
Positional Component-Guided Hangul Font Image Generation via Deep Semantic Segmentation and Adversarial Style Transfer





Abstract
1. Introduction
1.1. The Significance of Automated Font Generation
1.2. The Unique Challenge of Hangul Typography
1.3. Limitations of Existing Approaches
1.4. Proposed Framework and Contributions
- We propose a novel framework for Hangul font generation that, for the first time, explicitly leverages the positional semantics of initial, middle, and final components to guide the style transfer process.
- We introduce a robust methodology for creating a position-aware component dataset by employing the YOLOv8-Seg [15] instance segmentation model to accurately extract and classify jamo based on their structural roles.
- We design a component-conditioned Generative Adversarial Network (GAN) that uses these segmented components as explicit guidance, resulting in demonstrably superior structural integrity and style consistency in the generated characters.
- We conduct extensive experiments, including a crucial ablation study, that quantitatively validate the necessity and effectiveness of our positional component-guided approach, showing significant improvements over state-of-the-art baselines.
1.5. Paper Organization
2. Related Work
2.1. Generative Adversarial Networks for Image-to-Image Translation
2.2. Few-Shot Font Generation and Style–Content Disentanglement
2.3. Component-Based Font Generation
2.4. The Rise of Diffusion Models in Font Generation
2.5. Summary and Research Gap
3. Proposed Methodology
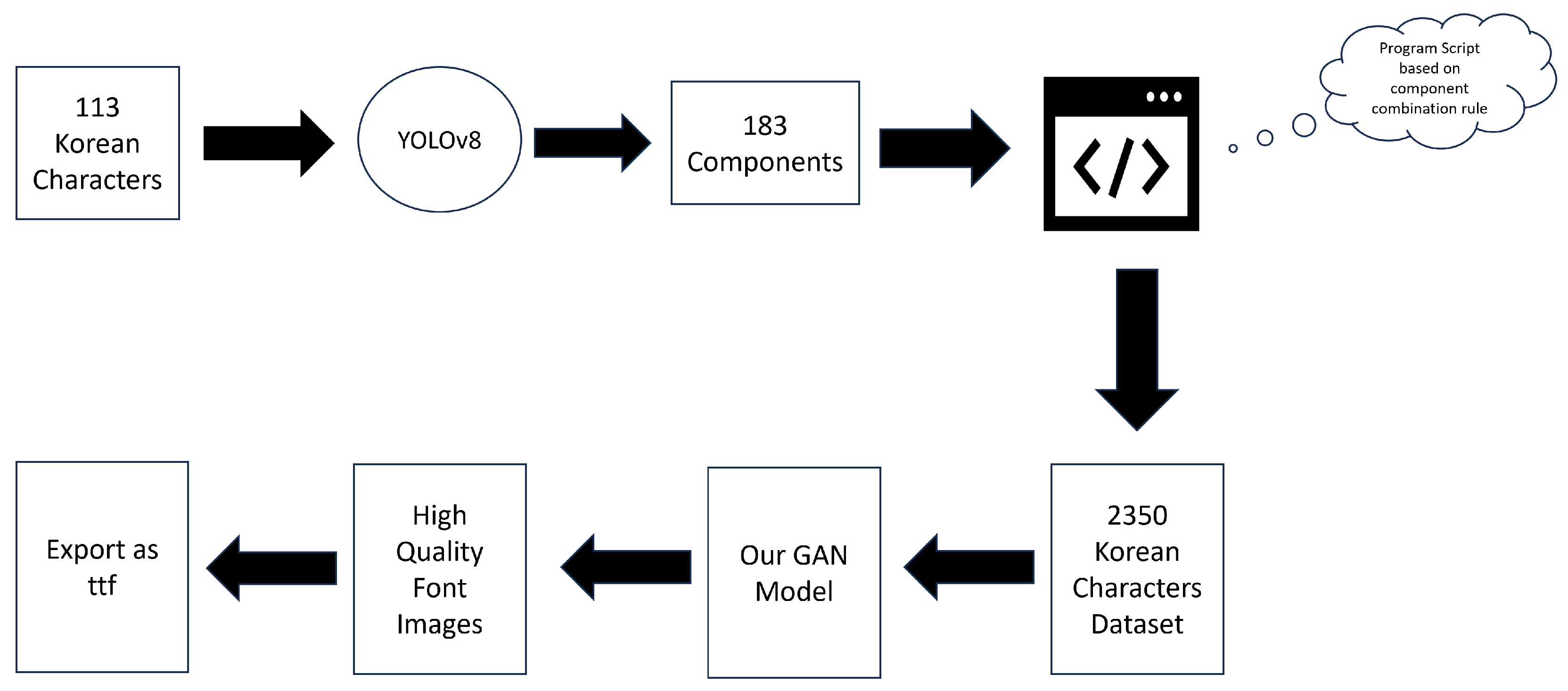
3.1. Stage 1: Semantic Decomposition via Instance Segmentation
3.1.1. The Role of Instance Segmentation and Choice of YOLOv8-Seg
3.1.2. Segmentation Dataset and Training Pipeline
- C1: Initial consonant (choseong)
- C2: Middle vowel (jungseong)
- C3: Final consonant (jongseong)
3.1.3. Generation of Positional–Semantic Masks
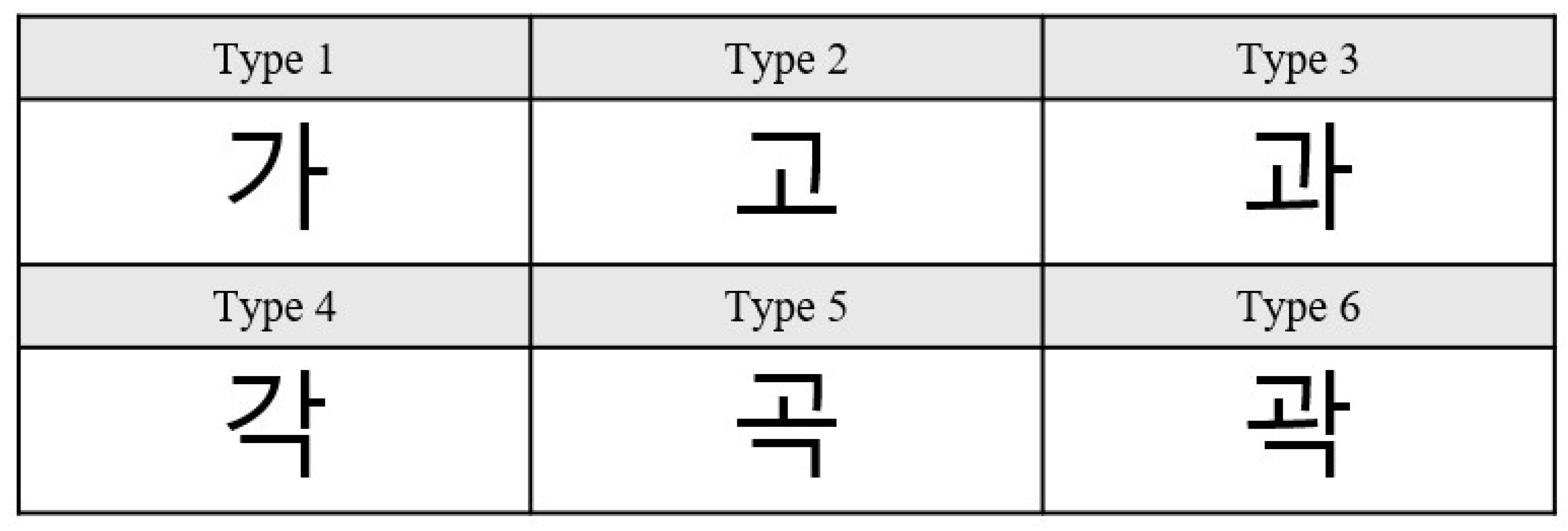
3.1.4. Component Shape Analysis
- The 19 initial consonants (Choseong) were grouped into 6 distinct shape categories.
- The 21 vowels (Jungseong) were divided into 2 categories, depending on whether or not they require a third (final) component.
- The 27 final consonants (Jongseong) were found to fall into a single shape category.
3.2. Stage 2: Adversarial Synthesis with Positional Conditioning
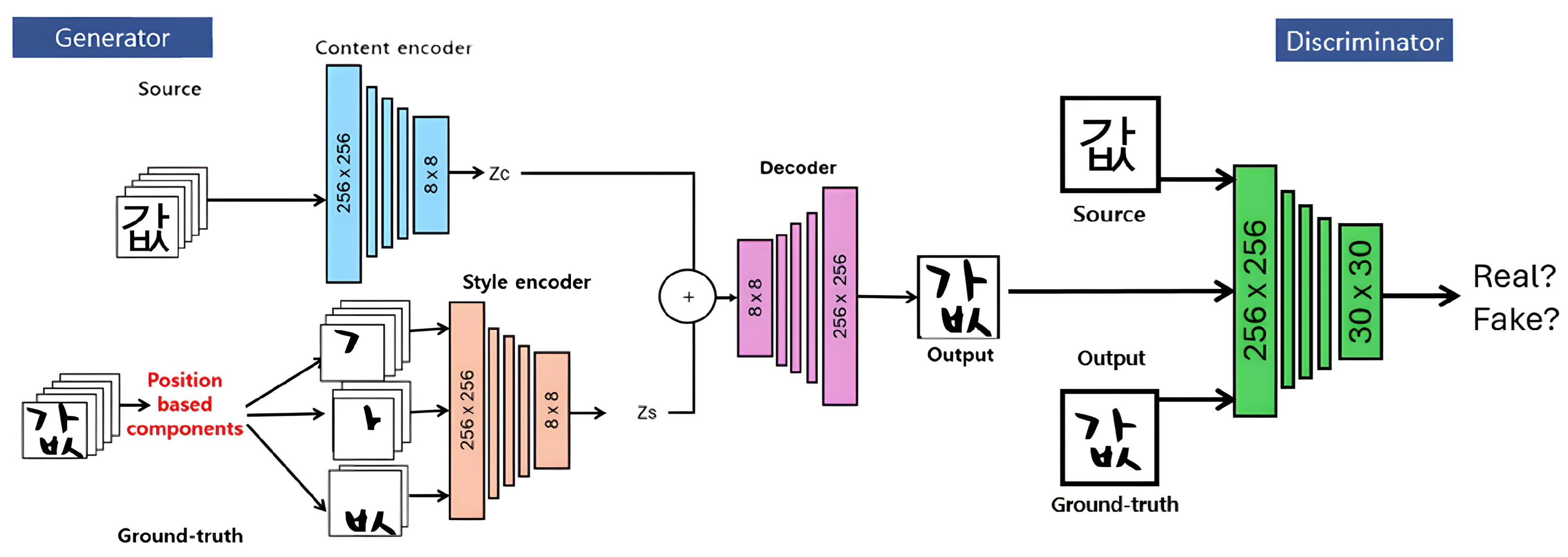
3.2.1. Generator Architecture
- Content Encoder (): This encoder takes the source character image as input, typically rendered in a standard, style-neutral font (e.g., Arial Unicode MS). Its function is to extract a high-level, style-agnostic feature representation, , that captures the abstract identity of the character (e.g., the concept of ‘값’).
- Style Encoder (): This encoder receives the three positional–semantic binary masks (C1, C2, C3) generated in Stage 1 as a concatenated input. Its function is to extract a feature vector, , that encodes the precise structural layout and stylistic shape of the components in the target font.
3.2.2. Conditional Discriminator Architecture
- Authenticity Classification: The primary adversarial task is to distinguish real image pairs from fake ones. It receives as input the source character concatenated with either the real ground truth target character or the fake character produced by the generator.
- Style Consistency Classification: The discriminator is also trained to classify the style domain of the input image. This auxiliary task forces the generator to produce images that are not only realistic but also consistent with the target style specified by the conditional masks.
3.2.3. Objective Functions and Optimization
- Adversarial Loss (): This is the standard GAN loss that drives the minimax game between the generator and the discriminator. The generator G aims to produce images from a source image x that are indistinguishable from real target images y, while the discriminator D aims to correctly identify them. It is defined asThis adversarial pressure encourages the generator to learn the distribution of realistic font textures and details.
- Style Loss (): This is an auxiliary classification loss that ensures the generated characters adhere to the correct target style. The discriminator predicts the style class of both real images () and generated images (). The generator is penalized if its output is not classified as belonging to the intended target style s.
- L1 Reconstruction Loss (): This loss provides a direct, pixel-level supervisory signal to the generator by measuring the Mean Absolute Error (MAE) between the generated image and the ground truth target image y. It is defined asThe use of L1 distance, as opposed to L2 (Mean Squared Error), is known to produce less blurry results and encourages sharpness in the generated images. This loss acts as a powerful regularizer, stabilizing the adversarial training process and guiding the generator toward a structurally accurate solution.
4. Experiment
4.1. Dataset for Font Generation
4.2. Implementation Details and Hyperparameters
4.3. Baseline Models for Comparison
- MX-Font: This model represents the state-of-the-art in implicit, learned component-based generation. It utilizes a Mixture of Experts (MoE) architecture where multiple expert networks automatically learn to specialize in different local regions or features of a character. It does not rely on explicit component labels, instead using weak supervision to guide the experts, making it generalizable to scripts without predefined components.
- CKFont: This model represents the state-of-the-art in explicit component-based generation for Hangul. It explicitly decomposes characters into their three constituent jamo classes (initial, middle, final) and uses this class-level information to guide a GAN-based generation process.
4.4. Quantitative Evaluation Metrics
- Structural Similarity Index (SSIM): SSIM [30] is a perceptual metric that evaluates image quality by comparing three key features: luminance, contrast, and structure. It is designed to align more closely with human visual perception of similarity than simple pixel-wise errors. A score closer to 1.0 indicates higher structural similarity. This metric is particularly critical for this study, as it directly quantifies the model’s ability to preserve character structure, which is the central claim of the paper.
- Fréchet Inception Distance (FID): FID [31] measures the similarity between the distribution of generated images and the distribution of real images. It uses the activations from an intermediate layer of a pre-trained InceptionV3 network to compute the Fréchet distance between the two distributions, capturing both image quality and diversity. A lower FID score indicates that the generated image distribution is closer to the real image distribution.
- Learned Perceptual Image Patch Similarity (LPIPS): LPIPS [32] measures the perceptual distance between two image patches. It utilizes deep features from a pre-trained network (e.g., AlexNet or VGG) that has been specifically fine-tuned to match human judgments of image similarity. A lower LPIPS score signifies that two images are more perceptually similar.
4.5. Quantitative Analysis
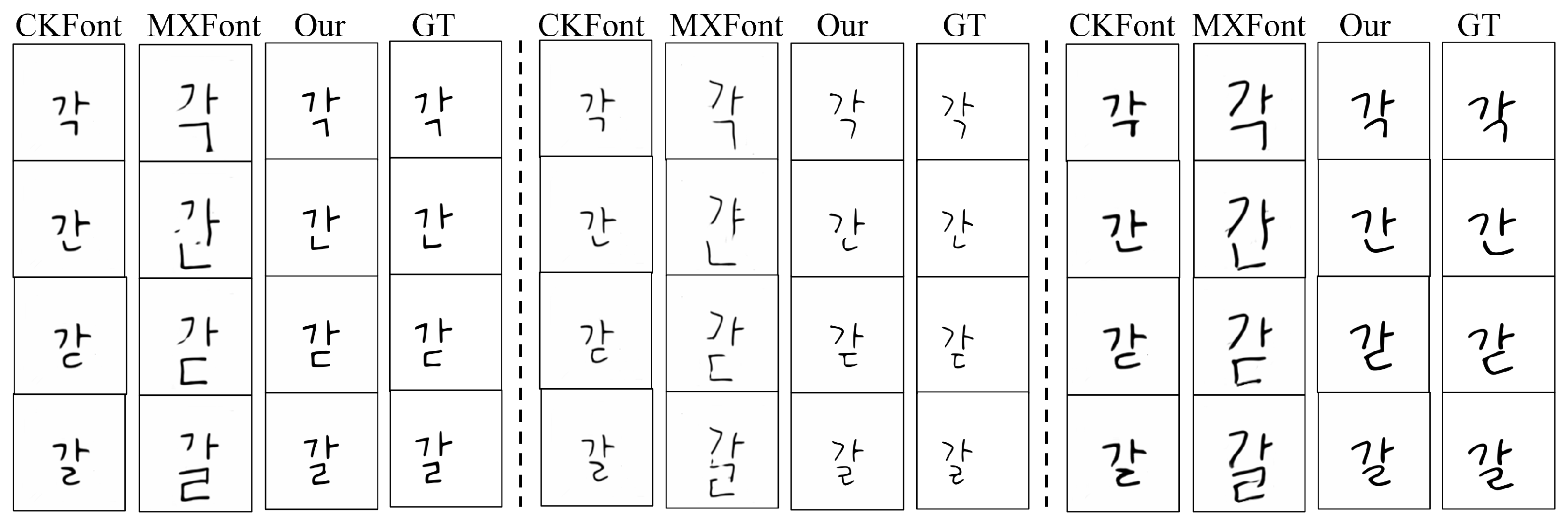
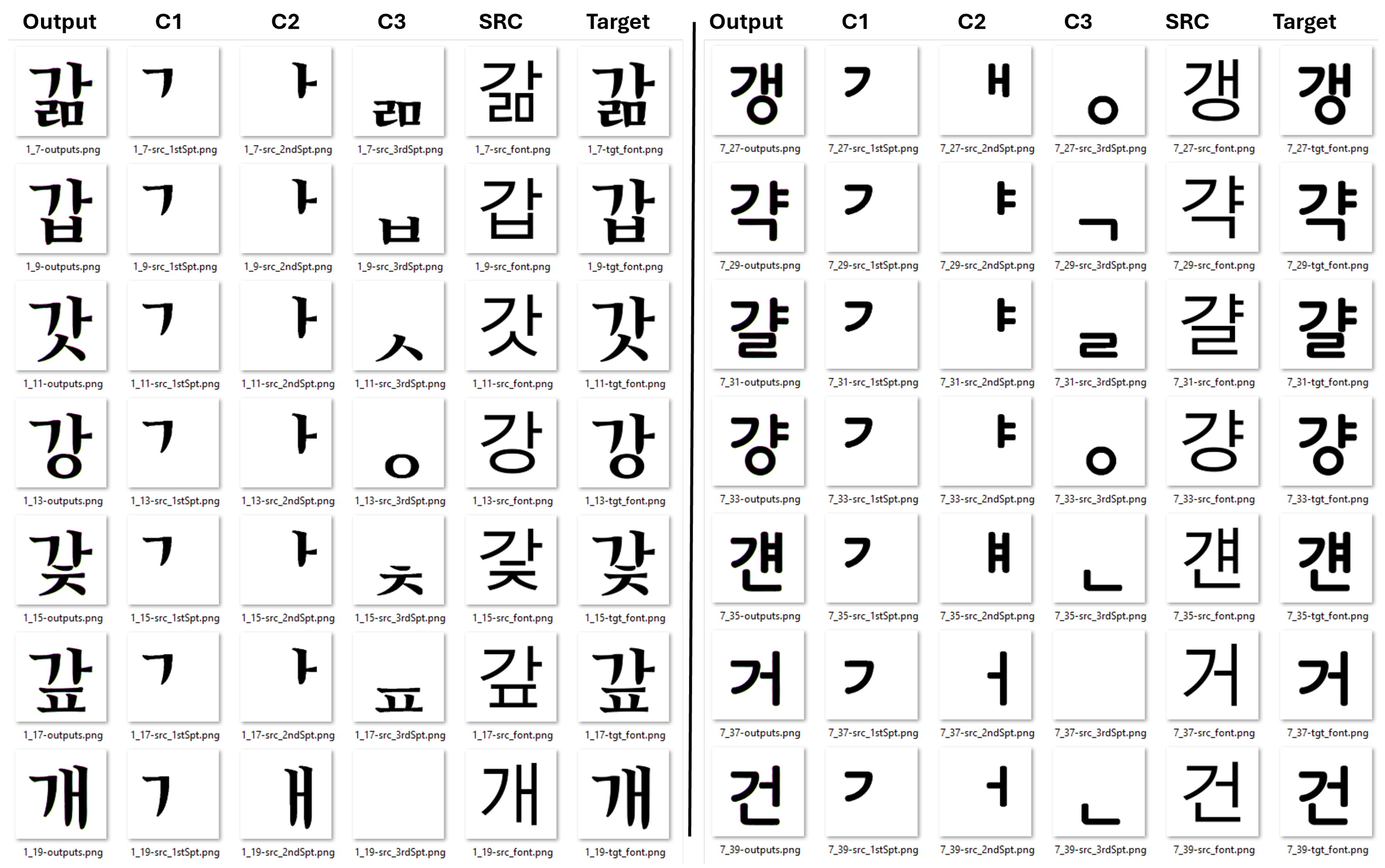
4.6. Qualitative Analysis
4.7. Ablation Study: The Impact of Positional Component Guidance
5. Discussion
5.1. Interpretation of Findings
5.2. Significance and Contributions
5.3. Limitations
- Architectural Novelty of the GAN: The main contribution of our work lies in the novel conditioning strategy rather than in the architecture of the GAN itself. The generator and discriminator components are based on standard conditional GAN (cGAN) frameworks and do not incorporate recent architectural advancements such as attention mechanisms or adaptive normalization layers, which have shown success in related style transfer tasks. The observed performance improvements are primarily due to the quality of the conditional input rather than architectural innovation.
- Dataset Scope: Although our training dataset covers all fundamental jamo components, it is limited to 113 representative Hangul characters. This does not fully reflect the richness and diversity of all 11,172 possible Hangul syllables, especially complex or infrequent combinations. Broadening the dataset to include more syllabic compositions could enhance the model’s ability to generalize to unseen characters.
- Dependency on Segmentation: The accuracy of the generated font heavily depends on the quality of the initial component segmentation stage. Although the YOLOv8-Seg model used in our framework performed reliably during our experiments, occasional segmentation errors, such as mislabeling a component or producing an imprecise mask, can negatively affect the GAN’s output, potentially leading to visual artifacts in the generated characters. At the time of our experiments, models referred to as YOLOv11 or YOLOv12 were either unreleased or lacked stable open-source implementations and benchmarking. Thus, we selected YOLOv8-Seg, which was the most mature and validated option available, with established support for instance segmentation.
- Lack of Perceptual Evaluation: Our evaluation relies on quantitative, pixel-based, and feature-based metrics (L1, SSIM, FID, LPIPS). While these metrics provide an objective measure of reconstruction quality and distributional similarity, they may not fully correlate with human perception of aesthetic appeal, legibility, and style consistency. A formal user study, where human evaluators compare and rate the outputs of different models, would be necessary to provide a comprehensive qualitative assessment. Such studies are critical for validating the practical usability of generated fonts and represent an important next step for this research.
5.4. Future Research Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Azadi, S.; Fisher, M.; Kim, V.G.; Wang, Z.; Shechtman, E.; Darrell, T. Multicontent GAN for Few-Shot Font Style Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7564–7573. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. StarGAN v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Jang-kyung, P.; Amar; Jae-young, C. Korean font generation model using minimum characters based on Korean composition. J. Korea Inf. Process. Soc. 2021, 10, 473–482. [Google Scholar]
- Park, J.; Hassan, A.U.; Choi, J. CCFont: Component-Based Chinese Font Generation Model Using Generative Adversarial Networks (GANs). Appl. Sci. 2022, 12, 8005. [Google Scholar] [CrossRef]
- Park, S.; Chun, S.; Cha, J.; Lee, B.; Shim, H. Multiple heads are better than one: Few-shot font generation with multiple localized experts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13900–13909. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Choi, J.; Kim, S.; Jeong, Y.; Gwon, Y.; Yoon, S. Conditioning method for denoising diffusion probabilistic models. arXiv 2021, arXiv:2108.02938. [Google Scholar] [CrossRef]
- He, H.; Chen, X.; Wang, C.; Liu, J.; Du, B.; Tao, D.; Yu, Q. Diff-font: Diffusion model for robust one-shot font generation. Int. J. Comput. Vis. 2024, 132, 5372–5386. [Google Scholar] [CrossRef]
- Yang, Z.; Peng, D.; Kong, Y.; Zhang, Y.; Yao, C.; Jin, L. Fontdiffuser: One-shot font generation via denoising diffusion with multi-scale content aggregation and style contrastive learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 6603–6611. [Google Scholar]
- Kuznedelev, D.; Startsev, V.; Shlenskii, D.; Kastryulin, S. Does Diffusion Beat GAN in Image Super Resolution? arXiv 2024, arXiv:2405.17261. [Google Scholar]
- Anonymous. Latent Denoising Diffusion GAN: Faster sampling, Higher image quality, and Greater diversity. arXiv 2024, arXiv:2406.11713. [Google Scholar]
- Zhou, X.; Khlobystov, A.; Lukasiewicz, T. Denoising Diffusion GANs. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2024. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wang, C.; Liu, Y.; Xiong, Z.; Liu, D. CF-Font: Content Fusion for Few-shot Font Generation. arXiv 2023, arXiv:2303.14017. [Google Scholar]
- Haraguchi, D.; Shimoda, W.; Yamaguchi, K.; Uchida, S. Total Disentanglement of Font Images into Style and Character Class Features. arXiv 2024, arXiv:2403.12784. [Google Scholar]
- Zhang, Z.; Chen, Y.; Zhang, Z.; Yu, Y. EMD: A Multi-Style Font Generation Method Based on Explicit Style-Content Separation. In Proceedings of the SIGGRAPH Asia 2018 Technical Briefs, Tokyo, Japan, 4–7 December 2018; ACM: New York, NY, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Kim, Y.; Wiseman, S.; Miller, A.C.; Sontag, D.; Rush, A.M. Semi-Amortized Variational Autoencoders. arXiv 2018, arXiv:1802.02550. [Google Scholar]
- Tian, Y. zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks. GitHub Repository. 2017. Available online: https://github.com/kaonashi-tyc/zi2zi (accessed on 12 October 2023).
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 4077–4087. [Google Scholar]
- Roboflow. Roboflow: A Platform for Managing Datasets and Training Computer Vision Models. 2024. Available online: https://roboflow.com/ (accessed on 7 August 2024).
- Google Fonts. Google Fonts: Free and Open-Source Fonts for Web and Desktop Use; Google Fonts: Mountain View, CA, USA, 2024. [Google Scholar]
- Naver Fonts. Naver Fonts: A Platform for Downloading Various Font Styles; Naver Fonts: Seongnam, Republic of Korea, 2024. [Google Scholar]
- He, X.; Cheng, J. Revisiting L1 Loss in Super-Resolution: A Probabilistic View and Beyond. arXiv 2022, arXiv:2201.10084. [Google Scholar]
- Mustafa, A.; Mantiuk, R.K. A Comparative Study on the Loss Functions for Image Enhancement. In Proceedings of the BMVC, London, UK, 21–24 November 2022. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Core Idea | Supervision | Component Handling | Positional Awareness | Key Limitation |
|---|---|---|---|---|---|
| zi2zi/pix2pix [2,23] | Paired Image-to-Image Translation | Paired Images | None (Global) | Low | Requires large paired datasets; struggles with structural details. |
| CycleGAN [18] | Unpaired Image-to-Image Translation | Unpaired Images | None (Global) | Low | Can introduce content artifacts; style control is indirect. |
| StarGAN [3,4] | Multi-Domain Image Translation | Paired Images + Style Labels | None (Global) | Low | Struggles with fine-grained local styles and complex structures. |
| CKFont [5] | Component-based GAN | Paired Images + Component Labels | Explicit decomposition into initial, middle, final classes | Medium | Acknowledges component classes but less sensitive to positional shape variations. |
| MX-Font [7] | Mixture of Localized Experts, Paired Images (weak component supervision) | Paired Images (weak component supervision) | Automatic learning of local features without explicit labels | Medium | Experts are not explicitly tied to the semantic/positional roles of jamo. |
| Diffusion | |||||
| Models [8,9] | Iterative Denoising | Paired Images | Varies (can be global or component-based) | Varies | High-quality output but computationally expensive and slow inference. |
| Our Method | Positional Component-Guided GAN | Paired Images + Component Masks | Explicit instance segmentation of positional jamo | High | Performance is dependent on segmentation accuracy; GAN architecture is conventional. |
| Model | L1 Loss ↓ | L2 Loss ↓ | SSIM ↑ | FID ↓ | LPIPS ↓ |
|---|---|---|---|---|---|
| MX-Font | 0.7268 ± 0.015 | 0.8928 ± 0.021 | 0.7891 ± 0.011 | 18.226 ± 0.45 | 0.072 ± 0.003 |
| CKFont | 0.7884 ± 0.018 | 0.8145 ± 0.019 | 0.8510 ± 0.009 | 23.861 ± 0.510 | 0.089 ± 0.004 |
| Our Model | 0.2991 ± 0.008 | 0.4621 ± 0.013 | 0.9798 ± 0.002 | 12.06 ± 0.32 | 0.047 ± 0.002 |
| Model | L1 Loss ↓ | L2 Loss ↓ | SSIM ↑ | FID ↓ | LPIPS ↓ |
|---|---|---|---|---|---|
| Our Model | |||||
| (Ablated—No Component Guidance) | 0.6542 | 0.7981 | 0.8655 | 21.543 | 0.081 |
| Our Model | |||||
| (Full—With Component Guidance) | 0.2991 | 0.4621 | 0.9798 | 12.060 | 0.047 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, A.; Memon, I.; Sami, A.; Jo, Y.; Choi, J. Positional Component-Guided Hangul Font Image Generation via Deep Semantic Segmentation and Adversarial Style Transfer. Electronics 2025, 14, 2699. https://doi.org/10.3390/electronics14132699
Kumar A, Memon I, Sami A, Jo Y, Choi J. Positional Component-Guided Hangul Font Image Generation via Deep Semantic Segmentation and Adversarial Style Transfer. Electronics. 2025; 14(13):2699. https://doi.org/10.3390/electronics14132699
Chicago/Turabian StyleKumar, Avinash, Irfanullah Memon, Abdul Sami, Youngwon Jo, and Jaeyoung Choi. 2025. "Positional Component-Guided Hangul Font Image Generation via Deep Semantic Segmentation and Adversarial Style Transfer" Electronics 14, no. 13: 2699. https://doi.org/10.3390/electronics14132699
APA StyleKumar, A., Memon, I., Sami, A., Jo, Y., & Choi, J. (2025). Positional Component-Guided Hangul Font Image Generation via Deep Semantic Segmentation and Adversarial Style Transfer. Electronics, 14(13), 2699. https://doi.org/10.3390/electronics14132699