1. Introduction
The global textile industry is accelerating its transition toward high-quality and sustainable development, with green intelligent manufacturing technologies becoming core drivers for reshaping industrial competitiveness [
1,
2,
3]. In textile production, defect detection in printed fabrics faces unique challenges [
4,
5]; for instance, densely patterned decorative surfaces, characterized by high-contrast color blocks and repetitive textures, inherently interfere with defect detection, resulting in inefficient manual inspection [
6,
7]. The strong coupling between patterns and defects renders printed fabric quality inspection a critical unresolved issue in the industry.
With the advancement of Industry 4.0, deep learning technologies have been increasingly applied across various domains, including fabric defect detection [
8,
9,
10]. Carrilho et al. [
11] combined the histogram of oriented gradients (HOG) with support vector machines (SVMs) for fabric classification through feature selection. However, their reliance on manual feature design and model assumptions led to false detections in complex textures. Zhu et al. [
12] extracted features based on fixed statistical rules; while achieving detection of typical defects, their approach failed to adapt to pattern variations. Chan et al. [
13] established detection criteria by analyzing frequency-domain energy distributions, but required textures to exhibit strict global periodicity. Ngan et al. [
14] developed a hybrid model combining wavelet transform and golden image subtraction. Although achieving a 93.7% detection rate, the method struggled with precise localization due to spatial resolution limitations. Zhu et al. [
15] proposed a spatial-frequency joint representation model, yet its predefined periodic parameters constrained adaptability to gradient patterns. While these traditional image processing methods laid the foundation for fabric defect detection, their heavy reliance on manual features and theoretical assumptions [
16] reveals inherent limitations in handling complex textural variations encountered in industrial scenarios.
The introduction of deep learning has opened up new research avenues for fabric defect detection. Zhao et al. [
17] reduced data dependency via transfer learning, yet their approach exhibited pronounced instability when confronted with significant textural variations. Lu et al. [
18] enhanced the YOLOv8n algorithm with a bidirectional feature pyramid network (BiFPN) and global-random attention mechanisms, but notably failed to develop targeted strategies for complex textural backgrounds. Mei et al. [
19] proposed the YOLOv8n-LAW algorithm, integrating LSKNet Attention and WIoU v3 Loss to improve defect discrimination, though textural complexity continued to undermine detection robustness. Liu et al. [
20] developed the lightweight PRC-Light YOLO model with optimized operators and Wise-IoU v3 to mitigate gradients from low-quality instances, yet similarly neglected to address performance degradation in textured environments. Hu et al. [
21] achieved defect detection using an SA-Pix2pix network and knowledge transfer, but incurred suboptimal inference speeds incompatible with real-time deployment requirements. Crucially, the trade-off between accuracy and efficiency persists. Complex models hinder deployment speed, while lightweight designs sacrifice precision, particularly in multi-scale defect detection.
To reconcile lightweight design with detection accuracy, the knowledge distillation (KD) framework [
22] has been introduced for performance transfer. Its core concept involves constructing a “teacher–student” training architecture, where the student model mimics the teacher’s feature representations and decision logic, preserving knowledge expression while compressing model size. Zhao et al. [
23] proposed a self-distillation method that improved detection performance but failed to address model compression. Xie et al. [
24] combined an improved YOLOv5 algorithm with KD, yet limited gains were observed due to inherent constraints of the YOLO architecture.
Recently, DETR (Detection Transformer) series models [
25,
26] have achieved new breakthroughs in object detection tasks due to their innovative bipartite matching strategies. Zhao et al. [
27] proposed the RT-DETR (Real Time—DEtection TRansformer) model, which avoided post-processing bottlenecks through architectural innovations. The synergistic optimization of the transformer and query selection mechanism enhances accuracy while maintaining real-time performance, and its diverse model variants provide flexible choices for teacher–student model pairing in knowledge distillation.
Building upon existing research, we propose RT-DETR-FFD, a lightweight and improved RT-DETR model specifically designed for printed fabric defect detection. Our method resolves the accuracy–efficiency trade-off in complex textural environments by integrating knowledge distillation with novel architectural innovations. Firstly, we introduce the Fourier cross-stage mixer (FCSM) module, which leverages Fourier transform to explicitly model the periodic patterns characteristic of printed fabrics and isolate the abnormal high-frequency signatures of defects, enabling precise defect feature separation. Secondly, to enhance multi-scale feature representation crucial for detecting subtle defects, we develop the FuseFlow-Net (FF-Net) to facilitate bidirectional multi-scale feature interaction and adopt an adaptive learnable positional encoding (LPE) to dynamically capture optimal hierarchical spatial correlations, significantly boosting fine-grained feature capture and localization. Finally, to optimize the knowledge transfer process critical for model efficiency, we design a novel dynamic correlation-guided distillation loss (DCGLoss) that explicitly utilizes dynamic feature correlations to guide the distillation, thereby significantly improving knowledge transfer accuracy and enhancing the generalization capability of the lightweight model. Together, these innovations within RT-DETR-FFD synergistically address the challenges of accurate defect detection in printed fabrics while maintaining high efficiency.
The remainder of this paper is structured as follows:
Section 2 elaborates on the RT-DETR-FFD methodology and the knowledge distillation framework design.
Section 3 introduces the dataset, experimental environment, parameter settings, evaluation metrics, and experimental results.
Section 4 analyzes the experimental outcomes.
Section 5 summarizes the entire study and proposes some future research directions in this field.
2. Materials and Methods
2.1. RT-DETR
RT-DETR addresses the challenges of difficult training and slow convergence in DETR by proposing novel solutions: First, RT-DETR adopts the intra-scale feature interaction (AIFI) mechanism, effectively avoiding semantic conflicts as well as information redundancy between low-level and high-level features during feature fusion. Secondly, through the efficient cross-channel fusion module (CCFM), it extracts high-level features rich in detailed object semantics from low-level features, significantly reducing computational costs while improving detection accuracy; further, RT-DETR introduces the IoU-aware query selection mechanism, ensuring that the selected Top-K features for prediction possess both high classification scores and Intersection over Union (IoU) scores, thereby enhancing detection precision. Finally, RT-DETR incorporates the advanced DINO detection head, avoiding severe errors caused by label variations during early training stages and substantially accelerating training speed.
Based on the aforementioned improvements, RT-DETR achieves an enhanced detection accuracy and speed compared to the original DETR algorithm. RT-DETR provides multiple model variants at different scales, including R18, R50, and RT-DETR-X. Considering the requirements for both detection accuracy and speed, this study adopts the R18 model as the baseline model for subsequent research, and its structure is illustrated in
Figure 1.
2.2. Fourier Cross-Stage Mixer (FCSM)
The periodic pattern structures of printed fabrics make it challenging for traditional spatial convolutional methods to effectively distinguish normal patterns from subtle defects. These approaches are inherently limited by their local receptive fields, which fail to capture long-range periodic structures, while further suffering from the confounding effect where high-frequency noise masks genuine defect features. To address this, this study proposes the Fourier cross-stage mixer (FCSM), which integrates the cross-stage partial network (CSPnet) and Fourier frequency-domain analysis.
This approach is grounded in Fourier transform (FT) principles, which decompose spatial signals into constituent frequency components to convert pixel-intensity distributions into spectral representations. For periodic fabric patterns, Fourier transformation exhibits a critical property: regular textures manifest as concentrated low-frequency energy peaks in the spectrum. Conversely, structural defects and noise emerge as anomalous high-frequency components. This inherent sparsity-separation characteristic enables effective distinction between background patterns and anomalies.
Leveraging this principle, the FCSM establishes a dual-path feature learning mechanism for fine-grained defect perception. As illustrated in
Figure 2, the network splits feature maps along the channel dimension to form dual information flows. The local detail stream focuses on capturing textural details, enhancing edge localization capabilities in defect regions. Meanwhile, the global perception stream achieves frequency–spatial joint modeling. Feature maps first undergo multi-scale depth-wise convolution (PDBlock) to enhance detail perception; then, they pass through the FourierUnit module for frequency-domain transformation and spectral enhancement. Ultimately, dynamic feature calibration is achieved through a channel attention mechanism. After the deep fusion of the two feature streams, an effective collaborative mechanism between local anomaly detection and global periodic pattern analysis is established.
This synergistic design thus effectively overcomes the limitations of spatial convolutions in modeling periodic contexts, achieving precise defect localization while suppressing interference from high-frequency noises.
2.3. StarBlock
StarBlock [
28] employs depth-wise separable convolution (DWConv) to construct an efficient feature enhancement module, combined with bilinear operations to significantly improve feature extraction efficiency and expressive power. Specifically, DWConv drastically reduces computational costs by decoupling spatial and channel-wise convolutions, while element-wise multiplication operations enhance inter-feature interactions, enabling the model to capture richer feature details. This module demonstrates unique advantages in resource-constrained scenarios. Therefore, our study selects the StarBlock as a critical component of subsequent feature extraction modules to strengthen the model’s feature interaction capabilities.
2.4. FuseFlow-Net (FF-Net)
With the increase in network model depth, feature maps progressively extract higher-level semantic information through hierarchical propagation, placing greater demands on the network’s comprehension capability, as shown in
Figure 3.
In the original RT-DETR architecture, the Encoder component utilizes RepC3 for feature interaction, but it suffers from issues such as computational redundancy, information flow bottlenecks, and inefficient feature representation. To address these limitations, this study innovatively designs a multi-branch feature aggregation structure, FuseFlow-Net (FF-Net), for the Encoder, and integrates StarBlock into it, as shown in
Figure 4.
FF-Net adopts a multi-branch fusion architecture to enhance efficiency through feature splitting, recombination, and parallel processing. The core components consist of two parts: Firstly, the PDBlock module for shallow feature extraction leverages lightweight depth-wise convolution (DWConv), which slashes computation by processing each input channel independently instead of all channels simultaneously, and partial convolution (PConv), which further eliminates redundancy by applying convolution to only a fraction of input channels while skipping others, to maximize the retention of effective feature maps while minimizing redundant computations. Secondly, the StarBlock-based cross-layer interaction system introduces a bilinear transformation mechanism to enable dynamic feature selection. When integrated with a hierarchical feature interaction architecture that progressively combines low-level textures and high-level semantics, this system strengthens the model’s non-linear representation capabilities. Additionally, the design of cross-layer information pathways explicitly propagates fine-grained details across network stages, systematically enhancing the model’s ability to capture fine-grained features. Notably, both components incorporate adaptive residual connections, which preserve the integrity of original features while ensuring gradient stability during optimization, mitigating training instabilities common in defect-imbalanced datasets.
By replacing the RepC3 module with FF-Net, the DWConv reduces the computational load, while the newly introduced bilinear operations improve feature interaction capabilities, enabling the model to capture richer detailed features. Benefiting from these innovations, FF-Net achieves improvements in detection performance while maintaining a lightweight design.
2.5. Learnable Positional Encoding (LPE)
In the original RT-DETR model, fixed sinusoidal-cosine positional encoding is employed to inject spatial information into feature sequences. Although this design provides basic geometric priors, it faces two core contradictions in industrial fabric defect detection scenarios.
Firstly, static encoding struggles to adapt to dynamic textures, as the sinusoidal function lacks adaptive modeling capabilities for local periodic features, making it difficult for the model to capture spatial pattern disruption in printed textures. For example, defects such as weft skew and warp breakage exhibit geometric distortion features that can be described, as through Equation (1):
where (
xk, yk) represents the defect center and
αk denotes the distortion intensity. Static encoding fails to dynamically adjust the corresponding weights for such non-linear spatial offsets, leading to increased false detection rates under complex textural backgrounds.
Secondly, multi-scale deployment complexity arises: traditional methods require a repetitive generation of positional grids for input sizes H × W, resulting in computational complexity of , where T denotes the number of scales. When processing multi-scale pyramids, the memory footprint and inference latency grow exponentially, severely limiting industrial deployment efficiency.
To address these challenges, this study adopts adaptive learnable positional encoding (LPE). By leveraging trainable embedding layers to autonomously optimize position-aware features, it breaks traditional encoding’s geometric constraints. This enables the model to self-discover task-relevant spatial hierarchies and identify aligned hierarchical spatial dependencies. A dynamic convolutional compression strategy is introduced, significantly enhancing spatial–contextual modeling capabilities with only O (HW × C) additional parameters. This method revolutionizes the traditional positional encoding paradigm, shifting spatial representation from predefined mathematical forms to a data-driven paradigm, allowing the model to autonomously explore optimal spatial representations.
2.6. Dynamic Correlation-Guided Distillation Loss (DCGLoss)
Traditional feature distillation methods such as MGDLoss [
29] exhibit three critical limitations. Firstly, their poor adaptability stems from fixed-threshold masking, which fails to adjust to diverse sample features, leading to insensitivity in capturing subtle patterns. Secondly, missing learning signals occurring as non-critical regions are entirely suppressed, depriving the student network of essential learning cues. Third, neglected inter-channel correlations in the teacher network hinder effective knowledge transfer by overlooking feature interdependencies across channels.
To overcome these challenges, this study proposes dynamic correlation-guided distillation loss (DCGLoss), which introduces dynamic mask adjustment and channel correlation modeling to enhance distillation efficacy.
Diverging from traditional static strategies, the dynamic mask generation mechanism locates salient regions in teacher features through a data-driven threshold strategy. Given a teacher feature map T ∈ R
N×C×H×W, the channel-wise average activation intensity is first calculated as
. This is normalized via Sigmoid to obtain
, which ultimately generates the dynamic mask. The dynamic threshold and generated mask are formulated as Equations (2) and (3):
Compared to fixed-threshold schemes, firstly, the dynamic threshold adjustment enables the precise capture of key regions across diverse samples. Secondly, the gradient preservation capability is significantly enhanced: a randomly weighted mask design ensures that non-salient regions still propagate effective gradient signals. Finally, the implementation introduces only a single mean computation, achieving a balance between performance improvement and computational efficiency while maintaining parameter counts comparable to the original MGDLoss. The formula for calculating the local generation loss is as Equation (4):
where
Conv represents the convolution operation,
denotes the dynamically generated mask matrix,
and
correspond to the
k-th layer features of the student network and teacher network, respectively, and
K indicates the total number of layers.
To further enhance structural awareness, a channel correlation loss is introduced to explicitly model feature interdependencies within the teacher model. Specifically, spatial dimension normalization and matrix operations are applied to construct channel correlation matrices
, enabling systematic alignment of cross-channel relationships between the teacher and student networks, as formalized in Equation (5).
Therefore, the final loss function comprises two collaboratively optimized components, as defined in Equation (6).
DCGLoss targets key fabric defect detection challenges through adaptive design. Specifically, unlike rigid masking, its dynamic thresholding automatically focuses on salient regions per sample, crucial for spotting subtle, irregular defects amidst the highly variable and complex background textures of printed fabrics. This ensures critical defects are not missed. Furthermore, its weighted relaxation for non-salient areas avoids completely suppressing background information. This prevents overfitting and reduces false positives by maintaining essential context about the normal fabric pattern, which is vital for distinguishing true defects from textural variations or shadows. Critically, DCGLoss explicitly models inter-channel feature relationships, aligning the structural patterns learned by teacher and student. This “local focus–global synergy” addresses core inspection difficulties: small anomalies and complex backgrounds.
2.7. Construction of Student and Teacher Models
In deep learning, transfer learning and knowledge distillation represent approaches for model compression [
30]. This study proposes a lightweight defect detection model RT-DETR-FFD based on knowledge distillation tailored for printed fabric inspection scenarios. Built upon the RT-DETR-R18 baseline, the model incorporates multi-dimensional enhancements to optimize performance. In the backbone network design, we replace conventional 2D convolution with an FCSM module. This module augments detail capture through frequency-domain interaction, effectively preserving fine textures in complex patterns. To refine positional awareness, the original adaptive intra-scale feature interaction (AIFI) mechanism is re-engineered into an LPE module, significantly improving the model’s ability to represent irregular defect geometries. Regarding multi-scale feature fusion bottlenecks, the encoder integrates an innovative FuseFlow-Net structure, substituting the standard C3f module. This design leverages a hierarchical feature flow fusion mechanism to enhance cross-level semantic consistency without compromising computational efficiency, ensuring a robust integration of multi-scale contextual cues.
By collectively enhancing feature representation capacity, our refinements enable efficient teacher knowledge assimilation without compromising the deployment-friendly lightweight design. Such synergistic optimization bridges the gap between knowledge transfer efficacy and practical application constraints, achieving a balance rarely seen in traditional approaches.
For the distillation strategy, the RT-DETR-X model, characterized by its significantly larger parameter capacity, is deliberately selected as the teacher. This choice is motivated by its demonstrably superior feature representation capability and detection accuracy on fabric defect benchmarks. However, while this high parameterization renders it computationally prohibitive for real-time deployment, a crucial advantage is its architectural homology with the student model. Specifically, they share core components including the hybrid encoder and adaptive spatial priors. This shared architecture minimizes structural misalignment during feature distillation. Consequently, this strategic selection ensures that the knowledge transfer process effectively leverages the teacher’s robust pattern recognition strengths while mitigating the risks of distortion caused by architectural discrepancies. Critically, we propose a novel DCGLoss that employs dynamic masking and spatially correlated matrices. This approach precisely aligns teacher–student feature distributions, preserving both local detail fidelity and global structural coherence. The architecture of the RT-DETR-FFD model is depicted in
Figure 5, illustrating the interplay of these innovations.
3. Experiment and Analysis
3.1. Dataset
The dataset utilized in this study is sourced from the Alibaba Cloud Tianchi Platform [
31], specifically collected from a textile workshop in Foshan Nanhai, China, focusing on printed fabric defect inspection. To ensure representativeness, the raw data underwent rigorous cleaning and filtering, resulting in 2318 validated samples. Data augmentation through horizontal flipping, contrast adjustment, and brightness adjustment simulated varying illumination conditions, producing 3528 images at 640 × 640-pixel resolution. Finally, the images were partitioned into training, validation, and test sets at a ratio of 7:2:1. The defect categories encompass typical textile anomalies including but not limited to Stain, Hole, Seam Mark, and Color Variation. For comprehensive categorical distributions, please refer to
Table 1.
To address challenges such as uneven illumination and device noise during image acquisition, a preprocessing pipeline was implemented. Firstly, Gaussian filtering was applied to smooth raw images, effectively suppressing random noise while preserving edge features of fabric textures. Subsequently, histogram equalization was employed to enhance contrast by redistributing pixel intensity values, homogenizing brightness distribution and accentuating surface details. Representative samples from the dataset are illustrated in
Figure 6, where the defects ordered left to right are Seam Mark, Stain, and Weaving Defect.
3.2. Experimental Environment and Evaluation Index
The following configuration was used for the experimental setup. The operating system was Linux, the CPU was an Intel(R) Xeon(R) Platinum 8255C CPU@2.50 GHz, and the GPU was an NVIDIA GeForce RTX 3090 with 24 GB of VRAM. The experiment utilized the PyTorch 2.1.0 framework and Python 3.10. The hyperparameters included an initial learning rate of 0.0001, 450 training epochs, and a batch size of 4.
Four fundamental evaluation measures were included in this study to fully assess the RT-DETR-Student algorithm’s performance in fabric defect detection: precision (
P), recall (
R), mean average precision (
mAP), model parameters (Params), and frames per second (
FPS). The following are the corresponding calculation formulas (see Equations (7)–(9)):
Precision reflects the accuracy of positive predictions, while recall indicates the coverage of actual positives. For multiclass tasks, mean average precision (mAP) is computed as the average of class-wise AP scores. This metric holistically evaluates detector performance across all categories. To comprehensively evaluate detection performance, we adopt mAP@50 and mAP@50:95 as evaluation metrics, where results are averaged over five independent runs with different random seeds to mitigate the impact of randomness. Specifically, mAP@50 denotes mean average precision at an IoU threshold of 0.5, while mAP@50:95 averages mAP over IoU thresholds from 0.5 to 0.95 in 0.05 increments.
3.3. Comparative Evaluation with Baseline Models
To validate the baseline model selection, a comparative analysis was conducted among algorithms including YOLOv5, YOLOv8, and a hybrid architecture integrating the DETR detection head into the YOLO framework to assess paradigm differences, as shown in
Table 2.
The YOLO-DETR series models achieved an absolute gain of approximately 2 percentage points in mAP@0.5 compared to the standard YOLO series, demonstrating the efficacy of the bipartite matching strategy in suppressing false positives induced by complex textural interference. Significantly, RT-DETR-R18 outperformed YOLOv8m-DETR by 0.7 mAP@0.5 while reducing parameters by 23%. These advantages originate from two key design innovations: first, RT-DETR’s transformer-based hybrid encoder captures global contextual dependencies to resolve spatial ambiguities beyond local receptive fields; second, its inherently efficient architecture optimizes the computational footprint for lightweight deployment. This synergistic design enabled RT-DETR-R18 to deliver superior accuracy while maintaining compact characteristics, outperforming competing models in both precision and computational efficiency to establish itself as our baseline solution.
3.4. Comparative Evaluation of Individual Enhancement Effectiveness
To rigorously validate the effectiveness of the proposed enhancements, a single-modification effectiveness evaluation was conducted by incrementally integrating each module into the baseline RT-DETR-R18 (R18) model. Firstly, the FCSM module was integrated into the backbone network to evaluate its impact on frequency-domain feature extraction. Subsequently, the LPE mechanism was introduced into the feature encoding layer to assess its capability in refining positional awareness for irregular defects. Further, the original C3f module in the encoder was replaced with the proposed FuseFlow-Net structure to investigate its efficacy in hierarchical feature fusion. Finally, all three modules—FCSM, LPE, and FuseFlow-Net—were systematically integrated into the baseline model to analyze their synergistic performance gains. The experimental results are presented in
Table 3.
Enhancement 1 replaces standard 2D convolutions with the FCSM module, reducing parameters by 16.1% while achieving absolute gains of 1.7 and 3.1 percentage points in mAP@0.5 and mAP@0.5:0.95, respectively. This confirms that Fourier-based high-frequency anomaly representation enhances defect sensitivity.
Enhancement 2 introduces LPE, achieving absolute gains of 1.3 and 3.1 percentage points in mAP@0.5 and mAP@0.5:0.95, respectively, which validates its adaptive spatial modeling capability for complex defect distributions.
Enhancement 3 substitutes the C3f module with FuseFlow-Net, leveraging adaptive residuals and cross-level pathways to achieve absolute gains of 2.4 and 5.3 percentage points in mAP@0.5 and mAP@0.5:0.95, respectively, which underscores its improved adaptability to complex textural variations.
Enhancement 4 integrates all modules into the baseline, achieving absolute gains of 4.5 and 6.6 percentage points in mAP@0.5 and mAP@0.5:0.95, respectively, alongside 11.7% fewer parameters and 14.3% lower computation. The unified model balances speed and accuracy, surpassing baseline performance.
3.5. Ablation Experiment
To comprehensively analyze the collective impact of the proposed modules, an ablation study was conducted by incrementally integrating each optimization module into the RT-DETR baseline model. The results in
Figure 7 and
Table 4 utilize “×” to denote the absence of a specific module and “√” to indicate its inclusion. Through systematic comparisons, this approach reveals the differential contributions of module combinations to accuracy improvements and their varying impacts on computational efficiency.
Ablation study results confirm the performance gains from each proposed module. Specifically, the Fourier cross-stage mixer (FCSM) enhances defect–background discrimination. This improvement stems from its ability to decouple periodic textile patterns from defect-induced anomalies. The FCSM achieves this through dual-path feature learning, incorporating frequency-domain transformation and channel attention. This module contributes a 1.7% improvement in mAP@0.5. Furthermore, FuseFlow-Net (FF-Net) elevates multi-scale feature integration by replacing conventional fusion structures with a hierarchical feature flow mechanism incorporating StarBlock bilinear transformations and cross-layer pathways, yielding an additional 1.6% mAP@0.5 enhancement. Finally, the Learnable Positional Encoding (LPE) module transcends rigid geometric constraints by establishing data-driven spatial correlations through trainable embeddings, enhancing irregular defect localization while reducing encoding complexity. Collectively, the integrated architecture achieves significant improvements. Specifically, it delivers a 4.5% absolute gain in mAP@0.5 and a 6.6% advancement in mAP@0.5:0.95. Concurrently, the architecture reduces model parameters by 11.7%. These results demonstrate the synergistic optimization of feature representation and computational efficiency. This establishes a reproducible technical pathway addressing industrial deployment’s dual demands for high-precision yet lightweight models.
3.6. Knowledge Distillation Experimental Results
A comparative analysis of the RT-DETR-X (teacher model) and RT-DETR-FFD (student model) performance before and after knowledge distillation is conducted, supplemented by benchmarking against the canonical RT-DETR-R50 variant to validate teacher model selection. The quantitative results are systematically summarized in
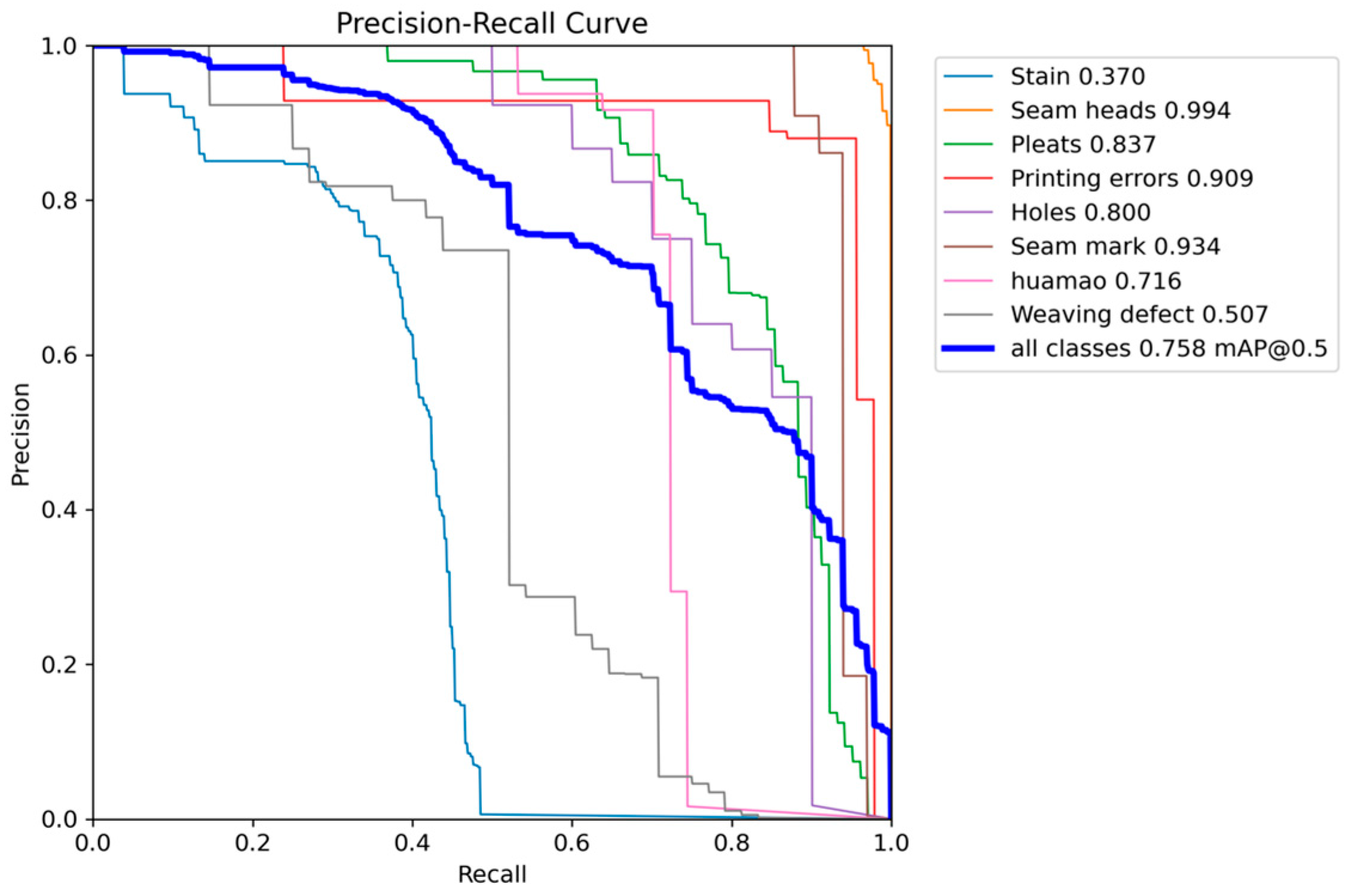
Table 5. To evaluate detection performance, this study constructed precision–recall (PR) curves using an Intersection over Union (IoU) threshold of 0.5 during the testing phase. Detailed comparative analyses are visualized in
Figure 8 and
Figure 9.
While the RT-DETR-X teacher model achieves 86.4% mAP@0.5 on the test set, its high parameter count and computational cost limit industrial viability. Through knowledge distillation, the student model preserves the original computational load but improves mAP@0.5 to 82.1% and mAP@0.5:0.95 to 60.3%, attaining 95.1% of the teacher’s accuracy with only 26.1% of its parameters while achieving 57.3 FPS versus the teacher’s 34.7 FPS. This validates the teacher’s role as an effective knowledge source, where the student model compensates for lightweight architecture limitations by inheriting the teacher’s feature distribution patterns. The framework establishes a “high-accuracy, low-cost” paradigm for industrial defect detection, balancing precision with efficiency while aligning with sustainable manufacturing requirements.
3.7. Comparative Analysis of Loss Functions
To validate the superiority of the DCG distillation loss function, a comparative experiment was conducted between channel-wise knowledge distillation (CWD) and masked generative distillation (MGD). The experimental results are presented in
Table 6.
Under identical training strategies, the RT-DETR-FFD model employing DCGLoss outperformed both CWDLoss and MGDLoss in terms of mAP@0.5 and mAP@0.5:0.95. CWDLoss misaligns texture-distorted features due to spatial unawareness in its global channel weighting mechanism, limiting channel-wise knowledge transfer. Meanwhile, MGDLoss is constrained by its fixed masking strategy, leading to matching biases in complex backgrounds. In contrast, DCGLoss innovatively introduces a dynamic adaptive masking mechanism that synchronizes local detail preservation with global channel correlations during feature generation. This approach effectively captures the multi-scale contextual patterns of the teacher network, thereby optimizing the distillation loss and offering a balanced solution for efficient deployment in resource-sensitive industrial scenarios.
3.8. Comparative Analysis of Loss Function Heatmaps
To visually demonstrate the enhanced capability of the DCG loss function in identifying fabric print defects, this study employs Grad-CAM [
32] (gradient-weighted class activation mapping) to visualize the model’s attention regions. The method generates heatmaps by analyzing spatial region importance during decision-making, visualizing feature concentration. As
Figure 10 shows, highlighted areas indicate a prioritized model focus, demonstrating enhanced localization of subtle defects.
As shown in
Figure 10, the heatmap effects of models using CWDLoss and DCGLoss are compared. The defects in the figure are clearly marked with red bounding boxes for visual reference. DCGLoss distillation yields concentrated defect activations that precisely localize anomalies and cover full extents. Such a reduction in false positives and false negatives is essential for deployable high-precision industrial systems.
3.9. Visualization of Model Detection Performance
Figure 11 illustrates the model’s detection performance, showcasing its capability to identify defects such as stains and seam marks. The results demonstrate a robust localization accuracy, effectively suppressing interference from wrinkle shadows and textural variations while precisely pinpointing defect regions.
3.10. Generalization Evaluation
To validate the generalization capability and robustness of RT-DETR-FFD, we conduct additional performance evaluations on the Denim Fabric Dataset from the Tianchi platform [
33]. Similar to printed fabrics, denim fabrics exhibit distinctive textural patterns where surface textures often visually resemble defects, leading to potential false negatives and false positives. The experimental results are presented in
Table 7, while
Figure 12 provides visual evidence of the detection performance.
The experimental results clearly demonstrate that the distilled RT-DETR-FFD model achieves a significantly enhanced detection performance compared to the R18 baseline. Notably, it attains 95.9% of the teacher model’s mAP@0.5, confirming the effectiveness of knowledge distillation. Crucially, the model maintains robust detection capabilities when handling complex textured noise interference, demonstrating the generalization performance.
4. Discussion
Fabric defects such as yarn breakage, holes, abrasions, etc., directly compromise product aesthetics and quality [
34,
35,
36], consequently reducing production efficiency and increasing costs. To address these challenges, this study proposes a knowledge distillation-based lightweight rapid detection model for print fabric defects, which demonstrates significant advantages in textile defect inspection by balancing accuracy, computational efficiency, and adaptability to industrial deployment constraints.
RT-DETR excels in real-time detection via its end-to-end Transformer architecture. However, it faces challenges in dynamic adaptability, small target feature modeling, and balancing efficiency with accuracy under resource constraints. To address these, we propose a knowledge distillation-enhanced RT-DETR framework for fabric defect inspection. First, the FCSM leverages Fourier transforms to project features into the frequency domain. This approach capitalizes on the distinct spectral signatures of periodic textile patterns versus defect-induced anomalies, enabling high-precision isolation of defect-related features. Complementing this, FuseFlow-Net employs StarBlock’s bilinear transformation for dynamic feature selection. Cross-level pathways are synergized to foster multi-scale interactions, thereby amplifying sensitivity to subtle defect morphologies. To further address spatial modeling limitations, LPE is adopted, which replaces rigid geometric priors with data-driven spatial correlations, achieving superior context awareness with minimal parameter overhead. Finally, the DCGLoss is devised to refine knowledge transfer. It integrates spatially adaptive masks derived from teacher–student feature discrepancies, alongside global frequency-channel correlation constraints. This integration ensures robust generalization across diverse defect patterns. Collectively, these innovations yield RT-DETR-FFD, which optimizes the trade-off among accuracy, efficiency, and adaptability for real-time textile defect detection in industrial settings.
However, this study still has certain limitations. Although the Fourier cross-stage mixing (FCSM) module effectively separates frequency-domain features for periodic patterns, its performance relies critically on spectral characteristics. When processing non-periodic textures or complex background interference, particularly under conditions of extreme non-uniform illumination or material-specific reflectance variations, the discernibility of anomalous high-frequency components may degrade. This can potentially lead to missed detections, despite the module’s inherent noise suppression capabilities. In designing FuseFlow-Net, a balance must be maintained between global structural awareness and local detail preservation. Achieving this requires extensive parameter tuning and validation to avoid issues such as feature over-smoothing or noise amplification under strenuous environmental fluctuations. While the learnable positional embedding (LPE) overcomes geometric constraints through data-driven learning, its spatial correlation modeling is tightly coupled with the distribution of the training data. This coupling can cause performance degradation in cross-domain scenarios. Furthermore, DCGLoss’s cross-domain fusion depends on the representational completeness of the pre-trained teacher model, introducing a dependency on the robustness of the teacher’s knowledge. This dependency constrains the model’s adaptation to radically novel defect semantics.
Future research will prioritize the following directions: Firstly, constructing multimodal fabric datasets capturing diverse industrial scenarios to analyze defect–environment interplay and enhance disturbance robustness. Secondly, structured pruning based on channel importance will eliminate redundancy while preserving critical features, combined with computational graph optimization to boost efficiency. Finally, deep integration of detection systems with automated production lines will be achieved through embedded deployment and multi-source data synergy, enabling intelligent quality inspection with online learning for closed-loop textile process optimization. These methodological advancements optimize fabric defect detection performance, delivering novel technological solutions and operational value to the textile manufacturing sector.
5. Conclusions
Fabric defect detection remains a significant technical challenge due to the diversity of defect types, varying scales, and stringent demands for real-time high-speed inspection. Timely identification and correction of anomalies are critical for enhancing textile quality, optimizing manufacturing processes, and mitigating economic losses, underscoring the practical importance of this research. To address these challenges, this study proposes an enhanced RT-DETR detection model leveraging model compression. By leveraging a lightweight RT-DETR architecture, the model reduces computational complexity and resource consumption compared to conventional frameworks. Key innovations include the FCSM and FuseFlow-Net, which improve detection accuracy and operational economy through Fourier-based spectral analysis and adaptive multi-scale feature fusion. Further enhanced by an LPE module, the model strengthens spatial–contextual modeling while preserving computational frugality. Notably, the integration of this teacher–student framework with a novel correlation-aware loss function elevates the knowledge transfer efficacy. Experimental results demonstrate an mAP@0.5 of 82.1%, outperforming mainstream frameworks in balancing precision and recall, validating the superior detection performance. Future work will focus on optimizing industrial deployment, refining sensitivity to subtle flaws, and exploring edge–device integration, a reduction in flaw occurrence, and sustainable textile manufacturing.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}