Re-Usable Workflow for Collecting and Analyzing Open Data of Valenbisi


Abstract
1. Introduction
1.1. Sustainable Mobility
1.2. Mobility and Open Data
- An electromagnetic loop system having 135 measurement points is installed to count the number of bicyclists across the city.
- Hybrid and electric buses are monitored with sensors to detect power consumption and passenger comfort.
- The data collected by noise sensors from multiple streets is published daily.
- The Universitat Politècnica de València (UPV) used Witeklab sensors in a study to evaluate the impact of tourism in the historic center of Valencia [15].
1.3. Workflow for Analyzing BSSs
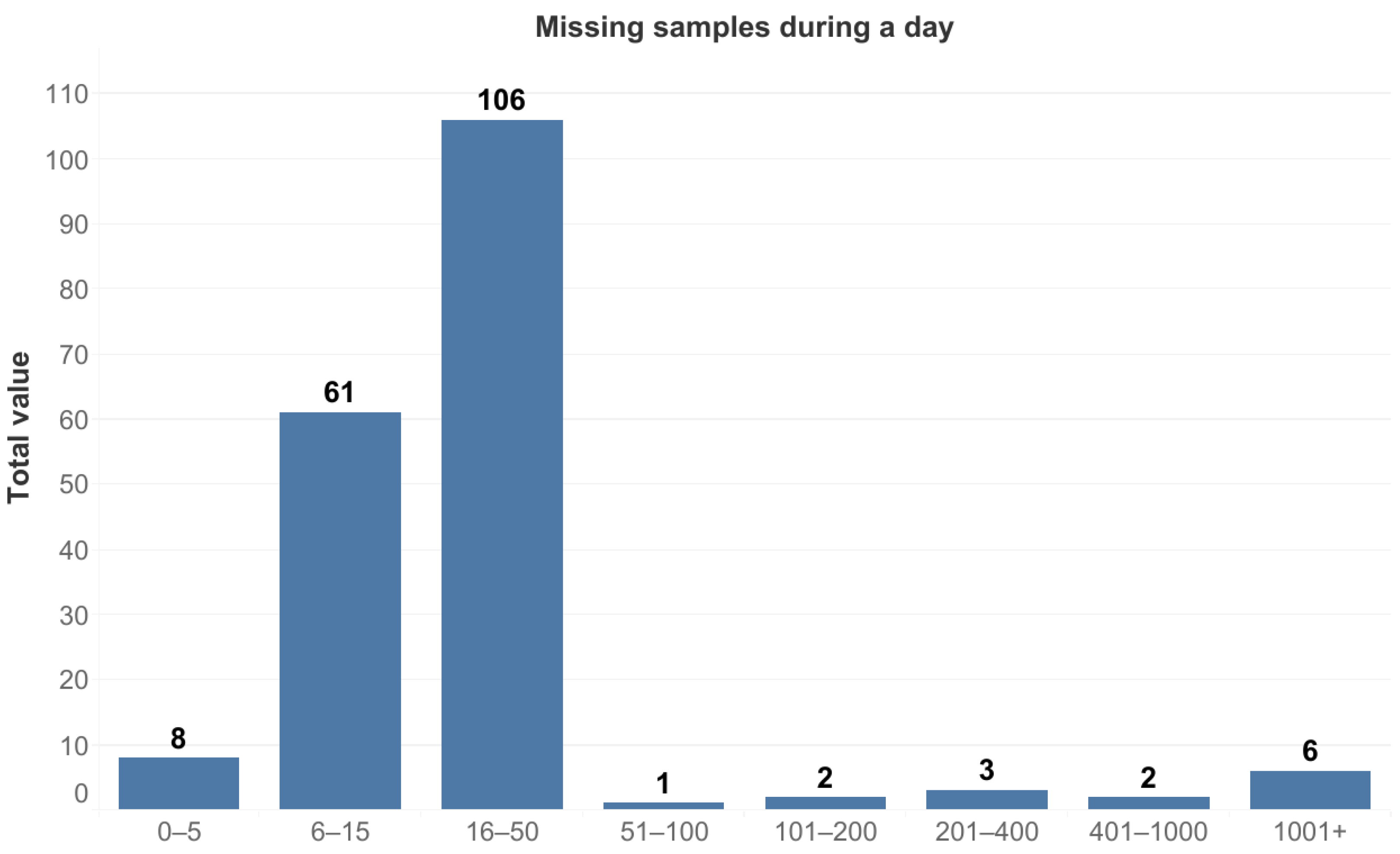
- Collecting data: First, the open data must be collected from the service providers’ API in the available format, using a chosen sampling period.
- Pre-processing data: Second, the static and dynamic features of the data must be identified and yielded to optimize the representation of the data and to choose a suitable compressed format. The data can be partitioned to cover shorter periods, such as weekly or monthly usages. In parallel, noises such as temporary-operated or dummy stations must be removed from the dataset, while the service data can be extended by other features, such as weather and geospatial information, that can affect the usage of the service.
- Analyzing data: Based on the actual research goal, a multidisciplinary analysis can be performed on the pre-processed data. For example, the usage of stations can be predicted using stochastic or statistical models, as well as data-mining methods.
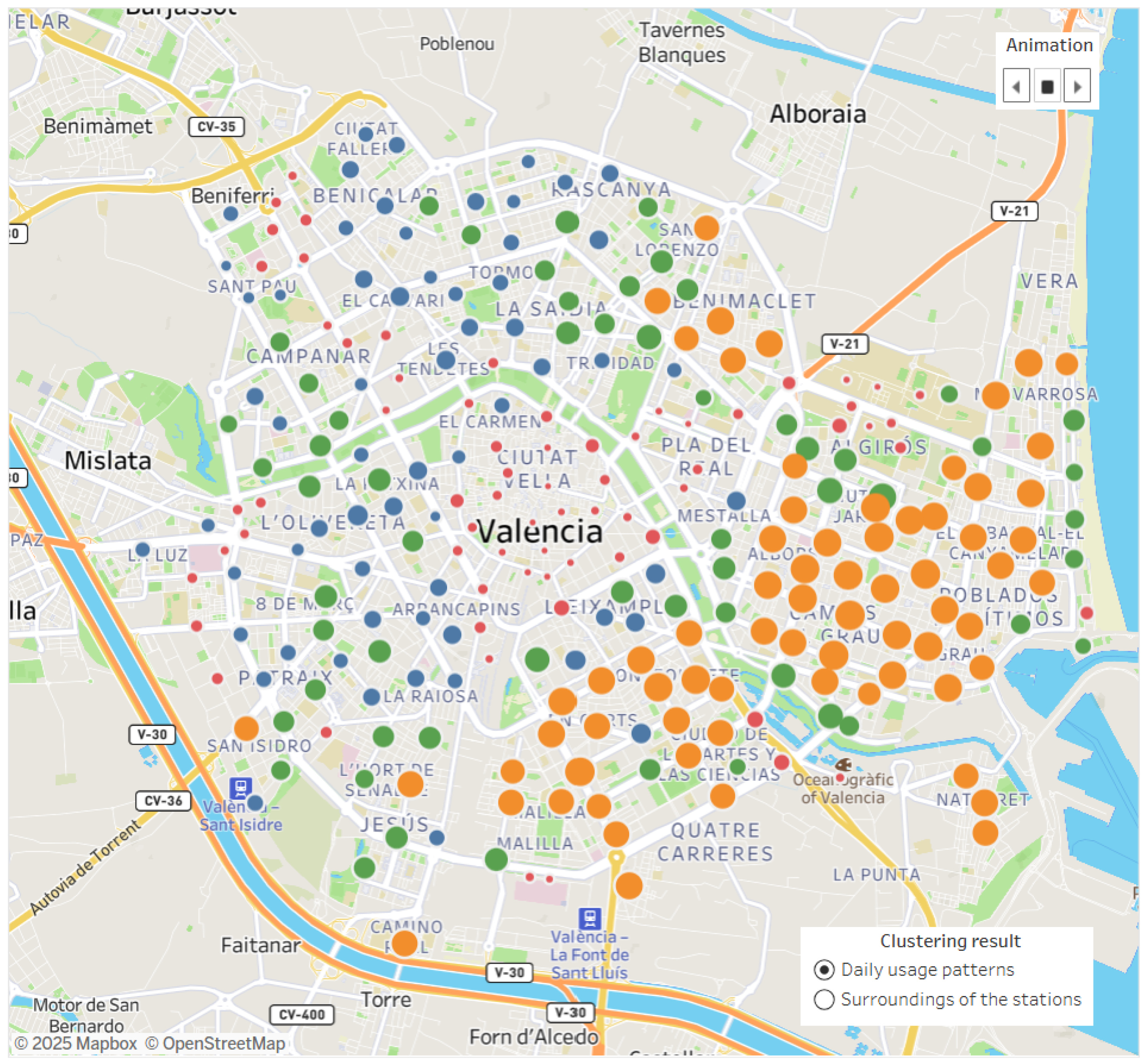
- The stations were clustered based on their hourly usage data to detect patterns.
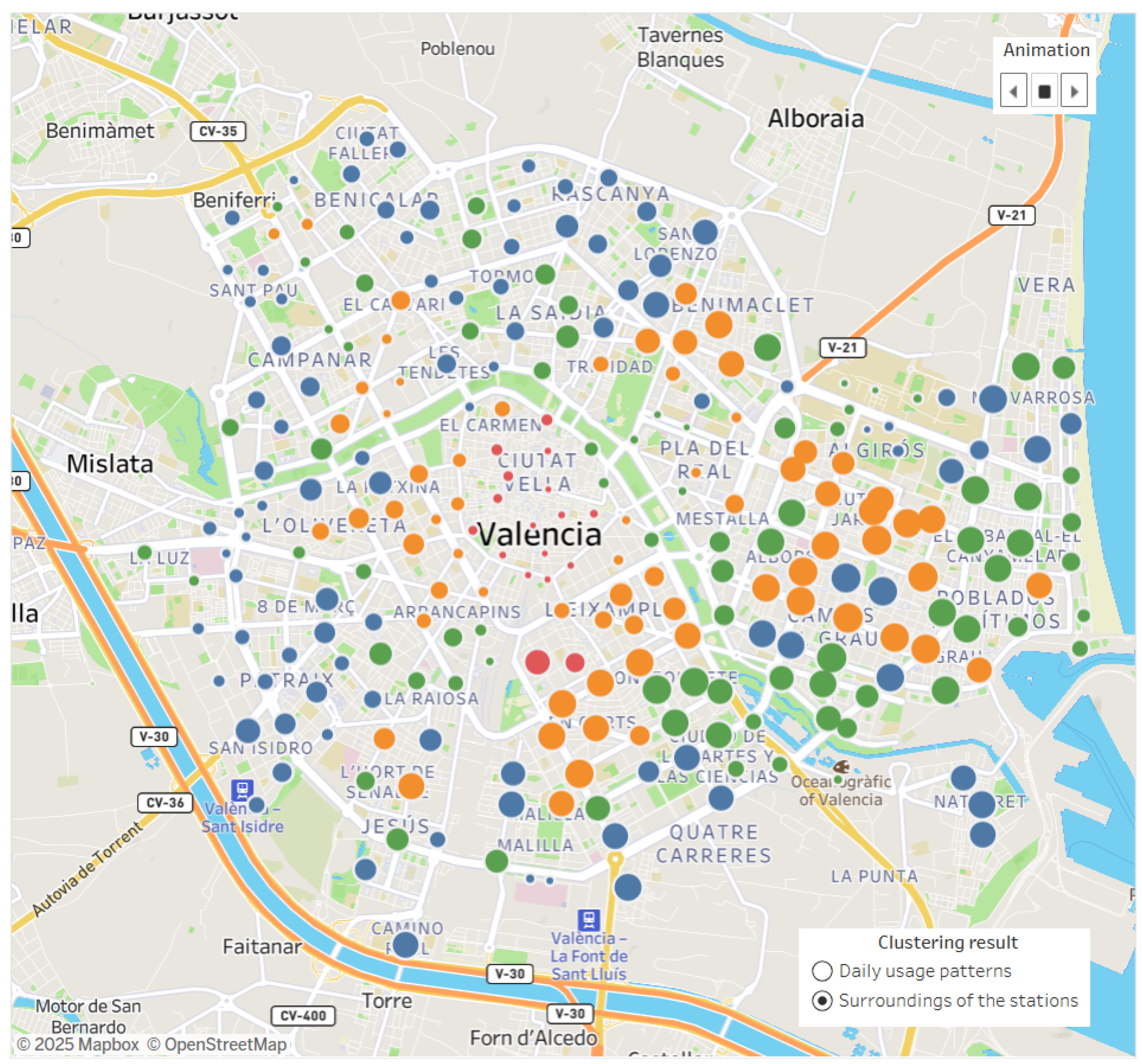
- The stations were clustered based on their vicinity’s geospatial data.
1.4. Structure of the Paper
- Data was collected from the JCDecaux developer website representing the usage data of the Valenbisi system’s stations.
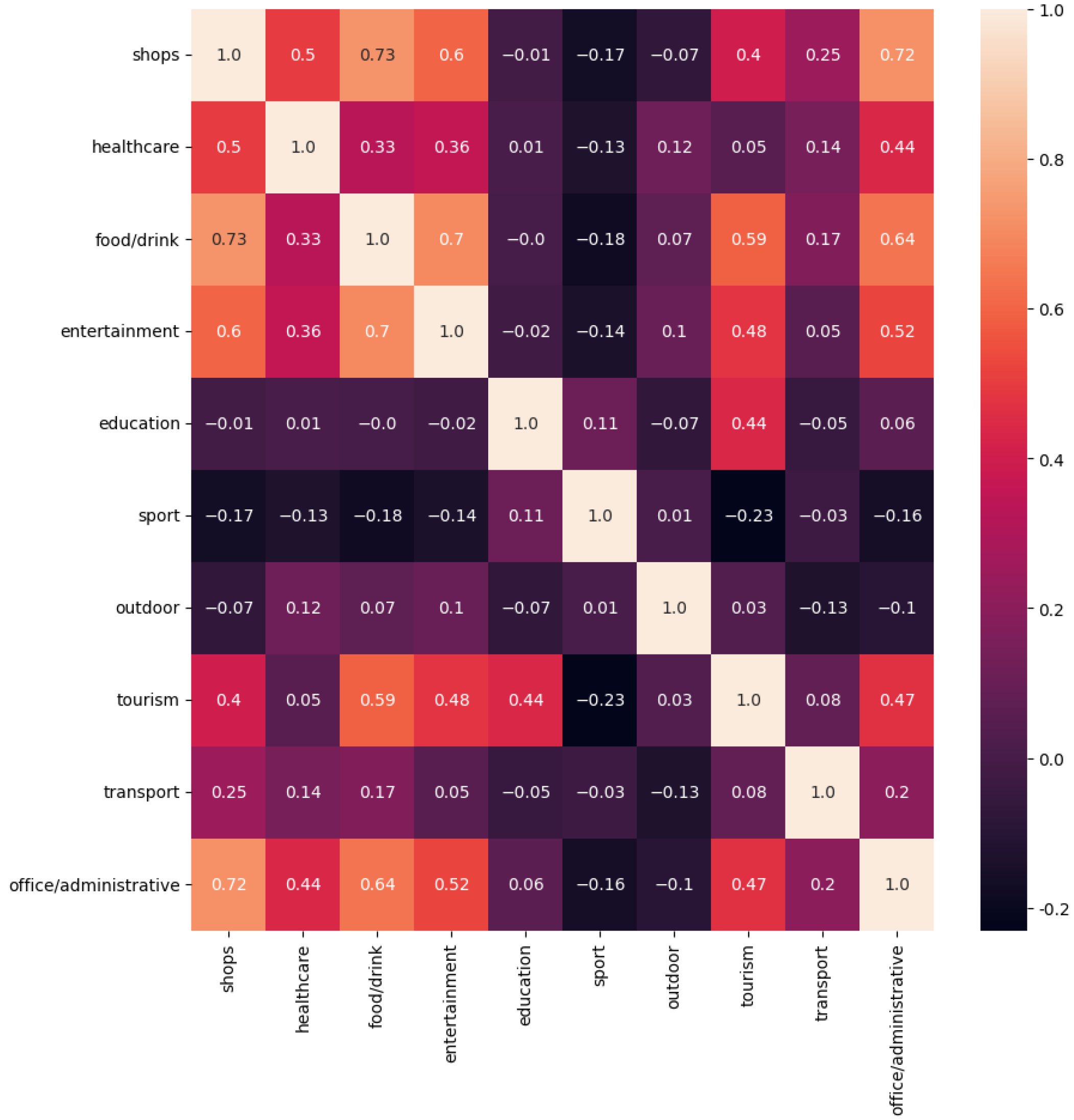
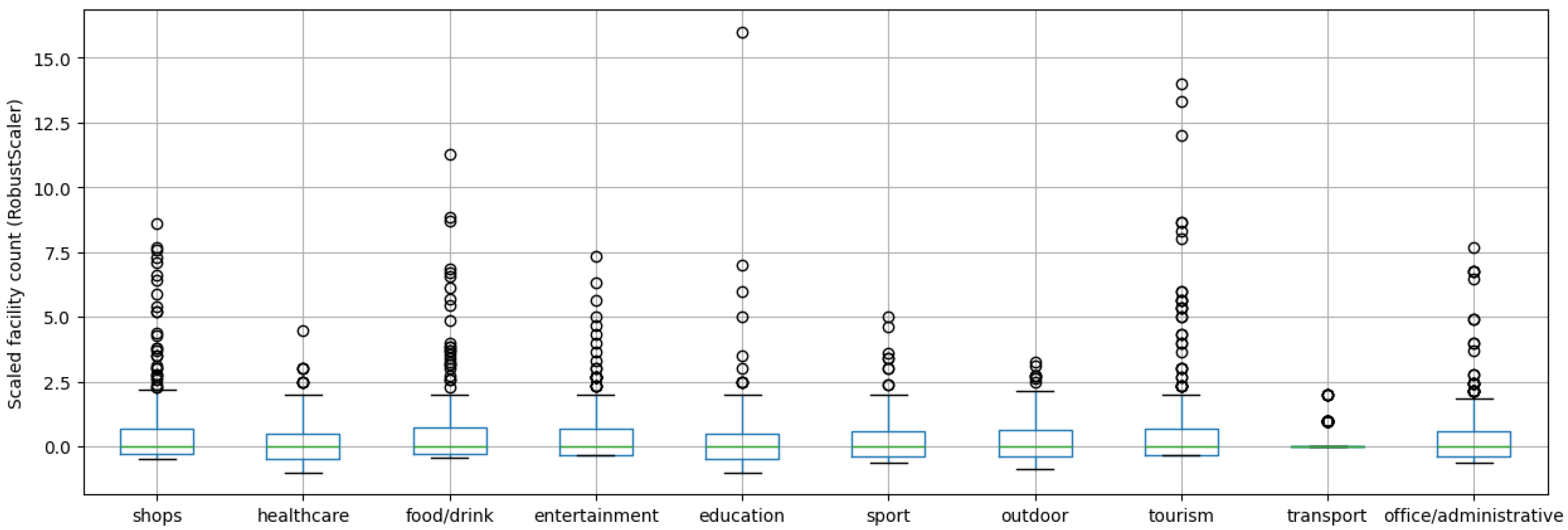
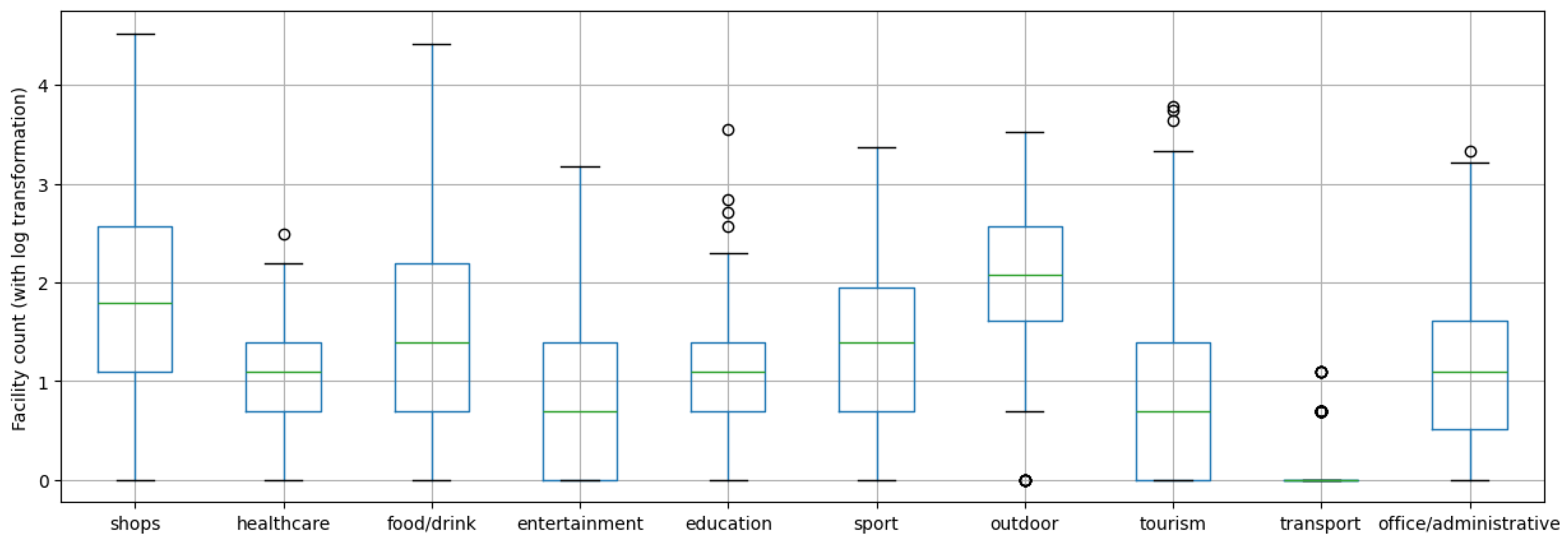
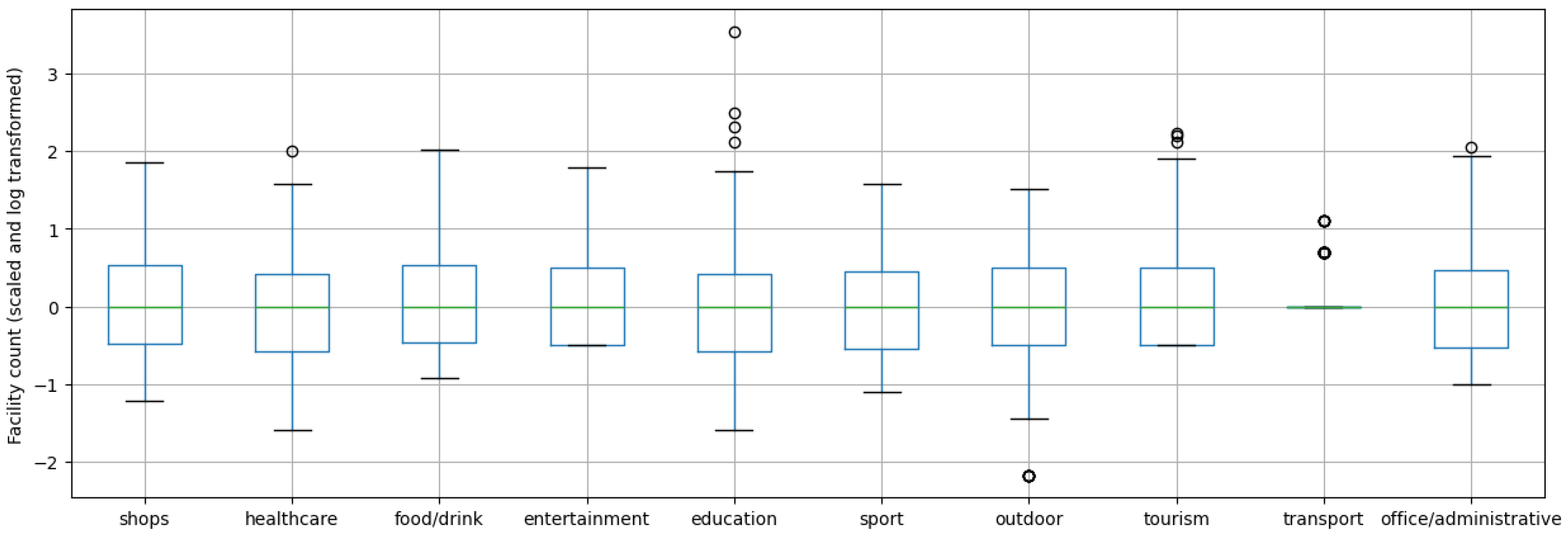
- The raw dataset collected from the JCDecaux developer website was filtered, and geospatial features were retrieved from OpenStreetMap (OSM). For the analysis of the stations’ surroundings, OSM data was classified into 10 major groups based on different attributes. Based on the groups created, the number of facilities within a 200 m radius of the stations was determined according to the categories, using the OverPass API (accessed on 2 July 2025).
- Experimental analysis was performed on the dataset:
- (a)
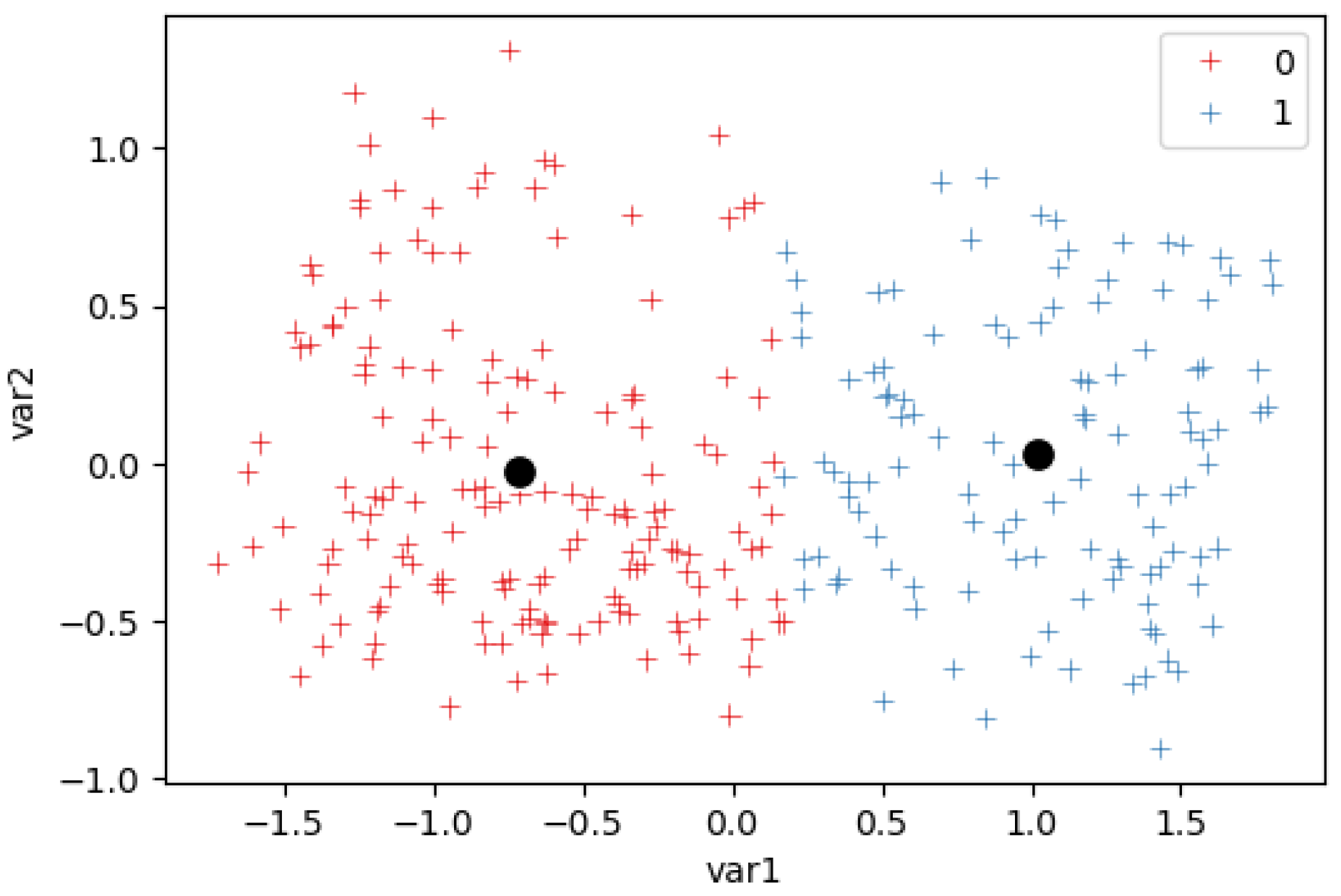
- We performed a cluster analysis of the stations’ daily usage and their environments, using the k-means method. We analyzed the results of clustering performed under various pre-processing steps, and the uses of various k values were compared using the Silhouette Coefficient (SE). The cluster analysis was carried out on the two datasets to select the most suitable method.
- (b)
- We compared the clustering results, using the Rand Index (RI). This allowed us to answer the research question of whether there was a correlation between the usage of the stations and their installation locations.
- (c)
- We present the visualization-driven analysis of the clusters and all the relevant pieces of information in the form of an interactive Tableau Dashboard, developed on the Tableau platform.
2. Materials and Methods
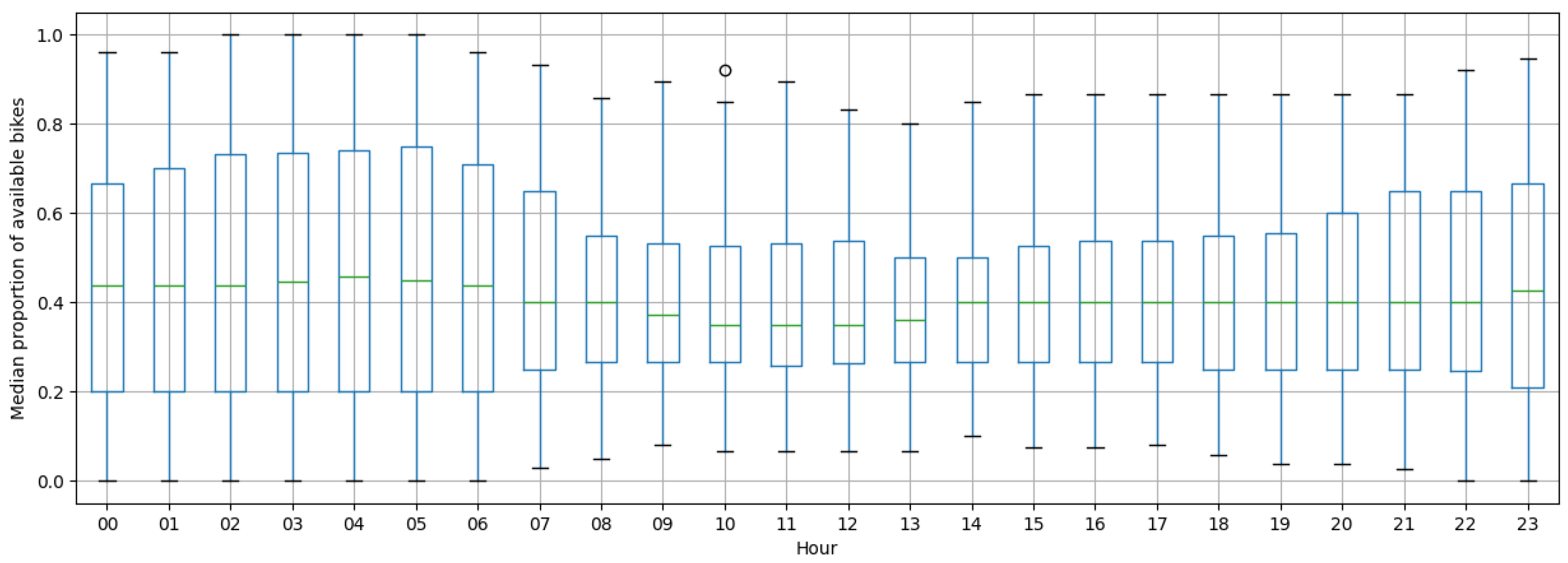
2.1. Service Data of Stations
- The most straightforward solution extracts the compressed dataset before applying the filtering function. The downside of this approach is that it generates unnecessary temporary files, and a single month’s data can take up about 30 GB of storage. These files should be deleted after filtering and writing the results to CSV.
- The second approach uses the SevenZipFile class from the py7zr module, which allows reading and filtering the contents of compressed folders without extracting them. This method optimizes disk space usage, but—based on our experience—takes longer to process and filter compared to the first solution.
- The third version aims to improve the non-extraction approach using the Pool class from the multiprocessing module, enabling parallel processing. However, this solution does not significantly speed up processing compared to the single-threaded version, primarily due to limitations imposed by Python’s Global Interpreter Lock (GIL) [23].
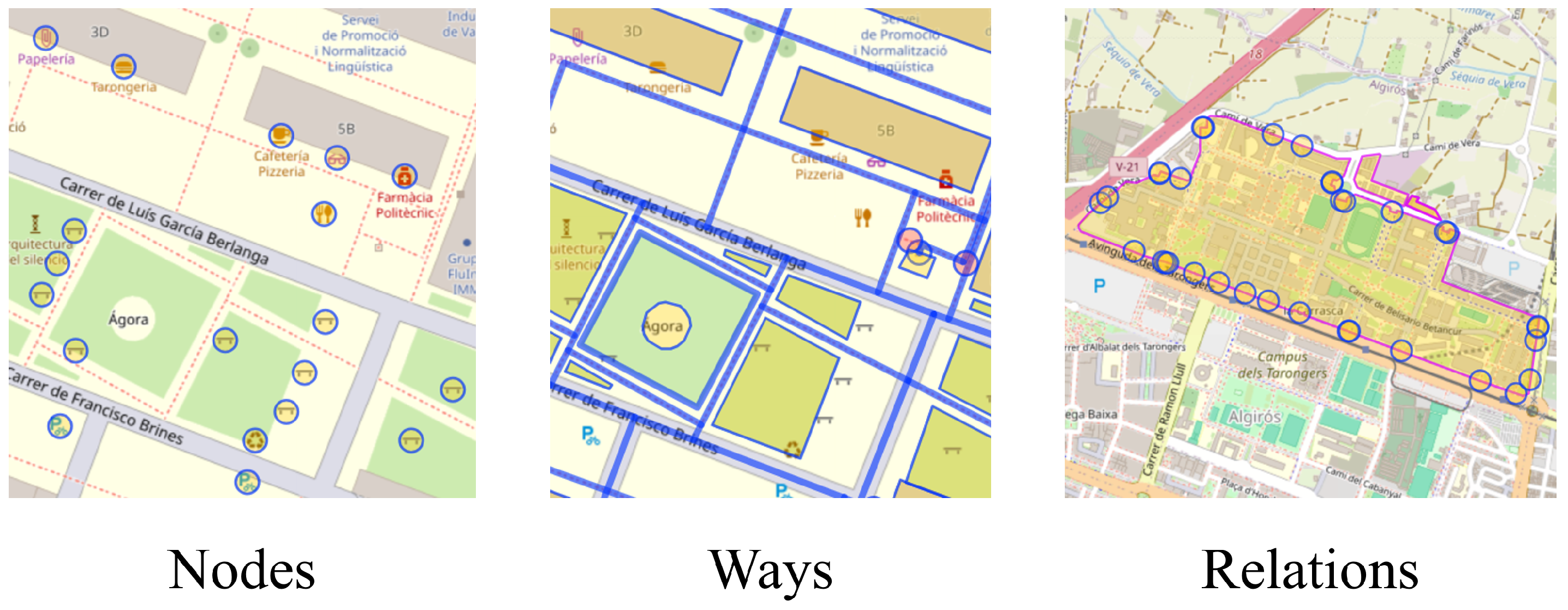
2.2. Geospatial Data of Stations
- Nodes represent a single geographic location, defined by latitude and longitude coordinates and a unique identifier.
- Ways are linear elements made up of multiple nodes. These can be opened (e.g., roads) or closed to form complex shapes (e.g., parks).
- Relations are structured collections of nodes, ways, or even other relations, allowing for logical or geographic relationships to be established between various objects.
2.3. Analyzing Dataset
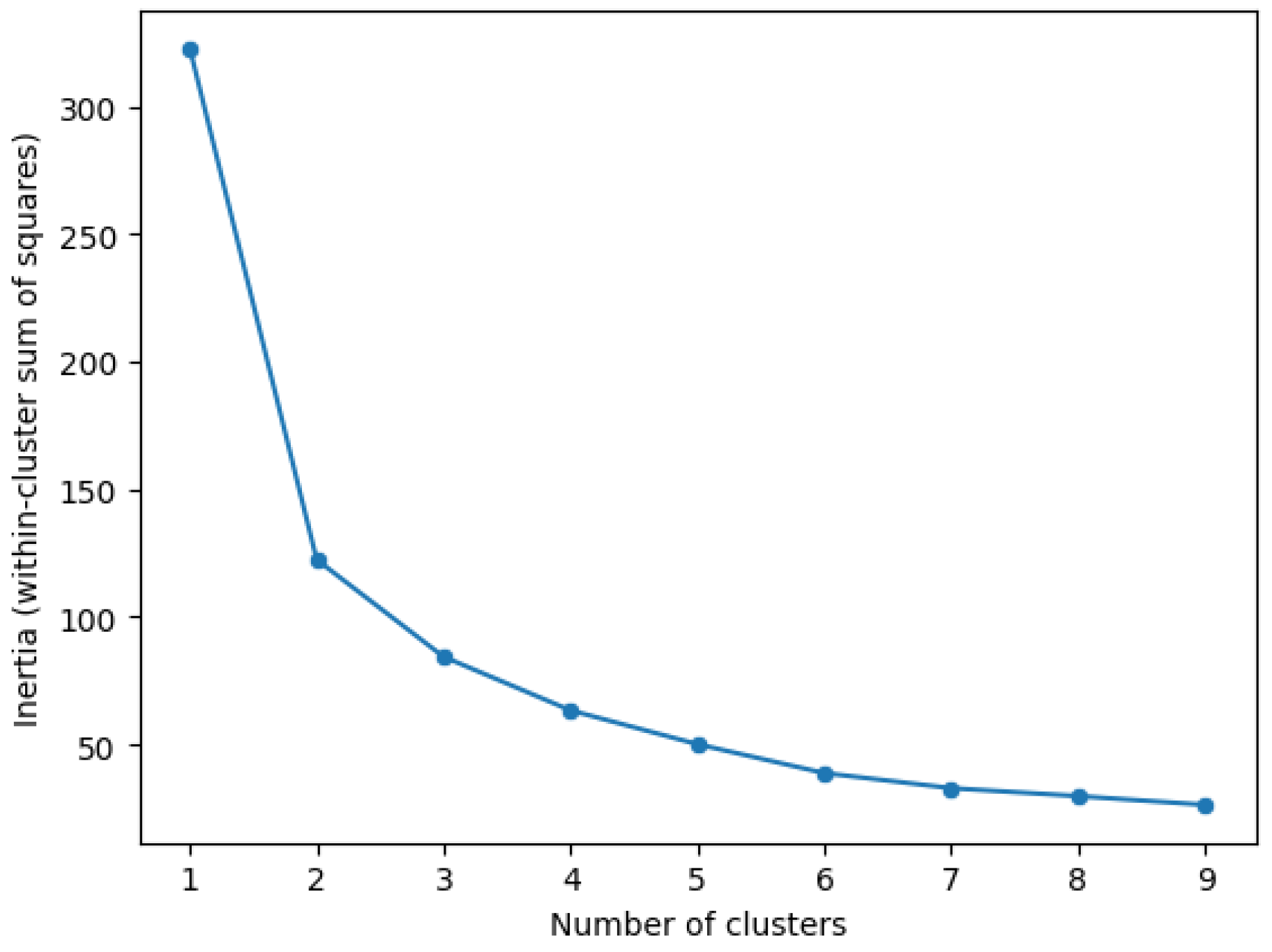
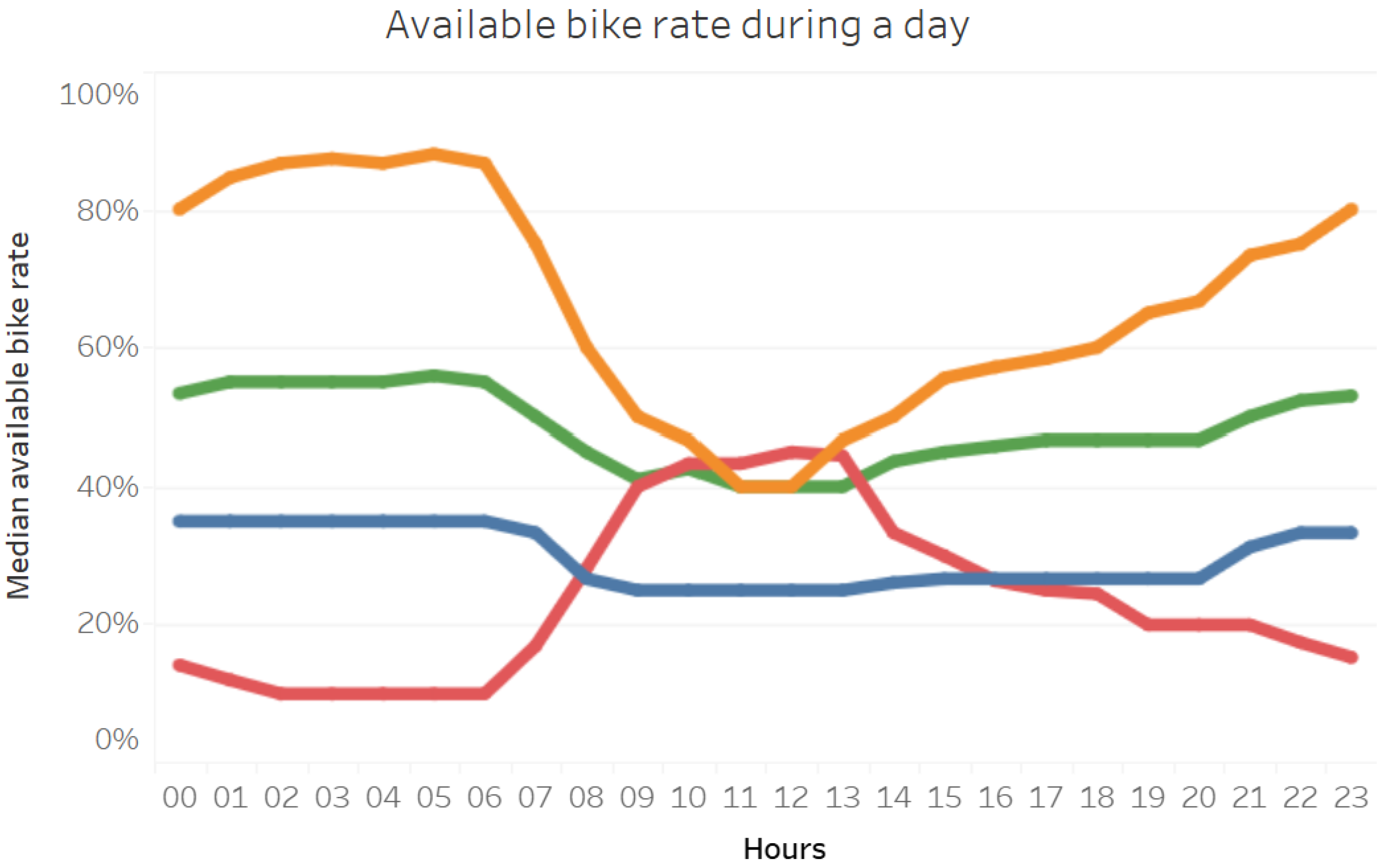
2.3.1. Clustering Stations by Their Usage
- Using the raw features without additional pre-processing;
- Using the scaled features without additional pre-processing;
- Using the dimension-reduced features;
- Using the scaled features, applying dimension reduction, too.
2.3.2. Clustering Stations by Their Environment
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| BSS | Bicycle Sharing Systems |
| EM | Elbow Method |
| GBFS | General Bikeshare Feed Specification |
| RI | Rand Index |
| SC | Silhouette Coefficient |
| SSE | Sum of Squared Errors |
References
- Nieuwenhuijsen, M.J.; Khreis, H.; Verlinghieri, E.; Rojas-Rueda, D. Transport and Health: A Marriage of Convenience or an Absolute Necessity. Environ. Int. 2016, 88, 150–152. [Google Scholar] [CrossRef]
- Vázquez-Paja, B.; Feo-Valero, M.; del Saz-Salazar, S. Environmental awareness and transportation choices: A case study in Valencia, Spain. Transp. Res. Part Transp. Environ. 2024, 137, 104487. [Google Scholar] [CrossRef]
- Kåresdotter, E.; Page, J.; Mörtberg, U.; Näsström, H.; Kalantari, Z. First Mile/Last Mile Problems in Smart and Sustainable Cities: A Case Study in Stockholm County. J. Urban Technol. 2022, 29, 115–137. [Google Scholar] [CrossRef]
- Qin, J.; Lee, S.; Yan, X.; Tan, Y. Beyond solving the last mile problem: The substitution effects of bike-sharing on a ride-sharing platform. J. Bus. Anal. 2018, 1, 13–28. [Google Scholar] [CrossRef]
- Villarasa-Sapiña, I.; Pans, M.; Antón-González, L. Public transport, social environment, and Bike Sharing System use to high school: A case study in València (Spain). J. Urban Mobil. 2025, 7, 100101. [Google Scholar] [CrossRef]
- JCDecaux Developer—developer.jcdecaux.com. Available online: https://developer.jcdecaux.com/#/home (accessed on 17 May 2025).
- Mix, R.; Hurtubia, R.; Raveau, S. Optimal location of bike-sharing stations: A built environment and accessibility approach. Transp. Res. Part A Policy Pract. 2022, 160, 126–142. [Google Scholar] [CrossRef]
- Fontes, T.; Arantes, M.; Figueiredo, P.; Novais, P. Bike-sharing docking stations identification using clustering methods in Lisbon city. In Distributed Computing and Artificial Intelligence, Volume 1: 18th International Conference 18, Proceedings of the DCAI 2021, Salamanca, Spain, 6–8 October 2021; Springer: Cham, Switzerland, 2022; pp. 200–209. [Google Scholar]
- Fazio, M.; Giuffrida, N.; Le Pira, M.; Inturri, G.; Ignaccolo, M. Bike oriented development: Selecting locations for cycle stations through a spatial approach. Res. Transp. Bus. Manag. 2021, 40, 100576. [Google Scholar] [CrossRef]
- Chen, W.; Chen, X.; Cheng, L.; Chen, J.; Tao, S. Locating new docked bike sharing stations considering demand suitability and spatial accessibility. Travel Behav. Soc. 2024, 34, 100675. [Google Scholar] [CrossRef]
- Spain’s Most Bike-Friendly Cities in 2024—idealista.com. Available online: https://www.idealista.com/en/news/lifestyle-in-spain/2024/03/18/815948-spain-s-most-bike-friendly-cities-in-2024 (accessed on 22 May 2025).
- i Díaz, F.G. The bicycle: Mass urban transportation—A paradigm shift. Case study: The City of Valencia. WIT Transactions on the Built Environment 2015, 146, 27–37. [Google Scholar]
- Valencia Walks Towards the Future: The Cycling Revolution in Valencia—Transformative Cities—transformativecities.org. Available online: https://transformativecities.org/atlas/energy11 (accessed on 17 May 2025).
- Agencia Municipal de la Bicicleta | Ajuntament de Valencia—valencia.es. Available online: https://www.valencia.es/agenciabici/ (accessed on 18 May 2025).
- Teruel, M.D.; Viñals, M.; Orozco Carpio, P. Analysis of tourist flows and the comfort of guided tours in the Seu-Cathedral district of Valencia using participant observation and digital itinerary monitoring tools. In Proceedings of the International Congress for Heritage Digital Technologies and Tourism Management (HEDIT 2024), Valencia, Spain, 20–21 June 2024; Editorial Universitat Politècnica de València: Valencia, Spain, 2024. [Google Scholar]
- What Is GTFS?—General Transit Feed Specification—gtfs.org. Available online: https://gtfs.org/getting-started/what-is-GTFS/ (accessed on 22 May 2025).
- Home—General Bikeshare Feed Specification—gbfs.org. Available online: https://gbfs.org/ (accessed on 17 May 2025).
- Elevating the Airport Experience with IoT | IoT For All—iotforall.com. Available online: https://www.iotforall.com/elevating-the-airport-experience-with-iot (accessed on 22 May 2025).
- Wayfinding and Proximity Marketing at Fraport | Favendo—favendo.com. Available online: https://www.favendo.com/case_studies/fraport/ (accessed on 22 May 2025).
- Passengers Can Validate Their Mobile Transportation Tickets in a New Way—debrecen.hu. Available online: https://www.debrecen.hu/en/local/news/passengers-can-validate-their-mobile-transportation-tickets-in-a-new-way-1 (accessed on 22 May 2025).
- An Introduction into ADS-B—Flightradar24.com. Available online: https://www.flightradar24.com/blog/ads-b/ (accessed on 22 May 2025).
- Temiz, H. Recording Performances of Some File Types for Pandas Data. Avrupa Bilim Teknol. Derg. 2022, 36, 55–60. [Google Scholar] [CrossRef]
- Meier, R.; Rigo, A. A way forward in parallelising dynamic languages. In Proceedings of the 9th International Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems PLE, ICOOOLPS ’14, Uppsala, Sweden, 28 July 2014; ACM: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Tran, T.D.; Ovtracht, N.; d’Arcier, B.F. Modeling Bike Sharing System using Built Environment Factors. Procedia CIRP 2015, 30, 293–298. [Google Scholar] [CrossRef]
- Map Features—OpenStreetMap Wiki—wiki.openstreetmap.org. Available online: https://wiki.openstreetmap.org/wiki/Map_features (accessed on 17 May 2025).
- Tan, P.; Steinbach, M.; Kumar, V. Introduction to Data Mining: Pearson New International Edition PDF eBook; Pearson Education: London, UK, 2013. [Google Scholar]
- He, X.; He, F.; Fan, Y.; Jiang, L.; Liu, R.; Maalla, A. An effective clustering scheme for high-dimensional data. Multimed. Tools Appl. 2023, 83, 45001–45045. [Google Scholar] [CrossRef]
- Banerjee, S.; Choudhary, A.; Pal, S. Empirical evaluation of K-Means, Bisecting K-Means, Fuzzy C-Means and Genetic K-Means clustering algorithms. In Proceedings of the 2015 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Dhaka, Bangladesh, 19–20 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 168–172. [Google Scholar] [CrossRef]
- Dudek, A. Silhouette Index as Clustering Evaluation Tool. In Classification and Data Analysis, Proceedings of the SKAD 2019, Szczecin, Poland, 18–20 September 2019; Jajuga, K., Batóg, J., Walesiak, M., Eds.; Springer: Cham, Switzerland, 2020; pp. 19–33. [Google Scholar]
- Marutho, D.; Hendra Handaka, S.; Wijaya, E.; Muljono. The Determination of Cluster Number at k-Mean Using Elbow Method and Purity Evaluation on Headline News. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication, Semarang, Indonesia, 21–22 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 533–538. [Google Scholar] [CrossRef]
- Thinsungnoen, T.; Kaoungku, N.; Durongdumronchai, P.; Kerdprasop, K.; Kerdprasop, N. The Clustering Validity with Silhouette and Sum of Squared Errors. In Proceedings of the 2nd International Conference on Industrial Application Engineering 2015, ICIAE2015, Singapore, 20–22 May 2015; The Institute of Industrial Applications Engineers: Kitakyushu, Japan, 2015. [Google Scholar] [CrossRef]
- Warrens, M.J.; van der Hoef, H. Understanding the Rand Index. In Advanced Studies in Classification and Data Science; Springer: Singapore, 2020; pp. 301–313. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | k = 2 | k = 3 | k = 4 | ||||
|---|---|---|---|---|---|---|---|
| Scaling | PCA | Average | Median | Average | Median | Average | Median |
| no | no | 0.4619 | 0.4610 | 0.3358 | 0.3335 | 0.2680 | 0.2678 |
| yes | no | 0.4429 | 0.4429 | 0.3454 | 0.3385 | 0.2820 | 0.2818 |
| no | yes | 0.5102 | 0.5091 | 0.3912 | 0.3927 | 0.3365 | 0.3365 |
| yes | yes | 0.4936 | 0.4936 | 0.4252 | 0.4258 | 0.3593 | 0.3582 |
| Method | k = 2 | k = 3 | k = 4 | ||||
|---|---|---|---|---|---|---|---|
| Scaling | PCA | Average | Median | Average | Median | Average | Median |
| no | no | 0.4622 | 0.4610 | 0.3415 | 0.3410 | 0.3069 | 0.3033 |
| yes | no | 0.4429 | 0.4429 | 0.3261 | 0.3164 | 0.3058 | 0.3138 |
| no | yes | 0.5112 | 0.5121 | 0.4084 | 0.4057 | 0.3889 | 0.3867 |
| yes | yes | 0.4936 | 0.4936 | 0.3838 | 0.3781 | 0.3792 | 0.3932 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Magura, Á.; Zichar, M.; Tóth, R. Re-Usable Workflow for Collecting and Analyzing Open Data of Valenbisi. Electronics 2025, 14, 2720. https://doi.org/10.3390/electronics14132720
Magura Á, Zichar M, Tóth R. Re-Usable Workflow for Collecting and Analyzing Open Data of Valenbisi. Electronics. 2025; 14(13):2720. https://doi.org/10.3390/electronics14132720
Chicago/Turabian StyleMagura, Áron, Marianna Zichar, and Róbert Tóth. 2025. "Re-Usable Workflow for Collecting and Analyzing Open Data of Valenbisi" Electronics 14, no. 13: 2720. https://doi.org/10.3390/electronics14132720
APA StyleMagura, Á., Zichar, M., & Tóth, R. (2025). Re-Usable Workflow for Collecting and Analyzing Open Data of Valenbisi. Electronics, 14(13), 2720. https://doi.org/10.3390/electronics14132720