
The Progress and Prospects of Data Capital for Zero-Shot Deep Brain–Computer Interfaces

 ,
,
Abstract
1. Introduction
- First, we use the IL framework to conduct a systematic literature review. We summarise both established and emerging DBCI data capitals which help understand the progress of each identified core technical milestone of DBCI.
- Second, the motivation of this article is to put the development of BCI models into the context of the IL framework. We identify key barriers preventing the development of large DBCI models in terms of devices, data, and applications.
- Third, we point those unaddressed technical challenges towards cutting-edge zero-shot learning techniques. Our findings establish a technical roadmap through inter-sample, inter-person, inter-device, inter-domain and inter-task transfer paradigms, multimodal visual–semantic neural signal models, and data synthesis and signal processing for higher SNR and scalable DBCI device adaption.
2. Research Background
- 1924: Hans Berger records the first electroencephalogram (EEG) signal.
- 1950s: Bio–neuro feedback was introduced, focusing on physiological and brain signals.
- 1960: Neil Miller demonstrates operant conditioning for controlling autonomic functions, like blood pressure and heart rate, in rats.
- 1973: First theoretical and technical review of brain–computer interfaces (BCIs).
- 1991: Event-related desynchronisation (ERD) is introduced for cursor control.
- 1999: Slow cortical potentials (SCPs) are applied to control devices for locked-in patients.
- 2000s: Development of P300-based BCIs for communication and control tasks.
- 2010: Adoption of ISO 9241-210 usability standards for BCI evaluation, focusing on effectiveness, satisfaction, and usability.
- 2020s: Emergence of advanced applications like brain painting for ALS patients and other neurofeedback-based tools.
Industrial Landscape
3. Methodology
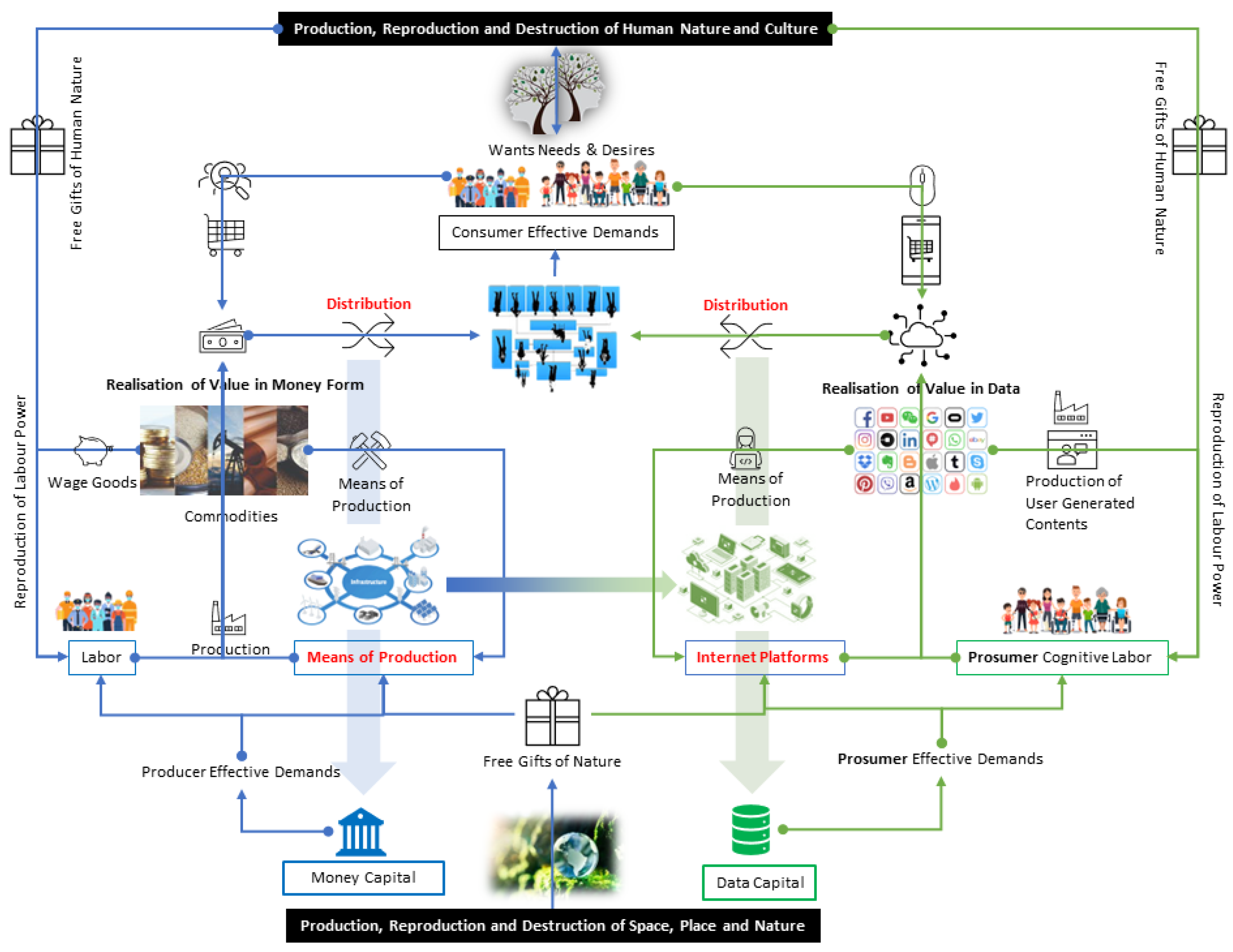
3.1. Conceptualisation of DBCI Industrial Landscape
- DBCI applications: These applications consider the impact of big data and artificial intelligence (AI) on the economic, social, and political systems of the world. AI has increased the ability to produce more for economic growth and development while also making human labour obsolete. This creates a trajectory where capitalism remains the ultimate system, controlling the lives of labour through big data. However, the growth of AI also promotes technological innovation and investment, leading to economic growth. The profit-driven technological singularity of AI creates social challenges and potentially fatal economic impacts under a neoliberal economic system. AI also creates a digital divide and potentially expands existing societal rifts and class conflicts. It is essential to develop policies to protect labour, privacy, trade, and liability and reduce the consequences of AI’s impact on employment, inequality, and competition. DBCI may create opportunities for individuals to monetise their personal data and potentially transfer control and ownership to actual data producers in a passive way, i.e., the mind activity and focused time consumption. Application is, therefore, a key parameter in evaluating the maturity and progress of the DBCI industrial landscape.
- The utility of DBCI: The economic landscape has undergone major changes in the past few decades with the emergence of new internet technologies and the creation of value through business model innovation using data and information. The factors of production have been redefined with data and information being recognised as new variables that have been made possible by technological breakthroughs in information and communications technology. The cost of computing power, data storage, and Internet bandwidth has decreased significantly, enabling the creation of increasingly rich digital information. This has given rise to new phenomena such as big data analytics and Internet platform companies. The democratisation of information and knowledge has also increased the bargaining power of workers and consumers whilst impacting Marxist philosophy in two areas related to the value-creation process. The commodification of cognitive labour is the foundation of the new capitalist system in which modes of control over production, consumption, distribution, and exchanges are very different from earlier forms of capitalism in history. This new economy of capitalist transformation is referred to as ‘cognitive capitalism’ [41]. This work provides empirical evidence supporting the role of cognitive abilities and intellectual resources in driving innovation, productivity, and economic growth. By aligning the discussion of DBCI utility with the principles outlined, we establish a stronger connection between the theoretical framework of cognitive capitalism and the practical implications of DBCI technologies. This addition strengthens our argument and highlights the transformative potential of DBCI within the broader economy and the industrial landscape.
- Value of cognitive workload: The traditional idea that the value of products and services is measured in labour hours has been challenged by the process of datafication, which involves dematerialisation, liquefaction, and density. Digitisation has made it possible for companies like Netflix to offer on-demand services and gather data on user behaviour. Digital products are also non-rivalrous and non-excludable, which means that they can be used by many individuals at the same time without reducing their availability to others. The availability of free digital services and products also challenges the use of labour hours to value a product or service, as many are provided through advertising or other business models. The concept of the prosumer [7] further undermines the traditional value-creation process. The definition of prosumer originates from the fact that most online content uploaded onto technology platforms today is actually produced by the consumer, free of charge. This means that the traditional value-creation process is rendered obsolete. While existing AIGC technologies have provided the premises for creation, the cognitive workload in DBCI provides one step further. The research on cognitive workload can potentially encourage a healthy and fair ecosystem for DBCI and other large models for real-world applications.
- Data and model ownership: The scoping review discusses how the traditional Marxist dichotomy between bourgeoisie owners of the means of production and proletariat workers has been upended by the emergence of platform-based internet companies. These companies, such as Amazon, Google, and Facebook, do not own the means of production but rather the means of connection to the internet, and they leverage large amounts of customer data to create value. This article also discusses the democratisation of information and the shift in power from traditional owners to individuals and entrepreneurs, as well as the emergence of the sharing economy and the de-linking of assets from value. In the AIGC era, the AI ecosystem is moving from the traditional data capital to the current model capital paradigm, such as ChatGPT. Large-scale deep models, whether they are open-source or not, are no longer accessible to common users for model fine-tuning. Deep model APIs or MLaaS have become dominant practices. In DBCI research, deep learning models are in the early stages of this model capital wave. Our review will discuss the influence of existing data and AI model capitals on the DBCI domain.
3.2. DBCI Data Capital Liquidation Process
4. Survey Results
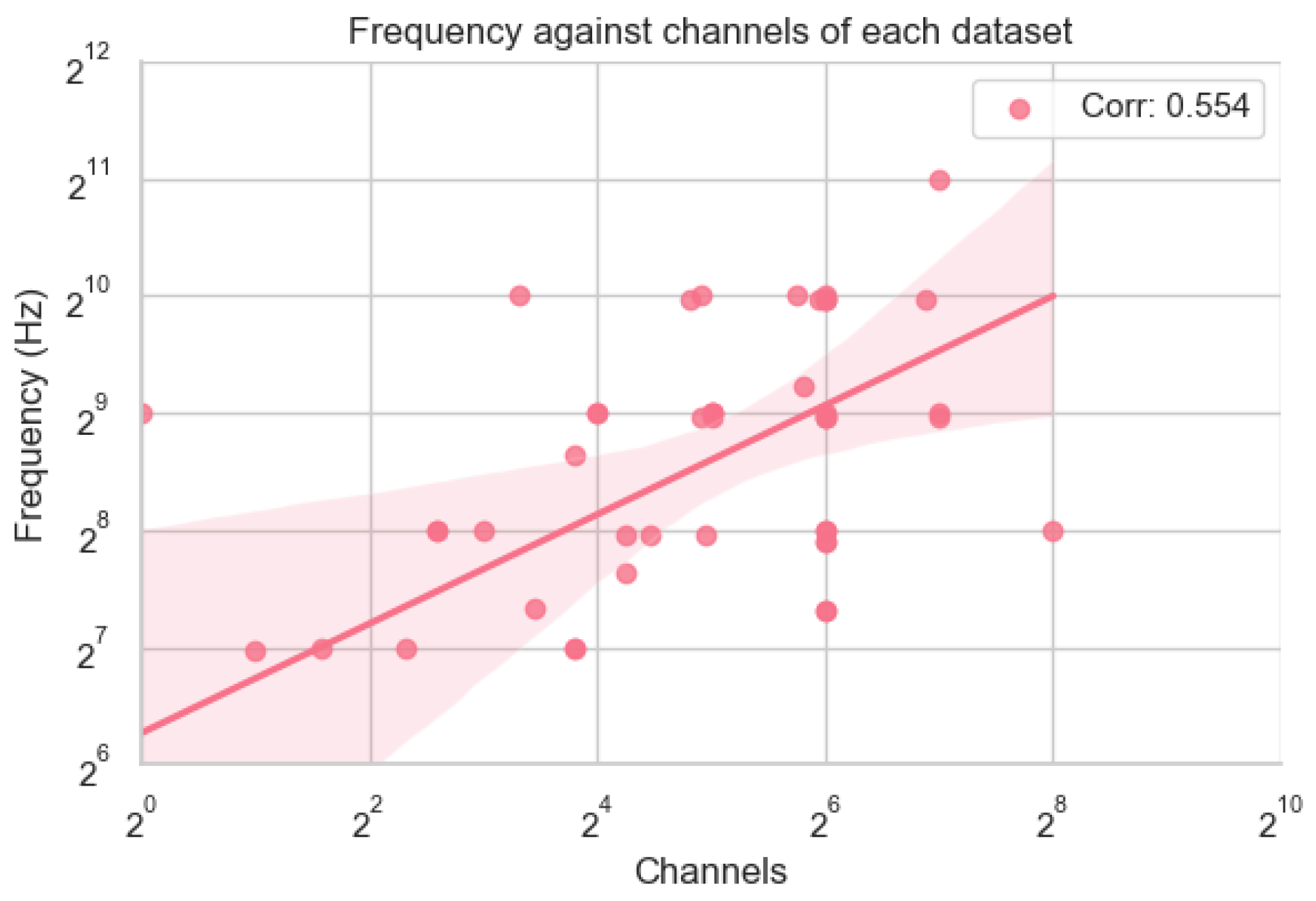
4.1. Device
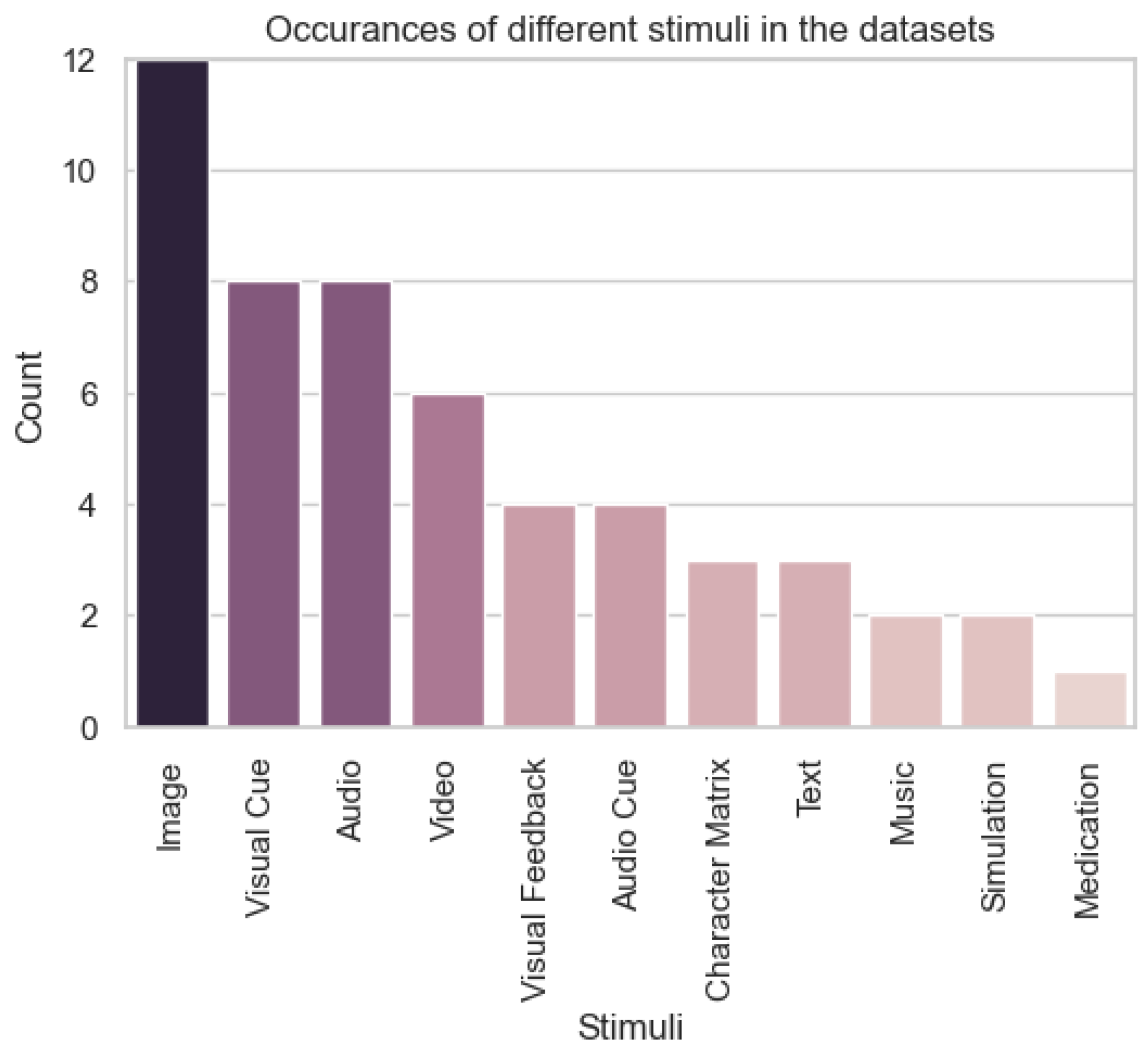
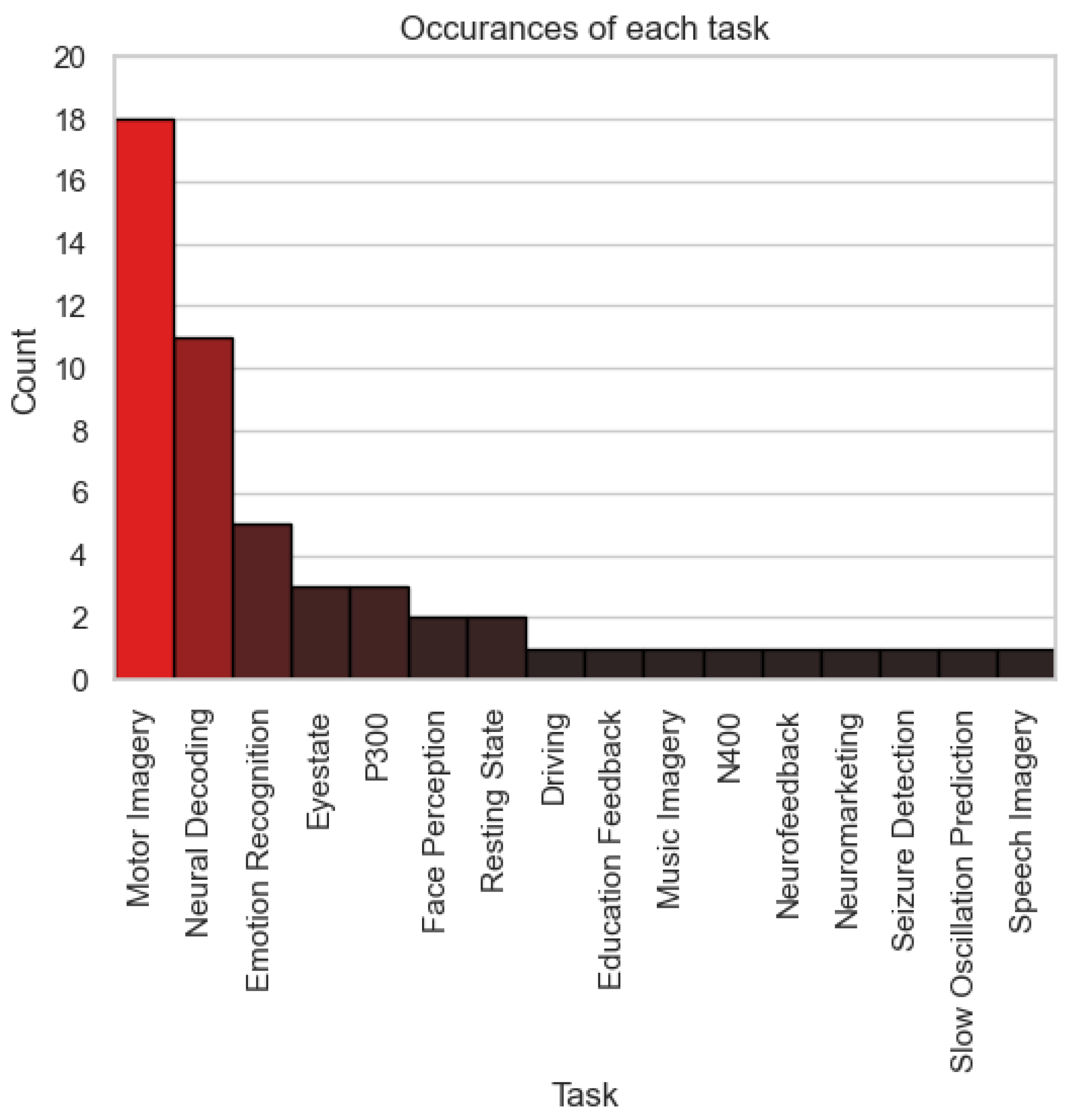
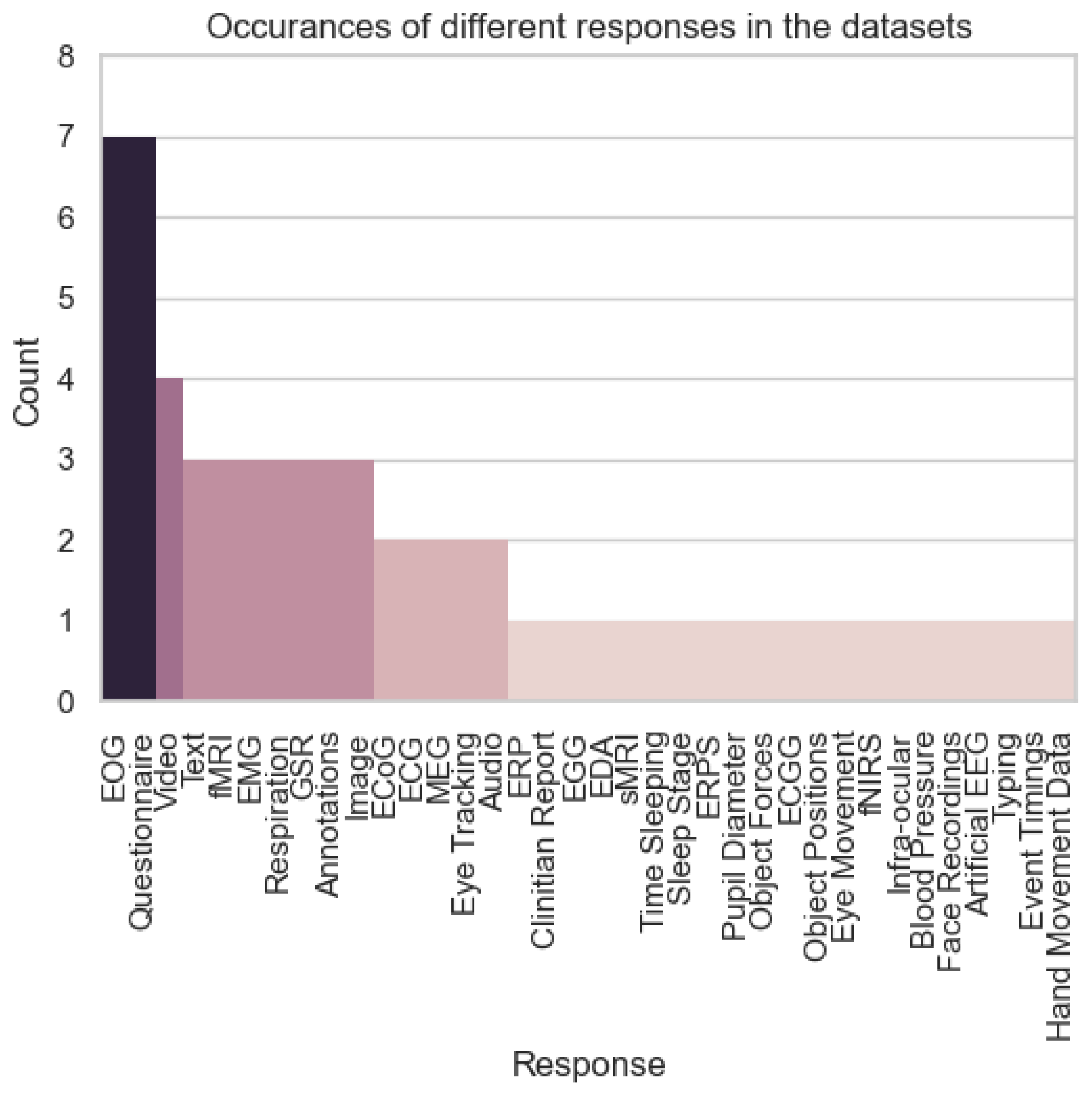
4.2. Data
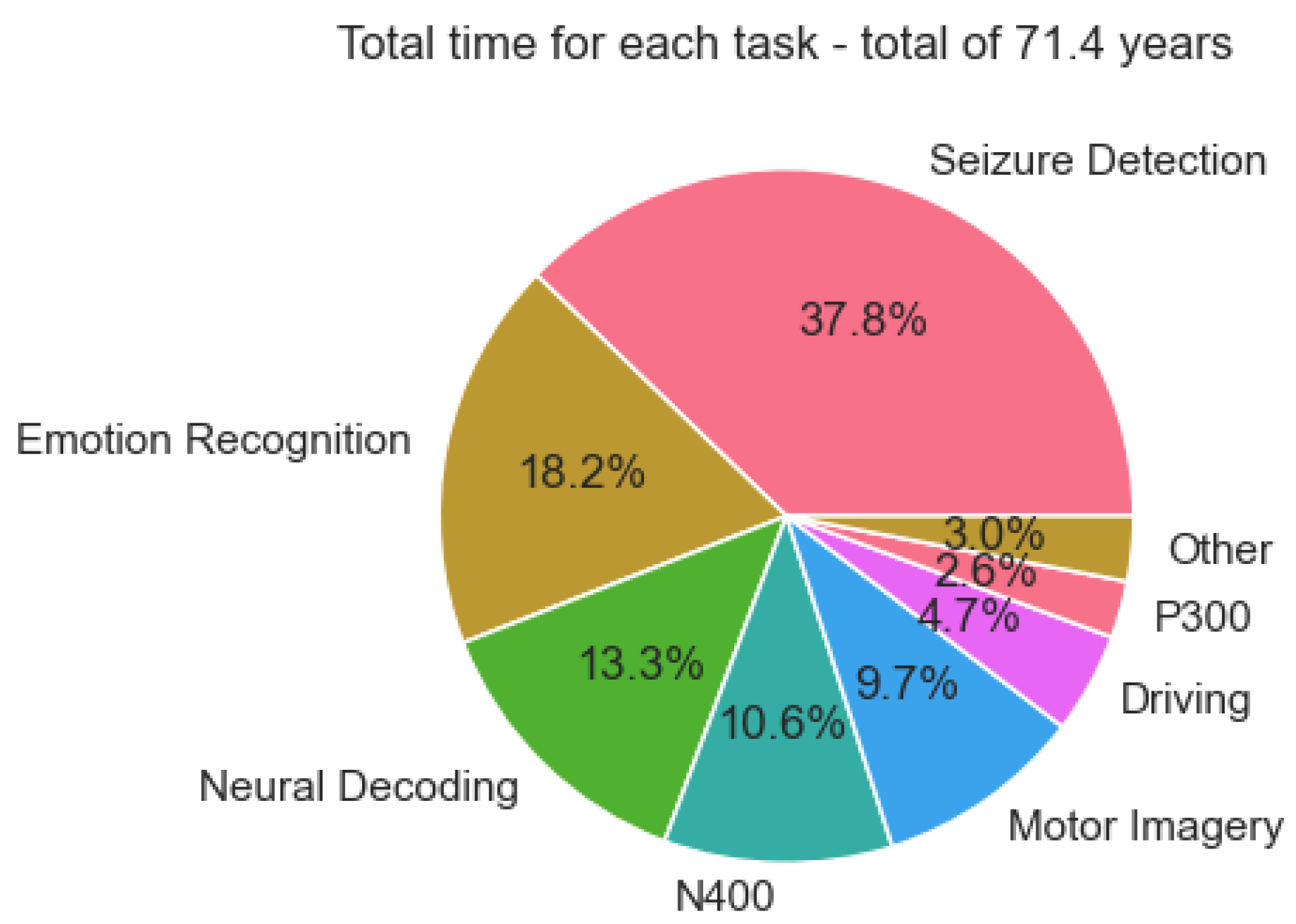
- Applications: The pie chart analysis highlights the dominance of seizure detection, accounting for 37.8% of the total data. This reflects the clinical priority of seizure detection in healthcare, where its applications in epilepsy diagnosis and monitoring are highly established. It is worth noting that the data for seizure detection comes from a single large data set, the TUH EEG Corpus (https://isip.piconepress.com/projects/tuh_eeg/) [75]. The impressive size of this dataset shows that a large volume of data can be gathered when a device is widely deployed. Furthermore, this is a very diverse dataset with data coming from over 10,000 patients, meaning that a model trained on these data will be robust due to the high inter-subject variability. These factors combined make the dataset well-suited for real-world deployment, showing that seizure detection is a mature task in the DBCI application landscape. On the other hand, tasks like emotion recognition (18.2%) and neural decoding (13.3%) represent expanding frontiers in BCI research. These emerging applications cater to the rising demand for adaptive systems in mental health, emotion-aware technologies, and cognitive analysis, showcasing their growing relevance in the industrial framework. However, tasks like driving (4.7%) and P300 paradigms (2.6%) remain under-represented despite their direct applicability to safety-critical applications and assistive devices, indicating the need for further investment to enhance their practical deployment.
- Utility: The dataset distribution underscores the significant utility of core tasks like motor imagery (9.7%) and N400 (10.6%) in the DBCI landscape. Motor imagery serves as a cornerstone for neurorehabilitation and prosthetic control, while N400 supports applications in linguistic processing and cognitive workload analysis. Their substantial data representation highlights their importance for developing reliable and scalable BCI systems. In contrast, the other category (3%) and specialised tasks like driving-related paradigms reflect limited utility due to insufficient data accumulation. Expanding data collection efforts for these under-represented areas could significantly enhance their scalability and integration into diverse real-world applications, fostering a more balanced utility across the DBCI domain.
- Value of cognitive workload: The significant proportion of datasets dedicated to emotion recognition and neural decoding reflects a growing emphasis on modelling cognitive workload within the DBCI landscape. These tasks enable the development of systems that adapt to users’ cognitive and emotional states, supporting advanced applications such as emotion-aware interfaces, cognitive workload management, and mental health monitoring. However, the limited data availability for tasks in the other category suggests missed opportunities for expanding cognitive workload research into less-explored domains. A more diversified dataset ecosystem could provide deeper insights into user cognition and behaviour, enhancing the adaptability and personalisation of DBCI systems.
- Data and model ownership: The dominance of seizure detection datasets highlights a relatively mature ecosystem for data collection, sharing, and model development in this domain. This maturity offers opportunities to refine data-sharing frameworks, ensuring equitable access and fostering collaborative research. However, the limited representation of lesser-explored tasks, grouped under the other category, presents challenges related to data ownership and accessibility. Addressing these challenges requires the establishment of robust frameworks for data sharing and ownership, particularly for under-represented tasks. This would support a more equitable and innovative landscape for developing open-access datasets and models across the DBCI spectrum.
4.3. Application
4.4. Zero-Shot Neural Decoding for Prospective DBCI
- Applications: ZSND extends the reach of DBCI systems by enabling flexibility in adapting to diverse and novel use cases, such as neurofeedback, emotion recognition, and motor control, without retraining.
- Utility: The incorporation of transfer learning and pre-trained multimodal models reduces reliance on expensive and proprietary datasets, enhancing scalability and reducing costs.
- Cognitive workload: By enabling adaptive and user-independent neural decoding, ZSND reduces the cognitive demands on users, facilitating broader accessibility and usability.
- Data and model ownership: ZSND aligns with the open-sourced large AI models and multimodal publicly available datasets and fostering collaborative research for ethical and inclusive model development.
- The inter-sample and inter-person transfer ZSND datasets, such as DIR-Wiki (with 2400 participants) and ThingsEEG-Text (with 8216 trials per participant (10 participants)), provide the diversity necessary for robust inter-person generalisation. These datasets enable models to adapt to neural variability across individuals, a critical requirement for DBCI applications such as personalized neurorehabilitation. Inter-sample transfer is enhanced by the trial-level richness of datasets, as seen in ThingsEEG-Text, which captures high temporal resolution (1000 Hz) data across multiple conditions.
- Inter-device and inter-domain transfer By incorporating multiple modalities such as EEG, fMRI, image, and text, ZSND datasets bridge the gap between invasive and non-invasive techniques, facilitating inter-device adaptability. For example, BraVL supports the alignment of brain signals recorded via EEG or fMRI with visual and semantic stimuli, ensuring models remain functional across diverse hardware environments. Inter-domain transfer is critical for applying DBCI systems in new contexts, such as transitioning from laboratory settings to real-world applications. The multimodal design of GOD-Wiki and DIR-Wiki exemplifies how datasets can support cross-domain learning.
- Inter-task transfer Neural decoding tasks in datasets like GOD-Wiki and ThingsEEG-Text demonstrate the capability of ZSND techniques to generalise across tasks. Models trained on image decoding tasks can seamlessly adapt to semantic decoding tasks due to shared latent representations. This inter-task flexibility is crucial for multi-purpose DBCI systems, enabling applications ranging from motor imagery control to emotion recognition.
- Utility enhancement frameworks like BraVL leverage multimodal data integration to create robust visual–semantic neural signal models. These models align brain activity with both visual and linguistic information, expanding the scope of DBCI applications to include cognitive workload assessment, attention monitoring, and adaptive feedback systems. The inclusion of high-resolution data (e.g., 64-channel EEG in all datasets and 1000 Hz sampling in ThingsEEG-Text) enables advancements in signal processing techniques to improve signal-to-noise ratio (SNR). Enhanced SNR is essential for the scalable adaptation of DBCI devices in real-world environments.
- Devices: High-frequency datasets, such as ThingsEEG-Text, ensure precise temporal resolution for decoding dynamic neural activity. The consistent use of 64-channel setups across datasets provides the spatial granularity necessary for diverse applications.
- Data: Datasets like DIR-Wiki, with its 2400 participants, address the need for diversity in neural data, improving inter-person generalisability.
- Applications: Multimodal stimuli in GOD-Wiki and DIR-Wiki datasets, including image and text, expand the applicability of DBCI systems to multimodal tasks. Neural decoding tasks recorded in these datasets align directly with the practical needs of applications such as neurorehabilitation, cognitive monitoring, and emotion recognition.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hosseini, M.P.; Tran, T.X.; Pompili, D.; Elisevich, K.; Soltanian-Zadeh, H. Multimodal data analysis of epileptic EEG and rs-fMRI via deep learning and edge computing. Artif. Intell. Med. 2020, 104, 101813. [Google Scholar] [CrossRef]
- Li, C.; Wang, B.; Zhang, S.; Liu, Y.; Song, R.; Cheng, J.; Chen, X. Emotion recognition from EEG based on multi-task learning with capsule network and attention mechanism. Comput. Biol. Med. 2022, 143, 105303. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Lan, Z.; Sourina, O.; Müller-Wittig, W. EEG-based cross-subject driver drowsiness recognition with an interpretable convolutional neural network. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7921–7933. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.X.; Chiu, T.F.; Huang, C.S.; Chuang, C.H. Leveraging Temporal Causal Discovery Framework to Explore Event-Related EEG Connectivity. In Proceedings of the HCI International 2022–Late Breaking Posters: 24th International Conference on Human-Computer Interaction, HCII 2022, Virtual Event, 26 June 26–1 July 2022; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2022; pp. 25–29. [Google Scholar]
- Takagi, Y.; Nishimoto, S. High-resolution image reconstruction with latent diffusion models from human brain activity. bioRxiv 2022. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its nature, scope, limits, and consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Walton, N.; Nayak, B.S. Rethinking of Marxist perspectives on big data, artificial intelligence (AI) and capitalist economic development. Technol. Forecast. Soc. Chang. 2021, 166, 120576. [Google Scholar] [CrossRef]
- Vazquez Hernandez, A. Wittgenstein and the Concept of Learning in Artificial Intelligence. Master’s Thesis, The University of Bergen, Bergen, Norway, 2020. [Google Scholar]
- Payani, A.; Fekri, F. Inductive logic programming via differentiable deep neural logic networks. arXiv 2019, arXiv:1906.03523. [Google Scholar]
- Cao, L. A new age of AI: Features and futures. IEEE Intell. Syst. 2022, 37, 25–37. [Google Scholar] [CrossRef]
- Morin, A. Levels of consciousness and self-awareness: A comparison and integration of various neurocognitive views. Conscious. Cogn. 2006, 15, 358–371. [Google Scholar] [CrossRef]
- Roselli, D.; Matthews, J.; Talagala, N. Managing bias in AI. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 539–544. [Google Scholar]
- Terziyan, V.; Golovianko, M.; Gryshko, S. Industry 4.0 intelligence under attack: From cognitive hack to data poisoning. Cyber Def. Ind. 2018, 4, 110–125. [Google Scholar]
- Morley, J.; Machado, C.C.; Burr, C.; Cowls, J.; Joshi, I.; Taddeo, M.; Floridi, L. The ethics of AI in health care: A mapping review. Soc. Sci. Med. 2020, 260, 113172. [Google Scholar] [CrossRef]
- Savulescu, J.; Maslen, H. Moral enhancement and artificial intelligence: Moral AI? In Beyond Artificial Intelligence: The Disappearing Human-Machine Divide; Springer: Cham, Switzerland, 2015; pp. 79–95. [Google Scholar]
- Walkowiak, E. Digitalization and inclusiveness of HRM practices: The example of neurodiversity initiatives. Hum. Resour. Manag. J. 2023, 34, 578–598. [Google Scholar] [CrossRef]
- Berger, H. Über das elektrenkephalogramm des menschen. DMW-Dtsch. Med. Wochenschr. 1934, 60, 1947–1949. [Google Scholar] [CrossRef]
- Gruzelier, J. A theory of alpha/theta neurofeedback, creative performance enhancement, long distance functional connectivity and psychological integration. Cogn. Process. 2009, 10, 101–109. [Google Scholar] [CrossRef] [PubMed]
- Vidal, J.J. Toward direct brain-computer communication. Annu. Rev. Biophys. Bioeng. 1973, 2, 157–180. [Google Scholar] [CrossRef]
- Kübler, A.; Kotchoubey, B.; Hinterberger, T.; Ghanayim, N.; Perelmouter, J.; Schauer, M.; Fritsch, C.; Taub, E.; Birbaumer, N. The thought translation device: A neurophysiological approach to communication in total motor paralysis. Exp. Brain Res. 1999, 124, 223–232. [Google Scholar] [CrossRef]
- Miller, N.E.; DiCara, L. Instrumental learning of heart rate changes in curarized rats: Shaping, and specificity to discriminative stimulus. J. Comp. Physiol. Psychol. 1967, 63, 12–19. [Google Scholar] [CrossRef]
- Taub, E. What Psychology as a Science Owes Neal Miller: The Example of His Biofeedback Research. Biofeedback 2010, 38, 108–117. [Google Scholar] [CrossRef]
- Schnakers, C.; Laureys, S. Coma and Disorders of Consciousness; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Smith, E.; Delargy, M. Locked-in syndrome. BMJ 2005, 330, 406–409. [Google Scholar] [CrossRef]
- Hill, N.J.; Lal, T.N.; Schroder, M.; Hinterberger, T.; Wilhelm, B.; Nijboer, F. Classifying EEG and ECoG signals without subject training for fast BCI implementation: Comparison of nonparalyzed and completely paralyzed subjects. IEEE Trans. Neural Syst. Rehabil. Eng. 2006, 14, 183–186. [Google Scholar] [CrossRef] [PubMed]
- Kübler, A.; Birbaumer, N. Brain-computer interfaces and communication in paralysis: Extinction of goal directed thinking in completely paralysed patients? Clin. Neurophysiol. 2008, 119, 2658–2666. [Google Scholar] [CrossRef]
- Hoesle, A. Between Neuro-Potentials and Aesthetic Perception. Pingo Ergo Sum; The International Library of Ethics, Law and Technology; Springer: Dordrecht, Germany, 2014; Volume 12, pp. 99–108. [Google Scholar] [CrossRef]
- Zickler, C.; Halder, S.; Kleih, S.C.; Herbert, C.; Kübler, A. Brain Painting: Usability testing according to the user-centered design in end users with severe motor paralysis. Artif. Intell. Med. 2013, 59, 99–110. [Google Scholar] [CrossRef] [PubMed]
- Farwell, L.A.; Donchin, E. Talking off the top of your head: Toward a mental prosthesis utilizing event-related brain potentials. Electroencephalogr. Clin. Neurophysiol. 1988, 70, 510–523. [Google Scholar] [CrossRef]
- Birbaumer, N.; Ghanayim, N.; Hinterberger, T.; Iversen, I.; Kotchoubey, B.; Kübler, A.; Perelmouter, J.; Taub, E.; Flor, H. A spelling device for the paralysed. Nature 1999, 398, 297–298. [Google Scholar] [CrossRef] [PubMed]
- Sterman, M.B. Basic Concepts and Clinical Findings in the Treatment of Seizure Disorders with EEG Operant Conditioning. Clin. Electroencephalogr. 2000, 31, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Irimia, D.C.; Ortner, R.; Poboroniuc, M.S.; Ignat, B.E.; Guger, C. High Classification Accuracy of a Motor Imagery Based Brain-Computer Interface for Stroke Rehabilitation Training. Front. Robot. AI 2018, 5, 130. [Google Scholar] [CrossRef]
- Kübler, A.; Holz, E.M.; Riccio, A.; Zickler, C.; Kaufmann, T.; Kleih, S.C.; Staiger-Sälzer, P.; Desideri, L.; Hoogerwerf, E.; Mattia, D. The user-centered design as novel perspective for evaluating the usability of BCI-controlled applications. PLoS ONE 2014, 9, e112392. [Google Scholar] [CrossRef] [PubMed]
- Kaufmann, T.; Schulz, S.M.; Köblitz, A.; Renner, G.; Wessig, C.; Kübler, A. Face stimuli effectively prevent brain-computer interface inefficiency in patients with neurodegenerative disease. Clin. Neurophysiol. 2012, 124, 893–900. [Google Scholar] [CrossRef]
- Vos, M.D.; Gandras, K.; Debener, S. Towards a truly mobile auditory brain–computer interface: Exploring the P300 to take away. Int. J. Psychophysiol. 2013, 91, 46–53. [Google Scholar] [CrossRef]
- Blum, S.; Debener, S.; Emkes, R.; Volkening, N.; Fudickar, S.; Bleichner, M.G. EEG Recording and Online Signal Processing on Android: A Multiapp Framework for Brain-Computer Interfaces on Smartphone. BioMed Res. Int. 2017, 2017, 3072870. [Google Scholar] [CrossRef]
- Bleichner, M.G.; Debener, S. Concealed, Unobtrusive Ear-Centered EEG Acquisition: cEEGrids for Transparent EEG. Front. Hum. Neurosci. 2017, 11, 163. [Google Scholar] [CrossRef] [PubMed]
- Blankertz, B.; Dornhege, G.; Lemm, S.; Krauledat, M.; Curio, G.; Müller, K.-R. The Berlin brain-computer interface: Machine learning based detection of user specific brain states. J. Univers. Comput. Sci. 2007, 12, 581–607. [Google Scholar]
- Lantz, D.; Sterman, M.B. Neuropsychological assessment of subjects with uncontrolled epilepsy: Effects of EEG feedback training. Epilepsia 1988, 29, 163–171. [Google Scholar] [CrossRef] [PubMed]
- Harvey, D. Marx, Capital, and the Madness of Economic Reason; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Rindermann, H. Cognitive Capitalism: Human Capital and the Wellbeing of Nations; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Luciw, M.D.; Jarocka, E.; Edin, B.B. Multi-channel EEG recordings during 3936 grasp and lift trials with varying weight and friction. Sci. Data 2014, 1, 140047. [Google Scholar] [CrossRef] [PubMed]
- Cho, H.; Ahn, M.; Ahn, S.; Kwon, M.; Jun, S.C. EEG datasets for motor imagery brain–computer interface. GigaScience 2017, 6, gix034. [Google Scholar] [CrossRef] [PubMed]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Kaya, M.; Binli, M.K.; Ozbay, E.; Yanar, H.; Mishchenko, Y. A large electroencephalographic motor imagery dataset for electroencephalographic brain computer interfaces. Sci. Data 2018, 5, 180211. [Google Scholar] [CrossRef] [PubMed]
- Sajda, P.; Gerson, A.; Muller, K.R.; Blankertz, B.; Parra, L. A data analysis competition to evaluate machine learning algorithms for use in brain-computer interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2003, 11, 184–185. [Google Scholar] [CrossRef]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [PubMed]
- Bhatt, R. Planning-Relax Dataset for Automatic Classification of Eeg Signals; UC Irvine Machine Learning Repository. 2012. Available online: https://archive.ics.uci.edu/dataset/230/planning+relax (accessed on 28 November 2024).
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Onton, J.A.; Makeig, S. High-frequency broadband modulation of electroencephalographic spectra. Front. Hum. Neurosci. 2009, 3, 61. [Google Scholar] [CrossRef] [PubMed]
- Savran, A.; Ciftci, K.; Chanel, G.; Mota, J.; Hong Viet, L.; Sankur, B.; Akarun, L.; Caplier, A.; Rombaut, M. Emotion detection in the loop from brain signals and facial images. In Proceedings of the eNTERFACE 2006 Workshop, Dubrovnik, Croatia, 17 July–11 August 2006. [Google Scholar]
- Yadava, M.; Kumar, P.; Saini, R.; Roy, P.P.; Prosad Dogra, D. Analysis of EEG signals and its application to neuromarketing. Multimed. Tools Appl. 2017, 76, 19087–19111. [Google Scholar] [CrossRef]
- Duan, R.N.; Zhu, J.Y.; Lu, B.L. Differential entropy feature for EEG-based emotion classification. In Proceedings of the 6th International IEEE/EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2011, 3, 42–55. [Google Scholar] [CrossRef]
- Faller, J.; Cummings, J.; Saproo, S.; Sajda, P. Regulation of arousal via online neurofeedback improves human performance in a demanding sensory-motor task. Proc. Natl. Acad. Sci. USA 2019, 116, 6482–6490. [Google Scholar] [CrossRef] [PubMed]
- Margaux, P.; Emmanuel, M.; Sébastien, D.; Olivier, B.; Jérémie, M. Objective and subjective evaluation of online error correction during P300-based spelling. Adv. Hum.-Comput. Interact. 2012, 2012, 578295. [Google Scholar] [CrossRef]
- Miller, K.J.; Schalk, G.; Hermes, D.; Ojemann, J.G.; Rao, R.P. Spontaneous decoding of the timing and content of human object perception from cortical surface recordings reveals complementary information in the event-related potential and broadband spectral change. PLoS Comput. Biol. 2016, 12, e1004660. [Google Scholar] [CrossRef] [PubMed]
- BioSENSE @ UC Berkeley School of Information. Synchronized Brainwave Dataset. 2019. Available online: https://www.kaggle.com/datasets/berkeley-biosense/synchronized-brainwave-dataset (accessed on 28 November 2024).
- Korczowski, L.; Ostaschenko, E.; Andreev, A.; Cattan, G.; Rodrigues, P.L.C.; Gautheret, V.; Congedo, M. Brain Invaders Calibration-Less P300-Based BCI Using Dry EEG Electrodes Dataset (bi2014a). Ph.D. Thesis, GIPSA-lab, Saint-Martin-d’Hères, France, 2019. [Google Scholar]
- Kappenman, E.S.; Luck, S.J. The effects of electrode impedance on data quality and statistical significance in ERP recordings. Psychophysiology 2010, 47, 888–904. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Chuang, C.H.; King, J.K.; Lin, C.T. Multi-channel EEG recordings during a sustained-attention driving task. Sci. Data 2019, 6, 19. [Google Scholar] [CrossRef] [PubMed]
- Broderick, M.P.; Anderson, A.J.; Di Liberto, G.M.; Crosse, M.J.; Lalor, E.C. Electrophysiological correlates of semantic dissimilarity reflect the comprehension of natural, narrative speech. Curr. Biol. 2018, 28, 803–809. [Google Scholar] [CrossRef] [PubMed]
- Torkamani-Azar, M.; Kanik, S.D.; Aydin, S.; Cetin, M. Prediction of reaction time and vigilance variability from spatio-spectral features of resting-state EEG in a long sustained attention task. IEEE J. Biomed. Health Inform. 2020, 24, 2550–2558. [Google Scholar] [CrossRef]
- Cattan, G.; Rodrigues, P.L.C.; Congedo, M. Eeg Alpha Waves Dataset. Ph.D. Thesis, GIPSA-LAB, Saint-Martin-d’Hères, France, 2018. [Google Scholar]
- Stober, S.; Sternin, A.; Owen, A.M.; Grahn, J.A. Towards Music Imagery Information Retrieval: Introducing the OpenMIIR Dataset of EEG Recordings from Music Perception and Imagination. In Proceedings of the ISMIR, Malaga, Spain, 26–30 October 2015; pp. 763–769. [Google Scholar]
- Roesler, O. UCI Machine Learning Repository: EEG Eye State Data Set. 2013. Available online: https://archive.ics.uci.edu/dataset/264/eeg+eye+state (accessed on 28 November 2024).
- Agarwal, M.; Sivakumar, R. Blink: A fully automated unsupervised algorithm for eye-blink detection in eeg signals. In Proceedings of the 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA,, 24–27 September 2019; pp. 1113–1121. [Google Scholar]
- Rösler, O.; Suendermann, D. A first step towards eye state prediction using eeg. Proc. AIHLS 2013, 1, 1–4. [Google Scholar]
- Zhao, S.; Rudzicz, F. Classifying phonological categories in imagined and articulated speech. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 992–996. [Google Scholar]
- Vivancos, D.; Cuesta, F. MindBigData 2022 A Large Dataset of Brain Signals. arXiv 2022, arXiv:2212.14746. [Google Scholar]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Predict Brain Deep Sleep Slow Oscillation. Available online: https://challengedata.ens.fr/challenges/10 (accessed on 28 November 2024).
- Begleiter, H.; Ingber, L. UCI Machine Learning Repository: EEG Database Data Set. 1999. Available online: https://archive.ics.uci.edu/dataset/121/eeg+database (accessed on 28 November 2024).
- Wang, H.; Li, Y.; Hu, X.; Yang, Y.; Meng, Z.; Chang, K.m. Using EEG to Improve Massive Open Online Courses Feedback Interaction. In Proceedings of the AIED Workshops, Memphis, TN, USA, 9–13 July 2013. [Google Scholar]
- Picone, J. Electroencephalography (EEG) Resources. Available online: https://isip.piconepress.com/projects/tuh_eeg/ (accessed on 28 November 2024).
- Cavanagh, J.F.; Napolitano, A.; Wu, C.; Mueen, A. The patient repository for EEG data+ computational tools (PRED+ CT). Front. Neuroinform. 2017, 11, 67. [Google Scholar] [CrossRef] [PubMed]
- Kappenman, E.S.; Farrens, J.L.; Zhang, W.; Stewart, A.X.; Luck, S.J. ERP CORE: An open resource for human event-related potential research. NeuroImage 2021, 225, 117465. [Google Scholar] [CrossRef]
- Penny, W.D.; Friston, K.J.; Ashburner, J.T.; Kiebel, S.J.; Nichols, T.E. Statistical Parametric Mapping: The Analysis of Functional Brain Images; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Du, C.; Fu, K.; Li, J.; He, H. Decoding visual neural representations by multimodal learning of brain-visual-linguistic features. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10760–10777. [Google Scholar] [CrossRef] [PubMed]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Metric | Why It Is Used | Connection to Industrial Landscape |
|---|---|---|---|
| Devices | Frequency (Hz) | Captures temporal resolution of brain activity. | Enables high-precision DBCI applications, and improves cognitive workload modelling, but is often tied to proprietary devices. |
| EEG Channels | Indicates spatial resolution of brain activity. | Supports diverse applications, increases utility and workload fidelity, but raises ownership challenges. | |
| Data | Length (s) | Determines duration of captured data for each trial. | Supports long-term applications, increases utility, and enhances workload assessment across varied contexts. |
| Trials | Reflects dataset robustness and reliability. | Ensures applicability in diverse scenarios, increases model reliability, and requires careful ownership considerations. | |
| Users | Represents diversity and generalisability of the dataset. | Enables cross-population applications, improves utility, and raises ethical issues about ownership and privacy. | |
| Applications | Stimuli | Defines the context of recorded brain activity. | Links directly to DBCI use cases, increases task-specific utility, and impacts workload relevance and accessibility. |
| Task | Defines the dataset’s relevance to specific DBCI applications. | Drives model training for targeted use cases, improves cognitive workload insights, and ties to ownership of annotations. | |
| Response | Determines modalities available for analysis (e.g., EEG, behavioural responses). | Increases flexibility across applications, improves model utility, but raises accessibility challenges due to ownership. |
| Devices | Data | Application | ||||||
|---|---|---|---|---|---|---|---|---|
| Dataset Name | Freq | Chan | Len | Tri | Use | Stimuli | Task | Response |
| WAY-EEG-GAL (https://www.kaggle.com/competitions/grasp-and-lift-eeg-detection/data) [42] | 500 | 32 | 10 | 328 | 12 | Visual Cue | Motor Imagery | EEG, EMG, Event Timings, Object Positions, Object Forces |
| GigaDB-EEG-MI (http://gigadb.org/dataset/100295) [43] | 512 | 64 | 3 | 260 | 52 | Visual Cue | Motor Imagery | EEG, EMG, EOG, Hand Movement Data, Questionnaire |
| PhysioNet-EEG-MI (https://www.physionet.org/content/eegmmidb/1.0.0/) [44] | 160 | 64 | 120 | 12 | 109 | Visual Cue | Motor Imagery | EEG, Annotations |
| Large-scale-EEG (https://figshare.com/collections/A_large_electroencephalographic_motor_imagery_dataset_for_electroencephalographic_brain_computer_interfaces/3917698) [45] | 200 | 19 | 3 | 900 | 13 | Visual Cue | Motor Imagery | EEG |
| BCI Comp II dataset 1a (https://www.bbci.de/competition/) [46] | 256 | 6 | 3.5 | 293 | 1 | Visual Feedback | Motor Imagery | EEG |
| BCI Comp II dataset 1b (https://www.bbci.de/competition/) [46] | 256 | 6 | 4.5 | 200 | 1 | Visual Feedback, Audio | Motor Imagery | EEG |
| BCI Comp II dataset 2a (https://www.bbci.de/competition/) [46] | 160 | 64 | 30 | 60 | 3 | Visual Feedback | Motor Imagery | EEG |
| BCI Comp II dataset 3 (https://www.bbci.de/competition/) [46] | 128 | 3 | 9 | 280 | 1 | Visual Feedback | Motor Imagery | EEG |
| BCI Comp II dataset 4 (https://www.bbci.de/competition/) [46] | 1000 | 28 | 0.5 | 416 | 1 | None | Motor Imagery | EEG, Typing |
| BCI Comp III dataset 1 (https://www.bbci.de/competition/) [46] | 1000 | 64 | 3 | 378 | 1 | N/A | Motor Imagery | ECoG |
| BCI Comp III dataset 2 (https://www.bbci.de/competition/) [46] | 240 | 64 | 2.5 | 92 | 2 | Character Matrix | P300 | EEG |
| BCI Comp III dataset 3a (https://www.bbci.de/competition/) [46] | 240 | 64 | 7 | 80 | 3 | Visual Cue, Audio Cue | Motor Imagery | EEG |
| BCI Comp III dataset 3b (https://www.bbci.de/competition/) [46] | 125 | 2 | 8 | 40 | 3 | Visual Cue | Motor Imagery | EEG |
| BCI Comp III dataset 4 (https://www.bbci.de/competition/) [46] | 1000 | 118 | 3.5 | 280 | 2 | Visual Cue | Motor Imagery | EEG |
| BCI Comp III dataset 5 (https://www.bbci.de/competition/) [46] | 512 | 32 | 240 | 4 | 3 | Audio Cue | Motor Imagery | EEG |
| BCI Comp IV dataset 1 (https://www.bbci.de/competition/) [46] | 1000 | 64 | 3.5 | 42 | 7 | None | Motor Imagery | EEG, Artificial EEG |
| BCI Comp IV dataset 2 (https://www.bbci.de/competition/) [46] | 250 | 22 | 6 | 576 | 9 | Audio Cue | Motor Imagery | EEG, EOG |
| High-Gamma (https://github.com/robintibor/high-gamma-dataset) [47] | 500 | 128 | 4 | 880 | 14 | Visual Cue | Motor Imagery | EEG |
| Planning-Relax (https://archive.ics.uci.edu/ml/datasets/Planning+Relax) [48] | 256 | 8 | 5 | 10 | 1 | Audio Cue | Motor Imagery | EEG, EOG |
| DAEP (http://www.eecs.qmul.ac.uk/mmv/datasets/deap/) [49] | 512 | 32 | 60 | 40 | 32 | Music, Video | Emotion Recognition | Face Recordings, Questionnaire, EOG, EMG, Blood Pressure, GSR, Respiration |
| HeadIT (https://headit.ucsd.edu/studies/3316f70e-35ff-11e3-a2a9-0050563f2612) [50] | 256 | 256 | 218 | 15 | 32 | Audio | Emotion Recognition | EEG, ECG, Infra-ocular |
| Enterface06 (http://www.enterface.net/results/) [51] | 1024 | 54 | 2.5 | 450 | 5 | Image | Emotion Recognition | EEG, fNIRS, GSR, Respiration, Video |
| Neuromarketing (https://drive.google.com/file/d/17XhqRXtMWvk8R_iZt-mjn_C0HjgqClaO/view?usp=sharing) [52] | 128 | 14 | 4 | 42 | 25 | Image | Neuromarketing | EEG, Questionnaire |
| SEED (https://bcmi.sjtu.edu.cn/~seed/seed.html) [53] | 1000 | 62 | 240 | 45 | 15 | Video | Emotion Recognition | EEG, Eye Movement, Self Assessment Questionnaire |
| HCI Tagging (https://mahnob-db.eu/hci-tagging/) [54] | 512 | 32 | 135 | 20 | 30 | Image, Video | Emotion Recognition | EEG, GSR, ECGG, Eye Tracking, Audio, Video, Questionnaire |
| Regulation of Arousal (https://ieee-dataport.org/open-access/regulation-arousal-online-neurofeedback-improves-human-performance-demanding-sensory) [55] | 500 | 64 | 45 | 24 | 18 | Audio, Simulation | Neurofeedback | EEG, ECG, EDA, Respiration, Pupil Diameter, Eye Tracking |
| BCI-NER Challenge (https://www.kaggle.com/c/inria-bci-challenge) [56] | 600 | 56 | 10.51 | 340 | 26 | Character Matrix | P300 | EEG, MEG |
| Face-House (https://purl.stanford.edu/xd109qh3109) [57] | 1000 | N/A | 0.8 | 300 | 7 | Image | Neural Decoding | ECoG, ERPS |
| Synchronised Brainwave (https://www.kaggle.com/datasets/berkeley-biosense/synchronized-brainwave-dataset) [58] | 512 | 1 | 319 | 1 | 30 | Video | Neural Decoding | EEG |
| Target vs Non-target (https://github.com/plcrodrigues/py.BI.EEG.2014a-GIPSA) [59] | 512 | 16 | 300 | 3 | 64 | Character Matrix | P300 | EEG |
| Impedance (https://erpinfo.org/impedance) [60] | 1024 | 10 | 1.5 | 1280 | 12 | Text | Neural Decoding | EEG, EOG |
| Sustained Attention (https://figshare.com/articles/dataset/Multi-channel_EEG_recordings_during_a_sustained-attention_driving_task/6427334/5) [61] | 500 | 30 | 5400 | 2.5 | 27 | Simulation | Driving | EEG, Questionnaire |
| Dryad-Speech (https://datadryad.org/stash/dataset/doi:10.5061/dryad.070jc) [62] | 512 | 128 | 105 | 20 | 92 | Audio | N400 | EEG |
| SPIS Resting State (https://github.com/mastaneht/SPIS-Resting-State-Dataset) [63] | 256 | 64 | 300 | 1 | 10 | None | Resting State | EEG, EOG |
| Alpha-waves (https://zenodo.org/record/2348892#.Y2ZRYOzP23I) [64] | 512 | 16 | 10 | 10 | 20 | None | Resting State | EEG, Questionnaire |
| Music Imagery Retrieval (https://github.com/sstober/openmiir) [65] | 400 | 14 | 11.5 | 12 | 10 | Music | Music Imagery | EEG |
| EEG-eye State (https://archive.ics.uci.edu/ml/datasets/EEG+Eye+State) [66] | 128 | 14 | 117 | 1 | 1 | None | Eye state | EEG |
| EEG-IO (https://gnan.ece.gatech.edu/eeg-eyeblinks/) [67] | 250 | 19 | 3.5 | 25 | 20 | N/A | Eye state | EEG, Annotations |
| Eye State Prediction (http://suendermann.com/corpus/EEG_Eyes.arff.gz) [68] | N/A | 14 | 117 | 1 | 1 | None | Eye state | EEG, Video, Annotations |
| Classifying Phonological Categories (https://pdfs.semanticscholar.org/5480/d270cc92b284e8ee7db7c6af8a3dec58e163.pdfl) [69] | 1024 | 64 | 2100 | 1 | 8 | Text, Audio | Speech Imagery | EEG, Video, Audio |
| MNIST Brain Digits (http://mindbigdata.com/opendb/index.html) [70] | 161 | 11 | 2 | 1,206,611 | 1 | Image | Neural Decoding | EEG |
| ImageNet Brain (http://www.mindbigdata.com/opendb/imagenet.html) [70] | 128 | 5 | 3 | 14,012 | 1 | Image | Neural Decoding | EEG |
| EEGLearn (https://github.com/pbashivan/EEGLearn/tree/master/) [71] | 500 | 64 | 3.5 | 240 | 13 | Text | Neural Decoding | EEG |
| Deep Sleep Slow Oscillation (https://challengedata.ens.fr/challenges/10) [72] | 125 | N/A | 10 | 1261 | N/A | None | Slow Oscillation Prediction | EEG, Sleep Stage, Time Sleeping |
| Genetic Predisposition to Alcoholism (https://archive.ics.uci.edu/ml/datasets/EEG+Database) [73] | 256 | 64 | 1 | 120 | 122 | Image | Neural Decoding | EEG |
| Confusion During MOOC (https://www.kaggle.com/datasets/wanghaohan/confused-eeg) [74] | 2 | 1 | 60 | 10 | 10 | Video | Education Feedback | EGG, Questionnaire |
| TUH EEG Corpus (https://isip.piconepress.com/projects/tuh_eeg/) [75] | 250 | 31 | 167 | 1.56 | 10,874 | None | Seizure Detection | EEG, Clinician Report |
| Predict-UNM (http://predict.cs.unm.edu/) [76] | 500 | 64 | 3.6 | 200 | 25 | Medication, Audio | Neural Decoding | EEG |
| ERP CORE (https://erpinfo.org/erp-core) [77] | 1024 | 30 | 600 | 6 | 40 | Image, Video, Audio | Face Perception | EEG, ERP |
| Statistical Parametric Mapping (https://www.fil.ion.ucl.ac.uk/spm/data/) [78] | 2048 | 128 | 1.8 | 172 | 1 | Image, Audio | Face Perception | EEG, fMRI, MEG, sMRI, EOG |
| GOD-Wiki (https://figshare.com/articles/dataset/BraVL/17024591) [79] | N/A | N/A | 3 | 590 | 5 | Image | Neural Decoding | fMRI, Image, Text |
| DIR-Wiki (https://figshare.com/articles/dataset/BraVL/17024591) [79] | N/A | N/A | 2 | 2400 | 3 | Image | Neural Decoding | fMRI, Image, Text |
| ThingsEEG-Text (https://figshare.com/articles/dataset/BraVL/17024591) [79] | 1000 | 64 | 0.235 | 8216 | 10 | Image | Neural Decoding | EEG, Image, Text |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, W.; Ma, T.; Organisciak, D.; Waide, J.E.T.; Meng, X.; Long, Y. The Progress and Prospects of Data Capital for Zero-Shot Deep Brain–Computer Interfaces. Electronics 2025, 14, 508. https://doi.org/10.3390/electronics14030508
Ma W, Ma T, Organisciak D, Waide JET, Meng X, Long Y. The Progress and Prospects of Data Capital for Zero-Shot Deep Brain–Computer Interfaces. Electronics. 2025; 14(3):508. https://doi.org/10.3390/electronics14030508
Chicago/Turabian StyleMa, Wenbao, Teng Ma, Daniel Organisciak, Jude E. T. Waide, Xiangxin Meng, and Yang Long. 2025. "The Progress and Prospects of Data Capital for Zero-Shot Deep Brain–Computer Interfaces" Electronics 14, no. 3: 508. https://doi.org/10.3390/electronics14030508
APA StyleMa, W., Ma, T., Organisciak, D., Waide, J. E. T., Meng, X., & Long, Y. (2025). The Progress and Prospects of Data Capital for Zero-Shot Deep Brain–Computer Interfaces. Electronics, 14(3), 508. https://doi.org/10.3390/electronics14030508