1. Introduction
Deep learning technologies are increasingly being adapted for use on devices with limited computational resources. In scenarios such as edge computing or real-time image recognition, factors such as model size and inference speed become critical. While large-scale models are powerful, they are often impractical for terminal deployment due to their heavy resource demands, which can significantly hinder real-time processing. In automotive applications, for example, where cameras are used to detect driver distraction or fatigue, compact and efficient models are essential for ensuring responsiveness and system integration within hardware constraints. Gaze tracking plays a critical role in applications such as driver monitoring and assistive technologies, enabling systems to interpret human attention with precision [
1]. While many lightweight models aim to reduce the computational load for edge deployment, they often do so at the expense of accuracy. For example, a comprehensive survey [
2] highlights that although deep-learning-based appearance gaze estimation models have significantly advanced accuracy under controlled conditions, they still struggle in unconstrained settings featuring head pose variation, occlusion, and lighting changes. These limitations point to a growing gap for models that can perform robustly in real-world scenarios while remaining efficient. In this work, we propose an improved gaze-tracking framework that balances speed and accuracy through architectural optimization. Our method builds upon the Look to Coordinate Space (L2CS) gaze estimation model by integrating GhostNet as the backbone and enhancing it with a custom-designed depthwise convolutional block. Through a comparative study of lightweight architectures, including MobileNets, ConvNets and ResNeXts, we have identified L2CS as the most effective method for capturing fine-grained eye movement. The resulting model achieves real-time inference with a reduction in parameters and FLOPs of nearly 50% while maintaining high performance with only a marginal 1.5% drop in accuracy. This demonstrates its practicality for deployment on resource-constrained devices.
Modern terminal devices, including smart phones, surveillance systems [
3,
4], IoT devices, drones, robots and in-vehicle systems [
5,
6,
7], are increasingly expected to perform AI tasks locally with real-time responsiveness [
8], minimal power consumption, optimized system performance and improved privacy. To meet these requirements, model compression [
9,
10] and acceleration techniques are necessary to reduce computational cost and model size without compromising prediction accuracy [
11].
Previous studies in lightweight deep learning have primarily focused on minimizing parameter counts, often at the expense of model accuracy. Thus, achieving an optimal balance between model efficiency and performance remains a central challenge. Recent research has introduced various strategies to overcome this issue, including developing inherently lightweight architectures, as well as compression and optimization techniques.
In the context of gaze tracking, appearance-based gaze estimation models aim to predict gaze direction directly from images of the face or eyes. These methods demonstrate strong adaptability across different image resolutions and environmental conditions, rendering them ideal for mobile and embedded systems. However, they still encounter significant challenges in unconstrained environments where factors such as variable head poses and lighting conditions can distort the appearance of the eyes and reduce the reliability of predictions. Advances in deep learning techniques and the availability of large-scale datasets have led to significant progress in developing improved gaze estimation solutions [
12,
13].
One notable lightweight architecture is GhostNet, which optimizes convolutional operations by reducing the generation of redundant features. GhostNet addresses the inefficiency whereby conventional convolution layers often produce excessive features that are computationally expensive yet contribute little to model performance. By introducing cost-effective GhostBlock, GhostNet significantly reduces training and inference overheads. Its lightweight design has been successfully applied in various domains. For example, it has been used to accelerate GIVTED-Net for medical image segmentation [
14], enhance YOLOv4 for UAV-based inspection of power transmission lines [
15], and improve real-time emotion recognition systems by reducing FLOPs while maintaining expressive feature extraction [
16].
Inspired by these successes, this study incorporates GhostNet’s convolutional efficiency techniques into the L2CS gaze-tracking model. Specifically, we have redesigned certain convolutional blocks and revised the fully connected layers to reduce parameter count while preserving spatial attention to subtle eye movements.
2. Related Works
This study focuses on improving gaze-tracking performance using lightweight deep learning techniques. The large-scale, publicly available Gaze360 dataset [
17] is used for training and evaluation purposes. Integrating lightweight models with targeted architectural optimizations achieves a reduction of over 50% in training and inference parameters while preserving high predictive accuracy. Specifically, the L2CS gaze-tracking model [
18] is selected as the baseline due to its strong angular prediction capabilities and is then optimized using GhostNet [
19] for improved computational efficiency. Additionally, depthwise convolutions [
20] are incorporated to refine grouped convolutions [
21], enabling efficient inference on both CPU and GPU platforms [
22].
2.1. L2CS Network
The L2CS (Look to Coordinate Space) network is based on the ResNet-50 [
23] architecture and uses a multi-loss framework combining regression and classification branches to improve the accuracy of gaze angle estimation. This dual-branch design uses parallel convolutional pathways to perform both gaze regression and discrete gaze classification simultaneously, enabling the network to correct the angular errors that are inherent in pure regression models.
The regression branch estimates continuous gaze angles, while the classification branch divides the angular space into bins and classifies the gaze direction accordingly. This hybrid strategy results in more robust performance when head poses and eye appearances vary. Two distinct loss functions are employed to supervise each gaze angle dimension: mean squared error (MSE) for regression and cross-entropy for classification. These are defined as follows:
where
is the ground-truth gaze angle,
is the predicted angle, and
is the number of samples.
where
denotes the predicted probability for the correct gaze angle class.
Recent gaze-tracking models such as GazeLSTM and HG-Net have also demonstrated promising performance on challenging datasets. However, L2CS offers the best balance between computational cost and gaze estimation accuracy, which will be validated by the experimental results presented later. Specifically, L2CS achieves lower MAE than GazeLSTM and comparable performance to HG-Net while maintaining significantly fewer FLOPs and parameters. These characteristics make it a strong candidate for further optimization and justify its selection as the baseline architecture in this study.
2.2. ResNet50
ResNet-50 is the main backbone in L2CS owing to its balance of representational power and computational efficiency. With 50 layers, ResNet-50 can capture both low- and high-level features, enabling precise estimation of subtle eye movements. Compared to deeper variants, such as ResNet-101 or ResNet-152, ResNet-50 is more resource-efficient, making it ideal for use in embedded or real-time systems.
The residual learning framework of ResNet effectively mitigates vanishing and exploding gradient issues during training, thereby improving convergence and generalization. Furthermore, its modular architecture facilitates easy adaptation and extension, allowing for enhancements specific to the task at hand, such as custom blocks for gaze tracking.
2.3. GhostNet
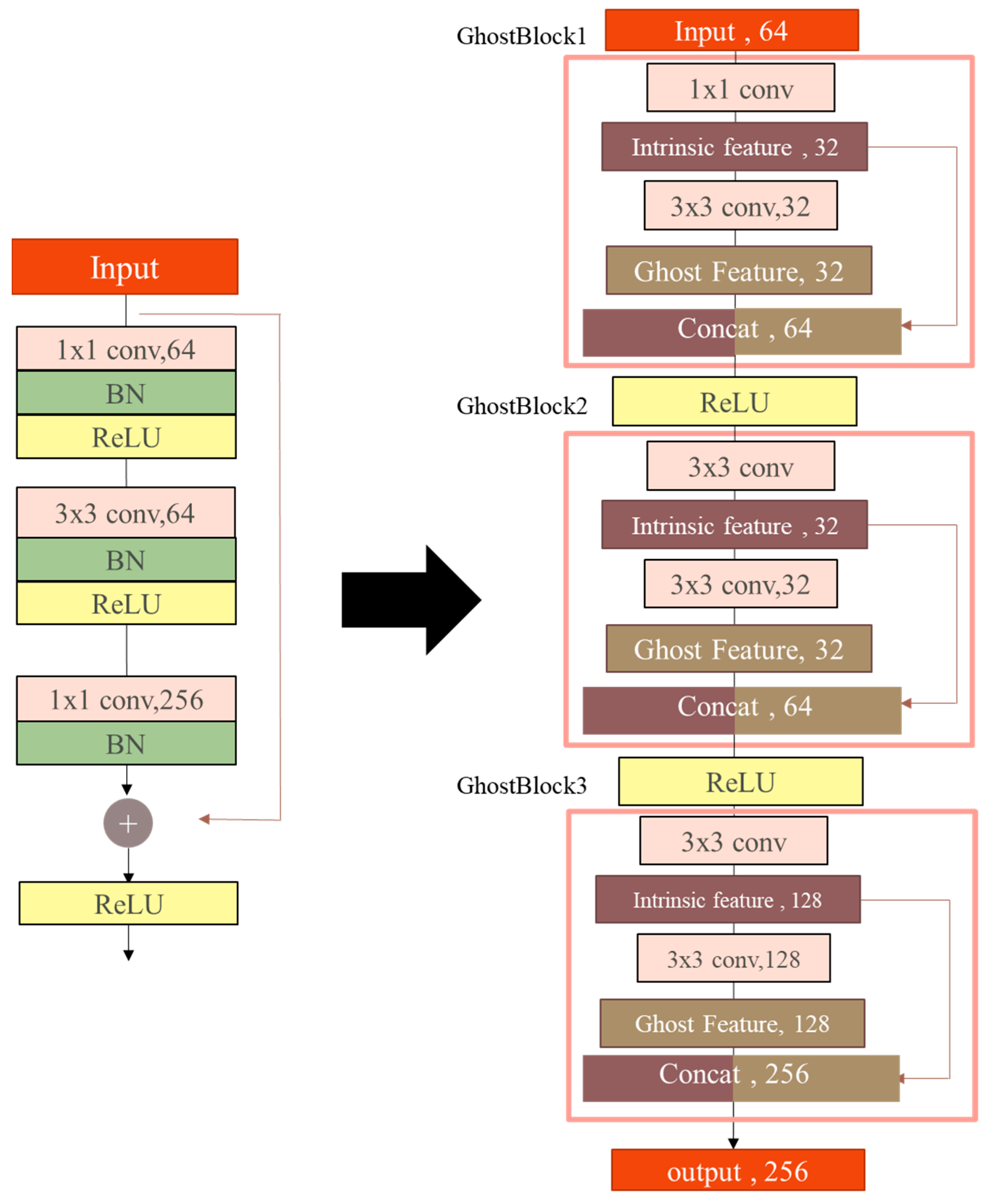
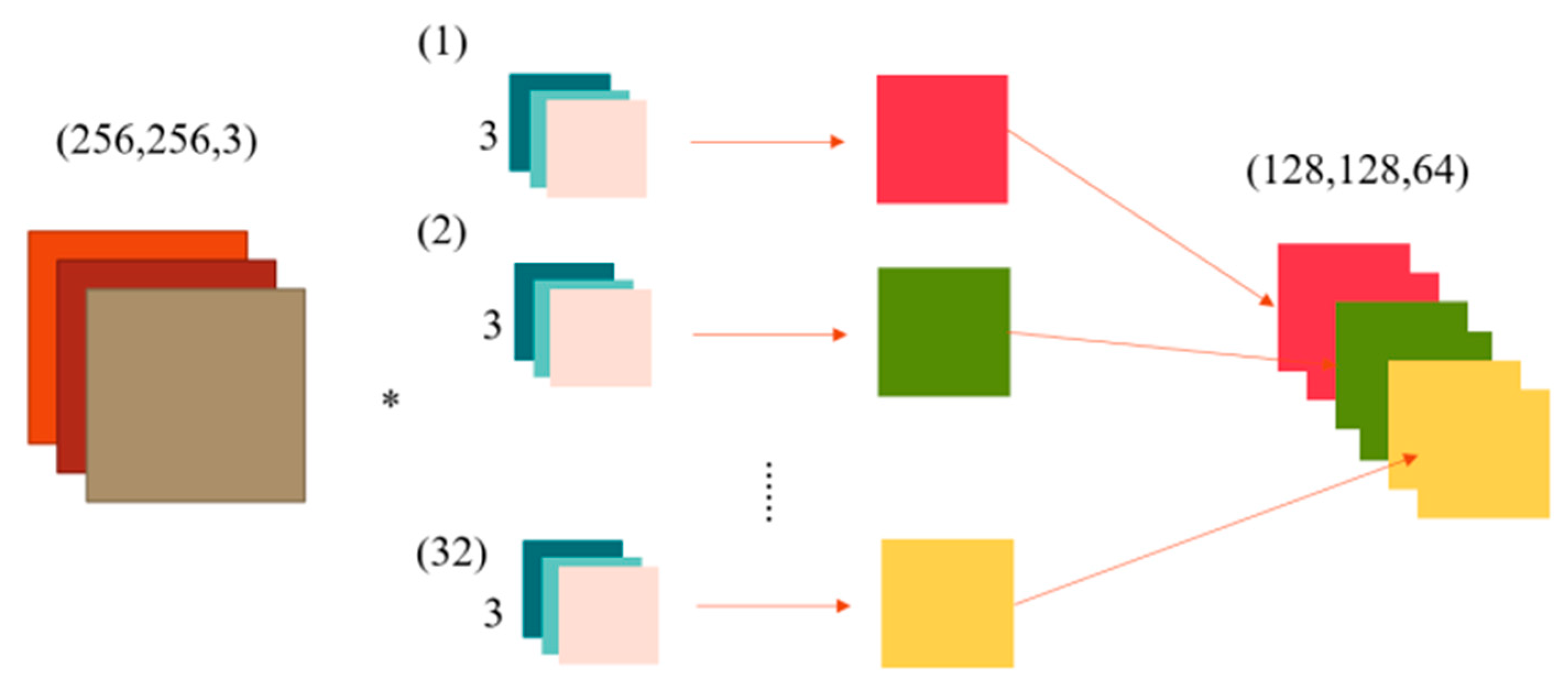
GhostNet introduces an efficient convolutional strategy comprising three stages: standard convolution, ghost feature generation and feature map concatenation. Firstly, a reduced number of intrinsic feature maps are generated through standard convolution with a predefined ratio. Next, ghost features are created by applying lightweight 3 × 3 convolutions to these intrinsic maps. Finally, the intrinsic and ghost features are concatenated to form the complete output feature map.
This mechanism enables GhostNet to maintain the same output dimensionality as standard convolution while reducing the number of parameters and the computational overhead by around 50%. This architecturally efficient approach has been successfully applied in various fields, including medical image segmentation, real-time UAV inspection systems, and emotion recognition applications.
2.4. Depthwise Separable Convolution
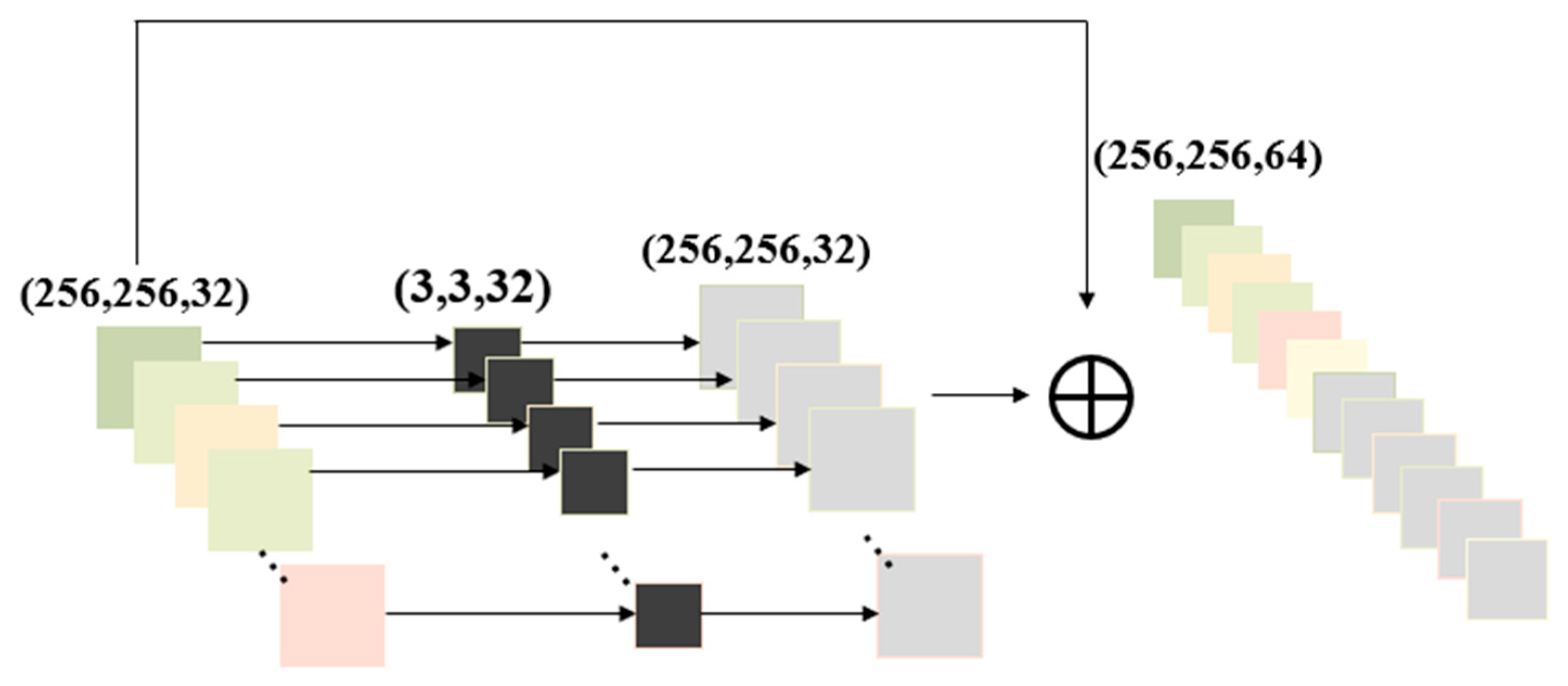
Depthwise separable convolution is a key operation in lightweight convolutional neural networks (CNNs) that significantly reduces computational complexity. It consists of a depthwise convolution, which applies a single filter to each input channel, followed by a pointwise (1 × 1) convolution that combines these features across channels. This operation is more computationally efficient than standard convolution yet still effective in capturing spatial patterns, making it ideal for mobile and edge computing tasks.
2.5. Group Convolution
Group convolution, originally proposed in AlexNet, was designed to enable parallel training on multiple GPUs by partitioning feature maps and filters into distinct groups. While this approach significantly reduces computation and parameter count, it limits information sharing between groups, potentially constraining the model’s learning capacity. Later enhancements, such as depthwise and dilated convolutions, were developed to address this issue.
2.6. Squeeze-and-Excitation Networks
The Squeeze-and-Excitation (SE) module is a channel attention mechanism which explicitly models the interdependencies between feature channels. It consists of three phases: Squeeze, Excitation and Feature Recalibration.
2.6.1. Squeeze
Global average pooling is applied to compress the spatial dimensions and create a channel-wise descriptor.
where
is the descriptor for channel
, and
is the corresponding channel in the input feature map
.
2.6.2. Excitation
The channel descriptors are passed through a gating mechanism comprising two fully connected layers with ReLU and Sigmoid activations.
where
and
are learned weight matrices,
is the ReLU function, and
is the Sigmoid activation. The reduction ratio
controls model complexity.
2.6.3. Feature Recalibration
Each channel is rescaled using the computed attention weights.
This rescaled feature map is then forwarded to the subsequent layers. The SE module is lightweight and modular, and it can be easily integrated into existing CNN architectures to enhance performance with minimal overhead.
2.7. Recent Transformer-Based Approaches
In recent years, transformer-based or hybrid CNN–transformer models have been applied to gaze estimation tasks, especially in real-world scenarios such as retail and human–computer interaction. One such approach utilizes a deep gaze estimation framework that combines convolutional backbones with transformer modules to enhance spatial attention and temporal modeling. While these methods show promising accuracy, they generally incur higher computational and memory costs, making them less suitable for deployment on resource-constrained edge devices [
24].
These limitations further motivate the development of lightweight alternatives. In contrast to transformer-heavy models, our proposed method focuses on CNN-based architectural optimization using GhostBlocks, which achieves substantial FLOPs and parameter reduction while maintaining competitive accuracy for real-time applications.
3. Materials
This study uses the Gaze360 dataset, which is publicly available and was jointly released by the Toyota Research Institute and the Massachusetts Institute of Technology. The dataset comprises annotated 3D gaze labels collected from 238 participants in both indoor and outdoor settings. It encompasses a wide range of head poses, gaze angles and subject distances. This diversity and comprehensive coverage makes the dataset particularly suitable for developing robust gaze estimation models under unconstrained conditions.
3.1. Dataset Characteristics
The key features of the Gaze360 dataset include:
The dataset supports the estimation of gaze in all directions, including those not directly visible to the eye (e.g., behind or peripheral gaze), providing a comprehensive representation of eye movement in natural settings.
It includes annotated pitch and yaw angles of the head, enabling the development of models that can compensate for variations in head movement and improve the robustness of gaze prediction.
The dataset includes 238 individuals of different ages, genders and ethnic backgrounds, ensuring that trained models generalize well across demographic groups.
The recorded data includes a wide range of gaze angles, from direct frontal gaze to extreme lateral and vertical gaze directions, which are critical for training models in real-world applications like driver monitoring or assistive technologies.
In this work, we utilized a subset of the Gaze360 dataset consisting of 112,251 facial images, which we split into 84,902 training images (75.6%), 11,318 validation images (10.1%), and 16,031 test images (14.3%). This partitioning follows the same practice as prior work on L2CS to ensure consistent evaluation across models.
3.2. Data Collection Protocol
To capture a wide range of gaze and head pose variations, the data collection setup uses a Ladybug5 360-degree panoramic camera mounted on a tripod at the center of the recording area. An operator holds a target board marked with a central crosshair and instructs the participant, positioned between one and three meters from the camera, to focus continuously on the target.
During recording, the operator moves the board dynamically in various directions and elevations around the participant and the camera to simulate a wide spectrum of gaze orientations. This setup enables the system to accurately annotate gaze vectors in relation to both head position and environmental context. The panoramic imaging ensures that gaze direction is captured across the entire sphere of visual space, including peripheral and occluded regions.
This flexible yet controlled recording protocol ensures that the dataset contains high-quality, densely distributed gaze annotations that are suitable for training and evaluating appearance-based gaze estimation models in real-world conditions.
5. Experimental Results
This section presents the evaluation results of the proposed lightweight gaze-tracking model. It highlights the model’s performance in terms of computational efficiency and accuracy, and compares it with existing approaches. In
Table 1, the proposed model achieves a significant reduction in computational cost. The FLOPs fall from 1.65 billion to 0.861 billion—a reduction of 47.9%. Additionally, the parameter count drops from 0.23 million to 0.12 million—a 48.74% decrease—demonstrating the effectiveness of the applied model compression techniques. Despite these reductions, the MAE increases by only 1.5%, from 10.7 to 10.87—a reasonable compromise given the computational gains.
To validate the model further, we compared it with several gaze-tracking methods that were trained using the Gaze360 dataset in recent years. In
Table 2, the proposed model significantly improves inference speed while maintaining comparable accuracy to other state-of-the-art methods, confirming its suitability for real-time applications.
While the 1.5% increase in MAE may appear marginal in general terms, its practical implications depend on specific application requirements. For instance, in driver-monitoring systems, an angular error tolerance within 3–5 degrees is typically sufficient to distinguish between on-road and off-road gaze. The proposed model’s MAE of 10.87° remains consistent with other state-of-the-art methods trained on the Gaze360 dataset while delivering substantial reductions in computational complexity. This trade-off between accuracy and efficiency makes the proposed model suitable for real-time deployment in resource-constrained environments.
Figure 6 shows the results of gaze tracking, visualizing two test images under different lighting conditions and viewing angles. The green arrow represents the ground truth gaze, while the red and yellow arrows show predictions from the proposed model and the original L2CS model, respectively.
Table 3 summarizes the corresponding pitch and yaw errors, demonstrating that the proposed model retains strong accuracy across varying conditions.
We also compared the baseline L2CS architecture with other lightweight models, including MobileNets, ConvNets and ResNeXts. As shown in
Table 4, L2CS outperforms the others in terms of mean absolute error (MAE) due to its gaze-specific architectural design. While other models excel in general vision tasks, the tailored structure of L2CS better captures subtle eye movements, making it an ideal foundation for further optimization.
When exploring the addition of attention mechanisms, we incorporated a Squeeze-and-Excitation (SE) block into our model. However, as shown in
Table 5, the SE block did not provide any significant improvement in accuracy and was therefore excluded from the final design to avoid unnecessary overhead.
Furthermore, we examined the impact of the feature reduction ratio when generating primary features in GhostBlocks. As shown in
Table 6, a larger ratio leads to smaller feature maps and faster computation but results in a higher error rate. A reduction ratio of
S = 2 was therefore adopted to strike the best balance between performance and speed.
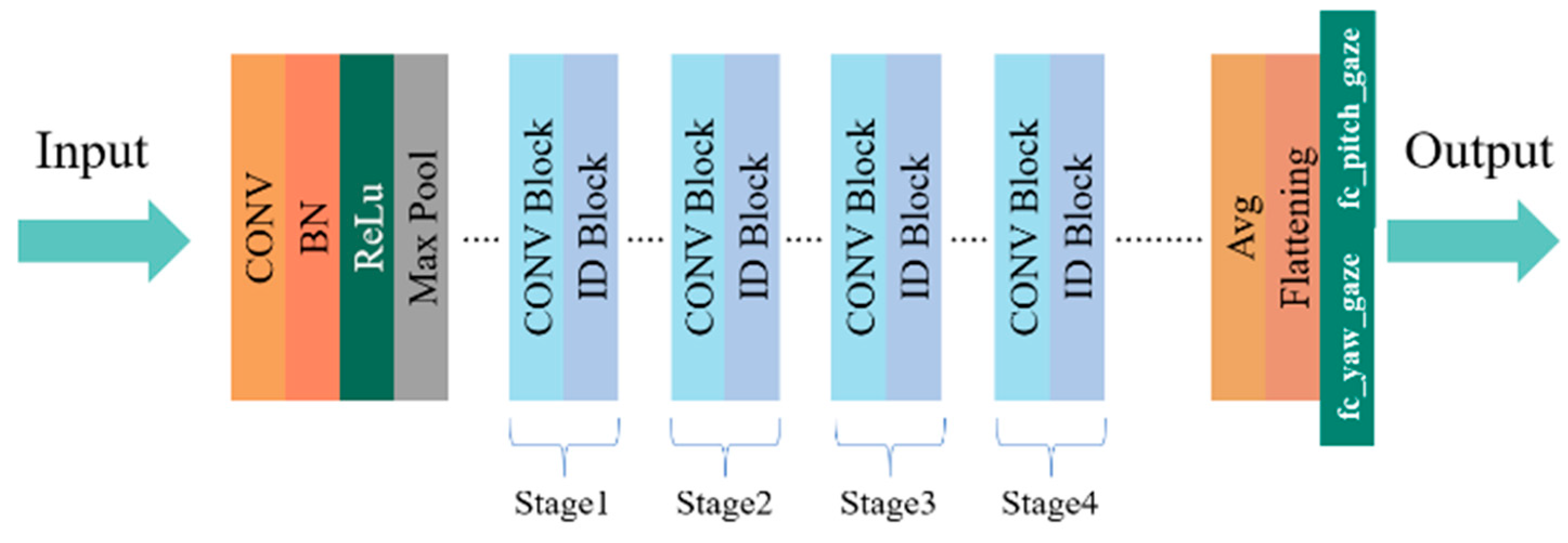
Finally, we evaluated the effect of applying the proposed optimization strategy to different convolutional blocks within the ResNet-based backbone. In
Table 7, the labels “1st Block” to “4th Block” correspond to the four sequential bottleneck block groups (Stages 1 to 4) in ResNet, as illustrated in
Figure 1. The results show that applying GhostBlock only to the first block (Stage 1) leads to a modest reduction in FLOPs and slightly increased MAE. As more blocks are replaced (e.g., Stages 1–3), the MAE temporarily degrades, likely due to partial feature inconsistency introduced in early and middle layers. However, when all four blocks (Stages 1–4) are replaced, the model achieves the best performance in both efficiency and accuracy. This confirms that uniformly applying architectural improvements across all stages is essential for maintaining feature consistency and enhancing overall performance.
In addition, we conducted a supplementary experiment to examine the impact of different group settings in the linear operation of GhostBlocks. Under the same configuration of S = 2 and full block replacement, we tested various group numbers for the grouped convolution. The results showed that setting the group number to 1 provides the best balance between accuracy and efficiency. In
Table 8, the results validates our design choice, as group = 1 is equivalent to a depthwise convolution and maintains strong gaze estimation performance without introducing excessive computational complexity.
To further evaluate the real-time performance of the proposed model in a practical setting, we conducted a live inference test in an indoor environment using a Logitech C922 Pro Stream webcam configured at 720p resolution. The experiment was carried out on a desktop system equipped with an Intel Core i7-12700K CPU, 32 GB DDR4 RAM, and an NVIDIA GeForce RTX 3060 Ti GPU running Ubuntu 20.04. We evaluated the real-time inference performance under continuous frame input in an indoor environment. The baseline L2CS model achieved 35.2 FPS, while the proposed lightweight model reached 45.6 FPS. These results demonstrate that the model reduces theoretical computational cost.
6. Conclusions
This paper proposes an efficient, lightweight gaze-tracking model designed for use on terminals and edge devices. By integrating GhostNet into the convolutional architecture of the L2CS model, redundant feature maps are effectively eliminated during convolution operations, reducing computational cost without significantly compromising accuracy. Through careful analysis of the feature representations at each layer, the proposed model selectively retains informative features while discarding non-essential ones using GhostNet’s lightweight convolutional mechanism. Consequently, compared to the original L2CS model (16.527 × 108 FLOPs, 2.387 × 105 parameters), the proposed model (8.610 × 108 FLOPs, 1.224 × 105 parameters) achieves a 47.9% reduction in FLOPs and a 48.74% decrease in the number of parameters, with only a 1.5% increase in mean angular error. These results demonstrate that the proposed optimization strategy successfully balances model accuracy, computational efficiency and deployment feasibility. This confirms the method’s suitability for real-time gaze estimation tasks on platforms with limited resources, such as in-vehicle systems, mobile devices, and embedded vision modules.
However, it is worth noting that the model exhibits slight performance degradation under challenging conditions such as extreme lighting, occlusion, and rapid head movement. Moreover, the current study evaluates performance solely on the Gaze360 dataset, which may not fully capture the diversity of real-world settings. To address this, future work will include cross-dataset evaluations using MPIIGaze to further validate generalization capability. We also plan to incorporate temporal cues from sequential frames and explore domain adaptation techniques to enhance robustness across varied environments and hardware constraints.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}