4.1. Dataset
Our proposed method, along with several competitive baselines, is evaluated using the CTISum dataset [
9], a benchmark specifically constructed to support the research, development, and evaluation of CTI summarization techniques. Covering a broad spectrum of cyber threats, attack behaviors, and security incidents from 2016 to 2023 across various regions and threat categories, CTISum serves as a representative and high-quality testbed for the cybersecurity domain.
The dataset aggregates intelligence from diverse sources, including open-source repositories (e.g., APTnotes), threat encyclopedias (e.g., TrendMicro), and vendor-specific threat reports (e.g., Symantec). This multi-source integration yields a semantically rich and contextually diverse corpus that captures the evolving landscape of cyber threats, offering valuable training and evaluation resources for CTI summarization models.
CTISum contains 1345 documents with an average input length of 2865 characters and an average summary length of 200 characters, yielding a compression ratio of approximately 14.32, which underscores the difficulty of generating concise and high-quality summaries from lengthy CTI texts. The dataset supports two summarization tasks: CTIS and APS, with APS defined as a subset consisting of 1014 annotated samples.
The two tasks differ in summarization focus and complexity. The CTIS task focuses on summarizing high-level threat intelligence, such as actor names, attack types, targeted sectors, and overall threat context. This task emphasizes coverage and readability of general threat narratives. In contrast, the APS task requires the extraction of fine-grained procedural information, including tactics, techniques, and indicators of compromise (IoCs). It demands greater factual precision and domain-specific understanding. As a result, APS requires greater challenges in both informativeness and faithfulness.
4.4. Implementation Details
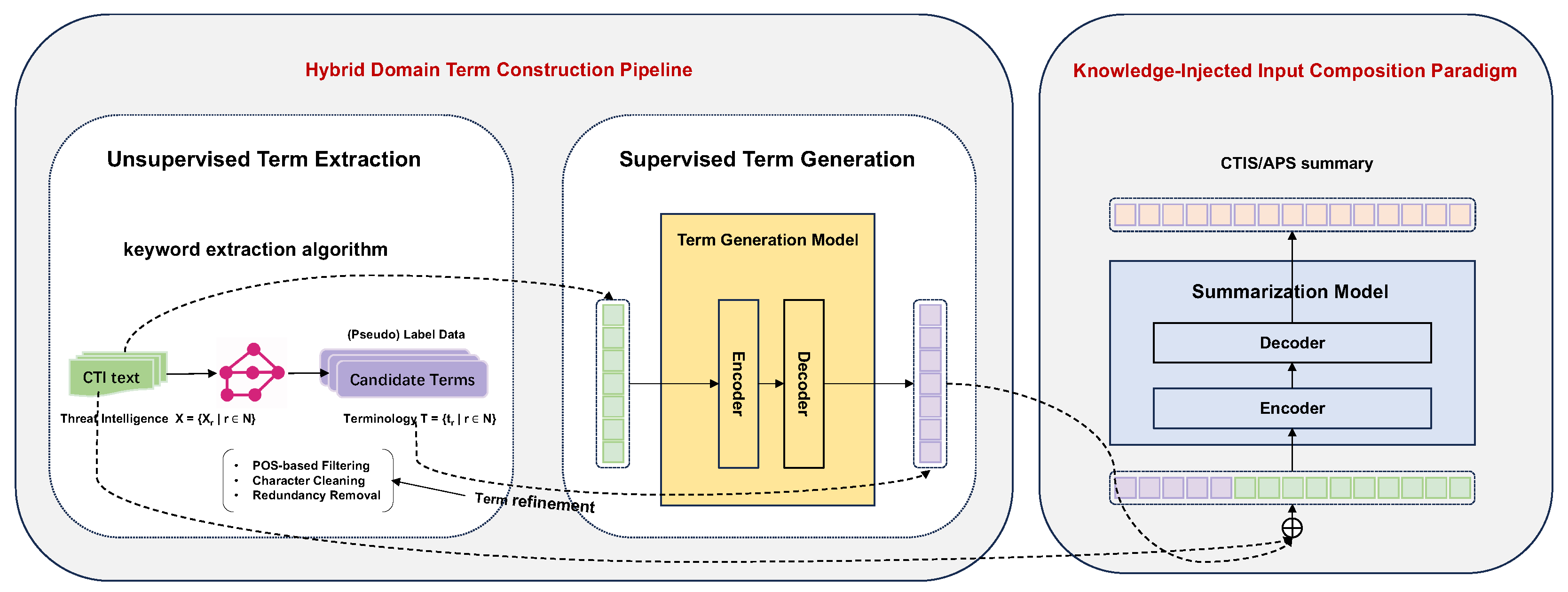
We implement the proposed knowledge-guided CTI summarization framework by combining standard NLP tools and pretrained language models.
In the unsupervised term extraction phase, we adopt KeyBERT with the all-MiniLM-L6-v2 sentence embedding model. Candidate terms are ranked based on their cosine similarity to the overall document embedding, which is computed by averaging sentence embeddings of the full text. The top terms are selected as the initial term set.
We apply a multi-step term refinement process to improve quality and semantic coherence of extracted terms. Specifically, we remove function words (e.g., pronouns, conjunctions, interrogatives), normalize characters (e.g., stripping punctuation and non-standard symbols), eliminate semantically redundant terms based on Sentence-BERT embeddings (cosine similarity threshold = 0.85), and filter out low-information or overly generic terms (e.g., “document”, “system”, “file”) using a curated blacklist.
In the supervised term generation stage, we treat the refined term set as pseudo labels and fine-tune a T5-small sequence-to-sequence model. The model is trained with a maximum input length of 512 tokens and an output length of 64 tokens. It learns to generate task-relevant domain terminology directly from raw CTI texts.
The final term set used for summarization is generated by the fine-tuned T5-small model and serves as the input prefix in the knowledge-injected summarization paradigm. This structured terminology acts as lightweight guidance to help the model attend to critical threat semantics, thereby enhancing both factual consistency and domain relevance in the generated summaries.
During summarization, we follow a unified input construction paradigm in which the term set is prepended to the original CTI document. Terms are separated by semicolons and terminated with a period (e.g., “malware; phishing; C2 server.+CTI document’’) to explicitly direct the model’s attention to key concepts.
Example: Given a refined term set such as:
[APT29, phishing, credential dumping, C2 server, PowerShell, lateral movement],
The knowledge-injected input is formatted as:
APT29; phishing; credential dumping; C2 server; PowerShell; lateral movement. <CTI document text>
This format guides the model to attend to salient threat entities and tactics during encoding. We conduct experiments under both zero-shot and supervised settings. In the zero-shot setup, we directly prompt instruction-tuned LLMs such as GPT-3.5, Vicuna-13B, and LLaMA3-8B. In the supervised setup, we fine-tune encoder–decoder architectures including T5-base, LED-base, and BART-base using the CTISum benchmark, using a maximum input length of 1024 and standard sequence-level cross-entropy loss. All models retain the terminology-injected input structure during training and inference, allowing us to systematically evaluate the generalization of the proposed strategy across paradigms and architectures.
4.6. Experimental Results
This experiment evaluates the performance of different models and input strategies on two CTI summarization tasks, CTIS and APS. The results, as shown in
Table 1 and
Table 2, indicate the following. (1)
Effectiveness of Terminology: Across all models and tasks, the input strategies—DirectLM, AutoTerm+LM, and GenTerm+LM—demonstrate a consistent upward trend in both BERTScore and ROUGE metrics. This confirms that incorporating and optimizing domain-specific terminology significantly improves summary quality, validating the effectiveness of the proposed hybrid domain term construction pipeline. (2)
Model Performance Comparison: Under the zero-shot setting, GPT-3.5 achieves the best performance on both CTIS and APS tasks, outperforming Vicuna-13B and LLAMA3-8B in terms of both BERTScore and ROUGE metrics. Under the supervised setting, BART-base performs the best among all models, especially when combined with the GenTerm+LM-SFT strategy. It achieves ROUGE-1/2/L scores of 57.37/24.20/36.06 on CTIS, and 57.87/24.07/39.42 on APS—the highest among all settings. Overall, supervised fine-tuned models significantly outperform zero-shot models, indicating the advantage of task-specific training. It is also worth noting that GPT-3.5 consistently achieves the highest BERTScore, reflecting its strong semantic understanding. (3)
Impact of Input Strategy: For all models, transitioning from DirectLM to GenTerm+LM leads to steady improvements in BERTScore and all ROUGE metrics. This demonstrates that optimized terminology not only improves lexical matching but also enhances semantic coherence. Notably, BART-base combined with GenTerm+LM-SFT yields the best overall performance, highlighting its strong generalization and robustness in real-world applications. (4)
Task Comparison: The CTIS task consistently yields higher scores than the APS task, suggesting that summaries for CTIS are relatively easier to generate with higher quality. Furthermore, under the same model and strategy, CTIS outperforms APS in both ROUGE and BERTScore. However, both tasks exhibit consistent performance gains from enhanced input strategies, indicating the generalizability and effectiveness of the proposed terminology-oriented approach across different summarization scenarios.
To further validate the reliability of our findings, we report the mean and standard deviation of evaluation scores over three independent runs for the BART-base model under all major supervised input strategies (see
Table 3 and
Table 4). The low standard deviations indicate stable performance across runs. In addition, we conduct paired
t-tests between the baseline DirectLM and our GenTerm+LM strategy. The improvements in both ROUGE and BERTScore metrics are statistically significant (
), reinforcing the robustness and consistency of the observed performance gains. Specifically, for the CTIS task, the
p-values for BERTScore, ROUGE-1, ROUGE-2, and ROUGE-L are
,
,
, and
, respectively. For the APS task, the corresponding
p-values are
,
,
, and
. These results confirm that the proposed term-oriented input strategy consistently and significantly outperforms the baseline approach.
4.7. Ablation Study
Compare with term-only input to assess standalone informativeness. To further examine the standalone contribution of domain-specific terms, we introduce an additional baseline—
TermOnly—where the summarization model receives only the generated domain terms as input, without the original CTI document. This setting isolates the informativeness of the selected terminology and evaluates its ability to support summary generation in the absence of context. As shown in
Table 5, TermOnly-SFT yields significantly lower performance compared to full-text input strategies. On the CTIS task, BART-base with TermOnly-SFT achieves ROUGE-1/2/L scores of 27.03/10.12/15.65, while GenTerm+LM-SFT yields 57.37/24.20/36.06. On the APS task, TermOnly-SFT obtains 29.56/11.45/17.24, compared to 57.87/24.07/39.42 for GenTerm+LM-SFT. Despite the gap, the summaries produced under the TermOnly setting still reflect key concepts and threat-related entities, suggesting that the generated terms retain substantial semantic information.
These results support the conclusion that domain terms—when carefully selected and refined—are semantically informative and can partially guide summarization even without full document input. They further emphasize the central role of terminology in enhancing both lexical and semantic relevance.
Remove term input to verify the contribution of domain terminology. To assess the contribution of domain-specific terminology in improving summarization performance, we remove the input strategies enhanced through our hybrid domain term construction pipeline, and compare the results of DirectLM (without terminology) against AutoTerm+LM and GenTerm+LM (with terminology). This comparison is conducted under both zero-shot and supervised settings across the CTIS and APS tasks. As shown in
Table 1 and
Table 2, the removal of domain terminology (i.e., using DirectLM as input strategy) leads to a noticeable drop in all evaluation metrics (BERTScore, ROUGE-1/2/L) for each model: In the CTIS task, for instance, BART-base with DirectLM-SFT achieves ROUGE-1/2/L scores of 45.76/16.88/29.03, while the same model with GenTerm+LM-SFT reaches 57.37/24.20/36.06—an absolute improvement of 11.61 (ROUGE-1), 7.32 (ROUGE-2), and 7.03 (ROUGE-L). Similarly, on the APS task, BART-base with GenTerm+LM-SFT outperforms DirectLM-SFT by 17.62 (ROUGE-1), 12.42 (ROUGE-2), and 14.36 (ROUGE-L), demonstrating the critical role of terminology in more complex summarization settings.
Consistent improvements are also observed in zero-shot models. For example, GPT-3.5 improves from ROUGE-1/2/L of 42.38/12.57/22.23 (DirectLM-ZS) to 43.56/13.64/23.20 (GenTerm+LM-ZS) on CTIS, indicating that even LLMs benefit from enriched terminology inputs. These findings clearly validate that domain terminology significantly contributes to enhancing both semantic relevance and lexical overlap in the generated summaries. Moreover, the effect is particularly pronounced under supervised settings, where the model can better exploit structured terminological inputs during training.
Compare unrefined and refined/generated term sets to assess term quality impact. To further evaluate the influence of domain terminology quality on summarization performance, we compare AutoTerm (automatically extracted but unrefined term sets) and GenTerm (refined or generated term sets via our hybrid construction pipeline). As shown in
Table 1 and
Table 2, using GenTerm consistently outperforms AutoTerm across all models and evaluation metrics: In the CTIS task, BART-base improves from 51.80/20.54/32.52 (AutoTerm) to 57.37/24.20/36.06 (GenTerm), with absolute gains of +5.57 (ROUGE-1), +3.66 (ROUGE-2), and +3.54 (ROUGE-L). On APS, the improvement is more pronounced, rising from 49.06/17.86/32.24 to 57.87/24.07/39.42, with gains of +8.81, +6.21, and +7.18, respectively.
Zero-shot models also benefit from term refinement. For instance, GPT-3.5 in the CTIS task improves from ROUGE-1/2/L scores of 42.95/13.05/22.78 (AutoTerm) to 43.56/13.64/23.20 (GenTerm), indicating the positive impact of higher-quality terms even without fine-tuning. These results demonstrate that not only the presence of domain terms, but also their quality—in terms of relevance, coverage, and expression—plays a vital role in enhancing summarization performance. The refined GenTerm sets, which incorporate semantic filtering and contextual generation, help guide the model toward more accurate and coherent summaries, especially under complex summarization tasks like APS.
Vary term set size to analyze sensitivity to the number of injected terms. To investigate how the number of injected domain-specific terms affects summarization performance, we vary the size of the term set used in the GenTerm+LM-SFT strategy. Specifically, we evaluate models using the top-
k terms where
, and report the results on both CTIS and APS tasks. As shown in
Figure 2, increasing the number of injected terms consistently improves summarization performance across all ROUGE metrics: In the CTIS task, ROUGE-1 improves from 50.10 (
k = 5) to 57.37 (
k = 20), a relative gain of +7.27. ROUGE-2 increases from 18.10 to 24.20 (+6.10), and ROUGE-L from 30.20 to 36.06 (+5.86). On the APS task, ROUGE-1 improves from 51.40 (
k = 5) to 57.87 (
k = 20), a gain of +6.47. ROUGE-2 rises from 18.90 to 24.07 (+5.17), and ROUGE-L from 33.20 to 39.42 (+6.22). These results indicate that injecting more high-quality domain terms leads to richer semantic guidance and improves both lexical overlap and content relevance. However, the performance gains gradually diminish as
k increases, suggesting that while more terms provide more information, the marginal benefit decreases—likely due to redundancy or noise in the lower-ranked terms. This observation highlights the importance of balancing quantity and quality in terminology injection. Selecting an appropriate number of salient terms is crucial to achieving optimal summarization performance.
Explore the impact of different term insertion positions within the input.To analyze the influence of term placement on summarization performance, we compare three insertion strategies: placing the domain terms at the beginning (
Prefix: Term+CTI), at the end (
Postfix: CTI+Term), and inline-before their natural occurrences (
Inline-Before) within the CTI text. We evaluate all strategies under the GenTerm+LM-SFT setting using BART-base in the CTIS and APS tasks. As shown in
Table 6, inserting terms at the beginning of the input consistently yields the best performance across all evaluation metrics for both tasks. On the CTIS task, the prefix strategy achieves a ROUGE-1 of 57.37, ROUGE-2 of 24.20, and ROUGE-L of 36.06, outperforming postfix and inline strategies. Inline-Before achieves intermediate performance with ROUGE-1 of 56.80, ROUGE-2 of 23.65 and ROUGE-L of 35.45, demonstrating a viable alternative.
In the APS task, prefix input achieves ROUGE-1 of 57.87, ROUGE-2 of 24.07, and ROUGE-L of 39.42, while Inline-Before yields 56.35, 23.25, and 37.80, respectively—both outperforming the postfix strategy. BERTScore shows a consistent trend across both tasks. These results suggest that prefix placement guides the model to attend to key concepts early in the decoding process, whereas Inline-Before, though slightly less effective, provides localized cues that may enhance interpretability and alignment.
4.9. Few-Shot Analysis
To assess the effectiveness of the proposed summarization approach under low-resource scenarios, we conduct a detailed few-shot analysis by varying the amount of training data from 1% to 100%. Specifically, we evaluate the performance of BART-base with the GenTerm+LM-SFT strategy across seven data proportions: 1%, 5%, 10%, 30%, 50%, 70%, and 100%. The results are presented in
Figure 4, reporting ROUGE-1, ROUGE-2, and ROUGE-L scores for both CTIS and APS tasks.
In the CTIS task, we observe consistent and substantial performance gains as the training data proportion increases: ROUGE-1 improves from 36.78 (1%) to 57.37 (100%), ROUGE-2 from 10.92 to 24.20, and ROUGE-L from 22.40 to 36.06. Notably, even at the 1% level, the model achieves reasonable scores, demonstrating its ability to generalize under extremely limited supervision. Significant improvements are observed with just 5% of the training data, and performance continues to improve steadily thereafter.
In the APS task, a similar trend is observed: ROUGE-1 rises from 37.22 (1%) to 57.87 (100%), ROUGE-2 from 11.04 to 24.07, and ROUGE-L from 22.18 to 39.42. The performance gap between 1% and 10% settings is particularly large, suggesting that even a small increase in data leads to notable gains in complex tasks like APS. The model reaches competitive performance with 30–50% of the data and saturates around 70%, confirming its efficiency and scalability.
These results validate the low-resource applicability of our term-guided summarization approach. The model exhibits strong learning capability from very few examples and achieves near-optimal performance with only a fraction of the training data. This makes the proposed framework particularly suitable for domains where annotated CTI summaries are scarce or expensive to obtain.






{kind=link}
{kind=link}
{kind=link}
{kind=link}