1. Introduction
In modern manufacturing systems, the steel strip serves as a fundamental product of the metal industry, with extensive applications in construction, automotive engineering, high-end machinery, aerospace, and electronic packaging [
1]. As precision manufacturing, intelligent production, and high-end equipment technologies advance, market demands for surface quality, safety, stability, and consistency of steel strip products have risen markedly [
2]. During the production process, interactions among the metallurgical organization of raw materials, rolling parameters, and variations in ambient lighting often give rise to surface defects such as cracks, delamination, scratches, and pitting [
3,
4]. These defects not only increase the cost of subsequent heat treatment and coating processes but also compromise the reliability of end products. Consequently, steel strip defect detection is critical for enhancing product quality and manufacturing efficiency.
Since the late twentieth century, both academia and industry have proposed various steel strip defect detection techniques, encompassing traditional approaches such as infrared thermography and magnetic flux leakage detection [
5,
6,
7]. Despite their widespread adoption, these techniques frequently suffer from high detection costs, limited coverage, and inadequate real-time performance. With rapid progress in computer vision, deep learning, and edge computing, real-time visual detection systems based on object detection have emerged as the mainstream solution [
8,
9].
Object detection is a longstanding research area within computer vision. Prior to the widespread adoption of deep learning, detection frameworks primarily relied on image processing and traditional machine learning methods. Existing research can be categorized into three main types. First, image processing methods that extract handcrafted features have been used to capture low-level surface defect cues [
10,
11,
12,
13]. Second, traditional signal-processing techniques based on frequency-domain and statistical feature extraction have been applied to characterize defect signals [
14,
15,
16]. Third, classical machine learning algorithms—including decision trees and autoregressive models—have been employed to classify defect types [
17,
18]. Although these approaches have yielded some improvements in metal surface defect detection, their reliance on handcrafted features renders them sensitive to variations in lighting and background noise, and their shallow representations limit robustness in complex industrial scenarios. As a result, despite numerous proposed models, the practical deployment of such methods remains constrained [
19].
Recent years have witnessed the emergence of deep learning as a powerful tool for metal surface defect detection, propelled by breakthroughs in artificial intelligence and the ever-increasing computational capacity of GPUs [
20,
21,
22]. Convolutional neural networks (CNNs), with their ability to perform end-to-end feature extraction, have set new benchmarks in object detection and image classification, garnering extensive research interest [
23,
24,
25,
26]. To date, numerous studies have explored the application of deep learning techniques for the detection of surface defects in metals. Li et al. [
27] proposed a steel surface defect detection model that integrates image enhancement strategies with a dense multi-backbone network. Compared to the then-popular YOLOv5s model, their approach achieved a 7.4% improvement in mAP
50. However, the model’s complexity far exceeded that of YOLOv5s, leading to poor real-time performance. Lin et al. [
28] designed a multi-scale cascaded CNN based on the lightweight MobileNet-v2 architecture, significantly reducing model complexity, but with negligible improvements in detection accuracy. Zhou et al. [
29] introduced the CSPlayer and reparameterized GAM attention mechanisms into the YOLOv5s framework to enhance detection accuracy for steel surface defects. Despite a slight 1.4% improvement in mAP
50, the increased model complexity undermined its practical applicability. Zhang et al. [
30] incorporated the lightweight GSConv and attention mechanisms into YOLOv5 to create a more efficient steel strip defect detection model. However, no significant accuracy improvements were observed, and inference speed was not notably enhanced. Li et al. [
31] proposed an enhanced YOLOv7 model, combining structures such as PConv and BiFPN to reduce the model’s FLOPs by 60%, thus effectively reducing the model’s weight while maintaining accuracy. However, no robustness testing was performed, leaving the model prone to overfitting. Zhou and Zhao [
32] extended the YOLOv8 framework by integrating multi-path convolutional attention (MPCA) and partial self-attention (PSA) units to optimize detection accuracy for steel surface defects. However, the increased model complexity was not sufficiently considered. Wu et al. [
33] optimized the YOLOv5n framework by introducing Ghost lightweight convolutions and attention mechanisms, achieving a good balance between model lightness and detection accuracy. Nevertheless, the model demonstrated poor robustness in experiments involving simulated environmental interference.
Although the aforementioned studies demonstrate advanced model performance compared to baseline models, an ideal balance between detection accuracy and inference efficiency in steel strip surface defect detection remains unachieved. Furthermore, many existing models are trained and evaluated on data collected in controlled laboratory environments, which fail to effectively address the real-world interference factors commonly encountered in industrial settings, such as overexposure and uneven lighting. In typical steel strip surface defect detection scenarios, the system must not only meet stringent robustness requirements but also possess high real-time capability. However, under these complex conditions, existing deep learning models often struggle to meet the dual demands of accuracy and speed, highlighting the urgent need for further optimization.
To address these challenges, this study proposes StripSurface-YOLO, a real-time steel strip surface defect detection method based on the YOLOv8n framework. This method significantly improves detection accuracy while maintaining a lightweight architecture and has been validated for stability through robustness testing. The proposed approach dramatically reduces model parameters and computational complexity without compromising detection performance, thus fully meeting the stringent requirements of online inspection systems in the metal forging industry. The key innovations presented in this paper are as follows:
- (1)
A GSResBottleneck module was designed by integrating GSConv lightweight convolutions with a one-shot aggregation strategy to form a cross-stage partial network (CSP) module called ResGSCSP. This design simultaneously elevates detection precision and curtails both computational burden and inference latency.
- (2)
An EMA mechanism was introduced before the SPFF (Spatial Pyramid Feature Fusion) layer to strengthen the model’s focus on critical features, improve feature representation and robustness, and further enhance robust object generalization across scales.
- (3)
Instead of conventional nearest-neighbor interpolation, DySample upsampling was integrated within the neck network to produce higher-fidelity feature maps, thereby enhancing the fusion of deep, multi-level features.
- (4)
Focal Loss was adopted as the loss function; by dynamically assigning weights to easy and hard samples, the model’s recognition accuracy for challenging defect samples and overall robustness were significantly improved.
- (5)
To evaluate robustness under production conditions, this study applied five types of data interference to the original dataset. The results indicate that StripSurface-YOLO maintains superior generalization capability, making it highly applicable to real-world steel strip manufacturing scenarios and effectively augmenting both quality control and throughput.
The structure of this paper is as follows:
Section 2 surveys existing research on the foundational YOLOv8 architecture, lightweight network designs, and multi-scale feature fusion techniques.
Section 3 details the dataset and elaborates on the proposed StripSurface-YOLO approach.
Section 4 describes the experimental methodology and presents the corresponding analyses. Finally,
Section 5 offers concluding remarks.
With reductions of 7.4% in FLOPs and 11.6% in parameter count, StripSurface-YOLO demonstrates an improvement of over 4% in mAP50. Its lightweight architecture ensures robust performance under varying illumination and noise conditions.
2. Related Work
2.1. YOLOv8
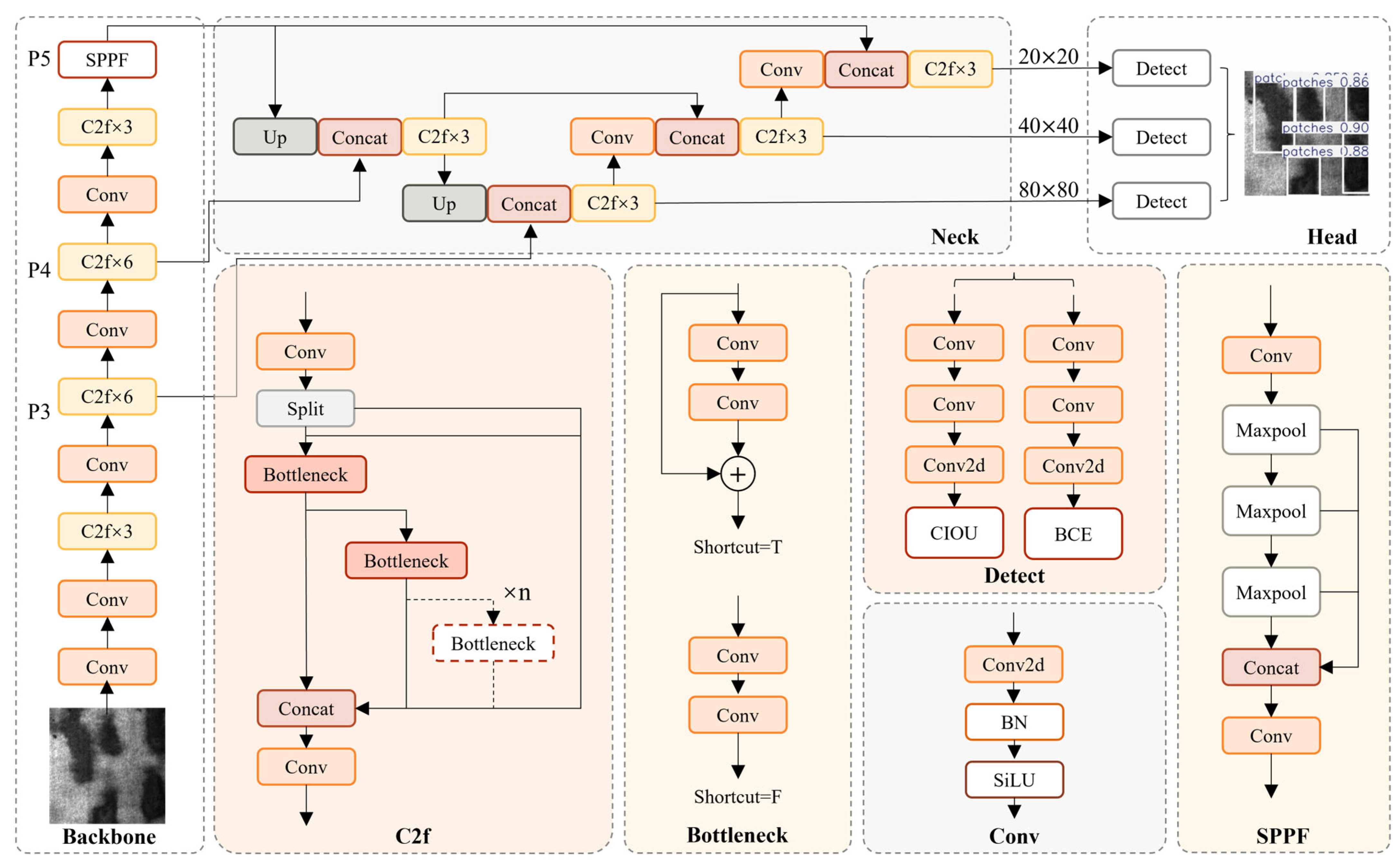
In this study, YOLOv8 adopts a modular architecture comprising three principal components—the backbone, neck, and head—that together achieve state-of-the-art performance in object detection tasks. The complete architecture is shown in
Figure 1.
Backbone: This module is tasked with extracting multi-scale features, including shallow, intermediate, and deep representations. After fusion in the neck, these feature maps are forwarded to the head for the detection of large, medium, and small targets. YOLOv8 employs CSPDarknet53 as its backbone and optimizes the C2F (“CSP2-Fast”) module by reducing the original three convolutional layers to two, thereby lowering computational complexity. The C2F module leverages gradient connections across feature layers, halving the feature channels relative to the previous stage; this design both reduces FLOPs and enhances representational capacity. In addition, YOLOv8 uses the CBS (Conv2D-BatchNorm-SiLU) block as its basic unit: Conv2D performs two-dimensional convolution, BatchNorm provides regularization, and SiLU serves as the activation function to strengthen feature expressiveness. Feature maps processed by CBS and C2F are then input into the SPPF (Spatial Pyramid Pooling-Fast) module. By employing slicing operations to reduce feature dimensionality, SPPF maintains the precision of the original SPP (Spatial Pyramid Pooling) while significantly decreasing computational overhead.
Neck: YOLOv8’s neck employs a PAN-FPN-based feature-fusion structure to enhance multi-scale information exchange. Compared to earlier YOLO versions, PAN-FPN omits the convolutional operation on upsampled feature maps within its PAN structure. Traditional FPNs construct feature pyramids via lateral connections, but the upsampling process often introduces blur and noise, which can degrade the semantic richness of high-level features. In contrast, PAN conducts both bottom-up and top-down information flow to fuse features at different scales, thereby improving detection accuracy and augmenting the model’s adaptability to targets of varying sizes and shapes.
Head: Within the detection head, YOLOv8 adopts a decoupled architecture that isolates category classification from bounding-box regression, thereby improving inference efficiency. Furthermore, this work replaces traditional IoU-based assignment and one-sided distribution with a task-aligned matching strategy and transitions from an anchor-based to an anchor-free framework, further strengthening detection robustness.
2.2. Lightweight Network
Lightweight neural networks are engineered to enable efficient deployment in resource-constrained environments by minimizing both parameter count and computational overhead, while preserving high task performance. To further curtail computational demands in object detection while maintaining detection efficacy, researchers have developed various lightweighting techniques. One class of methods reduces the precision of network weights through quantization, thereby shrinking storage requirements and accelerating arithmetic operations (e.g., [
34]). Another approach prunes redundant channels or convolutional kernels to streamline network topology and optimize computation. For example, Wu et al. [
33] introduced a CGH lightweight C3 structure built on YOLOv5n to create an efficient steel surface defect detection framework, albeit with a modest decline in accuracy. Liu et al. [
35] combined dilated convolutions with an attention module and multi-scale pooling to enrich semantic encoding. MADNet [
36] leverages dense connectivity to strengthen multi-scale feature representation and correlation learning. Su et al. [
25] integrated GhostConv with a one-shot aggregation paradigm within a CSP module to significantly reduce model complexity. Liang et al. [
2] propose LAD-Net, a compact ultrasonic-welding defect detector that incorporates SAM-Conv into a lightweight stride-attention module (LSAM), reducing model complexity while preserving fine-grained defect details. Lu and Qu [
37] replaced YOLOv8’s downsampling with SPD-Conv, integrated a CBAM module into the backbone, and substituted the neck’s C2f with a C2f-Ghost module, thereby lightening the model while maintaining its performance. However, these approaches predominantly focus on compressing pretrained networks or training small-scale models from scratch, which can unbalance overall performance.
To address these limitations, the present study introduces GSResBottleneck and ResGSCSP modules—both built upon the GSConv operator—to construct the StripSurface-YOLO detection model. The proposed design achieves substantial reductions in computational complexity and inference latency while safeguarding detection precision, thereby delivering an enhanced solution for lightweight object detection.
2.3. Attention Mechanism
This study recognizes that the attention mechanism—originating from insights into the human visual system and neural information processing—dynamically allocates computational resources according to the relative importance of input features and has attracted widespread interest in deep learning research. In recent years, this module has been successfully incorporated into various neural network architectures; by emphasizing the expression of critical information and suppressing redundant features, it has demonstrably enhanced model discriminative power and task sensitivity [
38]. Concurrently, the attention mechanism reduces network redundancy and increases robustness to noisy samples, thereby strengthening generalization performance on unseen data.
Standard neural architectures customarily ascribe equal significance to every input feature, subjecting them uniformly to subsequent layers. In contrast, real-world applications frequently depend on a critical subset of features for accurate inference; indiscriminate processing of the entire feature repertoire can squander computational resources, exacerbate overfitting, and impair model interpretability [
39]. In contrast, the attention mechanism assigns learnable weights to each feature, enabling the network to distinguish adaptively between critical and nonessential information. Visualization of these weight distributions further elucidates the model’s internal decision logic, guiding network-structure optimization and model tuning.
In computer vision, attention mechanisms allow models to emphasize image regions and feature channels most pertinent to the target class, markedly improving classification and detection accuracy. For instance, Zhou and Zhao [
32] embed a multi-path convolutional attention (MPCA) block into both backbone and bottleneck layers—via a C2f–MPCA module—and introduce partial self-attention (PSA) units in the backbone to capture long-range dependencies. This attention-centric design yields a significant boost in mean average precision with only a marginal increase in computation. Zhao et al. [
40] introduce HSC-YOLO, which augments the YOLOv10n backbone by replacing the neck’s dual concatenation operations with an SDI module to strengthen multi-scale feature fusion, and by integrating iterative attentional feature fusion (iAFF) alongside C2f.
Overall, through refined feature selection and targeted information filtering, attention mechanisms not only improve deep-model efficacy across a variety of tasks but also pave the way for enhanced interpretability and reduced computational overhead. As such, they have emerged as a central focus of contemporary deep learning research.
3. Methodology
3.1. StripSurface-YOLO Object-Detection Model
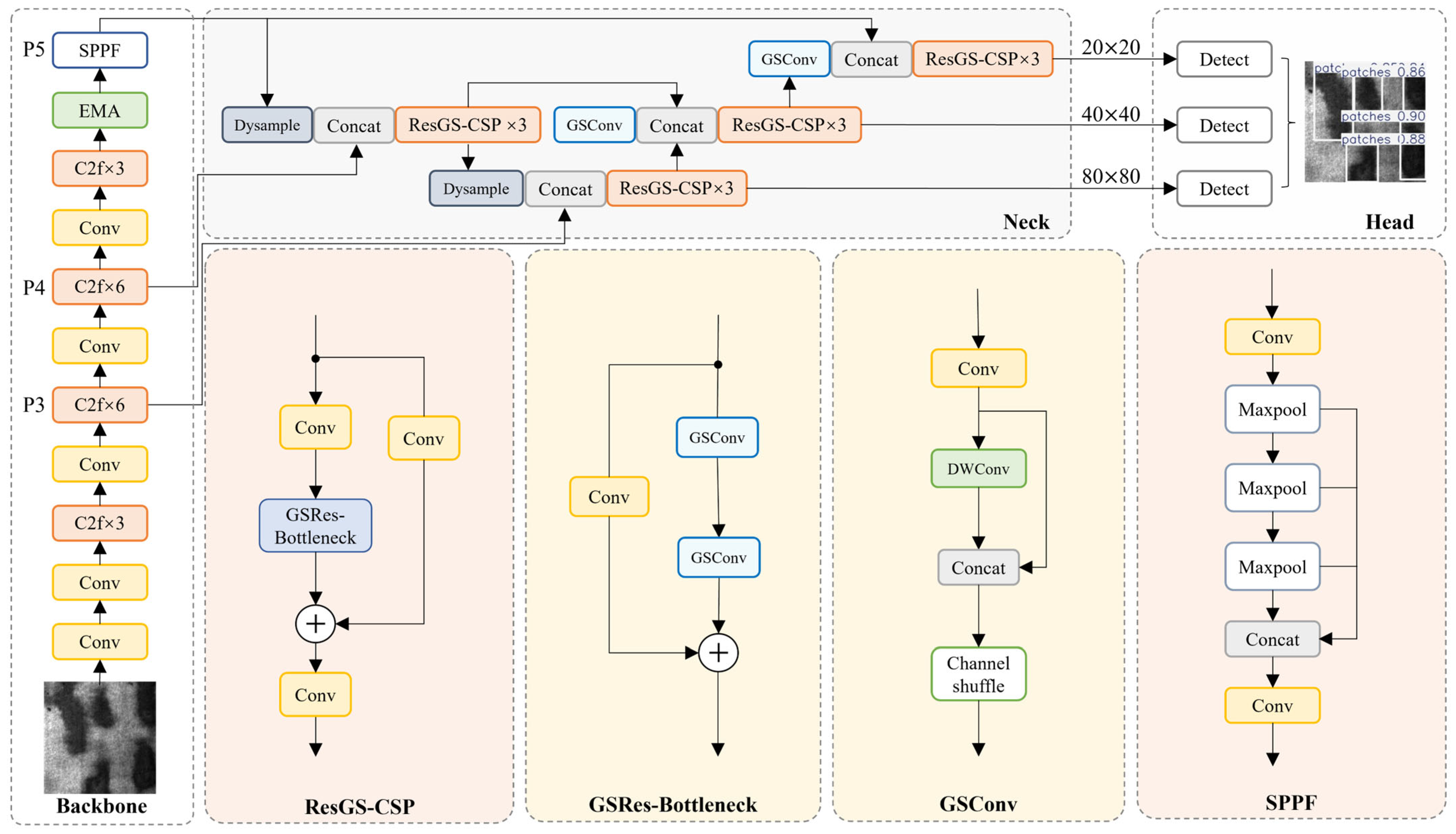
In strip surface defect detection tasks, YOLOv8n—despite its lightweight design—continues to exhibit limitations in detection accuracy and insufficient sensitivity to minute defects. To address these challenges, this study builds upon the YOLOv8n framework to propose an improved object-detection network—StripSurface-YOLO—combining high precision with a streamlined architecture; its overall structure is shown in
Figure 2.
An Efficient Multi-Scale Attention (EMA) module is incorporated into the neck immediately upstream of the SPPF stage, thereby sharpening the network’s focus on salient feature regions, enhancing representational robustness, and improving cross-scale detection fidelity. To further elevate feature-map quality and enhance the distinction of overlapping wear-type defects during fusion, this study replaces the conventional nearest-neighbor interpolation with a lightweight DySample upsampling method. In the loss-function design, Focal Loss is employed: by dynamically assigning distinct weights to easily classified and challenging samples, the model’s sensitivity to difficult defect instances and overall detection robustness are significantly enhanced.
Furthermore, this study introduces a GSResBottleneck residual block built upon GSConv, combined with a one-shot aggregation paradigm, to realize an efficient cross-stage partial (CSP) module, termed ResGSCSP. This configuration markedly reduces computational complexity while preserving detection accuracy, thereby enabling lightweight feature extraction and efficient information fusion.
Figure 2 depicts the complete network architecture of StripSurface-YOLO.
3.2. Design of the ResGS-CSP Architecture Based on GSConv
3.2.1. GSConv
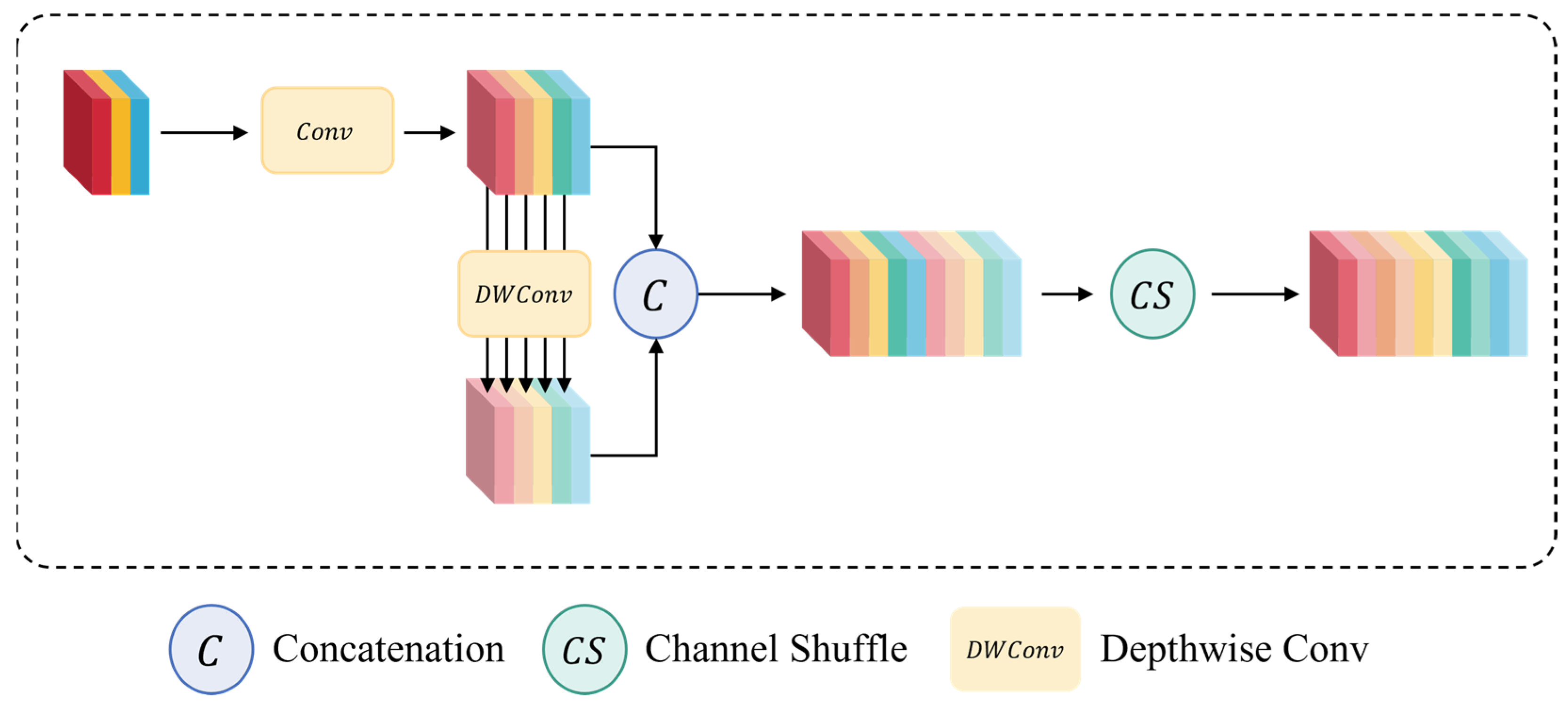
In the backbone network of YOLOv8n, this study introduces a novel convolutional operation—GSConv—to replace the standard convolution (SC) layers, thereby optimizing overall network performance. In conventional CNN architectures, an input image undergoes successive transformations that map spatial information into channel space. However, this process invariably sacrifices some semantic information, and standard convolutions incur substantial computational overhead that increases dramatically as model size grows, leading to slower inference. By contrast, depthwise-separable convolutions (DSCs) reduce complexity by processing each channel independently, but at the cost of somewhat diminished feature-extraction and fusion-capabilities compared with SC, which can limit representational power.
GSConv achieves an effective compromise between computational efficiency and expressive capacity by integrating SC and DSC within a single module. Specifically, GSConv retains implicit connections between channels while roughly halving the computational cost of standard convolution. As illustrated in
Figure 3, GSConv first applies grouped shift operations to redistribute spatial information across channels, and then employs a pointwise (1 × 1) convolution to fuse those shifted features. This combination preserves nearly the same feature-learning ability as SC but reduces FLOPs by approximately 50%.
3.2.2. ResGSCSP Structure
Building upon GSConv’s low-cost yet effective feature-generation properties, this study proposes a GSResBottleneck module (
Figure 4a) and further integrates it with a cross-stage partial (CSP) design to form the ResGSCSP block (
Figure 4b). Within GSResBottleneck, a dual-branch bottleneck structure is adopted. One branch performs lightweight feature mapping via GSConv, while the other implements identity mapping; these two branches are fused through a residual connection.
This residual design not only preserves feature-learning capacity but also mitigates gradient vanishing and explosion during deep network training, as expressed by
where
and
denote the input and output of the residual block, and
comprises a sequence of GSConv operations, activation functions, and normalization layers.
To further enhance nonlinearity and accelerate inference without incurring additional computational cost, this study incorporates one-shot aggregation into a CSP framework, yielding the ResGSCSP module. This specific fusion was motivated by the complementary strengths of GSConv and one-shot aggregation: GSConv’s channel-wise grouping and depthwise–pointwise factorization drastically reduce redundant computation, while one-shot aggregation maximizes information flow across parallel feature streams, together delivering richer representations at minimal cost. After channel grouping, multiple layers of GSConv extract features from each group in parallel; these groupwise features are then concatenated and fused via a 1 × 1 pointwise convolution. Compared with traditional CSP, ResGSCSP leverages GSConv’s low-cost characteristics to significantly improve the network’s expressive power and inference speed without increasing parameter count.
In summary, by inheriting GSConv’s efficient feature-generation advantage and carefully designing residual-based and cross-stage information flows, the GSResBottleneck and ResGSCSP modules achieve an optimal balance of lightweight architecture and high precision. This design provides robust technical support for online detection of surface defects in steel strip manufacturing.
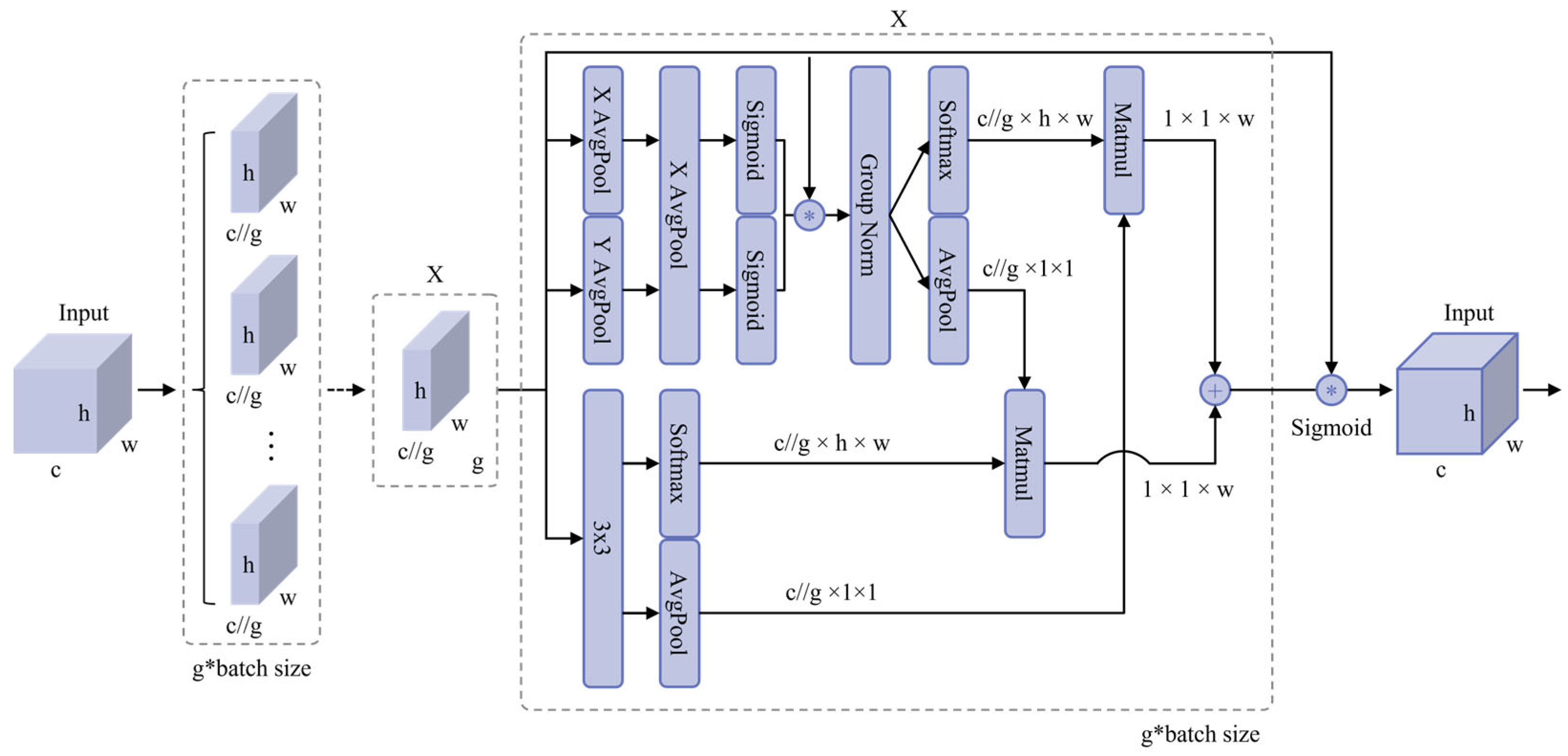
3.3. Efficient Multi-Scale Attention (EMA)
In steel strip surface defect detection tasks, the model must capture detailed features of defects at varying scales while simultaneously preserving global semantic context to avoid overreliance on convolutional translation invariance that can lead to contextual neglect [
41]. To address these requirements, this study incorporates the EMA mechanism [
42]. EMA achieves efficient extraction and fusion of multi-scale features through a combination of channel reshaping and cross-spatial learning strategies, thereby significantly reducing both computational and memory overhead.
Let the input feature-map tensor be
, where
,
, and
denote the number of channels, height, and width, respectively. EMA first partitions
along the channel dimension into
groups of sub-features:
Next, the module constructs three parallel multi-scale feature-extraction paths: two 1 × 1 convolution branches (each combined with one-dimensional average pooling along either the horizontal or vertical axis) and one 3 × 3 convolution branch. Specifically,
- ➢
Each 1 × 1 convolution branch preserves the number of channels and employs global one-dimensional pooling (horizontal or vertical) to capture long-range dependencies. Both branches share the same convolutional kernels to minimize parameter redundancy.
- ➢
The 3 × 3 convolution branch enhances local spatial information while interleaving channel interactions to expand feature dimensionality.
The outputs of all three branches are then encoded via two-dimensional global average pooling:
Subsequently, spatial attention weights are generated through a Softmax-based linear combination of these pooled features. In this way, while keeping the total channel count constant, features corresponding to small- or medium-scale defects—often difficult to distinguish—are assigned higher response weights.
As shown in
Figure 5, EMA’s carefully designed channel grouping and cross-spatial learning enable efficient perception and collaborative enhancement of features across scales. Compared with traditional deep convolutional networks, this mechanism maintains computational efficiency while markedly improving detection of subtle surface defects, such as microcracks and pits. Consequently, EMA provides a reliable and lightweight attention solution for industrial online defect detection systems.
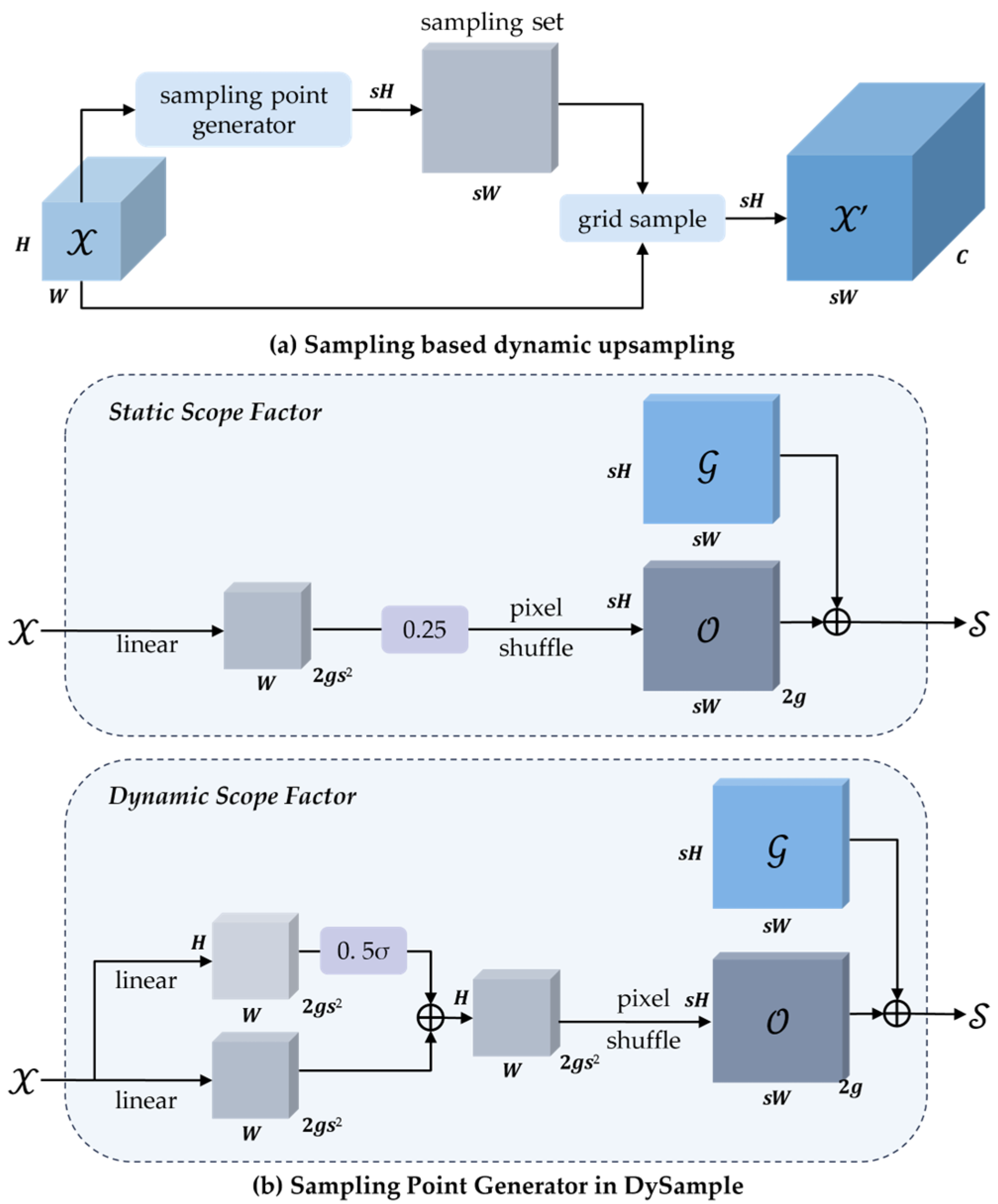
3.4. DySample Upsampling
In contemporary convolutional neural network frameworks, upsampling of feature maps constitutes a core operation whereby coarse, low-resolution activations are transformed into fine-grained, high-resolution representations, thereby enhancing the network’s ability to discern subtle patterns and local structures. Two mainstream upsampling strategies currently prevail. The first employs interpolation methods—such as nearest-neighbor or bilinear interpolation—which are widely used in subpixel space but fail to capture semantic richness, often resulting in feature degradation. The second approach utilizes transposed convolution (“deconvolution”) to expand spatial dimensions through learned convolutional kernels. However, transposed convolution applies identical kernels uniformly across the feature map, limiting responsiveness to local variations, compromising fine-detail preservation, and increasing parameter overhead.
In steel strip defect detection, diminutive flaws—such as pores, tiny pits, and microcracks—may be concealed by pixel-level distortions. To address this challenge, this study introduces a dynamically adaptive, sampling-based upsampling module—DySample—within the YOLOv8 framework, replacing the conventional UpSample operation. DySample improves responsiveness to minute defects while preserving the lightweight nature of the model.
At the core of DySample lies a combination of learned offset generation and coordinate-based bilinear interpolation. Let
be the input feature map, and let the upsampling scale factor be
. First, a linear projection maps the
channels of
to generate an offset tensor
of shape
:
Next, the PixelShuffle operation rearranges
into a coordinate-offset field of dimensions
. With the regular sampling grid denoted as
, the dynamic sampling grid
is obtained by elementwise addition of
to
:
Finally, DySample performs bilinear interpolation on
using the learned coordinate offsets
, producing the upsampled feature map
:
By learning pixel-level offsets, DySample amplifies regions containing small defects without requiring computationally expensive dynamic convolutions, thereby substantially reducing resource consumption. In steel strip surface defect detection, DySample preserves defect edges and texture information more effectively than conventional interpolation methods, improving the detector’s accuracy on small, low-contrast anomalies while maintaining real-time performance. The network architecture of DySample is illustrated in
Figure 6.
3.5. Focal Loss
The loss function plays a pivotal role in model optimization, affecting both training efficiency and ultimate performance. In steel strip surface defect detection tasks, the classification difficulty varies across defect types, and certain easily confounded samples can impede training. To increase emphasis on hard-to-classify instances, this study incorporates a dynamic modulation factor into the conventional multi-class cross-entropy loss, thereby diminishing the gradient contribution of well-classified samples and enhancing overall detection accuracy.
The standard cross-entropy loss is defined as
where
denotes the model’s predicted probability for class
, and
represents the corresponding ground-truth label.
Focal Loss extends this by introducing a modulation term
, which directs the network’s attention toward low-confidence—and thus more difficult—examples during training. Formally, Focal Loss is expressed as
where
is a tunable hyperparameter. For a misclassified sample,
is small, causing
to approach unity, thus making the Focal Loss functionally equivalent to the standard cross-entropy loss. Conversely, when processing easily classified instances with high
values, this modulation term diminishes toward zero, substantially suppressing their influence on the total loss. As
increases, the network’s focus on hard-to-classify samples intensifies, which benefits the recognition of subtle defect features and confusable cases in steel strip surface defect detection.
4. Experimental Findings and Discussion
4.1. Description of the Dataset
To assess the proposed StripSurface-YOLO framework, this study utilizes the NEU Surface Defect Detection benchmark (NEU-DET) as the primary evaluation corpus. NEU-DET encompasses six quintessential classes of steel surface anomalies, with each category comprising 300 gray-scale images at a uniform resolution of 200 × 200 pixels, summing to 1800 total samples.
The dataset is partitioned into training and test subsets in an 80:20 ratio: the training set is used for model parameter optimization and loss minimization, while the test set assesses classification performance in the surface defect recognition task.
Figure 7 presents exemplary images of the several defect categories from the dataset.
4.2. Evaluation Metrics for Experiments
4.2.1. Precision and Recall
Precision (
) reflects the fraction of correctly predicted positive instances among all instances labeled as positive by the model. It is expressed as
Recall (
) indicates the fraction of actual positive instances that the model correctly identifies. It is given by
where
TP denotes true positives,
FP false positives, and
FN false negatives.
4.2.2. mAP50 and mAP50:95
Mean average precision (mAP) represents the area beneath the precision–recall curve. For an individual class, the average precision (AP) is defined as
where
represents precision as a function of recall. The mean average precision over
classes is then
In this study, mAP50 denotes the mAP calculated at a single Intersection over Union (IoU) threshold of 0.50. By contrast, mAP50:95 provides a more stringent evaluation by averaging AP over multiple IoU thresholds, ranging from 0.50 to 0.95 in increments of 0.05.
4.2.3. Parameter Count, Computational Complexity, and Inference Throughput
The aggregate count of trainable parameters—including every weight and bias in the network—provides a direct measure of the model’s memory footprint and its representational capacity. In practice, architectures with larger parameter budgets incur greater storage overhead and typically demand longer durations for both training and inference.
FLOPs quantify the model’s computational complexity; a lower FLOP count indicates faster runtime. For a convolutional layer, FLOPs are calculated as follows:
When the spatial dimensions of input and output match and only pointwise convolutions are considered, this simplifies to
where
and
denote the numbers of input and output channels;
is the convolutional kernel size; and
and
represent the width and height of the output feature map.
Inference throughput is measured in frames per second (FPS), indicating how many images the model can process within one second—an essential metric for applications requiring real-time performance. In this work, FPS is obtained by averaging the per-image inference time over 300 test samples. Higher FPS values signify superior real-time suitability, making the model more viable for scenarios with stringent latency constraints.
4.3. Experimental Setup and Parameter Initialization
Computational evaluations were carried out on a Windows 10-based workstation using PyCharm 2024.1 (Professional Edition) as the development environment. The deep learning stack comprised CUDA 12.4, Python 3.11.0, and PyTorch 2.5.1. The hardware configuration included an NVIDIA RTX 4090D GPU with 24 GB of VRAM and an AMD Ryzen 9 7950X CPU clocked at 4.50 GHz. Detailed hyperparameter configurations are provided in
Table 1.
4.4. Model Performance Assessment
To demonstrate the merits of StripSurface-YOLO, this study conducted a comparative analysis against the baseline YOLOv8n model, with the results summarized in
Table 2.
Evaluation on the test set reveals that StripSurface-YOLO requires 11.6% fewer floating-point operations and 7.4% fewer parameters than YOLOv8n, while achieving improvements of 1.4% in precision, 3.1% in recall, 4.1% in mAP50, and 3.0% in mAP50:95.
To further elucidate StripSurface-YOLO’s defect detection capabilities, this study presents qualitative comparisons on representative test images (
Figure 8). As shown in
Figure 8, the baseline YOLOv8n model exhibits both missed detections and false positives when confronted with subtle defects, particularly cracks (Cr), patches (Pa), and rolled-in scale (Rs). In contrast, StripSurface-YOLO demonstrates enhanced robustness, effectively mitigating detection errors and exhibiting superior defect recognition performance.
4.5. Investigation of Attention Mechanism Effects
To rigorously evaluate the efficacy of the EMA mechanism for detecting surface defects on strip steel, this study replaced the lightweight YOLOv8n backbone with one of five alternative modules and conducted comparative experiments under an identical dataset and training regimen. CA integrates spatial coordinate encoding with channel-wise perception, thereby establishing pixel-level positional dependencies that improve localization accuracy over defect regions. SE leverages global channel statistics to adaptively recalibrate channel weights, mitigating information loss due to uneven inter-channel responses. NonlocalBlockND computes similarity between any two feature locations via nonlocal operations, enabling global context modeling of long-range dependencies; however, its high-order affinity computations incur substantial overhead on high-resolution feature maps. CBAM sequentially applies two attention submodules—first performing global average and max pooling to refine channel allocation, and then compressing across channels to highlight critical spatial regions, which can enhance detection performance but is less favorable for real-time deployment and resource efficiency compared to EMA’s lightweight design. SCSA combines spatial and channel interaction with multi-scale semantic fusion to balance local detail and global context, though its multi-branch architecture increases network complexity.
As shown in
Table 3, the overall detection performance of the model reaches its peak with the incorporation of the EMA mechanism into the baseline YOLOv8n framework. Compared to the original YOLOv8n, the EMA-enhanced model achieves precision (P), recall (R), mAP
50, and mAP
50:95 scores of 69.5%, 72.5%, 76.4%, and 43.2%, respectively, with the latter three metrics representing the highest performance among all configurations. Although the precision of the EMA model is marginally lower than that achieved by a few alternative attention mechanisms, it demonstrates an optimal trade-off between recall and precision, thereby significantly improving the model’s robustness in defect detection tasks. Moreover, the integration of EMA does not incur a substantial increase in FLOPs or parameter count, underscoring the mechanism’s efficacy in enhancing detection performance while maintaining a lightweight architecture—an essential attribute for practical deployment in steel strip surface defect inspection.
4.6. Findings from Ablation Studies
To systematically evaluate the contribution of each improved module to the strip steel surface defect detection task, a series of ablation experiments was conducted based on the lightweight YOLOv8n architecture (
Table 4). Model 0 serves as the baseline YOLOv8n, and subsequent models incrementally incorporate EMA, DySample, ResGSCSP, and Focal Loss to quantify the impact of each component on detection performance, computational complexity, and parameter footprint.
The ablation results in
Table 4 reveal the following key findings:
- (1)
Effectiveness of the EMA Module: The integration of the EMA module substantially augments detection performance. EMA introduces a cross-spatial learning scheme in which a portion of the channel dimension is reinterpreted as additional batch samples, allowing these channel subsets to be processed concurrently. By combining this grouping strategy with 3 × 3 convolutions, EMA captures features at multiple spatial scales, enabling joint modeling of both channel and spatial dependencies. Its parallel subnetwork architecture applies multi-scale convolutions to the grouped sub-features, while a dynamic modulation mechanism strengthens object responses without incurring the dimensionality-reduction penalties typical of conventional attention methods. Additionally, EMA adopts a cross-spatial feature-aggregation strategy—leveraging lightweight decomposition and depthwise-separable convolutions—to reinforce the representation of fine steel strip defect details while simultaneously reducing computational complexity. Experimentally, the addition of EMA yields increases in precision (P), recall (R), mAP50, and mAP50:95 of 1.9%, 2.2%, 2.4%, and 2.4%, respectively, thereby validating EMA’s efficient feature-representation capabilities.
- (2)
Impact of the ResGSCSP Lightweight Branch: The ResGSCSP structure, based on GSConv, substantially reduced FLOPs (from 6.9 G to 6.0 G) and parameters (from 2.57 M to 2.32 M) while maintaining comparable detection performance. This demonstrates the module’s effectiveness in balancing accuracy with computational efficiency, which is crucial for deployment in resource-constrained industrial environments.
- (3)
Contribution of DySample: Upon integrating the DySample upsampling module, recall (R), mAP50, and mAP50:95 all show significant improvements—1.0%, 0.8%, and 0.7%, respectively—indicating that DySample’s dynamic upsampling mechanism and lightweight decomposition design boost multi-scale feature representation with only a marginal parameter overhead. Notably, recall (R) exhibits a slight decrease from 70.3% to 70.2%; this minor drop may be attributable to DySample’s lowered response threshold for edge-blurred regions or background noise when optimizing feature sensitivity. Nevertheless, from a holistic performance standpoint, DySample’s cross-scale feature-aggregation strategy combined with dynamic sampling-point partitioning effectively enhances detection robustness while preserving overall model efficiency.
- (4)
Impact of the Focal Loss: Substituting the original loss function with Focal Loss improved recall by 0.8%, mAP50 by 0.7%, and mAP50:95 by 0.6%, with only a marginal drop in precision (–0.5%). This indicates that Focal Loss enhances the model’s focus on hard-to-classify samples, particularly benefiting the detection of small or subtle defects, without increasing computational or parameter burdens.
- (5)
Combinatorial Optimization of Multiple Components: Various combinations of the above modules were tested, showing synergistic improvements in detection accuracy. These enhancements incurred only minimal increases in computational complexity and parameter count. Specifically, the incorporation of ResGSCSP produced consistent decreases in computational overhead while maintaining detection accuracy, thereby demonstrating the practicality of multimodule collaborative optimization for industrial defect inspection.
- (6)
Overall Performance of StripSurface-YOLO: The fully integrated model, termed StripSurface-YOLO, outperformed the baseline YOLOv8n in all metrics. It achieved a 1.4% increase in precision, 3.1% in recall, 4.1% in mAP50, and 3.0% in mAP50:95, while reducing FLOPs and parameters by 11.6% and 9.7%, respectively. These results underscore StripSurface-YOLO’s superior capacity to detect minute surface defects with high accuracy and efficiency, making it a compelling solution for real-time industrial inspection applications.
4.7. Comparison of Different Methods
Several object-detection models with a computational footprint comparable to YOLOv8n were chosen as baselines, including YOLOv3-tiny, YOLOv5n, YOLOv9t, YOLOv10n, and YOLO11n. Larger mainstream models (YOLOv3, YOLOv9c, and RTDETR-ResNet50) were also included to evaluate the performance advantages of StripSurface-YOLO. Additionally, representative enhanced models from recent research—SDD-YOLO and EcoDetect-YOLOv2—were introduced to further validate model advancement. Under consistent experimental settings, the training results for each model are presented in
Table 5.
As shown in
Table 5, StripSurface-YOLO, which maintains a lightweight profile (6.0 G FLOPs and 2.32 M parameters), achieves the highest mAP
50 (78.1%) and mAP
50:95 (43.8%). Although its precision and recall are not the highest among all evaluated models, it demonstrates a more balanced precision–recall trade-off at an extremely low computational cost.
Specifically, compared to models of similar scale—YOLOv8n, YOLOv9t, YOLO11n, and SDD-YOLO—EcoDetect-YOLOv2 exhibits superior detection performance. Relative to larger-scale models such as YOLOv5s, YOLOv8s, YOLOv9c, and RTDETR-ResNet50, StripSurface-YOLO remains leading in mAP metrics while reducing computational complexity by approximately 60–95%. Collectively, StripSurface-YOLO delivers superior overall detection performance with minimal computational overhead, thereby underscoring its efficiency and robustness.
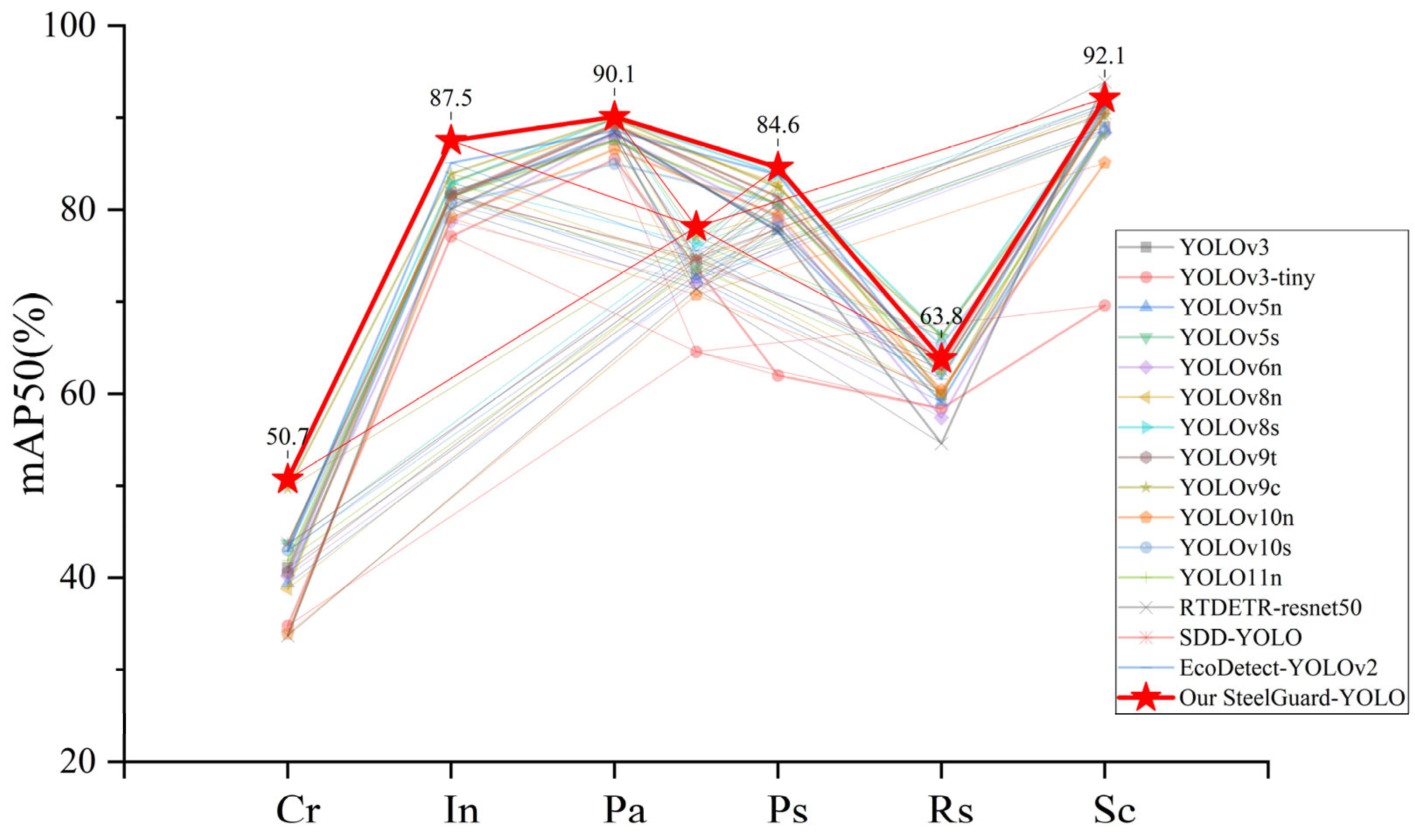
To evaluate the detection performance of StripSurface-YOLO across different defect types, this study conducted a comparative study against several representative object-detection models.
Table 6 summarizes the average precision (AP) values achieved by each model in six defect categories.
The results demonstrate that StripSurface-YOLO achieves the highest AP for four defect types—cracking (Cr), inclusion (In), patch (Pa), and pitted surface (Ps)—surpassing all other models by a considerable margin, especially for cracking and inclusion. For rolling oxide (Rs) and scratch (Sc), StripSurface-YOLO remains among the top-performing lightweight and mid-scale networks, thereby confirming its advantage in detecting both minuscule and structurally complex defects.
Figure 9 provides a visual comparison of per-category AP values and centroid distributions for each model, further highlighting StripSurface-YOLO’s overall superiority in the strip steel surface defect detection task.
In
Figure 9, each category’s AP and corresponding centroid visualization are displayed to offer an intuitive comparison of both aggregate and per-category performance. StripSurface-YOLO distinctly leads in overall detection capability and attains the highest AP in four key defect categories—cracking (Cr), inclusion (In), patch (Pa), and pitted surface (Ps)—illustrating its exceptional adaptability and robustness for multi-class surface defect detection.
4.8. Robustness Evaluation
In industrial settings, metal surface images are frequently degraded by various environmental factors—such as overexposure, insufficient illumination, and motion blur— which can significantly impede defect detection. To systematically assess the adaptability and robustness of the proposed StripSurface-YOLO model under such challenging conditions, this study applied five types of typical perturbations to the original dataset: a 50% increase in brightness, a 50% decrease in brightness, a 50% increase in contrast, a 50% decrease in contrast, and the addition of 5% Gaussian noise. A subset of the original images alongside their perturbed counterparts is illustrated in
Figure 10.
Table 7 reports the detection performance of the baseline YOLOv8n and our StripSurface-YOLO across each perturbed dataset.
Table 7 reveals the following key insights:
- (1)
Impact of Brightness Variations: In real industrial production environments, factors such as light occlusion and exposure instability frequently compromise the performance of strip steel surface defect detection systems. As shown in
Table 7, under substantial brightness reduction, both the proposed StripSurface-YOLO and the baseline YOLOv8n model suffer considerable performance degradation. Specifically, the mAP
50 of YOLOv8n drops sharply from 74.0% to 61.4%, a decrease of 12.6 percentage points, while StripSurface-YOLO exhibits a smaller decline from 78.1% to 67.4%, amounting to a reduction of 10.7 percentage points. When brightness is significantly increased, the performance impact on both models is marginal, with mAP
50 decreasing by only 3.5% and 3.0%, respectively. These results suggest that although StripSurface-YOLO is also affected under extreme illumination fluctuations—particularly under low-light conditions—it consistently maintains superior detection accuracy, demonstrating enhanced robustness and practical applicability in environments with variable lighting.
- (2)
Impact of Contrast Variations: In industrial settings, imaging contrast may deteriorate due to equipment aging, lens contamination, or dust accumulation on conveyor belts, whereas highly reflective stripes or background lighting may cause excessive contrast scenarios.
Table 7 indicates that when contrast is reduced by 50%, the mAP
50 of StripSurface-YOLO decreases modestly from 78.1% to 76.2%, a reduction of only 1.9 percentage points, whereas the baseline model suffers a larger drop of 2.5 percentage points. A similar trend is observed for the mAP
50:95 metric, where StripSurface-YOLO again exhibits a smaller decrease compared to the baseline (2.0% vs. 2.7%). Likewise, under a 50% increase in contrast, the mAP
50 reduction for StripSurface-YOLO is merely 1.4 percentage points, noticeably lower than the 1.8-percentage-point drop seen in YOLOv8n. These findings indicate that StripSurface-YOLO maintains greater stability in preserving discriminative defect features under severe contrast fluctuations caused by lens or lighting inconsistencies, effectively suppressing background texture interference under both low- and high-contrast conditions and ensuring more consistent detection performance.
- (3)
Impact of Gaussian Noise: In online strip steel inspection, factors such as sensor read/write errors, electromagnetic interference, and high-frequency vibrations can introduce additive Gaussian noise, leading to loss of image detail and texture blurring. After the introduction of 5% Gaussian noise, StripSurface-YOLO’s mAP50 drops only slightly from 78.1% to 77.0%, a reduction of 1.1 percentage points; in contrast, the baseline model suffers a larger decline of 2.2 percentage points. Similarly, in terms of the mAP50:95 metric, the performance degradation of StripSurface-YOLO is approximately 1.8%, which is also noticeably lower than the 2.1% decrease observed for the baseline. This comparison highlights the superior ability of StripSurface-YOLO to retain fine defect textures and edge features under noisy conditions, ensuring consistently high detection accuracy and exhibiting greater robustness and operational stability.
In summary, across various challenging scenarios involving substantial brightness and contrast variations as well as additive noise interference, StripSurface-YOLO consistently outperforms YOLOv8n in terms of detection precision, recall, mAP50, and mAP50:95. When aggregating results under all perturbation conditions, YOLOv8n shows average decreases of 4.5% and 4.1% in mAP50 and mAP50:95, respectively, whereas StripSurface-YOLO exhibits smaller corresponding reductions of approximately 3.6% and 2.4%. Overall, SteelGuard-YOLO not only demonstrates reduced performance fluctuation under noise and illumination disturbances but also achieves superior detection accuracy on perturbed images, even surpassing the baseline YOLOv8n’s performance on original, interference-free images. These results robustly validate the proposed method’s excellent robustness and generalization capability for online strip steel surface defect detection.
5. Conclusions
To address the challenge of poor model robustness in strip steel surface defect detection under complex industrial environments, this study proposes StripSurface-YOLO, a robust and lightweight real-time detection framework built upon the YOLOv8n architecture. The framework integrates a one-shot aggregation strategy and introduces an efficient cross-stage local network, ResGSCSP, constructed with the lightweight convolutional module GSConv, which substantially reduces both parameter count and computational complexity. Furthermore, an Efficient Multi-Scale Attention (EMA) mechanism is incorporated before feature fusion to enhance the model’s sensitivity to subtle and small-scale defects. In the neck network, the traditional nearest-neighbor interpolation is replaced with DySample upsampling, improving the quality of deep feature maps while accelerating inference speed. Additionally, Focal Loss is employed to dynamically adjust the weighting of easy- and difficult-to-classify samples, significantly boosting the model’s capability in detecting complex and minor surface defects. Experimental results demonstrate that, compared to the baseline YOLOv8n model, StripSurface-YOLO achieves reductions of 11.6% in computational load and 7.4% in parameter count, while delivering improvements of 1.4%, 3.1%, 4.1%, and 3.0% in precision, recall, mAP50, and mAP50:95, respectively. Under typical perturbations such as contrast variation, brightness fluctuation, and Gaussian noise—common in real-world industrial scenarios—the performance degradation of mAP50 and mAP50:95 remains limited to approximately 3.6% and 2.4%, respectively, validating the proposed method’s superior accuracy, real-time capability, and robustness in practical manufacturing environments.
To further advance the practical deployment of StripSurface-YOLO and close the gap between controlled experiments and real-world industrial applications, future work should pursue the following directions:
- (1)
Cross-Domain Generalization. Systematic pretraining on diverse, multi-source field datasets—encompassing different steel grades, rolling parameters, and operational environments—followed by targeted fine-tuning, will rigorously evaluate and enhance the model’s adaptability to unseen production conditions.
- (2)
Incremental and Continual Learning. The integration of online update strategies—such as self-supervised or weakly supervised incremental learning—will enable the detector to accommodate evolving production characteristics and emerging defect types, thereby preserving detection accuracy and reliability over extended operational periods.
- (3)
Multi-Modal Sensor Fusion. Fusing visual inputs with complementary data streams (e.g., infrared thermography, ultrasonic or acoustic emissions) promises to heighten sensitivity to subsurface anomalies and nascent defect signatures, particularly in scenarios of low illumination, surface occlusion, or complex background noise.
By addressing these research avenues, future efforts can extend the robustness, versatility, and autonomy of StripSurface-YOLO, ultimately facilitating the realization of fully adaptive, end-to-end inspection systems that satisfy the stringent throughput and quality requirements of modern steel manufacturing.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}