
Fast Resource Estimation of FPGA-Based MLP Accelerators for TinyML Applications



Abstract

1. Introduction
2. Background and Related Work
3. Proposed Resource Estimator
3.1. LUTs and DSPs Estimator
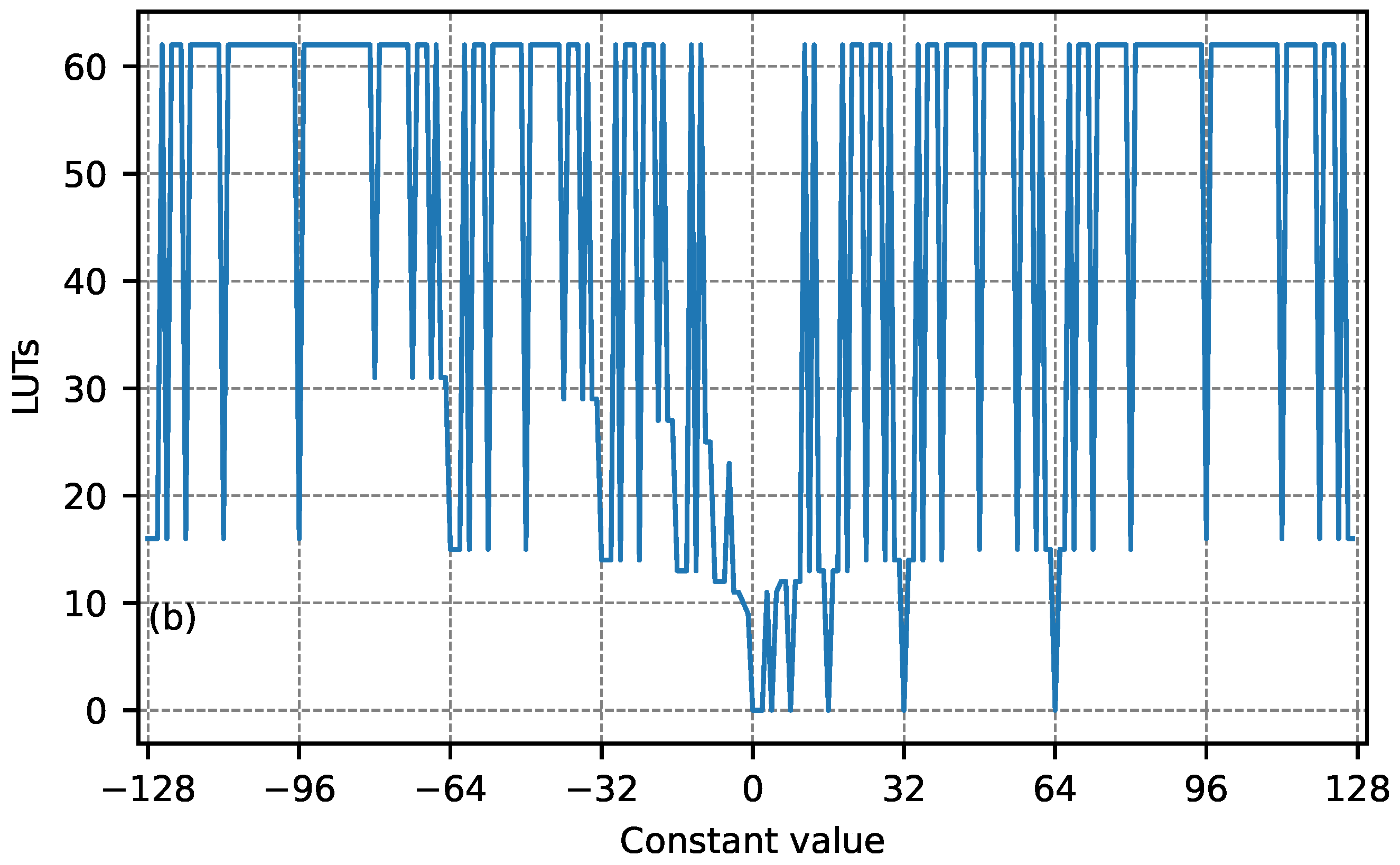
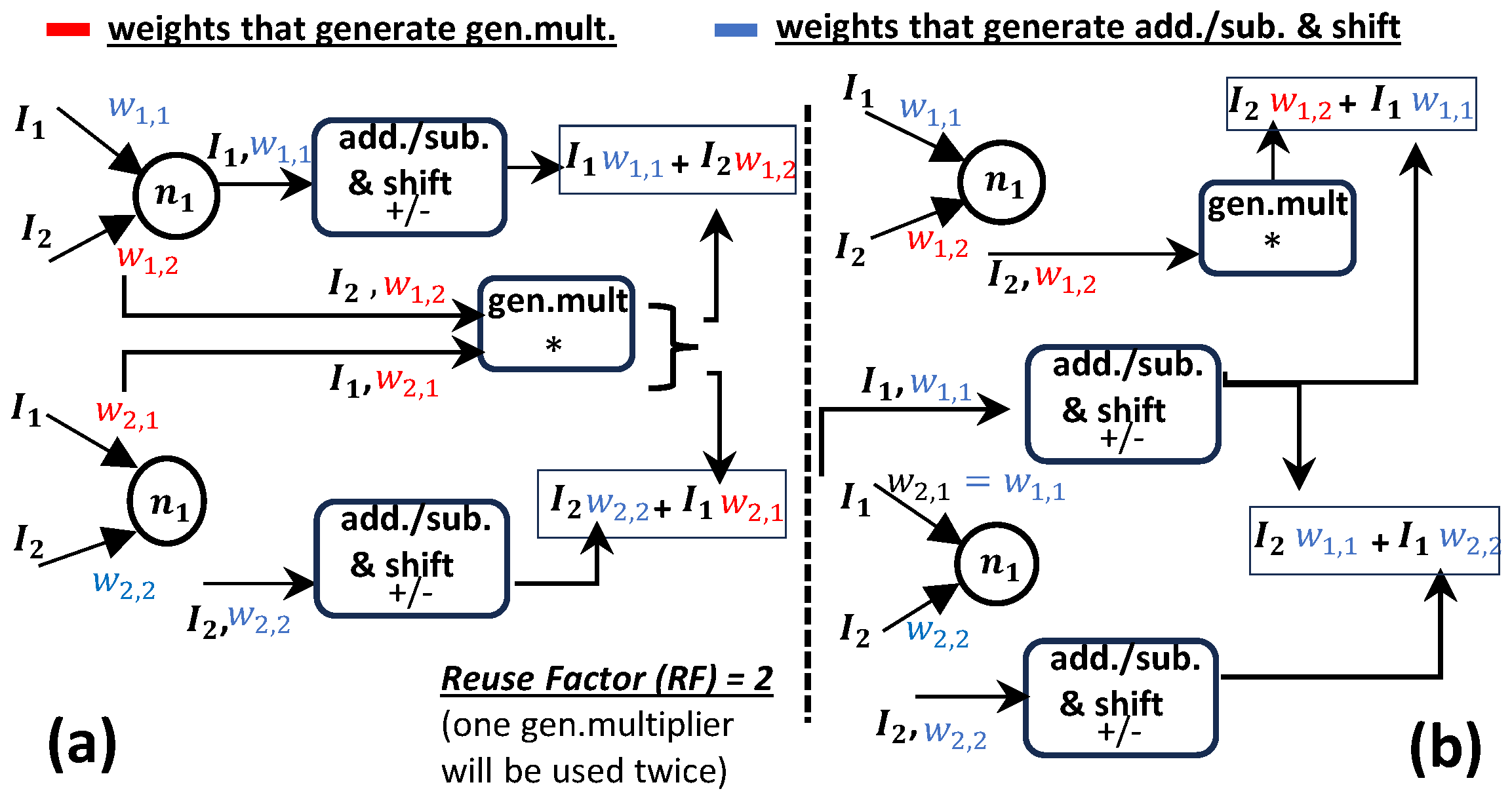
3.1.1. Multiplication in Bespoke MLPs
3.1.2. Accumulation
3.1.3. LUTs’ and DSPs’ Estimation
- LUT(gen.mult) and LUT(add/sub) are obtained using the table Tmul, the value of the weight, and the size of the input (see discussion in Section 3.1.1),
- is the LUTs’ sum for all weights, where their values do not lead to multiplication sharing and require generic multipliers,
- is the LUTs’ sum for all weights, where their values do not lead to multiplication sharing and generate multiplication circuits with add./sub. modules and shift operations,
- N and I denote the number of layer’s neurons and inputs, respectively,
- Zb and Zw represent the number of biases and weights that are zero, respectively,
- LUT(accum.) is derived from the size of the accumulators that are used (see Section 3.1.2).
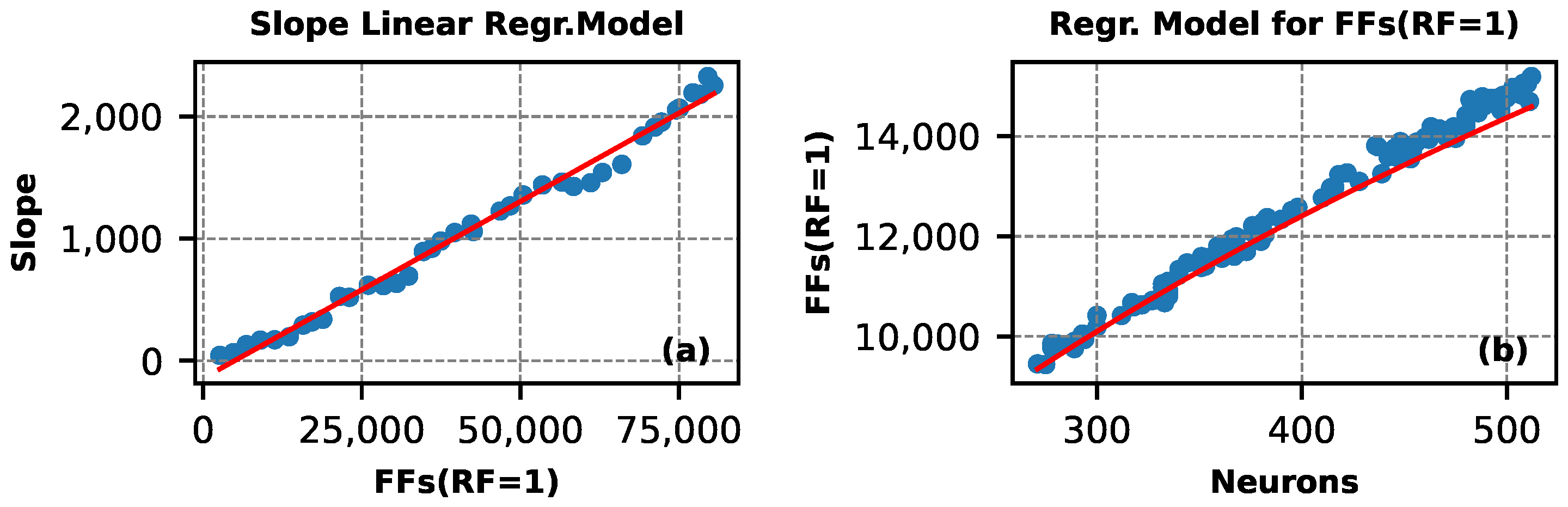
3.2. FFs Estimator
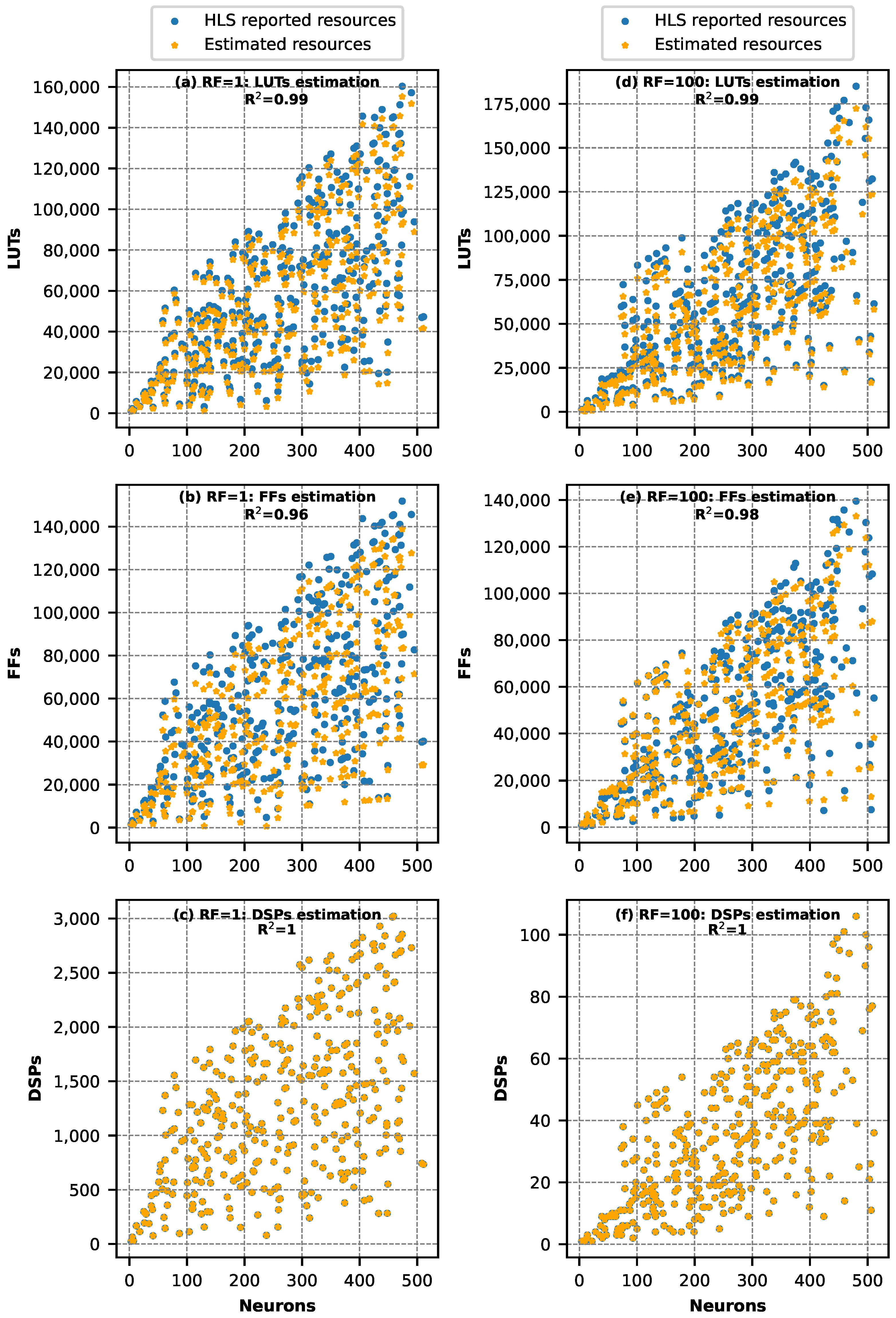
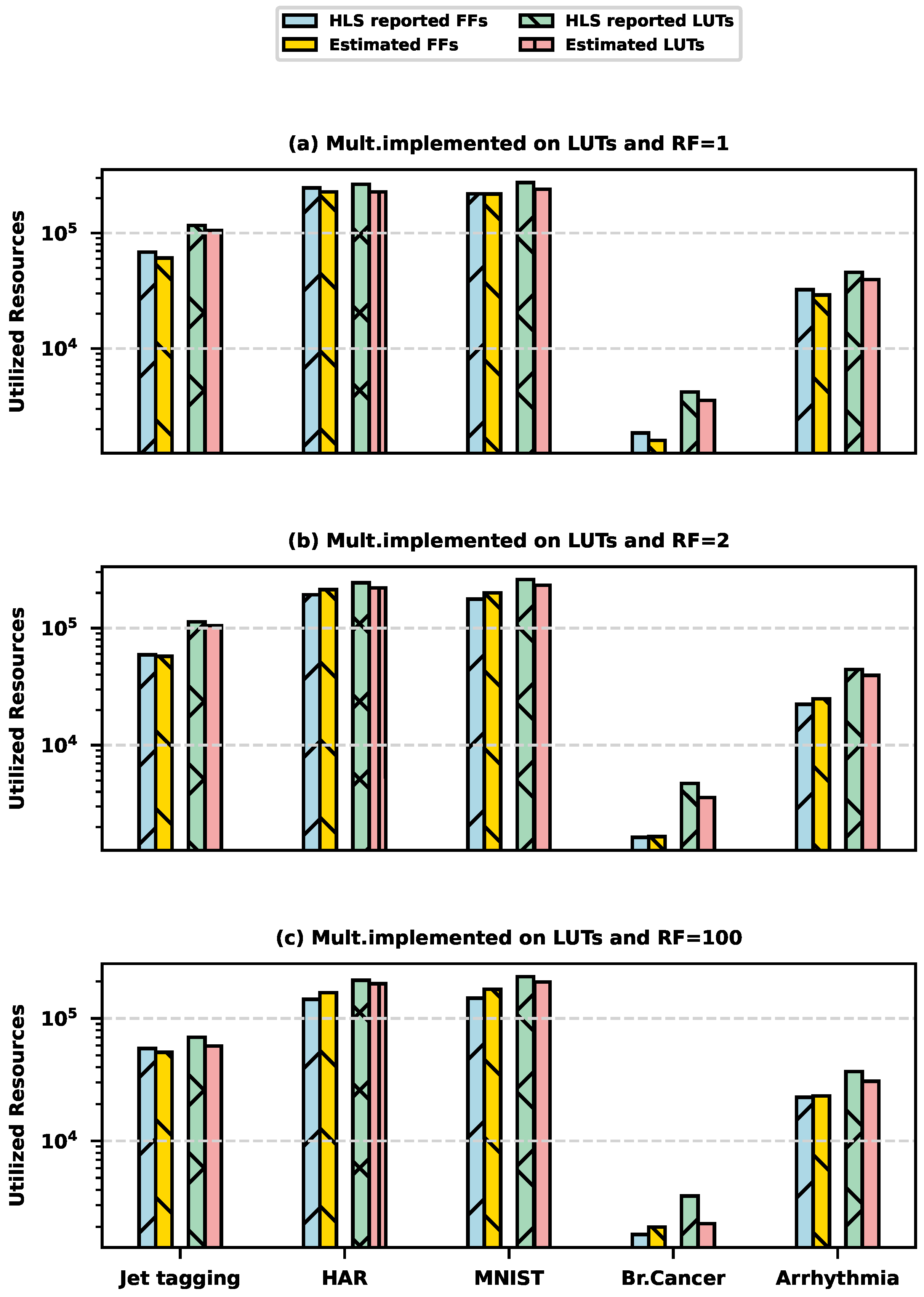
4. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Prakash, S.; Callahan, T.; Bushagour, J.; Banbury, C.; Green, A.V.; Warden, P.; Ansell, T.; Reddi, V.J. CFU Playground: Full-Stack Open-Source Framework for Tiny Machine Learning (tinyML) Acceleration on FPGAs. arXiv 2022, arXiv:2201.01863. [Google Scholar]
- Ray, P. A review on TinyML: State-of-the-art and prospects. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1595–1623. [Google Scholar] [CrossRef]
- Kok, C.; Siek, L. Designing a Twin Frequency Control DC-DC Buck Converter Using Accurate Load Current Sensing Technique. Electronics 2024, 13, 45. [Google Scholar] [CrossRef]
- Makni, M.; Baklouti, M.; Niar, S.; Abid, M. Hardware resource estimation for heterogeneous FPGA-based SoCs. In Proceedings of the Symposium on Applied Computing, Marrakech, Morocco, 4–6 April 2017; pp. 1481–1487. [Google Scholar]
- Fahim, F.; Hawks, B.; Herwig, C.; Hirschauer, J.; Jindariani, S.; Tran, N.; Carloni, L.P.; Di Guglielmo, G.; Harris, P.; Krupa, J.; et al. hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices. arXiv 2021, arXiv:2103.05579. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference. arXiv 2016, arXiv:1612.07119. [Google Scholar]
- Ngadiuba, J.; Loncar, V.; Pierini, M.; Summers, S.; Di Guglielmo, G.; Duarte, J.; Harris, P.; Rankin, D.; Jindariani, S.; Liu, M.; et al. Compressing deep neural networks on FPGAs to binary and ternary precision with HLS4ML. Mach. Learn. Sci. Technol. 2021, 2, 015001. [Google Scholar] [CrossRef]
- Meng, J.; Venkataramanaiah, S.K.; Zhou, C.; Hansen, P.; Whatmough, P.; Seo, J.S. FixyFPGA: Efficient FPGA Accelerator for Deep Neural Networks with High Element-Wise Sparsity and without External Memory Access. In Proceedings of the Conference on Field-Programmable Logic and Applications, Dresden, Germany, 30 August–3 September 2021. [Google Scholar]
- Borras, H.; Di Guglielmo, G.; Duarte, J.; Ghielmetti, N.; Hawks, B.; Hauck, S.; Hsu, S.C.; Kastner, R.; Liang, J.; Meza, A.; et al. Open-source FPGA-ML codesign for the MLPerf Tiny Benchmark. arXiv 2022, arXiv:2206.11791. [Google Scholar]
- Kallimani, R.; Pai, K.; Raghuwanshi, P.; Iyer, S.; Onel, L. TinyML: Tools, Applications, Challenges, and Future Research Directions. arXiv 2023, arXiv:2303.13569. [Google Scholar] [CrossRef]
- Rajapakse, V.; Karunanayake, I.; Ahmed, N. Intelligence at the Extreme Edge: A Survey on Reformable TinyML. ACM Comput. Surv. 2023, 55, 1–30. [Google Scholar] [CrossRef]
- Chen, C.; da Silva, B.; Yang, C.; Ma, C.; Li, J.; Liu, C. AutoMLP: A Framework for the Acceleration of Multi-Layer Perceptron Models on FPGAs for Real-Time Atrial Fibrillation Disease Detection. IEEE Trans. Biomed. Circuits Syst. 2023, 17, 1371–1386. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, W.; Shi, Y.; Hu, J. When Neural Architecture Search Meets Hardware Implementation: From Hardware Awareness to Co-Design. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Miami, FL, USA, 15–17 July 2019. [Google Scholar]
- Reddi, V.J.; Plancher, B.; Kennedy, S.; Moroney, L.; Warden, P.; Agarwal, A.; Banbury, C.; Banzi, M.; Bennett, M.; Brown, B.; et al. Widening Access to Applied Machine Learning with TinyML. arXiv 2021, arXiv:2106.04008. [Google Scholar]
- Sanchez-Iborra, R.; Skarmeta, A.F. TinyML-Enabled Frugal Smart Objects: Challenges and Opportunities. IEEE Circuits Syst. Mag. 2020, 20, 4–18. [Google Scholar] [CrossRef]
- TinyML. Available online: https://github.com/tinyMLx/courseware/tree/master/edX (accessed on 1 December 2024).
- Zhai, X.; Si, A.; Amira, A.; Bensaali, F. MLP Neural Network Based Gas Classification System on Zynq SoC. IEEE Access 2016, 4, 8138–8146. [Google Scholar] [CrossRef]
- Coelho, C.N.; Kuusela, A.; Li, S.; Zhuang, H.; Ngadiuba, J.; Aarrestad, T.K.; Loncar, V.; Pierini, M.; Pol, A.A.; Summers, S. Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors. arXiv 2020, arXiv:2006.10159. [Google Scholar] [CrossRef]
- Campos, J.; Mitrevski, J.; Tran, N.; Dong, Z.; Gholaminejad, A.; Mahoney, M.W.; Duarte, J. End-to-end codesign of Hessian-aware quantized neural networks for FPGAs. ACM Trans. Reconfig. Technol. Syst. 2023, 17, 1–22. [Google Scholar] [CrossRef]
- Banbury, C.; Reddi, V.J.; Torelli, P.; Holleman, J.; Jeffries, N.; Kiraly, C.; Montino, P.; Kanter, D.; Ahmed, S.; Pau, D.; et al. MLPerf Tiny Benchmark. arXiv 2021, arXiv:2106.07597. [Google Scholar]
- Hui, H.; Siebert, J. TinyML: A Systematic Review and Synthesis of Existing Research. In Proceedings of the IEEE, International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 21–24 February 2022. [Google Scholar]
- Wang, Y.; Xu, J.; Han, Y.; Li, H.; Li, X. DeepBurning: Automatic generation of FPGA-based learning accelerators for the neural network family. In Proceedings of the 53rd Annual Design Automation Conference, Austin, TX, USA, 5–9 June 2016; Volume 1. [Google Scholar]
- Zhao, Y.; Gao, X.; Guo, X.; Liu, J.; Wang, E.; Mullins, R.; Cheung, P.Y.; Constantinides, G.; Xu, C.Z. Automatic Generation of Multi-Precision Multi-Arithmetic CNN Accelerators for FPGAs. In Proceedings of the IEEE, International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019. [Google Scholar]
- Ye, H.; Zhang, X.; Huang, Z.; Chen, G.; Deming, C. HybridDNN: A framework for high-performance hybrid DNN accelerator design and implementation. In Proceedings of the 57th ACM/EDAC/IEEE Design Automation Conference, San Francisco, CA, USA, 20–24 July 2020. [Google Scholar]
- Jahanshahi, A.; Sharifi, R.; Rezvani, M.; Zamani, H. Inf4Edge: Automatic Resource-aware Generation of Energy-efficient CNN Inference Accelerator for Edge Embedded FPGAs. In Proceedings of the IEEE, 12th International Green and Sustainable Computing Conference (IGSC), Pullman, WA, USA, 18–21 October 2021. [Google Scholar]
- Ng, W.; Goh, W.; Gao, Y. High Accuracy and Low Latency Mixed Precision Neural Network Acceleration for TinyML Applications on Resource-Constrained FPGAs. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Singapore, 19–22 May 2024; Volume 1. [Google Scholar]
- Khalil, K.; Mohaidat, T.; Darwich, M.D.; Kumar, A.; Bayoumi, M. Efficient Hardware Implementation of Artificial Neural Networks on FPGA. In Proceedings of the IEEE 6th International Conference on AI Circuits and Systems (AICAS), Abu Dhabi, United Arab Emirates, 22–25 April 2024. [Google Scholar]
- Whatmough, P.; Zhou, C.; Hansen, P.; Venkataramanaiah, S.; Sun, S.; Mattina, M. FixyNN: Efficient Hardware for Mobile Computer Vision via Transfer Learning. arXiv 2019, arXiv:1902.11128. [Google Scholar]
- Jiménez-González, D.; Alvarez, C.; Filgueras, A.; Martorell, X.; Langer, J.; Noguera, J.; Vissers, K. Coarse-Grain Performance Estimator for Heterogeneous Parallel Computing Architectures like Zynq All-Programmable SoC. arXiv 2015, arXiv:1508.06830. [Google Scholar]
- Zhong, G.; Prakash, A.; Liang, Y.; Mitra, T.; Niar, S. Lin-Analyzer: A high-level performance analysis tool for FPGA-based accelerators. In Proceedings of the 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016. [Google Scholar]
- Dai, S.; Zhou, Y.; Zhang, H.; Ustun, E.; Young, E.F.; Zhang, Z. Fast and Accurate Estimation of Quality of Results in High-Level Synthesis with Machine Learning. In Proceedings of the Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018. [Google Scholar]
- Makrani, H.M.; Sayadi, H.; Dinakarrao, S.; Homayoun, H. Pyramid: Machine Learning Framework to Estimate the Optimal Timing and Resource Usage of a High-Level Synthesis Design. In Proceedings of the 29th International Conference on Field Programmable Logic and Applications (FPL), Barcelona, Spain, 9–13 September 2019. [Google Scholar]
- Choi, Y.k.; Cong, J. HLS-Based Optimization and Design Space Exploration for Applications with Variable Loop Bounds. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018. [Google Scholar]
- Li, P.; Zhang, P.; Pouchet, L.; Cong, J. Resource-Aware Throughput Optimization for High-Level Synthesis. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; Volume 1. [Google Scholar]
- Li, B.; Zhang, X.; You, H.; Qi, Z.; Zhang, Y. Machine Learning Based Framework for Fast Resource Estimation of RTL Designs Targeting FPGAs. ACM Trans. Des. Autom. Electron. Syst. 2022, 28, 1–16. [Google Scholar] [CrossRef]
- Schumacher, P.; Jha, P. Fast and accurate resource estimation of RTL-based designs targeting FPGAS. In Proceedings of the International Conference on Field Programmable Logic and Applications, Milano, Italy, 31 August–2 September 2008. [Google Scholar]
- Prost-Boucle, A.; Muller, O.; Rousseau, F. A Fast and Autonomous HLS Methodology for Hardware Accelerator Generation under Resource Constraints. In Proceedings of the IEEE, Euromicro Conference on Digital System Design, Los Alamitos, CA, USA, 4–6 September 2013. [Google Scholar]
- Adam, M.; Frühauf, H.; Kókai, G. Quick Estimation of Resources of FPGAs and ASICs Using Neural Networks. In Proceedings of the Lernen, Wissensentdeckung und Adaptivität (LWA) 2005, GI Workshops, Saarbrücken, Germany, 10–12 October 2005; Volume 1, pp. 210–215. [Google Scholar]
- Ullrich, K.; Meeds, E.; Welling, M. Soft Weight-Sharing for Neural Network Compression. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016; Volume 1. [Google Scholar]
- Duarte, J.; Han, S.; Harris, P.; Jindariani, S.; Kreinar, E.; Kreis, B.; Ngadiuba, J.; Pierini, M.; Rivera, R.; Tran, N.; et al. Fast inference of deep neural networks in FPGAs for particle physics. J. Instrum. 2018, 13, P07027. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 1 December 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | HLS * | Ours * | ||
|---|---|---|---|---|
| Jet-tagging | 0.76 | (16, 64, 32, 32, 5) | 480 s | 0.03 s |
| HAR | 0.95 | (561, 20, 64, 64, 6) | 13,800 s | 0.147 s |
| MNIST (14 × 14) | 0.97 | (192, 56, 64, 32, 10) | 3360 s | 0.11 s |
| Breast cancer | 0.99 | (10, 5, 3, 2) | 60 s | 0.018 s |
| Arrhythmia | 0.62 | (274, 8, 16) | 360 s | 0.022 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kokkinis, A.; Siozios, K. Fast Resource Estimation of FPGA-Based MLP Accelerators for TinyML Applications. Electronics 2025, 14, 247. https://doi.org/10.3390/electronics14020247
Kokkinis A, Siozios K. Fast Resource Estimation of FPGA-Based MLP Accelerators for TinyML Applications. Electronics. 2025; 14(2):247. https://doi.org/10.3390/electronics14020247
Chicago/Turabian StyleKokkinis, Argyris, and Kostas Siozios. 2025. "Fast Resource Estimation of FPGA-Based MLP Accelerators for TinyML Applications" Electronics 14, no. 2: 247. https://doi.org/10.3390/electronics14020247
APA StyleKokkinis, A., & Siozios, K. (2025). Fast Resource Estimation of FPGA-Based MLP Accelerators for TinyML Applications. Electronics, 14(2), 247. https://doi.org/10.3390/electronics14020247