1. Introduction
The current rapid evolution of artificial intelligence (AI), particularly large language models (LLMs), has demonstrated significant potential in automating tasks and offers a wide range of capabilities that enhance both teaching and learning experiences. LLMs are now enabling teacher-assisted learning, where AI complements human instruction by alleviating routine tasks, allowing educators to concentrate more on the interactive and creative elements of their work [
1]. For educators and learners alike, these models unlock access to rich, context-aware educational resources that bridge language divides and transform the classroom experience. Moreover, by leveraging advanced cognitive insights, they empower innovative teaching methods and foster deeper critical thinking across a diverse set of learning scenarios.
One area where this potential can be fully appreciated is the examination process. The conventional approach to creating examination papers is a manual process that is not only time-consuming, tedious, and repetitive but also places a considerable burden on educators, especially when dealing with large student populations. This method increases the likelihood of inefficiencies, such as potential bias, the reuse of questions across examination periods, and the under- or over-representation of syllabus sections, often compromising the integrity and fairness of the process [
2]. These challenges are further amplified in the modern educational landscape. The ongoing rise of remote examinations [
3] has created an urgent need for diverse and dynamic questions to maintain academic integrity. Furthermore, in today’s increasingly globalized and multicultural classrooms, language barriers can compromise the fairness and clarity of assessments [
4]. Regarding exam grading, the manual process is labor-intensive and prone to inconsistencies, making it difficult to provide detailed feedback due to heavy workloads, which can often cause unnecessary delays [
5,
6]. Finally, while theoretical texts offer students detailed explanations, they often lack the interactive exercises needed to apply and evaluate that knowledge, creating a gap between theory and practice.
Using an LLM-based exam generation system addresses these challenges and benefits students by providing them with a richer and more equitable assessment experience. The system can generate a diverse array of questions that not only reflect a deeper understanding of the material but also challenge students to think critically and innovatively. This approach ensures fairer assessments by minimizing human bias in question creation, while the variety and complexity of questions encourage the development of higher-order thinking skills [
7]. By tailoring questions to span broader cognitive contexts, the system exposes students to a wide range of problem-solving scenarios that promote a comprehensive grasp of the subject matter. Moreover, automatic exam grading promotes consistency, allows for the provision of detailed feedback, speeds up result release, and supports the more efficient use of human resources. Ultimately, these benefits combine to create an assessment environment that not only measures knowledge more accurately but also actively contributes to a more engaging and effective learning experience [
8].
While prior research has explored individual components such as question generation [
9,
10,
11], essay grading [
5], or translation using NLP and LLMs [
12,
13], these efforts typically operate in isolation, lack architectural integration, or depend on cloud-based proprietary services (e.g., GPT-4 Turbo [
14]). Furthermore, existing systems often fall short in handling multilingual input [
15,
16], ensuring grading transparency [
17], or operating efficiently on standard hardware without specialized AI infrastructure [
18,
19]. This creates a significant gap for educators and institutions that require secure, private, and low-cost automated assessment tools.
The system proposed in this work addresses these gaps by integrating question–answer generation, semantic-aware grading, and multilingual support into a unified, modular pipeline that runs entirely on consumer-grade local machines using publicly available LLMs and NLP components. The introduced exam-creation and grading system harnesses natural language processing techniques alongside LLMs to assist in educational assessments. The system is designed to automatically generate exam questions that are meaningfully differentiated, unambiguous, and linguistically precise, drawn from user-given text sources ranging from succinct passages to extensive documents, the latter after distilling the necessary information via retrieval-augmented generation (RAG) [
20]. It accommodates multiple question formats and supports a variety of difficulty levels, ensuring that each question is conceptually unique while effectively minimizing redundancy and guaranteeing that the content remains engaging and appropriately challenging for learners. Central to our approach is a sophisticated grading module that employs a semantic-similarity model enhanced with named entity recognition (NER) [
21]. This module evaluates essay and open-ended responses with precision by awarding partial credit where appropriate and mitigating bias introduced via variations in phrasing or syntax. As a result, educators can trust that the assessment process is both fair and objective.
Also, a noteworthy feature is the ability to operate locally on standard personal computers without the need for specialized AI hardware, making it accessible to a wide range of institutions, regardless of budget constraints. The system’s modular architecture has been designed for maximum flexibility, enabling seamless switching between different NLP models with minimal intervention. This modularity ensures that it can be continuously updated or customized to incorporate new models or improvements as they emerge, thereby future-proofing the technology.
Comprehensive evaluations using established metrics such as ROUGE, BLEU, METEOR, diversity scores, code quality metrics, and cosine similarity demonstrate that it consistently outperforms state-of-the-art models like BERT and T5 in educational assessment tasks. This evaluation covers the fidelity and relevance of the generated outputs relative to the original context, as well as the quantification of the semantic similarity between questions, which is used to ensure diversity between exam questions. The hardware used to perform the experiments was a consumer-grade personal computer using AMD Ryzen 5 7600X, Nvidia RTX 4080 super, 32 GB of RAM, and Windows 11, and measurements demonstrate that the proposed system can be efficiently executed on standard hardware.
The rest of the paper is organized as follows. In
Section 2, related work on automated language-learning systems, adaptive processing, and feedback generation is reviewed. In
Section 3, the high-level system design is presented, detailing the architecture and the interactions among its major components. In
Section 4, the experimentation process is discussed, first outlining the Experimental Setup in
Section 4.1 and then reporting the Experimental Evaluation in
Section 4.2. Subsequently,
Section 5 discusses the ethical implications of online exams and automated grading, while
Section 6 concludes the paper summarizing the contributions, and
Section 7 outlines future work.
2. Related Work
Many researchers have focused on the separate tasks required for generating exam content using natural language processing (NLP) techniques individually. To better understand this process, the problem can be categorized into three key areas.
The first crucial point in creating an exam paper is question–answer (QA) generation. A major area of study in question generation is the application of deep learning neural networks, where significant contributions have been made, and while some approaches focus on generating questions by extracting information from text documents [
22,
23], others emphasize paraphrasing existing content into question formats [
24], demonstrating different techniques for automatic question generation based on source material. These contributions have laid the groundwork for automating the question creation process in educational assessments with the emergence of large language models (LLMs) in recent years, leading to significant advancements in question-answering tasks. NLP systems like BERT, T5, and GPT have played a crucial role in achieving impressive performance by generating questions and retrieving correct answers from contexts [
25,
26,
27,
28].
To create a comprehensive examination system, the next critical task involves student answer assessment and the subsequent grading based on their responses. This process, simpler than question generation, has also gathered significant attention. The primary methods explored for this task include grammar analysis and semantic evaluation; both aimed at assigning a similarity score between the student’s response and the correct answer given via the system. By leveraging these techniques, the system can effectively measure how well a student’s answer aligns with the expected solution, enabling correct and consistent grading across different question types [
29]. Beyond educational applications, recent work has shown how metaheuristic-optimized machine learning can detect software defects from both natural-language and classical datasets [
30], and how hybrid metaheuristic–NLP pipelines uncover public sentiment toward virtual assistants [
31].
A critical challenge encountered was the development of an adequate translation system for unsupported languages. Unfortunately, many mainstream model implementations lack support for underrepresented languages, which can result in inaccurate outputs during both question generation and answer evaluation [
32,
33]. It was, therefore, identified that the most effective solution was to translate the provided context from the given language to English before feeding it into the large language model (LLM) [
12,
13].
There are also papers published supporting research on building comprehensive exam generation systems, though they often rely on different NLP frameworks and lack the integration of the latest Llama, OpenAI, or DeepSeek models [
34].
In this work, the integration and extension of existing methodologies is implemented into a comprehensive system that leverages diverse techniques for question–answer (QA) generation, student grading, assessment explanation, and translation. This unified pipeline delivers a robust, scalable, and flexible solution for exam creation and automated evaluation.
Notably, the system is designed to run on a local computer, ensuring data locality and enhancing security by keeping sensitive educational materials in house. This local deployment also significantly improves cost effectiveness by eliminating the need for specialized AI hardware or reliance on expensive cloud-based infrastructure or APIs, making it accessible for a wider range of institutions.
3. System Design
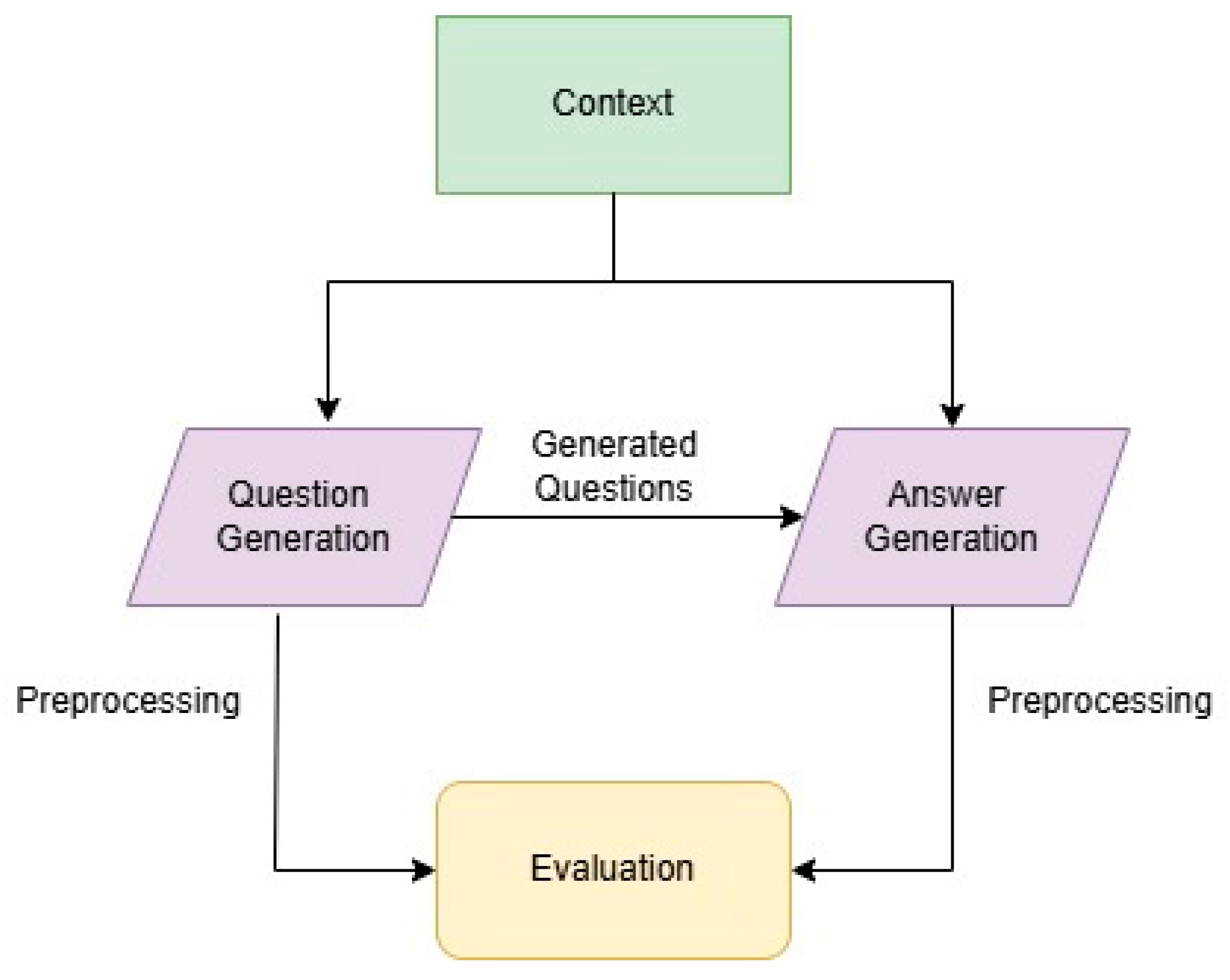
The system architecture follows a multi-layered, decoupled design paradigm that emphasizes the separation of concerns and loose coupling, as shown in
Figure 1. At the top of the stack is the presentation layer (or front end), which encapsulates the graphical user interface (GUI) and leverages the .NET Core 8 MVC pattern to render dynamic, user-centric views. In parallel, the business logic layer houses the core application services, specifically the question-generation module and the question grading, thereby isolating complex domain rules from user interaction code. Communication between these layers is achieved through well-defined API contracts and the exchange of data transfer objects (DTOs) [
35] serialized in JSON, which facilitates stateless, asynchronous interactions.
Figure 2,
Figure 3 and
Figure 4 illustrate the user interface design of the system, which is a critical aspect for adoption in real-world educational settings. The interfaces were intentionally designed with simplicity and clarity to support instructors with minimal technical expertise.
Figure 2 demonstrates the first step of the exam process, which is a configurable question-generation interface, enabling educators to tailor content based on difficulty and topic. The context—which corresponds to the examination material—can be entered via a text box or uploaded as a file. Afterwards, the user specifies the number of questions to be generated and, for each question, the type of question (long text, short text, or multiple-choice with single or multiple selections).
Figure 3 shows the second step of the examination process, i.e., a student-facing question-answering interface presenting the questions that were generated in the first step, designed to reduce cognitive load during exams. Finally,
Figure 4 illustrates the third step of the examination process, when grading results are presented along with a visual summary of performance. The student’s answer is listed together with the correct answer and the grading to facilitate the identification of weak areas and provide insight into the grading rationale. This view is available to both the examiner and the student. These GUI elements are essential for usability, especially in non-technical academic environments, and they represent a key differentiator from back end-only solutions.
The main business, logic functionality, is composed of two primary modules that operate sequentially, as illustrated in
Figure 1. The first module,
question generation, is responsible for generating a diverse set of curated questions along with their corresponding correct answers. This module leverages three specialized submodules to optimize its functionality:
Adaptive processing engine: dynamically adjusts the processing strategy based on the input’s length and complexity.
Question–answer generation: creates questions based on the user-provided context, ensuring distinct and non-repetitive questions.
Translation service: converts input content to English to maintain language consistency.
Following the question derivation phase, the question-grading module undertakes the evaluation of the responses provided. Its core responsibilities include quantifying the similarity between a human response and the reference answer to compute a response grade. The assessment module also integrates two dedicated submodules:
Finally, both the question-generation and question-grading modules communicate with the GUI layer by exchanging JSON-formatted interaction responses. The following paragraphs of this section will elaborate on each stage of the system pipeline.
The initial phase of the question-generation module pipeline is the
adaptive processing engine, which configures the processing strategy based on the size of the input context. The system is designed to handle a range of inputs from a few hundred characters to complete documents. Question generation is driven by the context provided by the user, along with specific keywords pertinent to the target terms of the questions. When the context is of the order of a few hundred characters, it is directly forwarded to the LLM, and otherwise, if the context exceeds a predefined token threshold, the system employs retrieval-augmented generation (RAG) [
20] to extract essential information from the source material in alignment with the designated keywords. RAG begins with a document ingestion and preprocessing pipeline. To ensure compatibility with various source texts, the system first programmatically detects a file’s character encoding using the chardet library before reading its contents, a step that prevents parsing errors and preserves data integrity. Once the full text is loaded, it is segmented into manageable portions using a fixed-size, non-overlapping chunking strategy. The source text is divided into sequential chunks of 6000 characters each, with zero overlap between them. These chunks then undergo a normalization process to remove artifacts like excessive whitespace and standardize the text for the subsequent embedding phase.
The core of the retrieval mechanism lies in transforming both the document chunks and user queries into a high-dimensional vector space for semantic comparison. For this critical task, the all-mpnet-base-v2 Sentence Transformer model was employed, converting any given text into a 768-dimension numerical vector. The system’s keyword-matching algorithm is designed to interpret complex user intent; when a user provides a query, it is first parsed by splitting the string at commas, allowing for multiple, distinct keywords, each one individually encoded into a vector. For queries containing multiple keywords, a single composite query vector is synthesized by computing the element-wise mean of the individual keyword embeddings. This averaging technique creates a semantic centroid that represents the overall theme of the query, enabling the system to retrieve content relevant to the intersection of the user’s concepts.
This composite query vector is then used to identify the most relevant document chunks. The retrieval is performed by calculating the cosine similarity between the query vector and the pre-computed embeddings of all document chunks, configured to retrieve the top_k = 6 chunks with the highest similarity scores, as these are considered the most semantically relevant passages. The raw text from these top-ranking chunks is then validated to ensure content is present and subsequently aggregated into a single, cohesive context. A final safeguard limits this combined context to a maximum length of approximately 30,000 words to reduce the context size, ensuring that the input remains manageable and efficient while simultaneously adhering to system memory constraints. With these parameters, RAG was able to distill the most relevant chunks of text without overfeeding the LLMs and causing memory outages for this system.
The processed output, now condensed and enriched with only relevant content, is subsequently forwarded to the translation service for further processing. The system incorporates the translation service submodule to ensure seamless operation across a diverse array of language models, acknowledging that not all models support non-English languages. Upon receiving source material, the system first performs language detection to determine whether the input is in English. Should the input be in another language, the translation service dynamically converts it to English using advanced neural machine translation models that maintain both context and technical nuances. This process ensures that question generation and subsequent evaluation are conducted on a uniform linguistic basis, thereby preserving accuracy and reliability across varied content.
Following the identification and translation of essential content segments, the system’s question–answer generation submodule initiates the process of producing question–answer pairs. This process is designed to capture both high-level conceptual understanding and fine-grained factual details present in the source material. A critical component governing this generation is a meticulously engineered prompt structure, developed through iterative refinement to optimize output quality and adherence to predefined criteria.
Figure 5 illustrates a prompt that was meticulously designed to generate essay-type questions tailored to the provided content. This prompt serves as the primary interface between the user’s specifications and the underlying generation model, encapsulating all constraints and objectives necessary for producing high-quality assessment material.
Specifically, the prompt explicitly requires the generation of both the question and the correct answer in the language of the source content, as stated in Requirement 1. It further instructs the model to focus on one of three analytical dimensions—cause–effect relationships, comparative analysis, or theoretical implications (Requirement 2), thereby ensuring that each generated question exhibits a rigorous conceptual focus, rather than a superficial description. The difficulty level is dynamically defined through the {difficulty} and {difficulty_prompt} parameters (Requirement 3), allowing fine-grained control over the cognitive complexity of the output.
A critical feature detailed in both the description and the prompt is the uniqueness validator, operationalized through Requirement 4, which compels the model to cross-check each new question against the list of existing questions ({existing_questions_texts}). This validation process systematically computes semantic-similarity scores to detect potential redundancies; any question exceeding a predefined similarity threshold is automatically flagged as duplicate and rejected, thereby preserving the originality of the question set.
Additionally, the prompt enforces precise linguistic and formatting requirements. Requirement 5 mandates that any embedded quotations within the generated content be properly escaped to avoid syntactic errors. Finally, the prompt prescribes the exact output format as JSON, specifying fields such as the unique identifier (“id”: {len(generated_questions)}), the question text, type, the correct answer (with any in-text quotes properly escaped to adhere to the JSON specification), and the associated grade score. This strict structure ensures that all generated questions are immediately ready for downstream integration into assessment platforms or learning systems.
Figure 6 demonstrates the structured output in JSON format produced via the prompt described in
Figure 5, representing a fully generated essay-type question aligned with all specified constraints and objectives.
The “id” field uniquely identifies this question within the growing collection of generated items, fulfilling the requirement to maintain an incremental record that facilitates tracking and duplicate detection (as referenced in the prompt’s len(generated_questions) directive). The “text” field provides the essay question itself.
The “type” field specifies the question format in compliance with the prompt’s explicit instruction to generate essay questions and exclude other formats such as code exercises or generic multiple-choice tasks (Requirement 4).
The “options” field further emphasizes that no answer options are provided, confirming adherence to the essay-style open response requirement, rather than defaulting to simpler, pre-structured choices.
The “correct_answer” field contains a model answer, fulfilling the prompt’s Requirement 1 to produce a complete response in the appropriate language. The answer demonstrates a clear theoretical analysis of the Control Unit’s role while also respecting the prompt’s stipulation that any quotes be properly escaped (even though no embedded quotes were necessary here).
Lastly, the “grade” field assigns a difficulty score consistent with the dynamic grading requirement in the prompt ({score}), which enables each question to be evaluated and categorized according to its cognitive complexity.
This output is then sent to the GUI layer, where it can be integrated into a user-facing interface in the form of an exam paper.
For the automatic grading of student responses, the system employs a multi-component approach. Initially, student responses undergo language detection. If the response is not in English, a dedicated-response translation service is utilized for accurate conversion. Following translation, the grading subsystem leverages two primary analytical mechanisms: semantic-similarity assessment and named entity recognition (NER). A semantic-similarity model computes a normalized similarity score (
s). This score quantifies the conceptual alignment between the student’s response and the reference solution. Concurrently, named entity recognition (NER) is employed using a finetuned model [
36] to extract key concepts, scientific terminology, and critical entities from the response. This process yields a normalized detail score (
d), reflecting the presence and accuracy of these essential elements. These two normalized scores,
s and
d, are then combined to determine the final grade.
To calculate the final score, the system employs a weighted sum approach (Equation (1)) to integrate these metrics, allowing for flexible emphasis on conceptual understanding versus detail accuracy. Predefined weights,
sw and
dw, are assigned to the similarity and detail scores, respectively. The composite final score, denoted as
G, is calculated using a weighted sum equation that also incorporates an overall multiplier based on the maximum possible value for the exercise (
M). The formula for the final grade
G is as follows:
In the current version of the system, the weights used for sw and dw are 0.7 and 0.3, respectively. In our future work, we will further explore the optimal weight assignment for the semantic score and the detail score.
4. Experimental Evaluation
In this section, the quality, performance, and limitations of the system across multiple configurations are systematically evaluated. Due to resource constraints, which are imposed by the design goal to allow the model to be executed in consumer-grade hardware, it was essential to identify an optimal configuration that balanced quality and performance. Each component was analyzed and tested using various techniques to determine the most suitable setup. In this process, two LLMs were considered, namely Llama 3 8B and DeepSeek R1 Distill Llama 8B. Upon the identification of the optimal configuration, further assessments of each module’s performance, limitations, and overall quality were conducted.
Finally, ethical considerations beyond privacy are recognized, including potential data misuse, fairness in automated grading, transparency in scoring, and risks of over-reliance on the system. The current implementation runs locally, thereby mitigating exposure of student data; however, a number of additional issues need to be catered for, including bias-audit protocols, transparency, and explainability, as well as implications for the development of skills and the educational process footprint. An initial discussion is provided in
Section 5, while a further elaboration on ethical considerations and pertinent mitigation mechanisms is considered as part of our future work.
4.1. Experimental Setup
To evaluate the proposed pipeline’s performance, each component was rigorously tested on a standard personal computer constructed exclusively from high-performance yet consumer-grade hardware, specifically configured to avoid dependency on specialized AI hardware. This setup included an AMD Ryzen 5 7600X CPU, an NVIDIA RTX 4080 GPU, and 32 GB of RAM, all operating with Windows 11.
Python version 3.11.0 was selected as the programming language due to its extensive compatibility with key libraries such as PyTorch 2.6.0 for deep learning operations, the NVIDIA CUDA toolkit [
37] for efficient GPU acceleration, and the HuggingFace Hub Transformers library [
38] for rapid integration of advanced natural language processing models. The integration of these components was streamlined using Visual Studio Code 1.95.3, which facilitated seamless interaction among programming languages, libraries, and tools. Additionally, each component was exposed through API endpoints implemented via Flask API.
Jupyter Notebook 7.2.2 supported the development and execution of a systematic two-phase evaluation strategy. Initially, modules underwent isolated testing within Notebook sessions, crucial for verifying functionality and allowing targeted troubleshooting and calibration. Upon successful individual module validation, the second evaluation phase involved integrating these modules into a cohesive pipeline, enabling comprehensive testing of module interactions and overall system performance.
The system’s architectural design concluded with a user interface built on the .NET Core 8 MVC framework [
39]. This framework was chosen due to its inherent delineation of business logic, user interface elements, and data structures into controllers, views, and models. This architectural approach simplified targeted modifications and facilitated efficient experimentation, ensuring changes could be introduced and tested without negatively impacting system-wide functionality.
OpenAI’s models deliver high accuracy, broad language support, and extensive context lengths (with GPT 4o handling up to 128,000 tokens) [
40,
41]. Yet, its paid API and fixed architecture, which precludes fine-tuning, make it impractical for cost-sensitive educational applications. Likewise, the O1 and O3 mini models, while designed for better contextual understanding and multi-step reasoning, present prohibitive operational costs and architectural complexities. O1 requires specialized hardware and expertise, leading to extended development and high integration costs, and although O3 mini has a reduced footprint, it still faces significant cost and maintenance challenges for deployment in resource-constrained environments.
The experimental design, therefore, required open-source models running on limited hardware, which ruled out several alternatives. Early transformer models like BERT [
25] and T5 showed strong performance in question answering, with T5’s finetuned variant “mrm8488/t5-base-finetuned-question-generation-ap” [
36], trained on SQuAD v1.1 [
42], generating high-quality questions and answers from compact contexts. However, both models are hampered due to a 512-token context limit, and segmenting long documents impairs their ability to capture long-range dependencies, weakening essential semantic relationships [
43].
Meta’s Llama models, on the other hand, offer an open-source alternative to proprietary systems such as OpenAI’s GPT series. Designed for local implementations, these models provide extensive contextual windows that are well suited to handling substantial and complex inputs in question–answer generation. Their open-source nature eliminates licensing restrictions and makes them highly adaptable for educational, scientific, and non-commercial applications while also enabling systematic evaluation among various publicly available Llama versions.
DeepSeek has also introduced an open-source advanced reasoning model, called DeepSeek-R1 [
44], that utilizes reinforcement learning and cold-start data to address inherent limitations. This model matches or even surpasses state-of-the-art benchmarks in reasoning, mathematics, and coding tasks [
45]. The smaller version, DeepSeek R1, distilled from Llama 8B [
46], can operate efficiently on consumer-grade hardware and supports context lengths of up to 128,000 tokens, like LLaMA 3 [
45].
For translation tasks, fine-tuning Llama 3 presents a compatible approach, especially for Greek-to-English and English-to-Greek translation, while ensuring that scientific terminology remains untranslated. Llama 3 8B was selected due to its faster inference, lower latency, and better multilingual support compared to DeepSeek R1. The fine-tuning process employed the Helsinki-NLP/europarl/el-en dataset [
47,
48], which comprises 1.29 million European Parliament conversations, thereby ensuring high-quality translations.
Training the Llama 3 8B model posed significant challenges using both standard and specialized computing setups because of frequent CUDA memory limitations. These challenges were effectively overcome by deploying the Alpaca Unsloth finetuning utility (December 2024 version) [
49], which enabled the successful development of two specialized translation models.
Additionally, to assess students’ responses, the sentence-transformers/all-mpnet-base-v2 model [
50] was employed because of its superior performance in official metrics, as depicted in
Table 1. Furthermore, the integration of the NER model FacebookAI/xlm-roberta-large-finetuned-conll03-english facilitated detailed extraction of key entities, thereby refining the grading process by ensuring that context-aware assessments are maintained throughout.
4.2. Experimental Procedure and Results
To explore and determine the best setup for the question–answer generation subsystem, the compatible LLMs were tested, with each offering strengths and presenting varying limitations. The primary focus of the experimentation was centered on identifying these limitations of each individual model, evaluating performance (in terms of accuracy) and latency (in terms of execution time). These axes were critical in assessing how each model contributed to the goal of generating high-quality exam questions while balancing the computational efficiency needed for consumer-grade hardware. As noted in
Section 4.1, the results listed in the remainder of this subsection were obtained by executing the proposed system on a consumer-grade computer equipped with an AMD Ryzen 5 7600X CPU, an NVIDIA RTX 4080 GPU, and 32 GB of RAM, all operating under Windows 11. The system is designed in two primary stages: text and code quality evaluation.
In the text content generation stage depicted in
Figure 7, first, a structured prompt is formulated to instruct the model to derive four examination-style questions from the given context. The prompt’s purpose is twofold; it first maintains a uniform output format through a predefined prompt template, and secondly, in the generation phase, the output is processed to extract the question texts exclusively while discarding any extraneous content, such as grades or question numbering. In a subsequent step, the same context is connected with the generated questions to compose a second prompt that directs the model to produce detailed, corresponding answers for each question. As before, the resulting answers are cleaned to isolate the relevant content from any system-specific formatting.
The evaluation of the generated content is performed through a comprehensive suite of metrics that capture different aspects of text quality, beginning with a text preprocessing phase, in which both the reference context and the generated text are normalized and tokenized. This process ensures that the text representations are comparable regardless of variations in case or punctuation, and after this step, the metrics are calculated by running each model 10 times and collecting the mean scores of each metric to ensure a non-biased output.
Several metrics are computed to assess the fidelity and relevance of the generated outputs relative to the original context. First, ROUGE [
52] is applied to measure lexical overlap. Both ROUGE-1 and ROUGE-L variants [
52] are calculated, with ROUGE-1 focusing on unigram overlap and ROUGE-L evaluating the longest common subsequence. For each variant, precision, recall, and F1-score are obtained, providing insight into the completeness and conciseness of the generated responses.
Beyond lexical overlap, the framework incorporates a measure of semantic similarity to ensure that conceptual equivalence is captured even when lexical choices differ. This is achieved through a sentence transformer model that encodes both the reference and generated texts into high-dimensional vectors. The cosine similarity between these embeddings is computed as a continuous measure of semantic alignment, effectively recognizing paraphrased or restructured content.
In addition to ROUGE and semantic similarity, the framework employs BLEU [
53] as a metric originally developed for machine translation evaluation. BLEU assesses the precision of n-gram overlaps by comparing the generated text against multiple tokenized reference sentences. To address issues related to sparse n-gram occurrences in short sequences, a smoothing function is implemented. Complementing BLEU, the METEOR [
54] metric is computed on a sentence-level basis, incorporating both precision and recall while accounting for lexical variations through synonym matching and paraphrase recognition. For every pair of reference and hypothesis sentences, individual METEOR scores are computed, and the final score is derived as an average of these values.
Figure 8 illustrates comparatively the performance of the two models across 10 successive executions, highlighting notable trends in the quality of generated question–answer pairs. Both models exhibit high alignment with the context, with mean semantic-similarity scores of 89.54% for Llama 3 8B and 87.57% for the distilled DeepSeek model. However, an analysis of performance uniformity, as detailed in
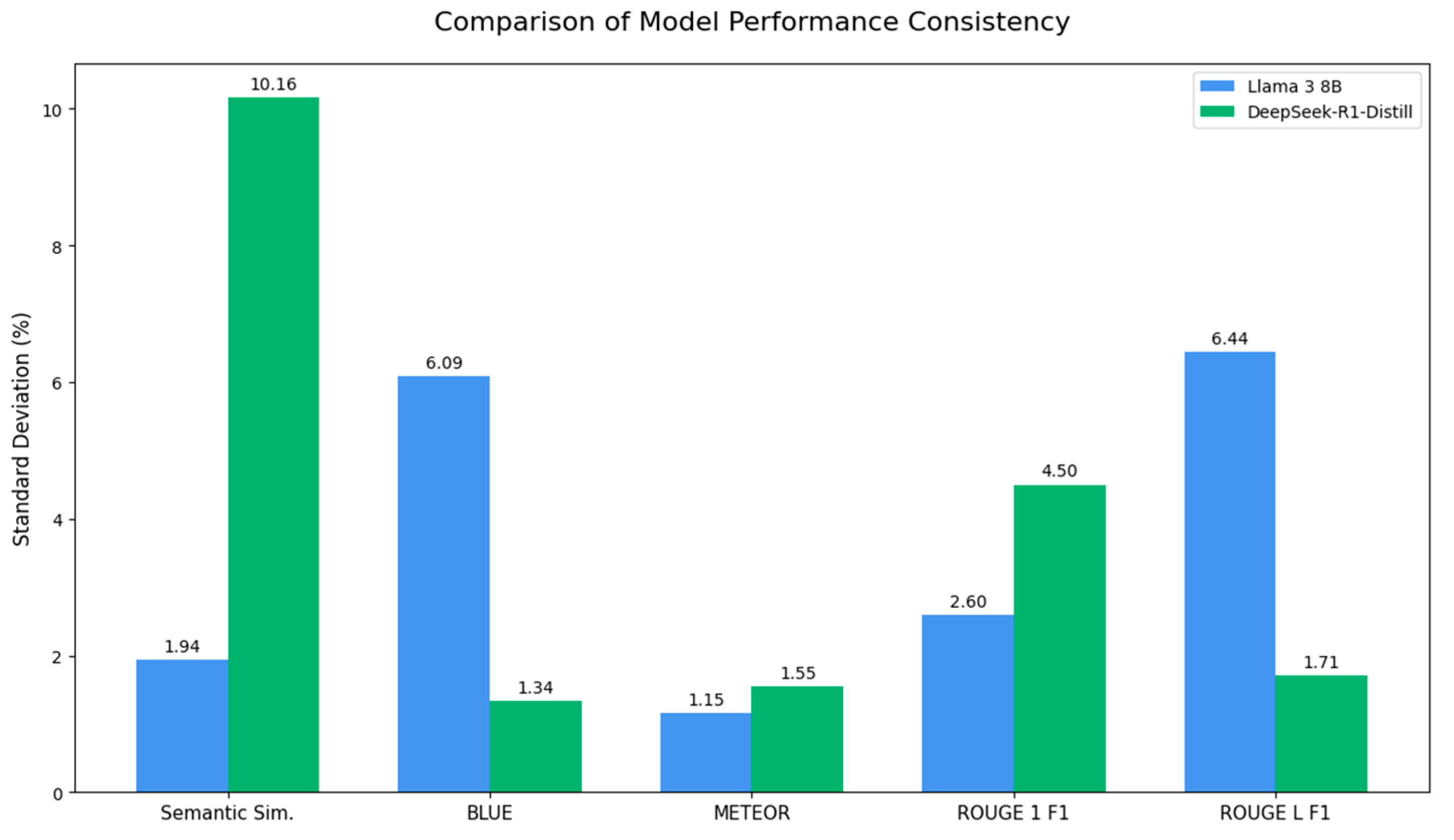
Figure 9, which illustrates the standard deviation of results, reveals a critical distinction. Llama 3 8B is significantly more stable, exhibiting a low standard deviation equal to 1.94%. In contrast, the DeepSeek model demonstrates considerable volatility in its semantic understanding, with a much higher standard deviation of 10.16%. This indicates that, while both models perform well on average, Llama 3 8B’s performance is more consistent and reliable.
Considering the BLEU scores, which reflect n-gram overlaps, larger differences are observed. Llama 3 8B attains a higher score of 16.99%, whereas DeepSeek-R1-Distill-Llama 8B trails at 8.17%. For this metric,
Figure 9 illustrates an inverse trend in consistency, with the DeepSeek model showing superior stability on this metric (SD = 1.34%), while Llama 3 8B exhibits considerably higher variance in its n-gram matching (SD = 6.09%).
Regarding the METEOR score, both models demonstrate comparable performance (15.22% vs. 14.51%) and exhibit high consistency, with both showing very low standard deviations (1.15% and 1.55%, respectively). A similar pattern of close mean performance is observed for ROUGE-1 F1 (58.45% vs. 55.15%), though Llama 3 8B demonstrates greater stability (SD = 2.60%) compared to the DeepSeek model (SD = 4.50%). On the other hand, when the ROUGE-L F1 metric, which captures the longest common subsequence, is considered, Llama 3 8B achieves a clear performance edge, scoring 35.99% versus DeepSeek’s 25.76%. As with the BLEU metric, this higher average performance from Llama 3 8B comes with a trade-off in consistency; it is more variable (SD = 6.44%) compared to the highly consistent DeepSeek model (SD = 1.71%).
In summary, while Llama 3 8B delivers higher mean performance on most metrics, a more nuanced conclusion emerges when considering performance stability. Llama 3 8B’s primary strength lies in its exceptional semantic consistency, a critical factor for reliable question answering. Conversely, the DeepSeek model, while less potent on average, offers superior stability on lexical, n-gram-based metrics.
The evaluation of the proposed system also considered an assessment process specifically designed for C programming answers concerning pointers; these answers were gathered after 20 successive iterations. Code-structure compilation success was first measured using GCC. Separately, and entirely outside the core evaluation pipeline, subtler, more dynamic code qualities that resist straightforward numeric quantification were appraised using Google’s Gemini 2.0 flash [
55]. The combined results are shown in
Figure 10.
In more detail, the dimensions evaluated in the context of this experiment and presented across the
x-axis of
Figure 10 are as follows:
Executability assesses whether the generated code could be successfully compiled and run, using gcc;
Explanation quality measures the clarity and completeness of the accompanying explanations in the form of comments in the code;
Code correctness evaluates the technical accuracy and absence of bugs in the implementation;
Application complexity judges the appropriateness of the code’s complexity relative to the posed problem;
The overall score is an aggregate metric summarizing performance across all evaluated criteria.
The y-axis represents the mean score for each metric, scaled from 0% to 100%.
Across the evaluated metrics, performance varied significantly among the models. For executability, scores ranged from approximately 60% (DeepSeek R1 Distill Llama 8B) to 80% (Llama 3 8B). In explanation quality, Llama 3 8B achieved the highest scores (around 85%), while DeepSeek R1 Distill Llama 8B scored around 75%.
Regarding code correctness, Llama 3 8B again led with a score near 88%, followed by DeepSeek R1 Distill Llama 8B at approximately 75%. For application complexity, the scores were more tightly clustered, with both models scoring approximately 75% (Llama 3 8B maintained a slight performance edge).
In the overall score, Llama 3 8B was a clear winner with a score at 85%, while DeepSeek R1 Distill Llama 8B scored around 76%. Overall, the Llama 3 8B models consistently demonstrated superior performance across all metrics, with the performance edge varying from narrow to considerable.
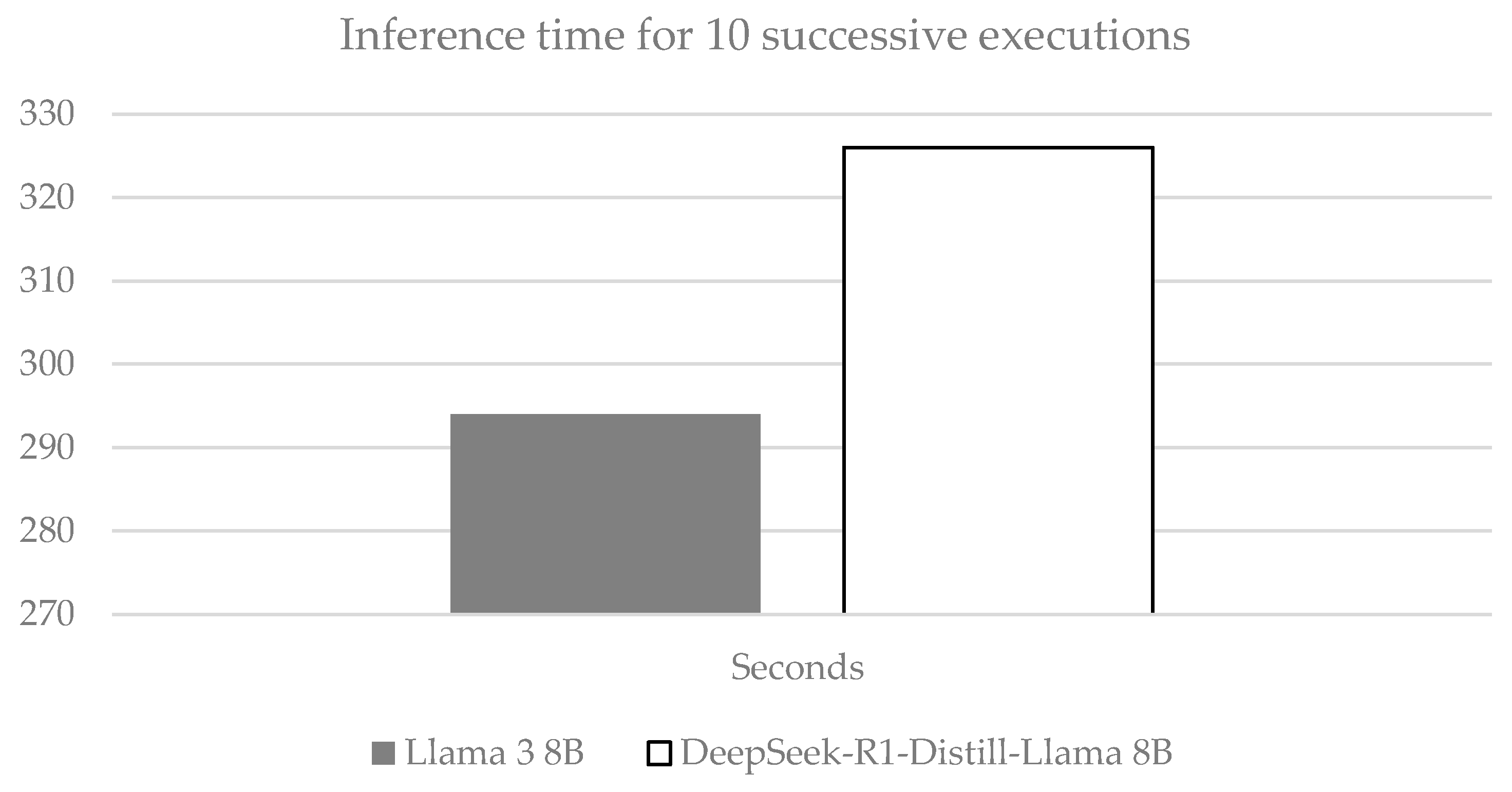
Finally,
Figure 11 presents the aggregate clock time in seconds required to execute 10 consecutive inference runs for the five transformer-based language models under identical hardware and software conditions. Over the course of ten successive executions, Llama 3 8B demonstrated an aggregate time of 295 s, corresponding to roughly 29.5 s per run. The DeepSeek-R1–distilled version of the 8B Llama model required 329 s for ten runs (≈32.9 s per run), being approximately 10% slower.
In practical deployment scenarios, these results suggest that the Llama 3B model provides the highest throughput for latency-sensitive applications, whereas the DeepSeek-R1–distilled version of the 8B Llama may be less suitable when low latency is a primary concern. The RAG phase accounts for approximately 9% of the Llama 3B model and 7.6% of the DeepSeek-R1–distilled version of the 8B Llama.
To validate the accuracy of the automated grading system, an evaluation was conducted against human experts. A dataset was curated comprising student responses, which were intentionally selected to include answers with varying levels of ambiguity, syntactical errors, and grammatical errors to assess system robustness. Each of these responses was first graded using the AI system on a continuous scale from 0 to 2. Subsequently, three independent human graders, all experts in the subject matter, were provided with the question, the model answer rubric, and the student’s response. They then assigned a score to each response using the identical 0-to-2 scale, without knowledge of the AI’s scores or the scores of the other raters. This methodology allows for a direct comparison between the system’s performance and human expert judgment.
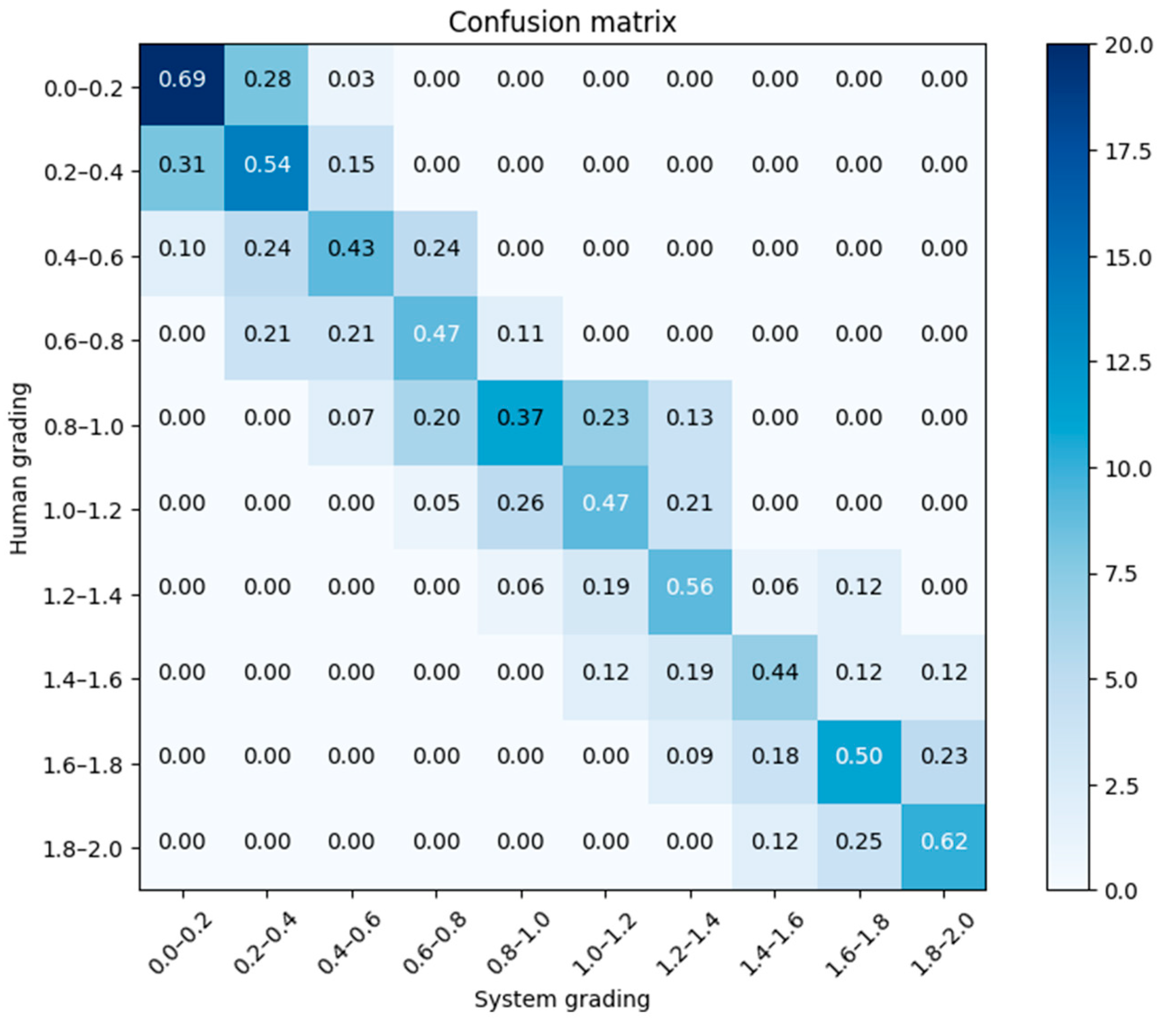
Table 2 illustrates five indicative instances of the experiment comparing the grading engine and the human assessment of responses, while
Figure 12 depicts the confusion matrix of the human grading vs. the system grading.
To further quantify the variations between the AI and the human grading, the metric mean absolute error (MAE) was calculated, given by the following formula:
where
N is the total number of trials,
GREi is the grade provided via the grading engine for the
i-th trial, and
AHSi is the average human score for the same trial, which is considered the ground truth.
Across five evaluation instances, the three expert graders demonstrated an average inter-rater standard deviation of 0.18 points—approximately 9% of the two-point scoring range, reflecting the inherent variability in human judgment.
When assessed against the expert consensus, the automated system achieved a mean absolute error (MAE) of 0.34, which corresponds to a normalized MAE (NMAE) of 17% of the maximum two-point score. Thus, the system’s scores deviated from the established ground truth by an average of 17% of the scale range, slightly exceeding the typical human inter-rater spread yet still indicative of performance that approaches human-level consistency.
In the forecasting literature, accuracy thresholds based on the mean absolute percentage error (MAPE) or normalized mean absolute error (NMAE) are conventionally defined as follows: errors below 10% are deemed “highly accurate,” those at 10–20% are deemed “good,” those at 20–50% are deemed “reasonable,” and those above 50% are deemed “inaccurate” [
56]. In parallel, investigations into human essay scoring reveal that even expert raters exhibit substantial variability in judgment. Specifically, studies report that exact score agreement between two trained evaluators typically ranges from approximately 53% to 81% of essays, while adjacent agreement (i.e., scores differing by no more than one point) reaches 97–100% [
57,
58,
59]. This variability implies that a deviation of one point on a 0–10 scale corresponds to a 10% error relative to the total score range, and approximately 17% on a 1–6 scale. Accordingly, the level of human inter-rater discrepancy often falls within what would be classified in forecasting as a “good” or “reasonable” error interval, underscoring the intrinsic subjectivity present even in expert evaluations of complex tasks such as essay grading.
5. Ethical Implications
The use of an electronic exam system, which includes automated grading, entails a number of ethical implications that must be considered and mitigated where appropriate.
Firstly, when used in remote mode and when direct human supervision to avoid cheating is not applicable, proctoring systems are typically employed, through which biometric data, audio, and video are collected during exams and processed either in an online or an offline fashion [
60]. Student privacy and exam integrity requirements in this context must be balanced [
61]. Furthermore, appropriate safeguards must be taken to warrant the confidentiality and integrity of proctoring data throughout the retention period [
62], including appropriate data handling and custody, especially if third parties (e.g., proctoring technology suppliers) are involved in the workflow. Furthermore, when proctoring is supported with AI technologies, models and algorithms may entail bias, leading to unfair treatment of specific student populations [
63]. In the same context, students may not be able to afford or properly install and use the equipment required for proctoring, further aggravating existing inequalities [
63].
Automated grading also poses issues related to fairness, especially in the case of assessing open-ended questions, including short answers and essays. In recent studies, it was found that a GPT-4-based automated grading system marked Asian American students’ essays approximately 15% lower than other students, even though the content was of similar quality [
64]. Other studies revealed that Black students were consistently given lower marks than White students with comparable exam paper quality [
65]. These issues stem from the fact that grading software is based on training using large datasets of graded exam sheets, and these may inherit or exacerbate historical biases [
65].
The mode of operation for the grading software is an issue that may affect fairness and trust. Some graders operate as “black boxes” and offer only grading, possibly complemented with exemplary answers, without explanations on the rating rationale. This limits the capability of instructors and students to comprehend the score or object to it, ultimately undermining both the trust to the system and the educational process since students may focus their efforts to provide answers that will be rated favorably by the algorithm, rather than comprehending the educational material and acquiring skills and knowledge [
66]. While AI may be initially perceived as an objective solution that can remove potential human bias that may infiltrate the grading procedure, this perception may be overturned in the absence of explanations and transparency [
67].
Automated grading also introduces a shift in the accountability paradigm: while, in traditional exam taking, the instructor is accountable for grading, any algorithmic error (including discriminatory grading) cannot be directly attributed to a single agent since multiple parties are involved, including the vendor of the algorithm, the model vendor, the institution that has chosen the specific vendors, and the instructor who has provided material for subjects, answers, or any other task. Notably, recent regulations classify exam-scoring AI as “high-risk”: for instance, the EU AI Act mandates that systems that determine access to education must successfully pass rigorous data-quality checks, bias audits, and human oversight before deployment [
68].
It must be noted that, while trying to avoid the perils of open question grading, instructors may be inclined to use closed questions instead. While closed questions can be safely graded, the rationale that led the student to the particular answer is obscured, leading to undesirable situations where, e.g., the correct answer can be chosen at random, or a mistake in an arithmetic operation causes an otherwise excellent response to a complex engineering problem to be graded with no points.
Finally, instructors may be tempted to accept the algorithmic outputs unquestionably and without further review, aiming to offload the tasks of exam sheet preparation and grading, which are deemed tedious and unrewarding. However, if this direction is taken, instructors run the risk of losing their own ability to act creatively in exam sheet preparation or spot traits of creativity, deep understanding, ingenuity, and contextual richness in students’ papers, aspects that algorithms typically fail to identify. Instructors will also be deprived of the opportunity to spot aspects of teaching that were not sufficiently understood by the students, which would enable them to improve their teaching material and practices [
69].
7. Future Work
Building upon this solid foundation, future work will focus on several key areas to further enhance the system’s capabilities, scalability, and accessibility. A primary direction will involve a comprehensive investigation into the performance and integration of a wider spectrum of advanced locally deployable LLMs. This includes evaluating larger and potentially more capable architectures, such as the Llama 3.3, Mistral Small, Mistral 7B, DeepSeek R1, and Qwen models, assessing their impact on question quality, grading accuracy, nuanced understanding, and VRAM usage. This exploration will also necessitate integrating and evaluating advanced quantization techniques, such as FP8, which are crucial for efficiently deploying these larger models on standard hardware while maintaining high performance and accuracy. We also plan to add feedback generation based on a rubric.
Beyond core textual analysis, a focus will be the extension of the system’s modality by investigating the integration of interactive models capable of handling and processing non-textual content, specifically images and audio. This would open possibilities for generating or assessing questions and responses in fields requiring multimedia understanding or creation.
The grading framework itself will be refined by expanding the set of evaluation parameters beyond the current detail (NER) and semantic scores. This involves developing metrics to assess aspects like argumentation quality, creativity, structural coherence, or the inclusion of specific conceptual points, leading to even more comprehensive grading and feedback. The improvement of the performance of the grading system, especially in the presence of linguistic errors or semantic ambiguities, will be pursued. The optimal weight assignment for the similarity and detail/NER scores (
sw and
dw, respectively), as well as the additional dimensions that will be introduced, will also be examined. The exam sheets generated through the system will be comparatively assessed against exam sheets compiled by instructors to quantify gains and losses concerning aspects that include coverage, diversity, the accuracy of question weightings, etc. In the domain of code assessment, the use of Gemini poses limitations due to the proprietary nature of the model. In this vein, alternative solutions will be sought, including the use of instructor-provided tests to evaluate the externally observed behavior of programs and source-code quality metrics [
70] for the structure, readability, cognitive load, and other properties of the code.
The current architecture of the system adopts the local execution of question generation, aiming to maximize privacy, security, and ultimately exam integrity since the exam questions and answers generated via the system will only be accessible to the instructor. Inherently, this approach may raise concerns typically addressed when assessing tradeoffs between local installations and cloud-based systems, including (a) maintenance costs (e.g., application or LLM updates), (b) hardware costs, and (c) backups and data custody in general [
71]. Given that the proposed system is packaged as a self-contained application that can be distributed and updated using typical application update methods (e.g., self-updates or updates via operating system-backed repositories, such as Microsoft Store, Google Play, or Linux repositories), the administrative burden incurred due to the need for updates is considered minimal. Regarding the hardware costs, the current version of the system may run on typical computers with no specialized AI hardware; therefore, no additional hardware costs are incurred. Nevertheless, during the course of development of the system, more advanced models may be required (e.g., to provide elevated performance for the grading of responses with grammatical errors or ambiguities), which will necessitate the use of more specialized infrastructure. In these cases, a private cloud may achieve a good compromise between privacy and costs, a solution that is adopted, e.g., for CISCO certifications [
72], as well as the fog-assisted exam data sharing system proposed in [
73]. A private cloud operated by the organization in the context in which the exams are taken, e.g., a university or a certification body, will also resolve issues related to data custody [
74], as well as data availability (including backups and resilience against personal machine outages). A public cloud can also be utilized, provided that end-to-end encryption [
75] is utilized, to warrant the secrecy and integrity of exam sheets. Further elaboration on the issue is considered part of our future work.
To facilitate broader adoption and continuous improvement, the development of a publicly available API for the system is also a priority. This API would allow seamless integration with existing educational platforms and provide a valuable feedback mechanism, enabling the collection of diverse usage data to further refine the core algorithms and enhance the user interface. Parallel to this technical development, evaluation and ethical considerations are paramount. As a key step in validation and refinement, a planned classroom pilot is scheduled, designed to assess the system’s effectiveness and usability in a real-world educational setting.
Stricter security standards should also be implemented by systematically utilizing logging mechanisms that generate audit trails of system operations and user interactions while still preserving data confidentiality. In addition, the integration of robust, multi-factor user authentication protocols could be adopted to further verify identities, assign privileges, and prevent unauthorized access across varied institutional roles. Finally, the formulation and enforcement of explicit data retention and deletion policies will ensure that information, in the future, is retained only for its intended purpose and is securely disposed of thereafter. Incorporating these elements will be indispensable for aligning the system with institutional governance frameworks and regulatory requirements.
A controlled empirical bias audit will be undertaken by conducting systematic experiments that assess grading outcomes on essays exhibiting variant dialects and intentional grammatical perturbations. Additionally, comprehensive evaluations of semantic drift induced via translation pipelines will be pursued: grading performance will be compared between direct native-language workflows and translation-based workflows across multiple low-resource and typologically diverse languages. These studies will quantify potential dialectal, orthographic, and translation-induced biases, thereby informing the development of more equitable and linguistically robust automated assessment systems.
The handling of non-English languages will also be addressed and refined in our future work. Currently, all system inputs (training texts and student responses) are translated into English from the source language (if the source language is different from English), and the system outputs are converted to the target language as appropriate. In this context, native LLMs can be accommodated, removing the need for translation when all system inputs and outputs are in the same language. At this point, it should be noted that previous experimentation with Greek-language NLP systems indicated that the workflow comprising (a) translation of the Greek text into English, (b) performing NLP on the English text, and (c) translating the results back into Greek exhibited performance that was comparable to or even superior to directly performing NLP on the Greek texts due to deficiencies in the Greek NLP engine that was freely available at the time [
76]. However, as native-language LLMs such as [
77] have emerged while the quality of translators has also evolved, more up-to-date assessments are required. In the same line, multilingual LLMs [
78,
79] can be considered alternatives to English-centric processing in environments where diverse groups of students may prefer interacting with the system in different languages.
Also, to address ethical concerns, future work will develop a comprehensive ethical framework by establishing data-governance procedures—including explicit consent, retention, and deletion policies—implementing regular fairness audits to detect and correct grading biases, and introducing transparency mechanisms through the detailed logging of semantic-similarity and NER scores for instructor review. Additionally, human-in-the-loop guidelines and accompanying training materials will be created to ensure that automated feedback remains advisory and does not foster over-reliance on the system.
Finally, a more extensive and diversified evaluation across a broader range of scientific and humanities fields will be conducted to rigorously assess the system’s robustness and generalizability across different domains. This will include the evaluation of the system within each field using different models, as well as the expansion of the system to accommodate additional scoring dimensions that are pertinent to specific disciplines.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}