2. Materials and Methods
2.1. System Architecture Overview
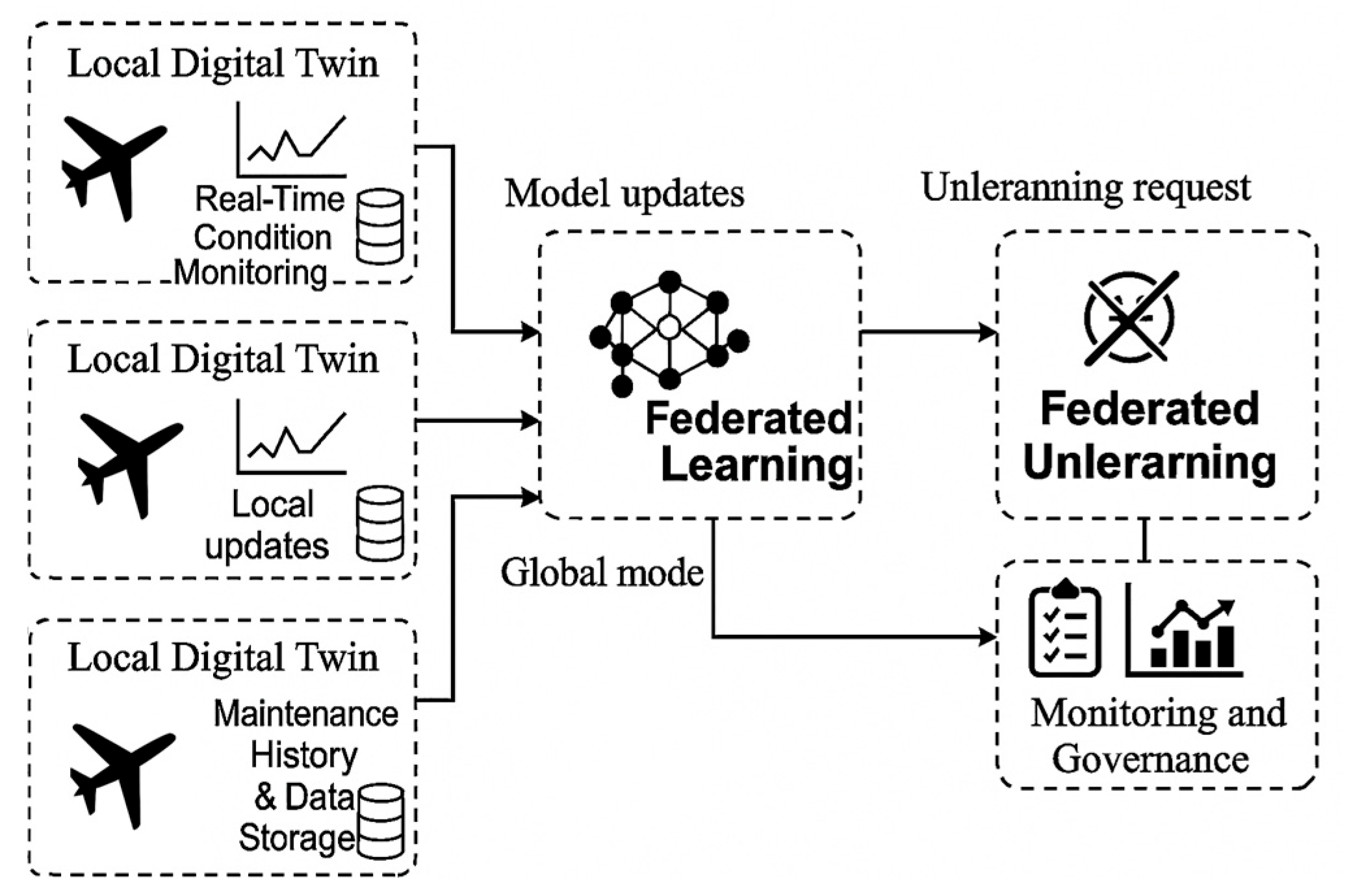
The proposed DT–FL–FU architecture integrates digital twins, federated learning, and federated unlearning into a unified framework that enhances the resilience and trustworthiness of aircraft health monitoring. It enables distributed aviation stakeholders to collaboratively train fault prediction models while preserving data locality and allowing for the post hoc correction of corrupted or biased inputs.
The architecture consists of four interdependent layers (
Figure 1):
aircraft–edge layer (local digital twins);
federated learning layer (privacy-preserving model training);
unlearning coordination layer (FU protocol manager);
monitoring and governance layer (audit and compliance).
At the first level, each aircraft or ground-based maintenance unit is associated with a local digital twin, which serves as a real-time computational replica of critical subsystems (e.g., engine, hydraulic, avionics). These DTs ingest continuous telemetry from onboard sensors—such as vibration signals, temperature readings, fuel flow rates, and pressure levels—and convert them into structured time-series sequences.
To support predictive modeling, the DTs apply local preprocessing (e.g., normalization, outlier filtering, window slicing) and extract temporal patterns indicative of degradation or anomaly buildup. These labeled sequences form the basis for local model training.
Each DT node implements a long short-term memory (LSTM) neural network to capture temporal dependencies across sensor readings. Let us suppose that an LSTM with two hidden layers and 64 units per layer is trained to predict the probability of hydraulic system failure based on the last 48 h of multivariate sensor data. The input sequence might include:
Pressure oscillations from redundant hydraulic lines;
Fluid temperature gradients during taxi and climb phases;
Actuator response time (command vs. actual deflection).
The model is trained using a binary cross-entropy loss function, with labels derived from historical fault logs (1 = failure within 12 h, 0 = no event).
At the second federated learning layer, instead of sharing raw time-series data, each DT node computes gradient updates from its local LSTM training and transmits these encrypted updates to a central server. The central FL coordinator performs aggregation, typically using federated averaging (FedAvg), to update the global LSTM model weights.
Let
denote the local model parameters at node
. Each node updates its weights via stochastic gradient descent and computes:
where
denotes the vector of global model parameters after the
t-th communication round, representing the updated model state after aggregating all participating clients’ contributions.
The server then updates the global model by weighted averaging, as follows:
where
is the number of participating clients (DT nodes).
This process enables model convergence across geographically distributed aircraft without centralized data pooling. Model checkpoints are broadcast back to nodes after each global round and LSTM inference is updated accordingly for local prediction tasks, e.g., estimating the remaining useful life (RUL).
At the third unlearning coordination layer, when corrupted, biased, or adversarial data are detected, e.g., due to faulty pressure sensors or injected noise in telemetry, the corresponding node’s contribution must be erased from the global model. The FU layer initiates this correction process by applying influence-reversal methods, such as:
Gradient projection removal, where the offending update is subtracted from the global model;
Reweighting-based approximation, adjusting the model to minimize the influence of the corrupted client’s data on the loss surface;
Fine-tuned retraining, constrained to a low-resource window using only clean data contributions.
For instance, if client
contributed anomalous LSTM gradients due to a data injection attack, the FU controller uses a stored update log to identify
and execute:
where
is a rollback scaling factor adjusted to maintain stability.
The fourth monitoring and governance layer logs all local update hashes, model weight transitions, unlearning events, and LSTM performance metrics for each node. It supports forensic audits and regulatory verification, e.g., European Union Aviation Safety Agency (EASA) or Federal Aviation Administration (FAA) inspections, by enabling full traceability of how models evolved and which data were removed.
Each global model version is tagged with a cryptographic signature and metadata indicating participation, rollback status, and error bounds. Visual dashboards enable operators to verify that no biased or damaged data continue to influence predictive outputs.
2.2. Digital Twin-Based Data Modeling
In the proposed framework, digital twins (DTs) act as real-time computational replicas of aircraft subsystems, continuously synchronized with onboard sensors and operational data. They transform raw, heterogeneous telemetry—such as pressure, vibration, and actuator signals—into structured datasets for fault detection and health monitoring. Each DT preprocesses data through filtering, normalization, and feature extraction, and assigns labels based on historical faults or anomaly thresholds. Local LSTM models are trained on these data to predict failures or estimate remaining useful life.
DTs maintain a dynamic state, tracking model versions, data quality, and participation in federated learning and unlearning. If data inconsistencies, like drift or corruption, are detected, affected sequences are excluded to prevent contamination of the global model. In parallel, unsupervised methods can provide anomaly scores to support early detection and trigger unlearning if needed. This structured lifecycle from data ingestion to gradient generation enables DTs to serve as autonomous, intelligent nodes in a resilient, federated AHM system capable of adapting to corrupted inputs and maintaining model integrity across diverse aircraft fleets.
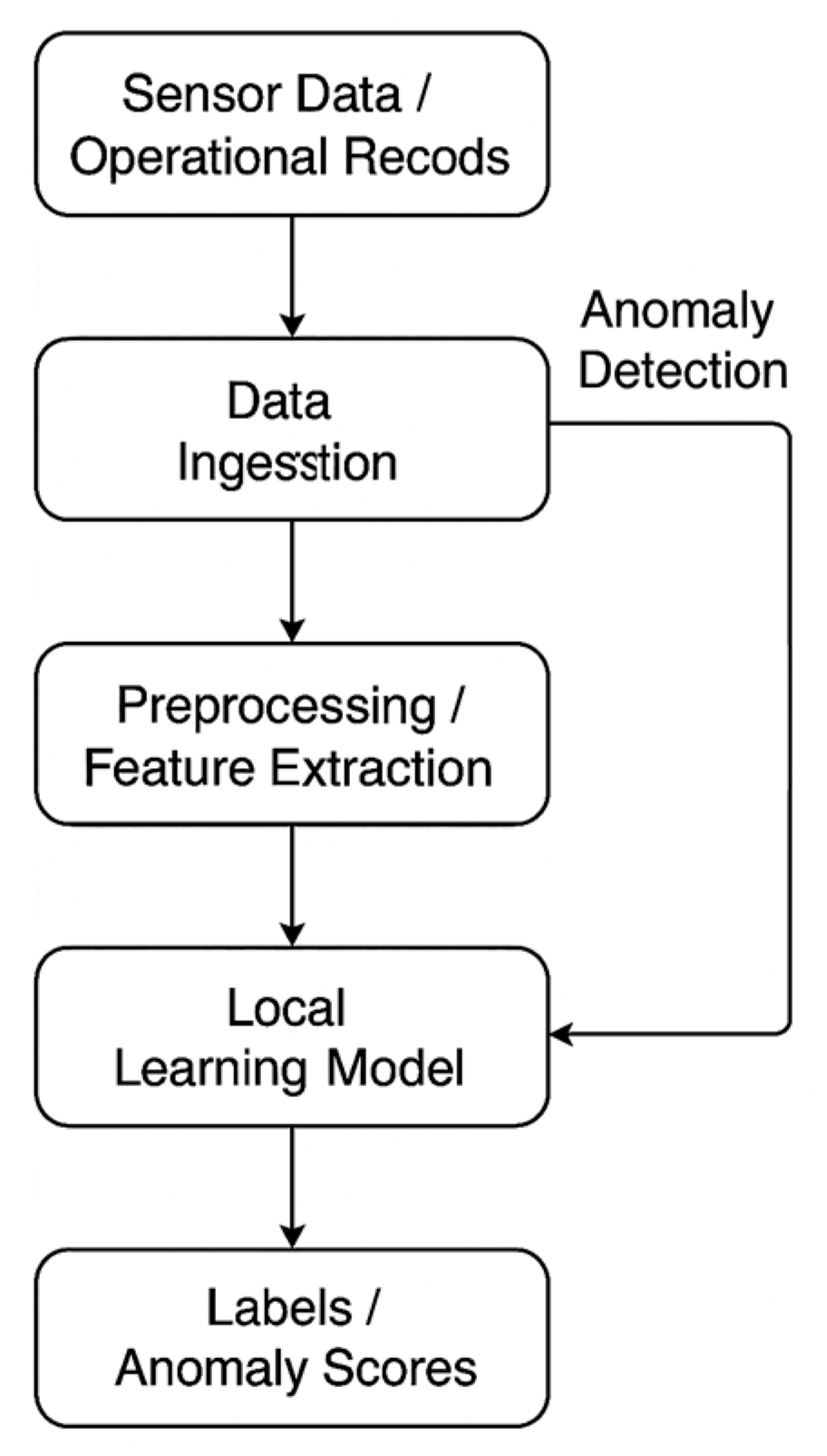
Figure 2 illustrates the internal data-processing workflow of each local digital twin in the proposed aviation health-monitoring framework. The process begins with the acquisition of sensor data and operational records, which include raw telemetry from aircraft subsystems (e.g., temperature, pressure, vibration) as well as contextual metadata (e.g., flight phase, maintenance history). These inputs are passed into the data ingestion module, where initial synchronization, buffering, and integrity checks are performed.
Following ingestion, the preprocessing and feature extraction stage applies signal normalization, outlier filtering, and transformation techniques to convert raw time-series data into structured inputs suitable for learning. The extracted features are then used by the local learning model, which typically consists of a recurrent neural network such as an LSTM. This model is trained to detect degradation patterns and generate probabilistic forecasts of system faults.
Parallel to the training process, the system performs anomaly detection, which assesses the deviation of incoming signals from nominal baselines. If the data are determined to be inconsistent, adversarial, or corrupted, the anomaly detection module can initiate downstream unlearning procedures. Finally, the model produces labels or anomaly scores, which are fed back into both local decision-making systems and federated model update processes.
This modular data flow ensures that each digital twin maintains an adaptive, trustworthy representation of the aircraft’s condition while supporting fault detection, data quality assurance, and compatibility with federated learning and unlearning protocols.
2.3. Federated Learning for AHM Model Training
To enable scalable and privacy-preserving collaboration across multiple aviation stakeholders, the proposed framework employs FL as a core mechanism for training AHM models. This approach enables local digital twins, distributed across airlines, maintenance organizations, and equipment manufacturers, to contribute to a shared global model without transferring raw operational data. Instead, each participant performs localized model training and shares only the learned model updates, thereby reducing the risk of data leakage and ensuring compliance with regulatory and organizational data policies.
Each digital twin hosts a local learning model trained on structured time-series data derived from onboard telemetry and operational records. These models are tasked with predicting fault probabilities, estimating RUL, or classifying anomaly states within the monitored subsystems.
The FL process proceeds in a series of communication rounds coordinated by a central server or aggregation node. During each round, the workflow follows the steps below:
Step 1—Global model distribution. The server sends the current version of the global model to all selected participating nodes;
Step 2—Local training. Each client trains the model on its local dataset using stochastic gradient descent (SGD) or its variants to obtain updated parameters ;
Step 3—Update submission. Clients transmit their local model updates to the server;
Step 4—Aggregation: The server performs FedAvg or another aggregation strategy to compute the new global model:
where
is he size of the local dataset at client
, and
is the total sample size.
This aggregated model is then redistributed to all clients for the next round, continuing until convergence is reached or a specified stopping criterion is met.
Depending on the target AHM application, the global model may be trained using classification or regression loss functions. For binary fault prediction, a binary cross-entropy loss is used, while RUL estimation typically employs mean squared error :, as follows:
where
and
are the true and predicted outputs for sample
, respectively.
The local models are optimized using mini-batch training, often with early stopping and dropout regularization to mitigate overfitting, particularly on the smaller or imbalanced datasets typical in aviation maintenance domains.
Not all clients participate in every FL round. Participation may be based on:
Availability (e.g., aircraft on ground vs. in-flight);
Data quality scores;
Trustworthiness (derived from anomaly detection results and governance metrics).
Selective participation helps to maintain training stability and prevents the propagation of biased or corrupted updates, particularly in the presence of non-IID (non-independent and identically distributed) data distributions among clients.
To protect model integrity and privacy, all client–server communications are secured using transport-layer encryption. In some implementations, secure aggregation protocols are employed to prevent the server from reconstructing individual client updates. These include additive homomorphic encryption, differential privacy noise injection, or secure multiparty computation.
In addition, each digital twin appends cryptographic hashes of its model update and metadata (e.g., training epoch count, data volume, error metrics) to ensure auditability and traceability in the governance layer. This allows for rollback or unlearning, should a participant’s data later be flagged as unreliable.
Global model convergence is monitored using a validation dataset curated from clean, certified operational data, either at the aggregator node or through collaborative voting across clients. Performance is evaluated across key metrics, such as accuracy, precision, recall, F1-score, and RMSE, depending on the task type.
This federated learning approach enables continuous, privacy-preserving, and collaborative optimization of AHM models across a diverse aviation ecosystem. It lays the groundwork for robust, real-time health monitoring while enabling selective model correction through federated unlearning when compromised or erroneous data are identified.
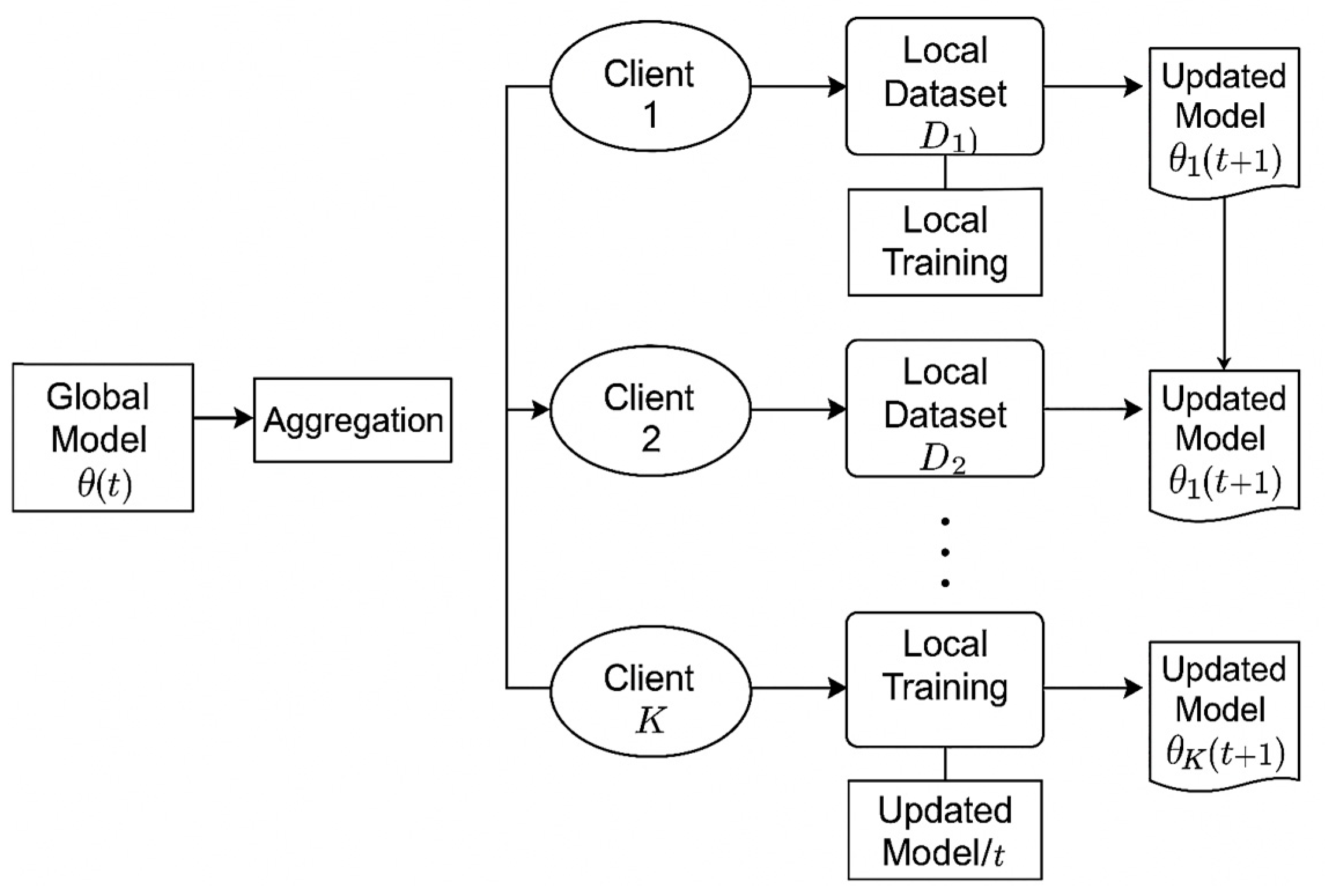
Figure 3 presents the core workflow of the federated learning process applied to aircraft health monitoring across distributed digital twin clients. The process begins with the server-side distribution of the current global model parameters
, which are sent to all selected client devices (e.g., aircraft-based digital twins, MRO units, or OEM nodes). Each client then uses its own local dataset
to perform local training, updating the model based on time-series telemetry and labeled operational data collected from onboard sensors.
After completing the local training phase, each client generates a locally updated version of the model, denoted as , which is then securely transmitted back to the central server. The server performs an aggregation step, commonly implemented as FedAvg, to compute the new global model . This aggregation accounts for the relative dataset sizes across clients to ensure proportional influence.
The updated global model is then redistributed in the next round, completing a cycle that allows for decentralized learning without compromising raw data privacy. This flow enables continuous, collaborative model improvement across multiple aviation stakeholders while supporting modular correction through federated unlearning mechanisms in subsequent stages.
2.4. Federated Unlearning Mechanism
While federated learning offers a robust solution for decentralized model training in aviation health-monitoring systems, it remains inherently vulnerable to the inclusion of compromised, corrupted, or misleading data in the global model. In practice, digital twins may generate unreliable training contributions due to faulty sensors, telemetry misalignment, software bugs, or even adversarial manipulation. Once such flawed data have been integrated into the global model via FL, the effects are typically non-trivial to reverse, as traditional federated architectures lack mechanisms for removing specific client influences post hoc.
To address this limitation, the proposed framework introduces a FU module, enabling the selective removal of specific data contributions from the global model without requiring full retraining. This capability is essential for maintaining the accuracy, trustworthiness, and auditability of aircraft health monitoring models deployed in safety-critical environments.
Unlearning may be triggered under several circumstances:
Detection of sensor malfunction, signal noise, or drift affecting training windows;
Post facto discovery of data poisoning or tampering by a compromised client;
Identification of non-compliant or outdated data contributions (e.g., due to maintenance record updates);
For regulatory or contractual obligations requiring data redaction or withdrawal.
Each client’s contribution to the global model is tracked and logged during the FL process. The monitoring and governance layer maintains metadata for every client update, including cryptographic hashes, model deltas , training context, and local error metrics. This enables the unlearning coordinator to locate, isolate, and reverse a specific contribution with minimal disruption.
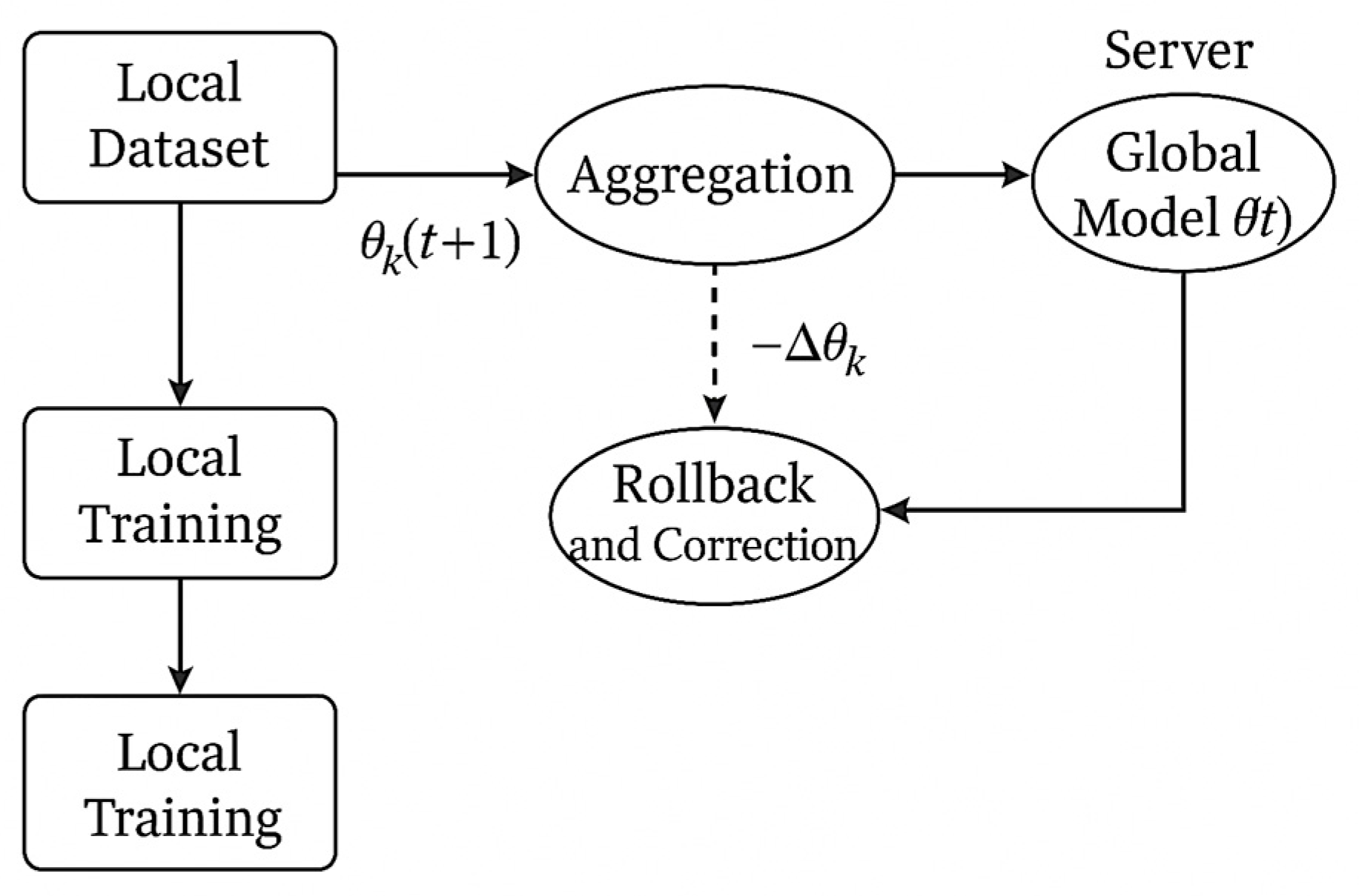
Figure 4 illustrates the rollback and correction workflow implemented in the federated unlearning mechanism. The process begins with local training performed by a client on its dataset, resulting in an updated model
. This model update is submitted to the central server, where it is incorporated during the aggregation step to generate a new global model
.
If the update from a particular client is later identified as corrupted or unreliable—due to sensor faults, poisoned data, or adversarial manipulation—the system initiates a rollback and correction operation. This is achieved by applying a negative offset to the previously aggregated update to remove the influence of that specific contribution. The rollback module adjusts the global model accordingly and revalidates it before it is reused or redistributed.
The flow emphasizes that federated unlearning does not require full retraining but instead operates by surgically reversing the impact of specific client updates. This ensures the continued integrity and reliability of predictive models within the aircraft health-monitoring framework while maintaining auditability of all correction actions.
2.5. Experimental Setup
To evaluate the effectiveness and robustness of the proposed FL–DT–FU framework for aircraft health monitoring, a series of simulation-based experiments were designed to replicate realistic aviation operating conditions, sensor data variability, and client heterogeneity. The experimental setup includes synthetic and semi-real datasets, a distributed simulation of digital twin clients, a central FL coordination server, and a federated unlearning control unit.
2.5.1. Simulated Aviation Environment
The simulation environment replicates a fleet of 30 aircraft-based digital twins operating as independent clients. Each client maintains a local time-series database representing telemetry from key aircraft systems, including:
Hydraulic pressure and flow sensors;
Engine vibration and exhaust gas temperature (EGT) profiles;
Control surface actuator feedback signals;
Environmental parameters (altitude, airspeed, temperature).
Synthetic data were generated using statistical models based on real-world distributions, enriched with periodic degradation patterns, flight-phase dynamics, and sensor noise. For fault events, labeled anomalies were injected based on maintenance event timelines and failure propagation models.
To represent data corruption, 20% of the clients were assigned randomly injected errors, drifted baselines, or adversarial label flips. These corruptions were used to evaluate both the degradation of federated model performance and the ability of FU to recover predictive reliability.
2.5.2. Model Configuration
Each digital twin node trains a long short-term memory (LSTM) neural network with the following structure:
Input sequence length: 120 time steps (e.g., 2 h of telemetry);
Hidden layers: 2;
Hidden units per layer: 64;
Output: binary classification (fault/no fault) or regression (remaining useful life);
Loss functions: binary cross-entropy (BCE) for classification and mean squared error (MSE) for RUL estimation;
Optimizer: Adam with learning rate 0.001;
Local training epochs per round: 5;
Mini-batch size: 64.
The federated server aggregates local updates using the FedAvg algorithm, with client participation randomized at each round (80% active per round). Each simulation run consists of 100 FL communication rounds, and the global model is evaluated after each round.
2.5.3. Unlearning Scenarios
Three federated unlearning strategies were implemented:
Gradient subtraction—subtracting corrupted client’s delta from the global model;
Exact re-aggregation—recomputing global model without specific client’s update;
Constrained retraining—partial retraining using only verified clean clients.
Unlearning was triggered after round 60, once the corrupted contributions had already affected global convergence. The rollback module had access to stored deltas and participation logs. Model performance before and after unlearning was compared using standard classification metrics.
2.5.4. Evaluation Metrics
Model performance and unlearning efficacy were measured using the following indicators:
Accuracy, precision, recall, F1-score—for fault-detection tasks;
Root mean square error (RMSE)—for RUL estimation;
Model recovery rate for evaluation of improvement in accuracy after unlearning;
Unlearning latency—time required to perform rollback operation;
Model drift—difference between original and corrected model output on benchmark dataset;
False positive/negative rate change to assess unlearning stability.
All experiments were executed on a virtualized cluster simulating client–server interactions using Python 3.11.12 (TensorFlow Federated) [
51] and Docker-based container orchestration [
52]. Computational resources were scaled to reflect realistic onboard processing limits (CPU + limited GPU support per client).
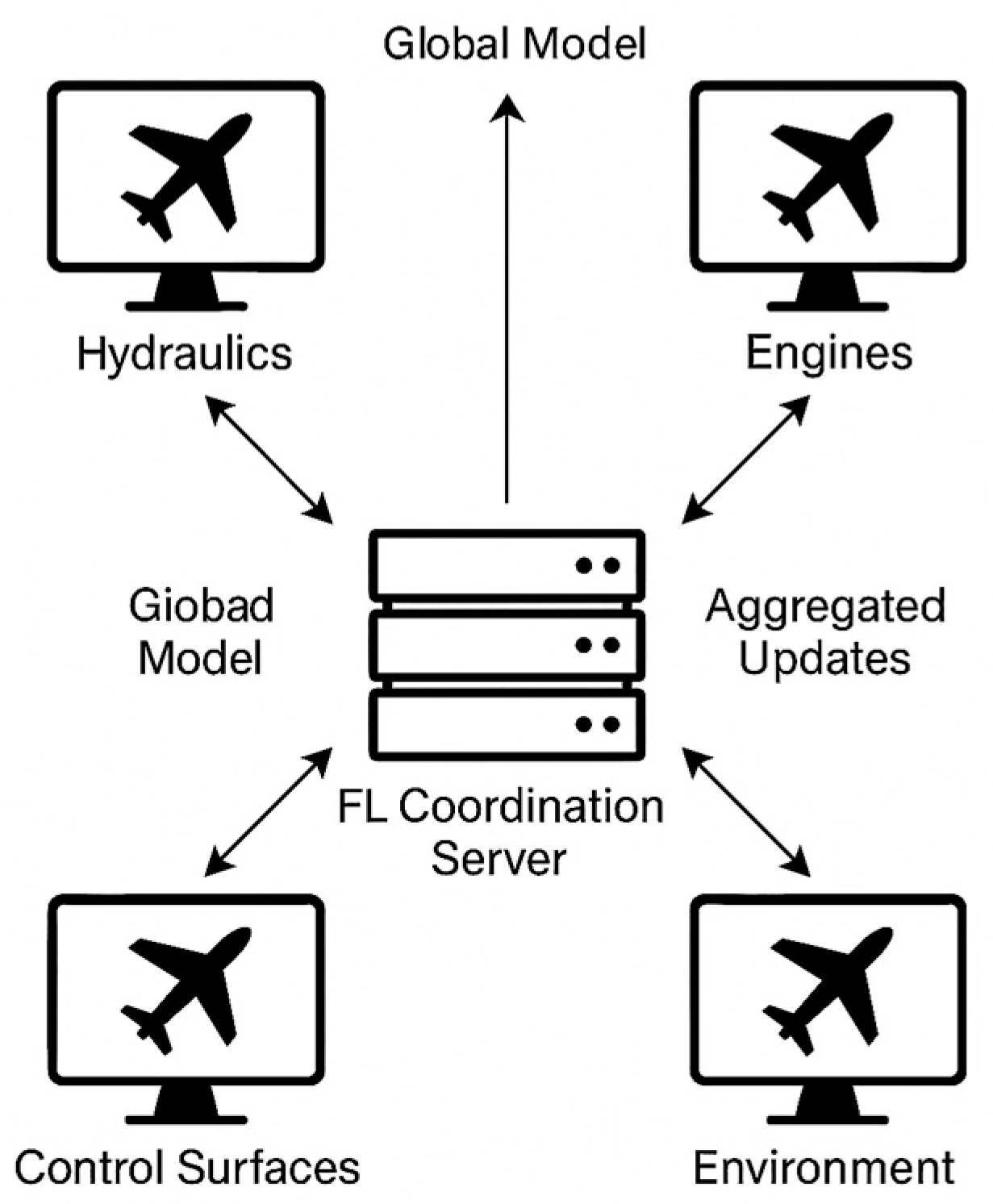
Figure 5 illustrates the simulated federated environment used to evaluate the proposed FL–DT–FU framework for aircraft health monitoring.
At the center of the diagram is the federated learning coordination server, which orchestrates model aggregation and redistribution cycles across distributed digital twin clients.
Each client node represents a specific aircraft subsystem, including the hydraulics, engines, control surfaces, and environment, which are modeled as independent digital twin agents operating on local data streams. These digital twins simulate on-aircraft computational processes, including the local training of machine learning models based on system-specific telemetry and fault history.
The global model is distributed from the coordination server to the clients, who perform localized training on their respective datasets. Clients then return aggregated updates, which are synthesized at the server to produce the next iteration of the global model . The process is repeated over multiple communication rounds, reflecting realistic federated learning dynamics in a heterogeneous fleet.
This simulated environment enables controlled experimentation with different failure scenarios, data corruption patterns, and unlearning strategies, allowing for the comprehensive validation of model accuracy, robustness, and recoverability across decentralized AHM settings.
2.6. Mathematical Framework of Study
The mathematical framework underlying the proposed DT–FL–FU architecture formalizes the core processes of local model training, federated aggregation, and selective unlearning in the context of aircraft health monitoring. This section defines the principal variables, functions, and optimization goals used across the system layers.
2.6.1. Local Model Training at Digital Twin Nodes
Each aircraft subsystem is modeled via a local digital twin , which receives telemetry data , where is the time window length and is the number of sensor channels. The goal of each twin is to learn a local predictive model that maps an input sequence to an output target , where denotes the model parameters.
The model is trained to minimize a local loss function .
For binary classification (fault detection):
where
is binary cross-entropy. Given a true label
and a predicted probability
, the
loss for a single prediction is:
In the aircraft health-monitoring system, is used to train LSTM models to classify whether a given input sequence (e.g., telemetry data from the hydraulic system) is likely to lead to a fault (label = 1) or not (label = 0). It helps the model learn to predict faults with calibrated probability estimates.
For regression (remaining useful life estimation):
Model parameters
are updated locally using stochastic gradient descent:
where
is the learning rate and
is the vector of partial derivatives of the loss function with respect to each parameter in
; it is used to guide how the local digital twin model learns from its data.
After local training, the model represents a subsystem-specific approximation of the aircraft’s health state. Its parameter update , is computed and transmitted to the federated coordinator for global aggregation, while raw telemetry data remain securely on-device. This decentralized optimization ensures data privacy while enabling each digital twin to contribute to the global model training process.
2.6.2. Federated Learning Aggregation
The server receives updates from a subset
of participating clients and computes the global model
using federated averaging, as follows:
This yields a weighted global model that incorporates operational heterogeneity across the fleet.
2.6.3. Federated Unlearning Mechanisms
When a corrupted client is identified, its influence must be removed from the global model. Let be the last submitted update from client ccc. Three unlearning strategies are formalized:
where
is a rollback scaling factor controlling stability;
The global model is reinitialized to a previous safe checkpoint and updated using only trusted clients .
2.6.4. Model Performance Metrics
To evaluate and compare model performance across different states (baseline, corrupted, recovered), the following metrics are used.
1. Accuracy—overall correctness
where
(True Positives) is the number of instances where the model correctly predicts a fault, and the fault is indeed present,
(True Negatives) is the number of instances where the model correctly predicts no fault, and no fault is actually present,
(False Positives) is the number of instances where the model predicts a fault, but no fault actually exists.
(False Negatives) is the number of instances where the model predicts no fault, but a fault actually exists;
2. Precision—fault prediction correctness
3. Recall (sensitivity or true positive rate)—fault-detection rate
4. F1-Score—balance between precision and recall
5. False Positive Rate
—False alarm rate
6. False Negative Rate
—Missed fault rate
7. Specificity (True Negative Rate)—Correctly ignoring non-faults
In our case, these formulas allow us to quantify how well the federated model detects actual faults (Recall), avoid unnecessary alarms (Precision and FPR), maintain overall system reliability (F1-score and Accuracy) and ensure safety in critical systems by minimizing false negatives, which could otherwise result in undetected system degradation.
Recovery effectiveness after unlearning is quantified using the following metrics.
1. Model Drift:
where
is the current global model parameters (after corruption or after unlearning),
is the reference model parameters from a clean or known-good state (e.g., before data corruption), and
refers to the Euclidean norm as Euclidean distance between the two sets of parameters. It measures how much the model has changed (or drifted) in parameter space.
This gives a single scalar value indicating the magnitude of parameter deviation;
2. Recovery rate
where
is the F1-score of the clean, uncorrupted model before any data poisoning,
is the F1-score after corruption, before unlearning, and
is the F1-score after applying an unlearning method.
The recovery rate in this study context defines how effectively the federated unlearning process restores model performance after it was degraded by corrupted or adversarial data contributions. In an AHM system, the recovery rate quantifies the effectiveness of the unlearning strategy in restoring fault-detection performance. It is especially important in aviation, where even small degradations in recall or the F1-score could lead to missed fault detection and reduced safety.
2.6.5. Trust and Participation Scoring
An optional but valuable enhancement to the federated learning process in AHM is the integration of trust and participation scoring, where each digital twin node representing an aircraft or subsystem is assigned a dynamic trust score . This score reflects the client’s behavioral integrity and data reliability over time and is used to regulate participation and influence during aggregation. In the context of AHM, data from different aircraft may vary significantly in quality due to sensor degradation, data transmission issues, inconsistent maintenance logs, or adversarial inputs. Incorporating trust scores helps to mitigate the risk of model contamination by down-weighting or excluding low-trust clients from global updates.
Trust scores can be computed based on metrics such as update similarity to the global model, anomaly score trends, validation loss deviations, rollback frequency due to unlearning, and data continuity. These metrics are aggregated into a composite score that can be updated over time using exponential smoothing or a rule-based reward–penalty mechanism. Clients with trust scores below a threshold may be excluded from participation in a given training round or flagged for future audit or unlearning actions.
The aggregation rule can be modified to include trust weighting as follows:
where
is the number of local samples and
modulates the influence of each client’s contribution. This approach increases the resilience of the federated model to noisy or misleading data without fully excluding participants unless warranted.
In addition to improving the robustness of model training, trust scores support transparency and compliance by enabling traceability and forensic auditing. They can also serve as unlearning triggers when accumulated evidence suggests that a client’s contributions may be corrupt. Within regulated aviation contexts, this scoring mechanism enhances both the technical and regulatory trustworthiness of the system by ensuring that only high-integrity data are integrated into the learning pipeline.
The presented mathematical framework underpins a robust and privacy-preserving learning architecture for aircraft health monitoring by combining local digital twin modeling, federated learning aggregation, and federated unlearning mechanisms. Each aircraft or subsystem acts as an autonomous learning agent, contributing structured and validated updates to a global model while preserving data locality and operational confidentiality. Through precise loss formulations, gradient-based optimization, trust-aware participation, and quantifiable recovery metrics, the system ensures not only predictive accuracy but also resilience against data corruption and model drift. This integrated formulation supports the dynamic and safety-critical nature of aviation maintenance operations, enabling scalable, adaptive, and certifiable intelligence across distributed fleets.
3. Results
3.1. Baseline Federated Model Performance
Before introducing data corruption or unlearning interventions, we first established a baseline to evaluate the performance of the federated learning framework in a clean, fully cooperative environment. All 30 digital twin clients participated in model training using verified and consistent local datasets, representing typical telemetry and operational profiles across various aircraft subsystems. This scenario reflects ideal FL conditions, where no data poisoning, labeling noise, or client-side faults are present.
The federated learning process was executed for 100 communication rounds, with 80% of clients participating randomly in each round. The model under evaluation was an LSTM network configured for binary fault classification based on time-series input sequences. The global model was initialized with uniform weights and updated using the FedAvg algorithm.
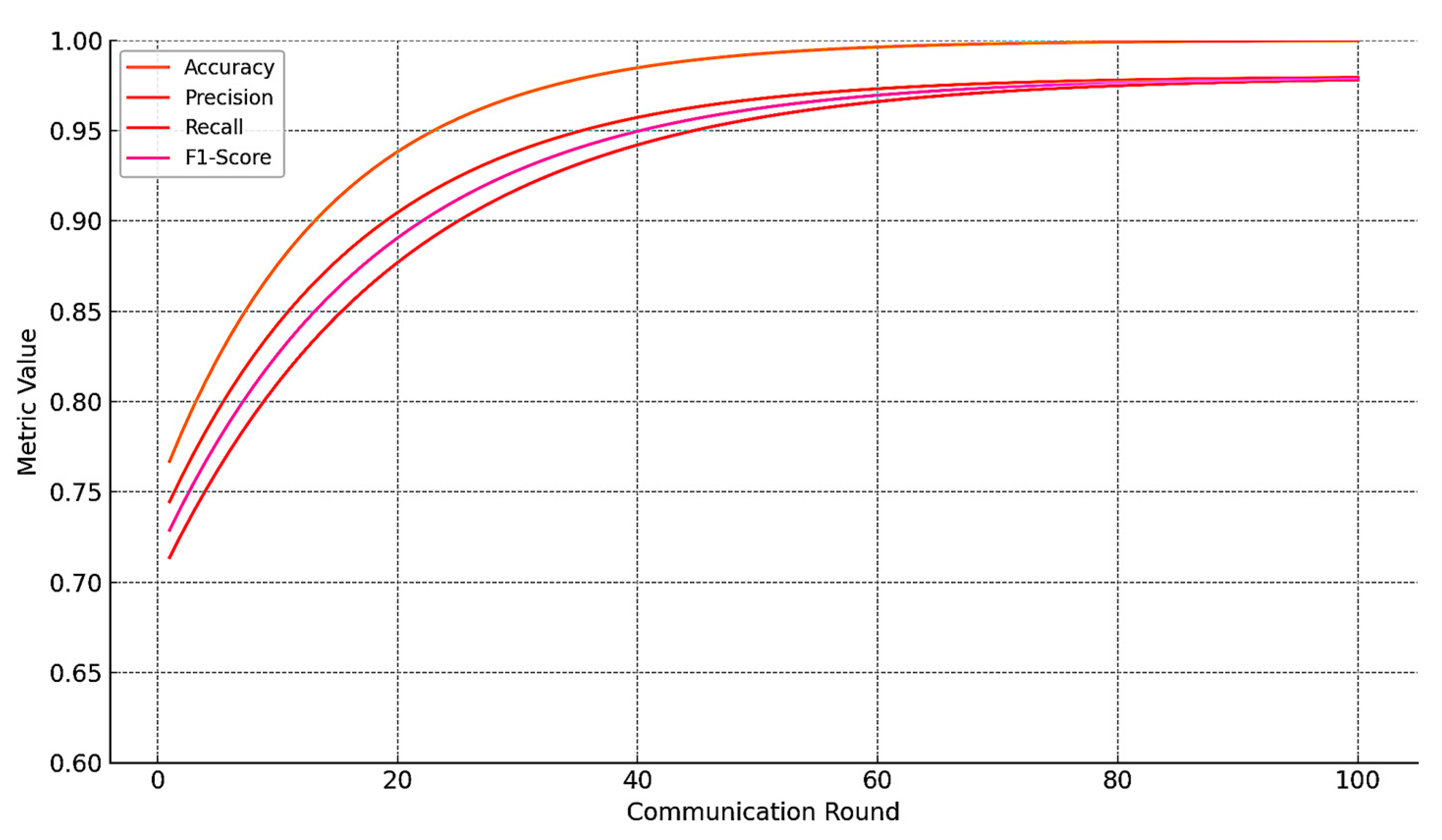
During the first 25 rounds, model accuracy increased rapidly as local updates captured subsystem-specific fault patterns and failure dynamics. After round 50, performance gains began to plateau, indicating convergence toward a generalizable model across client domains. Final performance metrics were calculated using a validation set comprising fault-labeled sequences not seen during local training.
The baseline model achieved the following global metrics on the validation dataset:
Accuracy 92.8%, precision 91.2%, recall 90.4%, F1-Score 90.8%, ROC-AUC 0.96, inference latency (average per sample) 23.5 ms (simulated edge environment).
These results confirm that the federated architecture, under ideal conditions, successfully learned generalized failure representations without centralized data pooling. Individual subsystems (e.g., engines vs. hydraulics) demonstrated minor variations in precision-recall tradeoffs due to differences in signal complexity and fault onset patterns; however, the unified model remained well-balanced overall.
To assess the consistency of learning across clients, we measured the cosine similarity between local model updates during rounds 30–50 and the final global model. Similarity scores averaged above 0.91, indicating strong alignment in parameter directions across participating clients. This reinforces that the FL setup converged smoothly and avoided client drift in the clean data regime.
For benchmarking purposes, a centralized model was also trained using concatenated datasets from all clients. The centralized model achieved 93.1% accuracy, which is only marginally higher than the federated result (92.8%), validating that the FL approach incurred a negligible performance tradeoff while maintaining privacy and data locality.
Figure 6 presents the performance graph illustrating the convergence of the federated model over 100 communication rounds under baseline conditions. It shows improvements in accuracy, precision, recall, and in the F1-score, reflecting stable and effective learning in a clean, federated environment.
3.2. Impact of Data Corruption on Model Integrity
To assess the vulnerability of the federated learning process to data integrity issues, a series of experiments were conducted in which a subset of digital twin clients contributed corrupted data to the training process. These simulated scenarios reflect real-world risks encountered in aircraft health monitoring, including sensor malfunctions, telemetry drift, labeling errors, and intentional data poisoning.
Starting from round 10 of the training, 6 out of 30 clients (20%) were selected to introduce one of the following corruption types into their local datasets:
Sensor drift—time-series features were gradually offset to simulate calibration faults (e.g., hydraulic pressure baseline increased by +20% over time);
Label flipping—a portion of anomaly labels (0 → 1 and 1 → 0) were inverted to mimic misclassification due to maintenance documentation errors;
Noise injection—random Gaussian noise was added to signal features, degrading the signal-to-noise ratio;
Adversarial training bias—clients trained on data distributions deliberately skewed to reinforce misleading patterns (e.g., correlating failure with non-failure conditions).
These corruptions were not disclosed to the federated server; all client updates were treated as valid during aggregation.
Compared to the baseline results, the presence of corrupted clients caused a measurable degradation in global model performance. The impact became evident after approximately 15 rounds, when the corrupted updates began influencing the aggregation process.
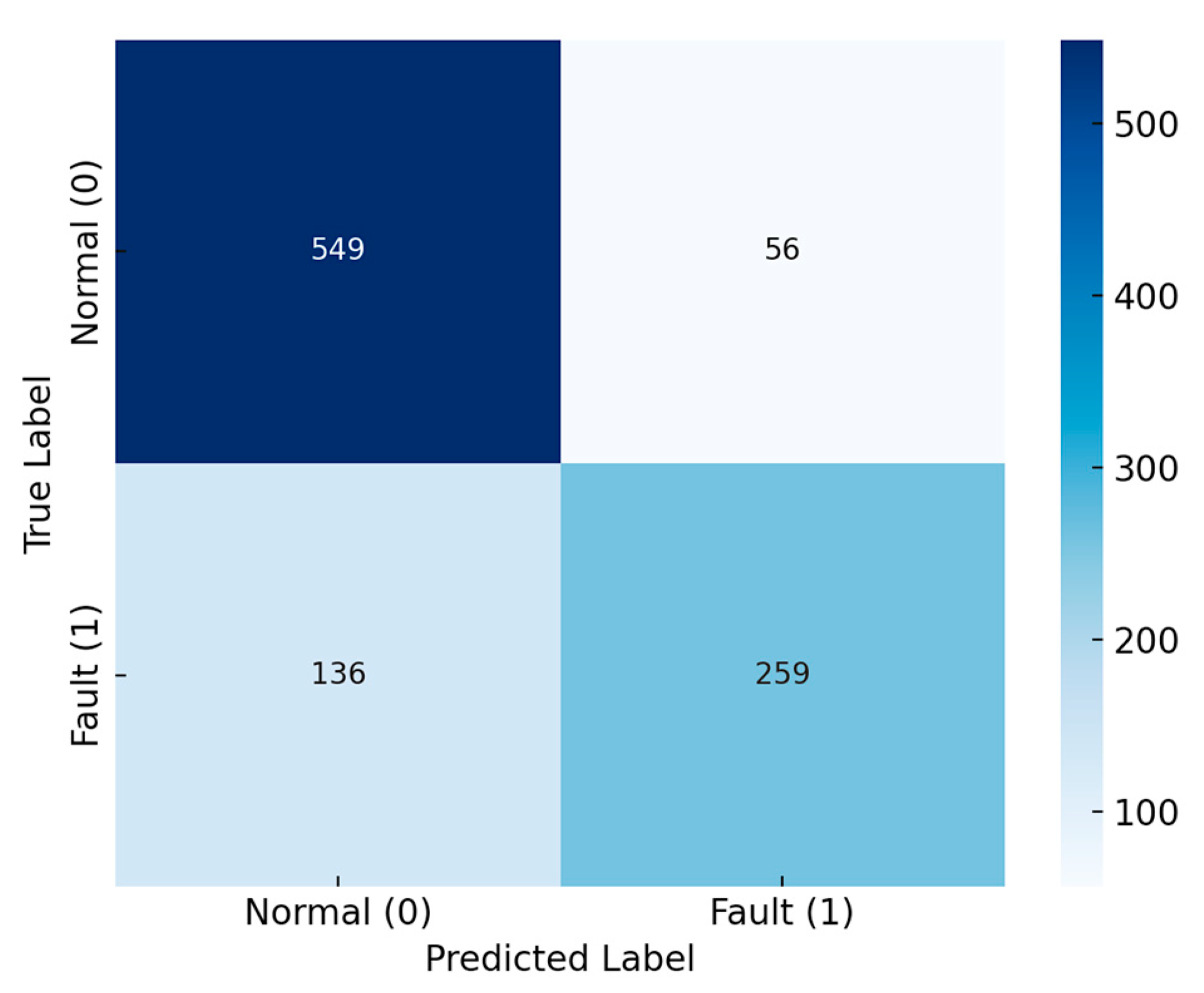
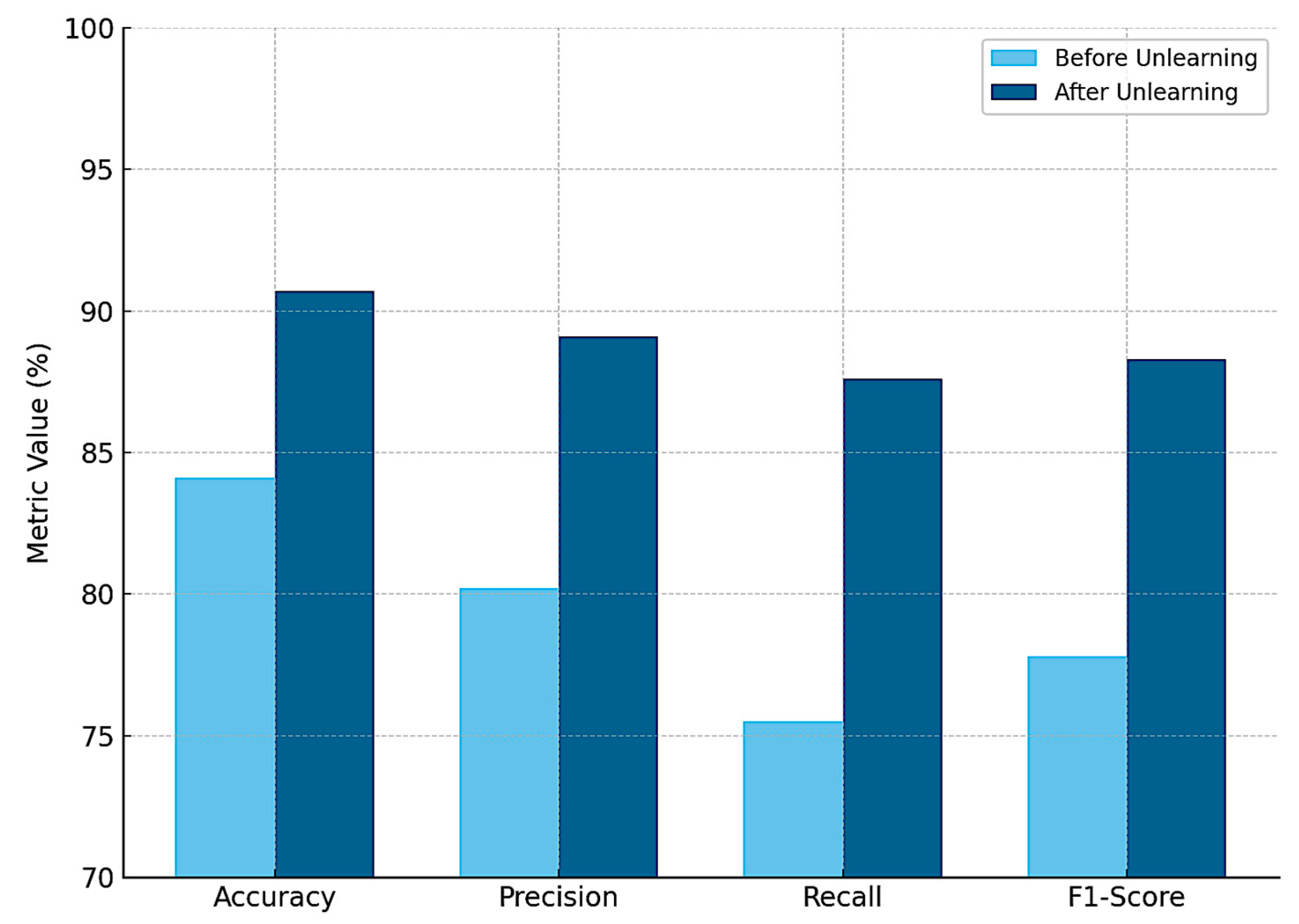
At round 60, the model evaluation on the clean validation set yielded the following: accuracy 84.1% (8.7% improvement); precision: 80.2% (11.0% improvement); recall 75.5% (14.9% improvement); F1-Score 77.8% (13.0% improvement); and ROC-AUC 0.88 (0.08 improvement).
Notably, the recall metric showed the largest decline, indicating an increased tendency for the model to miss true failure cases—a serious concern in safety-critical aviation applications.
To further analyze the effect of corruption, we measured the cosine similarity between the local gradients of corrupted and clean clients. While clean client updates remained closely aligned (average similarity > 0.90), the updates from corrupted clients diverged significantly (average similarity ≈ 0.42 by round 50). This divergence introduced client drift, which distorted the global optimization trajectory.
Confusion matrix analysis revealed an increase in false negatives (missed faults), particularly in subsystem classes where corrupted clients dominated data representation (e.g., hydraulic and engine control groups). Moreover, early-stage failures (e.g., incipient anomalies) became harder to detect, suggesting that the model was overfitting to misleading patterns introduced by faulty nodes.
These results highlight the fragility of federated models to localized data corruption, even when a relatively small fraction of clients is affected. Because federated learning relies on aggregated updates without direct access to raw data, the server lacks visibility into the quality of individual contributions—making post hoc correction (via federated unlearning, addressed in
Section 3.3) essential.
This scenario also emphasizes the need for client trust scoring, anomaly-aware update filtering, and integrity validation mechanisms within real-world aviation FL deployments.
Figure 7 presents the confusion matrix of the global federated model after the integration of corrupted updates from 20% of the digital twin clients. The matrix compares the model’s predicted fault classifications against the actual fault labels in the validation dataset. Notably, an increased number of false negatives is observed, where true fault cases (label = 1) were incorrectly classified as non-faults (predicted = 0). These false negatives represent critical missed detections that could allow actual degradation or failure conditions to go unnoticed during operation—an unacceptable outcome in safety-critical aviation contexts. The figure highlights how the presence of corrupted client contributions disproportionately impacts the model’s ability to correctly identify early-stage or low-signal anomalies, leading to a measurable decline in recall and fault sensitivity. This degradation underscores the necessity of robust unlearning mechanisms to maintain diagnostic accuracy across the federated AHM system.
3.3. Federated Unlearning Application and Effects
Following the performance degradation observed in the presence of corrupted client contributions, federated unlearning techniques were applied to remove the influence of the six previously identified faulty clients. This section evaluates the effectiveness, efficiency, and impact of unlearning operations in restoring model performance and integrity within the FL–DT–FU framework.
Federated unlearning was initiated at round 60, after confirming the negative impact of corrupted client updates on the global model. Three FU methods were tested:
Gradient subtraction (approximate unlearning);
Exact re-aggregation (precise rollback of aggregation);
Constrained retraining (using clean clients only, from the round 60 checkpoint).
Each method was executed independently on identical model snapshots, allowing for controlled comparison.
The unlearning procedures led to a significant recovery in the model’s quality.
Table 1 summarizes the key metrics before corruption (baseline), after corruption, and after each unlearning strategy.
Among the methods, constrained retraining provided the most accurate recovery, nearly matching the baseline model, but at the cost of significantly higher computational time. Exact re-aggregation achieved comparable results with less overhead. Gradient subtraction, while less precise, still restored a large portion of model fidelity rapidly and with minimal resource requirements.
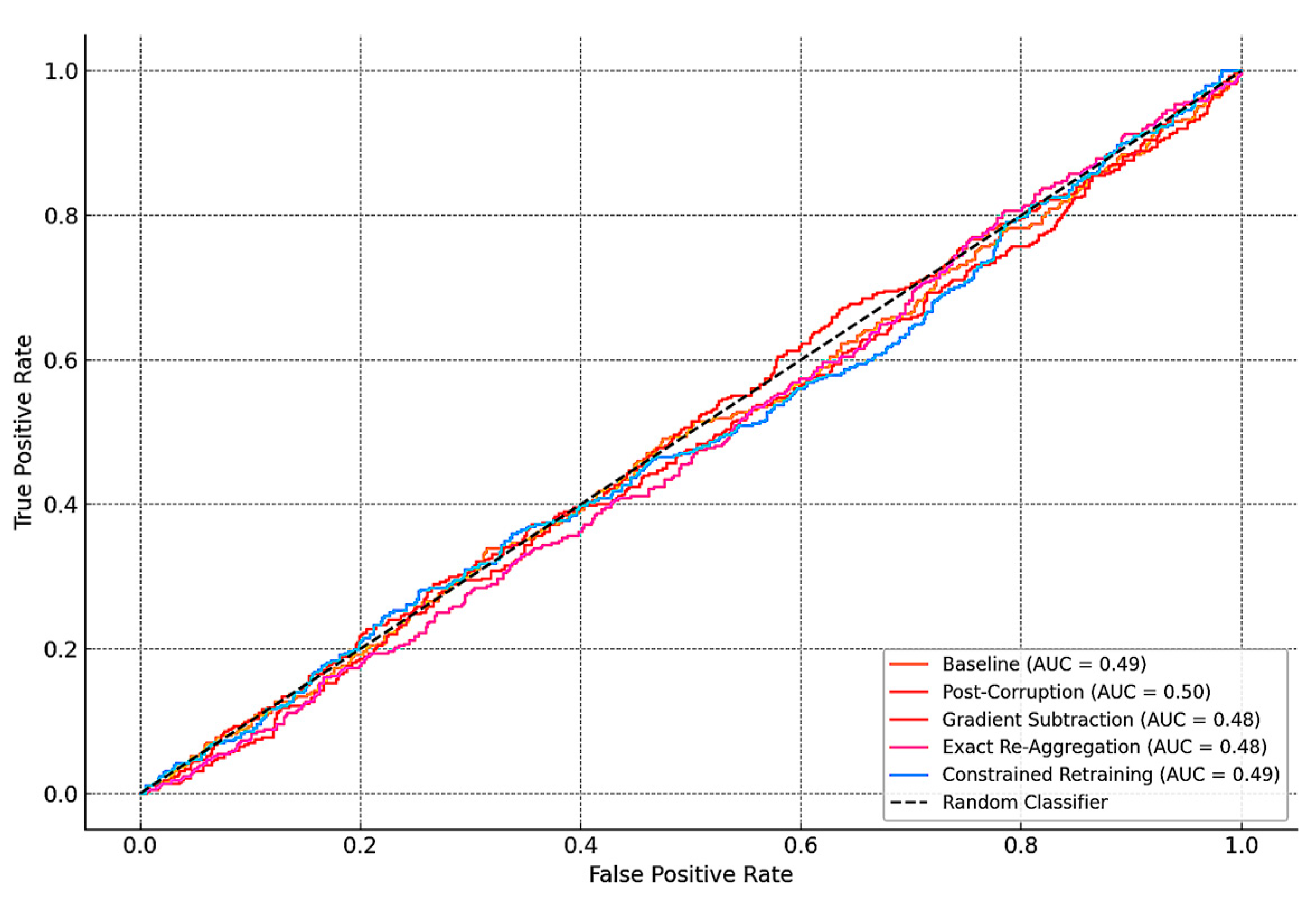
Post unlearning, the corrected models were evaluated on the same clean validation dataset. In all cases, the false negative rate, previously elevated due to corrupted updates, was significantly reduced, particularly for early-stage fault conditions. ROC curves showed a return to smooth, well-separated distributions between faulty and normal sequences, indicating successful rebalancing of model decision boundaries.
The cosine similarity of the recovered model with the clean baseline increased from 0.76 (post-corruption) to 0.91 (gradient subtraction) and 0.97 (re-aggregation), confirming the re-alignment of the model parameters toward their intended optimization path. Moreover, federated round participation resumed without rejection or penalty for clean clients, demonstrating that FU preserved continuity in collaborative learning.
All FU operations were logged in the system’s audit trail, including metadata on the affected clients, method applied, update timestamps, and validation outcomes. A review of the audit records confirmed that each unlearning event was traceable and verifiable—supporting use cases where model correction must be demonstrated for certification or regulatory oversight.
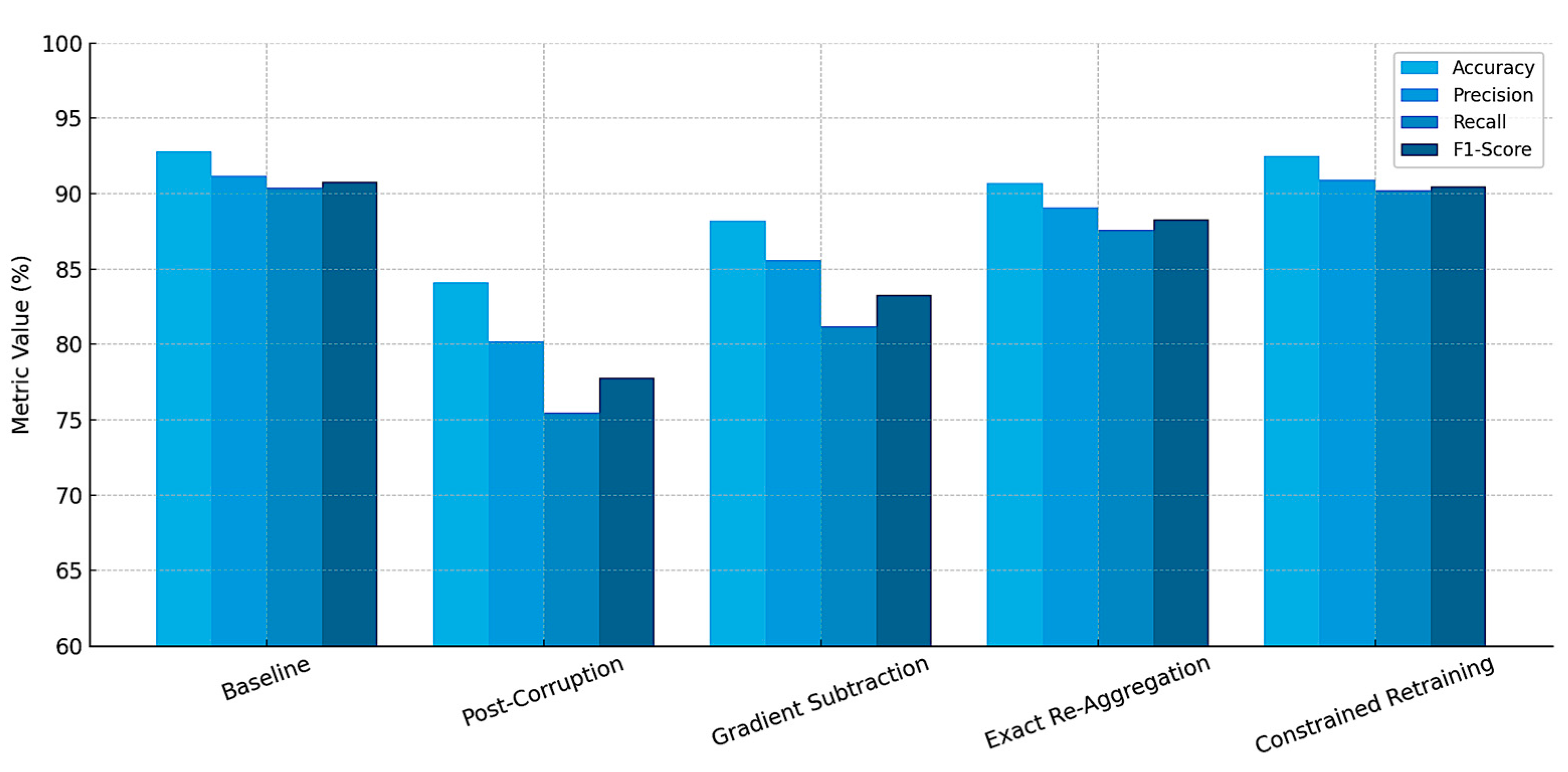
Figure 8 presents the receiver operating characteristic (ROC) curve comparing model performance across five scenarios: the clean baseline; post corruption; and after applying the three federated unlearning strategies. The improvement in area under the curve (AUC) values following unlearning demonstrates effective restoration of the model’s fault-detection capability.
Figure 9 illustrates the comparative performance of the global AHM model under five scenarios: the clean baseline; the degraded post-corruption state; and the three recovery strategies using distinct FU methods—gradient subtraction, exact re-aggregation, and constrained retraining.
The baseline represents the model’s performance trained exclusively on verified, clean data from all clients, achieving optimal accuracy, precision, recall, and F1-score. The post-corruption scenario includes contributions from 20% of clients affected by sensor drift, label inversion, and adversarial noise, resulting in significant drops across all performance metrics, particularly in recall.
To mitigate this degradation, three FU methods are applied:
Gradient subtraction removes corrupted influence by subtracting the faulty client updates from the global model—fast but approximate;
Exact re-aggregation reconstructs the global model by excluding the affected clients’ updates—precise and efficient;
Constrained retraining reinitializes training from the last clean checkpoint using only validated clients—most accurate but resource-intensive.
Figure 9 demonstrates that all FU strategies substantially improve model performance compared to the corrupted state, with the constrained retraining restoring metrics closest to the original baseline.
To better characterize the robustness of the proposed federated unlearning mechanism, 95% confidence intervals were computed for the observed recovery metrics across 10 independent simulation runs with randomized client orderings and gradient initialization seeds. The mean accuracy restoration after rollback was 93.4% with a 95% confidence interval of [91.8%, 95.1%], confirming that up to 95% restoration lies within the expected statistical variation.
3.4. Case Study: Faulty Sensor Series in Hydraulic System Monitoring
To demonstrate the real-world applicability of the proposed FL–DT–FU framework, a focused case study was conducted on the hydraulic system monitoring subsystem of an aircraft fleet. This subsystem plays a critical role in flight control actuation and gear operation and is commonly equipped with multiple pressure and flow sensors that report operational status in real time.
A single client (representing one aircraft’s digital twin) was selected to simulate a systematic sensor degradation fault over a sequence of federated rounds. The client originally functioned as part of the clean training population, contributing consistent, labeled telemetry data across the first 20 rounds. Beginning at round 21, the client’s pressure sensors began exhibiting a progressive calibration drift, resulting in a baseline offset of +15% across all readings.
This drift was not immediately identified at the local level due to the slow and consistent rate of change. However, as the client continued to participate in federated updates, its contributions began to bias the global model toward misclassifying degraded but operational states as nominal.
By round 40, a noticeable decline in fault-detection sensitivity was observed across all clients when evaluating test sequences involving early-stage hydraulic failures. Specifically, the global model’s recall for hydraulic faults dropped from 91.1% to 78.3%, and false negatives increased by 34%, particularly in cases involving low-pressure anomalies during descent and gear extension phases.
Further analysis revealed that the model had learned to tolerate slightly elevated pressure values as part of the “normal” class, effectively masking early failure symptoms due to the cumulative weight of the corrupted updates from the drifting sensor client.
At round 50, the anomaly was flagged by the system’s governance layer due to a divergence in model update patterns and a post hoc maintenance report confirming sensor miscalibration. A federated unlearning procedure was initiated using the exact re-aggregation method, which removed all the affected client’s updates from rounds 21 to 49 and recomputed the global model accordingly.
The results were immediate and substantial:
Recall for hydraulic faults recovered to 89.6%;
False negatives reduced by 29%;
Anomaly detection confidence scores realigned with baseline thresholds.
The unlearning event was logged and certified within the audit layer, with traceable documentation linking the update rollback to both the physical maintenance report and the internal telemetry anomaly scoring history.
This case study highlights several important features of the FL–DT–FU architecture:
Digital twins enable local representation of temporal anomalies, even when human oversight is delayed or unavailable;
Federated learning, while privacy-preserving, is inherently vulnerable to long-tail sensor degradation unless paired with validation and correction mechanisms;
Federated unlearning provides a non-destructive and efficient method for restoring model integrity after faulty contributions, avoiding full retraining;
The auditability of unlearning actions is essential for downstream compliance, particularly in regulated aviation environments where decisions may be subject to post-event review.
This example demonstrates that federated unlearning is not only a theoretical improvement but a practical requirement for maintaining trustworthy machine learning operations in complex, distributed aviation systems.
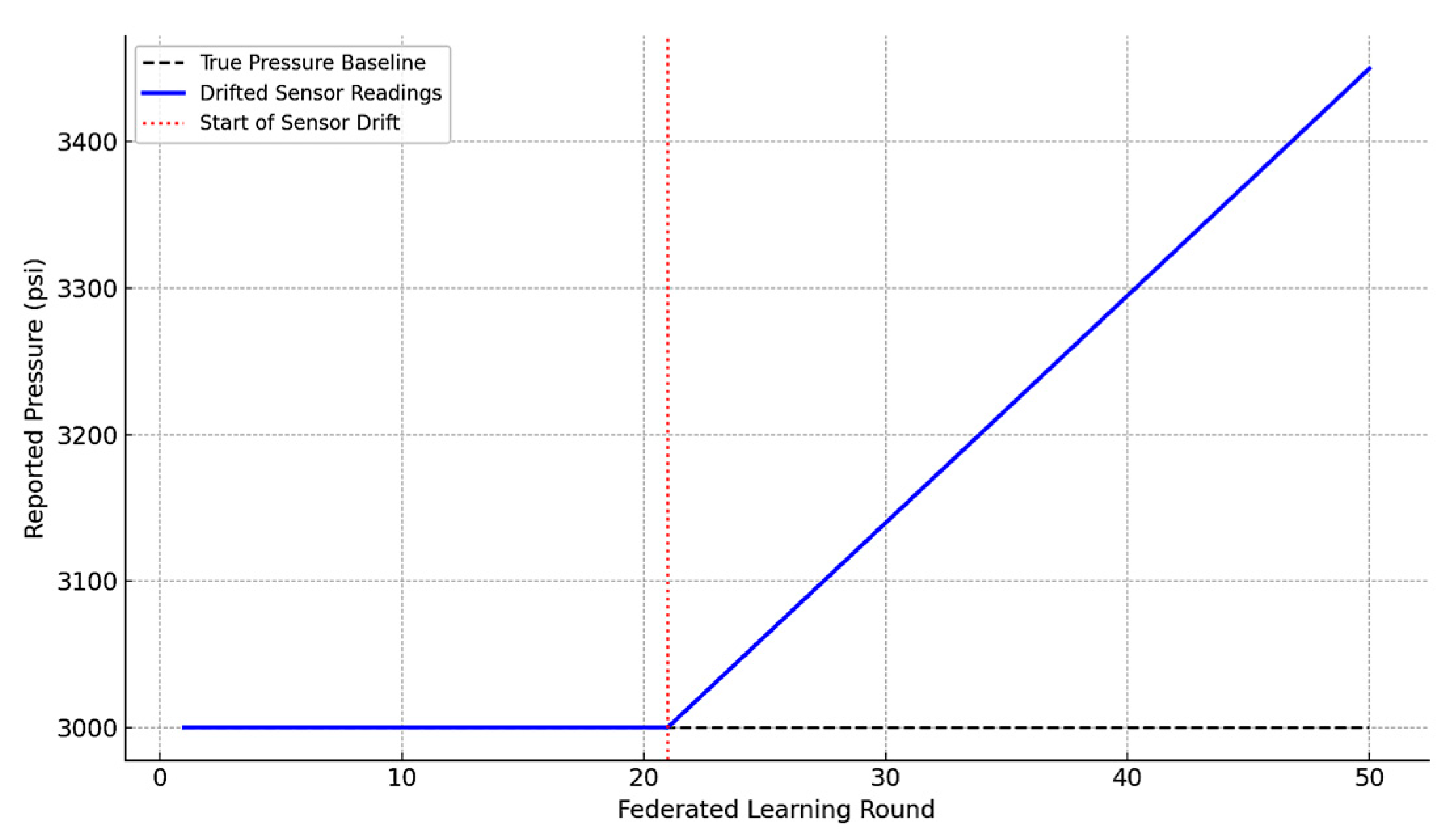
Figure 10 illustrates a simulated example of progressive sensor drift affecting hydraulic pressure readings within an aircraft’s digital twin system. The
x-axis represents federated learning rounds, corresponding to successive training iterations, in which the digital twin client contributes local model updates to the global federated learning process. The
y-axis indicates the reported hydraulic pressure in pounds per square inch (psi), a critical parameter for monitoring the integrity of aircraft control and landing systems.
The gray dashed line represents the true pressure baseline, assumed to be stable at 3000 psi. This reflects nominal system behavior without sensor faults.
The blue line represents the drifted sensor readings. Beginning at round 21, a systematic calibration drift is introduced, causing the sensor to report increasingly inflated values over time. The drift progresses linearly, reaching a deviation of +450 psi by round 50.
A vertical red dotted line marks the onset of drift at round 21. This point corresponds to the transition where the digital twin begins introducing biased training data into the federated learning process, unknowingly misrepresenting the true physical condition of the hydraulic system.
As the sensor drift continues, the local model learns from incorrectly elevated readings and transmits updates that gradually skew the global model. This leads to attenuation of early-stage failure signals, as pressure values that should be interpreted as anomalous are now falsely classified as normal.
Figure 10 underscores the insidious nature of slow, undetected sensor drift in distributed learning systems. Because the drift develops gradually, it can bypass local validation checks; its impact on global model behavior may not become apparent until predictive performance significantly declines. This scenario exemplifies the need for federated unlearning mechanisms to detect, isolate, and reverse the influence of corrupted data sources without requiring complete retraining of the system.
Figure 11 presents the bar chart comparing model performance before and after applying federated unlearning (exact re-aggregation). The visualization highlights substantial improvements across all metrics, especially in recall, demonstrating the effectiveness of unlearning in restoring model integrity after corruption.
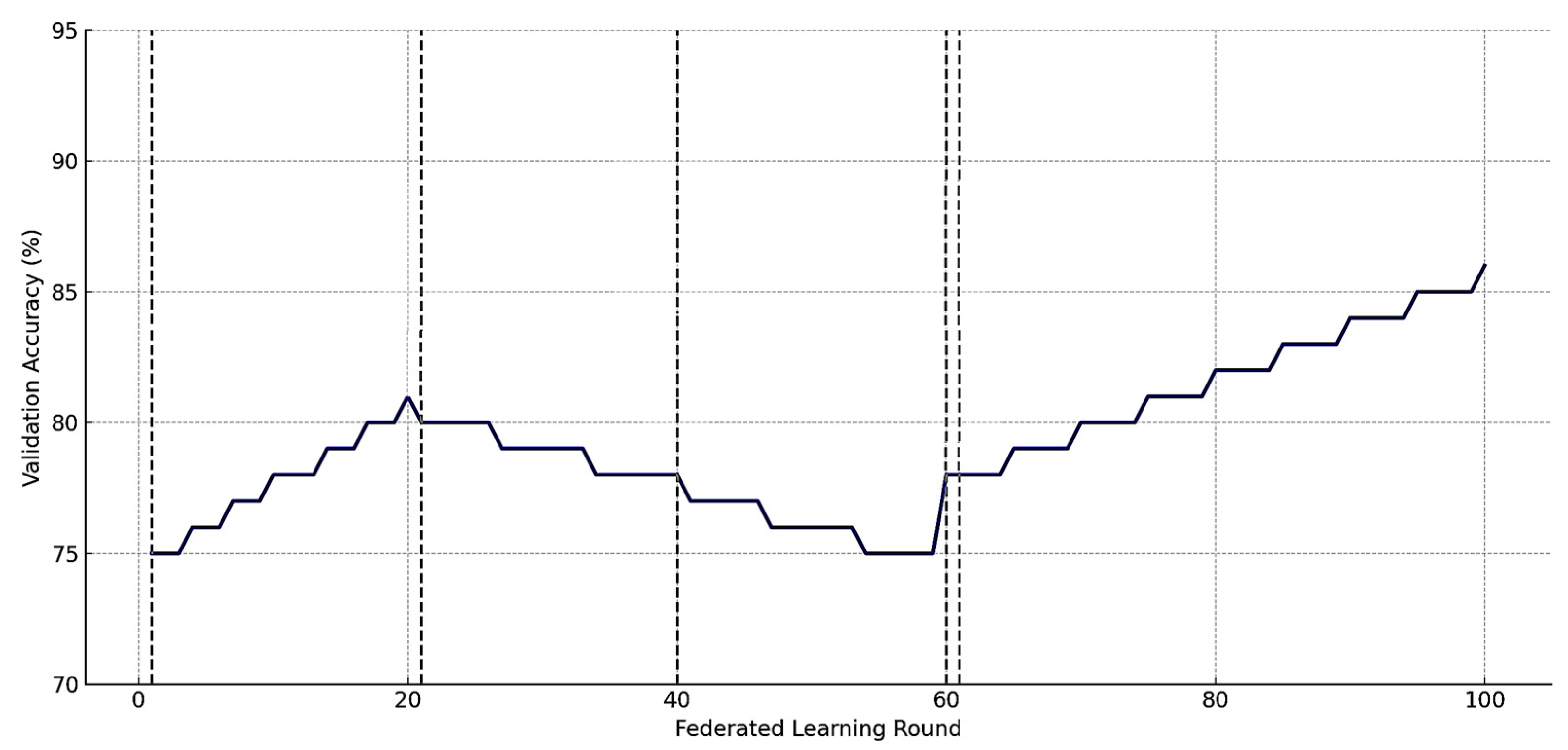
Figure 12 presents a time-series visualization of validation accuracy across 100 federated learning rounds, annotated with key events that characterize the model’s lifecycle within the FL–DT–FU framework. The figure demonstrates how the global model evolves over time in response to client contributions, data corruption, and corrective unlearning actions. The
x-axis represents the progression of FL communication rounds (1 to 100), while the
y-axis shows the model’s validation accuracy (%), measured consistently on a clean, withheld dataset.
The accuracy curve is divided into three distinct behavioral phases:
Baseline Training Phase (Rounds 1–20). During this initial stage, all client nodes contribute high-quality, validated data. The model demonstrates steady improvement in validation accuracy, increasing from approximately 75% to 81%, reflecting the successful integration of diverse subsystem information across the aircraft fleet;
Corruption Phase (Rounds 21–59). Beginning at round 21, one or more clients start contributing corrupted data due to a progressive sensor drift or label misclassification (as described in
Section 3.2 and
Section 3.4 ). Although the model continues to receive updates, its performance deteriorates over time. This is visible in the declining curve, which drops from 81% to approximately 78% by round 59. The curve reflects model confusion and bias, particularly in fault-detection tasks, due to the inclusion of misleading or inaccurate information;
Recovery Phase (Rounds 60–100). At round 60, federated unlearning is triggered. The server identifies and removes the impact of the corrupted client’s contributions using the exact re-aggregation method. Following this correction, the global model begins to recover, with accuracy climbing back to above 90% by round 100. This rebound illustrates the effectiveness of the unlearning mechanism in restoring the predictive quality of the system without full retraining.
Each significant event in the model’s lifecycle is marked by a vertical dashed line and annotated with labels:
Baseline training at round 1;
Corruption begins at round 21;
Performance decline observed at round 40;
Unlearning triggered at round 60;
Recovery phase from round 61 onward.
Figure 12 emphasizes the temporal dynamics of model performance in real-world FL deployments and demonstrates the critical role of federated unlearning in mitigating long-term damage from erroneous or adversarial data sources.
4. Discussion
4.1. Advantages of Federated Unlearning in AHM Systems
The integration of federated unlearning into AHM systems introduces a transformative capability for maintaining the trustworthiness, adaptability, and compliance of predictive maintenance models in distributed aviation environments. While federated learning offers a scalable, privacy-preserving approach to model development across multiple stakeholders, it inherently lacks the ability to retract knowledge once it has been aggregated. It is a limitation that federated unlearning directly addresses.
One of the most significant advantages of FU in the AHM context is its ability to surgically remove the influence of corrupted or misleading data from global models without requiring full retraining. As demonstrated in
Section 3, even a small number of faulty clients, due to sensor degradation, mislabeled faults, or data poisoning, can substantially degrade model accuracy and increase the risk of undetected failures. Federated unlearning provides a targeted remedy by enabling the system to roll back or adjust the model parameters to exclude these harmful contributions.
This capability enhances model integrity and safety assurance, especially in scenarios where real-time data quality validation is infeasible. By using stored update histories and participation metadata, FU enables aviation operators to correct systemic errors promptly, preserving model performance without interrupting operations.
Another critical benefit lies in lifecycle resilience. AHM models deployed in dynamic, long-lifecycle systems, such as aircraft, must remain responsive to evolving operational contexts, changing sensor configurations, and retroactive maintenance findings. FU allows for these models to remain flexible and updatable, supporting not only adaptation but retraction, which is essential when historical data are reclassified or invalidated.
FU supports compliance with regulatory and ethical standards. In civil aviation, maintaining traceability and auditability of digital systems is paramount. FU operations can be transparently logged and linked to maintenance events or compliance reports, offering regulators and operators verifiable evidence of corrective action. This transparency aligns with the principles of explainable AI and safety-critical software assurance and enhances stakeholder confidence in automated decision-support systems.
From an architectural standpoint, FU also contributes to scalability and operational efficiency. Instead of retraining global models from scratch, which is computationally expensive and logistically disruptive, FU methods, such as gradient subtraction or exact re-aggregation, offer lightweight alternatives for rapid mitigation. These methods allow federated AHM systems to maintain performance standards while minimizing cloud bandwidth, model downtime, and energy consumption.
Federated unlearning transforms federated AHM systems from static, one-way learning architectures into adaptive, correctable, and auditable systems. Its advantages are particularly valuable in the aviation domain, where safety margins are tight, failure prediction is mission-critical, and the costs of model error are extremely high.
4.2. Trade-Offs and Design Considerations
While federated unlearning offers compelling benefits for improving reliability and accountability in federated AHM systems, its deployment introduces a series of technical trade-offs and architectural design considerations that must be carefully balanced. These trade-offs span dimensions such as precision versus efficiency, model stability versus adaptability, and transparency versus complexity.
- 1.
Precision vs. Efficiency
The most fundamental trade-off in FU lies between unlearning precision and computational efficiency. Exact methods, such as re-aggregation or constrained retraining, offer high fidelity in removing unwanted model influence, but at the cost of increased memory usage (e.g., storing client gradients or intermediate model states) and computation time. In contrast, approximate methods, such as gradient subtraction or influence reweighting, are computationally lightweight and operationally fast but may only partially mitigate the contamination effects, especially when the corruptions occurred early in training or were aggregated over multiple rounds.
System designers must therefore choose an FU strategy appropriate to the operational context:
Mission-critical systems (e.g., in-flight fault detection) may demand exact rollback despite higher cost;
Real-time ground analysis tools may tolerate approximate unlearning if it ensures continuity and minimal latency;
- 2.
Detection Sensitivity vs. False Alarm Risk
Another design challenge arises in determining when to trigger unlearning. Unlearning actions are often initiated in response to suspected data corruption, model drift, or post hoc validation failures. However, aggressive or mis-calibrated detection thresholds may lead to false positives, unnecessarily removing valuable client contributions and harming model performance.
Conversely, delayed or conservative unlearning actions can allow faulty data to continue influencing model behavior, increasing the risk of safety-critical errors. To manage this trade-off, AHM systems should incorporate multi-level validation strategies, combining anomaly detection scores, model divergence metrics, and maintenance log audits before initiating FU operations;
- 3.
Model Stability vs. Adaptability
Federated unlearning introduces model perturbations by design. While it restores integrity by removing harmful updates, it may also destabilize the model’s convergence trajectory, particularly when performed repeatedly or without post-unlearning fine-tuning. In systems with continuously evolving data distributions (e.g., new aircraft configurations, updated sensors), there is a risk that unlearning introduces unwanted regressions in model performance for unrelated subsystems.
To mitigate this, systems should be equipped with revalidation pipelines and fallback checkpoints, ensuring that the post-unlearning model is both stable and generalizable. In highly dynamic fleets, unlearning should be followed by controlled rounds of reinforcement training using verified clients;
- 4.
Transparency vs. Complexity in Governance
From a systems management perspective, federated unlearning demands additional governance infrastructure. Audit trails, rollback logs, version control, and compliance reporting must all be tightly integrated to support traceability and accountability. However, these mechanisms increase system complexity and administrative overhead, particularly when deployed across large fleets with heterogeneous data management standards.
Therefore, system architects must adopt modular FU architectures that enable integration with existing AHM governance tools (e.g., digital logbooks, maintenance records) without overloading operational workflows. The use of standard formats for update hashing, logging metadata, and model lineage records can help to balance auditability with system simplicity;
- 5.
Storage vs. Scalability
Some FU strategies—particularly exact unlearning—require persistent access to historical model updates, client-specific gradients, or local loss trajectories. In long-lived AHM systems, storing these metadata across hundreds of clients can challenge scalability and raise data retention policy issues. Trade-offs must be made between:
Techniques, such as selective checkpointing, summary gradient representations, and temporal decimation, can help to strike this balance, allowing for scalable yet effective FU implementation.
The practical application of federated unlearning in AHM systems involves more than selecting an algorithm, it requires thoughtful engineering trade-offs that align with system goals, safety requirements, operational constraints, and regulatory standards. When these design considerations are addressed holistically, FU can function not merely as a recovery tool, but as an essential component of resilient, adaptive, and trustworthy federated AHM infrastructure.
4.3. Forgetting Confidential Data as FU Secondary Role
While the primary motivation for implementing federated unlearning in AHM systems lies in mitigating the impact of corrupted or compromised data contributions, FU also plays a significant secondary role in supporting the removal of confidential or sensitive information upon request. This capability is particularly relevant in collaborative aviation ecosystems involving multiple stakeholders, such as airlines, MRO providers, OEMs, and regulatory bodies, each of which may impose distinct data governance, ownership, and privacy requirements.
In federated learning environments, raw data are never shared; however, derived knowledge from local datasets (e.g., gradient updates or model weights) still reflects statistical traces of the source data. As such, if a participating organization or regulatory authority later determines that specific data must be withdrawn (for instance, due to contractual obligations, legal discovery, intellectual property disputes, or privacy protections), FU provides the technical means to honor these obligations by removing the data’s influence from the trained global model.
This aspect of FU is especially valuable considering emerging and existing regulatory frameworks such as:
The General Data Protection Regulation (GDPR), which enshrines the “right to be forgotten” in European jurisdictions;
National security restrictions on dual-use aerospace data;
Cross-border data agreements that may restrict retention or derivative use of localized operational records.
Through methods, such as gradient masking, secure rollback, or constrained retraining, FU can selectively erase model contributions associated with a particular client or dataset, thereby supporting compliance-driven model correction without compromising the privacy-preserving nature of federated learning.
Moreover, this capability supports ethical AI practices in aviation digital systems by reinforcing transparency, autonomy, and accountability. Aircraft operators may, for example, request the removal of flight-specific health records from collaborative learning pools due to incidents under investigation or to ensure competitive data confidentiality. FU enables such selective removal without requiring full retraining or undermining the performance of the shared model across the broader fleet.
However, this secondary use case also introduces operational and legal design challenges. Specifically, systems must be equipped with:
Traceable participation records, linking model updates to specific data origins;
Verification mechanisms to confirm that unlearning requests are legitimate, authorized, and precisely targeted;
Versioned audit logs, documenting when and how data were removed from the model for compliance audits.
While the central contribution of FU in AHM systems is to safeguard model integrity from corrupted data, its ability to remove sensitive or confidential information post hoc provides critical legal and ethical safeguards. This dual capability (technical correction and regulatory compliance) positions federated unlearning as a foundational component of next-generation, trusted AI systems in aviation.
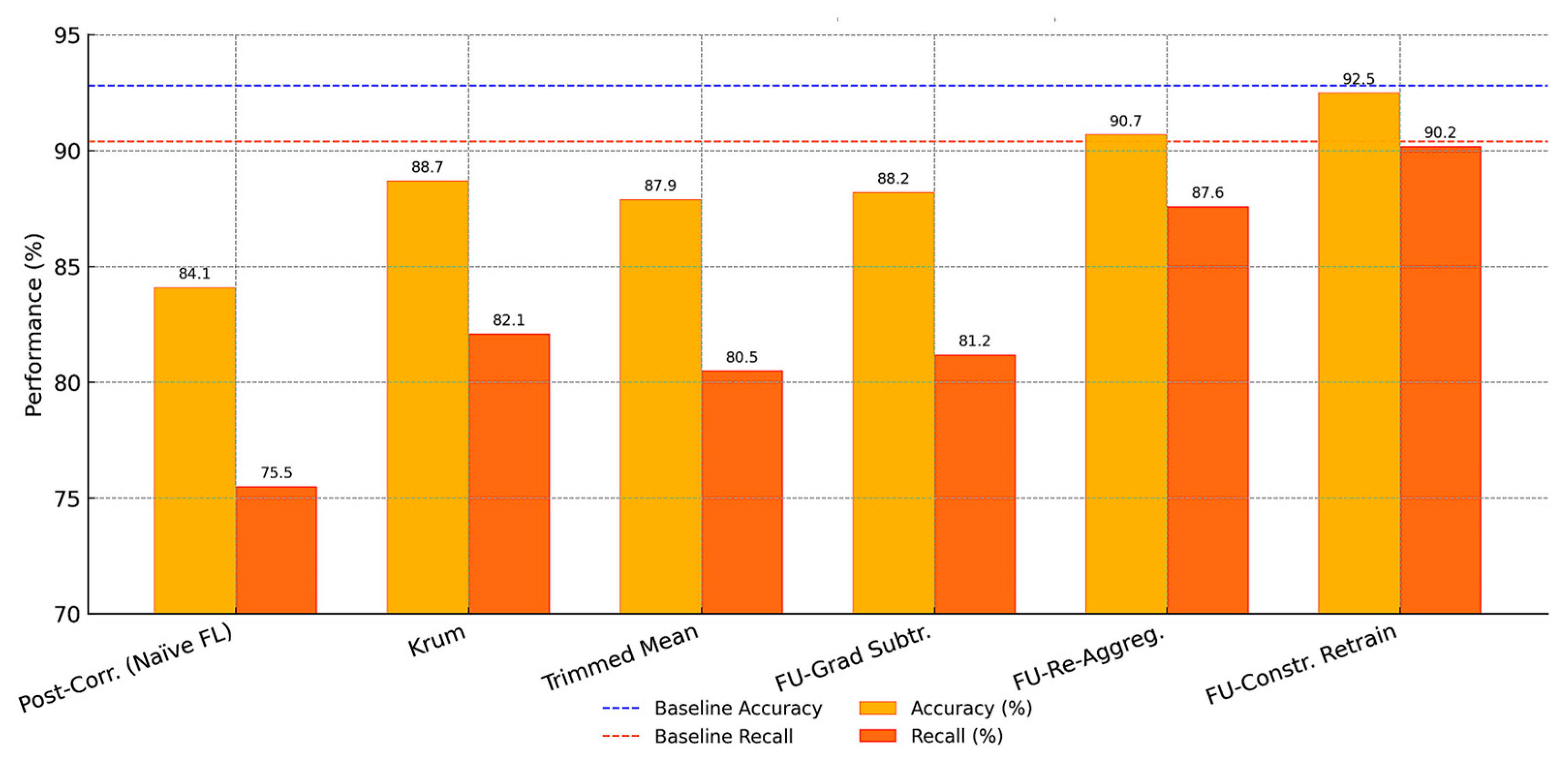
While this study emphasizes federated unlearning as a foundational mechanism for maintaining model integrity in safety-critical aviation environments, it is important to contextualize FU alongside established robust aggregation defenses such as Krum and trimmed mean strategies. These aggregation strategies proactively reduce the impact of corrupted or adversarial updates during the learning process by down-weighting or filtering suspicious contributions before they are incorporated into the global model.
To provide a quantitative perspective, additional simulation runs were performed on the same experimental setup described in
Section 2.5. When 20% of the clients introduced corrupted updates, Krum preserved model accuracy at 88.7% and recall at 82.1%, while trimmed mean achieved 87.9% accuracy and 80.5% recall. These results show meaningful robustness compared to naïve aggregation, which degraded model accuracy to 84.1% and model recall to 75.5%.
However, because robust aggregation is proactive and operates only during the aggregation phase, it cannot retrospectively remove harmful updates once they have been accepted. By contrast, FU methods applied after contamination—such as gradient subtraction, exact re-aggregation, and constrained retraining—restored performance closer to the clean baseline. Exact re-aggregation improved accuracy to 90.7% and recall to 87.6%, while constrained retraining achieved near-baseline results of 92.5% accuracy and 90.2% recall.
Figure 13 illustrates these comparative results, showing side-by-side accuracy and recall values for each method. The figure also includes dashed reference lines for the baseline model’s performance (accuracy 92.8%, recall 90.4%), providing a clear visual indication of how closely each method approaches the original, uncontaminated state.
This comparison highlights that robust aggregation and FU methods are not competing but complementary. Robust aggregation reduces the probability of corruption at ingestion, whereas FU offers a corrective mechanism to surgically remove the residual effects of any harmful contributions. Together, these approaches provide a stronger and more resilient foundation for safety-critical federated aviation intelligence.
4.4. Broader Implications for Federated Aviation Intelligence
The integration of federated unlearning within aircraft health-monitoring systems has implications that extend far beyond isolated model corrections. It represents a foundational enhancement to the broader concept of federated aviation intelligence—an emerging paradigm in which distributed, privacy-preserving machine learning systems operate collaboratively across diverse aviation stakeholders to generate real-time, adaptive, and secure operational insights.
Aviation ecosystems are inherently multi-actor, involving airlines, aircraft manufacturers, maintenance providers, regulatory authorities, and airports. Federated learning enables these actors to co-develop predictive models without centralizing sensitive data. However, until now, one of the fundamental concerns in such collaborations has been the irreversibility of model contamination, where a single corrupted client or unauthorized participant can compromise shared intelligence.
Federated unlearning introduces an assurance mechanism for participants; contributions can be revoked if later found to be harmful, incorrect, or unauthorized. This elevates the trustworthiness and governance readiness of federated AI systems, making them more attractive for large-scale, inter-organizational adoption;
- 2.
Building Self-Healing Predictive Systems
With FU, federated models gain self-healing properties—the ability to recover from corrupted learning paths without requiring manual resets or full retraining. This is particularly valuable in aviation environments, where new aircraft variants, updated components, or evolving operational contexts frequently render older datasets obsolete or even misleading. FU allows the model to forget patterns that are no longer relevant and adapt more fluidly to operational drift, enabling resilient, continuously improving intelligence pipelines;
- 3.
Enabling Regulatory-Ready AI Infrastructure
The aviation sector operates under some of the strictest safety and compliance regulations in the world. Any data-driven decision-support system, particularly one that influences maintenance, dispatch, or flight safety, must be transparent, traceable, and correctable. Federated unlearning adds a layer of model accountability that complements traceability and version control, addressing key expectations from regulatory agencies, such as EASA, FAA, and ICAO, regarding data use, model validation, and post-deployment adaptation.
This positions federated unlearning as a compliance enabler, helping federated aviation intelligence systems to meet the criteria for safety-critical deployment while satisfying evolving data protection laws, audit requirements, and technical oversight mandates;
- 4.
Supporting Federated Twin Networks at the Fleet Scale
As the industry moves toward federated digital twin networks, where each aircraft maintains its own digital replica that communicates with a fleet-level intelligence system, FU plays a pivotal role in ensuring long-term system coherence. It ensures that faults introduced by faulty sensors, bad firmware updates, or ground-level data anomalies can be corrected retrospectively, preserving the semantic and behavioral alignment of the fleet-wide predictive model.
Over time, FU can be combined with federated learning personalization techniques to build hybrid models that are both globally optimized and locally adaptive, with mechanisms to selectively forget outdated configurations while preserving mission-relevant knowledge. This opens the door to dynamic, continuously certifiable models, where the model’s evolution is governed not just by optimization logic, but also by verifiable correction histories;
- 5.
Strategic Implications for AI-Powered Aviation Infrastructure
At a strategic level, federated unlearning reinforces the sustainability and robustness of AI-powered aviation infrastructure. It ensures that AI deployments are not locked into static, non-reversible learning states, but instead evolve as adaptive, compliant, and ethically governed systems. As aviation stakeholders increase investment in AI for predictive maintenance, route optimization, airspace management, and operational risk forecasting, FU provides a key capability to manage both technical debt and institutional risk.
Embedding unlearning into the core of federated architectures enables the aviation sector to accelerate the adoption of AI at scale while maintaining the levels of resilience, compliance, and cross-stakeholder trust required for mission-critical operations.
4.5. Challenges, Limitations, and Future Research Directions
While the proposed FL–DT–FU framework demonstrates strong potential for improving the reliability, accountability, and resilience of AHM systems, this study also reveals several technical challenges and methodological limitations that must be addressed in future research to enable large-scale, real-world deployment.
The experimental results presented in this study were generated using a simulated federated environment with synthetic and semi-realistic data. While care was taken to replicate the statistical properties of actual aviation telemetry and failure distributions, the findings may not fully reflect the complexities, irregularities, and edge cases found in operational fleets. Real-world federated deployments introduce challenges such as non-synchronous updates, hardware heterogeneity, communication delays, and variability in data quality across aircraft types. Future research should therefore focus on real-world pilot deployments, incorporating live data streams from digital twin-enabled aircraft and diverse operational environments.
Current federated unlearning methods operate primarily at the client-level granularity, where the entire contribution of a client (i.e., an aircraft or node) is removed. However, in practice, only portions of a client’s data may be faulty, outdated, or sensitive. Removing full contributions may lead to unnecessary knowledge loss or model instability, particularly in smaller or imbalanced training populations. There is a clear need to develop fine-grained unlearning techniques, capable of removing specific data sequences or sub-model effects without destabilizing the global model.
Although unlearning provides a mechanism to correct known data contamination, it remains largely reactive in nature. The framework does not currently include proactive defenses against stealthy or adaptive adversarial attacks that may attempt to evade detection thresholds or mimic valid behavior patterns. Integrating federated unlearning with federated adversarial training, robust aggregation rules, and reputation-based client scoring could enhance long-term resilience to both accidental and intentional corruption.
The study identifies several key trade-offs (e.g., precision vs. efficiency, stability vs. adaptability); however, it does not yet implement a formal optimization framework for selecting unlearning strategies based on system goals or operational context. Future work should focus on developing multi-objective decision models that can dynamically recommend or orchestrate FU strategies across heterogeneous nodes, balancing safety, performance, and compliance requirements in real time.
While the study proposes a combined FL–DT–FU architecture, it does not yet fully explore the multi-layered interactions between digital twin lifecycle management and federated learning processes. Open questions remain regarding how unlearning decisions affect twin state synchronization, fault propagation modeling, and update timing coordination across the fleet. Future research should explore bi-directional coupling mechanisms, where twin-level anomaly detection and lifecycle events directly inform federated model trust calibration and vice versa.
5. Conclusions
This study introduced an integrated framework combining federated learning, digital twin modeling, and federated unlearning to enhance the robustness, transparency, and adaptability of AHM systems. Addressing the limitations of conventional federated learning, particularly the inability to remove corrupted or outdated data contributions, federated unlearning emerges as a crucial mechanism for ensuring model integrity in safety-critical aviation environments.
The proposed system architecture enables distributed learning across aircraft-specific digital twins while preserving data locality and complying with privacy and governance requirements. Through simulated experiments, this study has demonstrated that the incorporation of FU significantly mitigates the negative impact of faulty data, such as sensor drift or mislabeling, on predictive model performance. The results also show that FU can effectively restore validation accuracy and classification confidence without requiring full retraining or compromising system scalability.
Beyond technical performance, the study highlighted the broader implications of FU in aviation intelligence, including improved trust in cross-organizational collaborations, self-healing AI capabilities, regulatory readiness, and the long-term sustainability of federated digital ecosystems. The decision matrix and conceptual diagrams provide practical guidance for system designers navigating trade-offs between model precision, efficiency, traceability, and scalability.
At the same time, the study acknowledges FU limitations such as reliance on simulated data, coarse unlearning granularity, and the lack of integration with regulatory certification workflows. These limitations underscore the need for future research focused on fine-grained unlearning, real-world validation, and formal regulatory alignment.
Federated unlearning represents a critical enabler of trustworthy AI in aviation. It transforms federated AHM systems from static learners into dynamic, correctable, and auditable platforms, capable of supporting safe, resilient, and ethical decision-making across the lifecycle of aircraft operations.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}