

Sound Source Localization Using Hybrid Convolutional Recurrent Neural Networks in Undesirable Conditions

 ,
,  , , ,
, , ,  and
and 
Abstract
1. Introduction
- 1.
- Converting regression-oriented DOA estimation models into resilient classification frameworks, thereby enhancing both training stability and clarity.
- 2.
- Incorporating spatial and spectral features, including acoustic intensity maps, to increase directional sensitivity.
- 3.
- Embedding attention mechanisms and CRNN to improve the model’s focus on pertinent temporal segments.
- 4.
- Conducting a thorough evaluation using the STARSS23 dataset in realistic acoustic settings, which allows for equitable benchmarking across various performance metrics.
- 5.
- Analyzing the comparative strengths of specialized (M-DOAnet) and multifunctional (M-SELDnet) models, offering insights into their respective advantages in SSL and SELD tasks.
2. State of the Art
2.1. Conventional SSL Methods
2.1.1. Generalized Cross-Correlation with Phase Transform (GCC-PHAT)
2.1.2. Subspace Methods
2.2. Neural Network-Based Methods in Sound Source Localization
2.2.1. Convolutional Recurrent Neural Networks (CRNNs)

2.2.2. Attention-Based Neural Networks
- Handle polyphony: By enabling the model to focus on individual sound event streams or specific time-frequency bins where a particular source is active, effectively disentangling overlapping sounds.
- Improve temporal modeling: By allowing the model to weigh information from distant time frames directly, addressing the vanishing gradient problems often associated with traditional RNNs.
- Reduce redundancy: By selectively attending to the most informative features and suppressing less relevant ones, thereby making the learning process more efficient.
3. Methodology
3.1. Input Signal Representations
3.1.1. Spectrogram Representations for Speech Signal
3.1.2. Ambisonic Signal Representation
3.1.3. Sound Intensity
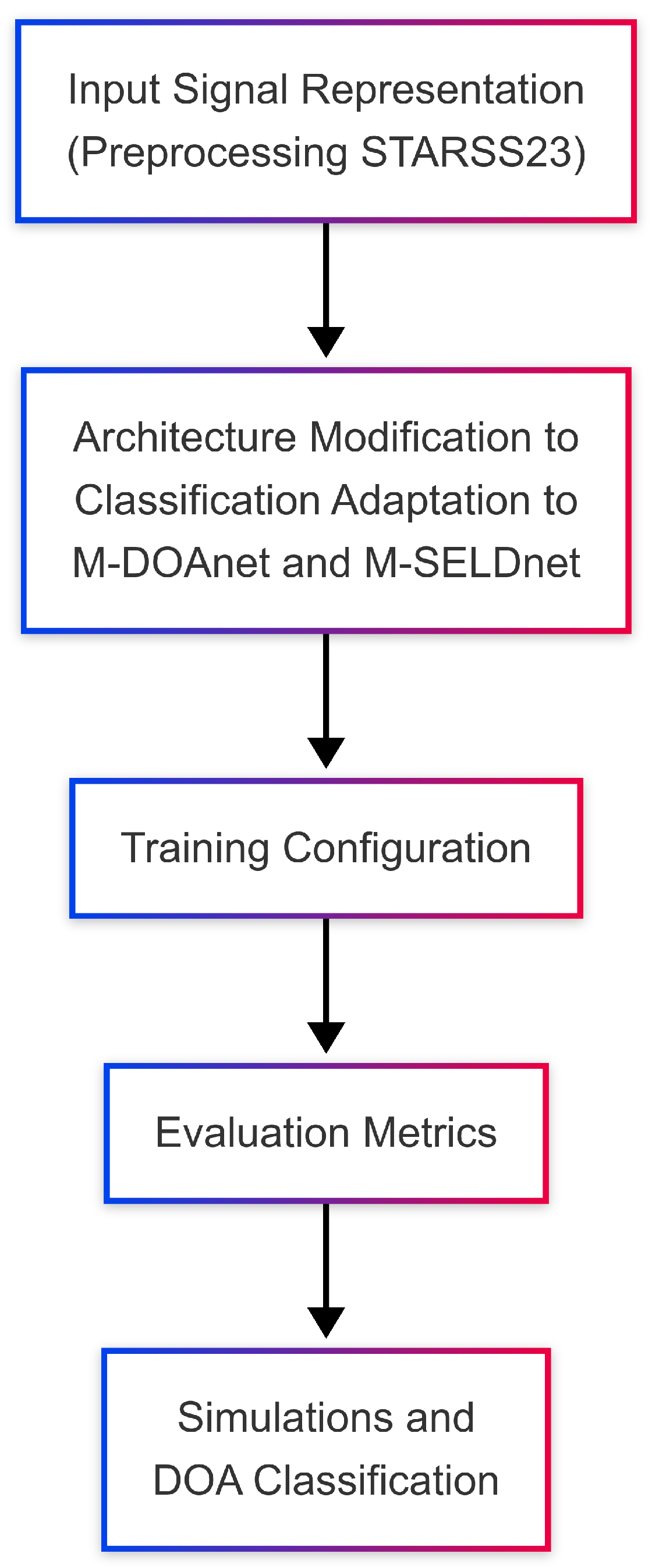
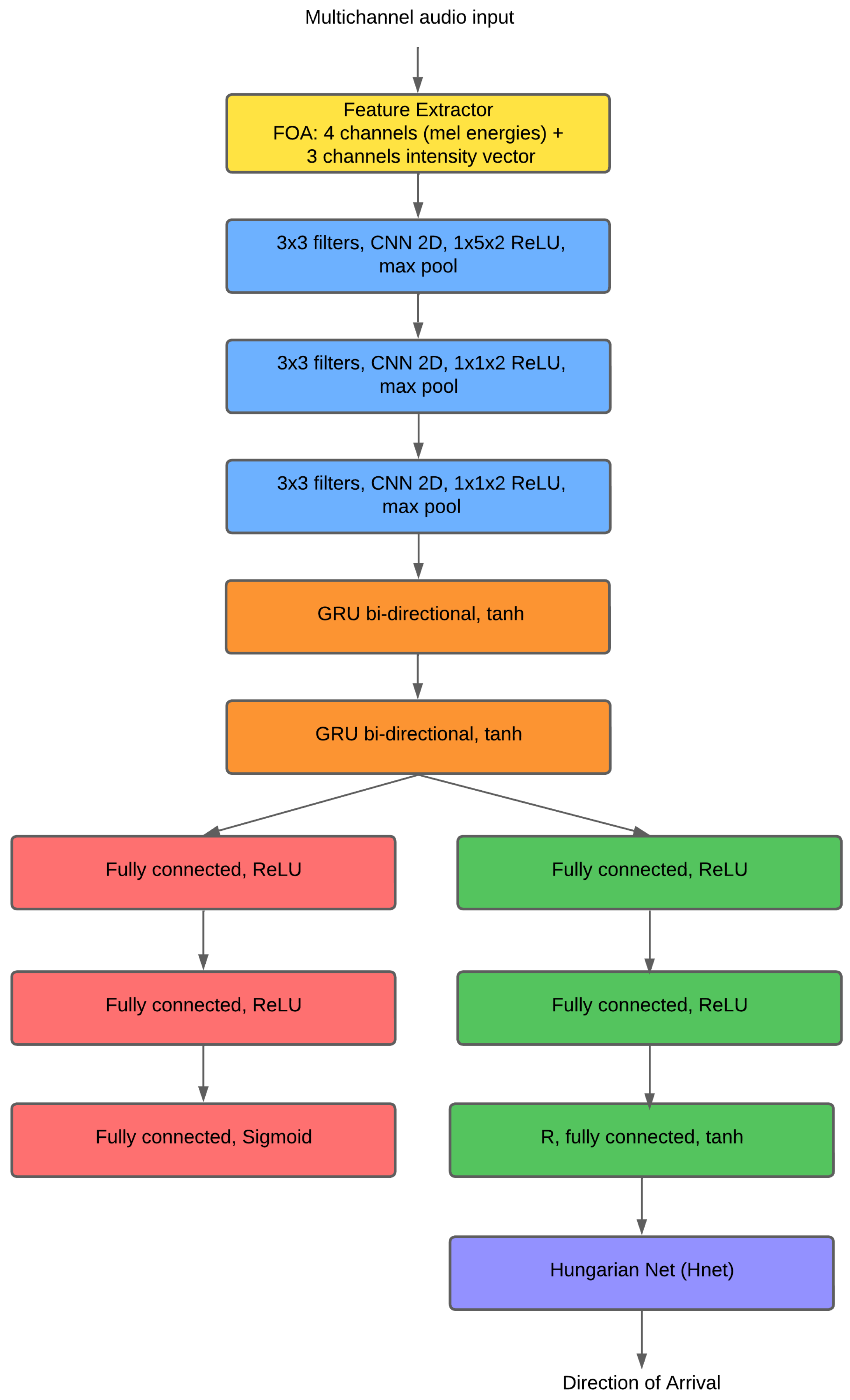
3.2. Model Architecture and Classification Adaptation
3.3. Modified Architectures
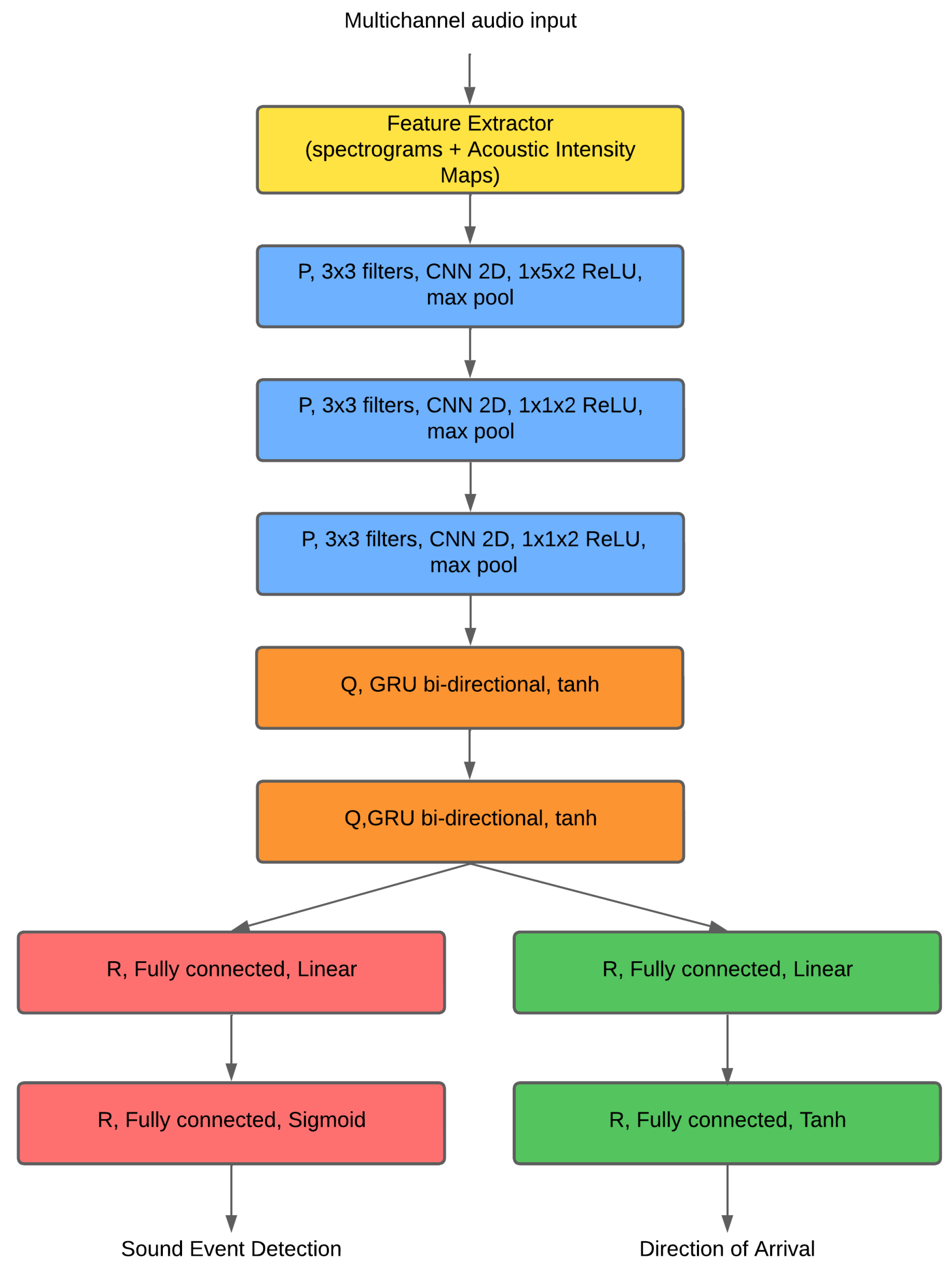
3.3.1. SELDnet
- CNN blocks (×3): These use filters of [64, 128, 128] with 3 × 3 kernels, followed by Batch Normalization and max-pooling layers. These blocks are crucial for extracting robust spatial features from the input spectrograms.
- RNN: Consists of 2 BGRU layers, each with 128 units per direction. The recurrent layers process the features extracted by the CNNs over time, enabling the model to learn temporal dependencies.
- Attention: A temporal weighting mechanism applied to the RNN outputs, allowing the network to focus on the most relevant time frames for localization.
- Outputs:
- -
- SED head: Uses sigmoid activation. However, for the specific objectives of this study, this head was deactivated, meaning we did not train or use M-SELDnet for sound event detection, focusing solely on its localization capabilities.
- -
- DOA head: Uses softmax activation across 36 distinct angular classes, optimized with categorical cross-entropy loss. This is the primary output for our classification-based DOA estimation.
- Regularization: Includes 0.3 dropout after the RNN layers and Batch Normalization after each CNN block to prevent overfitting.
3.3.2. DOAnet
- Dilated CNN (×9): Employs 3 × 1 kernels with dilation rates following a Fibonacci sequence. This use of dilated convolutions is particularly beneficial as it allows the network to expand its receptive field without losing resolution or requiring additional pooling layers. This design enables the model to capture multi-scale temporal patterns efficiently, which is crucial for tracking dynamic and multiple sound sources. Batch Normalization is applied after each convolutional block.
- RNN: Features 1 BGRU with 2 layers (128 units each) using tanh activation internally. This recurrent component excels at modeling the long-term temporal dependencies required for robust tracking.
- Output: For this study, M-DOAnet’s output is configured for multi-label classification of DOA, allowing it to predict multiple active sources simultaneously.
- -
- Multi-label: Uses sigmoid activation combined with binary cross-entropy loss. This setup is ideal for scenarios where multiple sound events can occur at different angles within the same time frame.
- -
- Single-label: tanh, given by the next equation.
- Tracking losses: Incorporates Differentiable CLEAR-MOT–inspired dMOTp and dMOTa as auxiliary training losses. These metrics are specifically designed to improve the model’s ability to consistently track sources over time, minimizing ID switches and localization errors for moving or overlapping events.
3.4. Training Configuration
- M-SELDnet:
- -
- LR = Initialized at 0.001. The LR is halved if no validation improvement is observed for five consecutive epochs. This strategy helps the model fine-tune its weights more precisely as it approaches convergence.
- -
- Early stopping: Training halts after 10 stagnant epochs (epochs without validation improvement). This is a vital regularization technique that prevents overfitting by stopping training when the model’s performance on unseen data no longer improves, thereby saving computational resources and improving generalization.
- M-DOAnet:
- -
- LR = Initialized at 0.01. The LR is reduced by 0.1 after three plateaus (epochs where validation performance stagnates). This aggressive reduction helps DOAnet navigate complex loss landscapes.
- -
- Early stopping: Training ceases after three reductions in the learning rate.
3.5. Evaluation Metrics
- F1-Score: This is a crucial metric for SED, specifically measuring the balance between precision and recall in identifying sound events. It is particularly useful in scenarios with imbalanced classes, providing a single score that represents the harmonic mean of precision and recall.where TP is True positives that are correctly detected events, FP is False positives (incorrect detections), and FN is False negatives (missed events).
- Error Rate (ER): This is a key metric for SED, quantifying the proportion of errors made by the system relative to the total number of ground truth events. It provides a comprehensive measure of event detection accuracy by considering substitutions, deletions, and insertions.where S is a correct event detected as an incorrect one, D is Missed events, I is a False Alarm, and N is Ground truth.
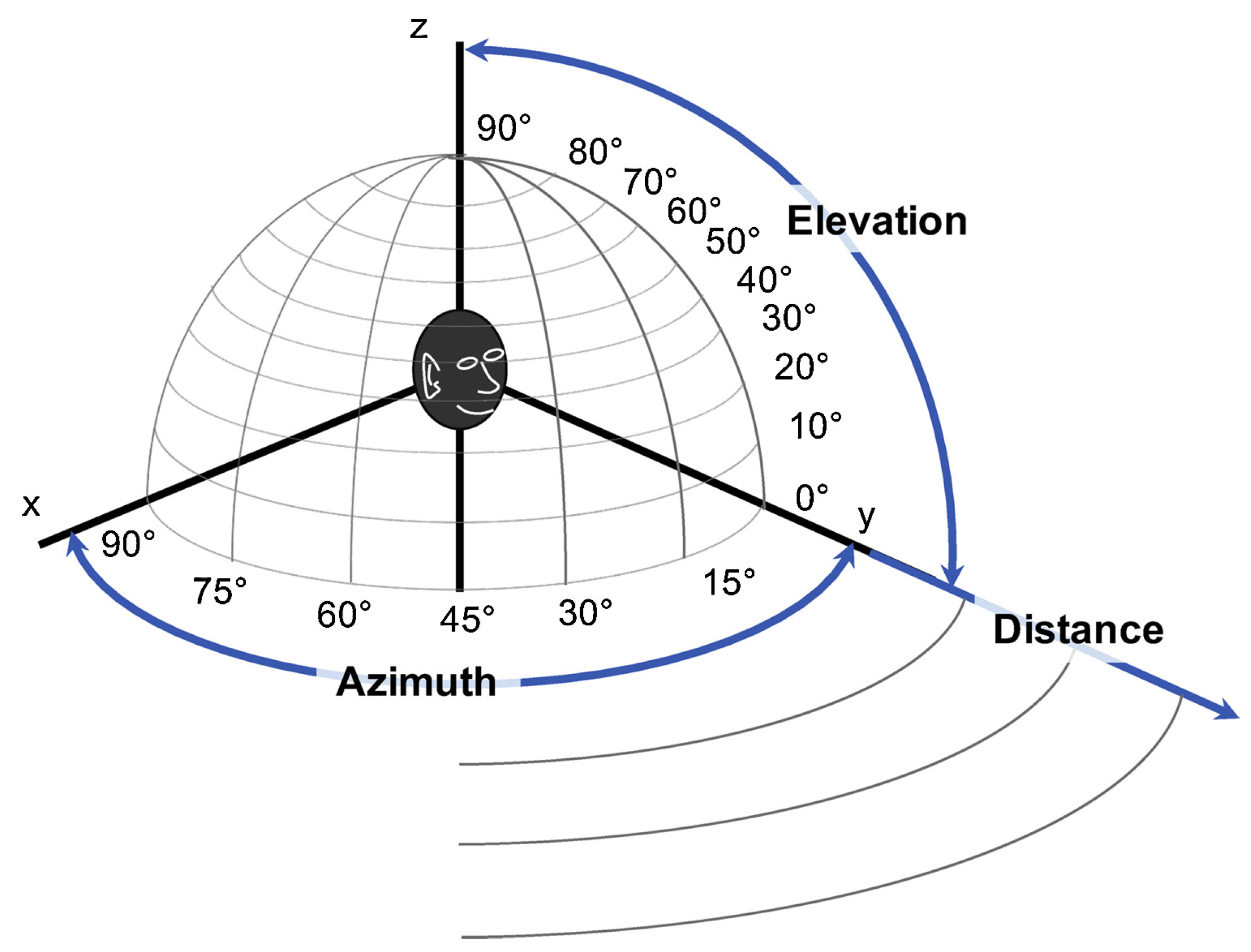
- Localization Recall (LR): Evaluates the proportion of sound sources that were correctly localized within a specified angular threshold (for this study used as ). It indicates the model’s ability to successfully identify the presence and approximate direction of active sound sources.
- Localization Error (LE): This measures the mean angular error between the detected and true sound sources, but only for those cases that were deemed correct according to the Localization Recall. It provides an insight into the precision of the localization when a source is identified successfully.where the angle is between the true vector () and the estimated one ().
- SELD score: This is a unified metric particularly utilized in DCASE challenges to offer a comprehensive assessment of a model’s effectiveness in both detection and localization. It combines the Error Rate, F1-score, Localization Error, and Localization Recall into a single value, providing a holistic view of the system’s performance. A reduced SELD score signifies improved overall model effectiveness.
- dMOTp and dMOTa: These are essential for M-DOAnet as presented by Xu et al. [50]. These are tracking metrics, which differ from the static DOA metrics by evaluating the consistency and continuity of source tracks over time, not just instantaneous accuracy. They are vital for assessing how well M-DOAnet manages multi-source scenarios, including handling ID switches and maintaining accurate localization for dynamic or overlapping sound events.
4. Results and Discussion
4.1. Dataset Description
4.1.1. Content Characteristics and Target Classes
4.1.2. Data Collection Method and Recording Setup
4.2. Signal Modeling and Feature Extraction
- M-SELDnet: spectrograms and acoustic intensity maps.
- M-DOAnet: spectrograms and intensity vectors.
4.3. Metric Analysis for M-DOAnet
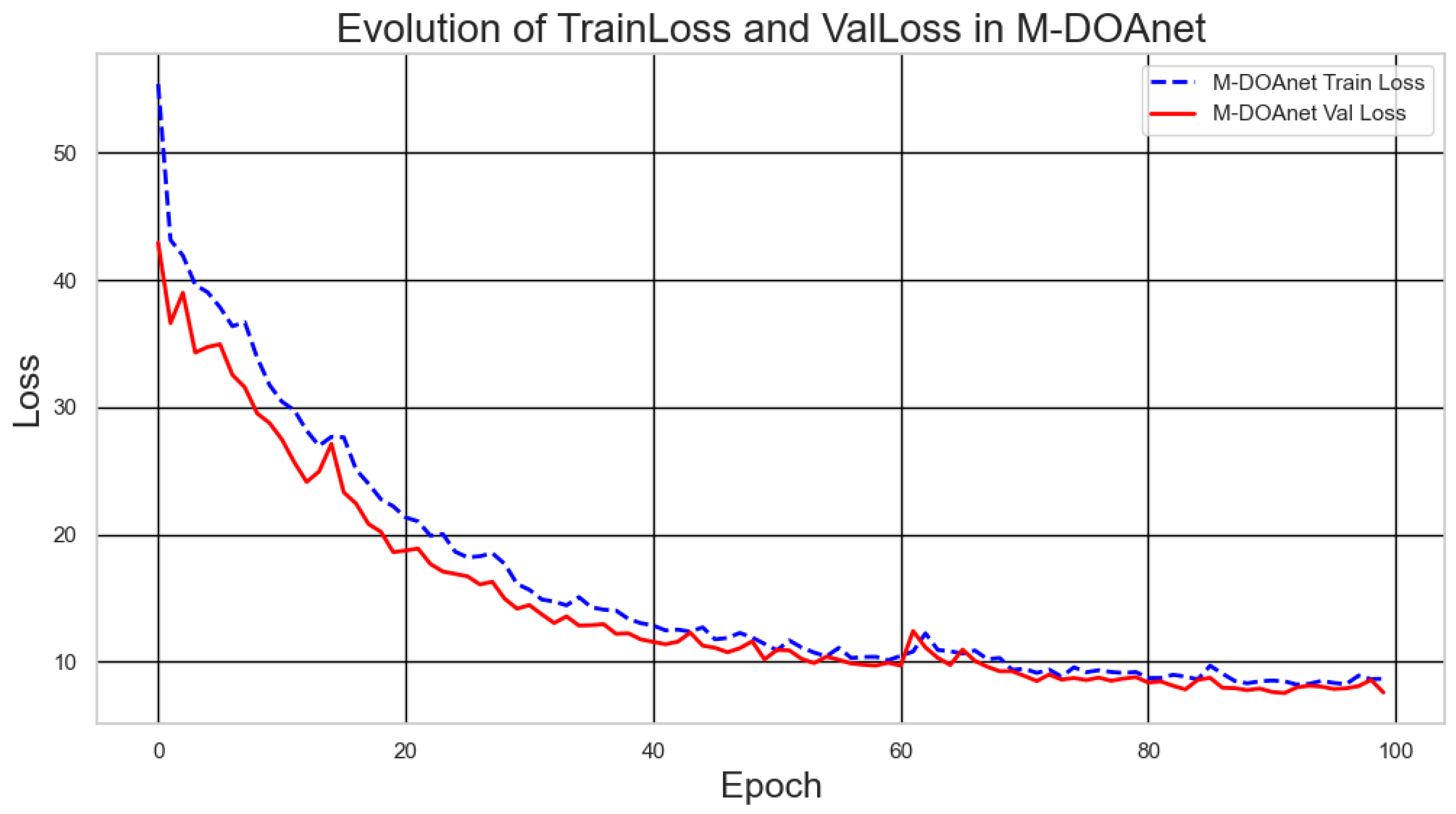
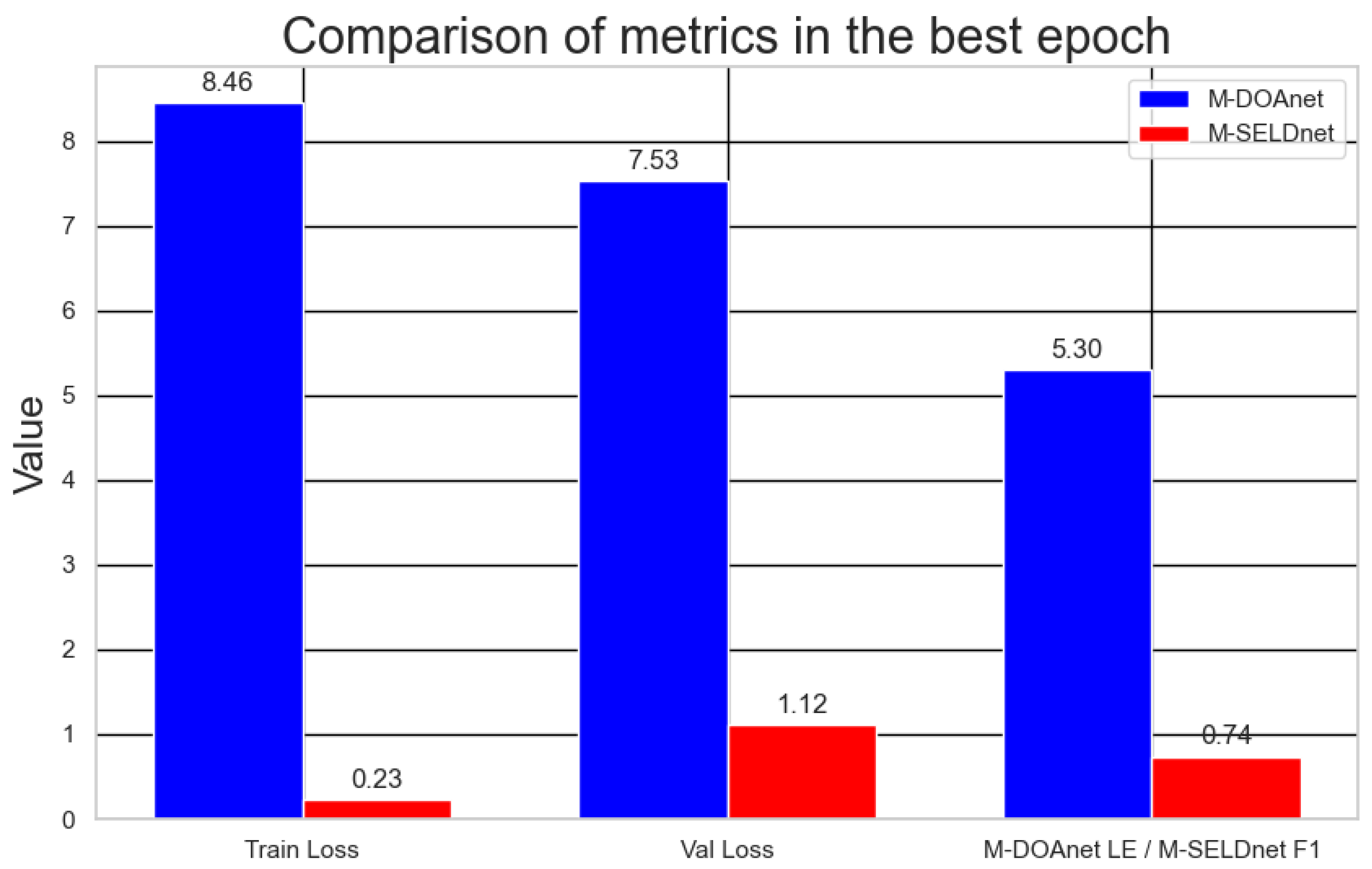
- Training Loss: The training loss decreased significantly from an initial value of 55.4 at epoch 0 to 8.66 at epoch 99, representing an 84% reduction. This indicates a substantial improvement in the model’s fit to the training data.
- Validation Loss: The validation loss also showed a marked reduction, from 42.92 at epoch 0 to 7.58 at epoch 99, reflecting an 82% improvement. The similar trend between training and validation loss suggests that the model generalizes well to unseen data. From epoch 60 onward, both training and validation losses stabilized within a range of 6 to 9, indicating model convergence. However, the lack of further reduction beyond this point may suggest limitations in capturing finer-grained patterns.
- Localization Error (LE): This key accuracy metric began at a high value of 32.43 degrees in epoch 0, reflecting the model’s initial lack of spatial awareness. However, LE steadily and significantly decreased throughout training, reaching minimum values of approximately 5.30–5.37 degrees in the final epochs, thereby demonstrating M-DOAnet’s effective improvement in spatial estimation.
- Multiple Object Tracking Accuracy (MOTA): This metric remained consistently at 100% throughout all training epochs. A MOTA of 100% suggests the model exhibits exceptional ability to maintain the identity of sound sources over time, without ID assignment errors or trajectory fragmentation. However, this result may be influenced by specific characteristics of the dataset, such as a potentially clear separation between sources.
- Number of Identity Switches (IDS): The IDS value remained at 0.0 throughout the entire training process, reinforcing the model’s consistency in assigning unique identifiers without erroneous identity switching.
- Localization F1-score (LF): The LF score remained stable at 72.79 across all epochs. This metric evaluates precision and recall in the spatial detection and classification of sound events. The constancy of this value, despite improvements in LE, suggests that the model’s ability to correctly identify the spatial occurrence of sounds remained largely unchanged.
Computational Efficiency During Training
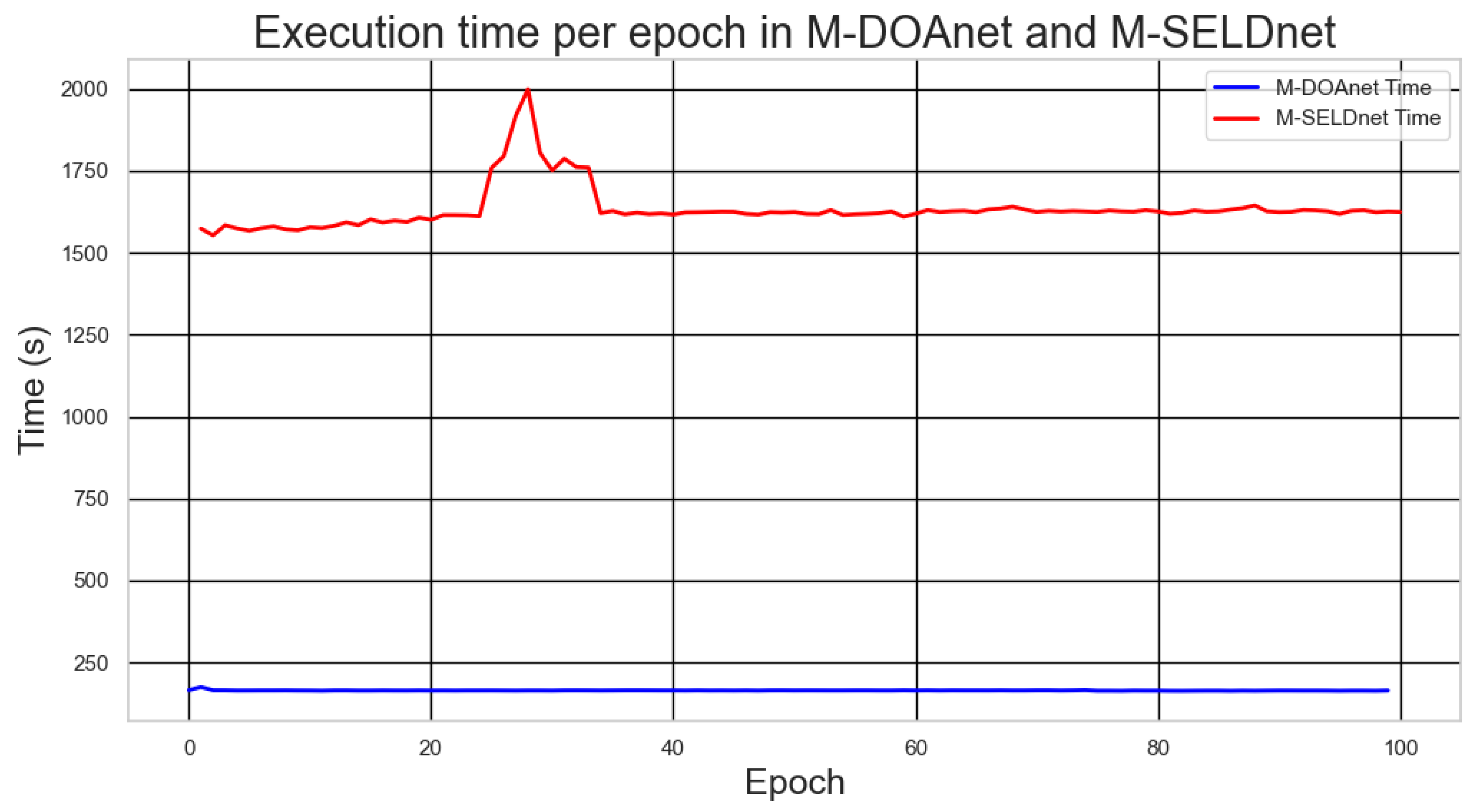
- Epoch Duration: The average time to complete one epoch was 164 s (approximately 2.7 min).
- Total Cost (100 Epochs): The estimated total training time for 100 epochs was approximately 4.5 h.
4.4. Metric Analysis for M-SELDnet
- DOA Error: This metric, which quantifies angular discrepancy, started at relatively high values. Over the course of training, the DOA error decreased steadily, reaching values between 0.32 and 0.34 radians in the final epochs. This consistent reduction indicates improved spatial localization accuracy by M-SELDnet.
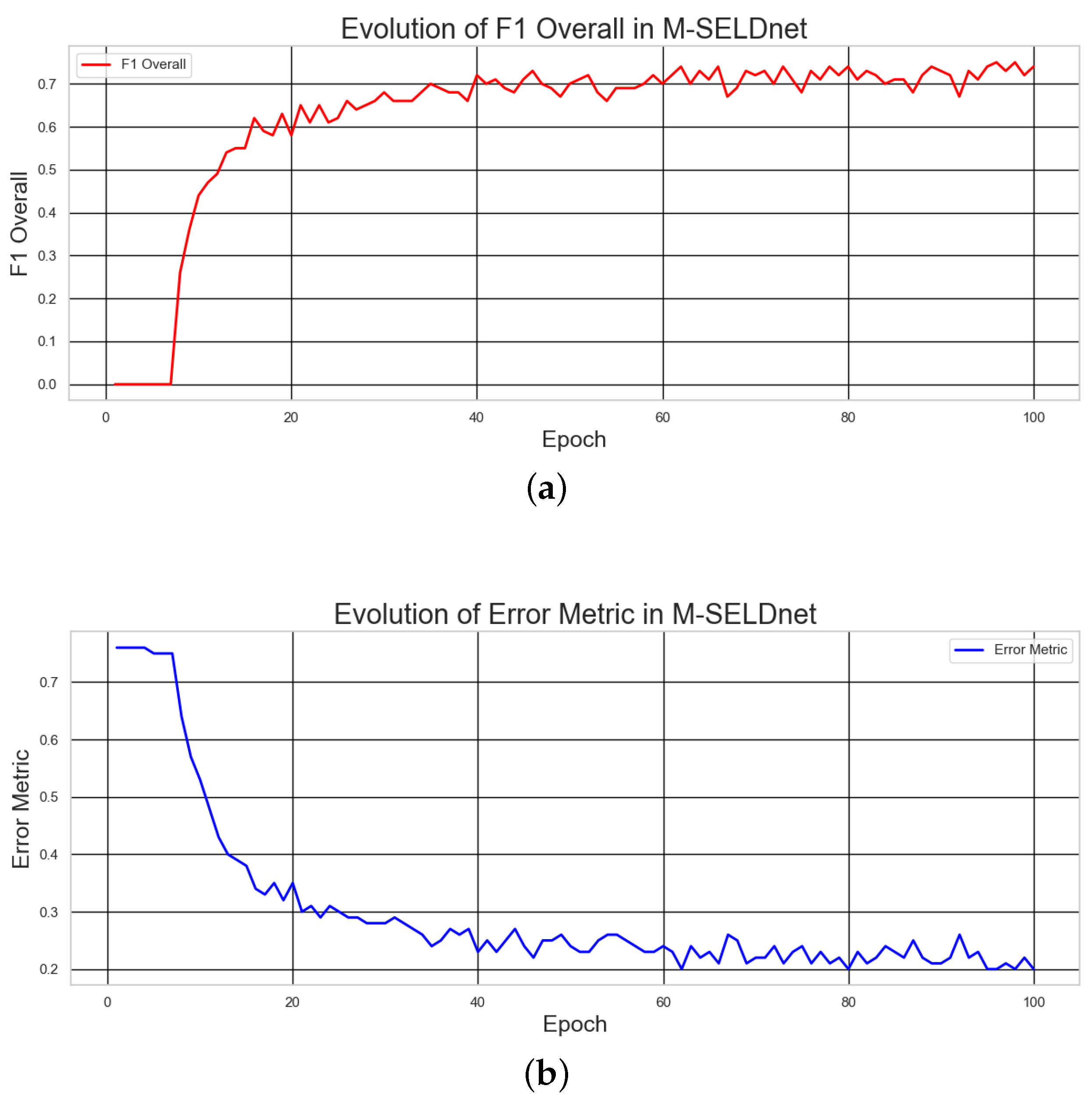
- F1-score Overall: As a key metric for event detection and classification, the F1-score overall began at 0.44. It showed a continuous increase, reaching 0.70 by epoch 50 and peaking at 0.75 in the later stages. This significant rise reflects M-SELDnet’s optimization in accurately detecting and classifying acoustic events.
- Overall Error Rate (Overall ER): This metric, which captures detection errors, initially stood at 0.75. With continued training, it progressively decreased, reaching 0.38 in the final epochs.
- SELD Error Metric: This composite metric integrates both localization and detection errors (based on F1 and ER). It declined from an initial value of 0.53 in early epochs to 0.20 in the final ones, demonstrating overall model improvement in balancing both tasks.
Computational Efficiency During Training
- Epoch Duration: The average training epoch duration was 1620 s (approximately 27 min).
- Total Cost (100 Epochs): The estimated total training time for 100 epochs was approximately 45 h.
4.5. Analysis of Results
4.5.1. Comparative Computational Efficiency M-DOAnet and M-SELDnet
4.5.2. Practical Implications in Real-World Scenarios
4.6. Limitations and Future Research Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADAM | Adaptive Moment Estimation |
| ATF | Acoustic Transfer Function |
| BGRU | Bidirectional Gated Recurrent Unit |
| CPS | Cross-Power Spectrum |
| CRNN | Convolutional Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| DCASE | Detection and Classification of Acoustic Scenes and Events |
| DNN | Deep Neural Network |
| DOA | Direction of Arrival |
| dMOTa | Differentiable Multiple Object Tracking Accuracy |
| dMOTp | Differentiable Multiple Object Tracking Precision |
| ER | Error Rate |
| ESPRIT | Estimation of Signal Parameters via Rotational Invariance Technique |
| EVD | Eigenvalue Decomposition |
| FOA | First-Order Ambisonics |
| GCC-PHAT | Generalized Cross-Correlation with Phase Transform |
| HOA | Higher-Order Ambisonics |
| ICU | Intensive Care Unit |
| IDS | Identity Switches |
| ILD | Interaural Level Difference |
| IoT | Internet of Things |
| ITD | Interaural Time Difference |
| LE | Localization Error |
| LF | Localization F1-score |
| LR | Localization Recall |
| MHSA | Multi-Head Self-Attention |
| MOTA | Multiple Object Tracking Accuracy |
| MUSIC | Multiple Signal Classification |
| NoS | Number of Sources |
| SELD | Sound Event Localization and Detection |
| SELDDE | Sound Event Localization and Detection with Distance Estimation |
| SH | Spherical Harmonics |
| SNR | Signal-to-Noise Ratio |
| SPS | Spatial Pseudo-Spectrum |
| SRP | Steered Response Power |
| SSL | Sound Source Localization |
| STFT | Short-Time Fourier Transform |
References
- Sun, H.; Yang, P.; Zu, L.; Xu, Q. A Far Field Sound Source Localization System for Rescue Robot. In Proceedings of the 2011 International Conference on Control, Automation and Systems Engineering (CASE), Singapore, 30–31 July 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, H.; Chu, P. Voice source localization for automatic camera pointing system in videoconferencing. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 1, pp. 187–190. [Google Scholar] [CrossRef]
- Swietojanski, P.; Ghoshal, A.; Renals, S. Convolutional Neural Networks for Distant Speech Recognition. IEEE Signal Process. Lett. 2014, 21, 1120–1124. [Google Scholar] [CrossRef]
- Mu, D.; Zhang, Z.; Yue, H.; Wang, Z.; Tang, J.; Yin, J. Seld-mamba: Selective state-space model for sound event localization and detection with source distance estimation. arXiv 2024, arXiv:2408.05057. [Google Scholar]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Audio Surveillance of Roads: A System for Detecting Anomalous Sounds. IEEE Trans. Intell. Transp. Syst. 2016, 17, 279–288. [Google Scholar] [CrossRef]
- Yasuda, M.; Saito, S.; Nakayama, A.; Harada, N. 6DoF SELD: Sound Event Localization and Detection Using Microphones and Motion Tracking Sensors on Self-Motioning Human. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1411–1415. [Google Scholar] [CrossRef]
- Firoozabadi, A.D.; Irarrazaval, P.; Adasme, P.; Zabala-Blanco, D.; Palacios-Játiva, P.; Durney, H. Three-dimensional sound source localization by distributed microphone arrays. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 196–200. [Google Scholar] [CrossRef]
- Dehghan Firoozabadi, A.; Abutalebi, H.R. A Novel Nested Circular Microphone Array and Subband Processing-Based System for Counting and DOA Estimation of Multiple Simultaneous Speakers. Circuits Syst. Signal Process. 2016, 35, 573–601. [Google Scholar] [CrossRef]
- Aparicio, D.D.G.; Politis, A.; Sudarsanam, P.A.; Shimada, K.; Krause, D.; Uchida, K.; Koyama, Y.; Takahashi, N.; Takahashi, S.; Shibuya, T.; et al. Baseline models and evaluation of sound event localization and detection with distance estimation in DCASE 2024 Challenge. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, DCASE, Tokyo, Japan, 23–25 October 2024; pp. 41–45. [Google Scholar]
- Zhang, X.; Chen, Y.; Yao, R.; Zi, Y.; Xiong, S. Location-Oriented Sound Event Localization and Detection with Spatial Mapping and Regression Localization. arXiv 2025, arXiv:2504.08365. [Google Scholar]
- Krause, D.A.; Politis, A.; Mesaros, A. Sound Event Detection and Localization with Distance Estimation. In Proceedings of the 2024 32nd European Signal Processing Conference (EUSIPCO), Lyon, France, 26–30 August 2024; pp. 286–290. [Google Scholar] [CrossRef]
- Raponi, S.; Oligeri, G.; Ali, I.M. Sound of guns: Digital forensics of gun audio samples meets artificial intelligence. Multimed. Tools Appl. 2022, 81, 30387–30412. [Google Scholar] [CrossRef]
- Damarla, T. Detection of gunshots using microphone array mounted on a moving platform. In Proceedings of the 2015 IEEE Sensors Conference, Busan, Republic of Korea, 1–4 November 2015. [Google Scholar]
- Boztas, G. Sound source localization for auditory perception of a humanoid robot using deep neural networks. Neural Comput. Appl. 2023, 35, 6801–6811. [Google Scholar] [CrossRef]
- Chen, G.; Xu, Y. A sound source localization device based on rectangular pyramid structure for mobile robot. J. Sens. 2019, 2019, 4639850. [Google Scholar] [CrossRef]
- Ogiso, S.; Kawagishi, T.; Mizutani, K.; Wakatsuki, N.; Zempo, K. Self-localization method for mobile robot using acoustic beacons. ROBOMECH J. 2015, 2, 12. [Google Scholar] [CrossRef]
- Müller-Trapet, M.; Cheer, J.; Fazi, F.M.; Darbyshire, J.; Young, J.D. Acoustic source localization with microphone arrays for remote noise monitoring in an intensive care unit. Appl. Acoust. 2018, 139, 93–100. [Google Scholar] [CrossRef]
- Ko, J.; Kim, H.; Kim, J. Real-time sound source localization for low-power IoT devices based on multi-stream CNN. Sensors 2022, 22, 4650. [Google Scholar] [CrossRef] [PubMed]
- Fabregat, G.; Belloch, J.A.; Badía, J.M.; Cobos, M. Design and implementation of acoustic source localization on a low-cost IoT edge platform. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 3547–3551. [Google Scholar] [CrossRef]
- Belloch, J.A.; Badía, J.M.; Igual, F.D.; Cobos, M. Practical considerations for acoustic source localization in the IoT era: Platforms, energy efficiency, and performance. IEEE Internet Things J. 2019, 6, 5068–5079. [Google Scholar] [CrossRef]
- Aguirre, D.; Firoozabadi, A.D.; Seguel, F.; Soto, I. Proposed energy based method for light receiver localization in underground mining. In Proceedings of the 2016 IEEE International Conference on Automatica (ICA-ACCA), Curico, Chile, 19–21 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Luu, G.; Ravier, P.; Buttelli, O. The generalized correlation methods for estimation of time delay with application to electromyography. In Proceedings of the 1st International Symposium on Engineering Physics and Mechanics (ISEPM), 25–26 October 2011; pp. 1–6. [Google Scholar]
- Firoozabadi, A.D.; Abutalebi, H.R. SRP-ML: A Robust SRP-based speech source localization method for Noisy environments. In Proceedings of the 18th Iranian Conference on Electrical Engineering (ICEE), Isfahan, Iran, 11–13 May 2010; pp. 11–13. [Google Scholar]
- Schmidt, R. Multiple Emitter Location and Signal Parameter Estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Khan, Z.I.; Awang, R.A.; Sulaiman, A.A.; Jusoh, M.H.; Baba, N.H.; Kamal, M.M.; Khan, N.I. Performance analysis for Estimation of signal Parameters via Rotational Invariance Technique (ESPRIT) in estimating Direction of Arrival for linear array antenna. In Proceedings of the 2008 IEEE International RF and Microwave Conference, Kuala Lumpur, Malaysia, 2–4 December 2008; pp. 530–533. [Google Scholar]
- Adavanne, S.; Politis, A.; Virtanen, T. Direction of arrival estimation for multiple sound sources using convolutional recurrent neural network. arXiv 2017, arXiv:1710.10059. [Google Scholar]
- Singla, R.; Tiwari, S.; Sharma, R. A Sequential System for Sound Event Detection and Localization Using CRNN; Technical Report; DCASE: Tokyo, Japan, 2020. [Google Scholar]
- Sharath, A.; Politis, A.; Nikunen, J.; Virtanen, T. Sound event localization and detection of overlapping sources using convolutional recurrent neural networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 34–48. [Google Scholar]
- Song, J.-M. Localization and Detection for Moving Sound Sources Using Consecutive Ensembles of 2D-CRNN; Technical Report; DCASE: Tokyo, Japan, 2020. [Google Scholar]
- Tian, C. Multiple CRNN for SELD; Technical Report; DCASE: Tokyo, Japan, 2020. [Google Scholar]
- Cao, Y.; Iqbal, T.; Kong, Q.; Zhong, Y.; Wang, W.; Plumbley, M.D. Event-Independent Network for Polyphonic Sound Event Localization and Detection. arXiv 2020, arXiv:2010.00140. [Google Scholar]
- Ronchini, F.; Arteaga, D.; Pérez-López, A. Sound event localization and detection based on CRNN using rectangular filters and channel rotation data augmentation. arXiv 2020, arXiv:2010.06422. [Google Scholar]
- Sampathkumar, A.; Kowerko, D. Sound Event Detection and Localization Using CRNN Models; Technical Report; DCASE: Tokyo, Japan, 2020. [Google Scholar]
- Comminiello, D.; Lella, M.; Scardapane, S.; Uncini, A. Quaternion convolutional neural networks for detection and localization of 3D sound events. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12—17 May 2019; pp. 8533–8537. [Google Scholar] [CrossRef]
- Perotin, L.; Serizel, R.; Vincent, E.; Guérin, A. CRNN-based joint azimuth and elevation localization with the ambisonics intensity vector. In Proceedings of the 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 241–245. [Google Scholar]
- Perotin, L.; Serizel, R.; Vincent, E.; Guérin, A. CRNN-based multiple DOA estimation using acoustic intensity features for ambisonics recordings. IEEE J. Sel. Top. Signal Process. 2019, 13, 22–33. [Google Scholar] [CrossRef]
- Grumiaux, P.A.; Kitic, S.; Girin, L.; Guerin, A. Improved feature extraction for CRNN-based multiple sound source localization. arXiv 2021, arXiv:2105.01897. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Phan, H.; Pham, L.; Koch, P.; Duong, N.Q.; McLoughlin, I.; Mertins, A. Audio Event Detection and Localization with Multitask Regression Network; Technical Report; DCASE: Tokyo, Japan, 2020. [Google Scholar]
- Phan, H.; Pham, L.; Koch, P.; Duong, N.Q.; McLoughlin, I.; Mertins, A. On multitask loss function for audio event detection and localization. In Proceedings of the Detection and Classification of Acoustic Scenes and Events Workshop (DCASE Workshop), Virtual, 2–4 November 2020. Technical Report. [Google Scholar]
- Schymura, C.; Ochiai, T.; Delcroix, M.; Kinoshita, K.; Nakatani, T.; Araki, S.; Kolossa, D. Exploiting attention-based sequence-to-sequence architectures for sound event localization. arXiv 2021, arXiv:2103.00417. [Google Scholar]
- Sun, X.; Hu, Y.; Zhu, X.; He, L. Sound event localization and detection based on adaptive hybrid convolution and multi-scale feature extractor. In Proceedings of the Detection and Classification of Acoustic Scenes and Events Workshop (DCASE Workshop), Online, 15–19 November 2021. Technical Report. [Google Scholar]
- Sudarsanam, P.; Politis, A.; Drossos, K. Assessment of self attention on learned features for sound event localization and detection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events Workshop (DCASE Workshop), Online, 15–19 November 2021. Technical Report. [Google Scholar]
- Schymura, C.; Bönninghoff, B.; Ochiai, T.; Delcroix, M.; Kinoshita, K.; Nakatani, T.; Araki, S.; Kolossa, D. PILOT: Introducing transformers for probabilistic sound event localization. arXiv 2021, arXiv:2106.03903. [Google Scholar]
- Hirvonen, T. Classification of spatial audio location and content using convolutional neural networks. Audio Eng. Soc. Conv. 2015, 138, 9294. [Google Scholar]
- Chakrabarty, S.; Habets, E.A.P. Broadband DOA estimation using convolutional neural networks trained with noise signals. In Proceedings of the 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 136–140. [Google Scholar]
- Chakrabarty, S.; Habets, E.A.P. Multi-speaker localization using convolutional neural network trained with noise. arXiv 2017, arXiv:1712.04276. [Google Scholar]
- Chakrabarty, S.; Habets, E.A.P. Multi-speaker DOA estimation using deep convolutional networks trained with noise signals. IEEE J. Sel. Top. Signal Process. 2019, 13, 8–21. [Google Scholar] [CrossRef]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How to train your deep multi-object tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6787–6796. [Google Scholar]
- Politis, A. STARSS23: Sony-TAu Realistic Spatial Soundscapes 2023. Zenodo 2023. Available online: https://zenodo.org/records/7880637 (accessed on 20 May 2025).
- Fonseca, E.; Favory, X.; Pons, J.; Font, F.; Serra, X. Fsd50k: An open dataset of human-labeled sound events. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 30, 829–852. [Google Scholar] [CrossRef]
- Trowitzsch, I.; Taghia, J.; Kashef, Y.; Obermayer, K. The NIGENS general sound events database. arXiv 2019, arXiv:1902.08314. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epoch | LE (Grades) | MOTA (%) | LF (%) |
|---|---|---|---|
| 0 | 32.43 | 100.00 | 72.79 |
| 10 | 20.04 | 100.00 | 72.79 |
| 20 | 13.65 | 100.00 | 72.79 |
| 50 | 7.84 | 100.00 | 72.79 |
| 100 | 6.00 | 100.00 | 72.79 |
| Epoch | F1 | ER | LE | Error Metric |
|---|---|---|---|---|
| 1 | 0.00 | 1.00 | 1.00 | 0.76 |
| 10 | 0.44 | 0.75 | 0.56 | 0.53 |
| 20 | 0.58 | 0.54 | 0.42 | 0.35 |
| 50 | 0.70 | 0.43 | 0.34 | 0.24 |
| 100 | 0.75 | 0.38 | 0.32 | 0.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Estay Zamorano, B.; Dehghan Firoozabadi, A.; Brutti, A.; Adasme, P.; Zabala-Blanco, D.; Palacios Játiva, P.; Azurdia-Meza, C.A. Sound Source Localization Using Hybrid Convolutional Recurrent Neural Networks in Undesirable Conditions. Electronics 2025, 14, 2778. https://doi.org/10.3390/electronics14142778
Estay Zamorano B, Dehghan Firoozabadi A, Brutti A, Adasme P, Zabala-Blanco D, Palacios Játiva P, Azurdia-Meza CA. Sound Source Localization Using Hybrid Convolutional Recurrent Neural Networks in Undesirable Conditions. Electronics. 2025; 14(14):2778. https://doi.org/10.3390/electronics14142778
Chicago/Turabian StyleEstay Zamorano, Bastian, Ali Dehghan Firoozabadi, Alessio Brutti, Pablo Adasme, David Zabala-Blanco, Pablo Palacios Játiva, and Cesar A. Azurdia-Meza. 2025. "Sound Source Localization Using Hybrid Convolutional Recurrent Neural Networks in Undesirable Conditions" Electronics 14, no. 14: 2778. https://doi.org/10.3390/electronics14142778
APA StyleEstay Zamorano, B., Dehghan Firoozabadi, A., Brutti, A., Adasme, P., Zabala-Blanco, D., Palacios Játiva, P., & Azurdia-Meza, C. A. (2025). Sound Source Localization Using Hybrid Convolutional Recurrent Neural Networks in Undesirable Conditions. Electronics, 14(14), 2778. https://doi.org/10.3390/electronics14142778