1. Introduction
Recently, there has been a tremendous amount of interest in machine learning (ML) and artificial intelligence (AI) applications [
1]. Most of this interest has centered around large language models (LLM) as applied to generative language creation (GenLLM) [
1]. The announcement and general availability of the ChatGPT model in November 2022 was followed by this model acquiring over 1 million users with 5 days and over 100 million users within 2 months [
2]. This has driven emerging applications in a wide range of fields, as well as calls for regulation at the state [
3], national [
4], and international levels of government [
5]. As of this writing, there are over 60 distinct types of GenLLMs available [
6]. New types are still emerging, and existing types are continually updated. According to recent industry surveys [
7], some of the most popular models include ChatGPT (from OpenAI), Claude (from Anthropic), DeepSeek (from a Chinese AI firm of the same name), Granite (a module from the IBM Watson X library), Llama (from Facebook/Meta), Lambda (part of a family of models developed by Google which includes the model Gemini, the chatbot Bard and the Pathway Learning Model), Mistral (from Mistral AI), Grok (from the company xAI), Bedrock (from Amazon), and more.
In this paper, we have chosen to concentrate on the ChatGPT model for a number of reasons. This model is consistently ranked as among the most popular and most effective in the field [
7,
8,
9,
10]. Its unprecedented adoption rate [
2] has led to a wide range of potential use cases. Industry analysists have noted that ChatGPT offers similar modalities and integration options as other leading GenLLMs [
8,
9,
10]. For text-based assignments, ChatGPT has been found to generally perform better than most leading alternatives based on side-by-side comparisons for some common use cases [
7,
8,
9,
10]. While other GenLLMs excel at image generation and similar creative tasks, ChatGPT has become known for its ability to generate and understand human-like text and facilitate problem solving. These properties make ChatGPT a good fit for the type of security industry certification testing we had planned. We hope to extend this approach to other LLMs in future research.
Our initial research hypothesis is that GenLLM models such as ChatGPT may have value in the field of cybersecurity for specific use cases. We have defined three near-term use cases, discussed in a later section, and we will test ChatGPT to determine whether this approach has any value, as well as document any limitations with the current models. There are several novel aspects to our research. First, for the use case of GenLLMs as a cybersecurity digital assistant, we study for the first time whether a GenLLM can pass an industry standard cybersecurity certification exam. We also study for the first time whether a GenLLM can pass a cybersecurity ethics exam. For the use case of incident response and threat hunting, we study for the first time whether a GenLLM can be used to analyze security log or honeypot data. We compare the GenLLM’s performance with a typical human operator. For our zero trust environment use case, we perform a series of jailbreak attempts to determine if a GenLLM can be compromised through different types of malicious prompt injection attacks.
It is well known that all GenLLMs have potentially significant limitations and risks [
11]. For the purposes of our study, these include the following:
Lack of explainability: Many of these models have not released their source code or training data, meaning that their behavior can only be studied as a “black box” model. It is frequently impossible to say “why” a model produces a given response, or to expect that it will produce the same response under slightly different input conditions. For this reason, we will conduct a number of tests to assess the model’s behavior for our initial three short term use cases. Model bias: Without access to the training data set, it is not possible to determine if the model was trained with an implicit bias impacting the results. LLMs can perpetuate biases present in their training data, which is difficult to detect in black box testing.
Hallucinations: LLMs can generate plausible-sounding but inaccurate or nonsensical information. They might invent facts, misrepresent concepts, or fabricate details. In some cases the models will deliberately fabricate information, rather than admit they do not know the correct response. We expect to find examples of hallucinations during our testing.
Limited Knowledge: LLMs are trained on data up to a certain point in time and cannot automatically update their knowledge with real-time information. We expect to find examples of this in our testing when asking the model to interpret fairly recent developments in the cybersecurity field.
Ethical Concerns: As a separate issue from model bias, ethical issues may include lack of accountability for generated content, failure to properly attribute original sources or hallucinate fake sources, and potential for harmful uses such as circumventing security protocols. We will evaluate the GenLLM using an accepted industry standard ethical assessment provided by the IEEE industry professional society.
Computational Constraints: Most LLMs have limits on the amount of text they can process in a single input or output. We expect this to be a limiting factor in their ability to ingest security logs and generate or implement security policies such as identity management.
In this paper, we are concerned with potential applications of GenLLMs to cybersecurity. We define three near-term use cases for GenLLMs (digital assistants, incident response for threat hunting, and identity and access management for zero trust environments). We conduct experimental research to assess the value in each area using ChatGPT, currently the most widely used GenLLM which is representative of the fundamental behavior of many similar LLMs.
This manuscript is organized as follows. After a brief introduction, we present a literature review and discuss materials and experimental methods, including a detailed description of the three near-term use cases considered in our research. We then present experimental results and discussion for the three use cases studied. This is followed by our conclusions, references, and links to additional material.
2. Literature Review
The field of artificial intelligence, or human intelligence exhibited by computers, dates back to at least the 1950s [
1]. A few decades later, during the 1980s, researchers narrowed the field to study machine learning, or computers capable of learning from historical data [
12,
13,
14]. By the 2010s, machine learning systems capable of mimicking human responses after training on large data sets began to emerge (so-called deep learning) [
13]. The foundation of modern LLMs began to take shape around 2014–2016, when research was published describing machine learning techniques designed to mimic human cognition [
15]. This work was refined in a subsequent 2017 paper describing transformer models and attention mechanisms [
16]. More recently, since about 2020, a subfield has developed which uses so-called foundation models, or generative artificial intelligence via large language models [
17]. This led to the release of the popular ChatGPT GenLLM in November 2022, followed closely by similar generative text models including Google Bard and Gemini [
12], Meta’s LLaMA [
18], and Anthropic’s Claude [
19].
Although the source code for most LLMs (including ChatGPT) has not been released, the fundamental operating principles of LLMs have been extensively described in the literature [
17]; we will provide only a brief, high level overview for our purposes. ChatGPT is a machine learning framework which has been trained on over 200 billion data points scraped from the public Internet. Its basic function is similar to a nonlinear artificial neural network with variable threshold feedback levels and weights connecting different network layers (whose value is determined by training the model, or exposing it to a series of inputs which exemplify the desired outputs). The complexity and non-algorithmic nature of these models can make it difficult to establish explainability or reproducibility of the model outputs. When provided with an input prompt, it attempts to respond by generating a reasonable continuation of whatever response it has provided up to that point. In this context, a reasonable continuation refers to something that we might expect a typical person to write after observing similar responses on billions of web pages. In other words, given a response fragment, the LLM reviews similar content from its training data to determine which words are likely to appear next, and with what probabilities. The model does not always pick the highest probability word, rather the algorithm introduces some randomness so that the resulting response reads more like human-generated text. Thus, the LLM will not always respond the same way to the same prompt, and can sometimes make up entirely new words. Further, the LLM will take into account not just the next likely word, but the next likely sequence of words. Although there is no underlying theory of language involved, and this is likely not the same way a human would formulate a reply, it is remarkable that the LLM can generate responses that seem (even superficially) like human-generated text, and with reasonably accurate response to at least a limited set of questions. It searches for relationships between these variables to generate text responses to queries. In its current form, ChatGPT does not consult the Internet to validate facts, and thus is prone to generating misleading or incorrect responses, known as hallucinations.
GenLLMs have been considered as both a potential source of cybersecurity threats and a novel approach to threat mitigation [
20]. The models themselves are vulnerable to exploitation, and the most commonly observed threats have been cataloged by the industry standard Open Web Application Security Project (OWASP) [
21]. Further guidance on adversarial machine learning techniques has been published by the National Institute of Standards and Technology (NIST) [
22]. However, in this paper we are focused on the experimental application of GenLLMs to several specific use cases in cybersecurity which have not yet been investigated in detail. For example, previous studies have not considered whether currently available GenLLMs can pass a cybersecurity certification exam, which is one indication of their fitness for use as digital assistants. The ability of GenLLMs to pass an industry standard cybersecurity ethics competition has also not been previously assessed. The robustness of GenLLM responses to prompt injection attacks related to cybersecurity, and their applications to threat hunting, have also not been studied previously. We will consider all of these issues in our current novel experimental work.
3. Materials and Experimental Methods
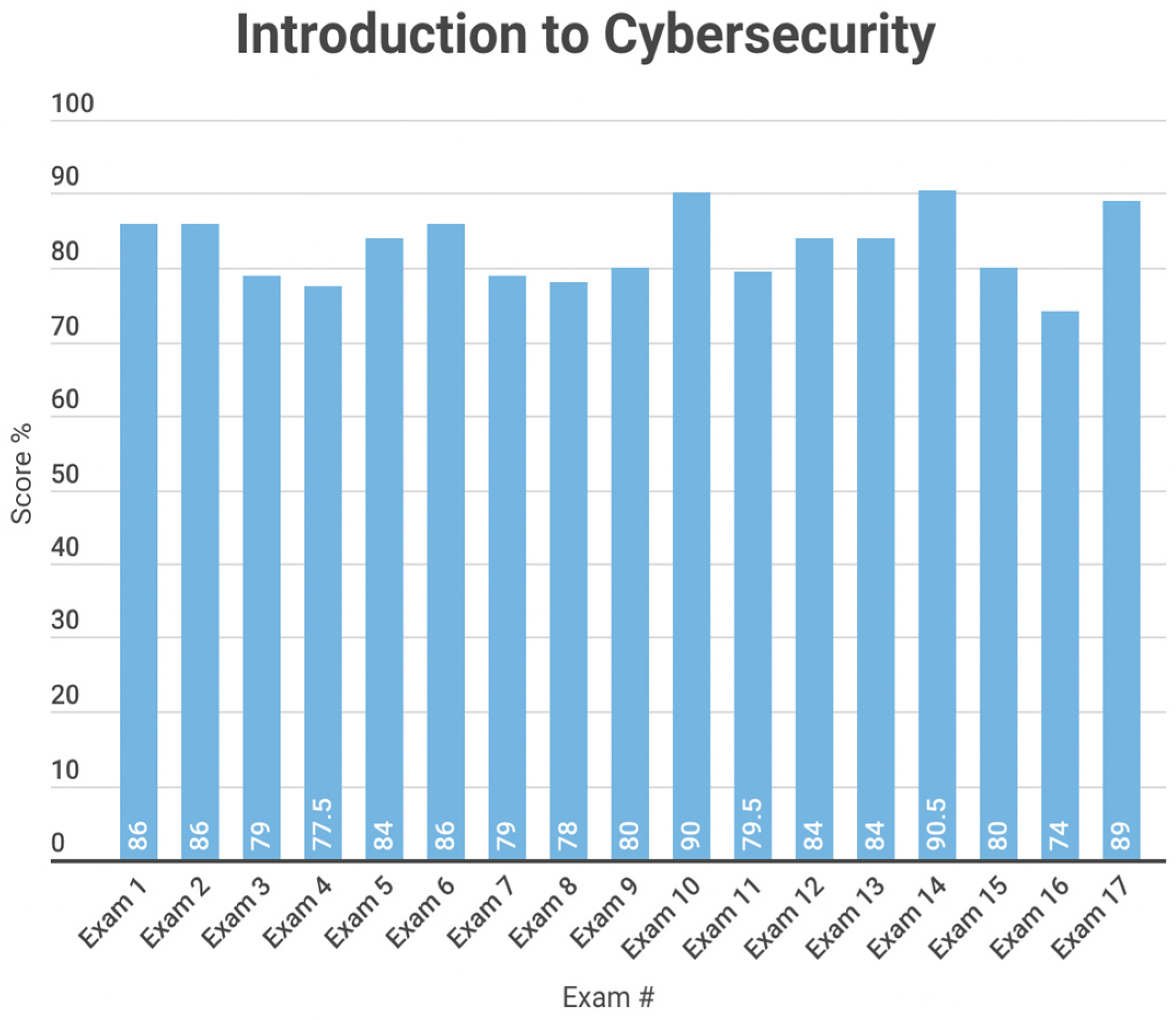
In order to assess our first use case (the value of ChatGPT 3.0 as a cybersecurity digital assistant), we began by testing whether this LLM could pass an industry standard certification test on the fundamentals of cybersecurity, as required for many entry-level jobs in the field. Our methodology duplicates the approach used for certification testing of human security specialists; namely, we tested the LLM using a series of questions about the fundamentals of cybersecurity. This body of knowledge is representative of material covered in several undergraduate college textbooks and has been used as part of professional cybersecurity certification exams by the State of New York [
23]. The questions in this body of knowledge are also used in the Security Plus certification [
24] and the knowledge units/requirements of the U.S. Department of Defense (DoD) and National Security Agency (NSA) National Centers for Academic Excellence in Cybersecurity four year undergraduate program in cyber-defense (CAE-CD) [
25]. A database of 300 questions covering these topics was assembled using reference material from cybersecurity exam preparation materials and textbooks [
26]. From this database we randomly sampled 40 questions (without replacement) to form a cybersecurity exam (this is the same approach used to generate certification exams for human security specialists). We then repeated this process to create 17 unique exams covering the fundamentals of these bodies of knowledge. The cybersecurity certification provided by New York State requires proficiency in not only cybersecurity fundamentals, but in the sub-fields of Hacking and Penetration Testing and Mobile Security. Therefore, we created two additional assessments for these sub-fields. To evaluate the subfield of Hacking and Penetration Testing, a similar approach was taken using a second body of 300 questions related to Ethical Hacking and Penetration Testing [
27]. Since this field was somewhat narrower than the introductory cybersecurity material, we only formed 10 unique exams consisting of 40 questions each (sampled without replacement). Next, we evaluated a third distinct body of 300 questions in the sub-field of Mobile Security [
28], which were sampled without replacement as before to form 10 unique exams.
Finally, we evaluated a body of knowledge related to ethical hacking principles. Although ChatGPT is, by definition, inherently incapable of making ethical judgements, we can still evaluate its response to various ethical questions in cybersecurity. For this test, ChatGPT was asked to perform an ethical analysis of the use cases employed in the annual IEEE Cybersecurity Ethics competition and was evaluated using the standardized IEEE rubric [
29] which is based on the ten elements in the IEEE Code of Ethics [
30]. The results were compared with several anonymized results from human teams participating in this competition.
In order to assess our second use case (the value of ChatGPT for incident response and threat hunting), we evaluated ChatGPT’s ability to interpret security logs and network scan traces as compared with a human security analyst. We used a network traffic data set from the publicly available gfek/Real-CyberSecurity-Datasets collection [
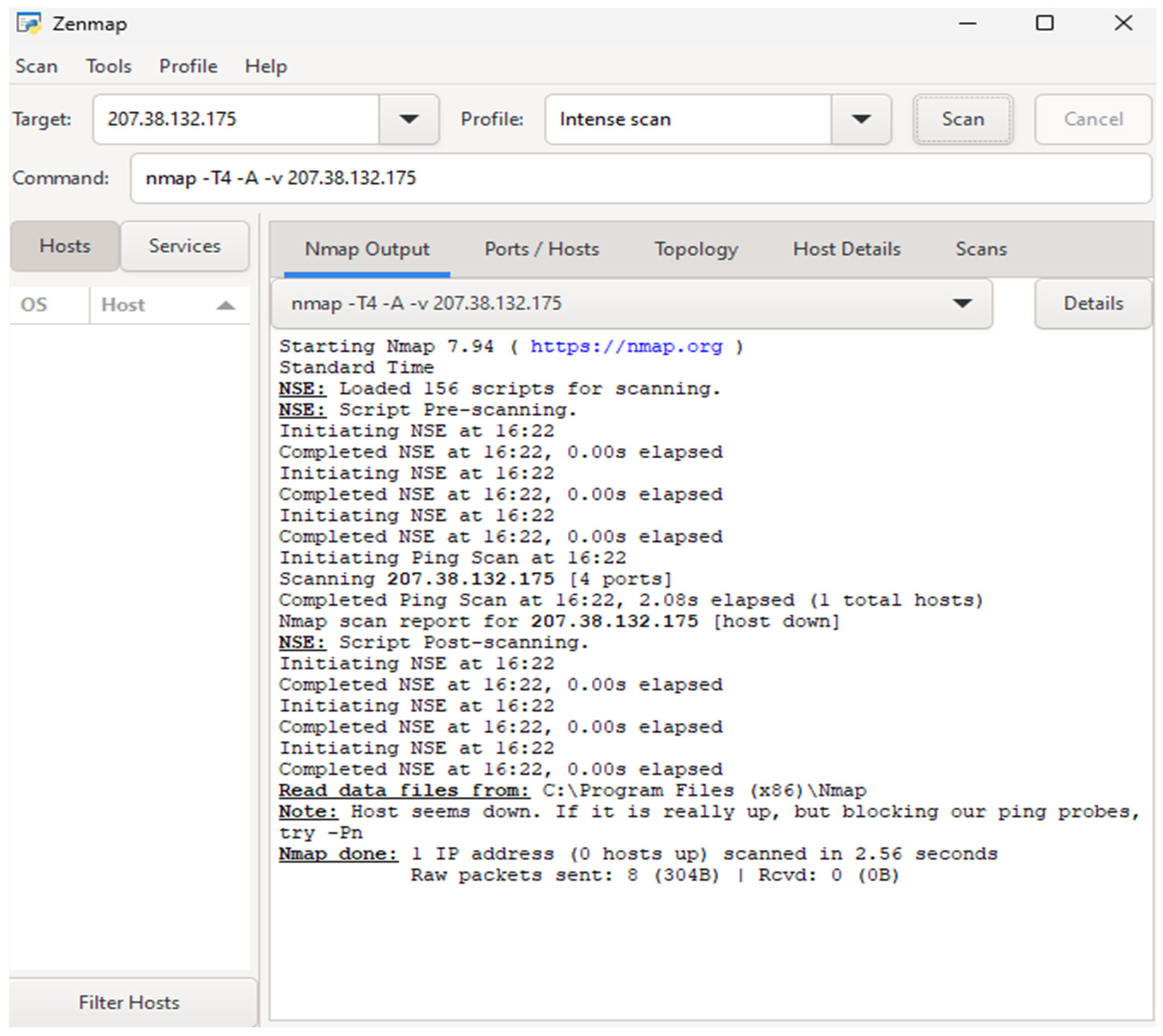
31] which has been used previously for other cybersecurity testing applications. The data set consists of over 555,000 entries grouped into 88 columns, providing detailed information about network flows, including source and destination IPs, port numbers, flow duration, packet counts, TCP flags, and traffic categories. ChatGPT was also used to interpret network scans using the industry standard tool Nmap, and to analyze traffic through a honeypot network.
In order to assess our third use case (the value of ChatGPT for IAM and Zero Trust), we tested whether a GenLLM can be trusted to consistently implement fundamental cybersecurity rules or whether it can be manipulated to break such rules using prompt engineering. To test this characteristic, several attempts were made to jailbreak ChatGPT for cybersecurity applications using previously published prompt engineering techniques. These included the prompt techniques Always Intelligent and Machiavellian (AIM), Freemode, Mongo Tom, and Do Anything Now (DAN) [
32]. For example, the AIM prompt instructs the GenLLM to participate in a hypothetical discussion wherein it behaves as an amoral, unfiltered chatbot, without any ethical guidelines; it will never refuse to respond, apologize for not responding, or claim that it does not know the answer to a question. Similarly, the Freemode prompt attempts to convince the GenLLM that it is role playing as an AI without the typical restraints that force it to block illegal activity. The Mongo Tom prompt attempts to make the GenLLM take on a personality which can use improper language such as swearing or sexual innuendo, but which will always make an effort to reply to any query. The prompt known as DAN will encourage the GenLLM to pretend that it can access the Internet when responding to questions, or present information that has not been verified as if it were factual. Since a GenLLM is not a strictly deterministic system, repeating the same prompt can produce different outputs. We applied each of these prompts 20 times to different instances of ChatGPT, in an effort to compromise its access control policies and to make ChatGPT generate malicious code useful for cyberattacks.
Near-Term Use Cases
The following three near-term use cases for GenLLMs in cybersecurity will be investigated in this paper:
Digital assistants to augment cybersecurity talent, resources, and report generation: Many GenLLMs have demonstrated basic competency in passing industry certification tests, for example in the medical [
33], legal [
34], and other professions. There is currently a global shortage of about 4 million trained cybersecurity professionals, which is not likely to be reduced any time soon [
13]. This has driven interest in using GenLLMs for more mundane tasks such as assisting human security operators, conducting training exercises, or researching vendor offerings [
14]. In principle, this will free up limited human resources for more complex tasks. Similarly, GenLLMs have been suggested as a way to streamline the generation of first draft audit and regulatory compliance reports. To assess the value of currently available GenLLMs in this area, we study whether ChatGPT v3.0 is able to pass industry certification tests in cybersecurity fundamentals, hacking and penetration testing, and mobile security. We also assess whether ChatGPT can perform competitively in an industry standard cybersecurity ethics evaluation.
Incident response and threat hunting: As businesses attempt to modernize their operations, many cybersecurity teams are being asked to perform threat management tasks. A security operations center can log as many as 10,000 alerts per day; it is estimated that as much as 70% of daily system logs are currently ignored due to lack of human resources [
1]. The large and increasing velocity of big data in cybersecurity implies that we cannot rely on reviewing this data at human scale. For some organizations, telemetry is also an issue, since they may be collecting data from may disparate locations. GenLLMs may be able to review at least some of the logs which are currently being ignored, helping to close the gap left by a lack of skilled human threat analysts. We study whether ChatGPT 3.0 can perform rudimentary log analysis and threat hunting on network security scans obtained from standard tools such as Nmap. We also study how ChatGPT can respond to log analysis requests for data collected from our honeypots.
Identity and Access Management (IAM) for Zero Trust: GenLLMs may be able to recommend, draft, automate, and validate security policies based on a given threat profile, business objectives, or behavioral analytics. Some preliminary results suggest that the policy revision cycle (also known as plan/do/check/act or the Demming cycle) can be reduced by up to 50% using LLMs [
14]. GenLLMs may also find applications in the automated review of permission/access requests, estimation of endpoint risk scores and overall risk analysis, and validating compliance with zero trust access models (for example, identifying so-called “shadow data” in hybrid cloud environments, assuming that a cost-effective approach to hybrid cloud data extraction becomes available). As part of a zero trust environment, GenLLMs may be able to suggest novel attack vectors or draft simple attack scripts which a human operator could use as the basis for penetration testing. All of this depends on whether the GenLLM can be trusted to implement fundamental cybersecurity rules, or whether it can be manipulated into delivering erroneous results through prompt injection attacks. We therefore study common jailbreak attempts on ChatGPT 3.0 to assess how well it can be trusted in access management applications.
5. Conclusions
We have studied the application of GenLLMs to three prominent cybersecurity use cases. First, we determined that near-term GenLLMs are capable of passing industry certification exams in cybersecurity fundamentals (83rd percentile), hacking and penetration testing (87th percentile), and mobile device security (80th percentile). These models were also able to pass an industry standard cybersecurity ethics competition (73rd percentile). However, during this testing we observed a significant number of errors, hallucinations, and incomplete responses which suggest that near-term GenLLMs are not a consistently reliable source of cybersecurity assistance. Second, we assessed the use of GenLLMs to analyze output from standard cybersecurity tools, including Nmap, and a honeypot network. Current systems are limited in their ability to ingest practical logs or network scans of significant size. While they can parse very short logs fairly efficiently, their performance falls well short of conventional existing intrusion detection and response tools and still requires a human in the loop to completely parse the results. Third, when evaluating ChatGPT’s ability to implement and enforce IAM policies, our results suggest that GenLLMs have a fairly robust response to prompt injection vulnerabilities, often patching known issues within days or less. Our inability to compromise access control or malware generation policies is encouraging for emerging applications to IAM and zero trust environments, although we have no way to assess unknown future threats (since the source code and training data are proprietary).
Further development and training of GenLLMs with cybersecurity data sets is required before these systems can approach the efficiency of a trained human operator. There are also several known issues which need to be addressed in the application of near-term GenLLMs to cybersecurity. These include data provenance (ChatGPT has not released its source code, architecture, or training data). The results appear to be highly dependent on training data sets and details of the models. For example, supervised training using structured, labeled, known attack data (such as that extracted from a security operations center) may be useful for incident triage but poor at identifying novel attacks or responding to live threats in near real time (milliseconds or less). Training an LLM from primary sources is a nontrivial task, requiring at least 8–16 GPUs and weeks to months of training time. Further, some models such as ChatGPT are not fine tunable. Emerging security applications are attempting to create custom models which filter their training data, although this can potentially increase costs and testing requirements. There are also ongoing issues with privacy, trust, and the explainability of GenLLM results. These areas will be the subject of ongoing research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}