
SVRG-AALR: Stochastic Variance-Reduced Gradient Method with Adaptive Alternating Learning Rate for Training Deep Neural Networks


Abstract
1. Introduction
2. Related Work
| Algorithm 1. The fundamental structure of the SVRG algorithm |
| Input: N training samples. The maximum allowable iterations for the outer loop M. The maximum allowable iterations for the inner loop T. The learning rate α. Output: Optimal parameter w*. |
| 1: Initialize the parameter . 2: for k = 1, 2, …, M 3: 4: . 5: 6: for t = 1, 2, …, T 7: Randomly pick up a training sample ∈{1, 2, …, N}. 8: . 9: end for 10: 11: end for 12: . |
3. SVRG Algorithm with Adaptive Alternating Learning Rate
3.1. Adaptive Alternating Learning Rate
3.2. The SVRG-AALR Algorithm for Training DNN
| Algorithm 2. The SVRG-AALR algorithm framework for training DNN |
| Input: N training samples. The maximum number of iterations M (max epoch) for the outer loop. The maximum number of iterations T for the inner loop. Learning rate parameters , , . The combination coefficient , and mini batch size b. Output: The optimal weights of DNN. |
| 1: Initialize the weight variable of the DNN and let . 2: for k = 0, 1, …, M − 1 3: . 4: if k > 1 then 5: . 6: . 7: Calculate the learning rate by utilizing , , and Equation (17). Let . 8: end if 9: 10: for t = 0, 1, …, T − 1 11: Randomly select b samples to create the mini-batch sample set . 12: . 13: . 14: . 15: end for 16: 17: . 18: end for 19: . |
- (i)
- In the input parameters, and represent the learning rates utilized during the initial two iterations of the outer loop, expressed as constant values. The initial values of and are chosen from the interval (0, 1], for instance, setting . In subsequent iterations, the value of is updated at line 7.
- (ii)
- The second line defines the outer loop of SVRG, implementing the epoch loop in DNN training.
- (iii)
- The third line is the calculation of the full gradient of SVRG.
- (iv)
- Lines 5 to 7 detail the computation of the AALR learning rate, denoted as . It is important to emphasize that is determined in the outer loop and possesses a global characteristic. The parameters necessary for calculating , specifically and , are derived from T iterations conducted within the inner loop. Consequently, after computing , an average correction is applied through the formula to mitigate the positive correlation between and T.
- (v)
- Line 10 defines the inner loop of SVRG.
- (vi)
- Lines 11 and 12 calculate the mini-batch average gradient .
- (vii)
- The 13th line updates the DNN weights utilizing and .
- (viii)
- Line 14 corrects and aggregates the average gradient of the mini-batch to derive a gradient with reduced variance, which is subsequently fed back into the outer loop for calculating the new learning rate. The selection of mini-batch samples is conducted randomly, introducing variability in the gradient as a result. To mitigate the adverse effects stemming from this randomness, line 14 implements inertial correction and aggregation on . In motion dynamics, an inertial effect is observed; leveraging this characteristic allows for utilizing historical gradients as an inertial component to adjust through a linear convex combination approach. This strategy effectively diminishes the variance in gradients induced by the stochastic nature of the mini-batch. When and are aligned in the same direction, their linear combination enhances the gradient and accelerates convergence. Conversely, when and are oriented in opposite directions, this linear combination mitigates the influence of the opposing gradient from , thereby reducing oscillations. The combination coefficient is a scalar value within the interval (0, 1], with one suggested method for its determination being to set it as 4/T, where . Upon completion of the inner loop iteration, the aggregated gradient is then relayed back to the outer loop.
- (ix)
- Lines 16 and 17 transfer the newly obtained weights from the inner loop back to the corresponding variables of the outer loop. This enables the outer loop to compute the full gradient and determine the learning rate .
3.3. Convergence Analysis of SVRG-AALR Algorithm
4. Results
4.1. Experimental Setups
4.1.1. Datasets
4.1.2. DNN Models
4.1.3. Comparative DNN Optimizers
4.1.4. Evaluation Indicators
4.2. Experimental Results and Analysis
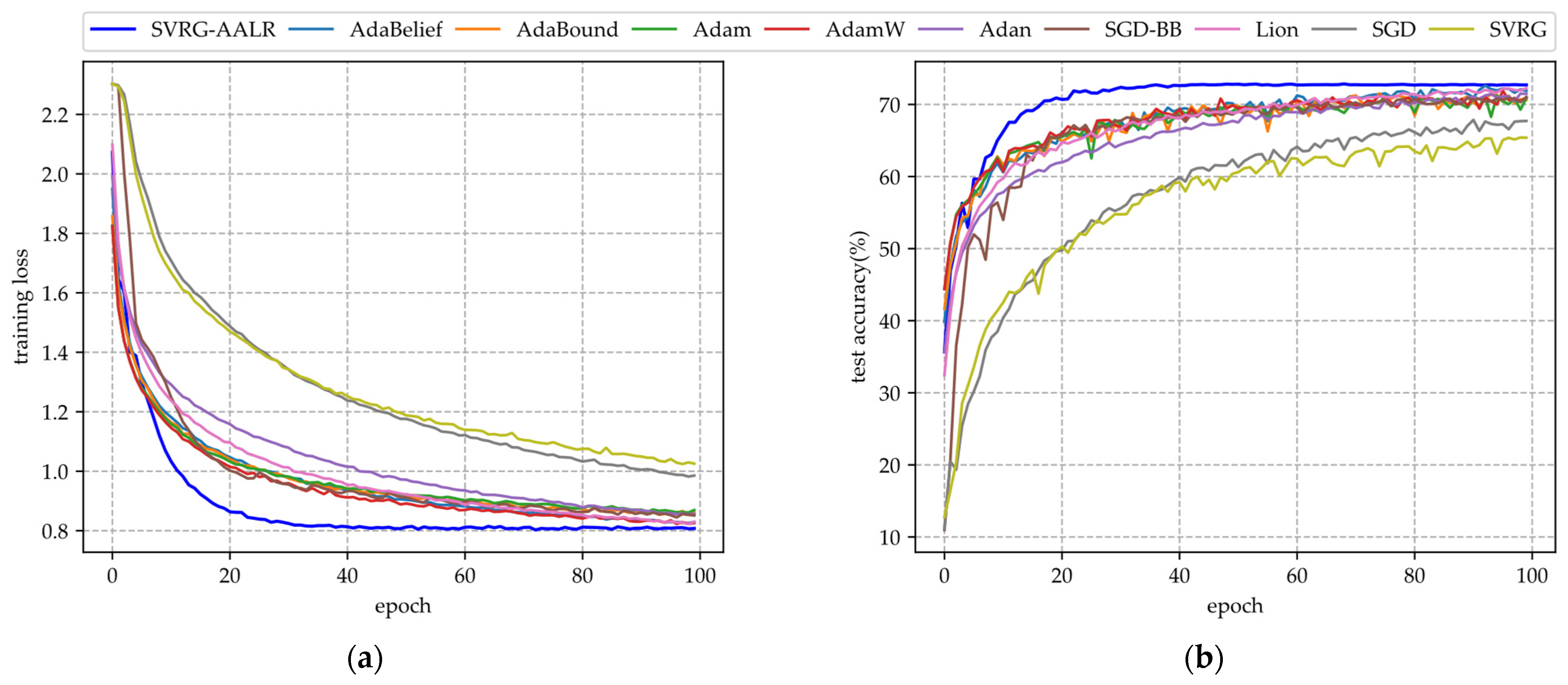
- (i)
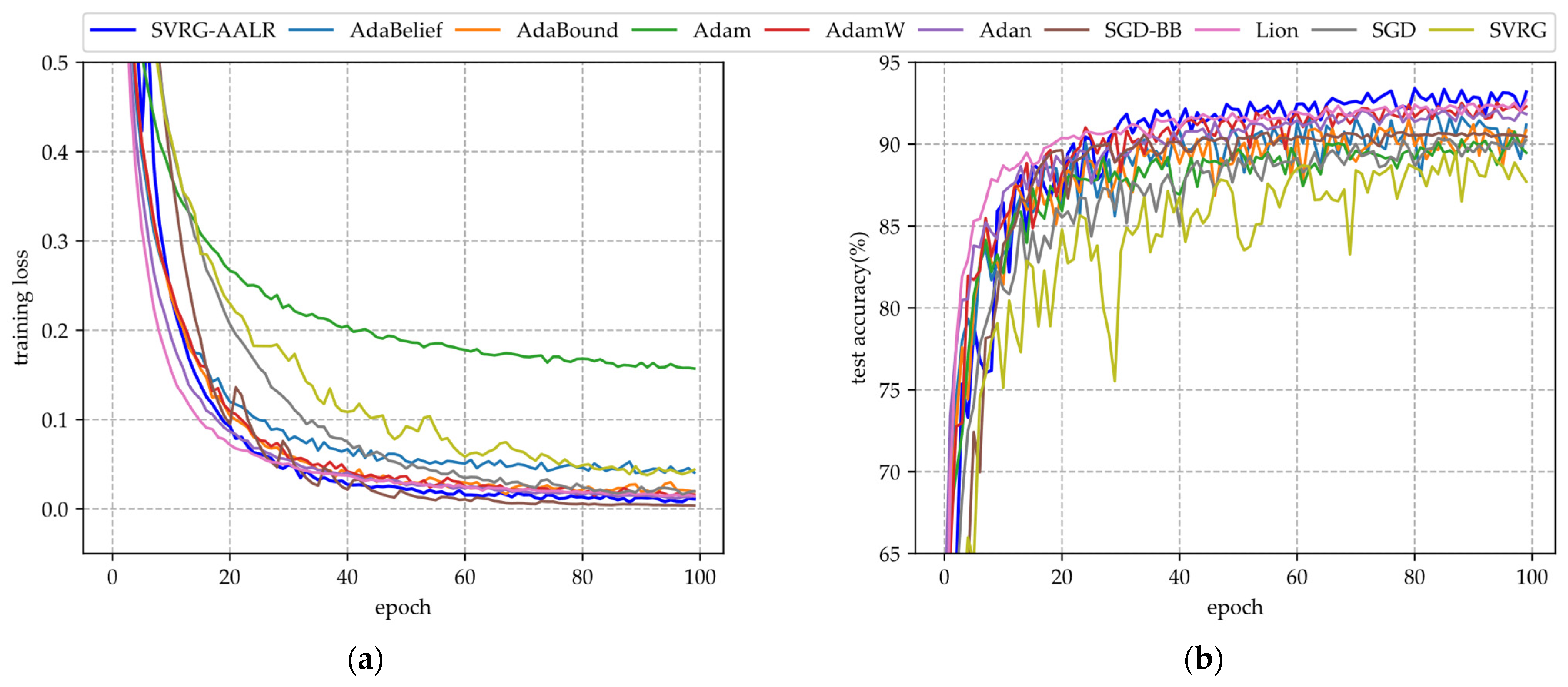
- In Figure 1a, SVRG-AALR exhibits the fastest convergence rate, reaching approximately 0.8 by the 40th epoch. In contrast, Lion, AdamW, and AdaBelief only attain a similar level by the 100th epoch. Furthermore, the loss function values achieved by these four algorithms are significantly lower than those of other methods, highlighting their exceptional convergence performance. Conversely, SVRG and SGD demonstrate the poorest convergence outcomes, with SVRG performing even worse than SGD. Despite incorporating mini-batches into the SVRG framework during experimentation, its convergence performance remains unsatisfactory.
- (ii)
- In Figure 1b, the test accuracy of SVRG-AALR is observed to be the highest, with the curve beginning to stabilize in a flat region at the 40th iteration. In contrast, Lion, AdamW, and AdaBelief only approach the test accuracy achieved by SVRG-AALR at the 100th iteration. This finding indicates that SVRG-AALR possesses superior optimization capabilities and can identify more effective weights to enhance the test accuracy of the LeNet model. Furthermore, with the exception of SVRG-AALR, the test accuracy curves for other algorithms exhibit pronounced sawtooth patterns, suggesting that SVRG-AALR demonstrates greater stability compared to its counterparts. Given LeNet’s relatively simple deep model architecture and limited classification ability, it is noteworthy that all algorithms yield a test accuracy around 70%. In Figure 1, it is also evident that the overall performance of SVRG is slightly inferior to that of SGD.
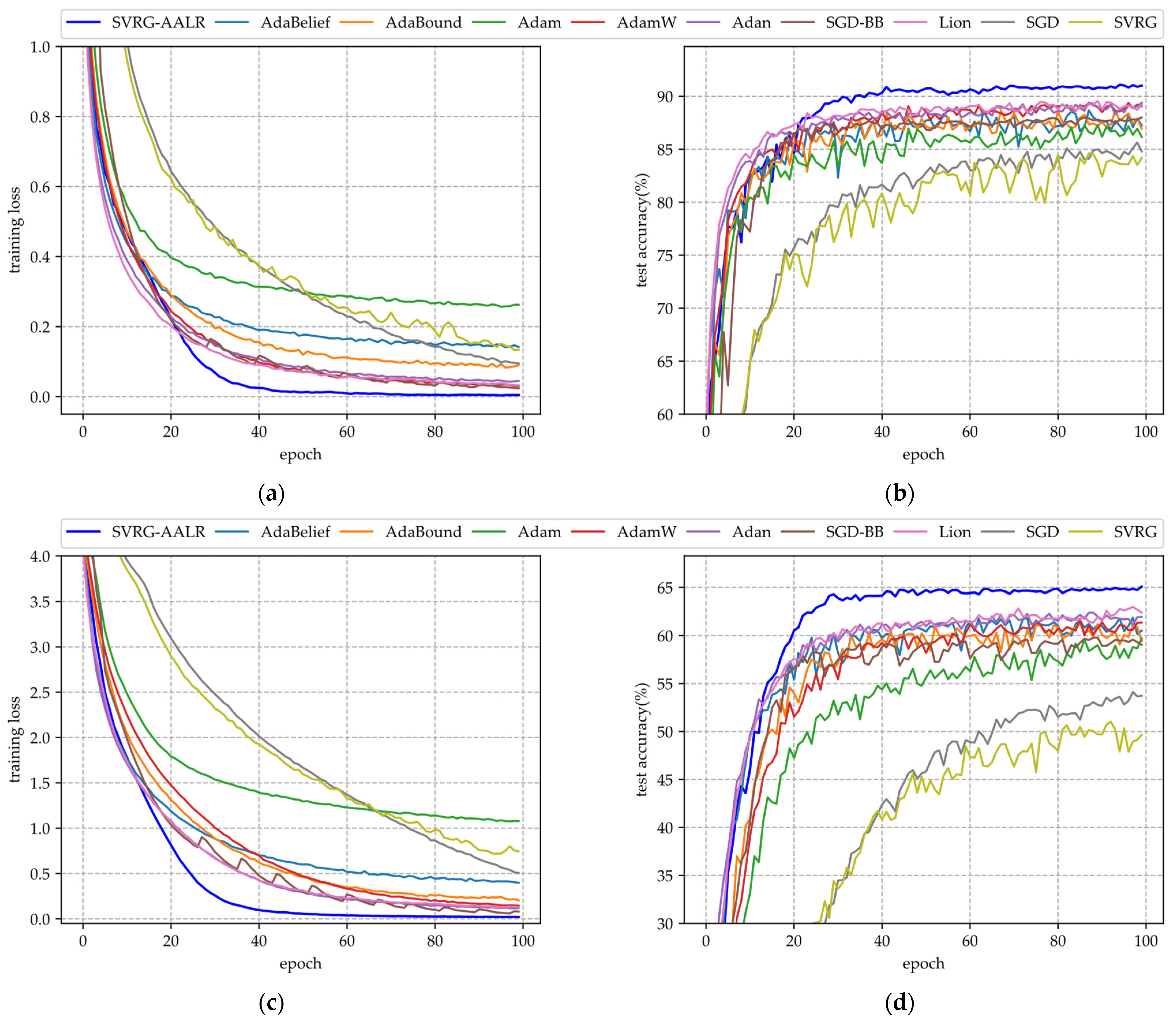
- (i)
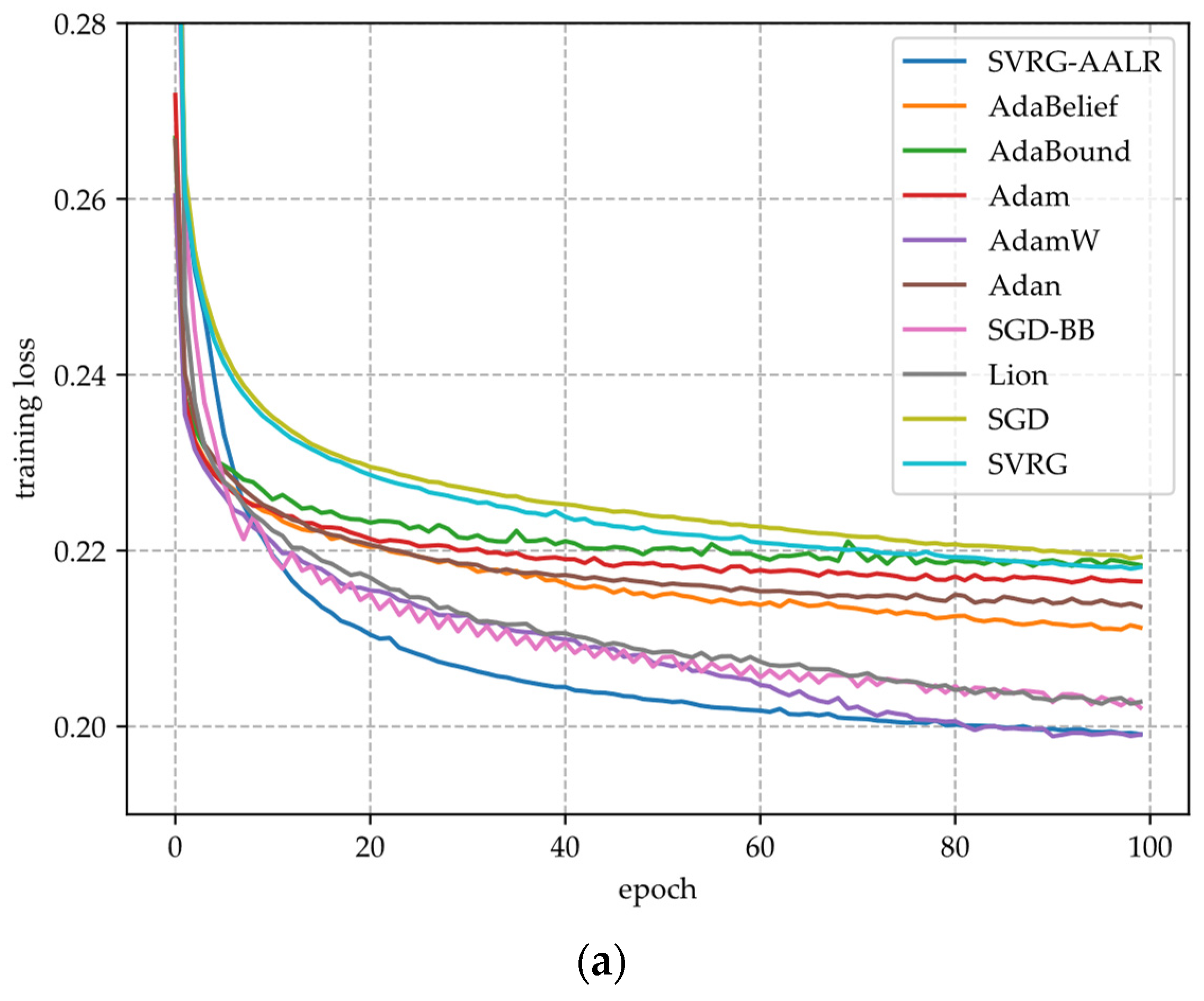
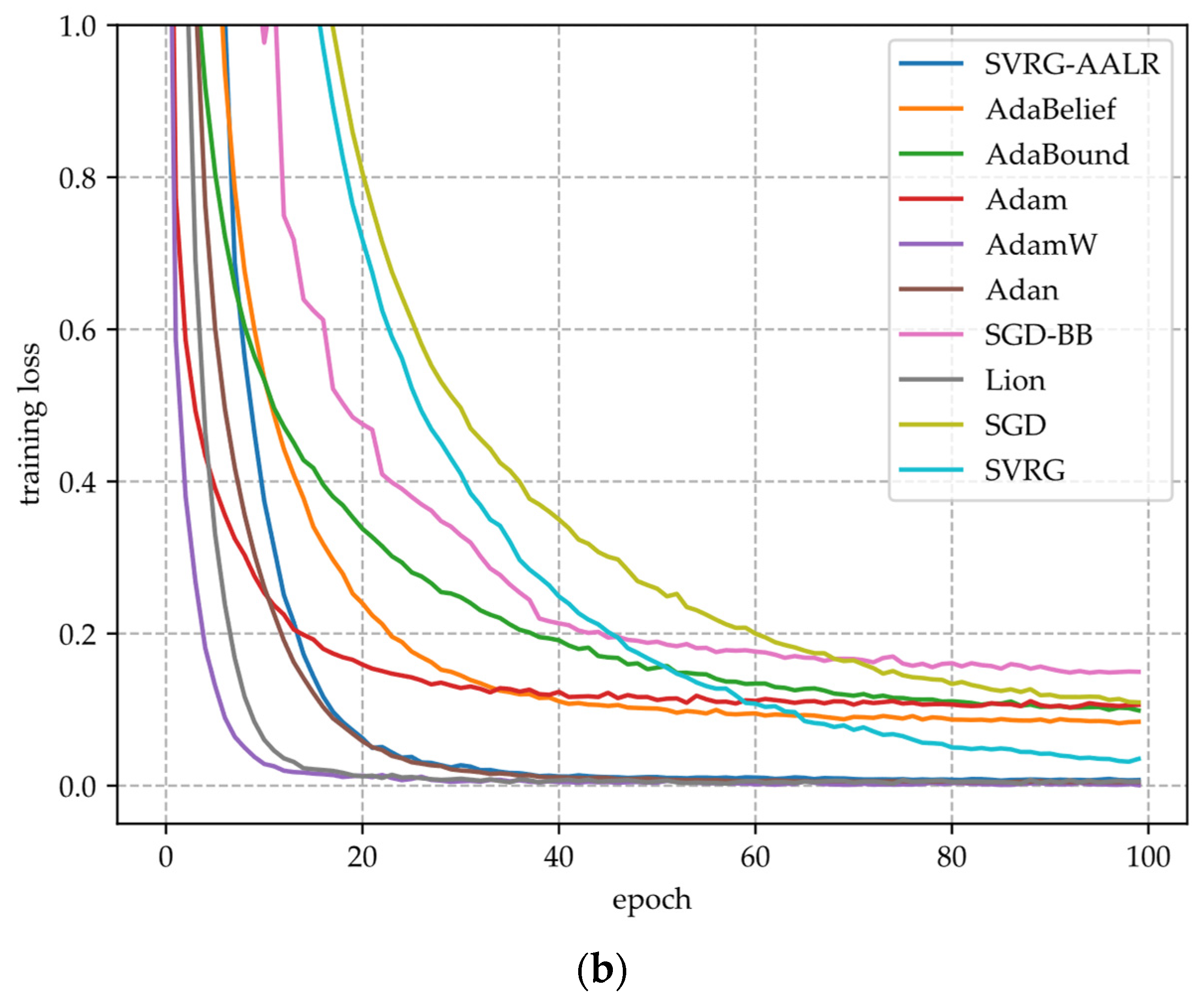
- Figure 2a,c,e illustrate the training loss function curves of various algorithms applied to VGG11 across three datasets. From these figures, it is evident that SVRG-AALR achieves a final loss value approaching zero after 100 iterations. Both Lion and SGD-BB demonstrate convergence performance on CIFAR10 and CIFAR100 that closely aligns with SVRG-AALR; however, minor discrepancies remain. In contrast, Adam, SVRG, and SGD exhibit relatively poor performance across all three datasets. On the large-scale CINIC10 dataset, the loss function value for SVRG-AALR can also approach zero, while Lion, AdamW, and SGD-BB show deviations of approximately 10%. This finding indicates that SVRG-AALR maintains excellent convergence performance even on large-scale datasets. Furthermore, in all three datasets examined, the convergence curves for SVRG and SGD-BB display pronounced sawtooth patterns; conversely, those for SVRG-AALR are notably smoother. This suggests that SVRG-AALR possesses superior stability compared to its counterparts.
- (ii)
- Figure 2b,d,f illustrate the test accuracy curves of various algorithms across three datasets. From these figures, it is evident that SVRG-AALR achieves the highest accuracy, underscoring its superior optimization performance in identifying optimal weights to enhance the generalization capability of the VGG11 model, thereby resulting in elevated test accuracy. In all three figures, the test accuracy curves exhibit varying degrees of sawtooth patterns. This phenomenon can be attributed to the CIFAR100 dataset’s composition of 100 categories with relatively few training samples per category, which leads to significant fluctuations in model accuracy during training. Notably, SVRG-AALR displays the least pronounced sawtooth pattern among them; its test accuracy curve begins to stabilize around the 40th epoch of training. This outcome further illustrates the excellent iterative stability and convergence characteristics of SVRG-AALR and suggests that this proposed algorithm holds considerable potential for application in multi-classification scenarios with limited training data. The number of training samples for each category in CIFAR-100 is lower than that in CIFAR-10, resulting in a significantly reduced test accuracy as illustrated in Figure 2d compared to Figure 2b. At this juncture, the test accuracy achieved by SVRG-AALR is approximately 5% higher than that of Lion, indicating that the model trained using SVRG-AALR demonstrates commendable robustness and generalization capabilities even in scenarios with limited training data. In Figure 2f, both the smoothness of the SVRG-AALR curve and its corresponding test accuracy are superior to those of all other algorithms. Furthermore, it is noteworthy that the test accuracy curve begins to stabilize when the algorithm reaches the 40th epoch. This observation suggests that SVRG-AALR can attain a high level of accuracy with fewer training iterations on large-scale datasets, highlighting its potential competitiveness in extensive applications. In Figure 2, the overall performance of SVRG is worse than SGD, while the overall performance of SVRG-AALR is better than Lion.
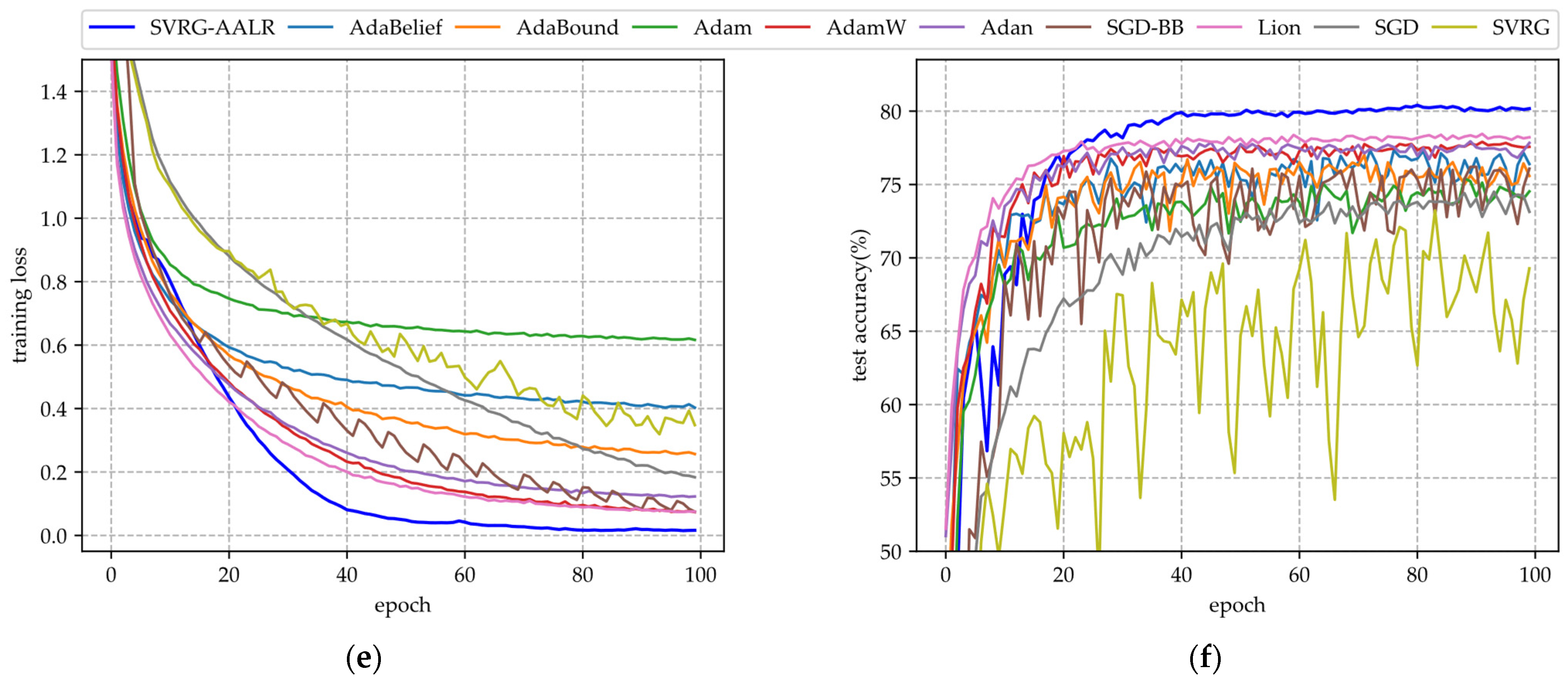
- (i)
- Figure 3a,c,e illustrate the training loss function curves of various algorithms across three datasets. From these figures, it is evident that the convergence curve of SVRG-AALR begins to enter a flat region at the 40th iteration and approaches zero, exhibiting a generally smooth trajectory. This behavior indicates that this algorithm possesses characteristics of rapid convergence and stable iterations. In contrast, the loss function values for Lion, AdamW, and SGD-BB only converge towards those of SVRG-AALR by the 100th iteration, suggesting that their convergence speeds are slower than that of SVRG-AALR. Additionally, the three curves corresponding to SGD-BB display more pronounced sawtooth patterns, reflecting its instability during iterations. Overall, across all three datasets, it can be concluded that the convergence performance of SVRG remains inferior to that of SGD.
- (ii)
- The test accuracy curves of various algorithms for the three datasets are presented in Figure 3b,d,f. From these figures, it is evident that the test accuracy curves of all algorithms exhibit varying degrees of sawtooth patterns, with those of SGD-BB, SVRG, and Adam being particularly pronounced. Notably, while the training loss function of SGD-BB converges to zero after 100 iterations, its corresponding test accuracy curve displays the most significant sawtooth pattern along with a relatively low overall accuracy. This observation indicates potential overfitting during training. Overall, SVRG-AALR achieves the highest accuracy among the tested algorithms. Its test accuracy curve begins to stabilize after approximately 40 iterations and exhibits the smallest amplitude in its sawtooth pattern. This suggests that SVRG-AALR possesses strong anti-overfitting capabilities and that the trained ResNet34 model demonstrates good generalization performance. The test accuracy curve for Lion ranks second overall; however, when compared to SVRG-AALR, there exists an average gap of about 5% in their respective accuracies. This finding implies that SVRG-AALR outperforms Lion in terms of optimization performance. In Figure 3, it is also observed that SVRG performs worse than SGD.
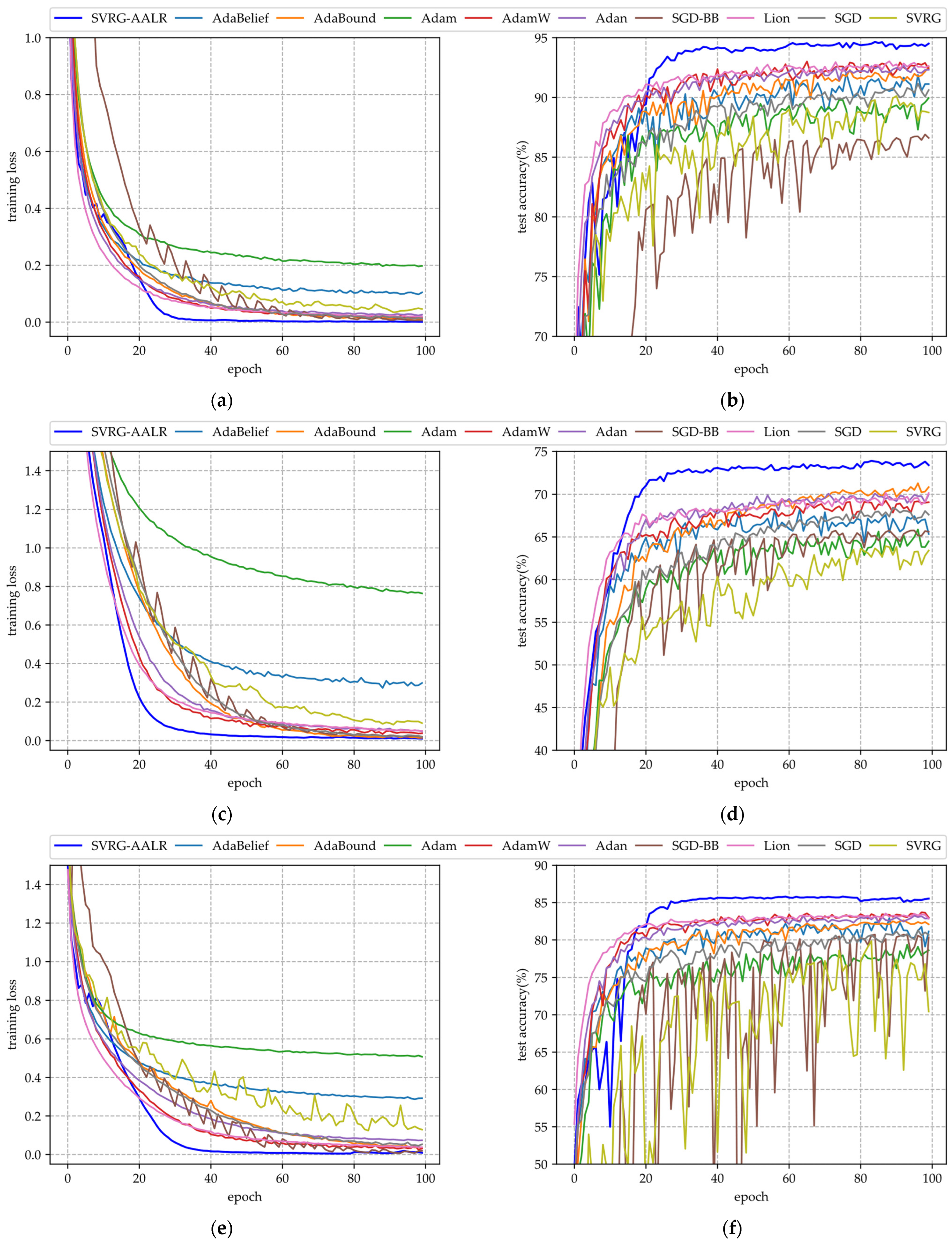
- (i)
- Figure 4a,c illustrate the training loss function curves for each algorithm across two datasets. From these curves, it is evident that SVRG-AALR and SGD-BB exhibit superior convergence, approaching a loss of zero after 100 iterations, thereby demonstrating excellent performance in terms of convergence. In comparison to Figure 2a,c and Figure 3a,c, the sawtooth phenomenon observed in Figure 4a,c is more pronounced. This phenomenon can be attributed to the structural characteristics inherent in the DenseNet model. To mitigate the parameter scale of the model, DenseNet employs dense connections and feature reuse techniques within its architecture. However, this dense connectivity introduces significant parameter coupling issues; specifically, each layer’s output in DenseNet is concatenated with feature maps from all preceding layers along the channel dimension. Consequently, there exists a high degree of parameter interdependence among layers. Adjusting any single layer may disrupt the global feature propagation path, complicating weight adjustments throughout the model. This challenge manifests as an increased number of sawteeth in the convergence curve.
- (ii)
- Figure 4b,d illustrate the test accuracy curves of various algorithms across two datasets. In comparison to Figure 3b,d, the sawtooth patterns present in each curve are significantly diminished, indicating that DenseNet, which utilizes dense connections and feature reuse techniques, exhibits a superior capability for mitigating overfitting when compared to ResNet. However, it is noteworthy that SVRG-AALR still achieves the highest accuracy in Figure 4b,d; nonetheless, its accuracy is slightly lower than before, with more pronounced sawtooth patterns relative to the corresponding curves in Figure 3b,d. This observation further suggests that weight adjustment within DenseNet poses greater challenges. Nevertheless, it is evident from Figure 4b,d that SVRG-AALR continues to outperform other baseline algorithms regarding accuracy. This finding demonstrates that SVRG-AALR maintains strong performance on DNN models where weight adjustment proves difficult. In Figure 4, while the overall performance of SVRG remains inferior to that of SGD, it is observed that SVRG-AALR performs slightly better than Lion overall.
- (i)
- On the CIFAR10 dataset, the model trained using SVRG-AALR achieved an F1 score of 0.9464, securing the top position among all optimizers. In comparison, the model trained with the Lion optimizer attained an F1 score of 0.9303, placing it in second position. Overall, on the CIFAR10 dataset, SVRG-AALR demonstrates a marginally superior performance compared to Lion.
- (ii)
- On the CIFAR100 dataset, the model trained using SVRG-AALR achieved an F1 score of 0.7383, securing the top position among all optimizers. In comparison, the model trained with the AdaBound optimizer attained an F1 score of 0.7133, placing it in second position. Overall, the performance of SVRG-AALR on the CIFAR100 dataset demonstrates a slight advantage over that of AdaBound.
- (iii)
- On the CINIC10 dataset, the model trained using SVRG-AALR achieved an F1 score of 0.8585, securing the top position among all optimizers. In comparison, the model trained with the AdamW optimizer attained an F1 score of 0.8364, placing it in second position. Overall, on the CINIC10 dataset, SVRG-AALR demonstrates a marginally superior performance compared to AdamW.
- (i)
- The training process demonstrates convergence, with a relatively rapid convergence speed. The experimental results presented above indicate that the training trajectory of SVRG-AALR across various DNN models and datasets exhibits a favorable convergence trend, aligning with the conclusions drawn from the convergence analysis of the SVRG-AALR algorithm. Furthermore, the number of iterations required for both the training loss function curve and the test accuracy curve of SVRG-AALR to stabilize in a flat region is lower than that observed with baseline optimizers; thus, this algorithm showcases a comparatively swift convergence rate. As illustrated in line 13 of Algorithm 2, the update formula for adjusting DNN weights iswhere the learning rate is derived from the quasi-Newton method as outlined in Equations (5) and (6). Consequently, incorporates second-order information and is adjusted to prevent it from being excessively large or small, thereby facilitating the acceleration of convergence for the SVRG-AALR algorithm.
- (ii)
- The trained DNN model demonstrates a high level of classification accuracy. The weight parameters are critical factors that influence the classification performance of the DNN model; thus, elevated classification accuracy reflects superior quality of these weights. In Algorithm 2, represents the gradient adjusted through mini-batch and variance reduction techniques, resulting in relatively low gradient variance for . As indicated in Equation (53), the adaptive AALR learning rate is capable of adapting to , which enhances the precision of the weight update term . This feature not only accelerates convergence for SVRG-AALR but also improves weight quality, ultimately leading to enhanced classification accuracy for the trained DNN model.
- (iii)
- The training process exhibits commendable stability. The accuracy of allows SVRG-AALR to maintain a high level of stability throughout the iterative process. This stability is evident in both the training loss function curve and the test accuracy curve, which display relatively smooth trajectories with fewer sawtooth patterns.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef]
- Shamshirband, S.; Fathi, M.; Dehzangi, A.; Chronopoulos, A.T.; Alinejad-Rokny, H. A review on deep learning approaches in healthcare systems: Taxonomies, challenges, and open issues. J. Biomed. Inform. 2021, 113, 103627. [Google Scholar] [CrossRef]
- Khallaf, R.; Khallaf, M. Classification and analysis of deep learning applications in construction: A systematic literature review. Autom. Constr. 2021, 129, 103760. [Google Scholar] [CrossRef]
- Li, C.; Zhang, S.; Qin, Y.; Estupinan, E. A systematic review of deep transfer learning for machinery fault diagnosis. Neurocomputing 2020, 407, 121–135. [Google Scholar] [CrossRef]
- Altalak, M.; Ammad uddin, M.; Alajmi, A.; Rizg, A. Smart agriculture applications using deep learning technologies: A survey. Appl. Sci. 2022, 12, 5919. [Google Scholar] [CrossRef]
- Khodayar, M.; Regan, J. Deep neural networks in power systems: A review. Energies 2023, 16, 4773. [Google Scholar] [CrossRef]
- Roux, N.; Schmidt, M.; Bach, F. A stochastic gradient method with an exponential convergence rate for finite training sets. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (2012), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Johnson, R.; Zhang, T. Accelerating stochastic gradient descent using predictive variance reduction. In Proceedings of the NIPS 2013, Stateline, NV, USA, 5–10 December 2013. [Google Scholar]
- Shang, F.; Zhou, K.; Liu, H.; Cheng, J.; Tsang, I.W.; Zhang, L.; Tao, D.; Jiao, L. VR-SGD: A simple stochastic variance reduction method for machine learning. IEEE Trans. Knowl. Data Eng. 2018, 32, 188–202. [Google Scholar] [CrossRef]
- Alioscha-Perez, M.; Oveneke, M.C.; Sahli, H. SVRG-MKL: A fast and scalable multiple kernel learning solution for features combination in multi-class classification problems. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1710–1723. [Google Scholar] [CrossRef] [PubMed]
- Tankaria, H.; Yamashita, N. A stochastic variance reduced gradient using Barzilai-Borwein techniques as second order information. J. Ind. Manag. Optim. 2024, 20, 525–547. [Google Scholar] [CrossRef]
- Fu, S.; Wang, X.; Tang, J.; Lan, S.; Tian, Y. Generalized robust loss functions for machine learning. Neural Netw. 2024, 171, 200–214. [Google Scholar] [CrossRef] [PubMed]
- Defazio, A.; Bottou, L. On the ineffectiveness of variance reduced optimization for deep learning. In Proceedings of the 2019 Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Shi, L.; Zhao, H.; Zakharov, Y. Generalized variable step size continuous mixed p-norm adaptive filtering algorithm. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 1078–1082. [Google Scholar] [CrossRef]
- Shi, L.; Zhao, H.; Zeng, X.; Yu, Y. Variable step-size widely linear complex-valued NLMS algorithm and its performance analysis. Signal Process. 2019, 165, 1–6. [Google Scholar] [CrossRef]
- Shi, L.; Zhao, H.; Zakharov, Y.; Chen, B.; Yang, Y. Variable step-size widely linear complex-valued affine projection algorithm and performance analysis. IEEE Trans. Signal Process. 2020, 68, 5940–5953. [Google Scholar] [CrossRef]
- Tan, C.; Ma, S.; Dai, Y.-H.; Qian, Y. Barzilai-Borwein step size for stochastic gradient descent. In Proceedings of the 2016 Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Yu, T.; Liu, X.-W.; Dai, Y.-H.; Sun, J. Stochastic variance reduced gradient methods using a trust-region-like scheme. J. Sci. Comput. 2021, 87, 5. [Google Scholar] [CrossRef]
- Li, J.; Xue, D.; Liu, L.; Qi, R. A stochastic variance reduced gradient method with adaptive step for stochastic optimization. Optim. Control Appl. Methods 2024, 45, 1327–1342. [Google Scholar] [CrossRef]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Yu, L.; Deng, T.; Zhang, W.; Zeng, Z. Stronger adversarial attack: Using mini-batch gradient. In Proceedings of the 2020 12th International Conference on Advanced Computational Intelligence (ICACI), Dali, China, 14–16 August 2020; pp. 364–370. [Google Scholar]
- Smirnov, E.; Oleinik, A.; Lavrentev, A.; Shulga, E.; Galyuk, V.; Garaev, N.; Zakuanova, M.; Melnikov, A. Face representation learning using composite mini-batches. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 551–559. [Google Scholar]
- Peng, C.; Xiao, T.; Li, Z.; Jiang, Y.; Zhang, X.; Jia, K.; Yu, G.; Sun, J. Megdet: A large mini-batch object detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6181–6189. [Google Scholar]
- Yang, Z.; Wang, C.; Zhang, Z.; Li, J. Mini-batch algorithms with online step size. Knowl.-Based Syst. 2019, 165, 228–240. [Google Scholar] [CrossRef]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 661–670. [Google Scholar]
- Chen, C.; Shen, L.; Zou, F.; Liu, W. Towards practical adam: Non-convexity, convergence theory, and mini-batch acceleration. J. Mach. Learn. Res. 2022, 23, 1–47. [Google Scholar]
- Dokuz, Y.; Tufekci, Z. Mini-batch sample selection strategies for deep learning based speech recognition. Appl. Acoust. 2021, 171, 107573. [Google Scholar] [CrossRef]
- Yin, Y.; Xu, Z.; Li, Z.; Darrell, T.; Liu, Z. A Coefficient Makes SVRG Effective. The Thirteenth International Conference on Learning Representations. arXiv 2025, arXiv:2311.05589. [Google Scholar]
- Dai, Y.-H.; Huang, Y.; Liu, X.-W. A family of spectral gradient methods for optimization. Comput. Optim. Appl. 2019, 74, 43–65. [Google Scholar] [CrossRef]
- Burdakov, O.; Dai, Y.; Huang, N. Stabilized barzilai-borwein method. J. Comput. Math. 2019, 37, 916–936. [Google Scholar] [CrossRef]
- Liang, J.; Xu, Y.; Bao, C.; Quan, Y.; Ji, H. Barzilai–Borwein-based adaptive learning rate for deep learning. Pattern Recognit. Lett. 2019, 128, 197–203. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 23 July 2025).
- Darlow, L.N.; Crowley, E.J.; Antoniou, A.; Storkey, A.J. CINIC-10 Is Not ImageNet or CIFAR-10. University of Edinburgh. arXiv 2018, arXiv:1810.03505. [Google Scholar]
- Chrabaszcz, P.; Loshchilov, I.; Hutter, F. A downsampled variant of imagenet as an alternative to the cifar datasets. arXiv 2017, arXiv:1707.08819. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. International Conference on Learning Representations. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Guolin, Y.; Shiyun, Z.; Hua, Q.; Yuyi, C.; Zihan, Z.; Xiangyuan, D. Robust 12-Lead ECG Classification with Lightweight ResNet: An Adaptive Second-Order Learning Rate Optimization Approach. Electronics 2025, 14, 1941. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (2012), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhuang, J.; Tang, T.; Ding, Y.; Tatikonda, S.C.; Dvornek, N.; Papademetris, X.; Duncan, J. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients. In Proceedings of the NeurIPS 2020, virtual, 6–12 December 2020. [Google Scholar]
- Xie, X.; Zhou, P.; Li, H.; Lin, Z.; Yan, S. Adan: Adaptive nesterov momentum algorithm for faster optimizing deep models. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9508–9520. [Google Scholar] [CrossRef] [PubMed]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar] [CrossRef]
- Chen, X.; Liang, C.; Huang, D.; Real, E.; Wang, K.; Pham, H.; Dong, X.; Luong, T.; Hsieh, C.-J.; Lu, Y. Symbolic discovery of optimization algorithms. In Proceedings of the NIPS’23: 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Sérgio, M.; Paulo, C.; Paulo, R. A data-driven approach to predict the success of bank telemarketing. Decis. Support Syst. 2014, 62, 22–31. [Google Scholar] [CrossRef]
- Jason, D.M.R.; Lawrence, S.; Jaime, T.; David, R.K. Tackling the poor assumptions of naive bayes text classifiers. In Proceedings of the Twentieth International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 616–623. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DNN Model | Dataset | Layer | BN | RHF | TP |
|---|---|---|---|---|---|
| LeNet | CIFAR10 | 5 | − | + | 62,006 |
| VGG11 | CIFAR10, CIFAR100, CINIC10 | 11 | + | + | 9,756,426 |
| ResNet34 | CIFAR10, CIFAR100, CINIC10 | 34 | + | + | 21,282,122 |
| DenseNet121 | CIFAR10, CIFAR100 | 121 | + | + | 6,956,298 |
| (a) CIFAR10 dataset | ||||
| Optimizer | Acc | Prec | Recall | F1 |
| AdaBelief | 0.9204 | 0.9222 | 0.9204 | 0.9207 |
| AdaBound | 0.9254 | 0.9252 | 0.9254 | 0.9250 |
| Adam | 0.8995 | 0.8999 | 0.8995 | 0.8990 |
| AdamW | 0.9301 | 0.9305 | 0.9301 | 0.9301 |
| Adan | 0.9267 | 0.9268 | 0.9267 | 0.9266 |
| SGD-BB | 0.8689 | 0.8690 | 0.8689 | 0.8688 |
| Lion | 0.9303 | 0.9304 | 0.9303 | 0.9303 |
| SVRG | 0.9012 | 0.9028 | 0.9012 | 0.9015 |
| SGD | 0.9116 | 0.9116 | 0.9116 | 0.9115 |
| SVRG-AALR | 0.9465 | 0.9465 | 0.9465 | 0.9464 |
| (b) CIFAR100 dataset | ||||
| Optimizer | Acc | Prec | Recall | F1 |
| AdaBelief | 0.6824 | 0.7000 | 0.6824 | 0.6815 |
| AdaBound | 0.7127 | 0.7176 | 0.7127 | 0.7133 |
| Adam | 0.6587 | 0.6813 | 0.6587 | 0.6584 |
| AdamW | 0.6926 | 0.7020 | 0.6926 | 0.6929 |
| Adan | 0.7009 | 0.7105 | 0.7009 | 0.7014 |
| SGD-BB | 0.6576 | 0.6604 | 0.6576 | 0.6577 |
| Lion | 0.7016 | 0.7061 | 0.7016 | 0.7006 |
| SVRG | 0.6392 | 0.6594 | 0.6392 | 0.6407 |
| SGD | 0.6844 | 0.6894 | 0.6844 | 0.6840 |
| SVRG-AALR | 0.7389 | 0.7405 | 0.7389 | 0.7383 |
| (c) CINIC10 dataset | ||||
| Optimizer | Acc | Prec | Recall | F1 |
| AdaBelief | 0.8292 | 0.8296 | 0.8292 | 0.8289 |
| AdaBound | 0.8264 | 0.8275 | 0.8264 | 0.8259 |
| Adam | 0.7937 | 0.7963 | 0.7937 | 0.7933 |
| AdamW | 0.8370 | 0.8366 | 0.8370 | 0.8364 |
| Adan | 0.8325 | 0.8345 | 0.8325 | 0.8230 |
| SGD-BB | 0.8071 | 0.8077 | 0.8071 | 0.8073 |
| Lion | 0.8355 | 0.8353 | 0.8355 | 0.8351 |
| SVRG | 0.7985 | 0.8008 | 0.7985 | 0.7977 |
| SGD | 0.8129 | 0.8147 | 0.8129 | 0.8135 |
| SVRG-AALR | 0.8587 | 0.8584 | 0.8587 | 0.8585 |
| Algorithm | Computation Time/s | |||
|---|---|---|---|---|
| LeNet | VGG11 | ResNet34 | DenseNet121 | |
| SVRG-AALR | 16.6 | 29.6 | 159.8 | 331.1 |
| AdaBelief | 10.1 | 17.3 | 64.3 | 138.1 |
| AdaBound | 9.5 | 17.5 | 63.3 | 135.8 |
| Adam | 9.1 | 17.8 | 58.9 | 115.3 |
| AdamW | 9.5 | 16.2 | 60.1 | 115.5 |
| Adan | 10.3 | 23.5 | 68.5 | 149.7 |
| SGD-BB | 8.7 | 15.3 | 60.6 | 123.9 |
| Lion | 8.9 | 16.9 | 60.4 | 130.5 |
| SGD | 8.6 | 15.1 | 57.7 | 114.9 |
| SVRG | 19.1 | 32.9 | 172.8 | 361.3 |
| (a) Bank marketing dataset | ||||
| Optimizer | Acc | Prec | Recall | F1 |
| SVRG-AALR | 0.9009 | 0.7789 | 0.6953 | 0.7266 |
| AdaBelief | 0.9020 | 0.7857 | 0.6900 | 0.7242 |
| AdaBound | 0.9014 | 0.7879 | 0.6782 | 0.7149 |
| Adam | 0.9014 | 0.7910 | 0.6723 | 0.7104 |
| AdamW | 0.9011 | 0.7816 | 0.6903 | 0.7234 |
| Adan | 0.9005 | 0.7810 | 0.6844 | 0.7185 |
| SGD-BB | 0.9011 | 0.7833 | 0.6860 | 0.7203 |
| Lion | 0.9024 | 0.7868 | 0.6910 | 0.7253 |
| SGD | 0.9010 | 0.7863 | 0.6780 | 0.7144 |
| SVRG | 0.8998 | 0.7834 | 0.6714 | 0.7080 |
| (b) 20 Newsgroups dataset | ||||
| Optimizer | Acc | Prec | Recall | F1 |
| SVRG-AALR | 0.8480 | 0.8471 | 0.8454 | 0.8457 |
| AdaBelief | 0.8403 | 0.8403 | 0.8375 | 0.8381 |
| AdaBound | 0.8347 | 0.8363 | 0.8315 | 0.8329 |
| Adam | 0.8469 | 0.8465 | 0.8445 | 0.8447 |
| AdamW | 0.8414 | 0.8398 | 0.8373 | 0.838 |
| Adan | 0.8321 | 0.8315 | 0.8287 | 0.8295 |
| SGD-BB | 0.8241 | 0.8255 | 0.8201 | 0.8213 |
| Lion | 0.8475 | 0.8481 | 0.8458 | 0.8457 |
| SGD | 0.8204 | 0.8206 | 0.8176 | 0.8184 |
| SVRG | 0.8294 | 0.8302 | 0.8265 | 0.8276 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, S.; Qin, H.; Yang, G.; Wang, P. SVRG-AALR: Stochastic Variance-Reduced Gradient Method with Adaptive Alternating Learning Rate for Training Deep Neural Networks. Electronics 2025, 14, 2979. https://doi.org/10.3390/electronics14152979
Zou S, Qin H, Yang G, Wang P. SVRG-AALR: Stochastic Variance-Reduced Gradient Method with Adaptive Alternating Learning Rate for Training Deep Neural Networks. Electronics. 2025; 14(15):2979. https://doi.org/10.3390/electronics14152979
Chicago/Turabian StyleZou, Shiyun, Hua Qin, Guolin Yang, and Pengfei Wang. 2025. "SVRG-AALR: Stochastic Variance-Reduced Gradient Method with Adaptive Alternating Learning Rate for Training Deep Neural Networks" Electronics 14, no. 15: 2979. https://doi.org/10.3390/electronics14152979
APA StyleZou, S., Qin, H., Yang, G., & Wang, P. (2025). SVRG-AALR: Stochastic Variance-Reduced Gradient Method with Adaptive Alternating Learning Rate for Training Deep Neural Networks. Electronics, 14(15), 2979. https://doi.org/10.3390/electronics14152979