1. Introduction
In the production process of polytetrafluoroethylene (PTFE), the liquid raw material must be coagulated into solid PTFE powder through agitation in a coagulation vessel [
1]. The key to this process is to dynamically adjust the agitation speed based on the state of the reactants to achieve optimal coagulation, which means a more concentrated particle size distribution of PTFE. Accurate identification of material states during coagulation is essential for maintaining product quality, enhancing process efficiency, and minimizing reliance on manual intervention. However, conventional sensing approaches often rely on indirect indicators (e.g., acoustic signals), which are prone to interference and have difficulty capturing physical and visual changes during state transitions. These limitations underscore a pressing need for reliable visual perception systems capable of capturing the subtle changes in liquid states during coagulation. Computer vision techniques based on deep learning offer a promising solution, and its ability to automatically extract features enables it to adapt to complex industrial environments and accurately identify liquid states.
In 2012, AlexNet (based on convolutional neural networks) was proposed by Alex Krizhevsky et al. [
2], demonstrating significant superiority to the traditional ImageNet competition (ILSVRC) methods, reducing the error rate. Its emergence marked the beginning of the deep learning era in computer vision, after which deep learning began achieving breakthroughs across a wide range of production activities. The outstanding performance of deep learning in image recognition provides a potential solution for the intelligent control of PTFE coagulation processes. By accurately capturing visual changes during state transitions and monitoring final-stage cleanliness, the powerful feature extraction capabilities of deep neural networks help to ensure higher product quality, reduce labor requirements, and enable full-process intelligent automation.
Convolutional neural networks (CNNs) have long been the dominant architecture in computer vision tasks as they can extract local features through parameter-shared convolution kernels and have better generalization performance while reducing computational complexity. Among them, ResNet (Residual Network), introduced by He et al. [
3], significantly advanced CNN-based models by incorporating residual connections, which alleviate the vanishing gradient problem in deep networks and enable the construction of substantially deeper architectures. These residual connections allow the network to learn identity mappings, facilitating the training of very deep networks and leading to better performance in a wide range of vision tasks, such as image classification, object detection, and segmentation.
Despite the success of convolutional neural networks (CNNs) and their variants such as ResNet, these models inherently rely on local receptive fields and often struggle to capture long-range dependencies. To address this limitation, vision transformer (ViT) [
4] has emerged as one of the most prominent deep learning frameworks in recent years. Unlike traditional CNN and RNN architectures [
5] that rely on convolution operations, ViT is entirely based on the transformer architecture and leverages a self-attention mechanism for sequence modeling. At the core of ViT is its self-attention mechanism, which segments an image into small patches and models the relationships between different patches, thereby effectively overcoming the locality constraints of CNN-based models. Its main strengths lie in the ability to capture long-range dependencies and its suitability for parallel computation. This architectural shift has profoundly reshaped the landscape of computer vision, inspiring transformer-based models across a wide range of visual tasks.
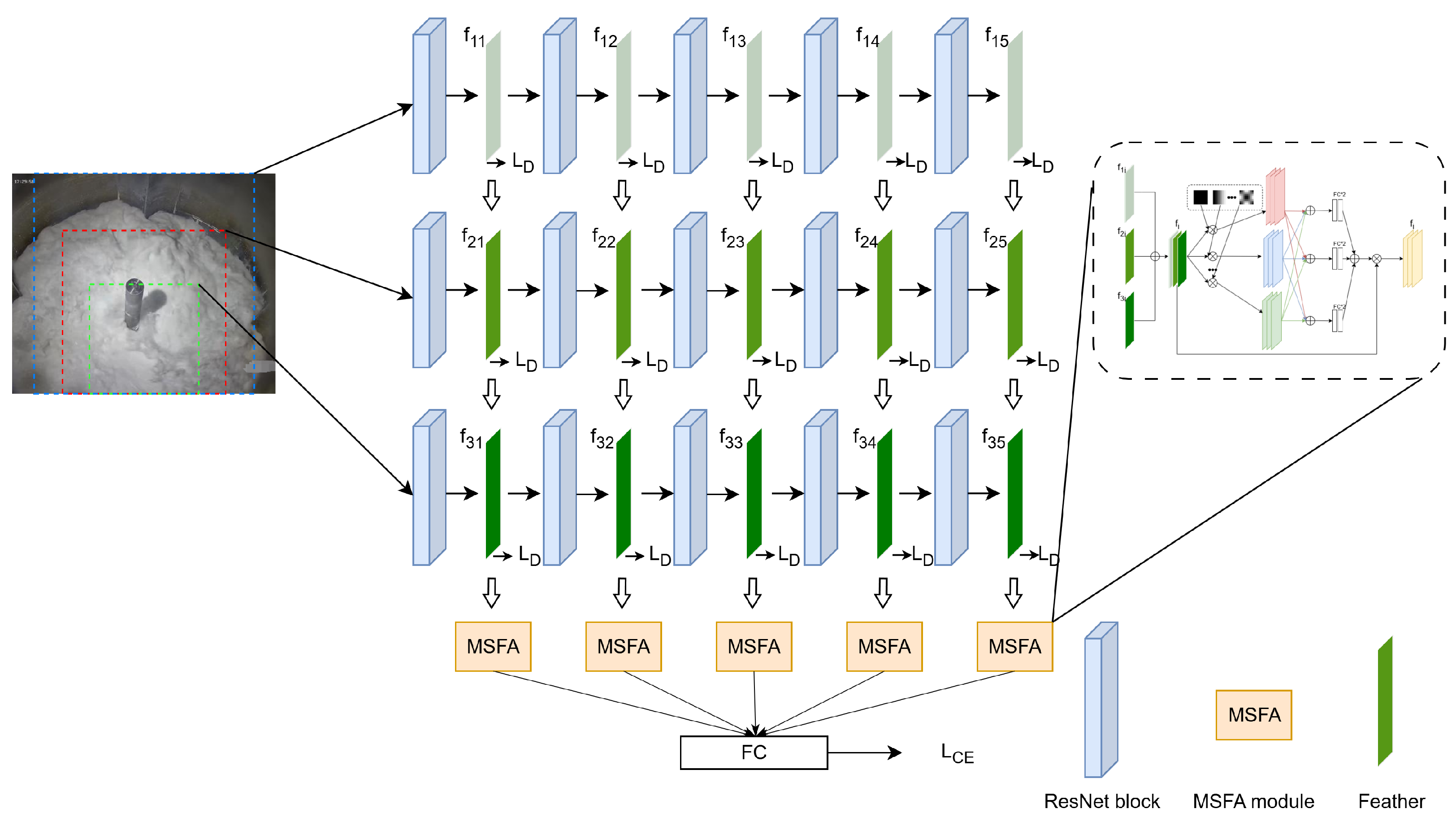
However, the unique characteristics of liquid present persistent challenges for conventional deep models. Unlike rigid objects, liquids exhibit dynamic, continuous, and often ambiguous visual patterns, where subtle changes in texture, boundary, or flow state carry significant semantic meaning. Although recent studies [
6,
7,
8,
9] have explored the application of deep learning to liquid-state detection, from multiphase flow analysis to real-time monitoring using sensor vision fusion, there are still some key limitations that have not been addressed. A key challenge lies in the inherent contradiction between the large image resolutions often required to observe fine-scale liquid behavior and the small fixed input sizes expected in most deep learning models. For instance, high-resolution visual data (e.g., 2560 × 1440 pixels) are commonly used in industrial settings as they retain more detailed spatial information—such as surface morphology, particle dispersion, and fluid flow patterns—that may be critical for distinguishing the liquid state. However, typical deep architectures are designed around much smaller input sizes (e.g., 224 × 224 pixels), especially when leveraging pretrained backbones. Increasing the input size not only significantly increases computational and memory overhead but also easily leads to unstable training and difficult convergence. Direct downsampling risks discarding fine-grained textures that are essential for recognizing liquid-state transitions, while cropping may omit broader contextual information that is necessary for global understanding. To address these challenges, we propose a multi-branch deep network that extracts multi-scale features from images as much as possible. Low-resolution branches aim to extract global contextual features by preserving more complete images, whereas the high-resolution branch focuses on texture patterns, enabling the model to accurately recognize the state of liquid reactants and achieve precise dynamic control. Furthermore, we introduce a feature fusion module based on frequency and channel attention, which allows the network to selectively emphasize informative features and suppress less relevant ones.
The method of calculating loss through the output of the final layer and propagating it backward to intermediate layers for optimization may lead to difficulties in optimizing intermediate layers [
10,
11]. To address this issue, deep supervision [
12] was proposed, which directly adds supervision signals to the intermediate layer for optimization. In this study, the multi-branch architecture may lead to imbalanced gradients across branches, which can prevent effective joint optimization and result in suboptimal feature learning in certain branches. To address this issue, we will use supervised contrastive learning as a form of deep supervision to ensure that each branch effectively learns meaningful and generalized features. Deep contrast supervision enables models to learn depth features at multiple scales simultaneously rather than relying solely on high-resolution texture details or low-resolution contextual information. Our network provides the capability to capture features at different scales, enabling the characterization of both microscopic liquid textures (e.g., particle distribution and surface morphology) and macroscopic rheological properties (e.g., viscosity and flow uniformity) of PTFE emulsions.
The main contributions of this paper are as follows: 1. Assembled and established a large-scale research cohort for PTFE coagulation vessel operation status in an actual industrial setting. 2. Designed a multi-branch multi-scale deep learning model incorporating frequency–channel self-attention and deeply supervised contrastive learning, achieving multi-scale feature learning for reactant status in the vessel. 3. Successfully deployed the applied model in actual production processes at a real factory base, achieving a 94.3% mean F1-score in recognizing two key reaction states (“gelation” and “granulation”) and the clean state during polytetrafluoroethylene coagulation, effectively supporting the automation of this industrial process.
2. Related Work
Deep learning has demonstrated significant advantages in liquid detection tasks. Its powerful capability for automatic feature extraction enables the accurate identification of complex liquid properties, facilitating high-precision end-to-end detection. Moreover, deep learning models exhibit excellent generalization performance, making them adaptable to various types of liquids and challenging environmental conditions. As a result, deep learning has emerged as a core technological solution widely applied in this field.
Marc Olbrich et al. [
6] proposed a deep learning-based image processing technique for the automatic extraction of liquid-level time series from high-speed videos of gas–liquid two-phase and gas–oil–water three-phase flows. Compared to traditional methods relying on image filters, this approach demonstrates superior robustness and generalization capability across varying liquid flow conditions.
Lu Chen et al. [
7] proposed a computer vision detection system based on a DBN–AGS–FLSS deep learning model. By integrating adaptive image enhancement and edge detection algorithms with a reverse judgment feedback mechanism, the system achieves high-precision real-time detection of pointers during liquid flow. This approach significantly improves the accuracy and robustness of liquid flow rate and viscosity measurements.
Zhong-Ke Gao [
8] proposed an innovative liquid detection method based on complex networks and deep learning. The method constructs a Limited Penetration Visibility Graph (LPVG) from multi-channel distributed conductivity sensor data to characterize gas–liquid two-phase flow behavior. Additionally, a dual-input convolutional neural network was designed to fuse the raw signals with the graph representations, enabling simultaneous liquid detection tasks of flow structure classification and void fraction measurement.
Li L et al. [
9] proposed a novel zero-shot gas–liquid two-phase flow pattern recognition strategy based on supervised deep slow steady-state feature analysis (SD-S
2FA) and a siamese network. By utilizing manually designed flow pattern attribute descriptors, the method achieves accurate identification of unknown flow patterns, including transitional and hazardous states.
This section reviews recent advances in deep learning-based liquid detection techniques, highlighting their strong feature extraction and generalization capabilities. Various innovative methods have been developed, including deep image processing for multiphase flow analysis, adaptive computer vision systems for real-time flow measurement, and complex network approaches for sensor data fusion. Additionally, zero-shot learning strategies enable accurate identification of unknown and hazardous flow states. Together, these advancements demonstrate the significant potential of deep learning to improve the accuracy, robustness, and applicability of liquid detection in diverse and challenging environments.
Recent advances have demonstrated the growing potential of deep learning techniques in various stages of polytetrafluoroethylene (PTFE) production. For example, Wang et al. [
13] proposed PatchRLNet, an automated detection framework that integrates a vision transformer and reinforcement learning to identify the separation between PTFE emulsion and liquid paraffin. This method addresses the safety and efficiency challenges of manual visual inspection and achieved over 99% accuracy on real industrial data. Another work [
14] introduced TransResNet, a hybrid architecture combining vision transformer and ResNet for real-time video-based detection of liquid levels in PTFE emulsion equipment, such as vibrating screens and waste drums. By using synthetic data to mitigate sample imbalance, the model achieved high accuracy and enhanced robustness in complex production environments. Additionally, in the early stage of PTFE synthesis, a hybrid kinetic model was developed [
15] that combines mechanism-based modeling with LSTM networks to improve the prediction of reaction rates. This method effectively addresses uncertainty in kinetic parameters and improves the precision of process control. Together, these studies highlight the critical role of deep learning in improving automation, safety, and modeling accuracy throughout the PTFE manufacturing pipeline, and they provide a strong foundation for further exploration of intelligent visual recognition methods in this domain.
4. Results
4.1. Experimental Setup
This subsection details the parameter settings and the selection of evaluation metrics used to assess the proposed method.
4.1.1. Parameter Settings
In the experiment, we use ResNet34 as the backbone network, initialized with pretrained parameters obtained from training on ImageNet. The model is trained for 100 epochs using the Adam optimizer [
28] with an initial learning rate of
and a batch size of 64. The temperature parameter
for the contrastive loss is set to 0.07. All the experiments are conducted on a single NVIDIA 3090 GPU with mixed precision training.
4.1.2. Evaluation Indicators
We use accuracy, mean accuracy, and mean F1-score as evaluation metrics to validate the effectiveness of our proposed method. Due to the practical application requirements, we focus on three categories: “gelation”, “granulation”, and “clean” for both mean accuracy and mean F1-score.
Accuracy is the most intuitive evaluation metric in classification tasks, representing the proportion of correctly predicted samples out of the total number of samples. This metric reflects the overall prediction performance of the model on the validation set. The calculation formula is as follows:
N is the total number of samples,
is the ground-truth label of the
i-th sample, and
is the predicted label of the
i-th sample.
In the preparation process of PTFE suspension, we mainly focus on predicting the three states: “gelation”, “granulation”, and “clean”. These three categories represent a smaller proportion of the total data. The accuracy may be largely dominated by the predictions of the “normal” category. To better understand the effectiveness of our method in practical applications, we consider calculating the average metrics for these three states. The formula for calculating the mean accuracy is as follows:
denotes the normal class, which is not considered.
The F1-score is a widely used classification performance evaluation metric in machine learning, especially in scenarios with class imbalance. It takes into account both precision and recall, providing a more balanced representation of the model’s classification performance. The formula for calculating the F1-score is as follows:
4.2. Model Performance Comparison
This subsection reports the classification performance of several representative deep learning models—including ResNet, DenseNet, ResNeXt, vision transformer (ViT), and Swin transformer—on the PTFE coagulation kettle state dataset, aiming to evaluate the effectiveness of the proposed method in comparison with both convolution-based and transformer-based architectures.
According to the results presented in
Table 2, the best convolution-based model is ResNeXt, while the best transformer-based model is Swin transformer. Overall, the convolution-based models outperform the transformer-based models. The method proposed in this study outperforms other commonly used models across all three evaluation metrics. As shown in the table, compared with ResNeXt, our method improves accuracy (Acc.), mean accuracy (Mean Acc.), and mean F1-score (Mean F1) by 1.6%, 4.9%, and 4.2%, respectively. Compared with Swin transformer, the improvements are 0.9%, 1.0%, and 7.2%, respectively. These results demonstrate that our proposed method effectively addresses the limitations of traditional models in classifying liquid states within the PTFE polymerization reactor. Although our method incurs higher computational cost—as reflected by both its increased GFLOPs and relatively lower inference throughput—accuracy is significantly more critical than computational efficiency in our application scenario. In industrial chemical processes, especially during the coagulation of PTFE emulsions, incorrect predictions of liquid state can lead to premature or delayed process control, which may compromise product quality or even pose safety risks. Therefore, the additional computational burden is a reasonable and necessary trade-off to ensure more reliable and accurate classification performance in such high-stakes environments. Moreover, the achieved throughput of 211 images/s remains acceptable for practical deployment in real-world industrial systems.
Figure 4 shows the confusion matrices of six models on the PTFE reactor liquid state classification dataset. It can be observed that the proposed method achieves near-optimal performance across all four categories. The only exception is that DenseNet performs slightly better than our method on the clean category; however, it performs significantly worse on the other categories. This may be due to differences in the types of features required to distinguish between categories. The multi-scale structure in our method enables more effective learning of such diverse features.
4.3. Ablation Experiment
In this subsection, we design ablation experiments to ensure that each proposed module effectively contributes to performance improvement. We designed three ablation settings: the baseline three-branch network (TBNet), TBNet with deep supervision loss, and TBNet with the MSFA module. The experimental results are shown in
Table 3. It can be observed that each of the proposed components effectively improves classification performance.
In the overall workflow of the PTFE coagulation reactor, it is essential to identify three key liquid states for effective process control. These three states exhibit distinct physical characteristics. The slurry state is characterized by the overall fluidity of the liquid and the smoothness of the surface, which primarily involves global features. The most prominent feature of the granulation stage is the appearance of solid particles on the liquid surface, which requires the model to capture fine-grained local details. The clean state, on the other hand, involves a combination of both local and global features. Such diversity in visual patterns implies that the model must possess strong multi-scale feature extraction capabilities. Our proposed three-branch network (TBNet) is designed specifically to equip the model with this ability, and the experimental results show that it improves the mean F1-score by 4.0% compared to the baseline.
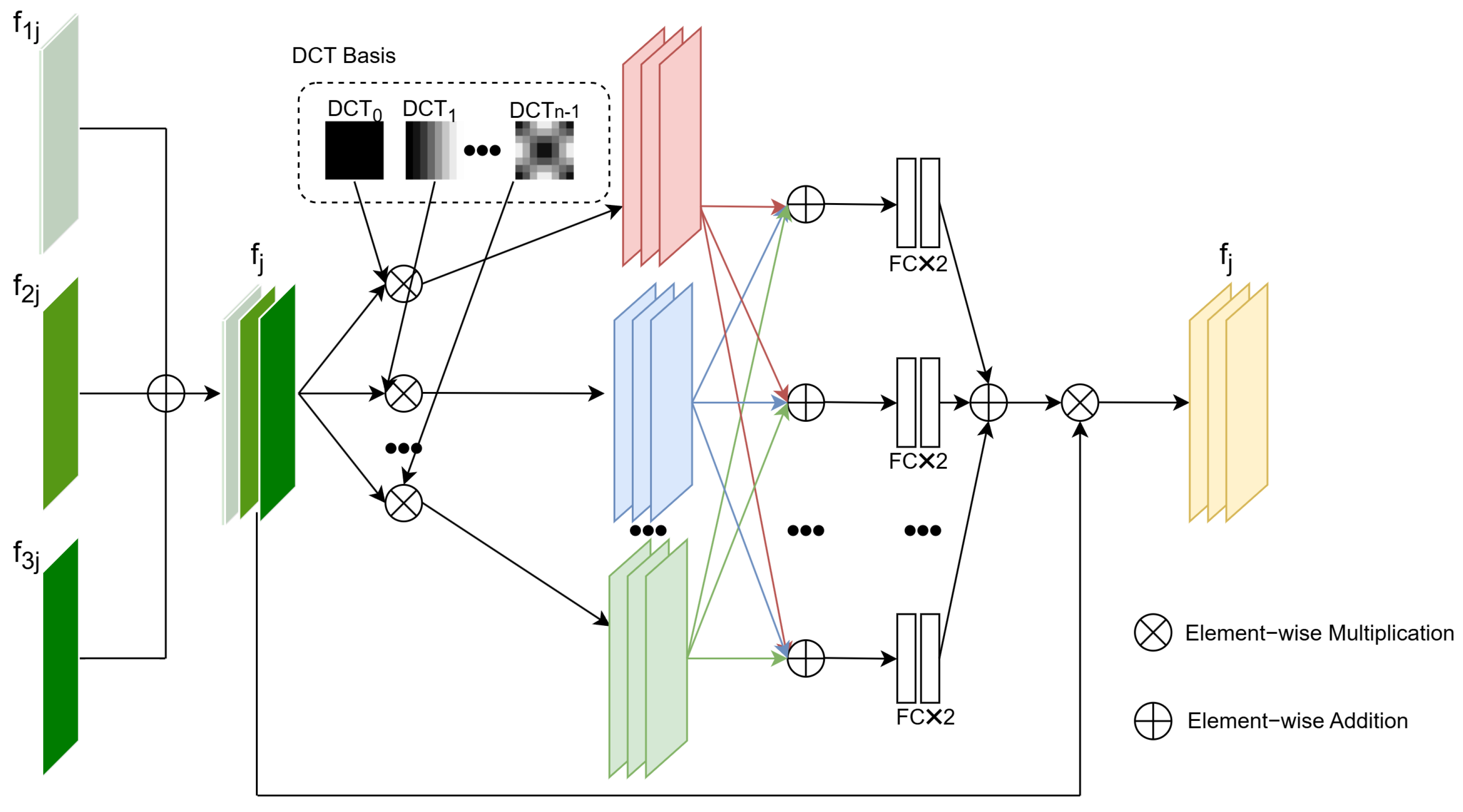
Given our multi-branch architecture, which extracts features from inputs at different scales, an important challenge arises: how to effectively fuse these multi-scale features from the backbone. The MSFA module is introduced to address this issue. It models the frequency-domain distribution of features to learn attention maps and integrates a channel self-attention mechanism to guide the effective fusion of multi-scale features. The experimental results demonstrate that our proposed MSFA enables efficient multi-scale feature fusion, leading to a 2.0% improvement in mean F1 after incorporating the MSFA module. The proposed method—built upon TBNet and deep supervision with the addition of the MSFA module—achieves an improvement in mean F1. However, it also exhibits a slight decrease in mean accuracy. Further analysis reveals that the model without the MSFA module tends to misclassify samples from the minority class gelation as the majority class normal. While this misclassification leads to a seemingly high accuracy for the gelation class—because most predictions are biased toward the dominant class—it severely reduces the recall. As a result, the mean accuracy becomes inflated due to the dominance of correctly predicted normal samples, whereas the more balanced mean F1-score more accurately reflects the model’s limited capacity to detect all the categories, especially the minority ones. The inclusion of the MSFA module mitigates this issue by improving feature discrimination, leading to more balanced predictions and a higher mean F1.
Our proposed deep supervision loss aims to provide explicit training objectives for each branch, enhancing their independent feature learning capabilities and improving the discriminability and consistency of the fused features. As shown in the results table, applying deep supervision significantly impacts performance. With deep supervision, we observe consistent improvements across all three metrics: 1.1% in accuracy, 1.7% in mean accuracy, and 2.7% in mean F1-score.
Table 4 summarizes the classification performance under different training hyperparameters. The proposed method achieves the best overall performance, with an accuracy of 0.9883, precision of 0.9348, and recall of 0.9431. When varying the learning rate, both higher (0.001) and lower (0.00001) settings lead to a decline in performance compared to the default configuration, indicating the effectiveness of the chosen learning rate. In addition, we conducted a control experiment by disabling data augmentation. The results show that, without augmentation, the model’s accuracy slightly drops to 0.9816, and mean F1 decreases to 0.9269, suggesting that data augmentation contributes positively to generalization performance.
4.4. Visualization of Feature Distribution
To further visualize the feature distribution learned by the model, we sampled correctly predicted instances from the test set and applied UMAP (Uniform Manifold Approximation and Projection) to project their high-dimensional features into a two-dimensional space. We then plotted the resulting feature visualization, where each point represents a sample. The color and shape of each point correspond to its class label, and the center of each class is marked with an “X”, indicating the central position of that class in the feature space.
This section presents the feature distributions of six models, including four commonly used baseline classification models, one variant of the proposed method without deep contrastive supervision, and the complete method proposed in this study. The comparative analysis, as illustrated in
Figure 5, demonstrates that the proposed complete method substantially outperforms the other models in terms of feature distribution. Specifically, the features extracted by this method form more compact clusters within each class, exhibit clearer inter-class boundaries, and show fewer misclassified or overlapping samples in the two-dimensional embedding space, indicating enhanced class separability and discriminative capability.
In contrast, the variant of the proposed method without deep contrastive supervision exhibits inferior feature distribution compared to several baseline models. This phenomenon can be primarily attributed to the three-branch network architecture being optimized solely with a single cross-entropy loss, which poses challenges for effective convergence of certain branches during training and consequently results in suboptimal feature learning. The introduction of deep contrastive supervision markedly improves the feature distribution, yielding more distinct and tighter category clusters with reduced intra-class variance. These findings substantiate that deep contrastive supervision facilitates the learning of more robust and discriminative feature representations, thereby effectively enhancing the model’s classification performance.
5. Conclusions
In this study, a three-branch image classification framework, TBNet, was proposed to identify liquid states in PTFE coagulation reactors. Built on data collected from real-world production environments at a major fluorochemical manufacturer in China, TBNet effectively distinguishes subtle liquid-phase transitions and bottom-material distributions, supporting more intelligent process monitoring.
TBNet integrates two key components: a Multi-Scale Frequency Attention (MSFA) module and a deep supervision strategy based on supervised contrastive learning. The MSFA module enhances channel feature representation by incorporating multi-scale frequency-domain information via 2D-DCT, enabling the network to better distinguish semantic structures and fine-grained patterns. The supervised contrastive deep supervision strategy injects semantically meaningful learning signals into intermediate layers, improving both inter-class separability and intra-class compactness. Compared to conventional training with cross-entropy loss, this design leads to more robust and discriminative feature learning. The experimental results show that our approach achieves an average F1-score improvement of 8% over the baseline methods.
Finally, the proposed method has been successfully validated in real-world industrial environments. It enables accurate and timely recognition of key process states, reduces manual intervention, lowers labor costs, and improves production efficiency. By combining multi-scale attention with contrastive supervision, the model effectively handles complex and noisy industrial data, paving the way for more intelligent and automated control in chemical manufacturing. These contributions demonstrate both methodological innovation and practical value, offering a scalable and adaptable deep learning solution for industrial visual classification tasks.
Despite the promising results, some limitations remain. First, the current model operates on inputs with fixed resolutions, which lack theoretical guarantees of optimality across varying visual scales. Future work could investigate adaptive scaling mechanisms to better handle scale variations in real-world scenes. Second, the model does not incorporate temporal modeling, even though the transitions between liquid states in PTFE production are inherently time-dependent. Integrating temporal information, such as through recurrent or transformer-based architectures, may further enhance the model’s ability to capture dynamic changes, thereby improving performance and robustness in complex process environments.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}