3.1. Optimization of Addition Operations
The SNOVA algorithm operates over the finite field
, defined by the irreducible polynomial
over
[
23,
24]. Each field element is represented as a 4-bit binary value corresponding to a polynomial of degree at most 3.
Addition in
is implemented using bitwise XOR:
This operation corresponds to binary addition without carry. For example, let
and
in binary. Then,
To optimize this operation on ARMv8, we leverage both scalar and SIMD instructions.
Table 3 summarizes the instruction set utilized in SNOVA’s matrix addition routines. This table is adapted from [
25], which presents a practical reference for vector-based bitwise operations.
Figure 1 shows the SIMD-optimized data flow for rank 4 matrix addition, illustrating how two 16-byte inputs are loaded into NEON registers, combined using EOR, and stored back into memory.
To maximize the SIMD efficiency, we design rank-specific addition strategies. SNOVA’s parameter configurations involve matrices of varying dimensions depending on the central map degree l. We present two optimized implementations tailored to rank 2 and rank 4, both of which benefit from the regularity of the matrix shapes and fixed byte sizes.
To illustrate the memory layout and vectorization strategies employed in our implementation better,
Figure 2 provides a visual overview of matrix addition in SNOVA for rank 2 and rank 4. In the rank 2 case, multiple
matrices are grouped and processed in a batched SIMD manner. In contrast, the rank 4 matrices exactly match the SIMD register width, allowing for the direct application of vector operations without additional restructuring.
Each matrix consists of 16 one-byte field elements (16 bytes total), perfectly aligned with NEON’s 128-bit vector register. This alignment allows us to process the entire matrix addition using a minimal instruction sequence, two loads, one XOR, and one store without requiring any iteration or branching. Such a structure is ideally suited to SIMD execution, enabling highly parallel and cache-friendly computation.
The instruction-level details of our rank-4 implementation are summarized in Algorithm 1:
| Algorithm 1 Rank 4 matrix addition in |
- Require:
: address of matrix A (16 bytes) - 1:
: address of matrix B (16 bytes) - 2:
: address of output matrix C - Ensure:
- 3:
LD1 {v0.16b}, [x0] ▹ load A into v0 - 4:
LD1 {v1.16b}, [x1] ▹ load B into v1 - 5:
EOR v1.16b, v0.16b, v1.16b ▹ - 6:
ST1 {v1.16b}, [x2] ▹ store result to C
|
Compared to the scalar baseline which iterates over all 16 field elements and applies separate load, XOR, and store operations per byte, this SIMD-based strategy executes a single instruction per operation type. By reducing the total instruction count by more than an order of magnitude and eliminating the loop overhead, our approach improves the instruction throughput and data locality, delivering highly efficient matrix addition on ARMv8 processors.
Each rank 2 matrix in SNOVA contains only four field elements (4 bytes), offering insufficient granularity for effective SIMD execution. A naive scalar implementation iterates over each field element using nested loops, issuing independent memory accesses and XOR operations for all 16 bits. While functionally correct, this results in a significant control overhead and inefficient use of the processor resources.
Unlike the rank 4 matrices, which occupy an entire 128-bit SIMD register, rank 2 matrices are too small to justify direct vectorization. Mapping a matrix to either a 64-bit general-purpose register or a SIMD register results in severe underutilization—only 25% of the register width is effectively used. Furthermore, the overhead introduced by the explicit register management and load/store instructions in assembly can degrade the performance even below that of the scalar C baseline.
To overcome this limitation, we adopt a batch-based vectorization strategy. By aggregating four matrices—totalling exactly 16 bytes—into a single 128-bit SIMD register, we fully utilize the vector width and perform all four additions in parallel with a single XOR instruction. This design amortizes the cost of memory operations and unlocks parallelism even for small matrix operations.
The low-level implementation of this routine is encapsulated in
gf16m_rank2_add_batch4, which takes pointers to two contiguous blocks of four matrices and performs element-wise XOR using NEON intrinsics. Its behavior is summarized in the following Algorithm 2:
| Algorithm 2 Rank 2 matrix addition in (4 matrices batched) |
- Require:
: address of 4 matrices (16 bytes) - 1:
: address of 4 matrices (16 bytes) - 2:
: address of 4 outputs - Ensure:
- 3:
v0 = vld1q_u8(x0) ▹ load – - 4:
v1 = vld1q_u8(x1) ▹ load – - 5:
v2 = veorq_u8(v0, v1) ▹ - 6:
vst1q_u8(x2, v2) ▹ store –
|
However, to use this batched kernel efficiently, the calling function must prepare four matrices in a contiguous memory layout. This requirement differs from the rank 4 case, where each matrix naturally fits a SIMD register and can be processed independently.
To enable batching, we introduce loop tiling and data restructuring into upper-level modules such as gen_F, gen_P22, and sign_digest_core. These routines are adapted to accumulate temporary results from multiple multiplications into aligned buffers, enabling the use of gf16m_rank2_add_batch4 instead of performing four separate scalar additions.
The following pseudocode captures the structure of this integration, as used in
gen_F:
| Algorithm 3 Vectorized rank 2 accumulation in gen_F |
- 1:
for to K step 4 do ▹ process four columns per iteration - 2:
▹ limit to remaining columns - 3:
for to do ▹ initialize accumulators - 4:
▹ copy base matrix - 5:
end for - 6:
for to do ▹ loop over vinegar variables - 7:
for to do - 8:
▹ rank 2 matrix multiply - 9:
end for - 10:
if then - 11:
gf16m_rank2_add_batch4(T, C) ▹ vectorized addition of four matrices - 12:
else - 13:
for to do - 14:
gf16m_add(C[k+kk], T[kk], C[k+kk]) ▹ scalar fallback - 15:
end for - 16:
end if - 17:
end for - 18:
end for
|
Algorithm 3 reflects the structure used in modules like gen_F to facilitate rank 2 vectorized addition. It works by tiling the k loop into blocks of four matrices, the exact size that fits into a 128-bit NEON register. The outer loop slices the k dimension into groups of four matrices, storing the results of matrix multiplications into a temporary buffer. If the current block contains exactly four matrices, the batched addition is applied using gf16m_rank2_add_batch4. For remaining tail cases (1–3 matrices), scalar addition is used instead to maintain correctness without vector underutilization.
This approach ensures that the memory alignment and batch size requirements of SIMD instructions are respected while preserving the functional logic of the original scalar loop. Compared to per-element scalar accumulation, this batched structure reduces the instruction count and improves the data locality, especially in inner loops where the same accumulation pattern is repeated.
3.2. Multiplication Optimization
Matrix multiplication over is one of the most performance-critical operations in SNOVA, appearing frequently during public key generation, signature creation, and verification. As its computational cost dominates the total execution time, effective optimization of this operation is essential.
To address this, we employ the NEON SIMD extension on ARMv8 processors. NEON provides 128-bit vector registers capable of performing parallel operations on up to sixteen 8-bit elements, which is particularly suitable for matrix arithmetic over .
Matrix multiplication in
is defined as
where both multiplication and addition are field operations. While addition is a simple XOR, multiplication requires polynomial arithmetic modulo, the irreducible polynomial
[
23].
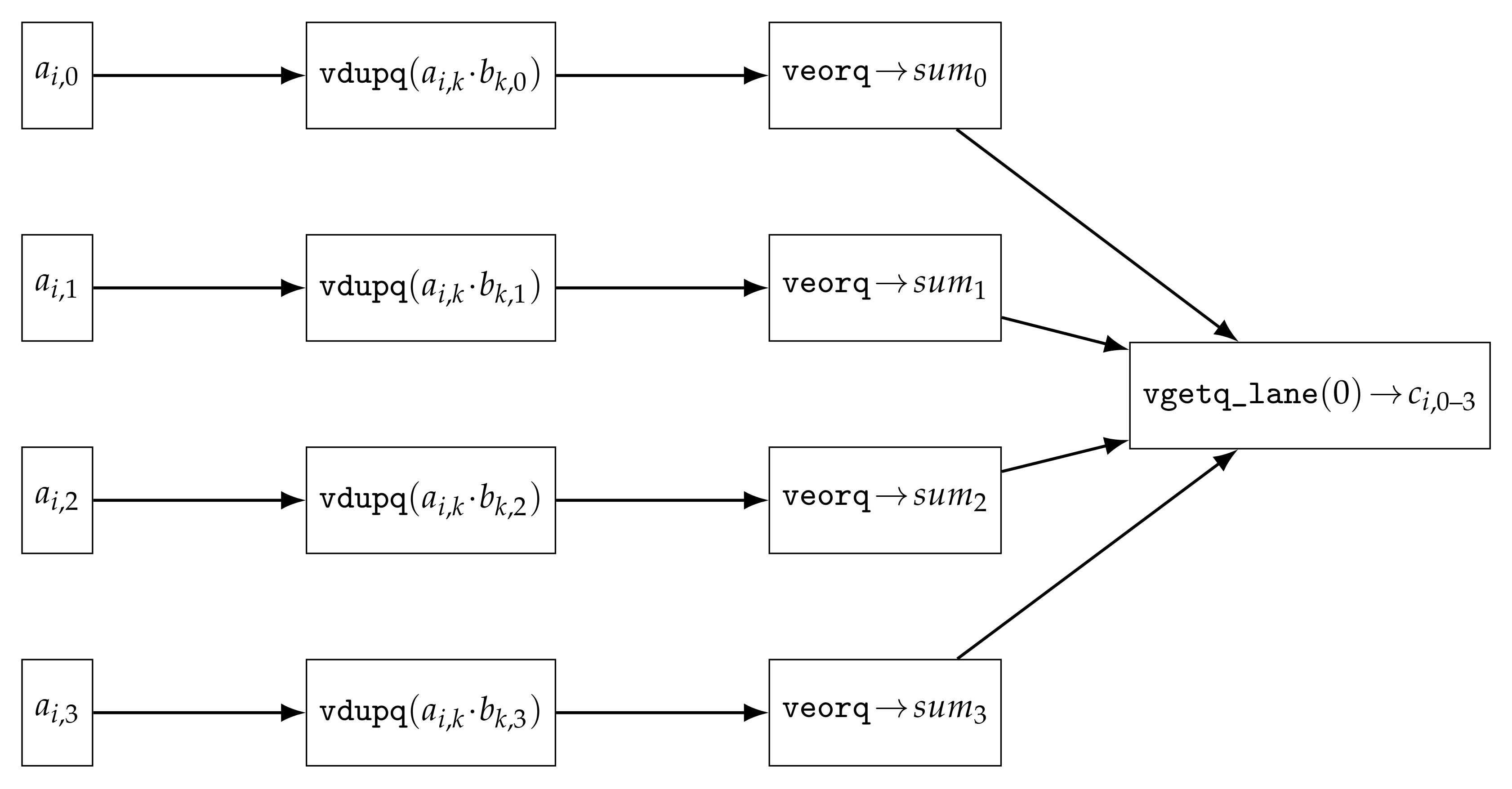
Figure 3 depicts the SIMD-based flow of rank 4 GF(16) matrix multiplication, where each element of the row vector is broadcast, XOR-accumulated, and extracted to produce the output.
To accelerate these operations, we implement all inner loops using NEON intrinsics.
Table 4 contains the following instructions that form the core of our multiplication kernel:
The NEON-based implementation avoids scalar instructions entirely. Scalar field elements are broadcast using
vdupq_n_u8, and vectorized XOR accumulation is performed using
veorq_u8. Once all products are computed and summed, the results are extracted using
vgetq_lane_u8.
Figure 4 provides a visual overview of how SIMD lanes are utilized in rank 2 and rank 4 matrix multiplications.
The following, Algorithm 4, presents the high-level logic behind SNOVA’s multiplication kernel. Each loop iterates over the matrix indices, performs broadcast and parallel accumulated multiplications, and writes the result to memory.
| Algorithm 4 SNOVA Multiplication Optimization |
- Require:
Matrix A and B of size - Ensure:
Matrix over - 1:
for to do ▹ iterate rows of A - 2:
for to do ▹ iterate cols of B - 3:
▹ clear accumulator - 4:
for to do ▹ dot-product index - 5:
▹ fused multiply–add over - 6:
end for - 7:
end for - 8:
end for
|
We implement a fully unrolled version of this algorithm for rank 4 matrices to exploit register-level parallelism like that in Algorithm 5:
| Algorithm 5 NEON-based matrix multiplication for rank 4. |
- Require:
Row vector , column vectors - Ensure:
Output vector - 1:
for to 3 do ▹ iterate rows - 2:
vdupq_n_u8() ▹ initial product, col 0 - 3:
vdupq_n_u8() ▹ initial product, col 1 - 4:
vdupq_n_u8() ▹ initial product, col 2 - 5:
vdupq_n_u8() ▹ initial product, col 3 - 6:
for to 3 do ▹ accumulate remaining terms - 7:
vdupq_n_u8() - 8:
vdupq_n_u8() - 9:
vdupq_n_u8() - 10:
vdupq_n_u8() - 11:
veorq_u8(, ) ▹ XOR accumulate - 12:
veorq_u8(, ) - 13:
veorq_u8(, ) - 14:
veorq_u8(, ) - 15:
end for - 16:
vgetq_lane_u8(, 0) ▹ extract result - 17:
vgetq_lane_u8(, 0) - 18:
vgetq_lane_u8(, 0) - 19:
vgetq_lane_u8(, 0) - 20:
end for
|
This SIMD-centric approach minimizes the control flow and the instruction count. The multiplication logic is embedded into a unified dispatch macro
gf16m_neon_mul, which ensures a consistent performance across all kernel variants. A comprehensive summary of the techniques is presented in the following,
Table 5:
3.3. The AES Accelerator for CTR Mode
The SNOVA signature scheme employs AES-128 CTR mode to generate the pseudorandom values required during key generation and signature sampling [
26]. In the original
mupq framework, this was implemented using BearSSL’s [
27] bit-sliced AES core, which prioritizes portability and side-channel resistance. However, due to its nonstandard key schedule and data layout, it is incompatible with ARMv8’s dedicated AES instructions, such as
AESE and
AESMC.
To address this, we replaced the BearSSL core with a custom AES-128 CTR implementation written in the ARMv8 assembly. This version uses the standard AES key schedule and adopts the CTR mode structure proposed by Gauravaram et al. [
28], originally developed for GCM on ARM platforms. The implementation leverages hardware-supported AES instructions and NEON vector registers to achieve high-throughput encryption.
The instructions used for the operation are as shown in
Table 6. All operations are performed using ARMv8 vector instructions, including
LD1,
AESE,
AESMC, and
ST1, minimizing memory latency while maximizing the throughput [
9]. These instructions form the backbone of SNOVA’s CTR mode pseudorandom generator, fully contained within the NEON register file.
The description of Algorithm 6 is as follows. The entire AES CTR routine is written in assembly to maximize the instruction-level control and eliminate runtime branching. Registers
x0–x3 are assigned to the output buffer, input length, nonce pointer, and round key pointer, respectively. The function prologue saves the frame pointer and the link register using
STP.
| Algorithm 6 AES-128 CTR mode accelerator. |
- Require:
Output buffer C, input length n (bytes), 16-byte nonce N, 176-byte round-key array - Ensure:
Encrypted ciphertext C of n bytes - 1:
Initialization: ▹ set up constants - 2:
▹ number of 16-byte blocks - 3:
Load into NEON registers ▹ preload round keys - 4:
▹ nonce + initial counter - 5:
▹ vector for counter++ - 6:
for to do ▹ encrypt each block - 7:
▹ copy counter - 8:
for to 9 do ▹ 10 standard rounds - 9:
- 10:
- 11:
end for - 12:
▹ final round (no MixColumns) - 13:
Store T to ▹ write ciphertext - 14:
▹ increment counter - 15:
end for
|
All 11 round keys (176 bytes) are preloaded into vector registers q6–q16. The counter block is initialized using v5 for the nonce and v1 for the increment, forming a 128-bit counter beginning with nonce ∥ 0x01. The increment is handled with ADD v5.16b, v5.16b, v1.16b for each 16-byte block.
For every block, the encryption process follows the standard AES-128 structure: ten rounds of
AESE/
AESMC, followed by a final round of
AESE only [
29]. The output is stored using a calculated offset in
x4, via
STR q0, [x0, x4, LSL #4]. The block loop progresses with
ADD x4, x4, #1 and is controlled by
CMP and
B.GE.
All computations—including the counter increment, round transformations, and memory access—are performed within NEON registers. This allows for efficient pipelining, minimal latency, and high energy efficiency on ARMv8 cores.
According to the benchmarks by Gouvea et al. [
28], AES-128 CTR on ARMv8 achieved 1.84 cycles per byte (cpb) on the Cortex-A57 and 1.19 cpb on the Apple A8X. This outperformed previous ARMv7 implementations using bit-sliced techniques, which required up to 9.8 cpb, showing an 8.1× performance gain when adopting native AES instructions.
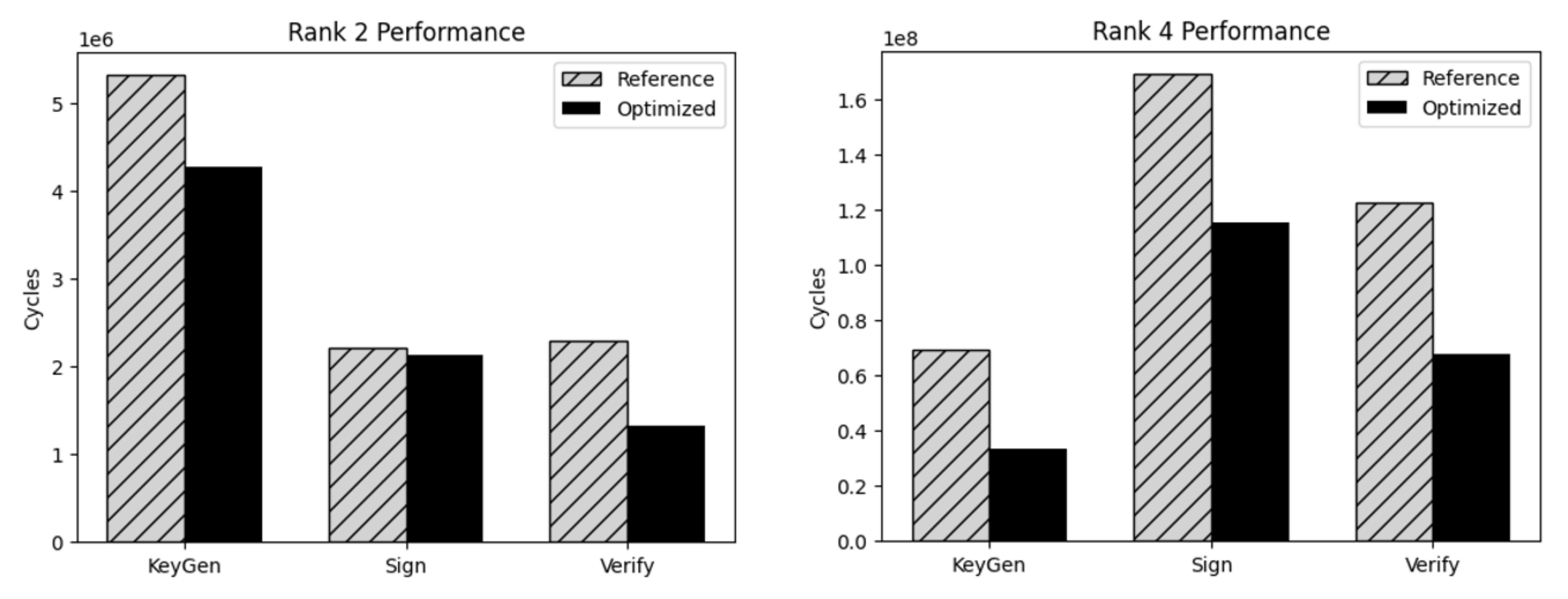
3.4. Overall Time Complexity and Performance Gains
This section analyzes the asymptotic and practical performance of SNOVA, comparing the baseline scalar implementation with our ARMv8/NEON-optimized variant. While the overall asymptotic complexity remains unchanged, our optimizations significantly reduce the constant factors in key routines.
According to the round 2 specification [
30], evaluating the central map involves
G operations, where , , and . The dominant term is asymptotically , driven by cubic matrix multiplications over small field elements.
The key contributors to the runtime are
Matrix addition: byte-wise XORs;
Matrix multiplication: G multiply-and-add operations;
Pseudorandom generation (PRNG): AES-CTR rounds with the cost proportional to the byte length.
While the asymptotic complexity remains unaffected, our ARMv8-optimized kernels offer significant constant-factor improvements in the performance. For rank 4 matrix additions, the SIMD implementation uses a single load, XOR, and store instructions to process 16 bytes at once—replacing 16 independent scalar operations. Similarly, rank 2 matrices are batched into groups of four, allowing a single NEON operation to handle what would otherwise require four separate scalar loops.
In the case of field multiplication, scalar multiply–add loops are replaced with vectorized broadcast and XOR operations using NEON lanes, enabling up to 16 field multiplications to be processed in parallel.
For AES-based pseudorandom generation, we replace the bit-sliced software implementation with native ‘AESE’ and ‘AESMC’ instructions. This reduces the cycle cost per byte from roughly 9.8 to 1.2, effectively removing PRNG from the critical path of key generation and signing.
The asymptotic order remains unchanged. Despite aggressive SIMD optimization, SNOVA retains its theoretical complexity of . The improvements are entirely in the leading constant, making the algorithm faster but not asymptotically different.
SIMD efficiency depends on the matrix rank. Rank 4 matrices (16 bytes) map exactly to NEON’s 128-bit registers, enabling minimal instruction sequences and substantial speed-up. In contrast, rank 2 matrices require batching strategies, which still offer measurable improvements but with reduced parallelism efficiency.
The PRNG overhead is eliminated. The switch from bit-sliced AES to native AESE/AESMC instructions reduced the cost of AES-CTR significantly. As a result, the pseudorandom generator is no longer a bottleneck in key generation and signing routines.
In summary, the NEON-optimized implementation maintains the asymptotic computational profile of SNOVA while significantly improving the constant-factor performance across key routines. Quantitative performance data is discussed in the next section.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}