1. Introduction
Wallboards are critical load-bearing components in packaging and printing equipment. Their machining precision and timely delivery directly affect the overall assembly quality and production cycle. In practice, most printing machinery manufacturers are small to medium-sized enterprises that lack the in-house capacity for full-process wallboard machining and thus rely heavily on external suppliers. Cloud manufacturing platforms aim to facilitate such outsourcing by providing recommendation-based supplier matching. However, the effectiveness of these platforms is significantly constrained by the quality, structure, and sparsity of the underlying enterprise data.
Specifically, the wallboard outsourcing recommendation task presents three fundamental challenges:
(1) Supplier-side information is often provided as lengthy, unstructured free-text descriptions, such as “We specialize in CNC milling with ±0.01 mm tolerance and offer integrated laser welding services.” These descriptions lack standardized terminology, making it difficult for traditional models to extract domain-relevant semantics.
(2) Demand-side rating data is sparse and highly limited, as manufacturing orders occur infrequently (e.g., every 3 to 6 months). Nonetheless, each recorded rating carries significant information about a demand enterprise’s preferences.
(3) Matching demand and supply involves non-linear, multi-attribute decision logic that considers technical compatibility, delivery lead time, pricing, and geographic proximity. Such complexity exceeds the representational capacity of standard collaborative filtering models, which typically assume linear preference relationships.
Traditional recommendation techniques can be broadly categorized into three types: content-based recommendation, collaborative filtering-based recommendation, and hybrid recommendation [
1]. Content-based methods [
2] analyze users’ historical preferences and related attributes to recommend items with similar characteristics. Collaborative filtering-based methods [
3,
4] infer preference patterns by leveraging interaction data between users and items. Among them, Probabilistic Matrix Factorization, a widely adopted collaborative filtering technique, models interactions through low-rank approximations. However, it assumes sufficient rating density and exhibits limited efficiency in incorporating auxiliary information such as supplier capabilities. Content-based and hybrid methods attempt to address these limitations by leveraging side features, but they often rely on structured inputs or fail to model complex textual semantics and non-linear user preferences.
In recent years, neural network techniques have made significant advancements in natural language processing [
5] and computer vision [
6], offering diverse solutions to challenges such as data sparsity, cold start issues, and personalized modeling in recommendation systems [
7]. Existing neural models—including convolutional neural network-based structures, such as ACNN-FM [
8], and graph neural network-based frameworks, such as MAF-GNN [
9] and GIENN [
10]—have demonstrated strong capabilities in automatic feature extraction and structural pattern learning. However, CNN-based approaches typically rely on fixed-size input representations and struggle to model long-range dependencies or interpret semantic nuances in unstructured textual descriptions. GNN-based methods, while effective in leveraging structural relationships, often require well-defined and densely connected graphs, which are difficult to construct in sparse industrial domains with heterogeneous entities and limited interactions. Meanwhile, multi-task and reinforcement learning-based methods, such as HP-GCN [
11] and NCRAE [
12], address data sparsity by building multi-level user preference representations or modeling temporal behavior. Yet, these methods generally depend on sufficient historical data and task-aligned supervision, which are rarely available in scenarios involving cold-start users or new outsourcing suppliers.
In this context, Long Short-Term Memory networks and attention mechanisms offer effective tools for extracting sequential and semantic features from unstructured supplier descriptions, while variational autoencoders provide a principled probabilistic framework for modeling latent preferences under sparse demand-side conditions. These properties make them especially suitable for tasks such as wallboard outsourcing recommendation, where input modalities are asymmetric and data sparsity is a key challenge.
The remainder of this paper is organized as follows.
Section 2 presents related work.
Section 3 provides a detailed description of the AttVAE-PMF model.
Section 4 introduces the experimental setup and results.
Section 5 presents a discussion and outlines directions for future research, while
Section 6 provides the conclusions.
2. Related Works
To address the unique characteristics of wallboard outsourcing recommendation, we organize related work into three categories aligned with our core modeling challenges: sparsity, unstructured supplier information, and multi-modal fusion.
2.1. Challenges in Modeling Unstructured Supplier Descriptions
Modeling unstructured supplier descriptions remains a significant challenge for recommendation systems, especially in industrial scenarios where inputs are lengthy, domain-specific, and inconsistently formatted. Traditional parametric models such as factorization machines and decision trees rely on structured input and engineered features, making them ill-suited for learning semantic representations from raw text. Hybrid architectures like DeepFM [
13] improve representation learning but still depend on reliable feature fields, which are often missing in noisy industrial data. Pretrained language models such as BERT [
14] have shown strong performance in text-based recommendation, yet they typically require large-scale annotated corpora and substantial computational resources. To better model sequential semantics under such constraints, Long Short-Term Memory networks have been explored due to their ability to capture temporal dependencies in input sequences. Prior studies have applied LSTM-based models in domains like sports [
15], healthcare [
16], and education [
17], though standard LSTM structures often treat all tokens equally. To overcome this, attention-enhanced LSTM models have been introduced—e.g., Kumar [
18] demonstrated improved session-based recommendation by weighting salient items. These advances motivate our use of an attention-LSTM encoder, which offers a practical and interpretable solution for extracting latent semantics from complex supplier descriptions in sparse industrial settings.
2.2. Challenges of Modeling Sparse Interactions in Industrial Contexts
Data sparsity in user–item interactions poses a persistent challenge for recommender systems, particularly in industrial applications. To address this, Rodpysh et al. proposed contextual matrix factorization using user and item feature matrices, yet its reliance on explicit labels limits adaptability in settings with incomplete semantic information. Guan et al. introduced a similarity model based on Wasserstein distance to improve robustness under sparse ratings, but it remains restricted to deterministic similarity without modeling preference uncertainty. Karabila et al. combined BERT with a multilayer perceptron to enhance content understanding from reviews, though their approach depends on extensive high-quality textual data and does not fundamentally resolve latent preference sparsity. While these methods improve representation or similarity modeling, they often lack a probabilistic treatment of uncertainty, limiting generalization in cold-start, heterogeneous environments. Among them, variational autoencoders provide a theoretically grounded framework for learning stochastic latent variables, effectively capturing the uncertainty and diversity inherent in user preferences. Liang et al. [
19] proposed a collaborative VAE that outperforms linear models under high sparsity; Li et al. [
20] applied VAEs to sequential recommendation to improve robustness; and Li et al. [
21] introduced a hierarchical inference mechanism that integrates neighborhood behaviors to enrich latent representations. These advancements offer key insights for our adoption of a VAE-based user encoder to address data sparsity in industrial recommendation environments.
2.3. Challenges in Unifying Semantic Encoding and Collaborative Filtering for Recommendation
In sparse and heterogeneous recommendation scenarios, the isolated application of collaborative filtering or deep neural networks often yields suboptimal performance. Matrix factorization-based methods are effective at capturing latent user–item preferences but struggle with sparse interactions and the integration of side information. In contrast, deep learning models can extract high-level features from unstructured inputs but often lack the inductive bias necessary for generalization under data scarcity. To address these limitations, recent studies have proposed hybrid architectures that integrate deep neural networks with collaborative filtering. Neural Collaborative Filtering (NCF) replaces the inner product in matrix factorization with multilayer perceptrons for more flexible interaction modeling. For example, Deng et al. [
22] introduced a trust-aware NCF model that incorporates item content and auxiliary features to mitigate sparsity. Dhawan [
23] extended NCF by incorporating GCN modules to enhance representation learning, while Song et al. [
24] proposed a deep NCF framework that overcomes the representational limitations of GAN-based recommenders.
Given the dual challenges of unstructured supplier descriptions and sparse demand-side interactions, a unified framework must simultaneously address semantic extraction and latent preference modeling. This motivates our design of a dual-channel architecture that combines the strengths of deep representation learning and probabilistic matrix factorization.
3. Materials and Methods
3.1. Problem Description of Wallboard Outsourcing Recommendation
Field research on wallboard production lines reveals that enterprises often need to outsource specific processing steps or entire components due to capacity limitations or equipment constraints. To facilitate supply chain collaboration, production demands and outsourcing services are typically uploaded to cloud platforms. However, once connected to the cloud platform, enterprises face a critical challenge: efficiently allocating outsourcing tasks within a complex supply chain to optimize production processes. Against this backdrop, developing a precise and efficient recommendation system has become essential for optimizing outsourcing task allocation and enhancing production efficiency.
The recommendation process can be summarized into the following three key steps:
(1) Demand Collection and Data Preparation:
Let D = {d1, d2, …, dN} denote the set of demand enterprises and V = {v1, v2, …, vM} the set of outsourcing enterprises. For each demand enterprise di ∈ D, its rating record is denoted as Rdi = {rdi,vj∣vj ∈ V}, where unrated entries are treated as missing values. To address the missing data, auxiliary attributes from both the demand and outsourcing sides—denoted as Pdi and Pvj—are collected and processed as input to the AttVAE-PMF model.
(2) Rating Imputation and Data Processing:
Due to the large number of unobserved ratings, the rating matrix is highly sparse. To mitigate this issue, the PMF module integrates the latent features learned by the VAE and Attention-LSTM components to predict the missing values. The predicted rating di,vj is computed by the inner product of the latent vectors U and V, enabling comprehensive preference modeling.
(3) Generating Recommendation Results:
Based on the predicted ratings, each demand enterprise di receives a ranked list of outsourcing enterprises. The top-K enterprises with the highest predicted scores constitute the final recommendation result Rdi′ ⊆ V. This process enables personalized outsourcing recommendations and enhances task matching efficiency.
This paper primarily focuses on the task of rating prediction for previously unrated outsourcing enterprises, with a particular emphasis on imputing missing values in the rating matrix to generate more accurate recommendation results.
3.2. Data Sources and Preprocessing
To achieve efficient and accurate outsourcing service recommendation, this study constructs a wall panel outsourcing dataset based on an enterprise-level collaborative cloud service platform. A systematic data collection and preprocessing pipeline was designed to automatically capture multi-dimensional attribute information from both service providers and demanders. Specifically, the platform frontend adopts JavaScript plugin embedding technology, enabling automatic logging of key attribute fields during user registration, task submission, and service response interactions. The raw data collected is transmitted in real time to the backend server via RESTful APIs and uniformly stored in a structured MySQL database. All data transmissions are secured using the HTTPS protocol to ensure communication security. At the database level, sensitive information is encrypted using the Advanced Encryption Standard (AES), and a strict access control policy is implemented to prevent unauthorized access and data breaches.
The collected data encompass core attributes of both outsourcing service providers and requesting enterprises. Attributes for service providers include enterprise ID, service type (e.g., cutting, assembly, and painting), service pricing, service descriptions, and geographic location. For demand-side enterprises, the dataset includes enterprise ID, required service types, price preferences, equipment preferences and regional service requirements. The combination of these structured and unstructured attributes provides a comprehensive information foundation for service recommendation.
To ensure data quality and consistency during the data collection process, the platform implements several data cleaning measures. First, a hash-based duplication detection algorithm is employed to identify and remove redundant content. Second, outlier detection mechanisms are applied to key numerical fields, such as service pricing, to identify anomalies, which are either removed or corrected through consultation. For missing values, a fault-tolerant strategy is adopted: non-critical field omissions are handled with default placeholders to prevent sample loss. In the final stage of data preprocessing, the attributes of service providers and demanders are merged into a unified preference description document. This document adopts a fixed-length field structure, where attributes are concatenated into standardized text sequences. These sequences are then segmented using Chinese word tokenization and processed accordingly. The final output is a word sequence of length L, which serves as input to the recommendation model.
3.3. AttVAE-PMF
As shown in
Figure 1, the wallboard outsourcing recommendation model based on dual-channel neural networks and probabilistic matrix factorization consists of three main modules. First, the Attention-LSTM channel extracts auxiliary information from outsourcing enterprises and generates the latent feature vector
V. Second, the VAE channel constructs the latent feature space of demand enterprises, producing the latent feature vector
U. Finally, PMF integrates the latent feature vectors from both channels to capture the underlying relationships between demand enterprises and outsourcing enterprises, thereby generating the final rating predictions.
3.3.1. Attention-LSTM Architecture
The architecture of this module comprises the following key components: (1) Input Layer; (2) Embedding Layer; (3) LSTM Layer; (4) Attention Layer; (5) Linear Layer; (6) Dropout Layer; and (7) Output Layer. The structure of the Attention-LSTM model is illustrated in
Figure 2. The input features are first converted into dense vector representations through the embedding layer, which captures the underlying semantic information of each element. These vectorized inputs are then processed by the LSTM layer to learn temporal dependencies and extract structured auxiliary features. Next, the attention mechanism adaptively assigns weights to the LSTM outputs, allowing the model to concentrate on the most informative parts of the sequence. The weighted output is passed through a linear transformation layer and regularized using dropout to prevent overfitting. Ultimately, the model generates a latent representation that serves as auxiliary input for the Probabilistic Matrix Factorization module.
Input Layer: Accepts business description documents from outsourcing enterprises.
Embedding Layer: Transforms each input word into a low-dimensional embedding vector using a pretrained Skip-gram model (Word2Vec). A business description document of length is converted into a sequence of embeddings: {y1, y2, …, yn}.
LSTM Layer: This layer captures the contextual semantic features of the input document. At each time step
t, the LSTM unit receives three inputs: the current word embedding
yt, the previous hidden state
ht−1, and the previous cell state
ct−1. The LSTM contains three gates—forget gate, input gate, and output gate—which jointly control the update of the cell state
ct and the computation of the hidden state
ht. The hidden state
ht serves as the contextual representation at time step
t and is forwarded to subsequent layers. The update process is abstractly represented as
where
ht represents the LSTM output at time step
t, and
yt denotes the LSTM input at time step
t.
Attention Layer: This layer is introduced to selectively aggregate the hidden states produced by the LSTM. Given the sequence of hidden states {
h1,
h2, …,
hn}, the attention mechanism assigns a weight to each hidden state to reflect its importance in the final context representation. The complete computation is expressed as
where
Ww is the weight matrix and
bw is the bias term for generating the intermediate vector
ut;
v is a learnable query vector that transforms
ut into a scalar relevance score;
at is the normalized attention weight computed through a softmax operation over all time steps
t’; and
S is the context vector formed by the weighted sum of hidden states
ht, with
at indicating their importance.
Linear Layer: The primary function of the linear layer is to project the context vector
S, derived from the attention mechanism, into a space suitable for output prediction. This transformation is defined as
where
Wl represents the weight matrix of the linear layer, and
bl denotes the bias vector.
Dropout Layer: During the training process, the dropout layer randomly deactivates a subset of neuron outputs, which disrupts co-adaptations among neurons and enhances the model’s generalization capability. The adjusted output is computed as
where
mask represents the randomly generated mask, and
p denotes the Dropout probability.
Output Layer: The output layer produces the latent feature vector
V for the outsourcing enterprise, calculated as
where
Woutv is the weight matrix of the output layer, and
boutv is the bias vector.
Through the above process, the Attention-LSTM architecture takes the business description documents of outsourcing enterprises as input and outputs the latent vector for each document. The entire process can be defined by the following formula.
where
W1 denotes the set of all weights in the LSTM,
Yj represents the
j subcomponent of the document,
vj is the business latent vector of the outsourcing enterprise, and
εj corresponds to the Gaussian noise.
To reflect the prior assumptions on network parameters, this paper assumes that each weight parameter
w ∈
W1 in the Attention-LSTM is independent and follows a Gaussian distribution with zero mean. Furthermore, given the network parameters
W1 and the input text sequence
Y, the latent representation vectors of all outsourcing enterprises
V = {
vj} follow the following conditional probability distribution. This Gaussian prior is chosen for its mathematical tractability, symmetry, and empirical suitability in modeling supplier-side feature distributions, which exhibit relatively smooth and unimodal behavior in our dataset. The specific formulations are as follows:
3.3.2. VAE Architecture
In the AttVAE-PMF framework, the Variational Autoencoder module is primarily responsible for constructing the latent feature space of demand-side enterprises. As illustrated in
Figure 3, the architecture of the VAE module comprises the following core components: (1) Input Layer; (2) Embedding Layer; (3) Feature Encoder; (4) Variational Sampling Layer; (5) Feature Decoder; (6) Linear Layer; (7) Dropout Layer; and (8) Output Layer. The input features are first transformed into dense vector representations through the embedding layer, which are then encoded via the feature encoder to extract high-level semantic representations. The encoder outputs the mean
μ and standard deviation
σ, from which latent variables
Z are sampled using the reparameterization trick. These latent variables are subsequently passed through the decoder to reconstruct feature representations. The reconstructed output is further refined by a linear transformation and regularized using a dropout layer to prevent overfitting. Ultimately, the output layer yields the latent representations, which serve as a foundational input to the downstream PMF module.
The Input Layer and Embedding Layer are structurally consistent with those in the Attention-LSTM module. The preference description document of the demand enterprise is converted into an embedding vector sequence {x1, x2, …, xn}, which serves as the input to the subsequent encoder.
Feature Encoder: The encoder is responsible for mapping the input document representation into a continuous latent feature space. Given the embedded input sequence
x = {
x1,
x2, …,
xn}, the encoder network compresses it into a latent distribution parameterized by a mean vector
μ and a log-variance vector log (
σ2). This process can be abstractly expressed as
where
μ represents the mean of the latent variables, and
σ denotes the variance of the latent variables.
Variable Sampling Layer: The latent variable sampling layer is responsible for sampling latent variables from the latent space distribution produced by the feature encoder. A noise vector is first sampled from a standard normal distribution, which is then transformed using the mean and standard deviation output by the encoder to generate the latent variables, as shown in the equation below:
where
σ = exp (0.5·log (
σ2)) represents the standard deviation, ⊙ denotes element-wise multiplication, and
ϵ is the noise variable sampled from a standard normal distribution.
Feature Decoder: Decodes the latent variable
z obtained from the latent variable sampling layer. The sampled latent variable is decoded together with the demand enterprise ratings
Si to generate the feature representation. This process can be abstractly expressed as
where
z ∈ R
d is the latent variable and
Si ∈ R
m is the rating vector of the
i-th demand enterprise.
Linear Layer: The primary function of the linear layer is to apply an affine transformation to the input feature vector, mapping it to a new space. This transformation adjusts the dimensionality of the data to match the model’s output requirements, as shown in the equation below:
where
Wl1 is the weight matrix of the linear layer,
bl1 is the bias vector, and tanh (·) applies non-linearity to enhance the expressiveness of the model.
Dropout Layer: To mitigate overfitting, the dropout layer randomly deactivates a subset of neurons during training by applying a binary mask to the input. The adjusted output is computed as
where
mask represents the randomly generated mask, and
p denotes the Dropout probability.
Output Layer: The output of the output layer is the latent preference feature vector
U of the demand enterprise, calculated as
where
Woutu is the weight matrix of the output layer, and
boutu is the bias vector.
Through the above process, the VAE architecture takes the preference description documents of demand enterprises as input and outputs the latent vector for each document. The entire process is summarized in the following formula:
where
W2 denotes the set of all weights,
Yi represents the
i subcomponent of the document,
Si represents the demand enterprise rating, and
εj corresponds to the Gaussian noise.
Similarly to the introduction of prior assumptions in Attention-LSTM, to incorporate prior knowledge about network parameters, each weight parameter
wk’ in
W2 is assumed to follow a Gaussian distribution. Furthermore, the preference latent vectors
U of all demand enterprises and
W2 are assumed to follow a conditional distribution. The Gaussian assumption is adopted not only for analytical convenience in variational inference, but also because the demand-side rating patterns in our datasets tend to follow symmetric and unimodal distributions. The specific formulations are as follows:
3.3.3. PMF Architecture
To achieve rating matrix fusion and completion, this paper employs the Probabilistic Matrix Factorization framework. From a Bayesian perspective, the joint posterior distribution over the rating matrix
R, the latent feature matrices
U and
V, and the auxiliary weight parameters
W1 and
W2 is defined as
Maximizing the posterior distribution is equivalent to minimizing the negative log-posterior, yielding the following objective:
The observed ratings
R are assumed to follow a Gaussian distribution with mean given by the predicted score
R0, and variance
σ2:
For each known rating
R, its predicted value
R0 can be obtained through the inner product of the latent feature vectors of demand enterprises and outsourcing enterprises, combined with a linear combination of auxiliary information:
where
Ui and
Vj are the latent feature vectors of the demand enterprise and outsourcing enterprise, respectively, and
W1 and
W2 are the weight parameters of Attention-LSTM and VAE, respectively.
By incorporating both the likelihood and prior terms, the final loss function is formulated as
where
λU,
λV,
λW2, and
λW1 are the regularization coefficients, and
λU =
σ2/
σ2U,
λV =
σ2/
σ2V,
λW1 =
σ2/
σ2W1,
λW2 =
σ2/
σ2W2. The above loss function can be optimized using the alternating minimization algorithm, which iteratively updates
U,
V,
W2, and
W1 until convergence.
4. Results
To validate the effectiveness of the AttVAE-PMF algorithm, this study employs PyTorch 2.2.2 (CUDA 11.8) as the deep learning framework and conducts comparative experiments under the following hardware and software environment: Windows 10 Professional Edition, 12th Gen Intel® Core™ i5-12400F 2.50 GHz, NVIDIA GeForce RTX 3060 Ti (NVIDIA Corporation, Santa Clara, CA, USA), PyCharm 2023.3.3 (Community Edition), and Python 3.8.
4.1. Datasets
This study employs two datasets: a self-constructed wallboard outsourcing dataset and the publicly available MovieLens-100K. While the primary objective is to address the wallboard outsourcing recommendation problem, the limited size of the proprietary dataset restricts the reliability of standalone benchmarking. To strengthen experimental rigor, MovieLens-100K is incorporated as a complementary benchmark. Although MovieLens-100K originates from a different domain, it shares several structural characteristics with the wallboard dataset—namely, high rating sparsity (93.7%), a user–item–attribute schema, and diverse auxiliary features. To ensure fair comparison and structural compatibility, an input alignment strategy is employed. Specifically, both datasets are abstracted into a unified representation format consisting of user-side rating vectors and item-side auxiliary features. In the wallboard dataset, supplier descriptions are used as free-text inputs, while in MovieLens, item genres and metadata serve as structured proxies. These inputs are encoded through parallel embedding pipelines to preserve architectural consistency across domains. These commonalities make MovieLens a suitable proxy for assessing the model’s capacity to handle data sparsity and leverage heterogeneous side information. Notably, the model architecture is specifically designed to address domain-specific challenges in wallboard outsourcing. Its successful application to MovieLens-100K reflects architectural robustness to structurally analogous data, rather than an intention to construct a domain-agnostic solution. A detailed comparison of the two datasets is provided in
Table 1.
4.2. Experimental Evaluation Metrics and Experimental Setup
To comprehensively assess the overall performance of the model, the dataset is randomly split into a training set (60%), validation set (20%), and test set (20%). For model evaluation, Mean Squared Error (MSE) is used to measure the overall error, while Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) serve as the core evaluation metrics. RMSE emphasizes larger errors, providing a stricter assessment of the model’s fit to the rating data, whereas MAE offers a more intuitive measure of prediction deviation, reflecting model robustness. A lower value for both metrics indicates better model fit to the actual ratings and improved predictive performance. The corresponding formulations are as follows:
where
n represents the total number of ratings in the test set,
yi denotes the actual rating, and
ŷi represents the predicted rating.
To validate the AttVAE-PMF model, this study selects four recommendation models for comparative experiments:
PMF: Probabilistic Matrix Factorization represents the user–item rating matrix as the product of low-dimensional matrices, capturing latent user–item relationships.
DLCRS: Deep Learning-based Collaborative Recommendation System leverages deep neural networks to learn complex, non-linear representations of users and items from sparse rating data, addressing limitations of traditional collaborative filtering.
SSAERec: Stacked Sparse Autoencoder Recommendation integrates stacked sparse autoencoders with matrix factorization to enhance rating prediction by learning effective latent representations from the user–item rating matrix, capturing both non-linear patterns and underlying user–item relationships.
MAF-GNN: Multi-graph Attention Fusion Graph Neural Network enhances recommendation performance by learning refined user and item representations through graph neural networks.
This study builds a recommendation system model using Python and employs a hyperparameter tuning tool, Optuna, to optimize model performance. In each tuning round, the model is trained for 100 iterations, during which the parameters are iteratively adjusted to identify the optimal configuration. To prevent overfitting or underfitting and to enhance the model’s generalization ability, a grid search strategy is adopted to thoroughly explore the predefined parameter space, thereby ensuring the robustness and appropriateness of the final model configuration. In the Attention-LSTM module, the following settings are used: the embedding dimension is set to 128, the maximum length of auxiliary information is 200, the LSTM layer consists of 32 hidden units, ReLU is used as the activation function, the dropout rate is 0.3, the batch size is 128, and the model is trained using the Adam optimizer with mini-batch optimization. In the Variational Autoencoder module, the user embedding dimension is set to 128. The encoder is composed of a three-layer fully connected neural network, with a latent variable dimension of 64. A dropout rate of 0.5 and ReLU activation are used, and training is also performed using the Adam optimizer. For the Probabilistic Matrix Factorization module, the latent factor dimension is set to 64. An alternating optimization strategy is employed to update user and item parameters separately, and five-fold cross-validation is used for performance evaluation.
4.3. Results Presentation
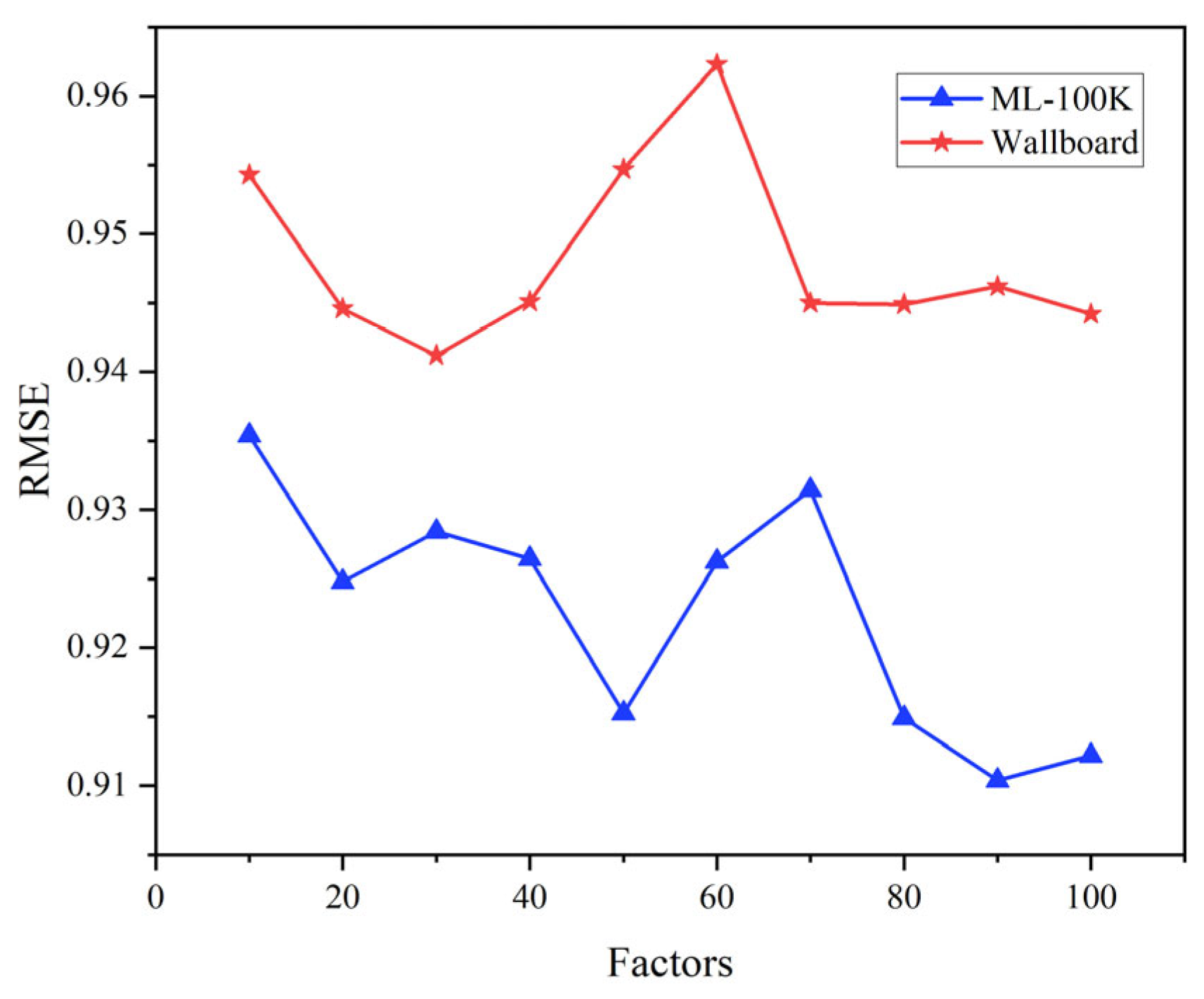
(1) As shown in
Figure 4, the variation in the number of latent factors significantly impacts the predictive performance of the model. This is because latent factors correspond to latent features that model user preferences and item characteristics; too few latent factors restrict the model’s ability to fully capture these complex relationships, while too many can cause overfitting and degrade generalization performance. Specifically, as the number of latent factors increases, the RMSE exhibits a non-monotonic trend. On the ML-100K dataset, when the number of latent factors increases from 80 to 100, the RMSE initially decreases and then rises, reaching its optimal value at 90 latent factors. On the wallboard dataset, the RMSE shows some fluctuations as the number of latent factors increases; however, the general trend is a decline followed by an increase, with the model achieving its best performance at 50 latent factors.
(2) As shown in
Figure 5, the selection of parameters
λv and
λu has a significant impact on the performance of the AttVAE-PMF model. These parameters control the strength of regularization on the latent vectors of outsourcing enterprises and demand enterprises, respectively, helping to prevent overfitting by constraining model complexity. Specifically, the variation of
λv exhibits a decline-then-rise trend in terms of its effect on RMSE. When
λv = 0.5, the RMSE reaches its lowest point, indicating that the model can effectively capture the latent features of users and items while maintaining generalization ability. Similarly, when
λu = 5, the RMSE also attains its minimum value, further demonstrating that this parameter setting contributes to improving the model’s prediction accuracy. Consequently,
λv = 0.5 and
λu = 5 are chosen as the final parameter settings to optimize model performance.
(3)
Figure 6 illustrates the convergence behavior of various models across the ML-100K and wallboard datasets. AttVAE-PMF and MAF-GNN exhibit the fastest convergence rates and consistently attain the lowest RMSE values throughout training. On the ML-100K dataset, their RMSE falls below 1.0 within the first 10 epochs and stabilizes around 0.91. Similarly, on the wallboard dataset, their performance converges to approximately 0.96. In contrast, PMF consistently yields the highest RMSE, stabilizing at approximately 0.95 on the ML-100K dataset and 1.21 on the wallboard dataset, with minor fluctuations observed during training. SSAERec and DLCRS demonstrate intermediate convergence trends and final RMSE values on both datasets.
(4)
Figure 7 illustrates the MAE convergence trajectories of various models on the ML-100K and wallboard datasets. Among the evaluated approaches, AttVAE-PMF and MAF-GNN exhibit the most rapid convergence and consistently attain the lowest MAE values throughout training. On the ML-100K dataset, both models reduce the MAE to below 0.76 within the first 10 epochs and ultimately stabilize around 0.74. On the wallboard dataset, their MAE converges to approximately 0.83. In contrast, PMF demonstrates the poorest performance across both datasets, with MAE values stabilizing around 0.79 on ML-100K and 0.88 on wallboard. SSAERec and DLCRS show moderate convergence behavior, with final MAE values situated between those of the top-performing models and PMF. Their convergence curves remain relatively smooth and stable, indicating consistent performance throughout the training process.
5. Discussion
This study empirically verifies the effectiveness of the AttVAE-PMF model in external manufacturing collaborative recommendation scenarios. Experimental results show that both the number of latent factors and the regularization parameters (λv and λu) significantly influence model performance. Too few latent factors lead to underfitting, while too many increase the risk of overfitting by capturing noise, as evidenced by the non-monotonic RMSE trends observed across datasets. Optimal performance is achieved at intermediate values. Similarly, proper regularization of user and item latent vectors—specifically λv = 0.5 and λu = 5—helps balance model complexity and generalization, resulting in improved predictive accuracy.
In terms of convergence behavior, differences across models can be attributed primarily to architectural design. AttVAE-PMF and MAF-GNN achieve faster and more stable convergence due to their expressive and structured modeling approaches. AttVAE-PMF integrates variational inference with attention mechanisms, enabling efficient learning of uncertainty-aware and informative latent representations. MAF-GNN benefits from graph-based relational modeling and multi-graph attention fusion, which capture high-order user–item interactions and neighborhood context with high fidelity. These designs lead to lower RMSE and MAE values early in training, and more rapid stabilization. In contrast, PMF, as a purely linear factorization model, lacks the ability to model non-linear and complex dependencies in sparse rating data. This results in slower convergence and inferior predictive performance, especially on the wallboard dataset, where interactions are more heterogeneous. DLCRS and SSAERec offer moderate convergence profiles. DLCRS leverages deep neural networks to capture non-linearities, but its convergence can be affected by the depth and complexity of the network. SSAERec, by integrating sparse autoencoders with matrix factorization, achieves better representation learning than PMF, but lacks the relational inductive bias provided by attention or graph-based mechanisms.
However, to ensure that AttVAE-PMF remains robust and scalable in real-world manufacturing scenarios, further optimization and expansion are needed in three key areas: selecting appropriate prior distributions, capturing dynamic user behaviors, and enhancing resilience to varying levels of data sparsity.
(1) Prior Distribution Choices: The use of Gaussian priors in both Attention-LSTM and VAE modules is also supported by the empirical characteristics of the data. In our datasets, both supplier-side features and demand-side preference patterns exhibit approximately symmetric and unimodal distributions, with limited outliers or skewness. This makes Gaussian priors not only computationally efficient but also statistically reasonable. However, in scenarios involving more extreme or asymmetric user behaviors, future work may consider using alternative priors such as Student-t (for robustness to outliers) or Beta (for bounded, skewed behavior modeling). These alternatives, while more complex, may improve modeling flexibility under specific data regimes.
(2) Modeling Dynamic User Behaviors: As the recommendation system continues to operate, behavioral data such as click sequences, search logs, and inquiry histories will naturally accumulate alongside rating information. These interaction records contain rich temporal signals that can be used to characterize the dynamic evolution of user preferences. In future research, we plan to gradually phase out generic proxy datasets, such as MovieLens, and instead fully integrate real, complex, and domain-specific behavioral data to build a more representative evaluation framework for industrial scenarios. To more effectively capture preference dynamics, we will explore transformer-based sequence modeling architectures capable of distinguishing long-term behavioral trends from short-term fluctuations. By unifying temporal interaction signals and static rating information through a multi-modal fusion framework, the model is expected to generate more adaptive user representations, thereby improving the system’s responsiveness to real-time preference shifts and enhancing the personalization and timeliness of recommendations.
(3) Sensitivity to Rating Sparsity: Although AttVAE-PMF has demonstrated promising performance on two real-world datasets with high sparsity levels, a systematic evaluation across a broader range of sparsity degrees remains an open research problem. In practical industrial recommendation scenarios, varying levels of sparsity frequently arise due to factors such as cold-start suppliers and infrequent task submissions. To comprehensively assess the model’s robustness, future work will design controlled experiments by progressively masking the rating matrix at different sparsity levels (e.g., 70%, 80%, 90%, 95%, and 98%) on a fixed dataset. This will help reveal the model’s performance degradation patterns and its resilience in extremely sparse environments.
6. Conclusions
This study addresses the challenges of sparse rating data, complex feature representation, and implicit information mining in the wallboard outsourcing process under the cloud manufacturing paradigm. To this end, we propose a wallboard outsourcing recommendation method that integrates a dual-channel deep neural network with probabilistic matrix factorization. Specifically, an Attention-LSTM channel is designed to capture heterogeneous auxiliary information from outsourcing enterprises, ensuring effective utilization of descriptive features. Simultaneously, a VAE module is employed to construct the latent feature space of demand-side enterprises, enabling the extraction of preference patterns and implicit demands. Finally, PMF is leveraged to fuse multi-source information, effectively integrating the outsourcing enterprise features with demand enterprise preferences.
Experimental results validate the effectiveness of the proposed AttVAE-PMF model, which consistently outperforms baseline methods including PMF, DLCRS, and SSAERec in terms of RMSE and MAE on two benchmark datasets. The AttVAE-PMF approach demonstrates superior convergence behavior, faster error reduction, and higher robustness to data sparsity. These results confirm that the dual-channel structure—leveraging both auxiliary enterprise features and deep user preference encoding—enables more accurate and stable recommendations. By effectively addressing the challenges of sparse interactions, unstructured supplier descriptions, and heterogeneous data integration, the proposed method significantly improves prediction accuracy, enhances enterprise recommendation quality, and optimizes information flow and decision support efficiency in wallboard outsourcing scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}