
Enhancing Mine Safety with YOLOv8-DBDC: Real-Time PPE Detection for Miners


Abstract
1. Introduction
2. Related Work
3. Methodology
3.1. Network Architecture
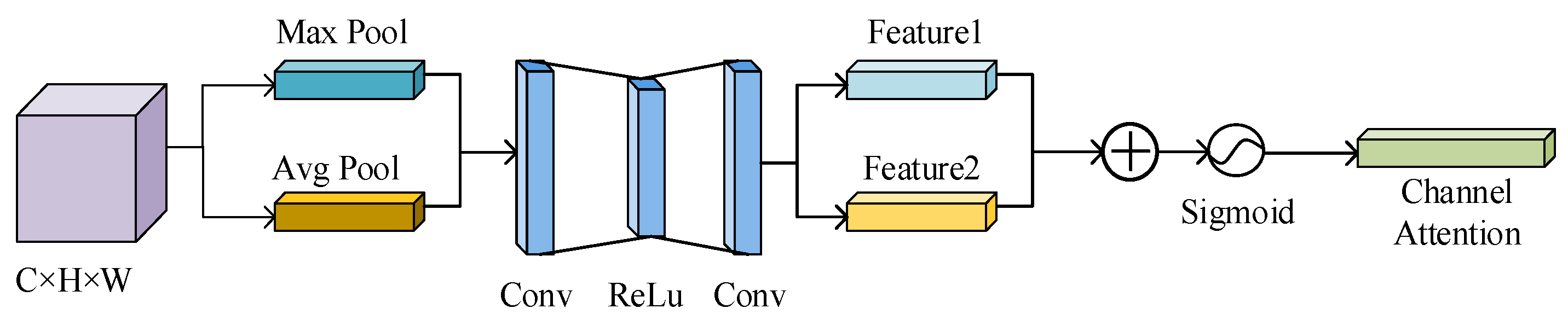
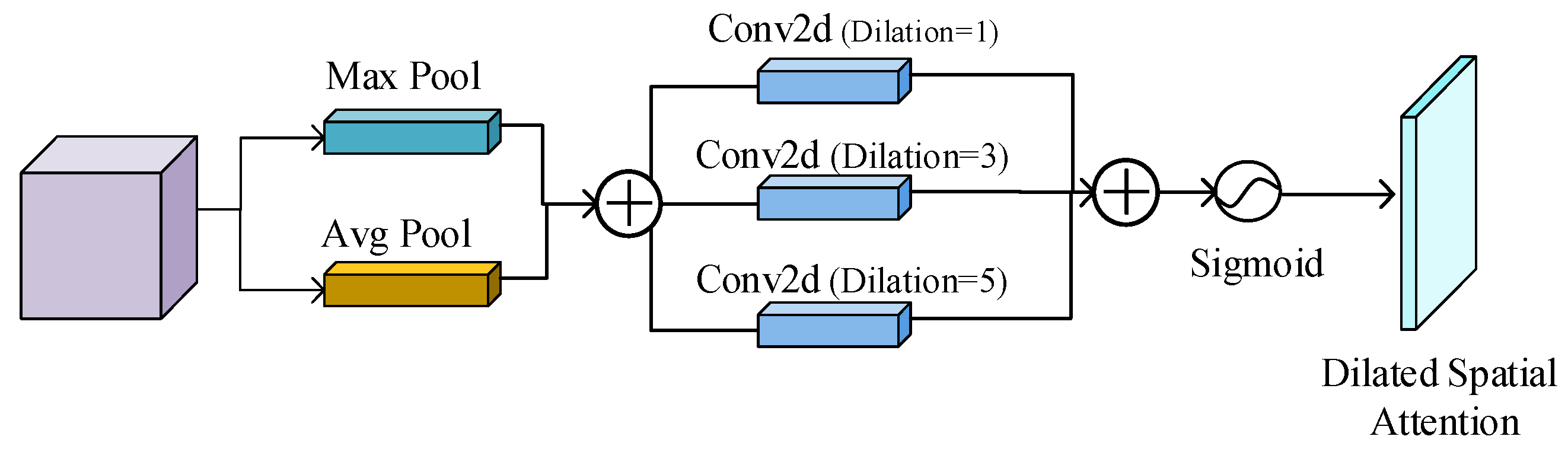
3.2. Multi-Scale Feature Enhancement Network Based on Dilated-CBAM
3.2.1. Channel Attention Mechanism (CAM)
3.2.2. Dilated Spatial Attention
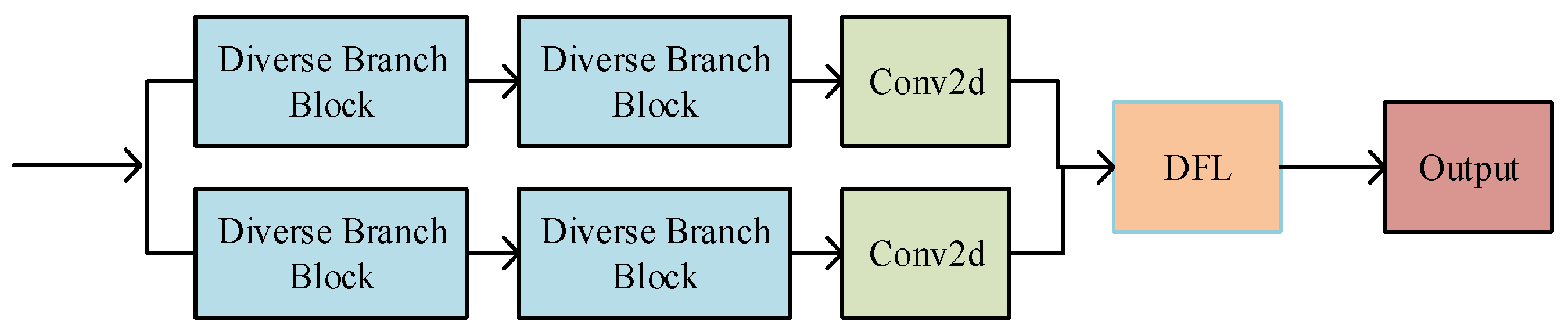
3.3. Efficient Detection Head Based on Multi-Branch Structure
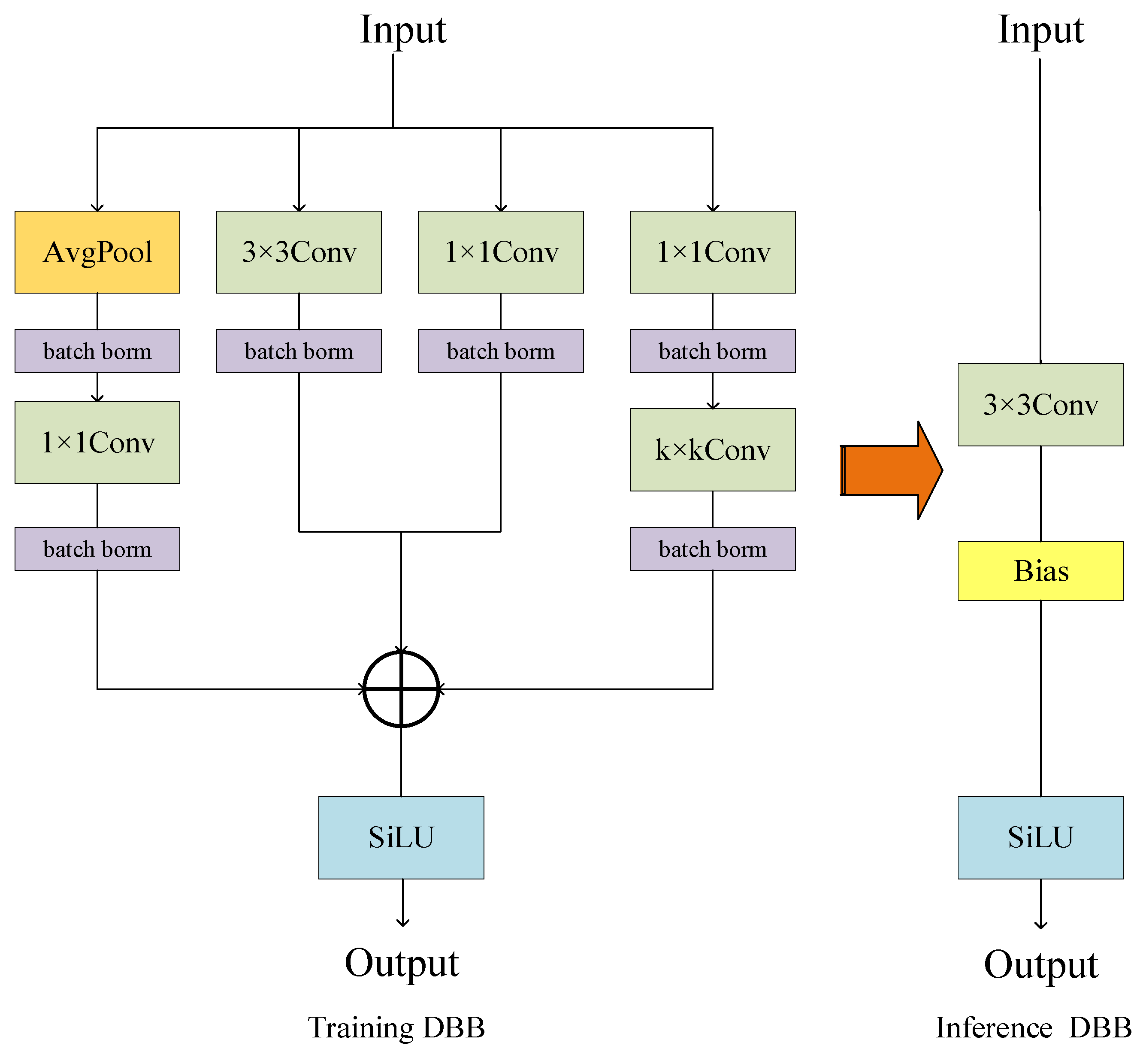
3.3.1. Diverse Branch Block Module
3.3.2. Distribute Focal Loss (DFL)
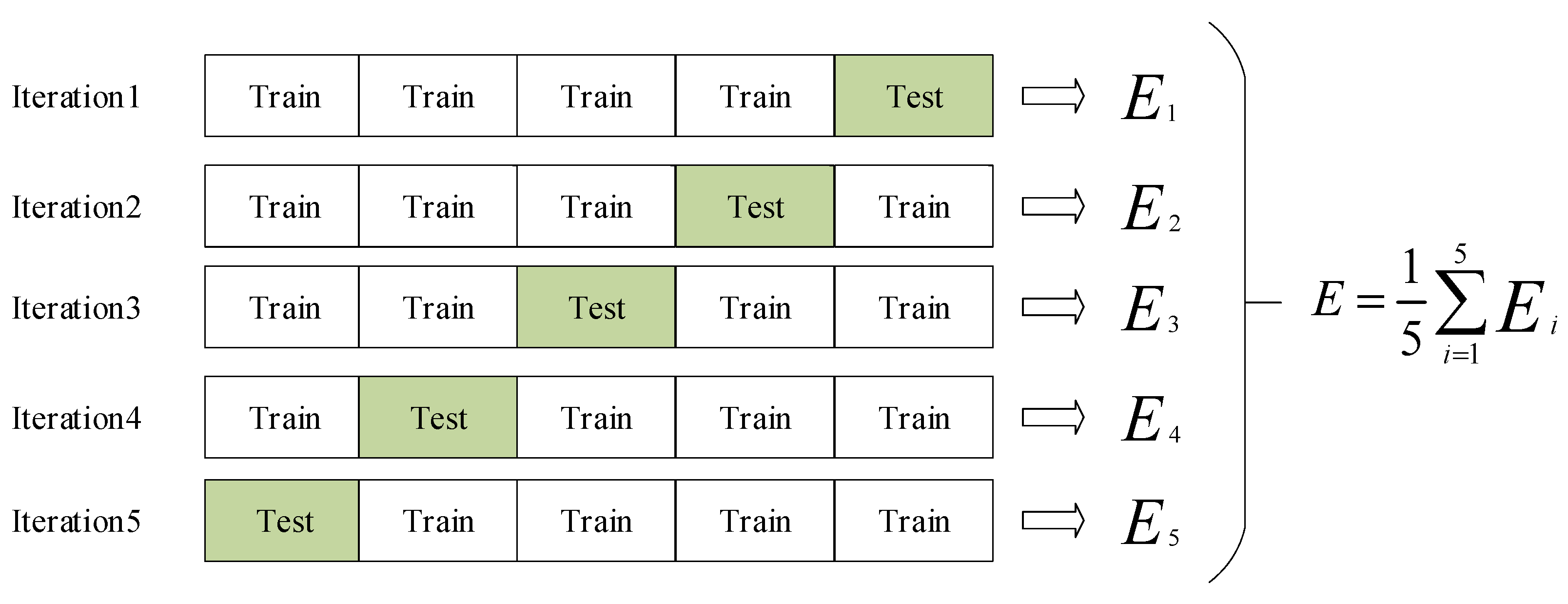
3.4. Miner’s Protective Equipment Detection Based on K-Fold Cross-Validation
| Algorithm 1. 5-Fold Cross-Validation Approach |
| ( as a vector) |
| (The training dataset minersPPE) |
| ( denotes the list of chosen classifiers) |
| in cl (Loop through all classifiers) |
| —> () and calculate the accuracy instances of CV |
| —>end for end for |
4. Results
4.1. Experiment Introduction
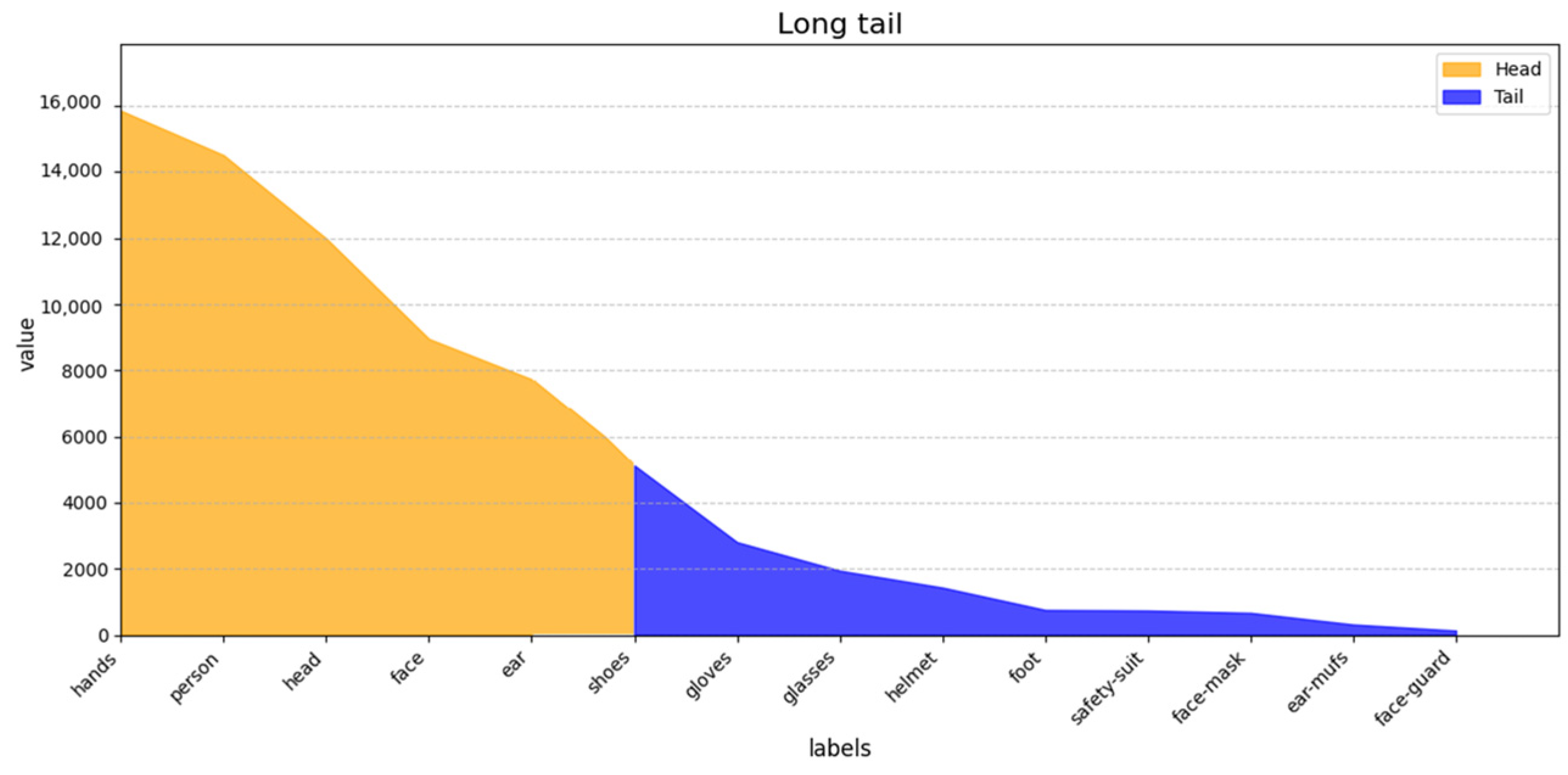
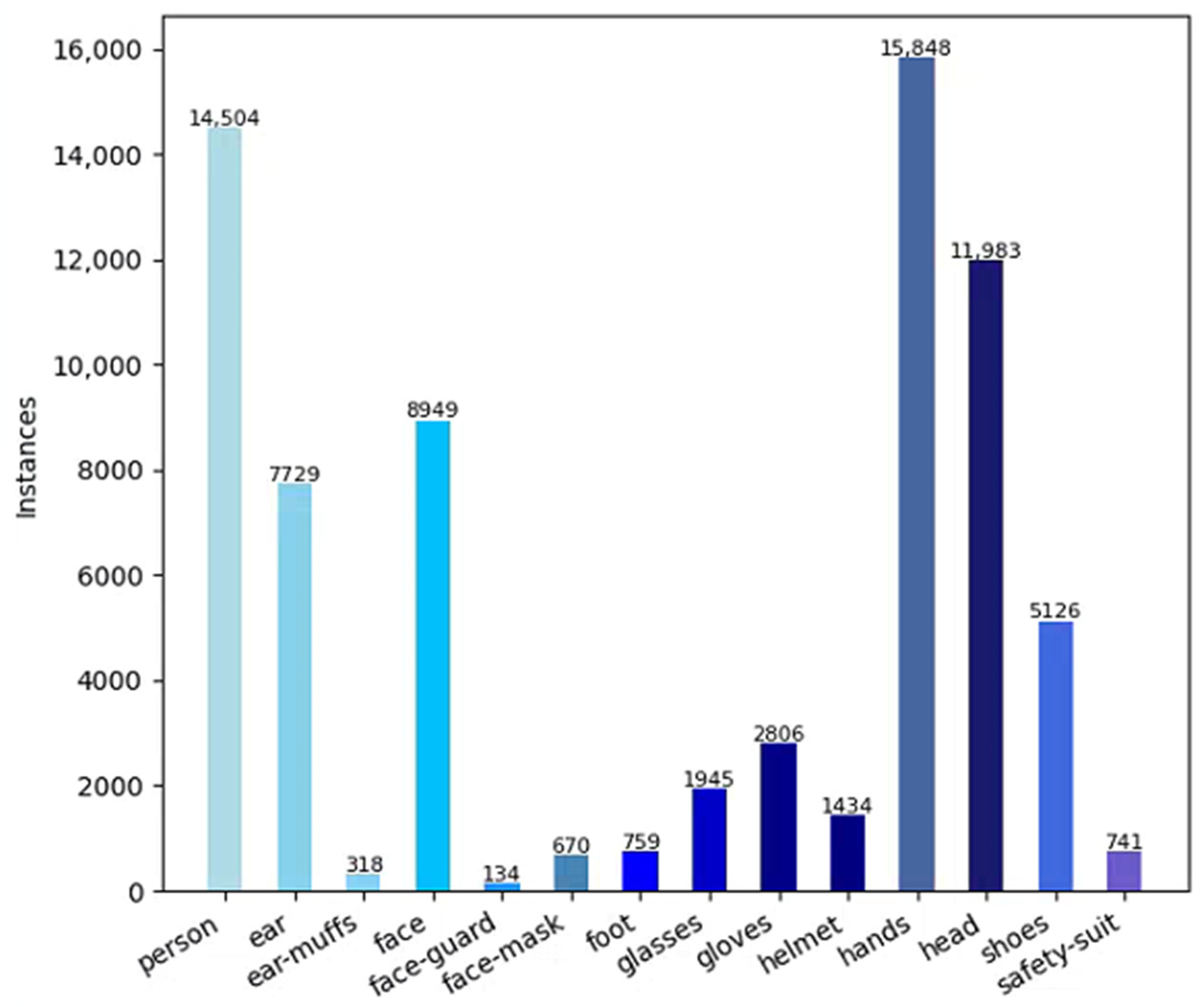
4.1.1. Dataset
4.1.2. Experimental Environment
4.1.3. Evaluation Metrics
4.2. Experimental Results
4.2.1. Ablation Experiments
4.2.2. Comparison Experiments
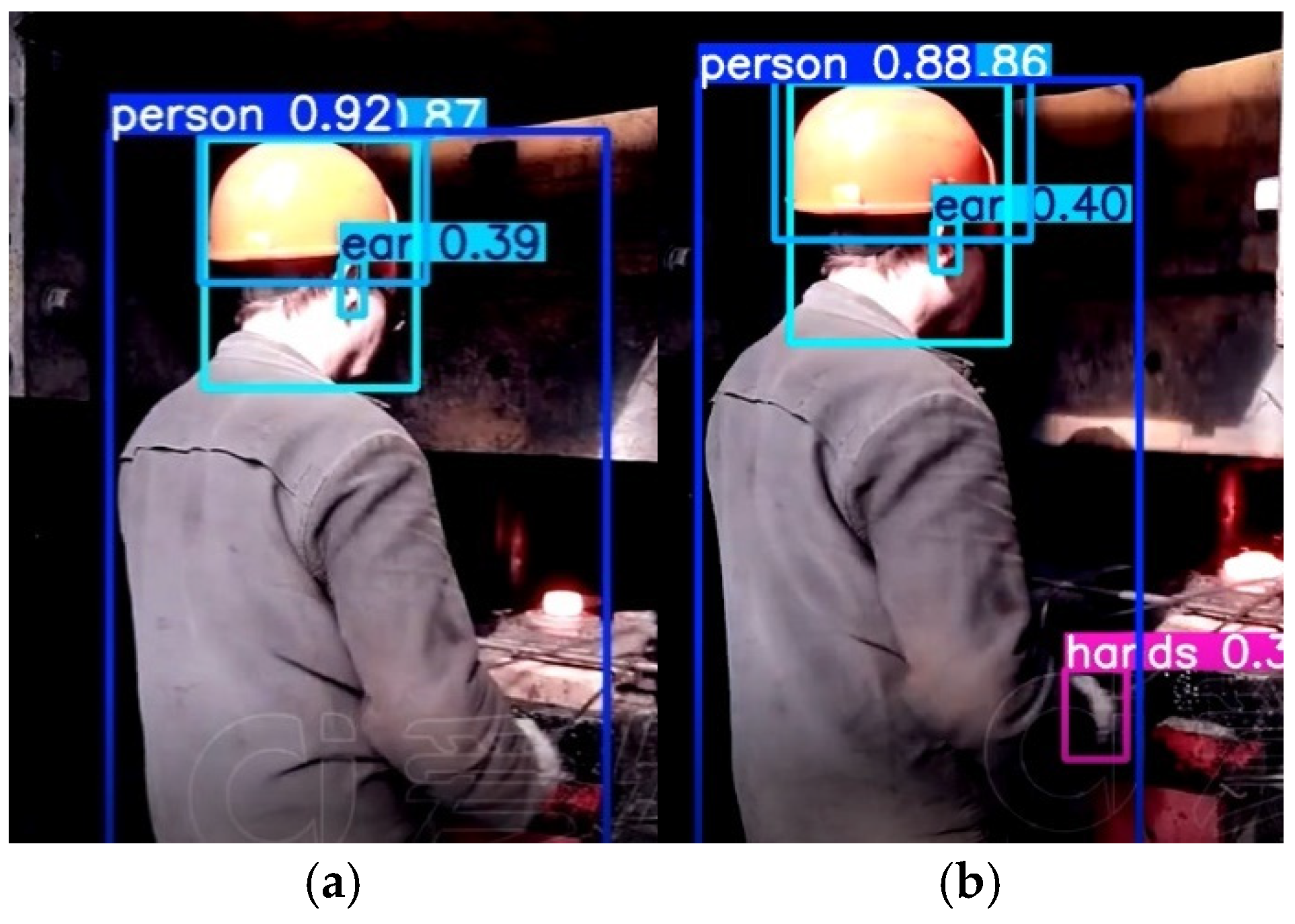
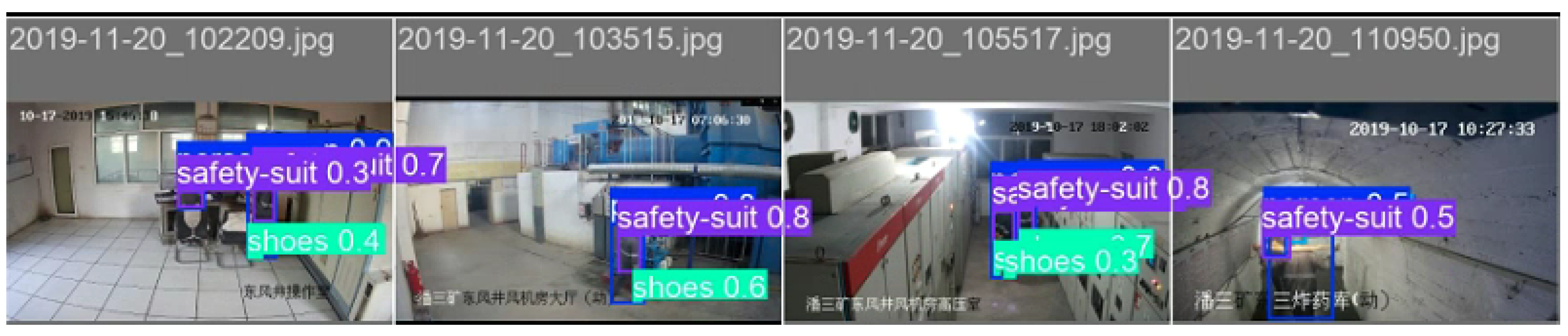
4.2.3. Qualitative Analysis
Ablation Study Qualitative Analysis
- Visualization of Dilated-CBAM Integration Effects
- 2.
- Performance of the Efficient Multi-Branch Detection Head Structure
- 3.
- Overall Performance of YOLOv8-DCDB
Comparative Analysis with Other Models
5. Discussion and Contributions
5.1. Summary of Research Contributions
5.2. Future Work Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Imam, M.; Baïna, K.; Tabii, Y.; Mostafa Ressami, E.; Adlaoui, Y.; Benzakour, I.; Bourzeix, F.; Abdelwahed, H. Ensuring Miners’ Safety in Underground Mines Through Edge Computing: Real-Time PPE Compliance Analysis Based on Pose Estimation. IEEE Access 2024, 12, 145721–145739. [Google Scholar] [CrossRef]
- Tian, S.; Wang, Y.; Ma, T.; Mao, J.; Ma, L. Analysis of the causes and safety countermeasures of coal mine accidents: A case study of coal mine accidents in China from 2018 to 2022. Process Saf. Environ. Prot. 2024, 187, 864–875. [Google Scholar] [CrossRef]
- Kursunoglu, N.; Onder, S.; Onder, M. The evaluation of personal protective equipment usage habit of mining employees using structural equation modeling. Saf. Health Work 2022, 13, 180–186. [Google Scholar] [CrossRef] [PubMed]
- Ayoo, B.A.; Moronge, J. Factors influencing compliance with occupational safety regulations and requirements among artisanal and small-scale miners in central sakwa ward, siaya county. J. Sustain. Environ. Peace 2019, 1, 1–5. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; pp. 900–903. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Jaafar, M.H.; Arifin, K.; Aiyub, K.; Razman, M.R.; Ishak, M.I.S.; Samsurijan, M.S. Occupational safety and health management in the construction industry: A review. Int. J. Occup. Saf. Ergon. 2018, 24, 493–506. [Google Scholar] [CrossRef]
- Chen, T.; Liu, J.; Li, H.; Wang, H. Study of influential factors and paths of the mine manager’s safety awareness. Min. Saf. Environ. Prot. 2022, 49, 109–113. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, J.; Ding, L.; Zhao, Y. Estimation of coal particle size distribution by image segmentation. Int. J. Min. Sci. Technol. 2012, 22, 739–744. [Google Scholar] [CrossRef]
- Paplinski, A.P. Directional filtering in edge detection. IEEE Trans. Image Process. 1998, 7, 611–615. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Ewees, A.A.; Oliva, D. Hyper-heuristic method for multilevel thresholding image segmentation. Expert Syst. Appl. 2020, 146, 113201. [Google Scholar] [CrossRef]
- Shen, Y.; Xie, X.; Wu, J.; Chen, L.; Huang, F. EAFF-Net: Efficient attention feature fusion network for dual-modality pedestrian detection. Infrared Phys. Technol. 2025, 145, 105696. [Google Scholar] [CrossRef]
- Yang, J.; Sun, S.; Chen, J.; Xie, H.; Wang, Y.; Yang, Z. 3D-STARNET: Spatial–Temporal Attention Residual Network for Robust Action Recognition. Appl. Sci. 2024, 14, 7154. [Google Scholar] [CrossRef]
- Mohammadpour, L.; Ling, T.C.; Liew, C.S.; Aryanfar, A. A Survey of CNN-Based Network Intrusion Detection. Appl. Sci. 2022, 12, 8162. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Valkenborg, D.; Rousseau, A.-J.; Geubbelmans, M.; Burzykowski, T. Support vector machines. Am. J. Orthod. Dentofac. Orthop. 2023, 164, 754–757. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-Aware Fast R-CNN for Pedestrian Detection. IEEE Trans. Multimed. 2018, 20, 985–996. [Google Scholar] [CrossRef]
- Ding, X.; Li, Q.; Cheng, Y.; Wang, J.; Bian, W.; Jie, B. Local keypoint-based Faster R-CNN. Appl. Intell. 2020, 50, 3007–3022. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Q.M.J.; Zhang, N. You Only Look at Once for Real-Time and Generic Multi-Task. IEEE Trans. Veh. Technol. 2024, 73, 12625–12637. [Google Scholar] [CrossRef]
- Wang, Y.; Niu, P.; Guo, X.; Yang, G.; Chen, J. Single Shot Multibox Detector With Deconvolutional Region Magnification Procedure. IEEE Access 2021, 9, 47767–47776. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, J.; Li, F.; Feng, Z.; Chen, L.; Jia, L.; Li, P. Foreign Object Detection Method for Railway Catenary Based on a Scarce Image Generation Model and Lightweight Perception Architecture. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, Z.; Chen, P.; Guo, F.; Qin, Y.; Long, S.; Ai, L. Hybrid learning architecture for high-speed railroad scene parsing and potential safety hazard evaluation of UAV images. Measurement 2025, 239, 115504. [Google Scholar] [CrossRef]
- Din, I.U.; Muhammad, S.; Faisal, S.; Rehman, I.u.; Ali, W. Heavy metal(loid)s contamination and ecotoxicological hazards in coal, dust, and soil adjacent to coal mining operations, Northwest Pakistan. J. Geochem. Explor. 2024, 256, 107332. [Google Scholar] [CrossRef]
- Adjiski, V.; Despodov, Z.; Mirakovski, D.; Serafimovski, D. System architecture to bring smart personal protective equipment wearables and sensors to transform safety at work in the underground mining industry. Rud. Geološko-Naft. Zb. 2019, 34, 37–44. [Google Scholar] [CrossRef]
- Nikulin, A.; Ikonnikov, D.; Dolzhikov, I. Smart personal protective equipment in the coal mining industry. Int. J. Civ. Eng. Technol. 2019, 10, 852–863. [Google Scholar]
- Wang, Z.; Zhu, Y.; Zhang, Y.; Liu, S. An effective deep learning approach enabling miners’ protective equipment detection and tracking using improved YOLOv7 architecture. Comput. Electr. Eng. 2025, 123, 110173. [Google Scholar] [CrossRef]
- Du, Q.; Zhang, S.; Yang, S. BLP-YOLOv10: Efficient safety helmet detection for low-light mining. J. Real-Time Image Process. 2024, 22, 10. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Wieczorek, J.; Guerin, C.; McMahon, T. K-fold cross-validation for complex sample surveys. Stat 2022, 11, e454. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, F.; Yang, Y. Air pollution measurement based on hybrid convolutional neural network with spatial-and-channel attention mechanism. Expert Syst. Appl. 2023, 233, 120921. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10886–10895. [Google Scholar]
- Yang, L.; Zhang, K.; Liu, J.; Bi, C. Location IoU: A New Evaluation and Loss for Bounding Box Regression in Object Detection. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Hardware and Software Information | Version and Model |
|---|---|
| CPU | Intel Core i9-13900KF |
| GPU | 2*NVIDIA GeForce RTX3080 |
| Pytorch | 2.7 |
| GPU Memory Size | 2048 M |
| CUDA Version | 11.7 |
| Operating System | Ubuntu 22.04 LTS |
| Dilated-CBAM | DDBDetection | K-Fold cv | Precision | mAP0.5 | mAP0.5:0.95 | FPS | Params |
|---|---|---|---|---|---|---|---|
| - | - | - | 0.736 | 0.661 | 0.432 | 106.6 | 25.9 |
| √ | - | - | 0.779 | 0.668 | 0.439 | 110.3 | 25.9 |
| - | √ | - | 0.766 | 0.679 | 0.442 | 116.7 | 31.4 |
| √ | √ | - | 0.798 | 0.675 | 0.444 | 100.1 | 31.5 |
| √ | √ | √ | 0.925 | 0.836 | 0.642 | 102.3 | 31.9 |
| Dilated-CBAM | DDBDetection | K-Fold cv | Precision | mAP0.5 | mAP0.5:0.95 | FPS | Params |
|---|---|---|---|---|---|---|---|
| - | - | - | 0.736 | 0.661 | 0.432 | 106.6 | 25.9 |
| √ | - | - | 0.753 | 0.669 | 0.438 | 110.3 | 25.9 |
| - | √ | - | 0.773 | 0.678 | 0.443 | 116.7 | 31.4 |
| √ | √ | - | 0.777 | 0.680 | 0.440 | 100.1 | 31.5 |
| √ | √ | √ | 0.925 | 0.826 | 0.646 | 102.3 | 31.9 |
| Model | Recall | mAP0.5 | mAP0.5:0.95 | FPS | Params |
|---|---|---|---|---|---|
| Faster R-CNN | 0.613 | 0.616 | 0.353 | 60.74 | 98 M |
| RetinaNet | 0.592 | 0.592 | 0.357 | 56 | 34 M |
| Yolov8 | 0.623 | 0.661 | 0.432 | 106.6 | 25.9 M |
| Yolov10 | 0.630 | 0.677 | 0.438 | 135.4 | 15.4 M |
| Yolov12 | 0.671 | 0.722 | 0.497 | 112.9 | 20.2 M |
| Yolov8-DCDB | 0.767 | 0.836 | 0.642 | 102.3 | 31.9 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Xie, H.; Zhang, X.; Chen, J.; Sun, S. Enhancing Mine Safety with YOLOv8-DBDC: Real-Time PPE Detection for Miners. Electronics 2025, 14, 2788. https://doi.org/10.3390/electronics14142788
Yang J, Xie H, Zhang X, Chen J, Sun S. Enhancing Mine Safety with YOLOv8-DBDC: Real-Time PPE Detection for Miners. Electronics. 2025; 14(14):2788. https://doi.org/10.3390/electronics14142788
Chicago/Turabian StyleYang, Jun, Haizhen Xie, Xiaolan Zhang, Jiayue Chen, and Shulong Sun. 2025. "Enhancing Mine Safety with YOLOv8-DBDC: Real-Time PPE Detection for Miners" Electronics 14, no. 14: 2788. https://doi.org/10.3390/electronics14142788
APA StyleYang, J., Xie, H., Zhang, X., Chen, J., & Sun, S. (2025). Enhancing Mine Safety with YOLOv8-DBDC: Real-Time PPE Detection for Miners. Electronics, 14(14), 2788. https://doi.org/10.3390/electronics14142788