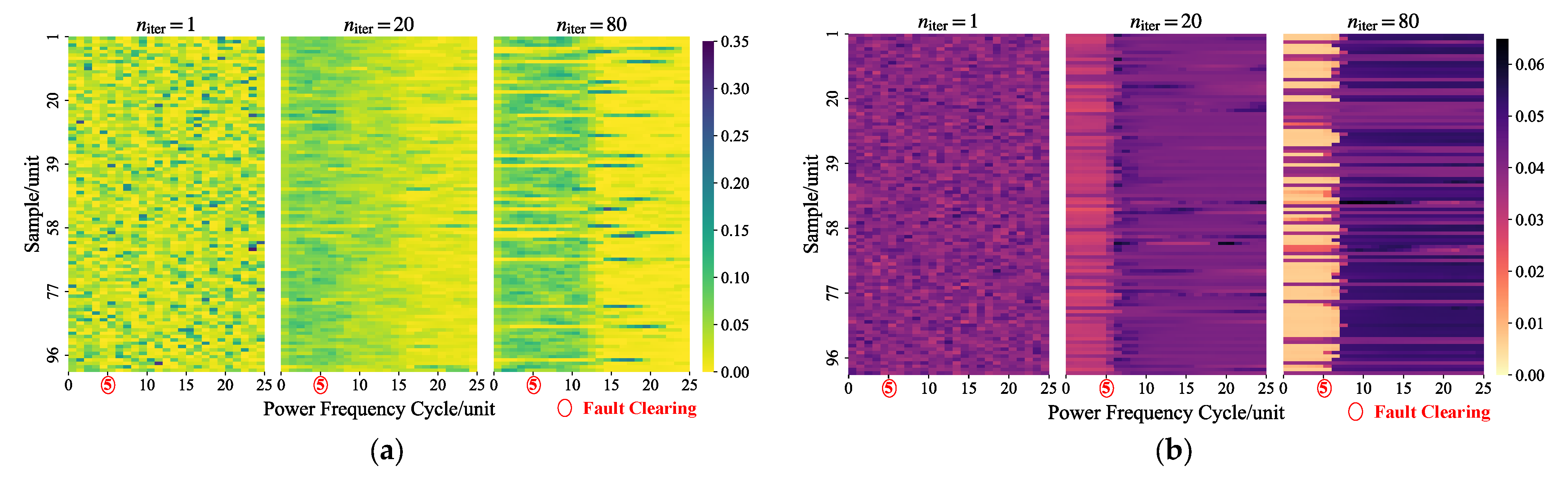
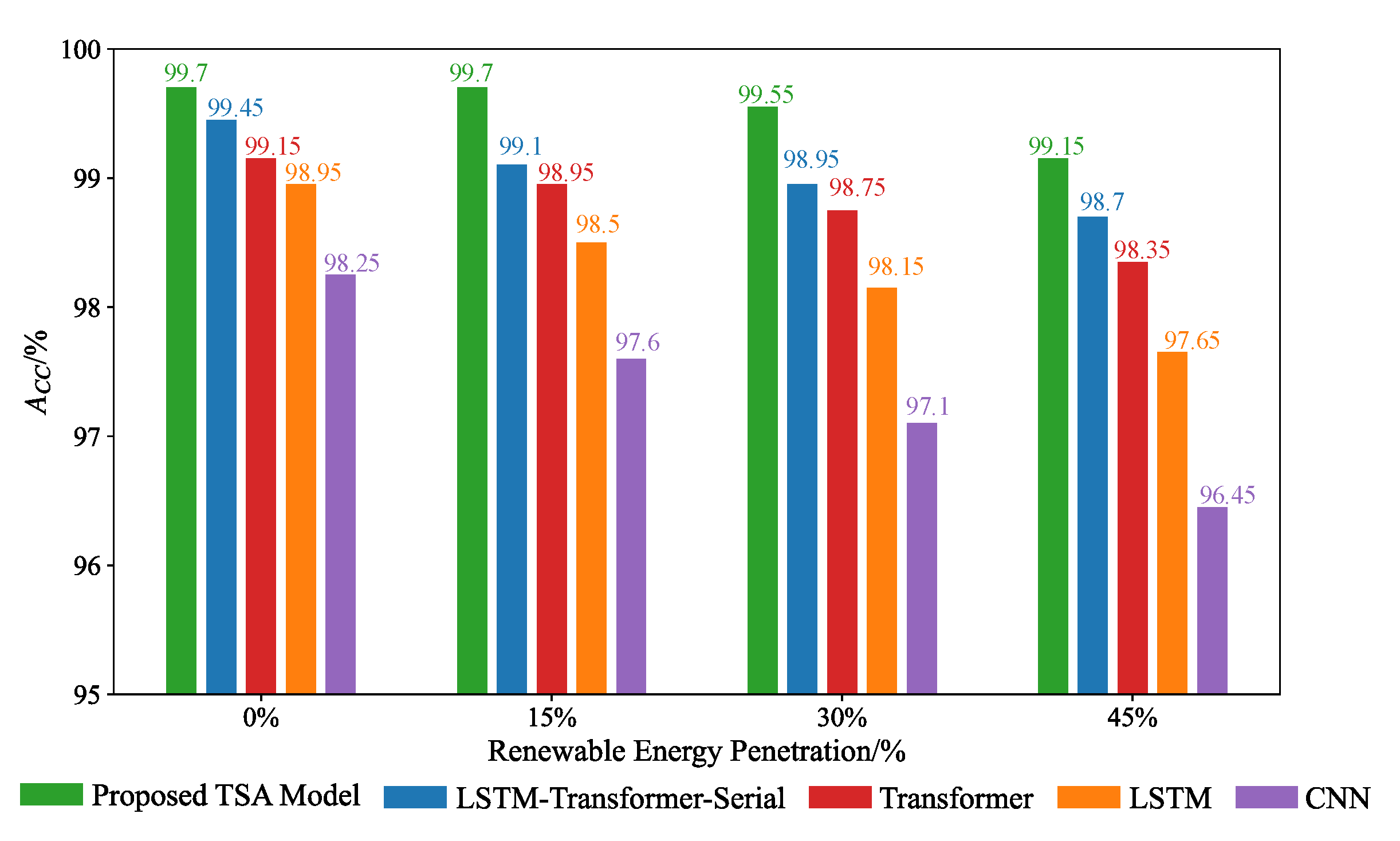
1. Introduction
With a large number of renewable energy sources being connected to the power grid through power electronic devices, the dynamic behavior of power systems has evolved from slow dynamics dominated by synchronous generators to fast responses with multi-timescale coupling. This transition increases system nonlinearity and uncertainty, thereby elevating the risk of transient instability [
1,
2]. In this context, developing efficient and accurate TSA methods is crucial for the secure operation of modern power systems.
Traditional TSA methods include time-domain simulation and the energy function method [
2]. Although the former can accurately capture system dynamics, it suffers from high computational complexity, whereas the latter is highly sensitive to high-order nonlinearities in systems with high renewable energy penetration. As a result, both methods are inadequate, especially for online assessment under multi-disturbance and multi-scenario conditions [
3]. In recent years, data-driven methods have emerged as a promising alternative by directly mapping WAMS data to system stability status. This approach eliminates the reliance on complex physical models and significantly improves assessment efficiency [
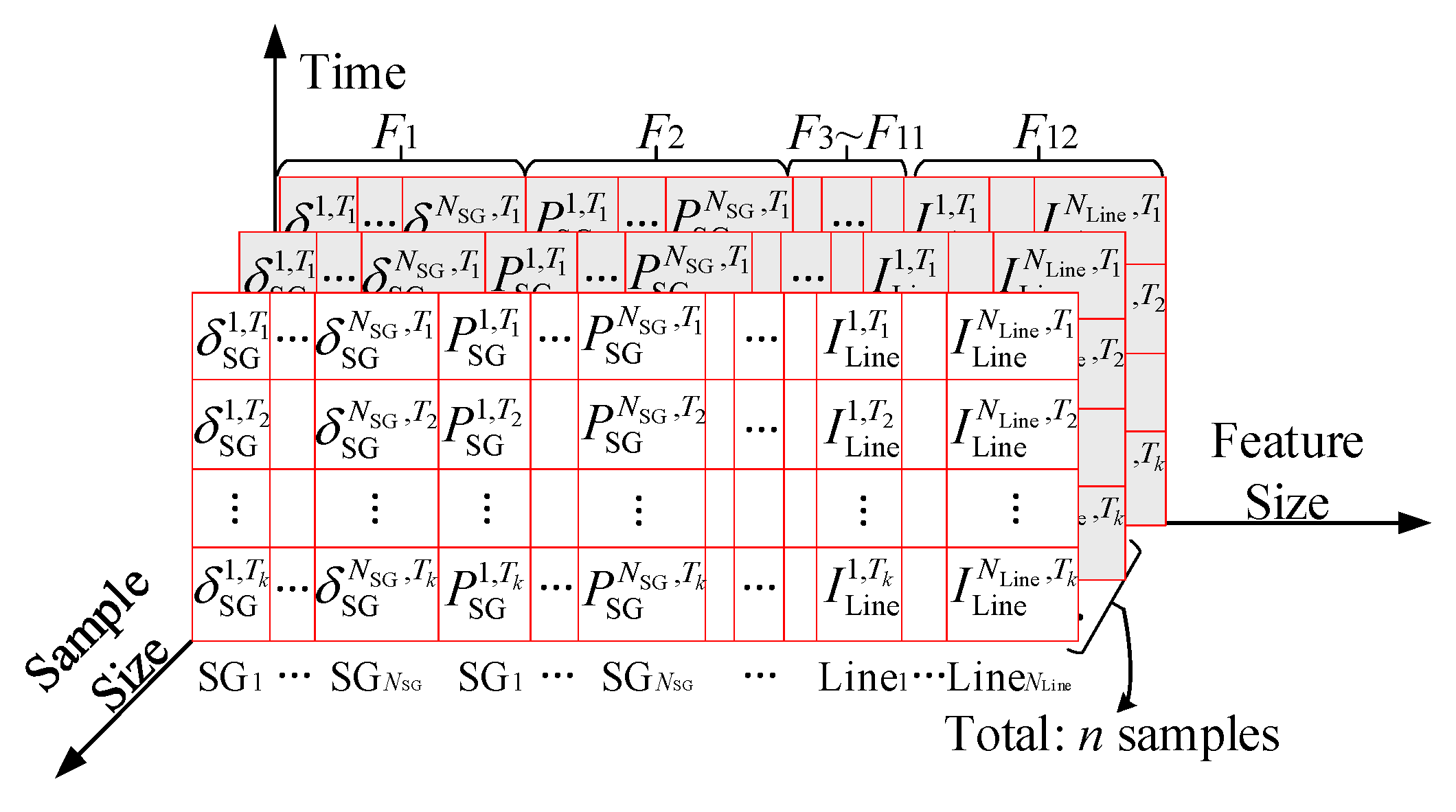
4]. A typical data-driven framework consists of three core components: dataset construction and preprocessing, stability-oriented representation learning, and classifier design and optimization.
In the dataset construction and preprocessing component, key steps include disturbance window extraction, data normalization, and the elimination of redundant or poorly discriminative features. These steps aim to improve data quality and reduce input dimensionality. Here, “features” refers broadly to the input data, while “representations” denotes the model-extracted temporal embeddings used for stability evaluation. Most existing studies construct datasets using bus voltage, frequency, and other measurements from WAMSs. However, due to strong correlations among variables and variations in the responses of the same type of measurements (e.g., voltage) across different buses, directly using all features often introduces redundancy, increases computational overhead, and leads to overfitting. To improve input effectiveness, previous studies have employed Pearson correlation [
5], gradient boosting-based dimensionality reduction [
6], and distance-based methods such as Relief-F [
7] and the Fisher Score [
8]. Some methods rely heavily on model structures and lack adaptability. Others are more general but focus on static features and cannot capture the dynamic dependencies in disturbance responses. High-quality inputs are essential for accurate and robust stability state representation. However, existing methods often overlook the temporal response behavior at the feature group level, leading to a mismatch with actual operating conditions and limiting model robustness and generalization [
9].
The stability-oriented representation learning component aims to reveal multivariate temporal dependencies and discriminative patterns during fault responses, forming dynamic representations that indicate system stability. Conventional machine learning methods, such as support vector machines [
10] and decision trees [
11], rely on expert-designed static features. These approaches struggle to capture the nonlinear dynamic behaviors of multivariate systems under high renewable penetration and often suffer from poor generalization [
4]. In contrast, deep learning enables end-to-end modeling, allowing systems to learn dynamic evolution patterns directly from raw data, thereby avoiding the subjectivity of manual feature engineering. Common deep learning models applied to TSA include deep belief networks (DBN) [
12], convolutional neural networks (CNNs) [
13], and long short-term memory (LSTM) networks [
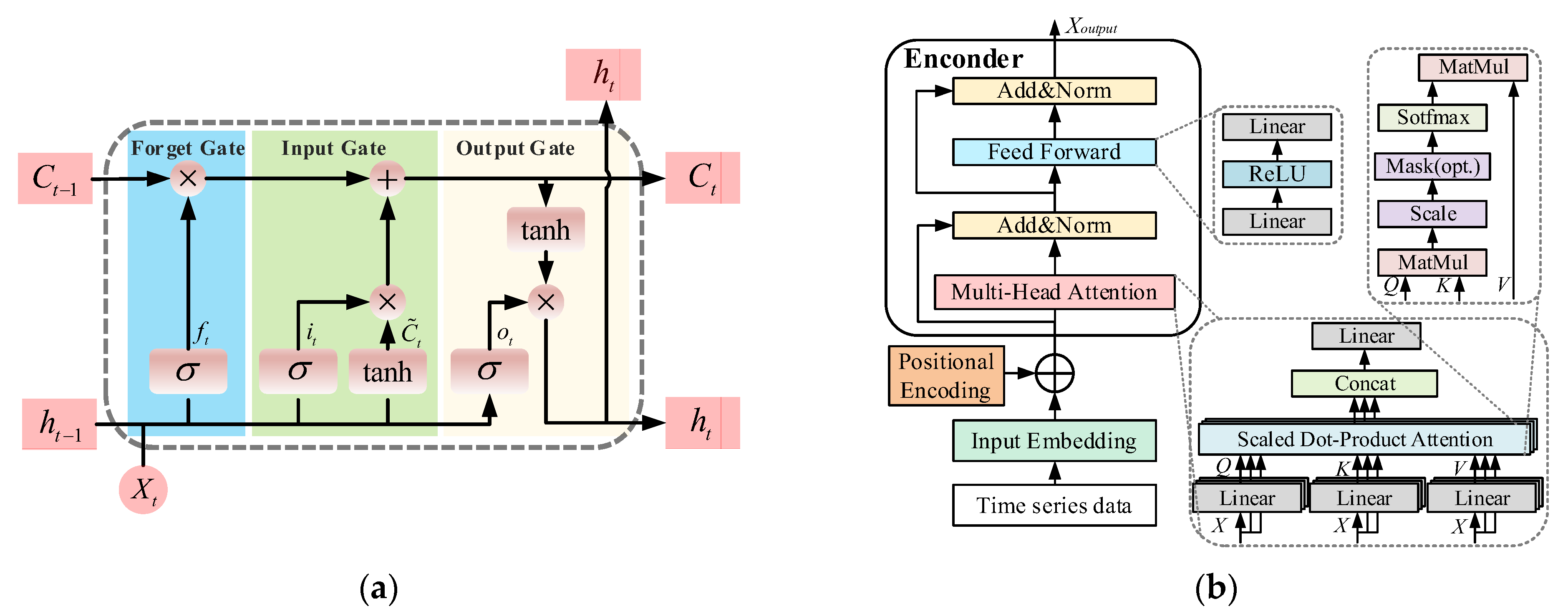
14], among others. LSTM excels at capturing short-term temporal dependencies as it is sensitive to local fluctuations in the early stages of a fault and can effectively extract sudden changes in individual measurements [
15]. In contrast, the Transformer, with its self-attention mechanism, is well-suited for modeling long-term dependencies, enabling it to capture system-wide responses throughout the entire fault process [
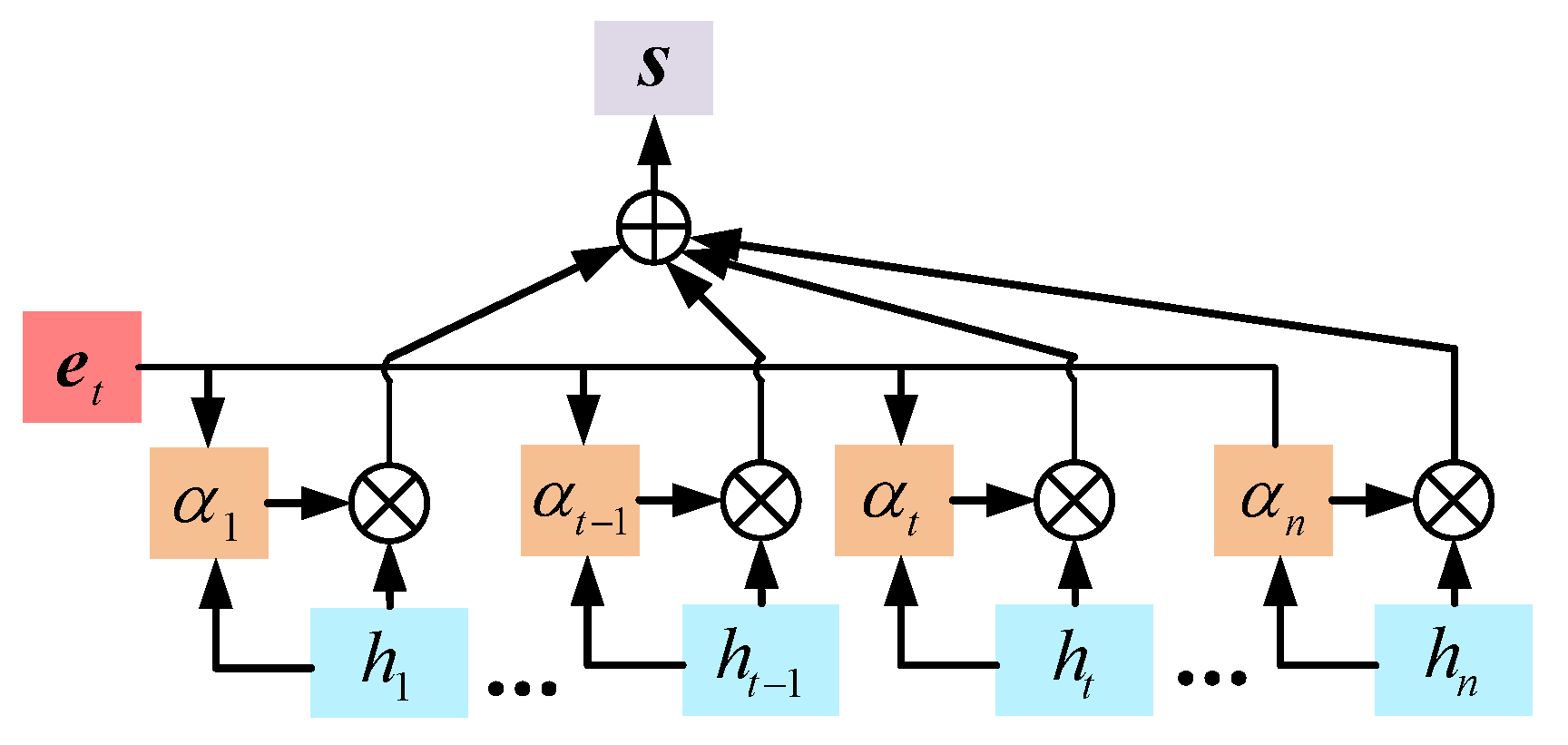
1,
16]. However, in modern power systems, the fast control responses of renewable sources coexist with the slow inertial regulation of conventional generators, resulting in multi-timescale dynamics that couple abrupt and gradual changes [
17].
Meanwhile, diverse control strategies and varying fault responses [
18] further increase the complexity of dynamic representation learning. Single-architecture deep learning models struggle to capture such multi-scale and multi-pattern behaviors, leading to limited perception and inadequate modeling capacity [
19]. To enhance the perception and discrimination of multi-scale representations, various hybrid network structures have been proposed. Representative efforts include CNN-LSTM frameworks for joint spatial–temporal representation extraction [
20], and multi-level assessment models integrating DBN, CNNs, and LSTM to quantify stability margins [
21]. Nonetheless, most methods combine learned representations from different networks through static concatenation or simple weighting, lacking adaptive integration of multi-source representations. This often leads to information loss and error buildup, increasing the risk of misclassification under complex disturbances.
The classifier design and optimization component mainly involves two aspects: the selection of classifier structures and the design of loss functions. The former typically employs perceptions or fully connected networks for stability classification, offering good performance. The latter involves designing loss functions to help the model distinguish between stable and unstable cases more effectively. Cross-entropy loss is widely used but struggles with class imbalance and ambiguous decision boundaries. To address these issues, some studies adopt focal loss to assign greater weight to uncertain or hard-to-distinguish samples [
13,
22]. To enhance the stability identification performance and generalization capability of TSA models, the loss function should be specifically designed based on both power system instability characteristics and the model architecture.
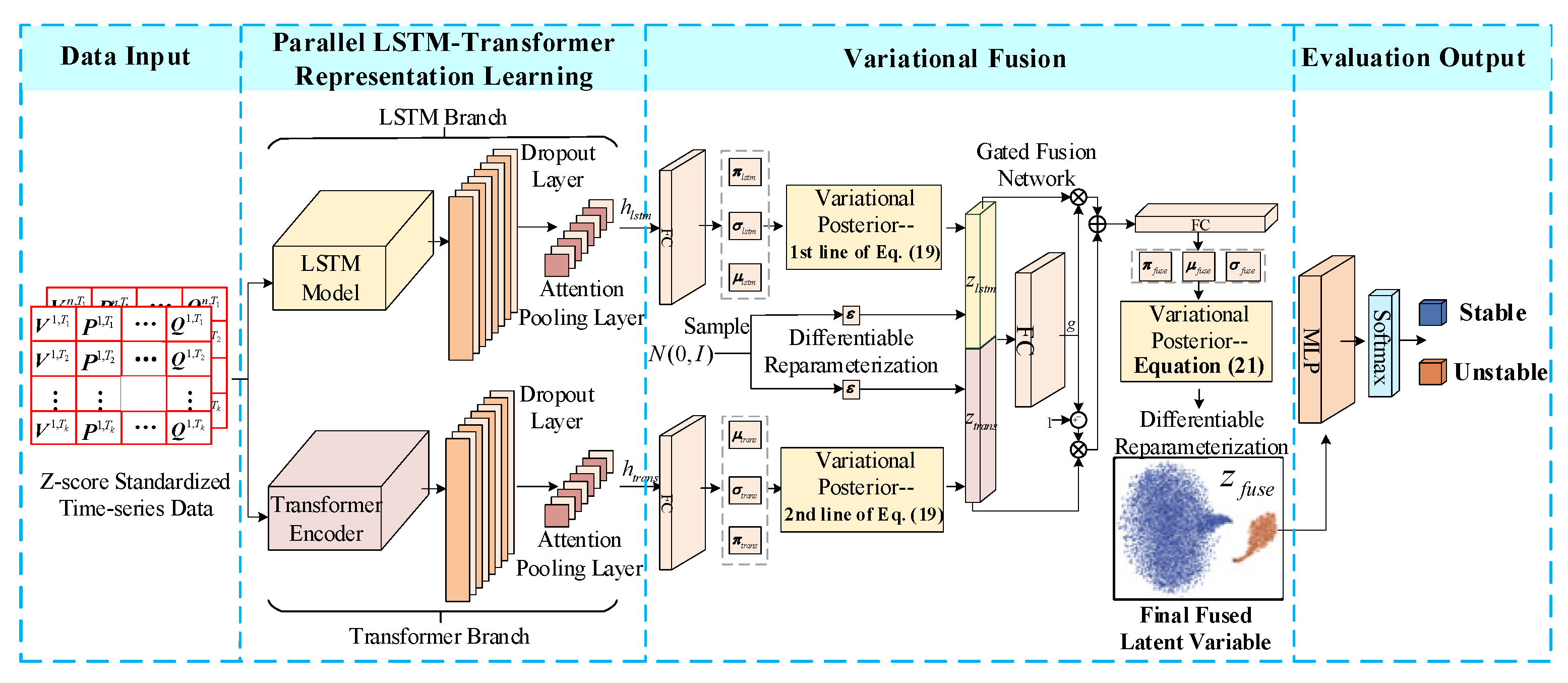
To address the above issues, this paper proposes a TSA method combining temporal feature selection with the variational fusion of representations extracted by LSTM and a Transformer. This design facilitates efficient representation learning across multiple temporal scales, particularly for power systems with high renewable energy penetration. The main contributions of this paper are as follows:
- (1)
A two-stage temporal feature selection method is proposed. It first evaluates the discriminative ability of feature groups via inter-class Mahalanobis distance, then removes redundancy using Spearman correlation coefficients and selects key features through an incremental feature subset strategy.
- (2)
A parallel LSTM-Transformer architecture is developed to extract heterogeneous representations at different timescales. Variational inference based on a GMM is applied separately to each branch for probabilistic modeling. A gated fusion network is further introduced to unify latent representations, forming a variational fusion mechanism capable of cross-scale perception.
- (3)
A composite loss function is designed by combining an improved focal loss with a KL divergence regularization term. It addresses class imbalance while guiding the model to learn latent representations with enhanced discriminability and distributional stability.
From an engineering perspective, the proposed method supports fast and reliable online stability assessment in power systems with high renewable penetration. The temporal feature selection strategy reduces input dimensionality, which, in turn, lowers the reliance on system-wide measurements and simplifies deployment and data requirements. It enables millisecond-level evaluation through a single forward pass, and the model is designed to be robust against noise and missing data, making it suitable for practical protection and control applications.
The rest of the paper is organized as follows:
Section 2 outlines the data-driven TSA principle and the construction of the input feature space. A two-stage temporal feature selection method is proposed in
Section 3.
Section 4 introduces the LSTM-Transformer variational fusion model, along with the design of a composite loss function. The overall implementation process is detailed in
Section 5.
Section 6 validates the effectiveness and superiority of the proposed method through case studies. Finally,
Section 7 concludes the paper and outlines future research directions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}