
Deep-CNN-Based Layout-to-SEM Image Reconstruction with Conformal Uncertainty Calibration for Nanoimprint Lithography in Semiconductor Manufacturing



Abstract
1. Introduction
1.1. Nanoimprint Lithography: Principles, Advantages, and Manufacturing Challenges
1.2. AI and Deep Learning for Layout-to-SEM Reconstruction in NIL
1.3. Need for Reliable Uncertainty Quantification
1.4. Conformal Prediction and Conformalized Quantile Regression
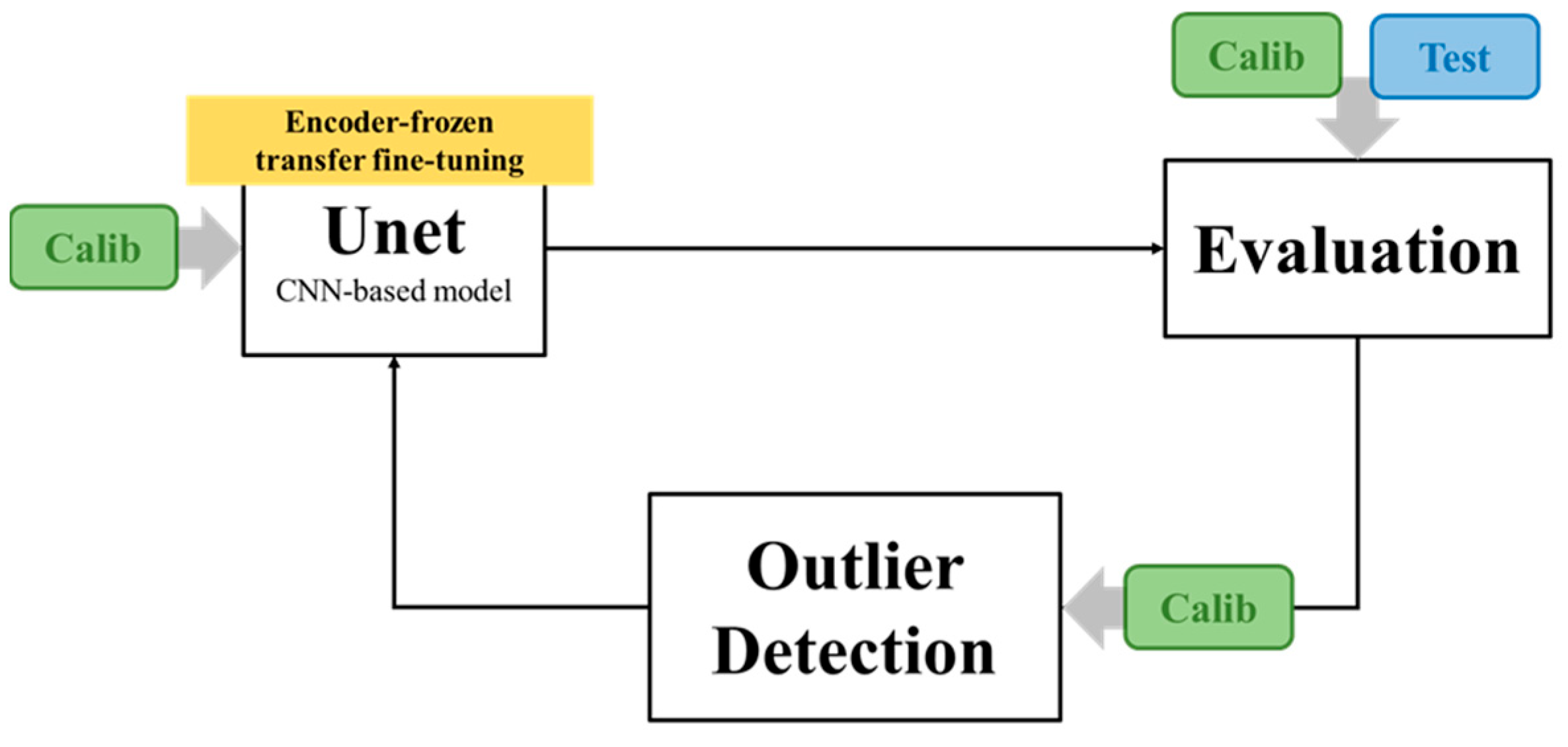
1.5. Calibration Flow and Transfer Learning
1.6. Contribution and Scope of This Work
- (1)
- A U-Net-based CNN model for hierarchical spatial feature learning;
- (2)
- CQR for interval-based predictions with statistical coverage guarantees;
- (3)
- Pixel-level outlier detection for localized uncertainty awareness;
- (4)
- An outlier-weighted fine-tuning strategy for enhancing adaptability to spatial variability.
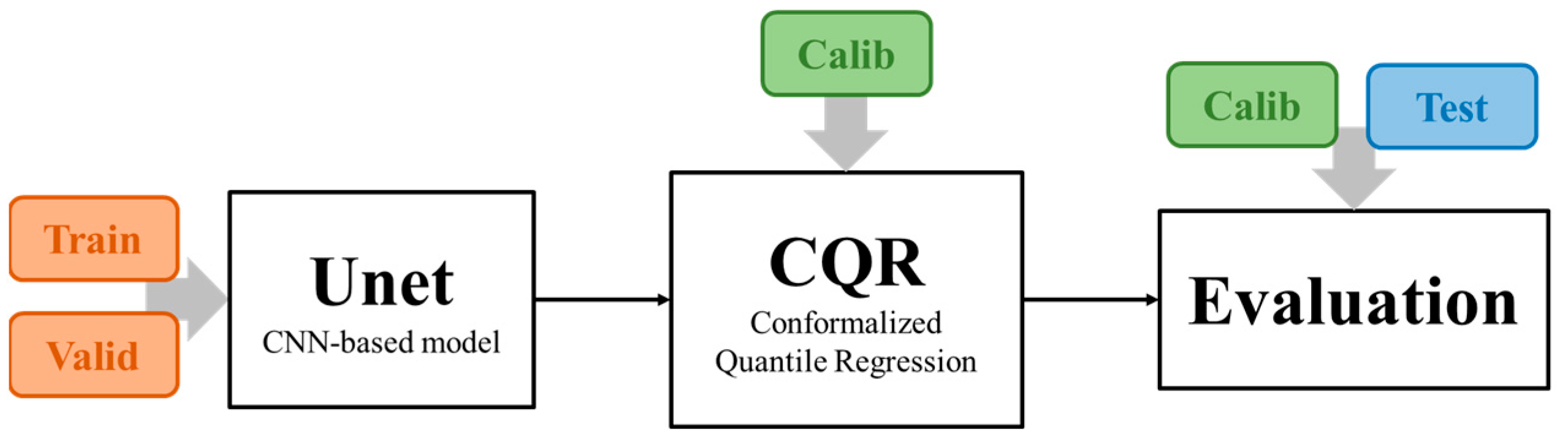
2. Materials and Methods
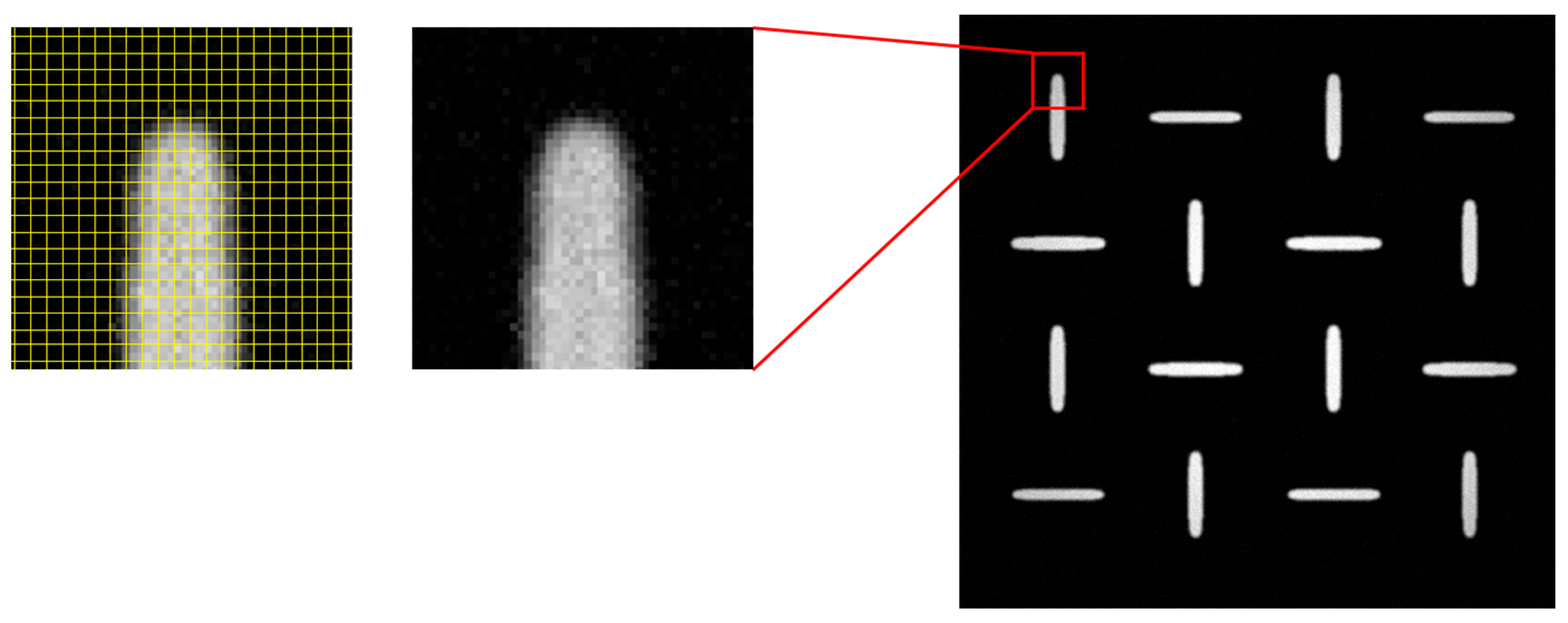
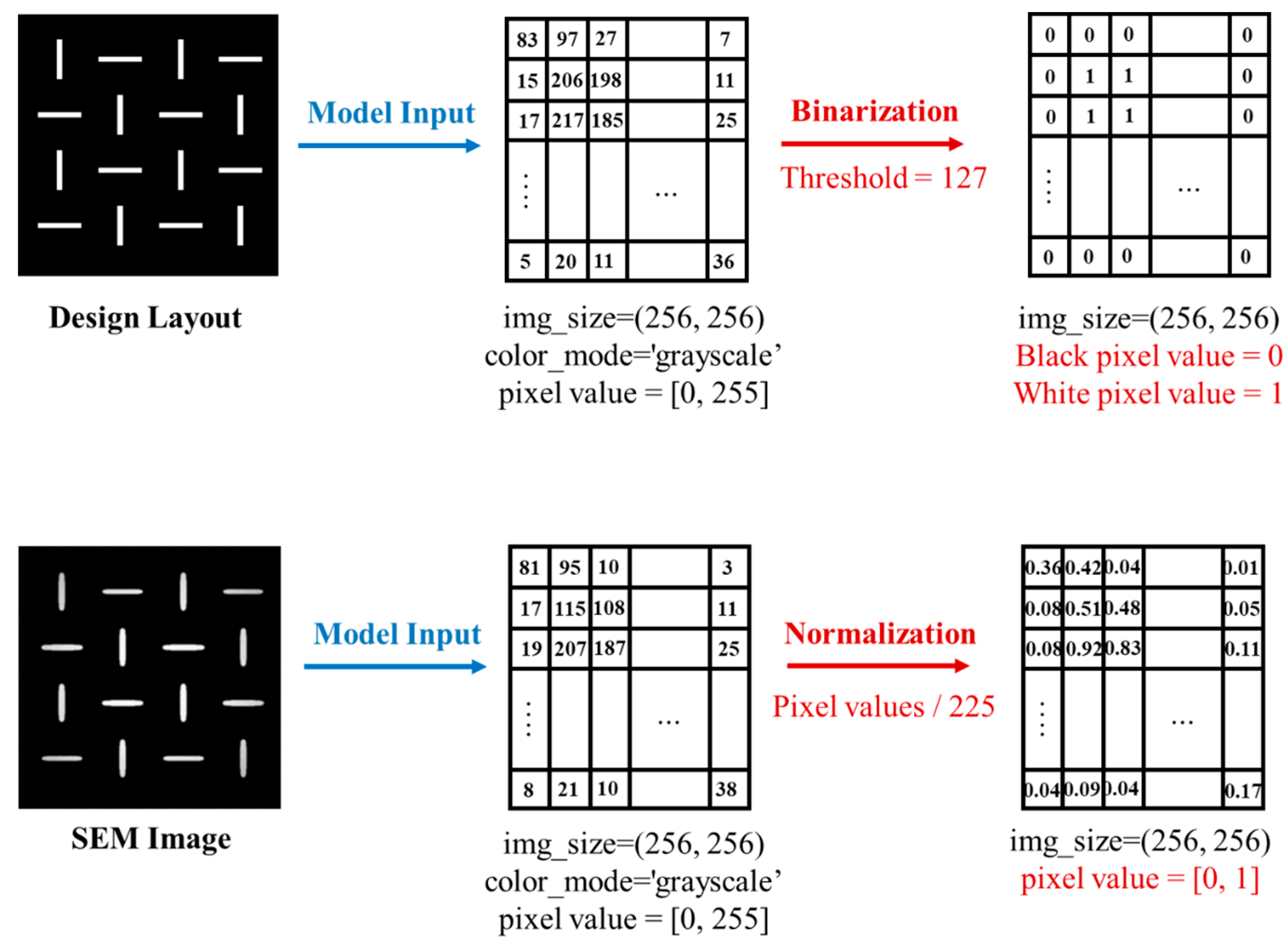
2.1. Dataset Preparation
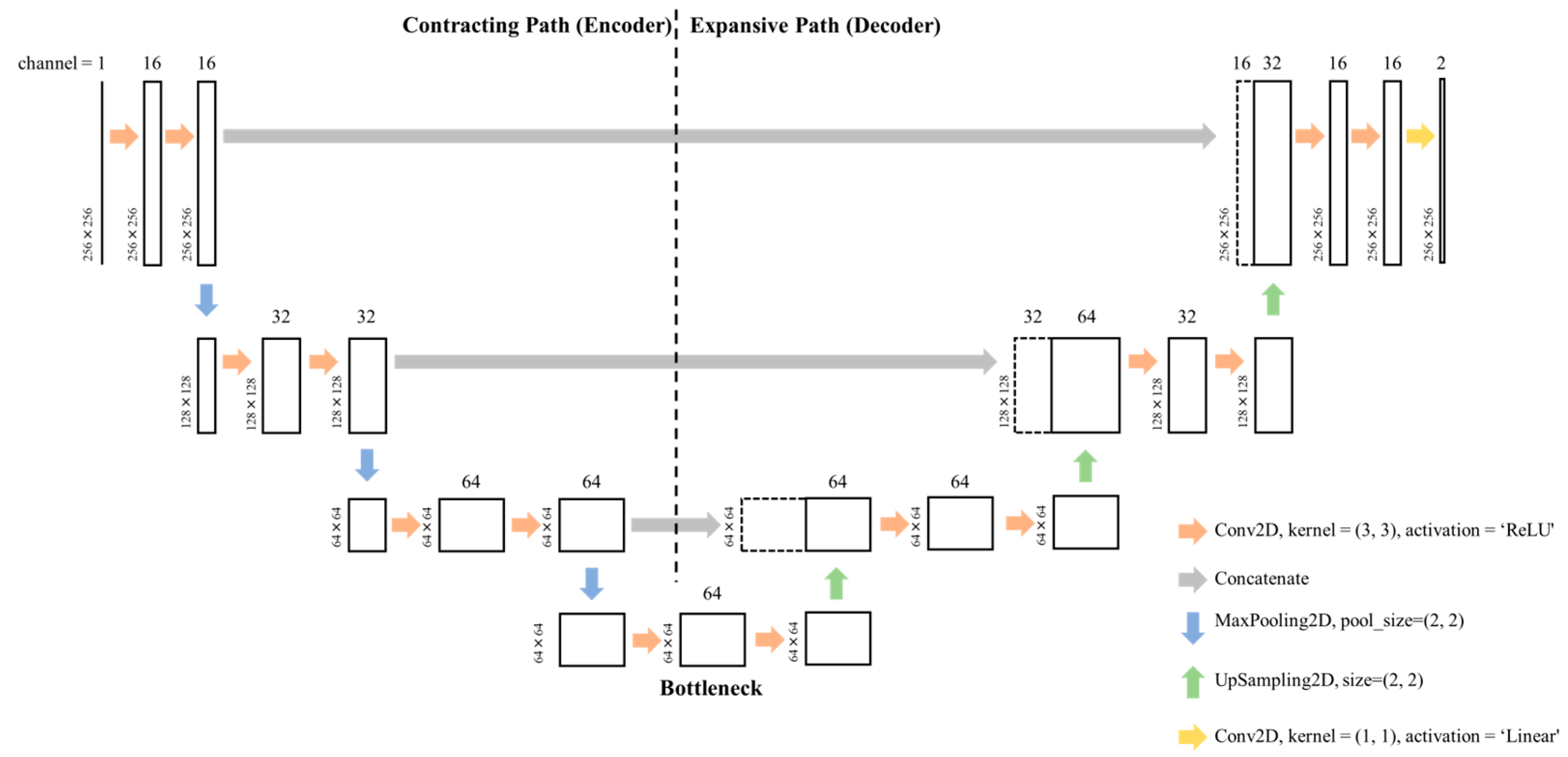
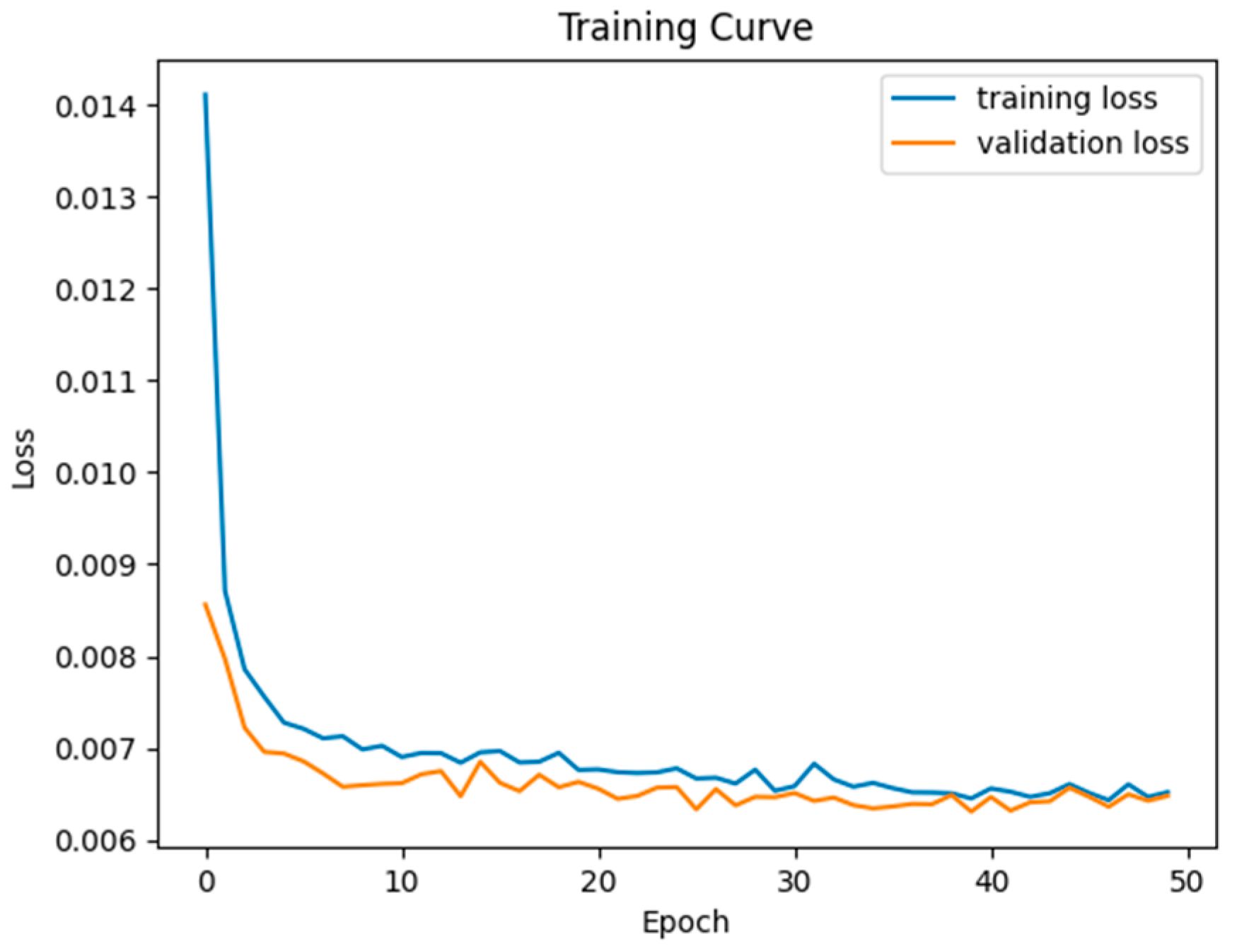
2.2. CNN-Based Model and Training
2.3. Conformalized Quantile Regression (CQR)
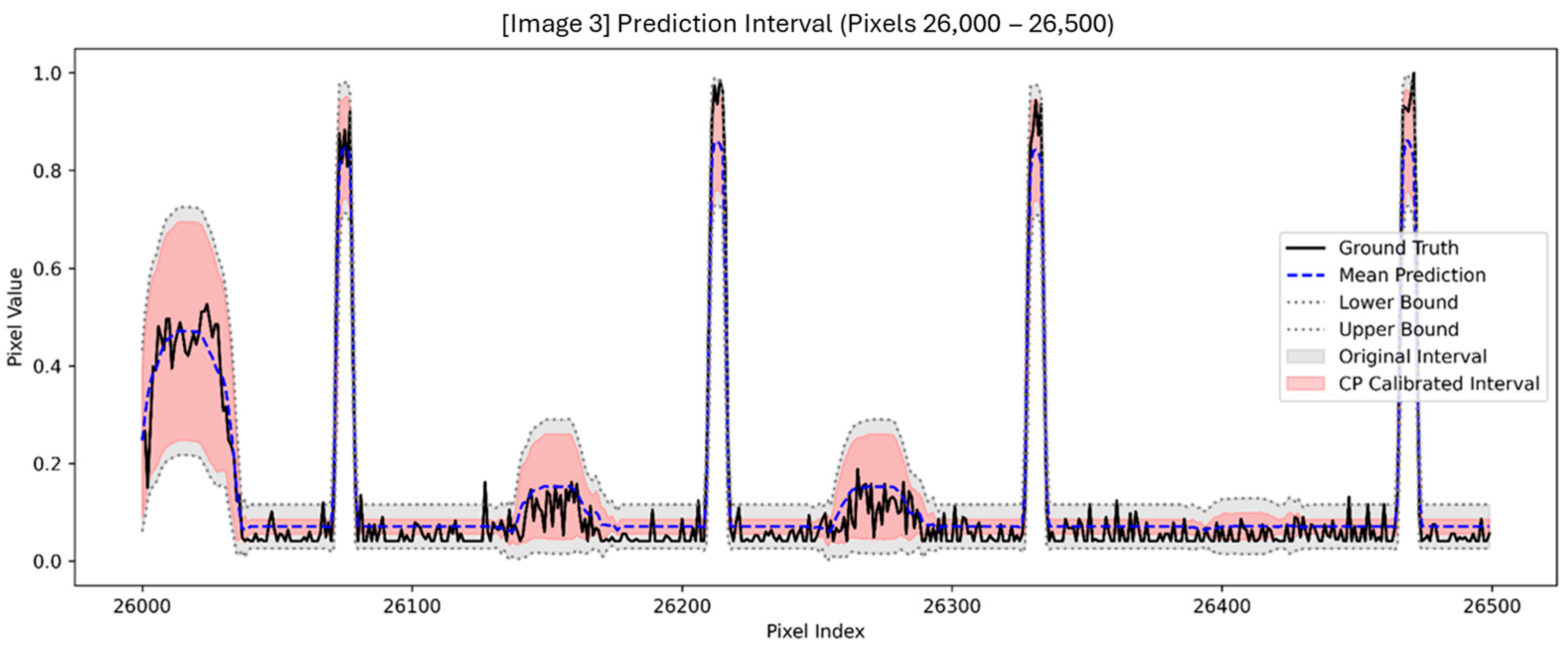
2.4. Outlier-Weighted Calibration and Transfer Learning
2.5. Evaluation Metrics
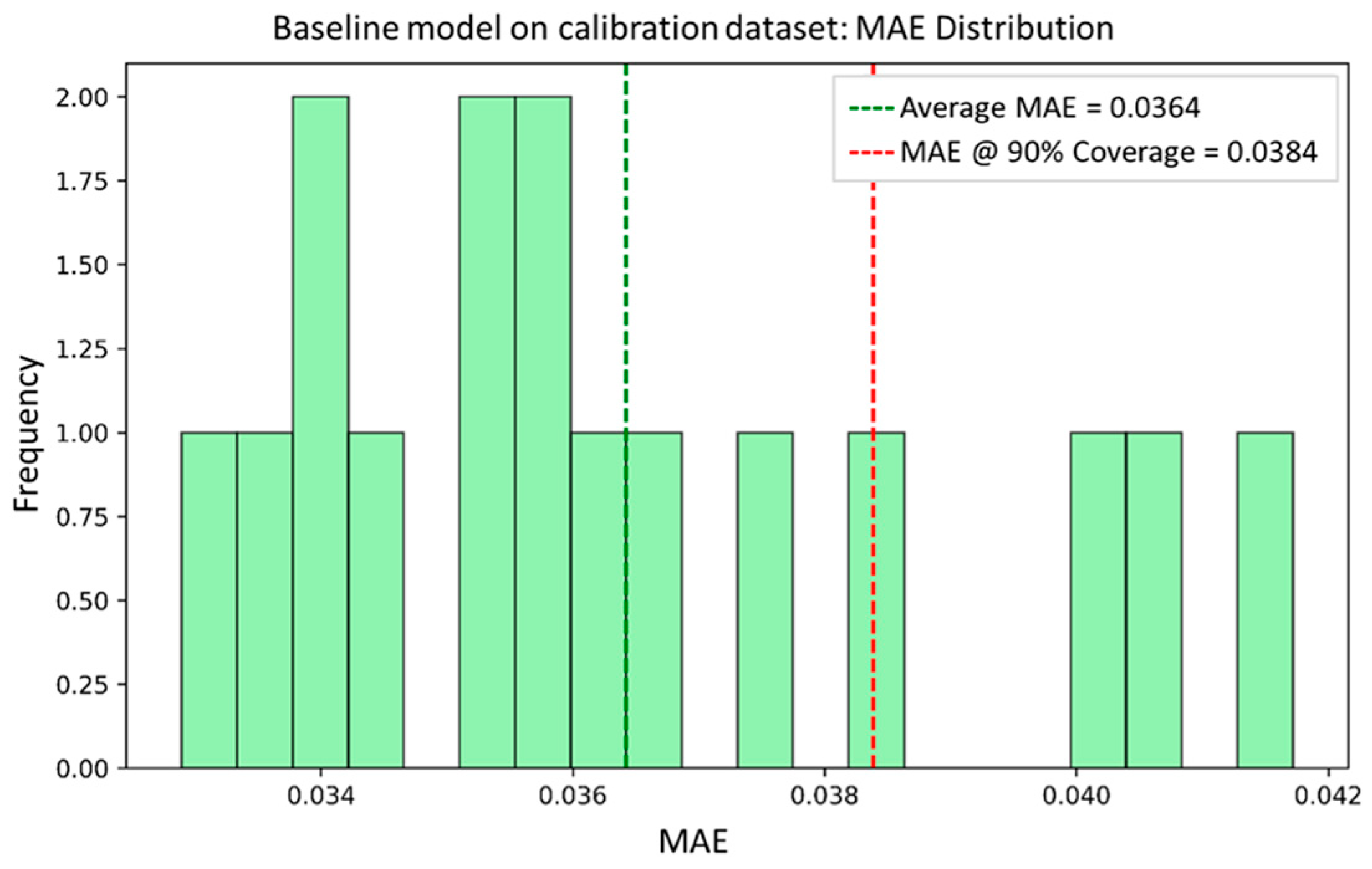
2.5.1. Mean Absolute Error (MAE)
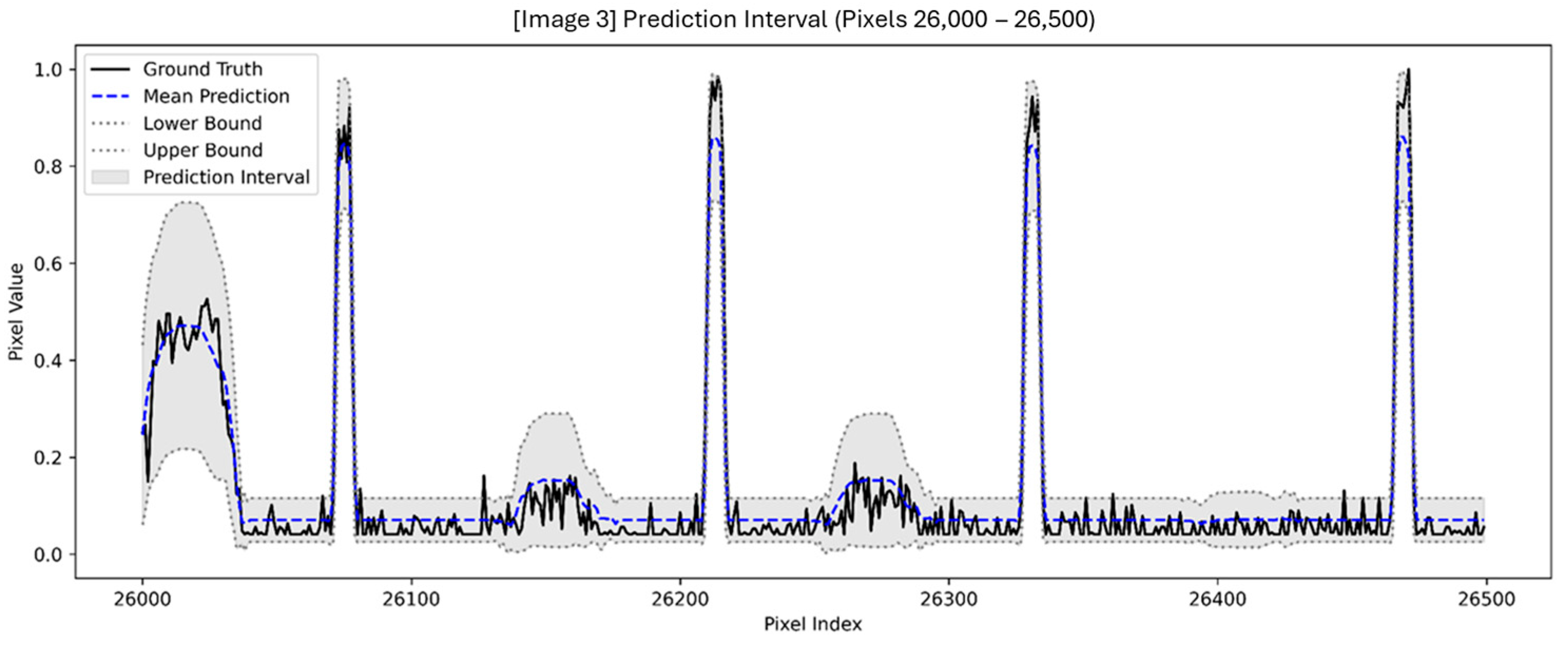
2.5.2. Prediction Interval Coverage
3. Results
3.1. Baseline Evaluation
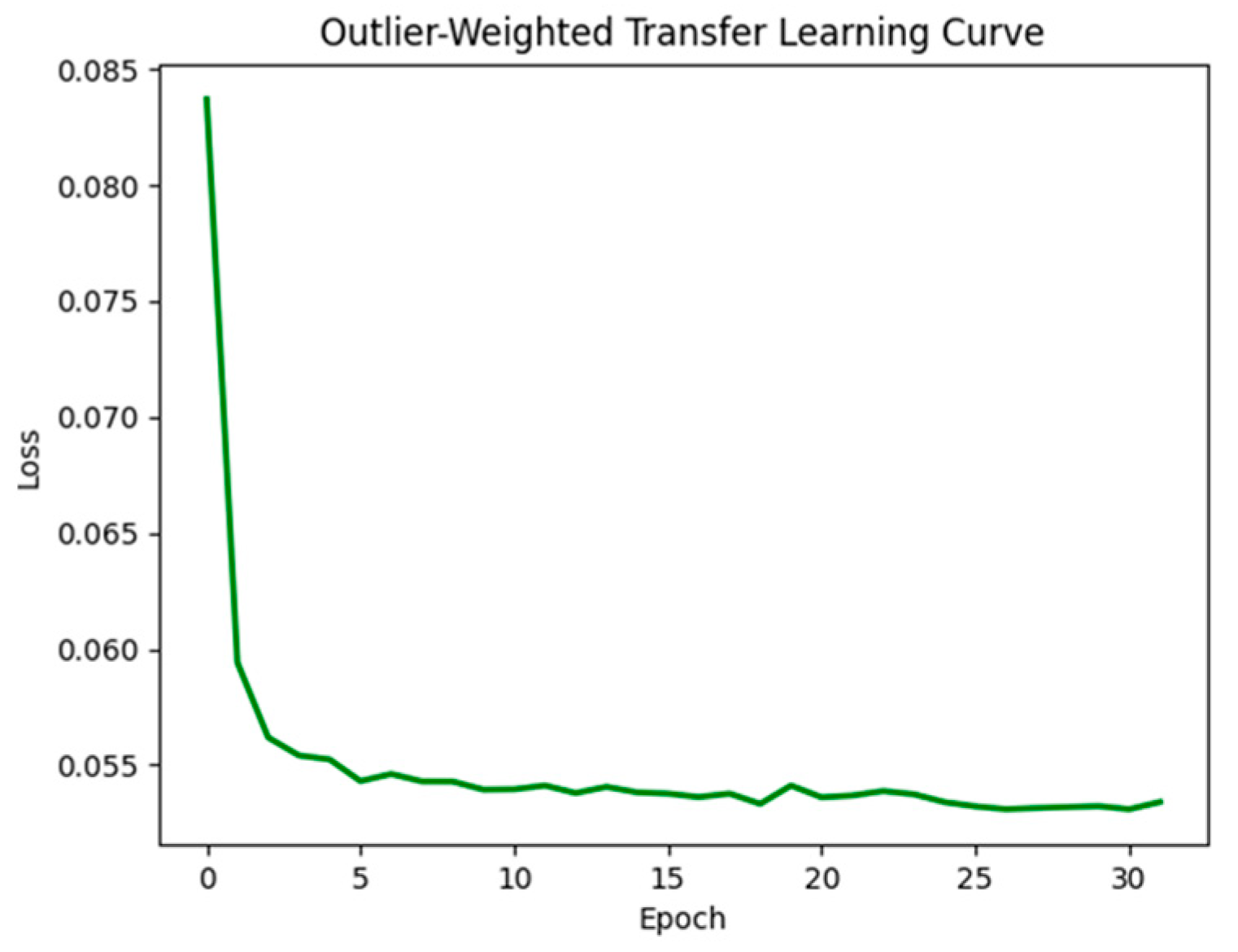
3.2. Outlier-Weighted Calibration and Transfer Learning Evaluation
4. Discussion and Implications
5. Conclusions and Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NIL | Nanoimprint lithography |
| CQR | Conformalized quantile regression |
| MAE | Mean absolute error |
| OPC | Optical proximity correction |
| AI | Artificial intelligence |
| SEM | Scanning electron microscope |
| ADI | After-development inspection |
| SMOTE | Synthetic minority over-sampling |
| UQ | Uncertainty quantification |
| ML | Machine learning |
| CNN | Convolutional neural network |
| CP | Conformal prediction |
| LWCP | Locally Weighted Conformal Prediction |
| EBL | Electron beam lithography |
| RIE | Reactive ion etching |
Appendix A
Appendix A.1. GPU Execution and Training Environment

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Detail |
|---|---|
| GPU Hardware | NVIDIA RTX 3060 (12 GB) |
| CUDA Version | 12.6 (Driver: 560.94) |
| Framework | TensorFlow 2.10.0 |
| Memory Growth Enabled | Yes |
| Input Image Size | 256 × 256 (grayscale, single-channel) |
| Batch Size | 1 |
| Training Epochs | 50 (baseline), 32 (fine-tuning with early stopping) |
| Data Split | 60% training, 18% validation, 12% calibration, 10% test |
| Augmentation | Geometric (Fixed Rotations ×4): 0°, 90°, 180°, 270° |
| GPU Time Reduction | 36 min (baseline) → 10 min (fine-tuning) |
| Labeled Data Reduction | 240 images (baseline)→ 48 images (fine-tuning) |
Appendix A.2. Model Hyperparameter Settings
| Hyperparameter | Value/Description |
|---|---|
| Model Architecture | Shallow U-Net |
| Input Shape | 256 × 256 × 1 (grayscale mask) |
| Output Shape | 256 × 256 × 2 (lower and upper quantile bounds) |
| Convolution Kernel Size | 3 × 3 (for all convolutional layers) |
| Number of Filters | [16, 32, 64, 32, 16] across layers |
| Activation Function | ReLU (all intermediate layers), Linear (final layer) |
| Output Quantiles (CQR) | q = 0.05 (lower), q = 0.95 (upper) |
| Optimizer | Adam |
| Learning Rate | Default (0.001) |
| Weighting Strategy | Pixel-wise reweighting for outliers (γ = 1.3) |
| Loss Function | CQR (90% coverage): sum of pinball losses at q = 0.05, 0.95 |
| Transfer Strategy | Encoder frozen; only decoder fine-tuned |
References
- Young, W.-B. Analysis of the nanoimprint lithography with a viscous model. Microelectron. Eng. 2005, 77, 405–411. [Google Scholar] [CrossRef]
- Hirai, Y.; Onishi, Y.; Tanabe, T.; Shibata, M.; Iwasaki, T.; Iriye, Y. Pressure and resist thickness dependency of resist time evolutions profiles in nanoimprint lithography. Microelectron. Eng. 2008, 85, 842–845. [Google Scholar] [CrossRef]
- Ifuku, T.; Yonekawa, M.; Nakagawa, K.; Sato, K.; Saito, T.; Aihara, S.; Ito, T.; Yamamoto, K.; Hiura, M.; Sakai, K.; et al. Nanoimprint lithography performance advances for new application spaces. In Proceedings of the SPIE Advanced Lithography + Patterning, San Jose, CA, USA, 25–29 February 2024; Novel Patterning Technologies 2024. SPIE: Bellingham, WA, USA, 2024. [Google Scholar]
- Rawlings, C.D.; Kulmala, T.S.; Spieser, M.; Holzner, F.; Glinsner, T.; Schleunitz, A.; Bullerjahn, F.; Panning, E.M.; Sanchez, M.I. Single-nanometer accurate 3D nanoimprint lithography with master templates fabricated by NanoFrazor lithography. In Proceedings of the SPIE Advanced Lithography, San Jose, CA, USA, 25 February–1 March 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10584. [Google Scholar]
- Sirotkin, V.; Svintsov, A.; Schift, H.; Zaitsev, S. Coarse-grain method for modeling of stamp and substrate deformation in nanoimprint. Microelectron. Eng. 2007, 84, 868–871. [Google Scholar] [CrossRef]
- Takeuchi, N.; Hasegawa, G.; Toshiaki, K.; Iwasaki, T.; Hatano, M.; Komori, M.; Kono, T.; Liddle, J.A.; Ruiz, R. Fabrication of dual damascene structure with nanoimprint lithography and dry-etching. In Proceedings of the SPIE Advanced Lithography + Patterning, San Jose, CA, USA, 23 February–2 March 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12497. [Google Scholar]
- Aihara, S.; Yamamoto, K.; Nakano, Y.; Kijima, H.; Jimbo, S.; Evans, H.B.; Ishida, S.; Fujimoto, M.; Takami, S.; Oguchi, Y.; et al. NIL solutions using computational lithography for semiconductor device manufacturing. In Proceedings of the SPIE Advanced Lithography + Patterning, San Jose, CA, USA, 25–29 February 2024; SPIE: Bellingham, WA, USA, 2024; Volume 12954. [Google Scholar]
- Chou, S.Y.; Krauss, P.R.; Renstrom, P.J. Nanoimprint lithography. J. Vac. Sci. Technol. B Microelectron. Nanometer Struct. Process. Meas. Phenom. 1996, 14, 4129–4133. [Google Scholar] [CrossRef]
- Guo, L.J. Nanoimprint lithography: Methods and material requirements. Adv. Mater. 2007, 19, 495–513. [Google Scholar] [CrossRef]
- Yan, Y.; Shi, X.; Zhou, T.; Xu, B.; Li, C.; Yuan, W.; Gao, Y.; Pan, B.; Diao, X.; Chen, S.; et al. Machine learning virtual SEM metrology and SEM-based OPC model methodology. J. Micro/Nanopatterning Mater. Metrol. 2021, 20, 041204. [Google Scholar] [CrossRef]
- Tseng, J.; Chien, J.; Lee, E. Advanced defect recognition on scanning electron microscope images: A two-stage strategy based on deep convolutional neural networks for hotspot monitoring. J. Micro/Nanopatterning Mater. Metrol. 2024, 23, 044201. [Google Scholar] [CrossRef]
- Ogusu, M.; Ishida, M.; Tamura, M.; Sakai, K.; Ito, T.; Ito, Y.; Kawata, I.; Kunugi, H.; Tamura, S.; Asako, R.; et al. Nanoimprint post processing techniques to address edge placement error. In Proceedings of the SPIE Advanced Lithography + Patterning, San Jose, CA, USA, 23 February–2 March 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12497. [Google Scholar]
- Dini, P.; Elhanashi, A.; Begni, A.; Saponara, S.; Zheng, Q.; Gasmi, K. Overview on intrusion detection systems design exploiting machine learning for networking cybersecurity. Appl. Sci. 2023, 13, 7507. [Google Scholar] [CrossRef]
- Dini, P.; Saponara, S. Cogging torque reduction in brushless motors by a nonlinear control technique. Energies 2019, 12, 2224. [Google Scholar] [CrossRef]
- Akpabio, I.I.; Savari, S.A. Uncertainty quantification of machine learning models: On conformal prediction. J. Micro/Nanopatterning Mater. Metrol. 2021, 20, 041206. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Acun, C.; Ashary, A.; Popa, D.O.; Nasraoui, O. Optimizing Local Explainability in Robotic Grasp Failure Prediction. Electronics 2025, 14, 2363. [Google Scholar] [CrossRef]
- Elhanashi, A.; Saponara, S.; Zheng, Q.; Almutairi, N.; Singh, Y.; Kuanar, S.; Ali, F.; Unal, O.; Faghani, S. AI-Powered Object Detection in Radiology: Current Models, Challenges, and Future Direction. J. Imaging 2025, 11, 141. [Google Scholar] [CrossRef] [PubMed]
- Elhanashi, A.; Lowe, D.; Saponara, S.; Moshfeghi, Y.; Kehtarnavaz, N.; Carlsohn, M.F. Deep learning techniques to identify and classify COVID-19 abnormalities on chest x-ray images. In Proceedings of the SPIE Defense + Commercial Sensing, Orlando, FL, USA, 3–7 April 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12102. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.; et al. Nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]
- Han, N.; Zhou, L.; Xie, Z.; Zheng, J.; Zhang, L. Multi-level U-net network for image super-resolution reconstruction. Displays 2022, 73, 102192. [Google Scholar] [CrossRef]
- Xu, W.; Deng, X.; Guo, S.; Chen, J.; Sun, L.; Zheng, X.; Xiong, Y.; Shen, Y.; Wang, X. High-resolution u-net: Preserving image details for cultivated land extraction. Sensors 2020, 20, 4064. [Google Scholar] [CrossRef] [PubMed]
- Yue, X.; Liu, D.; Wang, L.; Benediktsson, J.A.; Meng, L.; Deng, L. IESRGAN: Enhanced U-net structured generative adversarial network for remote sensing image super-resolution reconstruction. Remote Sens. 2023, 15, 3490. [Google Scholar] [CrossRef]
- Ma, X.; Yang, Y.; Shao, D.; Kit, F.C.; Dong, C. HyADS: A Hybrid Lightweight Anomaly Detection Framework for Edge-Based Industrial Systems with Limited Data. Electronics 2025, 14, 2250. [Google Scholar] [CrossRef]
- Zhai, G.; Zhou, J.; Yang, H.; Zhang, Y. A Sea-Surface Radar Target-Detection Method Based on an Improved U-Net and Its FPGA Implementation. Electronics 2025, 14, 1944. [Google Scholar] [CrossRef]
- Joo, Y.H.; Park, H.; Kim, H.; Choe, R.; Kang, Y.; Jung, J.-Y. Traffic Flow Speed Prediction in Overhead Transport Systems for Semiconductor Fabrication Using Dense-UNet. Processes 2022, 10, 1580. [Google Scholar] [CrossRef]
- Taylor, H.; Boning, D. Towards nanoimprint lithography-aware layout design checking. In Design for Manufacturability Through Design-Process Integration IV; SPIE: Bellingham, WA, USA, 2010. [Google Scholar]
- Haas, S.; Hüllermeier, E. Conformalized prescriptive machine learning for uncertainty-aware automated decision making: The case of goodwill requests. Int. J. Data Sci. Anal. 2024, 17, 1–17. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Ghanem, R.; Higdon, D.; Owhadi, H. Handbook of Uncertainty Quantification; Springer: New York, NY, USA, 2017; Volume 6. [Google Scholar]
- Ding, Y.; Liu, J.; Xu, X.; Huang, M.; Zhuang, J.; Xiong, J.; Shi, Y. Uncertainty-aware training of neural networks for selective medical image segmentation. In Proceedings of the Medical Imaging with Deep Learning, Montreal, QC, Canada, 6–9 July 2020; PMLR: Cambridge, MA, USA, 2020. [Google Scholar]
- Dawood, T.; Chen, C.; Sidhu, B.S.; Ruijsink, B.; Gould, J.; Porter, B.; Elliott, M.K.; Mehta, V.; Rinaldi, C.A.; Puyol-Antón, E.; et al. Uncertainty aware training to improve deep learning model calibration for classification of cardiac MR images. Med. Image Anal. 2023, 88, 102861. [Google Scholar] [CrossRef] [PubMed]
- Dawood, T.; Chen, C.; Andlauer, R.; Sidhu, B.S.; Ruijsink, B.; Gould, J.; Porter, B.; Elliott, M.; Mehta, V.; Rinaldi, C.A.; et al. Uncertainty-aware training for cardiac resynchronisation therapy response prediction. In Proceedings of the International Workshop on Statistical Atlases and Computational Models of the Heart, Strasbourg, France, 27 September 2021; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Palmer, G.; Du, S.; Politowicz, A.; Emory, J.P.; Yang, X.; Gautam, A.; Gupta, G.; Li, Z.; Jacobs, R.; Morgan, D. Calibration after bootstrap for accurate uncertainty quantification in regression models. npj Comput. Mater. 2022, 8, 115. [Google Scholar] [CrossRef]
- Ren, Y.; Gu, Z.; Wang, Z.; Tian, Z.; Liu, C.; Lu, H.; Du, X.; Guizani, M. System log detection model based on conformal prediction. Electronics 2020, 9, 232. [Google Scholar] [CrossRef]
- Campos, M.; Farinhas, A.; Zerva, C.; Figueiredo, M.A.T.; Martins, A.F.T. Conformal prediction for natural language processing: A survey. Trans. Assoc. Comput. Linguist. 2024, 12, 1497–1516. [Google Scholar] [CrossRef]
- Zhou, X.; Chen, B.; Gui, Y.; Cheng, L. Conformal prediction: A data perspective. ACM Comput. Surv. 2025. [Google Scholar] [CrossRef]
- Sesia; Matteo; Romano, Y. Conformal prediction using conditional histograms. Adv. Neural Inf. Process. Syst. 2021, 34, 6304–6315. [Google Scholar]
- Jensen, V.; Bianchi, F.M.; Anfinsen, S.N. Ensemble conformalized quantile regression for probabilistic time series forecasting. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 9014–9025. [Google Scholar] [CrossRef] [PubMed]
- Che, L.; Wu, C.; Hou, Y. Large Language Model Text Adversarial Defense Method Based on Disturbance Detection and Error Correction. Electronics 2025, 14, 2267. [Google Scholar] [CrossRef]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to reweight examples for robust deep learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; PMLR: Cambridge, MA, USA, 2018. [Google Scholar]
- Krishnan, R.; Tickoo, O. Improving model calibration with accuracy versus uncertainty optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 18237–18248. [Google Scholar]
- Zhang, L.; Garming, M.W.; Hoogenboom, J.P.; Kruit, P. Beam displacement and blur caused by fast electron beam deflection. Ultramicroscopy 2020, 211, 112925. [Google Scholar] [CrossRef] [PubMed]
- Manfrinato, V.R. Electron-Beam Lithography Towards the Atomic Scale and Applications to Nano-Optics. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2015. [Google Scholar]
- Cord, B.; Yang, J.; Duan, H.; Joy, D.C.; Klingfus, J.; Berggren, K.K. Limiting factors in sub-10 nm scanning-electron-beam lithography. J. Vac. Sci. Technol. B Microelectron. Nanometer Struct. Process. Meas. Phenom. 2009, 27, 2616–2621. [Google Scholar]
- Kaganskiy, A.; Heuser, T.; Schmidt, R.; Rodt, S.; Reitzenstein, S. CSAR 62 as negative-tone resist for high-contrast e-beam lithography at temperatures between 4 K and room temperature. J. Vac. Sci. Technol. B 2016, 34, 061603. [Google Scholar] [CrossRef]
- Bobinac, J.; Reiter, T.; Piso, J.; Klemenschits, X.; Baumgartner, O.; Stanojevic, Z.; Strof, G.; Karner, M.; Filipovic, L. Effect of mask geometry variation on plasma etching profiles. Micromachines 2023, 14, 665. [Google Scholar] [CrossRef] [PubMed]
- Schirmer, M.; Büttner, B.; Syrowatka, F.; Schmidt, G.; Köpnick, T.; Kaiser, C.; Behringer, U.F.W.; Maurer, W. Chemical Semi-Amplified positive E-beam Resist (CSAR 62) for highest resolution. In Proceedings of the 29th European Mask and Lithography Conference, Dresden, Germany, 25–27 June 2013; SPIE: Bellingham, WA, USA, 2013. [Google Scholar]
- Gangnaik, A.S.; Georgiev, Y.M.; Holmes, J.D. New generation electron beam resists: A review. Chem. Mater. 2017, 29, 1898–1917. [Google Scholar] [CrossRef]
- Thoms, S.; Macintyre, D.S. Investigation of CSAR 62, a new resist for electron beam lithography. J. Vac. Sci. Technol. B 2014, 32, 06FJ01. [Google Scholar] [CrossRef]
- Schmitt, H.; Frey, L.; Ryssel, H.; Rommel, M.; Lehrer, C. UV nanoimprint materials: Surface energies, residual layers, and imprint quality. J. Vac. Sci. Technol. B Microelectron. Nanometer Struct. Process. Meas. Phenom. 2007, 25, 785–790. [Google Scholar] [CrossRef]
- Uchida, H.; Imoto, R.; Ando, T.; Okabe, T.; Taniguchi, J. Molecular dynamics simulation of the resist filling process in UV-nanoimprint lithography. J. Photopolym. Sci. Technol. 2021, 34, 139–144. [Google Scholar] [CrossRef]
- Qi, H.; Xu, M. Stokes’ first problem for a viscoelastic fluid with the generalized Oldroyd-B model. Acta Mech. Sin. 2007, 23, 463–469. [Google Scholar] [CrossRef]
- Seeger, A.; Haussecker, H. Shape-from-shading and simulation of SEM images using surface slope and curvature. Surf. Interface Anal. 2005, 37, 927–938. [Google Scholar] [CrossRef]
- Inoue, O.; Hasumi, K. Review of scanning electron microscope-based overlay measurement beyond 3-nm node device. J. Micro/Nanolithography MEMS MOEMS 2019, 18, 021206. [Google Scholar] [CrossRef]
- Zhu, F.Y.; Wang, Q.Q.; Zhang, X.S.; Hu, W.; Zhao, X.; Zhang, H.X. 3D reconstruction and feature extraction for analysis of nanostructures by SEM imaging. In Proceedings of the 2013 Transducers & Eurosensors XXVII: The 17th International Conference on Solid-State Sensors, Actuators and Microsystems (TRANSDUCERS & EUROSENSORS XXVII), Barcelona, Spain, 16–20 June 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Swee, S.K.; Chen, L.C.; Chiang, T.S.; Khim, T.C. Deep Convolutional Neural Network for SEM Image Noise Variance Classification. Eng. Lett. 2023, 31, 328–337. [Google Scholar]
- Walsh, J.; Othmani, A.; Jain, M.; Dev, S. Using U-Net network for efficient brain tumor segmentation in MRI images. Healthc. Anal. 2022, 2, 100098. [Google Scholar] [CrossRef]


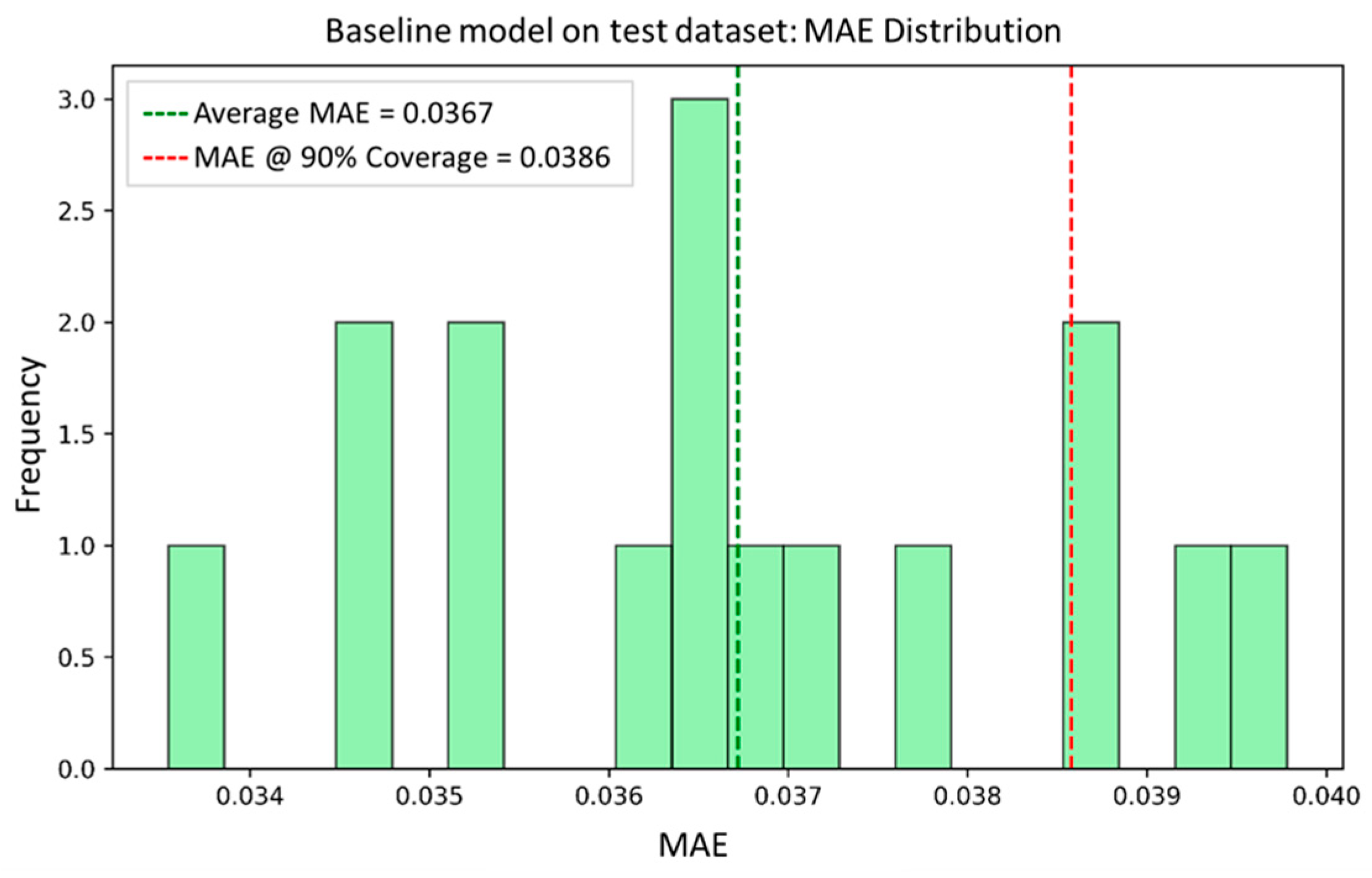
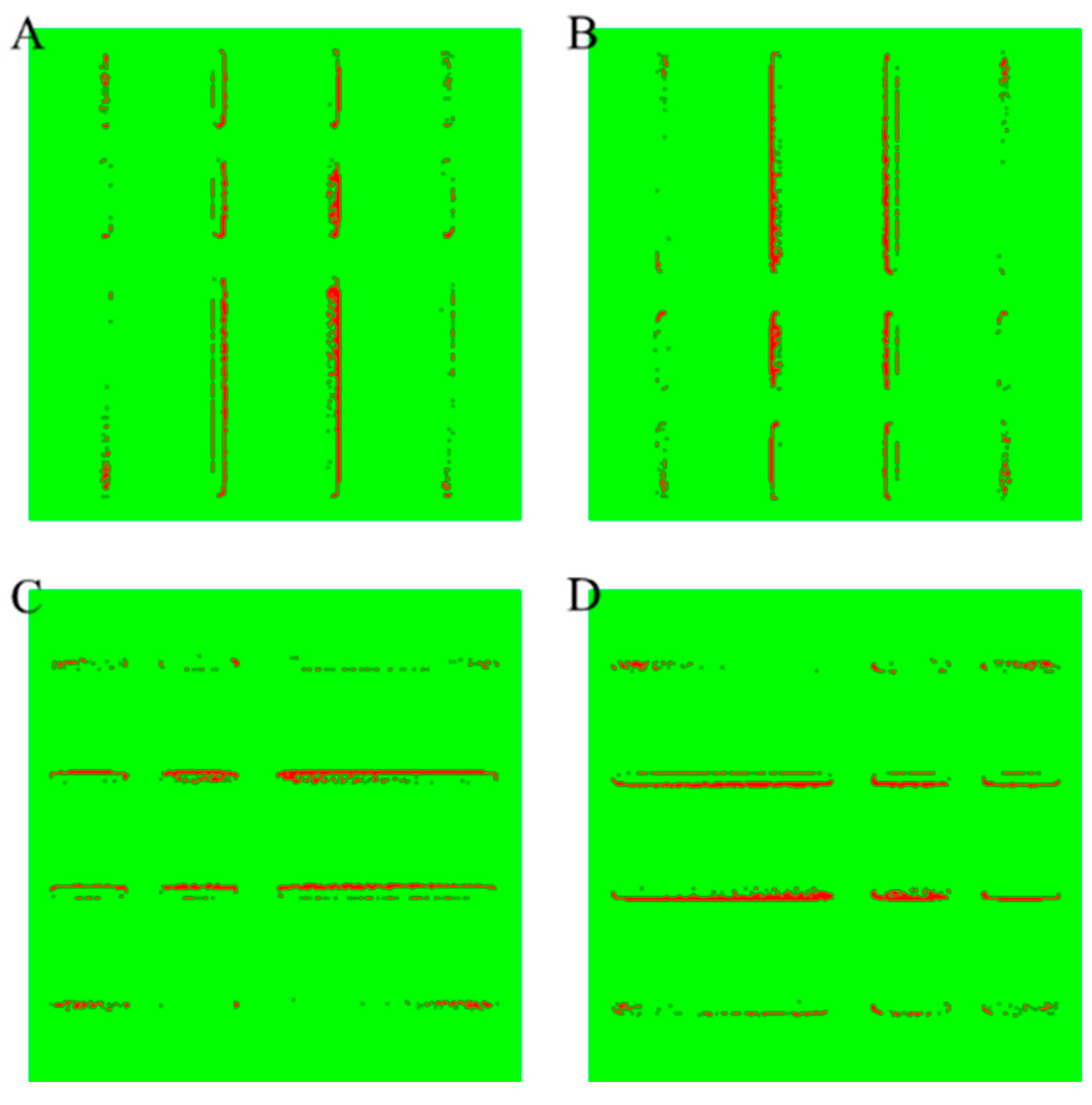

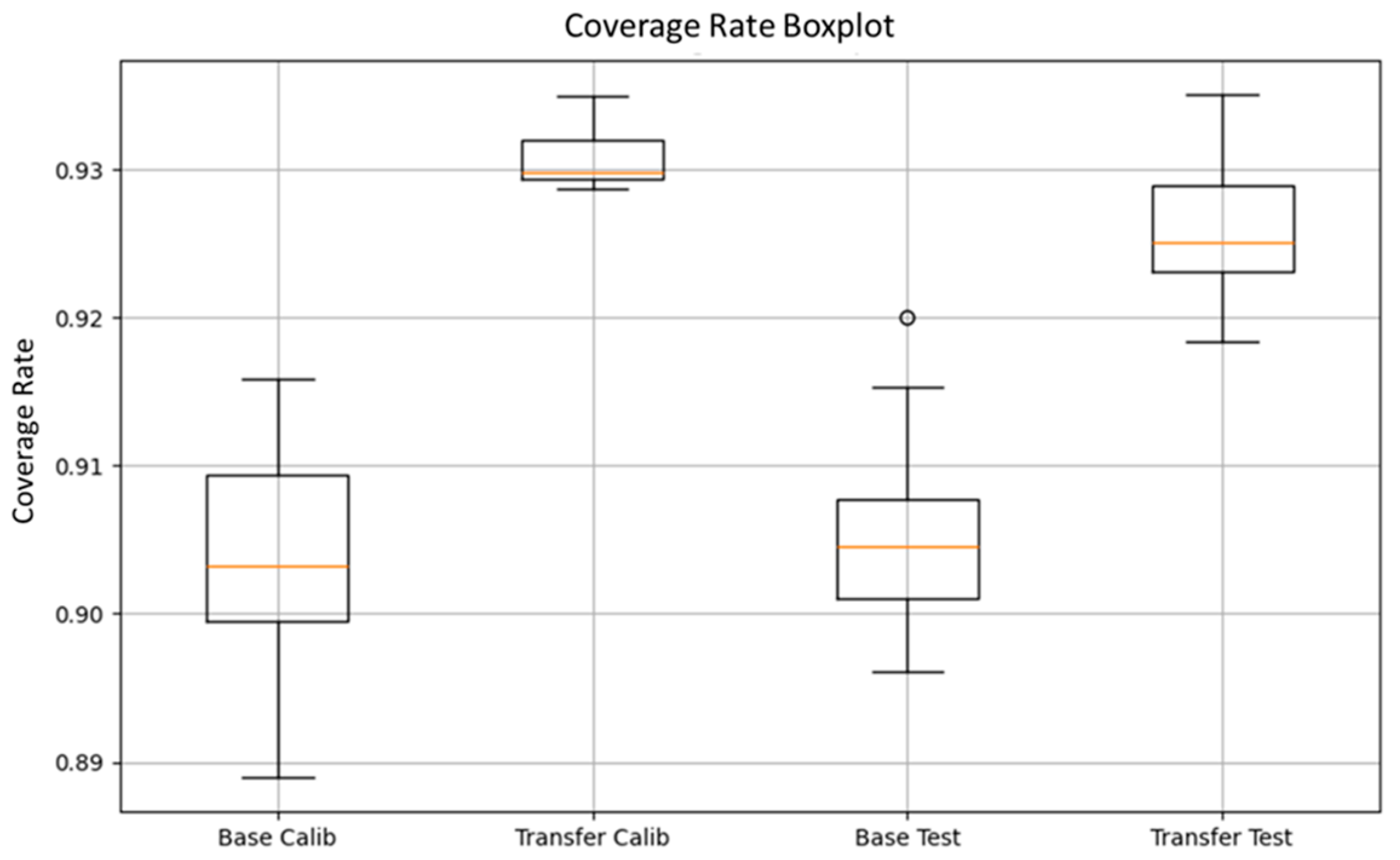

| Models vs. Metrics | MAE | Coverage Rate | |||
|---|---|---|---|---|---|
| Mean | STD | Mean | STD | ||
| Calibration | Baseline | 0.0355 | 0.0028 | 0.902 | 0.0085 |
| Transfer learning | 0.0235 | 0.0020 | 0.931 | 0.0020 | |
| Test | Baseline | 0.0365 | 0.0023 | 0.904 | 0.0065 |
| Transfer learning | 0.0255 | 0.0018 | 0.926 | 0.0040 | |
| Metric | Baseline | Transfer Fine-Tuning | Reduction |
|---|---|---|---|
| Images used | 240 | 48 | 80% |
| GPU time (RTX 3090) | 36 min | 10 min | 72% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chien, J.; Lee, E. Deep-CNN-Based Layout-to-SEM Image Reconstruction with Conformal Uncertainty Calibration for Nanoimprint Lithography in Semiconductor Manufacturing. Electronics 2025, 14, 2973. https://doi.org/10.3390/electronics14152973
Chien J, Lee E. Deep-CNN-Based Layout-to-SEM Image Reconstruction with Conformal Uncertainty Calibration for Nanoimprint Lithography in Semiconductor Manufacturing. Electronics. 2025; 14(15):2973. https://doi.org/10.3390/electronics14152973
Chicago/Turabian StyleChien, Jean, and Eric Lee. 2025. "Deep-CNN-Based Layout-to-SEM Image Reconstruction with Conformal Uncertainty Calibration for Nanoimprint Lithography in Semiconductor Manufacturing" Electronics 14, no. 15: 2973. https://doi.org/10.3390/electronics14152973
APA StyleChien, J., & Lee, E. (2025). Deep-CNN-Based Layout-to-SEM Image Reconstruction with Conformal Uncertainty Calibration for Nanoimprint Lithography in Semiconductor Manufacturing. Electronics, 14(15), 2973. https://doi.org/10.3390/electronics14152973