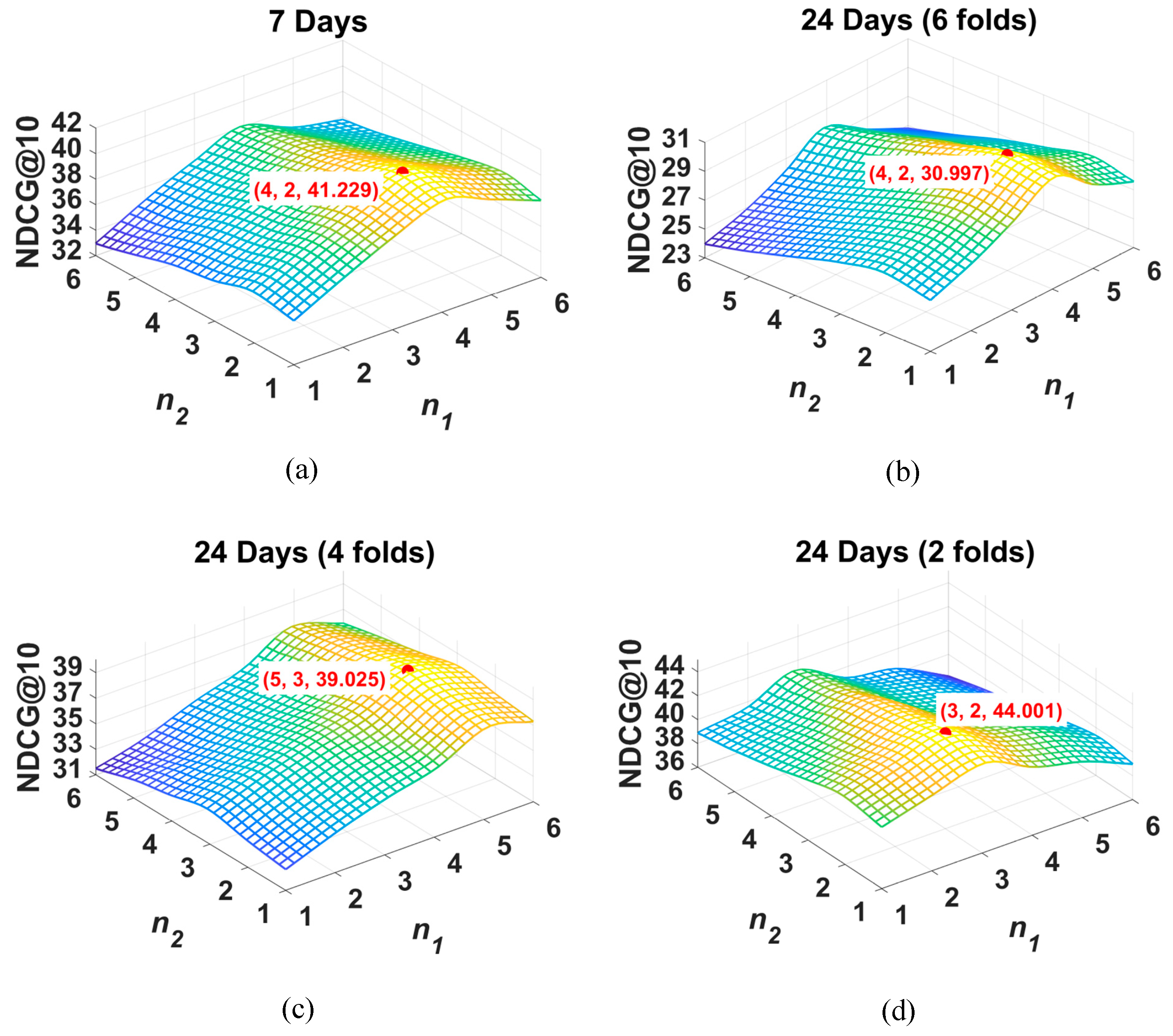
4.3.2. The Impact of the Number of Layers in Graph Element-Wise Attention Networks
4.3.3. The Impact of the Number of Transformer Layers and Attention Heads
4.3.4. Comparison of BPR, BCE, and NDCG Loss Functions
5. Conclusions
- A multi-level location-aware session-based news recommendation algorithm has been proposed, which realizes multi-level location-awareness at both the news and session levels.
- A session feature extraction network based on Transformer is designed to achieve high-precision and high-efficiency extraction of session features.
- A new ranking-based loss function is designed based on the evaluation metric NDCG, which improves the model’s ranking performance.
- Experimental results on real-world news datasets demonstrate that the performance of MLA4SNR significantly outperforms the baseline.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dias, M.B.; Locher, D.; Li, M.; El-Deredy, W.; Lisboa, P.J. The value of personalised recommender systems to e-business: A case study. In Proceedings of the 2008 ACM Conference on Recommender Systems, Lausanne, Switzerland, 23–25 October 2008; pp. 291–294. [Google Scholar]
- Joseph, K.; Jiang, H. Content based news recommendation via shortest entity distance over knowledge graphs. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 690–699. [Google Scholar]
- Das, A.S.; Datar, M.; Garg, A.; Rajaram, S. Google news personalization: Scalable online collaborative filtering. In Proceedings of the 16th International Conference on World Wide Web, Edmonton, AB, Canada, 8–12 May 2007; pp. 271–280. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. DKN: Deep knowledge-aware network for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1835–1844. [Google Scholar]
- de Souza Pereira Moreira, G.; Ferreira, F.; da Cunha, A.M. News session-based recommendations using deep neural networks. In Proceedings of the 3rd Workshop on Deep Learning for Recommender Systems, Vancouver, BC, Canada, 6 October 2018; pp. 15–23. [Google Scholar]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Zhang, L.; Liu, P.; Gulla, J.A. Dynamic attention-integrated neural network for session-based news recommendation. Mach. Learn. 2019, 108, 1851–1875. [Google Scholar] [CrossRef]
- Moreira, G.; Jannach, D.; da Cunha, A.M. Contextual Hybrid Session-based News Recommendation with Recurrent Neural Networks. IEEE Access 2019, 7, 169185–169203. [Google Scholar] [CrossRef]
- Sheu, H.S.; Chu, Z.; Qi, D.; Li, S. Knowledge-Guided Article Embedding Refinement for Session-Based News Recommendation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 7921–7927. [Google Scholar] [CrossRef] [PubMed]
- Tang, S.; Luo, F.; Wu, J. Smooth-AUC: Smoothing the Path Towards Rank-based CTR Prediction. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2400–2404. [Google Scholar]
- Goossen, F.; Ijntema, W.; Frasincar, F.; Hogenboom, F.; Kaymak, U. News personalization using the cf-idf semantic recommender. In Proceedings of the International Conferenceon Web Intelligence, Mining and Semantics, Sogndal, Norway, 25–27 May 2011; pp. 1–12. [Google Scholar]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 2004, 60, 493–502. [Google Scholar] [CrossRef]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A Deep Reinforcement Learning Framework for News Recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018. [Google Scholar]
- Tian, Y.; Yang, Y.; Ren, X.; Wang, P.; Wu, F.; Wang, Q.; Li, C. Joint Knowledge Pruning and Recurrent Graph Convolution for News Recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, ACM, Online, 11–15 July 2021. [Google Scholar]
- Jia, Q.; Li, J.; Zhang, Q.; He, X.; Zhu, J. RMBERT: News recommendation via recurrent reasoning memory network over BERT. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 July 2021; pp. 1773–1777. [Google Scholar]
- Sottocornola, G.; Symeonidis, P.; Zanker, M. Session-based news recommendations. In Proceedings of the Companion Proceedings of the the Web Conference 2018; Lyon, France: 23–27 April 2018; pp. 1395–1399.
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Berg, R.; Kipf, T.N.; Welling, M. Graph Convolutional Matrix Completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhinal, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhu, Q.; Zhou, X.; Song, Z.; Tan, J.; Guo, L. DAN: Deep Attention Neural Network for News Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Zhao, Q. D-HAN: Dynamic News Recommendation with Hierarchical Attention Network. arXiv 2021, arXiv:2112.10085. [Google Scholar]
- Wu, C.; Wu, F.; An, M.; Huang, J.; Huang, Y.; Xie, X. NPA: Neural News Recommendation with Personalized Attention. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Milne, D.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 509–518. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019; Available online: https://arxiv.org/abs/1902.10197 (accessed on 26 February 2019).
- Grover, A.; Wang, E.; Zweig, A.; Ermon, S. Stochastic Optimization of Sorting Networks via Continuous Relaxations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Jugovac, M.; Jannach, D.; Karimi, M. Streamingrec: A framework for benchmarking stream-based news recommenders. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 269–273. [Google Scholar]
- He, X.; Chen, T.; Kan, M.Y.; Chen, X. Trirank: Review-aware explainable recommendation by modeling aspects. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1661–1670. [Google Scholar]
- Ludewig, M.; Jannach, D. Evaluation of session-based recommendation algorithms. User Model. User-Adapt. Interact. 2018, 28, 331–390. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CF-IDF | DRN | KOPRA | RMBert |
|---|---|---|---|---|
| Author | Goossen | Zheng | Tian | Jia |
| Method | Only consider key concepts in the text | A deep learning-based online personalized news recommendation framework | Directly identify entities related to user interests and derive the final user representation | Circular memory reasoning network based on Bert |
| Model | Mixed Recommendation Model | GRU4Rec | DAINN | CAGE |
|---|---|---|---|---|
| Author | Sottocornola | Hidasi | Zhang | Sheu |
| Method | Digging into users’ short-term intentions | Using GRU to extract users’ short-term preferences during a session | Using dynamic attention networks to simulate users’ dynamic interests | Building auxiliary knowledge graphs enriches the semantic information of entities in news articles, and using graph convolutional networks enhances article embedding |
| Model | Frequency Domain Graph Neural Network Model | GCN | GraphSAGE | GAT |
|---|---|---|---|---|
| Author | Shuman | Kipf | Hamilton | Veličković |
| Method | Converting spatial domain graph data to frequency domain and using filtering operations to complete graph convolution | Semi supervised classification task | Sampling a portion of adjacent nodes to participate in information aggregation | Introducing attention mechanism into graph convolutional neural networks |
| Symbol | Explanation |
|---|---|
| The news set | |
| The session set | |
| The location set | |
| The i-th session. | |
| The location where session occurs | |
| The candidate news set for session | |
| The set of locations related to news article | |
| The news text feature set | |
| The location feature set | |
| The news feature matrix of session | |
| The sequence encoding matrix of session |
| Number of Sessions | Number of News | Average Length of Session | |
|---|---|---|---|
| 7 days | 460,633 | 4597 | 2.82 |
| 24 days | 1,575,240 | 16,678 | 3.21 |
| Dataset | Number of Geographical Entities | Number of Other Entities | Number of Relationships | Number of Triples |
|---|---|---|---|---|
| 7 days | 1687 | 45,233 | 502 | 81,414 |
| 24 days | 2547 | 69,745 | 684 | 123,584 |
| Dataset | Metrics | Item KNN | V-sknn | GRU4REC | Chameleon | CAGE | MLA4SNR |
|---|---|---|---|---|---|---|---|
| 7 days | HR@10 | 57.013 | 59.125 | 60.211 | 65.145 | 66.211 | 69.515 |
| NDCG@10 | 26.575 | 29.451 | 31.213 | 36.642 | 36.752 | 41.229 | |
| ESI-RR@10 | 39.225 | 43.12 | 44.561 | 55.46 | 56.154 | 59.356 | |
| EILD-RR@10 | 1.458 | 1.589 | 1.623 | 1.762 | 1.811 | 2.014 | |
| 24 days (6 folds) | HR@10 | 48.124 | 50.472 | 51.211 | 57.133 | 58.458 | 60.584 |
| NDCG@10 | 20.131 | 22.25 | 23.144 | 27.545 | 27.881 | 30.997 | |
| ESI-RR@10 | 29.91 | 32.131 | 33.655 | 46.322 | 47.243 | 50.003 | |
| EILD-RR@10 | 1.146 | 1.258 | 1.301 | 1.498 | 1.578 | 1.702 | |
| 24 days (4 folds) | HR@10 | 55.564 | 58.452 | 59.452 | 64.121 | 65.213 | 68.115 |
| NDCG@10 | 24.985 | 28.143 | 30.784 | 34.222 | 35.045 | 39.025 | |
| ESI-RR@10 | 37.243 | 42.687 | 43.211 | 54.011 | 54.982 | 58.68 | |
| EILD-RR@10 | 1.387 | 1.513 | 1.562 | 1.701 | 1.767 | 1.946 | |
| 24 days (2 folds) | HR@10 | 63.154 | 65.147 | 66.214 | 70.213 | 71.244 | 75.387 |
| NDCG@10 | 30.012 | 33.021 | 34.025 | 39.415 | 40.312 | 44.001 | |
| ESI-RR@10 | 45.471 | 48.556 | 49.111 | 60.014 | 60.453 | 64.568 | |
| EILD-RR@10 | 1.698 | 1.754 | 1.787 | 1.878 | 1.898 | 2.112 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Cui, S.; Wang, X.; Zhang, J.; Cheng, Z.; Mu, X.; Tang, B. A Multi-Level Location-Aware Approach for Session-Based News Recommendation. Electronics 2025, 14, 528. https://doi.org/10.3390/electronics14030528
Yu X, Cui S, Wang X, Zhang J, Cheng Z, Mu X, Tang B. A Multi-Level Location-Aware Approach for Session-Based News Recommendation. Electronics. 2025; 14(3):528. https://doi.org/10.3390/electronics14030528
Chicago/Turabian StyleYu, Xu, Shuang Cui, Xiaohan Wang, Jiale Zhang, Zihan Cheng, Xiaofei Mu, and Bin Tang. 2025. "A Multi-Level Location-Aware Approach for Session-Based News Recommendation" Electronics 14, no. 3: 528. https://doi.org/10.3390/electronics14030528
APA StyleYu, X., Cui, S., Wang, X., Zhang, J., Cheng, Z., Mu, X., & Tang, B. (2025). A Multi-Level Location-Aware Approach for Session-Based News Recommendation. Electronics, 14(3), 528. https://doi.org/10.3390/electronics14030528