1. Introduction
In recent years, the classification of underwater images has attracted the great attention of the computer vision research community because of its useful application in marine sciences, aquatic robotics, and sea exploration. Underwater imaging plays a very important role in a variety of analyses and evaluations of various kinds of underwater objects. It includes the evaluation of marine ecosystems, the analysis of biological habitats, and the observation of the condition of offshore oil, gas pipelines, and underwater optical fibers as well [
1]. This kind of imaging is predominantly achieved by making use of professional specialized cameras specially designed for underwater environments. These kinds of special camera are commonly encapsulated in waterproof enclosures to eliminate any water damage [
2]. It is a very challenging and difficult task to classify objects from underwater images. This is because the underwater environment is very challenging due to lightening conditions, color distortion, and scattering, making its analysis and processing more challenging. The underwater images are also degraded and poorly contrasted. This kind of challenge makes it difficult to extract useful information from foreground objects from underwater images using classical digital image processing and classification techniques [
3].
In recent years, deep learning technology-based methods have become influential tools to overcome these challenges by providing state-of-the-art solutions for underwater image classification tasks. The emergence of deep learning has transformed the domain of image analysis by empowering learning models to learn complex feature representations from raw data. For underwater images, deep learning models, including convolutional neural networks (CNNs), have shown unusual performance in the classification and recognition of objects in the presence of noise, distortion, and low visibility [
4,
5].
The CNN-based models can learn robust features from large datasets of underwater images, which can lead to notable improvements in classification accuracy. Despite these improvements, the classification task of underwater images employing deep learning techniques still suffers from various obstacles. The limited availability of high-quality annotated datasets, combined with the inherent variability of underwater conditions, often results in the poor generalization of trained models. Furthermore, underwater images suffer from issues like blur, non-uniform illumination, and degraded color fidelity, which complicates feature extraction. Therefore, designing deep learning models that can adapt to these underwater-specific challenges is an area of ongoing research [
6,
7].
Recent advances in neural network architectures, such as ResNet, EfficientNet, and attention-based models, have further improved the capabilities of deep learning in underwater image classification. These models introduce more efficient feature extraction mechanisms, allowing better handling of noise and distortions typical in underwater imagery. Coupling these architectures with advanced training techniques, such as adversarial learning and data augmentation, has shown great promise in pushing the boundaries of what is achievable in this domain. In this paper, we have focused on the binary classification of underwater images by using the ResNet-18 model, which is a CNN-based architecture. We have used a variety of underwater images to train our modified ResNet-18 model. Our proposed model performs very well in the presence of noise, illumination, distortion, and complex patterns, showing its strength in the classification task. We have conducted various experiments to fine-tune and train our proposed model in a training set and evaluate its performance on the test set. Moreover, distinguishing between raw and enhanced underwater images is crucial in many practical applications. Enhanced images, often produced using Underwater Image Enhancement (UIE) algorithms, are typically used in tasks such as object detection, habitat analysis, and infrastructure monitoring [
8]. In large-scale or automated image processing pipelines, it is not always clear whether an image has already been enhanced. An automatic classification of images into raw or enhanced categories can prevent redundant processing, improve pipeline efficiency, and support consistent dataset management. Thus, a reliable binary classifier is essential for maintaining operational accuracy and integrity in underwater image analysis systems.
The main contribution of this paper is as follows:
We have proposed a modified ResNet-18 model to perform the binary classification of underwater images.
Three new layers are added to the modified ResNet-18 model after frozen layers, namely, linear, ReLU, and dropout. These three layers are repeated three times in the form of blocks.
By adding these layers, we enabled our model to learn complex patterns present in the underwater images to obtain informative features and subsequently perform classification well.
Various complexities, including noise, distortion, and varying illumination conditions, are also addressed very well because of these additional layers added.
We have applied the data augmentation technique to fix the issue of class imbalance.
The remaining sections are organized as follows: In
Section 3, we have given the methodological background of the ResNet-18 architecture. Our proposed model of modified ResNet-18 is described and discussed in detail in
Section 4 along with a model overview. All the experimental results and their analysis are given in
Section 5. Finally, this paper is concluded in
Section 9.
2. Literature Review
Underwater imaging and its classification have attracted substantial attention from the computer vision research community in recent years. This is due to its importance in marine ecology, biodiversity conservation, and underwater exploration. Researchers have applied a variety of deep learning techniques [
4,
5] to deal with various challenges such as low visibility, color distortion, and limited labeled datasets. The use of transfer learning [
4,
6,
9,
10,
11], convolutional neural networks (CNNs), [
7,
11,
12,
13,
14,
15,
16,
17,
18] and image enhancement methods [
3,
12,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31] have improved the classification accuracy of underwater species and objects. In this section of the literature review, we have studied various techniques to explore various methodologies, from transfer learning with few-shot learning to deep residual networks and YOLOv3 [
31] architectures. We have provided insights into how these approaches have handled the complexities that are present in underwater environments.
The authors in [
4] use transfer learning with few-shot learning to optimize underwater sonar image classification with limited labeled data. The authors used pre-trained deep neural networks. After fine-tuning them, they used meta-learning techniques to obtain better accuracy. The work presented in [
19] proposed a method for the classification of underwater images. It combines various techniques such as image enhancement and information quality evaluation in order to improve the results. Their proposed method improved the visibility of underwater images by applying enhancement techniques. Fu et al. in [
12] introduced a deep learning-based model for the enhancement of underwater images. They performed this enhancement by combining water body pre-classification. Their proposed method first classifies the types of water. After that, they applied various enhancement techniques to improve image quality.
Another contribution giving a detailed survey is presented in [
3]. The authors of this work had given a survey of several deep learning techniques applied to underwater image classification, where [
1] analyzes and compares the performance of deep learning models (VGG-16, EfficientNetB0, SimCLR) in classifying unsupervised underwater images, using clustering and dimensionality reduction techniques to enhance accuracy and generalization. This study aims to identify the most effective approaches for improving underwater image analysis. Mahmood et al. [
20] offered a new method called ResFeats, a technique for underwater image classification. This methodology applies residual network-based features. They proposed a framework that carries the strengths of residual networks to optimize feature extraction from underwater images.
In [
21], a method was proposed to enhance underwater images and videos by combining multiple sources of images, using fusion methods. The authors of this work proposed a framework that improved visibility and color fidelity by incorporating both original and processed images, where the model presented in [
32] enhances underwater images through adaptive color correction and data-driven Retinex decomposition, while a hierarchical U-shaped transformer network improves contrast and reduces blur. This approach outperforms existing methods on benchmark datasets. Another approach [
22] has been proposed to enhance underwater images that integrate wavelength compensation and dehazing techniques. The authors of this work resolved the challenges of color distortion and reduced visibility present in underwater images. These challenges are triggered by light absorption and scattering. One approach integrates a light field module and a sketch module to improve color representation and preserve structural details [
33], while another combines Transformer and CNN in a parallel fusion design to capture both local and global features, leading to superior PSNR, SSIM, and detection performance [
34]. These methods demonstrate significant improvements over traditional techniques in both visual quality and computational efficiency.
In terms of datasets, there was a method [
23] to automate the annotation of images from the coral reef survey by applying some computer vision techniques. The system developed in this work can detect and classify various marine species within underwater images by facilitating efficient data collection and analysis for ecological studies. This method applied various deep learning algorithms to improve annotation accuracy and reduce additional manual effort.
Raveendran et al. [
24] have provided an inclusive review of underwater image enhancement techniques by discussing recent trends, challenges, and their applications. The authors of this review classified the existing techniques into traditional and deep learning-based techniques. A detailed review of advanced techniques [
25] in underwater image processing was provided that focused on restoration and enhancement techniques. The discussion discussed various methodologies to resolve multiple challenges, including color distortion, low visibility, and light attenuation present in underwater images due to their environment. A method presented in [
26] is a deep learning-based approach to the classification of lake zooplankton using image data. The authors employ convolutional neural networks (CNNs) to automate the identification and categorization of zooplankton species, addressing challenges in traditional manual classification methods.
Prasetyo et al. [
27] proposed a multilevel residual networking VGGNet for the classification of fish species. Its performance was enhanced by combining residual connections, resulting in improved feature extraction and fixing the vanishing gradient problem. Another approach [
7] was proposed for underwater gesture recognition based on its environment that integrates computer vision and deep learning methods. This technique worked well in challenging underwater conditions, demonstrating the effectiveness of their approach.
The cross-pooled FishNet technique [
9] based on the transfer learning model was proposed for the classification of fish species present in the images. It utilized pre-trained deep learning models to improve the classification performance and minimize the need for large labeled datasets. The fish species are identified by applying the CNN-based model [
14] that was trained on synthetic data generated using computer graphics. It effectively augmented the training data, leading to improved classification accuracy. Gori et al. [
15] proposed a method to recognize fish species by applying deep learning techniques for image classification. It uses various CNN architectures to improve identification accuracy and other evaluation measures. Another approach proposed by Guo et al. [
35] focused on the identification of underwater sea cucumbers using deep residual networks, such as ResNets, to improve classification accuracy. Its model architecture addressed various challenges raised by underwater imaging conditions.
There also exists a review for the classification of plankton within ocean ecosystems [
36] using computer vision techniques. It reviewed various techniques and algorithms utilized for effective plankton identification and analysis, emphasizing their significance for ecological monitoring. A CNN-based model [
16] was implemented by improving the squeeze and excitation blocks for the biometric classification of temperate fish species. Their proposed architecture improved the feature representation and classification accuracy for fish identification tasks. Wang et al. [
37] introduced a deep encoding–decoding network architecture for underwater object recognition to improve classification accuracy in challenging underwater environments. This novel architecture extracted features and then effectively reconstructed the images. It addressed various issues such as visibility loss and distortion in a better way.
Another approach equipped with an underwater drone panoramic camera was proposed for automatic recognition of fish using deep learning techniques [
2]. This system captured underwater images and analyzed them to enhance fish identification in real time. A methodology presented in [
10] transferred the knowledge from the deep learning model for object recognition in low-quality underwater videos. The proposed method uses pre-trained models to improve recognition performance despite the challenges posed by poor visibility and distortion. Szymak et al. [
38] proposed a model for underwater object recognition using deep learning techniques. Various neural network architectures were utilized for object classification, dealing with various challenges related to underwater image quality. Another architecture was proposed [
11] using the transfer learning technique with the deep CNN model to recognize live fish underwater. The authors of this methodology showed how pre-trained models can be fitted to enhance classification accuracy in challenging underwater conditions.
A deep learning-based technique for the accurate and efficient identification of coral reef fish in underwater images was also proposed by Villon et al. [
39]. They applied CNN-based models to improve classification accuracy and performance, addressing challenges in traditional identification methods. Machine learning and deep learning techniques were also applied [
40] to identify Posidonia meadows in underwater images. The authors proposed this methodology and compared various models, including convolutional neural networks, to improve the accuracy of underwater vegetation detection. Jin et al. [
41] studied the use of deep learning-based architectures for underwater image recognition with small sample-sized datasets. They presented a model to enhance classification accuracy by applying data augmentation and various pre-trained networks. Rathi et al. [
17] applied another approach for the classification of underwater fish species using convolutional neural networks and deep learning techniques. Their designed model performed effectively to classify fish species in challenging underwater environments.
In some proposed methodologies for underwater image classification, data augmentation techniques are utilized along the CNN-based model, as in [
18]. By enhancing the size of the underwater image dataset, the model trained very well and also performed well in a challenging environment. One more deep learning-based architecture named DeepFish was proposed [
28] for the precise recognition of live fish underwater. The authors design a model that effectively addresses the challenges of underwater image quality and fish species variability. Salman et al. [
29] presented a deep learning-based approach to the classification of fish species in challenging underwater environments. These challenges may include variable lighting, occlusion, and the poses of fish. Convolutional neural networks are used to extract and learn features from underwater images. The model performed well in the above challenges.
Some advanced image processing and deep learning techniques [
30] are used to deal with low-resolution underwater images for fish recognition. Various challenges established due to poor image quality, including blurriness and noise, which often delay accurate species identification, are addressed in this work. Their proposed CNN model improves recognition performance under these conditions. A deep learning model based on the YOLOv3 architecture [
31] was developed for underwater object recognition, basically designed for real-time object detection [
42]. YOLOv3 is applied to handle explicit challenges in underwater environments, such as low visibility and image distortion. In terms of datasets, an extended version of the marine underwater environment database was designed [
43] to collaborate with research on underwater image processing and object recognition. Deep detailed descriptions of the database were provided, including diverse underwater scenes and various marine species.
Various challenges of real-world underwater image enhancement are also addressed in [
44,
45]. These challenges are under natural light conditions and focus on various issues such as color distortion and low visibility. The authors of this work reviewed various existing benchmark datasets and used evaluation metrics to effectively assess enhancement algorithms. In addition, they proposed various solutions using deep learning techniques to improve image quality in underwater environments. Another approach for the classification of underwater objects was proposed in [
6]. The authors fixed the issue of limited labeled sonar data by producing synthetic data. They used it to further train their proposed deep learning models. Transfer learning is applied to improve the classification accuracy for the sonar image dataset. Lu et al. [
46] introduced the FDCNet model, which is a filtering convolutional network. They designed it for the classification of marine organisms in underwater environments. They added a novel filter layer to improve the model’s ability to handle underwater image noise and distortion in order to improve classification.
A technique for adaptive foreground extraction was proposed to improve fish classification in underwater imagery using deep learning models [
5]. Separating fish from complex underwater backgrounds enhances the performance of classification models. Their proposed method works well under varying environmental conditions, such as lighting and water clarity, to better segment fish in the images.
Several recent studies have investigated advanced techniques for underwater object detection and classification using deep learning. Pachaiyappan et al. proposed an approach that integrates diffusion models with the Convolutional Block Attention Module (CBAM) and the modified sweep transformer block (MSTB) to enhance underwater image quality. Their method effectively addresses challenges such as water turbidity and variable lighting conditions, resulting in improved accuracy for object detection and classification [
47]. Similarly, Roy and Talukder developed a deep learning-based underwater object detection system, integrating these models with autonomous robots for real-time image analysis [
48]. Their study emphasizes the importance of efficient processing for underwater exploration and maintenance, although specific performance metrics were not detailed.
The classification of underwater images has been approached using various methods, including transfer learning models [
4,
9], CNN-based classification [
3,
20], and image enhancement techniques [
21,
22]. However, these methods often face limitations such as the dependency of the dataset, inadequate feature extraction, and poor integration of enhancement and classification processes. YOLO-based models [
2,
31] improve processing speed but struggle with high noise levels and low-resolution images, which affects classification accuracy, whereas our proposed model is optimized for underwater conditions, ensuring improved robustness and accuracy. Unlike previous methods that focus on either enhancement or deep learning for classification, our approach offers improved feature extraction and classification in multiple challenging underwater conditions.
4. Model Overview
In this section, we have given a complete description of our proposed ResNet-18 model, which is designed specifically for our binary classification problem of underwater image datasets.
4.1. Model Selection
Recent studies have compared ResNet-18, ResNet-50, EfficientNet, and Vision Transformers (ViT) in various image classification tasks, illustrating their respective strengths and weaknesses. ResNet-18 has been identified as an efficient model due to its lightweight architecture and low computational cost [
52]. Although ResNet-50 offers deeper feature extraction, it incurs higher computational demands, making it less practical for resource-limited environments [
51].
EfficientNet provides high accuracy with optimized efficiency, but requires extensive tuning and more computational resources [
53]. ViTs are superior in learning complex patterns, but require large-scale datasets and significant computational power [
54].
Given these insights, ResNet-18 emerges as the optimal choice for our binary underwater image classification, effectively balancing accuracy, efficiency, and computational feasibility. It performs well on small to moderate datasets, requires less computational power, and can achieve high accuracy with appropriate enhancement and training. The evaluation results presented in
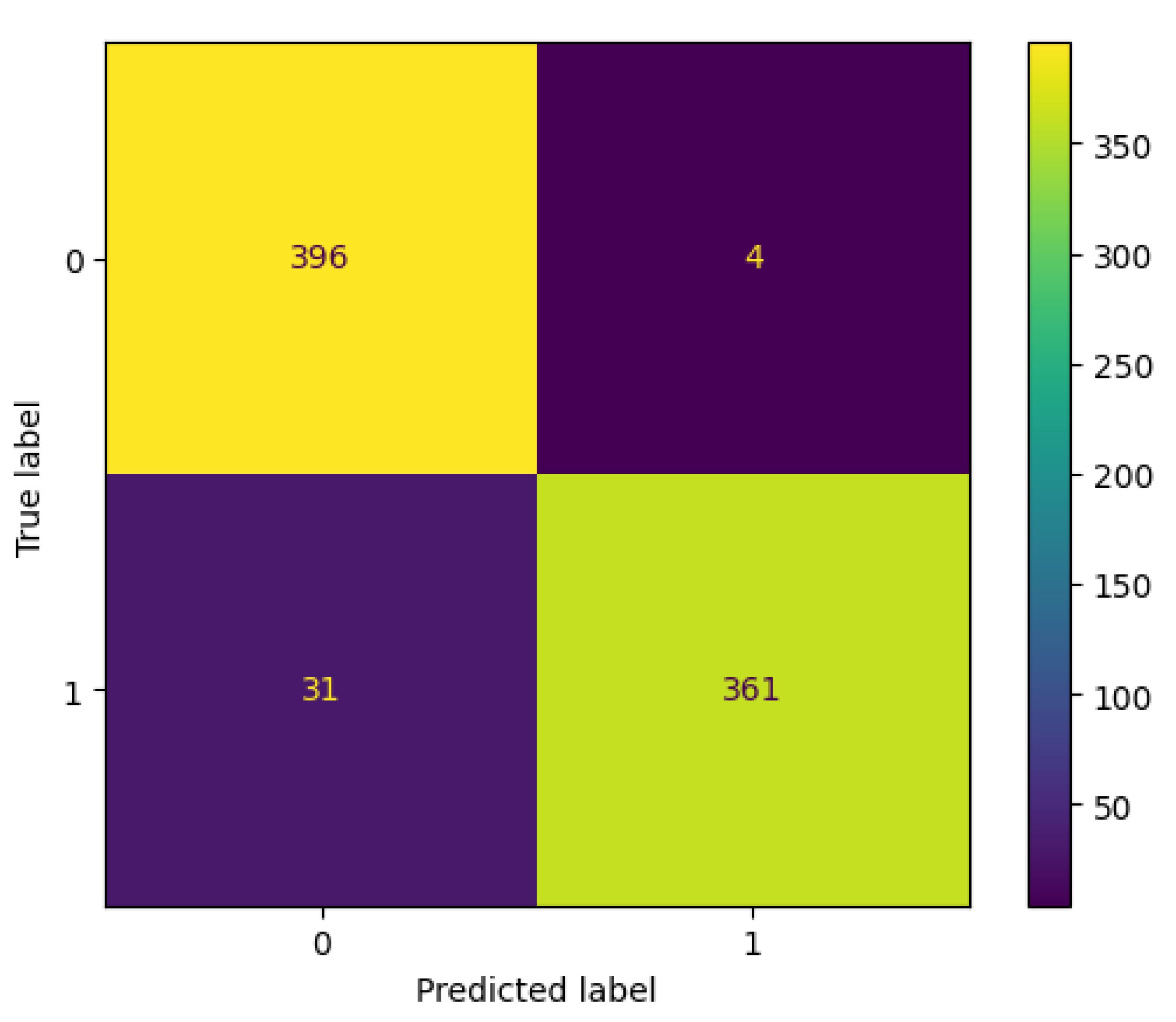
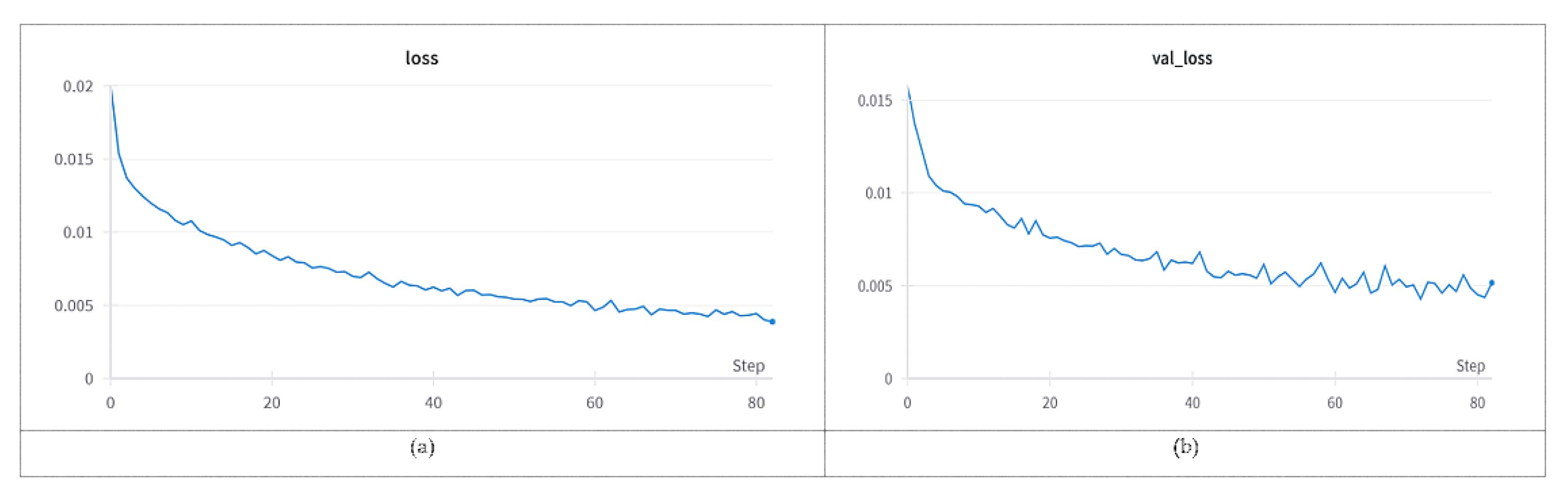
Section 5.5 further validate the effectiveness of ResNet-18 for this application.
Table 2 clearly compares the models on computational costs, strengths, and weaknesses, strengthening our choice of ResNet-18.
4.2. Proposed ResNet-18 Model
In this section, a brief overview of our proposed binary classification model is given.
The classification of underwater imaging is a challenging task, as it has various complexities in underwater image datasets, as discussed in
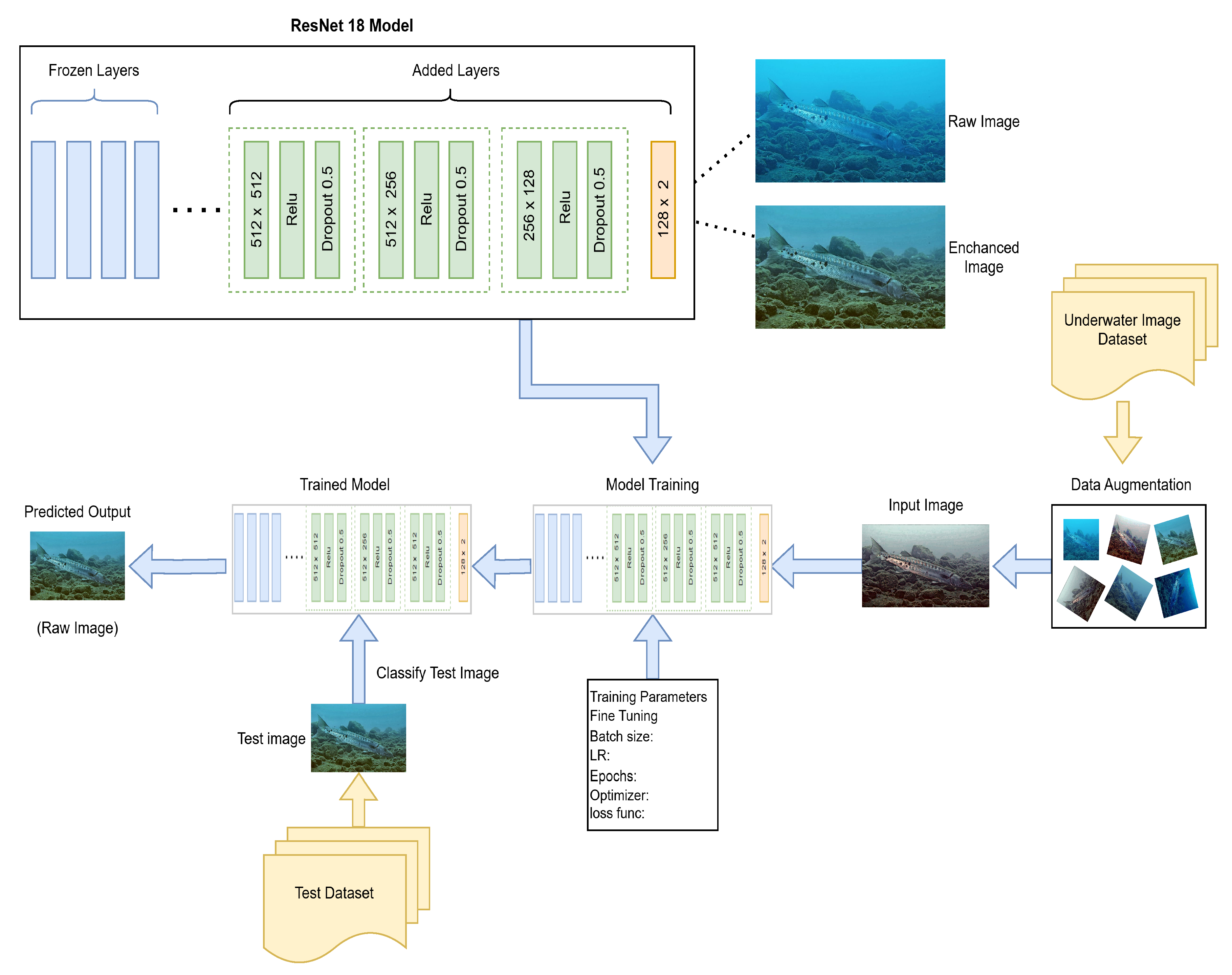
Section 1. There also exist problems of class imbalance, such as the imbalance number of samples in each class, which create hurdles in performing true classification. To overcome these challenges, we have proposed a modified version of the ResNet-18 model by adding several layers and freezing some of its layers. A detailed overview of the designed model is shown in
Figure 2. In this, the initial layers of the ResNet-18 model are frozen, so these initial layers are used as is. Their learned weights are not modified in it. We have used these learned weights by applying the transfer learning approach. After that, we added more layers to the ResNet-18 model. A linear layer of 512 × 512 is added, followed by ReLU activation and 50 percent dropout layer. After that, one more block of these three layers is repeated with a different linear layer of 512 × 256 and the same ReLU and dropout as earlier. The same block is repeated with the dimension of 256 × 128 of the linear layer with ReLU and dropout, and at the end the dimension of 128 × 2 is added. The model performs the classification of two classes such as raw and enhanced images. The designed model is trained using the SAUD [
8] dataset consisting of a variety of underwater images, but the dataset here is highly unbalanced because the raw images were less than the enhanced images. Each raw image in the dataset was enhanced to 10 different forms using UIE algorithms, which actually doubled the number of images in the enhanced image class. To address the issue of class imbalance, the data augmentation and downsampling technique is applied to balance the ratio of samples in each class. This augmented dataset is passed to the proposed architecture of Res Net-18 for its training. The parameters and hyper-parameters of the proposed architecture are fine-tuned during training according to our problem at hand, including batch size, learning rate, number of epochs, selection of optimizer, loss function, and more. After that, the performance of the model is tested using the test dataset.
4.3. Proposed Classification Model
In this section, we have given a complete description of our proposed model in detail step by step. We have used a pre-trained ResNet-18 model for binary classification of our dataset.
Let be a labeled dataset of underwater images, where
represents n samples and represents the labels corresponding to the samples in X.
Let the augmentation technique *flip* be applied to the dataset .
The augmented dataset is represented as .
Similarly, X and Y after augmentation are represented as and , respectively.
Each sample in is represented as a vector of characteristics of dimension d: . Assume that represents a sample that belongs to class j, where .
From each class j, 90% of the samples are selected for training and the remaining 10% of the samples are chosen for testing purposes to evaluate the performance of the proposed model.
Suppose denotes the training set and denotes the test set.
Similarly, and represent the labels of the training and test datasets, respectively.
After splitting the dataset, the augmented training dataset is passed to the proposed model, which consists of the following steps:
The designed model takes an input image in the input layer of the ResNet-18 model.
The input feature map f of the image , in the input layer l, is passed to the frozen layers of the ResNet-18 model.
This input feature map f is convolved with learned weights of the frozen layers (layer by layer).
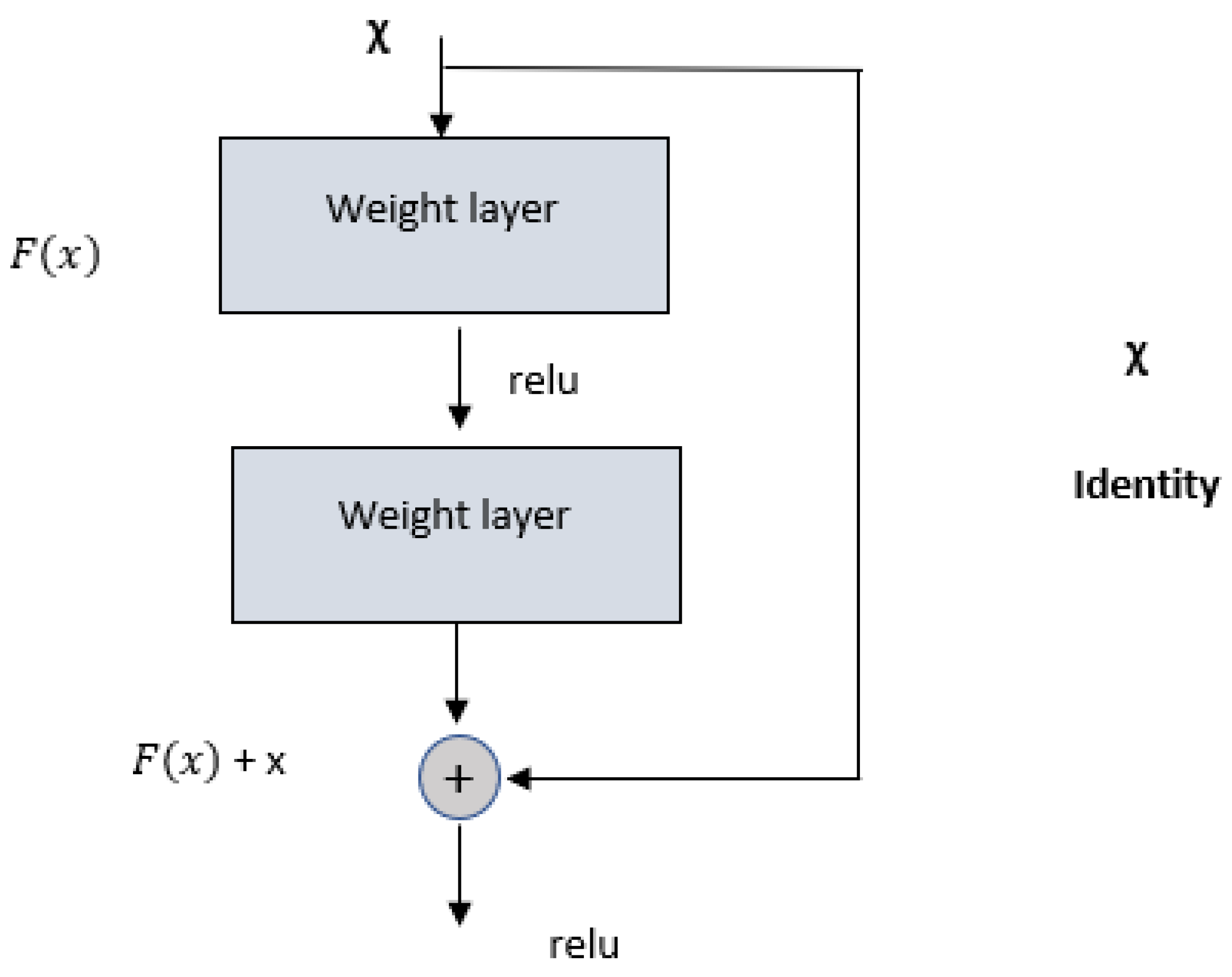
ReLU activation function is applied to activate convolved feature maps in each frozen layer as given in Equations (3) and (4).
The convolved feature maps are then passed to the newly added layers, such as linear layer, ReLU, and dropout. The description of these added layers is given in
Section 4.2.
The weights of these newly added layers (linear, ReLU, and dropout) are updated and optimized during the backpropagation of the ResNet-18 model using the optimizer function.
Before the last classification layer, a fully connected (FC) layer is added to reduce the output size to a single value.
The output of the FC layer is then passed to the last layer, such as the classification layer that has the sigmoid activation function for binary classification.
Several iterations are performed on the training dataset to train the ResNet-18 model.
Steps 1 to 9 are performed for all samples in the training dataset .
During backpropagation, the Adaptive Moment Estimation (ADAM) optimizer is used to optimize the loss of the model as given in Equation (
5).
where
The Binary Cross-Entropy loss function is applied to calculate the loss of the model, as given in Equation (
6):








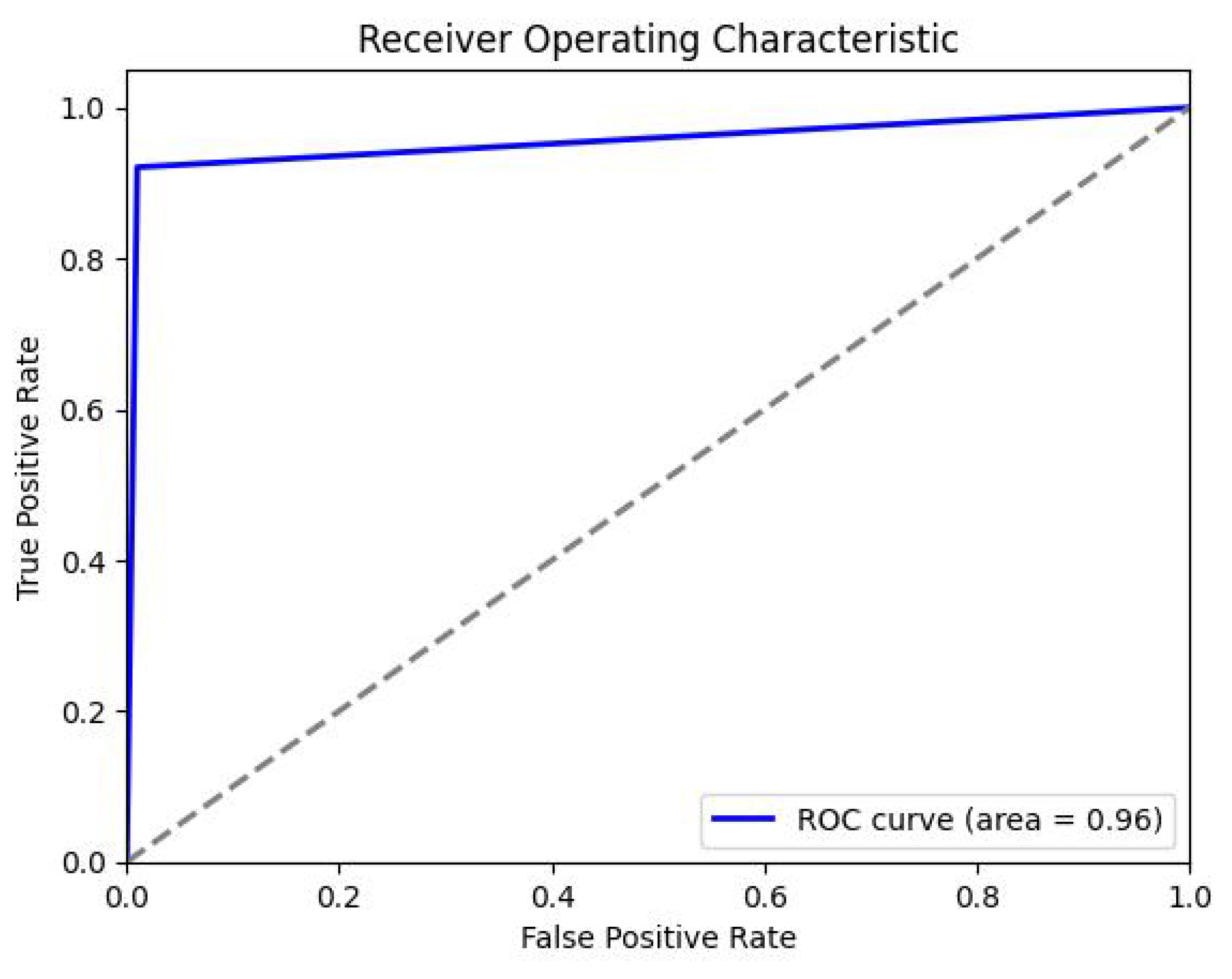

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}